
Abstract
Multidimensional (MD) analysis contributes to a comprehensive linguistic description of second language (L2) writing texts. However, cross-linguistic studies based on MD analysis are still insufficient and need to be increased. In particular, the unavailability of comparable corpora prevents current MD-based L2 writing research from making reliable comparisons of linguistic differences between native writers and L2 learners. Considering these, this study adopts corpora of maximum similarity for the cross-linguistic comparative analysis. Using Biber’s MD analysis, this study compares linguistic differences between native English writers and Chinese English learners in argumentative essays with similar communicative purposes. The analysis reveals that the two groups of texts show significant differences in slightly over half of the individual linguistic features but share more similarities than differences in textual dimensions. It also shows that the two groups are, in fact, different varieties of English language use, even though they share a similar text type of “involved persuasion.” The results confirm the importance of comparable corpora for cross-linguistic comparisons and the necessity of MD analysis for understanding L2 writing.
Introduction
Multidimensional (MD) analysis, also known as multi-feature multi-dimensional analysis (Biber, 1988), is a methodological approach to analyzing linguistic variation across registers (i.e., different situational contexts and communicative purposes) (Biber & Conrad, 2009). This approach integrates corpus linguistics and advanced statistical methods to identify clusters of co-occurring linguistic features and describe linguistic variation (Biber & Conrad, 2013). In contrast to other linguistic analyses (i.e., analyses of individual linguistic features and analyses of a set of features with similar textual functions or indicative of linguistic complexity), MD analysis provides a relatively comprehensive profile of a given text, register, or genre in terms of textual dimensions underlying linguistic co-occurrence patterns (Biber, 2014). As such, it has received increasing attention from researchers interested in descriptive and applied linguistics (cf. Biber, 2014; Conrad & Biber, 2013a).
The past two decades have witnessed a surge of interest in L2 writing research based on MD analysis. Studies have investigated language use and its variation in various situational contexts, such as registers or genres (e.g., Asención-Delaney, 2014; Goulart, 2021; Hardy & Friginal, 2016; Larsson et al., 2021), English proficiency (e.g., Kim & Nam, 2019; Pan, 2018), writing quality (e.g., Friginal et al., 2014; Jarviset al., 2003), writing tasks (e.g., Biber et al., 2016), and writing topics or prompts (e.g., Weigle & Friginal, 2015). Systematical cross-linguistic comparisons have also been considered in such studies (e.g., Abdulaziz et al., 2016; Cao & Xiao, 2013; Crosthwaite, 2016; van Rooy, 2008; van Rooy & Terblanche, 2009; Weigle & Friginal, 2015; Zhao & Wang, 2017). They reveal linguistic similarities and differences between writers from different L1 backgrounds, mainly native (L1) and non-native (L2) writers of English, providing significant implications for identifying linguistic features of L2 writing and understanding how L2 writers differ from native writers in their use of these features.
Although some cross-linguistic comparisons of L2 writing for research and publication purposes exist (e.g., Cao & Xiao, 2013; Crosthwaite, 2016; Pan, 2018; Weigle & Friginal, 2015), studies comparing linguistic differences between L2 learners’ and native spearkers’ writing remain insufficient and thus need to be increased. Moreover, such studies seem to rely more on corpora built in different writing contexts and for different purposes (e.g., van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017), possibly due to the unavailability of comparable corpora, that is, corpora of maximum similarity (Moreno, 2008). For example, the corpora of native writers and L2 learners used in previous studies were not equivalent in writing topics, time constraints, and text lengths. However, these factors are essential in contrastive interlanguage analysis (CIA) (Ishikawa, 2013). This inequivalence may lead to more differences than similarities observed between different L1 writing groups (e.g., van Rooy, 2008; Zhao & Wang, 2017). Likewise, this has led to the difficulty for related studies to explain confounding variables and even to provide reliable results (Moreno, 2008).
The two research gaps deserve further exploration. First, MD analysis contributes to a comprehensive linguistic description of learner writing (Biber, 2014; Biber et al., 2016). Second, for cross-linguistic comparisons, the use of comparable corpora is more reliable (Moreno, 2008). This study addresses these gaps to verify whether language differences in cross-linguistic MD analyses are related to uncontrolled writing variables. It uses a text corpus for CIA to compare language differences between native writers and non-native learners (i.e., Chinese English learners). This study will provide a reliable description of the linguistic features and functional dimensions of L2 learner writing and help to understand the differences between L2 learners and native writers in these two dimensions.
Literature Review
This section reviews multidimensional analysis (Biber, 1988) and MD-based L2 writing research, with a focus on cross-linguistic studies based on the 1988 MD analysis. It highlights the need to apply multidimensional analysis in L2 writing research, identifies current research gaps, and points out the importance of comparable corpora for cross-linguistic comparisons.
Multidimensional Analysis
Multidimensional analysis was originally proposed by American corpus linguist Douglas Biber in 1988 to describe the linguistic variation between spoken and written English registers. The corpus analyzed in the 1988 MD analysis consisted of 481 contemporary spoken and written texts in British English, sampled from 23 register categories, including 15 from the Lancaster-Oslo-Bergen Corpus and 8 from the London-Lund Corpus of Spoken English. The linguistic features (i.e., lexical, grammatical, syntactic, and rhetorical features) involved in this analysis are those used by speakers and writers to construct and realize different texts or discourses in a given context of language use. Based on the theoretical assumption that linguistic features co-occur in texts to achieve potential communicative functions, Biber extracted a seven-factor solution from 67 linguistic features through factor analysis to determine register variation dimensions (Biber, 1988, Chaps. 4 & 5; Biber, 1995, Chap. 5). According to Biber (1988), the first six factors (i.e., functional dimensions) have strong factor structures and the features clustered on each factor are functionally consistent and easily interpreted as dimensions of register variation. As shown in Table 1, these six factors are (1) Involved versus Informational Production; (2) Narrative versus Non-Narrative Concerns; (3) Explicit versus Situation-Dependent Reference; (4) Overt Expression of Persuasion; (5) Abstract versus Non-Abstract Information; and (6) On-Line Informational Elaboration. Table 1 also lists the descriptions of each dimension and the linguistic features in which they co-occur.
Descriptions and Summary of the Six Dimensions for MD Analysis (Biber, 1988) (Adapted from Nini, 2019).

The 1988 MD Analysis, built on a large text corpus and multiple linguistic features, has been widely used as a valid and comprehensive framework for register variation analysis in various domains (Biber & Conrad, 2013; Conrad & Biber, 2013b). First, studies based on this framework do not require the selection of new linguistic features for new factor analyses. Second, they do not need to interpret corresponding variation dimensions according to specific contexts. Third, by mapping the new corpus onto this framework, researchers can compare the new register with the established English ones (Nini, 2019). It is worth noting that another type of MD-based research exists, namely, studies that conduct new MD analyses. This type of research entails selecting new linguistic features, conducting factor analysis, interpreting potential functional dimensions, and comparing new registers (Conrad & Biber, 2013b).
The registers examined in current MD-based studies are at different levels of specificity, depending on the definition of textual units and the depth of analysis of situational parameters (Biber, 2014; Egbert & Gracheva, 2023; Goulart et al., 2020). As a relatively specialized register, L2 writing has been studied in a variety of situational contexts to differentiate sub-registers of learner writing (e.g., Abdulaziz et al., 2016; Biber et al., 2016; Biber & Gray, 2013; Cao & Xiao, 2013; Friginal et al., 2014; Friginal & Weigle, 2014; Jarvis et al., 2003; Pan, 2018; Ren & Lu, 2021; van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017). Although inadequate, these studies suggest that MD analysis is a powerful method for investigating the linguistic characteristics of L2 writing in different contexts.
Multidimensional Analysis Research in L2 Writing
Language and its use have long been at the forefront of L2 writing research, instruction, and assessment (e.g., Bulté & Housen, 2014; Crossley, 2020; Taguchi et al., 2013). To this end, many comparative and quantitative studies have examined the linguistic features of L2 writing in different contexts through different linguistic analyses. Relevant studies have been conducted mainly through the analysis of individual linguistic features (e.g., Ferris, 1994; Grant & Ginther, 2000; Hinkel, 2002; Lee et al., 2021) and the analysis of groups of linguistic features that have specific rhetorical functions or indicate linguistic complexity (e.g., Jiang, 2015; Larsson & Kaatari, 2020; Parkinson & Musgrave, 2014; Petch-Tyson, 1998; Zhang & Lu, 2022; Zhang & Zhan, 2020). However, over the past two decades, MD analysis has attracted growing attention from L2 writing research because it provides a relatively comprehensive description of textual features in terms of linguistic features and functional dimensions (Jarvis et al., 2003).
MD-based L2 writing research examines language use and its variation in relation to various factors, such as registers or genres (e.g., Asención-Delaney, 2014; Goulart, 2021; Hardy & Friginal, 2016; Larsson et al., 2021); English proficiency (e.g., Kim & Nam, 2019; Pan, 2018), writing quality (e.g., Friginal et al., 2014; Jarvis et al., 2003), writing tasks (e.g., Biber et al., 2016), and writing topics or prompts (e.g., Weigle & Friginal, 2015). Among these studies, cross-linguistic comparisons, although few, are one of the frequently studied areas (e.g., Abdulaziz et al., 2016; Cao & Xiao, 2013; Crosthwaite, 2016; Goulart, 2021; Pan, 2012, 2018; van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017). Research along this line generally falls into two streams. One strand of research focuses on linguistic variation in English academic writing for research and publication purposes (e.g., Cao & Xiao, 2013; Crosthwaite, 2016; Friginal & Weigle, 2014; Pan, 2018). The other strand centers on learner writing for general purposes (e.g., Abdulaziz et al., 2016; Goulart, 2021; Pan, 2012; van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017). This division highlights the need to improve research on learner writing; otherwise, there will be insufficient knowledge about the linguistic characteristics of L2 learner writing. In addition, as insightful as studies on writing for research and publication purposes may be in understanding textual variation across different L1 backgrounds, their findings cannot be indicative of L2 learner writing.
In the case of cross-linguistic studies on L2 learner writing, they have mainly compared the writing of English native writers with that of non-native learners, with or without considering additional variables (e.g., Abdulaziz et al., 2016; Goulart, 2021; Pan, 2012, 2018; van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017). For example, in a comparative analysis of Brazilian English learners’ and native learners’ language use in 11 registers, Goulart (2021) found more similarities but fewer differences between the two writer groups on most functional dimensions. She illustrated that group similarities stem from common communicative purposes in most registers. However, their differences were due to their different interpretation of the communicative purposes associated with particular registers (i.e., case studies, designs, exercises, and research reports). This study indicates that for linguistic differences between L1 writers, it is not necessarily L1 background that matters, but the registers and writers’ interpretation of registers. Pan (2012) is a typical example of a comparison of language differences between native writers and Chinese English learners involving various factors, such as genres and learner proficiency. She utilized a corpus that includes native writers’ essays (i.e., the Louvain Corpus of Native English Student Essays, LOCNESS) and Chinese English learners’ texts in two genres produced by learners of two proficiency levels. She concluded that the Chinese learner corpus differs from the native writer corpus in all five dimensions of the 1988 MD analysis she examined. Although the researcher compared the internal differences of each Chinese learner corpus, the cross-linguistic differences could not be attributed to language background.
In contrast to the above cross-linguistic studies involving more variables, other studies only compare linguistic differences between the writing of English native writers and that of non-native learners. For example, in a comparative analysis of student writing between the Tswana Learner English Corpus (TLEC) and LOCNESS, van Rooy (2008) observed significant differences between the two groups in 39 linguistic features and four functional dimensions. Zhao and Wang (2017) compared the corpus of Chinese English learners’ writing (WECCL) and LOCNESS. They found that the two writing groups significantly differed in all six dimensions and 57 linguistic features (more than 87% of 67 features). Based on the 1988 MD analysis, this pair of studies each reported more differences than similarities between L1 groups in linguistic features and textual dimensions. These findings may be related to the corpus they used. Specifically, the corpora used in these comparative studies were designed for different communicative purposes in different writing conditions. For example, they did not effectively control over factors such as writing topics, text length, and time constraints between corpora, possibly due to the unavailability of comparable corpora.
Previous research may need to pay more attention to writing specificity that can only be identified in texts produced under strict situational conditions (Ishikawa, 2013) and for specific communicative purposes (Biber, 2012; Biber & Conrad, 2009). First, research has identified those factors that affect language use in L1 and L2 writing, such as registers or genres (e.g., Goulart, 2021; Larsson et al., 2021; Larsson & Kaatari, 2020; Staples & Reppen, 2016), writing topics or prompts (e.g., Sarte & Gnevsheva, 2022; Weigle & Friginal, 2015; Yang et al., 2015; Yoon, 2017). Moreover, controlling writing conditions, such as text length and time constraints, is crucial for the CIA (Ishikawa, 2013). In addition, language varies depending on communicative purposes (Biber, 2012; Biber & Conrad, 2009). Taken together, as Moreno (2008) stated, “if corpora are not selected carefully, it will be more difficult to determine which contextual factor is responsible for the possible differences” in cross-linguistic research (p. 39). For these reasons, corpora of maximum similarity are crucial for cross-linguistic research. Based on the 1988 MD analysis framework, the present study seeks to expand current cross-linguistic comparisons by using corpora of texts produced in similar writing contexts (e.g., writing genres, writing topics, writing situations) and with similar writing purposes. With this study, it is possible to verify whether linguistic differences in previous cross-linguistic MD analyses are due to uncontrolled writing variables in the corpora under study. It is also possible to identify typical linguistic and functional features of L2 learner writing and provide significant implications for L2 writing research and pedagogy.
Methodology
This study compares the linguistic differences between L1 and L2 writing produced in similar writing contexts (e.g., genres, writing topics, writing situations) and with similar writing purposes. Based on Biber’s (1988) multidimensional analysis, the goals of this paper are trifold, (1) to reveal the differences between L1 and L2 writing in terms of individual linguistic features, (2) to reveal their differences in terms of textual dimensions, and (3) to describe their overall textual features.
Research Questions
Specifically, this study addresses the following three research questions:
What are the significant differences in linguistic features between L1 writing and L2 writing?
What are the significant differences in textual dimensions between the two groups of writing?
What are the overall characteristics of L2 writing, in comparison with L1 writing and other sampled registers investigated in Biber (1988)?
Data
The study is based on a corpus of English argumentative essays, including 162 texts by English native writers (ENS) and 338 by Chinese English learners (CEL) (see Table 2). These texts were sampled from the Written Essay 2.4 module of the International Corpus Network of Asian Learners of English (ICNALE), a learner corpus for CIA (Ishikawa, 2013).
Details of Corpora for English Native Writers and Chinese English Learners.

The texts were carefully controlled to ensure maximum similarity between ENS and CEL. First, they were sampled from the corpus for CIA and completed under identical writing conditions, such as time constraints, text lengths, and writing environment (Ishikawa, 2013). Second, to avoid potential linguistic differences caused by writing topics (e.g., Sarte & Gnevsheva, 2022; Weigle & Friginal, 2015; Yang et al., 2015; Yoon, 2017), these texts had the same topic (i.e., It is important for college students to have a part-time job). Third, to ensure maximum homogeneity in writing purposes, they were all one-sided arguments, that is, either for or against the viewpoint. For example, an essay supporting the view should demonstrate the importance of students taking a part-time job.
Two points are worth noting. The first is the different levels of English proficiency of the writers. Research has shown that advanced L2 writers have limited language reserves and limited access to linguistic devices in time-critical writing tasks compared to native writers (Hinkel, 2002). Moreover, even native writers have different proficiency. The native writers in this study are no exception, although ICNALE does not assess their level. In this sense, not controlling for L2 learner proficiency provides better diversity and makes their writing more representative, as is shown in previous cross-linguistic comparisons (e.g., Ai & Lu, 2013; Lan et al., 2022). The other is the imbalance in the number of essays between the two corpora. This imbalance does not influence the research results for the following reasons. First, the frequency counts of all linguistic features are autonomously normalized in the data analysis. Second, many MD studies use such unbalanced corpora (e.g., Biber, 1988; Biber & Gray, 2013). In addition, based on the 1988 MD analysis, this study does not require factor analysis but instead plots CEL and ENS on the previously identified dimensions. Most importantly, the analysis is completed using the Multidimensional Analysis Tagger (Nini, 2015) (see Section 3.3 below).
Overall, the corpora used in this study are better controlled between writing groups than those used previously.
Multidimensional Analysis Tagger
In this study, the Multidimensional Analysis Tagger (MAT) version 1.3 (Nini, 2015) was used for the MD analysis, as MAT successfully replicated Biber’s (1988) analysis (Nini, 2015). It works on the principle of how a new register is different or similar to other English registers (Biber, 1988) but without the need to extract new dimensions for the register(s) under study. MAT provides the overall register features of the newly investigated text and corpus, the normalized frequency per 100 words of each tagged feature, the z-scores of 67 linguistic features, and the six dimensions of each text and corpus (Nini, 2015, 2019).
Except for its reliability in analyzing English native texts from LOB and Brown corpora in Nini (2015), the reliability of MAT is high for non-native learners’ texts. On the one hand, current probability-based or rule-based POS taggers can provide 96 to 97% tagging accuracy for L2 learners’ texts, comparable to that for English native speakers (Liang, 2006). The Stanford tagger, on which MAT relies, is one of the most widely used accurate taggers available (Crosthwaite, 2016). It ensures tagging accuracy in the MAT tagger and subsequent statistics on textual dimensions and linguistic features. On the other hand, it has been used practically for L2 learners’ writing (e.g., Crosthwaite, 2016; Kim & Nam, 2019; Zhao & Wang, 2017).
Considering the relatively short text lengths of 200 to 300 words, in this study, 100 tokens were used to calculate the type-token ratio during the MAT analysis. In addition, a z-score correction was used to calculate the dimension scores as it can help short texts avoid the problem of infrequent variables affecting the overall dimension scores. Furthermore, the size and diversity of the corpora currently under study are not an issue in this MD analysis, as MAT does not produce exploratory factor analysis but rather maps new corpora on the given dimensions studied in Biber (1988). Finally, after MAT completed the annotation and analysis of both corpora, the statistics of all linguistic features and dimensions were exported to Excel 2019 and SPSS 25.0 for further statistical analysis.
Results
After the statistical analysis of the data MAT 1.3 generated, all the results are as below:
Comparison of Linguistic Features Between L1 Writing and L2 Writing
Using the z-scores of the 67 linguistic features, a non-parametric Mann-Whitney U-test was performed to identify the differences in individual linguistic features between ENS and CEL. Table 3 shows the means, standard deviations and Z values for linguistic features. As can be seen, 37 (of the 67 linguistic features) were statistically different, accounting for 55% of the linguistic variance between the two groups. Specifically, ENS had 22 features with higher scores but 15 with lower scores than CEL.
Means of Linguistic Features and Results of Mann-Whitney U-Test against Each Dimension.

Note. Linguistic features in square bracket are negative features on the dimensions, and the others are positive ones; M in bold marks the larger mean between ENS and CEL.
p < .05 (2-tailed). *** p < .001 (2-tailed).
Regarding the linguistic features on dimension 1, 19 features showed significant differences between ENS and CEL, accounting for 56% of the linguistic variance among the 34 features that co-occurred on this dimension (Biber, 1988). Of the 16 positive features, CEL used significantly fewer “demonstrative pronouns,” “causative subordinators,” “amplifiers,” “non-phrasal coordinations,” “adverbs,” and “conditional subordinators,” but significantly more “1st and 2nd personal pronouns,” “do as pro-verb,” “discourse particles,” “hedges,” “sentence relatives,” “possibility modals,” “direct WH-clauses,” “WH-questions,” and “contractions”) than ENS. For the negative features, CEL had significantly fewer “total prepositional phrases” and a lower “type-token ratio” but more “nouns.” For the other features on the left dimensions, CEL had significantly more “present participial clauses” (dimension 2), “time adverbials” (dimension 3), “necessity modals” (dimension 4), and “conjuncts” (dimension 5) but fewer “past tense verbs,” “3rd personal pronouns,” “perfect aspect verbs,” “public verbs” (dimension 2), “WH relative clauses on subject position,” “nominalizations” (dimension 3), “infinitives,” “prediction modals,” “suasive verbs,” “split auxiliaries” (dimension 4), “other adverbial subordinators” (dimension 5), “demonstratives,” “that relative clauses on subject positions” and “that clauses as verb complements” (dimension 6) than ENS.
Comparison of Textual Dimensions Between L1 Writing and L2 Writing
Table 4 shows the means and standard deviations for both corpora and the results of the textual dimension variances between the corpora via a Non-parametric Mann-Whitney U test. ENS and CEL had insignificant differences on dimensions 1 (Z = −0. 374, p > .05), 2 (Z = −1.498, p > .05), 3 (Z = −1.388, p > .05), and 5 (Z = −0.146, p > .05). Both corpora had positive scores on dimensions 1, 3, and 5, but they were manifested differently. That is, CEL had a higher score on involved production (M = 6.89) but lower on explicit reference (M = 2.24) and abstract information (M = 1.33) than ENS. In contrast to the above manifestations, both corpora had negative scores on dimension 2, with the dimension score of CEL (M = −2.33) being lower than that of ENS (M = −1.82).
Dimension Means for Both Corpora and Results of Mann-Whitney U-test.

p < .05 (2-tailed). *** p < .001 (2-tailed).
ENS and CEL showed significant differences in dimensions 4 (Z = −3.005, p < .05) and 6 (Z = −3.844, p < .001). Both corpora showed overt expressions of persuasion on dimension 4, but CEL (M = 3.90) was significantly less overtly persuasive than ENS (M = 6.94). On dimension 6, ENS (M = 0.95) scored significantly higher than CEL (M = −1.12), showing the opposite discourse characteristic. A stepwise regression analysis was conducted to further identify the linguistic features that determine group differences in these two dimensions. As Table 5 shows, “prediction modals” (β = −.191) and “suasive verbs” (β = .162) had significant influences on dimension 4 for ENS (R2 = 0.051), explaining 5.1% of the dimension variance, while “split auxiliaries” (β = −.133) and “necessity modals” (β = .110) had significant influences on dimension 4 for CEL (R2 = 0.033), accounting for 3.3% of the dimension variance. Table 5 also shows that “that relative clause on object positions” was the only predictor that negatively influenced dimension 6 for CEL (R2 = 0.015, β = −.121).
Stepwise Regression Models of Linguistic Features against Dimensions.
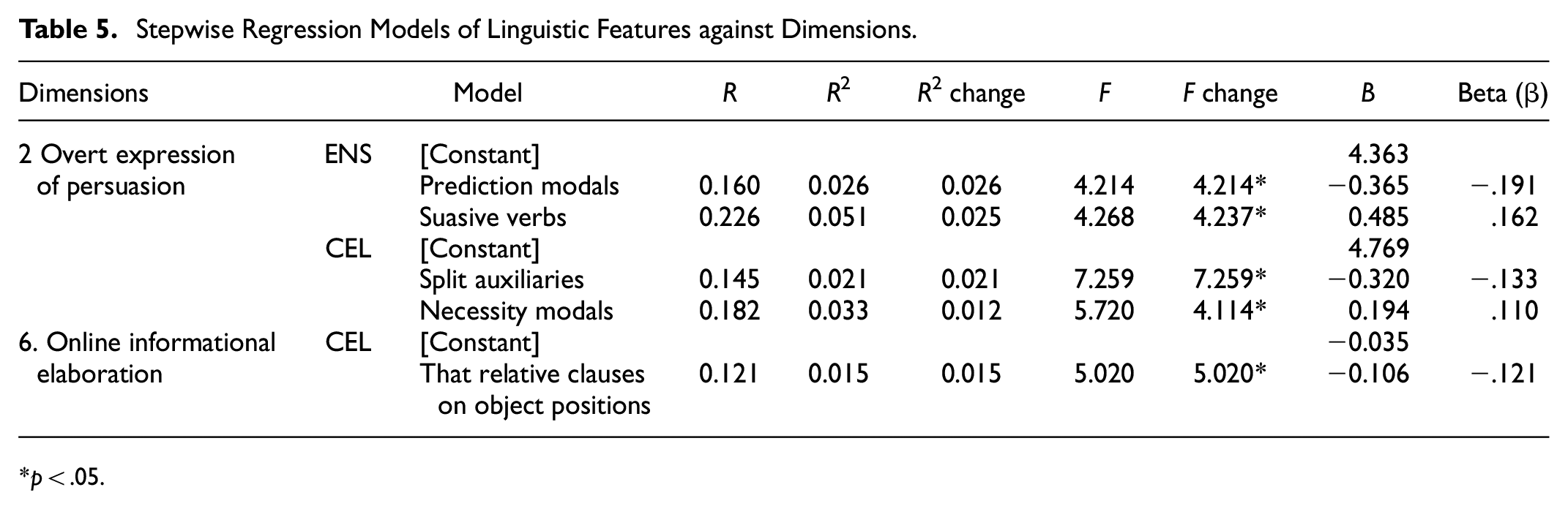
p < .05.
Comparison of Register Characteristics Between L1 Writing and L2 Writing
As can be seen from the dimension statistics produced in the MAT results, ENS and CEL resembled the “involved persuasion” text type, with high scores on dimension 1 (M = 5.69 for ENS, M = 6.89 for CEL) and dimension 4 (M = 6.94 for ENS, M = 3.90 for CEL).
Table 6 presents the mean scores of all six dimensions for ENS and CEL and those for comparable registers selected from Biber (1988). ENS and CEL were closer to prepared speech on dimension 1, academic prose on dimension 2, personal letters on dimension 4, and press reportage on dimension 5. However, they differed on dimensions 3 and 6, where CEL was closer to prepared speech on dimension 3 and broadcast on dimension 6, and ENS was closer to academic prose on both dimensions.
Dimension Means for ENS, CEL, and Others from Biber (1988).

Note. AcaW = academic writing; PreP = prepared speech; PerL = personal Letters; PresR = press reportage; BroC = broadcast.
Discussion
This analysis revealed significant findings regarding the similarities and differences between the writing of native English speakers and Chinese English learners in terms of individual linguistic features, textual dimensions, and overall registers characteristics through multidimensional analysis. This section summarizes the main findings and discusses them in the light of relevant previous studies on linguistic analysis, particularly MD-based analysis, and qualitative analysis.
Differences in Linguistic Features Between L1 Writing and L2 Writing
This analysis revealed some similarities but significantly more differences in linguistic features between L1 and L2 writing, indicating the usefulness of considering multiple linguistic features in the comparative analysis. This analysis also revealed consistency and variation in language use along textual dimensions, indicating the need to pay attention to linguistic co-occurrence patterns when understanding the language used in L1 and L2 writing.
A total of 37 features out of all the 67 linguistic features showed significant differences, indicating that 55% of the differences in language use between native writers and Chinese English learners were significant when writing identical genres for similar writing topics and purposes. Compared with previous studies based on the 1988 MD analysis framework, such as 68% between TLE and LOCNESS in van Rooy (2008) and 85% between TECCL and LOCNESS in Zhao and Wang (2017), this study presented a relatively lower percentage of linguistic variances among the same 67 features between L1 and L2 writing. The inconsistencies in the linguistic variances of these studies could be the result of different controls on the writing conditions of the corpora, that is, the extent to which the corpora are similar. If this is the case, studies based on comparable corpora may find more similarities than differences in language use, as in this study. Other linguistic studies also support the importance of using comparable corpora for comparative research. For example, research has consistently found that writing topics or prompts influence language use in writing produced by writers from different cultural and linguistic backgrounds. In particular, L2 learners’ writing is more susceptible to topic effects (e.g., Sarte & Gnevsheva, 2022; Weigle & Friginal, 2015; Yang et al., 2015; Yoon, 2017). Moreover, research has also demonstrated that other factors, such as genre or register, influence language use in L2 writing, even for the same topic (e.g., Hardy & Friginal, 2016; Qin & Uccelli, 2020). In this regard, it is understandable that this study (among the current cross-linguistic studies based on the 1988 MD analysis) found the slightest differences in language differences, as all texts from both corpora used in this study were of the same genre for the same topic and communicative purposes.
Textual functions of linguistic features lead to specific language use (Biber et al., 1999). On the dimension of Involved vs. Informational Production, linguistic features, such as “1st and 2nd personal pronouns,” “possibility modals,” “contractions,” altogether showed oral involved production, while others, such as “prepositional phrases,” “nouns,” and “type-token ratio,” showed a written informational focus (Biber, 1988, pp. 104–108). In this sense, the linguistic manifestations of the two corpora implied that CEL resembled involved writing more than ENS. For example, CEL used significantly more “1st and 2nd personal pronouns” (e.g., I, we, you), “possibility modals” (e.g., can, may, could), “contractions” (e.g., can’t, shouldn’t, isn’t), but lower “type-token ratio” than ENS. Previous cross-linguistic studies have reported similar findings regarding interpersonal involvement and writer/reader visibility in learners’ writing. For example, van Rooy and Terblanche (2006) found that Tswana learners’ English writing was less formal and more colloquial, as they used the features of involvement 20% more often than native writers. In analyzing the linguistic features that mark writer/reader visibility in EFL learners’ writing, Petch-Tyson (1998) found that L2 learners used more features of writer visibility in their writing and that learners from different L1 backgrounds manifest them differently. In other words, L2 learners’ writing is much more involved than that of native speakers, and different linguistic features are used to express personal feelings and attitudes. For example, Swedish English learners prefer first-person plurals, while Finnish learners use first-person singulars most often (Petch-Tyson, 1998).
The description of past events depends heavily on the features of “past tense verbs,” “3rd personal pronouns,” “perfect aspect verbs,” “public verbs,” and “present participial clauses” (Biber, 1988). A qualitative check on the corpora showed that native writers used more “past tense verbs” (e.g., did, experienced, led, needed, gained), “3rd personal pronouns” (e.g., he, she), “perfect aspect verbs” (e.g., have been done/ earned/ learned/made), and “public verbs” (e.g., agree, say, admit, assert). In contrast, Chinese English learners relied more on “present participial clauses,” such as having/ taking a (part-time) job is/can, having/taking a job, we/you can … For this reason, native speakers’ writing was more narrative than that of Chinese English learners. Example 1, taken from the corpus of English native writers, illustrates how they used past tense words (italicized) to recount a personal experience.
This finding is largely consistent with that of Zhao and Wang (2017), which found that native writers used more public verbs, past tense verbs, and perfect aspect verbs, while Chinese English learners used more negations, present tense verbs, and third personal pronouns. To some extent, this difference in using linguistic features that characterize narration between native English writers and Chinese English learners may be due to their respective rhetorical traditions, that is, Confucian rhetoric and Aristotelian approach (Hinkel, 2002; Liu & Huang, 2021). This difference may also be due to the lack of a morphological system for marking tenses and aspects in Chinese. Therefore, it is challenging for Chinese English learners to acquire and use these reflectional forms of verbs appropriately (Hinkel, 2002, 2009). Meanwhile, learners may intentionally avoid using the reflectional forms in order to avoid making mistakes (Zhao & Wang, 2017).
“Nominalization,” “WH relative clauses on subject position,” and “time adverbials” can distinguish texts with explicit or situation-dependent reference (Biber, 1988). Native writers used more features indicating explicit discourses, whereas Chinese English learners relied more on those marking situations. Specifically, native writers used more “nominalization,” such as graduation, happiness, occupation, situation, to expand their idea and integrate more information (Biber, 1988). They also used more “WH relative clauses on subject position,” such as students who devote much time to…, many problems which led to … to show explicit and elaborate identification of person, job, and other substances (Biber et al., 1999). Instead, Chinese English learners relied more on “time adverbials” to indicate temporal situations, such as after, now, once, today.
Features of “infinitives,” “prediction modals,” “suasive verbs,” “necessity modals,” and “split auxiliaries” characterize overt persuasiveness (Biber, 1988). A qualitative check of ENS showed that native writers used significantly more “prediction modals” (e.g., will, would, shall, won’t, ’d), “suasive verbs” (e.g., agree, disagree, ask, intend, suggest), and “split auxiliaries” (e.g., should be highly recommended, can be easily ruined, do not know, can be done easily). Similar to van Rooy (2008), native writers used more linguistic features that mark overt persuasion.
“Conjuncts,” “agentless passives,” “past participial clauses,” “WHIZ deletion relatives,” and “other adverbial subordinators” showed abstract, technical, and formal discourse (Biber, 1988). A qualitative study of both corpora was conducted to identify further the linguistic devices used in L1 and L2 writing to mark similar discourse. It was found that native writers primarily relied on “other adverbial subordinators,” such as since, while, whereas, as/so long as, to mark the logical relations between clauses, while Chinese English learners used more “conjuncts,” such as hence, however, furthermore, moreover, therefore, thus. Moreover, discourses of informational elaboration under strict time constraints are frequently represented with “demonstratives,” “that relative clauses on object positions,” and “that clauses as verb complements” (Biber, 1988). Example 2, taken from ENS, shows how often native writers used linguistic features, particularly “that verb complement” (italicized), to express stance or thoughts in real-time writing conditions. Since the verbs preceding that clause (i.e., think, thought, found, say, believe) are used more often in speech (Biber et al., 1999), the use of these features was consistent with those expressing involvement. Overall, L1 writers used significantly more features marking informational elaboration than Chinese English learners.
Differences in Textual Dimensions Between L1 Writing and L2 Writing
Under the control of similar writing conditions for both corpora, this study found more similarities than significant differences between L1 and L2 writing in terms of textual dimensions of linguistic co-occurrence. However, this finding is inconsistent with previous cross-linguistic studies based on the 1988 MD analysis, which consistently found more differences than similarities (e.g., van Rooy, 2008; Zhao & Wang, 2017). This inconsistency in the findings of textual dimensions may be due to the lack of control over the writing conditions. For example, writing topics and purposes influencing language use are not controlled in previous studies (e.g., van Rooy, 2008; Zhao & Wang, 2017).
In terms of the similar dimension distributions for both corpora, that is, on the positive sides of dimensions 1, 3, 4, and 5 and negative side of dimension 2, this study showed that L1 and L2 argumentative essays were, in nature, involved, persuasive, context-independent, abstract but narrative. This finding further illustrates that using comparable corpora is essential for any cross-linguistic comparative studies; only in this way can the similarities and differences between L1 groups be identified and explained reliably (Moreno, 2008). Another noticeable finding was that most dimension scores of ENS were higher than those of CEL, except dimension 1, indicating that ENS was more informatively persuasive than CEL, with more technical and elaborate information conveyed through narration and explicit reference in the timed conditions. In terms of involved or informational focus, native speakers’ writing was less involved but more informational than that of Chinese English learners. This finding is consistent with research on Chinese English learners’ argumentative writing in different contexts (e.g., Pan, 2012; Zhao & Wang, 2017), which indicates that Chinese English learners’ argumentative writing is characterized by involvedness regardless of the writing conditions. It is also congruent with studies regarding involvement and writer/reader visibility in argumentative essays (e.g., Petch-Tyson, 1998; van Rooy & Terblanche, 2006).
A closer look at the dimension scores for the two corpora reveals significant differences between ENS and CEL on dimensions 4 and 6. Although both were overtly persuasive, the persuasiveness of ENS was significantly more overt than that of CEL. This finding is opposite to that of Zhao and Wang (2017). One possible reason for the finding difference is the writing conditions for L1 and L2 writing rather than cultural or language differences. Although both studies compared the argumentative texts of native writers and Chinese English learners, they differed in the extent to which the corpora they used were equivalent. Compared with Zhao and Wang (2017), which relied on learner corpora (i.e., WECCL and LOCNESS) of texts produced under different writing conditions, this study used corpora developed for CIA (Ishikawa, 2013). In addition, it controlled the writing purposes (i.e., texts with one-sided discussions). Therefore, these findings may be more appropriate for understanding the cross-linguistic differences.
Furthermore, the significant difference on dimension 4 may correspond to their respective approaches to persuasion. Chinese English learners prefer to use authority and present the known truths to present their propositions and opinions. In contrast, native writers tend to express personal goals and viewpoints to validate their opinions and propositions (Hinkel, 2002). Examples 3 and 4, typical argument texts written to persuade readers show how writers from different rhetorical traditions support their arguments about the importance of taking a part-time job. Example 3, taken from CEL, shows that Chinese learners tend to benefit their readers by describing the facts from a third party’s point of view, whereas example 4, taken from ENS, shows that native writers prefer to share their ideas and experience to persuade their readers.
This line of difference between English and Chinese writing largely echoes Liu and Huang (2021) regarding how Chinese writers develop their expository paragraphs. They reported that Chinese learners’ writing prefers to quote authorities, stories, and the words of famous people and books to promote their trustworthiness, moderate their tone, and convey their voice less directly in their writing.
The significant difference in dimension 6 between L1 and L2 writing might result from the nativeness. Compared with L2 learners, native writers have a richer lexical and syntactic repertoire, making their writing more explicit and sophisticated. They primarily use features prevalent in written or informational discourse (Hinkel, 2002). Moreover, native writers used a larger number of syntactic structures, such as “that clauses as verb complements” and “that relative clauses on subject positions” which are often used for “informational elaboration under real-time production constraints” (Biber, 1988, p. 113). Thus, native speakers’ writing was more informational than Chinese English learners’ under the strict real-time constraints. They also used these features to express personal opinions, attitudes, or statements (Biber et al., 1999). The finding regarding the more use of these features in L1 writing suggests that L1 writing also involves the explicit marking of personal stances, thus echoing the finding that native speakers’ writing was more overtly persuasive on dimension 4. Consequently, it can be concluded that writing texts that express personal stances or attitudes also require informational elaboration under real-time constraints and vice versa.
Overall Register Characteristics of L1 Writing and L2 Writing
Overall, ENS and CEL are closer to involved persuasion (Biber, 1988), displaying the involved and persuasive nature of argumentative writing (Pan, 2012; van Rooy, 2008; Zhao & Wang, 2017). Moreover, this analysis revealed that both were involved, persuasive, context-independent, abstract but narrative. However, ENS was more overtly persuasive and appropriately informational than CEL.
A further comparison with the registers investigated in Biber (1988) revealed that L1 and L2 writing manifested linguistic differences on certain textual dimensions, even though they constructed similar textual functions. Take dimension 2 as an example. Although both corpora were closer to academic prose, they drew on different linguistic resources to construct their respective non-narrative discourses, as is seen in Table 3. The similarities and differences in linguistic features and textual dimensions between the two corpora have remarkably indicated that ENS and CEL were, in fact, particular sub-registers of language use within the specific register of argumentative writing. These findings have also illustrated the necessity and superiority of Biber’s (1988) MD Analysis in differentiating these sub-registers in terms of register variation, compared to other comparative linguistic analyses based on individual linguistic features or textual functions (Biber, 2012, 2014; Goulart et al., 2020).
Conclusion
Using two corpora of argumentative texts produced under similar writing conditions and with similar writing purposes, this MD-based study compared linguistic features and textual dimensions between the texts of native English writers and Chinese English learners. It also demonstrated the register characteristics of these two groups of writing texts through a more comprehensive comparison with the registers studied in Biber (1988). The analysis showed that the two groups of written texts used different linguistic resources to realize similar discourses. It also revealed that the two groups shared more similarities than significant differences in textual dimensions. They were, in fact, different varieties of English language used in the same genre of argumentative writing. The results confirmed the importance of comparable corpora for cross-linguistic comparative analysis and the necessity of MD analysis for understanding L2 learner writing.
The findings enriched the current understanding of L2 argumentative writing and have practical implications for L2 writing research and pedagogy. For example, the study demonstrated that L2 learners’ argumentative writing is inherently involved and persuasive, as previously noted (e.g., van Rooy, 2008; van Rooy & Terblanche, 2009; Zhao & Wang, 2017). The findings on the differences in linguistic features and textual dimensions between L1 groups showed the importance of corpora of maximum similarity for cross-linguistic comparison (Moreno, 2008). Moreover, the findings concerning the overall register characteristics of the two groups showed that MD analysis, especially the 1988 MD analysis, is suitable for characterizing any two or more registers with different levels of specificity for learner writing. In addition, it will be helpful for L2 writing pedagogy to analyze and understand why and how L2 learners differ from native writers in terms of actual language use and the textual functions they seek to realize.
However, limitations still exist, and future avenues are open. For example, this study is limited to argumentative texts by college-level learners. Future studies can examine such texts written by learners at different proficiency levels and even include more genres or text types. Future studies can use much more refined comparable corpora of argumentative essays, such as those supporting a particular viewpoint, to understand differences in language use between L1 and L2 writing for specific communicative purposes.
Footnotes
Acknowledgements
Special thanks are given to the anonymous reviewers for their insightful and instructive comments and suggestions.
Declaration of Conflicting Interests
I declare that I have no financial and personal relationship with any person or organization that could inappropriately influence this research.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics Statement
I declare that no ethics issue is involved in this research.