
Abstract
To examine the processing of phonological and configurational information in word recognition in discourse reading, we conducted two experiments using the self-paced reading paradigm. The materials were three-sentence discourses, in each of which the last word of the second sentence and the third word from the end of the last sentence formed a prime–target pair. The discourse in which the target word (T) was semantically congruent or incongruent with the prime word was converted into a new version by replacing the T with its homophone or with the control word (con-T) in Experiment 1. Similarly, the Ts were replaced by words that were similar to them in configuration or by the con-Ts in Experiment 2. We adopted mixed-effects modeling to analyze the participants’ reading times to the targets, the first words after the targets, and the second words after the targets. It is concluded that the processing of phonological information begins earlier than that of configurational information in activating the semantic representations for the upcoming words that fit the context in discourse reading.
Due to the grapheme–phoneme mapping, it seems difficult to disentangle the contribution of phonological from that of orthographic information in word recognition in alphabetic languages (Chen, Yamauchi, Tamaoka, & Vaid, 2007). As associations between Chinese characters and their pronunciations are largely arbitrary, however, it is possible to examine the role of phonology separately from that of orthography in word recognition in Chinese. Indeed, relevant studies have been conducted on words in (e.g., Liu, Jin, Qing, & Wang, 2011; Ren, Liu, & Han, 2009) and out of (e.g., Perfetti & Tan, 1998; X. Zhou & Marslen-Wilson, 1999) a sentential context. In the present study, a prime–target pair of words was embedded in a discourse, and we tried to examine how the understanding of the prime in a sentence would facilitate that of a word that was phonologically or configurationally similar to the target in the follow-up sentence. The results would provide some indications of the relationship between the processing of these two kinds of information in word recognition in discourse reading in Chinese and help to reveal more about the mechanism of word recognition in general.
Phonological Processing
There are two points of view concerning the processing of phonological information in visual word recognition in Chinese. One line of studies suggests that phonological information is automatically processed in the recognition of written words (e.g., Chen, Vaid, & Wu, 2009; Tan, Hoosain, & Peng, 1995; Tan, Hoosain, & Siok, 1996; Weekes, Chen, & Lin, 1998). Phonology plays a crucial role in mediating activations of semantic representations (Guo, Peng, & Liu, 2005; Kong et al., 2010; Leck, Weekes, & Chen, 1995; Li, Lin, Wang, & Jiang, 2013; Ma, Wang, & Li, 2016; Perfetti & Zhang, 1995; Spinks, Liu, Perfetti, & Tan, 2000; Tan & Perfetti, 1997; Xu, Pollatsek, & Potter, 1999; Q. Zhang, Zhang, & Kong, 2009; S. Zhang, Perfetti, & Yang, 1999; X. Zhou & Marslen-Wilson, 1999). In a priming task of semantic categorization (Ma et al., 2016), for example, the participants responded faster to the targets (e.g., 杯 [bei1] cup; 警官 [jing3guan1] policeman) that were preceded by the homophone primes (e.g., 悲 [bei1] sad; 景观 [jing3guan1] landscape) than they did to those that were preceded by the controls (e.g., 话 [hua4] word; 估计 [gu1ji4] estimate) at the SOA (stimulus onset asynchrony) of 47 ms. However, the participants’ reaction times to the targets that were semantically related to the primes were facilitated (e.g., 碟 [die2] dish; 法医 [fa3yi1] court doctor) at the SOA of 87 ms. The mandatory involvement of the processing of phonological information in accessing the semantic representations of the targets in Ma et al. (2016) seems to confirm Perfetti and Tan’s (1998) conclusion on the possibility of meaning retrieval as a result of the processing of phonological information.
Another line of studies, however, has failed to indicate the contribution of phonological processing to the activation of semantic representations in word recognition in Chinese (e.g., Chen, d’Arcais, & Cheung, 1995; Shen & Forster, 1999; Zhan, Yu, & Zhou, 2013; X. Zhou & Marslen-Wilson, 2000, exp 1; X. Zhou, Marslen-Wilson, Taft, & Shu, 1999). For example, when deciding whether or not a word referred to an entity which belonged to a pre-designated semantic category (e.g., 动物 [dong4wu4] animal), the participants did not find it harder to reject the inclusion of the homophone (e.g., 珠 [zhu1] pearl) of the category member (e.g., 猪 [zhu1] pig) than they did the control (e.g., 环 [huan2] loop) (Chen et al., 1995). The processing of the shared phonological information between the homophone and the category member failed to activate the semantic representations for the category member. Similarly, the homophonic primes (e.g., 洁净 [jie2jing4] hygienic) did not facilitate the participants’ responses to the targets (捷径 [jie2jing4] shortcut) in a priming task of lexical decision (X. Zhou & Marslen-Wilson, 2000; X. Zhou et al., 1999).
The contradictions between these two lines of studies might have arisen from the diverse nature of experimental tasks on word recognition out of a sentential context. Probably for this reason, researchers began to focus on the processing of words’ phonological information in a sentence reading task. For example, when the final Chinese character (枝 [zhi1] branch) in the target sentence 这是被压断的树枝 was replaced by its homophone (汁 [zhi1] juice), the participants were more reluctant to classify the sentence as unacceptable than they were to classify the control sentence 我买本书需要一块汁 (Liu et al., 2011). The last Chinese character (汁) is not at all related to the expected Chinese character (钱 [qian2] money) in the control condition. The processing of words’ phonological information seems to be inevitable during the silent reading of a sentence.
However, there is a lack of consensus as to when the processing of words’ phonological information begins in sentence reading. Some researchers propose that phonological information is processed at an early time (Liu et al., 2011; Tsai, Lee, Tzeng, Hung, & Yen, 2004), whereas others observe that it is processed at a late time (Meng, Jian, Shu, Tian, & Zhou, 2008; Ren et al., 2009). The cause of this discrepancy seems to be multifold. For one thing, the processing of the word on the sentential boundary is likely to result in a wrap-up effect. Different sources of information that are internal and external to the sentence are integrated in the understanding of the final word (Ferretti, Singer, & Harwood, 2013; Just & Carpenter, 1980; Kintsch, 1998). For another, the scores of contextual predictability were 86%, 90%, and 73% in Liu et al. (2011), Ren et al. (2009), and Meng et al. (2008), respectively, for example. High levels of contextual predictability tend to facilitate the activation of phonological codes (Rayner, Pollatsek, & Binder, 1998). Moreover, the findings on word recognition in the reading of short or simple sentences cannot be readily generalized to the cases in which rich contextual information is available (Daneman & Stainton, 1991). Indeed, researchers tried to track participants’ eye movements in the reading of short passages with a low contextual predictability (Feng, Miller, Shu, & Zhang, 2001; Wong & Chen, 1999). In short passages, targets (e.g., 识 [shi2] know), homophones (e.g., 食 [shi2] eat), Chinese characters that were orthographically similar to the targets (e.g., 织 [zhi1] knit), or controls (e.g., 考 [kao3] check) were embedded. However, they failed to reveal early activations of semantic representations as a result of the processing of phonological information. As only the first Chinese characters of the two-character words (e.g., 识别 [shi2bie2] recognize) were manipulated in these studies, the observed effects might have been an indication of orthographic and phonological processing at the sub-word level.
Given that words, rather than individual Chinese characters, are the basic units in the mental lexicon (Dronjic, 2011) and in sentence reading (Bai, Yan, Liversedge, Zang, & Rayner, 2008) for skilled readers, one needs to take two-character words as wholes. Moreover, phonological facilitation obtained from the direct comparison of readers’ performance on the target words, homophonic words, and controls does not necessarily reflect the phonological mediation of semantics, because silent reading often involves inner voice (Brysbaert, Grondelaers, & Ratinckx, 2000). Better performance on the homophonic pseudo-words might indicate that they do not sound weird compared with the controls, especially when only a componential character was manipulated in the two-character word context. Thus, the present study tried to make a step forward along this line of argument.
Orthographic Processing
The processing of orthographic information appears to be necessary in the recognition of Chinese words, and many studies tapping into the processing of phonological information often were coupled with the examination of orthography (Chen et al., 1995; Chen & Shu, 2001; Leck et al., 1995; Ma et al., 2016; Perfetti & Tan, 1998; Tan et al., 1995; Xu et al., 1999; X. Zhou & Marslen-Wilson, 1999). Although no homophonic effect was revealed in the semantic categorization task in Chen et al. (1995), for example, the Chinese distracter (e.g., 毒 [du2] poison) that was orthographically similar to the category member (e.g., 母 [mu3] mother) was harder to be rejected than the control (e.g., 冬 [dong1] winter) from the category (e.g., 亲属 [qin1shu3] relatives). Similarly, the participants were more reluctant to classify 扎到他的是这根汁 as unacceptable than they were to classify the control sentence in Liu et al. (2011). The last word (汁) is orthographically similar to the expected word (针 [zhen1] needle). In short passages, the orthographic error made on the words (e.g., 织别) that were orthographically similar to the target (e.g., 识别) was less likely to be detected in comparison with the controls (e.g., 考别) in Feng et al. (2001) and Wong and Chen (1999).
In these studies, however, the processing of orthographic information seems to be intertwined with that of morphological information, because the word-pairs share radicals. For example, 汁 and 针 share 十 ([shi2] ten), while 识 and 织 have 只 ([zhi1] single) in common. In such cases, the observed effect of orthography might be attributed to the processing of the morphological units in the stimuli. After all, the commonly used radicals in Chinese characters have independent representations for skilled readers of the language (L. Zhou, Peng, Zheng, Su, & Wang, 2013). Out of this concern, Ma et al. (2016) investigated the information processing of word configuration. By word configuration, they meant the overall shape of a word. The participants’ reaction times were slower when the primes (e.g., 两 [liang3] two; 拳击 [quan2ji1] boxing) were words that were similar to the targets (e.g., 雨 [yu3] rain; 泰山 [tai4shan1] Tai mountain) in configurations than when they were to the controls (e.g., 主 [zhu3] main; 洁白 [jie2bai2] white) at the SOA of 187 ms.
This inhibitory effect suggests that words’ configurations function as an independent source of information in word recognition. Activations compete between words that were similar to each other in configurations. However, no such study seems to have been conducted in the context of discourse.
A language unit longer than a sentence forms a discourse, within which elements are related in a highly structured way (Neumann, Epstein, Yu, Benasich, & Shafer, 2014). In discourse reading, readers integrate local information into the preceding context or create a coherent representation of the information accordingly (Guzmán & Klin, 2000). For example, after reading the context as they had agreed, Jane was to wake her sister and her brother up at five o’clock in the morning. But her sister had already washed herself, and her brother had even got dressed, participants’ performance on the word slow in Jane told her brother that he was exceptionally slow is expected to be poorer than their performance on the word quick in Jane told her brother that he was exceptionally quick. The influence of discourse context on readers’ comprehension of an upcoming word has been repeatedly confirmed (e.g., Camblin, Gordon, & Swaab, 2007; Filik & Leuthold, 2008; Nieuwland & van Berkum, 2005, 2006; van Berkum, Hagoort, & Brown, 1999; Wang, Hagoort, & Yang, 2009; Warren, McConnell, & Rayner, 2008; Yang, Chen, & Yang, 2014; Yang, Chen, Chen, & Yang, 2015; Yang, Chen, Chen, Xu, & Yang, 2013).
Similarly, when placed in a discourse context (e.g., 家人都说小李准备参加运动会, 近来他总去田径场 The family says that Li is going to take part in the sports meeting. Lately, he’s been going to the track field), the words (e.g., 游泳 [you2yong3] swim) that were discourse-incongruent but locally acceptable (e.g., 一遍遍地努力练习____准备比赛 to practice ____ over and over again for the game) took more time to comprehend than the words (e.g., 跑步 [pao3bu4] run) that were both discourse-congruent and locally acceptable in the carrier sentence (Yang et al., 2014). This phenomenon is regarded as the effect of congruency. Words that are discourse-incongruent are more difficult to understand than those that are discourse-congruent.
The Present Study
In the present study, we tried to investigate the processing of phonological and orthographic information of Chinese one- and two-character words in a discourse context. By examining how the activations of words’ semantic representations were mediated by the processing of these two types of information in discourse reading, the study was likely to provide new evidence for the theoretical development of word recognition. Specifically, we hoped to reveal how the processing of phonological information was similar to or different from that of configurational information in word recognition in the context of discourse by means of two experiments.
The materials were three-sentence discourses. In each discourse, the first sentence was the lead-in sentence. The remaining two sentences contained two critical words: The last word of the second sentence was the prime, and the third word from the end of the final sentence was the target. By changing the relationship between the prime and the target, two variables were manipulated.
In Experiment 1, the discourse in which the target word (referred to as T hereafter) was semantically congruent or incongruent with the prime word was converted into a new version of discourse by replacing the T with its homophone (referred to as pho-T hereafter) or with the control word (referred to as con-T hereafter). In (1) in Table 1, for example, the T (肺 [fei4] lung) was both locally acceptable and semantically congruent with the prime (吸烟 [xi1yan1] smoke); in (2) in Table 1, however, the T was locally acceptable but semantically incongruent with the prime (喝酒 [he1jiu3] drink). Two new discourses were created by replacing the T with the pho-T (费 [fei4] expense), and another two by replacing the T with the con-T (信 [xin4] letter). Similarly, the discourses, such as (3) or (4) in Table 1, in which the T (e.g., 杯子 [bei1zi] glass) was semantically congruent or incongruent with the prime word, respectively, were converted into new versions of discourse by replacing the T with a word (e.g., 坏了 [huai4le] damaged) (referred to as ort-T hereafter) that was similar to the T in configuration or with the con-T (e.g., 现实 [xian4shi2] reality) in Experiment 2.
Material Samples.

The moving-window, self-paced reading task was adopted, which was believed to be one of “the most widely-accepted experimental tasks for the investigation of sentence comprehension during reading” (Witzel, Witzel, & Forster, 2012, p. 106). In this task, participants read each segment (a word, a phrase, or a sentence) in a non-cumulative way by pressing the key(s) on the keyboard. The duration of each segment on the screen is automatically recorded, which is supposed to be indicative of participants’ reading performance. Therefore, we came up with the hypotheses as follows.
Experiment 1
Method
The design formed a 2 (congruency: congruent or incongruent discourse) × 3 (target: T, pho-T, or con-T) factorial of mixed measurements, with congruency as a within-subjects variable and target as a between-subjects variable. The dependent variable was the participants’ RTs to the regions of interest: the target word (Target), the first word after the target (Target 1), and the second word after the target (Target 2).
Participants
Eighty-seven college students (51 females; Mage = 19.6 years, age range: 18.4-23.2 years) were recruited by means of a flyer advertisement on the campus of a university in China. We divided the males into three equal groups randomly and did the same on the female participants. Then, we paired the three groups of males and those of females to make three groups of participants. Among the three groups of participants, there were no significant differences in age or male–female ratio. With 29 participants at each level of target, the design would have 80% power to achieve an effect size of 0.54 at the two-sided significance level of .05. At the beginning of the experiment, the participants gave their informed consent in written form in accordance with the Declaration of Helsinki. At the end of the experiment, they received 20 Yuan (US$2.9) as a reward. The implementation of the experiment was approved by the Ethics Committee of Qufu Normal University.
Materials
Twenty-four sets of three-sentence discourses were devised (see Appendix A). We matched the T in each discourse with a pho-T, which had the same pronunciation as the T but was not semantically or orthographically related to it, and a con-T, which was not related to the T semantically, orthographically, or phonologically. To make sure that the three types of targets were not significantly different from each other in frequency or number of strokes, one-way analyses if variance (ANOVAs) were conducted to the corresponding scores. As demonstrated in Table 2, there were no significant differences among the Ts, pho-Ts, and con-Ts in terms of log frequency according to the corpus by Cai and Brysbaert (2010), F(2, 69) = 0.11, p > .10, or in number of strokes, F(2, 69) = 0.04, p > .10. A new group of 24 students from the same pool as the participants rated the discourse congruency on a 7-point scale (1 = very implausible, 7 = very plausible). To make sure that the rating scores were significantly higher for the congruent than those for the incongruent discourses, paired-sample t tests were conducted to the rating scores. The results indicated that there were significant differences between the congruent (M = 5.75, SD = 0.66) and incongruent (M = 1.63, SD = 0.53) discourses in congruency, t(23) = 23.952, p < .001, r = .709. We then removed the Ts in the discourses and asked another group of 24 students to do a cloze exercise. A cloze probability score (in percentage points) was obtained for each discourse by dividing the number of students who correctly inserted the Ts by the number of the actually provided words, which ranged from 16 to 24 (see Table 2). There were significant differences between the congruent and incongruent discourses in cloze probability, t(23) = 5.122, p < .001.
Stimuli Properties.
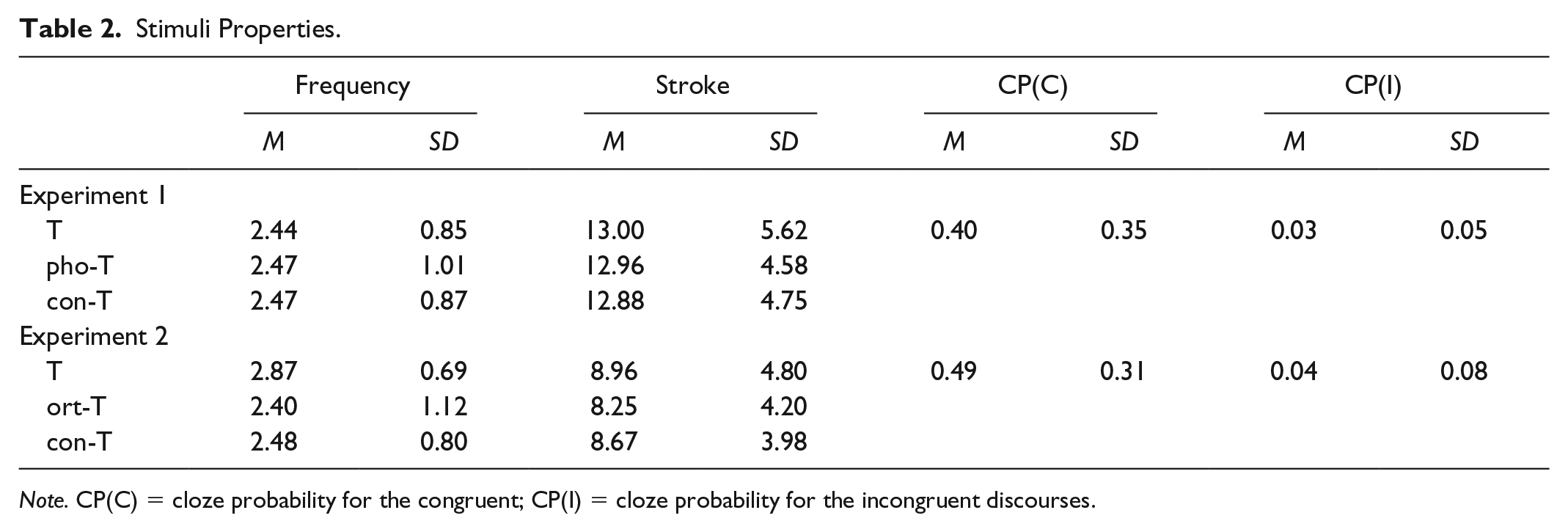
Note. CP(C) = cloze probability for the congruent; CP(I) = cloze probability for the incongruent discourses.
The congruent discourses were randomly divided into Groups 1 and 2, and the corresponding incongruent ones into Groups 3 and 4. Group 1 was mixed with Group 4 to make Discourse List 1, while Groups 2 and 3 were put together to make Discourse List 2. No discourse appeared more than once on each list. If a congruent discourse was on List 1, then its corresponding incongruent version was on List 2, and vice versa. To each list, 72 additional discourses were added as fillers. Given the semantic incongruity in half number of the critical materials, half amount of the filler discourses were made semantically anomalous for the sake of balance. The order in which the discourses were presented was pseudo-randomized so that no more than four consecutively presented discourses involved anomalies. Furthermore, the first and final three trials were fillers, and there were eight practice trials prior to the experimental trials. Participants were expected to read one of the two lists at one target level. The distribution of Lists 1 and 2 was counterbalanced across the participants.
Procedure
DMDX (Forster & Forster, 2003), a Windows display program with millisecond accuracy, was adopted to control stimulus presentation and to record participants’ responses. The stimuli were presented in white color in the font of “Song-28” in a black background. Participants were instructed to read at their own pace in a non-accumulative way. At the beginning of each trial, the prompt “Please begin your reading by pressing ‘Z’ or ‘/’” remained at the center of the screen until a key press was received. Then, the first sentence was shown on the screen as the result of a key stroke on “Z” or “/.” On the third stroke of the key “Z” or “/,” the first part of the second sentence was shown, and on the fourth press of the key “Z” or “/,” the remaining part of the second sentence appeared. The third sentence was read in a word-by-word style: each time the key “Z” or “/” was pressed, a new word popped up on the screen, with the previous word disappearing at the same time. At the disappearance of the last word, a yes/no question of reading comprehension was displayed on the screen. Half of the discourses were followed by a question and participants had to respond by pressing one of two definite keys before the next trial began.
Results
One participant achieved an accuracy of lower than .80 in responding to the reading comprehension questions; his data were excluded. RTs shorter than 50 ms and 2.5 SDs above the overall mean were deleted at each treatment level. The ratio of the discarded data was 3.2%, and see Table 3 for the descriptive results.
Descriptive Results.

We adopted lme4 (Bates, Maechler, & Bolker, 2011) in R (R Development Core Team, 2012) to conduct mixed-effects linear regression analyses. First, we did the analyses with probability as a predictor of fixed effect and subjects and items as those of random effects on the participants’ RTs to the targets in the T and pho-T conditions. The results suggested that the influence of probability was not significant in the T condition (t = 0.650, p = .516) but tended to be significant in the pho-T condition (t = −1.803, p = .072). That is, predictability was likely to change how the participants read the targets in the pho-T condition. Therefore, probability was included in addition to congruency and target in the mixed-effects modeling on the RT scores to the Targets, Target 1s, and Target 2s. Table 4 displays the results of fixed effects.
Mixed-Effects Modeling Results.
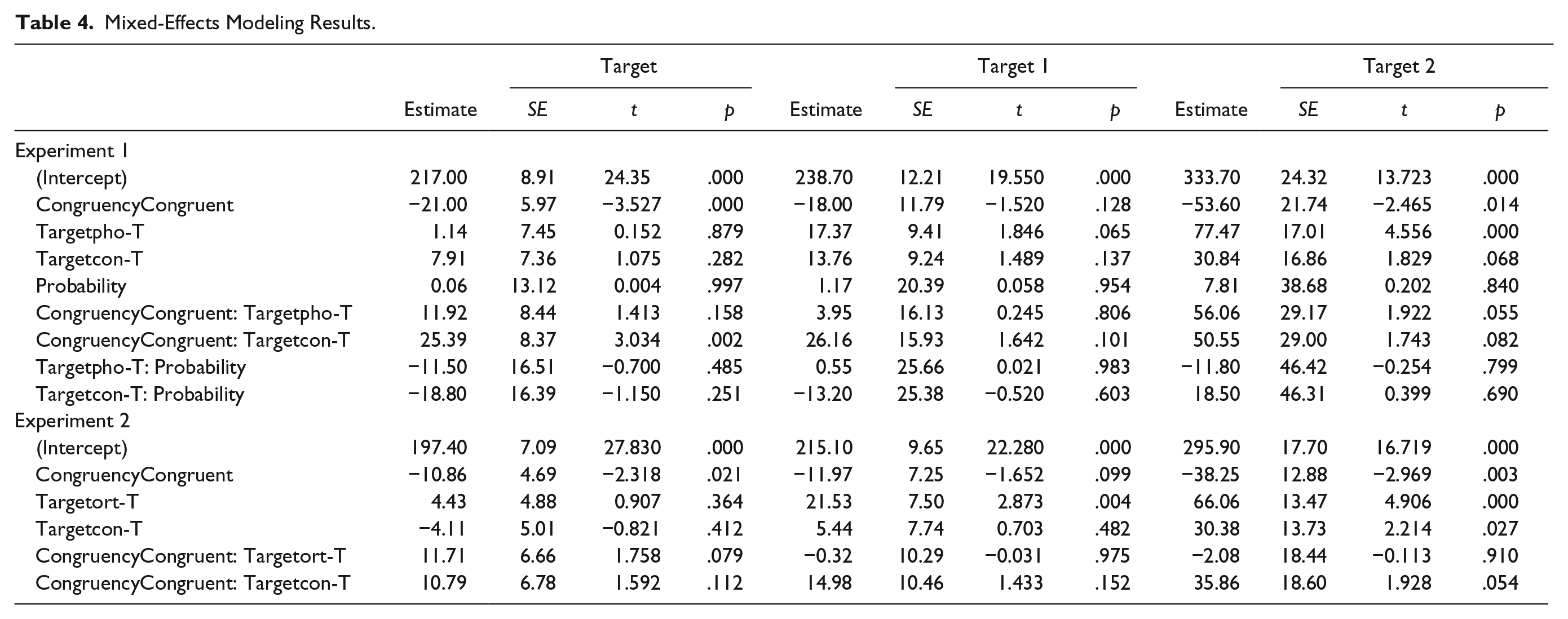
The interaction was significant between target and congruency (see Figure 1) in the participants’ RTs to the targets. Their RTs were significantly shorter in the congruent than in the incongruent discourses in the T condition (t = −3.527, p < .001), and significantly the same pattern of differences was revealed in the pho-T condition (t = 1.413, p = .158). In the congruent discourses, the RTs were significantly stable when Ts were changed into pho-Ts but were significantly longer when Ts were changed into con-Ts (t = 3.034, p = .002).
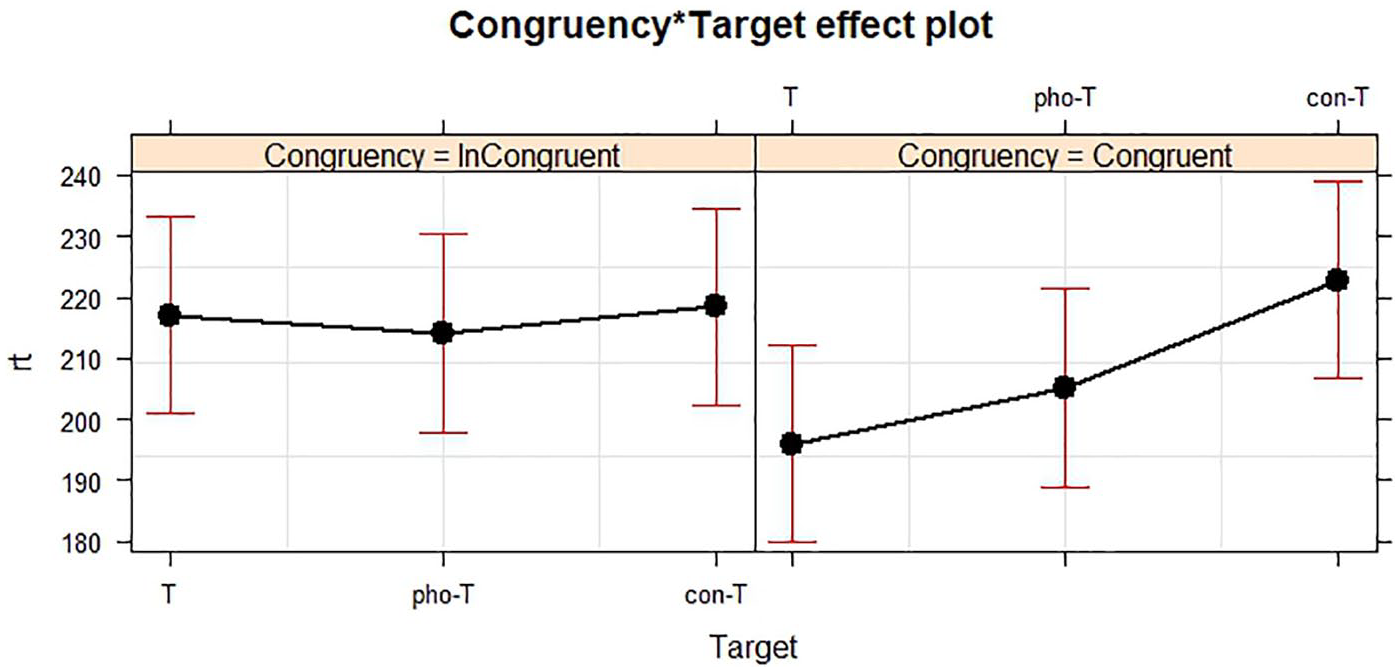
The interaction between congruency and target in RTs to the targets in Experiment 1.
The participants’ RTs to the Target 1s tended to become significantly shorter in the T than in the pho-T condition in the incongruent discourses (t = 1.846, p = .065), and this pattern of changes was significantly the same in the congruent as in the incongruent discourses (t = 0.245, p = .806).
The participants’ RTs to the Target 2s became significantly longer in the incongruent than in the congruent discourses in the T condition (t = 2.465, p = .014). Significantly the same pattern of difference tended to be revealed in the pho-T condition (t = 1.922, p = .055). The participants had significantly longer RTs in the pho-T than in the T condition (t = 4.556, p < .001) in the incongruent discourses. This pattern of changes tended to be even more significant in the congruent discourses.
Discussion
At the T level of target, the participants took more time to understand the targets in the incongruent than in the congruent condition, consistent with the findings of previous studies (e.g., Nieuwland & van Berkum, 2006; Otten & van Berkum, 2008; Wang et al., 2009; Yang et al., 2014; Yang et al., 2015; Yang et al., 2013). The effect of congruency was also observed on the Target 2s. The participants still tried to construct semantically coherent representations even when reading the second words following the targets. This kind of extended effect of congruency has also been observed in previous studies (e.g., Binder & Borecki, 2008; Rayner, Warren, Juhasz, & Liversedge, 2004; van der Schoot, Reijntjes, & Lieshout, 2012; Yang et al., 2014). After all, “good comprehenders detected the inconsistencies and made an attempt to resolve them. Probably, the extra time good comprehenders spent on an inconsistent target sentence reflected their effort to double-check the inconsistency and/or think up possible resolutions” (van der Schoot et al., 2012, p. 1676).
Most importantly, a similar pattern of congruency effect was observed on the targets in the pho-T condition. In agreement with the hypothesis, the processing of phonological information of the pho-Ts seemed to have helped trigger activations of semantic representations for the Ts. Different from the case of the T condition, however, the advantage of congruency effect failed to appear on the Target 2s in the pho-T condition. These results make sense with respect to the assumption that the participants had finally detected a kind of inappropriateness at the pho-T level of target.
According to the verification model (VM; van Orden, 1987), the activation of semantic representations of a word is initially triggered by the processing of its phonological information, followed by a subsequent stage of orthographic verification. That is, when encountering the pho-T (e.g., 费) in the congruent condition, the participants immediately activated the phonological representation (e.g., fei4), which indirectly resulted in the activation of the semantic representation for the T (e.g., 肺). In the follow-up stage of verification, however, discrepancies between the pho-T (e.g., 费) and the T (e.g., 肺) in orthography inhibited further activation of semantic representations for the candidate word (e.g., 肺). Such an inhibition led to the disappearance of congruency effect on the Target 2s at the pho-T level of target.
The early processing of phonological information echoes previous findings on Chinese word recognition out of sentential context (e.g., Kong et al., 2010; Ma et al., 2016; Perfetti & Tan, 1998) and seems consistent with the results revealed in sentence reading tasks in Liu et al. (2011) and Tsai et al. (2004). After all, skilled readers are quite likely to develop a strong association between a word and its pronunciation. This is especially true in discourse reading, as we often use an inner voice in silent reading (Brysbaert et al., 2000). The evidence of the visual tongue-twister effect found in McCutchen and Perfetti (1982) and the interference caused by phonological overlap in sentence reading (Frisson, Koole, Hughes, Olson, & Wheeldon, 2014) might also be indicative of automatic phonological activation in silent reading.
In summary, the results of Experiment 1 provide a strong piece of evidence to the literature in support of early integration of phonological and semantic information in discourse reading. The automatic processing of phonological information is helpful in retrieving the meaning of words that are congruent with the discourse context.
Experiment 2
The purpose of Experiment 2 was to test whether processing of orthographic information was helpful in retrieving the meaning of words that were congruent with the discourse context. If retrieval of the T’s meaning was constrained by the processing of its configurational information in discourse reading, then the RT would be shorter to the ort-T than to the con-T in the congruent condition, and a congruency effect would be observed in the ort-T as well as in the T condition.
Method
Similar to Experiment 1, the design also formed a 2 (congruency) × 3 (target) factorial of mixed measurements. Different from Experiment 1, however, the three levels of target were T, ort-T, and con-T.
Participants
Eighty college students (46 females; Mage = 19.3 years, age range: 17.8-23.6 years) were recruited in the same way as in Experiment 1. With 26 or more participants at each level of target, the design would have 80% power to achieve an effect size of 0.57 at the two-sided significance level of .05.
Materials
Similar to Experiment 1, the critical materials were 24 sets of three-sentence discourses (see Appendix B). We asked five graduate students to pair each T with a word (ort-T) which was similar to it in configuration but not phonologically or semantically related to it, and with another word (con-T) which was dissimilar to it orthographically, phonologically, and semantically. Then, like Ma et al. (2016), we asked 24 college students to rate the similarity in orthography between two members in each pair on a 7-point scale. The ort-Ts (M = 4.19, SD = 1.02) were significantly more similar than the con-Ts (M = 1.31, SD = 0.47) to the Ts in configuration, t(23) = 16.522, p < .001, r = .965. The property scores of the three types of targets are displayed in Table 2. There was no significant difference among the Ts, the ort-Ts, and the con-Ts in terms of log frequency, F(2, 69) = 1.90, p > .10, or number of strokes, F(2, 69) = 0.16, p > .10. The congruent discourses (5.78 ± 0.82) were significantly different from the incongruent ones (1.81 ± 0.69) in congruency evaluation, t(23) = 16.287, p < .001, r = .709, and cloze probability, t(23) = 7.532, p < .001.
Procedure
The procedure was the same as in Experiment 1.
Results
One participant’s data were discarded and the rest of the data were screened in the same way as in Experiment 1. The ratio of deleted data was 3.6%. The results are summarized in Table 3. The data were analyzed in the same way as in Experiment 1.
The influence of probability was insignificant in either the T (t = 0.711, p = .478) or the ort-T condition (t = 0.417, p = .677). Thus, we conducted the mixed-effects modeling with the influences of congruency and target taken into consideration on the RT scores to the Targets, Target 1s, and Target 2s. The results of fixed effects are displayed in Table 4.
As depicted in Figure 2, the participants’ RTs were significantly shorter in the congruent than in the incongruent discourses in the T condition (t = −2.318, p = .021). However, these differences tended to be diminished in the ort-T condition (t = 1.758, p = .079). Participants’ RTs remained significantly the same when Ts were changed into ort-Ts in the incongruent discourses (t = 0.907, p = .364), but they tended to be longer in the congruent discourses when Ts were changed into ort-Ts.

The interaction between congruency and target in RTs to the targets in Experiment 2.
The participants’ RTs tended to be longer in the incongruent than in the congruent discourses in the T condition (t = 1.652, p = .099), and this pattern of differences remained significantly the same in the ort-T condition (t = 0.031, p = .975). Their RTs became significantly longer when Ts were changed into ort-Ts in the incongruent discourses (t = 2.873, p = .004), and the pattern of RT changes were significantly the same in the congruent as in the incongruent discourses.
As depicted in Figure 3, the participants’ RTs were significantly longer in the incongruent than in the congruent discourses in the T condition (t = 2.969, p = .003), and significantly, the same pattern of changes was revealed in the ort-T condition (t = 0.113, p = .910). The participants had significantly longer RTs when Ts were changed into ort-Ts in both the incongruent (t = 4.906, p < .001) and congruent discourses.
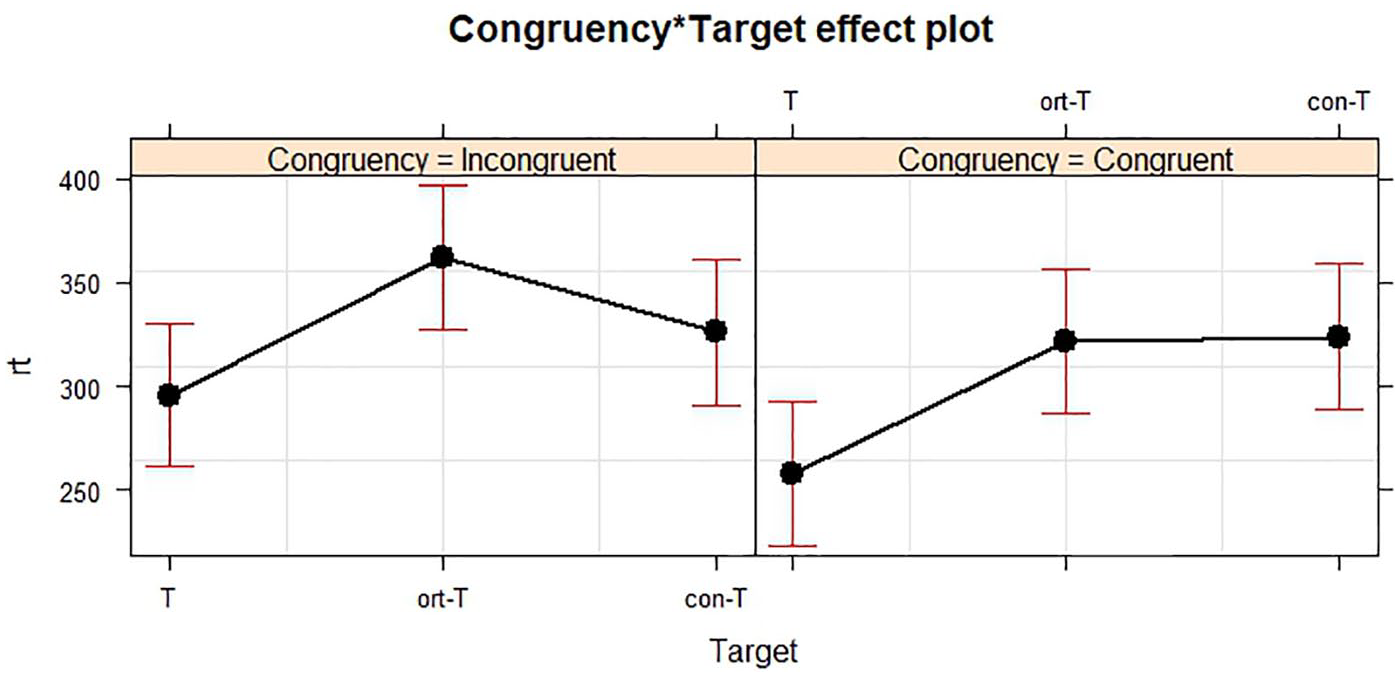
The interaction between congruency and target in RTs to the Target 2s in Experiment 2.
Discussion
Similar to Experiment 1, the congruency effect was observed on the targets in the T condition, which tended to be observed on the Target 1s but surely persisted on the Target 2s. Importantly, the congruency effect also tended to emerge on the Target 1s but surely emerged on the Target 2s in the ort-T condition. That is, the processing of the ort-Ts’ overall shapes helped activate the semantic representations of the Ts in the congruent condition. Different from the case with the pho-Ts in Experiment 1, however, the congruency effect in the ort-T condition failed to appear on the targets. These results can also be explained with reference to the VM. When confronted with the ort-T (e.g., 苗 [miao2] sprout), the participants initially retrieved its phonological information. However, no homophonic candidates were available to fit the context. When it came to the orthographic verification stage, the presentation of the ort-Ts (e.g., 苗) helped to activate semantic representations of configurationally similar words, such as 笛 ([di2] flute) and 黄 ([huang2] yellow). As the activation of the discourse-related word (e.g., 笛) took place at a relatively late phase, the congruency effect failed to appear at the targets, but tended to emerge at the Target 1s and definitely did so at the Target 2s. Van Orden (1987) recognized that “a false candidate is more likely to slip by the verification procedure if it is orthographically similar to the stimulus word” (p. 187). In the process of verification of orthographic information, words that are orthographically similar are activated, making it harder to detect the mismatch in forms.
Indeed, previous studies have suggested that it is faster to name Chinese characters of symmetrical configurations than it is to do those of non-symmetrical configurations (Chen & Huang, 1999). Skilled readers’ re-judgments of the visual similarity of Chinese characters were determined by the overall configurations of these characters (Yeh & Li, 2002). Ma et al. (2016) indicated that the global shape of a word constitutes an independent source of information in activating the representations for those that are configurationally similar to each other. The present experiment further extended the role of configuration in word recognition to discourse reading. Indeed, the processing of words’ holistic information is an indication of expertise in word perception in skilled readers (Chen, Bukach, & Wong, 2013), which may be strongly related to the square-shaped construction of Chinese characters (Tan et al., 1996).
In summary, the results of Experiment 2 are also compatible with the idea of immediate semantic integration in discourse reading. The congruency effect on the ort-Ts confirms the processing of configurational information in activating semantic representations of the upcoming words in a discourse context.
General Discussion
The present study tried to examine the processing of phonological and configurational information in word recognition in discourse reading with the paradigm of self-paced reading paradigm. The materials were three-sentence discourses. In each discourse, the last word of the second sentence and the third word from the end of the last sentence formed a prime–target pair. The discourse in which the target word (T) was semantically congruent or incongruent with the prime word was converted into a new version by replacing the T with its homophone (pho-T) or with the control word (con-T) in Experiment 1. Similarly, the Ts were replaced by the words (ort-Ts) that were similar to them in configurations or by the con-Ts in Experiment 2.
A robust effect of congruency was consistently observed across the two experiments on the targets and on the second words (Target 2s) after the targets in the T condition. Most importantly, the congruency effect was also revealed on the targets in the pho-T condition in Experiment 1 and on the Target 2s in the ort-T condition in Experiment 2. The processing of phonological or configurational information played an important role in activating semantic representations for the words that fit the contexts in discourse reading.
Although proposed based on the findings of a semantic categorization task, the VM is effective in accounting for the data collected in the reading of highly constrained texts (Rayner et al., 1998). By tracking readers’ eye movements, Rayner et al. found homophonic interference with the initial detection of the misspelling of homophone errors. They revealed that the processing of phonological information led to earlier and faster access to semantic representations than did the processing of orthographic information. When participants silently read a passage, “phonological analysis had progressed to the stage in which the target word ‘sounds wrong’ by the time the decision had been made to move the eyes, but orthographic analysis had not progressed to the stage where the target word ‘looks wrong’” (Rayner et al., 1998, p. 491).
One may make further speculations as follows, with the results of the present study taken into consideration. Immediately before the appearance of the targets, the relevant representations for the expected words were likely to be pre-activated to some extent in the participants. When the targets popped up in the congruent condition, the processing of the phonological, orthographical, and semantic information was separately fostered, and the enhancements persisted at the appearance of the Target 2s. If the targets were Ts, the processing enhancements for the three types of information got incorporated; if the targets were pho-Ts (ort-Ts), only the processing of phonological (configurational) information was enhanced in the congruent condition. As indicated by the VM, however, the enhancement for the targets’ configurational information became observable at a later time than the one for the targets’ phonological information, and faded at an earlier time for the targets’ phonological information than for their configurational information.
The early processing of phonological information in Chinese word recognition is also in accordance with an eye-movement-tracking study (Folk, 1999), in which the researcher embedded homophones in sentences in English and achieved results that “are consistent with models of word recognition in which phonological codes activate word meaning for both high- and low-frequency words” (p. 892). The findings of Folk (1999) and the present study (Experiment 1) seem to indicate that “phonology, as a constituent of visual word identification, is accessed universally across writing systems” (Tan & Perfetti, 1998, p. 40). However, it is less clear as to whether this is the case for less-skilled readers. The more we understand the factors that influence the use of these pathways to meaning in the process of reading, the more we can be sure of the determiners of reading development (Jared, Levy, & Rayner, 1999). Investigations into the reading performance of beginning readers or readers with reading problems should be of significance in revealing the relative development of processing of phonological and orthographic information.
It is noteworthy that in Feng et al. (2001) and Wong and Chen (1999), the words that were orthographically similar were beneficial at the early stages of processing, while the homophonic benefits were observed at a relatively late stage of processing. We would like to interpret their results as follows. First, the target Chinese characters (e.g., 识) in these studies were the first components of two-character words (e.g., 识别). When the target Chinese characters were replaced by their homophones (e.g., 食), Chinese characters (e.g., 织) that were orthographically similar to them, or controls (e.g., 考), two-character non-words were actually created. A non-word has no representations that can be accessed in the memory (Tree, Longmore, Majerus, & Evans, 2011). Second, the majority of the orthographically similar stimuli (e.g., 识 vs. 织) share a phonetic radical (e.g., 只) in these studies. The overlap of radicals might have contributed to the observed effect of orthographic benefit. In sentence reading, for example, a reliable preview effect was found during the first fixation when the homophonic previews shared phonetic radicals (Tsai et al., 2004). The benefit in the fixation duration was largely a reflection of information processing at the sub-lexical level.
Conclusion
In the two experiments, a reliable effect of discourse congruency was found on the comprehension of the target words. More importantly, the congruency effect was also observed on the words similar to those that fit the discourse contexts in phonology in Experiment 1 and in configuration in Experiment 2. However, the effect of discourse congruency emerged at a later time for the ort-Ts in Experiment 2 than for the pho-Ts in Experiment 1. The processing of phonological and configurational information is inevitable in activating semantic representations of expected words that fit the context in discourse reading, but the former started earlier than the latter. This finding should be inspiring for those who are interested in the development of reading ability in less-skilled readers and for those who try to examine the influence of contextual factors on word processing in discourse reading.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Social Science Foundation of China under Grant 17BYY016, by MOE (Ministry of Education in China) Youth Project of Humanities and Social Sciences under Grant 18YJC740104, and by Shandong Province Foundation for First-Class Discipline Development of Chinese Language and Literature of Qufu Normal University.