
Abstract
Extreme response style (ERS) is prevalent in survey research using rating scales. It may cause biased results in group comparisons. This research conducted two sets of simulation studies to explore the magnitude of the ERS impact on mean comparisons between two independent samples. Data were generated from a multidimensional nominal response model. Study 1 examined the influence of ERS on the estimate of group differences in the variable of interest. The results indicated that ERS led to biased estimates, especially when these groups differed significantly in ERS. The correlation between ERS and the variable of interest also moderated the ERS impact. The results were illustrated with an empirical example. Study 2 investigated the impact of ERS on the type I error and type II error in the independent t-test based on scale scores. When the variable of interest had no true difference between groups, ERS inflated the type I error rate. When the difference existed, ERS inflated the type II error rate. Two groups’ true difference in ERS and the variable of interest, unequal ERS variances, the correlation between ERS and the variable of interest, and the number of items moderated the impact of ERS on type I and II error rates. The implications for practices and further research are discussed.
Introduction
Social science researchers have recognized the threat of response styles to the self-report measures (Aichholzer, 2013; Baird et al., 2017; Baumgartner & Steenkamp, 2001; Van Vaerenbergh & Thomas, 2013). Response styles refer to the tendency to select certain response categories of rating-scale items (Wetzel, Böhnke, et al., 2016). Common response styles include: the acquiescence response style, the preference to select categories stating agreement; the disacquiescence response style, the preference to select categories stating disagreement; the extreme response style (ERS), the tendency to select extreme categories; and the midpoint response style (MRS), the tendency to select middle categories. Response styles are one of the major sources of common method bias (Podsakoff et al., 2012) and can cause biased statistical estimates (Moors, 2012; Mottus et al., 2012), group comparison (Moors, 2004), and correlations (Baumgartner & Steenkamp, 2001).
ERS is frequently observed (Bolt, 2015) and varies across populations (e.g., Benítez et al., 2016; Lu & Bolt, 2015). It may be a source of group-level variance in the scores of self-report survey instruments. Such a source of group-level variance may cause bias in the result of mean comparisons, and empirical studies have supported this notion (Moors, 2004, 2012). To appropriately account for the bias caused by response styles, we need to understand the properties of the bias (Khorramdel et al., 2019), such as the bias size and factors moderating the bias. However, no study has systematically investigated the magnitude of the ERS impact on mean comparisons and what factors may moderate the impact. The present simulation study aimed at addressing this gap. The data were generated from the multidimensional nominal response model (MNRM). We chose this model because prior studies have found that it performed better than two widely used methods for accounting for ERS, the mixed partial credit model (Rost et al., 1997) and IRTrees (Böckenholt, 2012; De Boeck & Partchev, 2012) in terms of the model-data fit (Leventhal, 2019; Leventhal & Stone, 2018) and correcting the effect of ERS on trait estimation (Wetzel, Böhnke, et al., 2016; Zhang & Wang, 2020).
Extreme Response Style (ERS)
ERS refers to the tendency to select the extreme categories in a rating scale irrespective of content, such as strongly disagree or strongly agree (Paulhus, 1991). Note when ERS exists, it does not mean that item responses are irrelevant to item content. Instead, it means that ERS acts independently of content (Kieruj & Moors, 2010, 2013), and both can affect the subjects’ responses. Empirical studies have supported this theoretical viewpoint. Past research revealed that ERS is consistent across content domains (Weijters et al., 2010a; Wetzel et al., 2013) and stable over years (Weijters et al., 2010b; Wetzel, Lüdtke, et al., 2016).
ERS varies across populations, such as those at different education levels (Meisenberg & Williams, 2008) and those from different cultures (e.g., De Jong et al., 2008; He & Van de Vijver, 2016). Therefore, both ERS and the content of self-report survey instruments are the sources of group-level variance in the instrument scores. It implies that the difference in the scores between groups may not reflect the real difference in the trait of interest. In other words, if researchers do not take ERS into account in mean comparisons, the result may be biased because of systematic measurement errors (Hoffmann et al., 2013; Moors, 2012). Although individual empirical studies support this notion (Moors, 2004, 2012), the literature lacks a systematic investigation of the amount of the bias and the conditions under which the bias arises. Simulation studies are appropriate for addressing this gap, which is what the current study did. We used a multidimensional item response model to generate the data. We discuss this model now.
Multidimensional Nominal Response Model (MNRM) for Extreme Response Style
Bolt and Johnson (2009) proposed a multidimensional extension of Bock’s (1972) nominal response model to measure both content and ERS factors. Bolt and Newton (2011) found that using the MNRM to simultaneously analyze multiple scales could measure and control ERS more effectively. Subsequent studies extended the work by allowing the MNRM to model other response styles, such as the acquiescence response style (Bolt et al., 2014; Wetzel & Carstensen, 2017). Falk and Cai (2016) further used a reparameterized MNRM, which allows loadings to vary across items, to model response styles. Henninger and Meiser (2020) integrated the above and other response style models into a superordinate framework. Based on the prior work, Henninger (2021) proposed a model that can detect irregular or unknown response styles. For example, ERS refers to the preference for the lowest and highest categories, while subjects with an irregular response style may only prefer the lowest category.
The current research adopted Falk and Cai’s (2016) edition of the MNRM because of its flexibility. Let there be k = 1, . . ., K possible ordered response categories, and d = 1, . . ., D latent dimensions. Under Falk and Cai’s edition, the probability of person j selecting category k on item i is modeled as

where
Assume that K = 4, and we utilize the MNRM to account for ERS. Then
The Current Study
Two sets of simulation studies were conducted to analyze the impact of ERS on mean comparisons. Mean comparisons can be performed on manifest variables (e.g., observed scale scores) or latent variables (Yuan & Bentler, 2006). Study 1 focused on the amount of bias in content difference estimates, which occurred due to the ignorance of ERS. The true value of content differences was at the scale of latent variables because the data were generated by a latent variable model, that is, the MNRM. It was impossible to determine the bias of the content difference estimate based on manifest variables. Thus, study 1 conducted mean comparisons with latent variables. The simulation in study 1 was further illustrated via an empirical example.
Study 2 aimed at investigating the impact of ERS on type I and II error rates in mean comparisons. Computing the error rates entails the information about whether the true content difference exists, but the computation does not require the exact value of the group difference. Thus, computing the error rates is viable in mean comparisons with either manifest variables or latent variables. Mean comparisons with manifest variables, for example, the t-test with observed scale scores, are more frequently used than mean comparisons with the latent variables in social science research. Thus, study 2 conducted mean comparisons with manifest variables so that the results could better guide research practices.
Study 1
Methods
Simulation design
This study simulated two samples, namely A and B, with each including 3,000 participants. Their responses were generated on a rating scale with N items. N was a factor of interest and had four levels (5, 10, 15, and 25). Each item had four response categories (e.g., strongly disagree, disagree, agree, and strongly agree). 1 We focused on four response categories because this format is used widely in self-report survey instruments, especially in large scale international surveys, such as the Program for International Student Assessment (PISA; OECD, 2014) and Trends in International Mathematics and Science Study (TIMSS; Mullis & Martin, 2013).
The MNRM was adopted to generate the data with ERS contamination. The factor parameters

We were interested in whether the group differences in content and ERS factors influenced the bias caused by ERS. We set the means of the content and ERS factors to zeros in sample A (μ
A
) so that the means in sample B (μ
B
) represent the true group differences, which were represented by μ and μ
ERS
. Prior research found that the correlation between content and ERS influenced the bias caused by ERS (Plieninger, 2016), so the correlation was manipulated, which was denoted by r in equation (2). ERS variances may not be homogeneous across populations, so we considered the unequal ERS variances between samples A and B. Samples A’s ERS variance was set to 1, while sample B’s ERS variance was manipulated and denoted by
The slope parameters, a, were generated from a truncated log-normal distribution,
There were five independent variables. (1) Test length, N = 5, 10, 15, and 25. (2) The correlation between the content factor and the ERS factor, r = −.5, −.3, 0, .3, and .5. (3) The group difference in the content factor, μ = 0, .3, and .5. It was also sample B’s content mean because sample A’s content mean in was 0. (4) The group difference in the ERS factor, μERS = −.5, −.3, 0, .3, and .5. It was also sample B’s ERS mean because sample A’s ERS mean was 0. (5) Sample B’s ERS variance,
More replications per condition guarantee more robust results. However, a set of factors limits the number of replications, such as the total number of conditions, whether the simulations entail parameter estimation, and the estimation time per condition. For instance, the simulations in Leventhal’s (2019) study conducted 25 replications per condition because the simulations entailed parameter estimation, and the estimation process was slow. In contrast, the simulations in Plieninger’s (2016) study did not require parameter estimation, and 100,000 replications were used. The current study conducted 100 replications per condition because of the large number of conditions, the requirement for parameter estimation, and the slow estimation process (1–4 minutes per replication per condition). The number of replications were the same to some of prior response style simulation studies (Bolt & Newton, 2011; Falk & Cai, 2016). The EM algorithm with fixed quadrature was used for parameter estimation. The maximum number of iterations was set to 500. Most estimation processes ended before reaching the maximum iteration.
Analyses
In each condition, the mean absolute bias (MAB; equation (3)) of the estimates of the mean difference between the two samples in the content factor was computed:

As beforementioned, μ refers to the true content difference, while
Results
Figure 1 displays an overview of the marginal MAB for each independent variable. The Appendix contains the MAB under each condition. When the data with ERS contamination were analyzed via the MNRM, MAB was close to the benchmark. However, when the data were analyzed via the GPCM, MAB was much higher than the benchmark. That is, ERS caused higher MAB. The impact of ERS on MAB increased as test length decreased (N), the absolute content-ERS correlation increased (r), the true content difference increased (μ), and the absolute ERS difference increased ( μ ERS ). Unequal ERS variances between samples A and B also enhanced the impact of ERS on MAB. The absolute ERS difference had the strongest moderation effect on the impact of ERS. When the absolute ERS difference was .5, the marginal MAB exceeded .055 (plot d in Figure 1). MAB reached the highest value (.133) when the ERS difference was −.5, test length was 5, the content-ERS correlation was .5, the true content difference was .5, and sample B’s ERS variance was .5.

Overview of the marginal MAB in the content difference estimate.
To further investigate how the independent variables moderated the impact of ERS on MAB and their interactions, we regressed MAB on these variables. Table 1 displays the results. Model 1 included the linear effect of independent variables and explained 21.6% of MAB variance. As plots b and d in Figure 1 indicates that r and μERS might have a quadratic effect on MAB, we added μ2
ERS
and
The Regression Coefficient of Independent Variables on the MAB of MNRM-GPCM.

Note. For simplicity, only significant effects in model 3 were presented. b = unstandardized regression coefficients; SE = standard errors; N = test length; r = the content-ERS correlation; μ and μERS = the content mean and the ERS mean in sample B, respectively;
p < .05. **p < .01. ***p < .001.
The Most Important Eight Variables in Model 3.

Note. N = test length; r = the content-ERS correlation; µ, μERS, and
Figure 2 demonstrates the interaction between the content-ERS correlation and the ERS difference. It displays the MAB when N = 5, μ = .5, and μ2 ERS = .5. When the ERS difference was −.5, MAB increased from .055 to .133 as the content-ERS correlation increased from −.5 to .5. On the contrary, when and the ERS difference was .5, MAB decreased from .090 to .054 as the content-ERS correlation increased from −.5 to .5. Figure 2 also displays the fitted lines and equations of regressing MAB on the ERS difference and its quadratic form under each level of content-ERS correlations. As the content-ERS correlation increased from −.5 to .5, the coefficient of the ERS difference declined .120 from .037 to −.083.
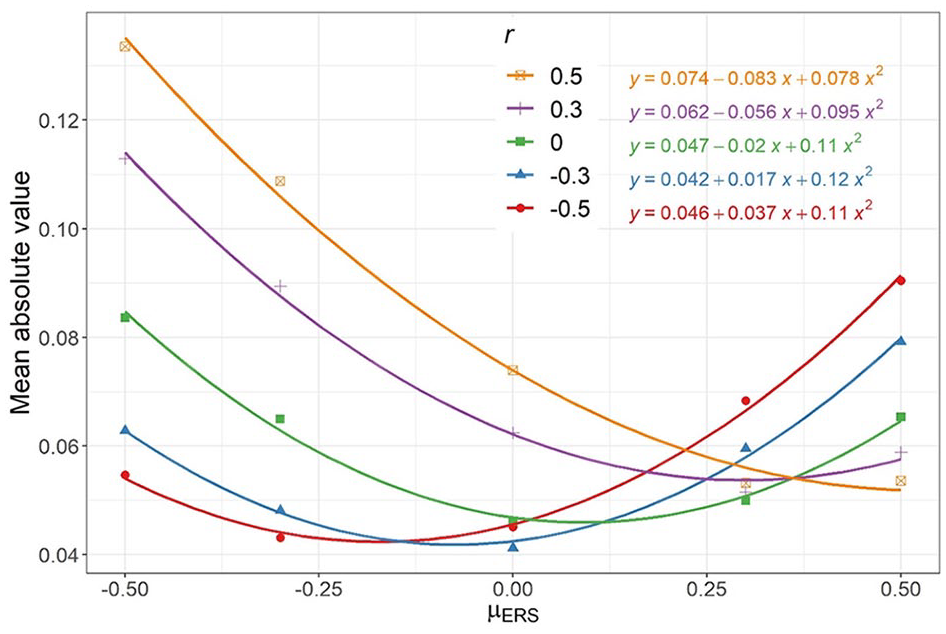
The MAB of the content difference estimate in MNRM-GPCM when N = 5, k = 4, µ = .5, and
Figure 3 uses sample B’s response distributions to demonstrate the quadratic effect of the ERS difference on MAB. It displays the response distributions when μERS = −.5, 0, and .5, given N = 5, r = 0, µ = .5, and σ2 ERS = .5. We did not present sample A’s response distributions because sample A’s ERS mean was fixed to zero. The ERS difference denoted sample B’s ERS mean and did not influence Sample A’s response distributions. When the data was free of ERS, sample B’s responses were mainly at categories 3 and 4 because their content mean was .5. When sample B’s ERS was at a low level (µERS = −.5), their extreme responses decreased greatly, and their middle responses increased greatly. By contrast, when sample B’s ERS increased to the median level (µERS = 0), their responses distributions became close to the response distribution when no ERS. However, as sample B’s ERS increased to a high level (µERS = .5), their middle responses decreased, and their extreme responses increased. This explained why the MAB in Figure 2 was smaller when µERS = 0 than when µERS = −.5 and .5, given r = 0.

Sample B’s response distributions when N = 5, r = −.5, μ = .5,
Empirical Example
We analyzed an empirical dataset from PISA 2012 (OECD, 2014) to check the effect of ERS on the content difference estimate in real data. We compared Austrian, China-Shanghai, and German students’ mathematics self-efficacy. We selected these samples because De Jong et al. (2008) found that Austrian students’ ERS level was higher than China-Shanghai students and close to German students. There were three forms of the PISA 2012 Student Questionnaire because of the rotation design in the student questionnaire (OECD, 2014). Only two forms contained the Mathematics Self-Efficacy Scale, and thus, we only included students who responded to these forms. Besides, students who responded less than half the items on the scale were discarded. Finally, the Austrian sample contained 3,111 students, with 49.9% being female and a mean age of 15.80 (SD = 0.29). The China-Shanghai sample contained 3,436 students, with 50.6% being female and a mean age of 15.80 (SD = 0.29). The German sample contained 2,801 students, with 49.7% being female and a mean age of 15.80 (SD = 0.29).
The Mathematics Self-Efficacy Scale contained eight items rated on a 4-point scale, with 1 = strongly agree, 2 = agree, 3 = disagree, and 4 = strongly disagree. The coefficient α was .85, .82, .92, and .81 in the whole sample, the Austrian sample, the China-Shanghai sample, and the German sample, respectively. The MNRM and the GPCM were used to fit the data, and the results were regarded as controlling ERS and without controlling ERS, respectively. The Austria sample was used as the reference group. Its means in mathematics self-efficacy and ERS were set at zero, and its variances in in mathematics self-efficacy and ERS were set at one. The other samples’ means and variances were freely estimated. Item parameters were constrained to be equal across groups so that the means were comparable. The analyses were conducted with the
Table 3 displays the goodness-of-fit indices. The MNRM fitted the data better than the GPCM in all indices, and the likelihood ratio test also indicated that the MNRM had a better model fit (χ2 = 232,708, df = 13, p < .001). In the MNRM, the correlation between ERS and mathematics self-efficacy was −.27 (SE = 0.01, p < .001). The ERS variances were .58 (SE = 0.01) in the German sample and 3.89 (SE = 0.06) in the China-Shanghai sample. Table 4 displays the mean estimates. China-Shanghai students showed much lower ERS than Austrian students (mean difference = −1.25, Cohen’s d = −0.81, p < .001). German students showed higher ERS than the Austrian students, but the difference was small (mean difference = 0.10, Cohen’s d = 0.11, p < .001). The results were consistent with previous research (De Jong et al., 2008).
The Goodness-of-Fit Indices of the MNRM and the GPCM in Responses to the Mathematics Self-Efficacy Scale.

Note: GPCM = the generalized partial credit model; MNRM = the multidimensional nominal response model; AIC = Akaike’s information criterion; BIC = Bayesian information criterion.
The Means of ERS and Mathematics Self-Efficacy.
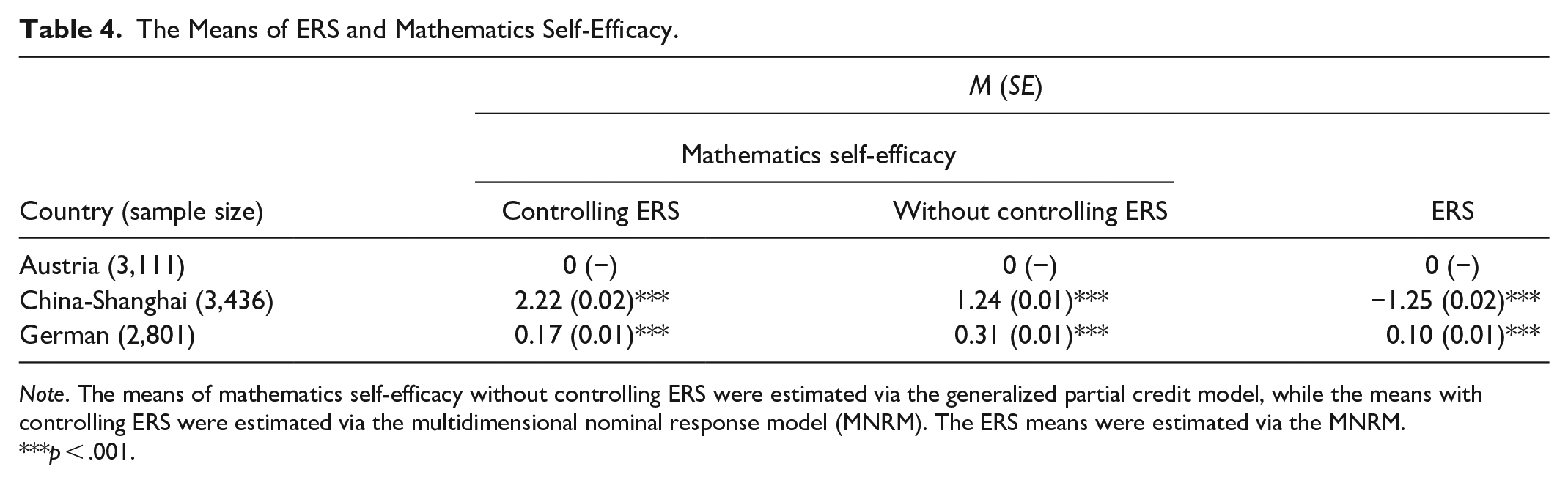
Note. The means of mathematics self-efficacy without controlling ERS were estimated via the generalized partial credit model, while the means with controlling ERS were estimated via the multidimensional nominal response model (MNRM). The ERS means were estimated via the MNRM.
p < .001.
The estimates of the mathematics self-efficacy differences between German and Austrian students were almost the same under the condition of controlling ERS (mean difference = 0.31, Cohen’s d = 0.31, p < .001) and without controlling ERS (mean difference = 0.17, Cohen’s d = 0.18, p < .001). Given that the MNRM fitted the data better than the GPCM, the two close estimates suggest that without controlling ERS might only cause a small bias in the estimate of the mathematics self-efficacy differences between German and Austrian students. The estimates of the mathematics self-efficacy difference between China-Shanghai and Austrian students differed greatly under the condition of controlling ERS (mean difference = 2.22, Cohen’s d = 1.66, p < .001) and without controlling ERS (mean difference = 1.24, Cohen’s d = 0.99, p < .001). The large difference between the two estimates suggests that without controlling ERS might cause a substantial bias in the estimate of the mathematics self-efficacy difference between China-Shanghai and Austrian students. These results were consistent with Figure 2, which showed that ERS caused greater biases when two groups had great ERS differences than when two groups had smaller ERS differences.
Study 2
Methods
Simulation design
The design of study 2 was nearly the same as that of study 1. The only difference was the levels of μ and the number of replications. The levels of μ changed from 0, .3, .5 to 0, .1, .2, .3 since pilot simulations revealed that the impact of ERS on the result of the independent t-test disappeared when μ reached .3 (see Figure 7). Simulations under the condition of μ > .3 could not generate more information about the impact of ERS than under the condition of µ = .3. The other settings were the same as study 1. The MNRM was used again to generate data with ERS contamination, while the GPCM was used to generate data without ERS contamination. Since study 2 did not entail model estimation, we increased the number of replications to 10,000 per condition.
Analyses
Study 2 focused on the mean comparison with manifest variables, so a scale score (the average across items) was computed as the manifest variable, and the independent t-test was conducted to compare the scale score between sample A and sample B. The null hypothesis assumed that there was no difference. Based on the p-value in the result of the t-test and the value of true group difference (i.e., μ), the results can be classified into four possible categories: true positives (the null hypothesis is true and not rejected, i.e., μ = 0 and p ≥ .05.), type I error (the null hypothesis is true but rejected, i.e., μ = 0 but p < .05.), type II error (the null hypothesis is false but not rejected, i.e., μ > 0 but p ≥ .05.), and true negatives (the null hypothesis is false and rejected, i.e., μ > 0 and p < .05.). When μ = 0, the type I error rate ([the count of type I error]/10,000) in every condition was computed to indicate the probability that the null hypothesis is true but rejected at .05 significance level. When μ > 0, the type II error rate ([the count of type II error]/10,000) was computed in every condition to indicate the probability that the null hypothesis is false but not rejected at .05 significance level. Comparing type I and II error rates between the data with and without ERS contamination will help understanding the specific impact of ERS on the result of the t-test.
Results
Type I error
Figure 4 shows type I error rates under various conditions. Overall, when ERS contaminated the data, the type I error rate was higher than the benchmark (the type I error rate when the data were free from ERS). Like study 1, the ERS difference (µERS) had a quadratic effect on the type I error rate. Taking the type I error rates when N = 5, r = 0,
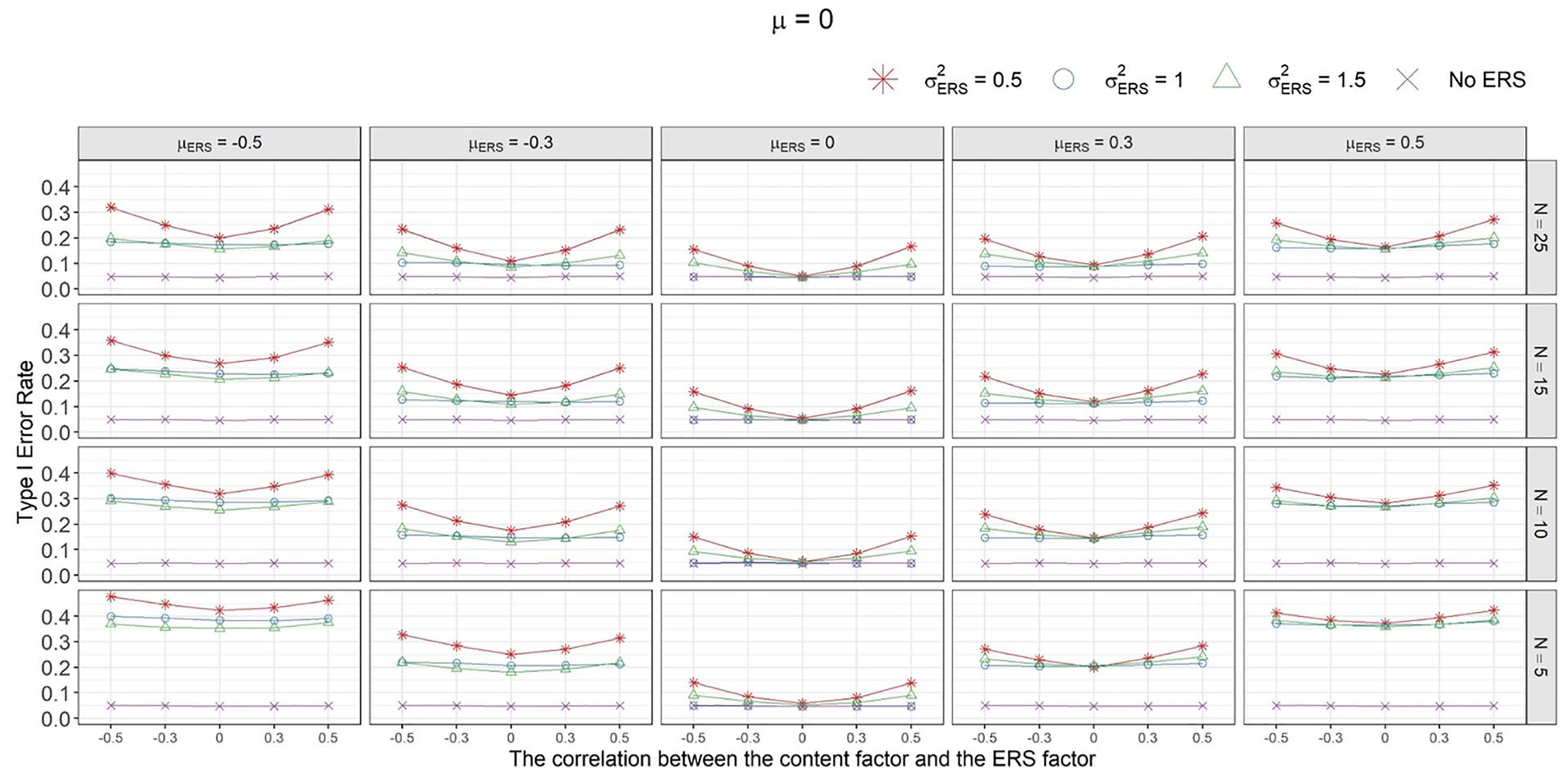
The type I error rate when μ = 0.
Sample B’s ERS variance (
Besides, test length mitigated the undesirable impact of ERS. For example, when µERS = −.5, r = 0,
Type II error
Figures 5 to 7 displays the type II error rate when µ = .1, .2, and .3, respectively. When µ = .1, the type II error rate in the data with ERS was higher than the benchmark. When µ = .2, the impact of ERS on the type II error rate was small, as indicated by the points overlapping. When µ = .3, the impact of ERS on the type II error rate disappeared (Figure 7).

The type II error rate when μ = .1.

The type II error rate when μ = .2.

The type II error rate when μ = .3.
The moderation effect of the other variables on the impact of ERS mainly existed under the condition of µ = .1 (Figure 5). The effects of the ERS difference and test length on the type II error rate were the same as their effects on the type I error rate. The type II error rate in the data with ERS rose as the absolute value of the ERS difference increased and test length decreased. The effects of sample B’s ERS variance and its interaction with the content-ERS correlation on the type II error rate were different from their effects on the type I error rate. When sample B’s ERS variance was .5, the type II error rate increased monotonously and quickly as the content-ERS correlation increased. When sample B’s ERS variance was 1, the type II error rate also increased as the content-ERS correlation increased, but the effect was small. When sample B’s ERS variance was 1.5, the type II error rate decreased monotonously as the content-ERS correlation increased. Taking the first plot in the first row of Figure 5 as an example, as the content-ERS correlation increased from −.5 to .5, the type II error rate increased from .05 to .41 when sample B’s ERS variance was .5. However, when sample B’s ERS variance was 1.5, the type II error rate declined from .25 to .08. When sample B’s ERS variance was 1, the type II error rate only experienced a small change, increasing from .13 to .20, as the content-ERS correlation increased from −.5 to .5.
Figure 8 helps in understanding how ERS inflated the type II error rate and the interaction between sample B’s ERS variance and the content-ERS correlation. It shows the response distributions when µ = .1, µERS = −.5, N = 5, which corresponds to the first plot in the bottom row of Figure 5. We first focused on how ERS inflated the type II error rate. The first column showed the response distribution when the content-ERS correlation was −.5. Compared with the data without ERS (green bars), when ERS existed in the data, sample A’s and B’s responses at category 4 were pulled toward middle categories. Sample A’s responses at category 1 were also pulled toward middle categories, but sample B’s responses were pushed toward category 1. This difference in responses at category 1 between samples A and B reduced their difference in the scale scores, which is why ERS caused higher type II error rates (recall sample B’s true content mean was larger than sample A). When the content-ERS correlation was .5 (the second column of Figure 8), sample A’s and B’s extreme responses were pulled toward middle categories to the same extent. However, more of sample A’s responses at category 1 was pulled toward middle categories than sample B. Thus, their difference in scale scores decreased. Consequently, ERS caused higher type II error rates.

The response distributions when N = 5, μ = .1, and μ ERS = −.5.
Next, we focused on the interaction between sample B’s ERS variance and the content-ERS correlation. When the content-ERS correlation was −.5, as sample B’s ERS variance increased from .5 to 1.5, the proportion of responses at category 1 increased, and the proportion of responses at category 2 decreased (the bottom left plot of Figure 8). This change in response distributions meant that, as sample B’s ERS variance increased from .5 to 1.5, their scales scores decreased, and thus, their difference with sample A in scale scores would decrease. Consequently, the type II error rates increased. In contrast, when the content-ERS correlation was .5, as sample B’s ERS variance rose from .5 to 1.5, the proportion of responses at category 3 decreased, and the proportion of responses at category 4 increased (the bottom right plot of Figure 8). As such, sample B’s scale scores increased, and their difference with sample A increased. Consequently, the type II error rates decreased as sample B’s variance rose from .5 to 1.5.
Discussion
There is an increasing interest in response styles, among which ERS is a common form (Bolt, 2015). ERS may cause biased results in mean comparisons (Moors, 2004, 2012). The current research systematically investigated the impact of ERS on the result of mean comparisons via two simulation studies. The results of study 1 indicated that ERS could cause biased estimates of the content difference between two groups, and an empirical study further illustrated the result. Study 2 found that ERS could inflate the rates of both type I and II errors. A set of factors moderated the impact of ERS in studies 1 and 2.
Moderating Factors in the Influence of ERS
The most notable factor that moderated the impact of ERS is the ERS difference between groups. In general, no matter the direction of the ERS difference, the greater it was, the stronger effect ERS had on mean comparisons (see Figures 1–5). Figure 3 demonstrates the quadratic effect of the ERS difference. If sample B’s ERS level were low, their responses would be pulled toward the middle categories. If sample B’s ERS level were median, their response distributions would be less influenced than when they had low ERS. If sample B’s ERS level were high, their responses would be pulled toward the extreme categories.
The linear effect of the content-ERS correlation was small, but its quadratic effect was stronger. Moreover, it had a substantial interaction effect with the ERS difference on the content difference estimate in study 1 (see Figure 2 and Table 2). It also had a substantial interaction effect with the unequal ERS variances on type I and II error rates in study 2 (see Figures 4 and 5). Plieninger (2016) found that the linear effects of the content-ERS correlation were weak on the estimates of coefficient α and the association between two content variables. However, the content-ERS correlation had a strong quadratic effect on the estimate of coefficient α. Besides, the interaction between two content-ERS correlations strongly impacted the association estimate between the two content variables. Putting Plieninger’s (2016) study and the current research together, the findings of the content-ERS correlation suggest that future research on the impact of ERS should consider the quadratic effect of the content-ERS correlation and its interactions with other factors. For instance, the simulation design needs to cover both positive and negative content-ERS correlations.
Adams et al. (2019) found that large variances in response style substantially reduced the precision of content estimates. The current research found that larger sample B’s ERS variance did not cause more bias in the content estimate (see the bottom plot of Figure 1). The different findings might be due to a set of factors. For instance, Adams et al.’s (2019) study focused on individuals’ content estimates, but the current research focused on the estimates of group content means. The MNRM in Adams et al.’s (2019) study was an exploratory model of response styles, while the MNRM in the current research was a confirmatory model because of using the scoring function. Nevertheless, this study did reveal that unequal ERS variance inflated type I and II error rates. Overall, these findings suggest that the variance of response style is an critical factor in the response style effect.
The bias caused by ERS on the content difference estimate increased as the true content difference increased, although the overall effect was weak. However, the true content difference had a marked impact on the type II error rate. When the true content difference was small (e.g., μ = .1 in Figure 5 is corresponding to Cohen’s d = 0.1), ERS significantly inflated the type II error rate and decreased the statistical power. Although the impact of ERS hardly existed when μ = .2 and disappeared when μ = .3, the results do not necessarily imply that that researchers can ignore ERS when the content difference is large. The size of each sample in the simulations was 3,000. When the sample size is much smaller, for example, 200 or 500, the impact of ERS may reoccur even in the condition of a large content difference. In addition, ERS resulted in more biases in the content difference estimates as the true content difference increased. Thus, no matter the magnitude of the true content difference, the influence of ERS on mean comparisons should not be ignored.
Test length buffered the impact of ERS weakly on the content difference estimate but effectively on type I and II error rates. The finding on test length was in line with prior research (Wetzel, Böhnke, et al., 2016), where the bias in content estimates caused by ERS decreased as test length increased. The reason for the moderation effect of test length might be that, as test length increased, individual extreme responses caused by one’s high ERS contributed less to their scale scores. So did individual middle responses caused by low ERS. Consequently, the t-test based on scale scores was less impacted by ERS as test length increased.
Implications
The large moderation effect of the ERS difference on the influence of ERS implies if evidence indicates that the groups of interest have substantial ERS differences, researchers need to control ERS. Otherwise, the difference estimate and the results of statistical tests would be untrustworthy. For instance, previous studies indicated that ERS is positively related to education levels and Hofstede’s cultural dimensions (individualism, uncertainty avoidance, masculinity, and power distance; see De Jong et al., 2008; Hofstede, 2005; Johnson et al., 2005). Thus, if the groups used for mean comparisons differed substantially in education and the cultural dimensions, the effect of ERS may be large and need to be controlled.
On the other hand, even if the groups of interest have no difference in ERS, researchers should still not ignore ERS. The other factors considered in this study, including true content differences, content-ERS correlation, unequal ERS variances, and test length, also moderated the impact of ERS on mean comparisons, and these factors interacted with each other in the impact of ERS. When there was a high content-ERS correlation, unequal ERS variances, or few items, the influence of ERS was nontrivial, no matter the size of ERS differences. The only case that researchers can safely ignore ERS may be that there is no ERS difference and no content-ERS correlation. It may be challenging to prove that these rigorous prerequisites are met in empirical studies. Thus, we recommend researchers control ERS in mean comparisons as possible as they can.
In particular, cross-country studies based on data from international large-scale surveys should control ERS. In the empirical example of this study, which used the PISA 2012 data, the estimate of mathematics self-efficacy difference between Austrian and China-Shanghai changed substantially after modeling ERS. This is in line with Khorramdel et al.’s (2019) study, which also analyzed PISA 2012 data and found that the correlations between personality scales and cognitive skills became more meaningful after correcting ERS and the midpoint response style. Khorramdel et al.’s study and the empirical example of this study call for correcting response style effects when making comparisons in country-level measures derived from international large-scale surveys.
The main method to control ERS is modeling it during data analysis, such as the MNRM used in the current research. However, models like MNRM are complex. Researchers may lack the necessary knowledge to apply these statistical methods to control ERS. Besides, modeling ERS after data collection may reduce stakeholders’ trust in the results because explaining the rationale and procedure of modeling ERS to them is challenging. In such cases, controlling ERS during tool design and data collection is a better option. Results in this study suggest increasing test length to mitigate the impact of ERS, but 15 items for a single construct may be sufficient because the impact of ERS weakened slightly when test length increased from 15 to 25 (see Figures 1, 4, and 5). Other characteristics of rating scale also reduce the presence of ERS, such as the number of response categories (Weijters et al., 2010a) and response format (Böckenholt, 2017). The data collection approach is also a critical factor. For instance, a face-to-face survey may trigger more extreme responses than a web survey (Liu et al., 2017).
There were contrary results in existing empirical studies about the impact of ERS on mean comparisons. For instance, Moors (2004) found that the group difference became significantly smaller when ERS was taken into account in data analyses, while He and Van de Vijver’s (2015) study, the group difference hardly changed after controlling ERS. The results in the current study might help us explain the contrary findings. Although test length was close in Moors’ (2004) as well as He and Van de Vijver’s (2015) studies, the ERS difference, content-ERS correlation, and unequal ERS variances might differ between the two studies given that they did not use the same sample. In Moors’s (2004) study, there might be a substantial ERS difference and content-ERS correlation, so ERS had a considerable impact on the result of mean comparisons. On the contrary, there might be no ERS difference and content-ERS correlation in He and Van de Vijver’s (2015) study. In this case, ERS would not influence the result of mean comparisons. In summary, further research on the impact of response styles should consider the moderation of multiple factors. Whether a response style influences the results of data analysis cannot be concluded based on a single dataset.
Limitations and Future Directions
This study focused on mean comparison in one variable between two independent groups. Other conditions, such as dependent groups, multiple groups, and multiple variables, are not covered herein and remain to be investigated. Whether ERS influences the type I and II errors rates in non-parametric tests is also an interesting topic. If ERS has weak effects in non-parametric tests, these tests may be used as an approach to control ERS, given that the current statistical models of ERS, such as MNRM in this study, are complex. It is challenging for researchers not familiar with these models to apply them to control ERS in practice. There are simpler methods for controlling ERS, such as the regression residual technique, which regresses the raw scale scores on ERS and uses the residuals as new scale scores (Baumgartner et al., 2001). However, the effectiveness of these methods may be less satisfactory than the complex models (Wetzel, Böhnke, et al., 2016; Zhang & Wang, 2020). Further studies need to develop a relatively simple yet effective approach.
ERS in this study refers to the tendency to select extreme options. Although this definition is used widely, some researchers may prefer a different definition, such as the tendency to select more extreme options (Jin & Wang, 2014; Tutz & Berger, 2016). The current results may not generalize to other ERS definitions. How ERS under other definitions influences mean comparison entails further research.
The current research did not cover response styles other than ERS, such as the middle point response style (the tendency to select middle categories) and the acquiescence response style (the tendency to select categories stating agreement; Van Vaerenbergh & Thomas, 2013). It would be interesting to investigate how these response styles influence the results of mean comparisons. Moreover, different response styles may exist in the same data (Wetzel & Carstensen, 2017). It is possible that different response styles interact with each other in the impact on mean comparisons.
The sizes of content difference, ERS difference, and unequal ERS variances in the simulations were smaller than the empirical example. For instance, the maximum ERS difference was .5 in simulations, while the ERS difference between Austrian and China-Shanghai samples was 1.25. Given that the effect of ERS strengthened as these factors became bigger, the ERS effect in simulations may be smaller than in empirical data. Indeed, the content difference estimate between Austrian and China-Shanghai samples increased .98 after controlling ERS, while the maximum bias in the simulation of study 1 was .133. Thus, researchers should keep in mind that the effect of ERS can be much larger in the real world than what the simulations showed.
Conclusion
This simulation research systematically investigated the bias that ERS caused in content difference estimates and type I and II error rates in independent t-tests. ERS differences and their interaction with the content-ERS correlation increased the bias in content difference estimates. ERS differences, short tests, and unequal ERS variances inflated the type I and II error rates. Besides, the interaction between unequal ERS variances and content-ERS correlations strongly impacted type I and II error rates. Future research on the ERS effect should consider the ERS variance and content-ERS correlations. Given that the undesirable effect of ERS depended on various factors and their interactions, it may be challenging to prove that ERS can be ignored in a particular empirical dataset. Thus, empirical research should account for ERS in mean comparisons, no matter the mean comparisons are based on latent or manifest variables.
Footnotes
Appendix
The MAB of MNRM-GPCM in Study 1 When Test Length is 25.
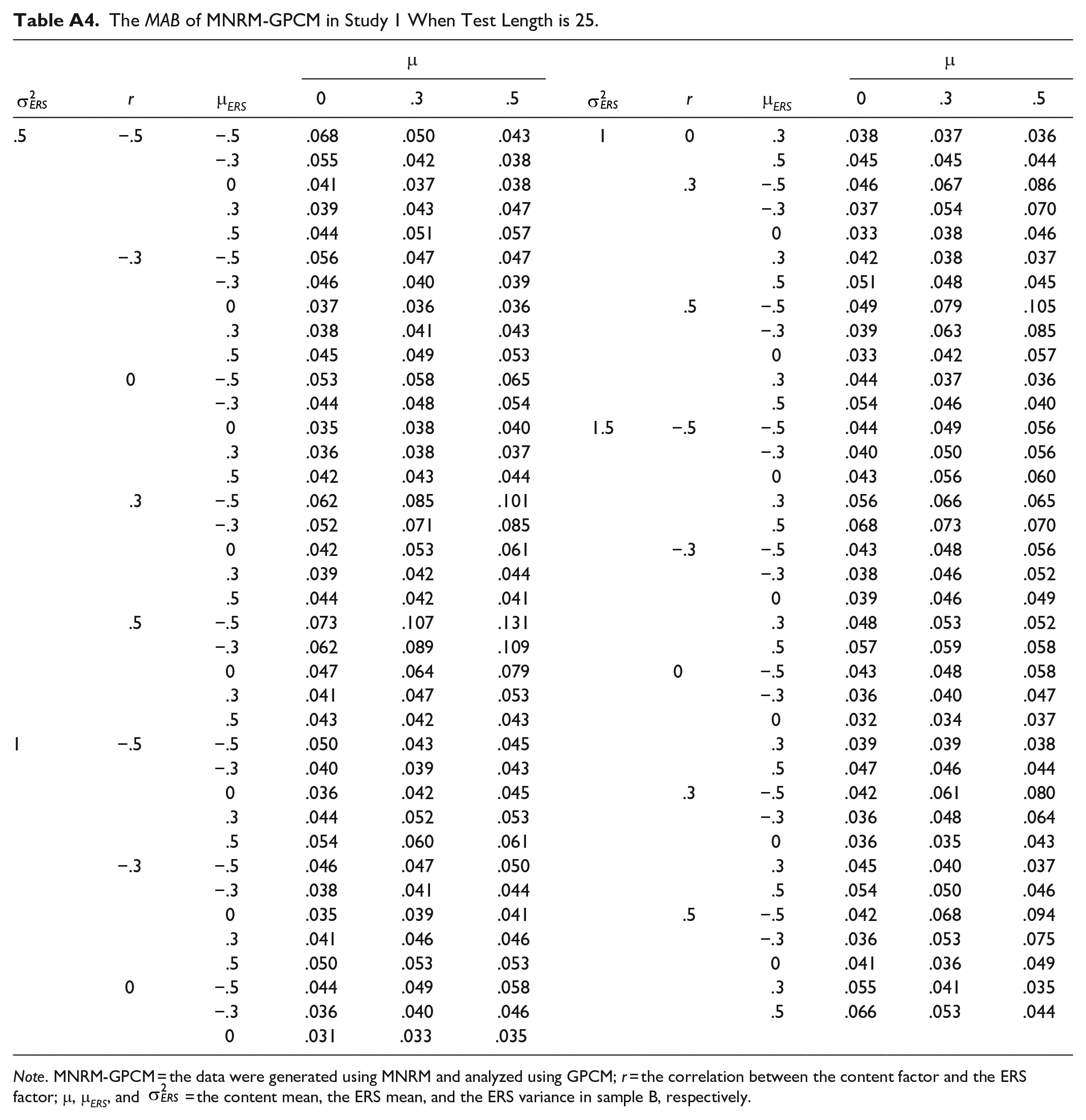
|
|
r | μ ERS | μ |
|
r | μ ERS | μ | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | .3 | .5 | 0 | .3 | .5 | ||||||
| .5 | −.5 | −.5 | .068 | .050 | .043 | 1 | 0 | .3 | .038 | .037 | .036 |
| −.3 | .055 | .042 | .038 | .5 | .045 | .045 | .044 | ||||
| 0 | .041 | .037 | .038 | .3 | −.5 | .046 | .067 | .086 | |||
| .3 | .039 | .043 | .047 | −.3 | .037 | .054 | .070 | ||||
| .5 | .044 | .051 | .057 | 0 | .033 | .038 | .046 | ||||
| −.3 | −.5 | .056 | .047 | .047 | .3 | .042 | .038 | .037 | |||
| −.3 | .046 | .040 | .039 | .5 | .051 | .048 | .045 | ||||
| 0 | .037 | .036 | .036 | .5 | −.5 | .049 | .079 | .105 | |||
| .3 | .038 | .041 | .043 | −.3 | .039 | .063 | .085 | ||||
| .5 | .045 | .049 | .053 | 0 | .033 | .042 | .057 | ||||
| 0 | −.5 | .053 | .058 | .065 | .3 | .044 | .037 | .036 | |||
| −.3 | .044 | .048 | .054 | .5 | .054 | .046 | .040 | ||||
| 0 | .035 | .038 | .040 | 1.5 | −.5 | −.5 | .044 | .049 | .056 | ||
| .3 | .036 | .038 | .037 | −.3 | .040 | .050 | .056 | ||||
| .5 | .042 | .043 | .044 | 0 | .043 | .056 | .060 | ||||
| .3 | −.5 | .062 | .085 | .101 | .3 | .056 | .066 | .065 | |||
| −.3 | .052 | .071 | .085 | .5 | .068 | .073 | .070 | ||||
| 0 | .042 | .053 | .061 | −.3 | −.5 | .043 | .048 | .056 | |||
| .3 | .039 | .042 | .044 | −.3 | .038 | .046 | .052 | ||||
| .5 | .044 | .042 | .041 | 0 | .039 | .046 | .049 | ||||
| .5 | −.5 | .073 | .107 | .131 | .3 | .048 | .053 | .052 | |||
| −.3 | .062 | .089 | .109 | .5 | .057 | .059 | .058 | ||||
| 0 | .047 | .064 | .079 | 0 | −.5 | .043 | .048 | .058 | |||
| .3 | .041 | .047 | .053 | −.3 | .036 | .040 | .047 | ||||
| .5 | .043 | .042 | .043 | 0 | .032 | .034 | .037 | ||||
| 1 | −.5 | −.5 | .050 | .043 | .045 | .3 | .039 | .039 | .038 | ||
| −.3 | .040 | .039 | .043 | .5 | .047 | .046 | .044 | ||||
| 0 | .036 | .042 | .045 | .3 | −.5 | .042 | .061 | .080 | |||
| .3 | .044 | .052 | .053 | −.3 | .036 | .048 | .064 | ||||
| .5 | .054 | .060 | .061 | 0 | .036 | .035 | .043 | ||||
| −.3 | −.5 | .046 | .047 | .050 | .3 | .045 | .040 | .037 | |||
| −.3 | .038 | .041 | .044 | .5 | .054 | .050 | .046 | ||||
| 0 | .035 | .039 | .041 | .5 | −.5 | .042 | .068 | .094 | |||
| .3 | .041 | .046 | .046 | −.3 | .036 | .053 | .075 | ||||
| .5 | .050 | .053 | .053 | 0 | .041 | .036 | .049 | ||||
| 0 | −.5 | .044 | .049 | .058 | .3 | .055 | .041 | .035 | |||
| −.3 | .036 | .040 | .046 | .5 | .066 | .053 | .044 | ||||
| 0 | .031 | .033 | .035 | ||||||||
Note. MNRM-GPCM = the data were generated using MNRM and analyzed using GPCM; r = the correlation between the content factor and the ERS factor; μ, μ
ERS
, and
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by the China Scholarship Council [Grant number 201806040180].