
Abstract
Chinese character size is the number of characters that a person can recognize and has been well documented as a critical measure of Chinese literacy. A variety of Chinese character size tests have been developed since the 1930s. However, systematic reviews have not yet been conducted on Chinese character size tests. The purpose of this article is to provide a comprehensive review of Chinese character size tests conducted between 1930 and 2021 among native Chinese-speaking children and Chinese language learners. There are three main findings. First, most character size tests were constructed using a frequency-based stratified-sampling method to select target characters, a mixed method focusing on both pronunciation and meaning to test target characters, and a holistic method to score the test-takers’ responses. Second, the majority of tests used Classical Testing Theory (CTT) for checking the item quality, reliability, and validity, and only two tests employed both CTT and Item Response Theory. Third, most tests estimated character sizes using CTT, while only three tests constructed character size norms. It is suggested that future studies address cross-group investigation, determine the most robust construction and estimation methods, develop computer-assisted tests, and apply character size tests to classroom settings.
Keywords
Introduction
The growth of vocabulary is fundamental to the development of literacy skills (Beglar, 2010; Cameron, 2002; Ishii & Schmitt, 2009; Karami, 2012; Nguyen & Nation, 2011; Zhao & Ji, 2018). For the development of Chinese literacy skills, it is crucial to master Chinese characters, which serve as the basis for Chinese words. As opposed to sound-based languages, Chinese is morpho-syllabic or meaning-based (DeFrancis, 1986). For instance, an equivalence of the word computer in Chinese is
Researchers have attempted to develop Chinese character size tests for assessing the size of characters acquired by native and non-native speakers of Chinese. Some tests were developed to differentiate between children with normal cognitive abilities and those with reading difficulties (Gai & Yang, 2006; Leung et al., 2008; Peng et al., 2017). Several tests have been developed to examine the developmental path of character recognition skills in Chinese children (e.g., Ai, 1949; Hung et al., 2008; Wang &Tao, 1996; Wen et al., 2015; Wu, 2012; Zhang, 1931) as well as learners of Chinese as a second language (CSL) (Li, 2003; Tseng et al., 2016; Zhang et al., 2021). While, in other studies, appropriate Chinese characters tests were developed to assess the role of orthographic awareness in character recognition (Li et al., 2012; Ruan et al., 2018; Song et al., 2015; Su & Kim, 2014; Yang et al., 2019; Zhang, 2017; Zhang & Roberts, 2019).
Although a number of Chinese character size tests have been developed since the 1930s, it remains unclear how these tests differ in terms of their methods for constructing the tests, checking their reliability and validity, and estimating the size of characters. For instance, some tests used more than 200 target characters (Wang & Tao, 1996), while others included only 31 characters (Hung et al., 2008). Thus, an analysis of these tests will enable us to better understand the differences and similarities among them. Additionally, researchers may be able to improve their test development by referring to the existing tests’ achievements and limitations. Lastly, such a review could help teachers select an appropriate character size test and tailor their Chinese character instruction accordingly. Taken together?, the present review aims to address the following questions:
RQ1: What methods have been used to construct the character size tests in terms of selecting, testing and scoring the target characters?
RQ2: What methods have been used to check the item quality, reliability and validity of the character size tests?
RQ3: What methods have been used to estimate character size?
Method
To minimize publication bias and provide a comprehensive picture of current research, the relevant literature was searched exhaustively. The steps are outlined in Table 1. Considering that studies on the development of Chinese character size tests were mainly published in Chinese, three major Chinese databases were utilized to search relevant studies, namely CNKI from mainland China (www.cnki.net), airiti library from Taiwan (http://www.airitilibrary.cn/) and Hong Kong Education Bibliographic Database (https://bibliography.lib.eduhk.hk/). Search terms included
A Brief Summary of the Literature Search and Inclusion Criteria.

This study adopted the following inclusion criteria in order to accommodate the focus of the review. First, the study should aim to construct a character size test for a specific population. In addition, the character size test should primarily target Chinese-speaking children with normal cognitive abilities or CSL learners. Third, the information concerning the construction, reliability, and validity of the character size test could be fully accessed.
According to the inclusion criteria listed above (Table 2), 11 studies were selected, including eight studies involving native Chinese speakers (one from Hong Kong, two from Taiwan and five from mainland China), and three studies for CSL learners (one from Taiwan and two from mainland China). As for publication type, there were nine journal articles, one book chapter, and one doctoral dissertation. In terms of publication language, three studies were published in English (two journal articles and one doctoral thesis) and eight studies were published in Chinese.
Summary of the Selected Studies Included for the Present Review.

Results
RQ1 Methods to Select, Test, and Score Target Characters
Table 3 summarizes the methods for selecting and testing the target characters.
Summary of the Construction of Different Chinese Character Size Tests.

Target characters selection
Target character selection involves selecting both the character pool and the sample of target characters.
Character pool selection
As shown in Table 3, the character pools have been constructed according to two different approaches. One approach referred to a single source as the character pool, such as a dictionary, a list of commonly used characters, or a set of character lists in a curriculum syllabus or CSL proficiency standards. Another approach was to combine different sources of information, such as a list of commonly used characters, textbooks, and curriculum syllabuses. According to Table 4, the character pool is dominated by commonly used characters.
Summary of the Character Pool Source.

In terms of the number of characters in the character pools, the mean was 6832.33 (SD = 5,162.31). Additionally, the pool volume varied with the source and target population. The average number of items in the character pools derived from dictionary and non-dictionary sources is 13,933.51 (SD = 1,758.11) and 3,281.75 (SD = 780.26), respectively. In addition, for character size tests targeting Chinese-speaking children based on non-dictionary sources, Taiwan had the largest character pool (Hung et al., 2008, n = 5,021), followed by that in mainland China (Wang & Tao, 1996, n = 3,500; Wen et al., 2015, n = 3,800), and Hong Kong had the smallest pool (Wu, 2012, n = 2,400). Conversely, the character pool in mainland China (Li, 2003, n = 2,900; Zhang et al., 2021, n = 3,000) was larger than that in Taiwan (Tseng et al., 2016, n = 2,400) for CSL learners. In addition, the average character pool volume for native Chinese-speaking children (M = 3,550.8, SD = 873.91) appeared to be larger than those for CSL learners (M = 2,766.67, SD = 262.47).
Target characters sampling
Two methods were commonly used to sample target characters: spaced sampling and stratified sampling. The spaced sampling method was used in two early studies (i.e., Ai, 1949; Zhang, 1931). A spaced sampling method involves selecting specific characters from a specific dictionary, such as the first character on every 10th page, to form a pool of target characters. Stratified sampling was used in the other nine studies. This type of sampling method involves dividing the pool into multiple levels based on one or more criteria and then randomly selecting a suitable number of target items from each level. As shown in Table 3, five studies used character frequency as the sole criterion (Hue, 2003; Hung et al., 2008; Li, 2003; Tseng et al., 2016; Wen et al., 2015), while four studies selected the target characters based on both character frequency and other factors, such as difficulty (Li, 1999; Wang & Tao, 1996; Wu, 2012) and the orthographic features (e.g., structure, orthographic regularity) of characters (Zhang et al., 2021).
The average number of target characters in previous character size tests was 112.47 (SD = 59.96), with a range from 31 characters (Hung et al., 2008) to 210 characters (Wang & Tao, 1996). The average ratio of target characters to the pool was 0.031 (SD = 0.024), ranging from 0.004 (Hue, 2003) to 0.08 (Li, 1999). In addition, character size tests for native Chinese-speaking children (M = 116.06, SD = 63.80) had more target characters than those for CSL learners (M = 93.33, SD = 24.94).
Target characters testing
Methods of testing for target characters can be examined from two perspectives: the measured content and the subjective versus objective nature of the measures.
Regarding the measured content, three typical methods are available (Zhang et al., 2022): semantic methods (n = 1), phonological methods (n = 3), and mixed methods (n = 8). Specifically, Chinese character size tests utilizing semantic methods required the participants to form words and phrases by using target characters (Wang & Tal, 1996). Tests adopting phonological methods asked the participants to read aloud or write down the pronunciations of target characters (e.g., Tseng et al., 2016; Wang & Tao, 1996; Wu, 2012). Tests that employed mixed methods measured the participants’ Chinese character size by their knowledge of pronunciations and meanings of target characters (Ai, 1949; Hue, 2003; Hung et al., 2008; Li, 1999; Wen et al., 2015; Zhang, 1931; Zhang et al., 2021), or their knowledge of pronunciations, meanings and orthography of target characters (Li, 2003). In addition, ten studies used only one testing method, but Wang and Tao (1996) used different methods for children of different ages, such as phonological methods for first and second graders, and semantic methods for third to fifth graders.
As for the perspective of subjective versus objective measurement, subjective tasks required participants to produce the pronunciations and meanings of target characters using a paper-and-pencil method (Hue, 2003; Hung et al., 2008; Li, 1999; Li, 2003; Tseng et al., 2016; Wang & Tao, 1996; Wen et al., 2015) or interview form (Li, 1999; Wang & Tao, 1996; Wen et al., 2015; Zhang, 1931). In contrast, the objective tasks asked the participants to select the correct answer from a set of items (Ai, 1949; Li, 1999). Although the majority of studies used either subjective or objective measures, the tests designed by Li (1999) included both subjective and objective measures.
Target characters scoring
In terms of character pronunciation scoring, it is common for researchers to assess participants’ global performance in syllables in the subjective tasks such as reading aloud or writing down the character pronunciation. However, researchers used different methods to score tonal errors. Two studies used a non-tone method without considering tonal errors (Wen et al., 2015; Zhang et al., 2021), one study used two scoring methods (tone scoring and non-tone scoring) among CSL learners (Tseng et al., 2016), and the other studies did not mention how tonal errors were addressed.
As for character meaning scoring, participants’ holistic performance in meaning tasks was generally taken into account, ignoring their orthographic errors in producing Chinese characters. However, two studies (Hung et al., 2008; Wen et al., 2015) considered characters with more than two stroke errors as incorrect. Furthermore, three studies allowed participants to use Pinyin or Zhuyin-Fuhao as part of the meaning task (Hung et al., 2008; Wen et al., 2015; Zhang et al., 2021). Pinyin and Zhuyin-Fuhao are phonetic systems for representing the pronunciation of Chinese characters, and they are commonly used in mainland China and Taiwan region, respectively.
RQ2 Methods to Check the Reliability and Validity of Character Size Tests
As seen in Table 5, three studies did not mention how the reliability and validity of character size tests were checked (i.e., Li, 2003; Hue, 2003; Zhang, 1931). Another eight studies employed Classical Testing Theory (CTT) and two studies utilized both CTT and Item Response Theory (IRT) (Wu, 2012; Zhang et al., 2021).
Summary of the Reliability and Validity Analysis in Different Chinese Character Size Tests.
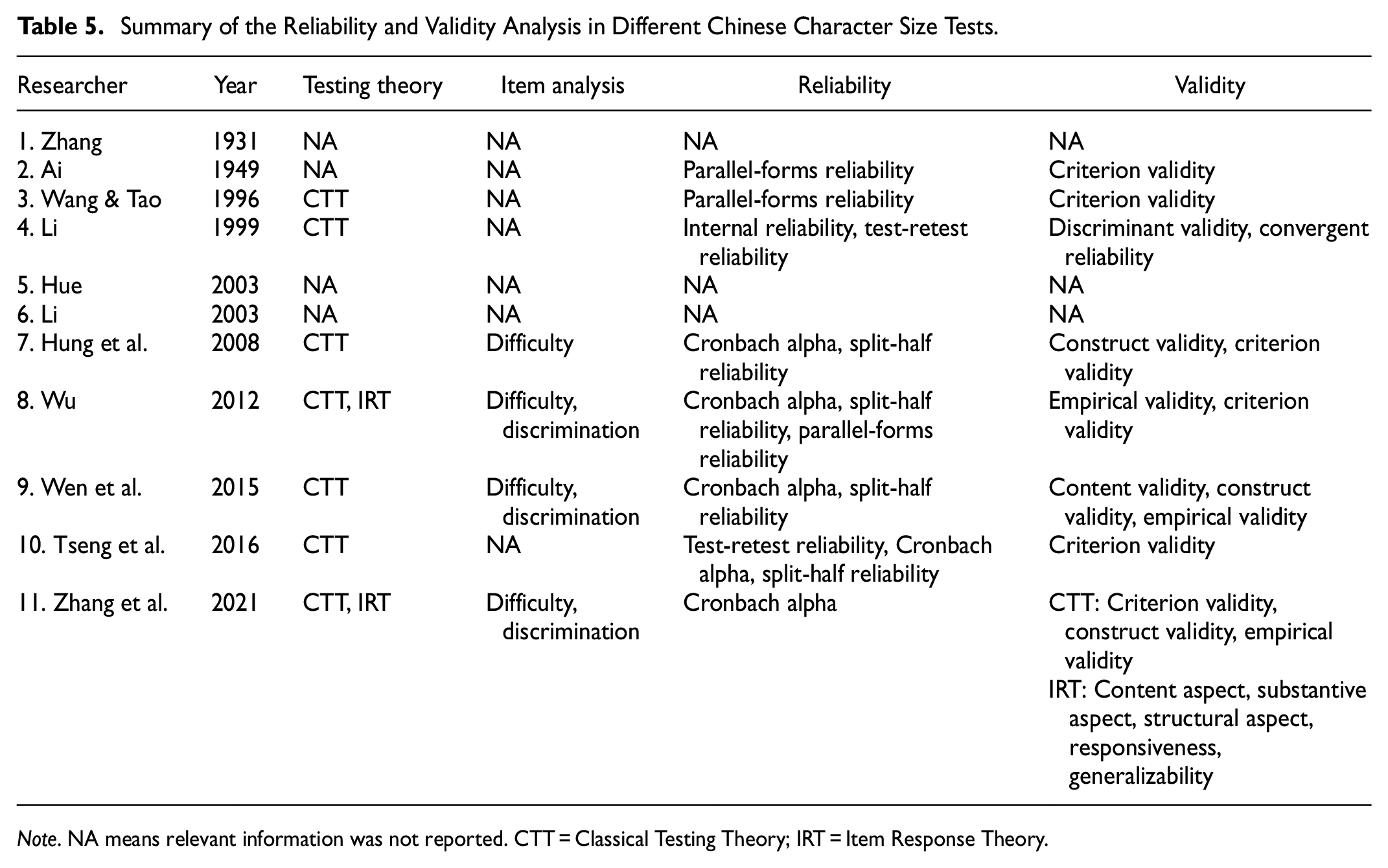
Note. NA means relevant information was not reported. CTT = Classical Testing Theory; IRT = Item Response Theory.
In terms of item analysis, four studies reported statistics about item difficulty (Hung et al., 2008; Wen et al., 2015; Wu, 2012; Zhang et al., 2021) and three studies reported statistics about item discrimination (Wen et al., 2015; Wu, 2012; Zhang et al., 2021).
In terms of reliability, six studies reported internal reliability such as Cronbach alpha and split-half coefficient (Hung et al., 2008; Li, 1999; Tseng, et al., 2016; Wen et al., 2015; Wu, 2012; Zhang et al., 2021), three studies reported parallel-forms reliability (Ai, 1949; Wang & Tao, 1996; Wu, 2012), and two studies reported test-retest reliability (Li, 1999; Tseng et al., 2016).
In terms of validity, six studies reported criterion validity (Ai, 1949; Hung et al., 2008; Tseng et al., 2016; Wang & Tao, 1996; Wu, 2012; Zhang et al., 2021), three studies reported construct validity (Hung et al., 2008; Wen et al., 2015; Zhang et al., 2021), three studies reported empirical validity (Wen et al., 2015; Wu, 2012; Zhang et al., 2021), two studies reported content validity (Wen et al., 2015; Zhang et al., 2021), one study reported discriminant validity and convergent validity (Li, 1999), and one study reported IRT-based validity such as responsiveness and generalizability (Zhang et al., 2021).
RQ3 Methods to Estimate Character Size
As shown in Table 6, seven studies used CTT-based methods to estimate the participants’ character sizes. The participants’ accuracy rate of the test was first calculated, and then the character size was estimated using certain mathematical equations, such as the accuracy rate × the number of characters in the pool (Ai, 1949; Hue, 2003; Hung et al., 2008; Zhang, 1931; Zhang et al., 2021), or by assigning weighted scores to the target characters (Li, 2003; Wang & Tao, 1996). Four studies did not report the participants’ character sizes (Li, 1999; Tseng et al., 2016; Wen et al., 2015; Wu, 2012). Furthermore, three studies constructed character size norms for children in mainland China (Ai, 1949), Hong Kong (Wu, 2012), and Taiwan (Hung et al., 2008).
Summary of the Character Sizes in Different Grades/Levels in Previous Studies.

Note. Wu (2012) only reported raw scores and the maximum score of the test was 150.
Discussion
It could be seen above that Chinese character size tests have been developed for a long period of time, demonstrating its significance for Chinese language learning. This section discusses how to construct character size tests, how to check their reliability and validity, and how to estimate character size in previous studies.
Construction of Character Size Tests
Target characters selection
As for the sources of character pools, dictionaries were primarily used in early studies (Ai, 1949; Zhang, 1931). However, dictionaries were later replaced by the lists of frequent characters due to the following two main reasons. First, different dictionaries have different numbers of characters, which range from thousands to millions, and are generally far more than any individual knows. Thus, using a dictionary as the character pool might overestimate the test-takers’ character size. Second, the use of dictionaries as character pools generally involves spaced sampling in selecting target characters, yet the main disadvantage of spaced sampling is that character frequency is ignored, resulting in an inaccurate representation of the entire dictionary. For instance, a highly frequent character (e.g.,
Although the lists of frequent characters have been the mainstream source to build character pools for different groups of test-takers from mainland China, Hong Kong and Taiwan, they were used differently for Chinese-speaking children and CSL learners. For Chinese-speaking children, the lists of frequent characters often serve as the single source of a character pool for measuring character size (Wen et al., 2015; Wu, 2012). In contrast, the lists of frequent characters are only partly used as the source of a character pool for CSL learners (Li., 2003; Tseng et al., 2016; Zhang et al., 2021). Such a difference is mainly due to two reasons. One reason is that CSL learners at different colleges/universities are exposed to a variety of textbooks (Li, 2002; Liang, 2020). Therefore, using part of the lists of frequent character may be able to better capture CSL learners’ character size. Another reason is that CSL learners tend to have a smaller character size than native Chinese-speaking children (Zhang et al., 2021). Thus, using the full lists of frequent characters may weaken the accuracy and representativeness of the character pools for CSL learners.
Although the character pools for Chinese-speaking children and CSL learners differ in the total number of characters, the use of frequently used characters as the main source of character pools makes the estimated character sizes of the two groups, particularly those from the same region, comparable. However, it should be noted that the lists of frequent characters are derived from native speakers’ data, yet CSL learners acquire Chinese characters primarily within the context of classroom settings. Therefore, it is debatable to directly use the lists of frequent characters to build character pools for CSL learners. Future research is suggested to examine whether L1-based lists of frequent characters are appropriate for measuring CSL learners’ character sizes, particularly those with low levels of Chinese proficiency.
The number of characters in the character pools varies across different areas and different populations. As for the wide variation in character pools targeting children in mainland China, Hong Kong, and Taiwan, it relates mainly to the local language policies. Despite the fact that both Hong Kong and Taiwan use traditional Chinese characters, Hong Kong promotes a “biliterate” (Chinese and English) and “trilingual” society (Bolton, 2011), thus less attention is paid to Chinese literacy education than it does in monolingual Taiwan. Although mainland China is also monolingual, the number of simplified characters commonly used in mainland China is less than that of traditional characters commonly used in Taiwan (Du, 2018). In respect to differences in character pool volumes for CSL learners between mainland China (Li, 2003; Zhang et al., 2021) and Taiwan (Tseng et al., 2016), the main explanation concerns the participants’ Chinese language proficiency. The participants in mainland China were intermediate and advanced learners, however, their counterparts in Taiwan were beginning and intermediate learners. To conclude, the use of different character pools for different groups of test-takers indicates the importance of ensuring that character size tests are appropriate for the target participants. It remains unclear, however, whether these different character pools produce comparable estimates of character sizes.
Target character selection is primarily conducted using stratified sampling, which divides the pool into different levels based on character frequency. While frequency-based stratified sampling can enhance the representativeness of sampled characters to a great extent over spaced sampling, it still has some limitations because character recognition can be influenced by a series of factors including frequency, orthographic, phonological, and semantic information (Hao, 2018; Tong & McBride-Chang, 2010; Tong et al., 2017; Wang et al., 2003). The limitation of frequency-based stratified sampling in selecting target items also exists for research on vocabulary size tests (de Groot, 2006; Hashimoto, 2021). The limitations of frequency-based stratified sampling imply that character frequency along with other factors should be taken into account, such as learners’ accuracy in pilot studies, orthographic, phonological, and semantic information of the characters (Wang & Tao, 1996; Wu, 2012; Zhang et al., 2021).
There was also a difference in the number of characters selected in previous tests, indicating a lack of consensus about the optimum number of characters for measuring character size. Wen et al. (2016), for example, explored the selection of the number of target characters using the Generalizability Theory and found that tests containing 20 or 30 characters could reach the .80 threshold of Dependability Coefficient (PHI), demonstrating a high degree of reliability. This finding is similar to Nation’s (2022) recommendation that at least 30 words should be tested to estimate vocabulary size. A recent study, however, found that at least 30 words should be used per 1,000-word frequency band (Gyllstad et al., 2020). These findings imply that it is reasonable to recommend that at least 30 characters be tested to estimate character size, and more characters may be tested if the conditions allow.
Target characters testing
Despite the fact that Chinese character recognition skill has been found unidimensional (Wen et al., 2016), researchers have not yet reached a consensus on its specific components. Character recognition may depend on different cognitive abilities and different brain areas for the tasks of phonological, semantic, and mixed methods to be completed (Wu et al., 2012), with phonological methods being the easiest, and mixed methods being the most challenging (Zhang et al., 2022). In spite of the significant correlations among the three methods of assessing character recognition competence (Everson, 1998; Jiang, 2003; Myers et al., 2007; Perfetti & Tan, 1998; Perfetti & Zhang, 1995; Zhang et al., 2022; Zhou et al., 1999), mixed methods and semantic methods may provide better item quality than the phonological methods (Zhang et al., 2022). As an example, mixed methods and semantic methods can generate higher item separation values than phonological methods, even though the three methods demonstrate similar item difficulty and item discrimination (Zhang et al., 2022). As a result, mixed methods or semantic methods are recommended for measuring Chinese character recognition.
Regarding the subjective versus objective nature of the measures, both have their advantages and disadvantages, however, subjective measures of character size are recommended for the following reasons. First, although subjective tasks might be time- and energy-consuming in terms of administration and scoring, their main advantage lies in enabling researchers to determine an individual’s real character size without providing cues, thus minimizing the effects of guessing and test-taking strategies on objective measures, as has been demonstrated by vocabulary size tests (Gyllstad et al., 2015; McLean, Kramer, & Stewart, 2015). For instance, in the case of measuring vocabulary size test, test-takers’ scores in multiple-choice tasks might be two times higher than their scores in L2-L1 translation task (Lemhöfer & Broersma, 2012; Nakata et al., 2020). Second, given that character sizes estimated by phonological methods, semantic methods, and mixed methods are comparable to some degree (Zhang et al., 2022), the web-based phonological methods that ask test-takers to provide character pronunciation using Pinyin or Zhuyin-Fuhao may be a viable alternative to mixed methods or semantic methods (Tseng et al., 2016). This is due to the possibility of automatically scoring Pinyin and Zhuyin-Fuhao, which might be as time-saving and efficient as objective tasks.
Target characters scoring
Tonal errors have been a controversial topic regarding scoring character pronunciation, since Chinese is a tonal language, and different tones indicate different meanings. Tonal errors, however, should be ignored when scoring character pronunciation for the following reasons. First, for reading by eyes, it is more important to be able to retrieve the semantic information rather than the tonal information of characters. Second, tone acquisition is the most difficult part for CSL learners compared with initials, finals, and meanings of characters, and CSL learners’ performance in tone acquisition may not improve with their Chinese proficiency (Wu et al., 2006). Third, the non-tone scoring method may enhance the discrimination of the items as well as the validity of character size tests, and may be more sensitive in measuring CSL learners’ proficiency in character recognition (Tseng et al., 2016).
Regarding the scoring of character meaning, it is recommended that the participants’ orthographic errors in character writing be ignored, although some studies have deemed characters with more than two stroke errors incorrect (Hung et al., 2008; Wen et al., 2015). This recommendation is based on two reasons. First, the purpose of a character size test is primarily to determine how many characters an individual knows, and it is reasonable to focus on a participant’s overall performance in the meaning task as long as the orthographic errors do not negatively impact the participant’s semantic performance in the meaning task. Second, orthographic errors only impact the estimated character size in tasks that required participants to write characters. Therefore, ignoring orthographic errors could enhance the comparability of estimated character sizes for different tasks, such as forming words using target characters and translating.
The above-mentioned aspects of the construction of character size tests are closely related to their practicality, item quality, reliability, and validity. Selection of the character pool and sampling method may have an impact on the content validity and item quality of the test. Specifically, the more characters that are tested, the more reliable and valid the test is likely to be. However, adding more items will result in a longer test, which may reduce the practicality of the test to some extent. When it comes to target character testing, the measured content could affect the construct validity of the test, since it reflects the perceptions of researchers about character recognition skills. A subjective or objective character size test could pose a considerable problem in terms of its practicality, since the format of the test and the duration of the test preparation, completion, and scoring could differ greatly between these two types of tasks. Additionally, the scoring methods for target characters may have some influence on the practicality of the character size test. The convenience of scoring answers depends largely on the scoring criteria, which are essential components of the test’s practicality.
Checking the Reliability and Validity of Character Size Tests
Character size tests have been updated with the development of testing theories, such as the shift from the CTT (Li, 1999; Wang & Tao, 1996; Wen et al., 2015) to the IRT (Wu, 2012; Zhang et al., 2021). While most of these tests have been validated using CTT, interrater reliability and face validity have not been reported which are also important indicators of reliability and validity (Kline, 2005). CTT has benefits in terms of administration and interpretation, but it also has disadvantages (DeVellis, 2006; Jabrayilov et al., 2016; Magno, 2009). For example, CTT-based tests do not adequately address measurement errors and may result in biased results. Additionally, CTT-based results are sample-dependent, making cross-group comparisons difficult.
To address the limitations of CTT, both CTT and IRT should investigate the reliability and validity of character size tests (Wu, 2012; Zhang et al., 2021). This would yield more comprehensive and robust results than those provided by CTT alone. In addition to being sample-independent, IRT can also minimize measurement errors and provide comprehensive information about various aspects of the assessment process, including items, raters, and test takers (Jabrayilov et al., 2016; Kline, 2005; Thomas, 2011). As a result, a combination of CTT and IRT is strongly recommended for a comprehensive analysis of the reliability and validity of character size tests.
Despite the fact that grade effect and gender effect have been commonly used to assess the empirical validity of character size tests, there has been more consensus on grade effect than on gender effect. The grade effect means that Chinese character size generally increases along with the participants’ grades. The grade effect might be universal across different literacy skills, as it has been widely observed in both character size tests (e.g., Ai, 1949; Hung et al., 2008; Wang & Tao, 1996; Wen et al., 2015) and vocabulary size tests (Beglar, 2010; Cameron, 2002; Segbers & Schroeder, 2017; Zhao & Ji, 2018). A similar effect has also been observed in CSL learners (Tseng et al., 2016; Zhang et al., 2021). These consistent findings suggest that grade effect could discriminate test-takers with different levels of Chinese character recognition skills and detect the longitudinal changes in learners’ character size growth, and it can be reliable in examining the empirical validity of character size tests targeting Chinese children and CSL learners,
Different from the consistent findings about grade effect, there is a lack of consistency in the findings regarding gender effect in character size tests. The gender effect refers to the hypothesis that female participants outperform their male counterparts in Chinese character size (Hung et al., 2008; Wen et al., 2015). Some studies, however, have not found any significant differences between the female and male participants (Li, 1999), or even found that the male students outperformed their female counterparts in less developed areas (Chen & Tan, 2012). These results are in accordance with the mixed findings regarding the role of gender in vocabulary size in alphabetic languages (Agustín Llach & Terrazas, 2012; Fernández-Fontecha, 2014). The main reason for this can be attributed to the interaction effects between gender and other factors (e.g., gender equality and socio-economic status) on character recognition. For example, male students from low socio-economic regions may outperform their female counterparts in character recognition in China. However, the performance of male students in character recognition may not necessarily be better than that of female students in more developed areas of China, where girls have equal access to education. These conflicting findings suggest that the role of gender in the development of linguistic (Eriksson et al., 2012; Frank et al., In Press; Hyde & Linn, 1988; Robinson & Lubienski, 2011) and cognitive abilities (Miller & Halpern, 2014) needs further investigation. It also indicates that the use of gender effect for validating the empirical validity of character size tests should be interpreted with caution.
In conclusion, the use of various testing theories and validation techniques has greatly contributed to the reliability and validity of character size tests for Chinese children and CSL learners. However, the application of IRT in character size tests is still limited and some advanced testing theories such as the cognitive diagnosis model (Templin & Henson, 2006) have not been utilized. Furthermore, the empirical validity of character size tests may be examined from a variety of perspectives, such as the frequency effect in character recognition, which has been widely proven in a number of studies, which may be used to examine the validity of character size tests empirically (Zhang et al., 2021).
Character Size Estimation
Character size is primarily estimated using CTT. A CTT-based method has the advantage that it is easy to understand and administer, and it can be calculated even by those who have no expertise in language testing. The CTT-based methods may, however, overestimate the participants’ character size. Based on simulated data, Wen et al. (2020) compared the effectiveness of CTT-based and IRT-based approaches for estimating character size. According to the results, the IRT-based approach reduced the risk of overestimating participants’ performance in low-frequency characters and produced a smaller estimated character size than the CTT approach. It remains unclear, however, whether this conclusion can be applied to actual data. The CTT-based approach tends to remain the mainstream approach for estimating character sizes due to its ease of estimation and explanation, however more research needs to be conducted on IRT-based estimation methods.
Character size norms have been established in limited studies in the past. A norm refers to “a standard or range of values that represents the typical performance of a group or of an individual (of a certain age, for instance) against which comparisons can be made” (Vandenbos, 2015, p. 715). Character size norms have served as a reference for teachers to assess Chinese children’s performance in character recognition to inform character teaching (Peng et al., 2017). However, they are still limited in the following areas. First of all, there were only three character size norms available for Chinese children, and there have been no similar norms in the field of CSL learning. The primary reason may be that a large sample size is necessary for the establishment of a norm. As an example, previous norms had an average of 3,226 test-takers (SD = 1,712) (Ai, 1949; Hung et al., 2008; Wang & Tao, 1996), while previous tests targeting CSL learners had a very small sample, such as the 318 participants in Zhang et al.’s (2021) study. Furthermore, some norms are city-specific and cannot be generalized. For example, the norm by Wang and Tao (1996) was Shanghai-specific, therefore applying this norm to other areas would be inappropriate due to the differences in education and economic development between this megacity and other areas. Third, some character size norms, such as those developed by Wang and Tao (1996) and Hung et al. (2008), need to be updated due to changes in educational development.
It is possible that methods for estimating the size of characters and the establishment of character size norms could influence the practicality of the test. The purpose of measuring an individual’s character size is to identify his or her position within a particular group and to tailor instruction accordingly. Therefore, the use of an appropriate estimation method and the creation of a reliable norm would facilitate the administration of the test and make results more understandable.
Directions for Future Research
Firstly, future research should consider conducting more cross-group comparisons of character size tests between different populations, since comparative studies between different populations are scarce (Li, 1999; Wu et al., 2015), and this is of significance in answering some important questions regarding the acquisition of Chinese literacy. For example, do Chinese children, ethnic minority CSL children, and adult CSL learners exhibit similar growth patterns with regard to their ability to acquire Chinese characters? Is it possible for adult CSL learners to acquire Chinese characters of the same size as native Chinese speakers? These questions may contribute to theoretical discussions, such as the ultimate level of L2 proficiency attained, age effects and the role of learning context (Dąbrowska, 2018; Granena & Long, 2013; Lardiere, 2006), individual differences (Dörnyei, 2005) in L2 learning, the Matthew effect in learning (Perc, 2014; Pfost et al., 2014; Protopapas et al., 2016), and how phonological capabilities affect reading skills (Perfetti, 2003; Ziegler & Goswami, 2005).
Second, future research could examine more robust approaches to testing character size. There have been a number of methods employed in developing character size tests, ranging from choosing target characters to estimating character size. However, it remains unclear whether these character size tests are similarly powerful or can yield comparable results. Therefore, more studies are required to compare the relative effectiveness of different methods in determining an individual’s actual character size. Research in the future may examine whether character size tests for Chinese children are suitable for CSL learners, whether CTT and IRT estimation methods yield different results in non-simulated contexts, and whether results produced by interviewing and using paper and pencils are comparable.
Third, future research may also focus on developing computer- or mobile-assisted character size tests. A variety of computer- or mobile-assisted software applications have been developed for Chinese character instruction, including MagiChinese, Skritter Chinese, TOFU learn apps, and for language testing such as computer-adaptive testing (Chalhoub–Deville & Deville, 2003; Young et al., 1996). However, only one web-based character size test has been developed to date (Tseng et al., 2016). A computer- or mobile-assisted test has several advantages, such as the automatic rating of participants’ answers and the ability to record the process of their responses, which could facilitate statistical analysis and enhance our understanding of Chinese character acquisition from a dynamic perspective. Technological advances in speech recognition, artificial intelligence, and deep learning have made it possible to develop and administer character size tests with ease.
Last but not least, further research is required regarding the application of character size tests in the classroom. For the purpose of assisting teachers in identifying children who require specific assistance, researchers have investigated the use of character size tests to screen Chinese children with deficit reading skills (Peng et al., 2017; Wu, 2012). In spite of this, studies tracking the development of character size are relatively few in number. In order to explore the longitudinal development of character recognition skills within a specific population, parallel forms of character size tests should be developed and administered. Research in this area can provide empirical evidence relating to the teaching of Chinese characters, particularly when selecting the characters to be used in Chinese language textbooks at various grade levels. Furthermore, exploring the impact of character size on children’s academic performance in other disciplines could assist in the development of the entire curriculum.
Limitations and Conclusion
The present review reveals that most of the existing character size tests were valid and reliable in testing character recognition skills, thus the estimated character sizes across different areas and different populations were roughly comparable to some extent. However, there are some limitations to the present study. First, the present study concentrated only on the character size tests developed for children with normal cognitive development and adult CSL learners due to the limited space available. By including tests designed for children with reading disorders in the present study, a more comprehensive picture of the development of Chinese character size tests would have been provided. Second, this study only reviewed how researchers developed and validated Chinese character size tests rather than conducting a meta-analysis, which may have provided more conclusive results.
Although there are several limitations to the present review, it is the first of its kind to our knowledge and provides a significant contribution to future studies on Chinese character size. The present review documents the noteworthy efforts of Chinese researchers to develop reliable and valid character size tests, in keeping with the increasing interest in Chinese character learning and research around the world (Gong et al., 2018; Li, 2020). Additionally, the review discusses future directions to facilitate the development of character size tests for different populations as well as vocabulary size tests in Chinese and other languages.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was supported by The Ministry of Education of China [20YJC740088] and Peking University [7101303321].