
Abstract
This study borrows elements of film text in the field of film studies to develop the potential of data analysis using AI algorithms, while aiming to explore the emotional and content relevances between the two narrative mediums in film, bullet screens and subtitles, as well as the narrative effect variations that they bring about. The film sample Forever Young was analyzed by deep learning, data analysis, and knowledge discovery algorithms and tools. The BERT model was used to quantify the intensity of emotions and conduct fine-grained emotional classification of film characters. Emotion curves are plotted based on time series data. Thematic words are extracted by the LDA algorithm, and text similarity is computed using Word2Vec. The study found differences in emotional expression between bullet screens and subtitles, and they also exhibit strong emotional and content relevances. Yet, this correlation is not only influenced by temporal deviation factors but also by specific emotional types, different stages of story development, and the collective emotions of online views. The conclusion suggests that the effective collection of plot metronomes in film narratives helps reveal crucial plot nodes and emotional trends in films that cause obvious emotional changes, and placing them appropriately is fundamental for continuously attracting and retaining viewers’ attention. The interaction between bullet comments and subtitles is not only about emotional expression but also enhances the effectiveness of the film narrative. Overall, this study demonstrates the importance of database logic and technology in understanding and expressing film emotions and meanings, and providing new ideas and methods for enhancing film narrative effectiveness.
Keywords
Introduction
Nowadays, concepts such as “cross-medium convergence” (Pizzo et al., 2023), “database cinema” (Duan et al., 2023), and “computer algorithms” (Pradeep et al., 2023) have profoundly influenced the narrative invocation of films. With the continuous development of computer technology, the internet, and new media, the future of film will inevitably be intertwined with medium technology. Therefore, it is imperative to research how to store, analyze and utilize narrative textual data of films to inspire future cinematic artistry, which directly refers to the reflection on the essence of cinematic narrative medium and the content presented by the medium. In the context of medium convergence, the focus of research on cross-medium narrative of films is to consider the film itself as a medium, mainly observing the cross-media narrative between literature and film (Baroni et al., 2023), with relatively fewer studies on the narrative medium elements of the film. In Pethő’s (2020) theory, movie images can incorporate multiple forms of medium, thereby inducing blending and dialogue between multiple mediums. The multimedium elements included in cinema refer to the presentation of narrative information through text, symbols, images, moving images, and sounds.
Movie storytelling pursues completeness and emotional triggering, whether it is the structural arrangement, plot design, or characterization, all be particular about a coherent beginning and end, cause and effect. These are primarily recorded in the script, where each line appears on the screen in the form of subtitle text, visuals, and stylized forms, profoundly influencing the narrative thinking of the audience’s viewing feedback. The emergence of bullet screens has reshaped the interface of online movie viewing for the masses, altering the interaction logic between the traditional movie and the audience. Bullet screens, as an interactive medium for the audience’s viewing feedback, enter into the narrative and meaning expression of the movie. They belong to the category of textual medium in film narration, along with subtitles. Both appear as text either separately or superimposed on the screen, presenting to the audience’s visual and auditory senses along with the visuals and sounds. Bullet screen narrative not only concerns how the audience speaks but also concerns how the film and the audience are spoken.
The linear narrative effects of movies and the non-linear narrative effects of fragmentary and open expression of bullet screens offer great potential to inspire future digital film creation, human-computer interaction, film recommendations, content quality assessment, and other database film creation thinking. Currently, research on the relevance between film bullet screens and subtitle text, two forms of textual narrative medium, in terms of content and emotion, is quite limited. Furthermore, it is necessary to strengthen the exploration of narrative elements of the film themselves, the audience, and their online viewing characteristics, particularly deepening the understanding of audience emotions. Therefore, this paper briefly outlined the story of the film Forever Young in the data section. In the methodology section, the BERT algorithm was employed to allocate sentiment intensity values and construct fine-grained emotional vectors for characters. The correlation between the expected emotional weight and content of the film, and the emotional feedback weight and content collected in bullet text form was analyzed, with emotional curves visualized. The LDA algorithm was utilized to extract thematic words. These methods were applied to the film Forever Young and the results were analyzed. The research aims to fully explore the medium information generated and narrative effect changes under the association of film’s textual narrative medium “subtitle” and “bullet screen”, considering how the presentation of two medium contents and emotional contagion affect individual and group emotions. This paper examines film content and emotions from the perspective of textual narrative medium, contributing to the guidance of practices, continuously expanding possibilities of “film narrative” and its boundaries with artificial intelligence algorithms and database cinema logic, and providing valuable references for evaluating and enhancing film narrative efficacy.
Literature Review
Research on Script Texts Analysis
A script is a literary style to present the story plot and serve as a reference for actors’ performance. In addition to the dialogue text, a script also includes other textual information such as speaker roles, scene descriptions, action cues, etc., which has significant potential analytical value. Due to its recording of characters’ dialogue within specific contexts, a script closely resembles authentic everyday conversations, thus providing rich corpus data (Jucker & Landert, 2023). Subtitles serve as a screen representation of movie scripts, and many scholars have noticed the potential value of subtitles and scripts in films and TV series. Purba et al. (2021) argued that movie provides a crucial window for understanding sociolinguistic diversity. They evaluated different language styles present in the film script of Papillon and categorized these styles into five types: intimate, formal, consultative, casual, and frozen, with the aim of revealing the application of these linguistic styles in the script and their roles in expressiveness, guidingness, referentiality, metalinguistics, and periodic. Arafat et al. (2022) emphasized movie scripts are crucial resources for analyzing social issues. Their study, through analyzing portrayals of suicide behavior in Bangladeshi movie scripts, aimed to elucidate attitudes, beliefs, and behavioral patterns within specific socio-cultural contexts. Cave et al. (2023) conducted corpus analyses on 142 influential AI movies from 1920 to 2020, revealing the underrepresentation of women in the field of AI movies. One explanation for this phenomenon is that movie scripts aim to depict societal issues, revealing gender imbalances in the AI industry and gender inequality in real life through gendered narratives.
With the advancement of AI technology, new approaches for parsing movie scripts are provided. Many studies have offered solutions to movie classification problems, using features derived from various sources such as plot, images, trailers, etc., which provide valuable references for movie recommendation system design, movie box office performance analysis, and understanding movie themes. Rajput and Grover (2022) proposed a movie genre classification algorithm based on movie subtitles, utilizing high-frequency words in movie subtitles as features to train a machine learning model to identify words related to movie genres for classification purposes. Jayashree and Varma (2022) introduced an MPAA rating prediction model based on script analysis, extracting dialogues from movie scripts using a bidirectional LSTM model and categorizing movies into five categories: R, G, PG, PG-13, NC-17, assisting in content regulation of movie works. There have also been studies utilizing LIWC text mining tools with AG spatial statistical models to predict and evaluate movie success during the development stage based on feature similarity and differences in script content, aiding investors in making decisions in the development phase (Moon et al., 2022).
Dialogue generation, story summarization, and alignment tasks are challenging endeavors within movie script research. Recently, deep neural networks have been employed to identify relationships in generated stories, comprehend narrative trajectories, and generate coherent movie narrative texts. According to Zhu et al. (2022), the ScriptWriter-CPre model is used to generate movie scripts based on predefined narratives, enabling the model to select the optimal response given the narrative and contextual situation. Dharaniya et al. (2023) implemented an EMCG-based movie script generation model, specifically using a deep belief network to extract deep features from textual data, which are then assigned to a model integrated by Bi-LSTM, GPT3, and GPT Neo X. Sadoughi et al. (2023) introduced the Multimodal alignmEnt aGgregation and distillAtion (MEGA) model, incorporating an alignment position encoding module DTW, which can handle cross-modal alignment of timed subtitles in movies with timestamps of script dialogues at a coarse temporal level, thus segmenting long movie videos. Evaluation metrics include total alignment (TA), partial alignment (PA), and distance (D).
Research on Bullet Screen Text Analysis
The cultural and interactive attributes of bullet screens have been the focus of attention for many scholars. Bullet screens as a novel form of video comments with accompanying attributes, originating from niche cultures in East Asian countries, have now become a unique form of medium communication and practice in Chinese social media technology and culture, driving the rapid development and popularization of platforms and applications such as Acfun, Bilibili video sharing platform, and Tiktok live streaming (Zhang & Cassany, 2023). Bullet screens and traditional static comments beneath the video both belong to user behavior in online videos, where static comments appear static and independent of the viewing process (Xi et al., 2021). In contrast, when users watch videos, they are allowed to engage in real-time, anonymous interactive comments, and bullet screens seem like bullets simultaneously on the screen, enabling viewers to see comments sent by other viewers at the same timestamp of the movie, creating a “pseudo-synchronous effect” atmosphere of information interaction, where individual discourse establishes connections through homogeneous groups and collective contextual (Xu & Jing, 2024). In the context of movies, bullet screen comments not only serve to analyze information about the film but also serve as evidence of relationships among viewers, the entire film, and its characters (Gee et al., 2012).
Bullet screens, as real-time comments displayed on the screen, play a crucial role in enhancing user emotions and supporting user interaction in live e-commerce. The functionality of live streaming technology with bullet screens provides opportunities for real-time bidirectional interaction between customers and sellers, facilitating the flow of information and emotions. This fosters trust between sellers and consumers (M. Zhang et al., 2022), which is conducive to increasing user purchasing intentions. The emotions of the anchor significantly affect the arousal and valence of group emotions (Wang et al., 2024), leading to widespread emotional or impulsive buying behavior (Sun et al., 2022). Thus, live e-commerce possesses the attribute of instant purchases driven by strong emotional reactions. Y. Zhang et al. (2024) collected data from Tiktok live e-commerce platforms including live bullet screens, user dwell time, sales volume, etc., quantified user interactions using the BERT model, and performed sentiment analysis using Baidu API, to explore how real-time interaction and emotions affect online sales.
Many studies conduct sentiment analysis on bullet screens and evaluate their emotional tendencies. Sentiment analysis based on sentiment dictionaries typically uses the sentiment polarity of sentiment words provided by the sentiment dictionary to analyze the text, assigning corresponding weight values to each word and determining the sentiment tendency based on the sentiment values. Bullet screen text based on videos typically involves analyzing and interpreting video segments, possessing knowledge attributes. Additionally, the content of chat bullet screens is highly colloquial and lacks complete contextual information. Moreover, bullet screen text often includes non-textual elements such as emoticons and emojis, making traditional sentiment dictionaries unsuitable for data analysis in the specific field of bullet screens. To address this issue, Li et al. (2020) proposed the construction of a bullet screens domain-specific sentiment dictionary to expand existing sentiment dictionaries. However, building a sentiment dictionary is time-consuming and requires a large amount of manpower, maintaining and supplementing the dictionary is also time-consuming. In contrast, deep learning methods have shown superior performance in fine-grained sentiment analysis tasks, with higher classification accuracy and transfer efficiency of feature extraction. Liu and Zhao (2020) proposed a bullet screen text sentiment classification algorithm based on the sentiment symbol space model and multi-attention convolutional neural network (CNN). They established a sentiment space model for emoticons and emojis and used an attention mechanism to model emoticons, enhancing the emotional semantic expression of bullet screen text and improving classification accuracy. Tan et al. (2022) proposed a hybrid model combining Transformer and RNN structures, called the RoBERTa-LSTM model. This model not only requires less computing time but also can effectively capture long-distance contextual semantics. Gao et al. (2022) proposed a short text sentiment analysis method based on CNN and Bidirectional Gated Recurrent Unit (BiGRU). As a type of CNN, GRU is known for effectively capturing long-term dependencies in long sequences. Therefore, the CNN-BiGRU model utilizes the power of CNN and BiGRU to extract features from the text and address the long-distance dependency of sequences, thus enhancing the reliability of training. Additionally, some scholars combine sentiment dictionaries with deep learning algorithms. Li and Zou (2024) proposed a hybrid model called PLASA for classifying the bullet screens sentiment polarity, with the pre-trained BERT model as the foundation of PLASA, considering word spacing by punctuation marks while retaining the attention mechanism of sentiment dictionary queries for word matching, so that it can adjust the relationship between word representations in sentence sequences and improve the performance of fine-grained sentiment analysis.
Overall, existing literature mainly utilizes movie elements and AI algorithms to explore the potential of data analysis, with varying interests in technological exploration, striving for the advancement of AI algorithm technology and predictive accuracy. Some other studies focus on exploring the linguistic features of subtitles and bullet screens as specific forms of social interaction, borrowing theoretical frameworks such as cultural studies, sociolinguistics, and medium. These studies collectively demonstrate the significant research value of movie subtitles and bullet screen texts as corpora. However, few studies have considered bullet screens as a narrative medium of film, and there is scant analysis connecting bullet screens with subtitles. In addition, quantitative analysis of character emotions in movie research is limited, with insufficient attention paid to movie characters from the perspective of sentiment analysis. This study tends to use AI algorithms to quantify the emotional tension overlaid by bullet screens from the viewer’s perspective, emphasizing the emotional flow and connection between movie content and user narratives. Furthermore, research also refines the granularity of emotion labeling, and investigates the distribution of seven emotional categories (disgust, like, happiness, sadness, surprise, anger, and fear) to present a movie’s emotional characteristics from multiple dimensions, comprehensively observing the shaping of character personalities and the expression of emotions through the alternating narrative of bullet screens and subtitles on the screen.
Therefore, the following research questions are proposed in this study:
RQ1: What are the effects of subtitles on audience emotions?
RQ2: What are the guiding effects of bullet screens on audience emotions and the mechanisms of emotional resonance?
RQ3: What cognitive effects do bullet screens have on enhancing the narrative presentation of subtitles? How do bullet screens perceive the predefined movie themes and character emotional presentations in subtitles?
Methods
Data Collection and Preprocessing
Selection of Film Sample
The film sample for this study is taken from the Chinese film Forever Young (Li, 2018), directed by Fangfang Li, with a duration of 138 min. The film depicts the fortunes and vicissitudes of four generations of youths in different temporal and spatial contexts, with the four epochal settings spanning a century from the Republic of China era in the 1920s, through the stormy and turbulence times of the Anti-Japanese War in the 1930s, to the passionate and burning times on the eve of the Cultural Revolution in the 1960s, and finally coming to the contemporary Tsinghua in the 21st century. Four chapter-style story interspersed with narration: (Story A) Guoguo Zhang is in the workplace full of competition, with everyone trying to cheat or outwit each other, but he finds clarity in direction and true self-worth; (Story B) Three young people, Peng Chen, Minjia Wang, and Xiang Li, each harboring aspirations, yet relinquishing much along the way, ultimately embarking on completely different paths; (Story C) Guangyao Shen, a student born into a prominent family, resolutely joins the army in the face of national crisis and sacrifices himself on the battlefield; (Story D) Linglan Wu is lost in an era that venerates practical sciences but eventually finds himself again. Overall, the emotional development trends are almost the same.
These seemingly unrelated stories gradually converge in a well-structured narrative, becoming one story, covering a broader narrative space and emotional dimension. Due to its unique temporal, spatial, characters, and structural settings, the film condensedly presents the fate trajectory and inner journey of Chinese intellectuals over a century. The main characters all experience difficulties and confusion, struggling and conflicting between secularism and ideals, filial piety and righteousness, but eventually grow. The film has several sudden plot twists, such as Shufen Liu’s sudden suicide by jumping into a well, and also reenacts many precious historical moments with strong emotional resonance, making it highly emotionally impactful. Moreover, the film’s narrative style leans toward documentary, with the subjective color of the subtitle’s narrative discourse minimized, which can considerably reflect the emotional impact of the film subtitles on the audience. Therefore, Forever Young is very suitable as a research sample for emotional analysis and content analysis.
Based on the six-act structure theoretical framework of film narration (Sadoughi et al., 2023), this study organizes the structural framework according to the actual content and narrative structure settings of the film sample Forever Young. Four stories are classified accordingly, with specific results shown in Table 1. Overall, segments ranging from 0 to 3006 s are used to present the background and initiating events of the four stories, 3006 to 4091 s depict new developments in the plots of Stories A and C, segments 4091 to 6881 s portray the conflicts and climaxes of Stories B and C, 6881 to 7737 s show the problem-solving stage of Stories A, B, and C, 7737 to 7896 s conclude the stories, and segments from 7895 to 8308 s are the bonus scenes of the film.
Narrative Structure Correspondence Table for the Film Sample Forever Young.

Collection and Preprocessing of Subtitle and Bullet Screen Data
The movie script of Forever Young was obtained from the internet using document collection, and seven parameter information was manually annotated to form a CSV file for subsequent data cleansing and analysis. The parameters include: “story” categorized as A/B/C/D to distinguish between four storylines, “scene_id” is the scene number, “order_id” is the order number of the data, “timeline” is the time when the script appears in the form of subtitles on the screen, “content” is the textual content of the script, “character” is the name of the character to be used for subsequent character sentiment testing, and “emotion” is the sentiment recognition results to be tested.
For the data collection of the movie sample’s bullet screens, considering data accessibility, after examining multiple platforms, the decision was made to obtain data from the bullet screen pool on the Bilibili platform (Website link for Forever Young: https://www.bilibili.com/bangumi/play/ep328592?theme=movie&spm_id_from=333.337.0.0). The unique numeric code used within the Bilibili platform to identify the video content of Forever Young is 184532240. On October 31, 2023, by constructing the corresponding API request link, bullet screen information was successfully extracted from the API response. The number of bullet screens obtained through web scraping from the Bilibili website is related to the length of the video. For the movie sample with a duration of 2 hr and 18 min, a total of 9,600 bullet screen messages were collected by the web scraper. The information contains nine parameters: “bullet screen appearing time”, “bullet screen mode”, “font size”, “font color”, “sending time”, “bullet screen textual content”, “user ID”, “row ID”, and “number”. Personal information is not recognized or stored during the process of bullet screen data acquisition, and the collected data is solely used for academic research purposes.
After obtaining the required bullet screen and subtitle corpora, the following data preprocessing steps were executed to form the final dataset for model training. Firstly, pandas was used to read the two datasets, with the original subtitle dataset retaining all columns for later use. Since this study does not consider the semiotic use of bullet screen mode and color, only “bullet screen textual content”, “bullet screen appearing time”, and “number” were extracted and retained using regular expression techniques. Subsequently, the data was processed by removing blank values and duplicates. Then, Python’s Chinese word segmentation third-party library Jieba was used for word segmentation. Jieba’s word segmentation is calculated by the probability of association between Chinese characters to form a word, and the one with a higher probability is considered to be a word. After segmentation, stopwords that were not helpful to the analysis were removed using the generic stopword document “stoplist.txt”. Punctuation marks were retained as they reflect emotional intensity.
Fine-Grained Sentiment Classification Based on the BERT Preprocessing Model
The BERT model is a pre-trained technique for natural language processing that uses a dual-transformer structure with a Mask language model for training. Compared to sentiment dictionaries, BERT is not constrained by a limited vocabulary size or fixed sentiment scores. allowing it to consider contextual information fully, making it more applicable for fine-grained sentiment classification and quantifying sentiment intensity in this study.
Currently, there is a relative lack of datasets for fine-grained sentiment classification in bullet screens. However, short texts such as Weibo comments share similarities with bullet screens, both representing users’ self-expression and often containing rich emotional information. The corpus of Weibo comments can assist in sentiment analysis of bullet screen texts (Li & Zou, 2024). Therefore, a dataset consisting of 16,674 Weibo comments was utilized to train the sentiment classification model. These comments were categorized into seven output labels, namely “happiness”, “disgust”, “like”, “anger”, “sadness”, “fear”, and “surprise”. Among them, there were 3,830 “happiness” comments, 3,262 “disgust” comments, 3,522 “like” comments, 1,992 “anger” comments, 2,596 “sadness” comments, 408 “fear” comments, and 1,064 “surprise” comments. It can be observed that the data amount of majority and minority categories differ greatly, resulting in an imbalanced data distribution. The prediction model of the machine learning algorithm may not be able to make accurate classifications but will tend to predict the majority set. To address this problem, upsampling was performed through random sampling with replacement to achieve data balance, resulting in a total of 23,390 samples. The dataset was then randomly divided into training and testing sets at a ratio of 7:3. And the labels for seven emotions were mapped to indices before training.
This experiment used the open-source Transformers library, specifically the BertForSequenceClassification model in the Hugging Face library, with PyTorch as the model training framework. The pre-trained textual language was selected as “bert-base-chinese,’ and the text was converted into numerical vectors using the Tokenizer under the Transformers package, transforming the dataset into vector sets as Dataset objects. Figure 1 presents the distribution of text lengths in the dataset used for training the sentiment classification model, ranging from 1 to 185. The time complexity of each attention mechanism layer is O(n2·d), where n denotes text length, and d represents the dimensionality of the vectors. Therefore, the maximum text length parameter in the BERT model was set to 128 to improve the efficiency of the model. The hyperparameters used in the experiment included an attention head number of 12, an attention layer number of 12, vector dimensionality of 768, a maximum sentence length of 128, a batch size of 32, a learning rate of 1e-5, and a training iteration number (epoch) of 10. The final output layer had seven neurons.

Text length distribution of sentiment classification model’s training datasets.
After obtaining a trained model, performance tests were performed on data that were not used during model training. The model was evaluated based on four indicators: accuracy, precision, recall, and F1 score. Accuracy refers to the proportion of correct predictions made by the model. Precision measures how many of the predicted positive samples were actually positive, and Recall measures how many of the actual positive samples were predicted as positives. The F1 score is a combined measure of the model’s ability to make accurate and comprehensive predictions, incorporating both precision and recall. Figure 2 shows a graph of the performance evaluation of the training process. It can be seen that after parameter optimization and long training time, the model achieved a peak accuracy of approximately 93.3%, precision of about 93.24%, recall of about 93.26%, and F1 score of about 93.23% on the test set. The evaluation results validate the superiority of the BERT model in fine-grained sentiment classification tasks.

Training effect of the sentiment classification model.
Generation of Emotion Curves Based on Time Series
The horizontal spread of the timeline represents the narrative writing of movie subtitles, while the vertical extension of the timeline reflects the traces of bullet comments from multiple audience perspectives triggered by emotions at a certain timestamp. The purpose of this study is to investigate the correlation between the emotional intensity of bullet narratives and the content of movies. The psychological theory of emotional contagion can partially explain the emotional communication between movie content and users during the viewing process, the user’s emotion is influenced and mobilized by the movie content, ultimately leading to emotional assimilation. Therefore, and the emotional changes reflected in the emotional curve of audience emotions in bullet screens should be positively correlated with the emotional changes in subtitle content, as hypothesized theoretically. To verify this hypothesis, the analysis of bullet screens and movie scripts can be conducted based on the timeline. Specifically, the data can be sorted in chronological order, sentiment analysis can be conducted based on the BERT model, and emotional intensity scores can be calculated for each timestamp, plotting two emotional intensity fluctuation curves. This method can better observe the emotional trends and intensity distribution and patterns of bullet screens and subtitles, comprehensively understand the fluctuation of audience emotional intensity during the viewing process, better explore the guiding effect of the cross-medium narrative of subtitles and bullet screens on audience emotions, and provide substantial support for further research on video content quality assessment and audience feedback.
Assigning Emotional Intensity Values
Emotional intensity typically refers to the strength or degree of emotions. In sentiment analysis, the emotional polarity (e.g., positive or negative) and emotional intensity (e.g., strong or weak) of text can be evaluated. The calculation of emotions in the text needs to be based on emotional polarity judgment. In this article, a binary sentiment classification model trained by BERT was used for prediction, and the probabilities of positive and negative sentiment for each short text can be obtained. If the prediction result indicates a more obvious positive sentiment, the emotional value is closer to 1, and if the prediction result indicates a stronger negative sentiment, the emotional value is closer to 0.
To improve the accuracy and comprehensibility of sentiment analysis, emotional values are normalized to the range of −1 to 1. This method improves the clarity of the emotional value range, allowing for easier comparisons. Moreover, taking the absolute value as the emotional intensity enables even negative emotions to possess emotional intensity, objectively reflecting the magnitude of sentiment intensity, and improving the credibility and reliability of sentiment analysis. Then, the emotional values of each bullet screen or subtitle at every time point are added to generate the emotional intensity value for each particular timestamp.
Resampling Discrete Timeline Data
Subtitle and bullet screen datasets are typically discrete data based on the timeline due to the irregular appearance times and release frequency. Moreover, aggregation of bullet screen data within a certain period can result in highly discontinuous emotional changes. All these factors will lead to data discontinuity, which not only affects curve feature presentation but also results in greater errors in correlation analysis. Therefore, to ensure effective feature selection and complexity of correlation analysis, it is necessary to convert these discrete time series data into continuous data. This involves the process of resampling the timeline, that is, sampling and interpolating the original data at a certain time interval to obtain continuous time series data.
Specifically, the original bullet screen and subtitle data were sorted chronologically according to the timeline. The “resample” function from the pandas library was then used to resample the data at a 1-s interval from 0 to 8323 s, which is the duration of the movie. This process improved the granularity of time and addressed data discontinuity. To fill in missing subtitle values, a forward filing upsampling method was adopted, which considered the sampling characteristics of the original subtitle data, thereby enhancing data integrity. While interpolation method was used to predict the missing bullet screen values by fitting a curve between the previous and next known data points, resulting in a more complete and continuous dataset. Figures 3 and 5 depict emotional intensity curves of processed subtitle and bullet screen data, with the range of Figure 5 normalized to 0–1 for easier observation of their correlation.

Emotional intensity curves of script and bullet screen (without normalization).
Results
Distribution of Sentiment Scores and Intensity Curves
For the movie sample Forever Young, there were a total of 1,105 subtitle samples and 9,600 bullet screen samples. After assigning sentiment scores to the text, it was found that the mean, standard deviation, first quartile, median, and third quartile of the sentiment scores for the bullet screens were all higher than those of the subtitles (Table 2). The average sentiment score for subtitles was −0.1492, indicating an overall tendency toward negative sentiment. In contrast, the average sentiment score for bullet screens was 0.0166, showing a slightly positive sentiment. This difference points to the fact that bullet screens present a diverse emotional experience dominated by positive emotions, while the subtitles of the movie sample itself convey more negative emotions.
Descriptive Statistical Analysis of Sentiment Scores and Emotional Impact Magnitudes in Individual Bullet Screen and Subtitle Texts for the Film Forever Young.

Examining the distribution of sentiment scores for subtitles, the median (Q2) was −0.2808, and the third quartile (Q3) was 0.4579, revealing that more than half of the subtitle samples tended to express negative emotions. Observing the scatter plot of subtitles sentiment scores in Figure 4b, intense negative emotions are relatively more concentrated, but overall shows an even distribution of emotional points ranging from strong negative emotions to strong positive emotions, indicating the diversity of emotional expression in the movie content.

Scatterplot of sentiment scores of individual bullet screen (a) and subtitle (b) texts in the movie Forever Young.
In contrast, the median of the bullet comments scores was 0.0666, and the third quartile was 0.6838, showing that more than half of the samples in the bullet screens displayed positive emotions, which differs from the sentiment tendency of subtitles. The bullet screens scatter plot in Figure 4a further illustrates the more densely distributed of positive and negative intense emotional attributes, especially in the positive emotion area, reflecting the concentrated reactions of the audience at specific emotional points. Sentiment intensity curves for both bullet screens and subtitles were plotted separately to explore the distribution characteristics of sentiment intensity (Figure 3). The sentiment intensity of subtitles showed a relatively gentle trend, while the sentiment intensity of bullet screens exhibited more pronounced fluctuations, with larger and more frequent peaks. As a whole, it can also be illustrated that the sentiment intensity of bullet screens is relatively high, while that of subtitles is relatively low.
Correlation Between Emotional Intensity Curves of Subtitles and Bullet Screens
The standard deviation of bullet comment scores is 0.6856, compared to 0.6453 for the script, which shows a similar degree of dispersion in emotional intensity between the two. The two subplots in Figure 4 also exhibit relatively uniform scatter characteristics. However, the subtitle scatter plot only vaguely shows a dense tendency to strongly negative emotions, whereas the bullet comment scatter plot displays a more obvious intense emotional feature, whether negative or positive, reflecting a certain consistency between audience feedback and film content. To better observe the shape of emotional intensity curves and analyze the correlation between bullet comments and subtitles, the curves in Figure 4 were normalized, as shown in Figure 5.

Emotional intensity curves of script and bullet screen (with normalization).
The Pearson correlation coefficient can be used to measure the degree of linear correlation between two variables. In the correlation analysis between bullet comments and subtitles emotion curves, the Pearson correlation coefficient result is 0.095, indicating a weak linear correlation between the two. Assuming the relationship between the two is nonlinear, the Pearson correlation coefficient may cause errors as it is only applicable to variables with a linear distribution. In contrast, the Spearman correlation coefficient can handle nonlinear relationships and outliers. According to the calculation results, the Spearman correlation coefficient of bullet comments and subtitles is 0.044, with a p-value of 0.00005475, indicating a certain degree of correlation between the two, although it is weak. Therefore, further exploration of the factors that affect the correlation between the two will require comprehensive consideration, and I found that the bullet screens and subtitles have different degrees of temporal deviation, which may affect the correlation results. The so-called temporal deviation refers to the time difference between the emotional reactions of the audience’s bullet screens and the film’s emotions at a certain time point. The correlation between the emotions of the audience’s bullet screens and the emotions of the movie varies at different time points and different deviation distances. Therefore, the “traversal” data analysis method is used to observe the deviation between the bullet narrative and the movie content. The segmented time control is set at 100 s, and the deviation distance is controlled within the range of 0 to 30 s. Correlation is calculated to analyze the degree of correlation between bullet screen emotions and film emotions. A 3D scatter plot is used to visualize the correlation between these three variables, which could be observed more intuitively.
The visualization results are shown in Figure 6. The deviation distance between bullet comments and movie content from 0 to 30 s exists in large numbers. In the middle of the movie, at approximately 4000 s, and in the later stage of the movie, at about 6600 s, when the deviation distance is within the range of 0 to 30 s, the Pearson correlation coefficient between bullet narrative emotions and the movie is mostly above 0.5, which is a moderate correlation. Among them, the highest correlation coefficient of 0.67 was reached when the movie proceeded to 6688 s with a deviation distance of 23 s, showing a strong correlation, indicating a strong linear relationship between movie emotions and bullet comments emotions at this time. In addition, It was also found that the deviation distance is roughly evenly distributed between 0 and 30 s, and the inclination is not very obvious, which indicates that there is always a different degree of delay in commenting on the movie content.

3D scatter plot of “deviation distance”, “Movie time” and the correlation between “bullet screen emotional intensity” and “subtitle emotional intensity”.
Emotional Intensity Influence Amplitude Curve
To further explore the audience’s aesthetic emotional response to the movie content, based on the existing intensity values of the bullet screen emotional intensity curve and the subtitle emotional intensity curve, the calculation formula is used:
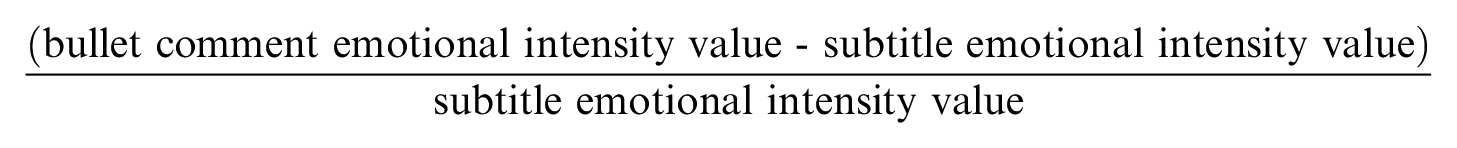
This formula calculates the difference between the emotional intensity of the bullet screens and that of the movie content, then divides this difference by the emotional intensity of the movie content itself, which is a reasonable measure to assess the audience’s emotional involvement in the movie and to analyze the degree to which the movie content triggers an emotional responses from the audience.
Influence amplitude about 8323 s of the movie was calculated using the formula. The maximum value of the influence rate was about 1,085.71 and the minimum value was −0.9998 (Table 2). Due to the large differences in values, the z-score standard version was used for normalization to avoid the influence of large numerical differences on the results. After normalization, the maximum emotional intensity growth value was 26.78 and the minimum value was −0.16. Figure 7 is a line graph of the normalized emotional influence amplitude. It shows that at different periods in the development of the story, there were significant changes in emotional experience. By calculating the rate of change in emotional impact magnitudes between adjacent time points and setting a threshold as the average slope plus the standard deviation, points of significant changes in emotional impact magnitudes were identified. These points, labeled as “Significant Changes” in the graph, correspond to pivotal moments in the movie’s narrative that cause abrupt shifts in audience emotional experiences.

Influence amplitude curve of emotional intensity of bullet screen compared with subtitle intensity curve.
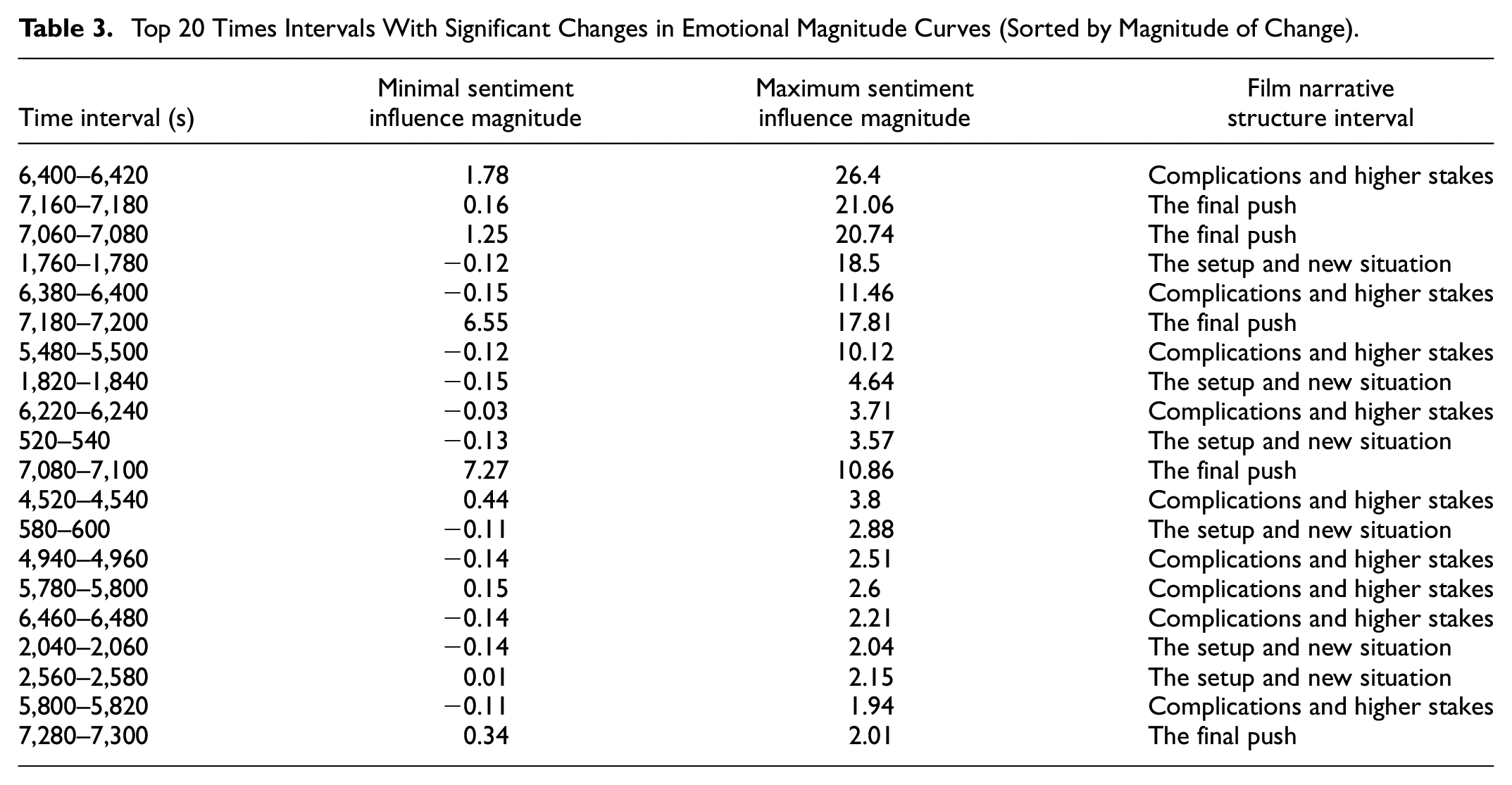
Table 3 presents the top 20 time intervals where significant changes in emotional magnitudes occur, along with their corresponding minimum and maximum emotional impact magnitudes and the corresponding intervals of the movie narrative structure. In the time interval of 6,400 to 6,420 s, during the “Complications and higher stakes” phase of the story, the emotional intensity impact magnitude increases from 1.78 to the first gradient peak of 26.4. It’s noteworthy that in the adjacent time interval of 6,380 to 6,400 s, the emotional intensity impact magnitude increases from −0.15 to 11.46, the emotional magnitude also undergoes a more significant change. Additionally, during two consecutive time intervals of 7,160 to 7,180 s and 7,180 to 7200 s, within “The final push” phase of the story, there are two successive peaks in emotional intensity impact magnitude within a short period of 40 s, ranging from 0.16 to 21.06 and from 6.55 to 17.81, showing significant fluctuations in emotional magnitude during this specific time period. At the interval of 1760 to 1780 s of the movie, which is at the stage of “The setup and new situation” of story C, a small peak of the second gradient appears, with a maximum value of 18.5. In the time interval of 5480 to 5500 s of the movie, which is the time interval when “The setup and new situation” of sroty B is nearing the end of the stage, the emotional intensity impact magnitude is at the small peak of the third gradient, with a maximum value exceeding 10.
Top 20 Times Intervals With Significant Changes in Emotional Magnitude Curves (Sorted by Magnitude of Change).
Emotional Contagion of Different Emotional Categories
Combining the magnitude of emotional growth with fine-grained emotional categories to analyze the script texts, can explore the extent to which different emotional categories affect the audience’s emotions, thus determining the emotional contagion of different emotional categories. The method is to select the 500 time points with the largest magnitude of affective impact, and sort the subtitles published at these time points into seven emotional categories. The first column of Table 4 effectively presents the proportional distribution of different affective categories appearing in these subtitle texts, which have a significant role in influence. In the film sample Forever Young, emotions such as like, disgust, and sadness are more involved in profoundly influencing the audience’s emotional experience. The same method was applied to analyze the bullet screens, and the second column of the table presents the proportion distribution of emotional category in bullet screen content released when the audience is most affected by the movie’s emotions. In the table, “↑” indicates that the distribution of emotional categories in bullet comments is higher than in subtitles, while “↓” indicates a lower distribution. Like and disgust have the highest distribution in subtitle samples, but their distribution decreases in bullet comments. For anger, happiness, surprise, and sadness, their distribution in bullet comments is higher than in subtitles.
Proportional Distribution and Influence Magnitude of Emotional Categories.

Furthermore, the table also records the influence magnitude values of different emotional categories, that is, their contribution to the audience’s overall emotional experience. The numbers in the table (① to ⑦) represent the ranking of emotional categories by size, with smaller numbers indicating greater proportional distribution or influence. It can be observed that the ranking of influence is not entirely consistent with the distribution trend of emotional categories in subtitles. For example, fear has the lowest distribution in subtitles, but its influence ranking is the highest, similar to the case of surprise emotions. This suggests that although fear and surprise emotions are less emphasized in the film content, their influence on the audience is the most profound when film characters experience fear and surprise emotions. Disgust and sadness, these two negative emotions, have distributions in the first half in subtitles, but their influence rankings are in the second half, indicating that these emotions in the film text may not necessarily have a significant impact on the audience’s overall emotional experience.
Influence of Collective Emotions on Individual Emotions
The fluctuation in the number of bullet screens over time can visually display the audience’s real-time reactions to the movie during the viewing process. As shown in Figure 8, the trend of the number of bullet comments over time indicates a wave-like distribution pattern throughout the entire duration of the film, with a tendency for more comments in the latter half compared to the first half, yet overall maintaining continuous activity. The highest number of bullet screens occurs at 5,609 s into the film, exhibiting a sudden increase. Additionally, the intervals of 8,313 to 8,323 s and 8,278 to 8,287 s toward the end of the film also experience a significantly high concentration of bullet comments. Besides, timestamps or intervals such as 7,174, 7,121, 17, 7,880 to 7,884, 2,587, and 6,561 s also witness a considerable distribution of bullet screens, indicating moments in the film that evoke excitement and discussion among the audience. A large number of bullet comments covering similar themes cover the top of the movie screen, allowing users to realize the gathering of emotions and rational sentiments, thus continuously enhancing the audience’s emotional experience. Along with this process, individual emotions are influenced by collective emotions.

Bar chart of the number of bullet comments over time.
By calculating the correlation between the number of bullet screens and the increase of influence magnitude, it is possible to understand whether there is a significant relationship between these two variables, as well as the strength and direction of the relationship, to verify the actual correlation between individual emotions and collective emotions. Pearson correlation coefficient between the bullet screen number and influence magnitude is 0.1253. Although the linear relationship is not significant, there is a positive correlation between the number of bullet screens and the increased influence on the magnitude of emotion, implying that the greater the number of bullet screens, the greater the extent to which emotions are influenced.
Preset Emotion Attributes in Subtitles and Perceived Emotion Attributes in Bullet Comments for Characters
The number of subtitles is directly related to the importance of characters in the story. Based on the script, the number of subtitles for all characters in the movie Forever Young was counted. To explore the relationship between the expected character image depicted in the film and the audience’s perception and understanding of the characters, the emotional types of the top 8 characters with the highest number of subtitles in the film subtitles were statistically analyzed. Additionally, the emotional types of these eight characters in the bullet screens were also recorded, as shown in Table 5.
Proportional Distribution of Emotional Attributees of Characters With Substantial Subtitle Count Under Film Preset and Bullet Screen Perception.

The proportional distribution of preset emotional attributes in subtitles can reflect the construction of character roles as well as the character’s personality traits in the movie story. For example, the high proportion of anger (36.96%) and sadness (26.09%) emotional attributes for the character Shufen Liu suggests that she is an irritable and moody character. As for the five main characters, Linglan Wu, Guangyao Shen, Minjia Wang, Peng Chen, and Guoguo Zhang, the “like” attribute is the highest in their preset emotional attribute proportions in the subtitles, reflecting the positive portrayal of these characters in the story construction. Among them, Linglan Wu’s proportion of “like” (53.85%) is the highest among these main characters, followed by Minjia Wang, indicating that the positive personality traits of these two characters are more prominent. Peng Chen has a similar proportion of “like” and “sadness” attributes, and this setting makes the character appear more complex and multidimensional, embodying both positive aspects and carrying a certain tragedy or deep emotional story in character design.
By comparing the data of preset subtitles and perceived bullet comments, differences between audience perception and preset emotions can be observed. For Guoguo Zhang, the “like” emotion significantly rises to 47.75% in perceived bullet screens, while other emotions such as “disgust” and “fear” decrease, indicating that the audience has more positive evaluations of Guoguo Zhang. Linglan Wu’s “like” emotion is very high in preset subtitles (53.85%), although it decreases slightly in perceived bullet comments, it remains relatively high, showing that the audience generally has a positive view of him. The “disgust” emotion of Xiang Li significantly increases in perceived bullet comments (43.28%↑), while the “like” emotion decreases substantially (11.94%↓), indicating that the audience is dissatisfied with certain aspects of this character’s performance.
Correlation Between Preset Themes and Keywords in Subtitles and Perceived Themes and Keywords in Bullet Screens
Themes and keywords, based on text mining methods, highly summarize the themes and contents of texts, representing the most important and representative information with textual data. Mining the theme words and keywords in the script texts can verify the artistic pursuit of the film producers, and evaluate the themes and content that are expected to be quickly recognized and emotionally accepted by the public, intending to effectively convey the film information. On the other hand, mining the theme words and keywords in the bullet comments can provide a more objective understanding of the audience’s evaluation and feedback on the movie, identifying which textual symbols have left a deep impression in the audience’s mind and meet the audience’s needs and preferences. Moreover, they can also reflect the ideological content of the film sideways. Therefore, calculating the similarity of keywords and theme words in the movie script and bullet comments can explore the cognitive differences between the audience and the film producers regarding the film. This process can further determine whether the audience comprehends and accurately accepts the thematic and keyword information conveyed by the movie.
The theme words are extracted using the LDA method and the keywords are extracted combined with TextRank and TF-IDF method. The cosine similarity of the keywords between the bullet comments and the script was 0.20, and the theme word similarity was 0.156. The low cosine similarity can be attributed to the linguistic expression differences between the movie script and the bullet comments. The movie script usually uses more standard language, whereas the bullet comments are more casual and colloquial. This difference may cause the keywords and theme words in the two texts not to overlap completely, thus lowering the similarity calculation result.
To solve the problem of synonyms and homonyms words, a word2vec-based method was used to calculate the similarity. This method, through semantic learning on extensive textual data, generates word vector representations accurately reflecting the semantic relationships between words, allowing themes with high similarity to possess similar semantic meanings and reflecting the similarity between film screenplays and bullet comments. The similarity results between the theme lists of film content and bullet content using word2vec are 0.928, and for keywords, the similarity result is 0.85, indicating a high degree of semantic similarity between these two lists, and the themes and ideas conveyed by the movie are well recognized and interpreted by the audience, which is consistent with our intuition.
Discussion
The Impact of Subtitle Narratives on Audience Emotions
Both the language of subtitles and bullet screens are spoken expressions in film screen presentation, implying emotional color. The difference lies in the fact that subtitles provide linear expressions, pre-produced colloquial content, and emphasize plot delivery, while bullet screens represent real-time non-linear expression based on the narrative of the story, integrating individual audience viewpoints, preferences, or interacting with other audience bullet comments. Moreover, bullet comments to some extent also serves as a “moral court” function, where viewers, based on personal experiences and their value standards, imbue emotional moral judgments on the fate or encounters of characters in the film. Thus, whether positive or negative emotions, the emotional values in bullet comments are more densely distributed in areas of strong emotional attributes. The narrative of bullet comments reflects viewers’ direct emotional experiences, allowing for more flexible and direct emotional expression. Therefore, the overall intensity curve of bullet screen emotions exhibits more noticeable fluctuations, frequent peaks, and relatively higher curve distributions. In contrast, emotional expressions in subtitles are more indirect and constrained, resulting in a relatively flat intensity curve with lower heights and an even distribution of emotional intensity scores.
Although there are significant differences between the emotional intensity distribution of subtitles and bullet screens, they also exhibit strong linear correlations, albeit influenced by various factors. Firstly, this process is influenced by temporal deviation factors, as the time required to contemplate and input textual content, which aligns with real-world situations. Secondly, different emotional types have varying degrees of emotional contagion. Specific emotional types, such as surprise or fear, although not much in subtitles, can significantly amplify audience emotional fluctuations. Therefore, plot arrangements involving unexpected and reversed plot arrangements, or unknown plots and scenes can enhance the intensity and depth of emotional experiences. Thirdly, emotional experiences vary significantly at different stages of story development. This study proposes a reasonable formula to calculate emotional growth magnitude, evaluating the emotional tension of film plots and character dialogues, and their impact on audience emotions. In the film sample Forever Young, significant emotional nodes that cause fluctuations in audience emotional experiences are mainly distributed in three narrative structures: the “Complications and higher stakes” interval has the most frequent occurrences, and the largest average impact magnitude exhibited in “The final push” segment. Multiple small peaks of emotional growth magnitude occur in the initial stages of the film, effectively establishing an emotional connection between the audience and the film. In the progress and aftermath phases, one is used to pave the way for the unfolding of the main plot and the other is to wrap up the story, the emotional experiences are relatively stable. Overall, effectively collecting the metronome of film narratives helps reveal crucial plot nodes and emotional trends in films which cause obvious changes in the emotional experience of the movie, while placing the movie metronome appropriately attracts and sustains audience engagement over prolonged viewing periods, which crucial for filmmakers to adjust and improve films in real-time, control pacing and emotional atmosphere for better narrative effects.
The Impact Effect of Collective Narrative in Bullet Screens on Audience Emotions
Audiences engage with films, allowing their emotions to be expressed through bullet screens floating on the screen, enabling strangers to see or persuade others to accept so-called moral solutions. Bullet screens remain in the bullet pool after being posted, allowing viewers from different times and spaces to perceive others’ emotional states and moral judgments through the retained bullet comments. Consequently, viewers reply to bullet comments to engage in communication and share their emotional states with others, sometimes leading to opinion conflicts and group discussions. Therefore, participatory bullet screen culture provides audiences with opportunities for instant sharing and communication, creating an atmosphere of co-presence with others, and fostering an interactive social space of virtual presence. In the film sample, during the initial 17 s before any content appears, the bullet screens flooding the screen with individual expressions serve as the best evidence of this phenomenon. As more and more viewers receive the same format of check-in information, emotions spread within the group, influencing other individuals to unconsciously or consciously acquire the same emotions and participate in the film check-in behavior. To investigate this further, this study calculated the correlation between the number of bullet screens and the relative change in bullet comment emotions compared to subtitle emotions, confirming the impact of collective emotions on individual emotions.
The high concentration of film attention points is not only reflected in the concentration of bullet comments at certain plot points’ timestamps but also in the frequent occurrence of abrupt changes in audience emotional experiences during the development of these plot intervals. In such concentrated areas, instant responses expressed through bullet screens tend to be more positive, and individuals also increasingly feel each other’s emotions more strongly. The magnitude of individual emotional influence within the group becomes greater. For example, in the conflict and climax parts of the film sample from 4091 to 6881 s, there are significantly more bullet screens and emotional experiences of abrupt changes of plot points compared to earlier segments. In the Final Push phase from 7120 to 7200 s, the emotional intensity impact magnitude and bullet screen number form two consecutive high gradient peaks in a short period. This result aligns with the theory of “interaction ritual chains” proposed by contemporary American sociologist Collins (2004), who suggests that users generate emotional resonance during ritual participation, thereby promoting the injection of collective emotional energy into individual emotions. The collective aggregation of physical virtual presence, bullet screen technology, the viewing barrier of the Bilibili platform requiring account registration and membership purchase, the emotional concentration within the audience, the emotional sharing in bullet screens, and the common emotional experiences among participating individuals collectively enable the construction of an interactive ritual space for online viewing, which satisfies the conditions for generating an interaction ritual chain.
The Cognitive Effect Presented by Bullet Screens on the Enhanced Narratives of Subtitles
François Truffaut once described films as implicit, indirect, and delicate art, with as much hidden as revealed. Subtitle is the narrative medium for film stories, often internalizing philosophical metaphors, and conveying certain ideological and spiritual emotions intended to resonate with the audience. Meanwhile, the discourse logic of the bullet screen is actually the overt ventriloquism of the movie, supplementing film information and enhancing the narrative. These two mediums reference to each other in meaning and correspond to each other in temporal positioning, forming a narrative structure that mirrors each other. From reality to the screen, the stance and emotional concerns expressed through bullet screens are stitched into the interstices of film narrative, rendering the development and twists of plots. The organic combination of subtitles and bullet screens adds specific narrative tension to the cinematic world within the drama. This cross-medium mirrored narrative structure also implies that subtitles presuppose the core of the film’s story and character attributes, and provide a conduit for audience empathy. For the audience, the alternating focus between bullet screens and subtitles during the film narrative process can provide dual aesthetic experiences and emotional support. This part considers the differences and consistencies between subtitle preset and bullet screen perceptions from the perspectives of story themes and character emotional attributes.
LDA topic modeling and keyword analysis are used to identify the key themes that films intend to express and to explore the audience’s primary points of interest. The similarity between the sets of keywords and thematic words in bullet screens and subtitles is remarkably high, indicating that the themes and ideas conveyed by the film are well understood and interpreted by audiences. The study also employs fine-grained sentiment analysis to analyze the emotional distribution of the movie’s preset characters. In the film sample Forever Young, all eight main and secondary characters are rounded individuals, rather than flat, black-and-white figures of binary opposition. Some characters come with conflicting attributes that endow a variety of possibilities for interpretation. For example, the even distribution of the main emotions of disgust and like in Guoguo Zhang and Xiang Li, and the dominant emotional distribution of like and sadness in Peng Chen and Linglan Wu. Diverse emotional characteristics signify the multi-layered personality traits of characters, providing audiences with more imaginative space and different aesthetic pleasures. The study compares the gap between subtitle presets and audience perceptions, revealing varying proportions of audience perceptions of characters, sometimes leading to shifts in dominant emotions. Generally, characters are creators of emotions, influencing the audience’s emotions, and a character’s dominant emotion can cause the character to appear in a way that unconsciously focuses the audience on that dominant emotion. However, in the film sample, compared to the film’s preset emotional expressions about characters, only Guoguo Zhang and Peng Chen’s audience-perceived dominant emotions maintain an upward trend. This indicates that while films are responsible for conveying stories and characters propositionally, audiences will explore the intrinsic factors of character and theme, integrating their emotions and thoughts into the understanding of characters and stories.
A Logical and Technical Exploration of Database Cinema
The development of digital technology and artificial intelligence has gradually fed films from traditional linear narrative modes, allowing them to use databases for internal self-indexing. As early as Lev Manovich’s book The Language of New Media, the connection between film and the database model in the field of data statistics was established. Database films address the relationship between databases and narrative, which does not necessarily imply reliance on a specific computer database for production but rather serves as a logical or cultural form involved in the filmmaking process. This study establishes a small-scale “database” for the film Forever Young, based on the time series of the film’s duration of 8,323 s, to resample and fill missing values in the timeline of subtitle and bullet screen datasets. This transformation converts the original discrete data into continuous time series data, implying that each frame of the movie is stored as a data unit.
Various deep learning methods were employed in the given dataset. For instance, fine-grained seven-category sentiment classification and sentiment intensity value assignment were conducted using BERT. LDA was used for theme word extraction, and TextRank and TF-IDF methods were combined to extract keywords. In addition, Word2Vec was used to calculate the similarity of keywords and theme words separately between movie subtitles and bullet comments to overcome the problem of low cosine similarity caused by synonyms. As a resource treasury for film creation, databases can nurture artistic exploration in various aspects. The use of these deep learning tools is precisely dedicated to exploring more of the signified and signifier covered by the research objects “bullet screens” and “subtitles”. Its signifieds and signifiers hold practical implications in reality. The curve features of the film and its bullet screens can instantly identify segments that have a significant emotional impact on the audience, such as plot turning points and climaxes. The correlation and similarity results between the film script and bullet screens can serve as objective feedback data for evaluating the quality of the film.
Conclusion
This study is based on algorithms and tools such as deep learning, data analysis, and knowledge discovery. It combines the perspectives of both the movie content and the audience to explore the different effects of subtitle narrative and bullet screens collective narrative on the audience’s emotional experiences. The research identifies differences in emotional expression between subtitles and bullet screens, as well as their correlations. It suggests that the reasonable setting of plot metronome in subtitles is fundamental for sustaining audience attention, while bullet screens, as a narrative medium in films, can evoke audience emotional resonance. In the online viewing environment, group emotions have a positive impact on individual emotions, and the interaction between subtitles and bullet screens is not only a means of emotional expression but also enhances and interprets film narratives.
However, the study has several limitations, some of which emphasize the necessity for further research. Firstly, the analysis is based on only one film sample Forever Young, which may affect the generalizability of the research findings. Different narrative structures, genres, and types of films may elicit different audience responses, thus future research requires increased diversification and representativeness in film samples. Secondly, since bullet screen data only come from the Bilibili platform, audiences from different platforms may have different cultural backgrounds, viewing habits, and communication styles. Therefore, integrating data from multiple platforms where the film samples are available would provide more comprehensive audience feedback. Thirdly, due to the uniqueness of the narrative structure of the film sample, scenes were manually segmented according to the theoretical framework, which may not be universally applicable. Although the study has confirmed the existence of biases in time series data, related issues remain unresolved, potentially leading to errors in scene segmentation and bullet screen matching, thereby affecting the analysis of the relationship between emotional fluctuations and movie plots. Future research could explore more refined scene segmentation methods or semantic analysis-based scene matching methods to improve matching accuracy.
In summary, the entire research process reflects the use of database logic and technology as fundamental means to understand and express the emotions and content of movie works. Therefore, the research itself has extensibility and modernity. It holds the potential to propel the ongoing advancement of film narrative creation, particularly within the realm of interactive movies, by continually improving narrative rhythm, logical sequence, emotions, themes, and the optimization of interactive elements in cinematic storytelling. This encourages filmmakers to explore the depth and breadth of database cinema, encouraging experimental creation beyond linear narratives, which is also in line with Manovich’s views on database films.
Footnotes
Author Contributions
The contributions of the author in this study are as follows: Wang Hanmei was responsible for data acquisition, data cleaning, data analysis, and the writing of the paper.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Availability of Data and Materials
The movie scripts and bullet screen data used in this research were obtained from publicly available online resources and do not involve direct human participant data. Wang Hanmei adhered to the terms of use and policies of the respective websites during the data collection process and did not infringe any copyrights. All data were used in an anonymous manner and do not involve personal privacy, therefore informed consent is not required.
Due to copyright and protection issues related to the movie scripts and bullet screen data, the author is unable to publicly share the raw data. However, WANG Hanmei welcome other researchers to contact via email for more detailed information about the data and potential collaboration opportunities. The author will do best to provide relevant information regarding data sources and descriptions so that other researchers can conduct similar research or verification.