
Abstract
By implementing Biber’s multidimensional analysis (MDA), the present study explored the linguistic co-occurrence patterns of English research article abstracts written by native speakers of Arabic authors residing in the Arab World and international authors from different contexts. The study analyzed three specialized corpora of 300 English abstracts in the field of applied linguistics. Each corpus comprised 100 abstracts named as Middle Eastern Arabs, North African Arabs (MENA), and international authors. Several linguistic features were extracted and tagged using Nini’s Multidimensional Analysis Tagger (MAT). Then, six dimensions representing several communicative functions were identified after conducting factor analysis. Overall, the study showed that the MENA Arabs abstracts tended to be more evaluative and currently information-focused, while the international abstracts showed more informational density features and narrative style. Finally, the study suggests pedagogical implications for raising the international community’s awareness of writing abstracts with linguistic features.
Keywords
Introduction
Publishing research articles in an international scholarly community has become crucial for researchers and professors at the university level. Research article (RA) abstracts, as a part-genre (Swales & Feak, 2009), have received important attention from scholars and researchers due to the fact that the abstract plays significant roles in publishing in scholarly journals, where the abstract “serves as an effective tool for readers to master and manage the ever-increasing information flow in the scientific community” (Ventola, 1994, p. 333). Therefore, writing clear, informative, and concise abstracts has become a necessary skill in academic writing for publications across disciplines. Furthermore, well-written abstracts attract the attention of journal editors. The knowledge of rhetorical structure and linguistic features of the abstract will help novice writers in different discourse communities to be able to understand and, therefore, to produce well-written abstracts.
The present study follows Biber’s (1988) pioneering multidimensional analysis (MDA) approach. The approach aims to identify and interpret systematic register variation in spoken and written registers to elicit the underlying patterns of linguistic features (Biber, 1988). The study investigated linguistic variation among three different registers: Middle Eastern Arabs writers, North African Arabs, and international. In the research tradition of MDA, registers are “a cover term for any language variety defined by its situational characteristics, including speaker’s purpose, the relationship between speaker and hearer, and the production circumstances” (Biber, 2009, p. 823). According to Biber and Conrad (2009), register variation refers to systematic and linguistic differences between two or more registers in a particular field. Studying linguistic variation is important because it serves major arenas of research: linguistic descriptions of lexical and grammatical features and descriptions of the registers themselves. In sum, these kinds of studies provide a baseline to understand cross-cultural and cross-linguistic variations among registers. Therefore, the present study intended to explore possible cross-cultural and cross-linguistic variations by implementing a statistical approach via an MDA to identify linguistic similarities and differences among the three sub-corpora.
English in the Arab World
The Middle East and North Africa (MENA) region comprises more than 22 countries with over 400 million population, most of which are Arab countries that speak the Arabic language as their mother tongue. Only three non-Arab countries with different languages are considered part of the MENA region: Turkey (Turkish language), Israel (Hebrew), and Iran (Farsi). Although each country in the Arab World has its own education system, history, and culture, several important similarities exist (Akkari, 2004). That is, MENA countries are located in the Expanding Circle proposed by B. B. Kachru (1992), where English is mostly considered a foreign language. The history of the foreign language in the Arab World can be traced back to the colonial period of the United Kingdom (UK) and France over some countries in the Arab World. For instance, France colonized the North African regions, that is, Algeria, Tunisia, Morocco, and the UK colonized most Middle Eastern countries.
Regardless of the strong connection between the Arabic language and people in the Arab World, the roles of the English language as lingua franca (ELF) have been increasingly important in the MENA regions. Nowadays, the English language is essential as a means of numerous international communications, where it has been recognized as the primary lingua franca and as a nation-building facilitator (McIlwraith, 2013). Academically, given the fact that the English language is “a tyrannosaurus rex . . . a powerful carnivore gobbling up the other denizens of the academic linguistic grazing grounds” (Swales, 1997, p. 374), the preeminence of English as the vehicular lingua franca for discipline-specific publication is self-evident. Therefore, English is considered the primary language for research publication in MENA regions (Abdeljaoued & Labassi, 2020; Elyas & Mahboob, 2020).
Accordingly, Hillman et al. (2021) conducted a scoping review of World Englishes Publications between 2000 and 2019 in the MENA region, where they concluded that MENA is considered an underexplored and undertheorized WE context. The authors reported that most studies (i.e., 59 peer-reviewed journal articles) investigated such issues as language policy and planning, macro sociolinguistic issues, and language teaching and learning. Therefore, there is a need for more large-scale corpus studies and longitudinal and ethnographic approaches to examine the MENA context (De Costa, 2021).
Corpus-Based Studies Focusing on RA Abstracts
The American National Standards Institute (ANSI) defines the abstract section as “an abbreviated, accurate representation of the contents of a document, preferably prepared by its author(s) for publication with it” (Bhatia, 1993, p. 78). The study focuses on the research article abstract because it is “generally the reader’s first encounter with a text, and is often the point at which they decide whether to continue and give the accompanying article further attention or to ignore it” (Hyland, 2002, p. 63). Also, RA abstracts are considered ideal for genre analysis studies and cross-linguistic analyses due to their brevity, explicit format requirements, and well-established purpose (Friginal & Mustafa, 2017; Swales & Feak, 2009).
Research article abstracts have been widely investigated through mostly macro-level and, lately, micro-level (Cao & Xiao, 2013). As for the former, the macro-level focuses on analyzing the rhetorical structure of the abstract (see Bhatia, 1993). In the micro-level analysis, the abstracts are analyzed by investigating specific linguistic features, such as lexical bundles, tenses, and reporting verbs (see Biber, 1995; Biber et al., 1998). Other comparative studies of different corpora have shown that linguistic features share several cross-linguistic and cross-cultural similarities and differences. For instance, Hu and Cao (2011) analyzed metadiscourse markers (i.e., hedges and boosters) in English and Chinese abstracts. The study revealed cross-linguistic differences between Chinese and English abstracts in terms of reporting results using hedges and making generalizations or conclusions. Alharbi and Swales (2011) conducted a contrastive analysis of 28 Arabic and English paired abstracts written by Arabic authors, revealing little use of first person pronouns or promotional elements in the English abstracts. The authors attributed these findings to certain scholastic traditions in the Arab World.
MDA and English as Lingua Franca
The literature of MDA shows paucity in English as lingua franca investigations. Xiao’s (2009) investigation was one of the earliest studies that explored variation across five varieties and twelve registers of English in the International Corpus of English (ICE) (i.e., Great Britain, Singapore, India, Hong Kong, and the Philippines). The results of the comparative analyses demonstrated similarities and differences across registers, confirming that the MDA is undoubtedly a powerful analytical framework for language variation study. Cao and Xiao (2013) explored textual variations from twelve academic disciplines between two corpora of English abstracts written by native Chinese and native English writers by integrating colligation features with grammatical and semantic features. The authors found that native English writers employed involvement and commitment features in their abstracts compared to Chinese writers. In a similar vein, Friginal and Mustafa (2017) identified the linguistic features of two corpora of English research article abstracts; RA abstracts published in Iraq and written by Iraqi authors and those published in the United States. The authors of the study implemented Hardy and Römer’s (2013) dimensions which were identified based on the Michigan Corpus of Upper-Level Student Papers. The study reported similarities and variations in how Iraqi authors structure their abstracts using various linguistic patterns. The authors attributed such variation to language-based or English-related reasons derived from intercultural or contrastive rhetoric studies. In detail, the analysis revealed disciplinary differences in how information is packaged and shared in Dimension 1 (Involved, academic narrative production vs. descriptive, informational production). In Dimension 3 (Situation-dependent, non-procedural evaluation vs. procedural discourse), establishing the procedural nature of abstract writing showed similarities across country groups. Lastly, Dimension 4 distinguished Iraqi and U.S.-based authors in terms of directness and argumentation. To explore linguistic variation in L1 and L2 academic writing, Pan (2018) analyzed three levels of professional writing (i.e., Master’s theses, PhD dissertations, and research articles) by implementing the MDA. The results indicated that L2 academic writing is narrative, less attitudinal, and academically involved than L1 academic writing.
The Focus of the Current Paper
This paper expands the current discussion on English as a lingua franca (ELF) in two important ways. First, this investigation was necessary since it may contribute to the fields of MDA and ELF research by revealing possible variations, particularly those related to potential cultural variation. The study also contributes to understanding how these abstracts are written in the three corpora in light of genre conventions influences. In the same vein, the above-mentioned studies have demonstrated that the systematic linguistic differences within and between the writing style of different discourse communities could be successfully captured via the MDA framework (Cao & Xiao, 2013; Friginal & Mustafa, 2017; Pan, 2018). The findings of these studies also have enriched our understanding of L1 and L2 writing, mostly in multidisciplinary academic writing, yet, few of them have investigated experienced writers from different linguistic and cultural backgrounds in English as Lingua Franca Academia (ELFA) (Tribble, 2017). Therefore, to the best of my knowledge, little research, if any, has been conducted to use MDA investigation, focusing specifically on RA abstracts in the MENA world. By implementing Biber’s (1988) MDA, the present study examined the co-occurrence patterns and linguistic characteristics of English RA abstracts in applied linguistics written by native speakers of Arabic authors residing in the Arab World and international authors from different contexts. Accordingly, the study intended to describe similarities and variations in linguistic characteristics of RA abstracts across three sub-corpora: Middle East Arab, North Africa Arab, and International.
The next section describes corpora compilation and the process of conducting MDA. Following that, the results and discussion are presented, and the last section concludes with pedagogical implications in light of the ELFA point of view.
Methodology
Corpora Compilation
Three specialized corpora of 300 English RA abstracts (with approximately 55,805 words) were purposively selected from 10 peer-reviewed journals in the field of applied linguistics, which was chosen in light of the researcher’s interest and the lack of MDA investigations in this field, especially in MENA contexts. Nwogu’s (1997) criteria (i.e., reputation, representativeness, and accessibility) were used in compiling the corpora. The inclusion criteria for abstracts included: the abstracts were published between 2013 and 2018, the international corpus did not include abstracts written by Middle Eastern and North African Arab authors to ensure a higher degree of comparability, and the abstracts were written by a maximum of two authors only. The abstracts in the international corpus were derived from the following journals: Journal of Second Language Writing, Applied Linguistics, Studies in Second Language Acquisition, TESOL Quarterly, and Journal of English for Academic Purposes. These journals were selected because they are reputable and leading journals in the field of applied linguistics. The abstracts in the MENA sub-corpora were selected from these international peer-reviewed journals: Arab World English Language, English Language Teaching, International Journal of Arabic-English Studies, International Journal of Linguistics, and International Journal of English Linguistics. Due to the limited and uneven number of publications by authors in MENA in the reputed journals and the lack of applied linguistics journals of similar rankings to the reputed journals, the author decided to include journals with a higher number of publications from the MENA world. This situation may raise comparability issues in terms of authors’ experience and training, which is beyond the scope of the study. In other words, the study aims to compare the linguistic features of RA abstracts regardless of the authors’ experience and training. Table 1 shows the details of the three sub-corpora.
Corpus Details of the Three Sub-Corpora.
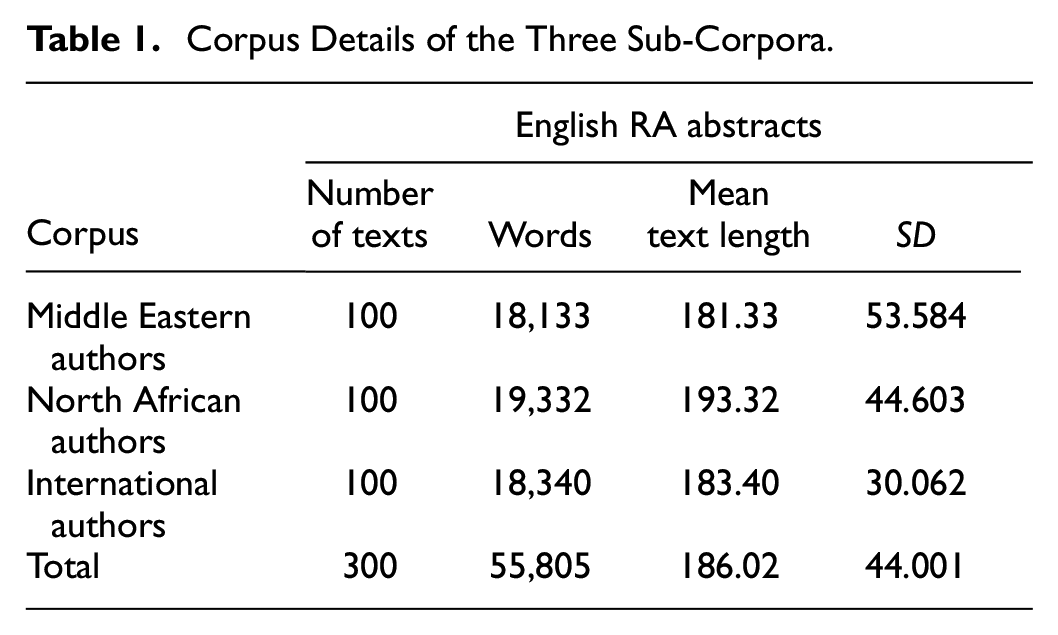
Each corpus comprised 100 abstracts labeled as Middle Eastern Arabs (ME_AR_Abst) (18,133 words), North African Arabs (NA_AR_Abst) (19,332 words), and international authors (INT_Abst) (18,340 words). The MENA corpus was subdivided into two sub-corpora (i.e., the Middle East and North Africa) to investigate possible internal register variations between both corpora as indicated later in Dimension 3, given that MENA countries are distributed into two continents (i.e., Asia and Africa). ANOVA test showed no significant difference across the three corpora in terms of word length, that is, F (df = 2, 297) = 2.138; p = .120. The authors in the two Arab corpora were native speakers of the Arabic language affiliated with universities in the Arab World countries, whereas the majority of the authors in the international corpus were international authors affiliated with universities in the United States, Europe, and Asia, but not from the MENA world. Following Wood’s (2001) criteria, that is, institution affiliation and authors’ Arabic names, I also checked authors’ biographies and websites to verify the Arabic authors’ native states and regions.
Conducting MD Analysis
The three sub-corpora were analyzed based on the methodological steps of MDA (Biber & Gray, 2013). First, the original linguistic features used in Biber (1988) were extracted from each abstract by employing the Multidimensional Analysis Tagger (MAT) developed by Nini (2018). With 95% tagging accuracy (Nini, 2018), the software can process, extract, and tag linguistic and lexico-grammatical features that replicate the ones found in Biber’s (1988) multidimensional analysis. The tagger identifies a range of grammatical features, including syntactic constructions (e.g., that-complement clauses), semantic classes (e.g., activity verbs), word classes (e.g., nouns, verbs, prepositions), and lexical-grammatical classes (e.g., that-complement clauses). The tagged features in the abstracts were normalized per 100 words using MAT (Nini, 2018) across texts to enable comparisons of texts of different sizes (Biber, 1988). Since MAT tagging accuracy is about 95%, the precision and recall had not been calculated; the analytical procedure is very demanding and taking on a larger corpus would hardly be feasible. Also, the Stanford parser included in the tagger is “currently one of the most widely used and accurate parsers available” (Crosthwaite, 2016, p. 171).
Factor analysis was performed by implementing the Dimension Reduction feature in SPSS ver. 20. By using Promax Rotation and the Point of Inflection in the scree plot (see Figure 1), multiple factor analyses were carried out to extract the factors (i.e., dimensions) and to allow each linguistic feature not to load on many factors for interpreting purposes; all features were weighted according to the factor loading and counted on all factors. Features reported loading on more than one factor were included in the computation of more than one factor. In fact, MD analyses typically move through several pilot analyses in which the variables used are refined, removed, and added (Sardinha & Pinto, 2019). In the present study, the first two factor analyses revealed seven and five factors that were difficult to interpret and might not add any more information. Then, after multiple factor analyses, six factors were generated and considered appropriate for interpretation. A total of 43 out of 63 linguistic features with factor loadings of ±0.3 or higher were reserved following Biber (2006). These particular text features were selected because “the size of the loading reflects the strength of the co-occurrence relationship between the feature in question and the total grouping of co-occurring features represented by the factor” (Conrad & Biber, 2001, p. 21).
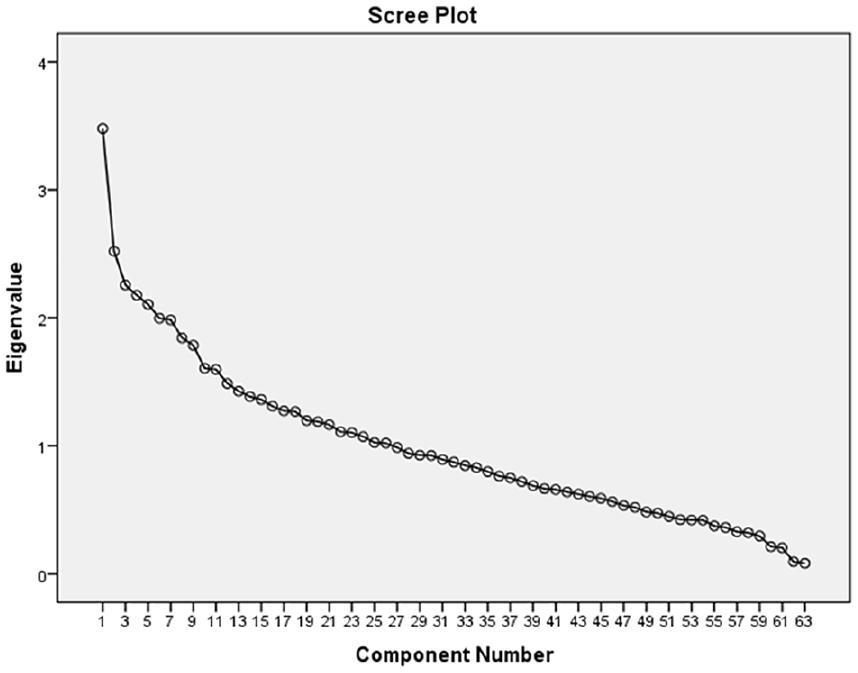
The scree plot of factor analysis.
Then, several statistical procedures were performed to analyze the elicited data further. First, the frequencies of linguistic features in each dimension were standardized across sub-corpora so that dimension scores would not be unequally influenced by features that were more frequent than other features. After calculating z-scores for each feature, the dimension scores for each text were computed by subtracting the sum of negative features from the sum of positive features (Biber, 2006). Following that, the mean dimension score for all texts in each corpus was calculated to characterize the dimension score of each corpus. Multiple one-way ANOVA tests were performed to compare among sub-corpora in the identified dimensions. Next, Tukey post hoc tests were performed for group comparisons with a p-value at .05 level. Finally, the functions of each factor were interpreted in light of the shared linguistic characteristics of the features of the factor (for more details, see Biber, 1995, pp. 136–138). This step is important in MDA investigations because it leads to an accurate definition and interpretation of the dimensions (Sardinha & Pinto, 2019).
As can be seen in Table 2, the multidimensional analysis of 300 texts identified six dimensions of RA abstracts with corresponding linguistic features and their factor loadings, representing 23.03% of the total variance. This percentage is not as high as the one in Biber’s (1988) dataset (i.e., 46.5%) due to the homogeneity and the size of the corpus (Kanoksilapatham, 2003). Given this study’s exploratory nature, the percentage covered by the six factors seems appropriate and adequate to represent the data. In addition to space (i.e., the article’s length), two dimensions (Dim 4: Expression of denial in scientific propositions and research findings, and Dim 6: Persuasion Focused) were not used in this study because these two dimensions did not show major distributional differences among sub-corpora. It is important to note that when positive and negative features load on the same dimension, they mostly reflect a complementary distribution among variables. That is, when a text has a high positive dimension score, the text tends to have more linguistic features loading on a positive pole than its negative counterpart.
Dimension Loadings.

p < .05.R2: the coefficient of determination.
Results and Discussion
The following sections describe cross-registers linguistic distributions and relationships among the three sub-corpora to better understand these distributions’ functional characteristics and significance. It is important to note that some dimensions had few features loading in them, which should be interpreted with caution.
Dimension 1: Current Information Versus Procedural Focused
Dimension 1 (Dim 1) analysis retained 14 linguistic features: ten features on the positive side of the factor and four features on the negative side. The factor explained about 5.52% of the total variance. Positive features loaded on Dim 1 included present tense, infinitives, possibility modals, WH-clauses, the pronoun it, total adverbs, third-person pronouns, demonstratives, necessity modals, and That relative clauses on subject position. On the other hand, negative features were past tense, total other nouns, past participial WHIZ deletion relatives, and total prepositional phrases. The combined dimension scores of the three groups (i.e., ME_AR_Abst, NA_AR_Abst, INT_Abst) are plotted in Figure 2.

Comparison of dimension scores for dimension 1: Current information versus procedural focused; ANOVA: F (df = 2, 297) = 3.858; p = .022, R2 = .015.
In detail, the present tense, the highest feature loading on the positive pole, is used to establish general knowledge, generalize specific findings, or deal with topics and actions of immediate relevance (Biber, 1988; Getkham, 2010; Pan, 2018). Further, the function of the present tense feature in academic writing is to “focus on the information being presented and remove focus from any temporal sequencing” (Biber, 1988, p. 224). The second highest loading feature is infinitives, generally used to expand or integrate ideas (Chafe, 1985; Getkham, 2010; Kanoksilapatham, 2003). Thompson (1985) also identified four more functions for infinitives in academic writing including: (1) to introduce an aim, goal, and purpose; (2) to introduce a method; (3) to introduce a complement; and (4) as predicates to frame points in a discussion. Possibility modals mark writers’ assessment of the reliability of their propositions, especially in presenting the implications of the study, whereas necessity modals help convey the writer’s obligation (Biber, 1988; Kitjaroenpaiboon & Getkham, 2016). WH-clauses function as an idea unit expansion (Chafe, 1985), and Biber (1988) finds that these clauses co-occur with interpersonal features such as first and second pronouns. The pronoun it can be used to implicitly express writers’ attitudes or comments (Biber et al., 1999; Hewings & Hewings, 2002; Kanoksilapatham, 2003). Total adverbs show the writer’s attitude and degree of certainty toward propositions (Biber, 1988). Third-person pronouns refer to other researchers when citing studies related to their research (Kuo, 1999). Demonstrative pronouns are used to refer to the preceding text or the textual context (Biber et al., 1999). That relative clauses on subject position are employed for informational elaboration (Biber, 1988).
The negative pole includes past tense, total other nouns, past participial WHIZ deletion relatives, and total prepositional phrases. Past tense is used to serve several functions, such as describing what has been conducted in the past and marking particular activities in the study (Biber, 1988; Hardy & Römer, 2013; Kitjaroenpaiboon & Getkham, 2016). Past participial WHIZ deletion is used to produce a highly informational discourse under severe time or space constraints as of the abstracts because they are more compact and integrated (Biber, 1988). Similarly, total prepositional phrases integrate high amounts of information into a text, and total other nouns provide an overall nominal assessment of a text (Biber, 1988). Thus, as a complementary distribution in Dimension 1, these features explain the communicative function of this dimension as Current Information vs. Procedural Focused.
In Dimension 1, according to Figure 2, Middle Eastern and North Africa Arab abstracts (Dim 1 score = 0.4840 and 0.8487, respectively) fall on the positive side of the scale, indicating that these two sub-corpora have more current information focus. The international abstracts, however, plot on the negative side (Dim 1 score =−1.3328), demonstrating procedural focus. One-way ANOVA test result showed significant differences among the three sub-corpora; ANOVA: F (df = 2, 297) = 3.858; p = .022. The Tukey post hoc analysis indicated that only the North African Arab sub-corpus was significantly different from the international at p = .027.
The samples below show the use of the following positive and negative features in Dimension 1: Present Tense1, Infinitives2, Possibility Modals3, WH-Clauses4, Pronoun It5, Total Adverbs6, Third-Person Pronouns7, Demonstratives8, Necessity Modals9, That Relative Clauses on Subject Position10, Past Tense11, Total Other Nouns12, Past Participial WHIZ Deletion Relatives13, and Total Prepositional Phrases14.
Excerpt (1) NA_AR_31 RA abstract, Dim 1 score = 15.25
Excerpt (2) ME_AR_79 RA abstract, Dim 1 score = 23.59
Excerpt (3) INT_11 RA abstract, Dim 1 score =−12.33
This
The excerpts were selected to represent texts from the three sub-corpora: Excerpt 1 (NA_AR_31) and Excerpt 2 (ME_AR_79) score high in the positive pole, whereas Excerpt 3 (INT_11) has a high negative score on Dimension 1. In the positive pole, the present tense feature co-occurs with the pronoun it, infinitives, third person pronouns, and possibility modals in North Africa Arab, mostly, and Middle East abstracts to focus more on introductory information and the purpose of the study. On the other hand, the authors in international sub-corpus used past tense with That relative clauses on subject position and total other nouns to describe the process of methodology and collecting data, and to report results, that is, completed actions. The results in the present study are contradictory to some extent with studies reported in the literature. In other words, Friginal and Mustafa (2017) indicated that both Iraqi and U.S. abstracts tended to have more past tense verbs compared to present tense verbs, which is consistent with the findings in this study, given the fact that the present study included authors from Iraq located in the Middle East region. Pan (2018), however, reported that L1 writers prefer using the past tense when writing abstracts compared with L2, who tend to use the present tense. Generally speaking, in RA abstracts, the present tense is used to summarize the article and conclude by providing recommendations, while the methodology and results are reported in the past tense (Swales, 1990), which is typically found in the international and Middle Eastern sub-corpora (i.e., Excerpts 3, 2 respectively). Overall, unlike the North African sub-corpus, the international and Middle Eastern sub-corpora display a certain degree of similarities since their results showed no significant difference between them.
Dimension 2: Evaluative Stance Focused
The second dimension comprised only positive features, including Be as the main verb, predicative adjectives, amplifiers, emphatics, causative adverbial subordinators, direct WH-questions, WH relative clauses on subject position, and the present tense. The factor explained about 4% of the total variance. The highest loading features are Be as the main verb and predicative adjectives, meaning that these two features frequently co-occur together in the sub-corpora to enhance the value of the research, form a single clause, or co-occur with amplifiers to mark certainty or conviction toward a proposition (Biber, 1988; Kitjaroenpaiboon & Getkham, 2016; Pan, 2018). Emphatics mark the reliability of the proposition and indicate a high degree of certainty toward that proposition. Considering amplifiers and emphatics as boosters and evaluative devices, Hyland (2004) asserts that these devices reflect the writer’s assessment of their own or others’ propositions (Baoya, 2015). Causative adverbial subordinator (i.e., because) provides reasons for the writers’ comments (Kitjaroenpaiboon & Getkham, 2016). WH relative clauses are devices used for the explicit, elaborated identification of referents in a text (Biber, 1988). Taking these features together, the communicative function of Dimension 2 can be interpreted as “Evaluative Stance Focused.” This dimension shares several features from Dimension 2 in Getkham (2010) and Baoya (2015) and Dimension 3 in Jin’s (2018) investigations.
In Figure 3, Dimension 2 shows scores of Middle East abstracts and North Africa abstracts (Dim 2 score = 0.7083, Dim 2 score = 0.3237, respectively). On the other hand, the international abstracts score is plotted on the negative pole (Dim 2 score =−1.0321). The results of the ANOVA test, F (df = 2, 297) = 4.468; p < .012, revealed a statistically significant difference among the three sub-corpora. The Tukey post hoc test indicated that the international abstracts were significantly different from the Middle East abstracts (p < .013). The findings show that the abstracts in the Middle East sub-corpus tend to be more evaluative compared to the international counterpart, whereas the North African sub-corpus shares features from the other two corpora. A closer look at the features contributed to this conclusion reveals that the abstracts produced by authors from MENA comprise more predicative adjectives associated with the verb Be, accompanied by frequent uses of amplifiers and emphatics. The international abstracts, however, contain fewer positive features loaded in the dimension, where about 70% of the abstracts score negatively.
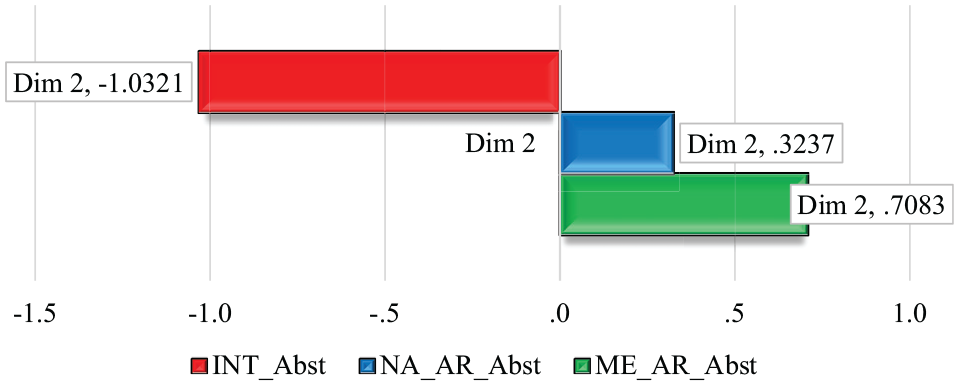
Comparison of dimension scores for dimension 2: Evaluative stance focused; ANOVA: F (df = 2, 297) = 4.468; p < .012), R2 = .026.
The excerpts below show the use of features on a positive pole as follows: Be as Main Verb1, Predicative Adjectives2, Amplifiers3, Emphatics4, Causative Adverbial Subordinators5, Direct WH-Questions6, WH Relative Clauses on Subject Position7, and Present Tense8.
Excerpt (4) ME_AR_68 RA abstract, Dim 2 score = 15.13
There
Excerpt (5) NA_AR_73 RA abstract, Dim 2 score = 28.15
Excerpt (6) INT_73 RA abstract, Dim 2 score =−6.24
[…] The results
The three text samples illustrate the possible cross-cultural variation in abstract writing in applied linguistics from MENA-based and international abstracts. To elaborate, Excerpt 4 (ME_AR_68) and Excerpt 5 (NA_AR_73) scored high on Dimension 2 (14.44 and 12.3, respectively), whereas Excerpt 6 (INT_73) scored (−6.89). To identify the functions and linguistic features, Excerpts 4 and 5 display more evaluative stances, including the verb Be, accompanied by predicative adjectives, amplifiers, or emphatic. In other words, the authors in the Arab sub-corpora tend to use be+predicative adjective structure to demonstrate their evaluative stance, further elaborated by employing adverbial clauses controlled by subordinators such as Because. A similar observation has been noticed in international abstracts with high dimension scores. From a cross-linguistic perspective, although the occurrence of boosters in Arabic writing seems quite normal (Sultan, 2011), Sultan found that Arab authors tended to employ more boosters than native speakers of English. However, Excerpt 6 shows a less evaluative stance, denoting authors in the international sub-corpus favor a more neutral evaluative stance. The authors employ various prepositions to modify nouns to add information, with almost no ‘be+ predicative adjective’ and evaluative stance.
Dimension 3: Informational Density Focused
Dimension 3 shares similar features with the negative factor of Biber’s (1988) Dimension 1 and several other studies, for example, Dimension 1 in Hardy and Römer (2013). These features were word length, nominalizations, independent clause coordination, present participial clauses, type-token ratio, gerunds, and attributive adjectives. The negative features included total prepositional phrases and agentless passives. The factor explained about 3.6% of the total variance.
According to Biber (1988), the high frequency of the features on the positive continuum indicates a high informational focus (i.e., density) and careful integration of information in the texts. In detail, word length ratio, type/token ratio, and nominalizations, including gerunds, mark a high density of information which lead to selecting precise lexical choice suitable for an exact presentation of informational content and conveying maximum content in the fewest words (Biber, 1988). And as an independent clause, coordination serves as a general-purpose connective device to link many different logical relations between two clauses (Biber, 1988) and to add a new idea unit to a preceding one (Baoya, 2015). Present participial clauses are used for integration or structural elaboration, and gerunds determine nouns (Biber, 1988; Chafe, 1985). Attributive adjectives function as further elaboration for nominal information by packaging information into a few words and structures (Biber, 1988; Hardy & Römer, 2013).
The dimension is characterized by total prepositional phrases and agentless passive on the negative pole. Total prepositional phrases integrate high amounts of information into a text. Agentless passives index an information focus on research activities (Kanoksilapatham, 2003). This dimension mirrors two features in Biber’s (1988) Dimension 1: “Involved vs. Informational Production.” Therefore, the features of positive and negative continuums are associated with more production of high-density information. Interestingly, the features loaded on both poles of this dimension, such as nominalizations, gerunds, attributive adjectives, type/token ratio, prepositions, and passives, have been found to co-occur in one dimension in several other studies (e.g., Biber, 1988). In the current study, however, some of these features split between both poles or co-occur with other features in other dimensions, for example, Dimension 1, having their own communicative functions. A possible interpretation would be related to the two markedly distinct genres (spoken versus written) in Biber’s investigations. The genre of this study (i.e., RA abstracts) displays a very similar style of academic writing among the three sub-corpora (Cao & Xiao, 2013).
According to Figure 4, the dimension scores of the three sub-corpora show a sharp contrast between the Middle East abstracts (Dim 3 score =−1.5584) and the international abstracts (Dim 3 score = 1.6966), whereas North Africa abstracts (Dim 3 score =−0.1382) are plotted almost in the center of the dimension. Obviously, the international abstracts display a co-occurrence of lots of nouns and noun modifiers, maintaining a discourse characteristic of being informational and descriptive, while the MENA abstracts involve an interactive discourse. ANOVA test indicated a significant difference among the three groups; ANOVA: F (df = 2, 297) = 18.769; p < 0.000). To investigate the internal relationship, a post hoc test revealed a significant difference between international abstracts and the other sub-corpora, the Middle East (p < .000) and North Africa (p < .002). Also, there is a significant difference between the Middle East and North Africa sub-corpora (p < .022). These results indicate that the authors in these sub-corpora use different writing styles to show informational density. The following examples explain the main differences among these sub-corpora.

Comparison of dimension scores for dimension 3: Informational density focused; ANOVA: F (df = 2, 297) = 18.769; p < .000), R2 = .112.
The excerpts below show the use of features from positive and negative poles as follows: Nominalizations1, Independent Clause Coordination2, Present Participial Clauses3, Gerunds4, Attributive Adjectives5, Total Prepositional Phrases6, and Agentless Passives7.
Excerpt (7) INT_58 RA abstract, Dim 3 score = 12.38
[…]
Excerpt 7 (INT_38) represents the international sub-corpus in the positive side of the dimension. As can be seen from the excerpt, the text displays several nominalizations frequently used in academic writing to mark informational density (Cao & Xiao, 2013). Also, average word length and type-token ratio tend to co-occur to mark “a highly exact presentation of information, conveying maximum content in the fewest words” (Biber, 1988, p. 238). The results indicate that authors in the international sub-corpus tend to write more informational dense abstracts than their equivalent in the MENA sub-corpora. The findings are somewhat incongruent with Friginal and Mustafa (2017) but contradict Cao and Xiao (2013); That is, Iraqi abstracts showed a descriptive and informational dense discourse, whereas Chinese abstracts exhibited more information focus than English native-speaker writers. A possible explanation could be related to the fact that Chinese, and perhaps some Arab writers, as non-native speakers of English, may believe that being direct, concise, and readable is better than employing “too many instances of nominalization [which] would make it difficult for readers to comprehend” (Cao & Xiao, 2013, p. 226). According to Biber and Gray (2011), academic writing is represented by a “dense use of non-clausal phrases and complex noun phrase structures with few clausal elaborations” (p. 226). This is observed in international abstracts, where sentence structures appear to be more complex and long.
Excerpt (8) ME_AR_40 RA abstract, Dim 3 score =−11.68
[…]
Excerpt (9) NA_AR_55 RA abstract, Dim 3 score =−8.46
[…]
On the other hand, Excerpt 8 (ME_AR_40) and Excerpt 9 (NA_AR_55) show that both sub-corpora share certain linguistic features, including total prepositional phrases and agentless passive. Positive features, such as nominalizations and gerunds, are also found in the text, yet few of them suggest a balance between positive and negative features (Pan, 2018). Prepositions frequently tend to co-occur with nominalizations and passives in academic prose to show informational density (Biber, 1988). Therefore, both texts indicate that involved linguistic features co-occur with informational features to represent academic involvement.
Dimension 5: Narrative Style
Dimension 5 contained four positive and three negative loadings, explaining 3.340 % of the total variance. The positive features included That verb complements, third-person pronouns, private verbs, and subordinator That deletion. The negative loadings were past tense, attributive adjectives, and total prepositional phrases.
As for the positive pole, That complement serves as an “elaboration of information relative to the personal stance of the speaker, introducing an affective component into this dimension” (Biber, 1988, p. 114). Third-person personal pronouns function as a reference to persons apart from the speaker and addressee. Private verbs (e.g., believe) indicate an internal, mental process or state (Quirk et al., 1985, p. 1182), which frequently co-occur with That verb complements or That deletion to expand ideas or comments. Subordinator That deletion helps make a sentence more concise, especially when this subordinator co-occurs with private verbs (Biber, 1988; Kitjaroenpaiboon & Getkham, 2016).
On the negative pole, the three features are loaded in other dimensions (past tense in Dim 1, attributive adjective in Dim 3, and total prepositional phrases in Dim 1 and Dim 3), displaying different functions. In Dimension 5, the past tense is used to mark past activities and completed actions. Biber (1988) considers past tense the primary marker of narrative or reported writing. In this study, the past tense is used to state the procedures of methodology and to report the findings of the study. According to Biber (1988), past tense tends to co-occur with third-person personal pronouns as a marker of narrative and reported styles. Attributive adjectives are used for both identificatory and descriptive purposes (Biber, 1988). Prepositional phrases also serve to integrate high amounts of information into a text. The features of Dimension 5 collectively mark the narrative style of discourse, especially the past tense feature.
As shown in Figure 5, all sub-corpora fall into the negative pole of the continuum, indicating that these corpora employ a narrative style to present methodology and to report the findings of the studies. The international sub-corpus scored the highest on the negative pole (Dim 5 =−11.1056), followed by the Middle East (Dim 5 =−9.0887) and North Africa (Dim 5 =−8.8255). However, the ANOVA test identified a statistical difference among these sub-corpora; ANOVA: F (df = 2, 297) = 7.289; p < .001. For further analysis, post hoc analysis revealed a statistical difference between the international sub-corpora on the one hand and the Middle East and North Africa on the other (p < .002 and p < .006), respectively. Both Arab sub-corpora showed a higher degree of similarity in their writing style (p = .914).

Comparison of dimension scores for dimension 5: Narrative style; ANOVA: F (df = 2, 297) = 7.289; p < .001), R2 = .039.
The samples below show the use of the following features in Dimension 5: Past Tense1, Attributive Adjectives2, Total Prepositional Phrases3, That Verb Complement4, and Private Verbs5.
Excerpt (10) INT_36 RA abstract, Dim 5 score =−20.82.
[…] An intervention study using this approach
Excerpt (11) ME_AR_23 RA abstract, Dim 5 score =−20.63
[…] Data
Excerpt (12) NA_AR_14 RA abstract, Dim 5 score =−16.29
[…] The study adopts Hyland’s (2005b) Model
The above excerpts explain how positive and negative features are represented in the three sub-corpora. In Excerpt (10) INT_36, past tense with several attributive adjectives and prepositional phrases are used to narrate and expand past actions, that is, describing data collection procedures and reporting study results. The abstract includes a few positive features, such as That complement controlled by private verbs. As for the Arab sub-corpora, Excerpt (11) ME_AR_23 shows that Middle Arab abstract shares similar features, yet, with more attributive adjectives and prepositional phrases. A private verb is the only positive feature that occurred from the positive pole. However, Excerpt (12) NA_AR_14 shows that the past tense is only used to report study findings, marking a clear distinction. Overall, it appears that the major difference between the international sub-corpus and the Arab counterparts relies on the frequent uses of attributive adjectives and prepositional phrases in the Arab sub-corpora with few past tense uses, especially in the North African abstracts, in reporting past action activities. The present study’s findings align with several previous studies (Baoya, 2015; Friginal & Mustafa, 2017; Jin, 2018; Kanoksilapatham, 2003; Kitjaroenpaiboon & Getkham, 2016). Friginal and Mustafa’s (2017) study found that abstracts written by Iraqi authors tended to have lower uses of private verbs and a higher frequency of past tense to show how the study has been conducted or completed.
Conclusion
The present corpus-based study examined the co-occurrence patterns and linguistic characteristics of 300 English RA abstracts in applied linguistics. The analyses also explored the extent to which these abstracts in the three sub-corpora differ in terms of linguistic characterizations. A total of 43 lexico-grammatical features were identified, and then six dimensions were generated using multidimensional analysis. Four dimensions (i.e., 1, 2, 3, 5) revealed differences among the three sub-corpora, whereas dimensions 4 and 6 showed higher degrees of similarities. Dimension 1 identifies current information vs. focused procedural styles through such features as present and past tenses, respectively, where the results state that the MENA abstracts display more current information focus, and the international abstracts have procedural focus characterizations. Furthermore, Dimension 2 illustrates the use of an evaluative stance in the abstracts; the MENA sub-corpora tend to be more evaluative, whereas the international abstracts favor a more neutral evaluative stance. Dimension 3 reports on the density of information production through nominalization and word length features which have been captured mostly in international abstracts. Lastly, the international sub-corpus displayed more narrative style than the other MENA sub-corpora in Dimension 5.
The variations and similarities reported in the present study are mainly descriptive. The study hopes to contribute to the ELFA paradigm methodologically by using MDA as a model to compare various linguistic features in specialized corpora to enrich the literature with new cross-cultural and linguistic information. Therefore, these similarities and variations should not be recognized as a deviation from standard English but as pluralizing academic writing (Canagarajah, 2006). Pluralizing English refers to norms and standards of particular and localized varieties of English that have uniquely emerged in national or social contexts (Canagarajah, 2006; House, 2012; Y. Kachru, 1995; Matsuda & Matsuda, 2010).
Hence, the variations on certain dimensions (i.e., Dims 1, 2, 3, 5) can be attributed to several factors, including that some authors may have appropriately followed the journals’ conventions and requirements (Friginal & Mustafa, 2017). Moreover, the specific choices of linguistic features on the six dimensions shape the writers’ unique academic writing styles. Mauranen (2010) asserted that writing and writing style preferences are culturally determined, and transferability into another language varies. Thus, the writings of the members of the ELF community “differ to some extent in various ways from those norms of North American or British English” (Ingvarsdóttir & Arnbjörnsdóttir, 2013, p. 141). Therefore, similarities and variations reported in the present study cannot be attributed to L1 writers’ backgrounds alone. Future studies could then investigate possible other factors, such as the involvement of literacy brokers in the process of writing these abstracts by interviewing the writers of these abstracts.
The findings suggest pedagogical implications for academic writing for publication targeting graduate students and newcomer scholars to the field of applied linguistics in general and applied corpus linguistics in particular. First, the present study contributes to the applied corpus linguistic and English as lingua franca academic fields by providing a systematic multidimensional analysis for linguistic characterizations of abstracts since there has been “no published MDA specifically of RA abstracts” (Friginal & Mustafa, 2017, p. 50) in these fields. Graduate students and those who are new to the field of corpus linguistics, especially in the MENA region, need to be fully aware of the currently preferred writing norms and conventions of international journals in specific disciplines. This awareness could be accomplished by incorporating data-driven learning (i.e., corpus linguistics) with genre pedagogy. Recently, corpus linguistics has become the primary learning resource to understand the target genre and to develop university students and novice writers’ rhetorical and linguistic repertoire (Cai, 2016; Suherdi et al., 2020). In other words, non-native speakers who wish to publish in internationally reputed journals need to access material and symbolic resources to understand how international publication spaces are shaped. They also need to know possible “scholars’ means of production, their capacity to access well-resourced libraries, and their opportunities to engage meaningfully with relevant members of their discourse communities” (Soler & Cooper, 2019, p. 3).
The present study has some limitations. The study systematically compiled 300 research article abstracts in applied linguistics. Future studies could incorporate a larger corpus in the same or different disciplines. Furthermore, given that this study is exploratory, a more detailed analysis of specific linguistic features loaded on these dimensions could show other similarities and differences in authors’ academic writing conventions and styles, which could be related to their cultural and/or linguistic backgrounds. The analysis in this study focused on only RA abstracts, and future research should consider exploring linguistic features in other research article sections, such as an introduction or discussion written by authors from the same region or other regions around the globe. Lastly, it would be interesting to see a similar analysis comparing English and Arabic (the variety used for academic writing) rather than Arabic speakers written in English.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.