
Abstract
Open science movement gains attention since it might enable a second scientific revolution that fundamentally changes research methods and standards across science. However, the discussion topics towards opens science both from the academia and the environments outside the scholarly communication process have not been formally identified. This paper contributes to that end by analyzing 145,716 open-science-related tweets and 3,200 research papers in Scopus from 2011 to 2022. The results show there is increasing interest about open science both on Twitter and from academia. There are similar foci for both the public on Twitter and the academia from Scopus, including cloud computing and COVID-19 pandemic. When the public on Twitter focus on open science events and citizen science, the scholarly research is more concerned about the detailed aspects and novel innovation in research. The findings might interest the policy-maker for offering evidence to facilitate open science policies and practices.
Introduction
Over the past years, science has witnessed a shift towards openness, transparency, and reproducibility, a movement known as “open science” (Bartling & Friesike, 2014). Open science is a umbrella concept and implies the opening of all phases of scientific research, as well as participatory process for determining the scientific and research agenda in relation to the public and their concerns (Nosek et al., 2015). The open science movement continues to gain momentum, attention, and discussion since it might enable a second scientific revolution that fundamentally changes research methods and standards across science, acknowledging the rapid technology changes primarily driven by the Internet (Choi, 2023; Homolak et al., 2020; Lefebvre & Spruit, 2023; Ramachandran et al., 2021).
Open science seeks new modes of relationship between the traditional creators of knowledge, such as scholarly researchers, and a wide range of users and those interested in it (Rodriguez-Pomeda et al., 2023). Hence, open science could be interested to not only those primary researchers, but also the general public (Voytek, 2017). Particularly, the challenge of the public health emergency, such as the COVID-19 pandemic gave evidences that open access to the critical scientific information and material is both crucial to the general public and the researchers (Besancon et al., 2021; Boby et al., 2023; Molldrem et al., 2021). As a potential public sphere (Dursun & Yildiz, 2022), social media platforms facilitate people to reflect and express opinions, so that could be connections between monotonic scholars and the general public (Y. Zhang et al., 2024). It is regarded that social media provide a platform to run “biggest research conference in the world” instead of offering costly affairs only available to the privileged relative few (Voytek, 2017). Zong et al. (2023) adopted the social media attention on articles to estimate the effects of open science badges and at last the effectiveness of the open science policy.
As a influential social media, Twitter is often adopted as an empirical source for scientific research (Brembs et al., 2023; Karami et al., 2020; L. Zhang et al., 2023). It is regarded that microblogging on Twitter extends public science communication by providing additional voices and directing attention (Buchi, 2017). Also, Twitter has been found to facilitate direct interaction between researchers and the public (Cheplygina et al., 2020). Hence, Twitter could be employed side-by-side with citations as “altmetrics” (Jia et al., 2020). Fang et al. (2022) analyzed scientific articles and academic tweets to focus on the user engagement behavior around scholarly tweets. Compared to other four open altmetrics data sources including Mendeley, News, Blogs and Policy, Twitter attention surrounding research output both starts and ends quickly (Taylor, 2023). Besides technologies, the impact of publications in the field of social sciences could also be evaluated adopting Twitter as open altmetrics (Sedighi, 2023).
In addition to act as new generation metrics for research quality and impact, Twitter is also adopted in public opinion mining on specific science-related topics. To understand patron engagement with the library, Stewart and Walker (2018) analyzed retweets and Twitter followers to identify that most tweets were related to “institutional boosterism.” One study examined Lanadian tweets on Marijuana legalization and terminology to demonstrate how this kind of research method may be used to inform library practice (Kung et al., 2024). DORA (Declaration on Research Assessment)-related tweets were collected to identified the viewpoints on social media (Orduna-Malea & Bautista-Puig, 2024). The open access movements were also examined on Twitter for its main features (Sadiq & Yadav, 2022; Sotudeh, 2023; Sotudeh et al., 2022). All the above research works demonstrate that Twitter is appropriate for both open altmetrics and opinion mining for science-related topics, but few of them formally identified the discussion topics and trends about open science on Twitter.
Besides opinion mining on Twitter, topic modeling is popular in mining the voice of the academic from research publications (Wang et al., 2023). In many cases, the academic view counts a lot in policy-making, especially in the development of some special disciplines (Luhmann et al., 2022; Walsh et al., 2022). Because of the importance of bibliometrics study in academic research, there are continuous publications of the literature focusing on the important facets. Bashar et al. (2023) found the influence of COVID-19 on consumer behavior as a guide for the researchers and decision-makers to strategies accordingly through a bibliometric review analysis. A bibliometrics study of the cancer research in the faculties of medicine and dentistry was reported in Al-Raeei et al. (2023) in order to investigate the scientific research outputs of the Damascus University. Hence, a comprehensive study is required to collect and analyze for both the public opinions on social media and the academic views studies to identify open science topics formally. Such comprehensive visions could act as public engagement for policy-maker that provide opportunities not to rethink their policies and practices, but to gain trust for a predetermined approach (Alexopoulos et al., 2014; Thorpe & Gregory, 2010).
For this aim, in this paper we raises the following research questions:
RQ1: What is the public opinion concerned about the umbrella concept “open science” on Twitter ?
RQ2: What kind of viewpoints does the academia hold towards “open science”?
RQ3: What is the consistency or difference between the public opinions and the academic view about “open science”?
These three research questions aim to consider open science both from public opinions on Twitter and the academic view in research publications. The first questions reflects the online public’s beliefs and focus on open science topics on Twitter. The second question describes the scholarly viewpoints the researchers hold for open science in their studies. The third question shows the consistency or differences between public opinions and academic views towards open science.
Data and Methodology
Research Design
To understand open science in a comprehensive way, the paper provides insights into both the tweets data and the Scopus data. A research framework shown in Figure 1 is designed to characterize the viewpoints from both the public and academic towards open science. Since both the public opinions and academic view towards open science are mainly objective statements, there were very few descriptions about emotion. And most of the tweets and research publications expressed support for open science.

The research framework of mining topics on open science.
As shown in Figure 1, the main procedures in this research included three steps: data collection and cleaning, data processing, and data analysis. In the first step, the raw data from Twitter and Scopus database were collected and cleaned. The tweets data was collected through the hashtag “open science,” and was cleaned by getting rid of noise, stopwords and POS (part-of-speech). While the Scopus data was sourced from the Scopus database with the keyword “open science.” Duplication deletion was applied on the Scopus data to get rid of the repetition.
The second step was data processing. The cleaned data from both data sets were processed with topic modelling, respectively. The temperature metrics was adopted on tweet data for annual hot spot. And the VOSviewer application was employed to visualize the keyword co-occurrence of the Scopus data. In this paper, topic modelling adopted latent topic analysis to model and aggregate when figuring out the major topics in tweets or research publications, respectively.
In the third step, we employed different data analysis methods on tweet data and Scopus data, and finally made the comparison analysis between the two datasets. This study observed the major topics and diachronic changes on open science. Additionally, keyword co-occurrence could help to clarify and understand the focus on open science from researchers. The comparison between the viewpoints both from the public and academia could provide evidences supporting to policy-maker and participator in future, and eventually help facilitate open science practice.
Tweets Dataset
To test our proposed methods, we used a tweets dataset collected from Twitter. This dataset used “open science” as hashtag to crawl open-science-related conversations on Twitter. After data cleaning, we have collected the tweets data from January 2009 to December 2022. It could be observed from Figure 2 that open-science-tweets in 2011 were about 2000 posts. In 2009 and 2010, the tweets collections were only 103 and 490. These “open science” tweets rose to 6180 in 2012 and keep increasing till 2017. There is a slight decline after 2018 and the tweets collection end in 12549 tweets in 2022. Since the tweets collections in 2009 and 2010 are not large enough for data analysis, we only used the data from January 2011 to December 2022. At last, we totally got 145,716 posts on “open science.” These posts were made of notices, advertisements, opinions, etc. Since there were few retweets and likes, we ignored them and only examined the posts on Twitter.

The change of the total tweet number on open science over year.
Scopus Dataset
We collected the published publications about “open science” from the Scopus database. We focused on the period from 2011 to 2022, which witnessed the bloom of the open science practice. The keyword “open science” was searched in the TIT-ABS-KEY field of Scopus search engine. Only articles and conference papers written in the English language were included. Totally 3,477 papers, including 2,649 articles and 828 conference papers, were returned in .CSV format. After deleting the duplication through checking the DOIs, we got 3,200 papers.
From Figure 3, we can see that the number of published papers increased from 41 in 2011 to 752 in 2022. The number of the published papers increased in a nob linear functionality and the increasing of the published papers is about 19 times. The increasing reflects the blooming of “open science” in academic. In Figure 4 and based on the Scopus data, we illustrated the published documents that are abstracted and indexed in Scopus database. It could be observed from Figure 4 that the published papers in computer science represent about 18.2% of the total published papers towards “open science,” and are the most. While the published papers in social science represent about 14.9%, are the second. Also, the third are the published papers in medicine, which count for 10.4% of the total published papers towards “open science.” This proportion reflects the various interests towards “open science” in different subject areas.
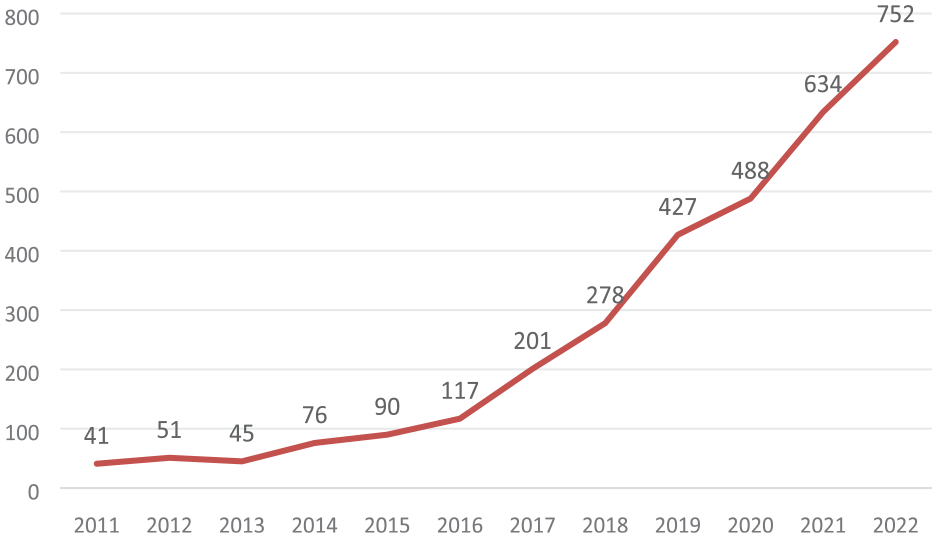
The “open science” papers abstracted and index in Scopus database from 2011 to 2022.
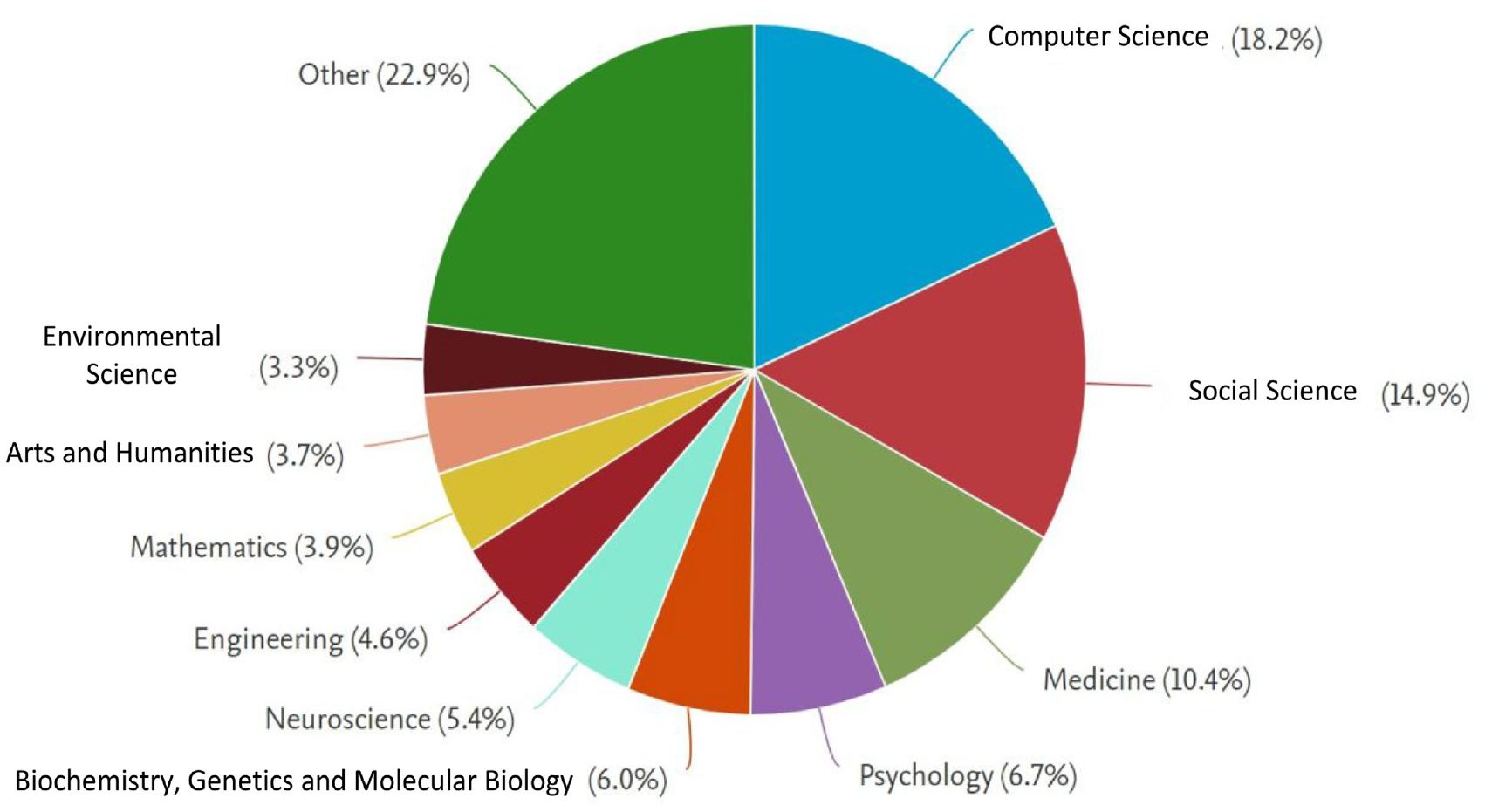
The proportions in different subject areas.
Temperature Metrics
In order to identify the focus of open science on Twitter each year, we need to find the representative keyword. Previous works (Troussas et al., 2019; S. Zhou et al., 2020) preferred high-frequency words as hot words to represent the hot spots. However, in this paper the hot words were almost the same for each year so that they couldn’t describe the changes of the viewpoints on open science over time. The reason for it is that experimental data were short text on various topics. Hence, there were a large number of low-frequency words and the high-frequency words tend to be fixed on some special words all the time.
To tackle the sparsity problems of the tweets data, we introduced temperature parameter to get more diversified results. The temperature parameter is a hyper-parameter used in language models such as GPT (Brown et al., 2020) to control the randomness of the generated text. It controls how much the model should take into account low-probability words when generating the next token in the sequence. The parameters control the degree of randomness or creativity in the generated output. Randomness could be regarded as the diversity of responses to multiple inquires. A high randomness might result in more creative responses, that is, a higher likelihood of answers without factual basis. On the contrary, low randomness could be described as multiple inquires being more likely to encounter repeated answers, while these answers are closer to fact, that is, closer to training data. The original metric was given in equation (1):

Where
In this paper we modified the original formulation to form our temperature metrics applied to the tweets and Scopus data. At first, we defined the probability of word wi appearing in the dataset in the jth year as pij:

Where tfij is the term frequency of wi in the dataset in the jth year, and Nj is the number of all the documents in the jth year. Here, j is from 2011 to 2022. Then, the temperature metrics of wi in the jth year is defined as:

Here, we adopted
Finally, the weight of the word wi appearing in the jth year was:

In this paper, we adopted Sij instead of term frequency to select the representative keywords for each year. The words with high Sij will be chosen as the representative keywords. The temperature metrics allowed us to control the deterministic factors. When T is almost 0, the value of temp(pij) becomes positively infinite. On the other hand, the infinite temperature will bring 1/11 to temp(pij) in each year so that the representative keywords with high Sij will be almost the hot words with high term frequency.
Topic Modelling and Aggregation
As an unsupervised machine-learning approach for discovering latent hidden semantic topics in large collections of documents, topic modelling could identify clusters of documents by a representative set of words. To understand the major topics being discussed in the data collections, this paper adopted Latent Dirichlet Allocation (LDA) proposed by Blei et al. (2003) as topic modelling techniques. The most highly weighted words in each cluster provide insight into the content of each topic. LDA requires users to input the number of expected topics. To determine the optimal number of topics, coherence score was adopted in this paper.
In the context of documents analysis, LDA has been criticized for producing non-replicable results by Steyvers and Griffiths (2007). Hence, aligning topics from multiple models was mentioned to ensure the reliability of LDA results. Many works have introducing approaches to increase the reliability of LDA (Blair et al., 2020). We took up this idea by adopting topic aggregation in our methods. When setting k topics in LDA model, we run n LDA models based on the previously determined hyperparameters and differing random states. This would provide n times k, that is, n × k topics. These topics are then clustered using k-means clustering, based on the cosine distance between their term probability distributions. In order to get rid of noise, we chose to perform topic modelling exclusively on nouns, proper nouns, and noun phrases. Since all function words are generally not relevant for identifying topics, the elimination provides noise reduction. As discussed in Martin and Johnson (2015), a nouns-only approach leads to better interpretable topics.
Assigning Themes in Public Opinions
There are several topics after LDA modeling on tweets data. Through discussions, the authors then grouped the topics of public opinions into broader themes. Our procedures are consistent with similar studies that have examined social media data using text mining and topic modeling (Chandrasekaran et al., 2020; Q. Zhou & Jing, 2020). In order to classify the open science topics, we adopted the classifications described in UNESCO (United Nations Educational Scientific and Cultural Organization) Recommendation on Open Science (UNESCO, 2021). In this Recommendation, UNESCO provide four open science themes: open scientific knowledge, open science infrastructures, open engagement of societal actors, and open dialogue with other knowledge systems. Besides the classifications described in UNESCO Recommendation on Open Science, there are still some ambiguous topics which are not clearly defined in UNESCO Recommendation. We classified these non-UNESCO topics into “others.” Since there were no topics about the theme “open dialogue with other knowledge systems,” we haven’t taken this theme into account in this paper.
Table 1 shows the tweet samples in the four themes in this paper. From these samples it could be observed that the tweet data covered various types of posts, including public opinions about open access, advertising of the projects or tools, testing of the open infrastructure, or open science in other disciplines. The intensive discussion on social media reveal the focus of the public on open science so that it could provide abundant material for policy maker to adopt appropriate open science policies.
Samples on the Four Open Science Themes.

When grouping the topics of LDA into broader themes, we adopted the weights provided by LDA and a self-building theme vocabulary. The self-building theme vocabulary consists of words from the UNESCO Recommendation, as well as the tweets data set we collected. Table 2 shows the sample of the self-building theme vocabulary.
Self-Building Theme Vocabulary.

In the processing of the topic modelling, LDA will give the value of probability p (w|t) for the word w in topic t. Suppose Tm is the word set of the mth theme/sub-theme of the self-building vocabulary. Here,

When grouping the topic to the themes, we assigned the Tm to tk if Um,k is the largest to tk.
After assigning the themes/sub-themes, we selected the representative keywords for the themes/sub-themes. For the word wi,

Here, pj(wi|tk) is the p(wi|tk) in jth year. Then, we could get the values of Vi,m in a descending order and select the top 5 keywords as the representative keywords for the mth theme.
Results Analysis on Tweets Data
Annual Hot Spots Analysis
In this paper, we obtained the representative keywords when T = 0.3. This value of temperature could ensure the specificity of these representative keywords, as well as refuse trivial nonsense. From equation (3), it could be observed that the temperature metrics will highlights the difference among various years. Hence, it could be inferred that the annual hot spots selected through temperature metrics could reflect the specific focus of the public opinions for each year. From Table 3, it could be observed that when T = 0.3, we could get appropriate keywords. When T = 1.0, the keywords were too general to describe the specificity of each year. While when T = 0.1, the keywords were very particular that it might lack a macro view towards open science. The top 10 representative keywords for each year were shown in Table 3. To provide a overview of the annual hot spot on open science, we observed the corresponding tweets of the representative keywords and found the important events and entities. Also, a brief is given for the character of the public opinion towards open science each year.
Top 10 Keywords for Annual Hot Spot.

2011 The Starting Year of Open Science: Some First-Time Discussion or Contest to Initiate Open Science
2012 Open Science Policy Establishment: Some Rules and Act Established as Basic Blocks of Open Science
2013 The Boom of Communities and Events on Open Science
2014 Tools and Services on Open Science
2015 the Beginning of the EU Cloud and Open Science Practice
2016 Practice on Open Science and Zika Virus
2017 Open Science Practice on Farming and Citizen Science
2018 Blockchain and Open Science
2019 Open Science Based on Blockchain and Online Course
2020 COVID-19
2021 More Open Science Practice, Especially on Health
2022 More Diverse Open Science Practice, Including Different Infrastructure, Discipline, or Gender
Themes and Prevailing Trends
Through topic modeling, we identified various topics on open science in different years, respectively. The numbers of topics in different years are shown in Table 4. Figure 5 shows the proportions of each themes on total tweets data set. From Figure 5, it is obviously that “open scientific knowledge” is the hottest theme (49%), which attracted most attention from social media. The theme “others” also accounts for a large proportion (34%) in total data set because it covered various topics outside of the UNESCO Recommendation. The theme “open engagement of societal actors” (11%) and “open science infrastructures” (6%) were less intensively discussed compared to the former two themes.
The Number and Proportions of the Themes in Each Year.


The proportion of the four themes on open science.
Table 4 shows the topic numbers and the proportions of the themes on open science each year, and Figure 6 describes the themes trends over time. From Table 4 we can observe that the topic numbers kept to increase until 2017, when the peak is 18. After that, there is a slight decline in the total topic numbers and it ended in 15 in 2022. The trend of the tweets topic numbers is consistent with the trend of the total tweets numbers shown in Figure 2. It is hence evident that the optimal numbers of topic modeling are reasonable.

The change of the four open science themes over time.
From Table 4, it is observed that the theme “open engagement of societal actors” started at 2012 (6.15%) and boomed in 2013 (20.68%). Also, the theme “open science infrastructures” began at 2015, which is consistent with the annual hot spot analysis-there appeared the first tweet about the EU cloud in 2015. In addition, as shown in Table 4, it is worth noting that the development of the open science could not be separated from the boom of the innovative technologies. For example, the open science for virtual infrastructures in 2015 was based on the cloud computing starting in 2014 (Dordevic et al., 2014). Also, before the start of “open engagement of societal actors,” the keyword “open business” was mentioned in tweets, which is the predecessor of “crowdfunding” and “crowdsourcing.” These facts provide evidence that the development of open science is closely linked to the advance of technology.
From Table 4 and Figure 6, we could find that the theme “others” exceeded all the other themes on open science in 2020. The reason is that in 2020, COVID-19 broke out, leading to the explosion of the related topics. These tweets were mainly about influence the COVID-19 exerted on open science practice, or the benefits of taking open science events in the pandemic. The interactions between “COVID-19” and “open science” indicate that open science practice was closely bound up with the current events and users’ needs.
Theme 1: Open Scientific Knowledge
The theme “open scientific knowledge” refers to open access to scientific resources (UNESCO, 2021). According to the Recommendation, there are five sub-themes contained in this theme: scientific publications, open research data, open educational resources, opensource software, and source code, as well as open hardware. Since opensource software and source code, as well as open hardware are all open tools, in this paper, we combined the two sub-themes into the open tool sub-theme.
Figure 7 shows the proportions of the different sub-themes in the theme “open scientific knowledge.” It is obviously that “scientific publication” possesses the largest share (50%) in this theme. The sub-theme “open data” accounts for 25% in the theme, much lesser than “scientific publication.” The share of the “open tool” (13%) and “open education” (12%) is similar. It shows that “scientific publication,” also mentioned as “open access,” was the most concerning sub-theme in the theme “open scientific knowledge.”

The proportion of the topics in the theme “open scientific knowledge.”
The five representative keywords in Table 5 describe the main contents of various sub-themes. It could be observed that these sub-themes contained different details on open science. “Scientific publications” is about “openaccess,” and users were more concerned about “article,”“preprint,”“journal,”“publish,” etc. “open data” include the science, rules, and visualization of data, such as “datascience,”“dataviz,” etc. This sub-theme also contains data itself, such as “bigdata” and “clinicaltrials” (clinical trials data). The sub-theme “open tool” was composed by “openhardware” and “opensource,” while “github” is a opensource community. The keywords for “open educational resources” were mainly “openscholarship,”“training,”“school,”“course,” etc.
Keywords Contained in Four Sub-Themes Belonging to Theme 1.

Theme 2: Open Science Infrastructures
The theme “open science infrastructures” refers to the sharing research infrastructures that are needed to support open science and serve the needs of different communities. It mainly includes virtual and physical infrastructures (UNESCO, 2021).
As shown in Table 6, these keywords could be classified into two classes: the virtual infrastructure, including “cloud” and “openaire”; and the supporting project, such as “h2020,” and “horizoneu.” Here, the keywords “openaire” is Open Access Infrastructure Research for Europe, an active network in 35 countries; “cloud” refers to the cloud computing platform. The keywords “h2020,”“horizon” and “horizoneu” all refer to the horizon project in Europe, the EU’s key funding program for research and innovation.
Keywords in Theme 2 and Theme 3.

Theme 3: Open Engagement of Societal Actors
The theme “open engagement of societal actors” is the extended collaboration between scientists and societal actors beyond the scientific community. They are mainly crowdfunding, crowdsourcing, scientific volunteering, and citizen and participatory science (UNESCO, 2021). The five representative keywords are shown in Table 6. In this theme, there were many projects and events of citizen science mentioned in the section “annual hot spot analysis,” such as “Cancermoonshot,”“sagecon,”“Openoxford,” etc.
Theme 4: Others
Besides the UNESCO classes, there are also some sub-themes which are not contained in the UNESCO Recommendation, as shown in Table 8. These sub-themes are open science events, open science definitions, open evaluation, blockchain, discipline, and COVID-19.
As shown in the Figure 8, “open science events” was the largest sub-theme (42%) in the theme “others.” The reason for that is because many organizations or authorities adopted Twitter as advertising platforms for their events. “open evaluation” accounts for 22% in the theme, shown that how to evaluate the performance of the open science projects or tools as well as the impact of the open access papers was most concerned by the public. The sub-theme “open science definition” (14%) describe the various definitions given to the umbrella concept “open science.” The sub-theme “blockchain” (10%) was mainly about the interaction between the blockchain and open science. The sub-themes “discipline” and “COVID-19” have the same share (6%), much smaller than the other topics.

The proportion of the topics in the theme “others.”
From Table 7, it is obviously that open science practice exert important influence on the researchers’ life. In the sub-theme “open science events,” the keywords “conference,”“workshop,”“discussion,”“session,” etc., reflected that people usually communicate “open science” in these way.
Keywords for Sub-Themes in Theme 4.

The keywords contained in the sub-theme “open science definitions” are all about the definition and classification of open science. Here, “ciencia” and “wissenschaft” are all non-English language, which mean “science.” The keyword “ouverte” and “abierta” all means “open” in English.
How to evaluate the performance of open science is always an important research problem. The “open evaluation” sub-theme began in 2012, a year after the open science starting year. The keyword “altmetrics” is non-traditional bibliometrics performed as an alternative or complement to more traditional citation impact metrics, such as impact factor and h-index.
2017 and 2018 witnessed the growth of blockchain. The keyword “linkedresearch” is a movement to encourage researcher to publish in a self-controlled and accessible way so that the free linkage to other research and reuse could be applied. “crypto” and “bitcoin” are all digital currency based on blockchain. These keywords show that blockchain technologies are applied to both open science research platform or tools, as well as to the finance.
The sub-theme “discipline” is the branches of learning that closely related to open science. The keywords show that “bioinformatics,”“climate,”“digital health,”“space,” etc., are all interconnected with open science. Instead of these traditional disciplines, open science could also facilitate novel subbranch of learning, such as “open sociology.”
Results Analysis on Scopus Data
Annual Hot Spots Analysis
To obtain the annual hot spots in scholarly research, we also applied temperature metrics to Scopus dataset. We extracted the keywords, title, and abstract of the research publications to get the hot spots. The results were shown in Table 8. In Table 8, top 10 keywords for different temperature values (T = 0.1, 0.3, 1.0) were described. It could be observed that the smaller temperature value will give more special keywords, while the high-temperature words tend to be fixed words and changed slowly over years. To get the annual hot spots of the Scopus data, the top 10 keywords were selected when T = 0.3.
Keywords for Different Temperature Values.

We observed the corresponding research papers and gave explanations to some special representative keywords every year. From these explanations, it could be observed that the annual hot spots of the research papers are mainly technical terms in research or neologism about novel technologies, especially in biology, computer science, medicine, etc. For example, the keywords “grid computing” (2011), “hadoop” (2012), and “mapreduce” (2012) are all technology innovations and the precursors of the new technique “cloud computing” in 2014. It demonstrates that the annual research hotspots might predicate new technologies in the industry.
2011
Cpass: Comparison of Protein Active-Site Structures.
Ldap: Lightweight Directory Access Protocol.
Grid: grid computing.
Svopme: Scalable Virtual Organization privileges management environment.
Saber: Sounding of the Atmosphere using Broadband Emission Radiometry.
Xquery: XML query.
Bioclipse: an open source workbench for chemo- and bioinformatics.
2012
Keeneland: Keeneland Initial Delivery System (KIDS).
Percolation: percolation problem.
Hadoop: an open-source data processing framework including mapreduce model.
Mapreduce: fault-tolerant and scalable distributed data processing model and execution environment.
2013
Onama E-Onama: Mobile high performance computing for engineering research.
AGRIS: International Information System for the Agricultural Sciences and Technology.
Diybio: do it yourself biology.
Euchinahealthcloud: The EUChinaHealthCloud proposal contributes to the aims of the Research Infrastructures part of the EU Seventh Framework Programme (FP7) by promoting cloud computing between the European and the China.
Condo: Condominium cluster.
Fmridc: the FMRI Data Center.
2014
Bronchiectasis: disease.
Dihydrospiro: a kind of chemical production.
Piperidine: a kind of chemical production.
Wrangler: the Texas Advanced Computing Center presents Wrangler.
Phantom: phantom study.
Street: Openstreetmap, an open map tool.
Elastography: imaging the elastic properties of soft tissues.
Sandhills: distributed execution platforms for Scientific workflows.
2015
Coalescent: a chemical product for coalescing.
Metastasis: cancer metastasis.
Pypedia: using the wiki paradigm as crowd sourcing environment for bioinformatics protocols.
Colon: The section of the large intestine extending from the cecum to the rectum.
2016
Gleon: Global Lake Ecological Observatory Network.
Vocalisation: Ultrasonic vocalisation.
Kademlia: A kind of Distributed Hash Table.
Braf: a kind of gene for cancer biology.
Tcga: The Cancer Genome Atlas.
Bosc: host site.
Craf: a kind of gene for cancer biology.
2017
Firmware: a kind of hardware.
fer2016: Finkel et al. (2017), a research publication.
Lateralisation: language lateralisation.
d’anthropologie: anthropology in French.
Laterality: language laterality.
Dysplasia: maldevelopment.
2018
Secretase: gamma secretase.
Dysbindin: lack of bond.
Cerebellum: the part of the brain at the back of the head that controls the activity of the muscles.
Rhoa: a kind of gene.
Rotenone: a broad-spectrum insecticide.
Bace: beta-site APP-cleaving enzyme.
2019
Badge: open science badge.
Testosterone: a kind of chemical substance produced in the body.
Perfusion: cerebral perfusion.
Rrid: research resource identifiers.
2020
Betacoronavirus: a kind of coronavirus.
Radiography: the process or job of taking X-ray photographs.
2021
ppds: purified protein derivative-standard.
Pocus: point-of-care ultrasound.
2022
Trial: biology experiments.
In 2013, the keyword “diybio” is about citizen science. This is consistent with the time of the open science community booming mentioned in annual hot spots in tweet dataset. Also, open science tool (e.g., open street map) in 2014 was also mentioned in 2014 hot spots in tweet dataset. It is evident that the annual hot spots of open science from both scholarly research and the public opinions are consistent. From the annual hot spot of the academic, it could be noted that with the development of open science, social science becomes one of the research hot spots besides the technologies. For example, there are research publications about language laterality and anthropology (d’anthropologie) in 2017, as well as psychology such as pride (2020) and happiness (2022). The COVID-19 pandemic are mentioned in 2020 (betacorahavirus) and 2021 (COVID-19).
Keywords Co-occurrence Analysis
In our study, VOSviewer software application was employed for creating a network visualization map. We adopted VOSviewer application to create the co-occurrence of keywords, which analyze and count the paired data and similarity of the document (Ariza-Garzon et al., 2021). As shown in Figure 9, the network is made up of 1,682 keywords and six clusters, which have occurred at least five times in the data set.

The visualization of keyword co-occurrence.
As shown in Figure 9, the largest cluster, represented by the red color, is made up of 665 keywords. The most prominent keywords (five for brief) in this cluster are open science, information management, software, open systems, publishing. These words shows the important aspects of the research on open science practice which describe the trends and focus on open science for the researcher in academic (Beamer, 2019; A. Bennett et al., 2022; Kusters & Klages, 2019). This cluster also indicated the evolution of research in the domain of information management, software, data handling, publish, etc. (Figueiredo et al., 2022; Mosconi et al., 2022).
The second largest cluster, which is in green, is based on 431 keywords. The top 5 prominent keywords in this cluster are human, female, male, systematic review, article. This cluster signifies the importance of the application and practice of open science in the research fields related to human being (O’Connor et al., 2022; Riches & Jackson, 2018; Smart et al., 2022). The application technology included systematic review, review literature as topic, etc. (A. Bennett et al., 2022; Carbine et al., 2019).
The third largest cluster (blue) consists of 244 keywords. The top 5 prominent keywords in this cluster are controlled study, priority journal, nonhuman, metabolism, and drug. These words shows the important aspect of open science in animal experiment, controlled study, drug, etc. (Barreda-Manso et al., 2021; Marsden et al., 2022).
The fourth largest cluster (grass green) is made up of 122 keywords. The top 5 prominent keywords in this cluster are ethics, information processing, procedures, biomedical research, and personnel. This cluster described the ethics consideration and the information processing and dissemination method for researchers in biology adopted open science practice (Bourgeat et al., 2013; Thumbeck et al., 2021).
The fifth largest cluster (purple) is based on 112 keywords. Reproducibility, human experiment, replication, preregistration, and meta research are top 5 keywords in this cluster. These keywords specify the nature of open science and the basic methods for researchers to practice open science, such as meta analysis, meta research, etc. (Draborg et al., 2022; Jackevicius et al., 2019).
The smallest cluster (sky blue) consist of 108 keywords. The top 5 keywords in this cluster are brain, neuro-science, diagnostic imaging, image analysis, and algorithm. This cluster described the open science practice on brain/neuro science and the implementation method, such as image processing, diagnostic imaging, algorithm, etc. (W. Bennett et al., 2018; Lefaivre et al., 2019).
Topics Analysis
We applied topic modeling on the Scopus dataset and got 10 topics. The topics and their proportions, as well as the top 5 keywords were shown in Table 9.
Topics and Keyword of the Scopus Data.
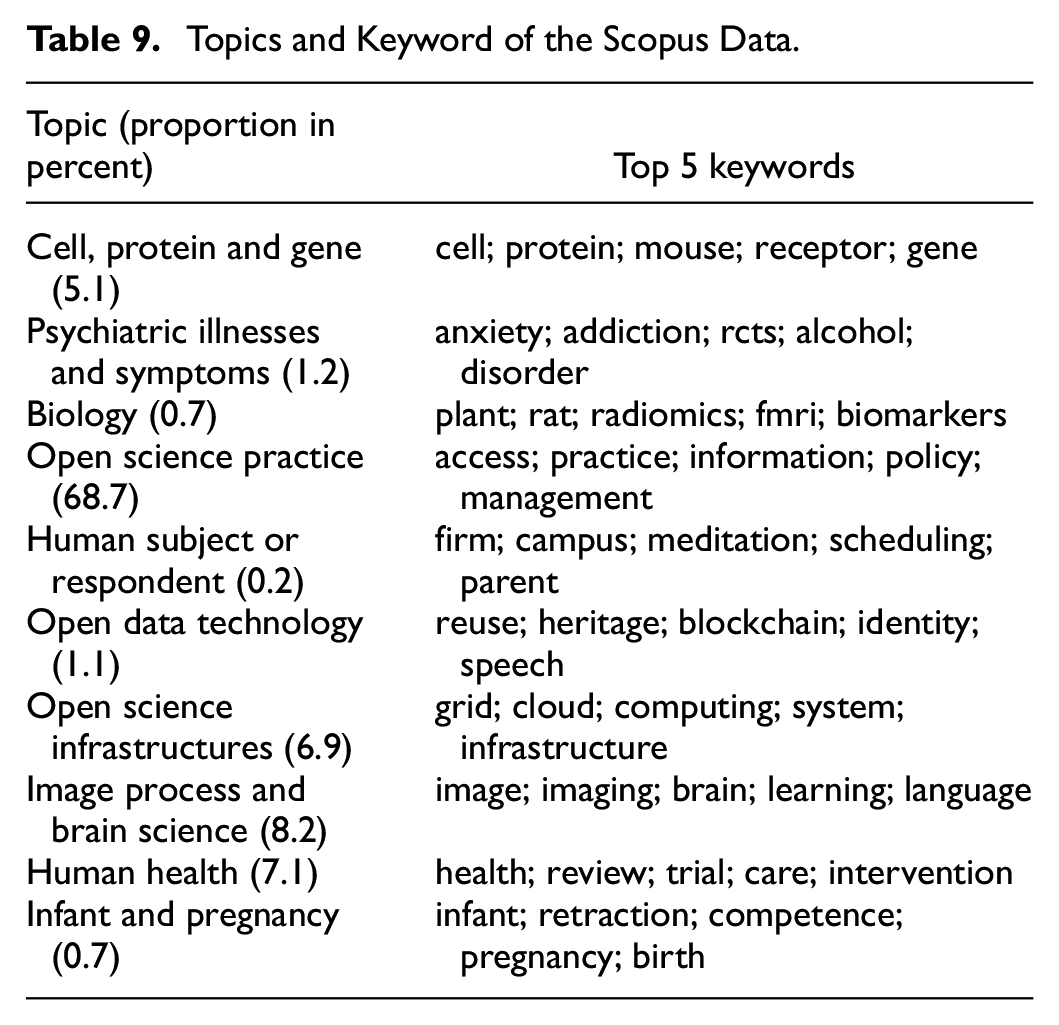
It could be observed in Table 9 that the largest cluster was topic “open science practice” (68.7%). This topic was mainly about open access, open science policy, open science practice, etc. (Hoces De La Guardia et al., 2021; Lefaivre et al., 2019). The second largest topic described image process and brain science (8.2%) (W. Bennett et al., 2018; Lefaivre et al., 2019). The third largest was “human health” topic, whose keywords included health, care, trial, etc. (7.1%) (Coro, 2020; O’Brien et al., 2021). The smallest cluster was about human subject or respondent (0.2%) (De Crescenzo et al., 2022; Klein, 2022). The human subject/respondent might come from firm or campus, and the experimental methods could be meditation, mindfulness, etc. (Bokk & Forster, 2022).
As Table 9 shows, the topic modeling results were consistent with the clusters of the keywords co-occurrence analysis: open science practice was the main focus for researchers towards open science. At the same time, open science infrastructures (6.9%) and open data technology (1.1%) were also mentioned in the academic papers. Besides the discussion on the components of open science, researchers were interested in open science practice in various disciplines, especially brain science (8.2%), human health (7.1%), gene (5.1%), biology (0.7%), psychiatric illnesses (1.2%), human reproduction (0.7%), etc.
Comparison Between Two Kinds of Viewpoints
When make comparison analysis between the tweet dataset and the Scopus dataset, we could find several noteworthy points. At first, from topic modeling, it could be observed that the topics about the open science knowledge and infrastructure attracted the most attention from both the public (55%) and the academic (76.7%). From these topics, open access was the hottest one. There were 24.5% posts from tweet data belonged to open access and scientific publications, while about 68% publications from Scopus data mentioned open access and open policy. Also, open science infrastructure was mentioned from both datasets, that is, 6% from the public and 6.9% from the researchers. Then, the topics about open data was more popular on social media (12.5%) then in academic (1.1%).
Secondly, the technologies of computer science have fostered open science practice from every aspect. From the analysis both on tweet data and Scopus data, it could be observed that the information technologies exerted important influence on the development of open science. Blockchain, for example, was a innovative technology for both open data management and the open science workflow (Tschirner et al., 2021; Yun-Chi et al., 2022). Cloud and grid computing, on the other hand, were the basic block for constructing the open science infrastructure (Fisser et al., 2020; Laurin et al., 2022). Also, the computer and information technologies were combined with other disciplines in open science practice. In brain science, for example, imagine processing and analysis were mentioned in open science practice (Gold, 2016; Mosser et al., 2021).
Thirdly, the topics about open engagement of societal actors were discussed more frequently on Twitter than in academic. Many citizen science projects were advertised and organized through Twitter, such as pdftribute, openoxford, phdvoice, etc. Hence, these projects or activities were frequently discussed on Twitter. There were also some studies on citizen science or crowd sourcing in Scopus data (Heigl et al., 2020; Sarpong et al., 2020), but it was not the burning issue for the researchers. The underlying idea might be that the public is more interested in open engagement than the academic since the public is the main participants for these projects. The public engagement of open science on social media reflected the urgent needs of the public to get benefit from the open science practice.
At last, by comparing the annual hot spots of the Twitter and the scholarly research, it could be noticed that the public on Twitter is more concerned about the social events and activities in open science, while the scholarly researchers focus on novel technologies and detailed research aspects. This difference between the annual hot spots on Twitter and in research publications further confirm the prior research results that the public pay more attention to the macroscopic aspects, while academia focuses on the more insightful and detailed spots (Q. Zhou & Zhang, 2021). In addition, technology hotspots might appear much earlier in scholarly research than on Twitter. For example, “Rrid” is mentioned in annual hot spots of research publications in 2019 and tweet dataset in 2022. Also, cloud computing appears in Scopus dataset in 2013 as “Euchinahealthcloud” and in tweet dataset as “Cambiare” in 2015.
Conclusion
Open science aims to make scientific knowledge openly available, accessible and reusable; to increase scientific collaborations and sharing of information; and to open the processes of scientific knowledge creation, evaluation and communication to societal actors. In this paper, a novel research framework has been proposed to disentangle the interest on Twitter and scholarly research towards open science, tracking the hot spots both from the public opinion and the academic view. For public opinion mining, after collected the tweets on open science, temperature metrics and topic modelling techniques were adopted to analyze the annual hot spots and the topics and themes. As to the academic view, VOSviewer application was employed for the visualization of the keyword co-occurrence. Also, LDA method was implemented for topic analysis. The comparison analysis between the two viewpoints towards open science were conducted. The results show that there were different needs for open science from the public and researchers though they are both interested in open science knowledge and infrastructure.
To address the first research question in this paper, themes/sub-themes, as well as the annual hot spots were mined from the public opinion on open science. Though open scientific knowledge is the most concerned theme for the public on social media, some breaking technologies or current events also attract attention. On one hand, the innovative technologies, such as cloud computing and blockchain facilitated the development of open science so that there were more novel open science research or practice. On the other hand, the public health emergencies, such as the COVID-19, promoted the public needs for open science and encouraged collaboration and open innovation.
In answer to the second research question, through the analysis of the Scopus data, the annual hot spots, keywords co-occurrence, and the topics modeling of open science could provide the insight for the development of open science in academic. Besides exploring the open science practice itself, the researchers are all interested in open science practice in their own fields, especially those in health, biomedicine, computer science, human and social, etc. The principles advocated by open science, such as reproducibility, open access, transparency, could help open cooperation in the researchers and thus lead to open innovation in academic.
As to the last research question, the results of the comparison analysis reflect that there were different needs towards open science from the public and the academic. The public and the researchers might have the similar interests towards open science, including open access, open data, open education, open infrastructure, etc. Based on these basic practice of open science, the public were more interested in open engagement of societal actors since there were intensive discussion on citizen science projects on Twitter. The academia were concerned more to make the research innovations.
For the future work, we planned to embedded semantics of words to get more precise topic analysis. At the same time, the research framework to get broader vision by comparing the viewpoints from the public and the academic could help policy-decision in other measuring problems. Hence, more bibliometrics analysis could be adopted in future experiments.
Limitation
Our research is limited in some aspects, and we call for future studies to extend our understanding of open science. First, the public opinion mining is applied on the tweet dataset collected from Twitter. Though Twitter is influential, it might be limitedly accessible in some countries. Therefore, this could lead to bias in this study. Future studies might consider integrating different social media platforms in the world to investigate the connections between the general public as well as professionals to make the results more robust. Second, LDA modeling was used in this study to identify topics, but LDA itself had limitations. LDA modeling could only cluster the words of the same topic through the probabilities of these word. The semantic similarities of the words are not adopted in LDA. As a result, our topics might be biased. In future studies, other method of topic modeling could be considered to adopt the semantics similarities of the words to get more precise classification.
Footnotes
Acknowledgements
Acknowledgements for Anonymous Reviewers. This work is supported by the National Social Science Foundation Project (No. 21BTQ030).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Social Science Foundation Project (No. 21BTQ030).
Data Availability Statement
The article’s supporting data and digital research materials can be accessed on https://github.com/cjp360/openscience/blob/main/openscience.7z.001 and ![]() .
.