
Abstract
Big data analytics (BDA) enhances knowledge and decision-making. Despite its importance, the connection between technical progress and political change is neglected in the administrative process. Most studies focus on e-government, e-governance, and how technology can improve existing operations of the bureaucracy. However, this article aims to explore the potential of BDA for public policy systems and provide a linkage for the transformation toward digital and smart governance using preferred reported items for systematic review and meta-analysis (PRISMA) approach to reveal the relevant documents and narrative review approach to interpret the application of BDA at each step of the public policy system. In addition, this study identifies several common public policy-related big data sources and techniques that could be used at the various stages of the public policy process. This study argues that BDA has the potential to be used for policy formulation in the four main phases—planning, design, service delivery, and evaluation. Most studies confirm its potential in the policy process for taxation, health, education, transportation, law, economy, and social system. This study reveals that it is also suitable for public policy execution stages, such as public supervision, public regulation, service delivery, and policy feedback. Previous studies have indicated that the application of BDA can transform traditional or manual governance systems into digital and smart governance. We contend that the policy cycle should be seen as a dynamic and iterative process characterized by continuous evolution. Though each step of transformation has its unique challenges in handling BDA and maintaining the Information and Communication Technology (ICT) infrastructure, it can ensure an accurate, prompt, and context-oriented public policy system. These insights provide a novel outlook on effectively managing the interplay between innovation and traditional approaches in the realm of public policy development.
Plain Language Summary
Importance: Big data analytics (BDA) enhances knowledge and decision-making. Despite its importance, the connection between technical progress and political change is neglected in the administrative process. Most studies focus on e-government, e-governance, and how technology can improve existing operations of the bureaucracy. Aims: However, this article aims to explore the potential of BDA for public policy systems and provide a linkage for the transformation toward digital and smart governance using preferred reported items for systematic review and meta-analysis (PRISMA) approach to reveal the relevant documents and narrative review approach to interpret the application of BDA at each step of the public policy system. In addition, this study identifies several common public policy-related big data sources and techniques that could be used at the various stages of the public policy process. Findings: This study argues that BDA has the potential to be used for policy formulation in the four main phases—planning, design, service delivery, and evaluation. Most studies confirm its potential in the policy process for taxation, health, education, transportation, law, economy, and social system. This study reveals that it is also suitable for public policy execution stages, such as public supervision, public regulation, service delivery, and policy feedback. Implications: Previous studies have indicated that the application of BDA can transform traditional or manual governance systems into digital and smart governance. Though each step of transformation has its unique challenges in handling BDA and maintaining the Information and Communication Technology (ICT) infrastructure, it can ensure an accurate, prompt, and context-oriented public policy system.
Introduction
Big data and data analytics are new paradigms in public administration practices. When implemented accurately, it produces positive public administration results in efficacy, efficiency, and citizen satisfaction (Arnaboldi & Azzone, 2020). These advantages result from a considerable increase in decision-making accuracy, a rapid internal “information task” performance, and a significant decrease in the running costs of the decision-making process (Bright & Margetts, 2016). This is made possible by digitizing various aspects of human life and the application of information technology (IT) developments, specifically for public administration. In big data methods, large amounts of data are processed based on reasoning by robust IT to gather the information that aids public administration in effectively performing its tasks (Klievink et al., 2017).
The term “big data” refers to collecting large amounts of data from several sources, including human input data, process data from sensors, and various monitoring systems (Desouza & Jacob, 2017). Data is being gathered at an unprecedented rate (Lee, 2020). Massive volumes of data have facilitated substantial innovation in the public and private sectors (Suominen & Hajikhani, 2021). The world is on the verge of creating a broad utility of big data and analytics, similar to companies like Google and Amazon, which are constantly innovating consumer services. This shift is being promoted by businesses because of the shift in the size of the industrial revolution (Khurshid et al., 2019b). However, when it comes to employing big data and data analytics in decision-making, public policy lags due to a lack of acceptance and several problems that limit the utility of these technologies (Giest, 2017).
As people’s lives become increasingly digital, there is an increase in the amount of electronic data created globally. All the devices connected to the internet generate and stream enormous amounts of electronic data, including smartphones, video recorders, sensors, smart home applications, other “Internet of things” systems, and work-related IT (Suominen & Hajikhani, 2021). Devices that directly interact with other devices to build autonomous systems could prove to be the next game-changers (Khurshid et al., 2019b).
New methods of gathering, storing, and processing data to enhance its accessibility and serviceability are developing simultaneously (Poel et al., 2018). New analytical and logical techniques are also being actively developed. The capacity to analyze data has reached unprecedented heights due to IT advancements, both in terms of hardware and software. Impossible to access and use of information in the early days are now possible due to information digitization, artificial intelligence and computational thinking, computerization, and automation (Rahmanto et al., 2021).
Data availability and innovative approaches are being increasingly understood in the public and corporate sectors (Wahyunengseh & Hastjarjo, 2021). Several public administrations have implemented big data strategies or policies. In terms of efficiency and effectiveness, big data and the strategies for using them are emerging phenomena in the management landscape that provide excellent outcomes (Kandt & Batty, 2021). A private sector example is the insurance provider, Aviva (Maciejewski, 2017), which created a big data app for smartphones that accurately records customers’ driving patterns. Previous statistics are employed to precisely determine a driver’s risk; hence, cautious drivers pay less for insurance compared to reckless drivers. Big data opportunities in public administration are comparable to those in private sector businesses (Visvizi et al., 2021).
To utilize big data in the public sector, the concerned authority must have data science-related knowledge and abilities (Spence, 2021). This includes software-based modeling, statistics, data management, data exploration, algorithmic machine learning, data product formatting, and computer programing. Additionally, the public sector needs a strategy-tailored to the general public goals, objectives, and policies. Big data have immense potential in public administration and for the public interest, irrespective of the required labor (Suominen & Hajikhani, 2021).
Publicly accessible, thorough research into big data theory and applications in government sectors is lacking. However, there is concrete proof of its meaningful outcomes. This encourages big data usage, broad conclusion formulation, and the identification of potential big data applications in the public sector (Joubert et al., 2023). Due to the creation and gathering of data at an amazing rate, using big data and data analytics has almost become an essential tool. Studies have been conducted regarding business and government applications of “big data” and “data analytics,” which have become popular buzzwords. Additionally, there is an increase in the use of big data analytics by government entities to address problems, such as sustainability issues and pandemics (Wahyunengseh & Hastjarjo, 2021). However, there are noticeable research gaps and a lack of a comprehensive study of the potential use of big data in public policy decisions.
New techniques of big data analysis can help governments better understand the behavior of their constituents and enhance public services (Goyal et al., 2022). According to contemporary research on the topic, big data may be utilized in various ways to enhance public sector results (Dritsakis et al., 2018; Lee, 2020; Suominen & Hajikhani, 2021). These include enhancing government efficiency (Maciejewski, 2017), effectiveness (Concilio et al., 2019), and openness (van Veenstra & Kotterink, 2017), making policy decisions with more knowledge (Blum, 2018), and delivering better services based on improved insight into citizens’ needs and wants (Shah et al., 2021). As noted by academicians, big data utilization has enormous promise in public policy sectors, including health care (Moutselos & Maglogiannis, 2020), the economy (Anejionu et al., 2019), the environment (Miljand, 2020), and transportation (Zannat & Choudhury, 2019). Although big data solutions are marketed as a method to address societal problems, concerns about how, where, and when they are likely to be effective, as well as the scope and potential of big data, remain unanswered (Maciejewski, 2017).
Furthermore, there is relatively little practical application of big data in the public sector. Most big data initiatives are either in the planning stage or in the early stages of development (Kinra et al., 2020). Effective use of big data can help make an effective public policy decision. Applying big data to policy formulation would advance evidence-based policymaking (Martins, 2018). Research continues to be conducted on the use of big data to support evidence-based policymaking, especially concerning the policy cycle. The evidence-based policy complements the theoretical model of the policy process. However, where and how big data may be utilized to support evidence-based decision-making has not been sufficiently discussed. Few academicians have examined its potential applications at various stages of the policymaking process (Concilio et al., 2019; Guenduez et al., 2020; Severo et al., 2016; Studinka & Guenduez, 2018; Suominen & Hajikhani, 2021; Taylor & Schroeder, 2015). In this study, the use of big data in the various stages of the public policy process is examined to fill the research gap, mentioned earlier. As a result, the research questions that inspire and direct this work are:
The findings will help to understand the sources of public policy-related data, the application of big data in policy analysis phases, the indicators of effective public policies, and the challenges of using big data in public policy. These findings can help administrators, related stakeholders, policymakers, and citizens to make rational and sustainable public policies. The remainder of the study is presented as follows: section 2 deals with methodology, sections 3 and 4 present the results and discussion, and the final section presents the conclusion, recommendations, limitations, and future research direction.
Methodology
Data were gathered for this study using a systematic review approach incorporating reliable sources. According to Saunders and Lewis (2012), a systematic literature review starts by defining pertinent keywords to look for and retrieve content from databases for presentation in the study. According to Tranfield et al. (2003), a literature review aims to identify knowledge gaps and limits. In addition, it classifies and assesses earlier research based on crucial issues and suggestions for further study. The preferred reported items for systematic reviews and meta-analyses (PRISMA) procedure, which is trusted for evidence-based systematic reviews and meta-analyses, is used in the current investigation. Its four main processes are identification, screening, eligibility, and inclusion, and it includes a 27-item checklist. The key advantages of the PRISMA approach are the assessment of strong and weak points, visualization of document identification quality, and replication of its structure and formatting. The following sections provide a chronological presentation of the research design, database selection justifications, publication criteria, period, search approach, search fields, and inclusion and exclusion criteria for the current study.
Research Design
This study employed a systematic review technique, which entails a protocol creation and looks for the most important information in the literature. According to Fink (2005), a systematic literature review is specific, exhaustive, and reproducible for finding, examining, and synthesizing the body of information held by researchers and practitioners. The PRISMA framework served as the foundation for the data collection proposals (Moher et al., 2009). PRISMA checklists were used to fulfill the four phases of identification, screening, eligibility, and inclusion.
Eligibility Criteria
The articles with targeted keywords, language, and publication date were considered as inclusion criteria. Only peer-reviewed journal papers written in English were chosen for this study. The period covered by this study was from January 2001 to May 2022.
Research Protocol Development
The established research protocol ensured scientific inquiry (Table 1). A detailed review of the existing literature, published during the preceding 22 years, was conducted. In addition, this study examined recent research to substantiate the claims for applying big data in public policy and administration practices.
Summary of the Research Protocol.

Search Strategy
Literature reviews, in general, allow for the investigation and synthesis of previous research, exploring its focus to uncover new knowledge that may aid in establishing a new educational and research paradigm. The PRISMA technique was used to conduct a comprehensive systematic review (Moher et al., 2009). With these features in mind, the current research searched terms, such as big data, big data analytics, public policy, policy analysis, and policy making in the Scopus database. Owing to the high quality of the papers and publications indexed in the Scopus database, it is often used in literature reviews, although it does not include all published articles due to its qualitative selection process. As a result, this database was selected as the current study’s information source. This research, carried out in May 2022, implemented search strings (Table 2).
Search String Criterion Input for the Study.

Criteria for Inclusion and Exclusion of Papers
This study used two criteria to determine the papers to be included and excluded:
(a) Does the paper present big data, BDA, public policy, and policymaking decisions?
(b) Are there any links between public policy, policymaking, policy process, and public policy decisions?
Analytical Approach
The qualitative analysis was carried out with MAXQDA software to increase the rigor in the coding procedure. The program makes it possible to directly annotate texts with codes, code them, and use the codes to conduct thematic analysis of the content. The analysis becomes more convenient, transparent, and reliable as a result of this program and coding system.
After performing the coding procedure, two experts were invited to recognize and verify the coded contents through cross-checking the papers and coding created earlier by the author. This method was performed to avoid capturing the same information more than once in different codes and thus improve the readability, validity, and consistency of the coded theme. The cross-tabulation of the codes, synthesized coded documents, and coded text portions were produced using the MAXQDA program (Suominen & Hajikhani, 2021). These were utilized in the process of interpretation.
Results
Identification of Documents
The PRISMA checklists served as the direction for this study (Appendix A). There were 66 papers located in the Scopus database during the identification step, and 13 more were located through references. The first search yielded several items, including books, book chapters, journal articles, conference papers, and book results. Additional documents were removed during the screening phase, except journal articles.
Working papers, books, conference proceedings, and journals were excluded once the search was constrained to “article types” and “keywords.” After the abstracts were reviewed, 21 papers were eliminated at the screening stage. An additional 21 documents that failed to fulfill the inclusion criteria were excluded at the eligibility stage, and 37 were chosen. Finally, 10 papers, which are not relevant to keywords (i.e., big data, BDA, and public policy) were removed, and thus, 27 papers were chosen for inclusion (Appendix B), including journal articles that could demonstrate how big data and data analytics may be used for public policy and policy decision-making and their execution (Figure 1).
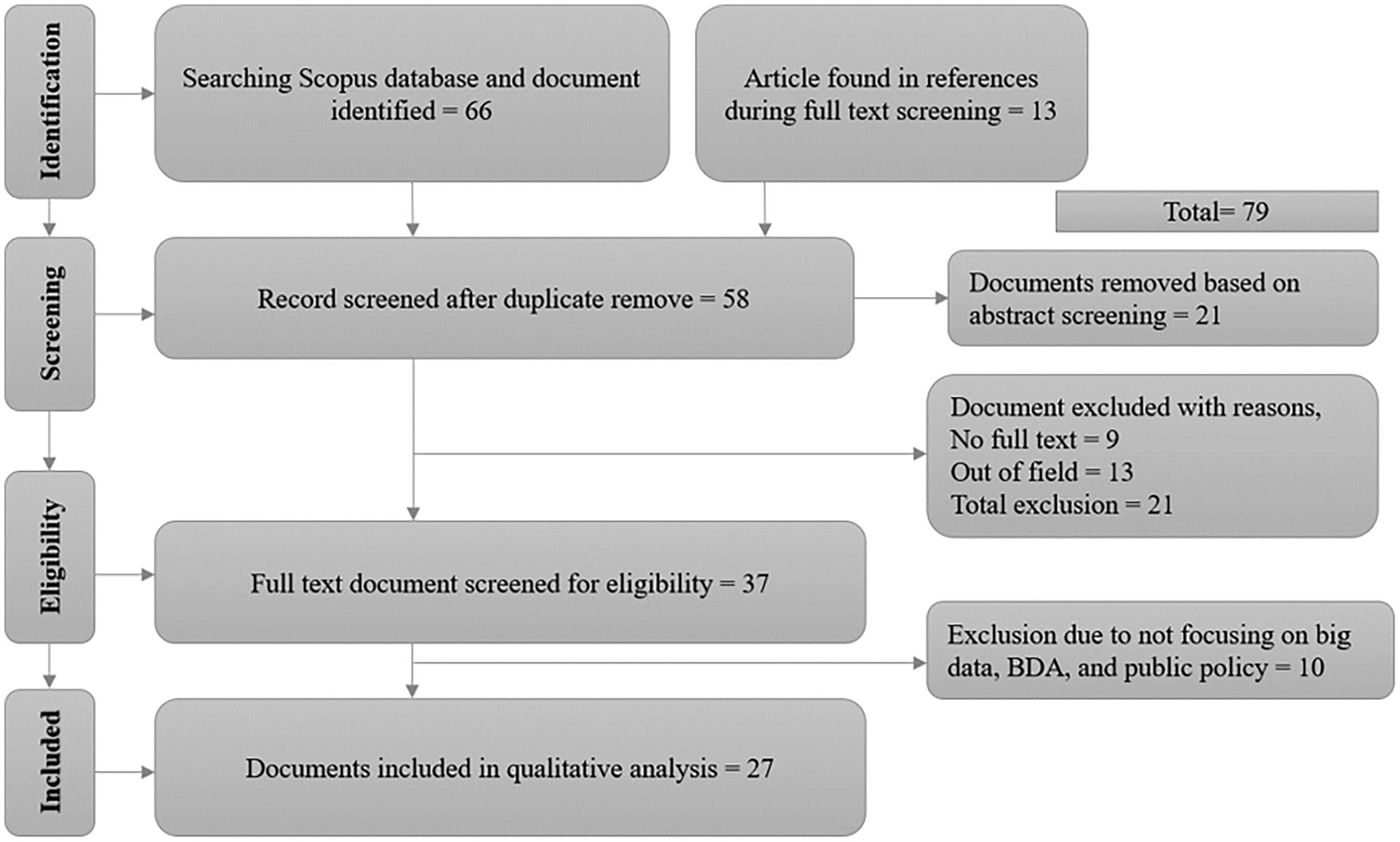
Document identification through PRISMA.
Data Processing, Analysis, and Visualizations
Data Preprocessing
Before data analysis and visualization, contents were preprocessed in a standard scientific way as part of natural language processing (NLP), such as text cleaning, normalization, removing stop words, and tokenization, to ensure accurate and reliable measurement from unstructured data. During text cleaning, unnecessary punctuation marks and special characters were removed. Additionally, all the contents were transformed to lowercase for normalization. Using the standard stop words list, the corpus was filtered by removing the stop words. These steps reduced word variations and redundant word counts and were used as the input in the tokenization process. Finally, the corpus was tokenized and used for data analysis and visualization.
Word Cloud and Counts for Data-Driven Public Policy
The python Wordcloud library was used to generate a word cloud from the contents. This word cloud generated an image and visualized the qualitative intensity of the most prominent words (i.e., frequently used words) in a given content and distinguished them from the other words in a quick view. Figure 2 illustrates the word clouds and depicts that big data, analysis, data analytic, decision-making, public health, and policymaking are among the most prominent words. However, the word cloud does not provide the exact word counts; thus, Figure 3 presents the top 20 most frequent words and their counts in the Y-axis as the quantitative measurement.

Word cloud from data-driven public policy corpus.

Word counts from data-driven public policy corpus.
Network Visualization Map for Data-Driven Public Policy
The VOSviewer program was used to create the network visualization map (Figure 4) and represents the two-dimensional map regarding the strength of the keyword links used in the publications. The strength of a keyword link increases when two keywords of the same link are found in the same publication. From the map, it can be observed that big data, data analytics, big data analytics, decision making, policy making, and public policy are directly and strongly interconnected with each other.

Keyword network visualization map regarding data-driven public policy.
Frequency Statistics
The network visualization map does not provide the frequency statistics for the keywords. Hence, Table 3 displays the frequency statistics, such as keyword frequency, term frequency, document frequency, and term frequency-inverse document frequency (TF-IDF) (Zhang et al., 2011) for the most relevant keywords. In this study, keyword frequency measures the number of occurrences for a particular keyword, whereas term frequency measures the average keyword frequency for each document. Document frequency measures the number of documents for a particular keyword. Lastly, the TF-IDF measures the average topic relevance for a particular keyword (Zhang et al., 2011). In addition, Figure 5 represents keyword frequency and document frequency, which allows readers a more visualized way to perceive and compare the keyword and document frequency.
Frequency statistics for most relevant keywords.

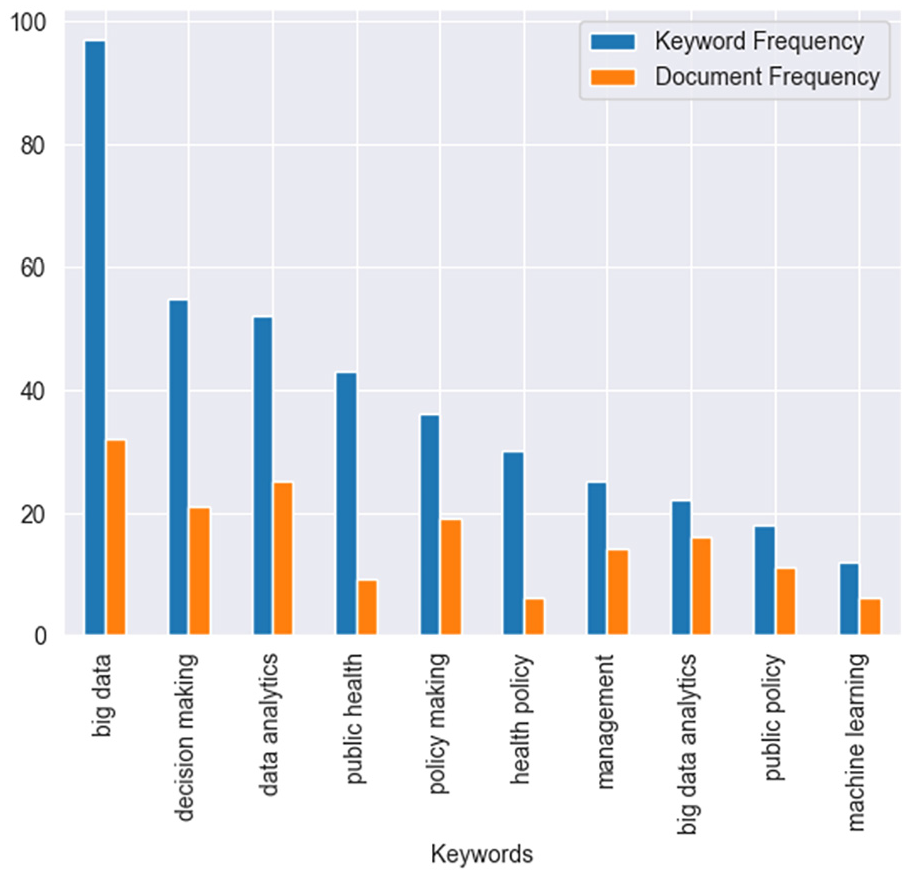
Keyword and document frequency from the corpus.
Analytical Results
Sources of Public Policy-Related Big Data
Big data, basically, refers to data sets that are larger than those that can be processed by traditional technologies, necessitating a more focused and advanced approach to analytics. The BDA could be crucial to this form of decision-making, particularly for the procurement of public services that use vast data sources to forecast the possible outcomes of various scenarios. The identified sources include public census data, face-to-face interviews, crowdsourced data, private sector transactions, social networking sites, government website queries, public development sector, tax information, and regular queries from various stakeholders to public agencies (Table 4).
Sources of Public Policy-Related Data.

BDA for Public Policy Formulation
Numerous studies demonstrate how big data may be used to enhance the overall policymaking process. According to Maciejewski (2017), big data improves policy creation and execution by bolstering the information intake for decision-making based on evidence and offering quick feedback on the policy and its effects. Big data have enormous potential for informing various stages of the policy analysis process, from problem conceptualization to the ongoing evaluation of existing policies, and empowering and involving citizens and stakeholders in the process. According to the studied literature, this section examines how big data may be used in the four stages such as planning, design, delivery, and evaluation of the policymaking process. This study identified four major steps of public policy formulation where the BDA can play a potential role in the overall policymaking process (Table 5).
Public Policy Formulation and the BDA.

Big Data Analytics for Public Policy Implementation
Big data can be utilized to observe the overall situation in a regulated region. Knowledge gathering enables better regulation and informed regulatory judgments. In addition, it aids decision-makers in comprehending the social effects of their actions and making informed inferences from social input. Big data may be applied to enhance existing public services and develop and deliver new services. Verifying a person’s eligibility for social assistance is an important way to use big data in this field. This could be useful for irregularity detections at a preventative stage. This study extracts the views and opinions of the researchers and argues that big data play a vital role at various stages of public policy decision-making, such as public supervision, regulation, service delivery, and policy feedback (Table 6).
Usage of the BDA for the Public Policy Execution.

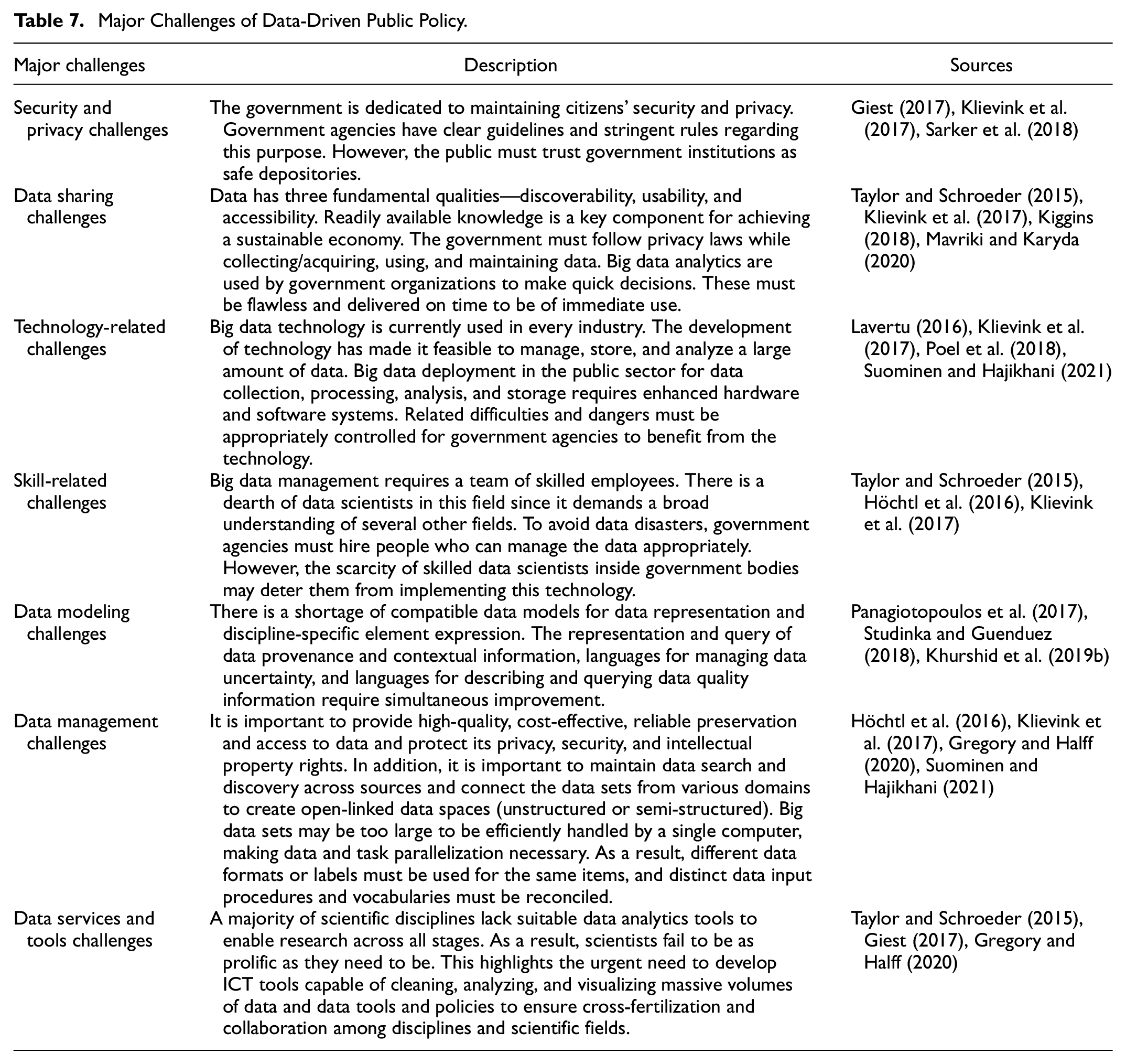
Major Challenges in BDA-Based Governance for Public Policy
According to the analysis, it is evident that to benefit from the prospective of big data, it is necessary to remove the technological obstacles preventing the sharing of data, knowledge, and information across disciplines and integrate activities with various ontological foundations (Höchtl et al., 2016). However, there are numerous difficulties to overcome. As mentioned earlier, issues in this field are caused by data volume, velocity, diversity, unpredictability, and virality. Despite enormous potential, big data faces several implementation-related challenges. The data size will steadily rise, some of which may be inaccurate. Adequate and efficient hardware and software must be implemented to manage the data volume. This study has identified several challenges in this process (Table 7).
Major Challenges of Data-Driven Public Policy.
Discussion
The thorough analysis and careful management of large-scale data pertaining to public policy, as mentioned earlier, contribute to the validation and support of the fundamental assumptions of this study. The use of comprehensive methodologies, which include PRISMA-based document recognition and complicated data preparation, plays a vital role in substantiating the empirical foundation of our theoretical claims. The findings obtained from this comprehensive investigation provide concrete evidence of the interrelation between big data, public policy, and decision-making.
In this study, the comprehensive search approach, which encompasses a wide range of resources, signifies an extensive exploration of the extensive scholarly domain related to big data and public policy. The choice to give priority to journal papers aligns with the existing body of literature that recognizes the rigorous peer-review procedures they undertake, therefore ensuring a high standard of academic quality. Furthermore, the use of natural language processing (NLP) methodologies for data analysis in policy research exemplifies a multidisciplinary convergence that has garnered momentum in recent years. The process of text preprocessing is essential for every comprehensive NLP application since it guarantees the precision of subsequent analyses. The use of word clouds, despite their seeming simplicity, is consistent with contemporary calls for more visual representation in policy research in order to enhance understanding. The use of VOS viewer highlights its increasing recognition in scholarly research for the purpose of visualizing bibliometric data. Nevertheless, doing detailed quantitative analyses, as seen in Table 3, may provide valuable insights.
Additionally, the summary of the findings has been presented in a graphical model (Figure 6). This model has four main steps—major big data sources, processing unit, data-driven public policy formulation, and public policy execution. The major big data sources include public census data, face-to-face interviews, crowdsourced data, private sector transactions, social networking sites, government website queries, public development sector, tax information, and regular queries to public agencies from various stakeholders. The processing unit mainly deals with the data warehouse and its characteristics. Planning, design, delivery, and evaluation are the four steps for data-driven public policy formulation. Public policy execution includes public supervision, public regulation, public service delivery, and policy feedback.
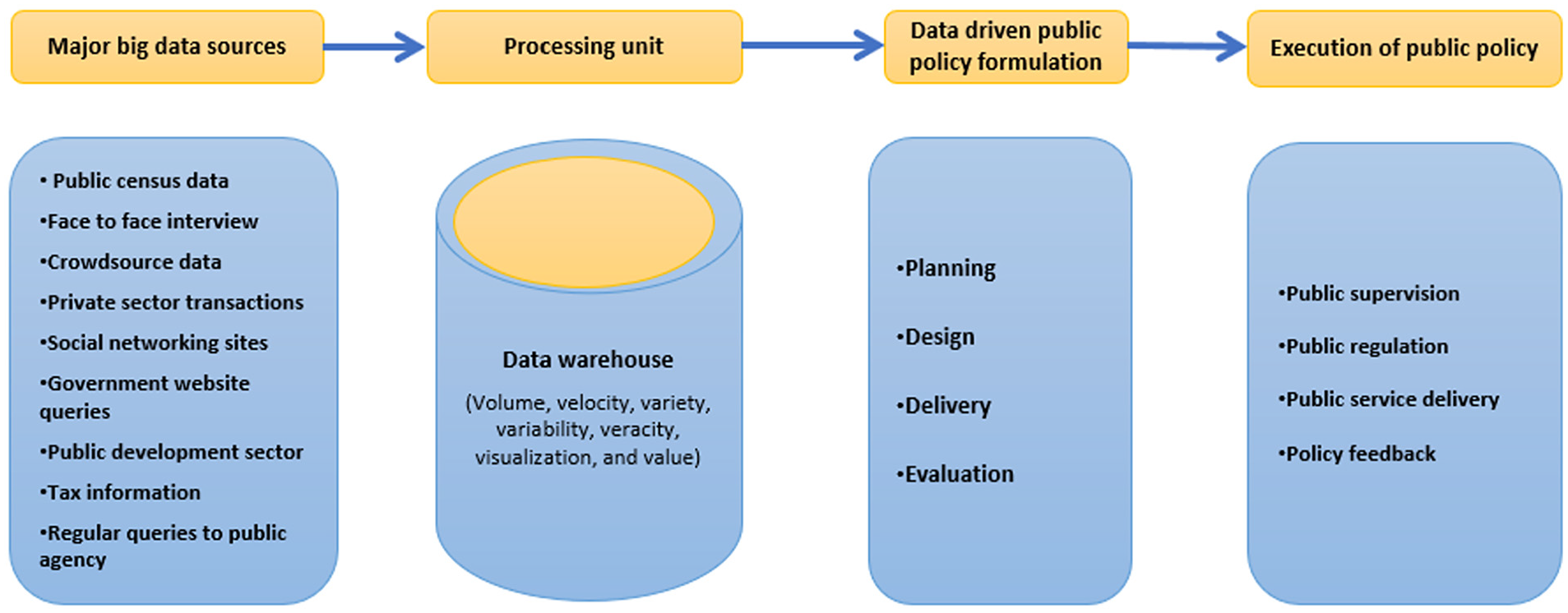
A conceptual framework of data-driven public policy formulation and execution.
Data Sources and Public Policy
New methods of gathering, storing, and processing data to enhance its availability and usability are developing simultaneously as huge data sets are produced by the systems mentioned above. New analytical and logical techniques are actively being developed. Hence, the capacity to analyze data and reason has reached unprecedented heights due to IT advancements, both in terms of hardware and software (Sarker et al., 2018). With traditional methods, it would have been impossible to access and use the available information. This has been made possible with the digitization of information and related data flexibility, advancements in artificial intelligence and computational thinking, computerization, automation of processes, and an increase in computing power. Data availability and innovative approaches to using it are becoming widely understood and accepted in the public and corporate sectors. Hence, several public administrations have implemented big data strategies and policies (Kyriazis et al., 2020).
Big data development has brought about a wide range of positive effects in several industries. Among these, public sector organizations can benefit from big data information to increase public service satisfaction. Social data analysis, historical data analysis, and predictive analysis are the advantages of big data implementation (Su & Hu, 2020). By creating a thorough ICT governance, data analytics can be used as a crucial component of data governance. Big data analysis using various digital tools increases data diversity through objective evaluations and helps in decision-making accuracy, which can impact policy planning factors. Big data are utilized in the public sector to gather public opinion and answers, which are used to inform policymaking and enhance public services. To create integrated services with precise criteria and develop data-based solutions to problems, these inputs may be collected through social media and government service information systems (Visvizi et al., 2021).
Public Policy Analysis Phases
Planning Phase
Agenda-setting, problem description, policy debate, and involvement are key to the conversations and instances of the planning phase. Agenda-setting, or identifying and clarifying the problems that could be the focus of public policy, is concerned with identifying the issues that require government attention. According to academicians, big data are used at the issue description and agenda-setting stages of the policy process (Amankwah-Amoah & Amankwah-amoah, 2015; Goyal et al., 2022; Guenduez et al., 2020). Big data may be used as a tool for defining a policy problem before it is perceived as such, showing where demand is being fulfilled or where a developing problem might be fought early. It has long been acknowledged that the media, through framing topics and disseminating pertinent information, plays a crucial role in creating agendas. Digital media complicate agenda-setting dynamics. Any audience member may start a new topic using social media, and participants can respond to an existing debate in a variety of ways, including text, voice, video, or graphics. Therefore, gathering information from social networks with high levels of participation to identify citizens’ policy preferences is one way for governments to identify emerging topics and create pertinent agenda items (Mueller, 2020).
The goal of the policy discussion is to debate the policy choices for the problem selected during the agenda-establishing phase. Big data can be helpful in deciding the specifics of urgent policy issues and establishing policy priorities for infrastructure, security, and education. For instance, Boston’s Street Bump Application uses mobile phone motions to gage the smoothness of a car journey to determine the locations to be prioritized for infrastructure upgrades. The best place to start could be to determine the use of this knowledge in open policy discussions (Poel et al., 2018). Sentiment analysis and opinion mining may be used to find sentiment streams associated with relevant public policy issues referenced in text communications. The following examples illustrate how internet-based big data may assist in agenda development and policy discussion in greater detail. Whitman Cobb (2015) examined big data-enabled metrics for monitoring public opinion of the United States space policy, including Google Trends and social media. Public opinion is crucial in determining the course of American space exploration; however, the instruments employed to gage it are restricted by time constraints and a dearth of data. By nation, state, area, and period, Google Trends provides a wide range of potential data sources. Twitter provides policymakers with information about people’s interests, while Google Trends offers a longer-term perspective. Together, they offer a versatile instrument for policy analysts to gage public interest. Policymakers in the political and space communities may find this kind of information useful as they work to persuade Congress and the executive branch to approve more activities or money for NASA. The importance of social media data in evidence-based policymaking is examined by Panagiotopoulos et al. (2017). The extensive exploratory Twitter dataset was summarized and depicted through the cluster mapping approach to show the development of discussions.
Design Phase
Governments strive to effectively and efficiently accomplish goals and are interested in utilizing knowledge and expertise concerning policy challenges. This is connected with policy design. Government officials develop detailed plans of action after a public issue is added to their official agenda. The creation of different courses of action for addressing (resolving or ameliorating) a public problem is part of policy formulation, where the majority of design efforts are involved (Giest, 2017). The policy design concept examines these factors of policy formation and result implementation. This provides policy tools with significant consideration. When considering policy alternatives, decision-makers think about both “what to do” and then “how to accomplish it.”Giest (2017) connected these ideas to big data and makes the case that the growing usage of big data is influencing the designing of policy instruments. With digitization, the enormous administrative data collected at multiple governmental levels and varied domains, such as tax systems, social programs, and health records, may be utilized for decision-making in the fields of education, economics, health, and social policy. Governments’ diverse information-based policy instruments illustrate the numerous ways of utilizing big data to pursue policy goals. Government initiatives to control information are described by procedural informational devices. These intend to influence policy processes through the control and selective supply of information in a manner consistent with government goals and objectives.
Certain initiatives encourage information release, while others restrict it. Government data releases or open data policy frameworks are pertinent examples of how big data may be utilized as procedural policy tools (El-Taliawi et al., 2021a). Important informational tools, such as judicial probes, executive commissions, national statistics agencies, surveys, and polls, assist in data gathering to promote evidence-based policymaking. Governments are increasingly combining these conventional statistics with big data based on social media, cameras, and sensor inputs (Giest, 2017). Education is an important field where real-time big data tools are increasingly being employed as policy instruments. Giest (2017) and Williamson (2016) claimed that these tools give policymakers current knowledge about the education system through digital and interactive data visualizations. Learning analytics platforms can collect data from children’s educational activities to monitor and evaluate their growth and achievement and algorithmically improve and personalize their educational experiences. This offers policymakers granular knowledge to create improved policy alternatives.
Stakeholder involvement may be crucial when leveraging big data in the design phase, especially regarding information-based policy tools. Using an app-based data-gathering approach, Semanjski et al. (2016) demonstrated how big data may be utilized for decision-making in the field of transportation systems. For example, citizens can share their mobility data with Routecoach. The findings of more than 8,300 participants in the city of Leuven could be utilized to draw insights on various sustainable mobility parameters, such as CO2 emissions or cost per trip, using a machine learning technique (Bellia et al., 2022). Policymakers gain immediate feedback about implemented initiatives, such as the installation of a new bike route, due to shorter data collecting and processing periods and better data relevance, speeding up the decision-making process.
Delivery Phase
Most scholars allude to the implementation stage, which frequently includes additional formulation or refinement of policies when discussing the use of big data in the delivery phase (Amankwah-Amoah & Amankwah-amoah, 2015). It consists of the resources, expertise, and effort committed to putting policy choices into practice. Although most tools to achieve a policy goal are determined in the policy decision, certain decisions, such as allocating cash, assigning staff, and creating procedure rules, are necessary to make a policy function. Hence, real-time data creation may impact the policymaking process during the implementation phase. New policy deployment instantly generates fresh data to assess their efficacy and enhance subsequent implementation procedures. Real-time evaluation of a new policy may reveal if it is having the desired impact or needs to be modified. As a result, public administrations have more autonomy and are better equipped to respond to evaluation outcomes promptly (Anisetti et al., 2018).
By modifying the input variables in the legislation, markets, architecture, social norms, and information, governments may employ real-time micro-experimentation to test policies. To propose, test, assess, and revise a policy intervention, one may precisely quantify the effects that correlate with the altered variables. Dunleavy (2016) illustrated how big data may be used for behavioral insights. Online randomized control trials (RCT) allow the evaluation of small-scale impacts, leveraging the accessibility of enormous datasets. Enterprises or government agencies frequently conduct these trials at low costs and in real-time. For instance, the United Kingdom collects court penalties from 1.9 million people each year by engaging contractors to pursue outstanding debts, which is expensive for the government. However, intrinsic elements, such as the layout, may impact people’s desire to pay. Several treatments, including revised versions of the reminder letter, can be delivered to sizable, randomly allocated treatment groups in an online RCT to compare them to a control group. Identifying the most effective therapy may result in significant cost savings for the government.
Another example of leveraging big data in the delivery phase is the predictive policy initiative. To use big data effectively, the Los Angeles Police Department (LAPD), which is at the forefront of data analytics, makes significant investments in its data-gathering, processing, and deployment capabilities (Desouza & Jacob, 2017). For a wide range of law enforcement-related tasks, such as algorithms that forecast the probable place and time of future crimes or risk models that pinpoint officers most likely to exhibit at-risk behavior, it uses big data systems and predictive analytics. Palantir, one of the top analytic tools for law enforcement and intelligence organizations, is used by the LAPD to gather and examine enormous amounts of data from various sources. The police are increasingly using this information to communicate with people who have never had any previous police encounters, which is one of the most fundamental changes. For instance, Automatic License Plate Readers (ALPRs) read everyone’s license plates and generate data that may be applied in several ways. Every automobile is photographed twice by the cameras on police vehicles and by stationary ALPRs at junctions, which log the time, date, and GPS locations (Studinka & Guenduez, 2018).
Evaluation Phase
The policy assessment phase determines how a public policy operates in practice, including its effects, effectiveness, and reasons for success or failure (Schintler & Kulkarni, 2014). It entails a review of the tools being used and the goals being pursued. Once a policy has been evaluated, it may be reconceptualized, or the status quo may be maintained. Reconceptualization can occur during the planning phase or at any other stage. It could include minor changes or a fundamental reformulation of the concern, including policy cancelation (Osborne et al., 2016). The use of big data at this stage of the policymaking process has been rarely discussed in the literature.
Evaluation often takes place after the policymaking process. Big data make it possible to evaluate policies quickly, allowing the relevant departments of public administrations to determine whether a policy is having the desired impact. As mentioned in the previous sections, big data may be used to constantly evaluate the policies rather than evaluate only at the end of the policy cycle. Big data assessment was referenced throughout the policy process in the works under consideration. Rather than having a distinct process step at the cycle’s conclusion, a continuous evaluation is described by Höchtl et al. (2016) as an inherent element of every phase of the policy process. They suggest redesigning the policy cycle such that “review occurs not after the process but continually, creating perpetual possibilities of reiteration, appraisal, and deliberation.” This is one of the significant potentials of big data in the policy analysis process. This could empower and include both stakeholders and citizens in the process.
Data-Driven Public Policy Implementation
Better Supervision—Detecting Irregularities
Finding irregularities, a critical component of a public monitoring system can be assisted by big data technologies. A public authority keeps an eye on a certain region, looks for behavioral anomalies, and takes supervisory action if irregularities are identified. The advantages of big data may be easily demonstrated in this domain. Big data are being used here in a variety of ways, including creating the broadest collection of data resources feasible to serve as the foundation for analysis and reasoning, creating digital models of irregularities, and applying the models to massive data sets, that is, having a computer filter the data, based on the models of abnormalities. This method results in the computer system choosing and presenting the facts that adhere to an applied irregularity model. The data analysis makes it possible to link any discovered abnormality to a specific entity. Before the official administrative procedure begins, big data approaches are applied in supervisory administration at the analytical level. At this point, big data enables an authority to identify the circumstances and organizations that may have broken the law and allows them to prepare supervisory action based on the vast amount of available information. However, the supervisory action is carried out through conventional administrative methods, such as on-site inspection. This reduces the risks associated with automated processes (Guenduez et al., 2020).
Large data allow abnormalities to be successfully and quickly discovered and assist in predictive and behavioral analytics, which can suggest the considerable possibility of irregularities even before they occur. In actuality, the application of suitable models may detect abnormalities with a probability of up to 95%. The use of big data to identify tax evasion and other abnormalities is an excellent example in this regard. The British Connect system, used by the British HM Revenue and Customs Office, is an example of successful big data analysis for this purpose. The effectiveness and efficiency of the public body increased dramatically with the use of big data. This illustrates that similar results can be attained in public administration as a whole (Xu & Liu, 2022).
Better Regulation—Promoting Awareness and Feedback
Big data techniques enable public bodies to track and manage areas in real-time or with a negligible delay. As a result, the authority has access to a wide range of information for decision-making, which helps it accomplish its regulatory goals (Maciejewski, 2017). The “physics” of exploiting big data revolves around amassing pertinent data as rapidly as feasible. The information must be presented in a helpful way for regulatory purposes. The regulatory authority can use this method to comprehend the functioning of the people and systems and decide on necessary regulatory actions. In addition, it is possible to include automatic notifications for particular situations in big data systems designed for regulatory purposes. When a reaction is required, these notifications alert a decision-maker regarding previously established occurrences. Additionally, if an administrative policy is not operating properly, it is feasible to monitor its impact and make the required modifications. This implies that large data usage can spot abnormalities as well. Regulated situations, however, require monitoring systemic abnormalities rather than individual ones. It could draw attention to compliant circumstances; however, other elements are crucial to the regulator (Shah et al., 2021). Public entities employing big data obtain more favorable results and advantages. Big data aid in establishing and implementing stronger regulatory policies by bolstering the information intake for evidence-based decision-making and offering quick feedback on policy effects (Casanovas et al., 2017).
Public Service Delivery—Offering Particular Products or Services
Big data techniques have major advantages for government agencies that supply public services, improving the quality of their delivery (Vydra & Klievink, 2019). This results from feedback and inputs about the “clients,” their requirements, and their behavior. Modern ideas of a “smart” city result from the widespread use of big data for urban public functions (Miljand, 2020). Although there are various definitions, most emphasize the following traits. When a wide range of public services are provided in a way that closely satisfies consumer demands and is done so logically and effectively due to the widespread use of information technologies, particularly “big data” and “internet of things,” the city is considered “smart” (Kandt & Batty, 2021). This is true for all types of public services, including fire protection, social housing, social allowances, and public highways, as well as for public electricity and water networks, grids, and other infrastructure. Big data in these public tasks encourage (a) customer behavior analysis to better understand demands and provide public services in line with needs, (b) checking applicants’ eligibility for public benefits, such as allowances, and spotting fraud, and (c) better functioning of service provider’s operations.
The example of Singapore’s public transportation serves as an illustration. Big data techniques are often well adapted to the public transportation sector and produce startlingly good outcomes. The Land Transport Authority (LTA) in Singapore has used big data techniques to develop a system that enhances the performance of public transportation for the 6.3 million daily commutes in Singapore (Khurshid et al., 2019a).
Policy Feedback
Big data techniques can be applied to sentiment analysis to learn public opinion about the policies. Feedback regarding policies or individual decisions is a distinct field of big data application. It enables quick action from government agencies. In addition, big data may be used to forecast public sentiment about potential government actions. Text analytics acquire and analyze internet data for sentiment analysis, including information from tweets, really simple syndication (RSS) feeds, social media, and mobile applications. The monitoring and social media analysis tool, called Vizie, was created by the Commonwealth Scientific and Industrial Research Organisation (CSIRO) (Maciejewski, 2017). To stop the spread of misinformation, for example, this program may use fresh social media material and instantly alert the authorities about the changes that may require their attention.
Challenges of Implementation of Data-Driven Policy
Government agencies need to be aware of data security and privacy. Some governments have open data rules that may result in massive data disasters if terrorists or parties with entrenched interests utilize the information (Sarker et al., 2018). Hence, government organizations must closely monitor this security concern. It must protect the privacy of citizen data since it is utilized to make decisions, catch criminals, lessen corruption, and promote social welfare (Ge & Wang, 2019). Before implementing big data technologies, a secure system needs to be developed.
Government organizations use big data analytics to make decisions quickly. It must be flawless and delivered on time for immediate use. Certain government organizations preserve data flow and accessibility by using standardized formats and metadata (van der Voort et al., 2019). Many countries today have open data policies, which make data sets accessible to the general public. Collaboration between multiple agencies is aided; however, privacy policies must be followed. A steady stream of accurate, available, discoverable, and useable data is needed for smart governance (Sarker et al., 2018).
Big data technologies demand low-cost memory, storage, cloud-based solutions, and high-performing servers and platforms. Cloud computing is one of the finest technologies for implementing big data in the public sector. It is simple to utilize for flexible computational analysis by government agencies. The agencies must ensure sufficient bandwidth and real-time data analysis when employing a cloud environment for timely and accurate decisions. Government agencies must collaborate with other internal and external organizations to convert data and reduce technological problems (McGee & Jones, 2019).
A team of experts is needed to gather, handle, process, and manage a large amount of data to assist the government and reduce the risk to government agencies. This is important for implementing and sustaining smart governance systems (Ju et al., 2018).
However, big data may produce false promises of objectivity and accuracy. Between qualitative and quantitative scientists, there is a significant division in science. It would seem that qualitative scientists would be involved in telling and interpreting tales, whereas quantitative scientists would be responsible for creating facts (Vydra & Klievink, 2019). Nevertheless, that is not the case, as claims of objectivity can be made even with subjective observations and decision-making. Additionally, many assumptions are used in data processing, and the final interpretation is subjective. Other issues include reliably integrating various datasets and the potential impact of friction and self-selection on internet databases. According to this perspective, big data may support claims of impartiality and accuracy that are not supported by reality (Poel et al., 2018).
Data quality is not necessarily correlated with data volume. There is a vast body of literature in every branch of research that aims to ensure the consistency of data gathering and interpretation (Lee-Post & Pakath, 2019). Instead of considering the methodological problems associated with data quality, big data scientists presume the quality of their data. Social media data, which are prone to self-selection bias, provide an obvious example. Given that 40% of Twitter users are not proactive, the concept of an “active user” may not be neutral. In addition, in some circumstances, high-quality research is purposefully conducted with little data, such as in the case of experimental game theory analysis. As a result, even while big data empowers managers and decision-makers to base decisions on evidence, the standard of scientific evidence must be regulated and the underlying assumptions of the study findings must be made transparent.
Expanding upon the fundamental comprehension of the impact of big data in the realm of policymaking, our research offers three original perspectives that add to the continuing scholarly conversation. First, we emphasize the remarkable benefits of using big data for real-time decision-making, indicating a significant departure from traditional policy execution models that are constrained by time and sequence. Second, by promoting an iterative perspective on the policy cycle, we emphasize the possibility of improving policy efficiency via ongoing reviews. This viewpoint enables the implementation of flexible policy modifications, timely interventions, and the possibility of discarding less efficient options in a dynamic manner. Finally, this study represents one of the first attempts to comprehensively examine the intricate dynamics associated with the incorporation of cutting-edge big data methods inside long-established bureaucratic environments. This study offers a comprehensive analysis of the complex issues, potential advantages, and strategic factors that public officials need to address when dealing with the intersection between advanced technology and long-established organizational cultures.
Conclusions
General Conclusions
This study provides a sense of big data’s potential in the public policy process, conceptually and practically. To identify future avenues for study and provide examples from policy domains, the article adopts a wide view of big data trends anchored in the public administration and public policy literature. Big data usage has been discussed in the planning phase, emphasizing the importance of social media data in agenda-setting, problem-defining, policy-discussing, and citizen involvement. Big data may aid in developing information-based policy instruments and formulating policies during the design stage. Several methods used at this stage include a predictive component. To enhance future implementation, the delivery phase focuses on instant feedback about the success of the policies and data production in real-time. Hence, big data may be used to evaluate policies throughout all the stages of the policymaking process. The incorporation of big data is undoubtedly having a significant impact on the policy domain. However, what distinguishes our contributions is our distinct focus on making decisions in real-time, the iterative process of the policy cycle, and the complexities associated with integrating bureaucratic systems. In light of the fast technological progress in the digital age, policymakers and stakeholders are faced with complex difficulties and significant opportunities.
According to the findings, the basic principles underpinning big data are not disruptively new; rather, there is a repackaging of phrases like data mining, business intelligence, and decision support, which subsequently become a part of the big data domain. However, the ability to make decisions in real-time is new, which has the potential to replace traditional models of sequential execution of specific stages of the policy cycle with a continuous evaluation model. This can dramatically speed up decision-making and lead to better conclusions by extracting useful information that would otherwise be classified as noise. The BDA techniques make it easier to include the public at various phases of the cycle since it is easier to deal with the vast amount of unstructured data acquired to account for the crowd’s wisdom. As illustrated, the BDA can help the policy cycle in various ways. The largest improvements can be made by examining the policy cycle as an iterative idea, especially when using methodologically big data-enabled, near-instantaneous evaluation outcomes. According to the traditional policy cycle, changes, if any, occur after evaluating the results. However, delegating evaluation to a separate phase at the end of the process makes little sense in the age of BDA. Continuous review of the measures at each stage of the policy cycle reduces inefficiencies in policymaking by allowing the pursuit of alternatives discovered through the BDA scenario planning, even early withdrawals from planned policies.
This study contributes to the policy analysis domain by proposing the use of the BDA at every step, from policy formation to evaluation, facilitated by technology improvements that allow access to, processing, analysis, and storage of huge volumes of diverse data. While acknowledging the advancements in technical capabilities, it is crucial not to be excessively captivated by them. These developments still occur within bureaucratic contexts characterized by distinct organizational cultures and dynamics. Stakeholders within these settings may be inclined to leverage emerging technologies to bolster their positions, occasionally at the detriment of others. Identifying the optimal balance of technical proficiency, transparency, and autonomy for governmental agencies in the digital age is a nuanced challenge. This is largely because various governmental traditions and cultural norms have differential engagements with technological innovations. A recurring challenge in the implementation of Big Data Analytics (BDA)-enabled, evidence-based policymaking is the selective endorsement by politicians, wherein evidence is often embraced only when congruent with political narratives. A viable remedial strategy might be to present evidence in an accessible format, enabling the broader public to form opinions grounded in transparent data and statistics.
Limitations and Future Research Directions
There are certain limitations of this study. It relied on carefully selected and well-recognized scholarly literature; however, it lacked empirical data. The concept of continuous evaluation is appealing; nevertheless, it is yet to be proven in practice. The authors do make preliminary attempts to introduce the BDA in each step of the public policy process. However, it requires primary investigation for suitability based on the context of an administrative system. Therefore, future research must investigate both primary and secondary data sources to further enrich the conclusions of this study.
The real change in the policymaking process and the shift from estimate-based policies to evidence-based policies are heavily reliant on political players’ commitment. Attempts are currently underway in several countries to establish independent auditing agencies to evaluate the efficacy of programs. It is critical to consider the present state-of-the-art ICT and BDA for such advances to be effective. As a result, information science research must build a theoretical apparatus suited for certain sorts of investigations, emphasis, technique, and analytic units. As big data and the BDA lead to exaggerated expectations, this becomes increasingly vital, paving the path for extensive and rigorous study.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440231215123 – Supplemental material for Big Data-Driven Public Policy Decisions: Transformation Toward Smart Governance
Supplemental material, sj-docx-1-sgo-10.1177_21582440231215123 for Big Data-Driven Public Policy Decisions: Transformation Toward Smart Governance by Md Altab Hossin, Jie Du, Lei Mu and Isaac Owusu Asante in SAGE Open
Supplemental Material
sj-docx-2-sgo-10.1177_21582440231215123 – Supplemental material for Big Data-Driven Public Policy Decisions: Transformation Toward Smart Governance
Supplemental material, sj-docx-2-sgo-10.1177_21582440231215123 for Big Data-Driven Public Policy Decisions: Transformation Toward Smart Governance by Md Altab Hossin, Jie Du, Lei Mu and Isaac Owusu Asante in SAGE Open
Footnotes
Acknowledgements
We would like to thank the anonymous reviewers and the associate editor (Gulati Navneet) for their in-depth, helpful, valuable, and constructive comments, which was very helpful to improve the manuscript during the revision process
List of abbreviations
ALPR Automatic License Plate Readers
BDA Big Data Analytics
CSIRO Commonwealth Scientific and Industrial Research Organisation
ICT Information and Communication Technology
IT Information Technology
LAPD Los Angeles Police Department
LTA Land Transport Authority
NLP Natural Language Processing
PRISMA Preferred Reported Items for Systematic Review and Meta-Analysis
RCT Randomized Control Trials
RSS Really Simple Syndication
TF-IDF Term Frequency-Inverse Document Frequency
Author Contributions
Md Altab Hossin planned the research and wrote the original manuscript. Md Altab Hossin and Jie Du conducted formal analysis and content editing. Jie Du and Lei Mu helped with the resources, investigation, modeling, and visualization. Isaac Owusu Asante contributed to the literature review and content revision.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by Chengdu University.
Ethics Statement
Not applicable.
Informed Consent
All the authors are well informed about the study’s objectives and provided consent.
Consent for Publication
Not applicable.
Availability of Data and Materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.