
Abstract
The construct of reading is presented in language assessment. Previous studies have focused on reading issues encountered by English learners, most of which are manifested by certain linguistic features: lexical bundles (LBs). Addressing this, the study aims to analyze LBs in reading comprehension passages in the Chinese National Matriculation Entrance Test (NMET) and contrast them with those in the International English Language Testing System (IELTS), by focusing on the form, function, and frequency of three-word formulaic units. Data collected from self-built corpora based on the two tests were analyzed using Biber et al.’s structural and functional taxonomies. Results suggested that NMET includes a substantially lower frequency of bundles and a notably limited range of bundle patterns than IELTS. Results also indicated that the structural forms of LBs in NMET are clausal and that the dominant function is referential. This study has pedagogical implications for test designers and English reading educators.
Introduction
Among all academic skills, reading is the most fundamental one for students to acquire (Martínez et al., 2014). The ability to read proficiently is a prerequisite for school admission, which is by no means an exception for students learning English as a foreign language (Oliver et al., 2012). In English learning, reading is considered an important element (Goodwin et al., 2015), and thus emphasized in classroom instruction. Beyond that, the construct of reading is well manifested in all ranges of assessments to measure whether learners are able to comprehend the texts (Harding et al., 2015).
Research on English reading assessment has mostly been conducted on issues confronted by L1 or L2 learners: new vocabulary, reading fluency, and wrong reference (Yang & Qian, 2017), to name just a few. Factors causing these reading issues include vocabulary recognition (Pearson et al., 2007), semantic processing (Perfetti, 2007), discourse structure and genre pattern recognition (Hyland, 2008a), and reading fluency skills (Collins et al., 2018), most of which are manifested by certain linguistic features, notably the lexical bundles (LBs). According to Hyland (2008a), LBs refer to multi-word sequences of three or more formulaic units that “follow each other more frequently than expected by chance” (p. 5), such as some of the and a result of. Such units, unlike relatively fixed idioms, are usually structurally incomplete (Biber & Conrad, 1999, p. 183) yet perform multiple functions: cohesive devices, discourse makers, genre, and discipline discriminators (Beng & Keong, 2017; Hyland, 2008a). Additionally, LBs help knowledge attainment and reduce processing time in time-constraint language assessment since these units are stored and retrieved as “chunks” in the brain (Tremblay et al., 2011). It is thus significant to explore LBs in reading assessment. To contextualize the reading test, reading comprehension passages within the Chinese National Matriculation Entrance Test (hereinafter NMET) are chosen. The rationale for choosing texts in NMET is that NMET reading prioritizes assessing candidates’ reading abilities and strategies, and its syntactic complexity is higher than those used in textbooks (Cheng & Chang, 2022). Furthermore, NMET, as the only criterion for admission to higher education and major selection in China (Wang et al., 2020), has been raising its stake recently, containing more lexical bundles beyond the curriculum standards (Wang et al., 2020; Yu, 2021). These units in reading tests may pose mental pressure on test participants, slow down reading speed, and hinder test performance (Beng & Keong, 2017; Jenkins et al., 1984), thus necessitating the exploration of NMET reading with respect to bundle use.
Against this backdrop, the present study extends the bundle approach to the reading texts in NMET. To further illustrate this, we contrast LBs identified with those retrieved from International English Language Testing System (IELTS). The contrastive analysis is based on the commonalities that two tests share: a) as NMET, IELTS is widely used as an entrance requirement for non-English speaking applicants; b) the reading section in both tests accounts for approximately 30% of the total scores; c) both assess the English application abilities of examinees (making sense of keynotes of the passage, author’s standpoints, and specific details). Examining and contrasting the potential LBs within the two tests is of great significance as it can deepen our understanding of the bundles used in reading assessment and thus inform assessment designers and educators of evidence-based references and implications.
LBs in Writing Genres
Over the past two decades, the applicability of bundle analysis to study academic genres has been attested by Biber et al. (2004), who probed into the characteristics of LBs in university teaching and textbooks and reported that classroom teaching densely use stance bundles and discourse organizers, revealing that LBs are a unique linguistic construct. More significantly, they initiated a new scheme, which gained prominence and has been extended in the field of EFL writing. Notably, despite the influence of their approach, conclusions in some studies are contradictory. For instance, Biber and Barbieri (2007) noted that written registers employ more bundle types, especially noun phrase-based (NP-based) and preposition phrase-based (PP-based) bundles, whereas spoken registers prefer verb phrase-based (VP-based bundles). They acknowledged that, functionally, spoken registers, especially conversations, extensively incorporate stance bundles, whereas academic proses rely on referential bundles. Liu and Chen (2020), however, by analyzing academic lectures, argued that the spoken register includes more referential and stance bundles to help deliver detailed information and express personal attitudes.
With attention increasingly devoted to LBs in academic genres, many scholars turned to examining the use of LBs in L1 and L2 academic writing (Ädel & Erman, 2012; Bychkovska & Lee, 2017; Chen & Baker, 2010; Pan & Liu, 2019; Pan et al., 2016). For instance, Chen and Baker (2010), in a contrastive study of bundle use in the writing of L1-English and L2-Chinese, reported that L1-English learners employ more LBs than their Chinese peers. However, they also found both groups utilize the same proportion of structural and functional bundles. Identical results were identified later in Ädel and Erman’s (2012) study. Nevertheless, Bychkovska and Lee (2017), who examined the argumentative writing of university students, presented a different picture. They concluded that L1-Chinese undergraduate writers use more bundle types and tokens than their L1-English peers.
Recent studies have focused their lenses on the differences in the writing of L1-L2 specialists. Pan et al. (2016), for instance, encapsulated that L1-Chinese experts exhibit a wider range of LBs in contrast to their English counterparts and that they are more inclined to use VP-based bundles yet underuse stance bundles. The pervasiveness of studies on LBs in student or expert writing has led researchers such as Hyland (2008a, 2008b) and Pan and Liu (2019) to delve deeper into disciplinary writing. All three studies demonstrated that disciplinary variation plays a critical role in the patterns of use. As Hyland (2008a) concluded, the hard science fields (engineering and microbiology) include more bundle types and tokens than the humanities and social sciences (applied linguistics and business). Furthermore, he argued that specific structural and functional bundle types used by experts differ from those used by students. This difference, as Hyland (2008b) asserted, may stem from the writing genres. Unlike published articles, students’ papers are a pedagogic genre requiring students to showcase their familiarity with the subject content of the discipline. This is comparable to the point made by Cortes (2008), who argued that student-produced papers, especially for undergraduate students, cannot be considered research papers. Although academic papers may contain a large number of general bundles, the genre remains an essential variable in the analysis of lexical bundles. In addition to these factors, through contrasting L1–L2 bundle differences in student and expert writing, Pan and Liu (2019) reported that both L1 background and level of expertise can influence bundle employment. This study can be considered as an expansion into EFL writing, but still, literature on reading context still proves to be rare.
LBs in Reading Genres
Among the scant available studies, Beng and Keong (2017) conducted a compelling study that distinguished itself from former observations via examining the form-and-function interplay between lexical bundles in reading assessment. Drawing on insights from bundle analysis from writing genres, they elucidated the linguistic and functional realizations of LBs in reading passages across disciplines in the Malaysian University English Test. According to their research, NPs mainly perform search-oriented functions, dependent clauses are text-oriented, whereas VPs most often function as stance-oriented bundles. Profoundly, this study displayed a new perspective on investigating reading comprehension passages of college entrance examinations by using bundle analysis approach. While this study has thoroughly explored the relationship between structural and functional categories of LBs, little information was available on the structural and functional subcategories. Furthermore, reasons caused the variations in bundle use were not given consideration. Therefore, LBs in reading assessment need to be further investigated (Beng & Keong, 2017). On that note, this study sets out to explore LBs retrieved from reading comprehension passages in NMET, and contrasts those from IELTS, trying to discover and account for differences in bundle use. In doing so, this study addresses the following two questions:
(a) How are the LBs in NMET used in terms of forms and functions?
(b) Are there any differences in the use of LBs between NMET and IELTS? If so, what are the possible factors?
Method
Corpora Building
For the oncoming research, we compiled two corpora by sampling reading texts in NMET and IELTS. Though NMET varies by province, it follows the standardized curriculum designed by the National Education Examinations Authority. To ensure the sampled passages would be broadly representative of NMET, we decided our focus on a 17-year timespan (2004–2021) as text papers of IELTS were publicly available only from 2004. The data retrieval was completed with a few steps. The reading texts of these test papers were initially downloaded electronically from the internet, scanned with an OCR tool, and then converted to word format. To make the corpus manageable, we removed additional information, including headings, subtitles, figures, and footnotes. Afterward, the passages were manually checked for errors and converted to plain texts for bundle scanning and selection. To warrant the homogeneity of corpora, we sampled the reading texts in IELTS (academic reading module for college applicants) in the same period and repeated the above extraction procedures. The meta-information of the corpora is exhibited in Table 1.
Basic Information of the Two Corpora.

Bundle Identification
In this study, variations in bundle use in NMET and IELTS reading comprehension were determined by retrieving one set of lexical bundles from each test respectively. In terms of word length, scholars argued that four-word bundles have clearer boundaries and are more common in discourse than five-word strings (Hyland, 2008a). Biber et al. (1999), nevertheless, suggested that three-word bundles are widespread, echoed by Simpson-Vlach (2006), who also emphasized the pedagogical importance of three-word bundles. To limit the scope of the investigation, only three-word bundles were considered in the present study.
Lancsbox (Brezina et al., 2020) was introduced to identify the potential three-word LBs via operating its N-gram function. These retrieved bundles were ordered based on their absolute frequencies. As the cut-off frequency varies in studies, we set the threshold at 40 times per million as Biber et al. (2004) did to select operable LBs. Regarding the text dispersion (range), the present study selected seven texts as the minimum (cf. Biber et al., 2004; Cortes, 2008; Pan et al., 2016). After the bundle list had been taken care of, we identified LBs that were topic-specific (e.g., in the brain) and context-dependent (e.g., in New Zealand), which were conceived as dependency on topic and context (Chen & Baker, 2010), and they thus were removed from the analysis.
Additionally, to avoid inflating quantitative results, we manually checked and merged overlaps if they fell into the same category, as defined by Chen and Baker (2010). Overlaps were classified into two types: “complete overlap” means that two three-word LBs, by definition, occur in the same sentence, for example, the bundles in the process and the process of both occur nine times in IELTS, and were thus combined into one four-word bundle: in the process of. “Complete subsumption,” means that two or more bundles overlap, with one being subsumed into the other, for instance, in IELTS, the end of occurs 17 times, while at the end appears ten times. We thus consulted concordance listings to analyze the functions they served in their extended discourse contexts. The results brought to light that all the 10 instances of at the end were subsumed within the end of. The less frequent bundles, on that account, were mixed into the more frequent ones to prevent exaggerating quantitative results.
Bundle Analysis
The structural taxonomy proposed by Biber et al. (1999) for the bundle analysis has been acting as a framework for describing LBs in different registers. We distinguished three primary structural categories, namely, NP-based, PP-based, and VP-based bundles. Each category, as outlined in Table 2, has its subcategories, whereby NPs are further divided into noun phrases with of-phrase (e.g., the beginning of) and post-modifier fragment (e.g., the fact that); PPs are divided into prepositional phrases with of-phrase (e.g., in the forms of) and other fragment (e.g., at the same time), and VPs are those with a verbal component (e.g., it will be, used as the and it is possible).
Structural Classification of Lexical Bundles.

Source. Adapted from Biber et al. (1999).
To classify bundles that do not belong to the structural framework proposed by Biber et al. (1999), we made slight adaptations by adding the subcategory of other noun phrase fragment to NPs and other verb phrase fragment to VPs. Additionally, we created a main category “Number” with subcategories number with of-phrase and number without of-phrase. The entire framework is listed in Table 2.
As indicated by Biber et al. (2004), LBs perform identifiable discourse functions representing the communicative repertoire of speakers and writers. In the same vein, we identified three primarily distinguished functions. Stance bundles convey attitudes and modality; discourse organizers signal linkage between the preceding and following information; and referential bundles identify an entity or some critical entity attributes. Each category has its subcategories associated with more specific functions and meanings. Table 3 illustrates these bundle groups of assigned functional categories.
Functional Classification of Lexical Bundles.

Source. Adapted from Biber et al. (2004).
Using Log-likelihood Calculator developed by Xu (2017), we structurally and functionally contrasted bundle tokens of each type and its subtype in both corpora to test whether there was a significant difference. The higher the value of log-likelihood, the more significant the difference between the two frequency scores: 3.84 or higher for LL, significant at p < .05; 6.63 or higher for LL, significant at p < .01; 10.83 or higher for LL, significant at p < .001.
Results and Discussion
Table 4 displays the types and tokens (frequency) of bundles identified in the two assignments. It is noted that the number of bundle types (131) and tokens (1,592) in NMET is lower than that in IELTS (155 types, 1,915 tokens), with tokens at a significant level. The difference may be explained by two reasons. First, the requirements of both tests, diverging from NMET exclusively designed for Chinese English learners, the IELTS is for worldwide college applicants wishing to continue higher education in English-medium universities. To be specific, IELTS may have a higher expectation for their examinees in terms of word recognition, phrase control, and sentence construction presumably, because qualified candidates (overall band score of 6.0 or 6.5) are about to study in English-speaking countries and are therefore required to have sufficient linguistic knowledge and language skills to access professionally relevant literature, express personal opinions, and write research articles. To meet the demands placed on candidates, IELTS designers choose reading materials with a richer variety of bundle types and tokens to test the capacity of the candidates to identify and comprehend those bundles. Another explanation for this may be related to the multiplicity of the theme of IELTS. Reading materials in IELTS covers a wider range of topics including culture, medicine, education, geography, and other aspects. All articles are based on popular science, and their content relates to current social issues (Feng & Chen, 2016). As Hyland (2008a) suggested, hard-pure and hard-applied disciplines are considered to include more bundle types and tokens when introducing experimental processes and methodological descriptions in reading materials.
Number of Bundle Types and Tokens in the Two Corpora.

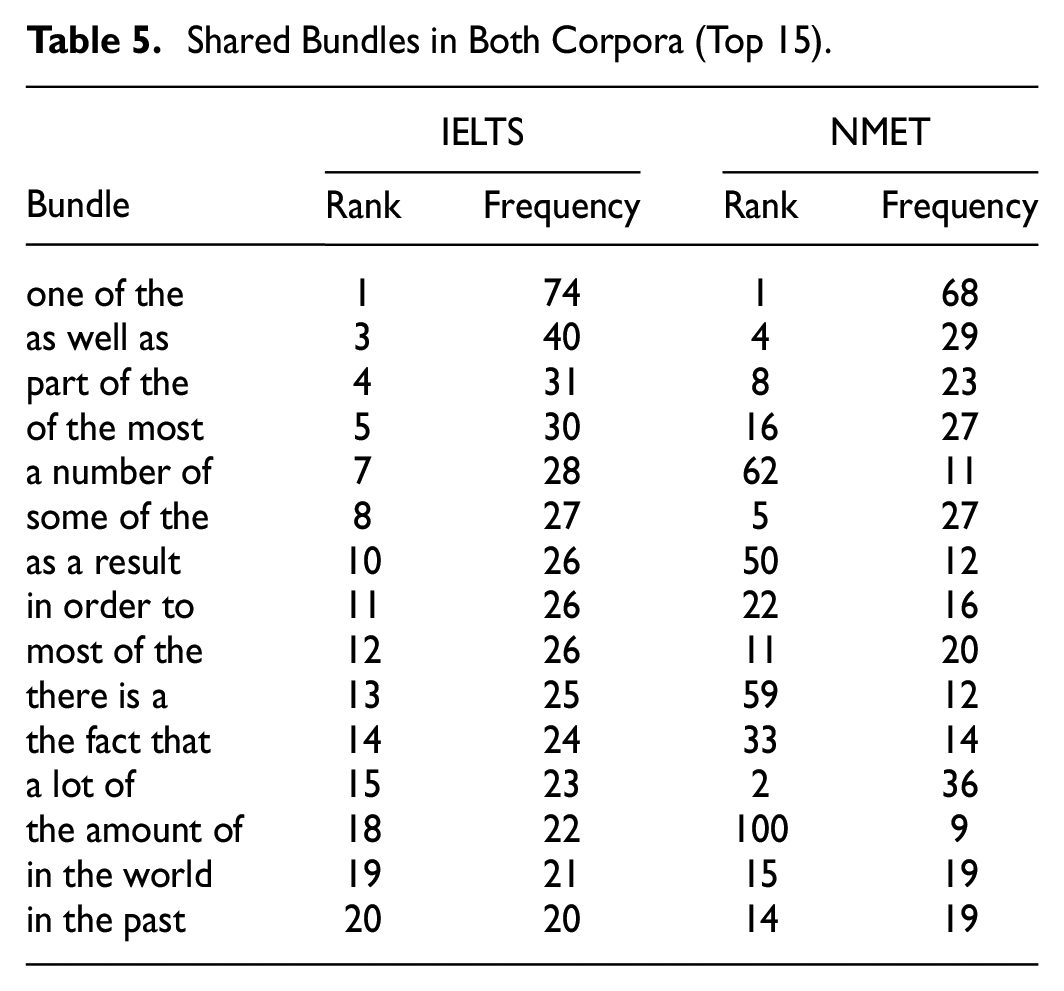
Top 15 Shared Bundles
Table 5 presents several shared bundles from both corpora. It is noteworthy that the two exams are consistent in their use of the top 10 shared bundles, with the majority denoting quantifying meaning. This finding implies the significance of these shared bundles in reading tests, informing candidates to have a good command of number bundles (e.g., one of the; part of the; some of the). Additionally, some of the top 100 shared bundles in NMET can be found in the top 20 shared bundles in IELTS, suggesting that Chinese test designers notice some of these typical bundles and insert them into the reading texts, albeit not in the same rank. Another striking point is that the frequency of shared bundles in the NMET is lower than that in IELTS, which may be due to the length of reading material. As shown in Table 1, the average length of the reading materials in IELTS (2,579 words) is twice as long as that of NMET (1,286 words), which may increase the occurrence of certain bundles.
Shared Bundles in Both Corpora (Top 15).
Structural Contrast of Lexical Bundles
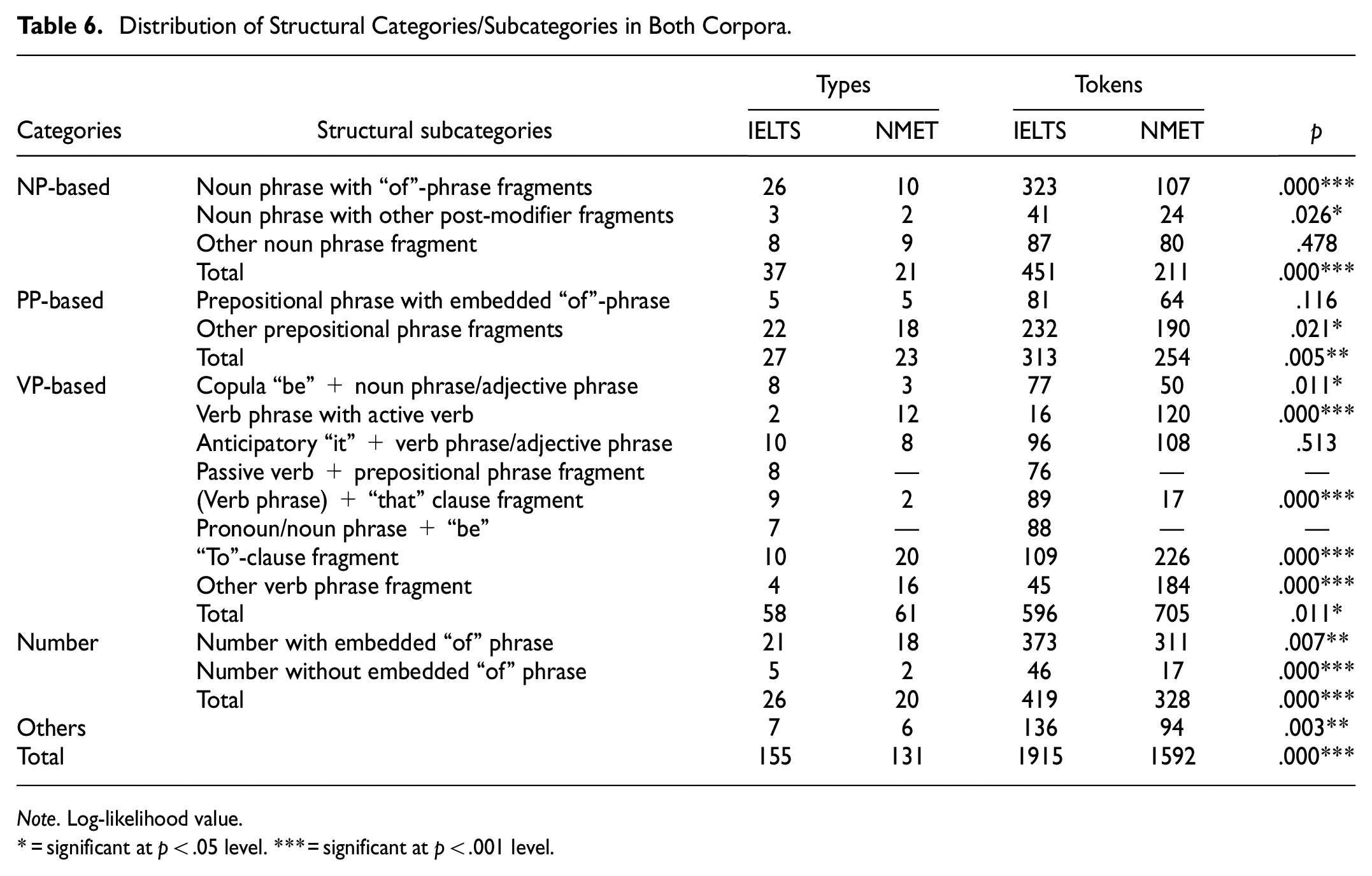
Table 6 summarizes the distribution of structural categories of bundles that occurred in the two assessments. Log-likelihood tests reveal that IELTS has a significantly higher use of NP- and PP-based bundles than NMET. For VP-based bundles, the pattern is different. Differences can be further analyzed in the subcategories of bundles across the two corpora.
Distribution of Structural Categories/Subcategories in Both Corpora.
Note. Log-likelihood value.
* = significant at p < .05 level. *** = significant at p < .001 level.
An examination of the NP subcategories revealed that IELTS significantly uses more bundles that represent “of”-phrase fragments compared to NMET, which seems to be attributable to the presence of abstract concepts and content in IELTS. To better prepare examinees for the upcoming professional study, test designers purposely incorporate scientific-oriented knowledge into assignment papers, involving many theories and terminologies, most of which are constructed in the form of NPs, particularly in the NP subcategories with “of”-phrase fragments. A similar pattern is also observed in the use of noun phrase with other post-modifier fragments. These results parallel findings obtained from Chen and Baker (2010), who reported that the use of embedded relative clauses as post-modifiers is absent in L2 MA articles. The absence is caused by typological differences between English and Chinese (Pan & Liu, 2019). Unlike English, Chinese relative clauses are head-initial with modifiers following the antecedent (Hu & Liu, 2007).
For PP-based bundles, although IELTS contained significantly more PP subcategories with of-phrase, NMET includes significantly more other PP fragments, most of which are time or place indicators (e.g., around the world, in the future). The pattern in the use of other PPs is identical to that of VPs in the two corpora. As shown in Table 6, the number of bundles identified as VPs is significantly larger in NMET than in IELTS, particularly in the verb phrase with active verb, and the “to”-clause fragment. Concordance lines of “to”-clause fragment demonstrated that the majority of these bundles share the “v + to + v” construction, which can be categorized into four types based on the type of the first verb (e.g., lexical verbs, semi-/auxiliary verbs, modal verbs) (Huang, 2011).
Their parents had done their duty and would probably continue to do so. (N/17/1)
This kind of “distracted focus”appears to be the best state for working on creative tasks. (N/21/2)
Reducing their losses needs to be the priority. (N/21/1)
As clearly shown above, the “to”-clause fragment has many variants, which has been proven to be challenging for Chinese English learners (Chan, 2010; Zheng & Park, 2013). In Chinese, serial verb constructions are widely acceptable, while it is not the case in English, implying that this construction deserves much attention from both the learners and educators to avoid negative transfer or mother-tongue interferences. As for the subcategory (VP)+“that” clause fragment, the result is surprising given the fact that there is a higher frequency of such bundles in IELTS than in NMET, which may be related to the length and complexity of the reading material. The IELTS test consists of three passages of 800 to 900 words each, while the Chinese test contains four to five texts of 300 to 500 words each. It is easy to see that the former is much longer; we thus predict that the sentences in the IELTS test may be more complex than those in NMET. A typical way to increase the length and complexity of sentences is to embed subordinate clauses, which are considered difficult and may cause psychological stress to L2-English learners (Yu, 2021). Our concordance lines also reveal that the (VP)+“that” clause fragment most often has two clauses involved (examples 4 and 5), including the main clause and the subordinated clause. The former typically is used to introduce the topic or claimer, whilst the latter is for argumentation and statement presentation. As a result, more bundles are identified as (VP)+“that” clause fragment in IELTS than in NMET.
4. We are aware that it is used to add motion and rhythm. (I/11/4)
5. Bekoff points out that play often involved complex assessments of playmates. (I/4/2)
Similar to the (VP)+“that” clause fragment, quantitative differences can be observed in other VP fragments, with NMET containing significantly more other VPs. Among them, most are embedded with modal verbs (e.g., would like to, may not be), while other VPs in IELTS is mainly concerned with the inflectional variation and functional use of auxiliary verbs have (e.g., would have been, had to be). As such, we subsequently suggest that NMET designers should consider combining bundle use with mood and tense expressions in reading texts to improve the English bundle repertoire of Chinese learners.
Table 6 further shows that IELTS contains significantly more Number bundles in tokens than NMET. Examining the specific types of the Number demonstrates that both tests incorporate many number bundles with of. It is also found that the subcategory of number without “of” in NMET is only presented with bundles such as only a few and more than a, which is rather limited compared with that in IELTS, suggesting that test-designers should integrate more number bundles in both types and frequency. Furthermore, IELTS includes more Others LBs, and the difference reached statistical significance in tokens, although its total type approximates that in NMET.
Table 7 illustrates the distribution of percentages of types and tokens of the main structural categories in both tests. As presented in the table, VPs dominate the two corpora, accounting for 37.42 and 46.56% of the types respectively. According to Biber et al. (1999), phrasal bundles can be mainly divided into NP-based and PP-based bundles, while clausal bundles consist of VPs that integrate the main clauses. Former studies on LBs in EFL writing demonstrated that phrasal types are more common in academic writing, while the clausal bundle is the primary type in the spoken register. As seen from Table 7, although VPs take the dominance in both types (37.42%) and tokens (31.12%) in IELTS, 41.29% of the bundle types and 39.89% of the tokens are identified as NPs and PPs. In general, IELTS reading belongs to the written register. However, in the NMET reading, the situation is different. Not surprisingly, the combined percentage of NPs and PPs is 33.59%, lower than that of VPs (46.56%). In addition, the total rate of tokens for both is 29.20%, still second to the rate of VPs (44.28%). Thus, it can be said that NMET reading, in effect, is spoken-oriented, which reflects that Chinese learners still have a long way to go in terms of noticing and mastering the appropriate registers in English.
Proportional Distribution of Structural Categories in Both Corpora.

Considering that the structural associations of LBs in NMET and IELTS are strikingly distinctive, we predict that their typical discourse functions may also differ. We turn to a discussion of those functions coming after.
Functional Contrast of Lexical Bundles
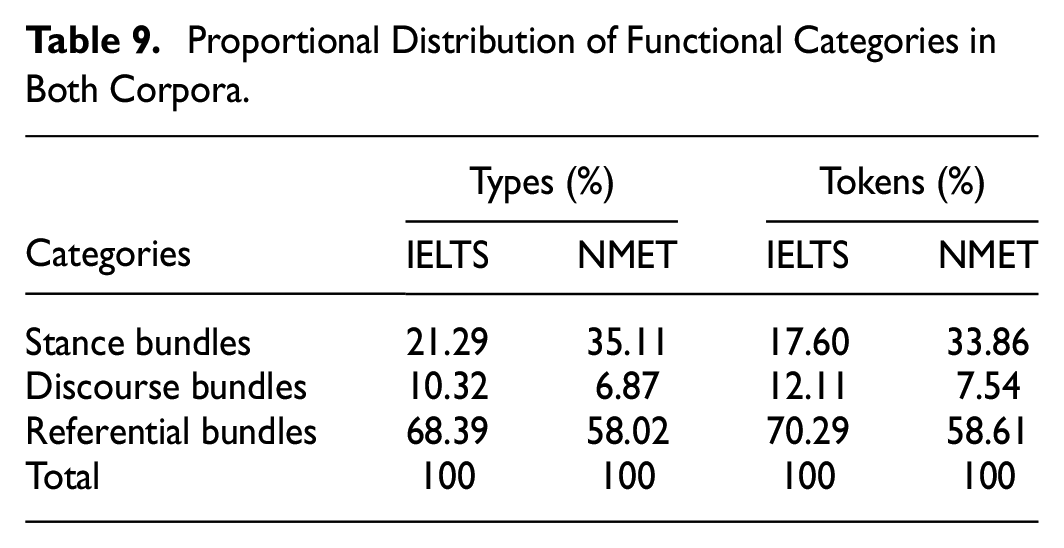
Table 8 provides a contrastive distribution of functional category bundle types and tokens in both corpora. One interesting finding is that there are significantly more stance bundles manifesting intention and predictive function in NMET. In contrast, IELTS contains more bundle types and tokens that serve as discourse organizers and referential signals at a statistically significant level.
Distribution of Functional Categories/Subcategories in Both Corpora.

Note. Log-likelihood value.
* = significant at p < .05 level. *** = significant at p < .001 level.
As shown in Table 8, IELTS includes significantly more referential bundles than NMET. Such a difference can also be observed in its subcategories: the time and place bundles, notably the bundle tokens (frequency), although the number of bundle types approximates (time: 10 vs. 9; place: 9 vs. 7). On the other hand, NMET significantly uses bundles performing multi-functional reference, reminding examinees about these referential bundles in test preparation and future learning.
Unlike the referential category, the observation of stance bundles presents something different. Surprisingly, the NMET reading contains significantly more stance bundles than the IELTS. Among such LBs, its subcategory of intention/predictive deserves discussion because it is the most numerous and frequent bundle subtype in both tests (9 out of 33 bundle types in IELTS and 25 out of 46 in NMET). Log-likelihood tests for this subcategory in both tests show that the Chinese test overuses the intention/predictive bundles. There are two contributing factors. First is the Chinese mode of thinking. In Chinese, personal willingness is expressed by saying wo xiang (equivalent to I want to in English), wo yuanyi (corresponds to I would like). When indicating that something is about to happen, they tend to say jiangyao or jijiang (will, be going to in English). The other is the genre of reading materials in the NMET reading. As mentioned above, the Chinese exam covers topics derived from both social sciences and the humanities, and its reading texts are, in essence, mainly narrative, indicating that the mental processes and states of the characters are highly valued, particularly their inner thoughts (intention/willingness).
It is also evident from Table 8 that IELTS designers included statistically significant obligation/directive bundles in the reading section of the test, which also accords with the earlier observations of academic writing (e.g., Bychkovska & Lee, 2017). A plausible reason for the widespread use of these bundles may be due to the contents presented in the exam, which are based on popular science (Feng & Chen, 2016). Popular texts are typically used to describe research (Parkinson & Adendorff, 2004), involving experimental procedures and specific operations to guide readers with operable and specialized experimental steps elaborated through a sequence of directive formulas. Such texts are constructed with lexis and phrases with non-negotiable and obligatory meanings, most of which share a “have to” grammatical structure.
The minimal, smallest varieties of bundles function as discourse organizers. Although no striking difference is observed in the frequency of topic introduction bundles, a divergence emerges in the use of topic elaboration/clarification bundles. As previously discussed, the Chinese test contains fewer clarification bundles, and we presume that the typological property of the two languages is responsible for this disparity. Chinese is a paratactic language, whereas English is a hypotactic type in which explicit linguistic strategies (function words such as conjunctive adverbs, and prepositions) are drawn to denote logical and semantic relations between elements within sentences (Yu, 1993). Phrases to clarify and elaborate topics are statistically significantly employed in IELTS, compared with NMET. As seen above, we suggest that Chinese instructors provide explicit instruction on illustrative and elaborative skills to develop the awareness of logical and in-depth discussion of L1 Chinese students.
As Table 9 further shows, proportionally more referential bundles are found in IELTS with respect to both types (68.39 vs. 58.02%) and tokens (70.29 vs. 58.61%). Secondary to referential type, stance bundles are more frequently used in NMET for both types (35.11 vs. 21.29%) and tokens (33.86 vs. 17.6%), notably its subcategories: desire and intention bundles. Analysis of the contexts where these bundles are used reveals that most desire bundles include mental verbs that display personal emotions or opinions (e.g., like, want, would like). The dense use of such bundles may guide readers to perceive writers as simply projecting their personal views. Compared with the two main types, the difference in the proportional distribution of discourse types is relatively small in the two corpora (types: 10.32 vs. 6.87%; tokens: 12.11 vs. 7.54%). This case, however, is different in its subtype of topic elaboration/clarification. As illustrated in Table 8, the percentage of elaboration is 100% in IELTS and 80% in NMET, indicating a significant difference.
Proportional Distribution of Functional Categories in Both Corpora.
Pedagogical Implications
The research set its focus on improving the reading abilities of NMET candidates by contrasting how lexical bundles are used in IELTS and NMET, and reporting the differences and reasons behind them. Through the description, interpretation, and contrast, it is suggested that NMET designers may consider balancing the selection of reading materials. As discussed in 4.2, many topics in NMET are sourced from the social sciences and humanities; thus, articles from natural sciences can be taken into account to broaden the themes of reading comprehension passages. Moreover, it is found that language in NMET is somewhat spoken-oriented compared with IELTS, and test designers are consequently suggested to proportionally incorporate academic words or expressions into test papers to raise the awareness of students in academic reading, preparing them for future academic learning. More importantly, NMET designers may consider to increase the use of formulaic languages (lexical bundles), as LBs are acknowledged as shortcuts of language processing and help reduce working memory (Tremblay et al., 2011), which may further improve comprehension performance.
Our findings also have potential pedagogical implications for classroom instructors. The bundles identified in our study could be integrated into English reading curricula, which might help enhance bundle competence. It also indicated that classroom teachers should assist students in developing a more specific, test-based lexical repertoire by applying explicit instruction on the use of LBs. For example, if students are introduced to lexical bundles that have an identification/focus function, students will be able to easily find the topic sentences and thus improve their comprehension of the entire text. Furthermore, EFL instruction should play a premium on typological differences between Chinese and foreign languages, English in particular, to avoid negative transfer and interference of the mother tongue by highlighting the structures of certain LBs that do not have their equivalent forms in Chinese.
Conclusion
This study investigated and contrasted three-word bundles identified in IELTS and NMET regarding forms, structures, and functions. Results of the present analysis suggested that IELTS included considerably more use of LBs than NMET. Structurally, IELTS relied heavily on the NPs and PPs but avoided the dense use of VPs. These patterns contrasted with NMET. As regards the proportional distribution of these main structural types, reading passages in the two exams include almost equal portions of PPs, but differ in that of NPs and VPs. Despite the higher proportion of VP-based bundles in IELTS, the style of the reading passages in IELTS is still phrasal, contrasting with the clausal style of NMET. Our findings support the developmental learning hypothesis of Biber et al. (2011) that both L1 and L2 academic writers move from clausal to phrasal writing style as their proficiency increases. Functional analysis of major categories in both corpora also indicated that IELTS includes significantly more bundle types and tokens. In the proportional distribution of functional categories, bundles performing referential function had a higher frequency of types and tokens in the two tests than did stance bundles and discourse organizers. In terms of statistical significance, the frequency of tokens for referring bundles was higher in IELTS than in NMET. These findings are not compatible with prior studies discovering that L1 and L2 students shared similar structural and functional distributions in their writing (Ädel & Erman, 2012; Chen & Baker, 2010). The reasons for the differences in the distribution of bundle types and tokens are multifaceted: the purpose of reading and writing, the genres of both tests, and the topics they address.
This study investigated the reliability and validity of reading tests by administering a lexical bundle approach as previous measures on the two indicators superficially reveal the reading difficulty (Salim, 2012). In this respect, analyzing how LBs are used in the reading test is a more eligible way of measuring validity. In a nutshell, this study extended bundle analysis to study the reading texts within IELTS and NMET, and offered a new perspective for studying this field. However, it should be noted that one limitation emerged while conducting this research: the size of the data obtained for this study. The data size was still small compared to past studies based on the million-word corpus, although the IELTS reading texts were collected from 2004 to 2021.
Further investigation would be in a position to suitably address the issue by expanding the size of the corpus and extracting four-, five-, or six-word bundles for structural and functional analysis. Moreover, as some LBs are ambiguous, this poses a difficulty for classification, as noted by Biber et al. (2004). Further research exploring other functions of these bundles in the same context or analyzing the association differences of lexical bundles in listening and speaking should also be considered.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.