
Abstract
Male humpback whales produce hierarchically structured songs, primarily during the breeding season. These songs gradually change over the course of the breeding season, and are generally population specific. However, instances have been recorded of more rapid song changes where the song of a population can be replaced by the song of an adjacent population. The mechanisms that drive these changes are not currently understood, and difficulties in tracking individual whales over long migratory routes mean field studies to understand these mechanisms are not feasible. In order to help understand the mechanisms that drive these song changes, we present here a spatially explicit agent-based model inspired by methods used in computer music research. We model the migratory patterns of humpback whales, a simple song learning and production method coupled with sound transmission loss, and how often singing occurs during these migratory cycles. This model is then extended to include learning biases that may be responsible for driving changes in the song, such as a bias towards novel song, production errors, and the coupling of novel song bias and production errors. While none of the methods showed population song replacement, our model shows that shared feeding grounds where conspecifics are able to mix provide key opportunities for cultural transmission, and that production errors facilitated gradually changing songs. Our results point towards other learning biases being necessary in order for population song replacement to occur.
Humpback whales have been intensely studied for more than 40 years, attracting different generations of researchers due to the complex, stereotyped songs produced by males (Payne & McVay, 1971). All over the world, whales in acoustic contact, usually within a breeding population, tend to conform to the same song display; across time, songs gradually change (evolve) and, generally, the individuals of a population manage to keep up with the changes, singing the most updated version of the display (Payne & Payne, 1985; Payne, Tyack, & Payne, 1983; Winn & Winn, 1978). In certain cases, this highly conformist system changes abruptly when a new song is introduced, presumably by a few individuals leading the whole population to quickly abandon the old song and conform to the novel display (Garland et al., 2011; Noad, Cato, Bryden, Jenner, & Jenner, 2000). While these population-level events have been recorded and studied extensively, the individual mechanisms that allow humpback whales to maintain a high degree of conformity over continuously evolving songs, as well as switch quickly to a novel song when this is introduced in the population, remain unclear. It is not currently feasible to track individual whales over timescales relevant to breeding seasons while also monitoring their acoustic interactions and song production. However the use of agent-based models, where individual agent behaviour can be controlled and the population-level outcomes can be compared to empirical observations, offers one way toward generating hypotheses about song learning at the individual level. Therefore, we present here a theoretical investigation based on agent-based modelling that aims to identify individual learning strategies that might produce the population-level song characteristics observed in humpback whales.
Theoretical studies that focus on conformity and cultural evolution across different taxa are extremely useful in providing new insights and contributing to the ongoing debate relative to the selective forces behind cultural evolutionary processes. Moreover, investigating vocal convergence can be extremely helpful in order to understand social structures, group cohesion, group identity and affiliation (Tyack, 2008) as well as social complexity (Freeberg, Dunbar, & Ord, 2012). The presence of song conformity within humpback whale populations is not an isolated instance across animal cultural evolution, but rather a very peculiar example of a more general process of group vocal convergence common to multiple taxa (Tyack, 2008). Birds represent a well-studied group in particular for the investigation of cultural evolution and transmission of acoustic displays such as songs. Birdsong dialects have a long history of study (Marler & Tamura, 1964) and the role of vocal learning in the development of song variation has been investigated in several species (Catchpole & Slater, 2008). Moreover, vocal plasticity affects the emergence of within-group song and call convergence even when the groups are artificially assembled from unrelated birds of different flocks (Baptista & Schuchmann, 1990; Farabaugh, Linzenbold, & Dooling, 1994; Hile & Striedter, 2000; Mammen & Nowicki, 1981; Nowicki, 1989). Among mammals, female greater speared-nosed bats (Phyllostomus hastatus) modify their calls as a result of group composition changes, achieving an increased similarity among the new group members (Boughman, 1998). Among marine mammals, killer whales (Orcinus orca) show stable vocal traditions over a period of 25 years (Ford, 1991), and captive studies suggest that individual killer whales can learn from their conspecifics (Bain, 1986; Crance, Bowles, & Garver, 2014). Sperm whale (Physeter macrocephalus) population structure appears to be characterised by vocal “clans” (Gero, Bøttcher, Whitehead, & Madsen, 2016; Rendell & Whitehead, 2003), that present strong conformity to a shared vocal pattern (Gero, Whitehead, & Rendell, 2016) which remains stable over decades (Rendell & Whitehead, 2005).
Humpback whales represent an extreme example of vocal conformity due to the large geographical and demographic scales at which this phenomenon occurs and the high fidelity with which vocal patterns are transmitted. Male humpback whales produce long, complex, stereotyped, and hierarchically organised sound sequences, “songs”, first described by Payne and McVay (1971). Songs consist of individual sound “units” grouped into a “phrase” – a series of phrase repetitions constitutes a “theme”, and a “song” is a cycling sequence of themes. The production of songs is exclusive to males (Glockner, 1983; Tyack, 1981; Winn & Winn, 1978), and this strongly indicates that song is a sexually selected trait which plays an important role in mating behaviour (Herman, 2016). Males within a population usually conform acoustically to a common song (Winn & Winn, 1978). Two species of birds present a similar type of male-only vocal convergence at the colony level: village indigobirds (Vidua chalybeata) (Payne, 1985) and yellow-rumped caciques (Cacicus c. cela) (Feekes, 1982), but with important differences compared to humpback song. Within a neighbourhood, indigobird males tend to imitate singers with high mating success and males tend to retain their songs from one year to the next, with only minor changes to the song structure (Payne, 1985). Conversely, the content of humpback whale songs changes gradually and continuously over time (termed “song evolution”) (Payne et al., 1983) as units and/or themes are added, modified or deleted (Cerchio, Jacobsen, & Norris, 2001; Payne & Payne, 1985; Payne et al., 1983). However, Noad et al. (2000) described another type of song change off eastern Australia, termed a “song revolution”, and characterised by a complete replacement of the song sung by the eastern Australian population between 1996 and 1998 by the introduction of a novel song, belonging to the western Australian population. This dramatic song replacement was a learning phenomenon of such speed it could only be explained by cultural transmission. Further studies have described the eastward spread of different song types across contiguous populations breeding in the western and central South Pacific (Garland et al., 2011), highlighting the potential importance of migratory corridors and feeding grounds for song transmission and population connectivity (Garland, 2011; Garland et al., 2013; Garland et al., 2015). All humpback whale populations, excluding the one found in the Arabian Sea, migrate annually between high-latitude feeding grounds and low-latitude breeding grounds (Clapham, 2000) and singing occurs predominantly, but not exclusively, during the migration and the breeding season (Cato, Paterson, & Paterson, 2001; Garland et al., 2013; Noad & Cato, 2007; Payne & McVay, 1971; Stimpert, Peavey, Friedlaender, & Nowacek, 2012; Vu et al., 2012).
The complexity and the dynamism (song evolution vs. revolution) of the acoustic behaviour of humpback whales, coupled with the geographical scale at which whales move and transmit their songs, make the experimental study of this species extremely challenging. Moreover, due to the logistics of fieldwork – and the impossibility of captive studies – recordings of individuals are typically applicable to only a single point in time. This means that there is very little information on song changes in individuals, and acoustic studies have mainly focused on song similarity within and between populations. Due to these difficulties, the mechanisms that drive whales to dramatically change their song repertoires during song revolutions while paradoxically retaining song convergence in between such events are yet to be understood. Similarly, the differing patterns observed in the North Pacific, where breeding populations separated by thousands of kilometres sing the same song (Cerchio et al., 2001) or similar versions of it (Darling, Acebes, & Yamaguchi, 2014), and the South Pacific, where periodic “revolutionary” changes typically cause breeding populations to sing different songs at any given time (Garland et al., 2011; Noad et al., 2000), are unexplained. The first step towards solving this conundrum is to understand how individual humpback whales learn from each other and how they are able to maintain population-wide song conformity while songs are showing continuous cultural evolution, but the challenges of following individual humpback whales for more than a few hours at a time are immense. Therefore, we used an agent-based modelling approach to study the humpback whale song system using a bottom-up approach, programming behaviour at the individual level and observing outcomes at the population level.
Individual-based models have shown how the accumulation of copying errors and the introduction of new song types through population turnover could lead to the development of local dialects (Goodfellow & Slater, 1986; Slater, 1986; Williams & Slater, 1990). Subsequent studies have highlighted how aggression towards non-conformers can evolve, and potentially lead to population convergence in song (Lachlan, Janik, & Slater, 2004). Other spatially explicit modelling studies looked at the factors affecting song divergence between contiguous populations of songbirds under a variety of vocal learning modes (pre and post-dispersal learning, song-based mating preferences, genetic and cultural mutations among others), finding that intra-sexual selection – song matching between neighbours – and female song preferences towards the songs of their population were the main factors driving the formation and maintenance of dialects (Ellers & Slabbekoorn, 2003; Rowell & Servedio, 2012). More recently, agent-based models have been developed to test the roles of conformity, innovation, and random errors (as well as other learning strategies) in the emergence of dialects in sperm and killer whales (Cantor et al., 2015; Filatova & Miller, 2015). While none of these models incorporate song that approaches the complexity of those produced by humpbacks, agent-based models have, however, been successfully used in music research to create autonomous composition systems in which agents construct their individual song repertoire through their acoustic interaction with other agents (Miranda, Kirke, & Zhang, 2010), as well as investigating the role of novelty in mate selection (Todd & Werner, 1999). Agent-based modelling has found significant application in linguistics, where researchers have used it to show that unidirectional vertical cultural transmission may be a driving factor in the emergence of structure in language (Kirby, 2001) and has also been used to explain how vowel systems change over time (de Boer, 2002). Finally, Kirke, Freeman, Miranda, and Ingram (2011) used agent-based modelling to produce a live musical interaction between simplified versions of humpback whale songs and a saxophone played by a musician. While biologically this did not provide new insight, it showed that these kinds of models could be adapted to the kinds of questions outlined here and hence directly inspired the present study.
The modelling approach presented here aims to simulate both the movement and acoustic behaviour of individual humpback whales. Since humpback whale migratory behaviour is of potentially key importance for the occurrence of inter-population song transmission (Garland et al., 2011), intra-population song conformity (Winn & Winn, 1978) and song revolution events (Noad et al., 2000), our models needed to be spatially explicit. A model that aims to reproduce a natural system in its entirety will likely fail, especially in a behaviourally complex system such as humpback whale populations. However, a bottom-up modelling approach informed by data, and incorporating the salient characteristics of the acoustic and movement behaviour of humpback whales, could still be useful to capture the emergent properties of this system, and to produce testable hypotheses for future field experiments. Using four different modelling scenarios developed from a single agent-based architecture we investigate: (1) the role of sound transmission loss and migratory movement in song conformity, (2) the effect of novelty on an individual’s song learning process as well as its influence at the population level, (3) whether song production errors may be an important factor in song evolution, and (4) which scenarios produce population-level characteristics comparable to the ones observed in the wild.
Materials and methods
Model design
In order to explain the design of the model, here we describe the behaviours of a single agent in detail. Behaviours are divided into three categories: (1) movement rules, (2) song production rules, and (3) song learning rules. At every cycle of the model, movement, song production, and song learning are carried out sequentially: an agent first moves, then, with a given probability, produces a song, and finally listens to, and potentially learns from, songs produced by other agents (Figure 1). A single model iteration (i) ends when every agent in the population has carried out these actions. Since only male humpbacks have been observed singing (Glockner, 1983; Tyack, 1981; Winn & Winn, 1978), all agents in the models are considered to be male, and the role of female whales is not investigated here. All models were created in Python using the SciPy package, and based on the design presented in Kirke, Miranda, Rendell, and Ingram (2015).

Flow diagram of the process of song production and learning. Each singer agent (I) possesses a numeric song representation, SR (II), for visual purposes we represent this with a coloured matrix (III) in which different colours indicate different transition probabilities. The singer agent samples its SR using the equation at (IV), where x is the output theme, c is the cumulative summation of the probability vector (the row of our transition matrix we are currently sampling from), and U is a uniformly distributed random number between 0 and 1, to produce a song sequence (V). The listener agent receives the song sequence (VI), estimates a SR from the song sequence (VII) and compares it to its own SR (VIII) using the weighted average equation (IX), where I is the received song salience. Finally, the listener agent updates its own SR completing the learning process (X).
Movement rules
In the model, agents exist on a two-dimensional Cartesian plane. In order to simulate the migratory movements of humpback whales at the ocean basin scale, the agents move both within and between a common feeding ground and two geographically distinct breeding grounds (each representing a distinct breeding population). During the feeding season, agents move across the feeding ground using a standard random walk. At the end of the feeding season they simultaneously start their migrations towards their respective breeding grounds (in the two breeding grounds case, half the agents are assigned to each ground). At the end of the breeding season the agents will return to the common feeding ground. Although time is not explicit in the model, the ratio between the numbers of iterations is set to mimic the relative duration of the different seasons, resulting in a migratory cycle comprising 12,000 iterations, divided into 2,000 migration, 4,000 breeding, a further 2,000 migration back to the feeding grounds, and finally 4,000 iterations in the feeding ground. The maximum speed of the agents is constrained so that agents cannot travel any further than a single integer on the Cartesian plane during a single iteration. This does not confine agents to a strict grid. Agents can exist on decimal points of the grid such as 0.5.
Surrounding each individual agent are two zones of influence with respect to movement: a zone of repulsion (ZOR) and a zone of attraction (ZOA). The ZOR is used to maintain a minimum distance among the moving agents. Two agents in each other’s ZOR will calculate a new trajectory in order to avoid each other. In the wild, males have been observed inhibiting each other’s singing activity when joining together (Darling & Bérubé, 2001; Darling, Jones, & Nicklin, 2012). To mimic this behaviour in the model, two agents will temporarily stop singing while in each other’s ZORs. The ZOA is used as an acoustic active space; agents will move towards the nearest singing agent within their ZOA. This behaviour is based on field observations of males’ attraction towards nearby singers (Darling et al., 2012). In the first part of the analysis we conducted a parameter space exploration in which we tested how varying values of ZOR and ZOA might influence agents’ song learning (Table 1). In the second part of the analysis we ran all the models with the ZOR and ZOA set to 0.1 and 10 respectively; these values were selected both on the outcome of the parameter space analysis and the song transmission loss characteristics recorded in eastern Australia (Noad, pers. obs.). These movement rules were modified from existing work on animal collective movement and flocking (Couzin, Krause, James, Ruxton, & Franks, 2002; Shiffman, 2012). At each iteration an agent’s movement is a combined function of the rules given by these zones and either a random walk, if on breeding or feeding grounds, or a migratory impulse to head toward a given destination if on migration. If an agent is seeking a target – such as breeding/feeding grounds or another agent – noise is added to the agent’s trajectory in order to make their movement patterns less linear. The breeding and feeding grounds are defined as circular areas, and once migrating agents arrive within the target area they revert to random walk movement (Shiffman, 2012).
Parameters used for the parameter space exploration.
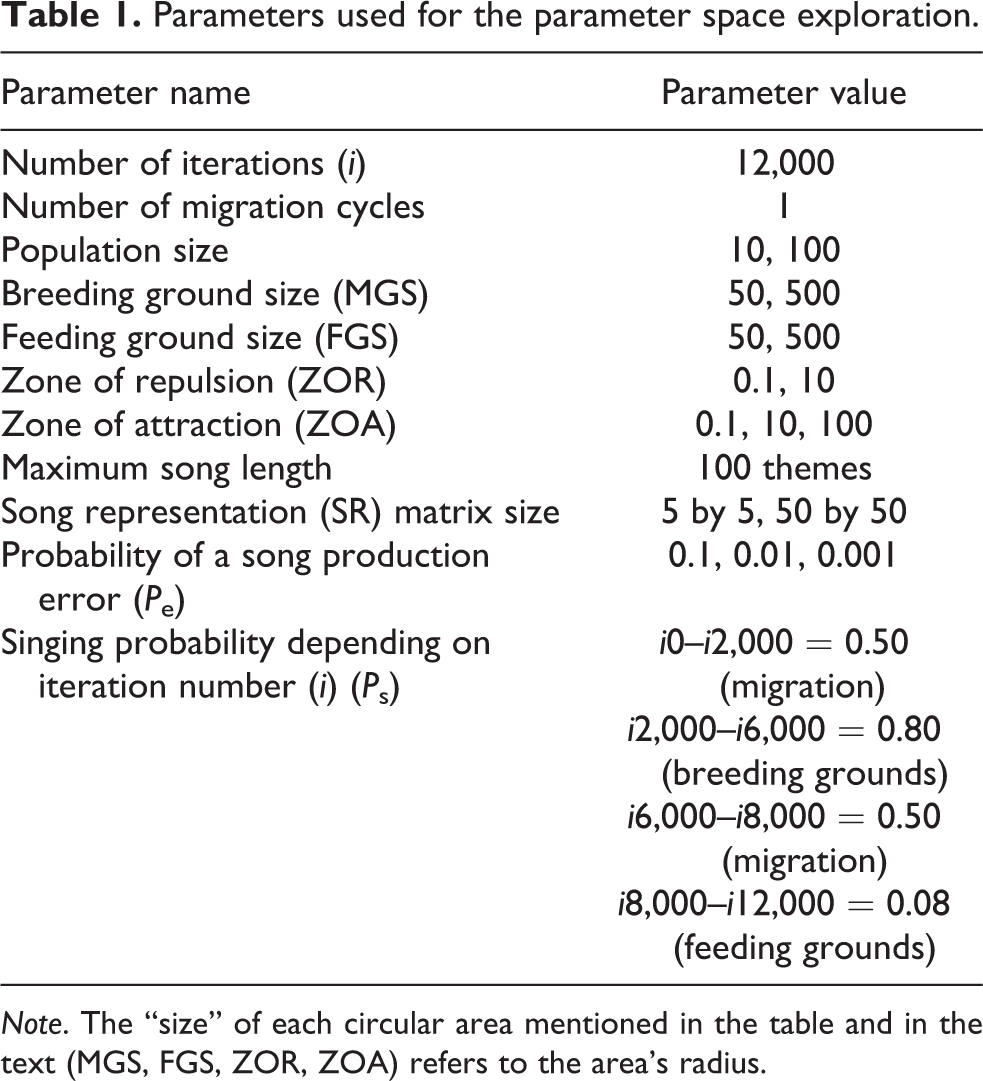
Note. The “size” of each circular area mentioned in the table and in the text (MGS, FGS, ZOR, ZOA) refers to the area’s radius.
It is important to note that we deliberately designed the distance values to correspond to the Cartesian plane, and the sizes of the feeding grounds, breeding grounds, and zones of influence are inspired by real-world ratios rather than by distance metrics such as kilometres.
Song production rules
Agents in the model are equipped with a first-order Markov model, enabled using a first-order transition matrix (Figure 1, II). Hereafter we will refer to this as a song representation (SR), as it is a numeric representation of a given song structure. In our model, songs are represented by a sequence of integers. Song is modelled at the theme level, so that each integer corresponds to a potential theme from a humpback whale song (Figure 1, V). While it has been shown that a Markov model cannot adequately capture the hierarchical structure of humpback whale songs when they are represented as a long string of units (Suzuki, Buck, & Tyack, 2006), more recently this method has been used successfully to represent songs at the theme level (Garland, Rendell, Lamoni, Poole, & Noad, 2017). Our model is best understood as representing songs as sequences of themes, while noting that this abstracts out the complexity of phrase structure found in real song. Agents have a given probability, Ps , of singing at each model iteration – this probability varies depending on whether the agent is on a breeding ground (Ps = 0.8), a feeding ground (Ps = 0.08) or on migration (Ps = 0.5), with values chosen based on empirical observations. An agent produces songs by sampling from the SR transition matrix using the equation in Figure 1, IV. The output theme, represented here by a number, is then appended to a list (Figure 1, V). The output theme also informs the agent which row to sample from next. Agents use this algorithm in a recursive function to generate songs of varying length. This process continues until the row sampling arrives at the last row of the matrix, at which point the song is considered complete and sampling stops. The resultant sequence of themes is then the realised song of that agent for that single model iteration.
Song learning rules
As song is an acoustic signal, we modelled its decay as a function of the distance between a singer and receiver. We calculated what we term the intensity, I, of a song arriving at a receiver, as 1/d2, where d was the Euclidean distance to the singer. When an agent, the listener, “hears” the song of another agent, the singer, then it will estimate the transition matrix that generated the received song based on the observed theme transitions. The listener will then update its own SR matrix as a function of this estimated transition matrix, the received intensity (I), and learning rules as specified in the following four model scenarios.
Model 1: Distance-only
Here, learning depends only on intensity, I. The listener’s new SR transition matrix,

Where SRl is the listener’s original transition matrix, and SRs is the transition matrix that the listener estimates from the realised song sequence produced by a singing agent. Hence, the degree of learning is a function of distance-only. This provides a baseline condition – agents learn what they hear and the closer the singer, the more they change their own song to match what they are hearing.
Model 2: Distance + novelty bias
One hypothesis in the literature is that novel songs might be more appealing learning targets for males, possibly due to a preference for novelty on the part of females (Garland et al., 2011; Noad et al., 2000). In order to test the role of song novelty in song convergence and evolution, we introduced a novelty bias, for which a metric of novelty was required. Taking inspiration from the work of Todd and Werner (1999), we calculate novelty as the difference between the transitions an agent expects to hear based on its own SR matrix, and the transitions it actually hears. These differences are then summed, and divided by the total number of transitions observed, in order to create α, our novelty value, which is then used to update the listener’s SR matrix as follows:

Figure 2 summarises the difference between the learning processes in Models 1 and 2.

Comparison of the learning processes of Models 1 and 2 using a common initial spatial scenario. At iteration i the listener hears two equidistant singers. Depending which model is implemented, the listener’s song representation (SRl ′) at iteration i+1 will vary. Using Model 1, the transition probabilities of both singer 1 (SRs1 ) and 2 (SRs2 ) will be equally represented in the resulting listener’s SR. Using Model 2, the listener will favour in its resulting SR the more “unexpected” transitions of singer 1.
Model 3: Distance + weighted-edit production error
Humpback whale songs are likely subject to production errors, as are any other animal vocalisations, and such errors may be important in cultural evolution (Slater, 1986). In order to test the effect of song production errors on song evolution we considered a model with no learning bias but errors in production. We used a weighted-edit approach to introduce production errors to the realised theme sequence, using empirical data to weight the probability of a theme being inserted, deleted, or substituted for another.
Based on empirical observations of theme-level song variation in the literature (Cerchio et al., 2001; Payne et al., 1983) a higher probability value (0.8) was given to insertions compared to deletions and substitutions, which were both weighted at 0.1. In order to carry out production errors, the agents first produce a song using their SR matrix, then a production occurs with probability Pe , a parameter of the simulation. If that probability is achieved against a random number draw, a sequence position is selected at random for editing. Insertion, substitution, or a deletion is selected based on the above probabilities against a random number draw and performed at the selected sequence position. In the case of insertions and substitutions, the new theme is selected at random.
Model 4: Distance + novelty bias + weighted-edit production error
This scenario represented the most complex hypothesis considered, including distance, novelty bias and production error in order to explore how the combination of all three mechanisms acting on song production and learning would affect the cultural evolution dynamics in the model system.
Model analysis
Models were analysed in terms of both the changes in the agents’ SR matrices, and in the realised song sequences through the model run. Song convergence was measured by calculating the mean SR dissimilarity between pairs of agents within and between breeding populations. The SR dissimilarity between agents a and b was calculated as
Mean SR dissimilarity therefore measured the degree of vocal conformity of a particular group of agents. Low dissimilarity indicates high convergence while high dissimilarity represents a more variable acoustic system. In order to have an empirical reference, we calculated mean SR dissimilarity based on theme transitions observed from 15 singers’ recordings from eastern Australia – in 2002 (7 singers), just before a revolution event, and 2003 (8 singers), just after. We use these empirical values as a reference to interpret how realistic our models’ results are, and not as a direct comparison. The realised song sequences produced by the agents were analysed using the Levenshtein distance metric (Garland et al., 2012) to illustrate the variation in songs produced by agents across the modelled populations in a way that is directly comparable to how actual songs are analysed from empirical recordings.
Model parameters
A parameter space exploration was carried out to evaluate the potential effect of the different parameters (and their interactions) on the degree of conformity within the agent’s population (mean SR dissimilarity). A total of 96 modelling experiments were run, in each experiment a different combination of the parameters indicated in Table 1 was used. These model runs consisted of a single population performing a single migration cycle of 12,000 iterations between one breeding ground and one feeding ground; song learning occurred according to the distance-only learning rule of Model 1 – as we consider this the baseline of the models designed – and agents were all initialised with random SRs. The parameter space for the model was large due to the complexity of the system. The complexity arises from the requirement to allow the creation of specific scenarios that may have a significant impact on cultural transmission in a population of agents.
The results of the parameter space exploration are summarised in Figure 3. In this figure, large ZOR size (10; Figure 3, black contour symbols) results in lower ΔMSR across multiple parameter generations when compared to a low ZOR size (0.1; Figure 3, grey contour symbols). This implies that large ZOR size results in low levels of song convergence. This is mitigated by increasing the population size, resulting in ΔMSR values going above zero in almost all parameter combinations. This is attributed to a higher density of agents on the feeding and breeding grounds. The only exception to this overall density related trend is represented by models with a large population size (100), large ZOR (10; Figure 3, black contour symbols), medium ZOA (10) and large breeding ground size (MGS)/feeding ground size (FGS) (500), in which the ΔMSR decreases to just below zero, indicating they have diverged slightly from the beginning of the experiment. A small ZOA (0.1) combined with a small ZOR (0.1; Figure 3, grey contour symbols), small population size (10) and large breeding and feeding grounds (MGS and FGS = 500) produced the lowest levels of song convergence (lowest ΔMSR in Figure 3).
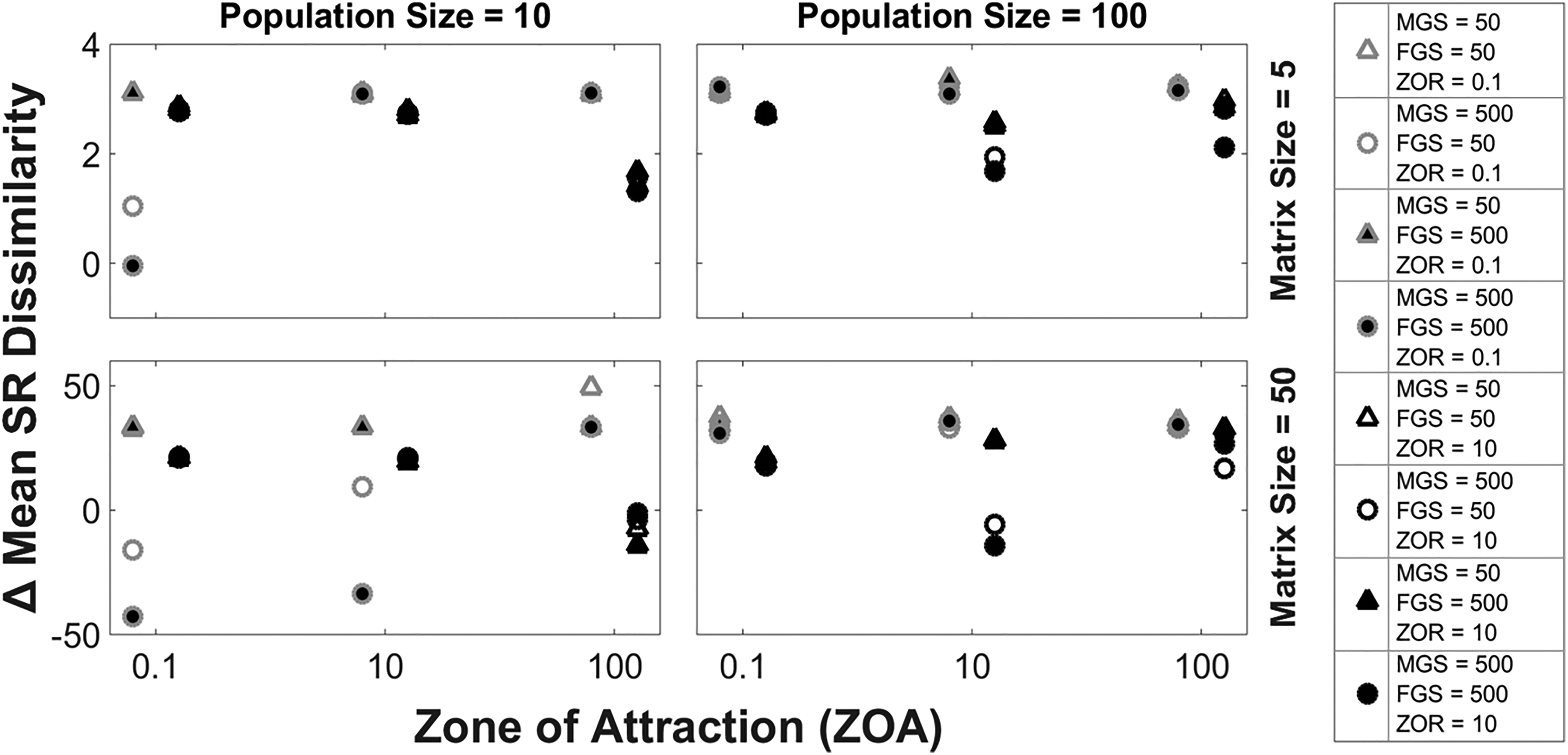
Results of the parameter exploration analysis using the distance-only learning bias (Model 1). A total of 96 modelling experiments are grouped into four quadrants; each quadrant representing different combinations of matrix size and population size. For each experiment, the Δ mean SR dissimilarity is plotted (y axis) against different zone of attraction (ZOA) sizes (x axis). Grey and black contour symbols represent models with a zone of repulsion of 0.1 and 10 respectively. Each combination of feeding (FGS) and breeding (MGS) ground sizes is represented with a different symbol according to the legend on the right-hand side of the plot.
Results
In the model experiments presented here, all the parameters listed in Table 2 were fixed with the exception of feeding ground size (FGS), and, when song production errors were introduced the production error rate (Pe ). We ran all models (1–4) with three FGS values (50, 100 and 500) and two breeding grounds in order to create three scenarios in which agents belonging to the two separate breeding ground populations either mixed well (FGS50), partially (FGS100), or remained largely separate (FGS500) while on the feeding grounds (Figure 4). These scenarios were chosen to explore the effect of feeding ground size, because acoustic contact on feeding grounds may be an important mechanism to allow song transmission between populations (Garland et al., 2013). For each of the following feeding ground modelling scenarios, 50 model experiments were run to get a representative view of the model’s behaviour.
Parameters used in the model experiments presented in this article.
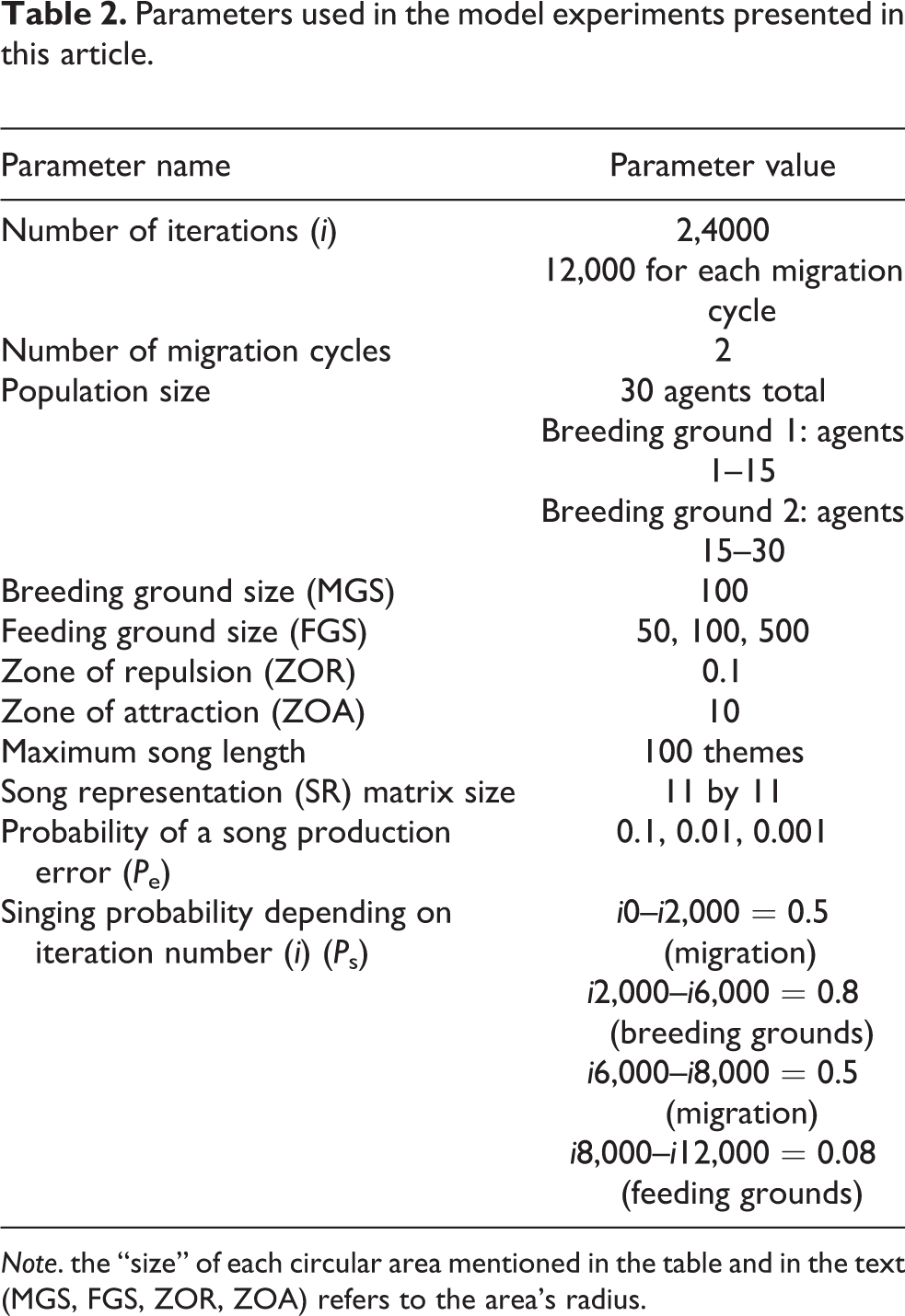
Note. the “size” of each circular area mentioned in the table and in the text (MGS, FGS, ZOR, ZOA) refers to the area’s radius.

Agents’ tracks plotted in the two scenarios in which feeding ground size varies from 50 (left panel) to 500 (right panel). Red circles represent the two breeding grounds, blue circles represent feeding grounds.
Model 1: Distance-only
In all runs the mean within-population SR dissimilarity decreased rapidly during the first breeding season (Figure 5). With the smallest feeding grounds (FGS = 50), once mean SR dissimilarity reached 0 it remained generally low across the remainder of the experiments with the exception of the first feeding season, in which a slight increase was observed due to the mix of agents from the two breeding populations (with different SRs). Mean between-population SR dissimilarity decreased during the first feeding season as agents returned to a small feeding ground until the degree of dissimilarity between the two populations was equal to zero (Figure 5, thick orange line, upper panel). If the feeding ground was large enough that the two breeding populations never met (FGS = 500), the mean SR dissimilarity between them remained constant across the two migration cycles (Figure 5, lower panel), indicating divergence between populations at the same time as convergence within each. This SR dissimilarity between the two populations was also reflected in the song sequences produced by the agents (Figure 6, i = 6,000); although within-population song convergence during each breeding season was complete (song dissimilarity = 0), the different breeding ground populations maintained two different songs. Depending how much the two breeding populations mixed during the feeding season, different degrees of song conformity emerged (Figures 6 and 7, i = 12,000). Generally, song sequences produced in all scenarios using Model 1 were short. This was due to the agents’ convergence on sparse SR matrices with transition probabilities made of 0 s and 1 s (Figure S1, see supplementary material online). If two breeding populations have limited contact during the feeding season and/or migration their songs will evolve independently – and likely diverge. However, if the two breeding populations mix enough across a common feeding ground, their original songs will be much similar (or exactly the same) at the end of the feeding season/migration (Cerchio et al., 2001; Darling et al., 2014). The mean SR dissimilarity results for Model 1 experiments with FGS = 100 can be found in the online supplementary material (Figure S2, upper panel).

Mean song representation (SR) dissimilarity calculated every 100th iteration (total number of iterations: 24,000) across the population of agents of Model 1. The upper panel shows the results for feeding ground size (FGS) = 50 while the bottom panel shows the results for FGS = 500. The blue and orange coloured lines represent respectively within and between-population mean SR dissimilarity. The median value for all the 50 modelling experiments (represented with thin lines) is shown with thick blue and orange lines. The light and dark grey areas represent breeding and feeding seasons respectively. The horizontal dashed and dotted lines are the mean SR dissimilarity estimates calculated respectively in 2002 and 2003, at the end of the breeding season in eastern Australia.

Song dissimilarities measured using the Levenshtein distance for Model 1. Shows song dissimilarities at the beginning of the experiment (i = 1), the end of the breeding season (i = 6,000) and at the end of the feeding season (i = 12,000). Agents 1–15 belonged to one breeding population, and 16–30 to the second. Here, FGS = 50.

Song dissimilarities measured using the Levenshtein distance for Model 1. Shows song dissimilarities at the beginning of the experiment (i = 1), the end of the breeding season (i = 6,000) and at the end of the feeding season (i = 12,000). Agents 1–15 belonged to one breeding population, and 16–30 to the second. Here, FGS = 100.
Model 2: Distance + novelty bias
When novelty bias was added to song learning, the mean SR dissimilarity generally increased both within and between populations during model runs. The within-population mean SR dissimilarity showed a steady decrease during the first migration cycle following a sudden increase during the second breeding season (Figure 8). This increase in dissimilarity was steeper when using a small feeding ground (FGS = 50, Figure 8, upper panel) compared to a larger feeding ground (FGS = 500, Figure 8, lower panel). Moreover, with larger feeding grounds, the between-population mean SR dissimilarity generally increased across all the experiments. Although the general pattern of mean SR dissimilarity fluctuation was completely different than for Model 1, divergence between the two breeding populations still emerged.

Mean song representation (SR) dissimilarity calculated every 100th iteration (total number of iterations: 24,000) across the population of agents of Model 2. The upper panel shows the results for FGS = 50 while the bottom panel shows the results for FGS = 500. The blue and orange coloured lines represent respectively within and between-population mean SR dissimilarity. The median value for all the 50 modelling experiments (represented with thin lines) is shown with thick blue and orange lines. The light and dark grey areas represent breeding and feeding seasons respectively. The horizontal dashed and dotted lines are the mean SR dissimilarity estimates calculated respectively in 2002 and 2003, at the end of the breeding season in eastern Australia.
The geographical clustering in songs observed in Model 1 was absent when novelty bias was present. The introduction of the novelty algorithm also produced more variable and longer songs compared to Model 1 (Figure 9). This was due to the fact that SR matrices showed lower and more uniform transition probabilities across themes compared to Model 1, leading to a more variable song output (Figure S3). The mean SR dissimilarity results for Model 1 experiments with FGS = 100 can be found in the online supplementary material (Figure S2, lower panel).

Song dissimilarities measured using the Levenshtein distance at the beginning of the experiment (i = 1), and the end of the breeding season (i = 6,000) and at the end of the feeding season (i = 12,000). Agents 1–15 belonged to one breeding population, and 16–30 to the second. Here, FGS = 100.
Model 3: Distance + production error
In this scenario the distance-only algorithm from Model 1 was coupled with weighted-edit production errors. Although these models were run with the usual three feeding ground sizes (FGS = 50, 100 and 500), we present here only the results relative to FGS = 50 with Pe = 0.01 and 0.001 (Pe = 0.1; Figure S4, upper panel) in order to simplify the presentation of results under the three different edit probabilities. The full results of experiments with FGS = 100 and 500 can be found in the online supplementary material (Figures S5 and S6), but to summarise, small feeding grounds led to partial (but never complete) song convergence during the feeding season, while larger feeding grounds led to more song divergence between populations, across all production error rates.
The introduction of song production errors triggered more abrupt fluctuations in the mean SR dissimilarity compared to previous results (Figure 10). Despite different error probabilities, during each feeding season any divergence accumulated between the two populations during the breeding season disappeared: within and between-population mean SR dissimilarity reached equal levels with all three edit probabilities. The lowest error probability (Pe = 0.001) still allows complete convergence (within-population median SR dissimilarity reaching 0) during the first and second breeding seasons (Figure 10, upper panel), similar to the outcome in Model 1. A higher error probability (Pe = 0.01, Figure 10, lower panel) increased the overall mean SR dissimilarity levels across the entire experiment. The introduction of error probabilities is also visible on the individual SRs, which show between-population divergence as well as more variable transition probabilities compared to Model 1 (Figure S7). To test whether this model scenario gave a genuinely different outcome, as opposed to simply slowing down the trends seen in Model 1, we ran a model for 10 migration cycles (FGS = 50, Pe = 0.001), and confirmed that production errors kept the populations from achieving complete within-population convergence (mean SR dissimilarity = 0) over these timescales (Figure S8). This model is important as it shows that simple production errors may be one of the mechanisms driving song evolution.
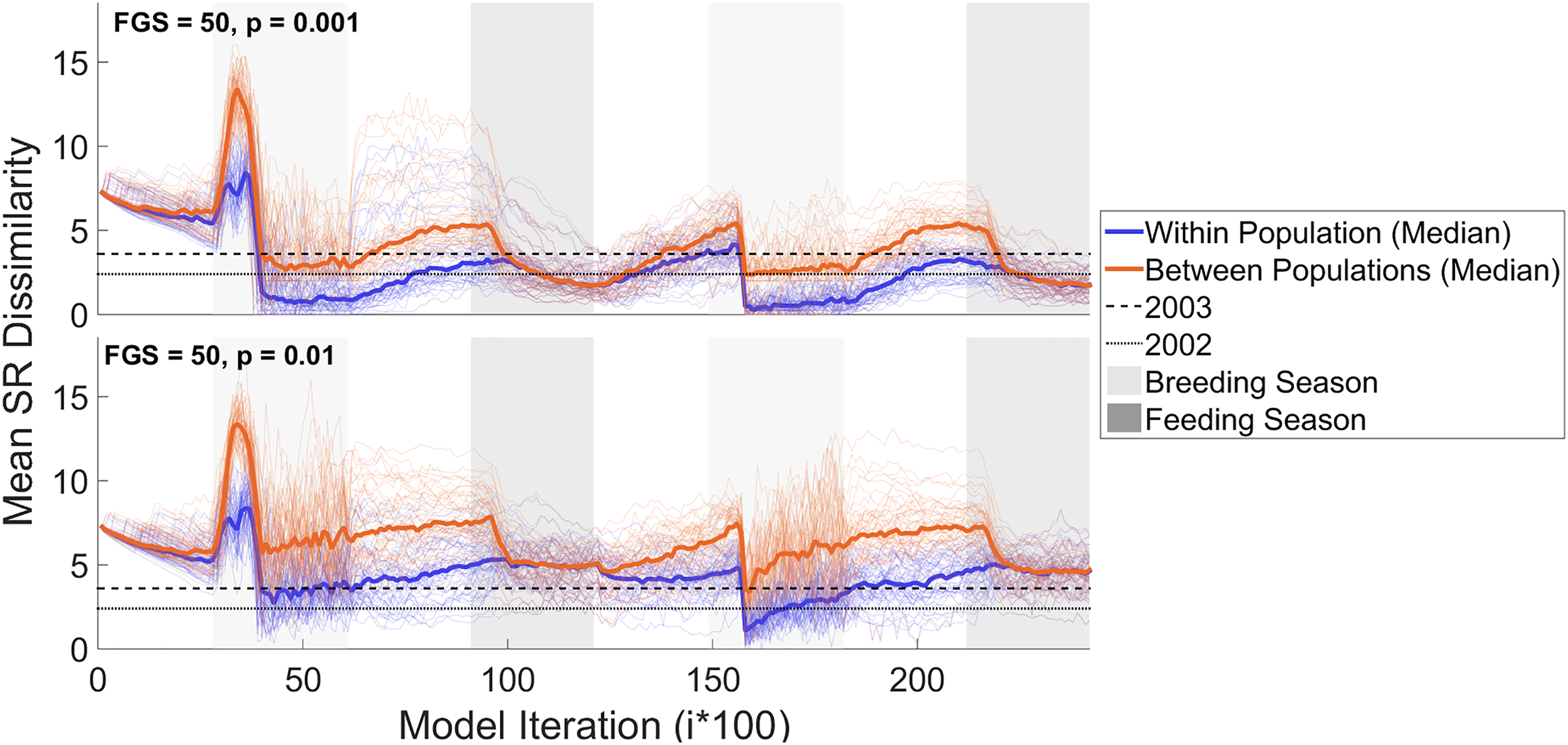
Mean song representation (SR) dissimilarity calculated every 100th iteration (total number of iterations: 24,000) across the population of agents of model 3. The upper panel shows the results for FGS = 50 and Pe = 0.001 while the bottom panel shows the results for FGS = 50 and Pe = 0.01. The blue and orange coloured lines represent respectively within and between-population mean SR dissimilarity. The median value for all the 50 modelling experiments (represented with thin lines) is shown with thick blue and orange lines. The light and dark grey areas represent breeding and feeding seasons respectively. The horizontal dashed and dotted lines represent the mean SR dissimilarity estimates calculated respectively in 2002 and 2003, at the end of the breeding season in eastern Australia.
Model 4: Distance + novelty bias + production error
In Model 4, the design of Model 2 was coupled with the weighted-edits algorithm to test how song production errors might alter the effect of novelty bias on the cultural evolution of song. Similarly to Model 3, only results from the experiment with a small feeding ground (FGS = 50, Pe = 0.01, 0.001) are presented here (experiments with FGS = 100 and 500 are shown in Figures S9 and S10). The introduction of song production error did not qualitatively change the impact of novelty bias, as the results obtained were similar to those for Model 2 (Figure 11, cf. Figure 8). There was a slight increase in mean SR dissimilarity during the first breeding season of the simulations when P e was 0.001 (Figure 11, upper panel) compared to 0.01 (Figure 11, lower panel). This increase is even more pronounced when P e = 0.1 (Figure S4, lower panel). The peaks of divergence between the populations encountered during the breeding seasons of Model 2 were reproduced in this model, and stabilised around the same values (between 6 and 10), irrespective of the production error probability.

Mean song representation (SR) dissimilarity calculated every 100th iteration (total number of iterations: 24,000) across the population of agents of Model 4. The upper panel shows the results for FGS = 50 and Pe = 0.001 while the bottom panel shows the results for FGS = 50 and Pe = 0.01. The blue and orange coloured lines represent respectively within and between-population mean SR dissimilarity. The median value for all the 50 modelling experiments (represented with thin lines) is showed with thick blue and orange lines. The light and dark grey areas represent breeding and feeding seasons respectively. The horizontal dashed and dotted lines represent the mean SR dissimilarity estimates calculated respectively in 2002 and 2003, at the end of the breeding season in eastern Australia.
The mean SR dissimilarity trends shown in Figure 11 are also consistent when models are run for 10 migration cycles (Figure S11). There is a pronounced cyclical pattern of increasing variation (i.e., increasing dissimilarity) between populations during breeding seasons when populations are segregated, which is then erased by the rapid learning of any new variations by the wider meta-population once they are reunited on the feeding grounds.
Discussion
The spatially explicit agent-based models we analysed broadly show that the spatial relationships between breeding and feeding grounds play an important role in determining song convergence at the population level. However, without some form of variation being introduced, for example by production error, it is very hard to sustain continual evolutionary change. The design of these models was motivated by the desire to understand more thoroughly one of the most striking examples of animal cultural transmission, the patterns of change in humpback whale song. Given the current impossibility of following individual singers in the wild to evaluate how they learn and produce songs, we developed a spatially explicit agent-based model to study how song learning by individuals might produce observed population-level patterns.
Our first model, in which the only factor controlling song learning was distance from the singer, produced total convergence within breeding populations, an unrealistically extreme result when compared to empirical measures of convergence from the eastern Australian humpback population. Varying the feeding ground size, and thus the extent to which members of the two populations were exposed to each other’s song during the feeding season, dramatically altered the extent of between-population divergence, even though singing probability was decreased by an order of magnitude between breeding and feeding grounds (0.8 vs. 0.08). Small feeding grounds, on which the populations were forced to mix, minimised divergence between populations, while large feeding grounds, where mixing was much more rare, resulted in high divergence between populations. Thus the simplest of our models demonstrates how the spatial arrangement of feeding and breeding grounds can produce quite different cultural evolution outcomes even when the underlying learning mechanisms are the same. This result supports published predictions that feeding grounds and migratory routes are key locations for song transmission (Garland et al., 2013; Garland et al., 2011). Contrary to observations in the wild, however, the length of songs produced by this model decreased drastically during model runs, and by the end of the model runs agents showed a high degree of song conformity on very short songs. It is not necessarily unrealistic for culturally evolving signals to decrease in length – for example, the range of movement in an invented sign language decreased over multiple generations of an iterated learning model (Motamedi, Schouwstra, Smith, & Kirby, 2016) – but the decrease in song length in this model is an artefact of the learning algorithm used here. Songs do not evolve within this scenario, because when complete song convergence is reached, the population’s song representations become fixed on purely 1/0 transition matrices, unless a new song is introduced (which can happen when two breeding populations with different songs mix on the feeding ground).
Since our simplest model produced unrealistic results, we added a new component to the model to try and understand how a population of agents could show song evolution by the simplest mechanisms possible. Song revolutions recorded in eastern Australia (Noad et al., 2000) indicate that males might be preferentially attracted to novel song introduced by conspecifics from western Australia, so we introduced a novelty bias in song learning. This novelty bias prevented the song fixation observed in Model 1; moreover, the mean SR dissimilarity values obtained were on average higher than our real song reference from eastern Australia. However, similarly to Model 1, large feeding grounds still led to a high degree of song divergence between the populations. This is consistent with what is observed in the South Pacific, where there is clear divergence between breeding populations (Garland et al., 2011). However, other aspects of the results were less realistic. While songs converged (i.e., mean SR dissimilarity decreased) during the feeding season as in Model 1 (albeit to a lesser degree), the transition probabilities within agents’ song representations decreased such that the produced song sequences became relatively unpredictable (Figure S3). This meant it was no longer possible for any agent in the population to have a “novel” song with respect to the song representation matrix, as each transition was equally as likely as any other and so there was no expectation to be violated. The increased song variability compared to the distance-only model also meant that while song representations partially converged, agents could produce many different song sequences from those matrices, and so the population did not show true vocal convergence in realised songs. Moreover, this increased song variability did not produce any quantifiable song evolution over time. This was also true for the model that combined novelty bias with production errors (Model 4) – the novelty bias had such a strong effect that it negated the effect of the production errors and resulted again in unrealistically variable song sequences. In future work, it will be important to investigate non-linear novelty effects in the model by allowing agents to have different degrees of novelty preference for songs, and to have increased preferences for songs of intermediate novelty.
Neither Model 1 (distance-only) nor Model 2 (distance + novelty bias) produced gradually evolving songs, so were not sufficient to explain observed song variation. To produce continued evolutionary song change after convergence, some mechanism was required to prevent populations “fixing” on purely 1/0 SR matrices from which no variation could occur. In order to address this we introduced the assumption of song production errors in Model 3, based on a weighted-edits algorithm. Informed by humpback whale song literature describing within-population song variation (Cerchio et al., 2001; Payne et al., 1983) we assigned a high probability of theme addition, with theme substitution and deletion being possible, but significantly less likely. The addition of production errors significantly changed the song evolution dynamics in the model. Rather than agents converging on identical transition matrices, they instead maintained a level of dissimilarity which oscillated to varying degrees depending on the probability of production errors. The mean SR dissimilarity calculated at the end of the breeding season in model runs with an error probability of Pe = 0.01 matched the empirical range of theme sequence dissimilarities measured from seven and eight singers respectively recorded in 2002 and 2003 off eastern Australia (Figure 10, lower panel). In contrast, the most complex model, Model 4, showed that novelty bias negated the impact of production errors with respect to cultural evolution, irrespective of their probability, producing results very similar to Model 2, and equally unrealistic. Theme sequence dissimilarities from populations other than the eastern Australian one were not available for this study and therefore caution should be taken in extrapolating these modelling results to other geographical areas. When analysing model results we did not use statistical hypothesis tests as suggested by White, Rassweiler, Samhouri, Stier, and White (2014). However, we fitted a linear model to the SR dissimilarity results to check how the SR dissimilarity variance was affected by feeding ground size and learning biases. This analysis confirmed that feeding ground size and its interaction with the different learning biases had a strong effect on SR dissimilarity, explaining 81% of variance between model runs (the linear model specifics can be found in the online supplementary material).
All models are thought experiments that force scientists to abstract out many real-world details, but the models we have presented here, while no different, have been closely informed where possible by empirical observations to help understand how the cultural evolution of humpback whale song might emerge from spatial structure and simple learning and production rules. Modelling for the purpose of studying vocal convergence is not a new idea. It has been used in several fields such as biology, linguistics and music (de Boer, 2002; Goodfellow & Slater, 1986; Kirby, 2001; Lachlan et al., 2004; Miranda et al., 2010; Slater, 1986; Todd & Werner, 1999; Williams & Slater, 1990). While these models study vocal conformity, they do so in strictly defined systems. This simplicity informed our choice of first-order Markov models as a song learning/production substrate in our model, leading to a simple song production and learning system that makes minimal assumptions about the cognitive capabilities of humpback whales whilst also allowing us to incorporate other influential factors that may impact song learning. Moreover, Markov models have been recently and successfully used to describe the structural characteristics of hybrid humpback whale songs at the theme level (Garland et al., 2017). However, there are a number of problems in using a first-order Markov model for song learning and production. Such models will never achieve the level of complexity observed in humpback whale song when songs are examined as a long string of individual units, due to its hierarchal and repetitive structure (Suzuki et al., 2006). Despite these shortcomings, our focus here was not on whether or not these models can recreate the syntactical fine-scale structures observed in humpback whale song. Instead, we aimed to model one commonly quantified, reported and representative hierarchal level within the complex song structure: the sequence of themes comprising a song (Cholewiak, Sousa-Lima, & Cerchio, 2012; Garland et al., 2017). By using a simple method of song learning and production, we could easily highlight the effect of environmental factors on the songs of our agents. We consider these Markov models as placeholders that should ultimately be replaced by a way of modelling fine-scale song production that is more closely informed by data from real humpback songs, once they become available (for example, the syntax modelling approach of Jin & Kozhevnikov, 2011, shows some promise in this regard). Humpback whale song learning is, of course, a biological system and will be subject to variance in many ways that have not been captured in the current model. For instance, variance among listeners in the rate of song learning in general (Mesoudi, Chang, Dall, & Thornton, 2016), and uptake of novelties in particular could potentially generate asymmetries that may be important in preventing complete song conformity among populations. Nonetheless, our model produces a number of interesting suggestions by modelling the interaction between humpback whales on the breeding ground, how migratory movements influence song learning, how the size of feeding grounds may impact transmission, and how the acoustic loss in transmission of song over distance, among other factors, might influence song learning.
The role of female humpback whales has purposely been excluded from the current implementation of the model, despite their obviously central role in real populations. This is partly motivated by the need to keep models simple and tractable, but partly also due to uncertainty over the role of females in song evolution. Songs are hypothesised to have a role in the mating system of humpback whales, but whether they function in mate attraction or to mediate male–male interactions is still debated (Herman, 2016). While it will be important to implement female agents in future modelling architectures, caution is warranted given our lack of understanding of how females may shape song evolution (and revolution). Given the notion that males’ drive for novelty is driven by female choice, one possible implementation comes from evolutionary musicology, where the role of females as “critics” has been investigated (Todd & Werner, 1999). The novelty algorithm that was implemented in the current study takes direct inspiration from this work, which used a similar algorithm to allow female judges in a population of agents to decide which male agent they will mate with. However, in this model, musical preferences are genetically inherited, and this process is not relevant to what seems to happen within humpback whale populations. Songs are not genetically inherited but rather they are learned horizontally from their conspecifics via cultural transmission (Garland et al., 2011). In future, the introduction of female agents as “critics” would potentially allow us to generate new theories on how female preferences may influence the evolution of song learning.
In summary, by using methods inspired by computational research into the origin of music and music composition, we have developed a multi-agent model that simulates the migratory movements, interactions and singing behaviour of humpback whales. Incorporating a sound transmission loss factor into our model allowed the simulation of song convergence within separate breeding populations and simultaneous divergence between populations. It also highlighted the potential importance of feeding grounds as being a key location for song cultural transmission for humpback whale songs, as hypothesised in the empirical literature (Garland et al., 2013; Garland et al., 2011). A novelty bias was found to increase the overall song dissimilarity among agents, and to produce high levels of song divergence when the agents were geographically separated in the two breeding grounds. Finally, introducing song production errors resulted in songs that gradually evolved, with song variation approaching that seen in the wild at the end of the breeding season. We were able to mirror the gradual cultural evolution of song, but none of our learning scenarios triggered a process comparable with what we observed during a song revolution, indicating that other learning biases might be necessary in order to produce such a dramatic population-level song replacement and suggesting an obvious next step in this line of research.
Supplemental material
Supplemental Material, Humpback-ABM-master - Using agent-based models to understand the role of individuals in the song evolution of humpback whales (Megaptera novaeangliae)
Supplemental material, Humpback-ABM-master for Using agent-based models to understand the role of individuals in the song evolution of humpback whales (Megaptera novaeangliae) by Michael Mcloughlin, Luca Lamoni, Ellen C. Garland, Simon Ingram, Alexis Kirke, Michael J. Noad, Luke Rendell and Eduardo Miranda in Music & Science
Footnotes
Acknowledgement
Authors would like to thank Jennifer Coxon and Oliver Leedham for assistance with song transcription. Song recordings from eastern Australia were made during the HARC project, and we thank everyone involved.
Contributorship
MM and LL contributed equally to this study. MM, LL, EM, LR, SI and AK conceived the study; MM and LL designed the models, analysed the data and drafted the manuscript; MN collected the song recordings; EG and MN provided expert knowledge on the humpback song system. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MM and LL were supported by a Leverhulme Trust Grant to LR, AK, SI and EM (grant reference RPG-2013-367). EG was supported by a Royal Society Newton International Fellowship. LR was supported by the MASTS pooling initiative (The Marine Alliance for Science and Technology for Scotland) and their support is gratefully acknowledged. MASTS is funded by the Scottish Funding Council (grant reference HR09011) and contributing institutions. Song recording was funded by the U.S. Office of Naval Research, the Australian Defence Science and Technology Organisation and the Tangalooma Marine Education and Research Foundation.
Peer review
Bruno Gingras, Institut für Psychologie, Universität Innsbruck.
Peter Tyack, School of Biology, University of St Andrews.
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.