
Abstract
As the most commonly established and attested language contact phenomenon, loanwords, also known as lexical borrowings, may undergo transformations when borrowed from the source language (SL) to the borrowing language (BL). Previous studies have separately illustrated the role of perception and phonology in the borrowing process. However, the speech perception or phonology contributes more to the adaptation pattern in some cases than others. Few studies attempt to explain this phenomenon. To fill in the gap, the present study hypothesizes that differences in borrowers’ L2 proficiency level of the SL are the potential source. To examine this hypothesis, an online adaptation experiment was designed and conducted. The experiment examines how Mandarin Chinese native speakers adapt the English non-words ended in the combination of low vowel and nasal coda. The results suggest that BL monolinguals and less proficient L2 learners of the SL tend to use a phonetic mapping strategy guided by the backness of vowels, while advanced learners of the SL are more likely to adopt a phonological mapping strategy based on coda nasal place. This paper concludes by proposing that borrowers’ L2 proficiency level has an effect on the certain randomized variations in the process of loanword adaptation.
Introduction
Loanwords refer to words taken from the source language and used in the borrowing language. The borrowing process will normally modifies the sound structures of loanwords, in order to satisfy the sound pattern of the BL (F. F. Hsieh, 2014; Kang, 2013).
This study explores whether loanwords change their spelling and structures when adapters have different L2/SL proficiency level, by having a close look at the variable adaptation of English co-occurrence of low vowel and nasal into Mandarin. For instance, Mandarin native speakers use either <an> [an]M or <ang> [ɑŋ]M as the adaptation of English <on> [ɑn]E, such as Fre
Past studies have disputes on how speech perception influences loanword adaptation. The perceptual view emphasizes that speech perception influences the lexical borrowing process, positing that the nature of loanword adaptation reflects the perceptual assimilation (e.g., Boersma & Hamann, 2009; Calabrese & Wetzels, 2009; Peperkamp, 2004; Peperkamp et al., 2008; Peperkamp & Dupoux, 2003; Silverman, 1992; Yip, 2006). On the contrary, the phonologically based approach claim that the lexical borrowing is determined by the mapping between the phonology of both SL and BL (e.g., Boersma & Hamann, 2009; Paradis & LaCharité, 2008; Paradis & Tremblay, 2009).
It seems that speech perception or the SL versus BL phonology contributes more to the patterns emerging in the loanword adaptation under certain circumstances than others. The paper aims to explore the reasons that contribute to this phenomenon, thereby addressing the core research questions in the present study. Differences in borrowers’ language experience, especially in their source language learning experience, have been recognized as a potential source for the random variations in the pattern of adaptation (Boersma & Hamann, 2009; C. B. Chang, 2008; Kang, 2009; Smith, 2006). Borrowers’ L2 proficiency influences the level of L2 sound perception constrained by the relative strength of the phonological pattern between BL and SL. In turn, this will result in variable adaptation patterns.
This paper adopts the following structure: Section 2 firstly gives an introduction about how English co-occurrence of low vowel and nasal is variably adapted into Mandarin, and then reviews the separate role of speech perception and the SL phonology in loanword adaptation, and then discusses the Perceptual Assimilation Model of Second Language Speech Learning (PAM-L2) and its implications for the present study. Section 3 illustrates how to implement the online adaptation experiment. Section 4 shows the experimental results. Section 5 makes a discussion about the results. The conclusion is arranged in Section 6.
Background
Variable Adaptation of English Co-occurrence of Low Vowel and Nasal Into Mandarin
Nasal [n] and [ŋ] are licit syllable codas, while nasal [m] is an illicit syllable coda in Mandarin. In contrast, nasal [n], [ŋ], and [m] are all licit syllable codas in English. Moreover, Mandarin requires the low front vowel [a] to precede [n] and the low back vowel [ɑ] to appear before [ŋ], a phonotactic constraint referred to as “rime harmony” (M. Y. Chen, 2000; Duanmu, 2000; Flemming, 2003; Mou, 2006). Thus, when English syllables [Cæn]E, [Cɑn]E, [Cɒn]E, [Cæm]E, [Cɑm]E, [Cɒm]E, [Cæŋ]E, [Cɑŋ]E, and [Cɒŋ]E are adapted into Mandarin, there are two possibilities, as explicitly presented in Figure 1 (revised from F. Hsieh et al. (2009); [C] represents any possible consonants). The phonological mapping in Figure 1a is based on the contrastiveness of the nasal coda because the low vowels are non-contrastive for the feature of [BACK] in Mandarin phonology (as indicated by the archiphoneme /A/; Slashes “//” are used for allophonic representations). So, the phonological mapping predicts that [n]E should be mapped to /n/M and [ŋ]E to /ŋ/M (Duanmu, 2000; F. Hsieh et al., 2009). Besides, the adaptation of labial nasal coda [m]E into [n]M can be predicted by a default mechanism called Place of Articulation (PoA) hierarchy proposed by de Lacy (2006). The PoA hierarchy argues that dorsals are more marked than labials, and labials are more marked than coronals across languages, as formalized by an output constraint, that is, *{dorsals, labials, coronals}. According to the prediction of PoA hierarchy, the labial nasal coda [m]E should be mapped to the less marked coronal nasal [n]M. The phonetic mapping in Figure 1b predicts a correspondence in vowels because the feature of vowel backness is predictable, and vowels are acoustically more salient and sonorous than coda nasals whose place features are relatively weak and easily subject to neutralization universally (Huang & Lin, 2019; Peperkamp et al., 2008; Zsiga, 2013). Hence, the vowel mapping would give a better match in phonetic details. The actual loanwords that exemplify these adaptation patterns are presented in Figure 2. Here the contrast between the non-rounded [ɑ] and the rounded [ɒ] is specially considered. American English (AE) and British English (BE) are two major varieties of standard English, and they differ in some pronunciations. In the current study, one noticeable difference comes to the combination of low back vowel and nasal, such as bond [bɑnd]AE& [bɒnd]BE, don [dɑn]AE& [dɒn]BE and don [dɑn]AE& [dɒn]BE, in which [ɑ] and [ɒ] are systematically different in terms of their roundness and length (Ladefoged, 2005; McMahon, 2020).

Phonological mapping and phonetic mapping in the predicted loanword adaptation: (a) phonological mapping and (b) phonetic mapping.

Phonological mapping and phonetic mapping in the real loanword adaptation: (a) phonological mapping and (b) phonetic mapping.
The Role of Phonology in Loanword Adaptation
The phonologically based approach of loanword adaptation posits that the non-existing phonemes in the SL will be replaced by its closest ones in the BL, even though they do not sound similar in acoustic details. The role of speech perception is minimal in loanword adaptation because the assumed borrowers are competent bilinguals and they have access to both SL and BL phonology (Boersma & Hamann, 2009; LaCharité& Paradis, 2005). In this sense, bilingual speakers do the first-round adaptation and set the preliminary standards for the broader borrowing language community. One typical example is the adaptation of English voiceless stops into Mandarin, reported by Paradis and Tremblay (2009). English aspirated voiceless stops are mostly adapted into aspirated voiceless stops, such as punk [
The Role of Speech Perception in Loanword Adaptation
In loanword adaptation, the perceptual view assumes that borrowers do phonetically minimal transformations, that is, they use the acoustically closest sounds in the BL to map onto the SL counterparts (Boersma & Hamann, 2009; Kenstowicz, 2007; Peperkamp, 2004; Peperkamp et al., 2008; Peperkamp & Dupoux, 2003; Silverman, 1992). Borrowers are not necessarily fully competent bilinguals. Monolinguals and L2 learners also represent the potential borrowers who actually constitute the majority of the adapters. They are very likely to set the standard in the BL community (Best & Tyler, 2007; Calabrese & Wetzels, 2009; Heffernan, 2005). F. Hsieh et al. (2009) discussed how the English co-occurrence of non-high vowel and nasal was adapted into Mandarin. As required by “rime harmony,” a Mandarin phonotactic constraint, non-high vowels have different allophones in the front-back dimension ([a] vs. [ɑ]), so as to strengthen a phonemic contrast between coronal ([n]) and dorsal nasal coda ([ŋ]) (Duanmu, 2000; Flemming, 2003; Lin, 2008). Based on a corpus study, F. Hsieh et al. (2009) found that it was the backness of the English vowels that determined the output and changed the place feature of nasal codas. For example, the English VN sequences of [æŋ]E and [ɑn]E were respectively mapped to [an]M and [ɑŋ]M in Mandarin. As vowels are acoustically more sonorous than nasals (Zsiga, 2013), F. Hsieh et al. (2009) attributed the above vowel mapping to the phonetic salience of vowels compared to nasals. In this sense, the perceptual salience is more important than the phonologically contrastive feature in determining Mandarin adaptation of English non-high vowel and nasal combinations. However, this conclusion was drawn from the analysis of loanword corpus, without a consideration of the source language (L2) proficiency level of borrowers. Many recent studies have demonstrated the impact of L2 learning experience on individuals’ L2 vowel perception and consonants (Kwon, 2017; Yang & Fox, 2014). It is therefore predicted that borrowers with different level of L2 proficiency may adapt the SL sounds differently by relying on different borrowing strategies, varying from phonological mapping to phonetic mapping. As more variations in the adaptation results would be expected if taken borrowers’ L2 proficiency into consideration, it is worth having a more in-depth study to examine and validate such variations.
PAM-L2 and the Present Study
As implied by the relevant literature review in the previous sections, different approaches toward loanword adaptation have different assumptions for borrowers’ identity. The phonology-based approach assumes that borrowers are normally competent bilinguals who have the same perception as SL monolinguals. As suggested by the phonological view, the effect of speech perception is minimum in the lexical borrowing because borrowers have access to both SL and BL phonology (Boersma & Hamann, 2009; LaCharité& Paradis, 2005; Paradis & LaCharité, 2008). In contrast, the perception-based approach claims that borrowers are not necessarily proficient bilinguals. Instead, BL monolinguals and less proficient bilinguals (or late bilinguals) are also potential borrowers. The phonetic view claims that speech perception determines loanword adaptation, and regards the lexical borrowing as a result of perceptual assimilation (Boersma & Hamann, 2009; Flege, 1995; Kang, 2003, 2009, 2011; Kenstowicz, 2007; Peperkamp & Dupoux, 2003; Silverman, 1992).
In loanword adaptation, there is a common phenomenon that perceptual or phonological similarity contribute more to lexical borrowing patterns under certain circumstances than others (Hsieh et al., 2009). Many studies have suggested this is largely attributed to differences in borrowers’ L2 proficiency (C. B. Chang, 2008; Kang, 2009; Kwon, 2017; Smith, 2006). The borrowers’ L2 proficiency level could influence the degree to which the BL (borrowers’ native language) versus SL phonology constrains their perception of the SL sounds. PAM-L2 posits that the acoustic similarity/dissimilarity between L2 and the L1 sounds constrains the learnability of L2 and predicts the sound perception of L2 by “functional monolinguals” (or “naïve listeners”) who inactively use and learn L2 in their daily speech and communication (Best & Tyler, 2007). In the current case of loanword adaptation, borrowers without or with extremely limited learning experience with the SL or L2 are compared to “functional monolinguals” or “naïve listeners,” according to the PAM-L2 term (Best, 1995; Best & Tyler, 2007). Best and Tyler (2007) propose that the proficient L2 learners’ perception is different from functional monolinguals and naïve listeners as they perceive not only to differentiate acoustic details, but also to additionally find abstract and useful phonological information. In this respect, PAM-L2 makes the prediction that L2 sounds are assimilated into L1 both phonetically and phonologically (Kwon, 2017; Pajak & Levy, 2014). In this sense, even the most phonological view regarding the adaptation of loanwords put forward by Paradis and Tremblay (2009) can be understood as L2 learners’ perceptual assimilation of the SL, while referring to the SL phonology to a large extent. This study aims to empirically examine whether borrowers with different L2 proficiency level may borrow the SL sounds in a different way, and whether such differences contribute to borrowers’ altered perception of the source language sounds.
There are three common types of categorized assimilations based on the prediction of PAM-L2. First, if the perception of two non-native L2 sounds are fine exemplars of two different L1 phonemes, which is called “two-category assimilation,” it would be easy for L2 learners to discriminate their differences. Second, if the perception of two L2 sounds are equally poor or good exemplars of the same L1 phoneme (this is the so-called “single-category assimilation”), it would be hard for L2 learners to discriminate their differences. Third, the two L2 sounds are perceived as the same L1 phonological category (phoneme), again, but they are different regarding their goodness-of-fit (category-goodness assimilation). Generally, the acquisition of different assimilation patterns may require different levels of perceptual efforts and L2 learning experience (Best & Tyler, 2007; J. C. Chang, 2013; Tyler et al., 2014). Thus, different English vowel-nasal combinations that constitute different assimilation patterns may be perceived by listeners (with Mandarin as their L1) with varying degrees of English (L2) in a different way.
Taken together, when borrowing English combinations of low vowel and nasal coda into Mandarin, the results may not only depend on the vowel quality and nasal codas, but also show influence of different degrees of borrowers’ L2 proficiency. The research question is therefore summarized below:
Research question: Is the likelihood of choosing a phonetic mapping strategy or a phonological mapping strategy in adapting English low vowel and nasal combination into Mandarin influenced by (1) the vowel backness; (2) the coda nasal place; (3) the borrowers’ L2 proficiency?
According to the findings of L2 sound acquisition studies, the initial age of most listeners exposed to L2 are less than 10 years show a perception like native speakers, while those whose initial age of exposure to L2 are greater than 10 years do not (Munro et al., 1996; Yamada & Tohkura, 1992). Based on the above perceptual findings of L2 learners, it is hypothesized that borrowers of less proficient bilinguals may be influenced by their L1 when choosing the target L2 borrowed structures, the degree of which is greater than fully competent bilinguals, but less greater than monolinguals.
Methods
The present study designed an online adaptation experiment. It examined whether adapters of L2 English learners with different proficiency level borrowed the English non-words into Mandarin differently. Participants were Mandarin native speakers with varying English learning experiences. To get the data of interest, the experiment asked the selected participants to borrow the English non-words ending in the combination of low vowel and nasal coda into Mandarin. Two choices were given to participants. One reflects a phonological mapping, while the other indicates a phonetic mapping, as illustrated in (1) and (2) in Section 2. Thus, the choices made by participants will directly tell their favorable adaptation strategies.
Stimuli
Stimuli include 54 items and 54 fillers. Items are monosyllabic English non-words with a structure of consonant-vowel-nasal (CVN). They vary in their onsets ([t, k, g, h, l, m, n, θ, w, ʃ, z]E), nucleus vowels ([æ, ɑ, ɒ]E), and coda nasals ([m, n, ŋ]E). The use of monosyllabic words is to exclude any potential disturbance of syllable count. Non-words are adopted to avoid the influence of lexical frequency. The complete list of 54 items are shown in Appendix I to III. Fillers are either monosyllabic English words or non-words, with the same structure as critical items. However, they have different onsets ([p, b, t, d, k, g, l, m, s, ʃ, f, z]E), nucleus vowels ([ɪ, e]E) and coda nasals ([m, n, ŋ]E). The full list of 54 fillers are presented in Appendix IV to VI. Some of items and fillers are shown in Figure 3a and b, respectively.

The adaptation of non-words in the experiment: (a) stimuli with nucleus vowels of [æ, ɑ, ɒ], and (b) stimuli with nucleus vowels of [I, e].
Two speakers were invited to record the sound of 108 stimuli. A native speaker of American English (age = 27 years) recorded the stimuli containing [æ], [ɑ], and [ɪ] as nucleus vowels, while a British English native speaker (age = 25 years) recorded the remaining stimuli with [ɒ] and [e] as their nucleus. We recorded the stimuli in a sound-attenuated room in the university phonetic laboratory. A Macintosh laptop was used to record the stimuli, using a TAKSTAR SM-16 microphone through Adobe Audition cc 2018 with a sampling rate of 44.1 kHz. The two speakers read each word in a carrier sentence, “say___aloud.” The speakers read each sentence three times, and the most natural token of each word was chosen for inclusion via Praat (Boersma & Weenink, 2019). We excluded the tokens with a noticeable pause/delay before or after the target item. The average intensity of the selected tokens was uniformly adjusted to 70 dB.
Participants
Participants were initially 45 self-identified Mandarin native speakers. Based on their English proficiency level, they were divided into three groups. The three groups were near monolinguals (henceforth NML, n = 15), intermediate English learners (IEL, n = 15), and advanced English learners (AEL, n = 15). NML participants were students at a local vocational training school. They can be classified into “functional monolinguals” or naïve listeners who have extremely limited English learning experience and inactively or never use English in their daily communication, according to the PAM-L2 (Best & Tyler, 2007). IEL participants were undergraduate or graduate students whose major was electric engineering/computer science at a key university in northeastern China. AEL participants were graduate students/lecturers learning or teaching at the same university, with their major in applied English linguistics. No participants reported that they had speech/hearing impairment. All participants received small gifts.
The classification of AEL and the IEL participants was based on the IELTS (International English Language Testing System) score, the age of initial exposure to English and the length of learning English. First, this study adopted the overall IELTS score of 7.0 and above as the first cut-off between AEL and IEL because band 7 indicates good English users according to the IELTS grading scale (https://www.ielts.org/about-the-test/how-ielts-is-scored). Additionally, the subset scores of listening and speaking should be no less than 7.5 since the listening and speaking competences are closely related to L2 learners’ speech perception abilities (Best & Tyler, 2007). Second, the age of 10 years, namely the age of initial exposure to English, was chosen as the second cut-off between AEL and IEL. According to the past studies about the critical period in language learning, most L2 learners who started learning English before 10 years old presented native-like perception, but those who started English learning after 10 years old did not (Flege, Munro, & Mackay, 1995; Munro et al., 1996; Yamada & Tohkura, 1992). Third, this study adopted the length of learning English of 15 years as the last cut-off between AEL and IEL. As implied by the related studies, it normally took 5 to 10 years to develop a preliminary academic English proficiency, and even longer to reach an advanced level (Aoyama et al., 2004; Hakuta et al., 2000; Jia et al., 2006; Nagel et al., 2015; Wang et al., 2005).
Data from four participants belonging to AEL group were excluded from further analyses because the overall IELTS score of one participant was lower than 7.0, two participants’ subset scores of listening and speaking were lower than 7.5, and the age of initial exposure to English of one participant was above the age of 10 years. Data from 1 IEL participant was also excluded for the same reason. The information of the remaining 40 participants was summarized in Table 1.
The Information of Participants.

Procedure
The experiment was built up via PsychoPy (version 3.2.4, University of Nottingham) (Peirce et al., 2019) on a Macintosh laptop equipped with a response pad (RB-x40 series, ADInstruments) attached. During the auditory presentation of stimuli, NML, IEL, and AEL participants listened to the stimuli in sequence and then adapted them into Mandarin. Two choices were given, namely CVn ([CVn]M) and CVng ([CVŋ]M). Participants were specially informed to ignore the tones and focused more on the adaptation of nasal coda. For example, when a participant heard the stimulus [gɑn]E, they were expected to make a choice between gan and gang. Only the adapted Mandarin Pinyin forms were presented on the screen (Mandarin Pinyin is the Romanization of the Chinese characters based on their pronunciation), as shown in Figure 4. The stimulus list has at least one filler between two items. The 108 stimuli, including items and fillers, were pseudo-randomized by intermixing fillers and items somewhat randomly but avoiding excessively long chains of similar trials. The whole test was self-paced. After making a choice, the test stopped unless participants used the space bar to continue the listening of the next stimulus. The play of each new stimulus lasted for 1 s after hitting the button. Besides, all the stimuli were only played over the headphone so as to avoid the influence of orthography. Before the actual test, all participants had a trial test to practice and be familiar with the procedure. PsychoPy automatically documented the choices of all participants.

The content presented on the screen in the experiment (English words in gray are not displayed on the screen).
Results
We analyzed the collected data by using the mixed-effects logistic regression model, which was implemented in the “lme4” package (Bates et al., 2014) in R version 3.6.1 (R Development Core Team, 2019). Three models were separately built, with each responding to each group, that is, NML, IEL, and AEL. The dependent variable in the three models was Can Response Rate, which was calculated by the number of Can responses divided by the total number of Can and Cang responses to stimuli with the same vowel-nasal combination by each participant. For example, the total number of [Cæn]E was 6 in this experiment, which means that the total number of Can and Cang responses is 6. If a participant made 2 Can responses, her Can response rate regarding the adaptation of [Cæn]E should be one-third (≈0.33). The independent variables were VowelBack (front [æ] vs. back [ɑ/ɒ]) and NasalCoda ([n] vs. [ŋ] vs. [m]), which were included into fixed effects. The reference level for VowelBack was [ɒ], and for NasalCoda was [ŋ]. A random intercept for Participant ID was included in the random effects.
The model predicted the probability that the adaptation of a target English stimulus into Can or Cang would be influenced by Group, VowelBack, NasalCoda and their interactions. The Can or Cang response, in turn, indicated different adaptation strategies (phonological mapping strategy vs. phonetic mapping strategy vs. mix), as illustrated in Section 2. To be specific, the phonological mapping strategy refers to the cases of Can response after hearing [Cɑn]E, [Cɒn]E, [Cɑm]E, and [Cɒm]E, and Cang response after hearing [Cæŋ]E. So, the adaptation patterns of [Cæŋ]E → [Cɑŋ]M, [Cɑn]E → [Can]M, [Cɒn]E → [Can]M, [Cɑm]E → [Can]M, and [Cɒm]E → [Can]M were coded as phonological mapping. The phonetic mapping strategy refers to the situation where the Can response was chosen after hearing [Cæŋ]E, and Cang response after hearing [Cɑn]E, [Cɒn]E, [Cɑm]E and [Cɒm]E. In this respect, the adaptation patterns of [Cæŋ]E → [Can]M, [Cɑn]E → [Cɑŋ]M, [Cɒn]E → [Cɑŋ]M, [Cɑm]E → [Cɑŋ]M, and [Cɒm]E → [Cɑŋ]M were coded as phonetic mapping. In contrast, the stimuli of [Cæn]E and [Cæm]E were predicted to be unitarily adapted into [Can]M ([Cæn]E → [Can]M and [Cæm]E → [Can]M,), while the stimuli of [Cɑŋ]E and [Cɒŋ]E were expected to be unitarily adapted into [Cɑŋ]M ([Cɑŋ]E → [Cɑŋ]M and [Cɒŋ]E → [Cɑŋ]M). Such adaptation patterns reflected a mixture of phonetic and phonological mapping strategy. Consequently, we could not directly tell the exact adaptation strategy that participants adopted, according to their Can or Cang responses.
Figures 5 to 7 visualized the descriptive data concerning the rates of Can responses made by NML, IEL, and AEL group of participants after they heard different stimuli composed by different low vowel-nasal combinations. Tables 2 to 4 presented the results from mixed-effects logistics regression models, which explained the Can response rates made by NML, IEL, and AEL participants, respectively. The results were further used to explain the changing probabilities of different mapping strategies (phonological mapping vs. phonetic mapping) adopted by NML, IEL, and AEL participants.
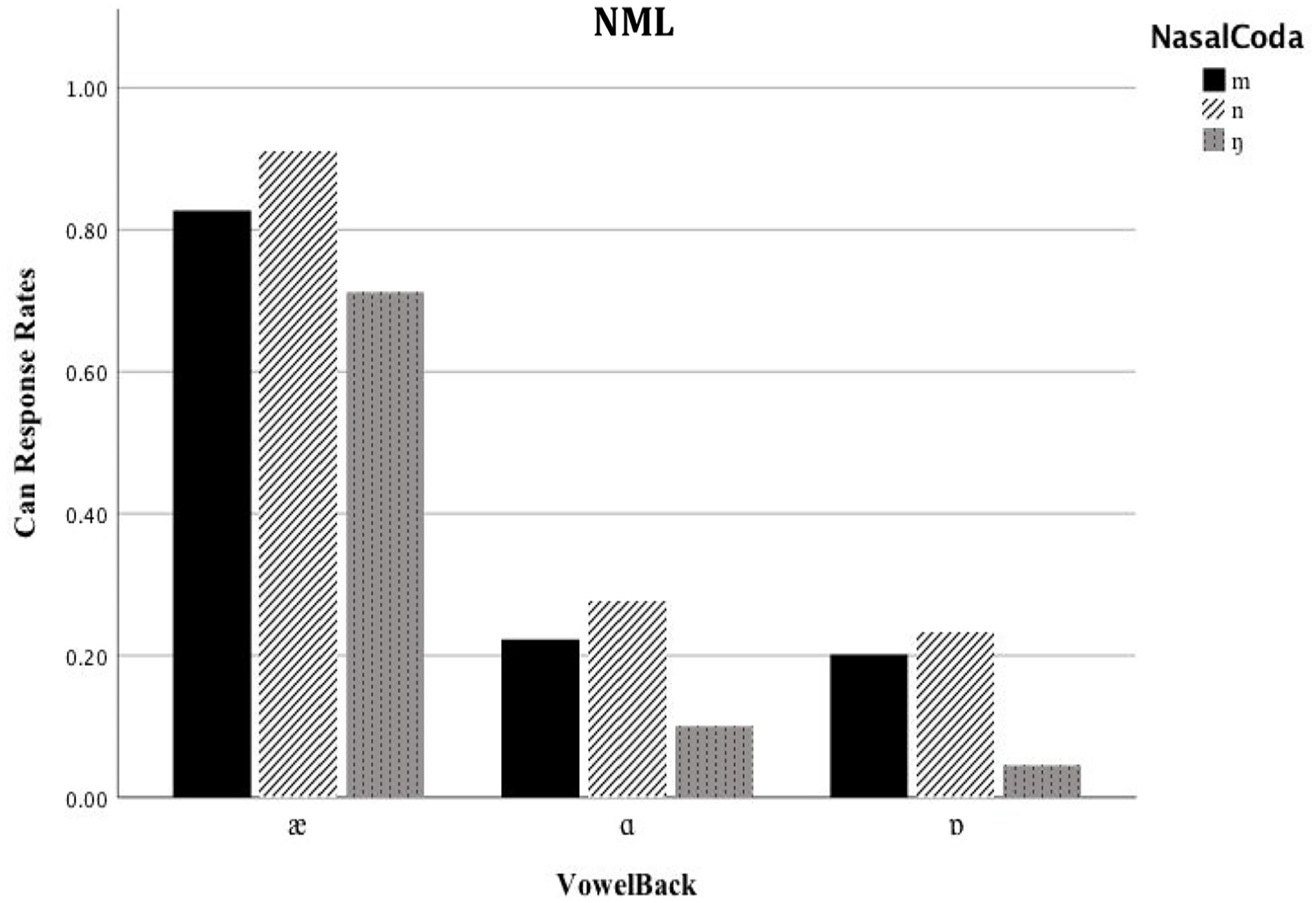
Can response rates by NML participants according to VowelBack × NasalCoda.

Can response rates by IEL participants according to VowelBack × NasalCoda.
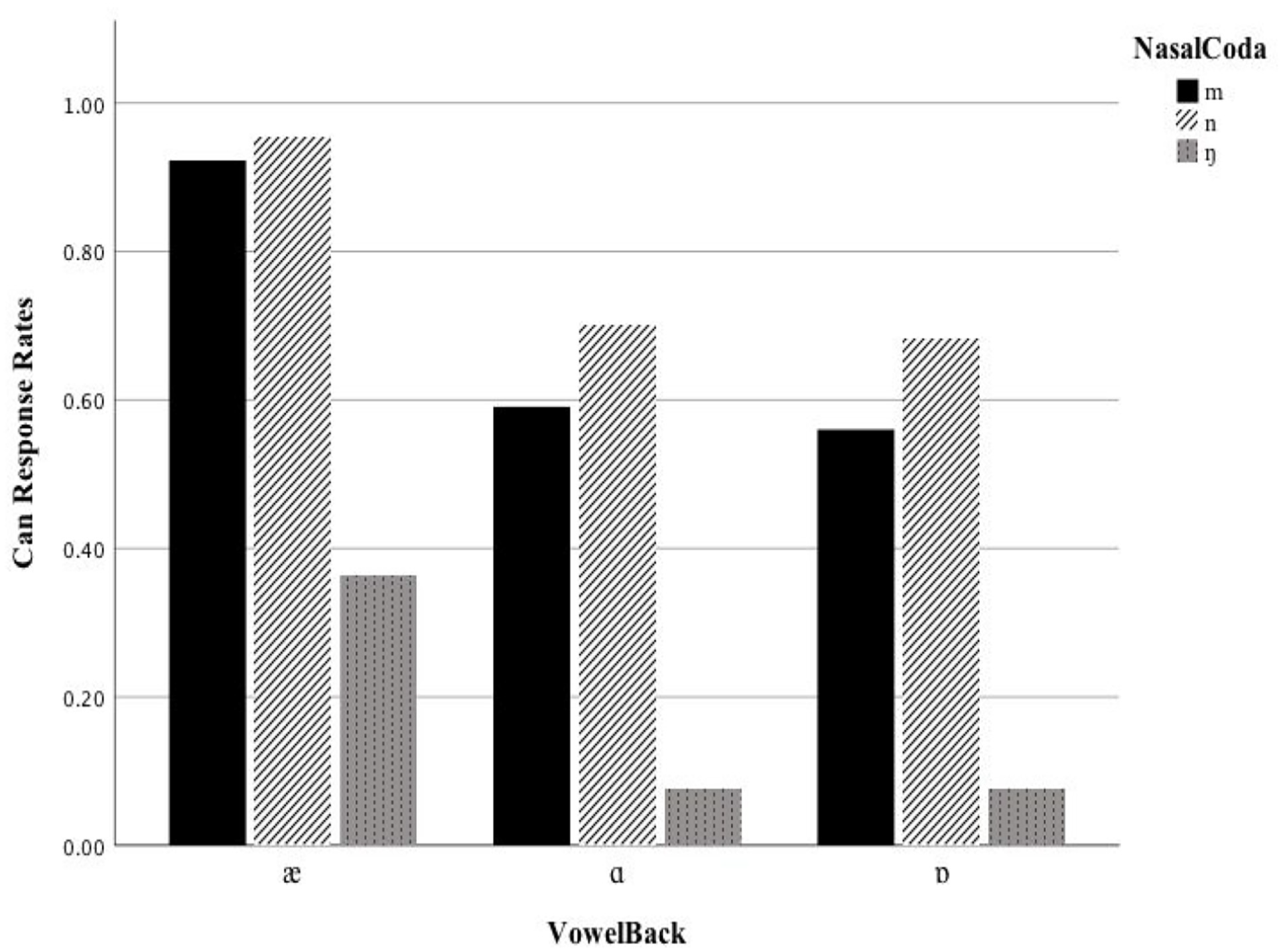
Can response rates by AEL participants according to VowelBack × NasalCoda.
Results From the Mixed-Effects Logistic Regression Model of Can Response Rates made by NML Participants (The Reference Category is [ɒ] for VowelBack and [ŋ] for NasalCoda).
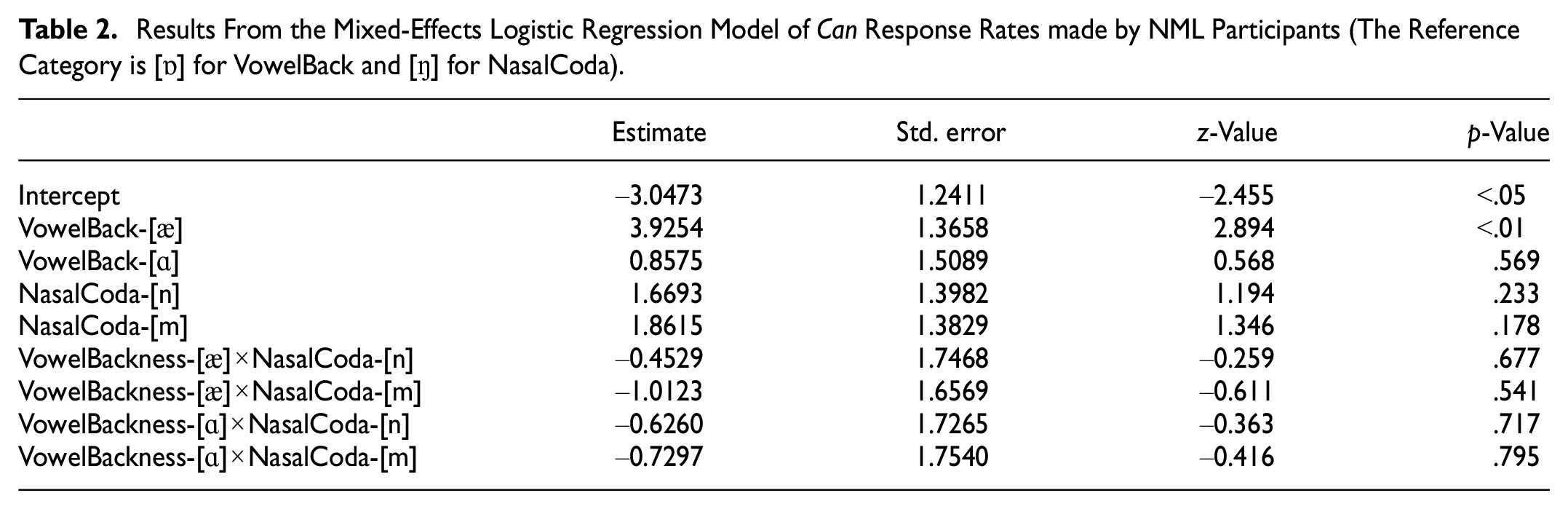
Results From the Mixed-Effects Logistic Regression Model of Can Response Rates Made by IEL Participants (The Reference Category is [ɒ] for VowelBack and [ŋ] for NasalCoda).
Results From the Mixed-Effects Logistic Regression Model of Can Response Rates Made by AEL Participants (The Reference Category is [ɒ] for VowelBack and [ŋ] for NasalCoda).

For NML participants, the results suggested a change in the variable from low back rounded vowel [ɒ] to low front unrounded vowel [æ] significantly increased the likelihood of Can response (β = 3.9254, SE = 1.3658, z = 2.894, p < .01). In contrast, when changing from low back rounded vowel [ɒ] to low back unrounded vowel [ɑ], the probability of Can response also increased, but not significantly (β = .8575, SE = 1.5089, z = .568, p = .569). Regarding NasalCoda effect, the NML model predicted that there would be no significant changes if the stimuli containing coda nasal [n] (β = 1.6693, SE = 1.3982, z = 1.194, p = .233) and [m] (β = 1.8615, SE = 1.3829, z = 1.346, p = .178) were replaced by those ending in [ŋ]. For the interaction between VowelBack and NasalCoda, the likelihood of Can response did not change significantly when the stimuli changed from [Cæŋ]E to [Cæn]E (β = −.4529, SE = 1.7468, z = −0.259, p = .677) and [Cæm]E (β = −1.0123, SE = 1.6569, z = −0.611, p = .541). Similarly, there were no significant changes concerning the probability of Can response when changing the stimuli from [Cɑŋ]E to [Cɑn]E (β = −.6260, SE = 1.7265, z = −.363, p = .717) and [Cɑm]E (β = −.7297, SE = 1.7540, z = −.416, p = .795). Within NML model, the results so far demonstrated a significant effect of VowelBack, while the NasalCoda effect and the VowelBack × NasalCoda effect were insignificant. The results were summarized in Figure 5 and Table 2.
IEL participants got similar adaptation results with NML participants. They were more likely to make Can responses after frequent exposure to the stimuli with [æ] as their nuclear vowel, when compared to those whose nuclear vowels were [ɒ] (β = 3.0647, SE = 1.0110, z = 3.031, p < .01). In contrast, the Can responses induced by [ɑ] and [ɒ] were similar, and not significantly different (β = −.2244, SE = 1.1696, z = −0.192, p = .848). In comparison to the stimuli ended by [ŋ], the stimuli that contained nasal coda [n] and [m] did not significantly induce IEL participants to make to more Can responses ([n] vs. [ŋ]: β = .9118, SE = 0.9925, z = 0.919, p = .358; [m] vs. [ŋ]: β = .9686, SE = 0.9880, z = 0.980, p = .327). Regarding the interaction between VowelBack and NasalCoda, the probability of Can response rates were similar after IEL participants listened to the stimuli with syllable rime of [æn]E, [æm]E, and [æŋ]E ([Cæn]E vs. [Cæŋ]E: β = .4093, SE = 1.5620, z = .262, p = .793; [Cæm]E vs. [Cæŋ]E: β = −.3922, SE = 1.3882, z = −.283, p = .778). Besides, the stimuli [Cɑn]E (β = .5031, SE = 1.4264, z = 0.353, p = .724) and [Cɑm]E (β = .3975, SE = 1.4359, z = 0.277, p = .782) did not significantly induce IEL participants to make more Can responses, in comparison to [Cɑŋ]E. As shown in Figure 6 and Table 3, the IEL model confirmed that the VowelBack effect was significant, while the NasalCoda effect and their interactions were not significant.
Different from NML and IEL participants, the likelihood for AEL participants to make Can response did not increase significantly when the nuclear vowel of stimuli changed from [ɒ] to [æ] (β = 1.7320, SE = 1.2178, z = 1.422, p = .155) and [ɑ] (β = −.2012, SE = 1.5424, z = −0.130, p = .896). As for the NasalCoda effect, IEL participants were more likely to make Can response as the stimuli were ended by nasal coda [n] ((β = 2.5328, SE = 1.2080, z = 2.097, p < .05) and [m] (β = 2.9834, SE = 1.2244, z = 2.437, p < .05), when compared to [ŋ]. Moreover, the interaction between VowelBack and NasalCoda was also significant within AEL model. To be specific, the probability of Can response significantly increased when the syllable rime changed from [æŋ] to [æn] (β = 2.1322, SE = 1.7269, z = 1.077, p < .05). The same results also applied to the situation where [Cæŋ] was replaced by [Cæm] (β = 2.3681, SE = 1.5826, z = 1.233, p < .05). In addition, when AEL participants increasingly listened to the stimuli containing [ɑn] and [ɑm], the probability for them to make Can responses was greater than the cases that they listened to the stimuli whose syllable rimes were [ɑŋ]E ([Cɑn]E vs. [Cɑŋ]E: β = 2.3610, SE = 1.7949, z = 1.201, p < .05; [Cɑm]E vs. [Cɑŋ]E: β = 2.3277, SE = 1.7675, z = 1.185, p < .05). The relevant results were presented in Figure 7 and Table 4, and demonstrated that there was a significant effect regarding NasalCoda and VowelBack × NasalCoda, while the VowelBack effect was insignificant.
In summary, the results concerning NML and IEL model provide evidence for the phonetic view as Can response rates were lower to vowel [ɑ] & [ɒ], but higher to vowel [æ] regardless of nasal contexts (bars with different colors), as visually presented in Figures 5 to 7. In contrast, the results regarding AEL model lend support to the phonological view because there were higher Can response rates to nasal coda [n] (black bar) and [m] (dark gray bar), but lower Can response rates to nasal coda [ŋ] (light gray bar), regardless of vowel contexts ([æ], [ɑ], [ɒ] in the x-axis), as shown in Figure 7. The effect from the mixture of the phonetic and the phonological view can be observed from the higher Can responses to [æ] + [n] across the three groups (see the black rectangles with solid lines), and lower Can responses to [ɑ/ɒ] + [ŋ] across the three groups (see the gray rectangles with dotted lines). Overall, the results can be further interpreted that NML and IEL participants tended to use phonetic mapping strategies based on the backness of vowels, much more frequently than AEL participants. When compared to NML and IEL participants, AEL participants were more likely to use phonological mapping strategies guided by the coda nasal place. Taken together, the results demonstrated a significant group difference in Mandarin adaptations of English coda nasals, which can be understood as the evidence for an L2/SL proficiency effect.
Discussion
L2 Perceptual Learning and Loanword Adaptation
Proficient L2/SL learners tend to use a phonological mapping strategy as they have access to both BL and SL phonology. By comparison, functional monolinguals and less proficient learners of the SL tend to perceive the differences in phonetic gradient details but not to attain abstract phonological information (Akturk-Drake, 2014; Best & Tyler, 2007; Kwon, 2017).
PAM-L2 predicts that naïve listeners, without non-native language experience, tend to do the perceptual assimilation of the foreign sounds into their native phonemes with the most similar acoustic properties. There are two common situations regarding the consequences, the categorized perceptual assimilation and the uncategorized perceptual assimilation. The former is that the perception of non-native sounds/L2 are recognized as equally good or poor exemplars of listeners’ native phonemes. The latter refers to the case of no matched pairs between the non-native sounds and the native phonemes. The categorized assimilation includes the two-category assimilation (TC), the single-category assimilation (SC) and the category-goodness assimilation (CG). The TC assimilation refers to the assimilation of two non-native sounds into different native phonological categories. The SC assimilation happens when the perception of two non-native sounds was equally poor or good exemplars of the native sound category. The CG assimilation means that the perceptual assimilation of one non-native sound is into a good exemplar and the other into a poor one in L1 (Tyler et al., 2014).
For the TC assimilation, the stimuli [Cæn]E and [Cɑŋ]E were separately perceived as [Can]M and [Cɑŋ]M for all participants. Each of [Can]M and [Cɑŋ]M belongs to the different Mandarin phonological categories. The findings indicate that the discrimination between [Cæn]E and [Cɑŋ]E achieves the highest accuracy, which is in accord with the prediction by PAM-L2. The TC assimilation also happens to the non-native sound pairs of [Cæm]E& [Cɑŋ]E, [Cæn]E& [Cɒŋ]E, and [Cæm]E& [Cɒŋ]E. From perceptual account, these stimuli are perceived as good exemplars of a given Mandarin (L1) phonological category. In this case, the perceptual learning efforts would be minimal. Though borrowers differ in their proficiency level of the SL, they can easily categorize the non-native sounds into the native phonemes when the phonetic segments in BL are also shared in the SL. Besides, the discrimination of the two contrasting non-native phones are more accurate if the perceptual assimilation of the two L2 sounds corresponds to different L1 phonological categories. However, the discrimination will be less accurate if their assimilations come to the same phonological category in L1. For instance, Mandarin borrowers, in regardless of their English proficiency, can easily tell [Cæn]E and [Cɑŋ]E are different sounds as indicated by their different Can responses (see Figures 5 and 6). However, borrowers with less proficient English proficiency may be uncertain whether [Cæn]E and [Cæm]E are different, because their Can responses are similar (see Figures 5 and 7), as both [Cæn]E and [Cæm]E are perceptually assimilated to the same Mandarin phonological category, namely [Can]M (Best & Tyler, 2007; Tyler et al., 2014).
For the SC assimilation, the contrasting non-native sounds of [Cæn]E and [Cæm]E are uniformly adapted into Mandarin as [an]M. Meanwhile, borrowers tend to borrow the stimuli of [Cɑŋ]E and [Cɒŋ]E as [Cɑŋ]M. This means that the perception of different L2 phonological categories turns out to be the same L1 phonological category. Furthermore, the current study also finds that for NML and IEL participants, [Cɑn]E& [Cɒn]E and [Cɑm]E& [Cɒm]E are mostly borrowed as [Cɑŋ]M, while these non-native sound pairs are adapted into [Can]M by AEL participants. It is always the case that L2 learning beginners equate L2 sounds with L1 ones, and perceive that they are pronounced in the same way at the lexical-functional level. The lexical-functional equivalence holds that the perceived phonological similarities between the sounds from L1 to L2 does not naturally imply their phonetic similarities, and vice versa. For example, the stimuli of [Cɑn]E are phonologically deviant from [Cɑŋ]M for their different coda nasals. However, they are phonetically quite similar and easily assimilated at the phonetic level. Besides, the stimuli of [Cɑn]E are phonologically similar to [Can]M, but they are perceived quite differently at the phonetic level. PAM-L2 posits that naïve listeners’ L2 perceptual learning ability develops progressively. With continuous learning, L2 learners gradually learn to discriminate the above-mentioned phonological contrasts between the L2 non-native phonetic segments and the L1 native phonemes. Compared to advanced learners of the SL, functional monolinguals are less sensitive about the lexical-functional differences (Best & Tyler, 2007; Tyler et al., 2014).
For the CG assimilation, the assimilation of two non-native stimuli yields in different native phonological categories. One is assimilated into a good exemplar and the other into a poor one. For NML and IEL participants, the stimuli [Cæn]E are consistently perceived as [Can]M, but the stimuli [Cɑn]E are more frequently perceived as [Cɑŋ]M and less frequently perceived as [Can]M (see Figures 5 and 7). Thus, the category goodness rating is “excellent” for the assimilation of [Cæn]E but “poor” for the [Cɑn]E. The same analyses also apply to the contrasting stimuli of [Cæn]E& [Cɒŋ]E, [Cæm]E& [Cɑn]E, [Cæm]E& [Cɒn]E, [Cæn]E& [Cɑm]E, [Cæn]E& [Cɒm]E, [Cæm]E& [Cɑm]E, and [Cæm]E& [Cɒm]E. Within these non-native stimuli pairs, the former stimuli are assimilated to a good exemplar and the later stimuli are assimilated to a poor exemplar. As a consequence, borrowers of NML and IEL can accurately discriminate between the stimuli [Cæn]E and [Cɑn]E in most occasions, thereby adapting them into different Mandarin sound categories by following a category goodness assimilation (Akturk-Drake, 2014; Best & Tyler, 2007; Tyler et al., 2014; Yang & Fox, 2014).
The present study also provides important support for a basic assumption of PAM-L2. That is, the CG (category-goodness) contrasts have a higher discriminability than the SC (single-category) contrasts in the perceptual assimilation of non-native sounds. In the case of single category assimilation, two or more different L2 or SL sound categories are also assimilated into the same L1 or BL sound category, with almost the similar level of high goodness-of-fit. For instance, the sounds of [Cɑn]E and [Cɒn]E tend to be perceptually assimilated into [Cɑŋ]M and they are often not accurately distinguished by the less proficient learners of the SL. In a category goodness assimilation, two or more different L2 or SL sound categories are also assimilated into the same L1 or BL sound category but with distinct levels of fitness. For example, the English non-words [Cæn]E and [Cɑm]E may be both adapted into Mandarin as [Can]M, but [Cæn]E and [Can]M have a higher goodness-of-fit than [Cɑm]E and [Can]M. As a consequence, borrowers of Mandarin speakers, even for those with limited English learning experience, can easily tell that [Cæn]E and [Cɑm]E are different sounds (see Figures 5 and 7).
The findings are not only consistent with F. Hsieh et al. (2009), but also made essential complements to their study. When borrowing English coda nasals into Mandarin Chinese, borrowers with extremely limited or insufficient L2 knowledge (represented by NML and IEL group of participants in the current study) will do the adaptation using a phonetic mapping strategy guided by the backness of vowels, while borrowers of advanced L2 learners with sufficient SL knowledge (corresponding to AEL participants in the current study) tend to adopt a phonological mapping strategy based on the coda nasal place.
Beyond Non-native Speech Perception: The Role of L1 Phonological Rules
Mandarin native grammar requires the low front vowel [a] to precede [n] and the low back vowel [ɑ] to appear before [ŋ], a phonotactic constraint referred to as “rime harmony” (M. Y. Chen, 2000; Duanmu, 2000; Flemming, 2003; Mou, 2006). This phonotactic constraint leads to a fixed co-occurrence of low vowel and nasal in Mandarin, namely [an]M and [ɑŋ]M (*[ɑn]M and *[aŋ]M are illicit Mandarin vowel-nasal combinations). It constrains how borrowers who are NML and IEL perceive the stimuli of [Cæŋ]E, [Cɑn]E, and [Cɒn]E to a greater extent than the borrowers of AEL. For example, the stimuli of [Cɑn]E and [Cɑŋ]E, despite their phonological differences in nasal coda, are more likely to be both perceived as [Cɑŋ]M (rather than [ɑn]M) by NML and IEL listeners (see Figures 5 and 7).
Thus, the borrowing of English sounds is not only “filtered” by the speech perception, but also informed by the phonological knowledge of borrowers’ native language. When perceiving non-native sound, L2 learners are constrained by the phonotactic of “rime harmony” to varying extents. The finding supplements the fundamental assumption of PAM-L2 models by proposing that naïve listeners and L2 learners’ speech perception, to a large extent, is constrained by both specific L1 sound inventory and general phonological principles across the languages (J. C. Chang, 2013; Y. Y. Chen & Lu, 2018; Pajak & Levy, 2014). Moreover, the usage-based framework explains this case by presuming that mental representations of phonological patterns and contrasts are accordingly and accumulatively acquired through gaining more language experience. Each sound category, no matter in L1 or L2, is both stored in memory by numerous marked tokens of that category. These memories are distributed on a cognitive map. Hence, memories with the most similar instances (also referred to as “exemplars”) are clustered, while those dissimilar instances are split. As a consequence, when naïve listeners and L2 learners hear each single English sound, such as [Cɑn]E, they naturally compare the perceived sounds [Cɑn]E with their stored exemplars of each sound category. Since functional monolinguals and less proficient L2 learners have less English experience than proficient bilinguals, the promising exemplar for the sound category [Cɑn]E will be [Cɑŋ]M for their phonetic approximation. Unlike bilinguals, it would be less likely for naïve listeners and L2 learners to instantly build up separate categories based on English phonology, especially for those related with the vowel-nasal combinations. Thus, they are unlikely to discriminate these sounds accurately, thereby leading to different adaptation results (Johnson, 2006; Pierrehumbert, 2001; Yang & Fox, 2014).
Conclusion
The principal findings are that Mandarin adaptations of English coda nasals in loanwords vary according to SL/L2 proficiency of borrowers. Borrowers without or with limited SL/L2 knowledge tend to use a phonetic mapping strategy guided by the backness of vowels, while those of advanced SL/L2 learners are more likely to adopt a phonological mapping strategy based on the coda nasal place. The use of different adaptation strategies was attributed to borrowers’ altered speech perception of the SL sounds. The strategy gradually transfers from the perceptual mapping to the phonological mapping as BL/L1 borrowers gain sufficient SL/L2 knowledge. If the L2/SL non-native sounds map onto a single L1/BL native sounds, the influence of L2 proficiency level is minimal. If the L2/SL non-native sounds are matched with two or more L1/BL native sound categories, a variable adaptation may appear due to borrowers’ different L2 proficiency of the SL. In addition, the findings also suggest that the native phonotactics restricts the L2 speech perception of borrowers.
The pedagogical implications of PAM-L2 in teaching or learning a foreign language are to take the perceptual assimilation to the L1 into consideration by incorporating PAM-L2 principles in the classroom of foreign language teaching or learning (Piske, 2007; Tyler, 2019). Before the acquisition of a large number of L2 vocabulary, it is strongly recommended for foreign language learners to tune in to the L2 phonological contrast marked by the phonetic differences (Piske, 2007; Tyler, 2019). To be specific, there are three detailed suggestions. First, students should have opportunities for perceptual training, especially for L2 phonological contrast. Teachers, on the other hand, should emphasize the importance of L2 phonemes’ perception in order to facilitate L2 word recognition. Second, considering the individual differences in L2 perceptual assimilation, teachers are advised to know how their students assimilate those L2 consonants and vowels, so as to provide effective perceptual training. Third, if possible, it is suggested to postpone the teaching of L2 orthography, especially L2 grapheme-to-phoneme pair. According to the related studies, L2 learners whose L1 have similar alphabetic system with L2 are more likely to apply their L1 grapheme-phoneme correspondence rules when reading new or uncertain L2 words (Daland et al., 2015; Detey & Nespoulous, 2008). This phenomenon will definitely hinder the L2 phonological development of foreign language learners.
In summary, the present study confirms a significant relationship between the selection of a variable adaptation strategy/pattern (perceptual mapping or phonological mapping) and borrowers’ L2/SL proficiency. Borrowers’ favorable adaptation strategies/patterns drift away from the perceptual mapping and tend to rely on the SL phonology as they gain more SL knowledge and learning experience.
Footnotes
Appendix
Stimuli (Fillers Ended by Coda Nasal [m]).

| [pɪm]E | → | pin [phin]M | [bɪm]E | → | bin [pin]M | [kɪm]E | → | jin [tɕin]M |
| ping [phiŋ]M | bing [piŋ]M | jing [tɕiŋ]M | ||||||
| [gɪm]E | → | jin [tɕin]M | [lɪm]E | → | lin [lin]M | [mɪm]E | → | min [min]M |
| jing [tɕiŋ]M | ling [liŋ]M | ming [miŋ]M | ||||||
| [sɪm]E | → | xin [ɕin]M | [ʃɪm]E | → | xin [ɕin]M | [zɪm]E | → | jin [tɕin]M |
| xing [ɕiŋ]M | xing [ɕiŋ]M | jing [tɕiŋ]M | ||||||
| [pem]E | → | pan [phan]M | [bem]E | → | ban [pan]M | [tem]E | → | tan [than]M |
| pang [phɑŋ]M | bang [pɑŋ]M | tang [thɑŋ]M | ||||||
| [dem]E | → | dan [tan]M | [kem]E | → | kan [khan]M | [gem]E | → | gan [kan]M |
| dang [tɑŋ]M | kang [khɑŋ]M | gang [kɑŋ]M | ||||||
| [fem]E | → | fan [fan]M | [sem]E | → | san [san]M | [zem]E | → | zan [tsan]M |
| fang [fɑŋ]M | sang [zɑŋ]M | zang [tsɑŋ]M |
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Talent Fund of Beijing Jiaotong University (Grant No. 2023JBRCW002).