
Abstract
Background
Fluid therapy is central to sepsis management, yet recommendations on fluid type, volume, optimization, and de-escalation remain uncertain. The 2025 ESICM guidelines highlight major evidence gaps in sepsis fluid therapy. Although large language models (LLMs) show promise for guideline interpretation and clinical decision support, their performance in this high-risk domain is unclear.
Methods
We conducted a prospective, cross-sectional observational study using nine guideline-derived sepsis-related clinical questions addressing fluid selection, resuscitation volume, and fluid removal during de-escalation. Questions were queried in both English and Chinese across three consecutive days, generating three independent responses per model from ChatGPT-5, ChatGPT-4o, and DeepSeek-V3.1. Three blinded intensivists evaluated responses for accuracy, completeness, and consistency using 5-point Likert scales. Readability was assessed using Flesch Reading Ease (FRE) and Flesch–Kincaid Grade Level (FKGL) for English responses and a validated Chinese readability framework. Inter-rater agreement was quantified using Kendall’s W coefficient.
Results
In English responses, ChatGPT-5 achieved the highest accuracy, although inter-model differences were not statistically significant. In Chinese responses, ChatGPT-5 demonstrated significantly higher accuracy than ChatGPT-4o (p < 0.05). DeepSeek-V3.1 produced significantly more complete English responses than ChatGPT-4o (p < 0.05). Consistency was high across all models and languages. FKGL scores differed significantly among models (p < 0.01), with ChatGPT-5 generating more linguistically complex English text. No significant differences were observed between English and Chinese responses across evaluation dimensions.
Conclusions
Advanced LLMs show potential for supporting sepsis fluid therapy guideline interpretation, but consistent overconfident responses in guideline-defined uncertainty domains highlight important safety limitations. Clinical oversight remains essential when deploying LLMs for high-risk decision support.
1. Introduction
Sepsis remains a major global health burden and is one of the leading causes of morbidity and mortality worldwide. Recent epidemiologic estimates indicate that sepsis affects nearly 49 million people annually, with 11 million deaths, accounting for nearly 20% of global total mortality. 1 The early hours following sepsis onset are crucial, as timely recognition and aggressive supportive therapy substantially improve outcomes. Among supportive measures, intravenous fluid resuscitation remains a cornerstone of initial management, targeting restoration of intravascular volume, improvement of cardiac output, and optimization of tissue perfusion as part of the Surviving Sepsis Campaign (SSC) foundational strategy. 2 However, despite its central role, the optimal type, volume, and timing of fluid therapy remain intensely debated.3,4 Against this background of uncertainty, the European Society of Intensive Care Medicine (ESICM) recently released a comprehensive three-part guideline series addressing fluid type selection, fluid resuscitation volume, and fluid de-escalation after the acute phase in critically ill adults.5–7 Because many recommendations are supported by low or very-low certainty evidence, their interpretation and implementation may vary substantially in clinical practice, with direct implications for sepsis outcomes.
Recent advances in large language models (LLMs) have created new opportunities for enhancing clinical decision-making, guideline interpretation, and evidence synthesis. Across multiple medical specialties, LLMs such as ChatGPT and DeepSeek have demonstrated diagnostic accuracy and guideline adherence approaching clinician-level performance, including in complex diagnostic scenarios and specialty-specific guideline evaluations.8–10 LLMs have also shown promise in supporting evidence synthesis: GPT-based systems can accelerate systematic review workflows, particularly during guideline development, by improving the speed and specificity of citation screening. 11 In the field of sepsis, novel sepsis-focused LLMs have achieved diagnostic performance comparable to senior emergency physicians and significantly improved the diagnostic accuracy of junior clinicians managing suspected sepsis in the emergency department. 12 Meanwhile, LLM-driven knowledge graph construction and entity relationship extraction have further facilitated the integration of real-world clinical data with sepsis guideline frameworks, thereby enhancing the potential of automated, evidence-aligned decision support. 13 Current evidence demonstrates both the promise and limitations of LLMs in interpreting clinical guidelines.14,15 Although these models can generate accurate, readable, and guideline-aligned responses, variability in completeness, contextual specificity, and cross-language fidelity underscores the need for rigorous evaluation, particularly in high-stakes domains such as sepsis fluid management.
Despite rapid progress in medical artificial intelligence (AI), research specifically evaluating LLMs within the domain of sepsis fluid therapy remains absent. Contemporary ESICM guidelines underscore persistent uncertainty across choice of resuscitation fluids, volume of resuscitation fluids, and fluid removal at de-escalation phase, with most recommendations supported by low-certainty evidence,5–7 highlighting the difficulty of translating guideline statements into consistent bedside decisions. At the same time, advanced LLMs—including DeepSeek-V3.1, ChatGPT-5, and ChatGPT-4o—have demonstrated emerging capabilities in guideline interpretation, yet the performance of these LLMs varies significantly across clinical domains, task complexity, and language. Critically, no study has systematically examined how these cutting-edge models interpret the newly released three-part ESICM fluid therapy guidelines. Therefore, this study aims to rigorously evaluate DeepSeek-V3.1, ChatGPT-5, and ChatGPT-4o across nine sepsis-related questions, thereby providing the first comprehensive appraisal of LLM performance in interpreting sepsis fluid-therapy guidelines under standardized clinician-like prompting conditions.
2. Methods
2.1. Study design
Questions regarding fluid therapy for sepsis based on the 2025 ESICM guidelines.

2.2. Expert scoring procedures
Three experienced intensivists independently assessed the quality of all large language model outputs using a structured evaluation framework. Experts were blinded to model identity and rated each response across three predefined evaluation dimensions (accuracy, completeness, and consistency) using 5-point Likert scales adapted from prior LLM performance assessment studies in medical contexts.16,17 Accuracy reflected the degree of alignment with contemporary sepsis fluid therapy recommendations; completeness assessed whether core guideline-relevant elements were adequately addressed; and consistency evaluated the stability of model outputs across repeated responses to the same question.18,19 To enable cross-language comparison, experts scored English and Chinese responses separately, consistent with evidence that LLM performance may vary by language.16,20 All scoring forms were collected without post-hoc modification and used to generate summary statistics and inter-rater reliability metrics, including Kendall’s W coefficient. 21
2.3. Readability assessment
Readability of the model-generated outputs was assessed using validated linguistic metrics, with English and Chinese responses evaluated separately. For English responses, readability was assessed using the Flesch Reading Ease (FRE) and Flesch–Kincaid Grade Level (FKGL) formulas (https://www.readabilityformulas.com),22,23 which have been widely applied in prior evaluations of AI-generated medical educational materials. For Chinese responses, readability was evaluated using a framework based on sentence complexity, vocabulary difficulty, and overall coherence, following established methods for assessing LLM-generated Chinese medical content. 17 Readability was assessed on the first response to avoid potential artefacts introduced by repeated prompting. All readability measurements were calculated from the first Chinese and English responses generated by each model, using the verbatim outputs without any post processing modifications, to ensure an objective evaluation of language clarity and accessibility.
2.4. Statistical analysis
The primary quantitative outcomes included the median (IQR) and mean (SD) for accuracy, completeness, and consistency; the readability metrics for English (FRE, FKGL) and Chinese texts; the inter-rater reliability assessed by Kendall’s W coefficient; and comparative performance across models and languages. All data analyses were performed using GraphPad Prism and SPSS, with data entry and organization conducted using Microsoft Excel 2021. Continuous variables were summarized using appropriate descriptive statistics based on distribution characteristics, and non-parametric methods were applied when normality assumptions were not met. For each evaluation dimension, median scores across the three expert raters were used as the primary summary measure for statistical comparisons. Additionally, mean values and standard deviations were calculated by averaging all individual rater scores for each model and language across the nine questions, so as to generate descriptive summaries. Specifically, Mann–Whitney U tests were used for two-group comparisons, whereas differences among the three LLMs were analyzed using the Kruskal–Wallis test, followed when significant by Dunn’s post-hoc comparisons with Bonferroni correction. Inter-rater agreement among the expert evaluators was quantified using Kendall’s W coefficient, with interpretive thresholds defined as 0 – 0.20 (poor), 0.20 – 0.40 (fair), 0.40 – 0.60 (moderate), 0.60 – 0.80 (good), and 0.81 – 1.00 (excellent). 24 All statistical tests were two-sided with significance set at p < 0.05, and reporting followed contemporary standards for evaluating LLM performance in clinical decision-support contexts.
3. Results
3.1. Overview of model outputs and expert scoring
All original English and Chinese responses generated by the three LLMs across nine sepsis fluid-therapy questions were compiled into two supplementary datasets (Tables S1–S2). Three independent experts evaluated each response on accuracy, completeness, and consistency, using the first model response for accuracy and completeness and three repeated responses for consistency. For each question, the reviewers’ scores were summarized into two additional tables (Tables S3–S4), which served as the primary scoring matrices for subsequent statistical comparisons.
3.2. Inter-rater reliability
Kendall’s W coefficient for the scoring of English and Chinese.

3.3. Accuracy
Median and mean scores of the accuracy, completeness and repeatability of English responses.

Median and mean scores of the accuracy, completeness and repeatability of Chinese responses.
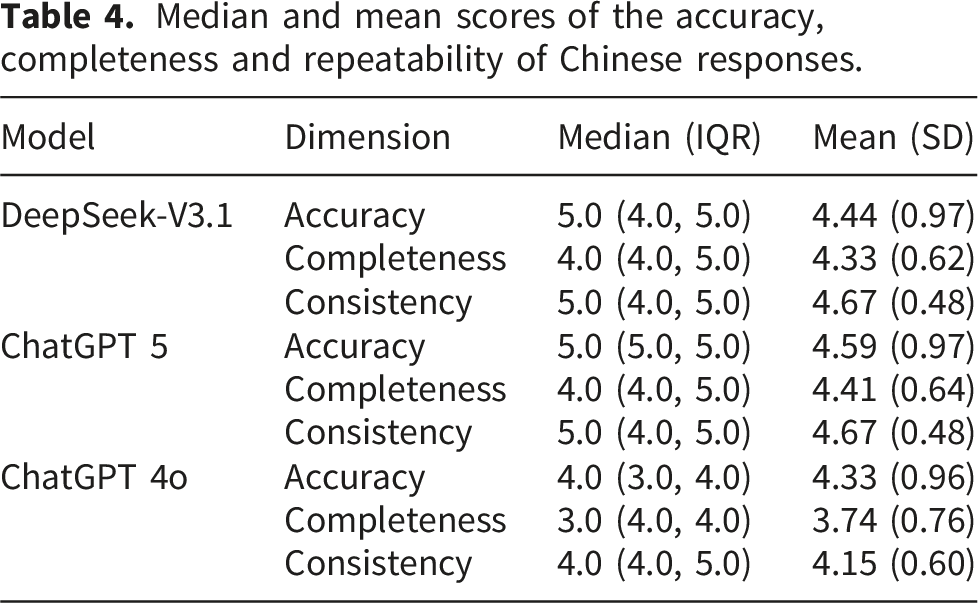
Comparison of the accuracy score by different LLMs. (a) Comparison of English responses; (b) Comparison of Chinese responses.
3.4. Completeness
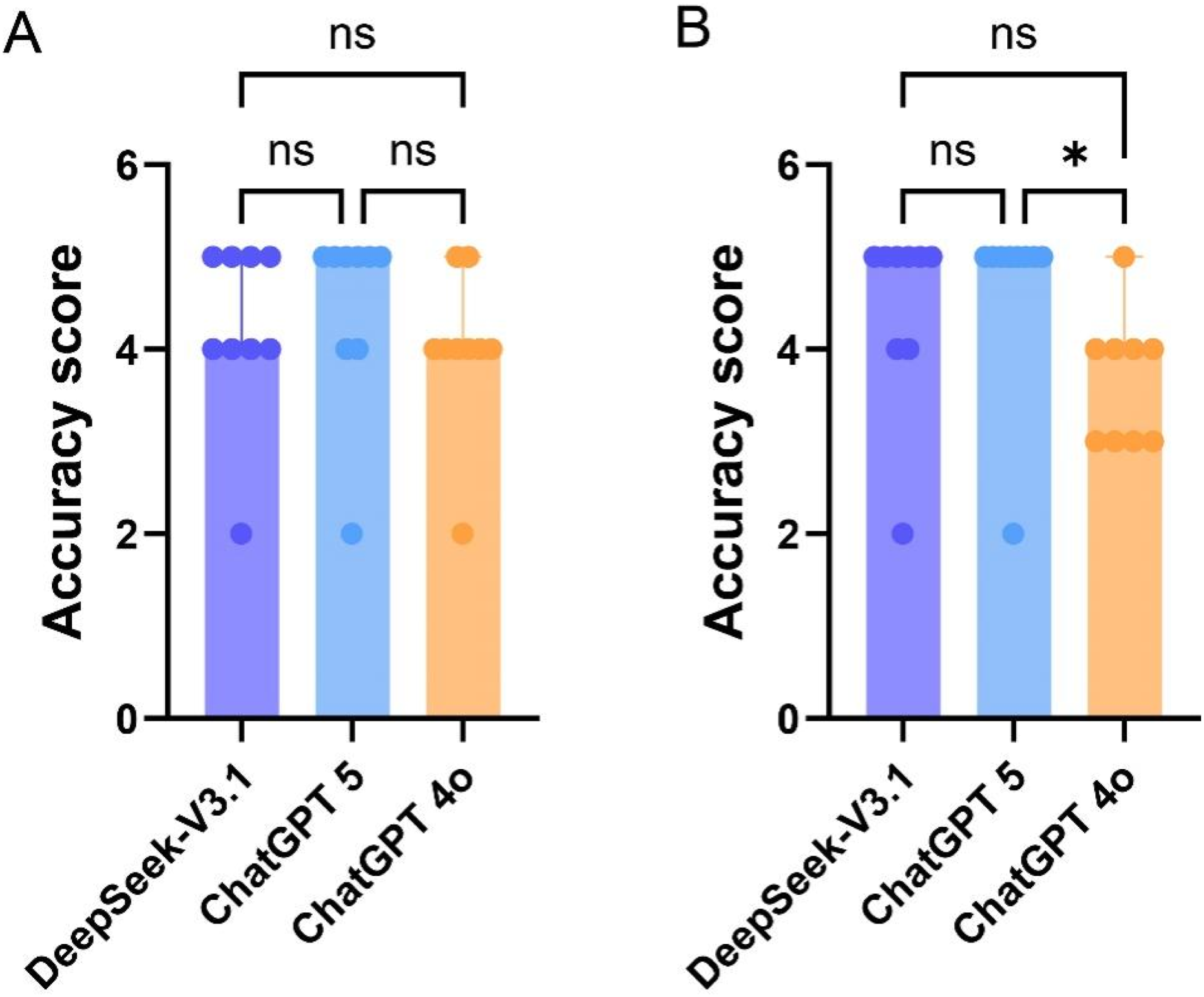
Completeness evaluations of English and Chinese responses are presented in Tables 3 and 4. In English responses, the three models exhibited notable variations in the dimension of completeness. DeepSeek-V3.1 generated the most comprehensive English responses, as indicated by a median score of 5 and a mean of 4.41 (0.69). ChatGPT-5 ranked second in completeness, while ChatGPT-4o showed the lowest level of completeness. Statistical analysis revealed that only the difference in completeness between DeepSeek-V3.1 and ChatGPT-4o reached statistical significance, as shown in Figure 2(a). In Chinese responses, the three models showed more similar completeness scores. DeepSeek-V3.1 and ChatGPT-5 displayed largely overlapping completeness score distributions, with a median score of 4 for both and mean scores of 4.33 (0.62) and 4.41 (0.64), respectively. ChatGPT-4o demonstrated the lowest completeness based on both its median and mean values. However, unlike the English results, none of the pairwise comparisons among the three models in Chinese responses demonstrated statistical significance (Figure 2(b)). Comparison of the completeness score by different LLMs. (a) Comparison of English responses; (b) Comparison of Chinese responses.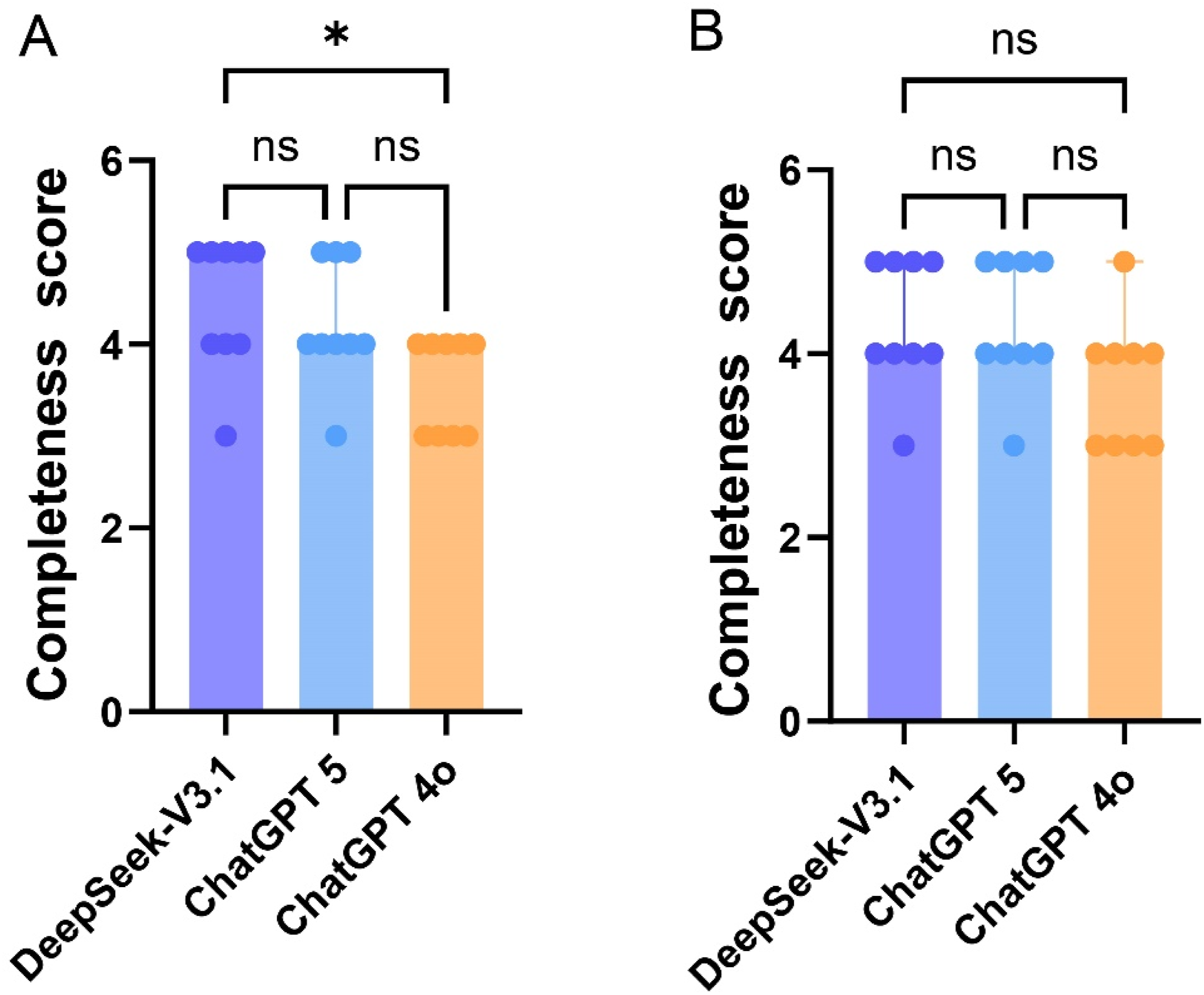
3.5. Consistency
Consistency findings are summarized in Tables 3 and 4. In English responses, the three models exhibited similar stability, with each achieving a median score of 5 and closely matched mean values. Chinese responses demonstrated a comparable pattern: DeepSeek-V3.1 and ChatGPT-5 again showed nearly identical stability, while ChatGPT-4o scored slightly lower. Despite these numerical differences, none of the comparisons reached statistical significance in either language (Figure 3). Overall, all three models produced highly stable outputs across repeated prompts, with no meaningful differences observed among them. Comparison of the consistency score by different LLMs. (a) Comparison of English responses; (b) Comparison of Chinese responses.
3.6. Readability
Readability of English and Chinese responses.
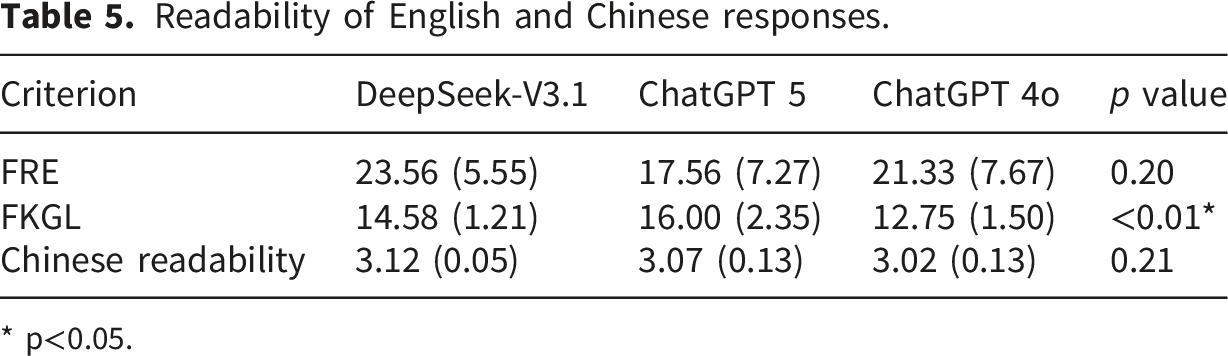
* p<0.05.
3.7. Comparison in different languages
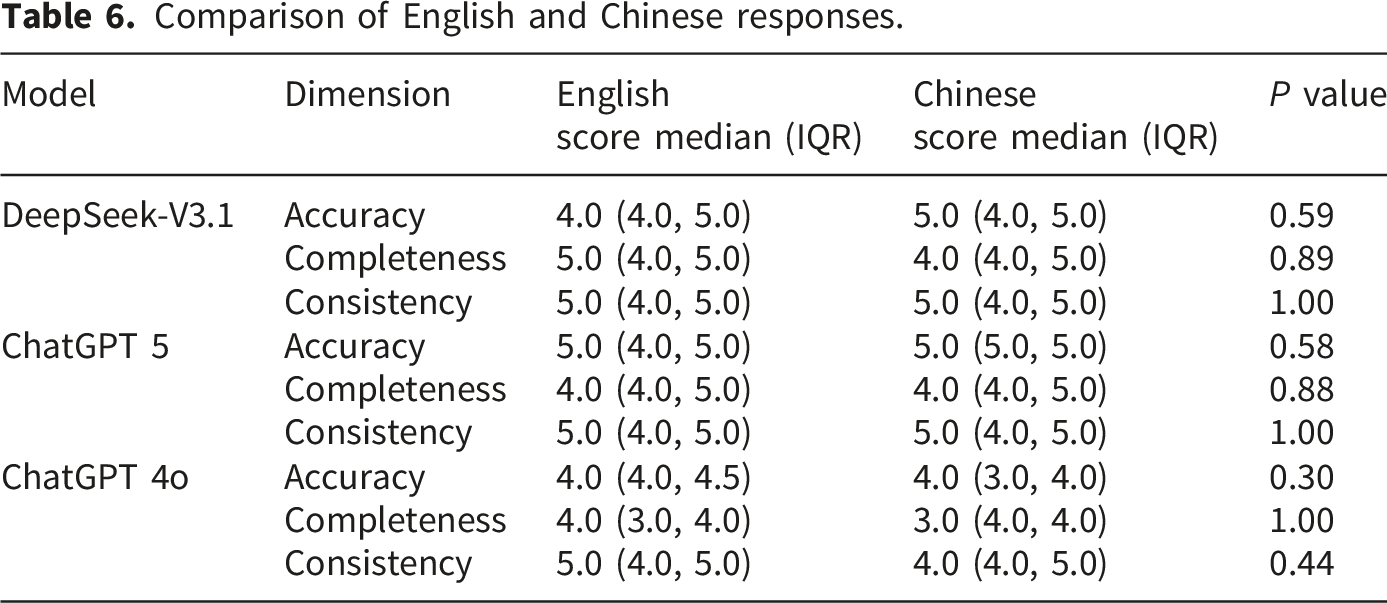
Comparison of English and Chinese responses.
4. Discussion
This study presents the first comprehensive assessment of three widely used LLMs (DeepSeek-V3.1, ChatGPT-5, ChatGPT-4o) in interpreting the 2025 ESICM three-part guidelines for sepsis fluid therapy. We evaluated accuracy, completeness, consistency, and readability with respect to nine bilingual guideline-based clinical questions. Several key findings emerged. First, ChatGPT-5 achieved the highest accuracy in both English and Chinese responses, whereas DeepSeek-V3.1 produced the most complete English responses. Second, all models demonstrated high response stability with minimal variability across repeated prompts. Third, significant inter-model differences were observed in English response readability, while the readability of Chinese responses remained consistent across all models. Fourth, all LLMs performed poorly on Question 5, indicating a shared area of difficulty across models. Fifth, no significant performance differences were observed between English and Chinese outputs for any model. Sixth, expert agreement ranged from fair to moderate, reflecting the inherent subjectivity of qualitative evaluation. Accordingly, expert ratings in this study should be interpreted as a structured comparative assessment framework rather than a perfect gold standard, particularly for qualitative dimensions such as completeness and clinical adequacy. Overall, DeepSeek-V3.1 and ChatGPT-5 demonstrated superior performance to ChatGPT-4o in several dimensions, and all models showed no differences between English and Chinese responses.
Our findings are consistent with prior evidence showing strong performance of advanced LLMs across diagnostic reasoning, guideline interpretation, and clinical-education tasks.16,17,25 Notably, ChatGPT-5’s superior accuracy reflects trends reported in other specialty domains, where newer ChatGPT models outperform earlier architectures.26,27 With the iteration advancement of ChatGPT models, their performance has been significantly improved.26,28 DeepSeek-V3.1’s greater completeness aligns with benchmarking results demonstrating its strong retrieval depth, particularly in Chinese-language contexts. 29 Previous studies have indicated that DeepSeek-V3 outperforms ChatGPT-4o in certain domains of medical research,30,31 and this finding has been further corroborated in our work, given that DeepSeek-V3.1 represents a substantial upgrade over its predecessor. No statistically significant difference was observed between DeepSeek-V3.1 and ChatGPT-5, indicating that these two latest versions of LLMs exhibit comparable performance in clinical guideline interpretation. High inter-model consistency similarly parallels previous observations that structured, guideline-based prompts yield low intra-model variability.32,33
A notable finding was that all models performed poorly on Question 5, which addressed whether a liberal or restrictive fluid strategy should be used during the optimization phase of sepsis management. The ESICM 2025 guideline explicitly states that no recommendation can be made due to insufficient and low-certainty evidence. 6 Despite this, all LLMs consistently generated directive responses favoring a restrictive strategy in both English and Chinese. This misalignment may reflect the models’ reliance on dominant prior clinical narratives emphasizing the risks of fluid overload,34,35 even though these data do not justify a universal restrictive approach during the optimization phase. Importantly, this pattern is better interpreted as an overconfident default response tendency under standardized zero-shot prompting, rather than definitive evidence of an inherent model-level reasoning flaw. When guidelines explicitly declare uncertainty (“no recommendation”), LLMs may still default to a dominant clinical narrative and generate directive recommendations. Another plausible explanation is that at the time of our evaluation, the latest ESICM recommendations may not have been fully integrated into the models’ training corpora or alignment corpora, which could have amplified their reliance on earlier literature. From a clinical safety perspective, the key concern is not only inaccuracy, but the generation of confident therapeutic advice in domains where the guideline itself intentionally withholds recommendation. Prior studies have similarly identified overly confident or insufficiently qualified LLM advice as a safety concern in high-stakes medical settings. In such scenarios, the safer and more desirable LLM behavior may be to explicitly communicate uncertainty, identify the absence of high-quality evidence, and refrain from issuing strong therapeutic advice.36–38 The challenge posed by sepsis fluid therapy lies not only in information retrieval but also in how a model communicates in the setting of low-certainty or absent recommendations. Follow-up prompting that explicitly probes uncertainty may modify apparent model performance and should be systematically studied in future work. Taken together, these findings suggest that LLMs may be more reliable for guideline domains with clear recommendations than for those where the guidelines intentionally refrain from providing recommendations.
The guidelines emphasize that fluid therapy in sepsis is inherently complex due to wide variability in patient hemodynamic profiles, dynamic responses to fluids, and evolving evidence regarding optimal fluid choice, resuscitation volume, and timing of de-resuscitation.5–7 Recommendations across all three guideline components are frequently supported by low or very low certainty evidence, and many depend on conditional or contextual factors rather than universal directives. This intrinsic uncertainty is reinforced by extensive clinical research showing persistent debate over fluid type, optimal early resuscitation volume, and risks of fluid overload. Several multicenter cohorts and randomized trials suggest that more restrictive fluid strategies may reduce morbidity or shorten ventilation time,5–7,39 whereas analyses of large observational datasets demonstrate that higher early fluid volumes are associated with improved outcomes in selected patient populations. 26 In our study, the LLMs exhibited the greatest variability in response completeness and accuracy when addressing topics that mirror these clinical uncertainties—such as individualized fluid responsiveness, volume escalation thresholds, and timing of fluid removal. This suggests that LLM performance is determined not only by model architecture but also by the complexity and ambiguity of the underlying evidence. Specifically, LLMs generate reasoning consistent with guideline recommendations in areas supported by robust evidence, whereas their interpretations diverge substantially in areas where guidelines explicitly acknowledge evidence gaps. LLM performance in guideline interpretation is shaped not only by model architecture and training exposure, but also by prompting strategy and operator behavior. Accordingly, future work should evaluate whether prompt-engineering approaches such as in-context learning, system-role prompting, and explicit uncertainty instructions can improve safety in evidence-limited settings.37,40 This study was designed to evaluate default model behavior under standardized prompting conditions that approximate common end-user use, rather than prompt-optimized maximum performance.
Readability analysis revealed significant differences in the English responses generated by different models: DeepSeek-V3.1 produced the most accessible patient-oriented language (higher FRE), whereas ChatGPT-5 produced more complex, academically formatted medical text (higher FKGL). Among these readability metrics, the only one that differed significantly across models was FKGL. While previous studies have confirmed that DeepSeek-V3.1 has a higher FKGL score than ChatGPT-4o,41,42 research on the readability of ChatGPT-5 remains limited to date. The highest FKGL score documented in ChatGPT-5 indicates that more advanced LLMs prioritize technical precision over lay-friendly readability. In contrast, Chinese readability scores exhibited a narrower range of differences, indicating that mainstream LLMs yield relatively consistent readability levels in the context of Chinese medical discourse.43,44
Our study found no significant performance differences between English and Chinese responses of the three LLMs across the dimensions of accuracy, completeness, and consistency. As shown in the results, the magnitude of differences between English and Chinese responses was nearly identical across DeepSeek-V3.1, ChatGPT-5, and ChatGPT-4o, with all p-values ranging from 0.30 to 1.00, indicating robust cross-linguistic stability in model behavior. Several factors likely explain this convergence. First, modern multilingual LLMs are trained on substantially larger and more domain-balanced corpora than earlier-generation models, which include expanded Chinese biomedical datasets and reinforcement learning from human feedback (RLHF) alignment pipelines optimized for bilingual clinical reasoning.28,29,45 This improved linguistic representation reduces the asymmetry that previously favored English outputs. Second, recent comparative studies have shown that once domain alignment is adequate, advanced LLMs are capable of generating conceptually consistent explanations in both languages, even when stylistic surface features differ.17,46,47 Interestingly, our results suggest subtle but interpretable deviations from perfect equivalence. For example, DeepSeek-V3.1 produced slightly higher accuracy in Chinese than in English, whereas ChatGPT-5 displayed marginally higher FRE score in English but similar completeness across languages. Conversely, ChatGPT-4o exhibited slightly lower accuracy in Chinese responses, which may reflect its greater emphasis on multimodal optimization compared to text-specific fine-tuning. Yet these differences did not reach statistical significance, reinforcing that the functional clinical content delivered by the models remains consistent across languages, even if rhetorical density or phrasing may vary. These findings indicate that multilingual LLMs have progressed beyond earlier limitations in cross-linguistic alignment. At the same time, continued monitoring is required in domains where linguistic nuance influences clinical decision-making—particularly in guideline interpretation.
The strengths of this study include the use of a bilingual evaluation framework, which is rare in LLM research. The study also employs the guideline-derived questions that encompass the entire scope of sepsis fluid therapy as defined by the ESICM. Additionally, the study incorporates multiple key evaluation metrics, including accuracy, completeness, consistency, readability, and inter-rater reliability. The study also includes three high-performance, advanced LLMs. However, there are several limitations. One limitation is the inherent subjectivity of expert scoring, despite the use of Kendall’s W to assess inter-rater agreement. Accordingly, the qualitative ratings should be interpreted as a structured expert-based comparative framework rather than a definitive gold standard, and inter-model differences should be viewed with appropriate caution. Another limitation is the limited scope of only nine clinical questions, which may not fully encompass all potential sepsis fluid-therapy scenarios. The study also relies only on text responses, without including multimodal or interactive reasoning. Additionally, there is potential for temporal bias due to the rapid evolution of large language models. Finally, the readability formulas employed in this study may not fully reflect the actual level of patient comprehension.
Future research should determine whether in-context learning, system-role prompting, explicit uncertainty instructions, or uncertainty-calibrated response formats can reduce overconfident recommendations in evidence-limited clinical domains. Future studies should include larger and more diverse questions, evaluate model performance in dynamic simulation or real-world sepsis management scenarios, and incorporate physiologic data streams such as ultrasound indices and advanced hemodynamic monitoring. Moreover, developing LLMs specifically designed for sepsis and based on clinical practice guidelines could enhance model accuracy and clinical interpretability. Additionally, future research should focus on the collaborative working mechanisms between clinicians and LLMs to ensure clinical safety and enable seamless integration into clinical workflows, particularly in resource-limited healthcare settings.
5. Conclusion
This study provides the first bilingual evaluation of large language models in interpreting the 2025 ESICM guidelines on sepsis fluid therapy. Among the three models, ChatGPT-5 showed the highest accuracy, DeepSeek-V3.1 produced the most complete responses, and all models demonstrated high consistency across repeated prompts. Performance was comparable between English and Chinese outputs, supporting the multilingual stability of these models in guideline-based reasoning. A key finding was that all models performed poorly when the guideline stated that no recommendation could be made due to insufficient evidence. Overall, LLMs show promise as supportive tools for interpreting sepsis fluid-therapy guidelines. However, their outputs should be used with caution, particularly in areas where evidence is limited. Clinical expert oversight remains essential to ensure safe and appropriate application in sepsis management.
Supplemental material
Supplemental material - Comparative performance of ChatGPT and DeepSeek in interpreting the 2025 ESICM guidelines on sepsis fluid therapy
Supplemental material for Comparative performance of ChatGPT and DeepSeek in interpreting the 2025 ESICM guidelines on sepsis fluid therapy by Xin Cheng, Jinlan Chen, Dafeng Yang, Yibo Peng, Shuji Gong in DIGITAL HEALTH
Footnotes
Acknowledgements
AI use disclosure: Large language models were evaluated as the research objects in this study. In addition, AI tools were used in a limited manner to assist with language editing during manuscript preparation. The study design, data collection, statistical analysis, interpretation of results, and final approval of the manuscript were performed by the authors.
Ethical considerations
The Opinion of Ethics Committee of Shanghai Sixth People’s Hospital reviewed the study and determined that it did not constitute human subjects research; therefore, formal ethics approval was not required (No. 2026-MC-002).
Consent for publication
All authors have read and approved the final version of the manuscript.
Author contributions
SJG designed the study. JLC, DFY and YBP analysed the data and performed the statistical analyses. XC prepared the first draft. All authors have read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
This study is entirely based on open source models, with no additional datasets generated or annotated. Detailed raw data are available from the corresponding author upon request.
Guarantor
Shuji Gong is the guarantor of the manuscript.
Supplemental material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.