
Abstract
After a brief review of methods for assessing the reliability of individual test, the article presents a method of obtaining reliability of a battery of tests where battery score could be defined as sum of weighted or unweighted scores of the component tests. Such battery reliability can be influenced significantly by method of selection of weights to arrive at the battery scores and methods of estimating reliability of component tests. Test reliability as per theoretical definition in terms of length of score vectors of two parallel tests and angle between such vectors in N-dimensional space also helps to find values of error score variance of the test fits well in estimation of battery reliability. Relationship between theoretically defined reliability rtt and split-half correlation rgh was established. For weighted battery score, a Lagrange multiplier-based solution for determination of weights is recommended with the use of reliability as per the theoretical definition. Weights found as above have the advantage that the battery score (Y) has minimum variance. Also, covariance between the battery score and the score of an individual test is a constant. Condition of battery score being equi-correlated with the standardized score of each constituent test was derived.
Introduction
In practical situations, a battery of tests is administered instead of a single test. Single tests may not be adequate to detect appropriately the required latent abilities. For example, aptitudes are made of a complex of abilities. Intelligence tests could be a combination of verbal and numerical aptitudes among others. Most diagnostic questions require the assessment of personality, intelligence, and perhaps even the presence of organic involvement. Thus, a battery of tests is needed to measure complex abilities and to identify individual’s strengths and weaknesses. In a battery, a set of component tests are grouped together and administered in situations like selection of personnel for employment, Health-Related Physical Fitness Test (HRPFT) for jobs, sports, and even for assessment of fitness of Astronauts, mental-health issues, and so on. Development of cognitive battery for clinical trials of cognition-enhancing treatments for schizophrenia was highlighted by Mesholam-Gately et al. (2008). Kassin (2003) observed that application of factor analysis to the study of trait organization has provided the theoretical basis for the construction of test batteries. Examples of such batteries include among others SRA Primary Mental Abilities (PMA), Differential Aptitude Tests (DAT), Guilford-Zimmerman Aptitude Test, and so on.
While estimation of reliability by various methods and error variance derived from reliability for individual test are widely discussed (Anastasi and Urbina, 1997; Franzen, 2000; Murphy and Davidshofer, 2005), evaluation of reliability of test battery as a whole along with properties does not appear to have been accomplished to a great extent. This is despite the fact that combining tests into a battery in no way reduces the potential for measurement error associated with both the individual test and the battery.
Thus, need is felt to estimate reliability of a battery as a function of reliability of each component test along with estimation of true score variance of the battery, considering battery score as a weighted sum of component tests and avoiding scaling of scores of component tests.
Rest of the article is organized as follows. Previous studies on measures of reliability of test and battery are elaborated in the following section. Conceptual framework for battery scores and issues relating to scaling of scores of component tests and aggregation methods are elaborated in Section “Battery scores.” Section “Battery reliability” deals with theoretical details regarding choice of methods of finding reliability of the component tests as per theoretical definition and associated properties. This was followed by method of the computation of the reliability of a battery of tests using summative scores and weighted scores with discussion on recommended method of finding weights which minimizes variance of the weighted sum. The article is rounded up in Section “Summary and discussion,”, by recalling the salient outcomes of the work.
Literature survey
Reliability of an individual test has been pursued in a variety of ways aiming to indicate consistency, precision, repeatability, trustworthiness, and so on of a test. Reliability as degree of consistency of test scores, that is, repeatability, has been recommended by Berkowitz et al. (2000). However, different values of test–retest reliability of a single test may be obtained depending on the time gap between the administrations. Cronbach’s alpha is widely used to find reliability as a measure of internal consistency. However, it is necessary to check that the data fit the unidimensional model before calculating alpha (Trizano-Hermosilla and Alarado, 2016). Violation of assumption of tau-equivalence will underestimate α (Graham, 2006; Raykov, 1997). Working with data which comply with this assumption is generally not viable in practice (Teo and Fan, 2013). Wilcox (1992) showed how coefficient alpha is vulnerable to modest numbers of outlying observations and may substantially inflate alpha. Limitations of Cronbach’s alpha have also been reported by Hattie (1985) and Ritter (2010). Parallel test or split-half reliability considers correlation of two parallel sub-tests obtained by dichotomization of the test score in one session. A major limitation of the split-half reliability is that the resulting estimate is not unique and depends on how exactly the split was carried out. Indeed, different splits into halves of an initial multiple-component instrument can well yield different reliability estimates. Zimmerman (2007) favored expressing reliability in terms of standard error of measurement (SEM). Thus, no popular method of finding reliability uses the theoretical definition of reliability which is defined as the ratio of the true score variance and observed score variance. Consequently, multiple values of the error variance and reliability can be obtained for the same test even if the sample remains unchanged. Reliability that conforms to the theoretical definition cannot be computed since true scores of individuals taking the test are not known. Moreover, estimates of reliability are themselves vulnerable to measurement error (Vacha-Haase et al., 2000).
The above are also applicable for estimating reliability of a battery of tests, where battery score is taken as sum or weighted sum of component tests scores. Reliability of the battery can be influenced significantly by method of selection of weights to arrive at the battery scores and methods of estimating reliability of component tests, since sources of errors of individual tests may get manifold for the battery. For estimation of reliability of a battery, Lubans et al. (2011) used test–retest approach. Berchtold (2016) opined that while reliability is the ability of a measure applied twice upon the same respondents to produce the same ranking on both occasions, agreement requires not only to preserve the relative order of the respondents in the two sets of measurements but also the same exact result that each respondent obtains on the two testing situations. Battery reliability using weighted sum of component tests was attempted by researchers like Wang and Stanley (1970), Feldt and Brennan (1989), Rudner (2001), Webb et al. (2007), and others using different approaches and scaling. However, the approaches gave rise to different values of battery reliability, especially when individual components measure multidimensional constructs. Rudner (2001) indicated that adding raw scores fails to recognize the relative importance of components to the overall composite; weights proportional to reliability of the components may results in lower SEM of the composite score in comparison to simple summative scores. In case of availability of pre-specified, quantifiable external criterion, weights of component tests may be found by linear multiple regressions with the criterion. Such method of finding weights may result in maximum validity of the composite score. Canonical correlation allows an extension of the parallel test situation and split-half technique. Safrit and Wood (2013) and Koch et al. (2003) used canonical correlation analysis (CCA) where randomized subsets were created first which were then correlated using canonical correlation technique. Essence of CCA is to form pairs of linear combinations of predictor and criterion variables to maximize the correlation between each pair. In the context of reliability of a battery, there may not exist unique efficient procedure to obtain predictor and criterion variables. In addition, CCA technique finds linear relationships between variables within a set and between pairs of canonical variates (linear pairings of canonical variates, one from each of the two sets of variables). Non-linear components of these relationships, if any, are not recognized and are not captured in the analysis. Outliers have mixed impact on the results of the CCA, and each set of variables is inspected independently for univariate and multivariate outliers. Because canonical correlation is very sensitive to small changes in the data set, the decision to eliminate cases must be made very carefully. Both multicollinearity (when variables are very highly correlated) and singularity (when one variable is a linear combination of two or more variables in that set) should be eliminated before analysis proceeds. Precautions for using CCA were mentioned by Lambert and Durand (1975). Equivalences among canonical factor analysis, canonical reliability, and principal component analysis were studied by Conger and Stallard (1976); they found that if variables are scaled so that they have equal measurement errors, then canonical factor analysis on all non-error variance, principal component analysis, and canonical reliability analysis give rise to equivalent results. However, the assumption of equal measurement errors is abstract and too difficult to achieve.
Battery scores
Battery scores can be viewed as a composite score of component tests, that is, aggregation of scores of component tests to a single value for an examinee. Stages for construction of composite score/index involve scaling of test scores and deciding appropriate method of combining.
Major points to be noted are as follows: (1) Component tests could be independent or dependent with various degrees; (2) Battery score could be weighted or unweighted sum of scores of component tests; (3) Reliability of the battery can be influenced significantly by reliability of each component test and also by the method of arriving at the battery scores; (4) In addition to battery reliability, it will be desirable to find estimates of true score variance and/or error score variance of the battery; (5) Reliability based on internal consistency may be relevant for an individual test but not for battery due to multidimensionality of a test battery.
Scaling
Usual practice is to consider standardized scores of component tests by subtracting from the sample mean and dividing by the sample standard deviation (SD). Distribution of standardized score of a test will follow normal distribution for large sample, even if distribution of original test score may be different from normal. There are many other ways to normalize test scores. Illustrative list is as follows:
Z= log(x); x > 0 to reduce skewness of (positive) data.
Note that there is no best method of scaling or normalization or transformations of component score. However, scaling will have significant effects on the composite score, its distribution, and battery reliability. Hence, it is felt desirable to find composite battery score avoiding scaling of component scores.
Combining method
Usual methods of combining scores of component scores may include (1) Summative score, that is, battery score of an individual is the sum of his or her score in each component test. This considers all tests are of equal importance. This allows compensability among component tests, which may not be desirable or (2) Weighted sum which assumes linear model with implication of full compensability, that is, poor performance in some component tests can be well compensated by high values in other tests. However, there are different methods of deciding weights even under the condition
Battery reliability
Since battery reliability will be function of reliabilities of the component tests, it may be prudent to select a method of finding reliability of a component test as per the definition, that is, as the ratio of true score variance
Reliability of tests
Chakrabartty (2013) proposed a method of obtaining test reliability as per the theoretical definition along with computation of error variance and true score variance from single administration of the test. The method uses lengths of two parallel tests and angle between the two vectors representing scores of the two parallel tests. A test consisting of n-items administered among N persons, when dichotomized in parallel halves say g-th test and h-th test, results in two points
Also,
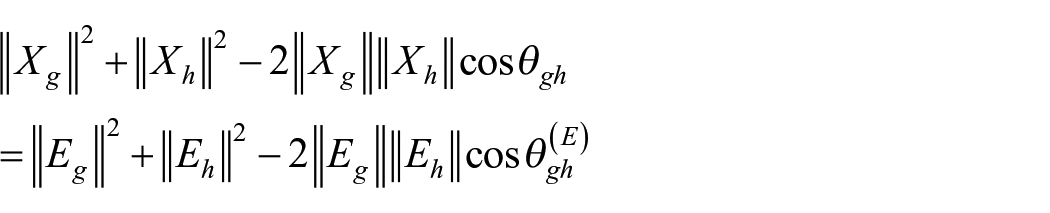
where
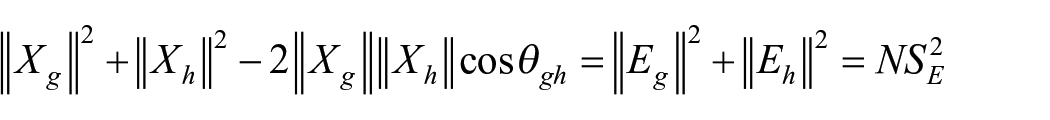
since
The above equation suggests
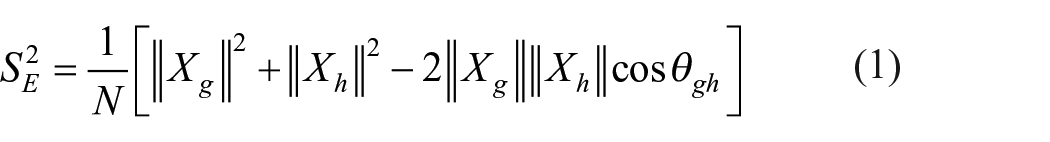
where
Hence, theoretical test reliability
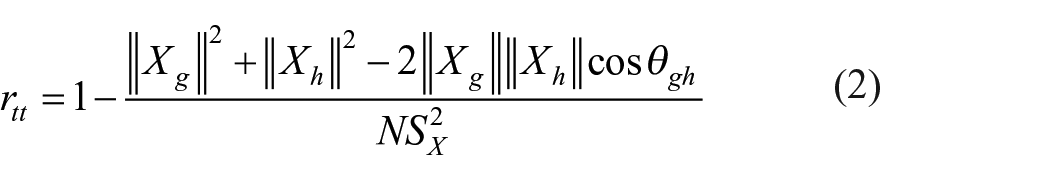
Since, it can be proved that parallel tests are of equal length, the formula (1) and (2) can be further simplified as

and
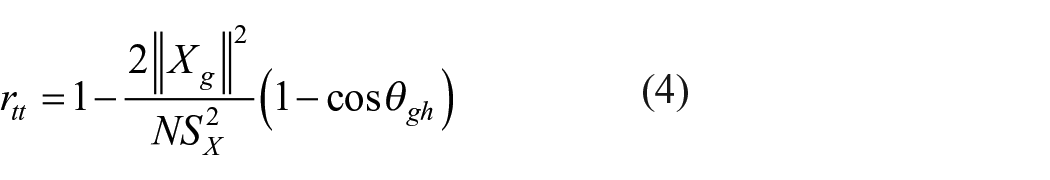
Equation (1) helps to find value of error variance of the test and hence true score variance as
Properties of theoretically defined reliability
Equations (1) and (2) were derived assuming dichotomization of a test in parallel halves. However, in practice, it may be difficult to dichotomize a test where means and variances of scores exactly match. Thus, the above two equations work well even if there are marginal differences in length of the vectors
Correlation between two parallel sub-tests,
Equation (1) gives a way to find error variance of the test avoiding popular method of first finding test reliability not conforming to the definition and then using
If g-th test and h-th tests are parallel,
Proof: equation (3.2) can be re-written as
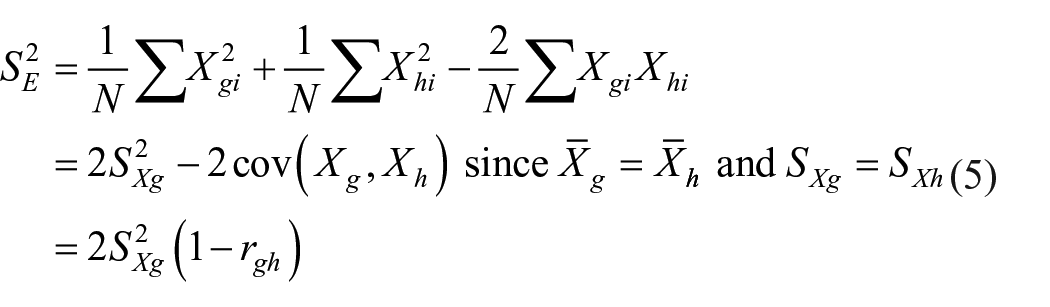
where
5. If g-th and h-th tests are parallel, theoretically defined reliability
Proof:
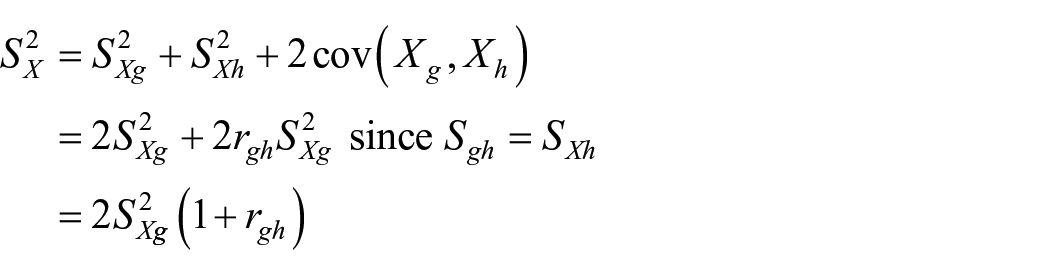
Thus,
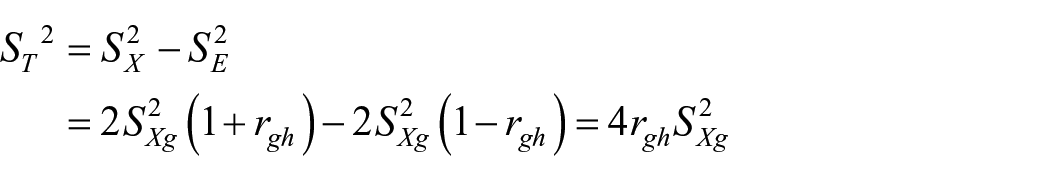
And theoretically defined reliability is
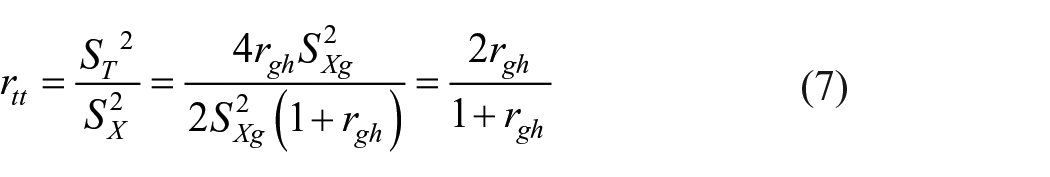
Equation (7) gives relationship between theoretically defined reliability
From (7),

6. For a given data set, sample values of
Estimation of battery reliability
The method of finding test reliability as per the classical definition can be extended to find the reliability of a battery of tests. The method of obtaining the reliability of the battery will depend on the selected method of reliability of the component tests and on the definition of the battery scores. Usually, battery scores are computed as the sum of the scores in the individual constituent tests (summative scores) or as a weighted sum of these tests scores. Here, we omit the discussion of difference scores–based battery computation for brevity’s sake.
Weighted sum of component tests
Suppose a battery consists of two tests: Test 1 and Test 2. For the i-th person, let
Now,
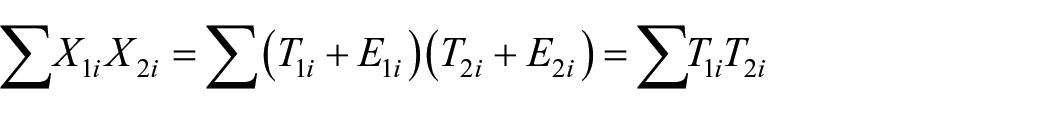
since
Thus,
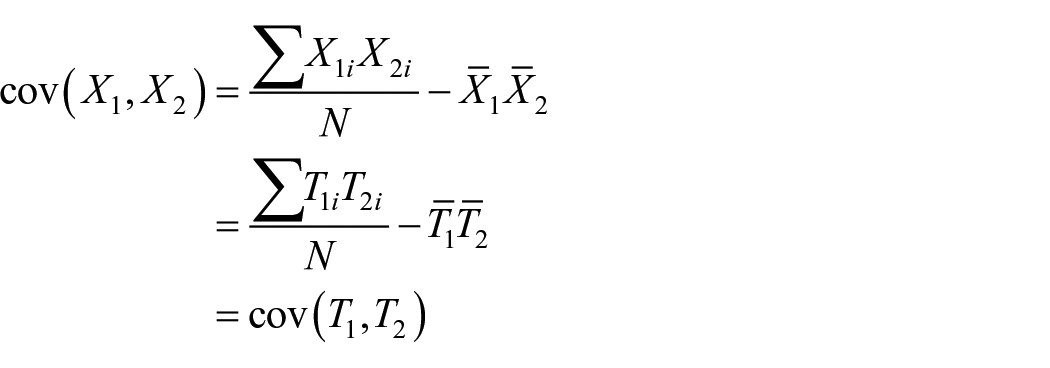
Now variance of true score of the battery is
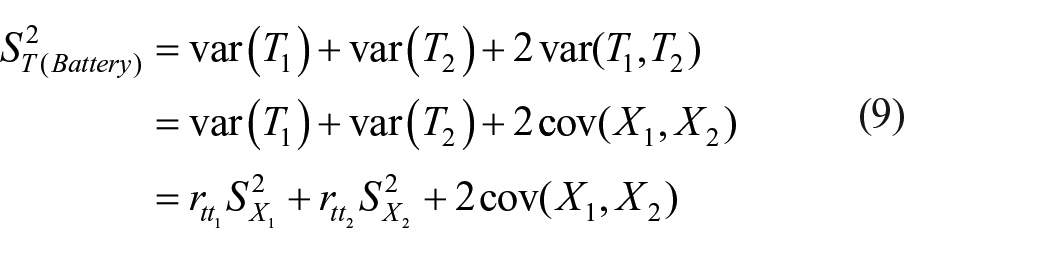
Thus, reliability of a battery is given by
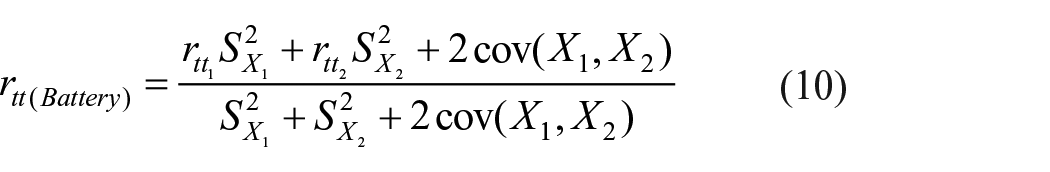
In general, if a battery has K-tests which are equally important and the battery score is a summative score of the K-constituent tests, then the true score variance of the battery and reliability of the battery will be given, respectively, by
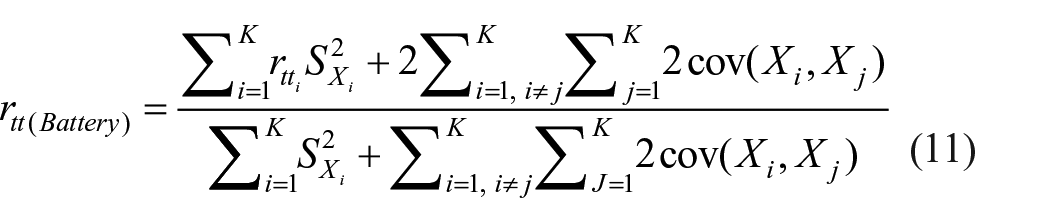
The idea can be extended to find reliability of battery where battery score is weighted sum of scores of the constituent tests.
Consider a battery of K-tests and weights
Clearly,
Then
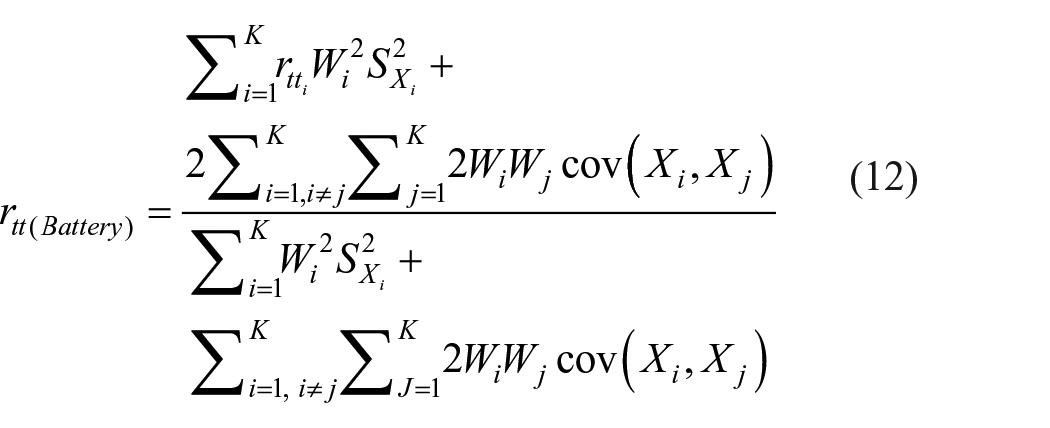
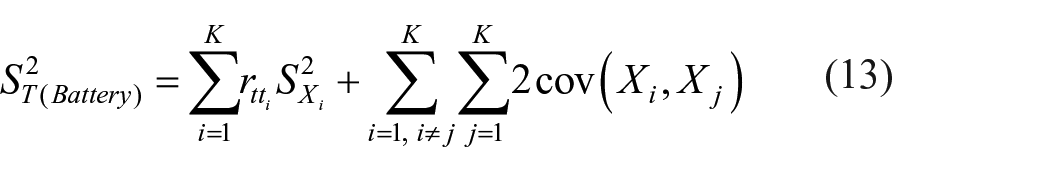
and
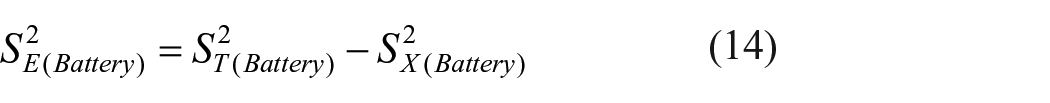
Equation (12) helps to find reliability of a test battery consisting of K-number of tests where battery score is defined as weighted sum of component tests. True score variance of the battery can be estimated using equation (13).
However, different choices of weights will give different values of the test battery. Thus, a major problem in the computation of battery reliability could be experienced in determination of the weights.
Proposed methods for determination of weights
Selection of weights is a central issue for weighted sum approach. Weighted sum approaches assume additive models. The weights which minimizes variance of weighted sum are referred as ideal weights as inverse of the variance by Hartung et al. (2008). Shahar (2017) gave three proofs (using method of Lagrange multipliers, Induction method, and Cauchy-Schwarz inequality) of the ideal weights that minimize the variance of a weighted average. His proposition was that if the component indicators
Major observations are as follows:
The component indicators may be independent or correlated with varying degrees. Hence, need is felt to find weights from a general perspective without assuming that variables are independent or they follow certain distributions and to satisfy one or more desired properties of the weighted sum.
Minimum variance is not the only criteria for a good weighted battery score. Determination of weights depends on desired outcomes of the weighted sum. Depending on purpose, one may like to find weights which are (1) proportional to covariance of variables and the weighted sum or (2) proportional to covariance and inversely proportional to SDs or 3. Weighted sum is equi-correlated with the component tests and so on.
The method of findings weights from a general perspective without assuming that variables are independent or they follow certain distributions is based on the following proposition:.
Proof: Consider
Clearly,
Solving the above two equations on the assumption S is non-singular,
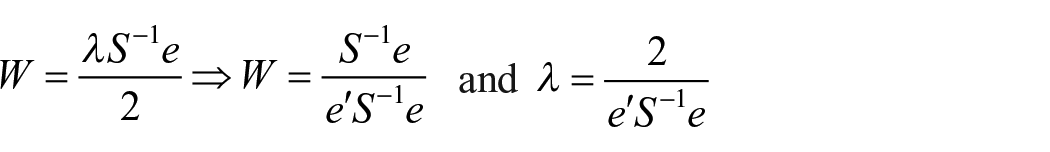
Properties
1. Weights obtained from the above method minimizes variance of the weighted sum
and
2. Covariance between the weighted sum Y and any component test
3. If we take normalized values
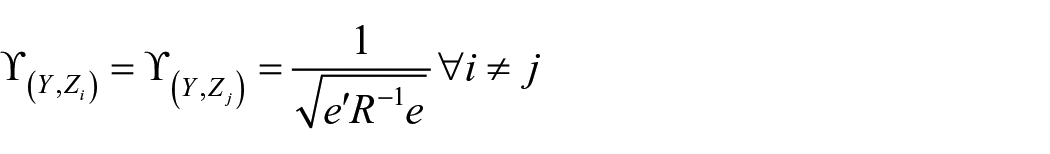
Proof: It can be proved that weights vector in this context are eigen vectors corresponding to the maximum eigen values of the variance-covariance matrix S on the assumption of S is positive definite, since
Properties
Weights are proportional to covariance of variables and the weighted sum;
Variables which are highly associated with the weighted sum linearly to get higher positive weights.

Proof: Here, W satisfies
Observe that here weights are proportional to covariance and inversely proportional to SDs
Recommended method to find weights
It is proposed to determine the vector
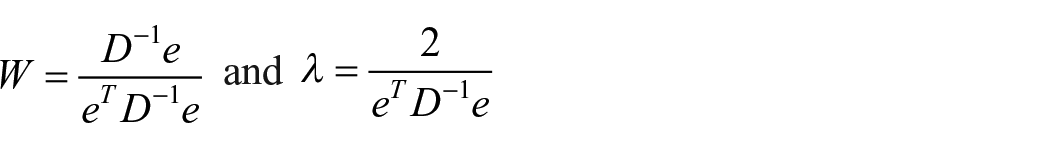
Benefits of the recommended method of finding weights
Weights found as above have the advantage that the battery score
In order to find the battery scores, weights of test scores can also be found by principal component analysis, factor analysis, canonical reliability, and so on. However, it is suggested that reliability of the battery scores be found as weighted scores where the weights are determined as per Proposition 1.
It is recommended to use theoretical definition of test reliability for each constituent test as per equation (2) for clear theoretical advantages and Proposition 2.
Summary and discussion
Assuming non-availability of pre-specified, quantifiable external criterion, the article presents a well-defined and easy approach to the computation of reliability of test batteries, where battery score could be defined as sum of weighted or unweighted scores of the component tests. The method avoids scaling of scores of component tests. Such battery reliability can be influenced significantly by method of selection of weights to arrive at the battery scores and methods of estimating reliability of component tests, since sources of errors of individual tests may get manifold for the battery. Reliability, which is theoretically defined as the ratio of the true variance to the total variance, is an important property of measurement and works well to find battery reliability. It is possible to find true score variances of the battery even if true scores of individuals taking the component tests are not known.
Test reliability as per theoretical definition in terms of length of score vectors of two parallel tests and angle between such vectors in N-dimensional space also helps to find values of error score variance of the test fits well in estimation of battery reliability. Relationship between theoretically defined reliability
There could be different methods of obtaining data-driven weights depending on the purposes. For weighted battery score, a Lagrange multiplier–based solution is recommended with the use of reliability as per the theoretical definition. Weights found as above have the advantage that the battery score
While in this work, the classically defined reliability of a test with binary items (one right and the rest wrong) was discussed, a future study is proposed on empirical illustration and to find bias of the classically defined reliability with simulated data and compare with other methods of obtaining reliability.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.