
Abstract
Ambiguities in information and difficulties in distinguishing truth from fiction during natural disasters produce negative emotions and create problems in emergency rescue work. In this study, we focused on two aspects. First, we propose a method that improves upon the existing streaming data clustering method based on twin networks, which is a single-pass topic clustering method based on the Siamese-bidirectional gated recurring units (BiGRUs)-attention technique. Second, a bidirectional encoder representation from transformers (BERT)-BiGRU-conditional random field (CRF) sentiment analysis model based on the idea of sequence tagging was designed. Combining this method with the proposed topic clustering method, we propose a new disaster management method that analyzes the public opinion before and after a disaster. We conducted experiments that showed that the single-pass topic clustering model based on Siamese-BiGRU-attention outperformed other clustering methods in terms of clustering performance. Simultaneously, the BERT-BiGRU-CRF model was employed to statistically analyze data on daily public opinion monitoring. The statistics of the clustering results before and after disasters occur and the emotion distribution based on each category were obtained. Overall, the proposed method can help rescue workers and governmental officials understand the sentiments of the public more clearly and provide the necessary response measures more effectively during disasters.
Introduction
Natural disasters have continuously been emerging in recent years. These disasters, which usually occur suddenly, not only negatively impact people’s lives in terms of property destruction and deaths, but also result in the dissemination of information that causes psychological panic among victims and affect regular operations in emergency response and rescue work. This results in the rise of negative social sentiments that are inconducive to governmental interventions aiming to manage the developing situation. Natural disasters such as earthquakes, volcanic eruptions, floods, droughts, tornados, typhoons, solar magnetic-field explosions, and black lightning are produced by natural forces and create widespread devastation, endangering human safety. Natural disasters will always exist and cannot be overlooked. Since humans cannot fully understand nature and how to prevent the occurrence of these disasters, the only feasible course of action is reducing the damage produced by them.
Regarding human-made disasters, they are caused by human errors in decision-making that lead to incorrect behavior. With scientific and technological advancements, decision-making mechanisms will become increasingly perfect, and the possibilities of errors will become increasingly low; unlike natural disasters, these disasters can be prevented in advance. Therefore, it is imperative to understand the public opinion on natural disasters in a timely manner and analyze them to avoid the associated risks (G. Wang et al., 2015). Nowadays, the public opinion about various natural disasters is aggregated on social media platforms such as Weibo, which has become an important channel for obtaining and evaluating the public opinion on various topics (Chen, 2020). With the development of information technology, artificial intelligence (AI) has become a key technical support tool for research on public opinion. It is very important to use AI technology to control potential human-made disasters caused by the improper dissemination of online public opinion to reduce the negative emotional impact of natural disasters on the public.
Online public opinion analysis is a data mining method that collects and integrates data aggregated using social media aggregators and other digital communication media data for analyzing information on public opinion, discovering various trends, predicting social reflections on different topics, and guiding the development of effective response strategies (Chen, 2016). Based on the technical modules involved, this field can be divided into topic detection and topic tracking. Our research topic is the application of a topic clustering model to public opinion analysis. Existing topic detection methods in this field are either based on semantic analysis, vector spaces, or topic clustering. Semantic analysis extracts textual information from different areas of a network, integrates information related to a particular topic or opinion for analysis, and summarizes data on trends in the public opinion on that network. In topic detection based on vector spaces, relational vectors are used to obtain relational research data, and then, relevant analysis results on trends, developments, and patterns are obtained. This method can analyze results based on interrelationships and infer changes in the public opinion on a topic to make the necessary quantitative decisions. Topic clustering analysis, the most widely used public opinion analysis method, detects changes in online speech at different times and summarizes the results of these changes for a more objective and effective evaluation. It analyzes different topics and viewpoints to determine highly-trending topics and then provides an accurate basis for public opinion analysis. Topic clustering is an unsupervised learning method that does not require pre-annotated dataset documents and can effectively organize textual information using end-to-end thinking. This method is simple, easy to implement, and has a fast convergence rate. There are also has scientific evaluation indexes for topic clustering that can accurately evaluate clustering performance and be used in public opinion analysis.
Our research has identified certain limitations in these mainstream methods of public opinion analysis. Regarding semantic analysis, discretization is obvious, and no systematic process or method currently exists. It is difficult to expect both timeliness and accuracy when performing public opinion analyses based on topic clustering. Regarding the use of vector spaces, more importance is attached to local information and less is attached to temporal characteristics. Generally, there is a lack of a topic clustering method with both timeliness and accuracy; therefore, a new topic clustering model that meets both these requirements is needed. Additionally, there is a lack of an emotion analysis method that can grasp the global structure of documents. Current mainstream sentiment analysis methods focus more on local features, whereas sequence tagging can masterfully obtain the global structure of documents. Therefore, sequence tagging was used in the construction of an emotion analysis model. Currently, there is no applicable systematic disaster management method that can analyze the public opinion before and after disasters occur and realize the daily monitoring of public opinions on natural disasters and the statistical analysis of clustering results before and after they occur.
Therefore, the main research direction in this study is developing a topic clustering model that implements the design obtained from the proposed research method that overcomes the shortcomings of other existing methods. First, the bidirectional encoder representations from transformers-bidirectional gated recurring unit-conditional random field (BERT-BiGRU-CRF) model was designed based on the concept of sequence tagging to monitor the daily public opinion. Second, a single-pass topic-clustering model based on Siamese-BiGRU-attention is proposed. This model focuses more on the similarity degree of the actual semantics expressed by different words or sentences and establishes a similarity measure between time series by learning the latent correlation inherent in the data. Finally, the proposed method was applied to the case of the 2021 typhoon “Fireworks” to realize the statistics of the clustering results before and after the disaster. Then, the clustering results were classified according to both the positive and negative emotions, and the proportion of different emotions in each theme category was further analyzed. This analysis provides a reference for the standardization and operability of AI-based analysis on the public opinion on natural disasters.
The remainder of this paper is organized as follows. The second section reviews existing literature related to clustering and semantic analysis, and the third section introduces the proposed method. The application of the proposed method to the case study of an actual typhoon is provided in the fourth section. The fifth section discusses the limitations of the proposed study and future research directions. Finally, the conclusions of the study are presented in the last section.
Literature Review and Theoretical Background
Topic detection and tracking are core research modules in public opinion analysis (Cai, 2019; Cheng, 2015; Zhou, 2012). This study focuses on using a model based on topic clustering, which belongs to the field of topic detection, to monitor the public opinion on natural disasters. Topic detection can either be based on topic clustering, document semantics, or graph vector spaces. The status of both domestic and foreign research on topic detection is presented below.
Topic Detection
Topic Detection Based on Topic Clustering
Allan et al. (2002) proposed topic detection using a single-path clustering strategy. Trieschnigg and Kraaij (2004) proposed an incremental hierarchical clustering algorithm intended for constructing an initial acyclic directed graph system with a few randomly selected samples and prepared fusion reports according to their relevance. Zhou (2012) proposed an incremental clustering algorithm to address the sparsity of microblog features and used a known knowledge base to extend the features in topic detection. Walls et al. (1999) adapted an incremental k-means algorithm for topic detection to obtain the specific characteristics of online topic detection. Wan and Yang (2004) employed an additive windowing technique to implement topic detection using the inverted-frequency and k-means clustering methods. Y. Wang et al. (2013) proposed topic detection based on an improved clustering algorithm, using a hierarchical clustering algorithm to improve the selection process of initial sample centers while maintaining intra-cluster consistency within the layers to improve the accuracy of topic detection. Fitriyani and Murfi (2016) used the mini-batch k-means clustering algorithm to address the problem of topic detection for large datasets and obtained satisfactory detection results.
Topic Detection Based on Document Semantics
Makkonen et al. (2004) proposed that semantic similarity in topic detection could be improved by dividing the term space into term groups according to their type meanings. X. Li et al. (2006) used a multidimensional document model to process forum messages and introduced an additive windowing technique to solve the semantic drift problem. They processed topic features separately according to their semantic differences to discover complete semantic information in the forum. Cataldi et al. (2010) proposed a new topic detection method to retrieve the latest emerging topics online by modeling the life cycle of terms connecting the newly emerged terms with semantically related keywords and detecting new topics within a specified time period. Yao et al. (2016) performed semi-supervised topic detection using the Dirichlet process mixture model (DPMM), which detected news topics considering the semantic connections inherent in news texts and assigned them to different class clusters after performing the initial lexical assignment. This was done to overcome the shortcoming of previous algorithms not having necessary semantic information and being unable to exploit the potential connections between words. C. Zhang et al. (2016) integrated information on semantic and word co-occurrence information into graphs and extracted topics from the graphs. S. Zhang and Zhu (2018) constructed query- and time-associated semantic networks based on temporal microblogging texts, overcoming the inability of existing methods to describe topic changes and topic drift in the dynamic tracking of microblog topics.
Topic Detection Based on Graph Vector Space
Juha (2003) divided a traditional single vector into four subvectors according to word meaning: common word vectors, place noun vectors, person noun vectors, and time noun vectors. The similarities of the subvectors were first calculated separately and then unified into a single similarity. Since this method carries out vector space division for news elements, it yields better results for news-topic detection. Song et al. (2006) proposed an improved vector space model that divided feature words into four groups according to semantics: time, place, task, and content; and they generated four subvectors separately. Using this method, better results could be obtained in news topic detection. Zhao et al. (2006) proposed a content analysis detection method, which considered the categorization of topics into mark vectors and content vectors, to overcome the difficulty in distinguishing any two similar topics; the performance of this method was experimentally verified. Sayyadi and Raschid (2013) implemented a topic detection algorithm called KeyGraph using keyword co-occurrence information to construct a keyword graph. Perera and Karunarathne (2015) used WordNet to extend the KeyGraph algorithm to keywords, which improved the algorithm’s topic detection capability. B. Liu et al. (2017) built on the KeyGraph algorithm using a two-layer clustering algorithm of undirected keyword and document graphs to extract distinguishable events. S. Yang et al. (2018) proposed a weighted directed graph clustering algorithm based on term frequency-inverse document frequency (TF-IDF) to improve the performance of topic detection.
There are certain limitations in these studies. Regarding public opinion analysis and research based on topic clustering, public opinion monitoring needs a certain degree of timeliness, and there is lack of a topic clustering method that considers both timeliness and accuracy. Regarding public opinion analysis based on semantics, most current research covers discrete semantic analysis, and there is no systematic process and method for opinion analysis. Regarding public opinion analysis based on the vector space, there is more focus on local information and less on the temporal order in the detection process and a lack of a method for mastering the global information of documents.
We conducted our research in the fields of topic classification and topic clustering, focusing on overcoming these limitations. In our previous research, we proposed the Siamese-BiGRU-attention semantic similarity calculation method, which introduced the BiGRU and attention modules into the basic framework of the Siamese network, improving the ability to capture contextual information and exploit the causality of contextual information to represent input text more effectively (Chen & Qiu, 2022). The focus of our recent research has been combining this method with topic-clustering models to improve topic-clustering performance. In this study, we propose a single-pass topic clustering model based on Siamese-BiGRU attention, which improves the timeliness and accuracy of topic clustering. Meanwhile, in our previous study, we designed the BERT-BiGRU-CRF model to predict the core functions of adjacency, applying the idea of sequence tagging to topic segmentation (Chen & Qiu, 2021). Recent studies have found that optimizing a model and migrating it to the field of sentiment analysis can provide favorable results. Accordingly, we propose a sentiment analysis model based on BERT-temporal convolutional network (TCN)-CRF that can realize the daily monitoring of public opinion information and effectively grasp global information. Our subsequent research work will thoroughly examine potential improvements in the applicability of the topic clustering model to different types of texts and the robustness of the text input order, considering existing limitations, to promote the paradigm transformation of the topic clustering model.
Studies related to semantic similarity and topic clustering, which are important concepts in the AI model proposed in the study, are discussed below.
Semantic Similarity
Semantic similarity is an important concept in natural language processing. Previous studies on semantic similarity computation considered these three dimensions: statistical semantics, knowledge bases, and deep learning.
Semantic Similarity Calculation Method Based on Statistical Semantics
Text similarity calculation based on statistical semantics requires a large-scale knowledge base; this method does not consider the structural or semantic information of text in the calculation process, assuming that similar words have similar semantics. Texts can be converted into word vectors using various types of text vectorization methods, and the semantic similarity between texts is evaluated by calculating the distance between the obtained vectors (D. Yang & Powers, 2005). An additional calculation method based on distance and attribute dimensions is discussed below.
Distance-based semantic similarity is based on the core idea of tree-level semantic similarity calculation, wherein the difference in distance between the positions of two nodes in a hierarchy is calculated to measure similarity. This difference is inversely related to the semantic similarity. This method has the advantages of high interpretability and low time complexity and is especially suitable for small-scale samples with simple structures. It is unsuitable for large-scale samples with complex structures since it focuses less on the structural associations between features and cannot disentangle the connections between units.
The attribute-based method extracts the attribute sets of two texts and performs similarity calculations between these sets. The number of identical attributes between the texts is directly related to the semantic similarity. Significantly, this method relies on the properties of a text attribute set (Camacho et al., 2015) and has different parameter settings for different types of text. Additionally, its performance depends on the size of the domain-specific corpus. A lack of sufficient information can produce a negative impact on this method’s performance.
Semantic Similarity Calculation Method Based on Knowledge Base
Considering that knowledge bases can be divided into two categories, namely ontology-structured semantic dictionaries and web-based large knowledge base resources (Shi et al., 2009), the calculation of semantic similarity can also be divided into two categories: those based on structured semantic dictionaries of ontologies and those based on large web-based knowledge-base resources.
The structure-based semantic dictionary approach has the disadvantages of poor generality, high labor costs, and poor adaptability to different syntactic structures. Semantic dictionaries are prone to heterogeneity in domain-specific applications, making algorithm migration difficult. Experts need to build a semantic dictionary that gets constantly updated according to the requirements; the associated labor costs can be quite high. Since this approach considers word granularity in calculating the similarity between sentences, and it does not consider the connection between syntactic structures when evaluating semantic similarity based on the weighted summation of similarities between words, the similarities for pairs of long texts get incorrectly calculated (Logeswaran & Lee, 2018).
Large web-based knowledge base resources, which are characterized by rich knowledge resources and fast iterations, also have many problems, such as large knowledge granularity, low knowledge structuring, the inability to directly analyze web pages, and computational difficulties (Yeh et al., 2009). Further studies are required on extracting information accurately from self-described structured data.
Semantic Similarity Calculation Method Based on Deep Learning
Unsupervised learning is a deep-learning-based approach, which usually means that semantic similarity can be computed without labeled data. This method involves self-supervised training of the information in the dataset itself, and the word vectors are weighted and summed to obtain the sentence vectors. Accordingly, the distance between the sentence vectors is calculated to evaluate the semantic similarity. This method is more generally applicable, particularly being suitable for areas where data resources are scarce (Le & Mikolov, 2014).
An unsupervised learning model does not consider labeled information and prior knowledge, resulting in a lower accuracy and longer computation time. Therefore, we introduced supervised learning to compute the semantic similarity (Hill et al., 2016). This method is trained on a labeled training set to obtain the semantic similarity between text. Since supervised learning models use labels, they outperform unsupervised learning models in most training tasks (Conneau et al., 2020).
Most supervised learning models follow the architecture of Siamese neural network models, which generally comprises an input layer, an encoding layer, and a similarity computation layer (Mueller & Thyagarajan, 2016). The input layer maps words into word vectors after sentence division, the encoding layer obtains sentence vectors by encoding word vectors in sentences, and the similarity calculation layer computes the semantic similarity between sentence vectors, using vector distance to directly represent the similarity. A Siamese network ensures that the input and encoding layers have the same model architecture and share weights when different sentences are concurrently inputted into it.
Topic Clustering
Text clustering is an unsupervised learning method that does not require the pre-annotation of dataset documents and can effectively organize textual information with end-to-end thinking. The core idea of text clustering is accurately dividing several topic cluster categories in a given text collection according to the degree of similarity between individual texts. Thus, similar topic categories will have high text similarity whereas different ones will have a relatively low text similarity. Clustering strategies are typically divided into static and incremental approaches; these approaches differ in the types of text changes obtained from calculating text similarity during clustering. Clustering methods can be classified into various types based on their implementation: hierarchical clustering, divisional clustering, density clustering, and incremental clustering.
Hierarchical Clustering Algorithm
Hierarchical clustering algorithms can be classified into two categories: top-down-split hierarchical clustering and bottom-up cohesive hierarchical clustering. The split hierarchical clustering algorithm places the sample points in the same category, then performs top-down hierarchical partitioning according to certain rules, and then stops partitioning when the termination conditions of the corresponding rules are satisfied (Dasgupta & Long, 2005). Divisive Analysis (DIANA) is the most common split hierarchical clustering algorithm, which first classifies all the sample points into a cluster and then cascades this classification according to the distance between the sample points, only stopping when the threshold of the distance between the clusters or the number of class clusters is exceeded. A cohesive hierarchical clustering algorithm follows the opposite approach. It first places all the sample points in a cluster and then subdivides them into smaller clusters until each sample is in a cluster or a set threshold is exceeded, and the termination condition is triggered. Agglomerative Nesting (AGNES) is a very common cohesive hierarchical clustering algorithm that first sets similar samples in the same category, calculates the distance between the sample points separately, computationally compares the sample pairs in each category with the smallest distance, and finally aggregates the related sample categories.
Divisional Clustering Algorithm
Divisional clustering algorithms are more commonly used. The core idea of these algorithms is enumerating all the possible division results and obtaining an optimal solution from them (Y. Zhang & Zhou, 2019). One of the most common algorithms, the k-means clustering algorithm, is a typical divisional clustering algorithm that considers the distance property for text similarity evaluation. This algorithm first selects K objects as cluster centers, sets a distance threshold, calculates the distance from the remaining text to each center in turn, and then classifies the text into the category belonging to the nearest center of mass, while adjusting and updating the center of mass. This process is repeated cyclically till the center of mass no longer changes.
Density Clustering Algorithm
The density-based clustering algorithm is different from hierarchical- and division-based clustering algorithms. Instead of calculating the distance between sample points, this algorithm considers the density of sample points to the cluster samples of arbitrarily shaped categories. Generally, it is used to obtain clusters of high-density samples by filtering low-density regions to ensure that samples of the same type are closely connected (Rodriguez & Laio, 2014). Density-based spatial clustering of applications with noise (DBSCAN) is a common density clustering-based algorithm. It can cluster different types of sample sets in an arbitrary shape space and has high noise immunity and a high clustering speed.
Incremental Clustering Algorithm
The core idea of the increment-based clustering algorithm is considering the first given sample point as a category cluster and then comparing all the remaining sample points with the first category cluster. If the calculated similarity result is less than the threshold, the point should be set as a new category cluster; if the conditions are reversed, it should be classified into this category cluster. This process is iterated until the set condition is satisfied (X. Zhang et al., 2012). A single-pass algorithm is a common incremental clustering algorithm that can categorize text units by performing just a single calculation. This algorithm has a simple structure and a high processing speed and does not require that the number of clustering categories be preset; thus, it has strong applicability.
Proposed Intelligent Modeling Method Based on Improved Single-Pass Model
Sentiment Classification
In this study, we used the concept of sequence tagging to solve the sentiment classification problem (Chen & Qiu, 2021). First, microblog public opinion texts were inputted into the BERT layer to obtain their semantic representations. Then, the sentence vectors were inputted into the BiGRU layer to obtain the contextual features, which were then inputted into the CRF layer by combining the relevance of the contextual sequence labels. Finally, the labeled sequences were outputted as negative, neutral, or positive. The structure of the sentiment classification model is shown in Figure 1.

Sentiment classification model based on BERT-BiGRU-CRF.
Input layer: Inputs U1, U2, U3, U4, U5, U6, and U7… are the microblog public opinion texts to be inputted to the pretrained BERT layer, which will produce a unified mapping of these texts.
BERT layer: The BERT model is a language model based on the transformer structure. This model constructs a multilayer bidirectional encoder network for deep bidirectional pretraining based on semantic understanding by jointly adjusting the bidirectional transformers in all the layers. The encoder of the transformer reads the entire text sequence simultaneously instead of sequentially from left-to-right or right-to-left. It can effectively capture information from the target word context, significantly reducing errors in the computational model due to information loss (Jacob et al., 2018). This model randomly uses the mask mechanism to mask certain words and uses the unmasked words to predict other words. The BERT model shows good results in preventing label leakage and handling non-fixed-length sequences.
BiGRU layer: The BiGRU model is an extension of the GRU that comprises two GRUs. A GRU, whose structure is based on that of long short-term memory (LSTM), combines the input and forget doors into an update door and updates the original output door as a reset door. Both a GRU and an LSTM retain important features of text sequences through the gate structure, with a GRU having fewer gates and parameters than an LSTM does; therefore, the training speed of a GRU is faster (L. Li et al., 2018). Since a GRU network cannot link all the contextual information, the reverse input of the GRU is added, and then the forward and reverse GRU units are combined to build the bidirectional GRU, which completely exploits contextual information to mine the causal relationship between text sequences.
CRF layer: The core function of a CRF is obtaining the dependency relationship between the preceding and following labels, which acts as a constraint on these labels. A CRF is a discriminative probability model that is a random field comprising a Markov random field obtained by outputting the assumption of random variables. Like the layout of a Markov random field, the layout of a CRF can be set arbitrarily; the commonly used chain-linked architecture layout is taken as an example, and the joint probability distribution can be written as the product of several potential functions.
Output layer: The microblog public opinion sentiment labels, which indicate different sentiments: negative, neutral, or positive.
Topic Clustering With Single-Pass Algorithm Based on Siamese-BiGRU-Attention
Evaluation Indices for Topic Clustering
The clustering algorithm is an unsupervised learning method; therefore, there is no absolute evaluation method for judging clustering results. Current evaluation indices for clustering algorithms can be divided into two categories: internal and external evaluation indices. An internal evaluation index primarily evaluates the clustering effect in terms of separation, overlap, connectivity, and compactness from the perspective of the structural information of the dataset and includes the Calinski-Harabasz (CH) index, cluster cohesion, and contour coefficient. The external evaluation index mainly evaluates the effect of different clustering models by comparing clustering divisions based on the external information of the dataset and obtaining the label information belonging to sample points. Since the dataset selected in the study contained labeled data, we focused on external evaluation indicators.
Rand index (RI)
The Rand index (RI) considers the clustering of a decision process. It measures the percentage of correct decisions and classifies two sentences in the same cluster if and only if they are similar:

where TP represents that similar sequence pairs are grouped into the same cluster, TN represents that dissimilar sequence pairs are grouped into different clusters, FP represents that dissimilar sequence pairs are grouped into the same cluster, and FN represents that similar sequence pairs are grouped into different clusters.
The larger the RI value, the more practical the clustering result; the maximum and minimum values are 1 and 0, respectively.
2. Adjusted Rand index (ARI)
The RI cannot guarantee that the score approaches zero for randomly assigned cluster labels results. Therefore, to ensure that the clustering evaluation index would be close to zero when the clustering results are generated randomly, an adjusted Rand index (ARI) with a higher differentiation was adopted. Equation (2) mathematically represents the ARI:
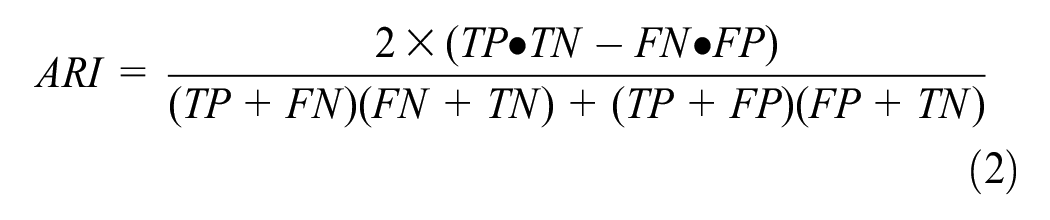
where TP, TN, FP, and FN represent the same values they did for the RI.
The larger the ARI value, the more practical the clustering result; the maximum and minimum values are 1 and −1, respectively.
3. F-value
The F-value can be regarded as the derivative of the RI evaluation index, and it can determine the clustering effect. The RI method matches the accuracy and recall rates with the same weight. However, practically, it may be necessary to focus on a certain index. The F-value is calculated from the precision and recall; these three measures are mathematically represented as follows:



where TP, TN, FP, and FN represent the same values they did for the RI and ARI.
The larger the F-value, the more practical the clustering result; the maximum and minimum values were 1 and 0, respectively.
4. Clustering accuracy (AC)
The clustering accuracy (AC) can be used to compare predicted and real tags; it is mathematically represented as follows:


where
Semantic Similarity Calculation Based on Siamese-BiGRU-Attention
The semantic similarity computation model based on Siamese-BiGRU-attention comprises two identical network structures: A and B. The network structure consists of an input layer, embedding layer, BiGRU layer, fully connected layer, and matching layer. The structure of the model is shown in Figure 2.

Structure of semantic similarity calculation model based on Siamese-BiGRU-attention.
Input layer: Sentences S1 and S2 from the microblog that are preprocessed and inputted into the embedding layer of the model.
Embedding layer: This layer maps each word in a sentence in a low dimension and transforms it into a dense vector. The equal-length sentence sequence after pre-processing is Sn, and each word needs to be transformed into a corresponding word-embedding vector, which is later inputted into the structure of the neural network.
BiGRU layer: We used BiGRU to extract the deep semantic features of the sentences. A GRU can solve the problem of gradient disappearance more effectively than an Recurrent Neural Network (RNN) can, and the BiGRU network can link all the contextual information.
Fully connected layer: We used the attention mechanism to assign a greater weight to words that contributed more to the semantics of the sentence and vice versa to more accurately express the semantics of the sentence. Regarding the connection form of the fully connected layer, each node was connected to all the nodes in the previous layer. This was done to completely synthesize the previously extracted features; the matrix vector multiplication could be regarded as the core of the fully connected layer.
Matching layer: We calculated the cosine similarity of the semantic vectors and obtained the corresponding results. After obtaining the semantic representations of the sentences S1 and S2, the cosine similarity of the two vectors was calculated in the semantic space of the sentences, and the semantic similarity between these sentences was examined.
Topic Clustering Based on Single-Pass Algorithm
The single-pass algorithm is a classical data-flow clustering algorithm that sequentially processes each piece of data once and classifies them to be processed into existing categories or adds a new category based on the matching degree between existing categories. Thus, incremental and dynamic data clustering can be achieved. This algorithm compares the newly read data with the clustered data. If a more similar category is present in the clustered data, then the newly read data are placed into this category; otherwise, the new data are treated as a new category and are iterated. This cycle is repeated until all the data are read and divided. The structure of single-pass algorithm is shown in Figure 3.
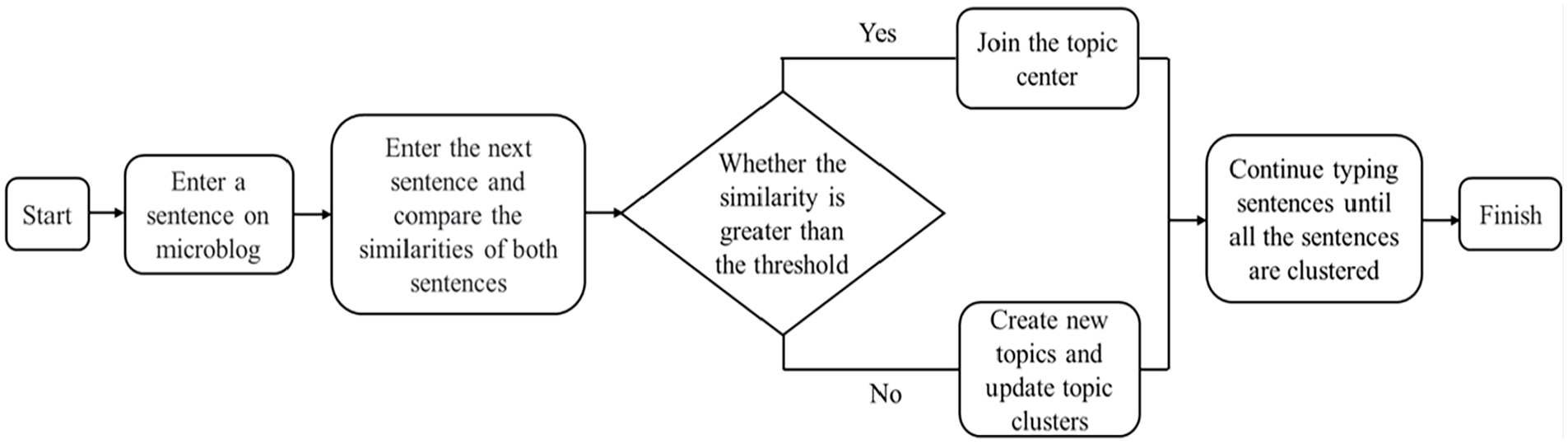
Structure of single-pass algorithm.
This algorithm is very simple in principle and has strong timeliness; however, it still has certain shortcomings. First, the traditional single-pass clustering algorithm employs metrics such as the Euclidean distance and cosine distance to calculate semantic similarity; since it only utilizes formulas for similarity calculation, it is unable to effectively employ category labels in guiding topic delineation. Traditional similarity calculation methods based on the cosine distance focus more on the properties of the data and do not consider the influence of contextual semantic relations on similarity. This is mainly because they generally only consider the spatial distance of sentence vectors in text similarity comparison, neglecting the similarity of the actual semantics expressed by different words or sentences. Secondly, the single-pass algorithm is a typical incremental topic-based clustering method. In the traditional implementation of this algorithm, each newly added document needs to be compared with the clustered documents. However, as the number of input documents increases, the cumulative computational effort increases, significantly reducing the running speed of the algorithm. We propose the following improvements to overcome these two shortcomings.
First, to solve the problems associated with using similarity metrics, we propose a semantic similarity calculation method based on a Siamese network that establishes similarity metrics between temporal sequences by learning their internal potential associations in the data. Simultaneously, the learned metrics can be used to complete the matching of the new samples. The network is suitable for scenarios with few data resources and scarce annotations; thus, the method has excellent applicability in similarity computation. The core idea of a Siamese network is forming a mapping model from the input to the target space and performing similarity computation in the target space. A Siamese network is a similarity computation application framework that is convenient to compute and does not depend on specific domain knowledge. Therefore, we propose a semantic similarity computation method based on Siamese-BiGRU-attention. This method introduces the BiGRU and attention modules to the basic framework of the Siamese network, enhancing its ability in capturing both preceding and following texts, exploiting contextual information to mine causal relationships, and represent input text.
Second, in response to the high computational complexity in the traditional single-pass clustering process stemming from new samples being sequentially compared with completed clustered samples, our proposed method reduces the number of new document cycle comparisons by setting the clustering center in real time during the clustering process, while constantly and dynamically updating the clustering center when performing similarity comparisons with new documents. Thus, when a new document is introduced, a two-part similarity calculation considering the similarity of the new document to the documents in the class and the similarity of the original clustering center to the documents in the class is needed. The results of the above calculations are averaged; the clustering center is updated if the average value of the new document is larger, and vice versa; the original clustering center remains unchanged.
This method determines the clustering centers by averaging the weights of all the texts belonging to the same topic. Equation (7) is represented as follows:
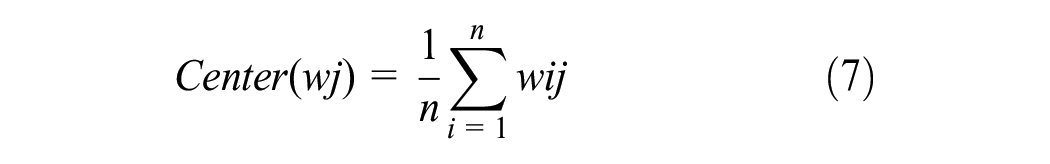
Where the center denotes the jth feature weight of the center vector, wij denotes the jth feature word weight in the ith sentence, and n indicates the number of sentences on a given topic.
When a new sentence is added, the cluster center is adjusted, as shown in equation (8):

where
The proposed improved single-pass model is shown in Figure 4.

Improved single-pass model.
Application of Proposed Method to Case Study of Typhoon Disaster
Preprocessing of Microblog Data
We used web crawling technology to preprocess the data of 18,234 microblogs before and after the occurrence of the typhoon “Fireworks” in 2021 and obtain the microblog corpus for the typhoon disaster. Owing to the characteristics of microblog data, such as repetitive content, high colloquialism, and the abundance of emoticons, it is necessary to clean and sort the prediction database data to standardize the data and thereby improve the effects of analysis and processing and the accuracy of results.
Text Pre-Processing
Removal of Repetitive and Low-Frequency Words
Owing to the unique social networking properties of microblogs, two types of text data on typhoon public opinions were removed. The first included duplicate data formed by forwarding, which greatly affect theme extraction. The other included the words and advertising texts that appeared only once in the text corpus, not significantly contributing to topic classification but reducing the performance of the model.
Text Segmentation
We used the Jieba word splitter to segment the public opinion data of the Typhoon “Fireworks.” The word segmentation results are shown in Figures 5 and 6; the research object of this study is Chinese microblogs, which have been translated into English as follows.

Original text to be divided.

Text segmentation results.
Processing of Emoticons
Since there are many emoticons available for expressing users’ emotions and opinions in microblog text and each one has a special meaning, they need to be translated to expand the diversity of public opinion corpus data on Typhoon “Fireworks” according to the impact to the topic classification. Some examples of emoticons are shown in Figure 7 (Zhu, 2019).

Some microblogging emoticons and their meanings.
Removal of Stop Words and Text Counter Vectorization
Stop words, such as auxiliary verbs, conjunctions, and modal particles, are common words that do not have different semantic meanings. These words appear in almost every text, often together with other words, and form themes. Considering the characteristics of the fragmented and sparse text information on the public opinion of typhoon disasters, there is a list of public opinion stop words from microblogs integrated with the list of commonly used stop words and manually customized stop words related to typhoon disasters. Some of these stop words are shown in Figure 8. The text was vectorized using a counter vectorizer, and the vectorization results are shown in Figure 9.

Partial list of stopping words.

Text counter vectorizer.
Sentiment Analysis
Overall, after preprocessing, 11,817 microblogs remained for sentiment analysis. The statistical results are shown in Figure 10. More than half of the microblogs showed extreme positive emotions regarding the 2021 typhoon “Fireworks,” followed by more than one-fifth showing extreme negative emotions.
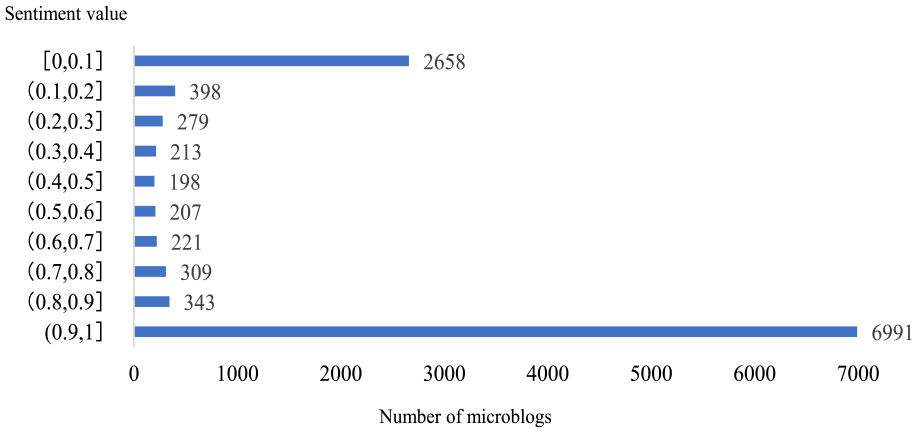
Sentiment analysis on microblog of typhoon “Fireworks” in 2021.
However, with increases in disasters and advancements in disaster relief, the public’s daily sentiments are in a state flux and need to be understood in a timely manner (L. Liu, 2018). In this study, we focused on collecting data when each microblog was released so that these microblogs could be grouped by date, and we could calculate the daily microblog sentiment average; the results are presented in Figure 11. The figure shows that the actual situation exceeded most citizens’ expectations and that the average value of microblog sentiment online is the most negative in Zhoushan City, Zhejiang Province, at 12:30 a.m. on July 25, 2021, despite the weather forecasts. With the Zhoushan government’s efforts toward disaster relief, the microblogging sentiment average gradually increased to over 0.87 on August 06, 2021, which was a rather positive sentiment. However, on August 07, 2021, this average dropped again after the public began reflecting on the measures taken by the government in response to the typhoon, which had a particularly significant impact on their lives. Accordingly, they demanded that the government improve the capacity of emergency response when a natural disaster strikes.
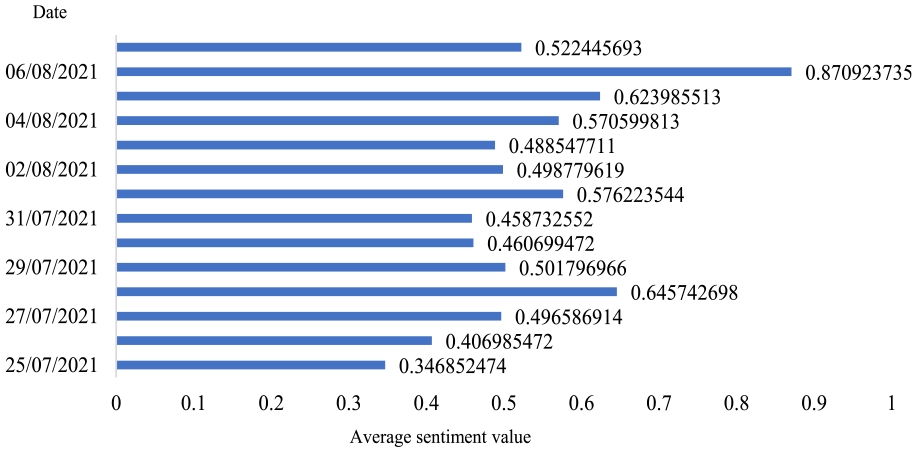
Average value of daily sentiment for typhoon “Fireworks” in 2021.
Topic Clustering Results
In this study, we selected the k-means and DBSCAN algorithms as analogical models for topic clustering to verify the performance of single-pass clustering based on Siamese-BiGRU-attention semantic similarity, and we evaluated the clustering results using external evaluation indicators. The clustering results are listed in Table 1, which shows the proposed model has the highest score among the models for all the external evaluation indicators, clearly showing its effectiveness. The Siamese-BiGRU-attention, a semantic similarity calculation method based on twin networks, was integrated into the single-pass data flow clustering algorithm, which had good applicability. The clustering results under the proposed model before the typhoon made landfall are shown in Figure 12, and the keywords and descriptions of the corresponding clusters are listed in Table 2. The data clustering results after the typhoon made landfall are shown in Figure 13, and the keywords and descriptions of the corresponding clusters are listed in Table 3.
Evaluation of Clustering Performance of Different Models.


Data clustering results before typhoon made landfall.
Keywords and Descriptions of Different Clusters Before the Typhoon Made Landfall.


Data clustering results after the typhoon made landfall.
Keywords and Descriptions of Different Clusters After the Typhoon Made Landfall.

Most text keywords in the class clusters had a clearer topic directivity, excepting those in the life class text clusters where categorizing the corresponding topics was difficult. In this study, we did not select all the microblogs in different class clusters, only choosing the 1,000 microblogs closest to each cluster center because expanding the selection range beyond this may lead to more ambiguous keyword extraction results (Ma & Zhao, 2021).
Based on the above topic clustering result obtained through the proposed sentiment analysis model, the distribution of microblogs with different sentiment attributes in each class cluster was further analyzed. The experimental results are shown in Figures 14 and 15.

Distribution of microblogs with different sentiment attributes in each class cluster before the typhoon made landfall.

Distribution of microblogs with different sentiment attributes in each class cluster after the typhoon made landfall.
Discussion
This study innovatively proposes a single-pass topic clustering model based on Siamese-BiGRU-attention that focuses on the similarity of the actual semantics expressed by different words or sentences, greatly improving upon the existing streaming data clustering method based on twin networks. The proposed method exhibited a better clustering performance than the other clustering methods did. Simultaneously, the Bert-BiGRU-CRF sentiment analysis model was designed using the idea of sequence tagging and combined with the proposed topic clustering method as a new disaster-management method that analyzes the public opinion before and after disasters occur. The topic clustering results before and after the disaster are discussed as follows.
Examinations of the keywords and descriptions of different clusters revealed that before typhoon “Fireworks,” the most popular topics posted by microbloggers included life class text, disaster forecast, disaster influence, nonsense text, disaster warning, and emergency preparedness. In each category cluster, the proportion of positive emotions was greater, excepting the disaster influence category cluster, where the proportion of negative emotions exceeded that of neutral emotions. Additionally, the proportion of neutral emotions in the other category clusters was also higher than that of negative emotions. This indicated that people did not panic too much when the disaster was approaching and that they could meaningfully use disaster-related information and protect themselves accordingly. After the typhoon made landfall, the most popular topics posted by microblog users included life class text, disaster reporting, disaster influence, nonsense text, disaster losses, and disaster relief. Here, the positive sentiment still occupied a larger proportion in each category cluster; the proportion of neutral sentiment was also larger than that of negative sentiment, indicating that people strongly believed in the country’s emergency response capability in the face of natural disasters. There were only slight differences in the concerns of netizens before and after landfall, with them all focusing on the disaster and its social impact. This showed the huge impact and strong social response produced by major natural disasters. Our analysis revealed that certain keywords in clusters could directly correspond to disaster hotspot events or even be in specific affected areas. Analyses of the combination of these keywords could reveal important events and important time points during a disaster and provide people with a certain perception of the overall situation and impact of the disaster.
The method proposed in this study has some limitations, which can be summarized in the following two aspects. First, the proposed method is an improvement on the single-pass model, which belongs to the streaming data clustering category. This method is relatively sensitive to text input order, and the clustering results may differ for similar clustered objects with different input orders. The same clustering object was input in different orders, which will have certain influenced the output result. In future work, the idea of hierarchical clustering and time series will be integrated into the incremental clustering method to improve its robustness to different text input sequences. Second, the proposed topic clustering method is more suitable for short-text clustering (dataset used in this study is Sina Weibo, which mainly includes short text); the performance of this method is affected to a certain degree when applied to long texts, which often have more noise and longer computation times. Further research should be conducted along two directions. First, hierarchical clustering and time series ideas should be integrated into the incremental clustering method to improve its robustness to different text input sequences. Second, long-text similarity calculation methods should be explored and integrated into the topic clustering algorithm. Regarding research on widening applicable cases, if the carrier of the acquired data information changes in different cases, the obtained text type obtained is more complex or the text order is more random, which affects the accuracy of the proposed clustering method. Therefore, in subsequent research, we will focus on improving the applicability of the method to texts of different lengths and reducing the sensitivity of the method to text input order, thereby reducing the uncertainty and sensitivity of this method in different cases.
Conclusion
We combined topic clustering and sentiment analysis to build an AI analysis model that could improve the monitoring of public opinion regarding natural disasters. The contributions of this paper can be summarized in the following two aspects. First, a single-pass topic clustering method based on Siamese-BiGRU-attention that improves the traditional single-pass clustering scheme is proposed. The improved model focuses more on the similarity degree of the actual semantics expressed by different words or sentences and establishes a similarity measure between time series by learning the latent correlation inherent in data. Second, a BERT-BiGRU-CRF sentiment analysis model based on sequence tagging was designed and combined with the proposed topic clustering method. Accordingly, a new method of disaster management that analyzes the public opinion before and after a disaster is proposed. The conducted experiments showed that the single-pass topic clustering model based on Siamese-BiGRU-attention outperformed other mainstream clustering models, such as K-means and DBSCAN, in clustering performance. In general, the proposed method can provide reference for the standardization and operation of the public opinion analysis belongs to natural disaster under the background of AI technology, and help rescue workers and governmental officials to grasp the trend of public opinion in time. When considering limitations of the proposed method, which are the robustness of the text input order and the applicability of the topic clustering model to different types of texts, we made the following conclusions. In future studies, we believe that integrating hierarchical clustering and time-series ideas into the incremental clustering method can improve the robustness of the proposed method to input text order. Additionally, we plan to explore long-text topic clustering techniques and determine how they can be applied to the proposed clustering method to improve its applicability to texts of different sizes.
Footnotes
Acknowledgements
I am thankful to Xie Kefan, Professor in the School of Management, Wuhan University of Technology, China, for his excellent supervision and support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics Statement
This research is not for animal and human studies. It is used in the field of public opinion monitoring.