
Abstract
On an annual basis, China’s “Two Sessions” draw researchers’ attention to the study of interpreting that comes along. However, the related research mostly focuses on interpreting strategies and skills, and rarely involves the interpreter who produces the interpreting. This paper collects both of two interpreters’ texts at the press conferences of the “Two Sessions” from 2010 to 2020 to build a parallel corpus. By comparing their interpreting, with the speeches of the leaders of the White House as a comparable corpus, the study seeks to probe into the similarities and differences between the interpreting styles of two interpreters from the linguistic perspective. It is found that when interpreting, the interpreter Sun has richer vocabulary and a higher lexical density than the interpreter Zhang. The interpreting style of Sun is closer to the written style, while Zhang’s style is more colloquial. Compared with the transcripts of the U.S. press conference, the linguistic features of Zhang’s interpreting is more similar to those in the comparable corpus in vocabulary richness, word length and readability. Therefore, Zhang’s interpreting might be more likely to be intelligible and acceptable to English speakers.
Introduction
China’s “Two Sessions” (i.e., NPC and CPPCC) are the official public meetings after the end of the National People’s Congress. As the most important form of communication between the government and the media and the public, “Two Sessions” are considered one of the most important events in China’s political calendar. On that account, during the “Two Session” the Chinese government uses well-developed media channels to increase its influence in political communication by demonstrating Chinese economical, cultural, and social development and to communicate with foreign public about China (Jia & Li, 2020). Interpreters have been serving as a bridge in the Press Conferences in the past sessions. The quality of their interpreting is directly related to whether the Chinese government can accurately state China’s position, clarify China’s attitude and establish China’s image at an international level. Translators and interpreters are often considered invisible and submissive (Dębska, 2021). However, the success of a conference interpreting cannot be achieved without excellent interpreters. On the basis of hearing and understanding the meaning of the speakers’ discourse, interpreters give full play to their subjective initiative, and use the target language to verbally restate and reproduce the semantic information of the source language within a limited time (Xu, 2018). The accuracy and reliability of interpreters have gradually drawn the attention of scholars to interpreting studies. In addition, different interpreters also show different characteristics in linguistic style when interpreting the similar type of text, which is of great value for studies. What’s more, the corpus-based study of interpreting style has become a new research trend as corpus linguistics is widely used in the field of translation.
Literature Review
For a long time, translating languages have been regarded by linguists as deviant and unnatural language variants and the emphasis and concern on “equivalence” or “correspondence” in prescriptive translation studies have kept translators in a marginalized and invisible position (Venuti, 1995) until Hermans (1996) put forward the idea of “translator’s voice.” Since then, translator’s style has gradually entered the vision of translation researchers. On the basis of analyzing the characteristics of the translator’s style, scholars have carried out research from the aspects of vocabulary application, sentence pattern, narrative structure, and so on, and obtained fruitful results. Especially after the publication of Corpus Linguistics and Translation Studies: Implications and Applications published by Baker (1993), translation studies on the “footprint” of translators have witnessed a rapid development in terms of quantitative methodology, the topics of which range from translation universals to translation style, from literary translation to interpreting studies, etc.
However, the previous corpus-based studies on translator’s style are primarily concerned with the written translated text, with only a few studies touching upon interpreting style—the commonness and consistent prominence of one or many linguistic, paralinguistic, phonetic features, and interpreting strategies used by interpreters when they interpret different contents for different people (Baker, 2000; Saldanha, 2011). As Baxter (2019) claims, the studies of interpretation fall behind those of written translation and there is a notable paucity of specific published research on the subject. This highly under-researched field may be attributed to the difficulties in collecting and processing the data. Due to the immediacy and impromptu nature of interpreting activities, all interpreting data must be transcribed, annotated and aligned after collection, which is time-consuming and labor-intensive. Therefore, a lot of researchers flinch in face of this challenge. Nonetheless, there are still some scholars who have tried to explore it, which has made groundbreaking contributions to this field.
The first systematic discussions and analyses of interpreting style emerged in the end of 20th century, when Yagi (2002) found that the differences in interpreting style between novice and professional interpreter can be assessed based on three main parameters: fluency, chunking and lag. The first parameter is indicated by completeness of sentences and frequency of excessive delays and pauses; the second parameter is evaluated by the usage of phrases or groups of words which can be used as a unit; and the third, which is also called “ear-voice-span,” can be observed by the duration of time between the onset of a source language chunk and the onset of its translation. In this way, Yagi proves that the seemingly elusive and intangible features of interpreting style can be explored and quantified.
Taking the English simultaneous interpreting corpus of Dutch interview activity as the object of study, Van Besien and Meuleman (2008) adopted a more sophisticated methodology than Yagi’s by encompassing as many as 18 parameters to detect the unique style of interpreters, such as backtracking, additions, omissions, diversity of vocabulary, intonation, even non-verbal behaviors. By proceeding from the perspective of the application of global strategy and local strategy, they conclude the paper with two categories of interpreting style: interpreters with a lean style and interpreters with an abundant style. Results show that the interpretation by the first interpreter was concise and rational, deleting much irrelevant redundant information of source language text, while the interpretation by the second interpreter was meticulous and clear, adding a great many words and sentences that played a role in restoring, clarifying the vague information expressed in the source text.
After applying the method of quantitative stylistics, Kajzer-Wietrzny (2013) proves that three parameters could be used to distinguish interpreters’ interpreting style and speaking style: the information load, lexical complexity and repetition. After comparing the interpreting output of two interpreters, he finds that there are significant differences between the style of two interpreters, who are native British English speakers and have interpreted for the European institutions for about 15 years. The first interpreter speaks faster, has a variety of intonation, uses more addition, and interprets more fully. The second interpreter has neutral intonation, less redundant information and more concise text. Kajzer-Wietrzny also suggests that the interpreting style should be manifested by more characteristic features than the ones investigated in his study.
Sukgasi (2020) built a corpus of the performances of three English-Thai simultaneous interpreters and found all three interpreters have their own ways of using formality-marking particles and first-person pronouns. After investigating the recorded performances of three interpreters, together with their interviews, the author finds some of their choices and preferences were affected by gender-related issues. When the interpreters use their own gender formality-marking particles during translation, less efforts can be made to decode and transcode the gender-related pronouns, which makes the interpreters sound more natural to the audience. Furthermore, Sukgasi argues that the indirect style interpreting may be more suitable for interpreting into Thai than direct style interpreting.
Based on the model proposed by Van Besien and Meuleman for interpreting style, which incorporates two groups of strategies, namely global and local strategies, Alkashef (2021) conducted a research into the idiosyncratic features of style in Arabic-into-English simultaneous and consecutive interpreting After comparing the performance of five interpreters who were interpreting a UN General Assembly speech from Arabic into English, he discovered some consistency in interpreting style regarding strategies such as speed of delivery, intonation and stalling. The results also manifest certain mode-related deviation in interpreting style repeating some other strategies (e.g., omissions).
While many studies have examined the issue of interpreting style based on corpus, most existing studies mostly focuses on interpreting strategies and skills, and rarely involves the interpreter who produces the interpreting. Moreover, they pay less attention to Chinese interpreters and their interpreting styles. As the chief interpreters of the Ministry of Foreign Affairs of China, Sun and Zhang have received wide acclaim for their accurate translation, stable performance and quick response. Their textbook-style translation at the press conferences of the “Two Sessions” each year is the learning materials of countless English lovers in China. For above-mentioned reasons, studying the interpreting style of the two interpreters can not only provide reference for the overwhelming majority of English learners, but also serve as an important supplement to the field of the study of interpreting style.
Therefore, this paper collects the interpreting texts of Sun Ning and Zhang Lu at the press conferences of the “Two Sessions” from 2010 to 2020 to build a parallel corpus. By comparing the interpreting of the two interpreters, with the transcripts of the U.S. press conference as comparable corpus, this paper aims to analyze the similarities and differences between the interpreting styles of Sun and Zhang from the linguistic perspective at lexical, syntactic and discoursal levels. The parameters such as standardized type/token ratio, word/sentence length, nominalization, sentential complexity, readability, are explored systematically in this study. Although commonly used in corpus-based translation studies in general, these factors have been scarcely probed into by the scholars who focus on interpreting style research, especially the parameters related to syntactic and discoursal levels, which deserve more attention in this field. As for the data collected, Wordsmith 8.0, Python, AntConc 3.5.7, CLAWS7 and VT Writer are used for statistic processing and some translation examples are also provided for qualitative analysis as a supplement to this quantitative-oriented study.
Research Design
Research Questions
This research attempts to compare the unique interpreting styles of Sun and Zhang, seeking to address the following questions:
First, what are the language features of Sun and Zhang in their interpretation in terms of lexical, syntactic and textual dimensions.
Second, what are the differences between the interpreting styles of Sun and Zhang?
Third, whose language style is more likely to be accepted by target listeners?
Corpus Selection
In China’s foreign exchange activities, there are many occasions when Chinese-English interpretation is needed, such as speeches on major occasions, investment promotion or introduction meetings, bilateral talks, negotiations, press conferences and so on. The annual “Two Sessions” (i.e., NPC and CPPCC) are the largest annual political meetings where economic priorities and the political tone are set for the year ahead. In recent 10 years in a row, Sun and Zhang have served as the interpreter of these important conferences. Therefore, we chose their interpreting of the “two sessions” press conference as a data source, which can better explore the behavior characteristics of interpreters in a specific scene.
After identifying press conferences of the “two sessions” as the main data source, we started searching for official videos on CCTV.com and China News. Since there is no ready-made transcribed texts available, transcribing becomes an indispensible step in order to obtain the complete translations of two interpreters. Due to the fact that Sun did not serve as the on-site interpreter of Foreign Minister’s Meetings with Chinese and Foreign Press in 2020, we transcribed and collected 10 translations of Sun during the 2010-2019 (hereinafter referred to as SC), and then 10 translations of Zhang between 2011 and 2020 (hereinafter referred to as ZC) one by one. Specifically speaking, we listened to the videos on above-mentioned websites and typed what we heard word-for-word into the computer before saving them in the format of text file.
It is worth mentioning that the two interpreters’ interpretation in the past 10 years is of continuity and timeliness, and the analysis of 10 consecutive years of interpretation can eliminate randomness and increase the reliability of the style comparison. In addition, CCP in China is famous for its stability in polices (Harmel & Tan, 2012), and its spokesman such as foreign ministers and prime ministers serve as the gatekeepers of publicity. Therefore, when talking about Chinese government’s policies and answering the foreign reporters’ questions during “Two Sessions,” their speech styles (i.e., the style of source texts) can be regarded as consistent.
After finishing the work of transcription, we established a comparable corpus, the transcripts of the U.S. press conference released by the U.S. government’s official website, https://www.whitehouse.gov (hereinafter referred to as UC) to conduct linguistic statistical comparison and analysis. White House minutes were chosen in present study for the following reasons. Firstly, the minutes of the White House meeting are the discussions between the U.S. Congress and the President on national and international affairs, which have similar forms of on-site questions and answers to those of the “Two Sessions.” Secondly, the transcripts of the U.S. press conference are mostly related to current affairs, politics and international situation, most of which are more similar to the content of China’s “Two Sessions”, though most of the topics in UN sessions are primarily pertaining to world health and military. In addition, despite the fact that the records of meetings in UN are written in English, some of which are literally the translated text from other languages such as Spanish or French, thus such minutes cannot be totally considered as authentic language said by native English speakers. The total number of characters in each corpus is shown in Table 1. The size of the three sub-corpora is similar, which helps to minimize differences.
Tokens in Three Corpora.

Since this study mainly focuses on Chinese-English translation, the part of Sun and Zhang’s English-Chinese translation was deleted. At the same time, filler words such as “emmm” and “ahh,” self-correction and repetition were omitted in the translation, in order to ensure the reliability of the corpora. Such interpreting strategies are not the targeted parameters to be explored in this study and may skew the statistics from the linguistic perspective. Moreover, the text in the UC corpus does not include any non-English language to ensure the comparability of three corpora. Some additional information, such as (Laughter) and (Applause), was also deleted to ensure the purity of the corpus.
Research Tools and Methods
Research Tools
Wordsworth 8.0 was used as the main data analysis software in this study. The software is a package that is mainly used to search and identify patterns in languages. It consists of three main modules: Concord, KeyWords, and WordList, which can be used to create index lines, generate word lists based on different criteria, and provide statistics such as type/token ratio, mean word length, sentence length, etc. (See Figure 1). Besides, Python was employed for sentence segmentation and to calculate the number of different kinds of sentences with the help of SpaCy, a free open-source library for Natural Language Processing in Python (See Figure 2). AntConc 3.5.7 was used to help retrieve relevant data, which is an easy-to-use, versatile language research software with seven main tools (See Figure 3).

WordSmith tools loading SC, UC, ZC for basic statistics.
Python importing spacy for sentence segmentation.
AntConc loading tagged corpus.
In addition, we used CLAWS7 (The Constituent Likelihood Automatic Word-tagging System) as the main tool for corpus annotation (See Figure 4). The tagging, also known as annotation, encodes explanatory language information in a corpus. The original corpus without part of speech tagged cannot provide any information about adjectives, nouns, verbs, conjunctions, pronouns and so on. Therefore, it is necessary to annotate it properly before further study. The free annotation service is provided on the website (http://ucrel-api.lancaster.ac.uk/claws/free.html). In this study, the C7 tag-set was selected for annotation. Equivalence attributes for all tag codes are also provided on the site. About the complete equivalence tag set code, please refer to http://ucrel.lancs.ac.uk/claws7tags.html. The last tool used in this study is VT writer (Visual Thread Writer), a language analysis platform founded in 2008, coming from a background of large-scale IT Delivery. It helps us with readability test, providing data about passive voice, readability, and grade level.

Corpus tagging.
In short, in this paper, we used Wordsmith 8.0 to retrieve statistics about language markup, such as type/token ratio, word length, sentence length, and so on. Python was employed for sentence segmentation and data analysis. AntConc 3.5.7 was used to locate specific information, for example, calculations of TagCode and totals in a given corpus. CLAWS7 was utilized for corpus tagging, encoding explanatory language information. At last, with the help of VT Writer, readability tests can be done, providing reference value for Sun and Zhang’s interpretations.
Research Methods
We adopted a combination of corpus-based analysis and comparative analysis as research methods so as to obtain more reliable conclusion in relation to the interpreting style of Sun and Zhang’s in the press conference.
Corpus-Based Analysis
After establishing the relevant corpora, we employed the corpus tools Wordsmith 8.0, AntConc 3.5.7, CLAWS7 and VT Writer to analyze the interpreting style of the two interpreters at the lexical, syntactic and discoursal level, based on the data collected from translations of Sun between 2010 and 2019 and Zhang between 2011 and 2020. The relevant conclusions will be drawn based on the statistical data extracted from these corpus tools. The parameters to be explored include standardized type/token ratio, word Length, nominalization, mean sentence length, sentential complexity, readability and conjunction.
Comparative Analysis
This study adopted a comparative analysis of the interpreting style between two renowned interpreters in China, Sun and Zhang, who have been working for Ministry of Foreign Affairs for more than 18 years. Along with Sun and Zhang’s interpretation of the “Two Sessions,” this paper also introduced transcripts of American press conferences as a comparable corpus to understand the similarities and differences between the two interpreters’ translations and those of native English speakers, attempting to find whose translation is more comprehensible to native English listeners and delve into the reasons behind it in combination with political, cultural and social factors.
Analysis of Sun Ning and Zhang Lu’s Interpreting Style
Lexical Level
Lexicon is the smallest unit and the basis of interpretation. It is a basic aspect of interpreting behavior, that is, stylistic effect, because the translator has his/her own reasons for choosing different words. Therefore, in the following parts, the interpreting style of Sun and Zhang at the lexical level will be explored by analyzing the standardized type/token ratio, word length, and nominalization.
Standardized Type/Token Ratio
Types and Tokens are the main elements in a given text. In addition, the standardized type/token ratio is a measure of the range and diversity of words used by an author/speaker/translator/interpreter in a given corpus (Baker, 2000). Tokens are the number of words in a given corpus. Different lexical inflections, whether singular or plural or different tenses, are counted as different words. Types, on the other hand, refer to the number of different words in a given corpus, excluding repeated words of different forms. This ratio is obtained by dividing all the different words by the total number of words in the text or text set. The higher the ratio, the wider the vocabulary used by the translator. A low type/token ratio indicates that the translator uses a very limited vocabulary. With Wordsmith 8.0, the relevant data for SC, ZC, and UC are as follows.
However, when the size or length of the three sub-corpora is different, the standardized type/token ratio is more reliable than the original type/token ratio, because as the total number of words increases, the diversity may decrease as the frequency of word-use increases and different words are used less. The Wordsmith tool calculates the number of types and tokens per 1,000 words for different type/token ratios (STTR basis: 1,000, as shown in Table 2). The final run-average result is then calculated, which indicates that the STTR is based on the average ratio of all 1,000-word sets. Through these statistics, we can find out more about the behavior of Sun and Zhang’s choice of words in the interpretation of reporters during the “Two Sessions.”
Type/Token Statistics of Three Corpora.

As can be seen from the table, the standardized type/token ratio of SC (40.74) and that of ZC (40.33) corpus has little difference. However, the standardized type/token ratio of UC corpus (37.26) is lower than those of SC and ZC. This means that out of every 100 words, Sun is likely to use about 41 different words and Zhang is likely to use about 40 different words, while the average native English speaker uses only 37 different words. The data show that the degree of vocabulary change of SC and ZC is higher than that of UC, which indicates that the vocabulary range used by Sun and Zhang in their interpretations is wider than that used by native English speakers in press conferences.
The reasons are complex. First, a qualified interpreter must have memorized as many set phrases or chunks in English as possible. Therefore, when he/she is interpreting, he/she often retrieves the information from memory directly to get the corresponding English expressions, with no need for restructuring and reinterpreting.
Second, the English translations of Chinese culture-loaded words and expressions are usually long and complicated owing to the rich cultural connotation embedded in the source text. The language used in “Two Sessions” represents Chinese image, which should be dealt with carefully. Therefore, the interpreter’s subjectivity is more or less limited on such a special occasion. In order to accurately express the connotation of the spokesman’s messages and avoid misunderstanding and misinterpretation, interpreters usually render the expressions with Chinese characteristics in a relatively complete way. That is why the concise Chinese phrase “双创” is translated into a relatively long English version of “mass entrepreneurship and innovation.” More highly-condensed expressions in the “Two Sessions” can be found in the following examples: SC:
Since the ancient times, holding government office and making money have been “two separate lanes.”
ZC:
The essence of governance is to always act in the overall interest of the whole country, rather than just acting in one’s narrow departmental interests. The essence of our government is to always respond to the people’s call.
From Sun and Zhang’s interpretation, we can see that both of the two interpreters have made supplementary explanations in order to make the Chinese expressions more specific and easier to be understood by foreigners. Because Chinese language is characterized by conciseness while English language is featured by preciseness, so this kind of expressions with Chinese characteristics require accurate explanation to exhibit the political stance of Chinese government, thus increasing the vocabulary range of English translation.
Word Length
Word length is an important indicator of lexical complexity, and calculating the mean word length and standard deviation is a specific method to reveal the lexical complexity of text. Mean word length is helpful to reflect the difficulty and complexity of words, and standard deviation is helpful to reflect the degree of dispersion of word complexity in a given corpus. The word length distribution in a language is not chaotic, but regular and closely related to the language style. The mean word length can be obtained by dividing the number of letters by the number of words. With the help of Wordsworth 8.0, the following table gives the word length frequency distribution of each sub-corpus (See Table 3).
Word Length Distribution in SC, ZC, and UC.

According to the above table, several conclusions can be drawn:
The mean word length and standard deviation of SC and ZC are not much different, but both of them are higher than those of UC. At the same time, SC and ZC have higher frequencies of words with more than five letters than UC, suggesting that both Sun and Zhang tend to use more formal and complex words, resulting in the higher degree of words dispersion in their interpreting. This difference suggests that the utterance made in US press conferences by native English speakers tends to have simpler words in their spoken language and fewer complex words.
In SC, the most frequently used words are 3-letter words, followed by 2-letter words, 4-letter words, 5-letter words, and 7-letter words. The most frequently used word in ZC is 3-letter word, followed by a 4-letter word, a 2-letter word, a 5-letter word and a 7-letter word. The top 5 most frequently used words in UC are 3-letter words, 2-letter words, 4-letter words, 5-letter words, and 6-letter words. Although they differ slightly, the top three are all 3-letter, 2-letter, and 4-letter words, with words with less than 4 letters being the most commonly used.
It can be seen from the above results that the lexical complexity of SC and ZC translation is higher than that of UC, which may be attributed to the formal reporting style of Chinese press conferences. Previous studies on corpus linguistics have shown that the mean word length is closely related to the formality of a text (H. Li et al., 2013; Pavlick & Tetreault, 2016; Sheikha & Inkpen, 2012). In general, formal texts tend to use longer words because most formal words are derived from Latin or Greek and use more syllables than Anglo-Saxon words used to express everyday life (mostly 1–2 syllables). As an important window for national propaganda, the NPC and CPPCC sessions cover scores of political terms concerning Chinese government’ policies, some of which have relatively long and complicated English translations, such as “moving toward greater multi-polarity, economic globalization, and cultural diversity, and is becoming increasingly information-oriented (
Nominalization
In English, verb nominalization refers to the conversion of a verb into or acting as a noun. The Table 4 shows the use of nominalization suffixes that are most commonly used in SC, ZC, and UC. Although it is not possible to include all nominalization suffixes, the ones mentioned below are reprentative enough to cover most nominalization cases in three corpora, which makes the results to be discussed more persuasive.
Comparison of Nominalization Among SC, ZC, and UC.

Note. Proportion is calculated by dividing the number of nominalization words by the total number of words in a given corpus.
The results show that nominalization is a prominent feature of Sun’s interpretation. To be specific, the proportion of nominalization in Sun’s interpretation is 3.54%, higher than both of that in Zhang’s interpretation and that used by native English speakers at US press conferences.
In addition, in the tagged corpus, we also studied the proportion of nouns and verbs in SC, ZC, and UC to obtain more information. The basic codes for nouns and verbs are “NN” and “VV” respectively. After typing the codes “NN” and “VV” in AntConc respectively and then selecting “Words,” all forms of nous and verbs can be found and located in AntConc. Using the retrieved data, the following Table 5 illustrates the differences in noun and verb usage in the three sub-corpora.
Comparison of Nouns and Verbs Usage Among SC, ZC, and UC.

Note. The proportion is calculated by dividing the number of nouns/verbs by the total number of words in a given corpus.
It is not difficult to see from the table that nouns in Sun’s translation is 11% higher than verbs. Nouns are more frequently used than verbs in his translation. However, there is not much distinction in the proportion of nouns and verbs used in UC.
Halliday (1982) argued that nominalization occurs in written language because the author can reduce his/her dependence on context through nominalization (although oral comprehension largely depends on context), and can use it as an object to show real-world experiences and phenomena, thus making the text more objective and formal. The extensive use of these nominalized verbs can make the translation more objective and formal. This is because in the process of nominalization of verbs when interpreting, the subject and object involved in the verb are often omitted, thereby creating an objective feeling independent of the agent (the person or thing that does an action) and patient (the person or thing i.e., affected by the action of the verb). At the same time, in the process of nominalization, the verb loses its original dynamic action image and becomes an abstract static concept. It gives the audience the impression that the content is scientific, that the facts are not subject to human will, and that the author or the translator does not express any inclination (D. C. Li & Wang, 2012). The frequent occurrence of nominalization in Sun’s translated works reflects a formal language style, which is similar to a written translation. For example: SC: ZC: With a particular focus on supporting jobs and people’s livelihoods, our people will have money to spend and UC: And that
Many nouns are used in Sun and Zhang’s interpreting. Both subject and object are nouns, such as “cooperation,”“rifts,”“consumption,” and so on. Verbs are used more often in White House minutes, such as “means,”“coming across,”“put…on.…” And the length of the vocabulary used by Sun and Zhang is also longer than that used in the White House minutes.
Syntactic Level
Sentence patterns can provide us with a window to analyze the translator’s style, and they can be used to reflect a speaker’s intention of language use. Specific indicators for this section include mean sentence length and sentence complexity. A careful study of the features shown in the corpora will help us better understand the interpreting style of Sun and Zhang.
Mean Sentence Length
The mean sentence length indicator reveals how many words a sentence contains on average in a given text. With the help of Wordsmith 8.0, the following Table 6 shows the statistical results of mean sentence length for SC, ZC, and UC.
Sentence Length in SC, ZC, and UC.
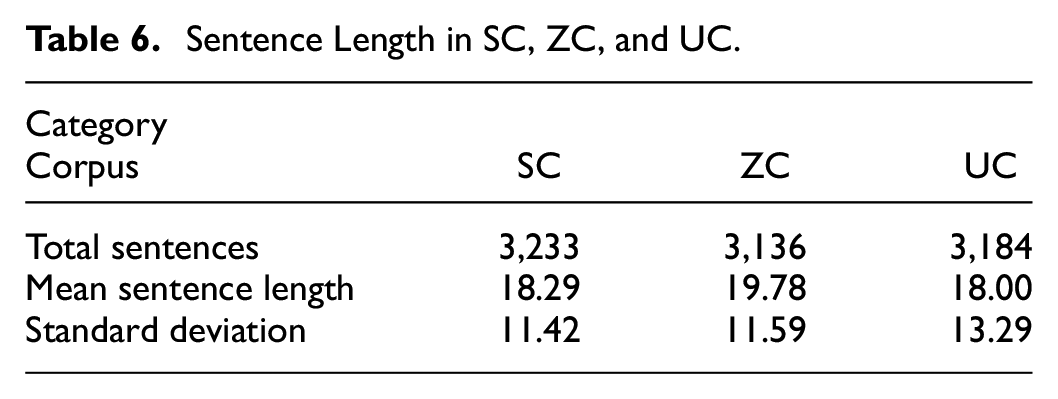
The above table shows that the mean sentence length for SC is 18.29, that for ZC is 19.78, and that for UC is 18.00. This means that Sun used an average of 18.29 words in a sentence in his translation, and Zhang used an average of 19.78 words in a sentence, while the native English speaker used 18 words in a sentence in US press conference. Butler (1985) points out that English sentences can be divided into three categories according to their length: short sentences (1–9 words), medium sentences (10–25 words), and long sentences (more than 25 words). According to his classification, overall, the sentences used by Sun, Zhang in the “Two Sessions” and those in American press conferences all fall into the category of “medium sentences.” However, it is worth noting that Sun and Zhang tend to use longer sentences than native speakers. The use of long sentences shows that Sun and Zhang have the tendency of making their interpretations more explicit by adding explanatory elements, modifiers, etc., in an effort to reveal most of the hidden meanings in the source language. For example: SC:
China urges the ROK to cease and desist, halt the
ZC: “民生在勤,
A good life hinges on diligence. With diligence, one does not
As shown in the example, when Sun interprets “
Another noteworthy group of statistics is the standard deviation in Table 6: the standard deviation of sentence length in UC is higher than that in other two corpora. Such comparatively low value in SZ and CZ indicates that their data are less spread out, implying a smaller diversity in the length pattern of the translations of “Two Sessions” compared with White House minutes.
In order to further investigate this interesting phenomenon, we calculated the number of short sentences (1–9 words), medium sentences (10–25 words) and long sentences (more than 25 words) in three corpora by employing Python, a popular programing language for data analysis. The results are presented in the Table 7.
Short, Medium and Long Sentences in SC, ZC, and UC.

Note. The percentage shown in brackets refers the proportion calculated by dividing the number of short/medium/long sentences by the total number of sentences in a given corpus.
From the data in the above table, it is apparent that two C-E interpreters used more medium sentences (60.06% and 60.49% respectively) than English native speakers (48.52%), but less short and long sentences. This finding accords with our earlier observation that the renditions of two interpreters exhibit a smaller diversity in the length pattern for “Two Sessions” interpreting compared with White House minutes. One possible explanation for this may be attributable to the pressure interpreters are faced with in their work. Conference interpreters face many sources of stress from physical enviromental factors to task-related factors (Cooper et al., 1982), which makes them tend to resort to the similar strategy of organizing and combining sentences under pressure, thus leading to less diverse sentence length than that of English native speakers.
Sentential Complexity
According to the sentence structure, English sentences can be divided into simple sentences, compound sentences, complex sentences and compound complex sentences. To a large extent, compound and complex sentences lead to a high degree of sentence complexity. Since the subordinate relation plays an important role in complex or compound complex sentences, the calculation and research of the subordinate relation are helpful to understand the complexity of the sentence. Therefore, this part will explore subordinate conjunctions to carry out research. Subordinate conjunctions (e.g., if, because, unless, so, for) are the main means of subordination. Label the three corpora and code the subordinate conjunctions in each of them as “CS,” which includes both word and phrase dependencies. The code “CS” can be used to retrieve information in corpus. After loading the tagged corpus, enter the code “CS” in AntConc to output the relevant data. The following Table 8 shows the retrieved statistics.
Distribution of Subordinating Conjunctions in Three Corpora.

Note. Proportion is calculated by dividing the number of subordinates by the total number of sentences in a given corpus.
It can be clearly seen from the above table that the proportion of clauses used in UC is twice that of SC, with the number of 2.92%, while the SC are only 1.46% and ZC 2.04% respectively. Statistics show that Sun and Zhang use fewer complex sentences than UC. Combined with previous research, it is revealed that although Sun tends to have longer sentence outputs, but the sentences he used are less complex in nature, indicating that translators usually use compound sentences rather than clauses. This finding may owe much to the style of the source language. At press conferences during the “Two Sessions,” speakers are mainly spokesmen, prime ministers and foreign ministers, who often use a large number of parallel sentences to convey their messages in Chinese. Since Chinese language does not always have connectives to make sentences coherent, interpreters are inclined to convey the same information without changing original syntactic patterns. Adding the conjunctions “and” to connect all the different information groups together is a common measure that many interpreters may take to reduce cognitive load of performing interpreting tasks and hence fewer subordinates are used in Chinese-English interpreting compared with Chinese-English translation in the written form. In addition, to some extent, fewer subordinate clauses can help to make it easier for the listener to understand the translation.
Discourse Level
After the analysis at lexical and syntactic levels, considering the translation as a whole provides a broader perspective, since the whole text is an integration of words, phrases and sentences. Through the readability test, we reveal various aspects of Sun and Zhang’s translation style from the aspects of readability and the use of conjunctions. Moreover, simply listening without the visual aid of written text makes it more difficult to understand a given piece of information. Therefore, the readability test can also provide some thoughts and insights into the whole process of interpreting.
Readability
Halliday and Hasan (1946) point out that cohesive devices link sentences and make them a whole text. Thus, their view provides a dimension to study the behavior of a particular translator at the textual level by observing connections. They classified cohesive devices into reference, substitution, ellipsis, lexical cohesion and connection. Here we only take the connection to reveal the interpreting style of Sun and Zhang due to space limitation. There are two types of tests, the Flesch Readability and the Flesch Kincaid Rank:


According to Flesch (1979), the score of the final result can be interpreted as follows (Table 9):
Interpretation of Flesch Reading Ease Score.

If the score is high, it means the text is easier to understand. It can also be interpreted as the number of years of education required to fully understand the text. Because the formula is quite complex, VT Writer was used to help calculate the final result. The following Table 10 shows the readability test results:
Readability Test in SC, ZC, and UC.

Based on the above results, the Flaisch and Flaisch Kincaid levels of Sun’s interpretation are 47 and 13.1 respectively, the Flaisch and Kincaid levels of Zhang’s interpretation are 51 and 10.9 respectively, and the English-speaking natives are 57 and 9.9 respectively. Statistics show that Sun’s interpretation is difficult to understand and requires the audience about 13 years of education or in college grade in the US to grasp the information firmly, followed by Zhang’s interpretation, which requires the audience 11 years of education or in 11th grade in the US. Readers may find it easier to follow texts of ZC, compared with those of SC. However, what a native English speaker says at a press conference is even more effortless to understand because a person with about 10 years of education or in 10th grade in the US can easily follow the questions and answers in US press conferences. Since the test focuses primarily on the written text, we can also infer that when the interpreting is done in a press conference, the difficulty of understanding may be increased to a higher level.
Conjunction
Halliday and Hasan (1946) put forward four main types of reference conjunctions, namely additive, adversative, casual, and temporal. Due to the uncertainty and infinity of conjunctions, it is difficult to include all conjunctions in this study. Please refer to Table 11 for the most representative conjunctions used in English.
Conjunctions to be Investigated in the Study.

While not all conjunctions are included, listed above are the simplest and the most used ones. The following Table 12 provides information regarding the number and proportions of different conjunctions in SC, ZC, and UC.
Distribution of Conjunctions in Three Corpora.

Note. Proportion is calculated by dividing the number of addtive/adversative/casual/temporal conjunctions by the total number of conjuctions in a given corpus.
As can be seen in Table 12, the proportion of conjunctions used by SC and ZC is slightly higher than that of UC. Compared with native English speakers, Sun and Zhang use more conjunctions to make their expressions fluent. The three ratios are different but close. In this sense, the way Sun and Zhang speak English is very similar to that of native English speakers. English is a hypotactic language while Chinese is a paratactic language. Chinese language does not have as many connectives as English language, which requires an interpreter to have a good understanding of the source language to clarify the relationship between the sense-group by adding appropriate linking devices. As a result, more conjunctions than expected may be added to the English text during interpreting so as to ensure textual coherence and fluency in target language.
Conclusion
In this study, the source and target texts of Sun’s interpreting from 2010 to 2019 and Zhang’s interpreting from 2011 to 2020 during the press conferences of the “Two Sessions” are transcribed and collected to study their interpreting style. Through a comparative analysis, the study summarizes the unique interpreting styles of Sun and Zhang. By comparing the interpreting of the two interpreters, with the speeches of the leaders of the White House as a comparable corpus, we find Sun’s and Zhang’s translations have the following characteristics:
On the lexical level, compared with Zhang’s renditions, Sun’s is more complex and diversified in terms of vocabulary, and has an obvious nominalization trend. Both Sun and Zhang use a larger vocabulary than native English speakers at the press conference. As a result, their expressions are more colorful and vivid. In addition, the longer mean word length in Sun’s interpretations reflects Sun’s tendency to use more complex words. The proportion of nominalization in the corpus is much higher than that in Zhang’s translation and that in the UC, which indicates that Sun’s translation is more formal in terms of lexical level.
On the syntactic level, Sun and Zhang prefer to use longer sentences than native English speakers. The use of long sentences shows that Sun and Zhang tend to make their interpretations more explicit by adding explanatory elements, modifiers, etc., in an effort to reveal most of the hidden meanings in the source language. Compared with Zhang’s translation, Sun’s translation mostly uses shorter sentences, which makes it easier for the listener to parse the sentence. On the other hand, Sun and Zhang seldom use complex sentences in their interpretations, and usually use compound sentences instead of clauses, which is ascribed to the style of the source language to a great extent. Since Chinese does not have to use connectives to assist in the logical flow of ideas, interpreters are inclined to convey the same information without reconstructing syntactic patterns, thereby reducing their cognitive load. Moreover, to some extent, fewer subordinate clauses can help to make it easier for the listener to understand the translation.
On the discourse level, similar to native English speakers, Sun and Zhang use quite a few conjunctions to make their English smoother. Sun’s interpreting has more conjunctions, which may prove that he paid more attention to the overall cohesion and logical relationship of the translation. Through a large number of conjunctions, the obscure clausal relationships and implied meanings in Chinese are clarified, making the translation sound easier to understand. Readability tests show that Sun’s interpreting is more formal, requires a higher level of English understanding and may be less acceptable to the public compared with Zhang’s.
This corpus-based comparative study may contribute to the interpreting style research by establishing the assessment model of lexical, sentential and discoursal level. The paremeters involved in three levels such as nominalization, sentence complexity, readability, can serve as prospective supplements to the existing ones that put focus on interpreting strategies including chunking, backtracking, addition (e.g., Van Besien & Meuleman, 2008; Yagi, 2002) and speech factors such as speed of delivery, intonation (e.g., Alkashef, 2021; Kajzer-Wietrzny, 2013). The model also allows us to quantify intrepreting style by calculating word length, the number of conjuctions and other lingusitic elements, making it easier to picture elusive aspects of consecutive intrepreting performance. With these being quantified, interpretation can be investigated in a more scentific and systemtic way, since the conclusion of relevant research can be drawn naturally from the numerical evidence.
Although this paper uses corpus software to analyze the translation of Sun and Zhang, it still has some limitations. Due to the limited time, the examples given in this paper only cover the renditions done by Sun and Zhang at press conferences in the past 10 years. There is still much room to be further explored. On the top of that, because of the heavy workload of transcribing and corpus-building and the lack of relevant interpreting videos on the Internet, we only chose the conference interpreters of Sun and Zhang in the past 10 years’“Two Sessions” as the research corpus. A more exhaustive research is expected in the future to explore the style disparity between the press conference interpreting of Sun and that of Zhang with more data and diverse research approaches. As comparison is pivotal for Translation and Interpreting Studies (Pérez, 2017), a future analysis could compare Sun with other diplomatic interpreters working in the Ministry of Foreign Affairs, such as Zhang Jing. In this way, we may find the stylistic differences among more influential interpreters. Last but not least, whether gender difference is a possible independent variable that has a direct effect on interpreting style is also an interesting topic for future research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Fundamental Research Funds for the Central Universities (Project 2662022WGYJ001).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author Bei Jin, upon reasonable request.