
Abstract
The speech-to-song illusion is a perceptual effect emerging at the interplay of two cognitive domains, music and language. It arises upon repetitions of a spoken phrase that shifts to being perceived as song, and varies in the likelihood, ease, and vividness of its occurrence among individuals. A prevailing explanation of the illusion suggests that listeners’ attention shifts to rhythm and melody of the phrase once their involvement with the linguistic meaning subsides. The present study tested this mechanism by manipulating meaning plausibility and structural complexity of French and English phrases and by obtaining measures of attentional and working memory capacity from 80 French and English listeners who were exposed to repetitions of sentences in their native language. The results show that the transformation was facilitated in listeners with fewer cognitive resources and in less plausible, more complex phrases, which is at odds with the previously proposed mechanism underpinning the speech-to-song illusion. The illusion-promoting effect of musical training was visible only in simple but not in complex phrases. We propose a new account of the perceptual transformation from speech to song as a cognitive effect arising from the accumulation of music-related priors in a linguistically ambiguous context of massed repetitions.
Keywords
Introduction
Our conscious experience of the world is a result of an external stimulation received by our senses and a processing effort made by our brain. As such, the process is prone to random error, though some errors appear more systematic, giving rise to what we might describe as perceptual illusions (McIntosh, 2022). The present article reports an empirical investigation of the speech-to-song illusion coined by Diana Deutsch (Deutsch, 1995; Deutsch et al., 2011; also referred to as the speech-to-song transformation, Falk et al., 2014; henceforth STS). This phenomenon describes an illusory transformation of spoken phrases which are perceived as singing upon repetition. Despite an extensive study of STS (e.g., Castro et al., 2018; Falk et al., 2014; Graber et al., 2017; Groenveld et al., 2020; Jaisin et al., 2016; Rathcke et al., 2021b; Simchy-Gross & Margulis, 2018; Tierney et al., 2018; Tierney et al., 2021; Vanden Bosch der Nederlanden et al., 2015), the exact mechanism evoking STS is still not fully understood.
STS is one of the two auditory illusions that arise upon repetitions of speech. The first discovery of illusory transformations upon repetition was made with single words (Warren, 1961; Warren & Gregory, 1958). When a spoken word is repeated for a prolonged period of time, listeners tend to report that their perception of the word changes and alternates between auditory impressions of various, sometimes phonologically unrelated words, interspersed with percepts of the original input. Verbal transformations have been extensively studied since their discovery in 1958 (e.g., Basirat et al., 2012; Mackay et al., 1993; Natsoulas, 1965; Sato et al., 2006; Shoaf & Pitt, 2002; Warren, 1961; Warren & Warren, 1966). The results of this research demonstrate that the number of transformations can be highly variable across individuals (Warren, 1961; Warren & Warren, 1966), giving rise to 5–20 unique forms during a several-minute exposure (Shoaf & Pitt, 2002). The ability to experience verbal transformations emerges at the age of 6 and declines from the age of 60, suggesting that the illusory effect recruits a cognitive mechanism required for skilled listening to speech and is susceptible to maturational constraints and decay (Warren & Warren, 1966).
Previous research into verbal transformations has mostly focused on isolated words. Some experiments examined the effect of word length and demonstrated that polysyllabic words lead to a higher number of transformations than monosyllabic words (Kaminska et al., 2000; Shoaf & Pitt, 2002). However, the original experiments by Warren and colleagues (Warren, 1961; Warren & Gregory, 1958) also included short sentences like “Our ship has sailed.” or “Our side is right.”, which caused fewer transformations than isolated words. The observed patterns resulted in a general conclusion that “the greatest distortions occurred with phonetically simpler stimuli” (Warren, 1961, p. 255), paving the way to an extensive study of words rather than sentences in years to follow. An illusory perception that prevails when more complex speech stimuli (such as words forming phrases or sentences) are repeated was described as STS some 30 years later by Deutsch (1995). Apart from the primary difference in linguistic complexity, STS differs from verbal transformations in that the illusion affects only the prosodic shape of speech but not its segmental phonology (i.e., the perception of individual speech sounds constituting the phrase remains unaffected, Deutsch et al., 2011).
Prosody comprises melody, pitch, and rhythm of both spoken and written language (Frazier & Gibson, 2015; Shattuck-Hufnagel & Turk, 1996) and constitutes the best-known link between language and music (McMullen & Saffran, 2004; Patel, 2003, 2012). Not surprisingly, much research on STS has focused primarily on acoustic-prosodic properties of spoken utterances and their ability to induce the perceptual shift from speech to song (Deutsch et al., 2011; Falk et al., 2014; Falk et al., 2014; Groenveld et al., 2020; Tierney et al., 2018). Prosodic properties that promote STS include temporal stability of pitch tracks (Falk et al., 2014; Groenveld et al., 2020; Tierney et al., 2018) and equalized duration of intervocalic intervals (as opposed to syllables, Falk et al., 2014). Moreover, sentence-inherent features that support the perception of pitch (Rathcke et al., 2021b) and individual characteristics that influence listeners’ ability to extract prosodic information from auditory signals (Tierney et al., 2021) both foster and enhance STS. Crucially, prosodic properties extend over large timescales that enable hierarchical relationships between neighboring structural units to be established (Beckman, 1996; Beckman et al., 2006; Beckman & Pierrehumbert, 1986). Such hierarchies are assumed to constitute mental representations of both language and music (e.g., Jackendoff, 2009; Jackendoff & Lerdahl, 2006; Patel, 2003, 2012). Accordingly, a hierarchical prosodic structure can hardly be derived from monosyllabic one-word utterances lacking alternations of strong and weak elements. Such utterances are thus very likely to give rise exclusively to verbal transformations rather than STS (Warren, 1961; Warren & Gregory, 1958), though even in case of verbal transformations, prosodic features such as (re-)grouping of phonemic constituents have also been hypothesized to shape the illusory effect (Basirat et al., 2012).
Repetition that is key to both STS and verbal transformations is also known to cause other auditory illusions. When non-linguistic sounds (like bee buzz, water droplets, chicken cackle or door noise) are played repeatedly to human listeners, they report perceiving musical excerpts as repetitions of the sound unfold in time (Rowland et al., 2019; Simchy-Gross & Margulis, 2018). This finding resonates with the observation that listeners tend to experience STS more readily and vividly when exposed to utterance repetitions spoken in a language that sounds foreign to them and is difficult for them to pronounce (Margulis et al., 2015). A “repetition-to-music” effect has been proposed and defined as a general perceptual tendency to induce musical attributes in any repetitive auditory signals (Simchy-Gross & Margulis, 2018). The proposal, however, overlooks the fact that massed repetitions of a single word in listeners’ native language(s) has not been previously reported to induce a musical percept (Basirat et al., 2012; Mackay et al., 1993; Natsoulas, 1965; Sato et al., 2006; Shoaf & Pitt, 2002; Warren, 1961; Warren & Warren, 1966). The “repetition-to-music” effect has so far been attested with non-linguistic sounds on relatively long timescales (2–5 s). 1 Moreover, these sounds had a measurable fundamental frequency, possibly enabling listeners to perceive pitch and to induce musical structure in the originally non-musical sound (cf. Rathcke et al., 2021b). In sum, a melody is never a note in isolation and requires time to evolve (Krumhansl, 2001; Krumhansl & Kessler, 1982).
Overall, existing theoretical accounts of STS have not yet determined if, and how, STS engages specific processes that are fundamentally different from the processes underpinning verbal transformations (Warren, 1961; Warren & Gregory, 1958) or those involved in the domain-general “repetition-to-music” effect reported for nonspeech sounds (Rowland et al., 2019; Simchy-Gross & Margulis, 2018). A good point of departure to uncover the potential uniqueness of STS is the linguistic complexity of the auditory stimulus. While verbal transformations have been reported with isolated words, STS typically arises in phrases formed of several words (Deutsch, 1995; Deutsch et al., 2011; Falk et al., 2014; Jaisin et al., 2016; Margulis et al., 2015; Rathcke et al., 2021; Tierney et al., 2018; Vanden Bosch der Nederlanden et al., 2015). Such linguistic phrases have an internal structure that defines semantic relationships between phrasal constituents (e.g., “who did what to whom”), giving them their contextualized meaning that goes beyond purely lexical semantics (e.g., “cat”, “mouse”, “eat”; Stubbs, 2001). A linguistic utterance is thus much more than a list of isolated words (Stubbs, 2001). While this issue has been largely overlooked within current research on STS, many accounts of STS rest on the assumption that linguistic meaning is somehow involved in the perceptual switch between speech and song (e.g., Castro et al., 2018; Falk et al., 2014; Margulis, 2013; Margulis et al., 2015; Rathcke et al., 2021b; Tierney et al., 2021). The present study addresses the currently unresolved issue of how the switch from speech to song is moderated by the sentence-level meaning.
The aims of the present study are two-fold. First, we seek to clarify if, and how, sentence-level meaning influences STS. Second, we aim to test how individual listener traits that are involved in cognitive computations of the linguistic meaning might moderate the experience of STS which is known to be individually very variable (Rathcke et al., 2021b; Tierney et al., 2021). Starting from the idea shared by many existing accounts of STS that linguistic meaning has to somehow decay in the perception of listeners before they can experience sentence repetitions as being sung (e.g., Castro et al., 2018; Falk et al., 2014; Margulis, 2013; Rathcke et al., 2021b; Tierney et al., 2021), the present study tests the hypothesis that linguistic meanings that are difficult to extract from a complex phrasal structure will reduce STS. Two aspects of the process of the linguistic meaning extraction are manipulated, namely meaning plausibility and syntactic complexity. Semantically implausible (e.g., “My cat was eaten by a mouse.”) as well as syntactically complex (e.g., “The cotton clothing is made of grows in Mississippi.” 2 ) sentences can cause difficulties during linguistic processing and comprehension (e.g., Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002). Accordingly, we predicted that implausible meanings and increased syntactic complexity would influence STS by interfering with the computation of linguistic meaning, and thus block, delay, and/or reduce the strength of STS-experience in listeners. In contrast to previous research that showed an increased tendency toward experiencing STS in a foreign or a non-native language of listeners (Margulis et al., 2015; Rathcke et al., 2021b), the present study focuses on native listeners only. Sentence parsing and comprehension are arguably more automatic for language experts than novices (e.g., Ito & Pickering, 2021). Listening to someone talk and deliberately not understanding them is a difficult task when the language of the interaction is native to the listener, indicating that it may be harder to forego lexico-syntactic computations in a native (as compared to a non-native or a foreign) language.
The role of the listener background in STS has been extensively tested with regard to musical training and general musical aptitude, focusing on the song aspect of STS (e.g., Falk et al., 2014; Margulis et al., 2015; Tierney et al., 2013; Tierney et al., 2021; Vanden Bosch der Nederlanden et al., 2015). However, listeners can also differ in terms of their ability to extract linguistic meanings from (complex) utterances of their native language(s) (e.g., Cunnings, 2017; Tan & Foltz, 2020). They also differ in cognitive resources available to them for the computation of meaning and for language processing in general (Hannon & Daneman, 2001; Park & Reder, 2012). Given that lexico-syntactic processing is cognitively demanding and costly (e.g., Daneman & Merikle, 1996; Just et al., 1996; Just & Carpenter, 1992), the termination of semantic computations during repetitions may free up attentional and working memory resources (Tierney et al., 2021) which then can be used for a prosodic reanalysis leading to STS (Deutsch et al., 2011; Falk et al., 2014; Rathcke et al., 2021b; Tierney et al., 2021). The present study tests this hypothesis by investigating how individual working memory, attentional flexibility, and divided attention moderate listeners’ experience of STS.
Both attention and working memory are known to be capacity-limited cognitive resources involved in language processing (Baddeley, 2003; Kim et al., 2018; Kurland, 2011). Working memory plays an important role during sentence comprehension as it keeps the information about the ongoing syntactic parse and guides the understanding of the semantic relationships between syntactic constituents, helping to resolve potential ambiguities (MacDonald & Christiansen, 2002; Waters & Caplan, 1996). Similarly, attentional resources are involved in the assignment of syntactic roles to the constituents of a sentence (Tomlin, 1999) and are drawn upon in many tasks dealing with the semantic processing of both isolated words and complex sentences (Myachykov & Posner, 2005). Such resources have long been discussed to play an important role in a variety of illusions involving language (e.g., Hannon & Daneman, 2001; Park & Reder, 2012). Here, we hypothesized that listeners with a reduced attentional and/or working memory capacity would differ in their experience of STS, assuming that limited resources may compete during the auditory analysis of an incoming acoustic signal and therefore influence the activation of alternative mental representations. These individual effects are particularly likely to occur in conjunction with those lexico-syntactic features that affect semantic plausibility and syntactic complexity of sentences that are repeated to create STS. Given that semantically implausible and syntactically complex sentences are more challenging to process (e.g., Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002), we expected that especially low-capacity listeners may have difficulties with the computation of linguistic meaning (Myachykov & Posner, 2005; Tomlin, 1999), and thus experience fewer, slower, or less vivid transformations. In addition, individually variable levels of musical training were measured and included as a control variable (e.g., Falk et al., 2014; Margulis et al., 2015; Tierney et al., 2013; Tierney et al., 2021; Vanden Bosch der Nederlanden et al., 2015).
The two hypotheses were tested with 80 listeners whose cognitive resources were assessed using established batteries of working memory and attention (Wechsler, 1997; Zimmermann & Fimm, 2004). To increase the generalizability of the hypothesized effects, participants of the present study were recruited from two prosodically and structurally distinct languages – English and French. The participants were asked to listen to repetitions of sentences in their native language, and indicate if, when, and how strongly they experienced a shift from speech to song. The sentences varied in semantic plausibility and syntactic complexity, with similar lexico-syntactic manipulations across all stimuli of the two languages. We investigated how the sentence features, along with cognitive resources of listeners, may affect the likelihood and speed (Falk et al., 2014), as well as the perceived strength of STS (e.g., Groenveld et al., 2020; Margulis et al., 2015; Tierney et al., 2018).
Method
Participants
Forty English and forty French listeners (59 F) aged 18–43 (mean age: 27) volunteered to participate in this study. Prior to an experimental session, they filled in an online questionnaire that collected information about musical training and screened for amusia. Answers to a part of the questionnaire led to the calculation of an individual musicality index which was an aggregate of the scores given to the questions about years of musical training (from 0 to 19 in the sample), presence of a regular practice (0 for non-active and 1 for active participants), number of musical instruments (including singing, from 0 to 6 in the sample), age at the beginning of musical training (below the age of 10 coded as 2, from 10 up to 20 years coded as 1, above 20 years coded as 0). The derived index varied between 0 (no musical training received) to 26 (a relatively high level of musical training). This (or a comparable) way of capturing individual difference in musical training has been used in previous research, with compelling results (Rathcke et al. 2021a; Šturm & Volín, 2016). No professional musicians or singers participated in the experiment.
Three tests were chosen to measure individual cognitive abilities. The auditory working memory (WM) capacity was tested using the forward and backward digit span test (WAIS-III, Wechsler, 1997) which measured individual storage and processing resources (Daneman & Carpenter, 1980). Additionally, three tests were selected from the Test Battery for Attentional Performance (TAP, Zimmermann & Fimm, 2004): divided attention, flexibility, and alertness. The TAP test of divided attention estimated listeners’ ability to pay attention to two tasks simultaneously. Participants were asked to monitor for certain patterns involving either visual symbols or auditory tones and to quickly respond to both visual and auditory patterns. Here, the measure of interest was the number of errors participants made. Attentional flexibility estimated listeners’ ability to quickly switch attention between two different tasks. Participants were asked to alternately respond to a letter and a number while both were present on the screen during each trial. Here, speed-accuracy trade-off characterized individual performance, with a compound measure derived from both reaction times and the total number of errors. Finally, alertness measured the general wakefulness in the presence of a stimulus (“phasic alertness”). Here, participants had to respond as quickly as possible to a visual stimulus appearing at randomly varying time intervals, with or without a preceding warning tone. The performance measure was calculated by subtracting reaction times to stimuli presented with a warning tone from reaction times to stimuli presented without a warning tone, divided by the median of total reaction times. The alertness index served as a control measure. Raw TAP and WM scores were transformed into percentiles of age-normed distributions (Wechsler, 1997; Zimmermann & Fimm, 2004). A correlation matrix of the listener characteristics is shown in Figure 1. None of the correlations between the individual measures was significant after the Bonferroni correction for multiple comparisons (α = .05/10), which is in line with previous studies (e.g., Keye et al., 2009; Mall et al., 2014).

Correlation matrix displaying correlation coefficients for all pairs of the individual characteristics (including alertness, divided attention, attentional flexibility, working memory capacity, and musical training) measured in the study sample (N = 80).
Materials
Two sets of sentence pairs varying in syntactic complexity of sentence-level structures and plausibility of sentence-level meanings were created in English and French. The first set (henceforth the “semantics set”) consisted of syntactically simple sentences and manipulated the plausibility of lexical constituents. It contained 12 sentences contrasting plausible constituents (e.g., English: “The granma ate the lunch.”) with implausible constituents (e.g., English: “The postbox ate the lunch.”). The second set (henceforth the “syntax set”) contained syntactically more complex sentences consisting of two verbal predicates and manipulated the mapping between syntactic constituents and prosodic breaks. It comprised 12 sentences in which the prosodic break location changed the sentence interpretability from plausible (e.g., English: “While the woman washed, the cat purred.”) to implausible (e.g., English: “While the woman washed the cat, meowed.”). The latter type of sentences introduces, or supports, the garden-path effect since the misplaced prosodic break invites incorrect syntactic parsing and results in the second verbal phrase lacking an argument (the subject). The prosodic break was expressed by means of an acoustic silence (with a constant duration of 200 ms across all stimuli). Minor changes in lexical choices (e.g., “purred“/ “meowed“) were implemented across pairs of the syntax set, to avoid monotony and to introduce some comparability to the semantics set. In the syntax set, the alternate items were taken from closely related semantic fields with the same syntactic roles. The full list of materials can be viewed on OSF (https://osf.io/8d9mt).
For each language, sentences of the two experimental conditions (plausible/ implausible) were matched in length (3–16 syllables) and syntactic structure. Attention was also paid to matching these aspects of the materials across the two languages wherever possible. By way of controlling for potential effects of phonology on STS (Rathcke et al., 2021b), each sentence was quantified in terms of its mean sonority. In the present materials, the sonority score varied between 4.0 and 5.35 (mean 4.68), reflecting the type of phonemes (e.g., high-sonority: approximants, nasals vs. low-sonority: stops, fricatives) that a sentence contained, and was balanced across the plausible/ implausible sentences as well as syntax/ semantics sets. Welch two-sample t-test confirmed that no systematic sonority differences existed in English (t = .65, df = 18.19, p = .53) and French (t = 1.16, df = 17.33, p = .26) sets.
To examine a potentially gradual effect of syntactic complexity across all materials, we additionally quantified the underlying structure of each sentence based on the following five aspects of its syntax: (1) the number of terminal syntactic nodes (i.e., the number of free morphemes); (2) the number of predicates (counting finite verbs, depending on whether or not a subordinate sentence was present); (3) the number of subordinate sentences; (4) the number of phrasal constituents (i.e., the number of arguments and adjuncts of the predicates); and (5) the probability of a garden-path effect (scored 0 in the “semantics” set, 1 or 2 in the “syntax” set, depending on the structure). A composite score of syntactic complexity was then derived. It varied between 6 and 19 (mean: 12.55) in the present materials, with higher scores reflecting higher levels of syntactic complexity. While syntax of any given sentence could be quantified and projected onto a continuum of complexity using the metric above, sentences of the syntax set were developed to contrast a relatively complex structure with a relatively simple structure of the semantics set. The difference is well reflected in the calculated scores. A Welch two-sample t-test confirmed that the syntax set had a significantly higher level of complexity than the semantics sets in English (t = 13.42, df = 19.74, p < .001) and in French (t = 13.58, df = 21.53, p < .001). We might expect STS-weakening to reflect either a relative difficulty of syntactic computations (captured on a scale) or an increased effort of integrating syntactic subordination into the sentence meaning (captured in the syntax set, cf. Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002).
Two female speakers (undergraduate students at the University of Kent) were recruited to read the sentences in their native language. They were instructed to match speech rate and pitch patterns across the two experimental conditions (plausible/ implausible) and recorded in a soundproof booth of the Linguistics Lab at the University of Kent. Only the most satisfactory renditions of the sentence pairs were included in the experiment. Both speakers were re-recorded if the requirement of matching speech rate and pitch patterns across the two conditions was not met (the stimuli were prepared and perceptually evaluated by the first author). Timing properties and pitch trajectories of the recordings remained unmodified.
Given that prosody – especially pitch stability and syllable/ vowel timing – plays an important role in STS (Falk et al., 2014; Groenveld et al., 2020; Tierney et al., 2018), Table 1 compares relevant prosodic features of the test sentences across all experimental conditions. The F0-measure focused on syllable nuclei only and excluded any abutting consonants, to avoid micro-prosodic perturbations of F0-contours (e.g., Hanson, 2009). To measure local F0, values were taken at the beginning (25%) and the end (75%) of each nucleus and converted into semitones to reflect pitch stability at the level of perceptually most salient, sonorous portions of sentences (Barnes et al., 2012; Rathcke, et al., 2021b). To measure global pitch stability within a sentence, we calculated coefficient of variability across F0-values measured at midpoint of all syllable nuclei using the formula:
Comparisons of prosodic properties of the test sentences.

Previous work shows that STS tends to be experienced during the third repetition of a spoken sentence, with the number of reported illusions increasing after shorter rather than after longer inter-sentential pauses (Falk et al., 2014). Accordingly, the test sentences were looped with eight repetitions in total, and the silent pause between repetitions was set to 400 ms – that is, the shortest pause from the experiments by Falk et al. (2014), yet twice as long as the duration of the intra-sentential break implemented in the syntax set. Examples of the stimuli can be found on OSF (https://osf.io/8d9mt).
Procedure
Experimental sessions took place in a sound-attenuated room at the University of Kent (experiments with English listeners) and the Sorbonne Nouvelle Paris-3 University (experiments with French listeners). Prior to the lab visit, the participants were emailed a copy of the consent form, along with web links to the online questionnaire that collected individual background information, with a request to fill in both. A lab session started with a baseline test that asked the participants to listen to the experimental sentences presented once and to judge each of them on a scale from 1 (clearly speech) to 8 (clearly song). The test tapped participants’ intuitions about the nature of speech and singing as we did not provide any auditory examples for what sounds may constitute clear speech or clear song. The baseline test was then followed by individual measurements of the attentional resources using the TAP battery (Zimmermann & Fimm, 2004). We first tested divided attention, then flexibility and finally alertness. Following TAP, participants performed the WAIS-III auditory working memory test (Wechsler, 1997). In this test, a series of digits had to be repeated back to the experimenter, first in the same order and then in the reversed order of the original presentation. The presentation of the digits was slow-paced, approximately one digit per second (which is more taxing to the working memory than a fast-paced presentation). The complexity of digit series varied from 2- up to 9-digit lists. For each correctly repeated digit series, participants scored 1. They received 0 if they made mistakes in the digit order or identity. A failure to correctly repeat back digit series within two lists of the same complexity led to the termination of the test. The maximal score of WAIS-III was 30.
The STS test concluded the experimental session. In this test, we instructed the participants to listen to the looped sentences of their native language and indicate when (and only when) they experienced a transformation by pressing the return button. Participants had to wait until the end of the loop without pressing any button if they did not perceive any changes. At the end of each STS trial, we requested the participants to use the same scale as in the baseline test, and to indicate how song-like the sentence sounded to them after the eighth repetition. This procedure combined a previous approach of obtaining speed and frequency of STS (Falk et al., 2014; Rathcke et al., 2021b) with the experimental approaches that focused primarily on the strength of the subjective STS-experience (e.g., Groenveld et al., 2020; Tierney et al., 2018).
Overall, each individual session lasted 45–60 min. We conducted the WM aurally with an in-person experimenter and ran the remaining tests on a laptop computer using DMDX (Forster & Forster, 2003) and good-quality headphones for the auditory presentation of the stimuli.
Statistical Analyses
We conducted all statistical analyses in Rstudio (running R-version 4.1.2). Apart from the basic packages, we used several add-on libraries, including ordinal (Christensen, 2019), lme4 (Bates et al., 2015) and lmerTest (Kuznetsova et al., 2017). In all regression models below, the data were not aggregated (only NAs removed where appropriate). Wilcoxon signed-rank tests were run on the data aggregated by item.
We fitted mixed-effects models to the ordinal data (song-like ratings on the scale from 1 to 8; repetition cycles from 1 to 8 during which participants reported STS) and to the binomial data (whether or not (1/0) participants reported STS during a given loop). For all models, linguistic predictors of interest included plausibility (plausible/ implausible) and syntactic complexity (implemented either as a categorical factor of sentence set (semantics/ syntax) or as a continuous measure of variable complexity). Individual factors of interest included musical training, working memory, divided attention, and attentional flexibility. To control for potential effects of segmental phonology and sentence length (Rathcke et al., 2021b; Rowland et al., 2019), we included mean sonority index and number of syllables per sentence as covariates. All continuous factors (including syntactic complexity, musical training, working memory, divided attention, attentional flexibility, and sentence-specific covariates) were mean-centered. All models further included two crossed random intercepts: listener and sentence. Random slopes were only retained if the models converged. Model comparisons using the likelihood ratio test helped to determine the best model fit. To select the final model, we implemented a stepwise backward-fitting procedure. First, we defined all predicted main effects and their interactions. Next, we reduced the model complexity by successively removing predictors that did not improve the model fit. Moreover, we checked for potential multi-collinearity issues among the predictors, by calculating the Variance Inflation Factor (VIF) of the best-fit models and checking it against established threshold values (Stine, 1995). Only converging best-fit models (whose VIFs were below the critical threshold of 5 for all significant predictors) are reported below.
Finally, we calculated Kendall's correlation coefficients τb to measure the strength and the direction of association between the three aspects of STS-experience (likelihood, speed, and strength of the transformation). For this test, the data were aggregated by item (using median ratings of song-likeness, median repetition cycle, and proportion of STS reported by all participants).
Results
Song-Like Ratings of the Test Sentences Before and After Repetition
Figure 2 displays “song-like” ratings of English and French sentences at baseline vs. post repetition. In both languages, baseline responses occupied the lower end of the Likert scale (median English: 2.5; median French: 3.2, with the highest median rating being 4 in both English and French) while responses to the same sentences after the exposure to eight repetitions clustered around the upper end of the Likert scale (median English: 5.0; median French: 5.3, with the highest median rating being 6 in both English and French). The slight numerical difference between the two languages was significant neither at baseline (Wilcoxon signed-rank, W = 230.5, n.s.) nor post repetition (W = 201, n.s.). In contrast, Wilcoxon signed-rank test confirmed that the sentences were rated significantly more song-like post repetition in both English (V = 0, p < .001) and French (V = 0, p < .001).
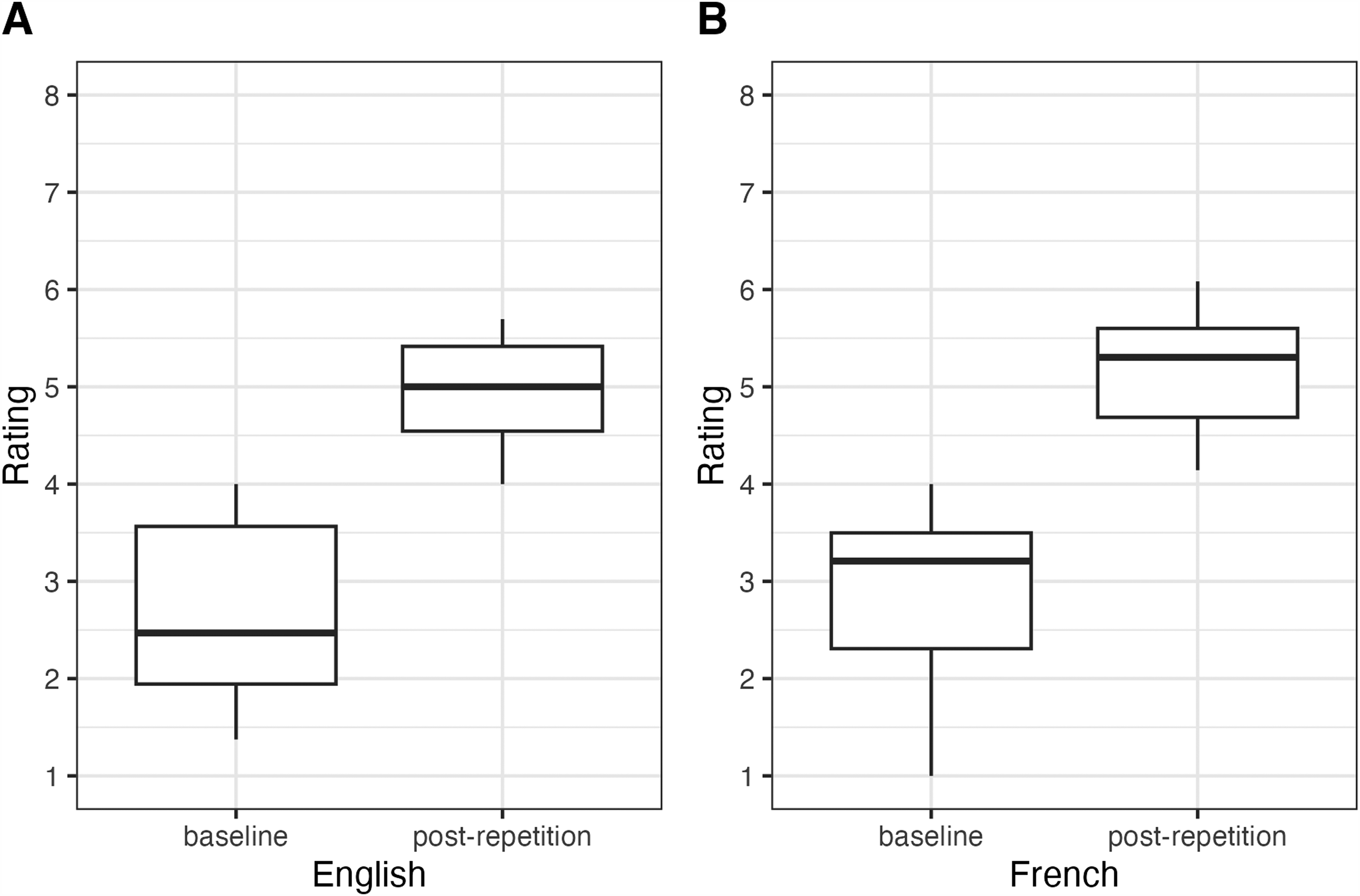
Perceptual ratings of the test sentences on the given Likert scale (1 = clearly speech, 8 = clearly song) after a single exposure (baseline) vs. after eight repetitions. Responses of the English participants are plotted in panel A, responses of the French participants in panel B.
Likelihood of STS
Overall, the rate of reported transformations was relatively low in the present dataset, amounting to approximately 40%. We fitted a logistic mixed model (estimated using maximal likelihood and the BOBYQA optimizer) to predict the likelihood of experiencing STS by sentence set (semantics/ syntax), plausibility (plausible/ implausible), and their interaction; syntactic complexity, individual musical training, working memory and attention measures, and two-way interactions of the individual measures with syntactic complexity, plausibility, and sentence set. Number of syllables was fit as a covariate, to control for potential effect of sentence length (Rathcke et al., 2021b; Rowland et al., 2019). We also checked if listeners of the two languages differed in their perception of STS in these materials. Of these predictors, the best-fit model retained main effects of plausibility (
Given the two-way interactions with the individual effects, we checked if musical training moderates the working memory finding but failed to find either a significant two-way interaction of musical training and individual working memory (
Figure 3 displays the main effects of interest. Accordingly, all implausible sentences introduced STS more often than the plausible sentences of the present stimulus set (β = .43, SE = .19, z = 2.22, p < .05, see Figure 3-A). Higher positive scores of attentional flexibility (measured as speed-accuracy trade-off, Zimmermann & Fimm, 2004) lowered the likelihood of individual STS-experience (β = −.42, SE = .19, z = −2.05, p < .05, see Figure 3-B). That is, participants with a tendency of being more accurate rather being fast in the flexibility task showed lower STS in contrast to those who tended to respond faster at a cost of accuracy. Figure 4 shows the interactions from the best-fit model. Both interactions involved syntactic complexity of the looped sentences and individual listener characteristics. Accordingly, syntactically more complex sentences led to a higher likelihood of STS-experience in listeners with lower working memory resources (β = −.20, SE = .09, z = −2.37, p < .05, see Figure 4-A). The promoting effect of musical training on STS (Tierney et al., 2021; Vanden Bosch der Nederlanden et al., 2015) was observed exclusively in syntactically simpler, but not in syntactically complex, sentences used in the present study. That is, listeners with lower levels of musical training had lower likelihood of experiencing STS in syntactically simple sentences in contrast to listeners with a high level of musical training, who showed the opposite effect (β = −.28, SE = .08, z = −3.52, p < .001, see Figure 4-B). No difference between the listeners was observed in syntactically complex sentences.

Model estimate plots obtained from the best-fit model of STS-likelihood, displaying the main effect of sentence plausibility (plausible vs. implausible sentences, panel A) and attentional flexibility (panel B, positive values of flexibility indicate that participants prioritized accuracy over speed of responses while negative values indicate a faster response at the cost of accuracy).

Model estimate plots obtained from the best-fit model of STS-likelihood, displaying the interactions of syntactic complexity with individual working memory capacity (panel A) and musical training (panel B). All values were scaled and centered around the mean (= 0). For the purpose of the visualization, listeners were grouped into high-scoring (1 standard deviation above the mean), average-scoring (i.e., close to the mean of the sample), and low-scoring (1 standard deviation below the mean).
Speed of STS
To examine how quickly participants experienced STS during repetitions, we fitted ordinal mixed-effects regressions to a subset of the data containing only those stimuli that induced STS and the accompanying information about the repetition cycle (1–8) during which participants reported to have experienced the transformation. The predictors of interest, again, included sentence set (semantics/ syntax), plausibility (plausible/ implausible), and their interaction; syntactic complexity, musical training, working memory, attention, and two-way interactions of the individual measures with syntactic complexity, plausibility, and sentence set. The final best-fit model contained only one predictor, sentence set (

Model estimate plot obtained from the best-fit model of STS-speed, displaying the main effect of the sentence set. The speed of STS-experience during repetitions is plotted along the y-axis (the total number of repetition cycles was 8).
This finding suggests that the ease of the STS-transformation does not reflect the relative ease of syntactic computations. The fact that the presence of syntactic subordination promotes STS rather than delaying it is at odds with the predictions of the linguistic meaning decay hypothesis that proposes a faster switch to the song percept in the absence of syntactic complexity (i.e., when the meaning of a sentence is easier to compute and is thus faster to decay).
Strength of STS
The last set of analyses examined the strength of the illusory experience. That is, how strongly song-like a given sentence sounded to the participants after the last repetition specifically in those trials that indeed showed the transformation. The ratings obtained on the Likert scale from 1 (clearly speech) to 8 (clearly song) were fitted to the predictors sentence set (semantics/ syntax), plausibility (plausible/ implausible), and their interaction; syntactic complexity, musical training, working memory, attention, and two-way interactions of the individual measures with syntactic complexity, plausibility, and sentence set. The best-fit model contained one predictor of interest, plausibility (
The main effect of interest is plotted in Figure 6, which indicates that all implausible sentences (i.e., from both semantics and syntax sets) sounded significantly more song-like upon repetition than their plausible counterparts (β = .27, SE = .13, z = 2.08, p < .05). The effect of the control variable (not shown) was in full alignment with previous findings (Rathcke et al., 2021b; Rowland et al., 2019), with shorter sentences sounding significantly more song-like to listeners upon exposure to repetitions (β = .07, SE = .03, z = 2.61, p < .05).

Model estimate plot obtained from the best-fit model of STS-strength, displaying the main effect of sentence plausibility. Responses after repetition were collected on an 8-point Likert scale from 1 (clearly speech) to 8 (clearly song).
Associations Between Likelihood, Speed, and Strength of STS
Correlation analyses showed that the three aspects of STS-experience were associated, at least to some extent. The strongest association was observed between the speed and the strength of the transformation (τb = −0.62, z = −5.17, p < .001). The correlation indicated that those stimuli that were perceived more song-like upon repetitions also tended to transform sooner during the repetition cycles. The strength and the likelihood of the transformation were also correlated (τb = 0.30, z = 2.63, p < .01), suggesting that higher transformation likelihood of a stimulus tended to be accompanied by a higher song-like rating upon repetition, though the correlation was relatively weak. In contrast, the speed and the likelihood of STS did not show a statistically significant association following the Bonferroni correction (τb = −0.25, z = −2.27, n.s.).
Discussion
The aim of the present study was to clarify several unresolved issues surrounding the cognitive underpinnings of the speech-to-song illusion (Deutsch, 1995). Even though the (dis)engagement of language processes that compute linguistic meaning has been frequently assumed to be the key prerequisite to an individual experience of STS (e.g., Castro et al., 2018; Falk et al., 2014; Jaisin et al., 2016; Margulis, 2013; Rathcke et al., 2021b; Tierney et al., 2021), previous studies did not provide sufficient evidence in support of this foundational assumption. The experiments presented here were conducted to fill this gap, by testing two specific aspects of STS: (1) the lexico-syntactic properties of the sentences that are repeated, and (2) the cognitive traits of the listeners who are exposed to sentence repetitions. The results obtained with French and English participants of the study did not differ, enforcing the generalizability of the findings discussed below.
The Contribution of Lexico-Syntactic Properties to STS
Guided by the idea that the transition from speech to song in STS is moderated by listeners’ engagement with the linguistic meaning of the repeated sentence (e.g., Castro et al., 2018; Falk et al., 2014; Jaisin et al., 2016; Margulis, 2013; Rathcke et al., 2021b; Tierney et al., 2021), we tested two aspects of sentence-level meaning. In contrast to word-level meaning that is part of the mental lexicon storing the general knowledge about language (Aitchison, 2012), sentential meaning is computed on the fly (e.g., Culicover & Jackendoff, 2006). The sentence-level meaning derives not only from the meaning of individual words but also from the semantic roles assigned to the words because they occur in specific syntactic positions and reflect relationships between the constituents of a hierarchical structure (Chomsky, 1957; Hagoort, 2003). For example, the word “cat” can be the agent of a semantically plausible sentence “The cat chased a mouse in the house.” or a semantically implausible sentence “The cat shot the mouse with a gun.” The results of the present study demonstrate that sentences of the latter type that violate lexico-syntactic expectations are more conducive to STS.
Even though semantic implausibility tends to slow down linguistic processing in online comprehension tasks (e.g., Ferreira, 2003), it did not show the predicted effect of reducing the STS-experience. This result is possibly due to temporal differences between an experiment measuring processing cost of a lexico-semantic violation vs. the present study. The relatively short processing delay previously reported for implausible sentences in the relevant literature (in the order of 300 ms, Ferreira, 2003; Patson & Warren, 2010) might have been obscured during sentence repetitions that are required for STS, interspersed with 400-ms long pauses. Similarly, implausible prosodic chunking of syntactically complex sentences (e.g., “While the woman washed the cat, meowed.” vs. “While the woman washed, the cat meowed.”) did not lead to a diminished STS-experience of the study participants as we had expected. Instead, implausible sentences of both the syntax and the semantics set transformed more often and sounded more song-like upon repetition, suggesting that online comprehension delays due to lexico-syntactic anomalies may be quickly resolved during repetitions. Moreover, the experimental task of the present study was not linguistic in nature. Listeners knew that their understanding of the sentences (and the depth of their lexico-syntactic processing) would not be examined at any point during the experiment. The task peculiarity (as compared to previous work on the processing of implausible sentences, Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002) may have encouraged listeners to forego in-depth computations of linguistic meaning from the lexico-syntactic structure (cf. Rathcke et al., 2021b).
Alternatively, listeners may have quickly assessed the meaning of sentences with lexico-syntactic violations as implausible, with meaning implausibility being the key driver of the effect. While lexico-syntactic implausibility may be both rare (Grice, 1989) and cognitively costly (Ferreira, 2003; Patson & Warren, 2010) in everyday language, it is far from uncommon in music. For example, text setting in lyrics obeys its own principles and often deviates from linguistic texts created for other purposes, especially with regards to prosodic segmentation and phrasing (Gordon et al., 2011; Liebling, 1908). Accordingly, prosodic breaks in lyrics do not always align with syntactic junctures between neighboring constituents. Rather, they serve the rhythmic structure that carries an expressive artistic effect and an emotional meaning. As a consequence, lyrics may frequently show enjambment, or incomplete syntax at the end of a line (Heller, 1977; van’t Jagt et al., 2014). Principles and demands of the internal structure of lyrics can override many linguistic constraints, including the placement of lexical stress (Janda & Morgan, 1987) and even the properties of lexical tone (Schellenberg, 2009).
Interestingly, both meaning and structure also influence verbal transformations that arise upon repetitions of single words (Warren, 1961; Warren & Gregory, 1958). Meaningful words tend to transform slower than meaningless nonce-words or structurally illicit pseudo-words, with the overall number of unique forms being higher in nonce- and pseudo-words than in real words (Natsoulas, 1965; Shoaf & Pitt, 2002). Such parallels between the two perceptual repetition effects highlight a shared origin of the two illusions, as previously identified in the connectionist account of STS (Castro et al., 2018). A certain level of (syntactic) implausibility can be frequently observed in STS-stimuli used in previous research. For example, the original phrase by Deutsch (1995) that introduced STS as a perceptual phenomenon – “sometimes behave so strangely” – is syntactically incomplete as it misses the subject (“they”) and cannot be fully parsed (e.g., Hagoort, 2003; Van Gompel & Pickering, 2007). Similarly, the database of high-transforming STS-stimuli created by Tierney et al. (2013, 2018, 2021) contain syntactic omissions of one or two constituents that also prohibit a complete syntactic parse (e.g., “here is no less”, “gave the houses”, “somehow I can get”), possibly enhancing the STS-effect.
Moreover, violations of the semantic plausibility constraints examined in the present study (Ferreira, 2003; Ferreira et al., 2002) are commonplace in (song) lyrics (Pattison, 1991). Interestingly, an example of such semantically implausible phrase of the famous song lyrics “Excuse me while I kiss the sky” (from “Purple Haze” by Jimmy Hendrix, 1967) is also an example of the most frequently misheard lines in song lyrics, being predominantly perceived as “Excuse me while I kiss this guy” and giving rise to the title of an archive of misheard song lyrics (https://www.kissthisguy.com/, Kentner, 2015). While displaying a segmentation error typical of mondegreens (Kentner, 2015), this misperception further demonstrates a perceptual repair of a semantically implausible phrase (cf. Beck et al., 2014) and is in line with many other illusory phenomena involving speech (Warren, 1970; Warren & Obusek, 1971; Warren & Sherman, 1974).
Adult listeners are likely to have gathered a lifetime’s worth of experience with lexico-syntactic discrepancies between speech and song that stem from the different structural and functional demands placed on spoken vocalizations by the linguistic vs. the poetic system. Casual music listeners with no formal training can implicitly acquire a wealth of knowledge about different aspects of music prevalent in their culture (Bigand & Poulin-Charronnat, 2006). Such everyday music exposure and implicit knowledge of musical structure have indeed been argued to shape STS in musically untrained listeners (Falk et al., 2014; Vanden Bosch der Nederlanden et al., 2015). A growing body of research (in both language and music) provides compelling evidence for the incredible ability of the human mind to extract underlying regularities from auditory signals without directed attention and to acquire substantial knowledge about such regularities without an explicit instruction (e.g., Bigand & Poulin-Charronnat, 2006; Oh et al., 2020; Rohrmeier & Rebuschat, 2012). The present findings further corroborate this idea and extend existing evidence to include implicit knowledge of lexico-syntactic structure in speech vs. songs.
Previous experience and knowledge are at heart of perceptual phenomena that heavily involve cognitive processes, and in which prior knowledge frames the experience of an ambiguous sensory input by computing a percept consistent with the priors (cf. Gregory, 1997, 2009; McIntosh, 2022; Stocker & Simoncelli, 2006). Many well-described illusions involving speech – for example, phoneme restoration (Warren, 1970; Warren & Gregory, 1958) or the McGurk effect (McGurk & MacDonald, 1976) – testify to speech perception being a constructive process and involving top-down biases. It is based on an active, adaptive engagement with the sensory input and as such, is shaped by listeners’ priors that arise from previous experience and knowledge (Davis & Johnsrude, 2007). Given the often fragmentary and noisy character of speech signals, top-down inferences enable listeners to efficiently deal with an impoverished signal (Pressnitzer et al., 2018). As argued in previous research on verbal transformations (Kaminska et al., 2000; Warren, 1983), massed, verbatim repetitions of speech create a situation of ambiguity for listeners, given the absence of any contextual information and an abnormal stream of invariant acoustic input. The invariance of speech acoustics during sentence repetitions is a prerequisite for STS (Deutsch et al., 2011; Vanden Bosch der Nederlanden et al., 2015), yet natural speech lacks such invariance as the same word spoken twice is never acoustically identical (cf. Perkell & Klatt, 2014). In contrast to speech, natural music has a more readily observable tendency toward repetition (e.g., of pitch and timing patterns), with present-day listeners being highly accustomed to repetition due to the ubiquity of recorded and synthesized pieces (Margulis, 2013). In addition, music of Western (and, to some extent, other) cultures maintains precise definitions of notes, intervals, and the corresponding pitch frequencies that lay foundations to melodies (Krumhansl, 2001). Such prior experience with musical signals and their difference from spoken language may help listeners frame the ambiguity of massed, acoustically invariant repetitions that are required to elicit STS and thus bias the perceptual interpretation of such linguistically ambiguous input towards singing.
The role of previous experience and other top-down processes that shape perception when sensory input is ambiguous, degraded, or distorted in some way (Gregory, 1997, 2009; McIntosh, 2022; Stocker & Simoncelli, 2006) might be an important – and so far, overlooked – aspect giving rise to STS. In previous discussions of STS, the linguistic ambiguity of an acoustically invariant stream of sentence repetitions has not been identified as a potential source of the illusory effect. In contrast, an existing account of verbal transformations recognized this mechanism early on (Kaminska et al., 2000; Warren, 1983). We therefore suggest that STS, like verbal transformations, is best understood as a cognitive effect, or an auditory illusion that relies on cognitive priors. This account of STS predicts that experiential and individual priors will play a crucial role in the emergence of STS, similar to other ambigous encounters of spoken language. It is in full alignment with existing evidence on the role of music- vs. speech-related acoustic priors in STS (Deutsch et al., 2011; Falk et al., 2014; Groenveld et al., 2020; Tierney et al., 2018). The present results further reinforce this account by showing that lexico-syntactic features of a spoken phrase can also serve as such priors and introduce a perceptual bias toward speech or song, depending on lexico-syntactic structures typically encountered in the expressive systems of language vs. music (cf. Fedorenko et al., 2020). The results of the present study thus extend previous findings on the signal-specific priors that can influence STS, by adding an indicator of the structure-specific priors (see also Rathcke et al., 2021b). Overall, the results of the present study provide compelling evidence that linguistic structures that convey meaning through lexical or syntactic choices play an important role in STS. They can influence not only the likelihood, but also the speed and the strength of STS. Implausible meanings that violate linguistic expectations (Grice, 1989) have been found to facilitate STS, with a specially notable effect of implausibility on the vividness of the song-like experience.
The Role of Listener-Specific Characteristics in STS
Viewing STS as an auditory illusion under the influence of prior knowledge paves the way to new hypotheses. Specifically, the cognitive account of STS predicts that listener experience and traits will affect the individually experienced transformation. Only a few individual effects have been studied and documented to date. Tierney et al. (2021) provide evidence that an increased musical aptitude (e.g., a greater skill in beat and tonality perception, a better selective attention to pitch) may lead listeners to experience STS more vividly. A heightened ability to detect musical attributes present in spoken phrases seems to bias the perception toward song upon repetition (Deutsch et al., 2011), though it is unlikely to constitute the only prerequisite of STS given that listeners with only casual music exposure can also experience the effect (Vanden Bosch der Nederlanden et al., 2015). Another possibility, not incompatible, is that variability in general cognitive capacities that are not music-specific may interact with the emergence of STS. The present study tested the relation between individual STS-experience and variability in selected cognitive functions that were hypothesized to play a role in STS (cf. Falk et al., 2014; Rathcke et al., 2021b; Tierney et al., 2021). As predicted, cognitive traits of individual listeners contributed to their experience of STS. The present experiments showed that both attentional flexibility and working memory (but not divided attention) influence the individual tendency to experience STS when exposed to massed repetitions of spoken phrases. While attentional flexibility had a general impact on STS, the effect of working memory capacity was specific to sentences with high syntactic complexity.
Attentional flexibility measures the ability to willfully alternate the focus of attention between different sources of incoming information (e.g., Calcott & Berkman, 2014; Zimmermann & Fimm, 2004). In the present experimental task, participants who traded speed for accuracy were more likely to experience STS. In other words, lower attentional flexibility (reflected in fast but incorrect responses) was associated with an increased likelihood of an individual STS-experience and was otherwise independent of any linguistic properties manipulated in the experimental stimuli. This finding suggests that the involvement of attention during STS is unrelated to the integration of semantic and syntactic cues necessary for language processing as we had originally proposed (cf. Myachykov & Posner, 2005; Tomlin, 1999). Rather, the present effect of attentional flexibility might be indicative of an individually variable ability to focus exclusively on what the listener expects to be the primarily relevant cue for the task at hand and to ignore other information concomitantly present in the sensory input (e.g., Guinote, 2007; Posner & Petersen, 1990; Rothbart & Posner, 2001). Under this explanation, listeners with an attentional tendency to privilege accuracy at the expense of speed (i.e., slow-speed, high-accuracy listeners) would maintain the veridical linguistic percept by attending to all aspects of the incoming linguistic input while listeners with lower attentional flexibility (i.e., high-speed, low-accuracy listeners) might be more likely to shift their attention from lexico-syntactic properties of a phrase to its prosodic shape and would thus be more prone to a musical reinterpretation of the phrase (Falk et al., 2014; Tierney et al., 2021). More work is required to further corroborate the present finding. If the current explanation is correct, similar results would be expected for individuals scoring high vs. low in focused attention, inhibitory control, and attentional flexibility tasks (e.g., Posner & Petersen, 1990; Rothbart & Posner, 2001; Tiego et al., 2018; Yantis & Johnston, 1990; Zimmermann & Fimm, 2004).
Working memory also influenced STS, but only in interaction with syntactic complexity of looped sentences. Specifically, individual capacity limitations seem to only play a role in syntactically complex but not syntactically simple sentences. Listeners with better working memory performance were unaffected by the variable levels of syntactic complexity in the materials as their STS-rates remained largely constant across all sentences they listened to. In contrast, listeners with lower working memory performance tended to report more STS in syntactically more complex sentences. The result is at odds with the frequently discussed hypothesis that the switch from speech to song is mediated by linguistic meaning decay or satiation of a semantic processing unit (e.g., Castro et al., 2018; Falk et al., 2014; Margulis, 2013; Rathcke et al., 2021b; Tierney et al., 2021). Being easy to parse syntactically and to process semantically, sentences with a simpler structure do not require increased processing resources (Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002). We would therefore expect them to be more readily reinterpreted as musical upon repetition by all listeners regardless of their working memory capacity (which was not the case).
There is some evidence to indicate that a reduced working memory capacity impinges upon syntactic parsing (King & Just, 1991), possibly making listeners more attentive to prosody. As Speer et al. (1996) suggest, speech prosody provides an initial structure in working memory where utterances are maintained until linguistic analysis has taken place and the comprehension process is complete. If comprehension becomes more vulnerable and prone to error under capacity limitations (cf. Myachykov & Posner, 2005; Tomlin, 1999), low-capacity listeners may rely more heavily on the initial stages of linguistic analysis and therefore on prosody (cf. King & Just, 1991; Kjelgaard & Speer, 1999; Speer et al., 1996). In general, sentence-level prosody is a key factor in parsing syntactic constituency in many languages of the world (Nespor & Vogel, 1986; Shattuck-Hufnagel & Turk, 1996). Sensitivity to prosodic detail is among the main developmental predictors of the syntactic mastery in both native and non-native language learners (Goad et al., 2003; Hawthorne & Gerken, 2014; Morgan & Demuth, 2014; Tremblay et al., 2016). Moreover, foreign language learners are known to frequently forego syntactic analyses and attend primarily to prosody when processing speech in their non-native language(s) (Harley, 2000; Harley et al., 1995), which is also in line with the finding of an enhanced STS-effect in listeners’ non-native languages (Margulis et al., 2015; Rathcke et al., 2021b). In the present experiment, only STS-likelihood (i.e., the likelihood to report an illusion) shows an effect of individual working memory capacity, in interaction with syntactic complexity. This result suggests that, given the requirements of the STS-task, listeners with a limited working memory capacity do not fully engage in the syntactic analysis of increasingly complex sentences, rather than starting and abandoning the computations prematurely which would have influenced STS-speed instead of STS-likelihood.
In sum, both findings of the present study confirm that STS is moderated by capacity-limited cognitive resources of attention and working memory (Falk et al., 2014; Rathcke et al., 2021b; Tierney et al., 2021). However, the hypothesized mechanisms supporting the involvement of basic cognition in STS have to be revised. The present results cast doubt on the idea that a reduction (or the termination) of lexico-syntactic computations during language processing simply frees up cognitive resources that then become available for the extraction of melodic and rhythmic characteristics of speech and their reassessment in terms of a musical structure (Tierney et al., 2021). If this were the case, high-capacity listeners and syntactically simple sentences would show enhanced STS. Instead, the illusion prevails in low-capacity listeners and syntactically complex sentences that are more difficult to process (Christianson et al., 2010; Ferreira, 2003; Ferreira et al., 2002). As an alternative to be more extensively addressed in future research, we propose that the availability of cognitive resources for language processing influences either listeners’ reliance on prosody (King & Just, 1991; Kjelgaard & Speer, 1999; Speer et al., 1996) or their attentional shifts to prosody (cf. Guinote, 2007), which in turn moderates the individual likelihood of experiencing STS.
The present study adds to the steadily growing body of evidence that STS crucially hinges on speech prosody in languages that do not use lexical tone to encode word meanings (Jaisin et al., 2016). Both the acoustic-prosodic shape of the phrase repeated (Deutsch et al., 2011; Falk et al., 2014; Rathcke et al., 2021b; Tierney et al., 2018) and the individually variable ability to attend to the prosodic properties of the phrase (Falk et al., 2014; Tierney et al., 2021) seem to unleash the perceptual effect. As far as listener-specific characteristics are concerned, the cognitive priors of STS discussed here and the musical priors discussed in previous research (Falk et al., 2014; Tierney et al., 2021) are orthogonal in that higher importance of prosody during linguistic analyses and a stronger bias toward interpreting prosodic relations as musical can be seen as stemming from different aspects of individual experience and arising at different stages of the hypothesized switch from a language percept to a music percept (e.g., Castro et al., 2018; Falk et al., 2014; Margulis, 2013; Rathcke et al., 2021b; Tierney et al., 2021). A potential interplay of these traits and their impact on the individual experience of STS is an empirical question worth pursuing in future studies of the illusion.
As a first step toward understanding such interplay, the results of the present study provide a more nuanced view on the role of listener musicality (as reflected by the amount of musical training) in STS. Accordingly, individually variable levels of musical training bring about different experiences of STS exclusively in sentences of reduced syntactic complexity. The STS-promoting effect of listener musicality disappears when linguistic structure gains in complexity. In a way, the results can also be interpreted as being indicative of a stable STS-effect in musically trained participants in contrast to a more variable STS-effect in musically less versed participants. As mentioned above, previous research often relied on syntactically simple, short phrases (e.g., “snags and sandbars”, “people in the neighborhood”, Tierney et al., 2013; 2018; 2021) which have likely foregrounded the effect of listener musicality at the expense of the contribution of linguistic structure to STS, obscuring the interaction of the linguistic and musical perception modes. This interaction is, however, key to the understanding of the perceptual foundations of STS. As the results of the present study suggest, the interaction may only be uncovered if sentence-level linguistic structure forms an important part of the theoretical account of STS, but is not amenable to empirical observation with word-level structures (cf. Castro et al., 2018).
Multiple Aspects of an Illusory Experience
The present study highlights that there are three different aspects to an individual experience of a cognitive effect such as STS: (1) whether or not a listener experiences the transformation, or the likelihood of an illusory effect; (2) the ease with which the experience arises in their perception, or the speed of an illusory occurrence; and (3) how vividly they experience it, or the strength of an illusory experience. Most of the present findings derive from (some) listeners’ (in)ability to experience STS in certain sentences. That is, these results are concerned with the STS-likelihood. Such findings can be easily overlooked in experimental approaches that divide linguistic materials into transforming vs. non-transforming a-priori (e.g., Tierney et al., 2013; 2018; 2021). Moreover, the transformation likelihood seems to be rather weakly – if at all – correlated with either strength or vividness of STS, signifying the central importance of this aspect of STS.
Previous research into STS has rarely distinguished between the three aspects of an illusory experience. It is not unlikely that an apparent disagreement regarding the role of listeners’ musical background in STS stems from the fact that some studies focused on the likelihood of STS, not finding an effect of musical training (Rathcke et al., 2021b) while others examined the vividness of STS, providing evidence in favor of musical skill (Falk et al., 2014; Tierney et al., 2021; Vanden Bosch der Nederlanden et al., 2015). Like many other auditory illusions involving speech, STS can be considered a cognitive effect that arises while an ambiguous sensory stimulation (cf. Warren, 1983) is supplemented with prior knowledge in order to arrive at an unambiguous perceptual interpretation (cf. McIntosh, 2022). In case of musically experienced or apt listeners, such perceptual priors might include rich tonal representations that bias their perceptual responses towards a more vivid impression of singing than the one observed in musically less experienced or apt listeners (Deutsch et al., 2011; Falk et al., 2014; Tierney et al., 2021). It thus seems plausible that specifically the ease and the strength of a song percept is shaped by an individually variable musicality, rather than their likelihood of experiencing STS per se.
Future studies of STS will benefit from a theoretically informed approach to testing those factors that may have a specific influence on each aspect of the illusion. Given that illusions such as STS are shaped by prior knowledge (McIntosh, 2022; Stocker & Simoncelli, 2006), it appears particularly informative to ask the question what cognitive traits determine an individual auditory experience – its occurrence, vividness, and ease. As seen in the present study, different factors may exert an independent influence on each aspect of STS, highlighting an intricate complexity of illusory phenomena involving cognition.
Conclusions
The speech-to-song illusion (STS, Deutsch, 1995; Deutsch et al., 2011) describes a striking perceptual experience of spoken phrases transforming into singing upon repetition and signifies one of the most complex auditory illusions connecting two phenomena of human cognition: language and music. The present results place STS among perceptual illusions that result from a process of integrating sensory evidence with individual experience and context-based expectations (McIntosh, 2022). Accordingly, massed repetitions of speech necessary for STS may create a context that frequently occurs in music (Margulis, 2013; Rowland et al., 2019; Vanden Bosch der Nederlanden et al., 2015) but is unlikely and ambiguous in language (Warren, 1983), thus setting a context-based bias toward song perception. An evidence-based bias toward song is added if auditory input contains acoustic or structural features known from song and music, like lexico-syntactic implausibility or stable melodies (Falk et al., 2014; Tierney et al., 2018), regular intervocalic intervals (Falk et al., 2014), and prolonged periods of vocal sonority (Rathcke et al., 2021b). An individual bias ignites the transformation. The latter bias can arise from individual reliance on speech prosody for complex linguistic analyses or attentional shift to prosody due to capacity limitations as argued in the present study (Goad et al., 2003; Hawthorne & Gerken, 2014; King & Just, 1991; Morgan & Demuth, 2014; Speer et al., 1996; Tremblay et al., 2016) or from an individual musicality as argued in previous work (Falk et al., 2014; Tierney et al., 2021). Overall, we propose that the linguistic meaning decay is unlikely to be the key mechanism driving the perceptual transformation from speech to song. Rather, it arises when experience-based and cognitive priors combine and set a strong bias for the interpretation of a contextually ambiguous phrase as musical. Each prior may influence one specific aspect of STS, be it the likelihood, the ease, or the vividness of the effect, though more work is needed to further advance the understanding of the individual aspect of STS. At this point, it is also unclear if the effect of the priors may be additive or non-linear, and to what extent. Multiple interactions of linguistic structure and individual listeners traits are, however, suggestive of a non-linear complexity among the involved priors.
In conclusion, STS resembles other illusory phenomena involving cognitive processes in that it testifies to auditory perception being an active, malleable process of an individual mind's engagement with sensory input, whose goal is to establish the most probable percept in noisy, ambiguous environments (Davis & Johnsrude, 2007; Pressnitzer et al., 2018; Stocker & Simoncelli, 2006). As such, the process can be strongly influenced by previous experience and is likely to be subject to maturational constraints (Warren & Warren, 1966). While adult listeners of all ages have been reported to perceive the transformation from speech to song upon repetition (Mullin et al., 2021), it is unclear when children start being able to experience STS. Even though the music network seems to develop rapidly within the first few months of life (Dehaene-Lambertz et al., 2010), the ability to categorize songs as such matures with age and experience (Vanden Bosch der Nederlanden et al., 2023). The present account of STS predicts that child listeners’ susceptibility to STS would evolve along with their musical enculturation, mirroring their ability to draw a distinction between speech and song. The cognitive view discussed here, thus, opens new avenues for future research on the perceptual phenomenon of the speech-to-song illusion.
Footnotes
Acknowledgements
We would like to thank our undergraduate research assistants Georgia Ann Carter and Katherine Willet at the University of Kent, Chloé Lehoucq and Sasha Lou Wegiera at the Sorbonne Nouvelle Paris-3 Université who helped with the data collection. This research was supported by a Small Research Grant from the British Academy (SG152108) to the first author.
Action Editor
Ian Cross, University of Cambridge, Department of Music.
Peer Review
Emily Graber, Allegheny College.
Christina Vanden Bosch der Nederlanden, University of Toronto Mississauga, Psychology.
Author Contributions
TR and SF researched literature and conceived the study. SDB contributed to the study design. TR was responsible for gaining ethical approval, experimental set-up, and data analysis. TR wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
The study received approval from the ethics committee of the University of Kent, UK (Reference number: 0031516; date of approval: 21/09/2015). All listeners gave an informed consent to participate in this research and were remunerated.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of the present study can be made available from the corresponding author, upon reasonable request.
Supplemental Material
Supplemental material for this article is available online (https://osf.io/8d9mt/).