
Abstract
Individuals acquire increasingly more of their political information from social media, and ever more of that online time is spent in interpersonal, peer-to-peer communication and conversation. Yet, many of these conversations can be either acrimoniously unpleasant or pleasantly uninformative. Why do we seek out and engage in these interactions? Who do people choose to argue with, and what brings them back to repeated exchanges? In short, why do people bother arguing online? We develop a model of argument engagement using a new dataset of Twitter conversations about President Trump. The model incorporates numerous user, tweet, and thread-level features to predict user participation in conversations with over 98% accuracy. We find that users are likely to argue over wide ideological divides, and are increasingly likely to engage with those who are different from themselves. In addition, we find that the emotional content of a tweet has important implications for user engagement, with negative and unpleasant tweets more likely to spark sustained participation. Although often negative, these extended discussions can bridge political differences and reduce information bubbles. This suggests a public appetite for engaging in prolonged political discussions that are more than just partisan potshots or trolling, and our results suggest a variety of strategies for extending and enriching these interactions.
Keywords
Introduction
Digital communication plays a critical role in our political infrastructure. Online platforms have expanded the reach of “kitchen table conversations,” as people increasingly turn to social media as a primary news source (Bakshy, Messing, & Adamic, 2015; Lee & Ma, 2012; O’Connor, Balasubramanyan, Routledge, & Smith, 2010) and elected officials use digital channels to communicate with their constituents (Farina, Epstein, Heidt, & Newhart, 2013; Kavanaugh et al., 2012). Such interactions are often modeled as one-shot games or as evidence of long-term links in a social network (Feng & Wang, 2013; Myers & Leskovec, 2014). Yet, much online activity consists not of single-shot, unidirectional interactions with elites, but repeated interactions among peers. These iterated interactions—conversations—have important implications for political theory: while conventional wisdom claims that brief social media interactions have little effect on subsequent online behavior, a number of recent experiments have shown modest but real effects of single-shot interactions (Friggeri, Adamic, Eckles, & Cheng, 2014; Munger, 2017). Deliberative theory suggests that repeated interpersonal interactions where individuals engage in extended conversation may have even more substantial effects (Axelrod, 1987; Bednar & Page, 2007; Habermas, 1984).
In this article, we focus not on persuasive outcomes but on the more fundamental question of what leads people to engage in extended online conversation and argument in the first place. Existing work in this area has generally had a more practical bent, focusing on tweet- or conversation-level recommendation and aiming to predict user interest in conversation threads to better curate and recommend targeted content. Such work has looked at user engagement in various forms of online conversation (Chen et al., 2012; He & Tan, 2015; Vosecky, Leung, & Ng, 2014; Yan, Lapata, & Li, 2012), as well as via retweeting (Feng & Wang, 2013; Hong, Doumith, & Davison, 2013) and re-entry back into existing conversations (Backstrom, Kleinberg, Lee, & Danescu-Niculescu-Mizil, 2013). Our work here is closest to the latter: We are more interested in the extended dynamics of conversation, particularly the decision to re-engage or exit, than in the initial decision to interact. We focus on users who have already made that initial participation, and seek to understand and predict whether and when they re-engage based on user, tweet, and thread-level features.
While ongoing deliberative conversation is the substantive focus here, this framing also turns an impossible problem—predicting initial responses to a tweet out of the entire pool of twitter users—into a practicable prediction task—predicting re-participation of users whom we know are already part of a conversation. This approach also conditions out the even harder problem of explaining the origins of an initial tweet or conversation, particularly given the immense variety of motivations behind those first moves. Instead, we focus on existing conversations—at least a first move followed by a response—and model the processes that lead to extended and branching conversations among existing participants. Twitter might seem less suited to such models than traditional online forums, but Twitter in fact produces immense quantities of impromptu extended, branching conversations, and by focusing only on re-entry by existing participants, we can study what causes individuals to continue an argument or drop out, bracketing the question of initial engagement.
By conditioning on existing user interaction, we aim to get more deeply at the question of why people bother arguing online. What brings them back to a repeated argument? What factors contribute to an individual returning to or abandoning an argument? While in face-to-face settings, social etiquette suggests that a comment will most likely be greeted with a response, there is no a priori reason to expect a response to the vast majority of online posts. While we expect to find many types of conversations occurring online, we might expect that more extreme content (positive or negative) will increase engagement, as trolls successfully incite arguments and partisan allies reinforce each other’s positions (Cheng, Danescu-Niculescu-Mizil, Leskovec, & Bernstein, 2017). Between the extremes lies a more productive and interesting mode of engagement: true deliberative argument, in which participants exchange content in a genuine attempt to persuade or inform. Such behavior is not as uncommon as skeptics might assume, and is prevalent in knowledge-sharing platforms such as StackOverflow, Yahoo! Answers, and other such forums, where users may be motivated to some degree out of a general sense of community (Adamic, Zhang, Bakshy, & Ackerman, 2008; Anderson, Huttenlocher, Kleinberg, & Leskovec, 2012; Oktay, Taylor, & Jensen, 2010) even as they argue over better or worse solutions to shared problems.
We find evidence for all of these behaviors in our data and, in particular, show that while many of these engagements are negative, conversations often cover a range of emotions and go on far longer than a single-shot attack or mutual trolling might suggest. While we leave for later the ultimate question of persuasive effect, we establish here that even a medium as apparently unpromising as Twitter is full of complex, extended political conversations, and that individuals’ decision to repeatedly re-engage in those conversations is surprisingly systematic.
Related Work
Much of the theoretical work around questions of conversational dynamics has been done within the literatures of deliberation and persuasion. While both these approaches focus their attention on back-and-forth conversations, they vary in their characterization of those conversations. The persuasion literature looks broadly at how people convince others and “win” arguments, while the deliberative ideal imagines thoughtful participants reasoning together to generate public opinion centered on the common good (Cohen, 1989; Habermas, 1984). “Reasons” may constitute factual arguments or emotional appeals (Mansbridge, 2015), but ideal deliberation is often taken to be free of persuasion, coercion, or other forms of instrumental action (Habermas, 1984). Contra persuasion models, ideal deliberators should engage in rational speech acts—aiming to honestly express themselves and truly trying to understand the other. Huckfeldt, Mendez, and Osborn (2004) argue that ideal citizens “are those individuals who are able to occupy the roles of tolerant gladiators—combatants with the capacity to recognize and respect the rights and responsibilities of their political adversaries” (p. 91) If political debate serves to sharpen our own understanding and build our collective knowledge, then we owe it to our interlocutors to press them on their positions, to find the holes in their armor and encourage refinement of beliefs. The process of debate makes us all better—thus allowing tolerant gladiators to walk away as friends. Citizens who silence their discussants, seek to coerce others, are easily persuaded by false beliefs, or who otherwise refuse to engage in rational argument, therefore, do a disservice to themselves and to their communities.
Experience tells us, however, that such a lofty deliberative ideal is rarely met in political conversation. Sunstein (2002) advances the “law of group polarization,” finding through numerous empirical studies that “deliberation tends to move groups, and the individuals who compose them, toward a more extreme point in the direction indicated by their own pre-deliberation judgments” (p. 175). Sunstein argues this polarization is the natural result of the social context, which serves as a significant driver of individual actions and opinions. Hearing friends express a view makes a person socially inclined to express the same view. In other words, deliberating groups tend toward extremism in the direction of the predeliberation median because nobody wants to take the social risk of expressing an unpopular view. Sanders (1997) similarly argues that the broader context of power dynamics frequently has a debilitating but under-recognized effect on deliberation, as marginalized individuals feel silenced and unable to share their true opinions. Importantly, the majority of participants may mistakenly assume that such power effects are negligible if “deliberation appears to be proceeding.”
Another line of work has tackled conversational dynamics from the perspective of the data-processing problem of platform curation, for example, trying to predict which posts will be popular for the purpose of highlighting those posts for users. Much of this work focuses on post-level engagement, predicting engagement as a function of topics (Hong et al., 2013) or social network structures (He & Tan, 2015; Pan, Cong, Chen, & Yu, 2013). Much of this work has considered “popularity” as a raw aggregate of engagement with an initial post, finding, perhaps unsurprisingly, that the popularity of a user’s past content is a strong predictor for the popularity of their future content (Artzi, Pantel, & Gamon, 2012). Backstrom et al. (2013) break the task into related subtasks: length prediction and re-entry prediction. Intuitively, these subtasks indicate distinctive types of threads: threads which are long because a high number of users chime in a small number of times—to offer congratulations or condolence, for example—while other threads are long because a small number of users contribute a large number of times in a back-and-forth conversation. Supporting this theory, Backstrom et al. (2013) find that the number of distinct users in long threads follows a bimodal distribution. Using data from Facebook and Wikipedia, Backstrom et al. (2013) find the identities of recent commenters is most predictive of conversation re-entry.
This lattermost line of work is largely atheoretical and not particularly concerned with normative issues. While the current study borrows many of their methods, we are also fundamentally interested in the dynamics of online conversation from a deliberative perspective. Thus, we are interested less in conversation recommendation or modeling engagement in conversations per se, and more focused on how individual speech acts (tweets) lead existing discussants to re-engage with each other or abandon a conversation. Regardless of the outcome of a conversation, it is important to understand what sustains conversations—particularly acrimonious ones—and keeps mutual opponents or supporters engaged with each other. As we will see, this engagement can take more or less productive forms, but simply understanding the deliberative dynamics is an important first step.
Data
For this study, we collected a corpus of 7,053 Twitter conversations during the month of October 2017 seeded by tweets with the keyword “Trump.” For each tweet discovered through keyword search, we extract the entire conversation tree of preceding and following replies, if there is one. Such trees may be composed of multiple branching threads, each connecting to the same root tweet.
We then used the Twitter API (Application Programming Interface) to retrieve tweet metadata for each tweet in the conversation tree. We discard trees which have no conversations longer than a minimum of three exchanges or in which tweets have been deleted, as metadata for those tweets cannot be retrieved.
Our full corpus contains 7,053 conversations comprised of 63,671 unique tweets. The distribution of thread length is heavy-tailed: by construction, the minimum thread length is 2, while the longest thread contains 108 tweets. The average length of a thread is 5.6 tweets with a standard deviation of 4.1, and the mean number of unique users in a conversation is 3.7, with a standard deviation of 1.2. The distributions of length and users by thread can be seen in Figure 1. Furthermore, as we might expect from social media engagement, responses tend to occur within a relatively compressed time period. Just under half (40%) of the tweets in our sample are posted within 5 min of the tweet which proceeds it in the conversation. About three quarters (70%) are posted within 1 hr, and nearly all (95%) take place within a day. The cumulative distribution of inter-event time—that is, the number of hours between tweets—can be seen in Figure 2.

Distributions of length and users by thread.

Cumulative distribution of the time taken to reply to a tweet for those tweets with replies.
Model
Our fundamental question is why someone continues to engage in (or stops engaging in) an online conversation. What makes a person participate in or abandon a discussion? We examine this question by modeling conversation as an interlaced exchange between two or more participants. For a tweet observed at time step
While anyone in the Twitter universe may conceivably reply to a tweet, our interest is in modeling the actions of those who are already part of a conversation in a loose sense: first, because this makes the prediction problem practical and, second, because it allows us to model engagement in dialogue, not just taking potshots on a microblog. Furthermore, as many threads on Twitter are initiated by entities unlikely to participate in conversation—such as corporations, celebrities, politicians, and bots—we take our pool of candidates to be users who have already responded at least once in a given thread, ruling out the user who initiated the thread unless they also replied to another tweet in the conversation. We consider self-replies to be a continuation of a thought, and thus not a “reply” in the traditional sense. We therefore do not include the author of a tweet in the list of candidates who may respond to that tweet.
Our predictive model is structured as follows: For conversation
Table 1 illustrates a conversation thread from time step
Example Conversation Flow Between Participants

For our dataset of 7,053 conversations, this results in 1,016,492 total observations, with 110,035 observed instances of 1 (candidate users who responded) and 906,457 observed instances of 0 (candidate users who did not respond). This gives us a baseline prediction accuracy of 89% if we guess that all candidates never respond.
Features
We expect a user’s tendency to reply to a conversation to be influenced by a number of factors and their interactions. Previous work (Artzi et al., 2012; Backstrom et al., 2013; Feng & Wang, 2013; Hong et al., 2013) has generally focused on predicting conversation-level engagement (i.e., whether a user participates anywhere in a conversation) and has, therefore, primarily focused on the candidate user who might reply as well as features of the overall conversational thread. As we are interested here in the more specific problem of predicting the points at which an existing participant replies or does not reply, we further include features related to the author who might receive a reply, as well as the tweet that may be replied to.
This gives us three sets of features and related hypotheses which we discuss in the follow subsections:
Candidate and Recent Tweet Features
At the most basic level, we would expect that active users will be more likely to reply at any given point in the conversation (H1a). The most readily available measures of engagement for a user are the number of others they follow (
At the level of thread–user interactions, we would also expect that a user is more likely to reply as a function of how engaged they have already been in the conversation (number of replies) up until that time, and presumably less likely to respond the longer it has been since their last comment (H1c). We include two features to capture this dynamic: a binary variable
We also examine content-level characteristics for candidates by evaluating the topical distribution and emotional valence of their most recent tweet in the conversation prior to time
Conversation Thread Features
Following recent work in this area (Artzi et al., 2012; Backstrom et al., 2013; Feng & Wang, 2013; Hong et al., 2013), we would expect various features of the conversation up until time
Current Tweet and Author Features
Our approach differs most significantly from past models in that we are interested not only in user engagement overall in a conversation but also in predicting the conversational points at which a user chooses to engage. To model this requires accounting specifically for the features of each tweet that may be replied to, as well as features of that tweet’s author.
For author characteristics, many of the user features discussed in “Candidate and Recent Tweet Features” section may also influence the probability of an author receiving a reply. This may be mediated indirectly via the tweet, or directly in those cases where the author is known to the potential respondent. The author’s activity levels, for instance, might be positively correlated with the likelihood of reply, indicating a tendency to produce more engaging tweets (H3a). Conversely, while popularity may decrease a candidate respondent’s likelihood of replying, a tweet from a popular author may be more likely to receive a response (H3b).
In regard to the current tweet itself, there are many coarse structural (as opposed to content) aspects which may reflect latent characteristics of the tweet such as its general popularity or interest. Using tweets’ time stamps, we calculate the count of the current tweet’s favorites, retweets, and replies which were visible at the time of a candidate’s response. We expect these features to generally have a positive effect on reply probability (H3c), although the first—favorites—may not have the opposite effect, if this action reflects silent agreement rather than a tendency to respond. A related measure of tweet “quality” is the ratio of retweets to replies, which we also include. We also include the length of the tweet and the device used to post it.
Because we would expect cyclical variation in activity, as users are naturally more likely to be active during certain hours of the day and on certain days of the week, we control for this tendency using cyclic transformations (Cox, 2006) of the day and hour at which a tweet was posted. These features are represented with the
Finally, at the level of the current tweet’s content, there are a wide variety of semantic and other linguistic characteristics that might increase the likelihood of reply (H3d). A tweet which mentions a large number of users may be more likely to elicit a response from those users or others; a larger number of hashtags may similarly increase the probability of response; and there is some evidence to suggest that tweets that include information such as a URL will be more popular as well (Bakshy, Hofman, Mason, & Watts, 2011).
At the level of sentiment and emotion, we hypothesize that users will be more likely to engage in conversations which are more emotionally extreme—whether participating in shouting matches of negative emotion, or vigorously reinforcing each other with positive emotion (H3e). We measure the emotional content of a tweet using several methods. These approaches use existing dictionaries to assign a valence score to each word and calculate the overall emotional value of a tweet as the average valiance of its component words. We capture a tweet’s
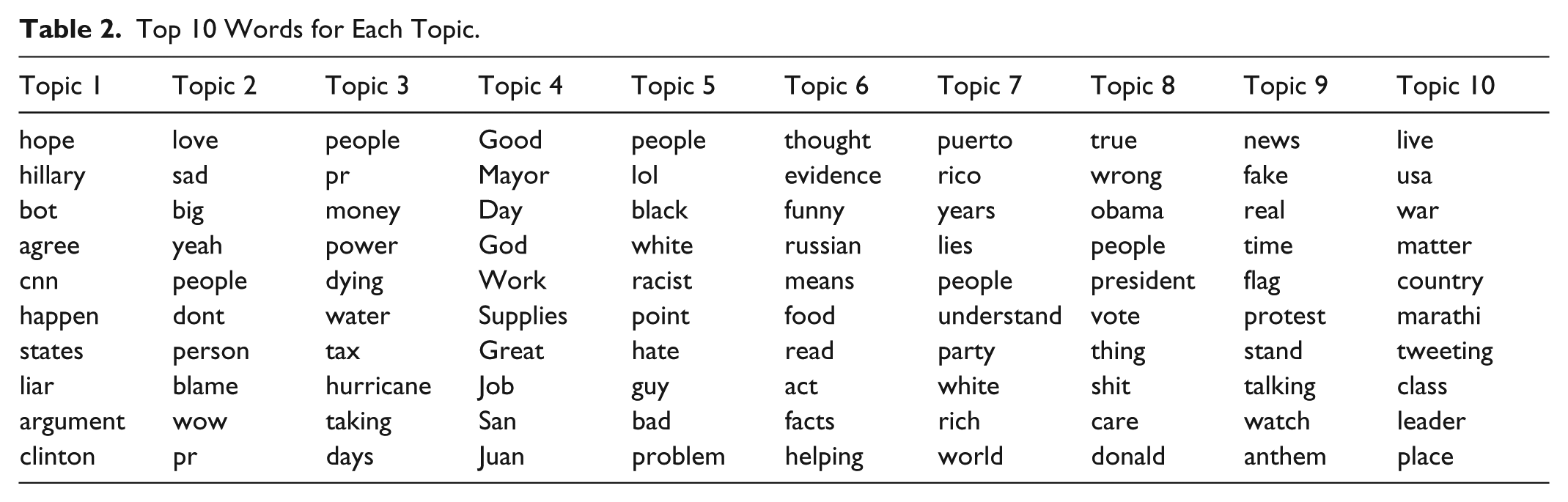
Finally, to capture higher level semantic content, we use Latent Dirichlet allocation (LDA) topic modeling (Blei, Ng, & Jordan, 2003) to identify topics in the corpus. In this model, each topic has an associated word distribution, and each document (tweet) has an associated topic distribution; by inspecting the former, one can discern the “meaning” of each topic, and by inspecting the latter, one can discern the topical focus of a tweet or, aggregated over all an author’s tweets, the topical interests of that author. We pre-process tweets by removing punctuation, user handles, and standard English and Spanish stopwords—the latter because tweets in our corpus contain code-switching between English and Spanish. In addition, we treat “Trump” as a stopword for this corpus as it is the search term from which conversations were collected. Running LDA for 10 topics, 3 we take as features the topic distribution of the current tweet (i.e., 10 features) as well as the topic distribution of the most recent tweet in the conversation by the candidate user.
Table 2 shows the top 10 words associated with each of the 10 topics derived from our corpus of tweets. Note that topics are arbitrarily numbered and the labels presented here do not reflect a ranking. We can see that our collection of political tweets from October 2017 focused on stories such as emergency response in Puerto Rico (Topics 3, 4, and 7), National Football League (NFL) players kneeling during the national anthem (Topic 9), racism (Topic 5), and comparisons between President Trump and Democratic leaders (Topics 1 and 8).
Top 10 Words for Each Topic.
Results
Prediction Accuracy
As responses are so rare, for a little under 90% of the observations, one would predict a response correctly by simply guessing a non-response for every possible respondent. This sets a relatively high baseline for prediction, but we find that using a straightforward logistic regression with the features described above significantly improves upon this baseline, achieving 94% out-of-sample accuracy 4 in predicting exactly who among the previous participants in a conversation will and will not respond to a given tweet.
Using a support vector machine (SVM; Boser, Guyon, & Vapnik, 1992), we are able to increase that accuracy to 98%, suggesting that there may be significant interactions and nonlinear effects among our features. Our SVM model is especially good at predicting nonresponses, erroneously predicting a response when the truth was a nonresponse only about 1% of the time. Conversely, as there are so few responses, we more often erroneously predict a nonresponse, getting about 13% of the true responses wrong, although that only amounts to another 1% of the total sample. In all, about half of our errors are false 0s and half are false 1s, showing that the model does a very good job overall of predicting both when people will choose to respond and when they will chose not to.
Tables 3 to 6 show the coefficients from the logistic regression model, as interpreting per-feature effects for SVMs is notoriously problematic. However, even for the logistic regression, identifying which features are “significant” is a non-trivial problem with so many features. With 1,016,49 observations, by most traditional measures of statistical significance, almost all of our features are statistically significant, regardless of the substantive magnitude of their effect. Even after multiple testing correction, 5 most coefficients are still significant.
Response Predictors: Candidate Respondent.

Note. FDR = false discovery rate.
p < .1. **p < .05. ***p < .01.
However, in another sense, we do not have nearly as many observations as it may appear, as for any given tweet, very few choose to respond, and most responses are 0s. Furthermore, all tweet- and author-level conditions are shared across all the individuals who may or may not respond to that tweet. Thus, it makes sense to cluster errors at the current-tweet level, reflecting the fact that the number of observations with variation in tweet- and author-level features is far fewer than the simple count of observations would imply. After doing this, approximately half of our features lose their significance, and even more do so if we run false discovery rate (FDR) correction after error clustering. However, from a prediction point of view, this may be going too far, as our testing suggests that almost every feature—even if not significant by traditional statistical measures—does increase out-of-sample accuracy. This gap between the prediction and statistics literatures (Lo, Chernoff, Zheng, & Lo, 2015; Shmueli, 2010) goes beyond the scope of this article, so we present significance levels for all three corrections, and focus on the cluster-corrected version in most cases as being the most prevalent approach in the social sciences.
As in the previous section, we discuss the feature effects by category, as each category speaks to a different family of hypotheses. But it should be reiterated that Tables 3 to 6 all derive from the same single logistic regression, and are only broken up for convenience.
Response Predictors: Candidate Respondent
Table 3 shows results for features pertaining to the candidate respondent who has previously participated in the conversation and now may decide whether to respond to the current tweet or not. At the general level, we find that as expected in H1b, more popular users are less likely to re-engage even though they have done so already. Similarly, users are less likely to respond if they are verified or have more followers, although this effect is more fragile to cluster correction.
Interestingly, although it is also nonsignificant after clustered-error correction, while users who are generally more active on Twitter are more likely to respond, as predicted in H1a, a user who has been more active in a given conversation may actually be less likely to respond. We measure conversation activity (comments count) as the number of comments made prior to time
Table 4 shows the effects for the candidate respondent’s previous tweet in the conversation. Note that in addition to the features discussed below, Table 4 also shows our controls for time-varying effects using cyclic transformations of hours and days of week, which control for periodicities such as the tendency to reply more in the evenings or on weekends (Cox, 2006). Many of these features are strongly predictive of response even after various error corrections. In support of H1c, users are significantly more likely to respond if they were the author of the previous response (
Response Predictors: Candidate Respondent’s Previous Tweet.

Note. FDR = false discovery rate.
p < .1. **p < .05. ***p < .01.
We find some evidence to suggest that candidates whose most recent tweet was longer (
We also see interesting effects around the emotions of a candidate’s most recent tweet. Based on a tweet’s VADER score, it appears that, in support of H1e, if a candidates’ most recent tweet was negative, they are more likely to maintain engagement in a conversation, whereas if their tweet was positive, they are less likely to continue interacting. We will return to interactive emotional dynamics in “Response Predictors: Current Tweet and Author” section.
Finally, in this corpus, users whose previous tweets focused on Topics
Response Predictors: Conversation
Table 5 summarizes the effects of the features of the conversation thread itself, specifically the number of
Response Predictors: Conversation Features.

Note. FDR = false discovery rate.
p < .1. **p < .05. ***p < .01.
Response Predictors: Current Tweet and Author
Perhaps the most interesting predictors are those involving the current tweet that may or may not be responded to. This is the area in which our model extends beyond previous efforts (Artzi et al., 2012; Feng & Wang, 2013; Hong et al., 2013), in that we are examining not just engagement in a conversation but responses and re-engagement at specific moments and in response to specific tweets.
The coefficient estimates for the tweet for which we are predicting replies are listed in Table 7 while the estimated coefficients for the features of that tweet’s author are displayed in Table 6. For the latter, we see that, as predicted in H3a, users who are more active in the conversation, for example, have contributed more
Response Predictors: Current Tweet Author.

Note. FDR = false discovery rate.
p < .1. **p < .05. ***p < .01.
Response Predictors: Current Tweet.

Note. FDR = false discovery rate.
p < .1. **p < .05. ***p < .01.
But at best, author-level characteristics are indirect effects unless the respondent actually knows the author; the most interesting and direct effects—as well as those potentially most subject to manipulation by the tweeter—are via the tweet itself, as shown in Table 7. As before, we find that day of the week has a strong effect, though time of day has less of an effect after clustering. Interestingly, the
In contrast to the behavior predicted by H3c, the previous
Interestingly, while tweets with more characters (
Tweets focused on Topics
Finally, the last two rows in Table 7 show the difference between the current tweet and the candidate respondent’s previous tweet. This is perhaps the most psychologically interesting variable, as it speaks to a deep question about who we choose to converse with: those most like ourselves (presumably to agree), those most unlike ourselves (presumably to disagree), or something in between. We find that respondents are more likely to reply to comments very unlike their previous comment. Interestingly, the estimated minimum reply likelihood is at a distance of 0.1, which is about 1.5 standard deviations below the mean reply distance. This suggests that while there is a slight tendency to respond to comments very similar to your own (
Contents of Responses
Although this project focuses mainly on the decision to reply or not reply, rather than on the content of those replies, we can briefly examine the interactions between the content of the current tweet and the contents of its replies. These results are mainly suggestive at this point, as we do not embed this within a nested model that also controls for the decision to reply as a first stage.
Figure 3 provides heat map illustrations of correlations between tweets and their replies, both on topics (left) and emotions (right). Red indicates positive correlations, while blue shows negative correlations. Topics are sorted by the first eigenvector of the correlation matrix to cluster similar topical or emotional response patterns together.

Correlation between tweet
On topics, we see that for this corpus, debate around NFL players kneeling during the national anthem seems to be highly contained, with tweets on this topic (
In addition, there are negative correlations between topics.
We can also see some of these dynamics in the purely emotional content of tweets and replies. Tweets with a positive VADER score are likely to receive replies which also have a positive VADER score, even if they are less likely to receive a reply at all (as we saw earlier). Tweets scored as neutral (rather than negative) are least likely to follow positive tweets, suggesting that many of these conversations consist of like-minded people reinforcing each other’s beliefs or using charged language for anyone who disagrees. Tweets which score high on the dominance measure are most highly correlated with arousal, indicating that words of strength and power are met with words of excitement—either to eagerly agree or to voraciously disagree. Neutral tweets are met with neutral tweets and are unlikely to elicit a positive response, but are also presumably less likely to receive any reply at all.
Conclusion
To summarize our results, we find that a number of user-, thread-, and tweet-level features are critical in predicting the dynamics of online conversations. While previous studies (Artzi et al., 2012; Backstrom et al., 2013; Feng & Wang, 2013; Hong et al., 2013) have primarily focused on predicting post-level engagement for the purposes of algorithmic content curation, we predict comment-level engagement as users exit and re-enter a conversation. Particularly novel is our inclusion of the features pertaining to the individual tweet that may be responded to, particularly the emotional and topical content of those tweets. Our logistic regression model predicts user response remarkably well, achieving 94% out-of-sample accuracy. The 98% accuracy achieved by our SVM model suggests that there may be further nonlinear and interactive effects among our features to explore in later work, perhaps via additional machine learning methods (such as random forests or deep neural networks); although at 98%, we are already near the ceiling of predictive accuracy.
We find support for many of the hypotheses outlined in “Features” section. In support of H1a, H1b, and H3a, we find that features of both of candidate respondents and current tweet authors have small but important effects on predicting response. Interestingly, in contrast to H3b, we find that the popularity of a tweet’s author has little effect on predicting whether or not a tweet will receive a reply. Because we only include users who have been active in a back-and-forth exchange, this suggests that conversations on Twitter are relatively free from the sort of social influence we may have found if we were examining replies to the initial tweet of a thread.
In support of H2b, we find that longer conversations are decreasingly likely to receive replies. Similarly, while in H1c we expected a candidate’s previous activity in a thread to predict additional activity, we found that users who have already offered numerous comments are less likely to re-engage. Taken together, this suggests that the time attention and cognitive energy that goes into participating in a back-and-forth exchange lead to a natural cutoff where conversations, though popular at first, become too much effort to continue or have their subject matter exhausted.
In addition, and in support of H1d and H3e, we find that the emotional and topical contents of tweets seem to play a significant role in driving the continuation of conversation. Users with negative-sentiment tweets are more likely to re-enter conversations, and tweets with fewer pleasant words are more likely to receive a response. While a small corner of our corpus may be primarily engaged in positive-to-positive conversations, it seems that the vast majority of Twitter dialogue around President Trump consists of acrimonious argumentation. This is reinforced by the finding that candidates are more likely to respond to tweets unlike their previous tweet. This could optimistically be interpreted as people engaging in dialogue across difference, but could just as well be mutual trolling—though if the latter, at least we do observe extensive repeated interactions rather than simple one-off attacks.
These findings paint a picture consistent with what some avid Twitter users might expect: At least when it comes to political dialogue around a controversial figure, most conversations are emotionally charged and negative in tenor. While such conversations fall far below the ideals of democratic deliberation (Cohen, 1989; Dewey, 1927; Habermas, 1984), our findings suggest this may not be the end of the story. First, within the broader deliberative system, it is commonly acknowledged that many “everyday” conversations will frequently fail to meet deliberative ideals (Mansbridge, 1999). Nevertheless, these conversations may still play an important and positive role in expanding people’s view points and encouraging refinement of beliefs (Huckfeldt et al., 2004; Mansbridge, 1999). Despite the predominately negative tone of our corpus, we do find that users are responding to topics outside their own talking points, and that users who are active in a conversation are more likely to receive a response. In other words, conversations are happening, and those conversations do not appear to be strictly confined within partisan bubbles.
Furthermore, it is difficult to fully characterize the democratic value of a conversation based on sentiment analysis alone. For example, within our corpus, we find that positive tweets are most likely to receive positive-sentiment responses. While, on the surface, this may suggest a collection of more civil exchanges, it is also possible that positive-to-positive conversations represent little more than in-party affirmation, with little deliberative value. The deliberative ideal imagines citizens as “tolerant gladiators” (Huckfeldt et al., 2004), who fight with strong words but who emerge from confrontation as friends. Our corpus finds evidence that there is no shortage of strong words—rather, its the long-term effects of these conversations which remain to be seen.
Taken together, these findings suggest that average citizens are participating in rich and engaging political conversations. While the extent to which these conversations support democratic ideals remains to be seen, if we wish to extend and enrich these interactions, we should seek to broadly increase conversational activity online, developing tools to make it easier to engage and follow long threads. In addition, given user’s willingness to respond to those unlike themselves, these findings suggest that there is value in adding noise to recommender systems—showing users new and different content, rather than overfitting recommendations based on the content with which they have already interacted.
In future work, we intend to analyze the dynamics of political conversations over time, looking at sentiment and opinion flows through whole threads of conversation, and we are developing a model to infer the role of latent ideology in these exchanges. In this article, we have identified a number of key factors predictive of conversation engagement and shown that these conversations are by no means chaotic, but in fact are systematic and highly predictable, reflecting a complex interplay of circumstance, topic, and emotion.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.