
Abstract
Covert contrast is the statistically reliable distinction between target language phonemes produced in the process of language acquisition that is nevertheless not perceived by a native speaker of that language. This paper examines the acquisition of contrasts in four Najdi Arabic fricatives, /s/, /ʃ/, /θ/, and /ð/, and seeks to identify the most common substitutions in producing these sounds. Words were elicited from 25 preschool children (aged 3–5 years). The target words contained the studied fricative followed by either long /a:/ or short /a/ in the initial position. Praat software was used for acoustic analysis to extract the four acoustic cues: center of gravity, fricative noise duration, F1, and F2. Participants performed a word repetition task and a picture elicitation task. The results showed six cases of covert contrast, seven cases of no contrast, and 87 cases of accurate production (overt contrast). The results also revealed stopping, gliding, and affrication as substitutions in the manner of articulation, while replacement in place of articulation occurred in backing but most commonly in fronting (24 cases). The present study sought to determine implications for children’s linguistic performance, and, consequently, for language education and for planning treatment for children with speech disorders.
Introduction
Phonological Acquisition of Language in Children
The language development of children has been the main subject of numerous linguistic studies (e.g., Al Huneety et al., 2023; Amayreh & Dyson, 1998; Byun et al., 2016; Eckman et al., 2015; F. E. Gibbon & Lee, 2017; Li, 2008; Macken & Barton, 1980; Mashaqba et al., 2022). Some studies have shown that children’s language differs from that of adults, as children sometimes resort to simplification or deletion in their production, and comparison of child and adult language is therefore difficult (Jakobson, 1968; Smith, 1979). Previously, a child’s language progress was judged based on the perception of native speakers, whose judgment, based on what they heard from the child, was used to characterize whether the produced sound was target-like or not. However, with technological developments, new methods and tools have emerged to judge the produced sounds more accurately. This paper sought to use one such program, Praat, to investigate the covert contrast of four Najdi Arabic (NA) fricative sounds, /s/, /ʃ/, /θ/, and /ð/, by Saudi Najdi preschoolers. The study further aimed to show whether children can produce these sounds much like adults, even though native speakers fail to perceive these sounds (covert contrast).
Meisel (2011) stated that acquiring a language is a process that requires endless effort. However, the kind of effort needed differs according to whether the acquired language is the first (L1) or second (L2). He stated that first language acquisition is “a process through which children engaged in communicative interaction acquire the language to which they are exposed in a seemingly effortless fashion” (Meisel, 2011, p. 240). In light of this and other definitions of L1 (Cruz, 2015; Lenneberg, 1967), it is evident that children attain full phonological and grammatical knowledge through a process described as “unconscious” compared to L2 acquisition.
The nativist approach to L1 acquisition is a well-known perspective that emphasizes the innate nature of language acquisition. According to Chomsky (1965), this innate knowledge is embodied in a language acquisition device, which enables humans to distinguish sounds around them. Moreover, it organizes the linguistic data into classes that are later reformatted. Furthermore, this knowledge accepts specific knowledge and refuses other knowledge (McNeill, 1970).
Acquiring a language includes the acquisition of the sounds, words, and rules of that language. According to Jakobson (1968), the starting point in acquiring a language is to acquire its sounds, as speech is the channel through which humans communicate and understand one another. Learning how to speak a language is a gradual process and one that is not mastered immediately, nor are humans born already possessing the skill. Nonetheless, humans are born equipped with the basic knowledge to produce language. According to Jakobson (1968), children’s creativity in acquiring their L1 is not pure creativity: They borrow as much as they create their language. This borrowing represents a kind of creative departure from prototypes, that is, what is common, meaning that the child eliminates or revalues some model constituents. In the process of acquiring an L1, certain elements are removed while others are revalued. Despite their intensive exposure to adults’ speech, there are elements in children’s language that are considered foreign to their language model.
Lust (2006) pointed out that in the process of acquiring the sounds of a language, children must:
Discover the required units—phonemes—in their language to “map from the continuous acoustic stimulus to a digital knowledge of language” (p. 143).
Discriminate between perception and production, such as distinguishing between /s/ and /z/ (i.e., +/− voice).
Discover the phonological and phonetic rules.
Discover the critical speech cues in their language.
According to Rowland (2014), infants are born with the ability to perceive some but not all sound contrasts, such as the contrast between [ba] and [da]. However, this ability decreases as children start acquiring their native language. By the end of the first year, they can distinguish most of their native language’s sounds, but they take much longer to reproduce sounds accurately. Newborn babies could not produce sounds even if they wanted to, due to their shorter vocal tract and higher larynx compared to adults.
A well-known theory in L1 acquisition, Jakobson’s (1968)“maturational theory,” argued that the structure of linguistic knowledge correlates with the structure of language acquisition. A child’s language begins with babbling, in which they can produce all conceivable sounds, but such sounds are not related to linguistic knowledge. This stage is followed by a universal, hierarchical course of development, from sounds familiar in all languages “unmarked” to the rarest ones “marked.” This maturation process is a genetic, universal, programed series that governs speech sounds. When this program is completed, the child ceases to make the associated errors as described in the following section.
In attempting to produce speech, a child might make certain errors due to problems in perception and articulation (Rowland, 2014). For instance, a child might not distinguish between two minimal pairs, for example, “fan” and “van,” due to misperception of speech sounds. Articulation is another such error, as in the case of pronouncing [l] instead of [r] in producing “road.”Lust (2006) and Al Huneety et al. (2023) identified several types of “deformations” in a child’s speech:
The omission of some sounds, as in the Arabic arnab“rabbit” becoming annab.
Mashaqba (2021) showed that gemination is acquired at an early stage, in which children produce sounds significantly longer much as adults do. Here, children may employ gemination to compensate the prosodic weight.
2. Substitution, as in pronouncing the Arabic word ʃadʒarah“tree” as sadʒarah.
3. Assimilation in the word itself, such as fus’ta:n“dress” becoming tit’ta:n.
4. Repetition of a syllable within a word, such as dadʒadʒh“hen” becoming dʒadʒadʒh.
Similar to the development of other language aspects, children acquire syllable structure gradually and increasingly over time. Syllable deletion and assimilation are the most noticeable phonological processes children employ to manage syllable structure complexity (Al Huneety et al., 2023).
Covert Contrast
The idea that children draw significant distinctions between sounds that adults do not always perceive this distinction was foreshadowed in the works of Kornfeld and Goehl (1974) and Smith (1979). This stage of acquisition, first explained by Macken and Barton (1980), is known as covert contrast, in which a child makes reliable, significant distinctions between sounds in ways that adults fail to perceive. This stage is opposed to overt contrast, in which adults are able to perceive the distinction in question. Listening to a child’s speech is not an easy task, as sometimes, the child can show covert contrast. Covert contrast “involves sounds that the child produces differently, acoustically or articulatory [but] are heard and transcribed by listeners with the same phonetic symbol” (F. E. Gibbon & Lee, 2017, p. 1).
Macken and Barton (1980) explained the types of contrast by identifying the stages of voice onset time (VOT) acquisition, which is the period between the release of the stop and the beginning of vocal cord vibration. They presented three stages of the VOT acquisition of English word-initial stops, although these stages can be generalized to any sound acquisition. These stages are as follows:
Children produce no VOT distinction at all.
Children produce a statistically reliable distinction between voiced and voiceless stops, but native speakers do not perceive this distinction. Supporting this, Scobbie et al. (1996) revealed that showing covert contrast is an intermediate stage between making no contrast and overt contrast.
Children produce VOT distinction like that produced by adults.
Scobbie’s (1998) idea of covert contrast was that any given language’s phonological system can be acquired differently from how that system is phonetically implemented. For Barrow et al. (2019), covert contrast is “a systematic and measurable contrast between two speech sounds that is neutralized in the ears of the listener” (p. 79). In the same vein, F. E. Gibbon and Lee (2017) argued that “the presence of covert contrasts in children’s speech has also lent support for the view that speech acquisition is a gradual process and that children can be making significant steps in phonetic mastery of the sound system” (p. 1). Accordingly, covert contrast results from children’s awareness of perceptual contrast between two phonemes. However, they lack the required motor control to produce these distinctions in their speech (Scobbie et al., 1996).
Byun et al. (2016) emphasized the importance of covert contrast in children’s speech for two reasons. First, “the presence or absence of covert contrast can offer evidence regarding the level of processing at which a child’s speech errors apply” (p. 2). Second, covert contrast is a positive diagnosis of a child’s speech development, meaning that a child who shows covert contrast does not need any intervention, as s/he is on the way to producing overt contrast.
The determination of a child having unperceived contrast is a major challenge in the field. Children are sometimes judged as producing two phonemes as homophony—that is, two words that have the same pronunciation but differ in meaning—due to immature speech production (F. Gibbon, 1990). Certain linguists (F. Gibbon, 1990; Scobbie et al., 1996) have stressed the importance of moving from listener-oriented data to speaker-oriented data to judge the speaker critically. For such a shift, it is necessary to use reliable and accurate tools in judging speech production, as human ears sometimes fail to identify the produced sound accurately. According to Scobbie et al. (1996), children are characterized as conveying a contrast in the following cases:
Mature contrast, in which the child uses the appropriate acoustic value for the appropriate cues.
Immature contrast, in which the child uses cues appropriate to the language but not to values, as in the case of producing a considerable duration of the VOT of voiceless stops.
Inappropriate contrast, in which the child uses inaccurate cues, such as producing /r/ as the round vowel /u/ after /b/, as in pronouncing the cluster /br/ as [bu]; or deviant contrast, in which the cues pronounced are marked as aberrations from the phonetic interface, as in showing high pitch to lateral cues.
A covert contrast occurs when the child produces immature, inappropriate, or deviant contrast, such that the listener does not perceive it.
Covert contrast in speech production offers support for the idea that children can show contrast. However, one limitation of studies of covert contrast is that if a study does not report any evidence of covert contrast in the study sample, it is possible that the parameters used were simply unable to detect the contrast (Byun et al., 2016). F. E. Gibbon and Lee (2017) emphasized this drawback in their own study, noting that “covert contrasts may have been present but manifest in cues that were not measured” (p. 2).
Fricatives of Arabic
Unlike English, Arabic is rich in fricatives, as these sounds form a large class of consonants. Fricatives are sounds that are produced with a narrow constriction in the vocal tract followed by turbulent airflow, which generates noise. Air turbulence produced by various kinds of constrictions in the vocal tract is the typical sound source for all fricatives. The Arabic fricatives are presented in Table 1.
Displays the Fricative Consonants in Arabic Language.

Note. The fricative consonants / dˁ, sˁ/ are [+emphatic].
According to Al Mashaqba (2015), Arabic fricatives constitute a class of 13 sounds: the plain fricative consonants /f/, /θ/, /ð/, /s/, /z/, /ʃ/, /x/, /ɣ/, /ħ/, /ʕ/, /h/, and the emphatic fricatives /dˤ/and /sˤ/. Aljutaily (2018) stated that Arabic contains two less-common fricative sounds, /x/ and /ɣ/, and two highly marked fricatives, /ʕ/ and /ħ/. This paper investigated whether Saudi preschool children show a covert contrast in producing the NA fricative sounds /s/, /ʃ/, /θ/, and /ð/. Moreover, it sought to add to previous research in this field by showing that children covertly produce fricative sounds. This study is significant as it may offer a starting point for other Arab researchers, especially Saudi researchers, to explore this field since studies on children’s covert contrast of Arabic sounds are rare (e.g., Mashaqba et al., 2022). Furthermore, this study may help alter the belief that children aged 3 to 5 cannot produce some sounds that adults can. This research may also be useful in speech therapy, as the same procedures can be used to prove that children with a speech disorder may be able to produce some sounds correctly. This paper therefore attempted to fill this knowledge gap by addressing the following research questions:
Are Saudi preschool children able to show contrast in producing the Arabic fricatives /s/, /ʃ/, /θ/, and /ð/? If so, what kind of contrast?
What are the most common substitutions concerning Arabic fricatives among children?
Literature Review
A large body of literature (Amayreh & Dyson, 1998; Bernstein, 2015; Ganser, 2016; F. Gibbon, 1990; Li, 2008; Mashaqba et al., 2022) has attempted to investigate how humans perceive speech sounds as well as the relationship between the acoustic structure of speech and the resultant psychological precepts. Many studies on adult L2 learners, children acquiring L1, or speech disorder diagnosis have examined the covert contrast of consonants and vowels. In the following sections, studies on covert contrast are surveyed. The first section concerns studies on covert contrast in children’s L1 acquisition. The second section considers the main acoustics parameters of fricatives.
Covert Contrast in Children’s L1 Acquisition
Over 100 years ago, the study of children’s language acquisition witnessed an expansion of investigations (Ingram, 1989). Researchers have addressed different aspects of L1 acquisition, such as its properties, theories, and phases. A recent topic of research interest in this area is covert contrast. This section will shed light on some of the many studies on this topic that are related to the scope of the current paper.
Studying covert contrast when producing stops is common. One Foundational study was conducted by Macken and Barton (1980) with four monolingual English child speakers. This study aimed to specify the age at which children acquire the voicing contrast and to describe the acquisition process. The researchers studied the acquisition of voicing contrast in stop consonants in the word-initial position. Fifteen tokens from each child were analyzed. This study concluded that the acquisition of VOT occurs across three stages: (a) no contrast, (b) showing contrast but not perceived by adults, (c) producing an audible contrast. Moreover, this study explained that the four children were indeed trying to produce the contrast between voiced and voiceless stop consonants. This contrast “fell within adult voiced phoneme boundaries and thus would not be perceptible to adult speakers” (p. 65). The researchers emphasized the importance of instrumental analysis to identify this kind of contrast. This study was the start of increasing research attention to the concept of covert contrast, although this speech phenomenon had not yet been named at the time of Macken and Barton’s study.
Similarly, Berti (2010) analyzed typical and deviant production by children whose average age was 35 months. The child speakers participated in a word repetition task of words containing /t/ and /k/ followed by /a/ or /u/ in a stressed position. The researcher adopted CV transition and durational characteristics as main acoustic parameters and used Praat software to analyze words. This study indicated that 11 cases of substitutions between /t/ and /k/ among 21 typically producing children indicated covert contrast (52.38%). Moreover, 80% (20 of 25 cases) of substitutions between /t/ and /k/ among deviantly-producing children corresponded to covert contrast.
Researchers have employed various methods to assess their comparative accuracy. A study by Byun et al. (2016) examined two children with velar fronting and two children who produced accurate velar–alveolar contrasts. This study investigated overt and covert contrasts in producing velar and alveolar stops and hypothesized that ultrasound measures would be more accurate than acoustic measures (VOT and spectral moments of the burst) in detecting covert contrast. This study found that velar and alveolar targets produced by children with overt contrast differed significantly between acoustic parameters (VOT, spectral moments) and the ultrasound measure. Furthermore, covert contrast was detected in the production of one child with velar fronting: once by acoustic measurements of kurtosis and once by ultrasound. This finding undermines their claim that ultrasound measures would be more precise than acoustic ones in uncovering covert contrast. Such findings encourage researchers to employ different methods in studying covert contrast. Furthermore, this study showed that if a study failed to detect covert contrast in the study sample, it would be possible that using other acoustic parameters or other methods might facilitate its detection.
Covert contrast in producing fricatives has received the attention of several scholars who have explored this concept in children’s L1 acquisition. Baum and McNutt (1990) examined the temporal, intensity, and spectral parameters of /s/ and /θ/. Four groups of English children participated in this study: two groups aged (5–6 years) who fronted /s/, and the remaining two groups (aged 7–8) that served as controls. The findings revealed that covert contrast was observed in spectral shape and amplitude between /s/ and /θ/ for children with fronted /s/. Furthermore, all four groups produced /s/ with a duration longer than /θ/, with a mean duration of 206 and 219 ms, respectively, for the control and misarticulated groups. The mean duration of /θ/ was 175 ms for control groups and 207 ms for misarticulated groups. Moreover, much like adults, all groups produced /θ/ with a lower amplitude than /s/.
Interest in studying covert contrast on producing fricatives flourished in the 2000s. Li (2008) showed that children aged 2 to 3 produced a statistically significant covert contrast and examined the production of /s/ and /ʃ/ by children speaking English, Japanese, and Mandarin Chinese. At the beginning of the experiment, adult productions in these three languages were examined to parameterize the acoustic space of fricatives. The results revealed that adults were not able to identify the phonetic differences produced by children, thereby revealing the need to characterize children’s pronunciation. Moreover, the produced English fricatives had higher centroid frequency values, which explained why adult listeners characterized all children’s productions as /s/. The same phenomenon occurred with Japanese fricatives, such that children produced higher centroid frequencies and higher onset F2 values, which led adult listeners to classify the Japanese children’s productions as the voiceless alveolo–palatal sibilant fricative/ɕ/, a Japanese sound that is produced like /ʃ/ in English.
In the same vein, Li et al. (2009) studied the production of /s/ and /ʃ/ by 20 Japanese and English children aged 2 to 3. The participants completed a word repletion task of CV words. In this task, the language learner was asked to repeat what they heard. The results showed that most English children produced /s/ correctly, compared to only seven Japanese children who showed mastery of this sibilant pronunciation. In addition, the English children tended to substitute /ʃ/ for /s/, while Japanese children implemented substitution by pronouncing /tʃ/ and /ɕ/. Furthermore, two Japanese and four English children showed covert contrast in their production. Five of the children showed covert contrast in a parameter other than the first spectral moment. Two demonstrated a significant difference in the fourth spectral moment (4.7 and 9.8) and one in the third spectral moment (5.1). The remaining two children produced a significant difference between /s/ and /ʃ/ in the onset F2 (8.8 and 10.1).
Li (2008) and Li et al. (2009) examined production by children from Japan and the United Kingdom on a single task. In contrast, the current study sought to achieve homogeneity in its study sample by studying children from the same language background (in this case, NA) and the same city (in this case Alzulfi). Furthermore, two tasks were implemented in the current study, the word repetition task and picture elicitation task, to ensure children’s production.
Similarly, a longitudinal study conducted by Song et al. (2013) sought to find the age at which children can show the contrast between /s/ and z/. It is also compared children’s speech with that of adults. Their study investigated whether the morphological content of the fricatives in the coda position affects the production of fricatives in children’s speech. Three children and their mothers were recruited for this study. The findings showed that the children were able to produce the friction noise of fricatives. Moreover, children were similar to adults in their durational cues in featuring contrasts, and the duration of their vowels and frication was similar to that of their mothers’ production. Therefore, the researchers concluded that the voicing contrasts for fricatives in coda positions are mastered by the age of 2.
Recently, researchers have sought to achieve more accurate results through the use of sophisticated tools. Zharkova (2021) analyzed the spectral and tongue shape in producing the voiceless alveolar /s/ and post–alveolar /ʃ/. Ten native speakers of standard Scottish English participated in this study, aged between years and 4 months (3;4) and 4;1. The target syllables were /ʃi/, /ʃa/, /si/, and /sa/. The researcher used Praat software and R development core team to analyze the tokens. The findings showed that the participants had clearer production before /a/ than before /i/ in articulatory and acoustic measures. Nine children showed contrasts between /s/ and /ʃ/ in at least one of the vowel contexts. The remaining child’s production varied in the syllable-final alveolar fricative and showed covert contrast in producing /s/ in the context of /a/. The syllable-final alveolar fricatives were perceived as dental, alveolar, alveolar lateral fricative, and glottal fricative.
Approximant sounds—sounds that are produced by the speaker slightly constricting the vocal tract to permit the air to pass through with turbulence—have also been a topic of study by researchers examining covert contrast in L1 acquisition. Roberts (2019) examined an English child over time, from the ages of 1;11 to 3;4, who was acquiring the contrast between /ɹ/ and /w/ in English. The researcher compared the data obtained from phonetic transcriptions and acoustic measurements. The findings undermined the claim by Scobbie et al. (1996) that covert contrast is a stage of acquisition. The results of this case study revealed that acoustic measurements and phonetic transcriptions mirrored one another. The child produced /w/ like adults and achieved mastery of /ɹ/ by age 2;11. Another important finding was that the child did not produce /tw/ in the onset as /tɹ/, which was evidence that the child was able to discriminate between /ɹ/ and /w/. This study’s results did not discover covert contrast in the study sample and claimed that both transcriptions and acoustic measurements reported the same results. However, there are several possible reasons for the researcher failing to observe covert contrast during the course of the study. The child was studied for an extended period, but s/he may have shown covert contrast for only a short period that was not recorded or noticed. Moreover, this study relied on only one acoustic measurement of formant measurements. If this study had employed more than one measurement or used ultrasound measures, it might have been possible to notice this acquisition stage.
Recently, Mashaqba et al. (2022) made significant contributions to our understanding of L1 phonological acquisition. They investigated the acquisition of the emphatic consonants /ṭ /, /ḍ/ and /ṣ/ as produced by 60 monolingual Jordanian Arabic children aged from 2 to 7;11. Based on measuring the acoustic of emphatics, they found that children’s ability to phonetically acquire the acoustics of emphatics occurred gradually rather than abruptly. Their findings revealed that, judged perceptually, children mastered the emphatic consonants at age 5; however, the children failed to produce them in an acoustically adult-like way until they reached age 6. Moreover, unlike the results of Amayreh and Dyson (1998), Mashaqba et al. found cases of covert contrast in which Jordanian children could produce the emphatic consonants earlier: 50% of the participants produced the emphatics by age 3; 75% by age 4, and 90% by age 5. They argued that the production accuracy of emphatics is based mainly on the frequency of occurrence and that the delay of mastery is due to the articulatory complexity of the emphatics.
Children sometimes merge or simplify consonant clusters. Smit et al. (1990) investigated this phenomenon in a typically developing girl aged 2;8. Transcribers characterized the subject as having a merge of the /s/ + labial consonant sequence, produced as [f]. Forty tokens of the consonant cluster /sp + sw + sm/ from two sessions were analyzed with ultrasound. This study found that the consonant clusters were not produced as [f]. The productions were a phonological effect of developing motor skills. The [f] was not a merging of /s/ with any of the labial consonants /p, w, m/. The child’s tongue raised in 9 out of 12 tokens, which offered clear evidence that the subject was producing /s/ accurately. Moreover, the tongue did not raise when producing /p, m, w, f/. These results suggested that the child showed the covert contrast stage of acquisition. Studies like this may enhance our understanding of certain errors in L1 acquisition. Children’s speech is sometimes misdiagnosed depending on our perceptions. However, by using acoustic programs or ultrasound images, it is possible to recharacterize such errors.
Acoustics of Fricatives
A growing body of research has been conducted on the acoustics of fricatives in different languages. However, there remains a dearth of research on Arabic fricatives (Al-Khairy, 2005). This section offers an overview of some studies on the acoustic cues of fricatives.
Acoustics of Fricatives in Other Languages
English fricatives have been discussed in multiple acoustic studies. Jongman et al. (2000) conducted a comparative analysis of places of fricative articulation in 20 English speakers, which compared static properties, such as spectral peak location and noise duration, as well as dynamic properties, such as relative amplitude and locus equations of English fricatives. The results showed that spectral and amplitude information were essential factors in discerning between fricative places of articulation. Moreover, spectral peak location/center of gravity (COG) helped in distinguishing /s, z/ from /ʃ, ʒ/ and /f, v/ from /θ, ð/. These researchers also found that the noise amplitude of sibilant fricatives was greater than that of nonsibilants. In addition, F2 transition and noise duration were unable to distinguish the places of fricative articulation. Finally, the spectral and amplitude parameters were found to help differentiate the four places of articulation for fricatives.
Some scholars have conducted comparative studies on fricative acoustics. For instance, Gordon et al. (2002) studied voiceless fricatives in seven languages: Aleut, Apache, Chickasaw, Scottish Gaelic, Hupa, Montana Salish, and Toda. Three acoustic measures duration, COG, and overall spectral shape—were analyzed in words that contained the target fricative sounds adjacent to the vowel /a/. The data were analyzed with Scicon’s PCQuirer software. The results showed that duration was the least efficient measure for distinguishing fricatives in all languages, because even if a fricative sound had the shortest duration in one language, such was not the case in other languages. COG, by contrast, was found to be a useful measure for differentiating many of the fricatives in the examined languages. The fricative sound /s/ was found to have the highest COG value among the seven languages. Generally, sounds produced at the front of the mouth tend to have a higher COG value, which is “attributed to the smaller cavity in front of the constriction of the relatively front fricative” (Gordon et al., 2002, p. 29). The results of this study showed a relationship between the noise peak in the spectrum and the backness of fricatives, such that the backer a fricative sound was, the greater the noise at lower “frequencies in keeping with the longer anterior cavity associated with relatively posterior fricatives” (Gordon et al., 2002, p. 29). This study showed that /ʃ/ had a noise peak between 2,000 and 3,000 Hz, and the sounds /f/ and /θ/were characterized by flat spectra. Furthermore, formant transition helped distinguish between velar and uvular fricatives and the degree of rounding among back fricative sounds. The greater the degree of rounding, the lower the F2 was in the adjacent vowel transitions.
Acoustics of Arabic Fricatives
Al Mashaqba (2015) described the main phonological and acoustic features of fricatives in Jordanian Arabic, which is very close to NA: voicing, duration of friction noise, as well as second, third, and fourth formant frequencies. He found that the voiced fricatives were produced with lesser force (breath) and had lower friction than their voiceless cognates. Acoustically speaking, voiced fricatives typically exhibited a resonance structure as a shadow of weak formants with little noise, displayed as a strong formant structure in a spectrogram, thereby highlighting the voicing. The voiceless fricatives usually showed a high noise. Thus, the friction duration of the voiceless sounds tended to be louder and longer in duration than the voiced ones. Emphatic fricatives have been shown to have shorter friction noise duration than non-emphatic fricatives (Aljutaily, 2018, 2021).
Another acoustic study by Al-Khairy (2005) investigated 13 modern Arabic fricatives spoken by eight adult Arabic speakers to find invariant cues for classifying fricatives according to their places of articulation. The study also examined the amplitude measurement, spectral measurement, temporal measurement, and formant information at the transition between fricatives and vowels. The friction noise of sibilant fricatives was found to be longer than that of nonsibilants, with means of 138.09 and 109.34 ms, respectively. This study also demonstrated a longer friction noise duration when fricatives were followed by the long high vowels /i:/ and /u:/ than by /i/ and /u/. Moreover, the amplitude measurement differentiated nonsibilants (/f, θ, ð, ðˁ/) as a class from sibilant fricatives (/s, z, sˁ, ʃ
In the same vein, Elmazouzi et al. (2014) investigated the duration and formant transition of Moroccan Arabic fricatives produced by eight adults. The results of their study showed that the mean friction noise duration for fricatives was 120 ms as a main effect of place of articulation. Moreover, the sound /z/ had the longest duration among the voiced fricatives, with a mean duration of 109 ms, while the voiceless /h/ had the shortest duration, at 100 ms. In addition, /s/ and /sˁ/ were longer than the other fricatives, and voiceless fricatives had higher F1 frequency for the vowel next to the fricative (mean of 486 Hz) than voiced fricatives (mean of 418 Hz). Moreover, the F1 values distinguished the voiceless from the voiced fricatives, while the F2 values classified the fricatives according to the place of articulation.
As evidenced by previous studies, covert contrast may occur as a stage of L1 and/or L2 acquisition. These studies form the basis of the researcher’s understanding of the nature of covert contrast and selection of the current study’s acoustic cues, as well as the best procedures to follow in conducting the experiment. The current study aimed to add to the growing literature and fill the gap caused by the scarcity of acoustic studies on covert contrast in Arabic. Therefore, four Arabic fricative sounds, /s/, /ʃ/, /θ/, and /ð/, were the focus of this study, which implemented word repletion and picture elicitation tasks. This study examined whether preschool children (aged 3–5) are able to pronounce these fricative sounds correctly and whether adults fail to perceive the produced sound, that is, whether adults are unable to identify the articulated sound. Therefore, based on the research goals and previous studies, the following hypotheses were established:
Some preschool children will show covert contrast in producing the four Arabic fricatives.
Substituting /s/ for /ʃ/ or vice versa will be the most common mispronunciation when producing the four fricatives.
To test these hypotheses and achieve the goals of this paper, we implemented the methods described in the following section.
Experimental/Materials and Methods
Adopting acoustic analysis and descriptive statistics, this paper aimed at (a) identifying whether Saudi preschool children produce the NA fricatives /s/, /ʃ/, /θ/, and /ð/ like adults do; (b) showing the types of contrast in realizing these sounds; and (c) determining the common substitutions in producing these sounds. This section describes the participants and data collection procedures. It also presents the stimuli and explains how words were segmented. Then, it describes the acoustic measures that were chosen to identify covert contrast in preschool children’s production of NA fricatives, which is followed by a discussion of how adult NA speakers identified the produced sounds.
Participants
A total of 25 Saudi Najdi preschool children (aged 3–5) from Alzulfi participated in this study. The sample included 13 girls and 12 boys (mean age = 4;2). All participants were monolingual Arabic speakers with no diagnosed history of speech problems as reported by their mothers. The participants were preschoolers from Ohoud Saleh Al Hamad Center for the Children Hosting and from the Alzulfi community. They were given gifts for their participation. As a control group, the study recruited five adult monolingual native speakers of Arabic (three women and two men), who were all graduate students. This control group allowed the researchers to determine the benchmark for acoustic measures.
Procedures
Permission for participation was obtained from each child’s parent before the beginning of the study. The consent form was translated into Arabic to ensure that each child’s parent could read and understand it fully before allowing their child to participate.
The preschool participants were recorded individually in a quiet room. Each child was asked to wear a headset with a microphone and was seated in front of an HP Pavilion laptop. Then, the microphone was placed approximately 5 cm from the child’s lips during recording to avoid direct airflow turbulence. Audacity 2.4.2 was used to record children’s production. All recordings were conducted at a 44,100 Hz sampling rate.
Before each task, the child was asked to complete several training items and could listen to their production to ensure that they understood each task. Each child participated in two tasks with a 5-min break between them. The first task was word repetition: The screen showed a cartoon picture of the intended word, followed by two repetitions of its production at a 5-s interval. To ensure accuracy, children were presented with the stimuli twice. There were two words for each fricative in this task, for a total of eight recorded words. The child was asked to repeat the produced word, and this repetition was recorded.
The second task was picture elicitation, in which the child was asked to identify a picture shown on an A4 card and then to record the produced word. As with the previous task, there were a total of eight words: two for each sound, /s/, /ʃ/, /θ/, and /ð/. If the child incorrectly identified the intended word during the recording session, the child was shown another picture, given a cue, or asked a question to produce the target word. If all previous elicitation attempts were unsuccessful, the experimenters modeled the word, and the child was then asked to repeat it.
Recording the two tasks took place in one session; all words containing a target sound were recorded in one sound file for each speaker for each task. The same procedures were followed for recording the adults and children recruited from the community. These participants were also recorded individually in a quiet room.
Stimuli
Preschool children were involved in two tasks involving the repetition of 8 NA words (see Appendix A). These words included the target fricative sounds, /s/, /ʃ/, /θ/, and /ð/, in the vocalic context of low front vowel /a and a:/ in the initial position. This structure helped the researcher easily distinguish fricatives. In addition, a picture elicitation task was employed with another eight NA words with the same fricative sounds and the same vocalic context. In this task, each child was asked to identify the objects presented on A4 cards. This task aimed to obtain a seminatural production of the four fricative sounds and to determine whether there was a difference between children producing the sound by themselves versus repeating it. All pictures and words used in this study were chosen to be age-appropriate for preschool children and were taken from kindergarten worksheets and curricula.
Segmentation of Sounds
Praat software (Boersma & Weenink, 2020) was used to segment words. Sound waveforms and spectrograms were used to facilitate the segmentation of the recorded words containing the target fricatives (/s/, /ʃ/, /θ/, and /ð/). Four points were specified for each token: the onset of friction, the offset of the friction, the onset of the vowel, and the offset of the vowel. The target sounds were designed to be in the initial position of the word to define the beginning of the friction noise easily. However, there were cases in which the influence of the Zilfawi dialect affected the child’s production. This influence appeared in epenthesis, which adds one sound or more to a word, usually in the initial position. For example, a few children produced the word ðara:ʕ “arm,” as əðara:ʕ. In such cases, the friction onset was identified by the point at which the high–frequency energy appeared on the spectrogram. The offset of the fricative sound was identified by either the absence of high-frequency energy or the minimum strength that preceded the onset of vowel periodicity (Jongman et al., 2000). The beginning of the vowel was defined by the point at which the fricative sound ended, and the offset of periodicity marked the end of the vowel. Figure 1 shows an example of these four points. The segmentation text grid file and sound file were then saved as a binary file for easier acoustic measurement.
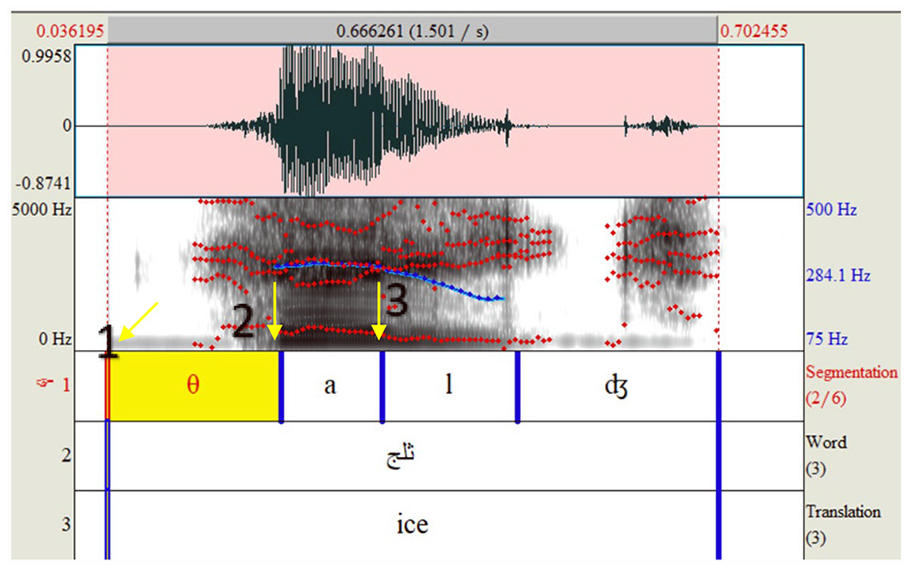
Example of Segmenting the Word θaldʒ “ice” for Speaker12.
Acoustic Analysis
Three acoustic measures were employed in an attempt to detect covert contrast in Saudi Najdi children’s production of the fricative sounds /s/, /ʃ/, /θ/, and /ð/. As noted, the researchers used Praat (Boersma & Weenink, 2020) for acoustical analysis, and a Praat script was used to obtain these measures: fricative noise duration, first and second formant frequencies (F1 and F2) of the adjacent vowel, and COG. To compare the acoustic measures for each child with adult measurements, first, for each word, the researchers calculated the median for each acoustic measure for the five adults. The median was chosen to avoid possible outliers in the adult measurements. Then, unpaired t-tests were used to compare the acoustic measures for each child with the adult measurements. The Judgment of preschool children as having covert contrast is based on the results of native speakers’ identification, supported by statistically significant results. Characterizing a speaker as having covert contrast in the statistical analysis was based on their producing a significant result in at least one of the four acoustic measures (COG, friction noise duration, F1, and F2). The following subsections offer brief explanations of these measures.
Fricative Noise Duration
Previous research has used the frication noise duration measure to distinguish between sibilant and nonsibilant fricatives (Al-Khairy, 2005). The duration of fricative noise is the interval between onset and offset of the frication, which coincides with the beginning of the following vowel. Some studies have found that voiceless fricatives have a longer duration than voiced fricatives (Al-Khairy, 2005; Crystal & House, 1988).
First and Second Formants
Elmazouzi et al. (2014) found that F1 values are affected by voicing; that is, the F1 of the subsequent vowel differs according to whether the preceding fricative is voiced or voiceless. Vowels following voiceless fricatives have higher F1 frequencies than those following voiced fricatives. Moreover, F1 increases as the vowel height decreases, and F2 classifies fricatives according to the place of articulation. A study by Wilde (1993) showed that F2 onset is higher as the place of articulation moves backward in the oral cavity; for example, the F2 onset of /ʃ/ is higher than /s/, at approximately 300 to 100 Hz, respectively.
Center of Gravity
COG is an acoustic measure that is used in identifying the highest of frequencies in a spectrum and is often used to describe fricative production. Styler (2020) showed that sounds with higher gravity center values are produced at the front of the mouth. In Gordon et al.’s (2002) study, the sound /s/ had the highest COG value among all seven languages examined because /s/ is produced at the very front of the mouth.
Sound Identification
Three Arabic teachers and native NA speakers from Alzulfi with >10 years of experience in teaching (henceforth, identifiers) participated in identifying the children’s production. The identifiers were given an Excel spreadsheet with 25 rows, each of which represented one child. The produced words were listed in columns. The identifiers were asked to listen to each word and identify the initially produced sound. They were also asked to identify the substitution errors when the target fricative was produced incorrectly. Identifiers were provided with the words and the target fricative sounds because some children’s words can be difficult for strangers (i.e., not a parent or the researcher) to recognize. The identifiers identified all fricatives for one child before moving to the next child. The reliability in identifying fricative sounds was high among all three identifiers, who made the same judgment 67.75% of the time (271 of 400 tokens). Two identifiers made the same decision an additional 28.25% of the time (113 tokens). The three identifiers differed in their judgment on just 16 tokens (4%). Those tokens were returned to two identifiers to make a final judgment.
Transcription or perception of produced sounds has been used to specify the age at which a child produces sounds correctly. These methods have also been employed to diagnose children with speech disorders (Li et al., 2009). Mastering a sound means that a child can produce it correctly and that adults can recognize and characterize the sound as correct. This concept has dominated the field for many years but has gradually changed with the development of acoustic measures.
The percentage of native speaker identification was calculated by multiplying the correct identified words by 100 and then dividing by 4 (the total words for the produced sound in both tasks). For instance, if a speaker produced two of four words correctly, the percentage would be calculated as 2 × 100 ÷ 4 = 50%. The judgment of sound mastery was based on the operational definition for “mastery” found in the literature, in which a child is described as producing a sound in a particular word position when 75% accuracy is achieved (Sander, 1972; Smit et al., 1990; Templin, 1957).
Results
This part endeavors, using the results obtained by the research, to answer the fundamental research questions. The following sections present the statistical results and the results from native speaker identifiers.
Statistical Results of Preschool Children’s Types of Contrasts
The results of identification by native speakers revealed that the alveolar /s/ was the most commonly correctly produced sound, followed by the interdental /ð/.
Three types of contrast were observed in the results of the unpaired t-test : (a) overt contrast, in which statistical analysis showed either significant or insignificant results, supported by the results of the identification of the native speakers at a rate of 75%−100%; (b) covert contrast, in which statistical analysis showed a significant result, and the results of the native speakers’ identification were ˂75%; (c) no contrast, for which there was no significant result observed in the statistical analysis and the native speakers’ identification results were ˂75%. Table 2 presents examples of these contrasts.
Examples of the Three Types of Contrasts Observed in the Results.

Note. Asterisks are used to show significant results.
The statistical analysis showed that six of the children produced statistically significant covert contrast (p ˂ .05). Furthermore, covert contrast was detected in the production of the palato–alveolar /ʃ/ (three of six cases). The results also showed seven cases of no contrast (among a total of 94). The acoustic measure for which the most significant results were observed was F2, followed by F1 and fricative noise duration. The lowest occurrence of significant results was detected for COG.
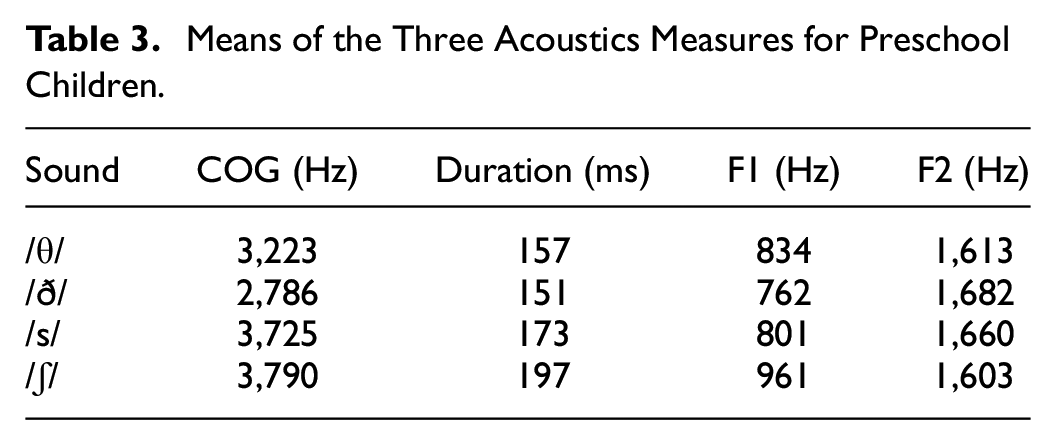
Table 3 compares the means of the four NA fricative consonants. Clearly, /ʃ/ had the highest COG value, followed by /s/. Similarly, /ʃ/ had the longest friction noise duration, with a mean of 197 ms, followed by /s/. As for F1, /ʃ/ had the highest value (961 Hz), followed by /s/ and /θ/. However, the F2 values for the four sounds were somewhat similar, with the voiced interdental /ð/ having the highest F2 value.
Means of the Three Acoustics Measures for Preschool Children.
The results obtained from the unpaired t-test support the first hypothesis, that covert contrast will be discovered in the production of Saudi preschool children.
Native Speakers’ Identification
Table 4 shows the number of correctly identified productions by 25 preschool children for each fricative sound. The total number of produced words was 400:100 for each sound. The percentages in this table were calculated for both tasks.
Number of Correctly Identified Productions of NA Fricatives.

Note. Based on adults’ perceptions, it is clear from Table 4 that the preschool children attained higher mastery of /s/ than of the other targeted fricative sounds, followed by /ð/.
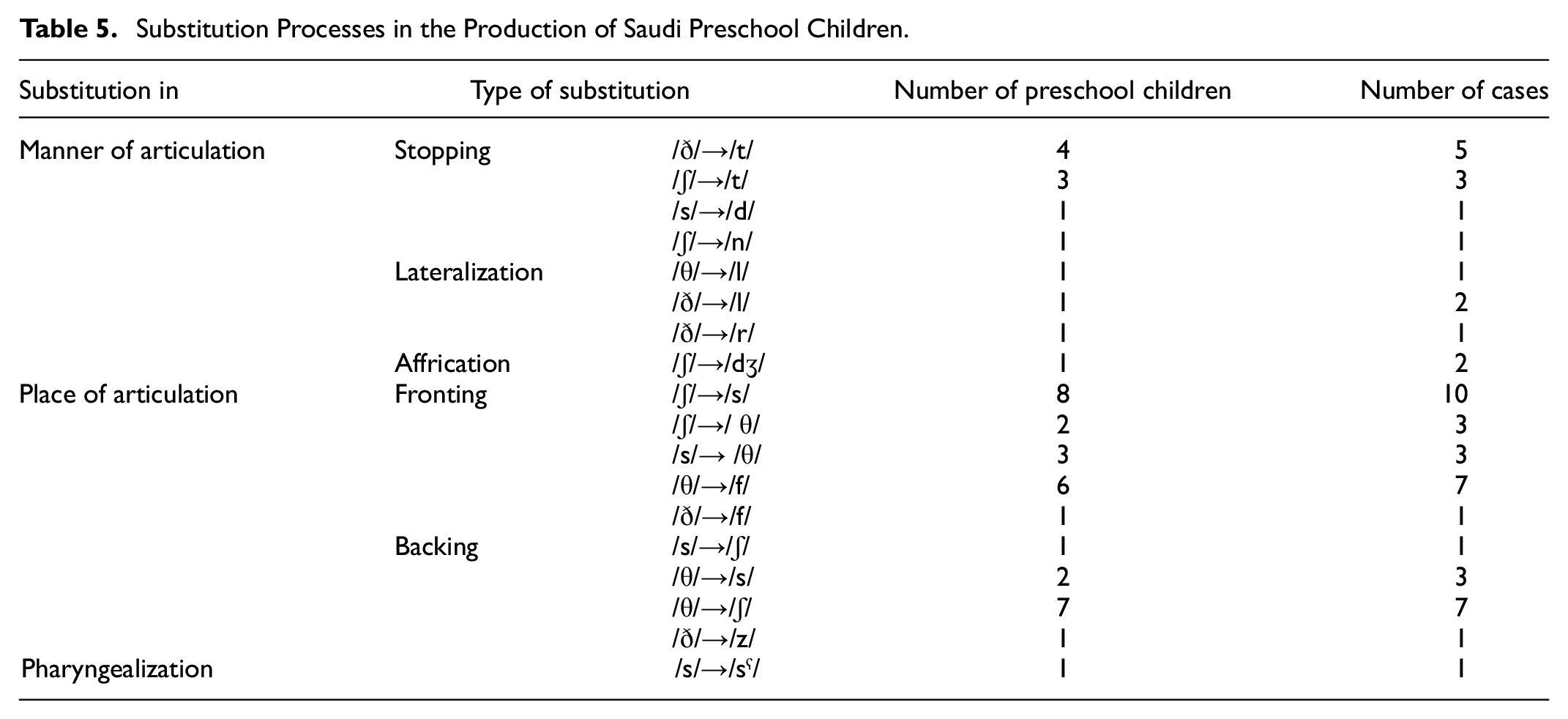
As shown in Table 5, substitution in place of articulation occurred more commonly than in the manner of articulation. Moreover, replacement in fronting occurred more often than in backing. Overall, replacing /ʃ/ with /s/ was the most common substitution among the study sample. Furthermore, errors were observed to occur more often when producing /ʃ/ and /θ/, with 19 and 18 cases, respectively. According to Shanks (2014), the sound /ʃ/ is expected to be mastered by age 5, while /θ/ is reported to be produced accurately by age 7. However, the mean age of preschool children involved in this paper was 4;2, which may explain why the preschool children produced more mistakes in these two sounds.
Substitution Processes in the Production of Saudi Preschool Children.
Discussion
This paper worked to expand our understanding of how preschool children produce /s/, /ʃ/, /θ/ and /ð/ accurately despite adults’ inability to perceive or characterize this production. Two essential findings are discussed in this section. First, the researchers found acoustic evidence of covert contrast in the production of some Saudi preschool children. Second, the most common substitutions in the production of Saudi preschool children were ascertained.
First, based on the literature, the researchers predicted that some preschool children would show covert contrast in their production of the target fricatives. The results were in line with this prediction, as six of the 25 preschool children (Speakers 3, 11, 16, 18, 22, and 23) showed covert contrast in producing the target fricatives of this study: /s/, /ʃ/, /θ/, and /ð/. This finding agrees with earlier studies on children’s production (Berti, 2010; Byun et al., 2016; Li, 2008; Li et al., 2009; Song et al., 2013; Zharkova, 2021) in which the participants produced covert contrasts. However, the findings of the current study contradict those obtained by Roberts (2019), in that covert contrast was not found as a stage of acquisition. Moreover, although Roberts (2019) results of both acoustic measurements and phonetic transcriptions mirror one another, in the current paper, three cases showed covert contrast in two acoustic cues (F1 & F2, and in duration & F2) and three cases in only one acoustic cue (F2, COG, and duration). No child produced covert contrast in all four acoustic measures. Most cases of covert contrast occurred in F1, F2, and fricative noise duration, with only one in COG. This result was unexpected, since COG is the main acoustic cue for fricatives (Gordon et al., 2002). Another unanticipated result in the current data is that half of the detected cases of covert contrast occurred in the production of the palato–alveolar /ʃ/. The researchers expected that at least half of the covert contrasts would occur in productions of /θ/ and /ð/, since these two sounds are acquired later than /ʃ/. However, based on the identification by adult native NA speakers, the percentage of words produced accurately for /θ/ and /ð/ was 83% and 90%, respectively, while for /ʃ/ the rate was 82%. The Saudi NA-acquiring preschool children with covert contrast distinguished acoustically between the target /ʃ/, transcribed as [t, s, and dʒ,]; the target /s/, transcribed as [θ and sˁ]; and /ð/, transcribed as [l, t, and r]. This result suggests that transcription data for L1, L2, and disordered speech must be questioned by acoustic analysis, since the results obtained from the acoustic analysis of the current paper and those of previous studies have revealed that preschool children are able to produce sounds accurately even when adults cannot identify their productions. This conclusion was also reached by Macken and Barton (1980) and Li (2008).
Furthermore, the three types of contrast observed in the current paper mirror Macken and Barton’s (1980) results. Their study identified three stages of contrast: no contrast, covert contrast, and overt contrast. In this paper, the three types of contrast are as follows:
Overt contrast: of 100 cases, 87 were produced by preschool children, much like adults, at a level of 75% accuracy or more. The sound with the most common overt contrast was /s/, with 24 children producing it accurately, followed by /ð/ (22 children), then /θ/ (21 children), and finally /ʃ/ (20 children).
Covert contrast, in which six cases were produced accurately as indicated by instrumental analysis but not by the identification of native speakers. The sounds in which the cases of covert contrast were detected were /ʃ/, /ð/, and /s/.
No contrast mastery, as determined by both acoustic analysis and identification, was found in the remaining seven cases: four cases in producing /θ/, two cases in producing /ʃ/, and one case in producing /ð/. It is likely that preschool children who show covert contrast in their production are on their way to mastering the target fricative without any intervention (F. E. Gibbon & Lee, 2017). These preschool children are aware of the target sound; however, they lack the control to produce it.
Such findings contribute to our understanding of L1 acquisition as a gradual process that passes through one stage to another.
The second point is related to adults’ identification of preschool children’s production. The results of the current paper have demonstrated that native speakers failed to perceive the correct production of six preschool children; however, the use of Praat software made it easy to identify precisely the correct production of those children.
In the current paper, more Saudi preschool children were characterized as producing /s/ accurately than other target sounds, that is, /ʃ/, /θ/, and /ð/. This result aligns with the universal acquisition of consonants, in which /s/ is acquired earlier than /ʃ/, /θ/, and /ð/. Li et al. (2009) demonstrated similar findings, in which /s/ was produced more accurately among English children than Japanese children. The sounds /s/ and /ʃ/ are expected to be acquired between ages 3 and 4, whereas /θ/ and /ð/ are acquired between ages 4 and 5 (Williamson, 2014). The findings of this study revealed that substitutions occurred more often in places of articulation. The most common substitutions were fronting errors, such as [s] for /ʃ/ and [f] for /θ/. These results are consistent with those obtained by Li et al. (2009), in which most participants replaced /ʃ/ with /s/. Fronting is a phonological universal and refers to changing the place of articulation of sounds produced at the back of the mouth to be at the front of the mouth. Locke (1983) argued that fronting is universal across languages in the acquisition of fricatives. In line with the researcher’s hypothesis, replacing /ʃ/ with /s/ was the most common substitution in the current study. As for backing substitutions, the results reported by native speakers showed that producing [ʃ] instead of /θ/ was the most common case. Furthermore, substitutions in the manner of articulation were noticed in preschool children’s production, with the production of [t] instead of /ð/ as the most frequent case.
Conclusions
This paper investigated the acquisition of contrasts of four NA fricatives, /s/, /ʃ/, /θ/, and /ð/, and identified the most common substitutions in producing these sounds. This paper reports the results of an acoustic analysis attesting to the existence of covert contrast in L1 acquisition. Perhaps the most important implication of this study is that six preschool children showed covert contrast in producing these fricatives. Another exciting finding was the replacement in the production of /ʃ/ with [s], which indicates that frontal misarticulation is universal. These acoustic results confirmed the hypothesis that some preschool children would display covert contrast in the production of the target fricative consonants even though adults failed to identify this accurate production in their perceptual judgment. Moreover, as expected, the replacement of /ʃ/ with /s/ was the most common substitution among these children, with 10 cases.
The current study focused on four sounds, which is considered a rather large number, to ensure that each sound was given appropriate attention. Furthermore, participants’ ages were not balanced, since the majority of the participants were approximately 4 years old. This study contributes to the linguistic literature, especially in the field of acquisition and phonetics in the Saudi context. The study’s results could have implications for the development of phonological awareness, speech therapy, and language education, particularly in Arabic-speaking countries where the acquisition of fricatives is a critical component of language development.
It is recommended for future studies to apply covert contrast in the medical field to evaluate children with speech disorders. Moreover, future studies are recommended to focus on two sounds with numerous words to obtain more accurate and generalizable results.
Footnotes
Appendix A
Picture Elicitation Task

| Sound | Arabic word | Transcription | Translation |
|---|---|---|---|
| /s/ | سمكه | samakah | fish |
| ساعه | sa:ʕh | watch | |
| /ʃ/ | شاهي | ʃa:hi | tea |
| شاحن | ʃa:ħin | charger | |
| /θ/ | شاحن | θaldʒ | ice |
| ثلاثه | θala:θh | three | |
| /ð/ | ذبان | ðaba:n | flies |
| ذيل | ðajl | tail |
Acknowledgements
We would like to express our sincere thanks and appreciation to Ohoud Saleh Al Hamad Center for the Children Hosting for their assistance in facilitating data collection. We also thank all the participants’ parents, for their permission to interview their children and their cooperation in collecting the data for this study. Researchers would like to thank the Deanship of Scientific Research, Qassim university for funding publication of this project.
Author Note
Mohammad Aljutaily is affiliated to Qassim University, Buraidah, Saudi Arabia. Eman Altoeriqi is affiliated to Majmaah University, Zulfi, Saudi Arabia.
Author Contributions
Eman Altoeriqi: Conceived the presented idea and designed the experiments; Performed the experiments; Analyzed and interpreted the data; Contributed reagents, materials, analysis tools or data; Wrote the paper. Mohammad Aljutaily: Conceived and designed the experiments; Performed the acoustic analysis; Analyzed and interpreted the data; Contributed reagents, materials, analysis tools or data; edit the final manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Informed Consent
All participants received a participant information sheet and consent form and were briefed about the project prior to their participation. This is just for making the parents’ children understand the nature of the study
Data Availability Statement
The data that has been used is confidential as requested by the parents of the participants.