
Abstract
Currently, self-report measures are the primary assessment tool for anxiety disorders. Since they have some limitations, alternative measurements, such as language-based measures, are worth investigating. This paper explores which language markers signal anxiety in fictitious stories written in response to four Thematic Apperception Test (TAT) cards. Participants (n = 492) from a non-probabilistic convenience sample were asked to write a short story next to each TAT card after completing the Generalized Anxiety Disorder-7. We used RoLIWC2015 to conduct the text analysis and applied the LASSO method to identify which language markers predict anxiety. The results showed that the respondents scoring high on anxiety also tend to use more words expressing negative emotions, and fewer words expressing positive emotions. Moreover, their language contained a higher frequency of words that implied semantic differentiation (i.e., but, else) and a lower frequency of words indicating leisure. In conclusion, this paper aims to shed new light on the multimethod assessment of anxiety, mainly focused on specific language signatures as reliable predictors of anxiety symptoms. Further research using more extensive text data is recommended to discover more linguistic markers and improve prediction accuracy.
Plain Language Summary
Although the common tools used to assess anxiety have proven to be quite effective, they come with some limitations due to the variability and complexity of human psychological processes. To explore beyond what self-report methods can reveal about one’s experience with anxiety, this study attempted to explain the participants’ anxiety through the language of the stories they created. Firstly, we asked them to complete a short form, Generalized Anxiety Disorder-7, about how they felt during the past two weeks, then write a short story with a beginning, middle, and an end for each of the four Thematic Apperception Cards they were exposed to. We analyzed the texts using specialized software (RO-LIWC2015) and a statistical method called LASSO to identify the word categories that best explain anxiety. The results suggest that people who experience anxiety can be identified by their language, which is marked by a low frequency of words or expressions related to positive emotions, and a higher incidence of words that describe negative emotions. They also use words that point to semantic differentiations (hasn’t, but, without) and fewer words or expressions related to leisure activities. Finally, this paper brings a fresh perspective on written language and its use in assessing emotional disorders. We recommend further research, using larger texts and participants who come from clinical settings to find more language markers that predict anxiety accurately.
Introduction
Emotional disorders such as anxiety are among the main contributing factors to health-related burdens. According to the Global Burden of Diseases, Injuries, and Risk Factors Study (GBD), one of the most disabling mental disorders in 2019 was anxiety, which ranked among the top 25 leading causes of burden globally (Vos et al., 2020). There has been no reduction in the global prevalence or burden of anxiety disorders since 1990 (Patel et al., 2016). These facts indicate the importance of further studies, especially in a post-pandemic world, knowing that COVID-19 has significantly exacerbated mental health issues since its emergence (Santomauro et al., 2021).
To improve the research on anxiety disorders, it is necessary to consider both its phenomenology and assessment procedures. At present, self-report measures are the primary means of assessment (Antony et al., 2001). There are, however, a set of limitations of self-report measures. For example, cognitive limitations such as introspective limits (Evans, 2008; Kuhl, 2000), intrusive beliefs regarding the most suitable response in the given situation (Clore & Robinson, 2012; Parkinson & Manstead, 1992), or excessive thinking about the personal affect (Wilson & Schooler, 1991). Motives of self-presentation and self-deception can additionally distort self-reports because of impression management tendencies (Cronbach et al., 1990; Paulhus, 1984; Tetlock & Manstead, 1985).
Considering the biases mentioned above, it would be worthwhile to investigate the language markers of anxiety to identify alternate means of assessing the anxious experience. Language-based measures of psychological processes have demonstrated convergent validity with other conceptualizations of the same measures (e.g., self-reports, behaviors, etc.) in areas such as well-being (Vine et al., 2020), socioeconomic status (Kacewicz et al., 2014), value systems (Bardi et al., 2008), and so forth. The linguistic style used, as well as the written content, reflects cognitive and emotional processes (Pennebaker et al., 2003). Therefore, in-depth investigations of respondents’ language may give some insight into the nuances of psychopathology (Pennebaker, 1993).
As online human interactions grow exponentially, one way of investigating the predictive value of language in personality and mental health issues is to look for digital traces (Kosinski et al., 2013). Artificial intelligence (AI) has helped scientists detect anxiety with high precision and accuracy in online written content (Coppersmith et al., 2015; De Choudhury & Kiciman, 2017; Gkotsis et al., 2016, 2017; Larsen et al., 2015; Saha et al., 2016). Additionally, some studies using social media content and artificial intelligence demonstrate the presence of anxiety in texts as well as particular linguistic indicators of the disorder. Larsen et al. (2015) found the frequent use of words such as envy, sadness, and shame to be related to anxiety, while Settanni and Marengo (2015) underlined the use of language categories such as negative emotions, negative emoji, anger, and sadness as related to anxiety.
On the other hand, for psychologists and other social science professionals who are less familiar with computer science and dynamic vocabularies solutions, the Linguistic and Inquiry Word Count (LIWC) represents a valuable alternative due to its simplicity of use. LIWC is a mainstream program with a word reference-based methodology created by James Pennebaker and his colleagues (Boyd et al., 2022; Pennebaker et al., 2001, 2007, 2015). It has been broadly applied to different psychological fields such as social psychology (Ritter et al., 2014), personality psychology (Chung & Pennebaker, 2018; Holtgraves, 2011; Holtzman et al., 2019), educational psychology (Robinson et al., 2013), behavioral science (Kliegr et al., 2020), and non-psychological fields such as politics (Matsumoto et al., 2014; Tumasjan et al., 2010, 2011). LIWC performs word tallies and categorizes words into psychologically significant classifications such as cognitive, emotional, social, and even biological processes such as perception and bodily functions (Pennebaker et al., 2015).
Besides content-based classifications, LIWC also detects extensive language classifications: word count, long words, tenses, function words (articles, pronouns, conjunctions), and other grammar features. Some of the most exciting discoveries originate from these categories, which at first glance, people would not think of them as significant because they may seem less intuitive. For instance, first-person singular pronouns have been related to negative events and affective disorders (Eichstaedt et al., 2018; Rude et al., 2004). Likewise, writers who are suicidal are more bound to utilize first-person singular pronouns than non-suicidal artists (Stirman & Pennebaker, 2001). However, when an entire community adapts to a mutual tragedy, for example, the terrorist assault on September 11, 2001, people focus less on the self, and the use of first-person singular pronouns diminishes (Cohn et al., 2004). To understand more about the weight and importance of pronouns in relationship with verbal behavior, James Pennebaker’s work “The secret life of pronouns” (2011) brings exhaustive descriptions of relevant studies as well as explanations. Other language highlights have likewise been connected to psychological factors: extrovert writers, for instance, will generally compose longer messages yet lean toward shorter words and less intricate language (Pennebaker & King, 1999).
Study Objective
Following an exploratory approach, the current study aimed to see which linguistic categories signaled anxiety in fictitious stories written by participants by responding to four Thematic Apperception Test (TAT) cards (Murray, 1943). Well known for their ambiguity, TAT cards were chosen to prevent subjects from solely focusing on everyday topics. Thus every respondent contributed with their own story. Even if they are fictional, the stories people write can reflect who they are as individuals and their inner emotional experiences, as their mental states might permeate the stories they tell (Joo & Park, 2021). Because anxious people tend to assign negative meaning to ambiguous stimuli (Ouimet et al., 2009), the fictional narratives they create in response to TAT cards might reveal linguistic patterns of anxiety. An additional benefit of using an instrument like these cards would be that it offers a fixed context in which the study’s participants can contribute with their own stories on standardized images, thereby lowering the variability.
The software version used to conduct this study was the Romanian version (Dudău & Sava, 2022) of LIWC2015 (Pennebaker et al., 2015). Its dictionary includes multiple language categories containing around 6,500 words and word stems. LIWC appoints each word to a particular linguistic category and reports all outnumbered words in every classification, standardized by the absolute number of words in the archive. A portion of these classifications is identified explicitly, for example, leisure, health, death, or psychological processes.
A suitable solution for language prediction in this type of study would be Lasso (least absolute shrinkage and selection operator), a statistical technique developed by Tibshirani (1996). Lasso is used for preventing overfitting in models with many predictors by shrinking coefficients using a penalty function λ (lambda) that minimizes the sum of regression coefficients’ absolute values. Even though it brings some disadvantages such as reducing in-sample prediction, this technique improves predictive performance in new samples (Elleman et al., 2020; McNeish, 2015; Tibshirani, 1996), assuring the accuracy of the model and enhancing its cross-validation.
Method
Participants
This study is based on a non-probabilistic convenience sample. The sample consists of a total of 492 (101 male and 391 female subjects), representing a mixed population consisting of students enrolled in psychology bachelor’s and master’s programs, as well as participants from the general population. The percentage of males is 20.53% and the percentage of females is 79.47%. The age range for the entire sample is 18 to 77 years. The mean age for the entire sample is 38.91 years, and the standard deviation is 13.35 years. The country of origin for the recruited sample is Romania. All subjects are of Romanian ethnicity and own at least a high school diploma (or equivalent) All previously outlined details have been reported in Table 1.
Demographic Data and Descriptive Statistics for GAD-7.
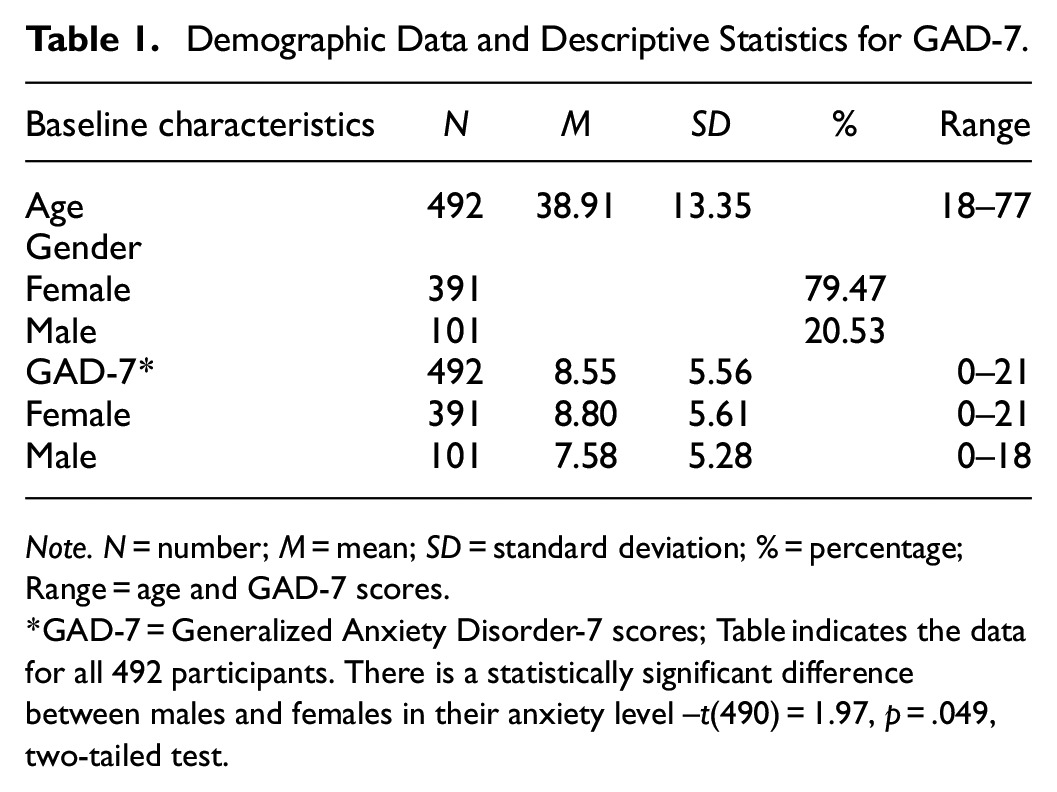
Note. N = number; M = mean; SD = standard deviation; % = percentage; Range = age and GAD-7 scores.
GAD-7 = Generalized Anxiety Disorder-7 scores; Table indicates the data for all 492 participants. There is a statistically significant difference between males and females in their anxiety level –t(490) = 1.97, p = .049, two-tailed test.
Materials
To conduct this study, we used the Generalized Anxiety Disorder Assessment screener (Spitzer et al., 2006), known as GAD-7, to measure anxiety, four TAT cards (Murray, 1943) (6BM, 12F, 13B, and Blank card) for the writing task, and Ro-LIWC2015 (Pennebaker et al., 2015) for linguistic analyses. The software R Studio (R Core Team, 2020) and IBM SPSS Statistics (Version 23) were used for the data analyses.
Procedure
A Google Forms survey was posted and promoted in exchange for student course credits. The survey consisted of informed consent with signature and questions to collect demographic data, focused on age, sex, place of provenance, and levels of study. For the anxiety measurement, the subjects completed the Romanian version of the GAD-7. In the accompanying segment, four of the TAT cards mentioned above were exhibited, next to an explicit guideline and solicitations for the participants to manufacture a story around them, with a beginning, middle, and ending. The instructions asked the participants to write at least 150 words next to each picture before moving to the following section of the exercise. All the texts were gathered and processed with the Romanian version of LIWC2015 (Dudău & Sava, 2022).
We presented a set of instructions in Romanian for each of the three Thematic Apperception Test (TAT) cards and the blank card, which were used in the study.
All participants in the study received the following instructions for the writing task:
Please look at the picture. Your task is to build a complete story starting from the image below. This story should be an imaginative one with a beginning, a middle, and an end. Try to portray who these people could be, what they feel, what they think, and what they long for. Try to detail what could have led to the situation perceived in the image and how things end up for these characters. Feel free to take as much time as you need for this task and try to develop a story as creative, comprehensive, and detailed as possible, based on your imagination. There are no right or wrong answers.
For the blank card:
Try to imagine a story instead of this *blank* image and describe in detail everything that goes through your mind. Try to develop a story as creative, comprehensive, and detailed as possible, based on your imagination. Feel free to take as much time as you need for this task. There are no right or wrong answers.
Data Analyses
We used a cross-validation approach to evaluate the performance of our predictive model, which combined an out-of-sample prediction strategy with lasso regularized regressions (Ranstam & Cook, 2018). The regularization is done through the parameter λ (lambda), which can be chosen using cross-validation. We randomly chose 1/5th of the data as a validation set (used to quantify the trained model’s error and explained variance) and the remaining 4/5th as a training set (the set where model parameters are estimated). The data used to test the model’s predictive performance was never used to train the model using this method, preventing any data leaks between training and test data. For each observation, prediction errors were saved and used to calculate the R2.
Results
Thirteen participants were excluded from the analyses for invalid responses (no written content or repetitive characters). Due to its exploratory nature, no priori power analysis was conducted to establish the sample size for this study. The average score of this sample on GAD-7 showed mild anxiety (M = 8.55; SD = 5.56) (Spitzer et al., 2006). The average word count per participant was M = 611 with an SD = 260, the whole sample summing up to 300.657 words. The median word count was 534. The LIWC2015 Romanian dictionary could capture around 85% of the words.
We report the coefficients for the Lasso regression model in Table 2, using the entire sample of participants to obtain more reliable estimates. Note that if the coefficients generated by the Lasso regression models differ from zero, they are considered relevant for prediction (i.e., “significant”). On the other hand, their estimates are not accompanied by a p-value. R Studio (R Core Team, 2020) and the glmnet package (Friedman et al., 2017) were used for all analyses.
LIWC Linguistic Categories That Predict Anxiety Symptoms.

Note. The results were obtained on the whole sample; N = 492.
Out of 85 predictors, the model selected four, which represented LIWC2015 subcategories: positive emotions, negative emotions, leisure, and differentiation. The four subcategories belong to larger LIWC2015 categories that classify affective processes, cognitive processes, and personal interests. The performance of this model was r2 = .06
In Table 2, it is shown that the vocabulary of anxious people, when engaged in a writing task, was centered around the LIWC2015 categories of affective and cognitive processes, as well as personal concerns. Respondents tended to use fewer words/expressions that reflected positive emotions. Thus, they used more words/expressions that fall into the subcategory of negative emotions. Regarding cognitive processes, the vocabulary revolved around words that implied semantic differentiation. As in personal concerns, the respondents’ vocabulary was less focused on words/expressions that indicated passion-related activities.
Additionally, Table 3 was included to list all 85 predictors that were analyzed. It should be noted that the variables highlighted in bold were selected using the LASSO technique, which is renowned for its conservative approach. As mentioned before, this method is utilized to decrease the number of predictors in situations where a significant number of variables are involved, to reduce overfitting, and to improve the regression performance.
Correlations Between LIWC2015 Categories and GAD-7.

Note. The abbreviations of LIWC categories presented in this table are in accordance with the author’s manual (Pennebaker et al., 2015). For a comprehensive list of the full names of these categories, please refer to the aforementioned citation.
Denotes significance at the .01 level (two-tailed).
Denotes significance at the .05 level (two-tailed).
Discussions
The current study aimed to see which linguistic categories signaled anxiety in fictitious stories by employing a conservatory statistical technique called LASSO to avoid overfitting in models with a large number of predictors and to improve the replicability of the results in cross-validation samples. The results suggest that anxious people may be detected through their specific language signature as they use more words belonging to the categories of negative emotions and emphasize differences/discrepancies, whereas, at the same time, they use fewer words belonging to the categories of positive emotions and leisure.
Although these general findings are in line with what the literature has shown so far (Burkhardt et al., 2022; Li et al., 2020; Settanni & Marengo, 2015; Tov et al., 2013), some aspects deserve consideration in the following lines. First of all, there is a notable absence of specific linguistic markers for anxiety in any of the Linguistic Dimensions of the LIWC (pronouns used, prepositions, auxiliary verbs) and also in the sub-domain of specific emotional states (Psychological processes – Affective processes – anxiety, anger or sadness). The presence of general affective states (negative vs. positive emotions) as the only linguistic markers for anxiety brings us back to the well-known linguistic differentiator for emotional states that extracts simple meanings out of reality evaluation, mainly based on three macro-dimensions of perception: pleasure, arousal, and dominance (Bradley & Lang, 1994; Mehrabian & Russel, 1974; Osgood et al., 1957).
The current results indicate a similar pattern—anxiety-prone individuals write stories containing basic emotional activation markers. They seem to delineate a map of anxiety lacking its mentions through valence evaluations (absence of pleasure and presence of negative valences) and implicit arousal alluded to in words that differ, bringing the inherent tension of the written reflection. The avoidance or absence of leisure activities would imply that a person could be too preoccupied with their obligations or inner experiences to pursue fun and would instead be dominated by these states.
The results prompt us to raise a couple of new questions for further research: Are these subcategories lexical specific—rather than cognitive-semantic specific—for anxiety? Are these markers showing anxiety, fear, or worry?
The 90s brought a wave of enthusiasm related to the cognitive content-specificity phenomenon (lexical specificity), which posited that specific cognitive content (formulated more or less as thoughts) could be attributed to a particular mood or affect. Specific thoughts were seen as characteristic of a given emotional state, especially if one tries to differentiate depression from anxiety. For instance, A. T. Beck et al. (1987) looked for proof of the cognitive model of psychopathology, which postulated specific semantic content for any given mood. Disenchantment shortly followed, and R. Beck and Perkins (2001) found contradictions in the initial idea of specificity. Several years later, Starcevic and Berle (2006) concluded the specificity hypothesis, affirming, in the case of anxiety, that both semantic and construct-related measures have a low predictive value for any single mood or affective disorder one might choose.
If content specificity is not the answer, what about lexical specificity? Preliminary research suggests that written text analysis could help clarify the issue. As mentioned earlier, affective disorders, suicide, and extraversion have their linguistic markers (Eichstaedt et al., 2018; Pennebaker & King, 1999; Rude et al., 2004; Stirman & Pennebaker, 2001). Could anxiety (or fear) stand next in the line, and could it be differentiated from anger and sadness, not content-related but lexically wise? Our study is quite small-scaled for such an answer, but it yields some directions on the subtle use of words and the moods they reflect. These research questions should be synchronically tested between subjects with different anxiety, depression, and anger scores, ideally controlling each concurrent mood condition.
Unfortunately, several limitations were brought by the text analysis software used in this study—Linguistic Inquiry and Word Count -2015 (LIWC2015). One of the downsides is that the Romanian LIWC2015 dictionary could capture only about 85% of the words from the text. Moreover, much like other text analysis programs, LIWC adopts a dictionary-based approach. Thus it can be error-prone when identifying and counting individual words. For instance, the term “mad” is assigned to the “anger” subcategory. Nowadays, the word “mad” typically does express some level of anger. But occasionally, it can reflect emotions of happiness (“he’s mad for her”) or emotional instability (“mad as a hatter”). The intent and meaning of people’s words can be miscoded as dictionary-based tools ignore context, irony, sarcasm, and idioms (Tausczik & Pennebaker, 2010). Other studies have also signaled these limitations (Bantum & Owen, 2009; Hirsh & Peterson, 2009).
Besides the technical limitations of the LIWC software, there are few drawbacks in the methodological aspects that may impede the generalizability of our findings. One primary shortcoming is the reliance on a non-probabilistic convenience sample. An additional limitation is the use of a non-clinical sample. A clinical sample may provide a more focused and detailed understanding of the language markers of anxiety in the written text. Moreover, the sample population of this study predominantly comprises females, thereby presenting a potential bias in the analysis of language prediction for anxiety. Unfortunately, this unbalanced ratio of 4 to 1, females to males as well as the existence of a higher level of anxiety in females and males, precludes appropriate investigation of potential differences in linguistic markers for anxiety in females in comparison with males. Furthermore, the fact that the Romanian language may possess certain linguistic traits that are distinct from other languages and cultures may hinder the replicability of our results to different contexts and populations. Therefore, future research in this area should aim to explore the language markers for anxiety in a wider range of languages and cultures.
Equally important, the utilization of an imaginative writing task, rather than a task that reflects real-life experiences, may identify linguistic predictors that could not necessarily correspond to those present in naturalistic communication. Besides all of the above, we have identified another noteworthy limitation that deserves to be highlighted, which was unintentional and might be related to a priming effect. Before being invited to produce the written content, all subjects were asked to complete the GAD-7, a well-known standard screener for generalized anxiety disorder. As a result, none of the linguistic markers contained words related to anxiety or kindred emotions. One of the possible explanations for this phenomenon could be an implicit cognitive avoidance of words directly on anxiety, following the mechanism theorized by Sibrava and Borkovec (2006). Cognitive avoidance, as a mechanism, could also help comprehend the true nature of the established relationship between the markers—since worry can be defined by Borkovec et al. (1983, p.) as “a chain of thoughts and images, negatively affect-laden […], an attempt to engage in mental problem-solving on an issue whose outcome is uncertain but contains the possibility of one or more negative outcomes.” Even if worry is related to fear, it is not fear itself and can be present both in GAD-affected and non-affected individuals. Therefore, with this definition at hand, we can notice that the subjects of our research elicited, with a higher probability, words from the lexical realm of worry, possibly primed by the GAD-7: generally, negatively affect-laden, tension provoking (the differentiation subcategory), and negatively linked to leisure and nonchalance. If the (priming) effect proved itself true, similar priming for panic and social anxiety, for example, should yield different markers, stronger in arousal and different in the dominance field but similar in the affective tonality.
Conclusions
Assessment of emotions, anxiety included, is still a field of dispute between taxonomic lumpers and splitters. Lexical exploration of written stories might bring some detail, either by the specificity dispute of emotions versus words (on a linguistic and not content level), or confirming that basic emotional experience is instead a lumping experience, also reflected in the use of written language, and reducible to three main dimensions (valence, arousal, and dominance). There is no definite conclusion, but rather a new window opened toward the multimethod assessment of anxiety—searching for both a lumping and splitting solution. Further inquiry on larger samples, even clinical samples (note the average score for anxiety on this study sample pointed to “mild anxiety”), with a wealth of written material and using priming or neuter conditions for producing written material, could bring this discussion further. We anticipate that any method eliciting more personal written material or any source able to increase the amount of text that is analyzed would improve the level of anxiety prediction. Therefore, it could provide more information to address the lexical specificity account better.
Footnotes
Acknowledgements
There are no acknowledgments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has received funding from the EEA Grants 2014-2021, implemented through the UEFISCDI project number RO-NO-2019-0412.
Ethical Approval
The study was reviewed and approved by the University Ethics Committee (5792/28.02.2019). The participants provided their written informed consent to participate in this study.