
Abstract
The COVID-19 coronavirus pandemic, a serious health risk, has affected information-related behavior and led to an upsurge in rumor-sharing on social media. Thus, combating COVID-19 necessitates combating rumors as well, which serves as a compelling incentive to examine rumor-related behavior during this unusual period. The analysis of the prior literature was summarized in the current study. For this, a number of well-known libraries were searched, including ScienceDirect, Springer, ACM, and IEEE Explore. The proposed research is based on a detailed overview of the detection and recognition of different deceptive news about the COVID-19 pandemic using various ML algorithms. It was found that with the implementation of the proposed approach, it is efficient to perform the classification of information into real and fake news on social media platforms. After studying different information detection techniques, various features have been identified from the literature. Then, important features extracted from the literature were used in the process of ranking. For the effective categorization of the available alternatives, the Graph Theory Matrix Approach is used. The alternatives are ranked based on their permanent function values. The current study has considered providing a comprehensive overview of the data that is currently available. The study demonstrates many methods for analyzing literature, enabling students to create fresh perspectives on the topic.
Plain language summary
The proposed research is based on a detailed overview of the detection and recognition of different deceptive news about the COVID-19 pandemic using various ML algorithms. It was found that with the implementation of the proposed approach, it is efficient to perform the classification of information into real and fake news on social media platforms. After studying different information detection techniques, various features have been identified from the literature. Then, important features extracted from the literature were used in the process of ranking. For the effective categorization of the available alternatives, the Graph Theory Matrix Approach is used. The alternatives are ranked based on their permanent function values. The current study has considered providing a comprehensive overview of the data that is currently available. The study demonstrates many methods for analyzing literature, enabling students to create fresh perspectives on the topic.
Introduction
With the emergence of various social media platforms, people can now access a vast amount of information conveniently and within no time. With various advantages of the modern media, there are many challenges including the spreading of false or fake news (rumors). True and trusted information can be provided in response to health-related queries of people. During the pandemic, the mental and physical health of people is greatly disturbed by false information and hence it is useful to avoid the spreading of the infodemic. However, it is difficult for the common people to distinguish between authentic and false news. In this modern technological era, digital media like Twitter is one of the best candidates for the gathering and obtaining of information about different circumstances and the same is true for the news associated with COVID-19. During this hard time of the pandemic, an effective role was performed by the information and communication technologies for providing people with safety measures and other analytics about the disease. But, with the employment of internet-based various techniques, a huge volume of data is generated on daily basis and it is important to avoid the spread of fake information among people.
The COVID-19 pandemic has been rapidly and alarmingly spreading over the past several times. In terms of health and the economy, the disease is regarded as a global crisis (Jain, 2022). Unfortunately, rumors and upsetting news have been spreading in conjunction with the COVID-19 outbreak (Hezam et al., 2023). Numerous rumor verification approaches have been established in recent years as a result of the negative effects of false information on social media (Roy et al., 2022). Patwa et al. (2021) have performed a study for the collection of data related to the COVID-19 pandemic and generated a dataset of about 10,700 posts from media. To help people in avoiding fake information about the disease, all the collected data were classified into fake and real ones with the usage of binary classification. Different machine learning (ML) procedures like Decision Tree (DT) and Support Vector Machine (SVM) were utilized with the other two algorithms. The analysis shows that with the employment of SVM, the study obtained high efficiency with about 93.32% F1 score. The fake news spread on social media is directly impacting people’s mental health. Al-Sarem et al. (2021) have proposed a system for the recognition of rumors about COVID-19 on the internet. The designed deep learning paradigm is the integration of Long Short-Term Memory (LSTM) and Concatenated Parallel Convolutional Neural Network (PCNN). The data for the evaluation of the project was obtained from the ArCOV-19 dataset including about 1,357 tweets. It was concluded that of all the considered tweets, about 46.87% were rumors while the remaining were true. The developed system is more effective than the other rumor detection approaches in terms of accuracy and precision.
Shams et al. (2021) have presented a smart system for the detection of false information about health-related queries. The proposed paradigm was developed by the utilization of Natural Language Processing (NLP) and Machine learning (ML). It is capable of providing authenticity to the query of the consumer and hence avoiding fake news during a search. The resultant data revealed that an accuracy of about 93% can be achieved by the employment of an Artificial Neural Network (ANN) with the system. For trust-worthy data collection in the online world, it can be utilized effectively.
Research Objectives
As the epidemic spreads, misinformation about COVID-19 is common on social media, and the risks are significant. Therefore, it is crucial to identify and dispel such false information (Ayoub et al., 2021). For the development of an effective machine learning methodology, there is a need for the availability of large data. So, ML-based techniques can be used precisely on the data obtained from social media about COVID-19. These procedures will help in the classification and separation of the news based on its authenticity. One misleading information can be extremely harmful and dangerous for the health of a lot of people due to the availability of the Internet. In the current study, the analysis of the earlier literature was summarized. Numerous well-known libraries, including ScienceDirect, Springer, ACM, and IEEE explore, were searched for this, among others. The main aims of the presented study are:
To outline the available intelligent architectures for the detection of false information on various online platforms.
Various qualities are recognized from the research area’s current methodologies after analyzing them.
From the listed traits, the valued ones are selected for the decision-making process.
By using the Graph Theory Matrix Approach, it is possible to rank the available paradigms.
Literature Review
By spreading various false information about the vaccination, the inaccurate news is preventing the world from achieving herd immunity. Social media was utilized in an unprofessional manner by most people during the spread of COVID-19. To accurately perform the recognition of fake news about the pandemic, a large number of datasets are developed for the evaluation of different machine learning and deep learning paradigms. The study was focused on the analysis of various datasets and the detection of untrusted news related to the pandemic (Gharaibeh et al., 2022). Paka et al. (2021) have proposed a study for the production of a large COVID-19 Twitter dataset for the classification of authentic and fake information. Additionally, a cross-stitch-based semi-supervised end-to-end neural attention model (Cross-SEAN) suggested by the researchers was employed on the unlabeled data. The evaluation of the system with the most important fake news recognition procedures shows that its performance is better and can achieve an F1 score of 0.91 on CTF. We also create Chrome-SEAN, a Chrome plugin founded on Cross-SEAN for real-time bogus tweet identification. From the start of the pandemic until now, there is still a need for an intelligent architecture for the detection of fake news about COVID-19. Choudrie et al. (2021) have performed a study in two phases, with the first one focusing on the implementation of an intelligent methodology for the separation of accurate and false information while the other deals with the information searching tactics applied by young people. The first part realized that with the usage of Decision Tree Classifier and Convolutional Neural Network for classification, an accuracy of 86.7% and 86.67% was achieved respectively. The later phase of the study analyzed that people are more comfortable with the usage of conventional media instead of new media.
Being an accurate candidate for the sharing of information easily and conveniently, social media can also be used for the spreading of rumors. Since dishonest reports may be exceptionally harmful, it is crucial to address the issue of isolating and reducing fake stories. In this article, the authors proposed a system for accurately identifying rumors at the network and individual levels. It scrutinized a sizable database to assess several machine learning algorithms. It was found that all of the approaches that were tested by the proposed study have improved the accuracy score but at the cost of longer runtimes (Bamiro & Assayad, 2021). Ashraf et al. (2022) have put forward an intelligent ML-grounded approach for the detection of bogus information in tweets about COVID-19 in both English and Arabic languages. Along with the employment of various machine learning methodologies, various features are identified with the utilization of Term Frequency/Inverse Document Frequency (td/idf). A comparative study of all the employed classifiers was conducted and their performance was monitored. One of the biggest hurdles during the time of pandemic was the search and selection of trustworthy information. For solving the issue of the identification of misleading information related to the COVID-19 virus, Malhotra and Mahur (2022) have presented a productive infrastructure for the acknowledgment of false information. Different ML-based procedures like Logistic Regression (LR), K-Nearest Neighbor (KNN), Decision Tree (DT), and Naïve Bayes (NB) were implemented for the classification of fake and real news. The experimental data show that with the employment of a Linear Support Vector Machine (LSVM), impressive testing accuracy can be obtained. In the case of Deep Learning (DL)-grounded algorithms, Long Short-Term Memory (LSTM) is the best choice.
It is important to develop an efficient architecture for the detection of fake or wrong information about COVID-19. Alenezi and Alqenaei (2021) have proposed three intelligent paradigms for the identification of false information about the pandemic. The recommended prototypes contain k-nearest neighbors, multichannel convolutional neural networks, and long short-term memory (LSTM) networks, a specific kind of RNN (KNN). The performance of these models was evaluated in terms of different assessment pointers. It was concluded that these systems are working more efficiently than the existing approaches. Weinzierl and Harabagiu (2021) have conducted a study for the automatic detection of false news related to the COVID-19 vaccines. The procedure models misinformation finding as a graph link prediction issue, positioning CoVaxLies in a misinformation knowledge graph. The link scoring functions are fully employed by the developed methodology which was discussed in different knowledge embedding techniques. The evaluation results show that this architecture is more efficient and effective than the state-of-the-art classification approaches. The timely verification of information in today’s technological world is of great importance. Kolluri and Murthy (2021) have proposed a system named CoVerifi for the verification of fake news about COVID-19. It is a web-based system that is grounded on machine learning and customers’ feedback. The end users can share their opinions about the authenticity of any news and will be beneficial for CoVerifi to stop the spreading of false information. The implementation of applications of the developed approach for standing against infodemic is discussed in the letter.
Ayoub et al. (2021) have designed a rumors detection system with the assistance of DistilBERT and Shapley Additive exPlanations (SHAP) to solve the issue of infodemic at the time of COVID-19. The proposed architecture is efficient because of its functionality of providing arguments to the users about the data being false or faked. The dataset of about 984 assertions related to the pandemic was made doubled with the usage of back-translation. The resultant data show that the DistilBERT paradigm achieved accuracy and area under the curve of about 0.972 and 0.993 respectively. The overall efficiency of this approach is productive for the separation of fake news from real ones. The spreading of unauthentic news on social media is harmful to the mental conditions of people during the pandemic. A stud for the filtration and separation of such kind of news from the real ones. In the suggested architecture, a practical approach was applied to about 8,560 tweets with the help of various ML-grounded strategies like Support Vector Machine (SVM), and various Deep Learning (DL) algorithms such as glove embedding. With the employment of this architecture, people can gain access to true and authentic information conveniently and productively (Kaushal et al., 2022).
Kulkarni et al. (2022) have conducted research for the classification of infodemics about COVID-19 with the assistance of deep learning. The process of token conversion into vectors was carried out with the usage of the Glove paradigm. For achieving accurate and precise output, various DL-based procedures like RNN, LSTM, and Bi-LSTM were evaluated on the data obtained from the preprocessing done by Natural Language Processing. There are a tonne of tweets on COVID-19 and associated news on Twitter, however, not all of them are accurate and exact. The results of the proposed study are depicted in a tabular manner. With the extensive usage of internet-based technologies, it is necessary to design an effective system for assessing the authenticity of the information. Bhowmik et al. (2022) have produced a three-level voting architecture for the classification of information as real or misleading. Five mining algorithms and three ensemble paradigms are employed for achieving the goal of information classification. The experimental data revealed that SVM and Bagging ensemble are proficient in the detection of misleading news. When employing TF-IDF for feature extraction, our advised model harvests the finest results with a 96% accuracy rate. Biradar et al. (2022) have developed a pioneering fusion-based approach for merging important characteristics from context-grounded embeddings like BERT, XLNet, and ELMo to improve perspective and semantic statistics gathered from the internet postings and accomplish improved precision for fake news recognition. With the proposed architecture, it was realized that the early fusion-based strategy performs better than infrastructures that use single embeddings. The study also carried out an in-depth analysis to label misleading information on social media sites appropriate to COVID-19 by applying a variety of ML and DL-based algorithms.
Micallef et al. (2020) have educated a classifier to yield a fresh dataset of 155,468 tweets on COVID-19, which includes 33,237 ambiguous assertions and 33,413 comments disputing them. The proposed research demonstrates that the volume and spread of expert fact-checking tweets are constrained. As opposed to this, it was observed that a spike in tweets that spread false information is quickly countered by an increase in tweets that discredit it. More significantly, stark variations were detected in how the audience responds to tweets; some tweets are just opinions, while others provide hard proof, such as a reference to a reliable foundation. The study offered an exceptional method for detecting fake news that implicates thoroughly mining the semantic relationships between the text and any connected images (FND-SCTI). With the implementation of an already trained VGG system, knowledge about image representation was obtained. Then, a merged demonstration of textual and visual material is learned using a multimodal variational autoencoder. The concluded data show that the developed architecture is more reliable and feasible than the existing paradigms. Using this approach, the semantic correlations among multimodal contents can be realized precisely (Zeng et al., 2021). Iwendi et al. (2022) have detected misleading information about COVID-19 by identification of 39 characteristics from social media and with the employment of DL-grounded infrastructures. The accuracy of the designed model’s false news feature removal amplified from 59.20% to 86.12%. The Recurrent Neural Network (RNN) procedure has a total high precision of 85%. Real news and authentic data are assembled for this letter via information fusion from websites related to news broadcasting, health, and the government, whereas false or fake news data are grouped from social media podiums. The study looks at how user views of chatbot information authenticity are influenced by literacy and trust (Shin, 2022). Results demonstrate that users’ views of the veracity of chatbot messages and recommendations are fundamentally influenced by their level of trust and algorithmic literacy. A helpful perspective on the idea of algorithmic credibility is offered by insights into the relationship between user trust and credibility. The identification of algorithmic information processing offers stronger bases for the creation of sense-making chatbot journalism as well as better foundations for the development of algorithms. The study demonstrates that algorithm awareness encourages users to imagine, perceive, and engage with algorithms depending on their comprehension of the information flow control mechanisms incorporated within them. Users’ understanding of algorithms affects how they trust algorithmic processes, how they assess privacy issues, and how openly they disclose themselves. Users can only assess privacy, determine information sharing, and comprehend how algorithms affect when they are completely aware of algorithm practices (Shin et al., 2022).
Methodology
With modern technologies like the Internet, people are doing a lot of their activities using online services and the same is true for information capturing. Twitter is mostly used as a social media platform and there is a lot of information available on it. To assist people in accessing accurate and precise data, various algorithms are developed with the utilization of artificial intelligence, machine learning, and natural language processing.
The study has suggested the knowledge graph-based rumor data augmentation technique: Graph Embedding-based Rumor Data Augmentation (GERDA), a technique that mimics the rumor-generation process from the viewpoint of knowledge (Chen, Zhu, et al., 2021). The research integrates knowledge representation into the text production process to describe the creation of erroneous information. Experiments demonstrate that our method can produce high-quality rumors on a variety of themes and that these rumors can further resolve the imbalance in rumor data to improve rumor detection performance. To stop the propagation of online rumors and lessen their negative effects, this study aims to develop a model for online rumor reversal (Wang et al., 2021). Based on the SIR model and considering both internal and external elements, the study developed a G-SCNDR online rumor reversal model by adopting the theory of scientific knowledge level and an external online rumor control method. The G-SCNDR model is simulated in this study, and key model parameters are subjected to sensitivity testing. By correctly implementing the isolation-conversion strategy as the external control approach to online rumors with improving the rate of popularization of the level of users’ scientific knowledge and accelerating the transformation efficiency of official nodes, the reversal efficiency of the G-SCNDR model can be enhanced. This research can assist shed light on how internet rumors start and end, as well as provide advice and preventative steps for their suppression in times of public health emergency. The proposed study examines a novel and ground-breaking strategy for suppressing COVID-19 rumors by harnessing the influence of OSN opinion leaders (OLs) (Jain, 2022). The entire procedure is broken down into two phases, the first phase outlines the revolutionary Reputation-based Opinion Leader Identification (ROLI) algorithm, which includes a special voting technique to identify the top-T OLs in the OSN. The method to calculate each user’s reputation and measure the aggregated polarity score of each tweet and post is described in the second phase. The empirical reputation is used to determine the truthfulness, entropy, and user trust for each post. The post is likely to be labeled as a rumor if its experimental entropy is less than the empirical threshold value. The proposed method used the social networks Reddit, Instagram, and Twitter to validate results. The final results demonstrate how crucial OLs’ impact is in tamping down COVID-19 myths.
To overcome the issue of anxiety and depression created by the generation of false or fake news about COVID-19, Thapa et al. (2022) have conducted a study for the comparison and analysis of various smart and intelligent algorithms for the classification of news into real or fake. The research also focused on the extraction of sentiment from the text with the assistance of language processing. The presented article inspects the opportunities by showing how systems attempt to comprehend human emotions. This offers a fresh perspective on how common people interact with false information and information obtained online during the epidemic. SVM produced results with an overall accuracy of 98%. The severity of the wrong and false news is the same as that of the pandemic. In the proposed research, four alternative machine learning algorithms—Naive Bayes, Decision Tree, Support Vector Machines, and Logistic Regression—are contrasted in terms of how well they can identify false news. The process makes use of a collection of annotated news stories. In terms of accuracy, precision, recall, and F1 score, the experimental findings demonstrate that Naive Bayes accomplishes better than other algorithms (Alsaidi & Etaiwi, 2022).
The current research has presented an overview of the analysis of the existing literature. For this, various popular libraries including ScienceDirect, Springer, ACM, and IEEE explore were searched. The searching materials for the year-wise distributions in the ScienceDirect library are given in Figure 1.

Searched materials on year basis.
The types of publications in the given library are shown in Figure 2.

Type and number of publications.
The publication title, subject area, and the number of publications in this library are depicted in Figure 3.

Publication title, subject area, and number of publications.
The content types and the number of publications in the Springer library are shown in Figure 4.

Content types and number of publications.
Figure 5 shows the discipline, subdiscipline, and number of publications in the same library.

Discipline, subdiscipline, and number of publications.
Figure 6 represents the publication title, conference location, publication topics, and a number of publications in the IEEE library.

Publication title, conference location, publication topics, and number of publications.
The publications and number of papers in the ACM library are given in Figure 7.

All publications and the number of papers.
The content type, media format, sponsors, conference event, and a number of publications are shown in Figure 8.

Content type, media format, sponsors, conference event, and number of publications.
The suggested strategy was used to address the problem of identifying false information about the COVID-19 virus as well as the problem of worry and despair brought on by the spread of false or fake news about COVID-19. Researchers have worked incredibly hard to develop methods for automatically detecting and identifying rumors. The traditional methods emphasize feature engineering. They are hard to generalize and necessitate numerous human efforts (Chen, Zhou, et al., 2021). Social media rumor verification is the task of identifying the veracity of questionable information circulating on social media. Research has yielded neural models achieving high performance, with accuracy scores that often exceed 90%. However, none of these studies focus on the real-world generalizability of the proposed approaches (Kochkina et al., 2023).
Extracted Features
A detailed examination of the available literature revealed various features, which are shown in Table 1.
Extracted Features.

Selected Features
As shown in Figure 9, the Graph Theory Matrix Approach is used to rank the alternatives using some of the most well-liked features from the recovered ones.

Selected features.
Graph Theory Matrix Approach
The mathematical model provides a thorough and logical technique. The ramifications of novel graph theory have been well researched in the literature. Graph/digraph model representations have shown helpful for producing to evaluate a wide range of conditions and challenges in numerous fields of research and industry. This method makes it incredibly easy and exact to select the choice that is most lucrative in a given circumstance from those that are offered. Graphs are a great method to understand and describe a variety of subjects and how they are related (Rao, 2006).
By employing matrices, the Graph Theory Matrix Approach represents and examines graphs. A graph is depicted in GTMA as an adjacency matrix, where the rows and columns represent the vertices and the entries denote the presence or absence of edges. A number of graph attributes, including the degree of a vertex, the separation between vertices, and the connectivity of the network, can be efficiently computed using the GTMA approach.
When graph theory is used to model and evaluate complex systems and networks, such as in computer science, operations research, and electrical engineering, GTMA is a helpful tool.
The GTMA input and output can be summed up as follows:
Graph input in the form of an adjacency matrix
Output: A solution to a specific graph-related issue, such as a vertex’s degree, the shortest path connecting two vertices, the graph’s connectedness, etc. Depending on the problem being addressed, this output may be a numerical result, a Boolean value, or a collection of vertices or edges.
GTMA Procedure
Figure 10 illustrates the key phases of the Graph Theory Matrix Approach methodology.
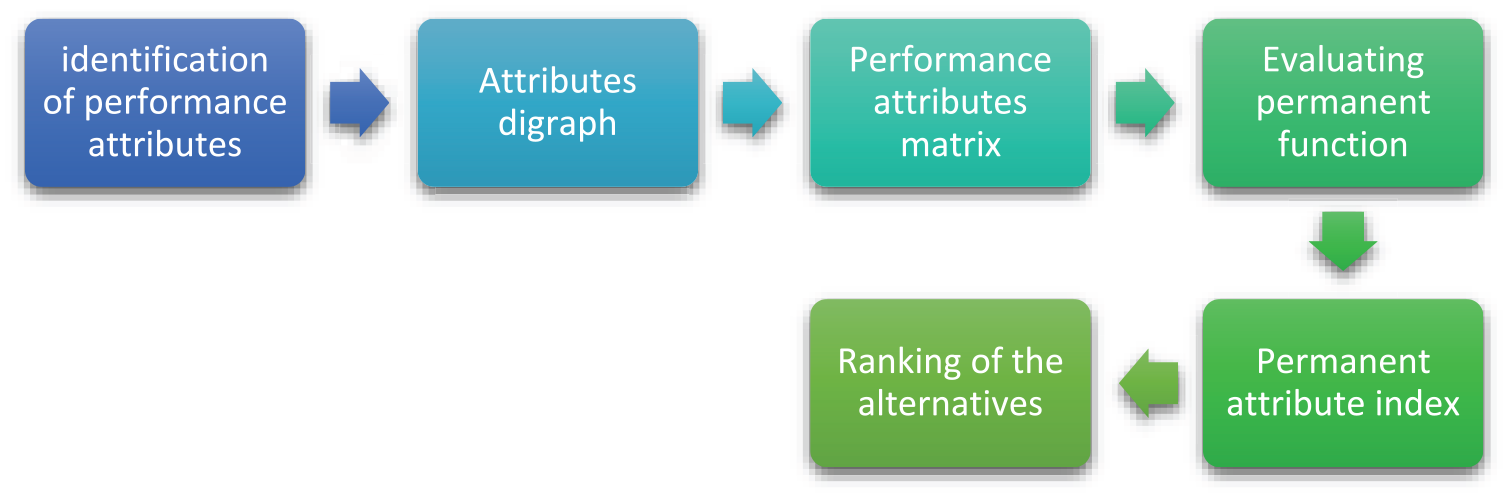
Flow of GTMA.
Decision Matrix
The GTMA system’s initial stage comprises selecting from a selection of options and standards. Then, each factor is assigned a numerical value based on the requirements of the customer. Table 2 displays the choice matrix for the current reality on a scale from 0 to 1. The values input were obtained from the experts’ opinion. The assigned values are shown in different tables. These values were cross checked by the other experts in the field.
Decision Matrix.

Normalized Matrix
The available decision matrix is generated into a normalized matrix using (1) and (2), as indicated in Table 3.


Normalized Matrix.

Attributes Comparison
To convert the supplied attribute digraph into a permanent matrix, one must determine the relative importance of one element versus another. As shown in Table 4, a range of 0 to 1 was chosen for this.
Attributes Comparative Values.

Permanent Attribute Matrix
The Performance Attributes Matrix provides all of the properties (Zi) and their major distinctions (Zij). An illustration of an NXN foundation is available in (3). Table 5 displays the performance attribute matrix for the current situation.

Permanent Attribute Matrix.

Permanent Function Values
Relying on the normalized choice matrix and the performance attribute matrix, the permanent matrix, and its weight are created for the grouping of the options. Using (4), as shown in Figure 11, the permanent function values of Techniques 1 through 6 are calculated.

Permanent function values.
Results and Discussion
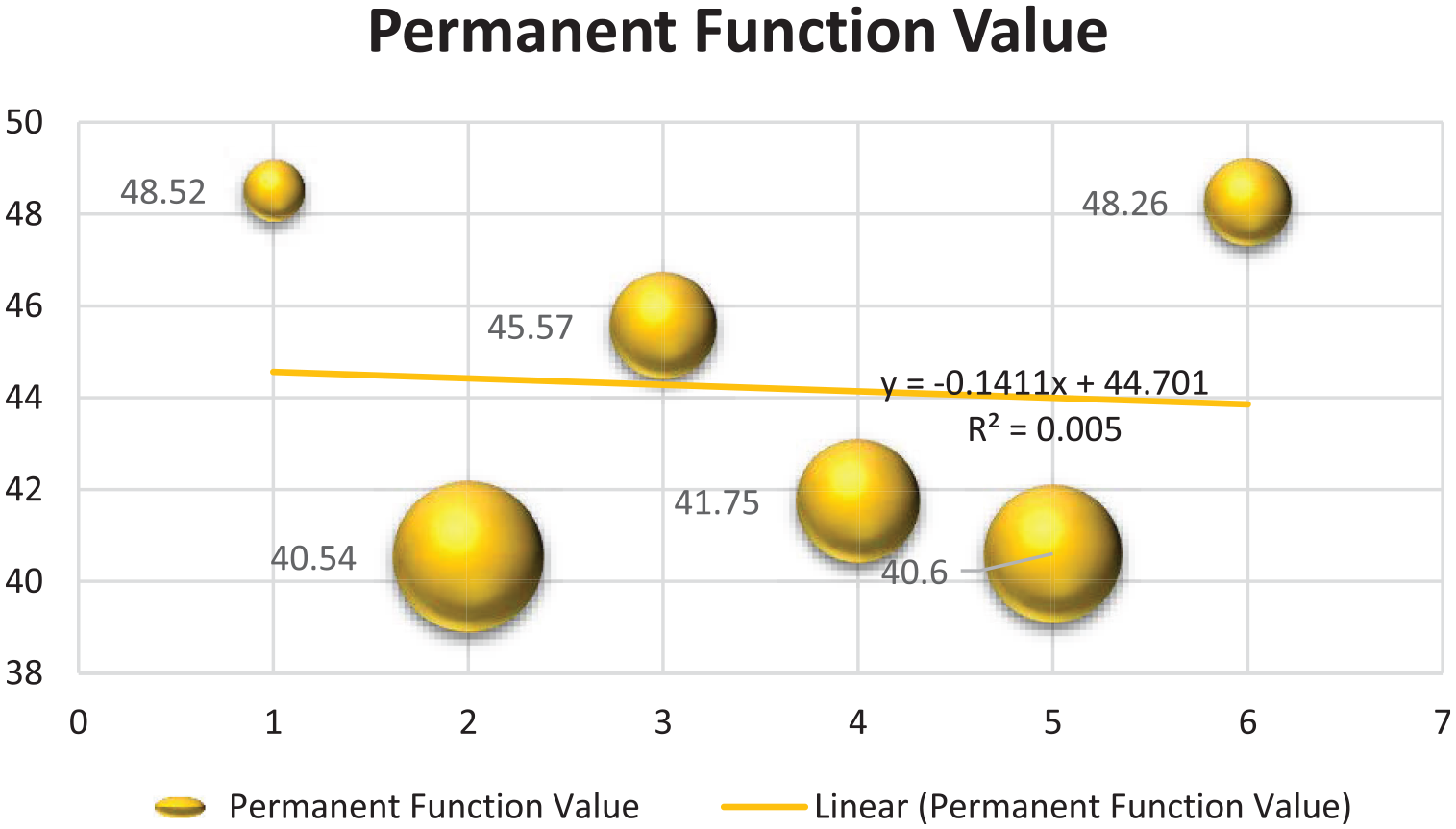
With the accessibility to a vast amount of data on various social media platforms, it is a challenging task to analyze the authenticity of the news. Sometimes, users spread misleading information on public platforms about different issues and people are unable to cross-check it. To avoid this from happening, researchers are using various intelligent procedures like Support Vector Machine, Naïve Bayes, and many more for the precise extraction of useful and validated data. In this era of information and technologies, the isolation of fake news from trusted ones is important to avoid various harm to people. With the employment of artificial intelligence methodologies, various effective systems can be developed for assessing the authenticity of the generated information about COVID-19. To assist the users in the selection and identification of suitable and real news in time of the pandemic, numerous kinds of AI and ML-based paradigms are implemented. After a comprehensive analysis of the existing architectures for the categorization of information associated with COVID-19, the proposed study selected seven features from the identified ones. Then, with the implementation of the Graph Theory Matrix Approach, the ranks of the available choices are obtained. The findings indicate that Technique 1 is rated first since it has the greatest permanent function value of 48.52, followed by the remaining options in the order of importance. Figure 12 depicts a comprehensive analysis of the rankings of the various options.

Ranking of the alternatives.
The overall outcomes of the GTMA process and the association among the different alternatives are depicted in Figure 13.
Association among alternatives.
Research Implications
The research was based on a thorough examination of the detection and identification of several false reports concerning the COVID-19 pandemic using different machine learning techniques. It was discovered that the classification of material into legitimate and fake news on social media platforms may be done quite well with the application of clever techniques. Numerous traits have been found in the literature after analyzing various information detecting systems. In the current study, the analysis of the earlier literature was summarized. Numerous well-known libraries, including ScienceDirect, Springer, ACM, and IEEE explore, were searched for this, among others. Then, crucial features are applied during the ranking process. The Graph Theory Matrix Approach is utilized to effectively categorize the options that are available. The permanent function values of the alternatives are used to rank them. The current study has taken into account giving a thorough rundown of the data that is currently available. The study provides numerous examples of literary analysis techniques, allowing students to develop original viewpoints on the subject.
Conclusion
With the start of COVID-19, people around the world suffered in one way or the other. Due to lockdowns and other preventive measures, people are unable to move out of their houses. The only way of interaction and information sharing during this time was through various social media platforms like Twitter, Facebook, and so on. These technologies are used efficiently for getting knowledge about the virus and safety precautions. Every day, millions of users are posting information on their social media handles. Now, the main hurdle is the identification and isolation of fake news from real ones. The proposed study threw light on the applications of machine learning methodologies and algorithms for overcoming this issue. These algorithms like SVM, KNN, and many more are reliable and productive for the recognition of authentic news. Based on these procedures, smart systems can be developed which can convince the user about the accuracy and preciseness of particular information. The wrong data can be labeled conveniently and can be distinguished from the true news. In the current study, the analysis of the earlier literature was summarized. Numerous well-known libraries, including ScienceDirect, Springer, ACM, and IEEE explore, were searched for this, among others. Numerous elements from the literature have been identified in the current study, and significant traits have been picked for decision-making. Then, using the Graph Theory Matrix Approach, the available options are sorted according to the values of their permanent function. The outcomes demonstrate the viability of the suggested research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was financially supported by Philosophy and social science fund project of Henan Province in 2023 (Grant No. 2023BYY005); Research project of Social Sciences in Henan in 2024 (SKL-2024-1495).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.