
Abstract
This study investigates the effect of grammar-focused hands-on in-class data-driven learning (DDL) with a heavily contextualized corpus on the frequency of written errors attributable to common interlingual interference issues in low–intermediate Turkish learners (n = 30) of English. Items representing the most common Turkish-to-English interlingual errors were selected through a two-step process involving the analysis of past studies and a subsequent ranking survey of teachers (n = 10) of Turkish learners of English. Participants’ grammar development in terms of types of written errors was measured over a ten-week period through written tasks in a pre/posttest design, producing 19,328 words for analysis. The results, although variable by item, suggest that targeted DDL with the TED Corpus Search Engine (TCSE) helps reduce written errors in Turkish learners of English to a significant degree with a moderate effect size. Consequently, the investigation of DDL with the TCSE for the targeting of interlingual interference in other first-language contexts is recommended.
Keywords
Introduction
Imagine replacing the needs analysis of a beginner-level Turkish-speaking learner of English with the SWOT (strengths, weaknesses, opportunities, threats) analysis common in the world of business. The shorthand first entries of each category may look something like: “Strengths”—already proven their ability to learn a language; “Weaknesses”—unable to comprehend/produce English; “Opportunities”—may benefit from similarities between Language 1 (L1), Turkish, and Language 2 (L2), English; “Threats”—L1, Turkish, may interfere with the acquisition of L2, English. Although many items would likely be added to each category, this analogy serves to highlight what many an experienced teacher of multilingual classes would surely agree with; “L2 acquisition is clearly affected by the transfer of learners’ knowledge of their first language” (Ellis, 2006b, p. 187). As the SWOT analogy above implies, language transfer can be both advantageous and problematic, leading to the obvious conclusion that language teaching practitioners should consider ways to, in business terms, maximize the opportunities and minimize the threats. This article attempts to address the latter by investigating the potential of a technique, language corpus study, for reducing the negative impact of L1 (in this case Turkish) on the acquisition of L2 (here English) through targeting susceptible items.
As with foreign language learners of most language combinations, Turkish-speaking learners of English typically struggle with some common problems, as well as some seemingly more specific to their context. Past studies have focused upon, among other topics, speaking (see Yildiz, 2016), pronunciation (see Bardakci, 2015), listening comprehension (see İnceçay & Koçoğlu, 2017), grammar (see Agcam et al., 2015; Balabakgil et al., 2016; Erarslan & Hol, 2014), and writing (see Demirel, 2017), all of which are common problem areas for most foreign language learners. The causes of these issues are multitudinous and include foreign language anxiety (Çağatay, 2015; Thompson & Khawaja, 2016), teaching/training shortcomings (Solak & Bayar, 2015), and, naturally, language transfer (Erarslan & Hol, 2014; Mede et al., 2014). Referring to the distance between Turkish and English, Erarslan and Hol (2014) suggest that most Turkish-speaking learners of English “are assumed to transfer linguistic structures in a negative way because of the distance between these two languages” (p. 7). Grammatical accuracy is particularly problematic in the written work of Turkish-speaking learners of English (Demirel, 2017) and, as written performance is paramount to academic success, a technique aimed at reducing the challenge is investigated here; targeting written errors deemed likely to have been caused by interlingual interference through the study of a context-heavy language corpus, a technique usually referred to as “data-driven learning” (DDL).
DDL “provides learners with attested usage examples, helps learners develop analytical and problem-solving skills, and promotes learner autonomy” (Vyatkina & Boulton, 2017, p. 2), incorporates technology into language learning, and, perhaps most importantly, is effective; “DDL works pretty well in almost any context where it has been extensively tried” (Boulton & Cobb, 2017, p. 379). In addition, recent improvements in concordancing software have facilitated a shift toward multimodal, aesthetically pleasing, and user-friendly corpus interfaces, further bolstering the argument in favor of DDL. One such program is Hasebe’s (2015) TED Corpus Search Engine (TCSE), which incorporates full video and transcript contextualization through a platform which is much less daunting than many other such interfaces.
In light of the above, attempting to assist Turkish-speaking learners of English in reducing written errors through DDL with the TCSE was deemed worthy of investigation. The data derive from samples of writing (totaling 19,328 words from 30 learners) taken before and after training, enabling the analysis of errors with items deemed likely (through a two-step item identification process) to be affected by aspects of language transfer.
Language Transfer and Cross-Linguistic Influence
The notion of language transfer has endured several misconceptions and challenges over the past century during its often fiercely debated journey to the current consensus. Odlin (1989) tentatively offers the definition: “Transfer is the influence resulting from similarities and differences between the target language and any other language that has been previously (and perhaps imperfectly) acquired” (p. 27). This may not seem controversial, yet during the backlash against behaviorism in the 1960s and 1970s denials of “language transfer” were voiced by several prominent scholars on the basis of transfer being a result of habit formation (Jarvis & Pavlenko, 2008), which subsequent work has shown to be inaccurate (Odlin, 1989). A further misconception of language transfer is it being predominantly a negative phenomenon, despite evidence of positive transfer (such as “borrowing” from L1) being referred to in early works (Jarvis & Pavlenko, 2008). Contributions such as that of Cummins (1979) have provided some balance in this respect. Cummins describes learners as developing a Cognitive/Academic Language Proficiency (CALP), above the level of Basic Interpersonal Communication Skills (BICS), in their first language which serves to aid the development of an L2 CALP. Thus, older learners benefit more because the CALP of their known language(s) is more advanced, although the effect is reduced in languages that are more distant (Cummins, 1979). Another key shift in thinking came from the recognition that the effects can flow both ways, that is, the target language can impact upon the known language(s) (Jarvis & Pavlenko, 2008). The combination of these tenets of language transfer (that it exists, can be both positive and negative, and is multidirectional), among other important developments, has resulted in changes in terminology.
The term language transfer is largely replaced with the broader term “cross-linguistic influence” (CLI) in works such as Odlin (1989), Jarvis (2010), and Jarvis and Pavlenko (2008) (although language transfer is often still used in place of, or interchangeably with, CLI). CLI can be seen as more of an umbrella term than language transfer, as it allows for all instances of influence, including the nonlinguistic (such as “conceptual transfer”; Jarvis & Pavlenko, 2008). Therefore, to appreciate the phenomena to which CLI refers, it is necessary to consider both the cognitive processes involved in CLI and the classification of CLI.
Ellis (2006a, 2006b) provides an insight into the aspects of the cognitive processes involved in CLI, arguing that linguistic cues are subject to selective attention based on salience to the learner; the less salient a cue is, the less likely it is to be focused upon (Ellis, 2006a). Linguistic differences between languages make things less salient and as such CLI is bound by the similarities and differences of the languages at play. This reflects “proactive interference” in which learning is inhibited by existing knowledge as a result of a kind of competition in the mind for attention (Ellis, 2006b). Of course, the influence can equally be positive, where similarities (such as cognates) occasion greater salience.
In addition to CLI being positive or negative, several other factors require consideration when classifying the types of CLI possible and the intricacies therein. Jarvis (2010) states that the evidence of CLI can come from four categories: “within” and “between” (intra and inter), languages and groups: intralingual (CLI from within the language, such as overgeneralization), interlingual (caused by similarities and differences between the languages), intragroup (speakers of X experience CLI when learning Y), and intergroup (comparing L2 performance in learners of different L1s). Jarvis believes that it is desirable to collect evidence from all four categories, but accepts that evidence can also come from past studies (Jarvis, 2010). Further to this, Jarvis and Pavlenko (2008) provide 10 dimensions which characterize CLI: area of language knowledge/use, directionality, cognitive level, type of knowledge, intentionality, mode, channel, form, manifestation, and outcome. These reflect the many combinations of types of CLI that intertwine to represent an intricately complex concept, making historical notions of “language transfer” appear rudimentary.
With the complexity of CLI in mind, it is advantageous to provide an operational definition which considers the various defining points and classifications discussed so far when applied to the context investigated here. First, as the learners here are university students, it can be safely stated that their L1 CALPs (Cummins, 1979) are developed. The languages (Turkish and English) cannot be said to be close, neither are they very distant, so the salience that is paramount to the processes of CLI (Ellis, 2006b) will vary accordingly from one item to another. The focus is on ungrammatical, written errors with items identified as being likely to be the cause of negative CLI, the interference to which Ellis (2006b) refers. In terms of the characterization of CLI according to Jarvis and Pavlenko (2008), the target items here are lexical, semantic, morphological, and syntactic, and the CLI is forward (L1 to L2), linguistic, explicit, unintentional, productive (written errors), visual, verbal, overt, and negative in nature. The forward and linguistic dimensions therefore entail interlingual evidence as opposed to intralingual (Jarvis, 2010). With these parameters in mind, the term used henceforth is interlingual interference, with the operational definition being instances in which errors occur in L2 as a result of inhibited processing of linguistic cues due to low salience caused by differences between L2 and L1.
Interlingual Interference and Turkish Learners of English
In recent years, there have been many studies related to CLI, although the literature has been dominated by English and European languages (Golden et al., 2017). This has led to a call for research into CLI with more diverse language combinations, such as the series of studies focusing on learner corpora compiled from the language of immigrants in Norway, presented by Golden et al. (2017). However, with the dominance of English as a global lingua franca (Jenkins, 2015), this article focuses (once again) on errors in English, but made by speakers of a non-European language, Turkish.
Considering the high level of interest in learning English which is evident in Turkey (Solak & Bayar, 2015), it is hardly surprising that there have been many studies which have focused on interlingual interference, with evidence supporting the dominance of interlingual as opposed to intralingual causes, that is, Turkish learners frequently make mistakes in English due to their reliance on Turkish language patterns, forms, and rules and the low salience caused by differences (Ellis, 2006a) between the two languages. The forward, negative CLI of morphological and syntactic aspects of language have been most often studied, with the majority of studies focusing on grammar rather than vocabulary or pronunciation.
Several recent studies have produced findings of interest in the field of Turkish-to-English interlingual interference. Denizer (2017) found that Turkish learners of English suffer from problems with determiners, tenses, and articles in particular, and in most aspects in general, as a result of L1 interference. Corroborating evidence comes from a study which reported that well more than half of mistakes in Turkish speakers’ English writing were found to be attributable to problems with verbs, nouns, and prepositions, and the cause of those mistakes were found to be mostly down to interlingual interference (Demirel, 2017). The main findings show that the first and second most common specific errors were the inclusion of unnecessary articles and missing articles where they are required, which accounted for 8.3% and 7.8% of all mistakes identified (Demirel, 2017). The fourth and fifth most common mistakes were noun/number disagreement (7.8%) and subject–verb agreement errors (7.1%). These four specific problems accounted for a combined total of 31.1% of all the errors categorized. A further finding was that the main cause of subject–verb agreement errors was failing to use the third person present simple form correctly (the third person “s”), which the author points out is an interlingual phenomenon (Demirel, 2017). Erarslan and Hol (2014) also identify the present simple as an area of difficulty affected by interlingual interference, although they found prepositions and vocabulary to be the main sources of errors (Erarslan & Hol, 2014), contrasting with the findings of Demirel, who found missing prepositions to account for only 3.9% of errors in total and preposition errors to account for 3% (Demirel, 2017). Mede et al. (2014), who investigated CLI issues with the acquisition of word order in terms of verb placement, found syntax to be a particular challenge. Agcam et al. (2015), focusing on the learning of syntactic movement, found that learners face more problems when noun clauses do not include auxiliary verbs, and also when the movement is in the subject position as opposed to the object position. As can be seen, there is a degree of variance in the results of these studies into Turkish-to-English challenges.
The differences in the findings of the above studies are likely in part due to research design types. The earliest of those studies featured translation tasks (Erarslan & Hol, 2014), the second utilized picture description and grammaticality judgment tasks (Mede et al., 2014), and the most recent study focused on essays of between 500 and 1,500 words (Demirel, 2017). This task type difference is important, as can be seen in the findings of Balabakgil et al. (2015), who tested 44 Turkish learners of English prior to and following a treatment period of explicit instruction on the use of possessives in English, a point of contrast between Turkish and English and therefore a potential interlingual interference issue. The participants were split into two groups and the experimental group received the explicit instruction. The results suggest that explicit instruction works to a significant degree when tested through translation tasks and multiple choice tasks. However, the study did not return a similar result in the productive task which involved describing a picture (Balabakgil et al., 2015). Agcam et al. (2015) also incorporated three task types into their study on the learning of syntactic movement by Turkish learners of English: a grammaticality judgment task, a scrambled sentence task, and an elicited imitation task. The results again suggested that task type variation affects findings significantly, with participants achieving higher accuracy rates in the grammaticality judgment test (Agcam et al., 2015).
Agcam et al. (2015) recommend the targeting of items for consciousness-raising activities to combat errors attributable to interlingual interference. This is congruent with Ellis (2006a), who recommends “techniques of attentional refocus and explicit learning” (p. 20). If one accepts that there are a great many instances of interlingual CLI between Turkish and English and that the subsequent mistakes of negative CLI not only occur across different task types but also well into strong proficiency levels of English, it seems that the suggestion of Agcam et al. with regard to targeting items has merit. The obvious question then becomes one of the manners in which such targeted learning is conducted. Although all manners of techniques exist within the atmosphere of informed eclecticism that has taken hold in the post-methods era of language teaching methodology, the persistent problem of interlingual interference suggests that the most effective strategy for dealing with these areas is as yet unclear. As Akbari (2008) suggests, in many cases the course book has become the method, with many course books being aimed at the international market to maximize sales potential. This leads to a lack of focus on interlingual interference in course books and ergo, in many classrooms due to the dominance of generic, international market course books from the top publishers. One solution may come from the growing area of corpus study for language development, commonly known as DDL.
DDL and Language Development
DDL, the term first coined by Johns (1991) for the study of corpora as a means for language learning, has risen in popularity in recent years with the advancement of software coinciding with fresh perspectives on language and language learning providing the backdrop to a growing body of evidence in favor of the benefits of DDL. Boulton and Cobb (2017) provide an insight into DDL studies in a recent meta-analysis featuring 64 experimental and quasi-experimental studies (following a rigorous selection procedure), highlighting the strong effect sizes of experimental and pre/posttest studies in favor of the efficacy of DDL (Boulton & Cobb, 2017).
In DDL, learners typically study concordances, often based on “Keyword in Context” (KWIC) searches, although many variations on the theme exist. The aim is to focus on language items in a style which can be considered “mass repetition” as described by Nation (1999), involving a greatly increased number of encounters of an item. The number of encounters needed to acquire a language item is disputed (Laufer, 2017) and varies according to factors such as item type; Webb et al. (2013) report that effective retention of collocations requires fifteen encounters. In terms of CLI, a high number of encounters are also desirable as this increases salience, which leads to a reduced risk of proactive interference (Ellis, 2006a).
Initially, KWIC concordances dominated DDL and were characterized by consisting of the target item in the center of each line, and the previous and following words up to a set limit, such as seven words either side. These parameters of earlier corpora allowed for criticism of their ability to provide context; “this is decontextualized language, which is why it is only partially real. If the language is to be realized as use, it has to be recontextualized” (Widdowson, 2000, p. 7). As more recent corpora have more commonly allowed full sentence concordancing (such as the British Academic Written English corpus), or, in the case of the TCSE, expanded segment concordancing, this recontextualization is now possible. With the proven potential of DDL and the contextualization issue answered, at least to some extent, it becomes necessary to consider the desirability factors of corpora for use in DDL.
Desirability Factors of Corpora for DDL
There are many variations on a theme in terms of DDL: in-class/autonomous, paper-based/on-screen, individual/interactive, teacher-guided/learner-guided, high proficiency/lower proficiency, and all the possible variations therein. Much of the early empirical research into DDL focused on higher proficiency, individual, on-screen (“hands-on”) learning (Boulton, 2007), although the research lines have opened up greatly in the past ten years following mounting evidence in favor of DDL as a form of language study. One of the factors that is prominent in the decisions made by DDL researchers is the nature of the selected corpus itself. Some corpora lend themselves better to in-class study than others (for example, some corpora could potentially contain text that is deemed unacceptable in a particular situation), whereas others are better suited to autonomous study than others (easier to use, free or low cost, etc.).
One of the first things many people are surprised or impressed by when encountering corpora for the first time is the sheer sizes that can be involved. Some of the most popular corpora run into the hundreds of millions of tokens; the Corpus of Contemporary American English (COCA) currently has 560 million words and the iWEB has 14 billion (https://www.english-corpora.org/corpora.asp; Davies, n.d.-(b), whereas other corpora may be small in size by “only” having a few million, such as the TCSE (https://yohasebe.com/tcse/; Hasebe, n.d.-a). “Does corpus size matter?” is the question posed and answered by Ebeling (2016), who found that in fact other variables, such as style, genre, and date of publication, seem to be of more importance. It is useful, therefore, to consider the various factors that would seem desirable for corpus selection in targeting the language transfer issues of Turkish learners of English for in-class, teacher-guided, interactive, hands-on DDL. Here, those factors are identified as cost, style, genre, and date of publication.
First, if one is to be realistic about the chances of DDL working its way into the mainstream of language teaching programs (perhaps as a once-a-week laboratory session), the cost must be considered. As learners need access to a computer each as well as a corpus, institutions may be averse to funding DDL (Gilquin & Granger, 2010). Corpora are expensive to host, and one of the main host centers for corpora, Benjamin Young University, follows various routes to secure funding, including licensing the use of the corpora they host on an individual basis or to academic institutions (https://www.english-corpora.org/; Davies, n.d.-a). Many other corpora are also limited or pay-to-use, which will of course negatively impact on learners’ willingness to autonomously choose to use corpora at home. However, the TCSE is free and unlimited, thanks to its design incorporating links to YouTube and TED (Technology, Entertainment, and Design), greatly reducing the hosting costs.
In terms of genre and style, the TCSE provides a very specific style of spoken English, the TED talk, within the genre of academic presentations. It could be argued, then, that a spoken corpus is not suitable for the targeting of language transfer issues in written production. However, it should be pointed out that TED talks are scripted to the point of perfection and thus represent a spoken account of a piece of writing. On the other hand, scripted or not, TED talks are of course governed by rules of oral production, and therefore the TCSE corpus is in the rather unique position of providing discourse that is useful as a resource for both spoken and written development, as well as listening and reading through watching and reading the transcripts. Indeed, one recent study successfully utilized TED talks for extensive listening development by asking learners to watch TED talks and write summaries (Takaesu, 2017), demonstrating their pedagogical potential in English teaching.
Finally, in terms of date of publication, a further factor identified by Ebeling (2016) as more important than size, the TCSE corpus again ticks all the boxes. Originally published in late 2014, the compiler of the TCSE has regularly updated and enlarged the corpus, as evidenced by the well-kept changelog (https://yohasebe.com/tcse/changelog; Hasebe, n.d.-b). The changelog gives specific details about additions, such as translated transcripts, software updates, and, most importantly here, more TED talks, allowing the TCSE to benefit from being up to date.
Place in the Literature
This study sets out to investigate the potential of targeting interlingual interference through DDL with a heavily contextualized corpus. Although past works in CLI have shown that young adults have already-developed L1 CALPs which can serve to scaffold L2 learning, distance between languages can cause lower salience (Cummins, 1979), which in turn leads to interference as multiple linguistic cues vie for attention (Ellis, 2006a). The CLI literature to date suffers from an overrepresentation of European languages (Golden et al., 2017), and as Turkish-speaking learners of English experience such interlingual interference they are focused upon here in the hope of adding to the rebalancing of the discourse. Recommendations of “consciousness-raising activities” (Agcam et al., 2015, p. 34) and “attentional refocus” (Ellis, 2006a, p. 20) to counter interlingual interference imply targeting problematic items to be logical, yet many past CLI studies of Turkish-speaking learners of English have instead focused on identifying or describing problems. Where targeting was tested, it was found to be successful when measured with a multiple choice task, but not so when measured in a productive task (Balabakgil et al., 2015). Therefore, this study attempts to find a strategy for targeting interlingual interference in the language production of Turkish-speaking learners of English.
Many studies have found DDL to be an effective language learning technique (Boulton & Cobb, 2017). DDL enables a large number of encounters, which, Laufer (2017) states, are necessary to aid retention, thus increasing salience in cues that may be suffering from interference from L1 (Ellis, 2006a). Here, these encounters are with a corpus that is heavily contextualized, suitable in terms of style and genre, and up to date in line with Ebeling’s (2016) suggested desirability factors of corpora. Further to this, the concordancer, the TCSE, benefits from being both free to use and seemingly user-friendly. It is hoped that this study will therefore fill a gap in targeting interlingual interference research in Turkish-speaking learners of English in terms of both DDL and targeting written errors, and in doing so contribute to the rebalancing of language types studied in CLI research.
The expectation is that targeted DDL with the TCSE will lead to a significant decrease in errors with items which are likely to have been caused by interlingual interference.
Method
Purpose of the Study
The purpose of the study is to investigate the effect of DDL with the TCSE on written errors caused by interlingual interference. Therefore, the null hypothesis is formed: There will be no significant decrease in error rates with items attributable to interlingual interference through targeted, contextualized DDL.
Participants
The participants were 30 Turkish-speaking learners of English in their first year of university study, including six Turkish learners of English as a third language. The second language of those trilingual learners was Arabic in three participants, Kurdish in two, and Russian in one. The ratio of female to male participants was 23:7 and the mean age was 19.74. All participants both verbally agreed to participate in the study (in class) and signed informed consent forms (on an individual basis).
The language level of the participants varied mostly within the domain of the B1 level. This is based on the following two criteria: all participants who had passed a general proficiency examination determining their English language level to be above A2, and the judgment of three long-experienced English as a foreign language (EFL) teachers who were at the time of the study teaching the class. As all the participants had come through the Turkish education system up to that point, the average length of learning English was between 7 and 8 years, although this should not be seen as a fair reflection of their English proficiency as there have been well-reported problems in EFL learning in Turkish schools (for a good overview, see Solak & Bayar, 2015). Those problems, which include teaching quality, extensive use of L1, and a lack of skills focus and practice, mean that there was a clear variance in skill areas in the participants; some were particularly weak in listening, others in speaking, many had very little experience of writing in English, others were more capable orally than when reading and writing, and so on. This also made it more difficult to judge with absolute certainty the precise proficiency level of each individual learner.
Item Selection
A two-stage process was implemented to identify and select items which are deemed likely to be caused by interlingual interference. First, journal articles, books, conference proceedings, and theses were analyzed to produce a list of all the grammar items reported to be problematic for Turkish learners of English due to interlingual interference. A list of the literature analyzed is presented in Supplemental Appendix 1. Repetitions and closely related items were combined, resulting in a total of 30 distinct items.
Next, a ranking task–type survey of the 30 items (Supplemental Appendix 2) was designed to aid the determination of the 10 most common problems. Each item was exemplified to further clarify the point in question. This survey was then answered by 10 EFL teachers with 4 to 15 years’ experience teaching Turkish learners. They were asked to choose the 10 most problematic items by ticking in the first column and then rank those items in the second column. They were also encouraged to add any extra thoughts and suggestions on the topic at the end of the task.
The results of the survey were then compiled by a reverse point system in which items ranked as first were given 10 points, second given nine points, and so on down to those items ranked 10th being given one point. This resulted in the 10 items receiving the most points being classified as the 10 most common issues caused by interlingual interference in Turkish learners of English, as shown in Table 1.
Interlingual Interference Error Item List.

Note. The items chosen for targeting are coded T1 to T5 as per the table and the nontarget items as NT1 to NT5.
Written Error Focus Rationale
Although an argument can be made in favor of a wide variety of task types to measure interlingual errors, a focus on written errors has some important advantages. First, from a research perspective, written errors are practical, measureable, and more comparable to other research. If one can invoke participants to produce samples of writing, there is less concern in terms of validity or reliability when compared with tasks such as grammaticality tasks (as used in Agcam et al., 2015; Mede et al., 2014). In terms of language production, picture description tasks (Balabakgil et al., Mede et al.) and speaking tests (Yildiz, 2016) were also rejected, with written data preferred for its lack of ambiguity; errors can be identified, categorized, and counted in a manner which produces effective data. Added to this, many past and current studies focus on written errors (such as Demirel, 2017), allowing for clearer, more salient comparisons. A second benefit of focusing on written errors is the expectation of accuracy that comes with written work. Interlingual errors in spoken discourse are more acceptable, as well as being less problematic, as often the interlocutor can signal their lack of comprehension.
Test Design
The pre/posttest design (Supplemental Appendix 3) was carried out following the item selection process so as to allow the design to be suitable for the measurement of the types of errors identified. Although other Turkish error-focused studies have utilized essays for data collection (Demirel, 2017; Kirmizi & Karci, 2017), it was felt that the conventions and writing style expectations of essay writing may adversely affect the performance of the participants. To this end, written tasks more in line with general English language learning tasks were deemed more appropriate. The prompts, written by the authors, were divided into four writing tasks: describing someone (third person), describing a family tree (third person), writing about daily routines (first person), and reflection on recent times (first person). The test design was then checked by three of the language teachers who had participated in the ranking task. Having reached agreement that the prompts were likely to produce the kind of written work that is deemed normal in style for language learners at the level of the participants and likely to provide sufficient opportunities for errors, the test design was accepted.
Corpus/Concordancer Selection
The choice of corpus and concordancer (the TCSE) was made according to several factors, namely, size, genre/style, appropriacy to the language learning context, user-friendliness, the degree to which it can be described as up to date, and cost, based on the ideas of Ebeling (2016) and the researchers’ experience. In terms of size, the TCSE is of a good size when one compares to other spoken corpora; at the time of the study, it consisted of 3,031 TED talks with a total number of 7,107,971. In terms of genre/style, TED talks, the result of a conference on TED, first held in 1984, then more successfully in 1990 and each year since, have become a phenomenon in their own right (see “History of TED,” n.d., https://www.ted.com/about/our-organization/history-of-ted). Today, the TED talks website boasts more than 3,200 talks (“TED Talks,” n.d., https://www.ted.com/talks) from a great many speakers. The use of TED talks has been the subject of much interest in language learning in recent years (see Chang & Huang, 2015; Elk, 2014; Nguyen & Boers, 2019; Takaesu, 2017) and as such the TCSE was deemed useful in terms of both genre/style and appropriacy to the language learning context. With free access and a simple and clearly explained interface, the factors of cost and user-friendliness were also satisfied. Finally, the TCSE is regularly updated through the addition of extra talks (among other improvements), all of which are detailed on a changelog (https://yohasebe.com/tcse/changelog; Hasebe, n.d.-b), and therefore it also seems satisfactory in terms of being up to date.
DDL Treatment
The course in which the study was conducted consisted of three hours a week focusing on improving learners’ awareness of specific language points in context. As the first week did not focus on DDL, the pretest was carried out in the second week, prior to the commencement of the treatment. Participants sat in test conditions and were only allowed to ask for clarification of task instructions during the 50-minute test session. Although participants were told that they could answer in any order, it was observed that most followed the task order as it was given, resulting in less data for the last question as participants generally spent a long time on the first three tasks. The posttest was carried out in identical conditions in the week following the final DDL session, meaning that the tests were 13 weeks apart, amounting to a three-month-long study.
A total of twenty 50-minute lessons in two lesson blocks involved hands-on interactive in-class DDL in a language laboratory over an 11-week treatment period. Each participant had their own computer and a set of headphones which they were encouraged to use to watch the videos to help them. This was done through verbal instructions (“Don’t forget, you can use your headphones to listen while you watch”) to encourage the learners to feel free to take charge of their learning. They were also encouraged to work in pairs or groups of three when analyzing (“If you work together you might see more than working on your own”). This was done so as to create an interactive experience more in keeping with productive language classrooms.
The sessions were organized in such a way as to first both train the learners in DDL in keeping with the induction-first approach recommended by Moon and Oh (2018) and familiarize them with the TCSE. The target items were sporadically included in among other items as shown in Table 2.
Timetable of Tests and Treatment.
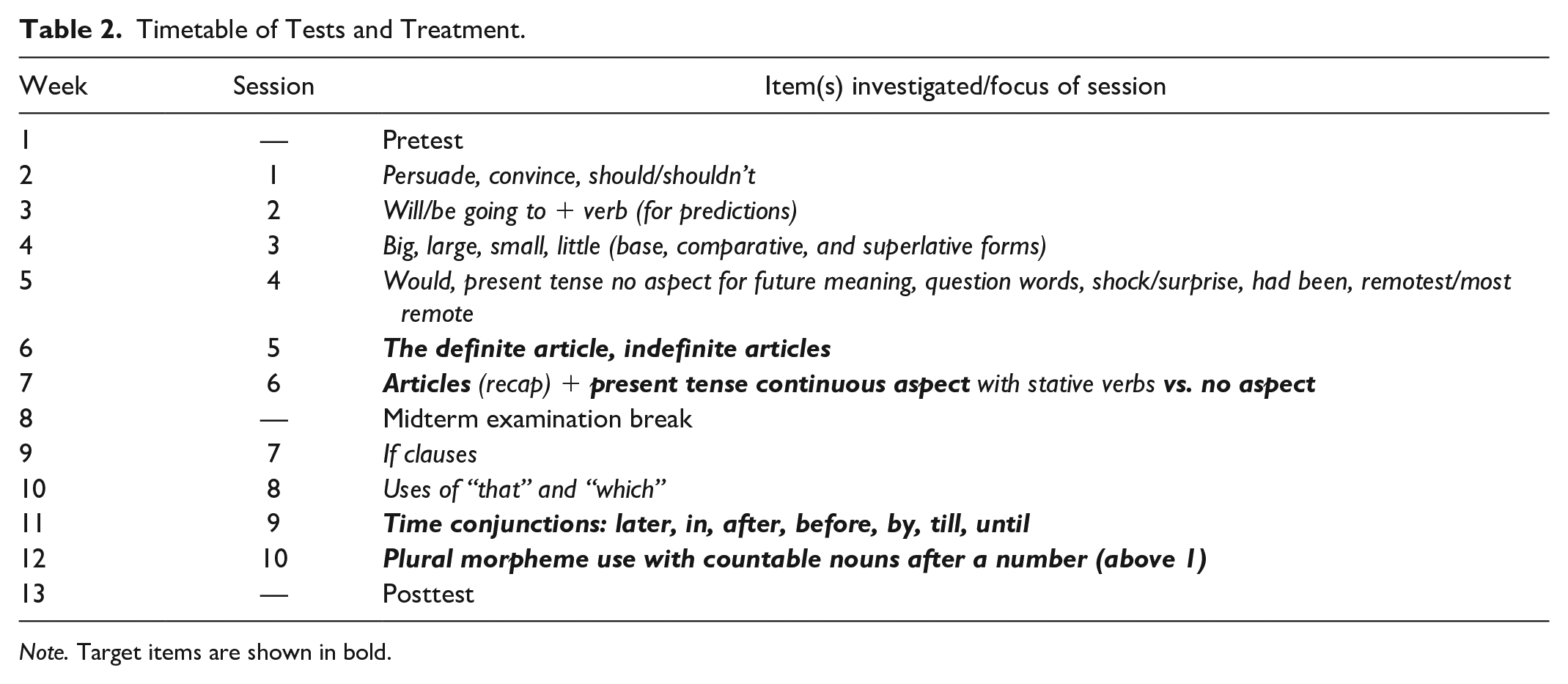
Note. Target items are shown in bold.
The first session (in Week 2) involved investigation of persuade and convince in the first lesson and uses of should/shouldn’t in the second as a nod to the early works of Johns (1991). As there was a large class screen at the front of the lab, initial tasks were set up through that screen and then learners were instructed to continue on their computers. For instance, persuade and convince were written up on the whiteboard in the first session and learners were asked “Without using a dictionary, who thinks they know one or both of these words?” with the expected outcome being that some knew neither, some knew one, and a few knew both. They were then shown how to generate results for those two items: Enter the word in the search bar, click on expanded segments, then click search. How many hits are there for persuade? How many hits are there for convince? Now I want you to become detectives. Try and prove to the class that these two words are the same or different. Find examples to prove your answer. Write the Talk ID down and the time of the example. Like this. You have twenty minutes.
And then the learners were shown (on the whiteboard) how to record such information as they studied. During these early sessions, the teacher then monitored and attended to troubleshooting as well as encouraging learners who were on task. The subsequent discussion was lively and enjoyable as the class debated the items and the evidence they had found for their similarities and differences.
The second and third sessions involved a lot of pair work followed by total class discussion to encourage unity in DDL skills development. The ratio of task length to class discussion was extended each session so that the learners had more DDL exposure, with tasks being around 30 to 40 minute in the third session. The items here included looking at predictions made using will or be going to + verb in Session 2 and investigating the similarities and differences between big, large, small, and little in their base forms and comparative and superlative forms in Session 3. The fourth session (Supplemental Appendix 4) gave learners a list of tasks which, in pairs and threes, they were encouraged to carry out in any order they wished (except for ignoring Task 1 which had been covered in Session 3). The researcher then monitored progress (here the full 50-minute sessions were now assigned to DDL) and helped ensure that all the participants were ready to conduct effective DDL.
With DDL induction suitably complete, Session 5 was the first to involve target items by incorporating an exploration of the in Lesson 1 and a/an in Lesson 2. These tasks were 40 minute long with a class discussion in the last 10 minute of each class. These items were revisited in Session 6 for the purpose of reinforcing the expectations of the session before focusing on the use of the present continuous in contrast to the present simple (Supplemental Appendix 5), a further target item.
Sessions 7 and 8 did not include target items, instead exploring if clauses (Session7) and comparisons between that and which (Session 8). Session 9 focused on the following time conjunctions: later, in, after, before, by, till, and until, amounting to a further target item. The final target item was covered in Session 10, highlighting the use of the plural with countable nouns following a number (above one).
Error Analysis
Data collection saw a total of 10,340 words in the pretest and 8,988 words in the posttest, a mean word count of 345 per participant in the pretest and 300 words per participant in the posttest. Each test was first photocopied and then every error was identified. A second reading then involved the categorization of errors; the top 10 interlingual interference items were individually categorized by item and the remaining errors were classed as “other.” The analysis was conducted by a native speaker of English with several years’ experience teaching EFL. This analysis was then blind-checked by a second native speaker EFL teacher by the analysis of five randomly selected tests from the pretest and five randomly selected tests from the posttest. There was an above 95% agreement rate and as such the initial analysis was accepted. Table 3 shows the raw data categorization totals.
Percentage of Total Errors.

The data consist of 1,175 errors in the pretest writing and 1,001 in the posttest. As a percentage of the respective test word count, this represents an error ratio of 11.36% and 11.14%, indicating only a slight improvement in the written accuracy of participants.
The items classified here as being the most common interlingual errors account for 46.64% (pretest) and 38.36% (posttest) of the total errors of the respective test. However, the decrease in error ratio in those items is only as a result of the reduction in errors in the target items, which is from 19.91% to 10.89%. The nontarget items show a small increase in error ratio from 26.72% to 27.47%.
To both provide data for comparison with past studies and better understand these two categories, the item-by-item raw data are presented in Table 4.
Item-by-Item Data.
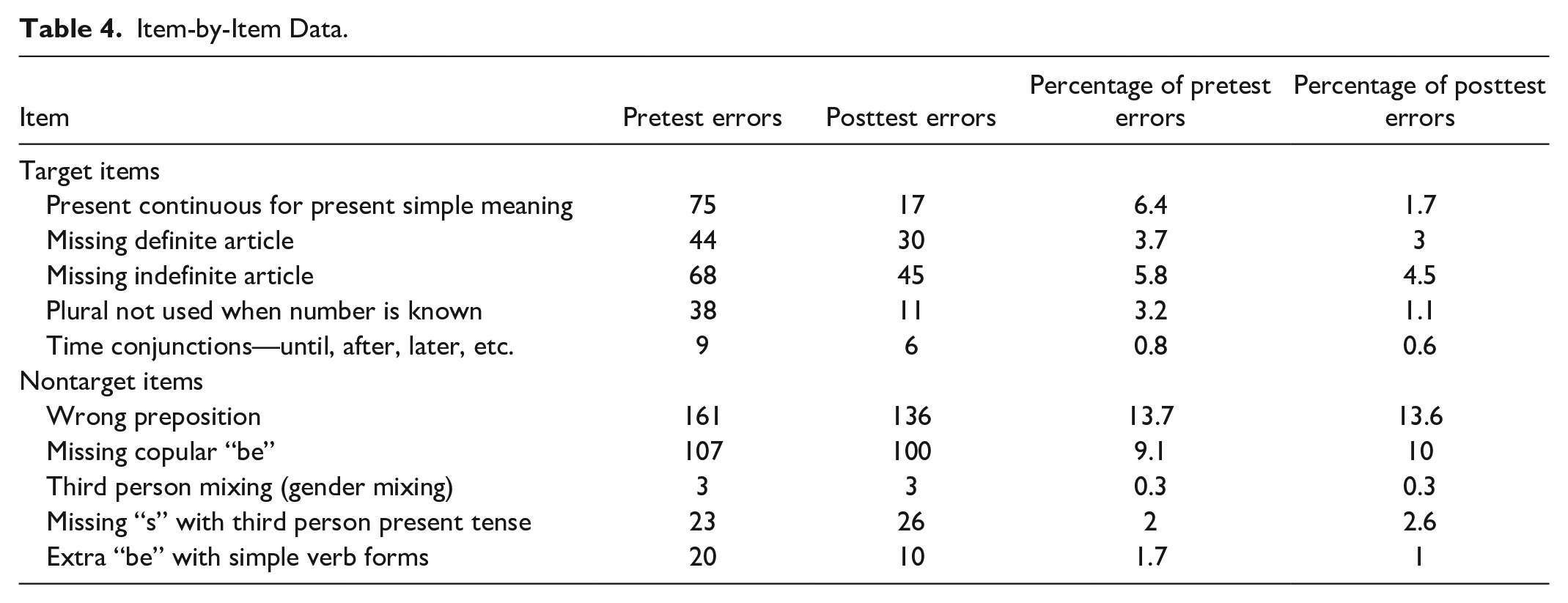
As a percentage of errors, all the target items show a decrease between the pretest and the posttest. This is only true of two nontarget items (NT1 and NT5). The sharpest decreases in target item errors are with T1, present continuous for present simple meaning, and T4, plural not used when number is known.
In the pretest, the two most common errors are with prepositions, NT1 (13.7%), and with missing the copula be, NT2 (9.1%), both nontarget items of this study. The next four most common errors are target items: T1, present continuous for present simple meaning (6.4%); T3, missing indefinite article (5.8%); T2, missing definite article (3.7%); and T4, plural not used when number is known (3.2%).
Some items did not produce many errors. NT5, the use of an extra “be” with simple verb forms (the top-ranked item in the classification process), produces 20 errors in the pretest and 10 errors in the posttest, representing just 1.7% and 1% of the total errors in the respective tests. Also worthy of note here is that time conjunctions (T5) and mixing third person genders (NT3) are much less problematic areas than others, accounting for only 0.8% and 0.3% of the total errors in the pretest, respectively.
Scale
As the number of words written between the two tests is different, scale is needed to make comparisons. To achieve this in a simple manner, the pretest error data are left intact and the posttest data are scaled by dividing by the total word count of the pretest (8,988) and multiplying by the total word count of the pretest (10,340), equivalent to a multiplication of 1.15 when rounded to two decimal places (rounding was not done in the calculations).
Analysis of Target Items
Analysis of the target items was conducted using SPSS 20. The results of the Kolmogorov–Smirnov test and the Shapiro–Wilk test confirm that the data are not fairly normally distributed. Based on these findings, a nonparametric paired-sample test, the Wilcoxon signed-rank test, was selected, the calculations of which are given in Table 5.
Wilcoxon Signed-Rank Test.

Note. X1 = Mean of the pretest data; X2 = Mean of the posttest data; r = effect size.
The result confirms that there is a significant difference (decrease) between the means of the pretest (7.56) and posttest (3.59) with the targeted items. This difference has an asymptotic significance of .005 and is therefore accepted with an alpha of .01. As a result, the null hypothesis is rejected with confidence. The effect size calculation is .36, with Cohen’s (1992) assessment of r effect sizes being a medium effect at .30 and a large effect at .50. There are 20 negative results, nine positive results, and one tie in the posttest of the target items.
Discussion and Conclusion
This study set out to investigate the effect of targeting items deemed likely to cause errors due to interlingual interference in Turkish-speaking learners of English through contextualized DDL. Although successful, the effect size here is lower than might be expected in the field. Plonsky and Oswald (2014) recommend interpretation of r effect sizes in L2 research as follows: .25 as small, .40 as medium, and .60 as large (above the initial suggestions of Cohen, 1992). DDL studies report strong and very strong effect sizes as revealed in a recent meta-analysis by Boulton and Cobb (2017). As such, it is necessary to consider the reasons for the effect being limited to a medium strength.
When one attempts to unravel the possible causes of the underwhelming effect size, the obvious answer is to revisit the nature of interlingual interference. The high number of encounters involved in the DDL that took place was predicted to increase item salience, aiding retention (Laufer, 2017) and countering interference (Ellis, 2006a). Perhaps then, the corpus did not provide encounters that were rich enough to adequately increase item salience, although this seems unlikely given that the quality of content, TED talks, is fairly consistent. Would a requirement for immediate productive output with the targeted items following each session have led to greater salience? Was the effect of the DDL on salience short-lived due to a lack of spaced repetition? Was the DDL simply not memorable enough to facilitate retention? Perhaps, all of these factors accumulated to restrict the effect of the DDL.
In terms of past studies identifying interlingual interference in Turkish-speaking learners of English, both supporting and contradictory evidence is produced here. The pretest data can be compared to the findings of Demirel (2017), who reports on written errors attributed to interlingual interference in essays. Demirel reports missing articles as accounting for 7.8% of all errors. Here, the percentage of errors in the pretest categorized as missing articles is 9.5%. However, this falls far short of the most problematic item in this study, wrong preposition (13.7%). This is more in line with Erarslan and Hol (2014), who found prepositions to be particularly problematic among grammar items. Demirel, on the other hand, reports only 3% of errors as wrong preposition and a further 3.9% as missing prepositions. Further incongruence between this study and that of Demirel comes with noun/number disagreement, that is, 7.8% in Demirel’s study and only 3.2% here. However, a caveat must be that the style of written work was not similar and the context was different so comparisons must be viewed within those confines. One area that this study and those of Demirel and Erarslan and Hol (as well as Denizer, 2017) agree on is the challenge Turkish-speaking learners face with the present simple. For example here, not marking the third person singular inflection and selecting the continuous aspect when no aspect (simple) should be used accounted for 8.4% of the total errors in the pretest.
It is also useful to compare the error data of the pretest with the ranking task results of the selection process. The highest ranked item, chosen by nine of the ten teachers, was including an extra “be” with simple verb forms, yet this only caused 1.7% of the pretest errors. Two other items also caused only very low numbers of errors: time conjunctions (0.8%) and mixing the gender in the third person (0.3%), although these two items ranked much lower at ninth and tenth being only chosen by four and three teachers, respectively. Conversely, the “wrong preposition” category only ranked seventh, yet was a clear first in error rate (13.7% of all pretest errors). These observations suggest that the teachers may not have been as aware of learner error types as might be expected given their long experience in the context. One possible reason for these differences could be that teachers, perhaps subconsciously, ranked items not only on their perception of commonality but on some other criteria, such as their own previous learning experiences or on their view of the seriousness of certain errors, perhaps their likelihood to cause communication breakdown or perhaps errors that teachers can find frustrating.
Some limitations of this study require consideration. First, there was no control group, either learning in a traditional manner or learning other items. This decision was based on the balance of justification (in terms of participants’ time and efforts) as effect size is commonly used for comparisons in DDL research (see Boulton & Cobb, 2017). However, a control group would have provided context-specific comparison opportunities and as such would have been beneficial. Second, the use of past studies to produce a list of items and the use of teachers to rank the list both produce opportunities for flawed item selection and classification of CLI to the items. Although Jarvis (2010) accepts past studies as a valid source of evidence of CLI, a larger scale study could seek evidence from all areas suggested by Jarvis. Third, the pre/posttest involved answering the same four questions, which may have affected the performance of the participants the second time around. This was deemed preferable to the problem of comparing different pieces of writing (as the cross-item comparison was the key focus), and, with a three-month gap and no prior knowledge of the repetitive nature of the test, it was hoped that the influence of any practice effect would be kept minimal. However, this could also be why the word count was less in the posttest, and participants may have felt less motivated by doing the task again. A further limitation comes from encouraging the participants to write quickly and expecting them to do four different tasks of product writing in 50 minute, which, while being successful in the aim of producing error-heavy data, means that the data cannot be said to represent the natural writing of participants under normal conditions. Finally, the number of target items tested was relatively low given the period of treatment, due to the status of those items being only part of a larger course of study. With these limitations in mind, further research could involve a control group, on a larger scale, varied test type, and a focus on more items.
Limitations notwithstanding, the positive results of the study lead to some more interesting implications for further research. First, the generalizability of this study seems to be logical; there appears to be no reason to doubt that interlingual errors of other first language learners of English would also be targetable through this style of contextualized DDL. However, this assumption needs to be tested and as such replication studies with other first languages would be a welcome addition. Furthermore, should equally useful corpora (in terms of contextualization and user-friendliness) be available in other languages, studies into further language combinations would help add to the understanding of the potential of corpora for interlingual interference work. A study that evaluates teachers’ awareness of interlingual interference items in Turkish-speaking learners of English on a large scale (within that context) may serve to benefit Turkish EFL. Finally, as this study focused on written errors, further research could explore the efficacy of contextualized DDL on targeting spoken errors caused by interlingual interference.
Finally, there are some immediate practical implications that may be drawn from this study, relevant to the Turkish learner of English context and to the wider field of interlingual interference issues in general. As many Turkish universities provide foundation or preparatory English education prior to faculty entry, often a 1-year period of study, and/or English for Academic Purposes (EAP) courses through modern language departments, there is a clear opportunity to allocate time to contextualized DDL to target interlingual interference–based written errors. In addition, in instances in which foundation or EAP courses for nonnative speaker university-level learners are provided (most countries with English medium instruction education), there is the potential to identify interlingual errors in individual learners, be it in multilinguistic or monolinguistic settings, train learners in the use of the TCSE or a similar corpus, and set development as autonomous project- or portfolio-styled work.
Supplemental Material
SO-19-0705_Appendix – Supplemental material for Targeting Turkish-to-English Interlingual Interference Through Context-Heavy Data-Driven Learning
Supplemental material, SO-19-0705_Appendix for Targeting Turkish-to-English Interlingual Interference Through Context-Heavy Data-Driven Learning by Keith John Lay and Mehmet Ali Yavuz in SAGE Open
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.