
Abstract
The study of learning behaviors with multi features is of great significance for interactive cooperation. The data prediction and decision are to realize the comprehensive analysis and value mining. In this study, hierarchical learning behavior based on feature cluster is proposed. Based on the massive data in interactive learning environment, the descriptive model and learning algorithm suitable for feature clustering are designed, and sufficient experiments obtain the optimal performance indexes. The data analysis results are reliable. On this basis, the hierarchical learning behaviors based on feature clusters are visualized, the rules of different learning behaviors are summarized, then we propose the practical scheme of interactive cooperation. The hierarchical learning behaviors can be realized by feature clusters, which can effectively improve the modes of interactive cooperation, and help to improve the learning effectiveness.
Keywords
Introduction
With the development of online interactive learning environments, learning behaviors have become a continuous process of different data and factors. The learning behaviors are described as the multi types (Doleck et al., 2021; Xia, 2020a), That determines the dynamics of learning behaviors, and there are much uncertainty (Schumacher & Ifenthaler, 2021). On the whole, learning behaviors involve three basic aspects: learners, teachers and learning content. Due to many restrictive factors, different learning periods, learning needs, teaching methods and assessment methods will produce different learning behaviors. In part, the learning behaviors are inseparable from learning tendency and preference. The same behavior features will produce different data, and also affect the correlation (Deng, Li et al., 2022). Learning behaviors might also reflect the individuality. Due to the groupness and individuality of learning behaviors, there is no statistically significant correlation between features (Deng, Zhang et al., 2022). Therefore, it is the key issue to construct the feature clusters, demonstrate the relationships between clusters, as well as realize the hierarchical learning behaviors.
The feature clusters of learning behaviors are composed of one or more features. When there are certain correlations among features, these features form a component, that is called as feature cluster (Mubarak et al., 2020; Tsai et al., 2021; Xia, 2022a). On the one hand, the feature clusters needs massive and continuous data; on the other hand, it needs to consider corresponding conditions. These two aspects put forward higher requirements for data tracking, and also bring great difficulty to the data analysis. Because of the adaptability and friendliness of interactive learning environments, there are more and more choices to obtain perfect learning behaviors, which might improve analyze data-driven feature clusters (Chan et al., 2021).
Based on the learning behaviors in an online interactive learning environment, this study will achieve hierarchical learning behaviors, in order to analyze and design feature clusters. Through designing suitable learning algorithms, the learning behaviors are trained and tested. In order to verify the effectiveness and feasibility of designed models and algorithms, through sufficient experiments, the optimal indexes are selected, and several approximate algorithms are used to compare. Based on the reliable experimental results, the accurate feature cluster is constructed, the relationships among clusters are visualized, and the hierarchical learning behaviors are realized, then the effective measures are evaluated and demonstrated. Finally, the research results are tested in specific learning practice.
Related Work
There are internal relationships between the learning behavior features, and the accumulated data makes the relationships produce different intensity. Different research objectives have different correlations. By setting the test standard, the effective feature clusters are realized (Xia, 2020b). It is helpful to construct the relationships between feature clusters. When feature clusters are viewed as basic elements, learning behaviors constitute different correlation domains, and different domains produce different descriptive needs and conditions (Avila et al., 2020). Therefore, the intervention and decision should be analyzed from two aspects: the inter domain relationships and the intra domain relationships. The analysis mechanism of feature clusters are the key problems in interactive learning environments.
To construct the feature clusters of learning behaviors, two aspects need to be considered: one is to design the process and related nodes, so as to find the features; The other is that learning behaviors involve many platforms, we should infer the features and possible relationships based on the comprehensive analysis. In this aspect, we have high requirements for data analysis and decision prediction (Aguilar et al., 2021; Xia, 2021b). This study will analyze and demonstrate the feature clusters in the second aspect.
In order to study the feature clusters of learning behaviors, it is necessary to adopt appropriate methods to achieve effective clustering (Winne, 2020). Since the second aspect needs to mine learning behaviors from massive data, unsupervised learning method is needed (Lavanya et al., 2021; Xia & Qi, 2023), Data analysis is to explore the possible rules through fully learning the unlabeled samples. Generally, the samples are divided into several relatively independent subsets by feature clustering. Each subset is a feature cluster, and each cluster can be defined as some potential topics (Li et al., 2022; Zhang et al., 2022). There are three types of feature clustering methods.
Prototype-Based Clustering
Prototype-based Clustering usually assumes the feature structure can be described by a group of prototypes. The clustering algorithm needs to initialize the prototypes first, then update the prototypes. Different methods will produce different algorithms (Chaudhuri et al., 2021). Prototype-based clustering is the common method, which produces some algorithms, such as k-means, learning vector quantization (LVQ), mixture of Gaussian clustering and so on.
Density-Based Clustering
Density-based Clustering assumes feature clusters can be determined by the sample distribution density. The clustering algorithm takes the density to investigate the correlation between different samples, and continuously expands the clusters to obtain the final results (Mirzaei et al., 2021). DBSCAN is a famous density-based clustering algorithm, which describes the sample distribution based on a set of neighborhood parameters.
Hierarchical Clustering
Hierarchical Clustering attempts to divide the features into different layers, and form a tree. When dividing the features, it usually adopts the “bottom-up” feature clustering strategy, or the “top-down” feature splitting strategy (Fuchs et al., 2021). AGNES is a typical hierarchical clustering algorithm. It adopts the “bottom-up” clustering strategy and regards each sample as an initial cluster. In each step, the nearest two clusters are found and combined until the preset number of feature clusters is obtained.
These three kinds of clustering methods have their own advantages, usually based on the features to optimize or design suitable clustering algorithms. But it is not feasible to directly use the classical clustering algorithms for data training and testing, which does not necessarily achieve the best results. The groupness and individuality of learning behaviors make the relevant features have obvious uncertainty. It is not sufficient to cluster the features, which might not analyze the overall and local relationships. According to these three clustering methods, this study constructs the association domain of learning behaviors through feature clusters, and realizes the hierarchical learning behaviors through the topological relationship between domains.
Learning Behavior Description and Standardization
Learning behaviors should involve the whole learning process and learning assessment (Ruipérez-Valiente et al., 2020; Xia, 2021a). The interactive learning environment is one important data source. Learning behaviors should be involved in the following aspects: ① when learners enter one interactive learning environment, they need to achieve the platform participation. Learners need to meet the precursor learning background conditions, that is the first part of learning behavior features; ② the data generated by learners in one interactive learning environment is the second part; ③ at the end of one learning process, it is necessary to evaluate the learning effects, relevant assessment methods and results are the third part.
According to the three parts of learning behavior features, we obtain the relevant data of four learning periods from one interactive learning environment, and some algorithms are used to mine the registration items, the interactive learning items and learning assessment items, involving multiple types of data structures and relationships. These data are represented by different models, with the help of appropriate media features, the models are correlated.
Table 1 shows the registration items, that are the basic data submitted by learners. “Module” and “Period” are options for learners, and learners determine their own module and period; “LID” is the number of learners, which is unique; “Gender,”“Region,”“Disability” and “BirDate” are the basic demographic items which is deterministic; “IMD” corresponds to “Region”; “HighEdu,”“PreAtt” and “StuCre” are related to learning background. With the continuous accumulation of learning behaviors, these data will also change.
Registration Items.

The interactive learning items are shown in Table 2, which are mainly divided into three types: the first type is the businesses that provides data support for learning process, the platform manages the learning contents through sharing mechanism, such as “dataplus,”“dualpane,”“folder” and others; the second type uses the businesses of interactive cooperation, such as “forumng,”“collaborative,”“questionnaire,” etc., and records the data with the help of relevant features; the third type realizes data management and interactive cooperation through web components, that is based on the first two types such as “homepage,”“subpage” and “url.”
Interactive Learning Items.

Table 3 shows the learning assessment items, which are mainly divided into two types: on platform and off platform. “quiz” is a stage test provided by the platform, while “externalquiz” is a stage test provided outside platform. In order to understand the learning effects, “quiz” and “externalquiz” are responsible for the assessment. ComAssessment is used to test the “Module” comprehensively. “TeaAssessment” is also an assessment method dominated by the teachers. “ComAssessment” and “TeaAssessment” complete the assessment of a “Module.”“exam” gives different weight factors and calculation models to evaluate the final learning effects.
Learning Assessment Items.

Based on the items in Tables 1 to 3, the corresponding records of learners are formed, and the relationships are shown in Figure 1. Taking learning results as feature clusters, the hierarchical learning behaviors are constructed and realized, and the data is fully trained and tested through the items. The following seven aspects are discussed.
(1) Correlation calculation and cluster analysis between the related features of registration items;
(2) Correlation calculation and cluster analysis between the related features of interactive learning items;
(3) Correlation calculation and cluster analysis between the related features of learning assessment items;
(4) correlation calculation and cluster analysis between (1) and (2);
(5) correlation calculation and cluster analysis between (1) and (3);
(6) correlation calculation and cluster analysis between (2) and (3);
(7) hierarchical design of (4), (5), and (6).
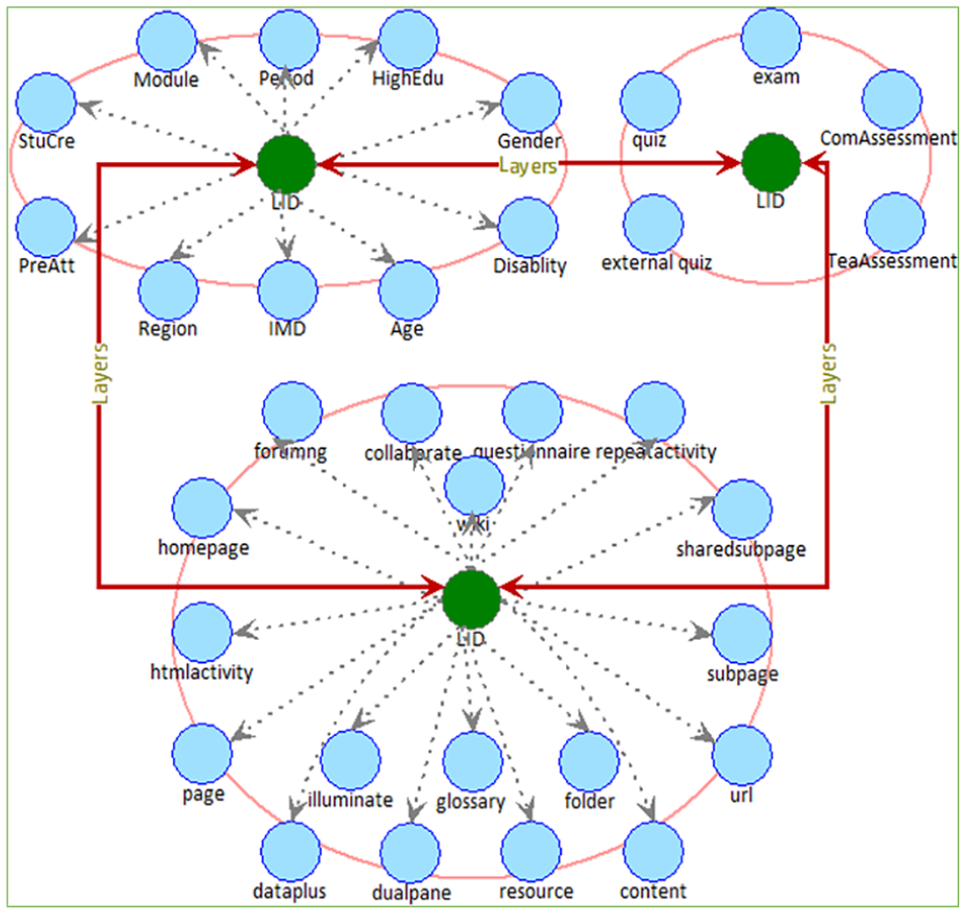
Feature relationships and potential correction.
Methods
The corresponding methods are mainly reflected in two aspects, (1) local feature clustering is realized according to the distribution of samples; (2) overall feature clustering is realized from different layers based on feature cluster. The local feature clustering is implemented based on the improved Mixture of Gaussian. The overall feature clustering is optimized to be suitable for learning behavior, and the reliability and accuracy of hierarchical relationships of feature clusters are improved.
Improved Mixture of Gaussian
Mixture of Gaussian is a clustering method based on probability model. Assuming that the random vector
If the feature set of learning behaviors
Based on this strategy, the analysis process is described as Algorithm MGA, its computation complexity is

Hierarchical Clustering Strategy
Based on the local feature clustering, we should first define each feature cluster as an initial basic unit, retrieve the nearest two feature clusters through each step of hierarchical clustering algorithm. Then, we can achieve the hierarchical division of all feature clusters. The key problem of the whole algorithm is to calculate the distance between feature clusters. We might use the distance calculation model to verify whether the feature clusters meet the clustering conditions. The calculation model of distance is as follows.
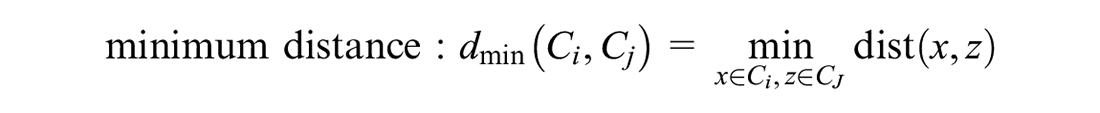


The minimum distance is determined by the nearest samples of the two feature clusters, the maximum distance is determined by the farthest samples of the two feature clusters, and the average distance is determined by all the samples of the two feature clusters. So the algorithm will correspond to different hierarchical analysis targets, it is suitable to use the minimum distance to realize the clustering.
The hierarchical clustering process is designed and described as Algorithm HCA. its computation complexity is also

By calling MGA, HCA can complete the local clustering analysis in Figure 1, and obtain effective feature clusters, then construct effective hierarchical learning behavior relationships. The whole computation complexity is
Experiments
The mixture of Gaussian and hierarchical clustering are used to analyze the features of learning behaviors. The data sets of four periods are used in the whole experiments. The four data sets have different distribution, correlation and scale, which are used to check the effectiveness and applicability of the algorithms. Accuracy (ACC), Adjusted Rand Index (ARI) and Normal Mutual Information (NMI) are selected as the performance indexes. After initializing the learning behaviors, the feature set description is shown in Table 4.
Feature Set Description.

In order to test the effectiveness of HCA, the comparative algorithms are selected, mainly including Fast Density Peak Algorithm (FDPA), K-means algorithm (K-means) and Affinity Propagation Algorithm (APA). About FDPA, it is necessary to set the range of sample neighborhood, and to determine the interval of the neighborhood by many experiments; k-means algorithm is affected by the distribution of the initial feature center points, and it needs to train the algorithm for each feature many times; the advantages of the improved APA are suitable for large-scale feature sets, which treat the features as a network, and each feature can be clustered. A sample is a node, and messages are transmitted between nodes through “Responsibility” and “Availability.” The Responsibility matrix and Availability matrix determine the similarity of the samples. The experiment results show that APA algorithm has better efficiency than others and ensures better clustering effects.
The program codes of the algorithms are completed by python 3.7. All comparative algorithms use sufficient experiments to determine the optimal clustering results, record the performance indexes corresponding to the four feature sets, and draw the comparative charts of ACC, ARI and NMI, as shown in Figures 2 to 4.

ACC.
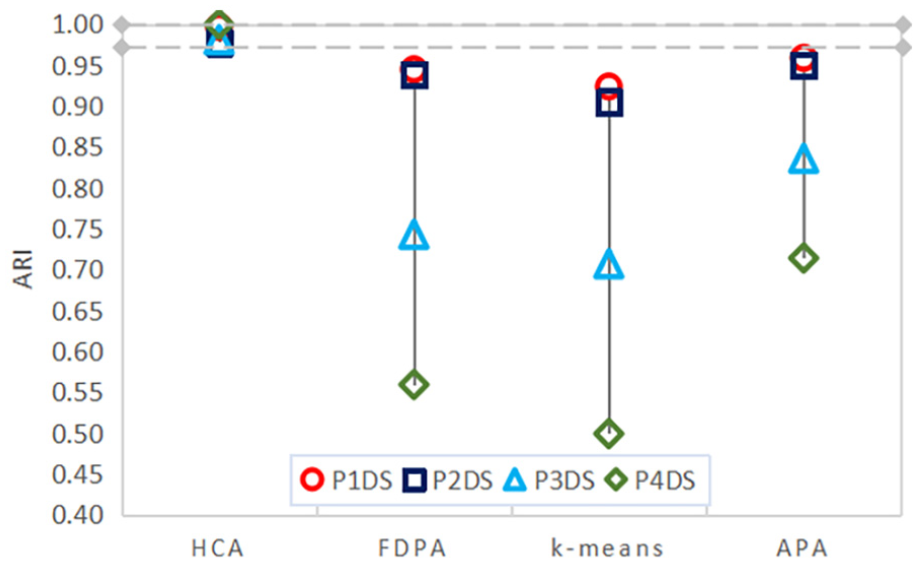
ARI.

NMI.
Figure 2 shows the clustering ACC of the four comparative algorithms. The ACC of HCA algorithm on the four feature sets is better than the others. At the same time, the span of clustering accuracy is the smallest. With the increase of feature scale and class, HCA algorithm shows a more stable accuracy.
ARI is shown in Figure 3. ARI distribution range of HCA algorithm is between 0.97 and 1, and the value is larger, indicating that the clustering results are closer to the real situation. The ARI of the other three comparative algorithms in P1DS and P2DS are larger and closer, but for P3DS and P4DS, the distribution range of ARI is larger, and the reliability of the three comparative algorithms is not stable in the case of larger scale and more classes.
NMI is used to measure the similarity of clusters, and evaluate the similarity between an actual feature cluster and standard one. The larger NMI, the more effective feature clusters. It can be seen from Figure 4 that NMI of HCA for four feature sets are close to or equal to 1. NMI of the other three comparative algorithms are larger for P1DS, but the NMI of the other three feature sets change greatly. The NMI of HCA algorithm is highly effective.
Taking learning assessment results as the test objectives, HCA and MGA cluster each feature set. The results are distributed as shown in Figure 5, HCA and MGA can achieve more significant clustering results.

Distribution of clustering results: (a) P1DS, (b) P2DS, (c) P3DS, and (d) P4DS.
Analysis Results
About the features related to registration items, interactive learning items and learning assessment items, we use HCA and MGA to analyze multi features, and visualizes the analysis results. Driven by the above experimental results, we construct the hierarchical learning behaviors from two aspects, (1) horizontally, the clusters formed by local features are visualized; (2) vertically, the correlation of feature clusters is demonstrated, and the hierarchical relationships between local clusters is realized. On this basis, hierarchical clustering results are constructed, as shown in Figures 6 to 9. These four figures has obvious similarities, but also has the unique differences.

Hierarchical clustering result of P1DS.

Hierarchical clustering result of P2DS.

Hierarchical clustering result of P3DS.

Hierarchical clustering result of P4DS.
The similarities of hierarchical clustering results of learning behavior are mainly reflected as the follows.
Learning Behavior has the Same Hierarchical Depth
After the hierarchical analysis of feature clustering, the learning behaviors corresponding to the four feature sets are divided into four layers. The related features of registration items are the first layer, the platform business is the second layer, the part of interactive learning features constitutes the third layer, and the assessment means is the fourth layer. The feature clustering of each layer drive the related features and their relationships of the next layer. The analysis in multi types and multi periods show that the learning behaviors are hierarchical.
There is a Strong Correlation Between Module and Period
The same module can lead to different interactive learning features in different periods. Different modules may produce similar learning behaviors in a specific period. Module and Period might form the key features that determine the next layer. According to the feature clustering analysis, Module and Period might work together on the feature data and behavior process.
Highedu, StuCre and PreAtt Have Strong Correlation
Learners’ educational background will affect their learning methods and learning effects. The academic level will also affect their learning attitudes and habits. HighEdu may influence learners’ planning about StuCre, and also have different correlations with PreAtt. The hierarchical correlation experiments of learning behaviors have proved that these three features have strong correlation.
Homepage, Subpage and url are the Key Business Support for Interactive Learning Features
The second layer of learning behavior is the key part to realize the first layer and the third layer. The interactive learning environment realizes business transfer and data sharing by providing suitable technical means. After clustering, homepage, subpage and url become the main business support for clustering and scheduling of learning behaviors. The interactive data shows that these three types of features have strong clustering correlation, and they are also the key mediators to assist the effective cooperation of other interactive features.
Forumng is an Important Feature for Clustering Interactive Features
forumng is the key interactive feature of the third layer. It is an effective way to participate in the learning process, it plays a significant role. As an effective interactive means, a large number of feature clusters with different scales are generated around forumng, which drives the participation frequency and intensity of other interactive features.
TeaAssessment and Exam are the Key Means to Assess Learners
Interactive learning environment provides several assessment methods, but it does not mean that all of them are suitable for all learning processes. From the analysis results of the four feature sets, TeaAssessment and exam are most suitable for learners, breaking through the limitations of Module, Period and other features. Based on these two methods, different learning content or different learning period, flexible deployment of quiz or externalquiz, the four feature sets have been analyzed some significant results.
The differences of hierarchical clustering of learning behaviors are mainly reflected in the following aspects.
Differences of P1DS
The hierarchical clustering results of P1DS are the strongest than the others, which shows that different modules have relatively centralized tendency. The seven interactive learning features form three clusters, and the learning assessment features form two clusters. P1DS involves three modules. The clustering results are directly related to the modules.
Differences of P2DS
P2DS involves five modules, but interactive learning features form four clusters, which shows that different modules have similar interactive cooperation. For the business features, homepage, subpage and url are not clustered into one cluster. Some modules only use homepage to realize business transfer and data sharing, and other features of interactive learning process are not necessary to schedule homepage, subpage and url together.
Differences of P3DS
The 10 interactive learning features of P3DS produce five clusters, corresponding to six modules. Similar to P2DS, different modules produce the same groupness. Through the analysis of interactive learning data, a unified local cluster is formed. The three business features, homepage, subpage and url have a strong supporting role. Quiz is the basic feature for these six modules.
Differences of P4DS
The hierarchical clustering results of P4DS show obvious module differences, which is most complex. The learning behaviors of seven modules form seven local clusters of interactive cooperation, which mainly focus on forumng to build feature clusters with strong local correlation. Some modules show non obvious interactive cooperation. Only content has significance in the whole learning process. homepage, subpage and url are different obviously, and subpage is the main component to support the interactive learning features independently, four learning assessment features form three clusters.
Through the analysis of the similarities and differences of hierarchical clustering, it can reflect the internal similarities and association rules. With the help of the visual relationships, the similarities and differences are strengthened. On this basis, we can put forward feasible intervention measures to improve learning behaviors. It is mainly reflected in the following four aspects.
We Should Build a Learning Process With Interactive Cooperation as the Key Guiding Feature of Forumng
In order to realize the reliability, instantaneity and integrity of forumng, it is necessary to continuously improve the business mode of forumng, according to the development trend of interactive learning environment and learning needs (Xia, 2021b). Through appropriate technical means and business patterns, we might effectively improve the interactive cooperation friendliness and convenience of forumng
Different Training Strategies and Learning Feature Recommendation Strategies are Designed According to the Learning Background
Learning background will affect learning objectives and methods. Interactive learning environment should design business functions driven by learning background, such as real-time profile of learning background, effective classification, adaptive learning methods, guidance strategies and learning preference process.
Different Modules Need to Design Corresponding Interactive Learning Features
Through the above analysis of similarities and differences, we can see that different modules may have similar interactive feature sequences, and there are obvious differences, which is directly related to the learning objectives and modules. Therefore, it is necessary to evaluate the similarity and correlation between modules, so as to realize the sharing of interactive features. At the same time, the personalized feature recommendation strategy is constructed.
Interactive Learning Environment Should Constantly Introduce New Learning Analystics, Business Support Means and Data Management Mode
In order to effectively support data analysis and tracking, the interactive learning environment should have good data management, analysis and business support (Misiejuk et al., 2021), and build a business system to update learning needs and interactive process at any time. This requires a flexible platform for interactive cooperation, data management and learning analytics, so as to build a data mechanism of tracking, learning and feedback, and constantly meet the learners’ interest and participation.
Application and Discussion
With the help of the hierarchical analysis and feature clustering, the intervention measures are obtained, which can further test the feasibility in application practice. Therefore, it is applied in the learning process of “software engineering and management,” that is a undergraduate course. There are 38 learners, the learning process mainly includes theoretical learning, project design and exercise training. These three parts cross the whole learning period. In order to effectively promote the needs of group cooperation and interactive cooperation in project design, 38 learners are divided into 10 groups, each group includes three or four learners. Ten groups of learners participate in the research and development of two online software systems: student management system and library management system. At the same time, the service processes of the systems are divided into five key modules, namely: I-data management, II-business engine, III-function module, IV-platform architecture and V-interaction mode. These five modules are detailed into related requirements. It realizes group clustering of learners and task clustering of interactive cooperation.
In order to improve the interactive cooperation of group clustering and task clustering, a sufficient channel is built. forumng is constructed at different layers. The learners’ interactive cooperation is achieved through online forumng. The entire interaction is shown in Figure 10. forumng in layer 1 is used for group clustering and applied to the interaction of a module, it is used is to serve the R&D of a module; forumng in layer 2 is used for the interaction between different modules of the same system, and the goal is to achieve the coordinated R&D and functional improvement of the whole system; layer 3 builds effective interactive means between this two systems. The software system has a large universality in technology, architecture and business process. Some business functions can be developed into common components. Therefore, the cooperation between the two systems can be strengthened, which might ensures the R&D performances. With the help of forumng, the learners have constructed different clusters, which are linked by project design, and guide the learners to help and communicate in theory learning and exercise training.
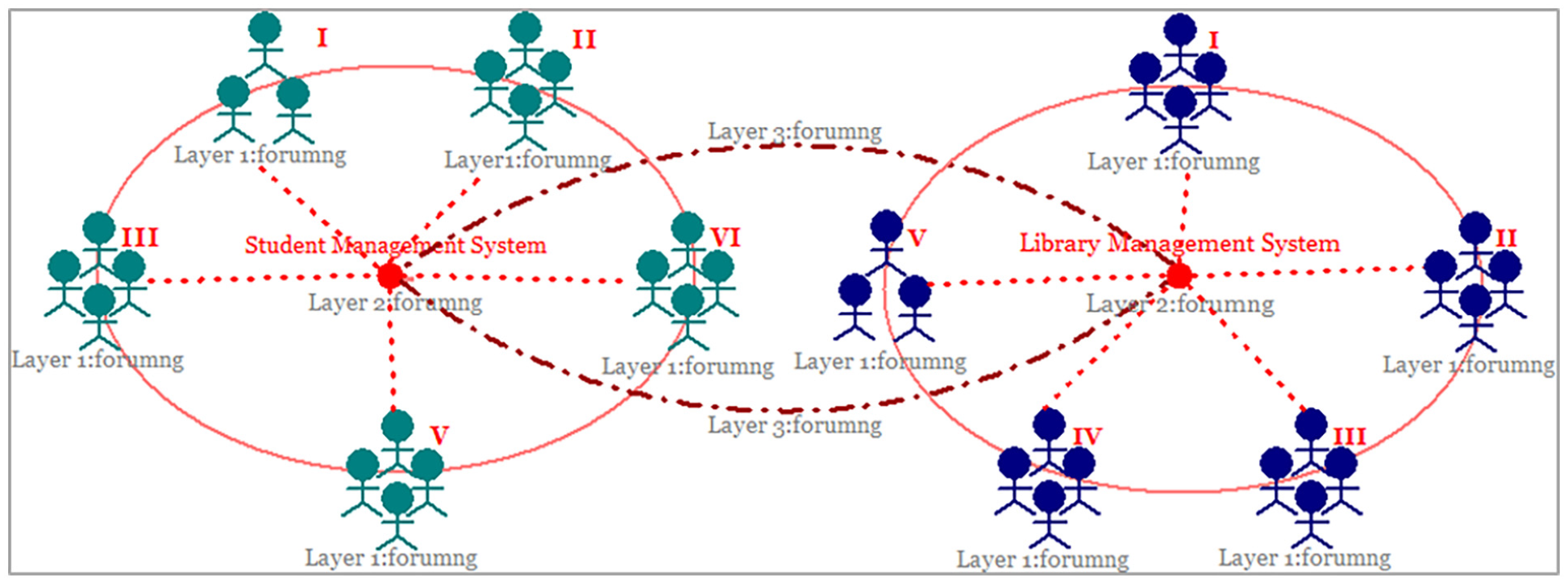
Multi interactive cooperation clustering relationships.
The difficulties of student management system and library management system are similar. The same teacher completes the theory teaching, project guidance and exercise analysis. The multi clustering model of learners and tasks becomes the key methods. In order to effectively test the learning effects, the theory learning, project design and exercise training are taken as three parts of the assessment. The assessment items are shown in Table 5. An evaluation organization is composed of experienced third-party developers, designers, testers and ordinary users, that can evaluate the R&D quality of the systems, and analyze the evaluation results, and the final evaluation results are obtained through data classification and effective data analysis; exercise training adopts quiz, which was evaluated from five aspects of accuracy, independence, adequacy, timeliness and simplicity, and real-time tracking was achieved by both teacher and platform.
Assessment Items.

For theory learning and exercise training, each learner is taken as the basic statistical object, combined with project design, we further evaluate the significance of learners’ clustering. Project design takes the smallest group clustering and task clustering as the statistical objects. After data statistics and analysis, the assessment results of theory learning and exercise training are shown in Figure 11. Two subgraphs correspond to the student management system and the library management system respectively. From the data curve distribution of the two graphs, the performances of each group cluster tend to be stable, but the data of the library management system presents discrete distribution and obvious personalization.
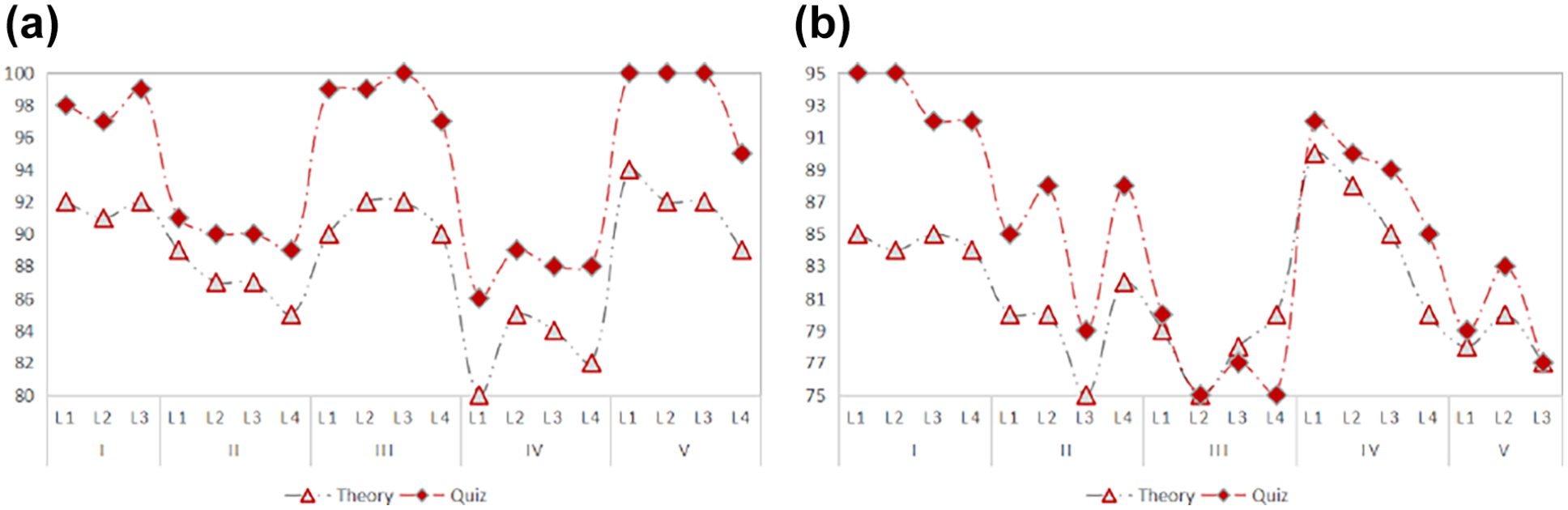
Evaluation results of theory learning and exercise training: (a) student management and (b) system library management system.
Project design records two types of data. First, the learner participation is checked. The results are obtained for each module result. When each item is calculated, the highest and lowest scores are removed and the average value is obtained. The distribution of the scores is shown in Figure 12. The group with good performances in project design has also achieved good scores in theory learning and exercise training. This shows that the interactive cooperation of group clustering has positive guiding effects. Good interactive cooperation can improve learning behaviors and learning effects.
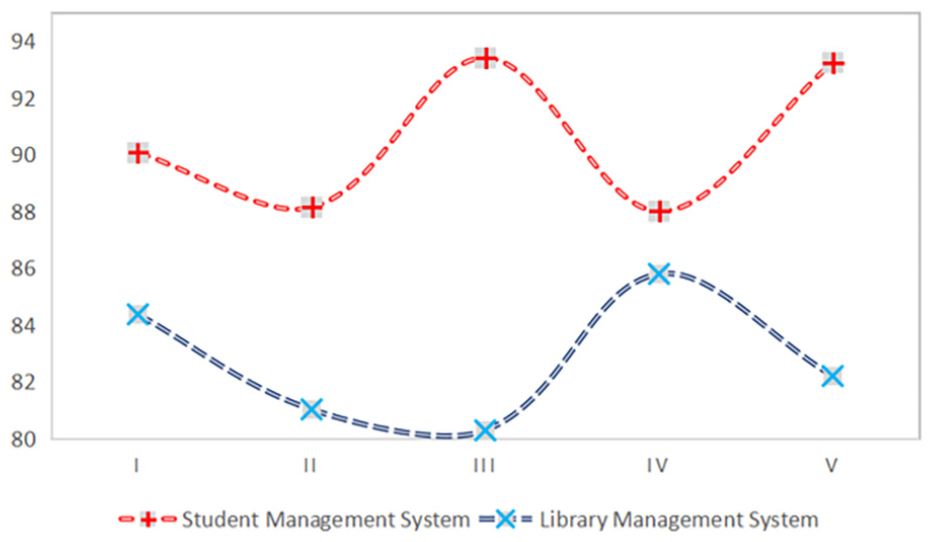
Evaluation results of project design.
The log data of three layers of forumng mainly reflects in the topic, time, click rate, etc., the forumng independently forms the participation of each learner, the different layers are corresponding to different learner groups, the second and the third layers are based on the group clustering of the first layer. T-test is used to verify the influence of theory learning, project design and exercise training. After many data analysis and calculation, the significant results are shown in Table 6. It can be seen that the first layer can have a strong significant impact on theory learning, project design and exercise training; the second layer can also have a much stronger significant impact; the third layer only has a relatively strong significance on project design, but no significance for others.
Clustering Significance of Different Layers of forumng.

p < .001. **p < .01. *p < .05.
When the hierarchical learning behavior scheme based on feature clusters is applied to the actual learning process, for the course of combining theory with practice, the group clustering and task clustering can improve the learning interest and quality of interactive cooperation. But the construction of interactive cooperation between two different systems can not have a significant impact. Therefore, the clustering scale is not too large. Two-layer clustering based on the same research and development topic is more helpful for good learning effect.
Conclusion
Learning behaviors with multi features are important parts of interactive learning environment (Mangaroska et al., 2021). To improve the interactive cooperation, it is needed to provide effective data description, value mining and decision feedback (Chan et al., 2021; Xia, 2022b). With the application of online and sharing technology, it is possible to mine the features from the interactive learning environment. The heterogeneity of the features and relationships are the key problems (Pereira et al., 2020; Xia & Qi, 2022).
This study proposes hierarchical learning behavior supported by feature clusters. In order to analyze hierarchical learning behaviors, the clustering and modeling of features are defined. Firstly, all the features are initialized into three parts: learner registration items, interactive learning items and learning assessment items, which are normalized into four feature sets; secondly, the descriptive models and learning algorithms suitable for feature clustering are designed. After sufficient training and testing, the optimal performance indexes are obtained. Through the comparative experiments of several approximate algorithms, it is proved that the model and algorithm designed in this study are feasible, and the experimental results are effective; thirdly, the four types of hierarchical learning behaviors are visualized. In the final, we put forward feasible guiding measures to improve interactive cooperation of learning behaviors, and the effective interactive cooperation scheme is applied in the actual learning process.
Because the learning behavior itself has strong discreteness and autonomy, and it is not easy to achieve good clustering effects, At the same time, the learning behavior has a certain group tendency. The design of the feature clusters realizes the value mining and analysis of learning behaviors. The experiment shows that the efficiency of the interactive cooperation of learners has been greatly improved, and it has also been verified in the experiments, which is novel.
It is very useful to design the models and algorithms of massive learning behaviors, clustering features and constructing hierarchical relationships might mine more implicit data, that can build or improve learning behaviors and learning effects. In the follow-up research, we will further expand the effective interactive cooperation, deepen the application of feature clustering, and realize the continuous optimization.
Footnotes
Acknowledgements
Thanks for the technical support provided by the laboratory of School of Software of Tsinghua University, as well as the theoretical guidance and practical reference provided by Qufu Normal University.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by National Office for Philosophy and Social Sciences “Research on the integration and classification of moral education documents in modern China” (Grant NO. BEA190107).