
Abstract
This study explores the similarities and differences in reading strategies applied by students to Chinese versus English reading. 842 students responded to a reading strategy inventory in terms of their habits when reading in Chinese versus in English. The result validates the general structure of a reading strategy inventory originally designed for English. The general scale seemed reasonable for Chinese reading as well as English reading. However, gender differences were found on some items. In addition, there was no statistically significant correlation between strategy use and test scores, which is inconsistent with previous research. Besides, we found a strong correlation between English and classical Chinese reading scores, but not between English and modern Chinese reading. Language as L1 or L2, curriculum and restricted test formats may partly explain the low correlations while social and educational environment can contribute to the high correlation observed. This study also serves as a rare example of a complete cycle of invariance test for ordinal data with a repeated design in Mplus. Implications for research and pedagogy were discussed.
Plain language summary
Although there are common underlying structures that can explain reading behavior, practice in context can vary. It is necessary to consider the local milieu and gender differences to better serve students for foreign language education. This study explores the similarities and differences in strategies by students when reading in English as a foreign language versus in Chinese as a native language. We evaluated an established strategy scale in context, validated the scale structure, and then explored the language and gender factors. Results supported the general structure of the scale but also revealed gender differences on some items. No significant correlation was found between strategy use and test scores, which is inconsistent with previous research. The correlation between English reading scores and two types of Chinese reading scores is different. There is no significant relationship between English and modern Chinese reading, but a significant one between English and classical Chinese reading. Cultural and pedagogical traditions may be part of the reason, and attention to individual differences is suggested. This study uses a convenient sample, which limits the generalizability of specific results. However, it provides a rare example with a complete cycle of scale validation procedures for ordinal data based on an up-to-date procedure in Mplus. Example syntax is provided.
Introduction
Reading comprehension requires an array of processes where large amounts of information must be processed at both the word and text level (Stanovich, 1982a, 1982b). When readers’ knowledge is limited, text material is too difficult, or a reading task is complex, readers will have to use strategies to aid comprehension. This is widely acknowledged and true even for experienced readers (Graesser, 2007).
Due to its importance in rescuing non-native reading, strategy use has attracted much attention in foreign/second language teaching and research. Evidence generally supports a strong relationship between strategy use and reading comprehension (Brevik, 2017; Grabe, 2009; Muijselaar et al., 2017). Moderating factors such as gender and language proficiency have also been explored (Denton et al., 2015; Maghsoudi, 2022; Oxford, 1990). However, a consensus is not reached (e.g., Arabmofrad et al., 2021; Habók et al., 2019). There is an implication that not all strategies work equally well for all learners (e.g., Sun et al., 2021).
Learners’ first language and gender have been found to be partly responsible for these discrepancies (Cantrell & Carter, 2009). As Hofer and Sinatra (2010) have put it that theory in one culture may not be “productive” in another. Since concepts of major and influential reading strategies trace back to native English researchers, their applicability and validity in different contexts require more research. In this study, we focus on two factors, language (English as a foreign language vs. Chinese as the native language) and the gender of learners to explore the reading strategy construct.
Literature Review
Language Impact on Reading Strategy Use
There is rich evidence that first language (L1) influences reading in second language (L2). Research shows that experiences and habits in L1 play an important role (Sun et al., 2021; van Gelderen et al., 2004). Not only does proficiency and literacy in L1 matter, so do the reading strategies acquired (Bernhardt, 2011; Koda, 1993; Maghsoudi, 2022). Reading strategies can transfer between languages even when the linguistic distance is great, such as from Arabic, Japanese, or Chinese to the English language (Chiswick & Miller, 2005; Chuang et al., 2012; Nakada et al., 2001).
However, research dispels the unidirectional impact of L1 (Davis & Bistodeau, 1993). Clarke (1979) proposed a “short-circuit” effect to explain that a ceiling in L2 competence can prevent the complete transfer of skills from L1. When challenged with difficult tasks in L2, good L1 readers may revert to similar strategies as poor L1 readers. A recent study again consolidated this proposal between L1 and L2 English speakers (Feller et al., 2020). More interestingly, one study on “outlier” students implies that L1 impact may be less important to L2 reading compared to other factors such as interests and motivation. Thus, a person can be good in L2 reading because of motivation even though they are poor in L1 reading (Brevik & Hellekjær, 2018).
Strategy use across languages is also heterogeneous. For example, Lin and Yu (2015) found that participants used more diverse strategies for English reading than for Chinese reading. Researchers believe that the linguistic features of L1 and the learning experience of individuals can affect L2 strategic decisions (A. D. Cohen, 2011; Grabe, 1991; Sun et al., 2021). So do other factors, such as culturally determined literacy practice through schooling (Davis & Bistodeau, 1993; Taki, 2016). For example, Lau and Chen (2013) found that instruction had different effects on self-regulated learning for students depending on whether they were in Hong Kong versus Beijing.
In sum, reading strategies can vary due to linguistic or cultural features in L1 and L2 languages. When exploring strategy use, local context needs to be taken into consideration.
Gender Impact on Reading Strategy Use
While language reflects a cultural difference more broadly, gender exerts an influence at the individual level. Gender difference in reading strategy has been reported for both L1 and L2 learners, where results tend to support female dominance over males (Cantrell & Carter, 2009; Denton et al., 2015). Females are found to have more knowledge of reading strategies and they also use them more frequently (Bećirović et al., 2018; O’Reilly & McNamara, 2007). This is also true for online reading, contrary to the assumed disadvantage for girls (Cooper, 2006; J. Wu, 2014).
Despite these general patterns in findings, there is also evidence for the opposite. For example, Phakiti (2003) found that boys reported more metacognitive reading strategies than girls, and Tsai (2009) found that boys applied more control and procedural reading strategies than girls when reading online. Divergent results on gender were partly attributed to reading mode (Tsai, 2009) or proficiency (Poole, 2005, 2009). For example, Poole (2005) found no gender difference on reading strategy for advanced learners in the U.S. but a significant difference for low to intermediate learners in Bogotá (Poole, 2009).
Besides quantity difference, there also seems to be a qualitative difference in strategy use. For example, both Martinez (2008) and Bećirović et al. (2018) found that female students differed from male students on supporting strategies when reading, but they did not differ on global strategies. Roy and Chi (2003) found that girls preferred reading in a linear sequence while boys preferred scanning information in a horizontal way. Neuroscience provides evidence that boys prefer a rule-governed approach to reading (Baron-Cohen, 2002) and that the synthetic phonics method at the word level favored boys more than girls (Logan & Johnston, 2010).
In sum, strategy use differs between genders in addition to the languages involved. Understanding of this can contribute to theory building as well as to benefit classroom teaching. However, for both purposes, being able to measure the strategy is a must.
Measuring Reading Strategies
Reading strategies have been measured with different tools, such as self-reporting questionnaires (Feller et al., 2020; Schmitt, 1990), interviews (Craig & Yore, 1995; Maghsoudi, 2022), verbal protocols (Magliano et al., 2019; Smith et al., 2020), observation (McHardy et al., 2021), computer-based log tracking (Umarji et al., 2021), and eye movement (Jian et al., 2019). Every approach has its strengths and weaknesses (Desoete, 2008; Gascoine et al., 2017). A questionnaire is easy to conduct, but may reflect the quantity rather than the quality of strategic behavior; concurrent verbal protocols provide measures of online strategy use, but it is intrusive and may change the reading process; tracing and eye-tracking allow for direct observation of information processing and strategy application, but it is not feasible for daily use by classroom teachers.
Afflerbach et al. (2008) proposed that strategies are compensatory tools and should be taught and monitored regularly so that they can transform into automatic skills in the end. This formative feature speaks to the strength of the questionnaire as a friendly tool for classroom studies, which matches the context of this study.
A quick survey of the literature reveals several popular questionnaires, one of which is the Metacognitive Awareness of Reading Strategies Inventory (MARSI, Mokhtari & Reichard, 2002). It was developed for Grades 6 to 12 and has been revised, updated, and applied actively to various groups including English language learners (ELLs) (Mokhtari et al., 2018; Mokhtari & Sheorey, 2002). Grade six is the beginning age group for strategy competency requirements by China’s Standards of English Language Ability (CSE) (National Education Examinations Authority (NEEA), 2018), which starts from Level 2 (around Grade 6). Thus, MARSI offers a good starting point for measuring reading strategies for this study.
The scale development process of MARSI implies that it aims for general reading strategies and can apply to various populations or learning environments (Mokhtari & Reichard, 2002). The original inventory was field-tested with 825 students between Grades 6 and 12 from 10 different school districts and five different states in the US. Three factors were revealed, including global reading strategies (GLOB), supporting strategies (SUPP), and problem-solving strategies (PROBS). The scale structure was confirmed with a similar, but new sample of students.
However, though the total sample size is big for scale development, individual group size is small. For example, there are only 31 students representing Grade 6. Despite this, Cronbach’s alpha, a reliability statistic, is impressively high between .86 and .93 across grades. In 2002, Mokhtari and Sheorey modified it into the Survey of Reading (SOR) for ELLs, based on 302 university students in the Midwest US. In 2018, MARSI was revised again and was reduced to 15 items (Mokhtari et al., 2018). The reduced MARSI was validated with students between Grade 6 to first-year community college students.
Mokhtari and his colleagues suggested using SOR for students with low English proficiency and either SOR or MARSI for students with advanced proficiency (Mokhtari et al., 2018; Mokhtari & Sheorey, 2002). However, they also cautioned against limitations in its application in consistency with research that has confirmed or challenged this scale with other populations or languages (Alvarado et al., 2011; Guan et al., 2011).
Rationale for the Current Research
Theoretical understanding has to be supported by empirical data before it can help guide practice. Reading strategies are important for English learning in China. However, there is no locally developed theory or strategy scale that meet our expectation. Replication studies are essential for behavioral and psychological science to advance theory (e.g., Koul et al., 2018; Zwaan et al., 2017). Cross-validation of an existing popular tool with different samples and methodology improvements are two pivotal approaches for this purpose.
As explained above, the individual group size that validated the original MARSI tool was not big, thus validating the tool serves not only to test the generalizability of this operationalized theory of reading strategy but also guarantees quality data to explore differences between L1 and L2 reading and the gender differences as reviewed.
However, we have not found an example with a multi-factor model that involves all relevant statistical challenges brought by Likert-type ordinal data, a repeated measurement design, and correlated error residuals together that have to be addressed in our study (to be described under the methodology section). We located a set of up-to-date statistical procedures proposed by H. Wu and Estabrook (2016) and Svetina and her colleagues (Svetina et al., 2020) that are appropriate for these features. Our research, however, may be a rare concrete example available in the literature based on the procedures they recommended.
Although there are studies comparing strategy use in L1 versus L2, many are based on different groups of students rather than the same students to see how the same participants apply the strategies in different contexts (Feller et al., 2020). Repeated measures have stronger statistical power and such research design can better detect the strategy transfer or non-transfer from L1 to L2.
Grade 10 is of primary research interest to us because this age group is in the optimal center range for strategy instruction (Alexander et al., 1989). Their English proficiency is at a medium level where strategy can have a strong effect on reading (Maghsoudi, 2022). In addition, they have learned English as a foreign language long enough to employ various reading strategies but are not so proficient that differences in metacognitive strategic awareness may be “washed out” (Mokhtari & Reichard, 2004). In other words, they can still identify the strategies that they intentionally employ and researchers can detect them.
To control for extraneous confounding issues, we decided to use a homogeneous group with similar L1 and L2 language proficiency and schooling background, we only studied the paper and pencil reading mode and we applied observational study rather than experimental research design. The benefit of these restrictions, however, is that they enable direct comparison of reading strategies between L1 and L2 reading and enrich the validation studies on a critical developmental group that deserves more attention (Alexander et al., 1989).
Research Question
There are three research questions:
How well does MARSI measure the reading strategies of a group of typical high school English learners in China?
Are metacognitive reading strategies the same or different between L1 (Chinese) reading and L2 (English) reading?
Are there gender differences?
Method
Instrument
To avoid the influence of academic English vocabulary that may go beyond students’ language proficiency, the original MARSI (Mokhtari & Reichard, 2002) was translated into Chinese. Some terms were also simplified for easy understanding. The first Chinese draft has been field-tested with a seventh-grade girl in a less-developed area in China and a sixth-grade boy in an advanced city in China. The former received language education in a traditional way and with limited educational resources while the latter had been exposed to rich academic terminologies and complex teacher languages. Interviews were conducted separately to explore how accurately they could understand the translated inventory items. Then the wording in Chinese was modified and refined. Since the whole research is framed as exploring the habits while reading, we clarify the meaning of the Chinese word “ ” as “will” rather than “can” (this Chinese word can mean both will as a habit and can as the ability to do something). All these are done to ensure that participants with varying language proficiency can respond to the items with correct and consistent understanding as intended.
” as “will” rather than “can” (this Chinese word can mean both will as a habit and can as the ability to do something). All these are done to ensure that participants with varying language proficiency can respond to the items with correct and consistent understanding as intended.
Participants and Procedures
All Grade 10 students (aged 15–16) in a high school in Southeast China were invited to participate in the study. This is a convenient sample. There were 20 classes with around 1,000 registered students. Most of these students were top graduates from different middle schools in the city and were highly motivated for further academic pursuits. Digital devices, such as cell phones, were not allowed on campus and there was a strict and tight schedule for students to follow. Students had heavy homework after school and teachers rushed between duties and tasks. This school environment ensured good student habits in completing any task they decided to participate but restricted other possible explorations such as additional time for interviews. This is a limitation in this study. Since digital devices were forbidden for students, all questionnaires were handed out as hardcopies and data were manually checked and typed into a data file.
Ten English classroom teachers handed out the questionnaire to the students and collected them the next day. Students were informed of the purpose of the study and were told that the results would not affect their grades in any way. Participation was voluntary. Responses were anonymous except for two classes (see explanations below).
There was one coordinator on-site in the school who managed the logistics. Responses were mailed back to the first author, and eight graduate and undergraduate assistants worked in pairs to enter the data. Suspicious and missing data were marked and the researchers double-checked problematic responses with the corresponding assistants and the on-site teacher.
To balance objectivity and follow-up exploration, we collected four sets of English reading scores from regular quizzes for two classes (n = 106) and four sets of Chinese reading scores from one of them (n = 46). Except for these two classes who provided names so that we can check for response validity and establish a link between questionnaire responses and reading performance, the only demographic data required of all participants is gender.
Nine hundred forty-nine students in total responded to both the English and Chinese reading strategy questionnaires. There is missing data, but the highest missing rate for individual items is just 0.8%. No apparent missing pattern is detected; thus the data is regarded as missing completely at random (MCAR) (Allison, 2003). For a clear presentation of findings and model comparisons, we used all complete cases (N = 842) for scale validation and invariance tests between languages. Due to missing data on gender and some quiz scores, invariance tests between genders and correlational analyses both involve different sample sizes.
Software
We used SPSS 25 and Mplus 8.4 for all analyses, including exploring and validating the scale structure, testing measurement invariance, comparing between languages and genders, and checking the relationship between strategy use and reading scores.
Analyses and Results
Descriptive Statistics
Overall, students who were required to write down their names reported similar strategy use as their anonymous peers (Figure 1). Out of the original 60 items for two languages, only eight show differences with statistical significance, out of which only two reached the level of moderate effect size (>0.3; J. Cohen, 1988). The pattern is also consistent across classes (Appendix 1). In brief, anonymity does not seem to distort reporting behavior very much and the data of all classes reflect the participants’ stable perception in general.

Strategy Use by Item between Anonymous Classes and Non-Anonymous Classes.
Scale Structure
Since response data is ordinal, a robust estimation method, the weighted least square parameter estimates with standard errors and mean and variance adjusted (WLSMV) was used. Model fit was evaluated based on overall fit indices including root mean squared error of approximation (RMSEA), comparative fit index (CFI), Tucker-Lewis index (TLI) and standardized root mean square residual (SRMR). Item-level indices such as modification index (MI) and expected parameter change (EPC) were also examined.
Table 1 summarizes the confirmatory model results on English reading strategies.
Fit Indices for Confirmatory Factor Analysis (CFA) on MARSI and MARSI-R for English Reading.

Note. N = 842. All single model χ2 statistics are significant at p < .001, thus omitted from the table. Adequate fit criterion: RMSEA ≤ 0.08, CFI ≥ 0.90, TLI ≥ 0.90, SRMR ≤ 0.06. Good fit criterion: RMSEA ≤ 0.06, CFI ≥ 0.95, TLI ≥ 0.95, SRMR ≤ 0.05.
Model 1 replicates the original MARSI structure with all 30 items. All indices, including RMSEA (>0.08), SRMR (>0.06), CFI (<0.90) and TLI (<0.90) indicate poor fit (Browne & Cudeck, 1993).
Model 2 is based on 15 MARSI-R items, SRMR (<0.05) indicates a good fit, RMSEA (<0.08) indicates an adequate fit but neither CFI (<0.90) nor TLI (<0.90) is adequate.
Model 3 collapses the two lowest response categories and reduces the 5-point scale to a 4-point scale as Mokhtari et al. (2018) did. With this change, all general fit statistics are now adequate, but only SRMR (<0.05) indicates a good fit. In addition, there are many cross-loading items with high (>10) MI values (11 in Model 2 and 9 in Model 3). This is an important issue that has guided the revision of MARSI by Mokhtari et al. (2018) and needs to be solved before measurement invariance can be explored in this study.
In summary, our data do not support the original MARSI or the MARSI-R strongly. Considering that all five categories are actually present in the responses and that collapsing categories may cause criticism in data validity (Rutkowski et al., 2019), we decided to maintain the 5-point Likert scale and explore the best local model for English reading strategies.
All of the 30 strategies in the original MARSI seem reasonable in theory and they all have standardized loadings higher than 0.3 in preliminary analyses. We decided to maintain the general structure and removed cross-loading items with high MIs following common exploratory confirmatory factor analysis (ECFA) procedures (Brown, 2015; MacCallum et al., 1992). Half of the data (n = 421) was used for model-building and the other half (n = 421) for cross-validation. Our best model happened to settle with the same number of items as MARSI-R although specific entries are different (Mokhtari et al., 2018). Model fit is even better when residuals of two items are allowed to covary. Table 2 reports the key modeling results for English reading strategies.
Fit Indices for Exploratory Confirmatory Factor Analysis (ECFA) for English Reading Strategies.
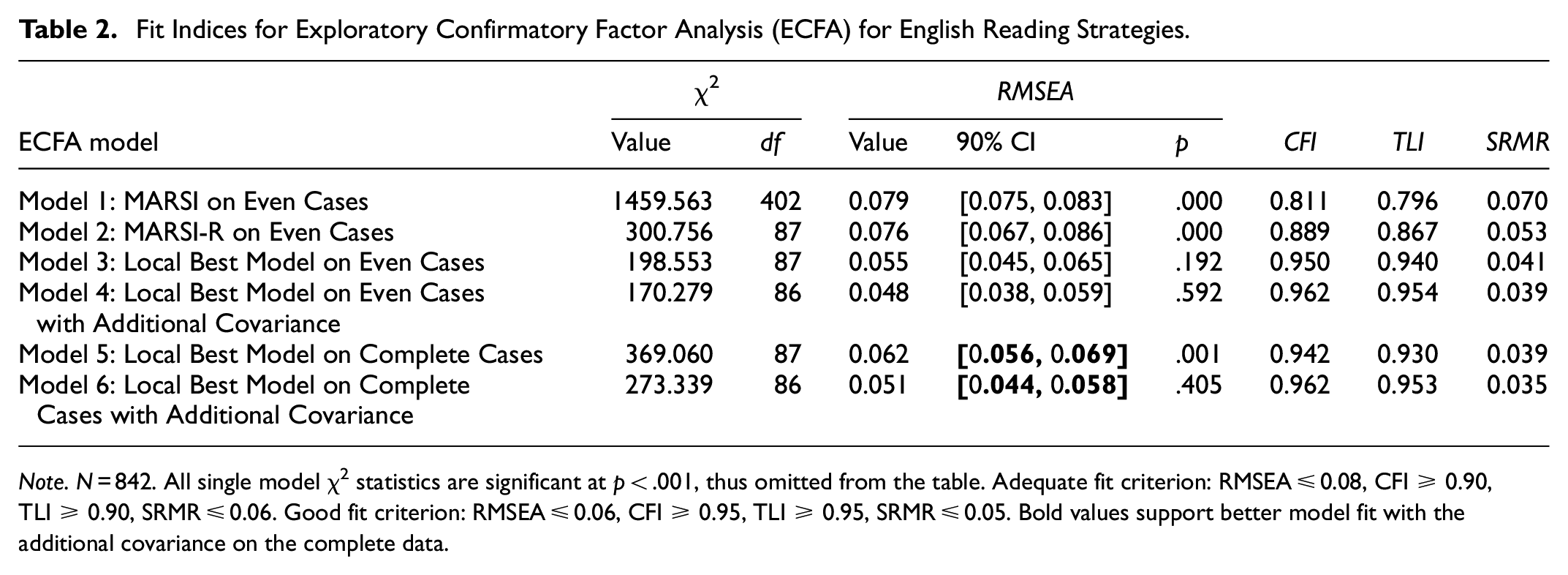
Note. N = 842. All single model χ2 statistics are significant at p < .001, thus omitted from the table. Adequate fit criterion: RMSEA ≤ 0.08, CFI ≥ 0.90, TLI ≥ 0.90, SRMR ≤ 0.06. Good fit criterion: RMSEA ≤ 0.06, CFI ≥ 0.95, TLI ≥ 0.95, SRMR ≤ 0.05. Bold values support better model fit with the additional covariance on the complete data.
Model 5 and 6 include Items 1, 3, 5, 6, and 12 from the original MARSI GLOB factor, Items 1, 2, 4, 7 and 9 from the SUPP factor and Items 1, 2, 4, 7 and 8 from the PROBS factor. All indices support a good fit of the model to data (Table 2). Cronbach’s alpha is .82 for the overall English reading scale, and .69, .63, and .80 for the GLOB, SUPP and PROBS subscales. These are comparable to the original MARSI-R study (Mokhtari & Sheorey, 2002). Figure 2 shows the standardized estimates for Models 5 and 6. Anything that does not change is no longer presented in the figure for Model 6.

Final Best Models for English Reading Strategies.
Invariance Between Languages
Comparison between groups is meaningful only after measurement equivalence (ME) or measurement invariance (MI) of the tool is established (Horn & McArdle, 1992). To check ME/I, a series of tests are usually conducted starting from the least restrictive model and gradually moving to the most stringent one (Brown, 2015; Vandenberg, 2002; Vandenberg & Lance, 2000). However, Likert-type measures bring more challenges to ME/I studies, because more parameters such as large amounts of thresholds are added to the model yet the ordered responses do not follow a normal distribution as for continuous responses. We decided to follow the approach recommended by H. Wu and Estabrook (2016) and Svetina and her colleagues (Svetina et al., 2020), but with an extension to accommodate the repeated design that leads to a correlation between the pairs of responses to the same item in both languages. In addition, theta parameterization is used to enable tests on residuals.
To simplify the syntax and facilitate the presentation of results, we recoded the final 15 items for the next two sections. Correspondence between the maintained items and the original MARSI items can be seen in Appendix 2.
Separate sample analyses for English and Chinese reading strategies both support the 15-item model (Table 3). RMSEA is 0.062 for the former and 0.057 for the latter, CFI is 0.942 and 0.952, TLI is 0.930 and 0.942, and SRMR is 0.039 and 0.038 respectively.
Fit Indices for Measurement Invariance Tests Between Languages.

Note. N = 842. All single model χ2 statistics are significant at p < .001, thus omitted from the table. Adequate fit criterion: RMSEA ≤ 0.08, CFI ≥ 0.90, TLI ≥ 0.90, SRMR ≤ 0.06. Good fit criterion: RMSEA ≤ 0.06, CFI ≥ 0.95, TLI ≥ 0.95, SRMR ≤ 0.05.
Single model fit is evaluated by the fit indices for each model.
Model comparison is evaluated by fit improvements in the current model from the previous one, which is measured by DIFFχ2 and Δdf.
Model 0 is the equal form model which does not consider the repeated measures; it does not fit the data, especially according to CFI (<0.90) and TLI (<0.90). Model 1 is the equal form model with correlated responses; it fits the data adequately by all standards (RMSEA = 0.044, CFI = 0.951, TLI = 0.943, SRMR = 0.040), and it significantly improves Model 0 (DIFF χ2 = 1198.885, p < .05). Model 2 and 3 support the threshold and loading invariance hypotheses, but Model 4 to 4b support only partial intercept invariance. Five items do not have equivalent intercepts, among which X8 is higher for Chinese reading and X4, X5, X7, and X15 are higher for English reading (Table 4).
Non-invariant Patterns for the 15 Items.

Note. + means higher/larger in English; – means lower/smaller in English.
Model 5 and 5b show that only two items (X10 and X15) do not have equivalent error residuals between languages and that error residuals for both X10 and X15 are smaller for English reading than for Chinese reading. In other words, most items are measured with equivalent reliability for both languages except for these two. There are more measurement errors with these two strategies in Chinese reading than in English reading.
After taking measurement error into consideration, factor variances and covariances turned out to be equivalent, but two of the three latent means are higher in Chinese reading than in English reading (an estimated 0.601 vs. model specified 0 for GLOB; 0.234 vs. 0 for SUPP). There is no difference for PROBS means (Figure 3).

Final Model 8b of Measurement Invariance Tests Between Languages with Repeated Measures.
In sum, all 15 items are stable predictors of the corresponding factors and bear equivalent discriminating power in measuring reading strategies between languages. At least partial invariance is supported for both the measurement part and structural part of our model, implying the comparability of reading strategies between languages using this abbreviated inventory. There are some differences in the base level of the strategies reported, indicating more frequent use of the strategies when reading English than in Chinese. However, although reading strategies in both languages consist of the same three dimensions, global and supporting strategies are relied upon less in English than in Chinese. There is no difference in the problem-solving dimension.
Invariance Between Genders
Some participants did not provide gender information thus analyses in this part reduced to 760 cases (378 girls and 382 boys). Separate sample input is appropriate for this analysis and the model with correlated residuals between X2 and X3 now serves as the baseline. RMSEA, CFI, TLI, and SRMR all support a good fit for all of the models listed in Table 5.
Fit Indices for Measurement Invariance Tests Between Genders.

Note. N = 760. Those who did not provide gender information were not included for these analyses. All single model χ2 statistics are significant at p < .001, thus omitted from the table. Adequate fit criterion: RMSEA ≤ 0.08, CFI ≥ 0.90, TLI ≥ 0.90, SRMR ≤ 0.06. Good fit criterion: RMSEA ≤ 0.06, CFI ≥ 0.95, TLI ≥ 0.95, SRMR ≤ 0.05.
Single model fit is evaluated by the fit indices for each model.
Model comparison is evaluated by fit improvements in the current model from the previous one, which is measured by DIFFχ2 and Δdf.
Comparison between the baseline model (Model 0) and Model 1 shows that thresholds are invariant between genders (DIFF χ2 = 32.660, p = .338). However, loadings are not all invariant (DIFF χ2 = 27.431, p = .007). The highest MI is for X1 (17.972 for boys and 17.978 for girls). Model 2P releases the equivalence constraint on this item and partial loading equivalence is supported (DIFF χ2 = 16.263, p = .132). X1 is about the purpose of reading.
The loading is higher for girls than for boys (see Figure 4), which means this item discriminates girls better than boys, or it is a stronger indicator of girls’ global strategy use than that of boys.

Final Invariance Test Results Between Genders.
Model 3 constrain the intercepts to be equivalent between genders. This model degrades the model fit at a statistically significant level (DIFF χ2 = 67.182, p = .000). Based on MI indices, Model 3P releases intercept constraints on X1, X6, and X7, which supports partial intercept equivalence (DIFF χ2 = 13.366, p = .147). X1(having a purpose for reading) does not function the same within the global scale between genders according to the previous step, thus intercept difference at this step is not meaningful. However, intercepts of X6 (taking notes while reading), and X7 (reading aloud when text becomes hard) are higher for girls, meaning girls systematically reported these strategies more frequently than did boys. These are also supported by t-tests on the raw responses, where boys reported far less use of X6 (t = −4.094, p = .000) and X7 (t = −3.429, p = .001).
Model 4 tests the equality of residuals of indicators, which is supported by data (DIFF χ2 = 23.736, p = .070), implying that strategies are measured with equivalent reliability for both genders.
Model 5-7 tests the structural invariance between genders. Results show the equivalence of factor variances, covariances, and means. For example, all fit indices are good in Model 7 even by the stringent criterion (RMSEA < 0.05, CFI > 0.95, TLI > 0.95, SRMR < 0.05); and model fit does not degrade significantly (DIFF χ2 = 4.204, p = .240). Model 7 is the final model with all possible constraints and Figure 4 presents the invariance test results after measurement error is controlled. The graph on the right presents only two parameters that are different between genders.
In sum, girls and boys do not differ on the overall scale structure nor the majority of individual strategies maintained in the model. However, girls take notes more frequently than boys and tend to read aloud more (see Appendix 3), which agrees with previous research (Denton et al., 2015).
Relationship With Test Scores
In order to cross-validate the scale, we check the correlation between the reported strategies (hereafter referred to as MARSI-C10, i.e., MARSI for Chinese 10th-grade students) and mean reading scores from tests. Because modern Chinese is very different from classical Chinese in vocabulary and syntax, we explored the two scores separately. Results show that only two strategies are statistically correlated with all reading scores (Table 6). In addition, the correlation between English reading scores and modern Chinese reading scores is significant, yet the correlation between English and classical Chinese reading is not; neither is the correlation between modern Chinese and classical Chinese reading.
Descriptive Statistics of Reading Strategies and Reading Tests.

Significant at p < .05. Non-significant correlations are not reported.
A low correlation between Chinese reading scores and MARSI-C10 is acceptable since MARSI was not originally designed for the Chinese language. However, the low correlation between English reading scores and MARSI-C10 is unexpected. Examination of the quiz items quickly reveals several aspects that may lead to these results.
First, MARSI assumes general reading strategies which may involve long materials and a variety of reading environments. However, the quiz passages are much shorter (fewer than 500 words per task) and students have to respond within a limited time. They are not allowed to disturb others, nor can they refer to any resource. In this context, strategies such as “When text becomes difficult, I read aloud to help me understand what I read” (X7) or “I discuss what I read with others to check my understanding” (X8) may be irrelevant.
Second, test items in this study are not designed to measure the reading process, but rather, to quantify the comprehension result. Most of the items are in the multiple-choice (MC) format which further masks the manifestation of strategies. Students may not have the motivation to “ask myself questions I like to have answered in the text” (X10) rather than figure out the best answer to the test item. This can also explain the significant correlation involving X4, that is, students are actually directed by test questions to “decide what to read closely and what to ignore” (X4). When MC items are involved, test-taking strategies to eliminate unlikely answers may also bring a confounding issue that prevents the full use of reading strategies.
The insignificant correlation between classical Chinese reading and modern Chinese reading is expected. The insignificant correlation between classical Chinese reading and English reading is not surprising either since they are different languages in the end. The significant correlation between modern Chinese reading and English reading scores may seem unreasonable at first sight, but the commonality in the pedagogical and social environment may explain this. Both modern Chinese and English are lively and vibrant languages in China. Modern Chinese is the language of instruction in school and is the official language on public and social media. English is taught in school starting from Grade 3 and is widely accessible through numerous apps and public media. There may be significant overlap in text genre, topic, and reading purpose in the two languages, which can contribute to the correlation between the two. This speculation is consistent with observations in the previous section where model fit improves significantly once the correlation between responses to the same strategy is built into the statistical models (see Table 3 and Appendix 4).
In sum, our data do not support a strong correlation between MARSI-C10 and reading test scores.
Discussion
Value of Local Validation and Usage of Tools
In this study the general factor structure of MARSI is supported, confirming a reasonable construct that applies to our English learners. However, the final model does not involve the same items as the aforementioned MARSI-R. Similar clues can be found in previous studies where researchers sometimes select only a subset of the items from the complete inventory to measure reading strategy, which reflects an implicit belief that manifestation of the construct can vary (e.g., Gnaedinger et al., 2016; Karimi, 2015; Lau & Chen, 2013; Law, 2009).
Our participants report the problem-solving strategies with the highest frequency means, followed by global strategies, then supporting strategies. The priority of problem-solving strategies is consistent with the majority of previous research involving high school English learners (Arabmofrad et al., 2021; Dabarera et al., 2014). However, the order of the other two dimensions is different. For example, Stopar and Ilc (2017) found the same order with their 10th-grade Slovenian students as we did, but Ghaith and El-Sanyoura (2019) found that their 10th-grade Lebanese students used more supporting strategies than global ones. In universities, the order of these dimensions also varies where problem-solving strategies sometimes are not the priority strategies (Barrot, 2016; Chen, 2017). Thus, although a common structure seems reasonable in theory, a local imbalance between subscale dimensions is likely.
This leads to an important note of validation studies: Psychometric validation is not the same as practice validation. In this study, although 15 strategies are deleted from our final model, they all seem reasonable components in theory, eight of which even have high reported means (>3.5; bold numbers in Appendix 2) according to Oxford (1990). This means that students agree with the value of these strategies and have used them a lot. Some items have smaller standard deviations which may be part of the reason why they are not maintained in the model statistically. We speculate that if teachers plan for intervention, they may find little change in these strategies as found in previous studies. For example, Cantrell et al. (2010) found significant changes only in problem-solving strategies by the sixth graders in their study but no change for the ninth graders. They explained that older adolescents already mastered these basic strategies (mean = 3.14), thus growth after the intervention is not detectable. The effects of instruction on these strategies may be obvious for younger and less proficient students, but they may function for older students—such as our participants—only when tuned to more complex tasks or more challenging materials. Based on all this, we caution that statistical insignificance in scale validation cannot be taken as evidence that individual strategies are irrelevant in practice. They serve different purposes.
Universal or Language-Specific Strategy Use?
The repeated design enables a direct comparison of reading strategies between two languages in this study. We found strong correlations between Chinese and English reading strategies. We also found parallel factor structures.
However, there are also language-specific differences in individual strategies. For example, getting back on track when losing concentration is significantly related to Chinese reading but not to English reading. On the contrary, deciding what to ignore is related to the latter, but not to the former. The proficiency gap between L1 and L2 may be a factor since our participants are proficient in Chinese, but not as so in English. We are also suspicious that getting back on track may be a frequent strategy due to demotivating topics or material content more than linguistic challenges. On the other hand, unknown vocabulary with sparse clues in context can pose insurmountable obstacles in foreign language reading. We speculate that that “guessing the meaning of unknown words” is not frequently used because it is a low-efficiency strategy. As a result, ignoring them is a logical, though involuntary, decision for L2 learners in practice.
Whether or not language itself is a factor cannot be settled with existing evidence in this study. However, other research has also shown an insignificant relationship between MARSI strategies and L2 reading comprehension (e.g., Arabmofrad et al., 2021; Fitrisia et al., 2015; Habók et al., 2019). One hypothesis can be that L2 reading comprehension may be achieved through heterogeneous strategies that are shaped by a variety of equally effective factors, rather than by a homogeneous set. Still, more research needs to be done to see how a universal construct operationalizes into contextually different indicators.
Gender Difference
The result of this study supports gender differences in some strategies in favor of girls such as taking notes and reading aloud. This is consistent with previous research (e.g., Poole, 2009). The authors of this paper all have rich experience teaching English and have also noticed boys’ reluctance to use these in practice.
However, we also noticed other strategies that were excluded from our best model but showed statistically significant gender differences in both English and Chinese reading (see Appendix 3). For example, boys reported to “critically evaluate what is read” more, while girls reported to “underline information in text” more. Again, this pattern is consistent with previous research (e.g., Poole, 2009).
The fact that there is no difference in reading scores between genders in our sample suggests that some strategies may not play an important role in reading comprehension, at least not directly for boys. The fact that boys and girls differ on specific items, as constantly found in previous research, suggests that we may need to refine the strategy theory. These results can be interpreted from a new perspective. For example, do some commonly recommended strategies in school reflect girls’ nature more than boys’? Are there boy-friendly reading strategies that are underrepresented in current literature?
Pedagogical Implications
The Role of Local Curriculum
For our participants, problem-solving strategy means are high (>3.5) and supporting strategy means are low (around 2.5). Part of the reason could be that these students may have little chance to read long pieces other than test-type passages. As a result, supporting strategies aiming at “sustaining responses to reading” may not be crucial in local academic life (cf. Mokhtari & Reichard, 2002). Kong (2019) has also found that her Chinese participants took all reading comprehension activities in tests as problem-solving activities regardless of testing formats.
We propose that reducing reading to a kind of problem-solving activity may be true for all language-learning tasks in a non-native environment. This is based on our real-life observation of the overarching cognitive ability of these students in L1 that has been established by this age, the typical reading activities in school, and the instrumental motivation for college admission. For example, none of the reading materials in this study includes a graph or a table, revealing that the participants have little experience with visual cues in daily English reading. This can explain why “using tables, figures and pictures in the text to increase understanding” is reported with the lowest frequency in the study. In addition to this, all passages are narrative, which deviates from the rich target that reading activities can aim for. A detailed study on the linguistic features of the reading test items is in preparation, but preliminary analyses reveal that non-fictional reading materials may be underrepresented in school materials, which restricts the range of useful reading strategies that MARSI has intended for.
Shifting the Focus to Individual Difference
While large samples as used in this study can reveal general patterns of strategy use, relying on general models may restrict our understanding of individuals. Gender is taken as a grouping variable much smaller in scale compared to native language but the findings already show differences on this scale. Individuals can be even more varied. For example, Dabarera et al. (2014) used MARSI before and after an instructional intervention and found that the mean scores increased on each strategy subscale for the experimental group. This was reasonably interpreted as evidence that instruction helped to increase strategy use. However, a closer look at the summary tables shows that the variances of almost all subscale scores have also increased for the experimental group. Even within the control group, whose subscale means did not change, variances are larger for two of the three subscales in the post-survey. Is this increase in variability a good thing or a bad thing? Could it reflect the different yet equally efficient routes to reading comprehension growth? If meaning is constructed by readers through interaction with text, then exploring the atypical cases or various combinations of strategies in different situations may direct us to another valuable perspective, that people can successfully process the same textual information through different approaches (Bjorklund, 1990; Gui et al., 2021).
Limitations
This study used only student-reported data and the sample size for test scores was limited. A follow-up study should also include other data sources such as eye-tracking and reading activities designed specifically for detecting strategy-in-use. Internet-based reading strategy is another category that needs more exploration, although feasibility in schools where digital devices are not allowed limits its value for daily instruction. This study uses a convenient sample which may prevent the generalizability of some results. Students from different schools and grades will provide a complete picture for a possibly dynamic reading strategy construct, dynamic with culture, language proficiency, or simply with age.
Footnotes
Appendix 1
Appendix 2
ID Linkage and Raw Data Statistics for English Reading Strategy (N = 842).

| Original MARSI scales | ID of items in the final model in Section 5 | Original MARSI items in abbreviation (Mokhtari & Reichard, 2002) | Mean | SD |
|---|---|---|---|---|
| Global Strategies | X1 | G1: Having a purpose for reading | 3.49 | 1.27 |
| G2: Using prior knowledge |
|
1.02 | ||
| X2 | G3: Previewing text before reading | 3.45 | 1.30 | |
| G4: Checking how text content fits the purpose | 3.01 | 1.33 | ||
| X3 | G5: Skimming to note text characteristics | 3.29 | 1.34 | |
| X4 | G6: Determining what to read | 3.37 | 1.28 | |
| G7: Using text features (e.g., tables) |
|
1.21 | ||
| G8: Using context clues |
|
1.04 | ||
| G9: Using typographical aids (e.g., italics) | 3.12 | 1.41 | ||
| G10: Critically evaluating what is read | 3.23 | 1.14 | ||
| G11: Resolving conflicting information |
|
1.01 | ||
| X5 | G12: Predicting or guessing text meaning | 3.72 | 1.23 | |
| G13: Confirming predictions |
|
1.19 | ||
| Supporting Strategies | X6 | S1: Taking notes while reading | 2.66 | 1.27 |
| X7 | S2: Reading aloud when text becomes hard | 2.74 | 1.48 | |
| S3: Summarizing text information | 3.39 | 1.21 | ||
| X8 | S4: Discussing with others | 2.58 | 1.28 | |
| S5: Underlining information in text |
|
1.29 | ||
| S6: Using reference materials | 3.28 | 1.33 | ||
| X9 | S7: Paraphrasing for better understanding | 3.07 | 1.33 | |
| S8: Going back and forth in the text |
|
1.16 | ||
| X10 | S9: Asking oneself questions | 3.23 | 1.27 | |
| Problem-Solving Strategies | X11 | P1: Reading slowly and carefully | 4.07 | 1.04 |
| X12 | P2: Trying to stay focused on reading | 4.07 | 1.02 | |
| P3: Adjusting the reading rate |
|
1.10 | ||
| X13 | P4: Paying close attention to reading | 4.10 | 1.05 | |
| P5: Pausing and thinking about reading | 3.25 | 1.23 | ||
| P6: Visualizing information read | 2.31 | 1.32 | ||
| X14 | P7: Re-reading for better understanding | 4.15 | 1.02 | |
| X15 | P8: Guessing the meaning of unknown words | 4.18 | 1.00 |
Appendix 3
Items with Significant Gender Difference (N = 760).

| Item ID in Section 5 | Original MARSI items in abbreviation (Mokhtari & Reichard, 2002) | English reading | Chinese reading | ||
|---|---|---|---|---|---|
| t | p | t | p | ||
| G10: Critically evaluating what is read | 2.499 | 0.013 | 3.436 | .001 | |
| X6 | S1: Taking notes while reading | −4.094 | 0.000 | −3.676 | .000 |
| X7 | S2: Reading aloud when text becomes hard | −3.429 | 0.001 | −2.629 | .009 |
| S5: Underlining information in text | −6.249 | 0.000 | −5.063 | .000 | |
| X12 | P2: Trying to stay focused on reading | −2.130 | 0.033 | −1.542 | .124 |
| P3: Adjusting the reading rate | −1.957 | 0.051 | −2.610 | .009 | |
Appendix 4
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
The dataset for the current study is available from the corresponding author upon reasonable request.