
Abstract
There is a rekindled interest in the four-parameter logistic item response model (4PLM) after three decades of neglect among the psychometrics community. Recent breakthroughs in item calibration include the Gibbs sampler specially made for 4PLM and the Bayes modal estimation (BME) method as implemented in the R package mirt. Unfortunately, the MCMC is often time-consuming, while the BME method suffers from instability due to the prior settings. This paper proposes an alternative BME method, the Bayesian Expectation-Maximization-Maximization-Maximization (BE3M) method, which is developed from by combining an augmented variable formulation of the 4PLM and a mixture model conceptualization of the 3PLM. The simulation shows that the BE3M can produce estimates as accurately as the Gibbs sampling method and as fast as the EM algorithm. A real data example is also provided.
The four-parameter logistic item response model (4PLM) was first mentioned as far back as McDonald (1967) and formally proposed by Barton and Lord (1981). Despite this, for many years, it received very little attention in the literature due to doubts about its utility, as well as technical difficulties related to parameter estimation. Recently, however, the psychometrics community has rekindled its interest in the 4PLM after three decades of neglect.
Increasingly, applications of the 4PLM have appeared in the literatures as supporting evidence of its usefulness. Several studies argued that the slipping parameter from the 4PLM can be estimated to account for early careless errors to improve ability estimation (Liao et al., 2012; Rulison & Loken, 2009). In psychology, it has been noted that there is value in modeling the lower and upper asymptotes of item response functions (Reise & Waller, 2003; Waller & Reise, 2010) in instances where subjects with higher levels of psychopathology may be reluctant to self-report attitudes, behaviors, and/or experiences which may indicate a social desirability bias (Rouse et al., 1999). In education, recent studies have shown the prevalence and implication of the slipping effect in low-stakes large-scale educational assessments (Culpepper, 2016, 2017).
Despite this work, one daunting challenge regarding the 4PLM pertains to the difficulty in estimating item parameters. The lack of a fast and stable implementation of the 4PLM remains a major barrier to its widespread application in practice. Few studies to date have addressed the item calibration issue for the 4PLM. All the methods fall into two approaches: MCMC methods and marginal maximum likelihood (Feuerstahler & Waller, 2014). For MCMC methods, Loken and Rulison (2010) presented Bayesian model formulations with Metropolis-Hastings (MH) sampling using the general-purpose software (e.g., “bayesmh” module in Stata). More recently, Culpepper (2016) proposed a flexible Gibbs sampling method. Both MCMC methods can provide accurate item estimates, but are inherently time-consuming. Even for Culpepper’s (2016, 2017) Gibbs sampling approach, calibration is expected to take at least 1 hour, which also motivates us to find a faster Bayesian estimation.
Another recent implementation of the 4PLM was done by Waller and Feuerstahler (2017). In their work, they extended the Bayesian modal estimation method (BME) to the 4PLM using the R package mirt (Chalmers, 2012). Compared to MCMC methods, BME is a fast calibration method, but several issues need to be explored to evaluate the utility of BME and its implementation in the mirt package. For example, Guo and Zheng (2019) found that the item parameter estimates yielded by BME were unstable for the 3PLM when changing priors of guessing parameters. Moreover, in the mirt package of version 1.30, the standard errors of all item parameters cannot be calculated as a consequence of program errors in computing the Hessian matrix when a Beta distribution prior (“expbeta” in mirt) is imposed on guessing or slipping parameters.
At present, we propose an alternative Bayesian modal estimation approach that we term Bayesian Expectation-Maximization-Maximization-Maximization (BE3M) method, which is developed by using a latent variable augmentation approach for the 4PLM in conjunction with the mixture modeling approach for the 3PLM (Zheng et al., 2017). The remainder of the manuscript is as follows: First, we present a detailed derivation of the BME and discuss potential difficulties in item calibration. Second, we present a latent variable augmentation approach to formulating the 4PLM (Béguin & Glas, 2001; Culpepper, 2016), and the resulting BE3M estimation method. Third, we present two simulation studies assessing the accuracy of parameter recovery for the four calibration methods (BE3M, mirt, fourPNO, Stata). Fourth, we apply the four methods to bullying item responses of 7,491 adolescents from the 2005 to 2006 Health Behavior in School-Aged Children (HBSC) study. Lastly, we discuss future research directions and concluding remarks.
Bayesian Modal Estimation for the 4PLM
Following Culpepper (2016), the slope-intercept form IRT formulation of the 4PLM is:

with

where
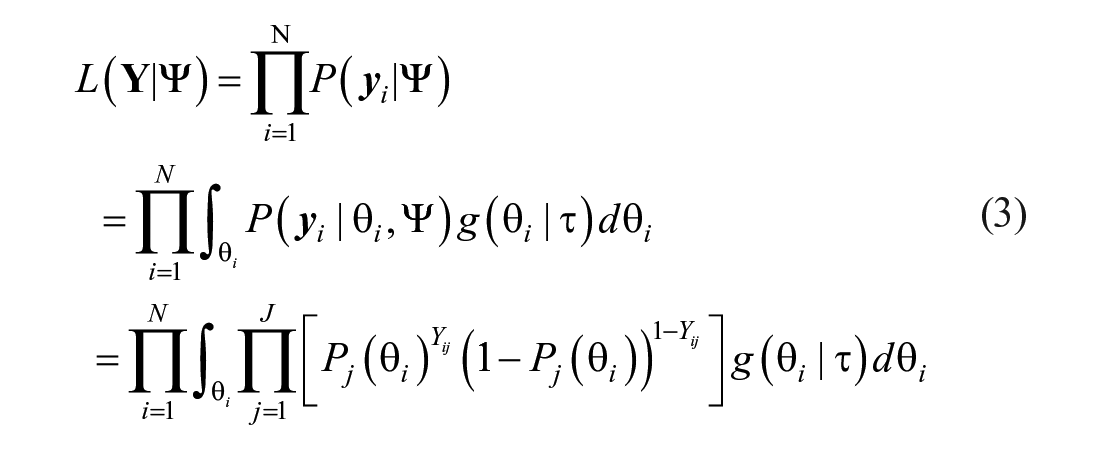
with


where
The Latent Mixture Modeling Reformulation of the 4PLM
From inspection, we can determine that the 4PLM can be regarded as a latent mixture model. First, note that

Next, we define a latent indicator variable
From the mixture-modeling perspective, depending on the value of
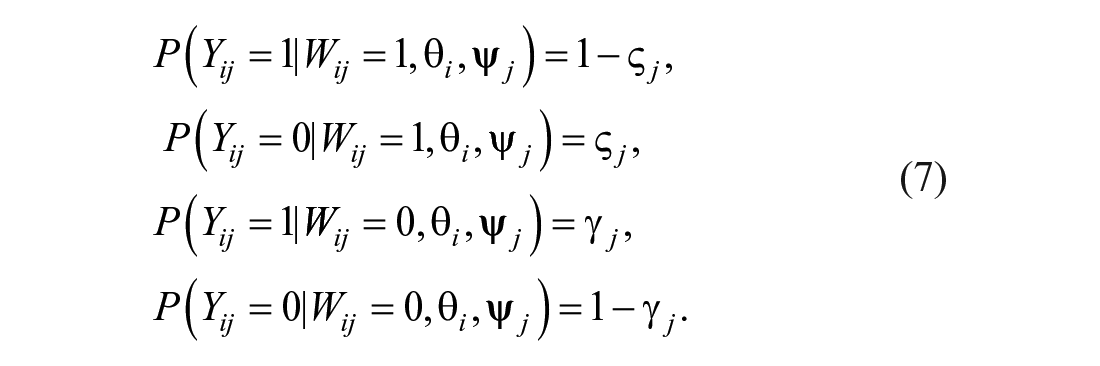
Thus, we find the joint distribution of
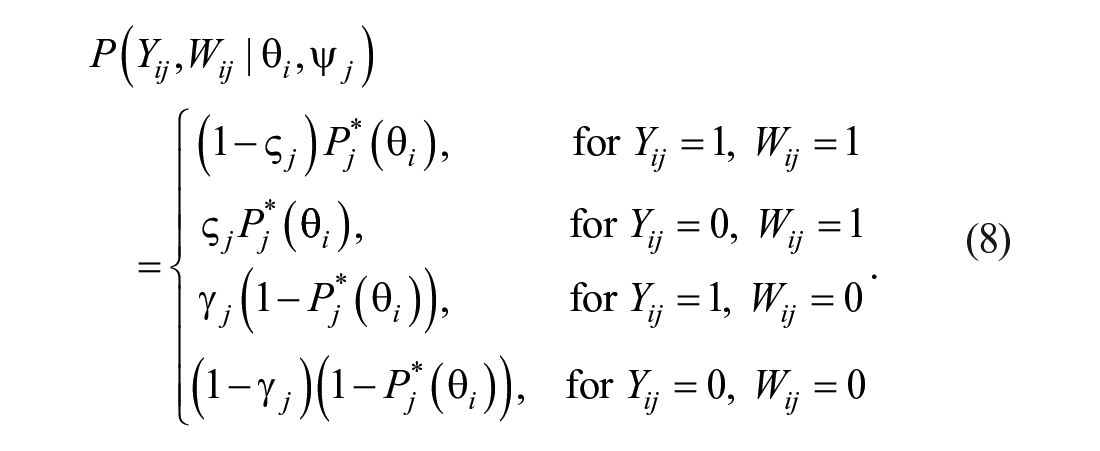
Let

where

Just like the MMLE/EM algorithm, the BE3M algorithm also marginalizes out the latent ability variable, so the likelihood function of the BE3M without priors is:
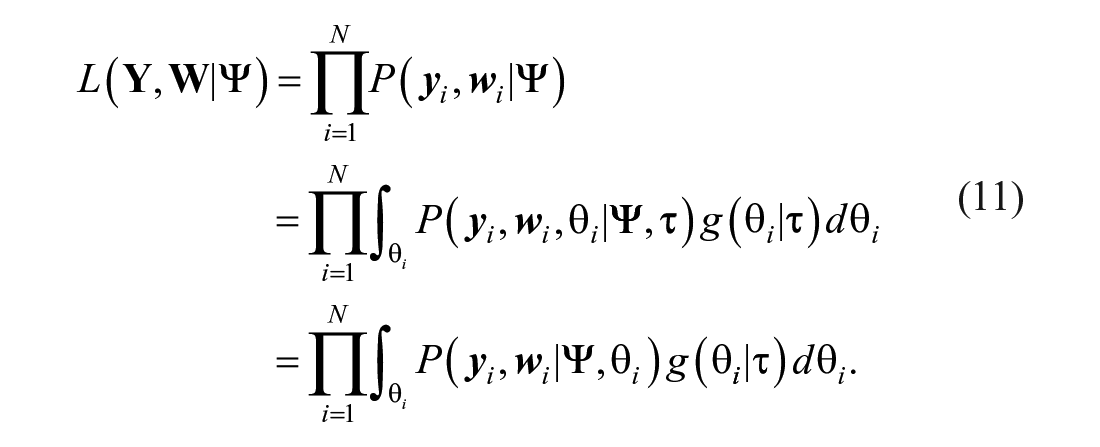
This formulation follows Culpepper (2016) for 4PNO. In contrast to his work, however, we now develop a Bayesian modal method to estimate model parameters for the 4PLM. This approach follows the basic premise of an EM algorithm and proposes to split the maximization step into three parts: first maximizing over
Expectation Step and Artificial Data
In the expectation step, we take the expectation of the log-likelihood over the incomplete portion of the data, the latent variables

with
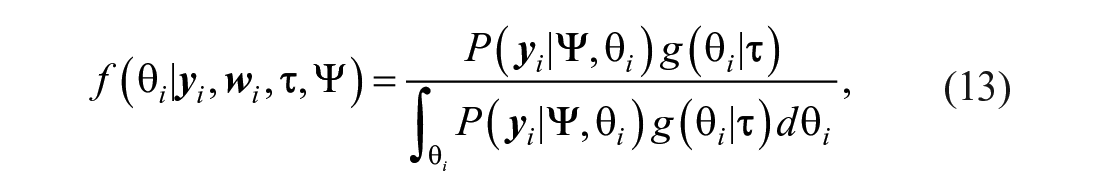

Notice that the above expression includes the latent variable

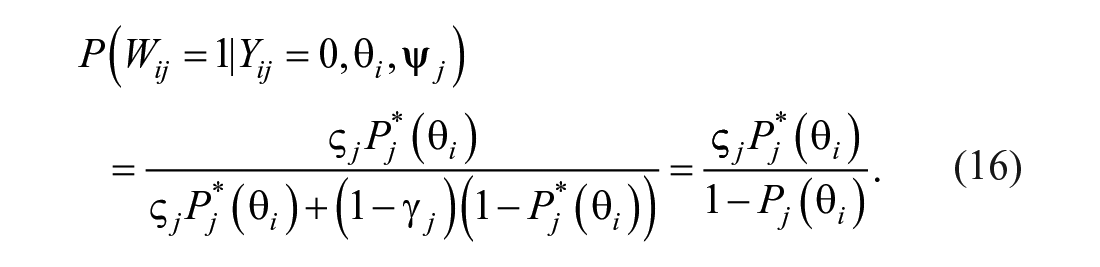
Thus, we find the conditional expectation of

Finally, let

with


where

and

By taking their expectations, we find that these expressions have very intuitive interpretations:
Maximization Step 1:
-Parameters
Let

By setting

Standard errors will require the expected second derivative as well, which is

Maximization Step 2:
-Parameters
Let

By setting
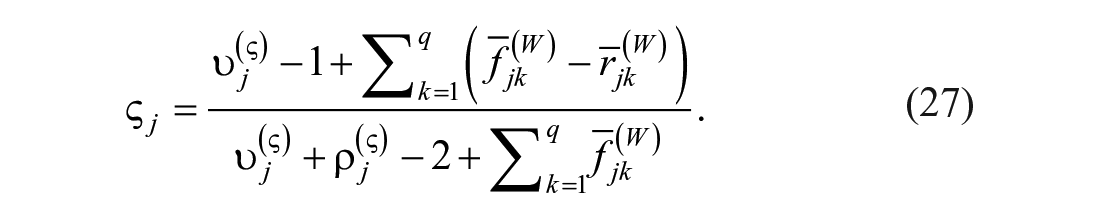
Standard errors will require the expected second derivatives as well, which is

Maximization Step 3:
- and
-Parameters
Let

and

Unlike the guessing and slipping parameters,


and

Standard Errors of Parameter Estimation in BE3M
An important index of estimation quality is the standard error (SE). However, one major criticism of the EM algorithm is that parameter estimate SEs are not a natural product of the algorithm, and so other methods have to be devised (McLachlan & Krishnan, 2007). BE3M falls prey to this criticism, just as all members of the EM algorithm family do.
It can be shown that the inverse of the negative expected value of the matrix of second derivatives of the log-likelihood (i.e., the inverse of the information matrix) is the asymptotic covariance matrix of the estimates (Stuart & Kendall, 1968). As such, the square roots of the diagonal elements of the resulting matrix are the asymptotic standard errors of the parameters. Generically, the expected second derivative matrix can be written as

in which each entry is the expected partial second derivative of the log-likelihood with respect to the subscript parameters for a given item j. Convergence issues resulting from the ill-conditioning of the matrix plague the MMLE/EM for 4PLM just as it does for the 3PLM (Baker & Kim, 2004).
In contrast, due to the divide-and-conquer strategy implemented in BE3M, we contend that the resulting expected second derivative matrix does not have these issues. In BE3M, the item parameter estimation problem is separated into three smaller distinct estimation problems: (1) estimation of the guessing parameter, (2) estimation of the slipping parameter, and (3) joint estimation of the difficulty and discrimination parameters. This separation has the benefit that any instabilities present in one of the three steps will not negatively affect either of the other two steps. Statistically, this separation implies that the covariances between

The standard errors of the estimates for item j, then, are the square roots of the diagonal elements of the matrix
Simulation Studies
This section presents Monte Carlo results regarding the accuracy of the developed BE3M procedure for estimating 4PLM item parameters, compared to the BME in mirt (version 1.30) package (Chalmers, 2012) and the MCMC in R package fourPNO (Culpepper, 2016) and “bayesmh” module of Stata/SE 16. Results from two simulation studies are reported. The goal of the simulation studies was to assess the influence of various design features, including the location of item threshold, sample size, and priors in educational (Simulation 1) and psychological (Simulation 2) scenarios.
Item and Person Parameter Generation
For Simulation 1, the item parameters were generated in the same way as in Culpepper (2016). Specifically, item parameters for 20 items were generated from
The Setting of MCMC in R Package FourPNO
Since Culpepper (2016) introduced an extra latent variable and imposed various truncation restrictions on the item parameters, the priors in the fourPNO package have obvious differences from the traditional MCMC procedures (see Culpepper (2016) for details). Thus, the current studies used the same setting in the fourPNO package as the simulation studies of Culpepper (2016) in each condition: (1) the
The Setting of BE3M, BME in R Package mirt and MCMC in Stata
Both the BE3M and mirt used 61 quadrature points to approximate the Gaussian distribution from −6 to +6 in all simulation studies and real-data examples. The priors for α and β parameters were set as follows:
In sum, for both the educational and psychological testing scenarios, 21 conditions were simulated: Seven estimation method conditions (fourPNO, BE3M with prior conditions 1 and 2, mirt with prior conditions 1 and 2, and Stata with prior conditions 1 and 2) each crossed with three examinee sample size conditions (2,500, 5,000, and 10,000). For each condition, 100 replications were run to reduce sampling error. Each condition was assessed by its accuracy in recovering individual item parameter as defined by bias and the root mean squared error (RMSE) across the 100 replications:


Furthermore, since Waller and Feuerstahler (2017) pointed out that the item parameter recovery for the individual parameter cannot reflect the entire situation of the accuracy of fitting the 4PLM, the current studies also introduced the root integrated mean squared error (RIMSE; Ramsay, 1991) to assess the entire accuracy via the item response function of the 4PLM:

Results
The results of two simulation studies will be respectively reported at two levels: the individual level for each type of parameters and the whole level for the item response function of the 4PLM.
As for the individual level, the detailed results for two simulation studies are presented in tables in Supplemental Appendices B and C, respectively. Only RMSEs (Tables 1 and 2) for the condition of 5,000 examinees are summarized and presented here since those for other conditions are very similar. The results of two simulation studies can be briefly summarized as follows: (1) In general, the results of MCMC in the fourPNO package replicate the previous study in both scenarios; (2) The item parameter recovery of BE3M are very similar with MCMC although the RMSEs of the α parameters yielded by the fourPNO package and Stata are slightly larger than those from the BE3M in the first simulation study; (3) The mirt package and the BE3M have similar bias and RMSEs for α and β parameters, but the BE3M has better performance in estimating the γ and ζ parameters; and (4) Compared with the mirt package, the BE3M, and Stata can provide more stable estimates when changing priors for γ and ζ parameters.
The RMSEs of Item Parameter Recovery for 5,000 Examinees in the Simulation Study 1.

Note. Bold indicates the relatively larger RMSEs in the same conditions.
The RMSEs of Item Parameter Recovery for 5,000 Examinees in the Simulation Study 2.

Note. Bold indicates the relatively larger RMSEs in the same conditions.
As for the whole level, the RIMSEs for two simulation studies are presented in Figure 1. In general, with the increasing of the sample size, the RIMSEs of BE3M, fourPNO, Stata, and mirt package gradually decrease, and all of the RIMSEs across different conditions are relatively small. Furthermore, the results of RIMSEs show that there is no obvious difference between BE3M and BME in R package mirt although the BE3M has better performance in estimating the asymptotes, which is consistent with Waller and Feuerstahler (2017).

The RMSEs of item parameter recovery for all simulation conditions.
Real Data Example
The 4PLM is applied to bullying items collected as part of the 2005 to 2006 Health Behavior in School-Aged Children study (Iannotti, 2005) funded by the National Institute of Child Health and Human Development. This real data example was chosen to replicate previous results (Culpepper, 2016), and to demonstrate comparability between BE3M and the MCMC approaches (fourPNO package and “bayesmh” module in Stata) in terms of estimation accuracy and BE3M’s advantage in terms of estimation time. The prior settings for the “bayesmh” module in Stata are the same as those for BE3M and BME in the simulation studies. To further compare BE3M with BME, items were also calibrated with BME in the mirt package. In addition, as we have discussed in the introduction, there is no available SEs for all item parameters in the mirt package because the Beta priors (“expbeta” in mirt) were imposed on the guessing and slipping parameters in this example.
The data includes student responses on ten items related to bullying behavior for 7,491 adolescents. The ten bullying items asked students “How often have you bullied another student(s) at school in the past couple of months in the ways listed below?” The items were dichotomized as “1→0” and “>1→1” to indicate the student has not bullied or has bullied, respectively, in the given way over the past couple of months. For this application, the latent variable

so that
Results
Item calibration results from the three methods are summarized in Table 3. The estimates and SEs yielded by fourPNO are the same as in Culpepper’s (2016) study due to we used identical package (fourPNO) and estimation conditions. The BE3M produces point estimates comparable to both MCMC approaches, and estimates of the BE3M and Stata remain stable when changing priors. Unlike the performance of the mirt package in the simulation studies, it is interesting to note that the changing of priors has no obvious impact on the guessing and slipping parameters, but rather on the sloping parameters for the Item 1 and 2, which perhaps caused by the unstable Hessian matrix of the BME method. The implication is that careful consideration of priors should be taken if one uses the mirt package (which implements the BME method) to pursue precise estimates of the 4PLM.
The Estimated Item Parameters and the SEs for HBSC Data.
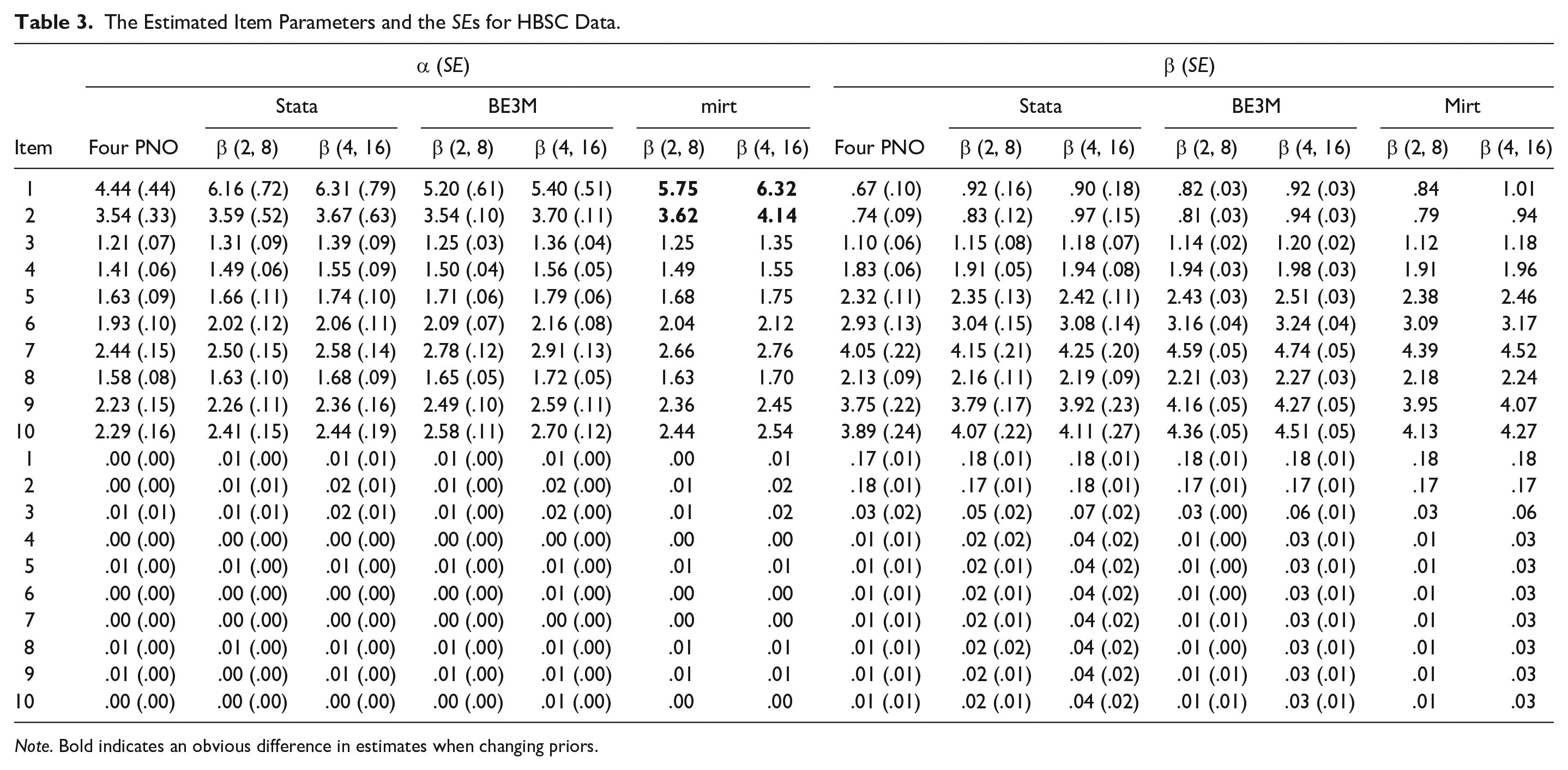
Note. Bold indicates an obvious difference in estimates when changing priors.
In terms of SEs, the two priors do not seem to influence the quality of estimation with similar values for the SEs in general. We also find that the SEs for the MCMC approaches are similar to those obtained with BE3M, with the exceptions of the sloping parameters.
The main finding is that BE3M is much more computationally efficient than the MCMC. The Gibbs sampler in the fourPNO package required approximately 47 minutes to complete 100,000 iterations and the MH sampler in Stata required approximately 3 hours to complete 10,000 iterations with N = 7,491 using a 2.4 GHz processor and 6 GB of RAM while BE3M only needed about 1 minute. We hope that this finding in particular will help to promote further applications of the 4PLM in practice.
Discussion
In recent years, interest in the four-parameter IRT model has been on the rise in measurement research. The current study presented a new Bayesian formulation of the 4PLM model. Through two simulation studies and a real data analysis, we demonstrated that the BE3M combines the strengths of these two approaches; the BE3M can produce estimates as accurately as the Gibbs sampling method as quickly as the Bayes model estimation approach using mirt. To facilitate calibration, the authors have made available an R package IRTBEMM (will be published on CRAN soon). The authors believe this package offers a better alternative for 4PLM calibration, helping to promote the use of the 4PLM in educational and psychological research.
Several opportunities exist for future research related to the 4PLM. First, future research can help to identify other substantive research areas and large survey datasets that could benefit from modeling the slipping effect (Beghetto, 2019). Second, for successful, high-efficient integration into a CAT testing system, being able to implement online calibration of item parameters is important (Zheng, 2016). Since the method proposed at present is a member of the EM family to which most online calibration algorithms belong, there is little barrier to developing online calibration methods based on the BE3M.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440211052556 – Supplemental material for Fast Bayesian Estimation for the Four-Parameter Logistic Model (4PLM)
Supplemental material, sj-docx-1-sgo-10.1177_21582440211052556 for Fast Bayesian Estimation for the Four-Parameter Logistic Model (4PLM) by Chanjin Zheng, Shaoyang Guo and Justin L Kern in SAGE Open
Footnotes
Author’s Note
Chanjin Zheng and Shaoyang Guo contributed to the work equally and should be regarded as co-first authors. Chanjin Zheng is affiliated with the Department of Educational Psychology, Faculty of Education, East China Normal University, China. Shaoyang Guo is affiliated with the Institute of Curriculum & Instruction, Faculty of Education, East China Normal University, China.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
This article does not contain any studies with human participants performed by any of the authors.
Data Availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Flower of Happiness Project in social science of East China Normal University (2020ECNU-XFZH007, 2019ECNU-XFZH015) and the Peak Discipline Construction Project of Education at East China Normal University.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.