
Abstract
To better understand the actual rating variables that affects Auto insurance Policyholders’ premium, this paper attempts to provide empirical evidence to justify which ones are significant and needed to be considered by insurers by adopting the autoregressive distributed lag (ARDL) model. In satisfying all the conditions for ARDL application, unit root, Heteroskedasticity, normality, dynamic stability and serial correlation tests were conducted. We estimate the effects of each rating variable on Premium taking into consideration whether the policy of the insured is Third-Party or Comprehensive. These rating variables in the ARDL model serves as the independent variables that establishes the short and long-run relationships between them and the Premium as the dependent variable. The results suggest that not all the classical rating variables used in the market significantly impact Premium. Whiles, to some extent, we found a varying degree of variables impact on Premium depending on the insurance type, the autos cubic capacity, which plays a cogent role on the basic Premium in Ghana, is insignificant. Also, policyholders’ age characteristics are statistically significant but are excluded in the premium calculations. Thus, this paper shows the need to consider all the other possible rating variables, including policyholders’ age into the Ghanaian insurance pricing system, whiles autos cubic capacity considering the weight it put on the basic Premium should be re-examined. This would help to obtain a financially balanced and optimal pricing system for policyholders.
Keywords
Introduction
Automobile insurance, particularly the third-party (TP) category, is mandatory in most countries (Aeron-Thomas, 2002; Bülbül & Baykal, 2016; Isotupa et al., 2019; Lemaire, 1998). Automobile use has embedded morbidity and mortality risk, as well as loss through theft and fire in several countries (Lemaire, 2004), and thus its associated insurance was developed to handle the potential loss (Boucher et al., 2009; Frangos & Vrontos, 2001). Automobile insurance was introduce to safeguard policyholders from potentially enormous financial losses as well as losses to third parties. However, the premium, which is computed based on the policyholder’s risk, can influence the decision to purchase a policy (Alhassan, 2016; Alhassan et al., 2015; Alhassan & Biekpe, 2016a; Azaare et al., 2021; Bülbül & Baykal, 2016; Isotupa et al., 2019). Majority of studies look at premium estimates from a traditional perspective on the basis of claims frequency and severity from policyholders’ (Azaare et al., 2022; Deniut et al., 2007). From both a priori and a posteriori point of view, the frequency and severity of policyholder claims have been the major dependent variables in rate-making models. In the priori and posteriori structures of the bonus-malus system, some attributes of the policyholder and the vehicle are considered regressors. Classical variables such as the driver’s age, experience, career, marital status, gender, and the age of the vehicle, cubic capacity, mileage, garage location, and so on have been used in the priori premium determination setup (Jacob & Wu, 2020; Bolanc’e et al., 2007; Bülbül & Baykal, 2016). Nonetheless, the literature is not loud on the individual impacts of these classical variables on policyholders’ final premium, especially in the Ghanaian market (Azaare et al., 2021).
Furthermore, articles in the literature look at policyholders premiums by concentrating specifically on their driving patterns based on vehicle usage. As a result, premiums might be computed by relying on policyholders’ yearly distance traveled (Edlin, 2004; Ferreira & Minikel, 2012). In addition, the pricing system takes into account policyholders’ driving speed records, the most frequently plied roads, the type of such roads, and the time of day they are mostly on the roads (Langford et al., 2008; Litman, 2005; Paefgen et al., 2013, 2014; Sivak et al., 2007). According to Ayuso et al. (2014), “policies with these elements are mostly targeted at young drivers, but yet, there is a report on significant differences between novice and experienced young drivers, indicating a heterogeneous risk group among young policyholders.” Thus, insurers using policyholders age variable could lead to lower premium because older and experience drivers posed lower accident risk (Ayuso et al., 2014; Azaare et al., 2021). There are a number of interesting results when it comes to insurance variables that predict premiums. For instance, Boucher et al. (2013), as well as Litman (2005) and Langford et al. (2008) emphasized that the association between drivers’ number of claims and his distance driven may not be linear. Furthermore, the gender gap was linked to the frequency of vehicle use by Ayuso et al. (2016). While gender is important in explaining the time to the first accident, the authors argue that it is no longer necessary when the average distance traveled per day can be captured by telematics in the model to provide ample information on driving habits.
Surprisingly, despite all of the variables used by insurers in premium calculations, the Ghanaian auto insurance market based solely on vehicle age, cubic capacity, type of use for third-party policies, and inclusion of the vehicle’s sum in the comprehensive (C) premium case (Awunyo-Vitor, 2012; Ghana National Insurance Commission [NIC], 2015; Laryea, 2016), which this study discovers that not all of these variables are significant. The pricing model used by the market does not also capture any characteristics of the insured driver or the policyholder involved but relies on only the limited classical variables of the insured auto, leaving a mixed feeling from policyholders on variables considered because of the high nature of premiums (Azaare et al., 2021). According to the Ghana National Insurance Commission’s (NIC, 2015) pricing system, vehicles with fewer than 5 years of age are not charged age loading, but those with 5 to 10 and more than 10 years are paid 5% and 7.5% of the basic premium as age loadings, respectively. On the other hand, policyholders pay 5% and 10% of the basic premium for autos with a cubic capacity (CC) of 1601 to 2000 and >2000, respectively. Furthermore, in Ghana, the seating capacity of an insured vehicle plays a significant role in determining the final premium. “Except for the linear association between auto mass and accident severity, there is no sufficient evidence in the literature to support its inclusion” (Azaare et al., 2021).The standard number of seats included in the flat-rate system for both third-party and comprehensive insurance is five. In this situation, each vehicle with more than five seats pays 5 and 8 Ghana cedis per seat for private and commercial use, respectively (Azaare et al., 2021; Ghana National Insurance Commission [NIC], 2015).
Interestingly, extensive research conducted by Ayuso et al. (2017) indicates an insignificant relationship between insured auto age and accident or claims patterns, even in the telematics information model. Following Ayuso et al. (2017), we assume that since higher claims always lead to higher premiums, see Lemaire (1995), Mert and Saykan (2005), Denuit et al. (2009), and Sarabia et al. (2004), then Ayuso et al. (2017) findings implies an insignificant relationship between premium and auto age. Additionally, Boucher et al. (2013) postulates a non-proportional relationship between vehicle mileage/cubic capacity and claims occurrence. Beside, certain characteristics of the insured driver/policyholder, for examples the age, can never be underestimated in the quest for fair premiums since there is a distinctive heterogeneity among young and old drivers (McKnight & McKnight, 2003; Nicoletta, 2002). Thus, policyholders’ age is proportional to accident frequency and severity; older and experienced drivers have low accidents risk (Kelly & Nielson, 2006). Nonetheless, this risk variable is conspicuously missing from the pricing system used by the Ghanaian auto insurance market. This leads to the question: is the Ghanaian auto insurance market using the right rating variables that significantly have impact to justify high nature of policyholders premium? Hence, using the autoregressive distributed lag (ARDL) model, this study seeks to present empirical evidence to support which variables are significant and ought to be considered by insurers in order to better understand the actual rating variables that affect Policyholders premium. After thorough study, the data on the market met the requirements for ARDL, with no variable being I(2). “The ARDL model has a number of advantages/benefits over competing econometric models, including the fact that the dependent variable is explained not only by the independent variable(s), but also by its lag” (Bahmani-Oskooee & Brooks, 2003; Narayan, 2005; Pesaran et al., 2001; Phillips & Perron, 1988). “Endogeneity is less of an issue in the ARDL technique since it is free of residual correlation because each of the underlying variables stands as a standalone equation (i.e., all variables are assumed endogenous)” (Emeka & Aham, 2016). The ARDL approach can distinguish between dependent and explanatory variables, allowing us to assess the reference model. That is, the ARDL method presupposes that the dependent variable and exogenous variables have just one reduced form equation relationship (Pesaran et al., 2001). ARDL model can identify cointegrating vectors when there are several cointegrating vectors. The Error Correction Model (ECM) can be created from the ARDL model using a simple linear transformation, which integrates short run adjustments with long run equilibrium without destroying long run information. The ECM model’s lags are large enough to represent the data creation process in general to specialist modeling frameworks.
This model has been considered extensively in the literature. See, for example, Gouri’eroux and Jasiak (2004) who applied the autoregressive model to count for serial dependence in the count process.
Moreover, in the literature is level and long-run relationships determination through bound testing by Alhassan and Fiador (2014), Bahmani-Oskooee and Brooks (2003), Emeka and Aham (2016), Kaodui et al. (2020), Narayan (2005), Osuagwu (2020), Pesaran et al. (2001), and Phillips and Perron (1988). The ARDL model was used by Alhassan and Fiador (2014) to establish a long-run link between insurance company penetration in Ghana and economic growth by using the Pesaran et al. (2001) bound testing approach. Also in recent times, liquidity and firms viability nexus (Kaodui et al., 2020), output of manufacturing firms and agriculture long-run relationship (Osuagwu, 2020) are established. In addressing the gap as mentioned above in the literature, we present the first study analyzing the effects of rating variables on Premium using data from the Ghanaian auto insurance market in ARDL model.
“The Ghanaian auto insurance market is one of the largest in West African and, therefore, for many industry players, the most important sales market for their insurance policies” (Azaare et al., 2021). The historical backdrop of the insurance business in Ghana traces all the way back to the 1920s. The Guardian Royal Exchange Assurance Ghana Ltd was the first insurance company to start operation in the then Gold Coast in 1924 (Amoah & Nkrumah-Arkoh, 2009). From the year 1924 till date, the Ghanaian economy has been experiencing unprecedented penetration of insurance companies from both local and foreign front. The number of insurance businesses permitted to operate in the country increased to 53 at the end of 2018, according to the NIC annual report. A breakdown of the organizations shows that 17 are into life guaranteeing and 22 non-life. The statistics shows that 29 of these companies operate non-life (mostly auto) business whiles the remaining 24 do life business. Additionally, there are 82 insurance broking companies, three loss adjusting firms, four reinsurance brokers, and four reinsurance companies (Ghana National Insurance Commission [NIC], 2018). “The insurance business in Ghana is regulated by the National Insurance Commission (NIC), which has the object of guaranteeing successful organization, oversight, guideline, and control the matter of insurance in Ghana” (Duodu & Amankwah, 2011).
We had exclusive access to one of Ghana’s top insurance companies’ data sets in the sector of auto insurance. This study provides to the literature a better understanding of both long and short-run relationships that characterizes policyholder’s risk (rating factors) and their insurance cost (premium). Our results show that some of the rating factors, for example, cubic capacity of the auto, claims, and seating number for the comprehensive policy has an insignificant relationship with premium whiles there is the need for policyholders age inclusion into the pricing system particularly in the comprehensive policies because of its significance.
The contribution of this paper is to help insurers and government policy makers addressed concerns by policyholders on significant premium determinants for a fair pricing system by understanding the limitations and or opportunities involved in incorporating all other factors involved in auto insurance. According to studies, acquiring new policyholders costs five times more than keeping existing ones (Ampaw et al., 2019; Bhattacherjee, 2001; Chen & Myagmarsuren, 2011). As a result, the findings of this paper will serve as a forerunner and policy guide for insurance industry players in developing fair pricing systems by considering only rating factors that have a significant impact on premiums in order to improve policyholders’ retention rates with their various insurers. In addition, the paper aims to generate conversation topics that will elicit interest and debate on all possible premium determinants in the context of vehicle insurance in general. Although the study focuses on Ghana, the similarities in terms of factors considered by insurers when calculating auto insurance premiums in the sub-region and globally make our findings transportable.
The rest of the paper is organized as follows: Section 2 explains the materials and methods used for the study. In Section 3, we analyze and present the results. Finally, in Section 4, we discuss the findings and conclude.
Materials and Methods
In this section, the data, variables under consideration, and methods used to obtain desired results are discussed.
Data
Table 1 shows risk exposure and premium payment information for (N = 23,434) automobile insurance subscribers collected from a major Ghanaian insurance firm throughout 2018. The sample includes drivers who underwrote both third-party and comprehensive insurance policies. In the entire sample, n = 3,731 (15.9%) drivers had recorded claims, with a mean age of 48 years for both comprehensive (C) and third-party (TP), whereas the whole portfolio and those with no reported claims had a mean age of 49 years. We divided the data into two categories: TP n = 1940 (52.0%) and comprehensive n = 1791 (48.0%), with each category analyzed independently due to explanatory variable differences. For instance, with a comprehensive policy, we have the insured auto value, which is not required in a third-party policy. The descriptive statistics in Table 1 shed more light on the differences between policyholders who have reported claims and those who haven’t, as well as those who have comprehensive and third-party policies. The insured vehicle’s features are likewise shown in Table 1. Table 2 also shows the variables that were used in the model. The explanatory variables in our model are classical premium variables that are found in market data, such as policyholder age, insured vehicle age, cubic capacity, claims size, and vehicle seating capacity (Awunyo-Vitor, 2012; Azaare et al., 2021; Ghana National Insurance Commission [NIC], 2015; Laryea, 2016).
Claims and Variable Categories Descriptive Statistics (Quantitative Variables).

Description of the Variables.

The Autoregressive Distributed Lag Model
The autoregressive distributed lag model (ARDL) is an infinite lag distributed econometric model that is used to deduce long-run associations from short-run situations. The ARDL model has a number of advantages/benefits over competing econometric models, including the fact that the dependent variable is explained not only by the independent variable(s), but also by its lag (Bahmani-Oskooee & Brooks, 2003; Narayan, 2005; Pesaran et al., 2001; Phillips & Perron, 1988). In order to investigate the existence of a relationship between premium and our explanatory variables, we formulate our ARDL in broad terms as follows:

From (1), we expand it as;

Where
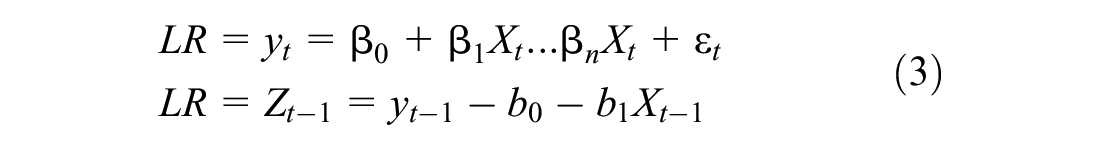
In this approach, the error correction term is substituted with

with estimated long-run coefficients given by;

It’s worth noting that Y(y) is the X1 reading from our Table 2 variables.
There are various conditions that must be met in order to determine the appropriateness of an ARDL application, which, as previously said, characterize the data under consideration. These conditions have also received a lot of attention in the literature. For example, unit root testing and other conditions such as heteroskedasticity, normality, dynamic stability, serial correlation test, and others, used by Dickey and Fuller (1979, 1981), Engle and Granger (1987), Granger (1983), and Granger and Lin (1995), in applying ARDL model to identify relationships among I (0) or I (1) dependent and independent variables.
Testing Long-Run Relationship Presence
With the help of the EViews version 10 software used in this paper, we established the existence of long-run relationships between premium and the independent variables by adopting the Pesaran et al. (2001) bound testing. In this case, we use the F-statistics to test depending on the number of lags the individual or joint null hypothesis as follows;
The decision here is that there is statistical evidence to support the existence of a long-run relationship if the null hypothesis is rejected (F- value >Pesaran upper critical bound value at 0.05 level).
Analysis and Results
Ascertaining Data Conformity with ARDL Conditions and Optimal Lag Selection
To choose the best model to establish the underlying long-run relationship, it was important to use proper model order criteria selection in determining the optimum lag. This was needful in obtaining standard normal error terms that satisfy normality, free from autocorrelation and heteroskedasticity. The appropriate model order selection criteria employed in this study are the Akaike Information Criterion (AIC) and the Schwarz Information Criterion (SIC). In concluding as to which lag is appropriate for the long-run model, various lags of the variables were estimated, compared, and the lag length with the smallest AIC and SIC was considered the most optimal. As shown in Table 3, lag 1 and lag 3 are optimal for comprehensive and third-party, respectively. Hence, we developed our original ARDL models for both categories based on their optimal lags as shown in Tables 4 and 5.
Statistics for Selecting Model Optimal Lag.

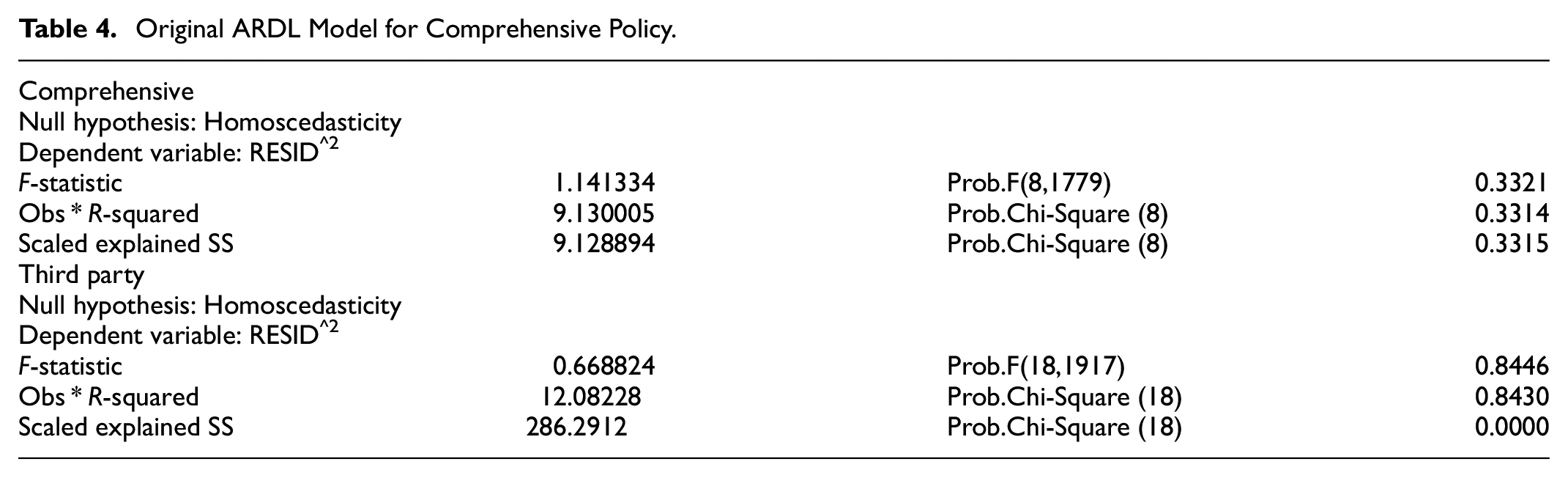
Original ARDL Model for Comprehensive Policy.
Original ARDL Model for Third Party Policy.

Before we developed our ARDL model, conditions to satisfy its application in this paper were also very important to be examined. Evidence, for example, has shown that ARDL model would not run if any of the independent variables or the dependent variable is I (2), for detail, see Bahmani-Oskooee and Brooks (2003), Dickey and Fuller (1979, 1981), Engle and Granger (1987), Granger (1983), Granger and Lin (1995), Narayan (2005), Pesaran et al. (2001), Phillips and Perron (1988). Therefore, we performed the Augmented Dickey-Fuller unit root test. As shown in Table 6, all our involving variables in both policy categories under consideration exhibited stationarity at either I (0) or I (1). This is so because, in both the comprehensive and the third-party category, the p-values for all the variables are less than 5% significant level. Moreover, the test statistic in each case is greater than critical values at (1% and 5%) significant levels. Hence, we reject the joint null hypothesis that the variables got unit-roots. Another required condition for the ARDL model application is that there should not be any Heteroskedasticity existence among the involving variables. Thus, all the variables should have equal standard errors (Homoscedasticity). We, therefore, applied the Breusch- Pagan-Godfrey Heteroskedasticity Test, and the results are shown in Table 7. We tested the null hypothesis; there exist Homoscedasticity. In this case, we decide that when the Obs * R-squared value had a p-value of less than .05, then we conclude that there exists Heteroskedasticity, and otherwise, we accept the null hypothesis. As indicated in Table 7, we recorded an Obs * R-squared of 0.3314 and 0.8430 for both Comprehensive and third-party. Comparing these values with the .05 significant level gave us enough evidence to accept our null hypothesis indicating the presence of Homoscedasticity. Also, it is indicated in Figure 1 through the Q-Q plot that our data is normally distributed.
Augmented Dickey-Fuller Unit Root Test for Both Comprehensive and Third-Party Policies.

Breusch-Pagan-Godfrey Heteroskedasticity Test.


Normality test for comprehensive in red and third-party in black.
Models Diagnostics Checks
After satisfying all the needed conditions and selected our optimal lags, we then estimate the ARDL for both data groups under consideration and as already mentioned shows the results in Tables 4 and 5 which also depicts the long-run impacts of each independent variable on the dependent variable. We then proceeded to perform some diagnostics check. This was to be sure that the errors in our model are serially not correlated, dynamically stable, and also the existence of long-run relationships. We therefore, in this paper employed serial correlation LM test, Cusum test for stability, and bound test for long-run relationships between our dependent and independent variables. For more details, readers may see, for example, Alhassan and Fiador (2014), Bahmani-Oskooee and Brooks (2003), Emeka and Aham (2016), Narayan (2005), Pesaran et al. (2001), and Phillips and Perron (1988).
First of all, we performed the serial correlation test for both variables category. In Table 8, we show the details of lag one model, which satisfied optimality for the comprehensive policy and lag 3 for a third-party. It is also shown in Table 8 that the probability value of 0.616 for the observed R-squared in the comprehensive case and 0.053 in the third-party case are both above the benchmark value of 5%, indicating that the models satisfy the condition of serial correlation. In Figure 2, we illustrate how our model is stable. As clearly indicated, our models also satisfy the condition of dynamic stability as the blue trend line falls within the boundary of the red lines for both the comprehensive and third-party category. We went ahead to establish long-run relationship amongst our variables. The standard F-statistics from Table 9 are 89.63 and 70.64, respectively, for both comprehensive and third-party categories. These statistics, when compared with Pesaran critical value at 0.05 levels because our models are unrestricted intercept having no trend, indicates significant long-run equilibrium relationship among the involving variables. This is because the standard F-statistics values are far greater than the upper bound value of 3.61 and 3.39, respectively, from the Pesaran Table with p-values of .000 in each case, and hence we reject the null hypotheses in Table 9. See Pesaran et al. (2001) for details.
Breusch-Godfrey Serial Correlation LM test.

Wald Test Result for the Existence of Long Run Relationship Among Variables.


Stability test for comprehensive (C) and third-party (TP).
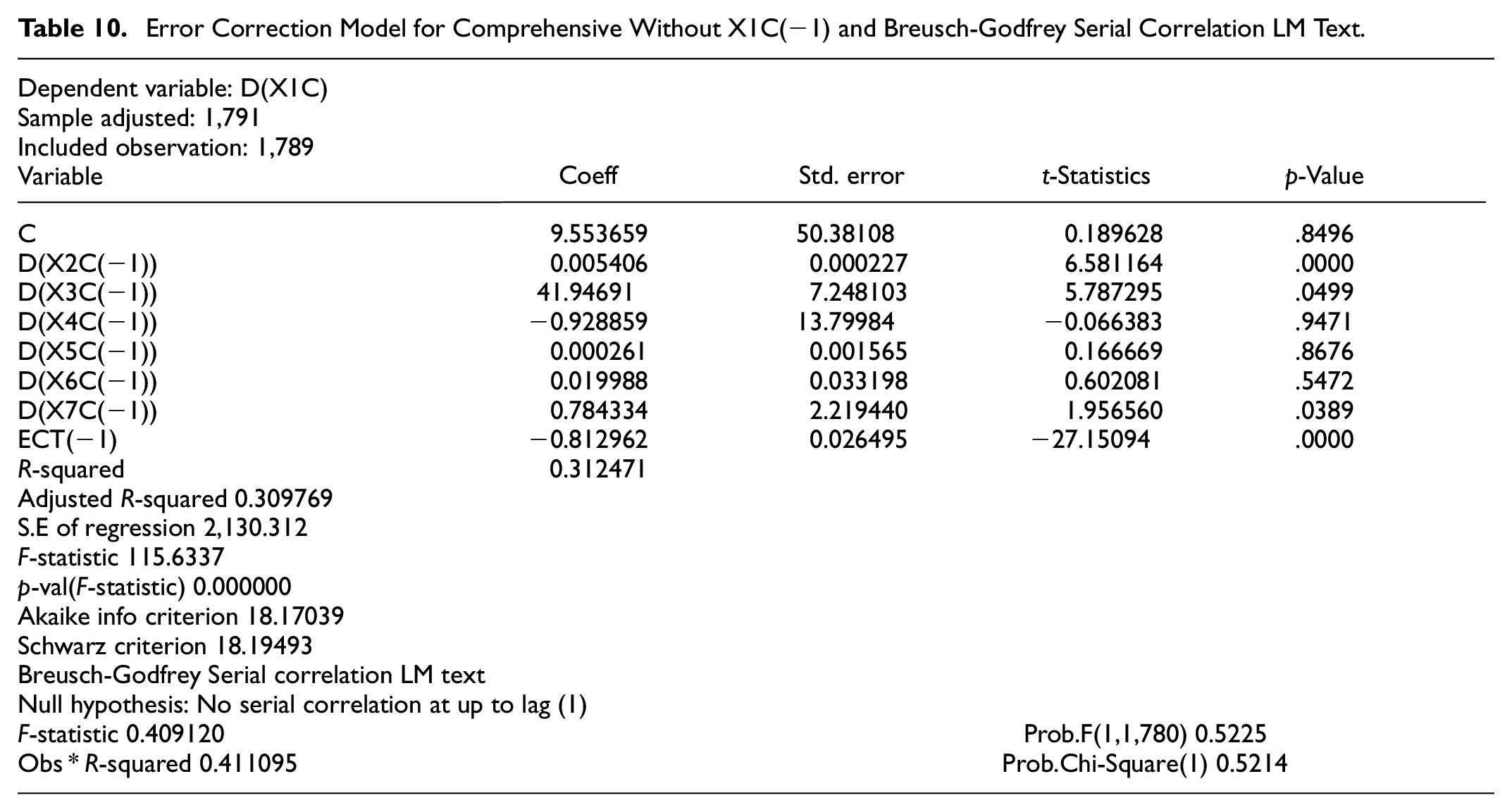
Now, we developed the residual models using our optimal lag (1) and lag (3) for comprehensive and third-parties respectively and illustrate the results in Tables 10 and 11. From Table 10, we show the short-run coefficients using (4) for the regressors a significant value of the residual representing the speed of adjustment of our model at 81.29% toward long-run equilibrium. We then proceed to investigate whether this long-run model satisfies the condition of serial correlation and dynamic stability once again. As it’s shown in Table 10 and Figure 3 respectively, this model has p-value of .521 for theR-squared observed, which implies no serial correlation; however, it’s dynamically unstable. The model dynamic unstable situation, was caused by the lag (1) of our independent variable, and therefore we removed it to ensure that the system is stable as illustrated in Figure 4. The resulting ECT model excluding X1C(−1), as shown in Table 10, also satisfies the condition of serial correlation.
Error Correction Model for Comprehensive Without X1C(−1) and Breusch-Godfrey Serial Correlation LM Text.
Error Correction Model for Third Party and Breusch-Godfrey Serial Correlation LM Text.


Unstable dynamic ECT (C).

Dynamic stable ECT model (C).
In the third-party case on the other hand, we show in Table 11 the short-run coefficients for the regressors also using (3) a significant value of the residual representing the speed of adjustment of our model at 79.17% toward long-run equilibrium. We then proceed to investigate whether this model in Table 11 satisfies the condition of serial correlation and dynamic stability. From the analysis, the models satisfied both stability and serial correlation test, as illustrated in Figure 5 and Table 11.

Dynamic stability ECT model (TP).
At this point, after ascertaining the appropriateness of our models, we continue to explore from Tables 10 and 11 for both comprehensive and third-party respectively to establish if there exist short-run effects of our regressors on the dependent variable. Therein, we tested a set of hypotheses in Section 2.3 by employing the Wald test, and the results obtained are illustrated in Table 12 below.
Descriptive Statistics of Explanatory Variables Effects on Premium for Comprehensive (lag 1) and Third Party (lag 3).

Discussion
Determination of car insurance price impacts policyholder’s decision. Before the insurance premium amount is calculated, the actuary has to consider a lot of rating factors that have bearing effects on the final Premium. These risk-based rating factors are dependent on the specific policyholder. Globally, many attempts have been made, and today’s insurers take into account both technological factors from the insured car and drivers’ characteristics, according to Ayuso et al. (2016). Nevertheless, despite all of these initiatives, the Ghanaian auto insurance market continues to based solely on the age, cubic capacity, use, and inclusion of the sum insured in the comprehensive policy of the vehicle. As a result of the high nature of premiums, policyholders have differing opinions on the factors taken into account (Azaare et al., 2021). To better understand the individual variables impacts on Premium, and call for the introduction of other possible variables for fair premium determination, this paper provides parsimonious explanations on the effect of each classical variable on Premium using data from the Ghanaian insurance market.
After ascertaining the appropriateness of our models, we continue to explore from Tables 10 and 11 for both comprehensive and third parties respectively to establish if there exist short-run effects of our regressors on the dependent variable. In doing so, we tested a set of hypotheses in Section 2.3 by employing the Wald test, and shown in Table 12 is the results obtained. From Table 12, hypothesis C(2) = 0 with F-statistics and significant p-values of 43.3117 and .000 respectively gave us enough evidence to reject our null hypothesis at 5% level. This significant probability value with a positive coefficient is an indication that the sum of the insured car (X2) in the auto insurance market in Ghana has bearing effect in the determination of premiums, meaning Premium is high when the value of the insured car is higher.In effect, policyholders are compensated with the insured autos’ sum once they are able to pay the premium and the insured event happens (Awunyo-Vitor, 2012). In the case of vehicle’s age variable (X3), we illustrated in Table 12 these hypotheses; C(3) = 0 and C(5) = C(6) = C(7) = 0 for comprehensive and third-party respectively. We have F- statistics and p-value of 3.8497, .0499 and 7.6144, .0000 respectively for each category. These significant values at a 5% level also indicate that the vehicle’s age at lag (1) for comprehensive and lag (1)-(3) jointly for the third-party have short-run causality on Premium. Thus, policyholders with older cars pay higher premiums because older cars have high accidents rate (Awunyo-Vitor, 2012; Jacob et al., 2020). This finding which correlates with the markets’ practice contradicts Ayuso et al. (2017), who posits non-linear relationship between auto age and accidents occurences. Moving forward, we consider our next hypotheses for the vehicle’s seating capacity (X4) in both cases as; C(4) = 0 and C(8) = C(9) = C(10) = 0. As indicated in Table 12, the various statistics yielded an insignificant Probability value of 0.9471 supports our null hypothesis acceptance at 5% level. This means that the vehicle’s seating capacity lag (1) has no short-run causality on Premium in the comprehensive case. This finding confirms the reality in the market because cars that are insured with a comprehensive policy are mostly private individuals or corporate, which has no more than five seats and hence does not attract extra charges. However, the third-party category gave us contradictory findings to the former. From Table 12, the F-statistics value of 27.5399 with a significant p-value of .0000 allowed the rejection of the null hypothesis indicating that vehicle’s seating capacity lag (1–3) jointly causes high third-party Premium. The common practice in the market is in a reverse way to the comprehensive insurance, where almost all third-party policies are for commercial purposes with so many seats. This ultimately is the reason for the significant relationship between these two variables in the TP. Generally speaking, vehicles with more seats are bigger, heavier, and less likely to get into accidents (Kahane, 2012; Mela, 1974; Puckett & Kindelberger, 2016). The fact that most comprehensive policies are restricted to a set number of seats, which has no influence on premiums, may be the cause of our inconsistent findings. However, when it comes to third-party policies, our findings are consistent with other research that found a direct link between the severity of claims and premium hikes (Boucher et al., 2009; Jacob & Wu, 2020; Lemaire, 1995; Mert & Saykan, 2005; Sarabia et al., 2004). This finding is most likely explained by the size and mass of third-party vehicles, which frequently are greater in size for commercial purposes and produce severe impact during accidents, leading to high claims and premiums (Kahane, 2012; Mela, 1974; Puckett & Kindelberger, 2016).
Furthermore, when it comes to policyholders claim (X5), several kinds of research have revealed a proportional association between claims and Premium (Ayuso et al., 2017; Bolanc’e et al., 2007; Denuit et al., 2009; Lemaire, 1995; Mert & Saykan, 2005; Sarabia et al., 2004). However, we have a different finding which contradicts our expectation. From the null hypotheses C(5) = 0 and C(11) = C(12) = C(13) = 0 in Table 12, both C and TP were accepted with p-values of .7284 and .8100 at 5% level respectively. This shows an insignificant relationship between premium and claims. We are again not too surprised about this finding concerning the TP, but with the comprehensive, available statistics always proportionate claims increment to premium change (Ayuso et al., 2017). However, we are convinced that this could be as a result of the non-robustness nature of the pricing system used in the market that does not take into consideration severity and frequency of past claims into the premium calculations, see Awunyo-Vitor (2012), Jacob and Wu (2020), and Laryea (2016) for details. Additionally, in the case of vehicle’s cubic capacity (X6), we accepted the null hypotheses: C(6) = 0 and C(14) = C(15) = C(16) = 0 in both category with p-values of .7569 and .4618 respectively at 5% level. This finding supports recent research (Boucher et al., 2013) that found a non-linear connection between vehicle cubic capacity and accident frequency. The most plausible reason for these observations is that the more a car’s horsepower, the greater its acceleration and performance, as well as the longer the distance it travels. Long-distance drivers, without a question, are more at risk. They do, however, become more skilled and experienced as a result of being in their cars for extended lengths of time (Azaare et al., 2021). As a result of their competence and experience, they are less likely to be involved in an accident (Isotupa et al., 2019). Therefore, insurers and policymakers could find other variables more technological in pricing instead of relying on this classical variable, which ends up with high premiums for policyholders just because they have cars with high CC.
Finally, we consider the null hypotheses C(7) = 0 and C(17) = C(18) = C(19) = 0 for policyholder age variable (X7). The F-statistics and the p-value from Table 12 are respectively 5.9150 and .0089. This p-value is significant at a 5% level, and hence we reject the null hypothesis indicating that the age of the policyholder affects comprehensive Premium. Our finding is in line with (Ayuso et al., 2014, 2017; Bolanc’e et al., 2007; McKnight & McKnight, 2003; Nicoletta, 2002). On the contrary, we accepted the null hypothesis in the TP case with a p-value of .8483 at a 5% level, indicating no short-run causality effect from policyholders or drivers age lag (1)–(3) to Premium. From Table 1, policyholders’ mean age in our portfolio is 49 which is an indication of old drivers pricing system.Thus, insurers using this variable could lead to lower premium because older and experience drivers posed lower riks (Ayuso et al., 2014; Azaare et al., 2021). Though there is a contradictory result on this variable effect to Premium for both C and TP, however, according to Ayuso et al. (2014), policies with age elements are mostly targeted on young drivers but yet, there is a report on significant differences between novice and experienced young drivers, indicating heterogeneous risk group among young policyholders. This demonstrates that the risk of claims between older and younger policyholders differ significantly. Premiums are calculated in this scenario based on the policyholder’s age to establish optimal pricing systems (Jacob & Wu, 2020).
Therefore, following these findings, we recommend the inclusion of policyholders age variable into the Ghanaian insurance pricing system whiles autos cubic capacity considering the weight it put on the basic Premium should be re-examined. The policyholder’s driving speed profile, the types of roads they regularly traveled, and the timing are all factors in a conventional insurance pricing scheme.
Conclusion
To better understand the individual variables impacts on Premium, and call for the introduction of other possible variables for fair Premium, we provide in this paper parsimonious explanations on the effect of each classical variable on Premium using data from the Ghanain insurance market in ARDL model. The models developed are dynamically stable, which statistically satisfied the condition of ARDL, and there is well established long-run relationship among dependent and explanatory variables, which are I (0) or I (1). Insurers in the market only based on classical variables such as the auto age, cubic capacity, auto usage, and sum insured in the comprehensive case, which normally results in high premiums for policyholders. The models used in this article has shown that not all the variables that impacts premium used in the pricing system are statistically significant and hence the market need to revise the rating factors (e.g., inclusion of policyholders age, re-examined autos cubic capacity) to obtain an optimal and financially balance pricing model for policyholders.
Managerially, the empirical findings of this paper is to help insurers and government policy makers addressed concerns by policyholders on significant premium determinants for a fair pricing system by understanding the limitations and or opportunities involved in incorporating all other factors involved in auto insurance. According to studies, acquiring new policyholders costs five times more than keeping existing ones (Ampaw et al., 2019; Bhattacherjee, 2001; Chen & Myagmarsuren, 2011). As a result, the findings of this study will serve as a forerunner and policy guide for insurance industry players in developing fair pricing systems by considering only rating factors that have a significant impact on premiums in order to improve policyholders’ retention rates with their various insurers. Also, the article seeks to generate topics for dialog that may provoke interest and discussion on all possible premium determinants within the framework of auto insurance in general. Although the focus of the study is on Ghana, the commonalities in terms of factors considered by insurers in auto insurance premium calculations in the sub-region and globally make our findings transferable.
Due to data limitations, this study was confined to only one insurer and hence, we recommend that future research should be longitudinal and incorporate data from different insurance portfolios. Further, recommending for future studies is understanding omitted variable bias, which this paper tactfully neglected due to analytical approaches used.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation of China (project No: 71871044). We also acknowledged Dr. Gabriel Armah of CKTUTAS for proofreading and editing of this paper.