
Abstract
This article explains how to calculate thematic proximity within a mixed methods content analysis approach. Thematic proximity of two themes can indicate the presence of meta-themes. Meta-themes are themes which acquire their meaning through the systematic co-occurrence of two or more other themes. By combining qualitative and quantitative techniques of content analysis, the researcher can reveal these latent text patterns. Using a study on Jihadi media as a showcase, the article describes how to detect meta-themes through content analysis. To this end, the article introduces a novel theme-correlation coefficient that adds valuable information to traditional theme relation metrics. It enables researchers to make new empirical observations in text data.
Keywords
Introduction 1
There are different ways to measure thematic proximity and code relations in content analysis. This article reviews some of them and introduces on this basis a new theme relation coefficient. A theme is a generalized and summarizing description for a set of interrelated issues. In the technical sense, “a theme is an outcome of coding [and] categorisation” (Saldana, 2013, p. 14), whereby codes, categories, and themes represent different levels of the researcher’s abstraction from the original data. “Data” in content analysis can be anything that has “content,” but this article exclusively focuses on text data. Following the hierarchical order of codes, categories, and themes, this article explains how to analyze relations between these analytical units. It refers to these relations as “thematic relations.”
Used in combination with existing theme relation coefficients, the proposed coefficient can reveal how frequent, consistent, and elaborated themes, categories, and codes relate to each other. This information helps researchers to identify meta-themes; themes that are implicitly rather than explicitly stated in textual data.
The analysis of thematic proximity inquires the subtext of verbal information in a standardized fashion. As a showcase, the article presents a content analysis study on Jihadi statements from al-Qaeda (AQ) leaders and demonstrates how the detection of meta-themes works in research practice.
Literature Review: Content Analysis and Theme Relation Metrics
In practice, many researchers combine different strands of content analysis into hybrid (inductive-deductive; Fereday & Muir-Cochrane, 2006) and mixed methods (qualitative and quantitative) designs.
Content includes practices as diverse as fully automated text mining approaches (Angus, Rintel, & Wiles, 2013; A. E. Smith, 2003; A. E. Smith & Humphreys, 2006; Stockwell, Colomb, Smith, & Wiles, 2009) and hermeneutic approaches (Rantala & Hellström, 2001). Often its purpose is to summaries, retrieve, and analyze information from documents. A core task therefore is to identify meaningful clusters of information often referred to as themes, concepts, codes, or categories. There are numerous interpretative and algorithm-based techniques to do so but there are only two directions from which a researcher can apply these techniques: Themes can be identified following inductive (observation based) coding and deductive (theory based) coding (Glaser, 1978; Glaser & Strauss, 1967; Mayring, 2000). It is also possible to approach the data from both directions which is then referred to as hybrid (observation and theory based) coding of text data.
Observation and Theory-Based Coding
The purpose of explorative (inductive) content analysis is to identify analyzable units (codes) in primary or secondary text data (newspapers, office documents, interview transcripts, field notes, etc.) and to summaries them under meaningful labels (categories). Depending on how complex the material under investigation is, the researcher has to decide how to organize the units of analysis. There are at least two approaches to this: According to the Coding Manual for Qualitative Researchers (Saldana, 2013) on the first level, the researcher attaches a code to certain segments of text. On the second level, he organizes interrelated codes into categories thereby creating a taxonomy or category scheme with different categories and subcategories. On the third level, the researcher arranges groups of categories into themes. On top of this pyramid stands a “theory” about the subject as the result of the analysis.
Other approaches allow for coding themes directly into the data, without the process of extracting codes and building categories. This is called thematic coding (or “themeing” the data according to Saldana, 2013, p. 175).
According to one common practice of thematic coding (Attride-Stirling, 2001), one can use three hierarchical levels, or category classes named basic, organizing, and global themes to discriminate in different degrees between rather abstract and rather concrete content. A basic theme is “the most basic or lowest-order theme that is derived from the textual data,” an organizing theme is “a middle-order theme that organizes the Basic Themes into clusters of similar issues,” and global themes “are super-ordinate themes that encompass the principal metaphors in the data as a whole” (Attride-Stirling, 2001, p. 388).
So the main point of difference between the two approaches is whether the researcher can apply (or identify) an analytical unit from the third level directly to data. The common ground of both approaches, and this is the decisive point of the methodology proposed here, is that these analytical units have a hierarchical order.
Next to this organizational structure, the coding procedure also requires coding heuristics: standardized rules that guide the decision of the researcher about when to create a new analytical unit, how to label it, and how to separate codes, categories, and themes from each other. It is important to spell out rules and thereby make the coding and classification process as transparent and replicable as possible. For calculating the theme-correlation coefficient, use the following heuristics (Heuristics 1-3; taken from Kelle & Kluge, 2010).
In explorative content analyses, the researcher usually has to code the entire data set, or at least substantial parts of it, several times until the coding scheme becomes stable. During these iterations, the coder creates, modifies, deletes, and merges the units in accordance to the coding heuristics, thereby steadily developing the taxonomy.
When conducting theory-based (deductive) coding, the researcher starts with a given set of analytical units (codes, categories themes), that is, the number and the label of units is fixed through the theory from which they derive. Coding Heuristic 1 therefore does not apply to theory-based coding, but Heuristics 2 to 4 do. If internal and external homogeneity cannot be achieved, then this indicates a mismatch between the theory and the data.
Thematic Proximity
Coding is a time-consuming and tedious process and of course not an end in itself. One purpose of coding is to reduce complex text structures to analyzable units. A fully coded set of documents enables the researcher to address a wide range of research questions with a large repertoire of (qualitative and quantitative) analytical approaches. One of them is the analysis of thematic proximity (the relation between units). Its purpose is to identify latent patterns in the content that cannot be observed by simply reading the material. The analysis of latent patterns is called relational content analysis.
Relational content analysis usually combines qualitative and statistical interpretation of verbal data into one coherent instrument (Bos & Tarnai, 1999). Still it is not a mixed methodology in the strict sense of the term, insofar as it does not necessarily require collecting “both quantitative and qualitative data” (Creswell & Plano Clark, 2011, p. 276; Onwuegbuzie & Teddlie, 2003). The “mix” is the stage of analysis where a numeric coefficient indicates how strong two themes are related to each other. Still, the detection and interpretation of meta-themes goes beyond “quantitative analysis of qualitative information” (Fakis, Hilliam, Stoneley, & Townend, 2014), and is more than just “two separate approaches to studying the same phenomena” (Symonds & Gorad, 2008, p. 11).
There are different means available to determine the thematic proximity of two descriptive units. The work of Oleinik (2011) provides a useful overview. Cosine similarity, for example, is a vector-based method often used in automated text mining, such as Leximancer.
To a certain extent, theme relation coefficients resemble metrics for intercoder reliability, such as Krippendorff’s alpha (Krippendorff, 1995, 2004; Neuendorf, 2017). Both indicate code overlapping, however, for different purposes. It could be worthwhile to “hack” alpha coefficients in a way that they indicate thematic proximity instead of intercoder reliability.
Another means to determine thematic proximity is to analyze the frequency and pattern of theme co-occurrences within a given set of documents. The c-coefficient used in content analysis software ATLAS.ti (Friese, 2014) measures how often and consistently two codes co-occur or overlap throughout the entire text sample. The c-coefficient represents the frequencies and patterns of code co-occurrence “similar to a correlation coefficient statistics” (Friese, 2014, p. 189). It is based on the Jaccard similarity coefficient. 3 Many content analysis software packages do not provide this function, but the researcher can use the code retrieval function “near within one paragraph” to determine the number of co-occurrences, and then calculate the c-coefficient manually using the formula (Friese, 2014, p. 190):
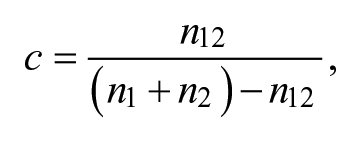
with
Co-occurrence means that that both codes either code the same segment or overlapping segments. The coefficient can take values between 0 (indicating perfect independence) and 1 (indicating perfect relation). The greater the discrepancy between
The c-coefficient has two important limitations: First, it can underestimate the strength of a thematic relation when one analytical unit has considerable more codings (the number of discrete text segments that are associated with a given code) than the other. 4 The c-coefficient does not take into consideration the proportion of overlapping content. Therefore, it can remain low although the thematic link might be quite elaborated in terms of word frequencies. Second, it is not standardized and disregards the overall coding pattern of the data set making it difficult to compare c-coefficients from different studies.
To prevent this loss of information, the following section proposes an additional coefficient that takes into account not the frequency of code co-occurrences but the proportions of text intersections based on word frequencies. Taken together, these two coefficients can better assess the qualitative and quantitative relation of two themes.
Proposed Methodology: The t-Coefficient
The c-coefficient measures how often and consistently two codes (units) co-occur throughout the entire text sample but disregards how elaborated their relation is. This, however, is a valuable piece of information about thematic structure of the content. The proposed coefficient therefore indicates how much content two descriptive units actually share with each other in terms of words frequencies. This can be relevant because the information about how frequent and how consistent two themes co-occur does not necessarily tell anything about how important or elaborated the thematic link is within the research context. Taken together, the two coefficients can reveal latent structures in text samples that might constitute a meaningful meta-theme. I refer to the proposed coefficient as the t-coefficient (t for theme). It is defined as
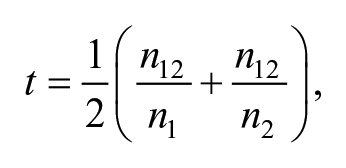
with
The t-coefficient measures the average proportion of content that two descriptive units share with one another. It can take values between 0 (indicating mutual exclusiveness of coded text segments) and 1 (indicating complete overlap [congruency] of coded text segments).
A t-coefficient of 0.10, for example, provides the information that each of the two units shares on average 10% of its content with the other unit (i.e., usually none of the two categories shares exactly 10% unless they both have the same number of words). In combination with the c-coefficient we can also say how often and how consistently this co-occurrence appears. Large t-values combined with low c-values indicate that the link is elaborated but not frequent and consistent, whereas large t-values combined with large c-values indicate that the thematic link is elaborated, frequent, and consistent. The t-values greater than .5 should be interpreted with caution because it might indicate a lack of discriminant validity, that is, two themes are so closely related, that they are not distinguishable and may actually represent the same theme. If this happens, then it could indicate a violation of the coding Heuristic 3 (see above).
Standardizing the Theme Relation Coefficient
It is important to note that the sample size, coding heuristics, and number of descriptive units can affect the t-coefficient. What may be a high coefficient within the scope of one study may indicate a rather weak thematic relation within the other. This obstructs comparability of the t-coefficient between two studies. To eliminate the influence of the coding practice on the results, it is necessary to calculate the standardized t-coefficient
The standardized t-coefficient is adjusted in regard to these two general coding patterns. It is calculated in four steps. First is to calculate the proportion of text retrievals with more than one coding in relation to the sum of all text retrievals:

where
P states the extent of multiply coded text in all documents of the sample. The P value in the showcase study is P = .62 and states that 62% of all coded words are coded with more than one unit. 8 P has to be interpreted in relation to the degrees of freedom, that is, the number of all possible (yet, not measured) bivariate correlations. The higher the number of categories within the coding scheme, and with that, the number of possible bivariate correlations, the lower is the average influence of P on any given bivariate correlation.
The degrees of freedom are determined by the number of potential correlations between the k categories. They are calculated by dividing all fields of the code-correlation matrix (

The next step is to calculate the adjustment coefficient U. It indicates the average bivariate correlation if all multiply coded text were equally distributed among all units of the category scheme. It works as a baseline comparison for the observed correlation t.
The adjustment coefficient U is
The standardized t-coefficient is:
It is in the judgment of the researcher to decide whether to report every single standardized t-coefficient. In some cases, it might be sufficient just to report the overall adjustment coefficient U, namely, when U is so small that it hardly affects the difference between t and
Interpreting t-Coefficients
There are two ways to judge whether a given t-value indicates a weak, moderate, or a strong relation. First is to compare different t-values with each other. As can be seen in Table 1, the highest correlation between two categories is .129 between the theme “theological justifications for the use of force” and the narrative about the “global conflict.” Compared with other thematic links, this is strong. The c-coefficient (.058) is also comparably high signaling that this link is also more frequent and consistent than most other links in the table.
Theme Relations.
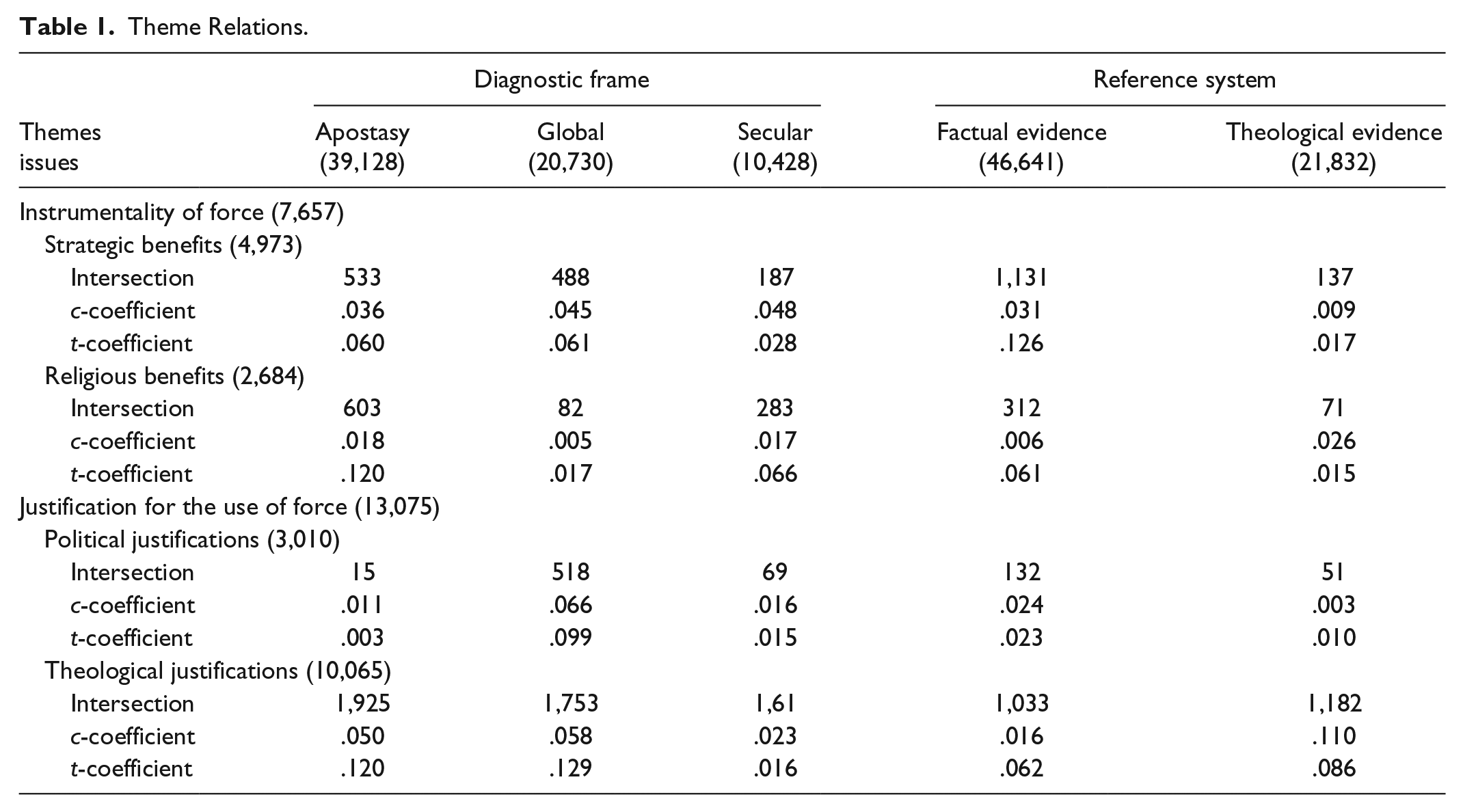
Another way to judge the strength of the correlation is to compare observed t-values against the unobserved t-values of two mutually independent themes (here U = .0002). A t-value of .129 then indicates that the correlation is significantly different from independence. It is also possible to base this benchmark test on randomly, instead of equally distributed content. This would in some way resemble the statistical test for significance and could be the method of choice in quantitative content analysis.
The standardized coefficient
Detecting Meta-Themes, or How to “Read Between the Lines” of Qualitative Data
When two or more descriptive units systematically co-occur in the text data and when the co-occurrence is not only frequent but also elaborated in terms of word frequencies, then this can indicate the presence of a meta-theme. The two coefficients therefore are quantitative indicators for meta-themes. Meta-themes are themes which acquire their meaning through the systematic co-occurrence of two or more other themes. The prefix “meta” means that these themes are themes of a higher informational order, or in other words, they are not explicitly but implicitly communicated within the content. A meta-theme might mark subconscious communication and tells the researcher something about the source, namely, that it systematically refers to two distinct themes.
The statistical coefficients should always be interpreted in combination with a qualitative assessment of the meta-content. Not every thematic correlation is necessarily a meta-theme. Likewise, the detection of a meta-theme does not necessarily reveal the reason why the originator communicates subconsciously and not explicitly and intentional. This question can be answered only within the context of a particular study.
To give one example of subconscious communication, we now turn to the showcase study.
Worked Example
Within Islamic studies, the “unusual combination of logic, religion, politics and violence” of Islamism has been acknowledged (Jansen, 1997, p. xvi). This “dual nature of Islamic Fundamentalism” (Cozzens, 2007; Sedgwick, 2004) is the point of departure for this showcase study. Jihadi ideology comprises not only strategic thinking, rational argument, and common sense logic but also doctrine, theological reasoning, and religious fanaticism. To date, there is no systematic empirical research on the question how exactly both rationalities are connected. The showcase study demonstrates how the analysis of meta-themes in Jihadi ideological statements can shed light on this link. Its objective is to explore the ideological origins of religiously inspired violence through content analysis of public statements from AQ’s leadership.
Literature Review: Content Analysis of Jihadi Media
Over the last 15 years, the Jihadi movement has produced an abundance of media and propaganda material, and the academic community was not idle to investigate this material with a great deal of interest. Despite the wealth of available data and scholarly work, systematic content analysis of this material is still the exception. It seems that the availability of highly interesting and politically relevant research material was conductive for an atmosphere in which “the terrorism studies community seems to have deviated from the guidelines of academic conduct” (Hellmich, 2008, p. 111). The availability of primary sources coincided with the “post-9/11 money surge into terrorism studies” for which Marc Sageman (2014) provocatively diagnosed “deleterious effect” (p. 566). Although there are also examples of good scientific practice, terrorism studies have not yet exploited the full potential of content analysis approaches.
Authors of studies who apply content analysis techniques often remain descriptive. Eveslage (2013), for instance, counted the number of threats against domestic and foreign targets within 23 public statements of the Nigerian Jihadi group Boko Haram. Torres, Jordán, and Horsburgh (2006) used qualitative and quantitative thematic coding to summaries a sample of 2,878 documents from AQ. Salem, Reid, and Chen (2008) classified 706 media files produced by Jihadi groups in regard to their production features, purpose and usage as documentary, propaganda, operational, hostage, executions, statement/communique, tribute/eulogy, training, and instructional videos. Pennebaker and Chung (2008) described differences in linguistic styles between bin Laden and Zawahiri, and Beutel and Ahmad (2011) inferred from their analysis of 49 bin Laden speeches, that the now deceased leader of the Jihadi movement cited policy-based grievances for his militancy twice as often as religious-based ones.
Descriptive content analysis of Jihadi media gave researchers a first glance into the wealth of data but to come to more generic conclusions about the groups who communicate these messages, more sophisticated analysis is needed. A common approach in terrorism studies therefore is to compare extremist groups who engage in violence with those who do not (A. G. Smith, 2004). For example, A. G. Smith (2008) and A. G. Smith, Suedfeld, Conway, and Winter (2008) applied three psychological measurement constructs (value reference, motive imagery, integrative complexity) to media content of violent and nonviolent Islamist groups, and identified those variables that are statistically significant predictors to distinguish between groups. Conway, Gornick, Houck, Towgood, and Conway (2011) investigated “hidden implications of radical group rhetoric” by analyzing random text samples with integrative complexity coding from violent and nonviolent Islamist groups. Pennebaker (2011) identified in a text sample of 296 documents statistically significant predictors for a violent attack in the 2 to 6 months following the statement of the group. Rieger, Frischlich, and Bente (2013) integrated ethnographic content analysis of Jihadi and right wing media into a randomized experimental design to investigate the individual’s response to ideological messaging.
Methodology of the Showcase Study
Sampling
The text documents of the showcase study (transcripts of AQ video statements) were sampled in several stages. Although desirable, representative sampling of documents was not feasible because an exhaustive register of Jihadi media does not exist. As a work-around for this problem, I sampled documents from a pool of Jihadi statements compiled by experts. 9 The selected statements are therefore representative of the Jihadi ideology to a certain extent (although this extent is not quantifiable). The final sample consists of 31 transcripts of AQ video messages (about 178.000 words).
hierarchical levels of analytical units
Using software MAXQDA, 10 I combined a theory-based coding with explorative coding into a hybrid coding design. Therefore, the coding structure includes both theoretically and empirically driven units of analysis, also referred to as deductive and inductive categories (Mayring, 2000). It has five hierarchical levels:
Ideology as discourse (theory driven)
Frame (theory driven)
Narrative (global themes)
Theme (organizing themes)
Issues (basic themes)
Basic, organizing, and global themes (Attride-Stirling, 2001) or codes, categories, and themes/concepts (Saldana, 2013) represent the empirically driven units. To utilize these units for the particular purpose of studying ideologies, I call them “issues,” “themes,” and “narratives.” They discriminate in different degrees between rather abstract and rather concrete content within the Jihadi statements (see Figure 1). Frames and discourse are theory-driven units of analysis and represent the most general characteristics of Jihadi ideology. Discourse, frame, narrative, theme, and issue represent different hierarchical levels the coding scheme. They represent the functional elements of ideologies—the mechanisms through which they frame the world—but they do not tell anything about the actual grievances, claims, positions, strategies, and visions of the movement that embraces this ideology. Each level therefore has a certain number of descriptive categories that summaries the actual meaning of the ideology and represent the substantial elements. In the sample of 31 video statements, I identified one discourse, four frames, 11 narratives, 26 themes, and 55 issues.

Category classes.
The level of “discourse” is the most comprehensive and general one. In fact, all content belongs to it. Its purpose is to acknowledge that Jihadism is not mutually exclusive from other Islamist ideologies but remains in a constant discursive relation with them, and therefore can be analyzed as such, for instance, when conducting a discourse analysis of statements published by AQ vis-à-vis statements from the Islamic State or the Muslim Brotherhood. For the purpose of this article, the analytical unit “discourse” has no further function.
The level “frames” has four descriptive units borrowed from Social Movement Theory (Snow & Benford, 1988; Wilson, 1973). Social Movement Theory has an intuitive appeal for the analysis of Islamist movements and has been used for this purpose across disciplines (Lohlker, 2013; Snow & Byrd, 2007; Wiktorowicz, 2004a, 2004b). It states that all ideologies are comprised of three principal components, also called frames: The “diagnostic frame” of an ideology describes (perceived and actual) social problems (i.e., “the war on Islam”) and specifies alleged political, economic, and social reasons for these problems. The “prognostic frame” describes the goals the movement pursues, namely, to replace the unjust status quo with an auspicious alternative (i.e., “the caliphate”) and the “motivational frame” describes strategies how the goals can be achieved (e.g., “jihad”). For coding purposes, I used a fourth frame (reference frame) as an auxiliary unit to designate all content that is nongenuine, that is, when the authors of the statements refer to external sources to substantiate their socioreligious positions, claims, and grievances. For instance, Jihadi leaders use theological evidence (references to Quran and Sunnah) to substantiate their theological argumentation, factual evidence (references to mainstream media or governmental reports) to back up their political claims, and aesthetic “evidence” (Islamic poems and lyric) to increase the “narrative fidelity” (Snow & Benford, 1988, p. 210) of their message.
When conducting hybrid coding, one can start the coding procedure top-down by coding the most general units into the data, or bottom-up by looking for the smallest informational units first. Starting with the most general (theoretically driven) unit has the advantage that it usually requires little prior knowledge about the content. It also gives the coder a first glance into the material so that he gets a rough idea about the thematic complexity and the approximate number of empirically driven (inductive) themes present in the material. In the study of Jihadi media, it was straightforward to recognize whether the author of the statement describes the status quo, talks about his vision or utopia, or advices followers to take action. In the most simplistic manner, coding frames into ideological statements follows the ABC model (Account, Better World, Change) of Mark Sedgwick (2012). Unlike the empirically driven units, frames must be mutually exclusive. However, the empirically based subunit of frames can cut across two or even three frames.
The next task is to identify the empirically driven themes. Here the researcher starts from the scratch with nothing else than the four coding heuristics (see above) to guide him. Processing one statement after the other in no specific order, I created, modified, deleted, and merged the descriptive units in accordance to the coding heuristics, thereby steadily developing the coding structure. After working through 10 statements, the coding structure began to stabilize, meaning that fewer new units emerged and that fewer modifications were necessary to satisfy the coding heuristics. At the end of the first coding iteration, the coding scheme was entirely stable and the last few documents did not trigger any more modifications. This indicates that the coding structure represents the content adequately and also that the sample is saturated. A second coding iteration was necessary to adjust the content of the first processed documents to the finally developed scheme. The final version of the scheme has four frames, 11 narratives, 26 themes, and 55 issues. To visualize the thematic structure, I created a mind map that depicts all 96 categories (Armborst, 2013).
Results: Interpreting t-Coefficients and Detecting Meta-Themes in Jihadi Media
The systematic content analysis approach has helped to clarify and dissect the otherwise rather indistinct bulk of ideological messages. The main research objective of the study was to explore the ideological origins of religiously inspired violence in Jihadism. The analysis shows that Jihadism is a complex ideology that touches on a plethora of explicit socioreligious issues. The main thematic structure of the ideology consists of four frames, 11 narratives, 26 themes, and 55 issues. It contains rigorous theological argumentation mixed with political analysis expressed in the language of journalism or even scholarly argument. It is beyond the purpose of this article to describe all these aspects in detail. The important point here is to show the application of the theme relation coefficient.
Figure 2 and Table 1 present some of the quantitative results of the showcase study. Within the motivational frame of AQ ideology, two narratives and four themes are of particular interest in regard to the research objectives: the narrative about the (1) “instrumentality of force” in which the authors describe what they think the movement can actually achieve through the use of force. These expectations are further detailed within the two themes (1.1) “strategic benefits” and (1.2) “religious benefits.” The other narrative is the (2) “justification for the use of force” with its two themes: (2.1) “political justifications” and (2.2) “theological justifications.”

Text proportion for frames, narratives, and themes.
To operationalize the broader research objective, I formulated the following working question: Which other narratives, themes, and issues co-occur systematically with (1) and (2), and how strong are the thematic relations between them in terms of quantity and quality? Relational analysis helps to assess how the rationale of violence is embedded in the wider narrative structure of AQ’s ideology, not only in terms of statistical co-occurrence but also in terms of elaboration and meaning.
Figure 2 shows the absolute and relative word frequencies of selected categories. Beginning with the most extensive narrative (about apostasy), categories are ranked and grouped according to the hierarchy of the coding structure (frames, narratives, themes). The information about word frequencies helps to put the qualitative description of each frame, narrative, and theme into a broader perspective about the general outline and composition of Jihadi ideology. It empirically supports the observation made in other studies that Jihadism is mainly about Islamic rivalry (the near enemy) and to a lesser degree concerned with geopolitical affairs (the far enemy), but both aspects are certainly connected, as the relational analysis shows.
The coefficients in Table 1 reveal how frequent and how strong categories are linked. It displays c- and t-coefficients for the thematic relation between the four themes about the rationale of violence (rows) and the three narratives within the diagnostic frame (columns). The numbers in the table can be interpreted in a similar way than a crosstab with categorical variables. To give a reading example of the numbers in the table, the narrative about the instrumentality of force (7,657 words) has two subthemes: strategic benefits (4,973 words) and religious benefits (2,684 words). These subthemes correlate to different degrees with the three narratives in the diagnostic frame (apostasy, global conflict, and secular governance) and are backed up to different degrees by factual and theological evidence from the reference system (nongenuine content). To pick out one example, the two categories “strategic benefits” and “apostasy” share 533 words, which correspond to a c-coefficient of .036 and a t-coefficient of .060, indicating a moderately elaborated and rather infrequent thematic relation.
As noted before, the coefficients should always be interpreted in connection with a qualitative assessment of the thematic link. When reviewing the meta-content (533 words) cutting across the themes “strategic benefits” and the “apostasy” narrative, it reveals a tacit message: AQ asserts quite plainly that jihad is as much a matter of strategic choice as it is a matter of Islamic law and individual duty. What they claim rather implicitly is that this distinction makes them superior to competing Islamist groups who act much more strategically (“opportunistic” in the view of AQ). AQ promotes active participation in jihad, even against all strategic odds, to demonstrate its pristine interpretation of Islam and to claim religious supremacy over competing Islamist movements (often labeled apostates) who refrain from the alleged duty of jihad for purely political and strategic considerations.
But why is this claim communicated implicitly rather than directly? A plausible explanation is that the strategic flaws of Jihadi military doctrine are both a powerful and vulnerable aspect of the ideological message. It is powerful because only this way AQ can credibly claim religious supremacy over competing Islamist groups. And it is a vulnerable point because AQ can be (and actually is) criticized for being strategically and militarily ineffective and therefore not worth of support. Therefore, this aspect of the ideology has to be communicated in a subtle way as to disguise its contradiction.
This observation is an intriguing and important aspect of AQ’s ideology, much more important than the rather moderate correlation of t = .060 would suggest. This demonstrates that it is important to review the statistical results always in combination with a qualitative assessment.
Other themes systematically co-occur without carrying any implicit message. For example, the theme about the strategic benefits of jihad are backed up quite strongly (t = .126) by factual evidence but not so strongly by theological references to Quran and Sunnah (t = .017). There is nothing more to conclude from this observation other than the Jihadists use rational (factual) instead of theological reasoning when describing the strategic utility of Jihadi warfare.
Finally I want to use the showcase study to give an example of how to interpret the unstandardized coefficient t together with the standardized coefficient
Discussion
The most important limitation in the use of the proposed coefficient is to keep in mind, that the statistical “facts” it produces are eventually contingent upon coding decisions. Despite the use of clearly spelled out coding heuristics, there remains some interpretative leeway. It is therefore good scientific practice to involve several coders and then test intercoder reliability. 11
Without the aid of content analysis software, it is not possible to systematically read between the lines of large text samples and to detect latent structures. The proposed theme relation coefficient enables researchers to discover subtle patterns in verbal content. It allows the researcher to draw analytical conclusions about his study object through a transparent and replicable methodology. To substantiate this claim, this article uses an empirical study on Jihadi media to demonstrate how the application of the coefficients has produced more generic information about the ideology of Jihadism as it is communicated in a sample of Jihadi media.
Unlike conventional co-occurrence (Friese, 2014) or code relation metrics that show how often and how consistent two themes co-occur within the text sample, the new proposed coefficient indicates how much content two units actually share with each other and how elaborated their thematic link is. The combined use of both coefficients can add important information to conventional analysis because the observation how often and how consistent two themes co-occur in the data is not necessarily an indicator for how important, relevant, and meaningful this thematic relation is within the research context.
The methodology proposed in this article is applicable in various scenarios of content analysis and with different types of data (interviews, field notes, public documents, and other text data). The standardized version of the t-coefficient makes the results from different studies comparable. This is important because differences in sample sizes and researcher’s coding practice can affect the values of conventional theme relation metrics. The standardized coefficient offsets this potential bias and enables researchers to compare results regardless of sample size, number of extracted categories, and extent of code overlaps.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.