
Abstract
Hate speech is a challenging problem, and its dissemination can cause potential harm to individuals and society by creating a sense of general unwelcoming to the marginalized groups, which usually are targeted. Therefore, it is essential to understand this issue and which techniques are useful for automatic detection. This paper presents a survey on automatic hate speech detection on social media, providing a structured overview of theoretical aspects and practical resources. Thus, we review different definitions of the term “hate speech” from social network platforms and the scientific community. We also present an overview of the methodologies used for hate speech detection, and we describe the main approaches currently explored in this context, including popular features, datasets, and algorithms. Furthermore, we discuss some challenges and opportunities for better solving this issue.
Introduction
Social media platforms allow users to publish content about different subjects quickly and easily. Easy content dissemination and anonymity on social media platforms can increase the published harmful content. Different information types can intentionally or unintentionally harm (Giachanou & Rosso, 2020), including misinformation, disinformation, and mal-information. Misinformation (Aswani et al., 2019; Kar & Aswani, 2021), often defined as satirical, is incorrect or fictional information created and spread, disregarding the proper intention. Disinformation (Nasir et al., 2021), for example, fake news is deliberately created to mislead the target users. Mal-information (Davidson et al., 2017; Giachanou & Rosso, 2020), for example, hate speech is created to incite or cause harm. In this survey, we particularly investigate the hate speech detection task.
Hate speech is a challenging problem that demonstrates a clear intention to incite harm or promote hatred against others. This issue is considered a worldwide problem faced by many countries and organizations. With the growth of online social media, millions of users can spread much information every second, and the problem has become quite significant. There is a general understanding that when a person feels physically safe, the person’s speech tends to be more aggressive (Watanabe et al., 2018). Moreover, there is a real movement from hate groups to recruit people to create and diffuse hate speech messages (Del Vigna et al., 2017).
The easy spread of hate speech on online platforms is a serious concern for our society, considering that the dissemination of hate speech can cause potential harm to individual victims and society, for example, raising hostility between groups (Miškolci et al., 2020; Teh et al., 2018). Particularly, repetitive exposure to hate speech can lead to desensitization to this form of violence, thus lowering the victims’ evaluations and increasing the bias against the target groups (Mathew et al., 2019).
Social media platforms, such as Facebook, Twitter, and YouTube, have claimed they have intended to solve this problem, which they present in policies on hate behavior and attempts to combat hate speech (Facebook, 2020; Twitter, 2020; YouTube, 2020). Much of this content moderation currently requires manual review of questionable documents (Waseem & Hovy, 2016). However, the speed with which such messages are transmitted (shared) makes manual control over message content labor-intensive, time-consuming, expensive, and not scalable (Cao et al., 2020; Zhang et al., 2018).
Furthermore, the hate speech detection task suffers from several weaknesses related to specific nuances of this subject and the complexity of this classification task (Poletto et al., 2021). A relevant issue consists of clearly defining hate speech to understand the problem better and avoid strong subjective interpretations. As we will present in this survey, several disciplines have different definitions for the term “hate speech,” which are complementary.
All the listed issues and limitations of the manual approaches have motivated considerable research. This survey also aims to provide an overview of better aspects of the problem, such as its definition, different features used in this problem, datasets, and methods. Furthermore, we highlight challenges and draw future work directions, obtaining a theoretical starting ground for new scientists on the topic.
Understanding the better aspects of hate speech detection is relevant to dealing with this issue. As a general basis for this area, we found some surveys proposed in this field exploring different questions. In Schmidt and Wiegand (2017) and Fortuna and Nunes (2019), the researchers also survey critical tasks employed for hate speech detection. Nevertheless, it is relevant to note that this field has received increasing attention from the scientific community, and different resources included in the present survey had not been released when these surveys were published or at least when the researchers performed the search. Other works have focused on survey-specific characteristics of hate speech detection, such as multilingual corpus (Al-Hassan & Al-Dossari, 2019), annotated corpora (Poletto et al., 2021), and hate speech on the social media platform Twitter (Ayo et al., 2020).
This contribution aims to complement these works and present a critical analysis of theoretical aspects and practical resources since this field has constantly grown. (i) We overview a general methodology for hate speech detection on social media, focusing on textual data. (ii) Besides, we present a comprehensive overview of recent resources from different social media and languages, such as the datasets, features used, and algorithms. (iii) We describe the advantages and limitations of several feature extraction techniques currently used in the literature. (iv) We point out different open challenges and opportunities in this field.
This paper is organized as follows: We first present an analysis of different definitions for the term “hate speech” based on several sources; Then, we explain the methodology used to select the works for this review; Next, we discuss a general methodology for hate speech detection; Then an overview of the related datasets; After, we summarize several feature extraction approaches and present the advantages and limitations of the features explored; Then, we discuss several classification methods used in the literature; Furthermore, we present different challenges highlighted in the literature and opportunities in this field; finally, we conclude this survey with the final remarks.
What is Hate Speech?
Hate speech is a complex phenomenon, and detecting whether a text contains hate speech is not a trivial task, even for humans. Therefore, a precise definition of hate speech is crucial to automatically distinguish hate speech from other content (Ross et al., 2016). We have seen an increasing number of studies that have addressed hate speech detection with different definitions of the term. There is probably because of the fog limits between hate speech and appropriate freedom of expression (MacAvaney et al., 2019).
Thus, we have decided to analyze different sources’ definitions, considering the wide range of origins. We have analyzed the description of hate speech presented by social media in their “terms and conditions” contracts (Twitter, Facebook, YouTube) because hate speech often occurs on those platforms and some related studies, to include the perspective of the scientific community. Since Cohen-Almagor (2013) proposed one popular definition in the communication literature, Fortuna and Nunes (2019) analyzed several sources and considered distinct aspects, and Davidson et al. (2017) annotated a dataset used in several works. Thus, we will be considering those three aspects in our work.
Facebook: “We define hate speech as a direct attack on people based on what we call protected characteristics – race, ethnicity, national origin, religious affiliation, sexual orientation, caste, sex, gender, gender identity, and serious disease or disability. We define attack as violent or dehumanizing speech, harmful stereotypes, statements of inferiority, or calls for exclusion or segregation.”Facebook (2020)
Twitter: “Hateful conduct: You may not promote violence against or directly attack or threaten other people on the basis of race, ethnicity, national origin, caste, sexual orientation, gender, gender identity, religious affiliation, age, disability, or serious disease. We also do not allow accounts whose primary purpose is inciting harm towards others on the basis of these categories.”Twitter (2020)
YouTube: “Hate speech is not allowed on YouTube. We remove content promoting violence or hatred against individuals or groups based on any of the following attributes: age, caste, disability, ethnicity, gender identity and expression, nationality, race, immigration status, religion, sex/gender, sexual orientation, victims of a major violent event and their kin, veteran status.”YouTube (2020)
Cohen-Almagor: “Hate speech is defined as a bias-motivated, hostile, malicious speech aimed at a person or a group of people because of some of their actual or perceived innate characteristics.”Cohen-Almagor (2013)
Fortuna and Nunes: “Hate speech is language that attacks or diminishes, that incites violence or hate against groups, based on specific characteristics such as physical appearance, religion, descent, national or ethnic origin, sexual orientation, gender identity or other, and it can occur with different linguistic styles, even in subtle forms or when humour is used.”Fortuna and Nunes (2019)
Davidson et al: “Language that is used to expresses hatred towards a targeted group or is intended to be derogatory, to humiliate, or to insult the members of the group.”Davidson et al. (2017)
In some aspects, these definitions can be considered similar. A common theme is that hate speech is used against a specific targeted group or group members. Besides, it has been seen by different sources as an attack or incitement to violence. Davidson et al. (2017) define as a language that intended to be abusive, derogatory, humiliating, or insulting. While Cohen-Almagor (2013) considers hostile and malicious speech based on innate characteristics. In general, these definitions have complementary nuances to each other. In particular, Fortuna and Nunes (2019) specifically considers that hate speech can occur even in subtle forms. The authors argue that subtle forms of discrimination can use humor to reinforce stereotypes and racial discrimination, causing adverse effects for some people.
Considering these definitions, we can point out four main characteristics of hate speech described: (1) promotes attack or incites violence; (2) used against a specific target group or members of the group based on any characteristics such as gender, race, sexual orientation, religion, ethnicity or other aspects; (3) may or may not use “abusive language” and derogatory terms; (4) can occur in subtle forms, for example, subtle metaphors “expecting gender equality is the same as genocide,” this example of hate tweet does not contain explicit hateful lexical (Zhang & Luo, 2019).
Research Methodology
We have surveyed to understand hate speech detection on social media better, focusing on textual data. Our goal is to investigate the most recent studies developed in this field. To limit this research’s scope, we have decided to restrict our search to documents published starting in 2015. The reason for this decision is the fact that in Fortuna and Nunes (2019), it was shown that before 2014 this theme received little attention in computer science and engineering research, which is highlighted by the fact that many resources had not been released when previous surveys were published (Poletto et al., 2021).
We searched the documents in different sources, such as ACM digital library, IEEE, Elsevier, and Springer. The keywords selected were “hate speech detection,”“hate speech classification,” besides also considered the search for “Abusive language,” considering that abusive language is a sub-category of hate speech. The keywords selected were searched in the publication title, abstract and keywords. We also used Google Scholar to search for references that cited the original work. We check on these sets and search for the keyword “hate speech detection” on the titles of the documents. Several entries appeared as results of more than one search string.
We have focused on the field of computer science and engineering research. Also, we only included papers with at least four pages and peer-reviewed scientific resources. Furthermore, we restricted the works as automatic hate speech detection to the only ones performed on social media platforms, particularly from textual data. The text published on these platforms have specific characteristics (e.g., a limited number of characters, URLs, emojis, mentions, and so on). Thus, we have selected a total of 83 papers in the search period. Figure 1 presents the distribution of papers over the selected time interval.

Number of publication toward the years for hate speech detection from January, 1st 2015 to July, 31st 2021.
It is quite clear the scientific community’s recent efforts toward dealing with automatic hate speech detection relate to the processing and analysis of textual data. The following sections present several automatic hate speech detection techniques that explore this aspect.
Automatic Hate Speech Detection
The automatic hate speech detection process includes tasks such as data collection and processing, feature extraction, detection, and classification. We analyze and summarize the main tasks typically employed in automatic hate speech detection on social media platforms. Figure 2 presents an overview of the architecture for hate speech detection.

Overview of architecture for hate speech detection on social media platforms.
Social media platforms provide a wide variety of information that can be collected using the programing libraries known as Application Programming Interface (API). The researchers have adopted different strategies to crawl data related to hate speech, such as derogatory words, common slurs, hashtags, specific profiles, following “trigger events, and so on (Burnap & Williams, 2015; Davidson et al., 2017; Fortuna et al., 2019; Founta et al., 2018; Waseem & Hovy, 2016). Moreover, several works have used pre-filtering to exclude spam, samples with no content, and samples not in English (Founta et al., 2018; Pratiwi et al., 2018). According to Founta et al. (2018), abusive tweets are relatively rare, and the percentage can range between 0.1% and 3% of the samples collected.
The methodology employed to collect and annotate the dataset should be carefully chosen to avoid bias in the dataset (Wiegand et al., 2019). The annotation task in different studies used CrowdFlower (CF) workers (Chatzakou et al., 2017; Davidson et al., 2017; Founta et al., 2018; Kumar et al., 2019; Waseem, 2016), but this approach can be expensive. The authors Chatzakou et al. (2017), Founta et al. (2018) used a default payment scheme for batch (each with
In the context of social media platforms, the text used frequently has specific characteristics, such as abbreviations, incorrect spelling, slang, acronyms, URLs, hashtags, emojis, mentions, and so on. The unstructured text and, at times, the informal language can introduce noise in the classification task (Naseem et al., 2021). Several pre-processing methods are explored before the feature extraction task in order to reduce noise in the dataset, such as lower-casing of words, stemming, removing punctuation, URLs, stop-words, replacing emoticons and emojis, elongated characters (Dorris et al., 2020; Nugroho et al., 2019; Pratiwi et al., 2018; Sohn & Lee, 2019; Watanabe et al., 2018; Zhang et al., 2018). Naseem et al. (2021) evaluated 12 different pre-processing techniques and the combination of them in three datasets of hate speech (proposed in Davidson et al., 2017; Golbeck et al., 2017; Waseem & Hovy, 2016). The authors concluded that the lemmatisation and lower casing of words presented a high performance in most cases. On the other hand, removing punctuation and URLs, user mentions, and Hashtags symbols presented a low performance in most cases. Moreover, some studies focused on techniques to deal with the class imbalance problem, such as oversampling and undersampling. The oversampling technique is applied in the training data to increase the minority class (Chatzakou et al., 2017; Elisabeth et al., 2020), while the undersampling technique reduces the majority class (Miok et al., 2019). However, most of the works did not deal with class imbalance.
Feature extraction is an important task in text analysis. Several approaches are explored in hate speech detection and related subjects. Among these, dictionary or lexical resources (Burnap & Williams, 2015; Gitari et al., 2015; Mathew et al., 2019; Nobata et al., 2016; Teh et al., 2018), distance metric (Mossie & Wang, 2020; Nandhini & Sheeba, 2015), bag-of-word (Burnap & Williams, 2016; Senarath & Purohit, 2020; Waseem et al., 2018),
Although the feature engineering process’s effective for text representation, the feature space can present a high dimensionality. However, in the context of hate speech detection, few studies (Robinson et al., 2018; Zhang et al., 2018) have evaluated the feature selection process’s impact. The automatic feature selection algorithms can reduce the original feature space by 90% and improve machine learning algorithms’ performance for hate speech detection (Robinson et al., 2018; Zhang et al., 2018).
Classic supervised machine learning methods have been explored for automated hate speech detection. Among these, Support Vector Machines (SVM) (Burnap & Williams, 2015; Salminen et al., 2020), Logistic Regression (LR) (Davidson et al., 2017; Khan et al., 2021; Waseem & Hovy, 2016), Naive Bayes (NB) (Ibrohim & Budi, 2019; Salminen et al., 2020), Random Forest (RF) (Almatarneh et al., 2019), C4.5 decision tree learning (Watanabe et al., 2018). Although more expensive, ensemble approaches have presented robust results of the different classification task (Burnap & Williams, 2015; Markov et al., 2021; Nugroho et al., 2019; Paschalides et al., 2020; Zimmerman et al., 2018). Another approach explored is the DNN, which has been used for feature extraction and classifiers’ training. The most used approaches are CNN, LSTM, and GRU (Al-Makhadmeh & Tolba, 2020; Alsafari et al., 2020; Cao et al., 2020; Dorris et al., 2020; Marpaung et al., 2021; Mossie & Wang, 2020; Pitsilis et al., 2018; Rizos et al., 2019; Santosh & Aravind, 2019; Zhang & Luo, 2019). This work discusses several methods used for hate speech detection on social media platforms in the following section.
The following sections present an overview of the datasets, feature extraction techniques, and classification methods employed for automatic hate speech detection.
Datasets for Hate Speech Classification
Representative publicly available datasets are essential for developing automatic hate speech detection approaches. However, collecting and annotating data in the context of hateful messages is challenging, especially, as previously mentioned, no universal definition is adopted. The most common way of labeling this type of content is using social media platforms’ definitions. Besides, the number of hate speech texts compared to non-hate on social media platforms is significantly smaller. The studies adopted some strategies to collect the dataset, such as using terms and phrases related to hate content from dictionaries like HateBase, specific profiles, hashtags and keywords (Davidson et al., 2017; Fortuna et al., 2019; Founta et al., 2018; Waseem & Hovy, 2016).
Table 1 summarizes the main information from several datasets proposed in the literature. These datasets vary considerably in their labels, number of instances, characteristics of hate speech, etc. The most popular data source is Twitter, which has attracted a significant part of the research due to the increasingly available data and free APIs (Davidson et al., 2017; Waseem & Hovy, 2016; Watanabe et al., 2018). English has been the most popular language analyzed, but we can also find works exploring other languages, such as Arabic, Spanish, Indonesian, Portuguese, German, French, and Greek.
Summary of Datasets for Hate Speech Classification.
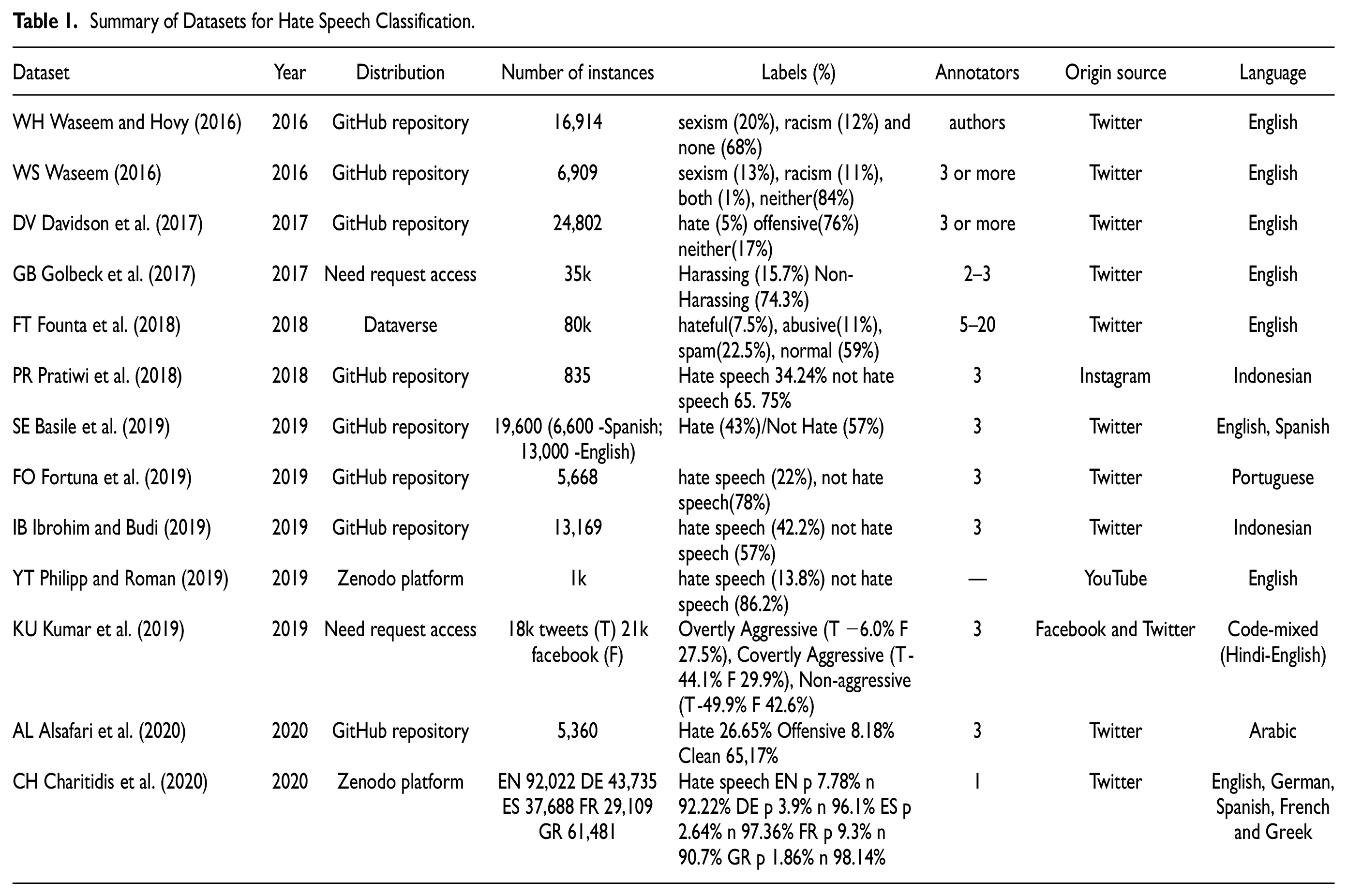
Overall, the publicly available datasets for hate speech detection in different languages and social media platforms are scarce, with few studies publishing their datasets. In most cases, the datasets are not available for external researchers, such as a large annotated dataset of abusive language detection from the “Yahoo! Finance and News” (Nobata et al., 2016); Facebook, Italian language corpus of hate speech (Del Vigna et al., 2017), Amharic language corpus for hate speech detection approach to vulnerable community identification (Mossie & Wang, 2020). Poletto et al. (2021) performed a further analysis in several datasets for hate speech detection, including methodology, topical focus, language, and other factors. The results presented different data sources and highlighted some issues and improvements.
Feature Extraction Approaches
An essential task in text analysis is the meaningful feature extraction from data. The approaches selected often have a significant impact on the data analysis itself. However, extracting insights and patterns from a text can be challenging, especially in the context of social media, where there is the issue of unstructured text. Table 2 presents the advantages and limitations of the most widespread techniques for feature extraction used in the context of hate speech detection and related subjects. In this section, we analyze features used in hate speech detection and related subjects.
Overview of the Features Used in the Context of Hate Speech Detection. Where

Dictionaries or Lexical Resources
Dictionary is a relevant approach used in natural language processing (NLP) based on keywords. This strategy lists potential keywords and counts the number of occurrences in the text or context.
These frequencies can be used as features or to compute scores. For hate speech context, different dictionaries have been available:
Hatebase is a multilingual dataset of derogatory terms with data across 95+ languages and 175+ countries. This resource offers constants updates in the terminology and a broad vocabulary (https://hatebase.org/);
Dictionary of general swear words and insults in English (https://www.noswearing.com/);
Urban dictionary of colloquial language and slang words in English (https://www.urbandictionary.com).
Previous works used this approach, in general, considering negative or derogatory words (Burnap & Williams, 2015; Gitari et al., 2015; Mathew et al., 2019; Nobata et al., 2016; Teh et al., 2018). Gitari et al. (2015) built a lexicon of hate-related verbs which encourage violent acts (such as to discriminate, loot, riot, beat, kill, and evict). Mathew et al. (2019) created a lexicon with 45 hate words selected from the Hatebase and Urban dictionary for further analysis of hateful and non-hateful users on Gab. Teh et al. (2018) constructed a lexical of profane words frequently used in different types of hate speech from comments on YouTube which showed that 35% of profane words are related to sexual orientation, based on 500 comments. Burnap and Williams (2016) focused on specialized lists toward particular subtypes of hate, such as LGBT slang terms, ethnic slurs, and negative connotation against disabled people. Hayaty et al. (2020) focused on local languages in Indonesia for hate speech detection and created a dictionary of abusive words containing of 250 terms.
Despite their general effectiveness, a limitation of this approach is the dependency oon hateful keywords (MacAvaney et al., 2019). Thus, lexical features can be employed as an additional step of feature extraction (Schmidt & Wiegand, 2017).
Distance Metric
The presence of noise and conjugations often makes it difficult to perform automatic detection of hateful content. Once derogatory words are intentionally used in text messages (Nobata et al., 2016), it is possible to identify such words with characters substitution such as “ni99er,”“@ss,”“sh1t” which can make the whole process even more challenging for automatic detection. Approaches to compute the minimum number of edit operations of individual characters like Levenshtein distance can also be used for this end (Nandhini & Sheeba, 2015). There is no lexicon for hate speech detection in some languages, such as the Amharic language. Thus, one approach employed was translating the text into English using the Google translator tool. In this approach, the researchers used the cosine distance to evaluate the semantic similarity between each input word and the corresponding vectors in the model (Mossie & Wang, 2020).
Bag-of-Words (BoW)
Bag-of-Words (BoW) is another technique used to detect hateful speech (Burnap & Williams, 2016; Nobata et al., 2016; Senarath & Purohit, 2020; Waseem et al., 2018). Similarly to the dictionary, this technique uses keywords, the main difference being that it creates a corpus from the collected training data, while the dictionary uses predefined words. After the data collection stage, word frequencies are used as a feature for training a classifier. A limitation of this approach is ignoring word sequence and its semantic and syntactic content. Hence, it may lead to the mistaken classification of words used in various contexts. Another technique that can be adopted to overcome this limitation is
A statistical analysis conducted using BoW with all typed dependencies and with only hateful and derogatory terms to investigate its influence in the classification task is presented in Burnap and Williams (2015), which follows the assumption that BoW can confuse the classification task when the same word is frequently in non-hateful and hateful scenarios. The study showed that using only hateful and derogatory terms can potentially increase the number of false negatives because the hateful content does not necessarily uses derogatory or hateful terms.
N-grams
The
Its main disadvantage is that it suffers from a high level of distance between related words (Burnap & Williams, 2016), which is closely associated with the selection of the
These features often are combined with other features to improve the hate speech classification. For instance, in Watanabe et al. (2018), the authors explored different features for hate speech detection, such as the most common word unigrams, pattern features, sentimental, and semantic features. They believed that unigrams features could help identify explicit forms of hate speech. Overall, unigrams features presented high accuracy, but all features combined performed better.
Part-of-speech (POS) is a subclass of the
Furthermore, it was also used to collect unigrams with a specific syntactic function (e.g., noun, verb, adjective or adverb) from the training set to investigate occurrences in hateful and offensive tweets (Watanabe et al., 2018). However, POS, when used as a feature, can promote confusion between the classes due to the abundance of similar patterns (Burnap & Williams, 2015; Fortuna & Nunes, 2019).
Term Frequency
The word or term frequency indicates the relevance of the word in the document that contains it. The most common types of word frequency are Term Frequency (TF), Term Relative Frequency (TFR), Inverse Document Frequency (IDF), and Term Frequency-Inverse Document Frequency (TF-IDF) (Liu et al., 2019). In Plaza-Del-Arco et al. (2020) used TF weighting to represent unigrams and bigrams as vectors of numerical features to misogyny and xenophobia detected in Spanish tweets. Several works used TF-IDF weighting features for hate speech detection (Almatarneh et al., 2019; Elisabeth et al., 2020; Mossie & Wang, 2020; Salminen et al., 2020). The TF-IDF provided good classification performance for hate speech detection with the same dataset to train and test the models. However, it did not help the model generalize well when used across different dataset domains (Senarath & Purohit, 2020).
Typed Dependencies
Typed dependencies have been widely used for hate speech detection (Alorainy et al., 2019; Burnap & Williams, 2015, 2016). The probabilistic parse trees, provided by Stanford Typed Dependency Parser (De Marneffe & Manning, 2008, can be used to extract a subset of dependency relationship labels and provide a description of the grammatical relationships in a sentence (Alorainy et al., 2019). The introduction of typed dependency features for hate speech detection can reduce the false positive rate, but this can lead to an increase in false-negative instances. This approach performed better when combined with other features (Burnap & Williams, 2016).
Template Based Strategy
In this strategy, the main idea is to build a corpus of structured sentences. Mondal et al. (2017) proposed the follow sentence structure “I < intensity> < userintent > < hatetarget >,” to search hate speech post. Thus, they additionally designed two templates, focusing on exploring hate against groups of people. The first was simply “< one word> people” for scenarios when hate was directed toward a group, and the second template used words collected on Hatebase for < hate target> tokens.
Text Embedding and Deep Learning Approaches
The embedding technique is aimed at training a model to provide a vector representation of sentence/word, which captures the semantic and the syntactic relationship between the words (Indurthi et al., 2019). Word embedding methods have improved prediction accuracy for hate speech classification (Liu et al., 2019), which can be illustrated by several studies using pre-trained word embedding approaches, such as Word2vec, GloVe, FastText, ELMo, LASER, XLM, BETO (Cao et al., 2020; del Arco et al., 2021; Miok et al., 2019; Senarath & Purohit, 2020; Sreelakshmi et al., 2020; Vitiugin et al., 2021). The pre-trained word embedding had been proven effective for abusive text classification. Besides, it required fewer training samples to obtain a good performance (Founta et al., 2019). Another approach is sentence embedding which represents sentences as vectors. Miok et al. (2019) proposed a model for hate speech detection in three datasets (from Twitter and YouTube) using word and sentences embedding. The approach used the LSTM model with Monte Carlo dropout obtained better performance by using pre-trained sentence embedding than word embedding and state-of-the-art features.
However, an issue faced with pre-trained word embedding is out-of-vocabulary (OOV) words. Particularly, present on social media data because of its colloquial nature, users often perform intentional obfuscation of words which can be mitigated by performing pre-processing before feature extraction for noise reduction (Zhang & Luo, 2019). Corazza et al. (2020) investigated the impact of word embedding and emoji embedding on the specific domain and compared it with pre-trained embeddings, such as FastText. Specific embedding improved the results but needed a large amount of data. On the other hand, pre-trained embedding using binary models could mitigate the issue of OOV word, since this approach provided sub-words information.
Deep neural network (DNN) techniques have been recently explored to learn abstract feature representations for hate speech detection. The most popular approaches are the Convolutional Neural Network (CNN) and the Long Short-Term Memory network (LSTM). In the context of hate speech classification, CNN was applied as a feature extractor, and LSTM was used for modeling sequences of word or character dependencies (Bouazizi et al., 2021; Kapil & Ekbal, 2020; Sajjad et al., 2019; Santosh & Aravind, 2019; Zhang et al., 2018).
Even though very expensive, another approach explored was deep learning ensembles that used CNN for feature extraction (Zhou et al., 2020; Zimmerman et al., 2018). These techniques are robust and improve the results of the different classification tasks. In a study conducted in seven datasets from Twitter in the English language (Zhang & Luo, 2019), CNN showed more effectiveness for specific types of hate (racism and sexism) than polarized data (hate and non-hate).
Other approaches have investigated the language model pre-training BERT (Bidirectional Encoder Representation from Transformers) (Calabrese et al., 2021; Wich et al., 2021). BERT was designed to pre-train deep bidirectional representation. In Hendrawan et al. (2020), analyzed the BiLSTM and the BiLSTM with BERT multilingual trained with Wikipedia from 104 languages. However, the BiLSTM with BERT was less effective than the BiLSTM and the Random Forest Decision Tree.
Sentiment Analysis
Sentiment analysis is often considered synonymous with “opinion mining,” a field of study that aims to analyze a person’s feelings, opinions, and emotions toward “elements” (Serrano-Guerrero et al., 2015). The “elements” in this context can represent individuals, events, services, products, and topics. Sentiment analysis and hate speech are related, and often negative sentiments are associated with hate speech messages (Schmidt & Wiegand, 2017).
Several works have used the sentiment as a feature for hate speech detection (Cao et al., 2020; Corazza et al., 2020; Gitari et al., 2015; Rodriguez et al., 2019). Features based on emotions and sentiments are relevant approaches and can improve classification tasks on hate speech detection (Corazza et al., 2020; Markov et al., 2021). However, supervised methods required labels for sentiment classification and hate speech datasets often did not have this information. Different automatic tools were explored to overcome this limitation of supervised methods for sentiment analysis, such as JAMMIN, an emotion analysis tool, and VADER (Valence Aware Dictionary for sEntiment Reasoning), a sentiment analysis tool (Cao et al., 2020; Rodriguez et al., 2019).
Although related, it is arguable that hate speech detection is a different task requiring more sophisticated techniques (Watanabe et al., 2018). In sentiment analysis, the presence of positive/negative words or expressions can be considered helpful in this process. The presence of negative words or expressions, even in such sentences using the word “hate,” depending on the context, does not make them related to hate speech. Thus, this approach for feature extraction is usually used with other techniques to improve results (Cao et al., 2020; Corazza et al., 2020; Watanabe et al., 2018).
Meta-information
Additional information from social media can help better understand the characteristics of the post-context and provide valuable data for hate speech detection. Social media platforms offer a wide variety of information that can be collected through APIs, such as user gender, demographics data, timestamp, user profiles, and network structures (Ayo et al., 2020; DeSouza & Da-Costa-Abreu, 2020).
Background information about the user can improve the predictably of hateful messages since hateful users are densely connected (Ribeiro et al., 2018). In a study about the impact of information like user gender and demographic information in tweets (Waseem & Hovy, 2016), these features brought slight improvement, but this could be because of the lack of coverage. Information about user gender was also explored in Unsvåg and Gambäck (2018), which used a similar approach performed in Waseem and Hovy (2016), to identify the user gender based on username or profile names as well as the user description in messages. However, a limitation of this approach is names used for both female and male. Another approach investigated the metadata based on text content to analyze specific attributes in tweets, such as the number of hashtags and mentions of other users, emoticons in the tweet, words with only uppercase letters, URLs included, and frequency of punctuation marks (Al-Makhadmeh & Tolba, 2020; Chatzakou et al., 2017; Del Vigna et al., 2017; Founta et al., 2019).
Furthermore, another meta-information relevant is the user network, such as user friends and followers. These features are beneficial in classifying aggressive user behavior (Chatzakou et al., 2017). Features about user behavioral are also useful for detecting racist and sexist messages (Pitsilis et al., 2018). These features can help describe the user’s tendency toward the class based on their tweets history, post content, and subsets of those tweets with labeled messages. This information is scarce and often not readily available for external research (Cao et al., 2020; MacAvaney et al., 2019). Since these data have sensitive information about users and publishing raises privacy issues. Moreover, user information can introduce bias in the model against particular users or groups (MacAvaney et al., 2019).
Other Techniques
Other features used in the classification task are based on Flesch-Kincaid Grade Level (FKGL) and Flesch Reading Ease (FRE) scores to measure the quality of a document (Şahi et al., 2018); Pattern features ( Watanabe et al., 2018); Latent Dirichlet Allocation (LDA), typically used for topic modelling. Cao et al. (2020)used LDA to determine the posts’ topic distribution in each dataset, considering each post as a single document.
Texts extracted from social media platforms often contain URLs, punctuation, symbols, username, and tags such as “@,” RT and < >. Some studies, before the feature extraction stage, have used stemming and removed special characters and stop-words (Zhang et al., 2018). However, using stemming, some words in the Indonesian language can be converted into words with different meanings, such as “dadakan” which means all of sudden to “dada” which means chest. Besides, stop-word removal can reduce the information from the sentence (Hendrawan et al., 2020).
Classification Methods
Automated hate speech detection on social media is a complex problem. Several approaches have been explored to deal with this problem, such as classic supervised machine learning methods, ensemble, and DNN techniques. Table 3 summarizes several studies with the results for the best model for each work.
Summary of Studies for Hate Speech Detection on Social Media.
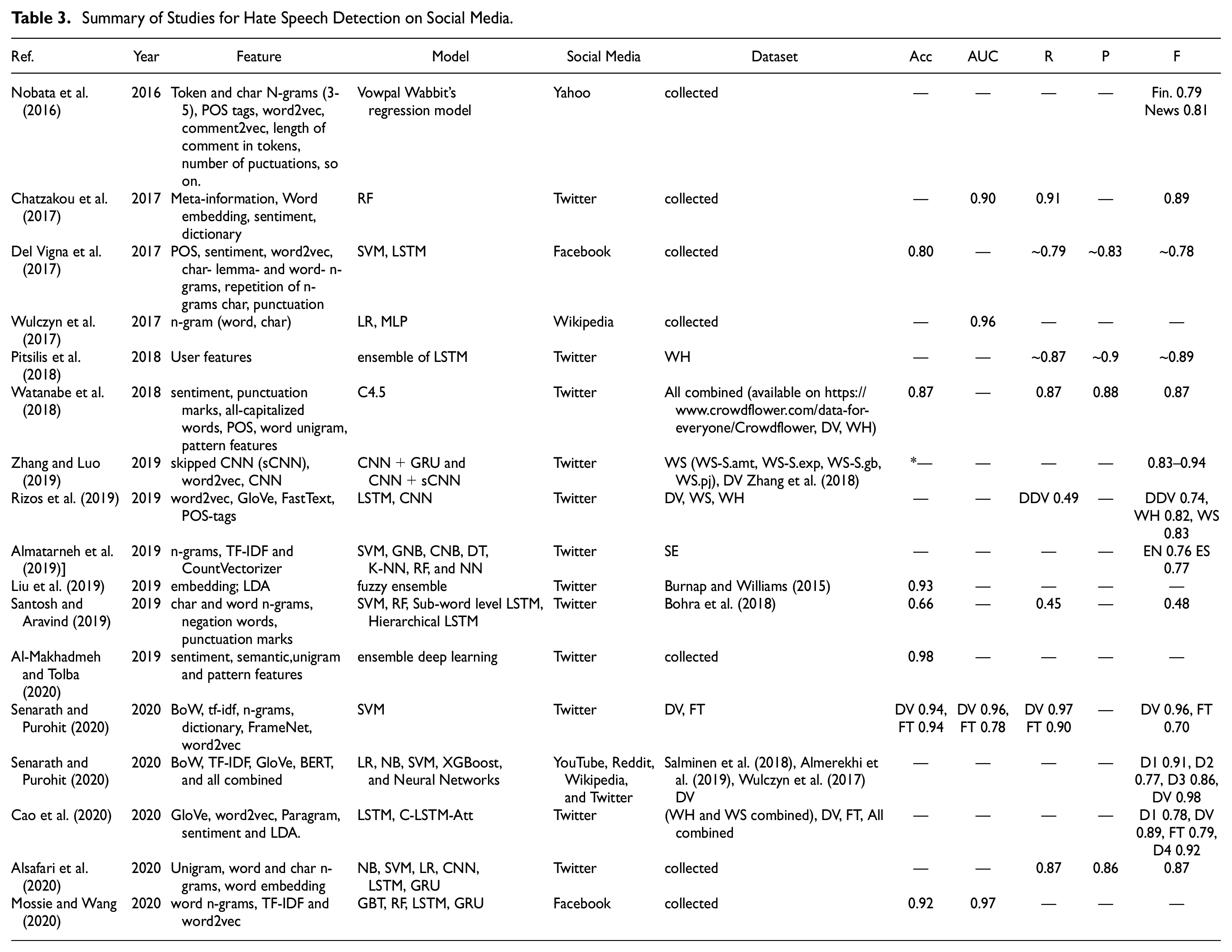
Classic supervised machine learning methods have been explored for automated hate speech detection. Nobata et al. (2016) developed a machine learning based method to detect hate speech from the “Yahoo! Finance and News” dataset that outperformed a deep learning approach. The decision tree classifiers were also explored for hate speech detection and related subjects (Chatzakou et al., 2017; Watanabe et al., 2018). In the study Chatzakou et al. (2017), the Random Forest classifier presented a better performance in classifying bullying and aggressive behavior from a Twitter dataset than other tree classifiers experimented (J48, LADTree, LMT, NBTree, and Functional Tree), with 90% AUC (Area Under Curve). The authors in Watanabe et al. (2018) also analyzed datasets from Twitter. The data was collected and combined from three different datasets labeled as hateful, offensive, or clean. They selected the C4.5 decision tree to classify the data in two explored approaches binary and ternary. The binary classification (polarized the tweets as offensive and clean) obtained an accuracy of 87.4%, and the ternary classification (polarized the tweets as hateful, offensive, and clean) had an accuracy of 78.4%.
Del Vigna et al. (2017) analyzed the SVM classifier and a recurrent neural network LSTM on a dataset from Facebook in the Italian language. The classifiers presented a similar performance for hate speech detection. The LR and MLP are used in Wulczyn et al. (2017) both classifiers obtained 96% AUC. Several classifiers are explored in Almatarneh et al. (2019). In the study, the Complement Naive Bayes (CNB), SVM, and RF presented the best performances to identify specific hate speech against women and immigrants in English and Spanish languages. The SVM was also used in Senarath and Purohit (2020) to evaluate semantic features of social media messages for hate speech detection.
Salminen et al. (2020) analyzed hate speech as a problem of multiple social media platforms (YouTube, Reddit, Wikipedia, and Twitter). They investigated multiple algorithms and individual features as well as combined features. The ensemble algorithm XGBoost (Extreme Gradient Boosted Decision Trees) presented a more significant performance than the other algorithms analyzed (F1 = 0.92). In the analysis of the features, the models show the best performance with BERT features.
Another approach explored is the Deep Neural Network (DNN), which has been used for feature extraction and classifier training. The most used classifiers are LSTM, CNN, and GRU (Al-Makhadmeh & Tolba, 2020; Alsafari et al., 2020; Cao et al., 2020; Mossie & Wang, 2020; Pitsilis et al., 2018; Rizos et al., 2019; Santosh & Aravind, 2019; Zhang & Luo, 2019). Cao et al. (2020) proposed a framework for hate speech detection on social media, namely DeepHate. They evaluated the DeepHate using three public datasets and the combination of the three datasets. The DeepHate outperformed different CNN models.
An ensemble of recurrent neural networks is also investigated for hate speech detection (Pitsilis et al., 2018). The authors proposed an ensemble of LSTM with the user’s tendency toward each class as a feature method. Their model proposed has obtained more effective results than state-of-the-art with the detection of sexist messages (about F1-score = 0.99), neutral (about F1-score = 0.95), and racism (about F1-score = 0.70).
The ensemble deep learning method was also explored in Al-Makhadmeh and Tolba (2020). The authors proposed a hybrid approach, namely Killer Natural Language Processing Optimisation Ensemble Deep Learning (KNLPEDNN), which combines NLP and machine learning techniques. They used Stormfront (a neo-Nazi website) and CrowdFlower Twitter datasets. The ensemble method was used to minimize the weak features and to improve the prediction of hate. The system obtained 98.71% accuracy.
The models used different metrics to evaluate the performance of the models, such as Accuracy (Acc), AUC, Precision (P), Recall (R), and F-measure (F). Accuracy measures the number of correctly predicted samples among all predicted samples. The AUC computes the area under the ROC Curve. Precision measures the percentage of true positives among the true and false positives predicted. Recall measures the percentage of true positive cases that are correctly predicted positive. The F-measure calculates the harmonic average of precision and recall. Despite the results obtained in the studies evaluated, it needs to be clarified which model performed better. Furthermore, several works evaluate only the dataset collected by itself without evaluating whether the model generalizes well to other domains.
Research Directions and Gaps for Hate Speech Detection on Social Media
This section aims at presenting challenges and points out automatic hate speech detection opportunities on social media platforms. As our previous sections suggested, the community has developed several resources to benefit from benchmark datasets for hate speech detection on social media platforms. Several feature extraction techniques and classification methods are employed on hate speech detection and related subjects. Figure 3 presents information about the popularity of the approaches used for feature extraction, and Figure 4 presents the classification method’s popularity. The feature extraction techniques more used are embedding and DNN, and the
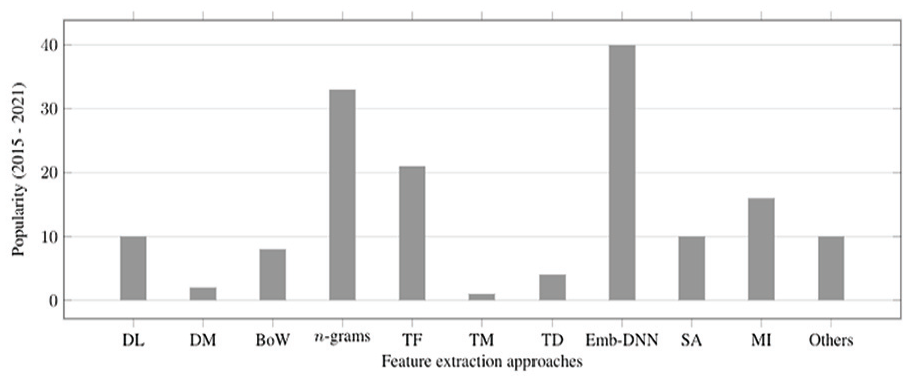
The frequency of feature extraction techniques from 2015 to July 2021.
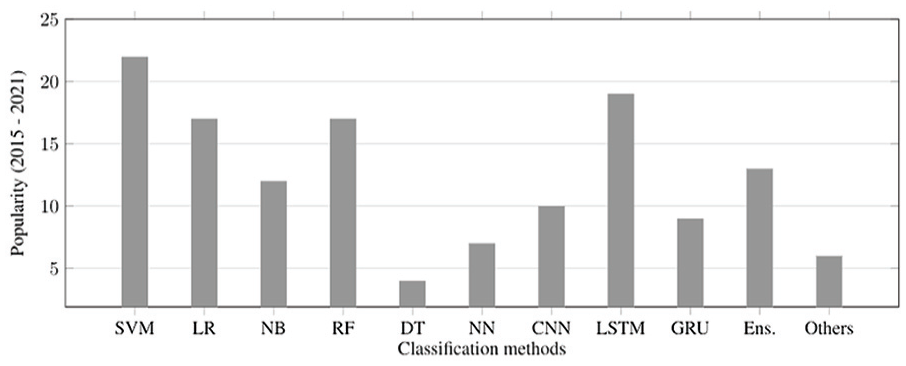
The frequency of classification methods from 2015 to July 2021.
Challenges and Opportunities
Hate speech detection is a complex phenomenon and difficult to recognize, both by humans and machines. Despite the efforts of the scientific community, different open challenges can be highlighted:
Issues with datasets: include bias because, in many cases, most data belong to the same user. Thus, dataset bias can overestimate the current state-of-the-art (Arango et al., 2019; Calabrese et al., 2021). In particular, one of the most widely used datasets, proposed in Waseem and Hovy (2016), most of the data are generated by a few users. The dataset has more than 16k tweets annotated as racist, sexist, and neither sexist nor racist, where only nine users sent the 1,972 for racist content;
Context-dependent: transfers poorly across datasets, different approaches present high performance, however only within specific datasets, in which training and test sets were taken from the same dataset (Arango et al., 2019; Gröndahl et al., 2018; Senarath & Purohit, 2020). This issue can be motivated by the influence of the social-demographic and cultural context of the dataset collection that can affect the data sampling and annotation methodology (Waseem et al., 2018);
Polysemy words: when the word has many different meanings, hidden the actual text interpretation (Senarath & Purohit, 2020);
Imbalanced dataset: detection methods should not be vulnerable to imbalanced classes. Usually, hate speech datasets are highly imbalanced, with a small percentage of hate content, while most data are non-hate content. Practical resources often need to focus on the minority class (hate content). Therefore, the results evaluated using micro-average metrics on the entire dataset can hide the real performance of minority classes (Charitidis et al., 2020; Zhang & Luo, 2019);
Despite the efforts to automatically identify hate speech, a limitation is classifying messages without explicitly hateful words (Alorainy et al., 2019; MacAvaney et al., 2019);
Despite the challenges, we also can point out some opportunities in this field.
Conclusion
In this paper, we have presented a critical overview of automatic hate speech detection in text from the period between 2015 and 2021. So far, this task has been designed as a supervised learning problem and has used different techniques for feature extraction. Several works have applied simple features and feature extraction techniques, such as BOW,
Judging which approaches are the best is a complex issue because several studies evaluate only one dataset, and many are private. Hate speech detection is a recent subject, and different weaknesses still need to be explored.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article: This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001 and Scholarship no. 88887.484211/2020-00.