
Abstract
This study evaluates the performance of five modeling approaches—unconstrained growth mixture model (GMMU), constrained GMM (GMMC), latent class growth model (LCGM), covariance pattern mixture model (CPMM) with compound symmetry (CPMM-CS), and CPMM with Toeplitz (CPMM-TP) structure—in identifying heterogeneous growth trajectories in longitudinal data. A Monte Carlo simulation was conducted using a three-class growth mixture model with five time points as the population model, varying sample size, class separation, and class proportion disparities. Model performance was assessed based on convergence rate, class enumeration accuracy, and parameter estimation accuracy. The results indicate that GMMU exhibited the lowest convergence rates, particularly under small sample sizes and low class separation. CPMM-TP achieved the highest class enumeration accuracy and outperformed GMMU in both convergence and classification, especially with small samples where GMM typically struggled. While CPMM-CS showed stable convergence and accurate parameter estimation, its class enumeration performance was comparatively lower. LCGM and GMMC demonstrated significant bias in slope and intercept estimates when class separation was low. These findings suggest that CPMM-TP provides a viable alternative to GMM, offering improved convergence stability and class enumeration accuracy, which are critical for the reliable identification of underlying trajectories.
Plain Language Summary
Understanding how people change over time is important in fields such as education, psychology, and health. For example, students may learn at different rates, or patients may recover at different speeds. To capture these differences, researchers use statistical models that group individuals with similar developmental patterns. Traditional approaches, such as Growth Mixture Models (GMM), are widely used but often face problems. They may fail to converge on a solution or give biased results when data are complex. A newer method, the Covariance Pattern Mixture Model (CPMM), was developed to overcome these issues by modeling correlations among repeated measurements more directly. This study compared five approaches—two forms of GMM, the Latent Class Growth Model (LCGM), and two CPMM variants with different covariance structures—under various simulation conditions. The results showed that CPMM with a Toeplitz structure consistently outperformed traditional models, especially in identifying the correct number of groups when samples were small or groups were not clearly separated. These findings suggest that CPMM, particularly the Toeplitz variant, provides a more stable and accurate tool for studying diverse growth patterns, offering practical guidance for researchers analyzing longitudinal data.
Keywords
Introduction
Understanding the heterogeneity in individual growth trajectories over time is a central focus in social sciences and education research. Identifying distinct subpopulations with unique developmental patterns is crucial for designing tailored interventions, optimizing resource allocation, and informing evidence-based policymaking. Growth mixture models (GMMs; Muthén & Shedden, 1999) are widely used methodological approaches to uncover such hidden population structures. By classifying individuals into latent subgroups based on their growth trajectories, GMMs provide a nuanced understanding of longitudinal data. Unlike traditional methods that assume homogeneity within a population, GMMs offer flexibility by modeling heterogeneous subpopulations (Jung & Wickrama, 2007), making them popular in disciplines like psychology, education, and public health (Guerra-Peña & Steinley, 2016).
Despite their utility, GMMs face significant challenges, including computational intensity and frequent non-convergence issues. Non-convergence arises when the model fails to reach a stable solution due to high parameter complexity and local optima in the likelihood function (McNeish & Harring, 2020). To address these challenges, researchers often constrain the variance of growth factors across latent classes (a constrained GMM) or simplify models by removing within-class variance entirely (a latent class growth model; LCGM; Nagin, 1999). While these adjustments improve computational efficiency, they often compromise the model’s ability to capture true heterogeneity. Constraining variance parameters can obscure meaningful variability among subpopulations, potentially leading to biased findings and incorrect conclusions (Diallo et al., 2016; Morin et al., 2011). Such practices are frequently driven by computational convenience rather than theoretical justification, limiting the broader applicability of GMMs (Bauer & Curran, 2003).
To overcome these limitations, McNeish and Harring (2020) introduced covariance pattern mixture models (CPMMs), which are better understood not as a single model but as a modeling framework (a class of models) that accommodates covariance structures. In this framework, specific covariance structures such as compound symmetry (CS) and Toeplitz patterns (TP) represent variants of CPMM. This innovative framework simplifies estimation, improves computational efficiency, and enhances convergence performance and stability while retaining the ability to model longitudinal patterns effectively. CPMMs also accommodate diverse covariance structures, including CS, first-order autoregressive (AR(1)), and TP, and have demonstrated superior performance in terms of convergence rates, class enumeration accuracy, and parameter estimation bias compared to GMMs and LCGMs (McNeish & Harring, 2020, 2021). For clarity, Toeplitz refers to a structure that estimates distinct correlations at each time lag, offering greater flexibility than AR(1). These attributes make CPMMs a promising alternative for real-world applications where data complexity and computational challenges are prevalent.
However, the broader applicability of CPMMs remains underexplored. Existing studies primarily evaluated CPMMs under fixed simulation conditions, focusing on limited sample sizes and simplified covariance structures. This narrow scope restricts the generalizability of their findings, leaving key questions unanswered about CPMMs’ performance under more complex scenarios. For instance, the impact of varying class proportions and covariance structure specifications has not been thoroughly examined. Moreover, no prior research has systematically evaluated the performance of TP versus CS under conditions of class imbalance and low class separation—scenarios frequently encountered in applied longitudinal studies. To systematically evaluate CPMMs’ robustness, this study employs Monte Carlo simulations varying sample size, class separation, and class proportion disparities—conditions known to influence mixture model performance in applied longitudinal research. By addressing these conditions, this study offers novel contributions that extend previous research and provide new insights into CPMMs’ utility, thereby establishing CPMMs as a robust alternative for modeling heterogeneous subpopulations in longitudinal data and potentially advancing both theoretical understanding and practical applications.
Purpose of this Study
This study aims to address these research gaps by systematically evaluating CPMMs under diverse simulation conditions and comparing five models in total: (1) an unconstrained GMM (GMMU), (2) a constrained GMM (GMMC), (3) an LCGM, and two CPMM variants with alternative covariance structures—compound symmetry (CPMM-CS) and Toeplitz (CPMM-TP). The evaluation focuses on three critical dimensions: convergence rates, class enumeration accuracy, and parameter estimation accuracy.
To provide a more refined evaluation, class enumeration was assessed not only with a three-class population model but also with a multi-class framework (i.e., testing models with two-, three-, and four-class solutions) to capture performance across a range of class solutions. By building on the foundational work of McNeish and Harring (2020, 2021), this study provides a comprehensive evaluation of CPMMs’ strengths and limitations under diverse simulation conditions. Additionally, this research contributes to the field by offering practical guidelines for researchers in selecting appropriate modeling strategies for analyzing longitudinal data. The findings aim to address challenges associated with modeling heterogeneity in subpopulation dynamics, ultimately supporting more robust and reliable applications of CPMMs in social and behavioral sciences. Based on these objectives, our research questions were as follows:
Literature Review
Covariance Pattern Mixture Models
The covariance pattern mixture models (CPMMs) were developed to effectively model the covariance structure of individuals while simultaneously estimating class-specific growth trajectories. This approach, introduced by McNeish and Harring (2020), integrates the framework of population-averaged models, also known as marginal models (Liang & Zeger, 1986), into a mixture model context. Population-averaged models are frequently used in fields such as psychology, epidemiology, and public health, where analyzing changes over time is a fundamental objective. They are often preferred over random-effects models because they address marginal covariance with fewer assumptions and reduce computational demands (Burton et al., 1998).
CPMMs are specifically designed to capture the average growth trajectory in longitudinally measured outcomes while accounting for relevant covariates, such as sex or treatment group. A widely used constrained form of growth mixture modeling (GMM) is the latent class growth models (LCGMs), which eliminate within-class variance and assume that individuals within the same class follow identical trajectories (Nagin, 1999). While LCGMs improve convergence, they reduce flexibility in capturing heterogeneity. This limitation reflects a common trade-off in traditional mixture approaches. Against this backdrop, CPMMs offer a viable alternative by shifting the focus from constraining variance to directly modeling the covariance structure, thereby achieving computational stability without sacrificing flexibility. In addition, whereas latent growth models rely on random effects to explain the covariance between repeated measures, CPMMs directly model this covariance, allowing more accurate estimation of class-specific trajectories in longitudinal data (McNeish & Harring, 2020).
The distinction between GMMs and CPMMs can also be illustrated mathematically. In the context of GMM, for a given class k, the observed outcomes of an individual i, denoted by

In Equation 1,

The expected mean structure of the model, assuming uncorrelated random effects and residual variances with a mean of zero, is expressed as:
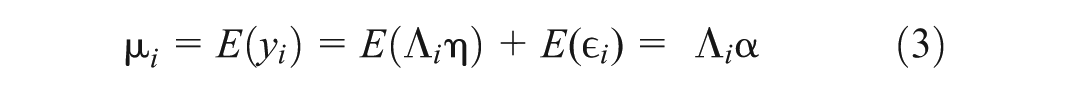
By focusing on the marginal covariance structure, CPMMs avoid the complexities associated with estimating random effects. Instead, they model the residual covariance matrix

Path diagram of growth mixture model and covariance pattern mixture model.
Covariance Structures in Covariance Pattern Mixture Models
One of CPMMs’ strengths is its flexibility in specifying covariance structures, allowing researchers to adapt the model to the design and characteristics of their data. Four commonly used covariance structures in CPMMs are compound symmetry (CS), first-order autoregressive (AR(1)), Toeplitz pattern (TP), and unstructured.
Compound Symmetry (CS)
The CS structure assumes that the variance remains constant across all time points and that the correlations between any two repeated measurements are equal. This structure is particularly useful for uniformly spaced data collected under stable environmental or measurement conditions.
First-Order Autoregressive (AR(1))
The AR(1) structure models correlations that decrease exponentially as the time lag between measurements increases. This pattern is mathematically written as
Toeplitz (TP)
The TP structure provides even greater flexibility by estimating distinct correlation parameters for each time lag. Unlike AR(1), which assumes a fixed decay pattern, TP allows each lag to have its own correlation value. This makes it especially useful for datasets with irregular intervals or non-standard correlation patterns.
Unstructured
The unstructured model offers the highest level of flexibility by placing no constraints on the covariance matrix. In this model, each variance and covariance is estimated independently, allowing it to capture unique relationships between all pairs of repeated measures. However, this flexibility requires a significantly larger number of parameters to be estimated, which can pose challenges for model convergence and interpretability.
Figure 2 illustrates the structural differences among these covariance models, while Table 1 summarizes their key assumptions, strengths, and limitations. Selecting the most appropriate covariance structure depends on factors such as the number of repeated measures, the spacing between time points, and the expected pattern of correlations.

Common covariance pattern structures.
Summary of Covariance Pattern Structures.

Advantages of Covariance Pattern Mixture Models
CPMMs offer several advantages over traditional models, such as GMMs and LCGMs. First, CPMMs reduce computational burden. By directly modeling the residual covariance, CPMMs eliminate the need for iterative estimation of random effects. This streamlining of the estimation process results in improved convergence rates, even in complex modeling scenarios. Another notable advantage of CPMMs is their flexibility. The method allows researchers to specify various covariance structures, such as CS, AR(1), or TP. This flexibility enables CPMMs to adapt to diverse longitudinal patterns and designs, making it a versatile tool for a wide range of research contexts. Additionally, CPMMs demonstrate robustness in handling challenging data scenarios. They perform well in situations characterized by high within-individual correlation, complex growth trajectories, and unevenly spaced measurements. These capabilities make CPMMs a reliable approach for accurately modeling longitudinal data in diverse research applications.
Previous Simulation Studies
Simulation studies have demonstrated the strengths of CPMMs compared to traditional GMMs and LCGMs. McNeish and Harring (2020) conducted a foundational study comparing CPMM with unconstrained and constrained GMMs under conditions that varied sample sizes (e.g., 500 and 1,500). Their results highlighted CPMM’s superior performance in terms of convergence rates, class enumeration accuracy, and reduced trajectory bias, especially when the sample size was small. This study marked a turning point in showcasing CPMM’s potential for addressing challenges associated with GMMs.
In a subsequent study, McNeish and Harring (2021) extended their analysis by exploring additional simulation conditions. These included varying levels of class separation, sample sizes ranging from 150 to 500, and attrition rates of 0%, 25%, and 45%. The findings revealed that CPMM-CS consistently outperformed traditional models in scenarios with low class separation or high attrition. While GMMs and LCGM struggled with convergence and classification accuracy under these challenging conditions, CPMM-CS demonstrated robustness, making it a valuable tool for longitudinal data analysis.
More recently, Neely et al. (2023) provided further insights into CPMMs by focusing on its sensitivity to covariance structure specification. They evaluated CPMM with AR(1) and CS covariance structures and compared its performance to LCGM. Their study underscored the importance of correctly specifying covariance structures, as CPMM’s performance was notably robust when covariance structures aligned with the data’s true characteristics. However, the study also highlighted potential biases and errors in class enumeration when covariance structures were misspecified, particularly under conditions of high within-individual correlation. Based on these results, it was indicated that specifying a covariance structure in which the true structure is nested (e.g., specifying TP when AR(1) or CS is the true structure) may have less impact on class enumeration in CPMMs.
Despite these promising findings, existing research on CPMMs has been limited to narrow simulation conditions, such as small to moderate sample sizes and simplified covariance patterns. Important questions remain unanswered, such as how CPMMs perform with more complex covariance structures like TP or unstructured patterns, or under varying class proportions. Additionally, prior studies have not systematically evaluated the impact of selecting different covariance structures on CPMMs’ performance compared to traditional models across a broader range of conditions.
Taken together, these studies suggest that CPMMs consistently demonstrate stronger convergence and class enumeration accuracy than traditional approaches under challenging conditions. However, its robustness under more complex covariance structures and class distributions remains uncertain, underscoring the need for further investigation. Although previous research has established the foundational advantages of CPMMs, it has not yet clarified how these models perform under diverse and realistic data conditions frequently encountered in applied research. Addressing this issue is essential to determine whether CPMMs can maintain their strengths across various covariance structures and sample configurations. Therefore, this study seeks to address these gaps by systematically evaluating CPMMs under diverse simulation conditions, including CS and TP covariance structures. By comparing CPMMs with GMMs and LCGM, this study aims to provide practical guidelines for researchers on selecting appropriate covariance structures and demonstrate CPMMs’ effectiveness in addressing heterogeneity in longitudinal data.
Simulation Design
Data Generation
A Monte Carlo simulation study was conducted to evaluate the performance of five different models in estimating latent class trajectories. The models included an unconstrained growth mixture model (GMMU), a constrained growth mixture model (GMMC), a latent class growth model (LCGM), and the CPMM with compound symmetry (CPMM-CS) and the CPMM with Toeplitz covariance structure (CPMM-TP). The data generation model followed an unconstrained GMM, ensuring a flexible representation of class-specific heterogeneity. To reflect realistic research conditions, all models except GMMU were intentionally misspecified by incorporating nontrivial random slopes and incorrect covariance structures. This approach follows the recommendations of McNeish and Harring (2020), who suggest that such misspecifications prevent artificially inflated performance estimates of CPMMs and provide a more realistic assessment of model robustness. This design choice may complicate interpretation, as estimation bias could arise either from inherent model limitations or from the imposed structural mismatch. Nevertheless, intentional misspecification was deemed important to avoid overly optimistic conclusions about model performance, particularly given that in practice the true population model is never known.
The population model consisted of three latent classes, a decision grounded in previous research indicating that most educational studies extract between two and four classes (Chen, 2022; Enders & Tofighi, 2008). The three trajectory classes were based on prior studies on early childhood externalizing behaviors (Petras & Masyn, 2010; Silver et al., 2010). The high-declining class exhibited high initial levels followed by a moderate decline, the low-escalating class started at a low level but increased over time, and the low-stable class remained consistently low. Each individual’s growth trajectory was measured at five time points, providing sufficient statistical power while ensuring model complexity remained manageable. The growth process was modeled as linear, with class-specific intercept and slope variances differing across latent groups. Time-specific residuals were assumed to be homoscedastic, and misspecification of residual variances was considered beyond the scope of this study. The population model is illustrated in Figure 3 and the final parameter values defining each latent class are presented in Table 2.

A population model in the study.
Parameters for the Population Model.

Models
This study evaluated five distinct models, each characterized by different specifications of the within-class variance-covariance and residual structure. The first model, the unconstrained growth mixture model (GMMU), freely estimated all variance and covariance parameters within each latent class. This approach allowed for maximum flexibility in capturing within-class variability but often introduced computational challenges. The second model, the constrained growth mixture model (GMMC), constrained all variance and covariance parameters to be equal across classes. By reducing the number of freely estimated parameters, the GMMC aimed to improve computational stability while potentially oversimplifying the heterogeneity within the data.
The third model, the latent class growth model (LCGM), assumed no variability within each class by setting the variances of growth factors to zero. This simplification effectively removed within-class variability, making the LCGM computationally efficient but less capable of modeling nuanced patterns in the data. The fourth model, the covariance pattern mixture model with a compound symmetry structure (CPMM-CS), specified a covariance structure where the variances remained constant across time points, and the correlations between repeated measures were assumed to be equal within each latent class. This model was particularly suitable for datasets with uniformly spaced measurements collected under stable conditions.
The fifth model, the covariance pattern mixture model with a Toeplitz structure (CPMM-TP), allowed for distinct correlations at each time lag within each latent class. This approach provided greater flexibility compared to CPMM-CS, making it ideal for datasets with irregular time intervals or non-standard correlation patterns among repeated measures.
Manipulated Conditions
The simulation study followed a fully crossed design, manipulating three key factors: sample size, class proportion disparities, and class separation. These factors were selected based on prior research demonstrating their significant impact on latent class identification and parameter estimation in growth mixture modeling (Depaoli, 2013; Enders & Tofighi, 2008; Li & Hser, 2011; Lubke & Muthén, 2007).
First, sample size varied across four levels: 200, 400, 700, and 1,500, representing small to large sample sizes commonly encountered in GMM research (Diallo, Morin & Lu, 2016; Nylund, Asparouhov, & Muthén, 2007). Prior studies indicate that larger samples improve class enumeration accuracy, but CPMM models have shown robustness in small-sample conditions (McNeish & Harring, 2020, 2021), necessitating further investigation of their performance across varying sample sizes.
Next, class proportions were manipulated at three levels: equal (33%, 33%, 33%), relatively unequal (25%, 25%, 50%), and severely unequal (10%, 20%, 70%). Previous research has demonstrated that unbalanced class proportions can reduce class enumeration accuracy, particularly in small samples (Depaoli, 2013; Enders & Tofighi, 2008). In the unequal conditions, the low-stable class had the highest proportion, while the low-escalating and high-declining classes were progressively smaller, consistent with prior studies on early childhood externalizing behaviors (Petras & Masyn, 2010; Silver et al., 2010). Lastly, class separation was manipulated at two levels: high and low. Entropy values ranged from .82 to .89 for high separation and .54 to .68 for low separation, aligning with previous mixture modeling studies (Diallo et al., 2016; Lubke & Muthén, 2007). Class separation was manipulated by adjusting the variances of growth factors within each latent class, as prior research has identified it as a key determinant of model performance (McNeish & Harring, 2021).
Crossing these 3 factors yielded 24 experimental conditions, with 500 replications per condition, producing 12,000 simulated datasets across the 5 models. For class enumeration, replications were reduced to 100 per condition, whereas 500 replications were retained for convergence and parameter estimation. This reduction was due to the higher computational demands of class enumeration, which involves estimating multiple latent class solutions (e.g., 2-, 3-, and 4-class models) for each dataset, thereby greatly increasing the total number of model estimations required (about 300 runs per 100 replications). All models were estimated using Mplus Version 8.3 with robust maximum likelihood estimation (MLR). The Mplus Automation package in R (Hallquist & Wiley, 2024) was used to automate model estimation, ensuring efficient handling of the large number of replications.
Evaluation Criteria
Model performance was evaluated based on convergence rates, class enumeration accuracy, and parameter estimation accuracy. Convergence rates were calculated as the proportion of replications that resulted in properly estimated solutions without encountering issues such as non-convergence or improper estimates. A model was considered non-convergent if it failed to reach a solution despite multiple starting values, while improper solutions were identified when estimates were out of bounds, such as negative variances, correlations exceeding 1, or non-positive definite Hessian matrices (Diallo et al., 2016). Given that unconstrained growth mixture models involve a larger number of freely estimated parameters, they were expected to exhibit lower convergence rates compared to constrained models.
Class enumeration accuracy was assessed by determining the proportion of correctly identified three-class models across all replications. Models were estimated sequentially with two, three, and four latent classes, and the best-fitting model was selected using several information criteria (ICs), including the Akaike Information Criterion (AIC; Akaike, 1987), Bayesian Information Criterion (BIC; Schwarz, 1978), sample-size-adjusted Bayesian Information Criterion (SABIC; Sclove, 1987), and model comparison test metric including the bootstrapped likelihood ratio test (BLRT; McLachlan & Peel, 2000). These criteria were chosen based on prior research demonstrating their effectiveness in identifying the correct number of latent classes, particularly when sample sizes are moderate, class separation is weak, or class proportions are highly unbalanced (Enders & Tofighi, 2008; Yang, 2006).
While SABIC has been shown to outperform other information criteria in mixture modeling contexts, AIC was also included given its common use in prior studies, despite its generally less notable performance. BIC, on the other hand, often underestimates the number of classes (Peugh & Fan, 2012), though it has demonstrated good performance under certain conditions (Diallo et al., 2016; Enders & Tofighi, 2008; Gilthorpe et al., 2014; Neely et al., 2023). The BLRT was included because prior simulation studies have reported it as a highly consistent indicator across various model types (Nylund et al., 2007), and there is no consensus on a single definitive index for class enumeration. Following the recommendations of Nylund-Gibson and Choi (2018), we therefore combined the BLRT with multiple ICs (AIC, BIC, SABIC) to capitalize on its strength in detecting model fit improvements while mitigating the risk of overestimating the number of classes through complementary IC-based evaluations. To account for potential biases introduced by non-convergence, class enumeration accuracy was calculated based on the subset of replications that successfully converged. A model with k classes was selected when a significant BLRT result for the k-class model was followed by a non-significant result for the k + 1 class model.
Parameter estimation accuracy was evaluated using relative bias and root mean square error (RMSE) for class-specific intercepts and slopes. Relative bias was calculated as the percentage difference between the estimated and true parameter values, with values below .10 considered acceptable (Finch et al., 1997; Kaplan, 1988). RMSE was used to measure overall estimation precision by accounting for both systematic and random errors. In addition to numerical accuracy metrics, qualitative recovery of trajectory patterns was examined through visual inspection of estimated class trajectories, following the approach of McNeish and Harring (2020), who emphasized that models may accurately capture latent class structures despite minor parameter estimation biases.
Results
Convergence Rates
The performance of each model was assessed based on convergence rates, representing the proportion of replications that successfully reached a three-class solution. The convergence rates for each model type are presented in Figure 4. Across all models, convergence rates improved with larger sample sizes, greater class separation, and more balanced class proportions. This trend was particularly evident in the GMMU and CPMMs. By contrast, both the GMMC and the LCGM achieved convergence rates close to 100% under all conditions. Once the sample size reached 700 or more, convergence rates across all models displayed minimal differences.

Convergence rates under two types of class separation (CS).
Despite these general patterns, the models exhibited notable differences. The GMMU consistently produced the lowest convergence rates, particularly when the sample size was below 400. The combination of a small sample size (200) and low class separation resulted in significantly lower convergence rates. For the CPMM-CS, convergence rates were generally favorable; however, an exception was observed when class separation was high and class proportions were relatively unequal, leading to the lowest convergence rates among all models. The CPMM-TP achieved convergence rates above 80% in all conditions, except when the sample size was 200 and class separation was low, where it dropped to between 70% and 80%. It also exhibited higher convergence rates in conditions with greater class separation, whereas CPMM-CS performed better under low class separation.
In summary, the GMMC and the LCGM consistently achieved convergence rates close to 100% across conditions. The CPMM-TP generally followed, with rates exceeding 80% in most settings, while the CPMM-CS showed somewhat weaker but still competitive performance. By contrast, the GMMU consistently produced the lowest rates, particularly with smaller samples.
Class Enumeration Accuracy
The accuracy of class enumeration was assessed using four model selection criteria: AIC, BIC, SABIC, and BLRT. Tables 3 and 4 report the proportion of replications in which each criterion correctly identified the true three-class model out of 100 replications under conditions of high and low class separation, respectively. To provide a concise summary of model performance across criteria, medians rather than means were reported, given the substantial variability across conditions. Because the number of simulation conditions was even (12, combinations of 3 class proportions and 4 sample sizes), the reported medians represent the average of the two central values.
Class Enumeration Rates Correctly Identified the True Three-Class Model in High Class Separation.

Note. The shaded cell indicates that the three-class model had the highest selection proportion among the two-, three-, and four-class models.
Class Enumeration Rates Correctly Identified the True Three-Class Model in Low Class Separation.

Note. The shaded cell indicates that the three-class model had the highest selection proportion among the two-, three-, and four-class models.
High Class Separation
Under high class separation conditions (Table 3), class enumeration accuracy—defined as the proportion of replications that correctly identified the true three-class model—was highest for the GMMU and the CPMM-TP across most criteria. According to AIC and SABIC, both models achieved high accuracy, often exceeding 70% and approaching 100% as sample size increased. BLRT results showed similar patterns, although both models had reduced accuracy at smaller sample sizes and under unequal class proportions. Based on BIC, the GMMU maintained relatively strong accuracy except at the smallest sample size of 200. By contrast, the CPMM-TP showed competitive accuracy at the largest sample size of 1,500, while its performance declined substantially with smaller sample sizes and unequal class proportions.
In comparison, the GMMC showed limited accuracy, with median values ranging from 23.0% to 28.5% depending on the criterion. The LCGM exhibited low accuracy in most conditions, though it reached 45.0% at sample size of 200 with severely unequal proportions and then declined sharply as sample size increased. The median accuracy of CPMM-CS was near zero when evaluated using AIC, SABIC, and BLRT. According to BIC, CPMM-CS showed modest improvement at small sample sizes (up to 42%), but this was not sustained across conditions.
Low Class Separation
Under low class separation conditions (Table 4), class enumeration accuracy was generally reduced across all models and criteria compared to the high separation conditions. The CPMM-TP outperformed the GMMU, particularly with SABIC, where it achieved the highest selection proportions among the two-, three-, and four-class models across all conditions. This advantage was evident at the smallest sample size of 200. By contrast, the GMMU showed lower accuracy when sample size was below 400, although it improved with larger samples.
Among the remaining models, the GMMC showed median accuracy values ranging between 8.5% and 21.0%, occasionally reaching 50% in specific conditions but without a consistent pattern. The LCGM remained near zero across nearly all conditions. The CPMM-CS generally displayed very low accuracy when evaluated using AIC, SABIC, and BLRT. However, according to BIC, it showed elevated accuracy at sample sizes of 200, up to 89%. Moreover, when evaluated using BLRT, the CPMM-CS also reached 50% at a sample size of 200, although this result was not sustained across larger samples or other conditions.
In summary, class enumeration accuracy was generally higher under high separation than under low separation, with the GMMU and CPMM-TP showing the most consistent performance overall. The CPMM-TP demonstrated particular advantages with SABIC, especially under low separation, whereas the GMMU tended to perform better at larger sample sizes. By contrast, the GMMC, LCGM, and CPMM-CS rarely achieved accurate enumeration across conditions. Additionally, when the three-class solution was not selected, the GMMC, LCGM, and CPMM-CS frequently overestimated to four-class solutions with AIC and SABIC, whereas the GMMU tended to underestimate by selecting two classes, regardless of class separation level (not shown in tables for brevity).
Parameter Estimation Accuracy
The performance of each model was examined in accurately estimating parameters both quantitatively and qualitatively, emphasizing parameter estimation bias, RMSE, and graphical representations of growth trajectories. Since patterns across different sample sizes were highly consistent, results are reported only for a sample size of 200. Tables 5 and 6 summarize bias in intercept and slope estimates, respectively, while Tables 7 and 8 report RMSE for intercept and slope estimates. Bias measures the extent to which the estimated values deviate from the true population parameters. Lower bias values correspond to higher accuracy in parameter estimation, with an absolute bias value of .1 considered an acceptable threshold (Finch et al., 1997; Kaplan, 1988). In this study, the bias of intercepts and slopes was assessed for classes 1 to 3 under each condition. Similar to bias, lower RMSE values indicate that the parameter estimates are closer to the true population values. Since negative differences between the population and estimated parameters could offset parameter estimation bias, RMSE was calculated as an additional measure.
Bias of Intercept Estimates with a Sample Size of 200.

Note. The shaded cell represents the model with the lowest absolute value of bias among five models.
Bias of Slope Estimates with a Sample Size of 200.

Note. The shaded cell represents the model with the lowest absolute value of bias among five models.
RMSE for Intercept Estimates with a Sample Size of 200.

Note. The shaded cell represents the model with the lowest value of RMSE among five models.
RMSE for Slope Estimates with a Sample Size of 200.

Note. The shaded cell represents the model with the lowest value of RMSE among five models.
Bias of Parameter Estimates
Table 5 summarizes the bias of intercept estimates at a sample size of 200 across both high and low class separation conditions. Under high class separation, the GMMU, the CPMM-CS, and the CPMM-TP generally maintained bias below the .1 threshold, indicating acceptable accuracy. The intercept bias in the GMMC exceeded .1 under equal class proportions, and the LCGM exhibited biases greater than .1 primarily when class proportions were severely unequal.
In low class separation, every model produced bias estimates exceeding .1 for at least one parameter. In particular, the GMMC and the LCGM showed excessively high frequencies of bias exceeding .1 under all conditions. By contrast, even in conditions where bias was present, the GMMU, the CPMM-CS, and the CPMM-TP maintained biases below .2. The CPMM-CS exhibited a bias above .1 primarily when class proportions were equal, while elevated biases were observed in the CPMM-TP under severely unequal proportions.
Overall, the model that achieved the lowest bias among the five alternatives varied depending on the level of class separation: The GMMU most frequently yielded the lowest bias with high separation, whereas the CPMM-TP did so under low separation. In contrast, the LCGM and the GMMC consistently exhibited larger biases across conditions, regardless of separation level.
Table 6 presents bias in slope estimates at a sample size of 200 under both high and low class separation conditions. For slope estimates, a higher frequency of bias exceeding .1 was observed compared to intercept estimates. In high class separation, the LCGM showed substantial bias in nearly all conditions, often exceeding .5 in absolute value. By contrast, the GMMU, CPMM-CS, and CPMM-TP exhibited slope biases greater than .1 only with severely unequal class proportions, while the GMMC did so under equal and relatively unequal proportions.
In low class separation, slope biases increased considerably across all models. The LCGM showed large biases in every condition, while the GMMU had the fewest instances exceeding .1. The GMMC exhibited relatively higher biases when class proportions were equal, whereas both the CPMM-CS and the CPMM-TP displayed the most severe biases under severely unequal class proportions.
In summary, bias patterns were strongly influenced by class separation and, to a lesser extent, by class proportions. Bias increased markedly under low separation across all models. Across conditions, the GMMU most frequently showed the smallest bias, whereas the CPMM-TP produced smaller intercept bias under low class separation.
RMSE for Parameter Estimates
Table 7 presents RMSE results for intercept estimates. Overall, the tendency for all models to yield larger errors under low class separation was consistent with the bias results. The GMMU also showed the smallest RMSE most frequently in high class separation, similar to the bias findings. However, under low separation, the CPMM-CS most often exhibited the smallest RMSE among the five models. The LCGM generally produced the largest RMSE under high class separation; yet, under low separation, the GMMC showed comparatively greater RMSE values.
Table 8 presents RMSE results for slope estimates. Overall, RMSE values were generally smaller than those for intercepts. Consistent with the intercept results, the GMMU most frequently exhibited the lowest RMSE under high class separation, while the CPMM-CS and CPMM-TP produced comparable values. In contrast, under low separation, the GMMU and CPMM-CS tended to have the lowest RMSE overall.
In summary, RMSE values also increased substantially under low class separation, consistent with the general tendencies observed for bias. Although class proportions had a lesser effect on RMSE compared to class separation, the lowest RMSE was observed under conditions with equal class proportions. Across all conditions, the GMMU most frequently achieved the smallest RMSE, while the CPMM-CS and the CPMM-TP also demonstrated comparable performance.
Growth Trajectories
Accurate parameter estimates indicate improved model performance, but they alone do not fully capture how well a model reproduces the true population structure. To evaluate this, the estimated growth trajectories from each model were compared to the true population trajectories. Figure 5 presents the results for low class separation with severely unequal class proportions (sample size = 200), as this condition posed the greatest challenge to model estimation. The dashed lines represent the true population trajectories, while the solid lines denote the estimated average trajectories for each model.

Comparison of population class trajectories (dashed) to average class trajectories of estimated models (solid) under low class separation, severely unequal class proportions, and a sample size of 200.
As shown in Figure 5, under this most challenging condition, all models exhibited greater deviations from the true population structure compared to easier conditions. Among them, the CPMM-CS demonstrated greater robustness in capturing the overall trajectory patterns. Notably, it successfully replicated the intersection between the first- and second-class trajectories, a critical feature of the population model that even the GMMU failed to capture. The GMMU and the CPMM-TP also captured the overall trajectory patterns, though they slightly underestimated the slope of the low-escalating class, leading to a less pronounced upward trend. In contrast, the GMMC and the LCGM exhibited the lowest performance. The GMMC severely overestimated the intercept of the high-declining class, producing biased trajectories that disrupted the expected pattern. The LCGM failed to represent the low-escalating trend altogether.
Taken together, these findings underscore the limitations of traditional growth mixture models under complex real-world conditions. They also highlight the superior adaptability of the CPMM-CS in preserving key trajectory features in the presence of low separation and severe imbalance.
Summary
Table 9 summarizes overall performance by reporting the proportion of design conditions in which a model achieved the best result for each criterion. Specifically, across all crossed conditions, the frequency with which each model performed best was counted, and these counts were converted to proportions by dividing by the total across the five models. The rank reflects the ordering of models based on these proportions, with higher proportions corresponding to better ranks.
Overall Proportions of Best Performance Across Conditions.

Note. Values in bold indicate the highest proportion or rank.
Based on this summary, the GMMU achieved the highest overall rank due to its strong performance in parameter estimation accuracy, but it also showed the lowest convergence proportion. By contrast, the CPMM-TP demonstrated the highest class enumeration accuracy and competitive parameter estimation, indicating more balanced performance across criteria.
Conclusion
GMMs are extensively applied in education and behavioral science; however, their reliance on random effects often leads to convergence issues and unreliable results due to the complexities of estimation (McNeish & Harring, 2020). To mitigate these challenges, CPMMs have been proposed as simpler alternatives that capture heterogeneous subgroups in longitudinal data without the need for random effects, thereby reducing computational demands and offering a practical solution where GMMs frequently require arbitrary constraints for convergence. However, few studies have systematically compared CPMMs with traditional models under diverse data conditions. Addressing these gaps, this study systematically compared the performance of the GMMU, the GMMC, the LCGM, and two CPMM variants—the CPMM-CS and the CPMM-TP—across varying class separations, class proportion disparities, and sample sizes.
Monte Carlo simulation results revealed distinct performance patterns across models. The GMMU showed the lowest convergence rates, while the GMMC and the LCGM achieved near-perfect convergence across all conditions. Both CPMM variants demonstrated strong and stable convergence overall, with the CPMM-TP showing particular robustness under challenging conditions. These findings reaffirm the known instability of GMMs and the greater stability of covariance-pattern models, while extending prior results (McNeish & Harring, 2020) by demonstrating that a flexible covariance structure, as implemented in the CPMM-TP, can mitigate convergence failures without relying on random effects. Contrary to findings from a previous simulation study (McNeish & Harring, 2020), the CPMM-CS showed the lowest convergence rate in specific conditions such as small sample sizes. This discrepancy may arise from the simpler covariance structure of the CPMM-CS. However, since the population model was based on a GMM, drawing definitive conclusions regarding the effects of covariance structures remains challenging, thereby necessitating further research.
Regarding class enumeration, the CPMM-TP achieved the highest accuracy, followed by the GMMU, whereas the GMMC showed moderate accuracy and both the LCGM and CPMM-CS frequently overestimated the number of classes. Given the convergence patterns, it can be inferred that the GMMU and CPMM-TP did not select the four-class model because they failed to converge in those cases. However, the CPMM-TP occasionally selected the three-class model even when the four-class solution converged. As previous studies (Kreuter & Muthén, 2008; McNeish & Harring, 2020) have noted, rigidly constrained models may over extract classes to compensate for covariance misspecification, a pattern similarly observed in this study. This overestimation tendency underscores the inherent limitations of highly constrained models such as LCGMs, while highlighting the flexibility of CPMM-TP as a more balanced alternative.
Moreover, the performance of information criteria (ICs; AIC, BIC, SABIC) and BLRT for class enumeration mirrored findings from prior GMM research. In previous studies (Enders & Tofighi, 2008; Tofighi & Enders, 2008; Yang, 2006), SABIC consistently provided the best performance in detecting the correct number of classes, while BIC and BLRT performed well under certain conditions, and AIC demonstrated poorer results (Diallo et al., 2016; Enders & Tofighi, 2008; Gilthorpe et al., 2014, Neely et al., 2023). In this study, SABIC again showed the best performance, although AIC performed comparably. As observed in prior studies (Peugh & Fan, 2012), BLRT was more effective with larger sample sizes, while BIC tended to underestimate the number of classes.
Lastly, regarding parameter estimation accuracy, the GMMU achieved the highest accuracy, whereas the LCGM showed the greatest deviations from population parameters. Both CPMMs displayed minor errors in specific parameters; however, their estimates remained relatively close to the population model when considering trajectory patterns. Notably, they demonstrated robust performance even under challenging conditions, such as low class separation, unbalanced class conditions, and small sample sizes, aligning with previous simulation research (McNeish & Harring, 2021).
Implications
This study offers several important implications. First, by evaluating multiple outcome indicators, it identified the model that best balances convergence and estimation accuracy. Although the CPMM-TP showed slightly lower convergence rates than the GMMC and the LCGM, it outperformed other models in class enumeration and trajectory identification. This suggests that CPMMs, which eliminate random effects while accommodating class-specific covariance structures, can serve as a viable alternative to traditional models that impose arbitrary constraints for convergence. However, the use of a GMM-based population model may have been relatively favorable to the GMMU; therefore, CPMMs’ advantages should be interpreted with this potential bias in mind.
Second, the findings provide practical recommendations for applying CPMMs. When data show weak class separation or limited sample sizes, the CPMM-TP appears to be the most appropriate model. The superior performance of the CPMM-TP across all indicators suggests that the Toeplitz structure is particularly well-suited for moderate numbers of evenly spaced time points (McNeish & Harring, 2020), such as the five repeated measures used in this study. Applied researchers may therefore consider the CPMM-TP a reasonable alternative to the GMMU under conditions of small samples and assumed weak separation, particularly when convergence is problematic.
Third, the study reaffirmed the effectiveness of class enumeration criteria. Overall, information criteria such as SABIC and AIC provided the most reliable guidance, while others showed more variability across conditions. Given these differences, researchers are advised to avoid relying on a single index and instead assess convergence patterns and substantive interpretability in conjunction with multiple information criteria. In practice, SABIC may serve as a useful starting point for identifying the optimal number of classes, but model selection should also consider theoretical plausibility, parameter stability, and model parsimony rather than numerical fit alone.
Limitations and Significance
The limitations and suggestions for future research are outlined below. To simplify factors not included in the study conditions, a linear growth function was used in the population model. However, prior research where the CPMM-CS performed better employed a quadratic function (McNeish & Harring, 2020). The differences in findings may stem from this distinction, making the exclusion of quadratic functions a limitation of this study. Future research should incorporate both linear and quadratic slopes to examine their impact on model performance. Additionally, since McNeish and Harring (2020) used a four-class model, expanding future research to include more classes could provide further insights into CPMMs’ applicability. This study also focused primarily on comparisons with GMMs, leading to a GMM-based population model and the evaluation of only two covariance structures in CPMMs. Accordingly, the results may have been relatively favorable to the GMMU, which in turn suggests that the generalizability of the findings may be limited. Additionally, to enhance CPMMs’ broader applicability, future studies should assess their performance with a wider range of covariance structures. In particular, given that the number of repeated measures influences the choice of covariance structure, further research should explore how varying the number of time points affects the optimal covariance specification.
Despite these limitations, this study is significant in demonstrating CPMMs as a viable alternative for researchers facing convergence issues with GMMs. It provides empirical insights into CPMMs’ performance across different conditions and offers a detailed evaluation of class enumeration criteria. As GMMs continue to be widely used, CPMMs present a promising solution to its computational challenges. Overall, the findings underscore the CPMM-TP as a particularly promising approach and highlight the need for continued methodological research to advance its application in social sciences.
Footnotes
Appendix
Mplus Code for CPMM-TP Analysis.

|
|
|
|
| |
| |
| |
|
|
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data supporting the findings of this study were generated using the methodology outlined in the appendix. The appendix provides detailed instructions and necessary resources for replicating the data generation process.