
Abstract
Background/Objectives
This study aimed to evaluate the response variability and temporal instability of responses generated by the artificial intelligence–based model ChatGPT-5.2 to structured clinical questions derived from the 2025 ESC/EACTS Guidelines for the Management of Valvular Heart Disease (GMVHD).
Methods
This prospective observational study employed a test–retest design. A structured set of 100 guideline-based questions—comprising 60 binary (true/false) and 40 multiple-choice items—was developed by two cardiologists (Ç.M. and Z.U.) in accordance with the 2025 ESC/EACTS GMVHD. The question set was administered to ChatGPT-5.2 on two separate occasions with a 14-day interval. The model was instructed to provide answers only, without any explanatory commentary. ChatGPT-generated responses were independently evaluated and coded as correct or incorrect by two cardiologists (Y.K. and Ç.M.). Numerical changes in responses were assessed using McNemar’s test, while test–retest reliability was evaluated using Cohen’s kappa coefficient.
Results
For binary questions, ChatGPT demonstrated an accuracy of 96.7% in both assessments. Accuracy for multiple-choice questions increased from 75.0% at baseline to 87.5% at the second assessment. When all questions were analyzed together, overall accuracy improved from 88.0% to 93.0%. A numerical increase in accuracy was observed between T1 and T2, without a statistically significant temporal difference. (p > 0.05). Cohen’s kappa analysis indicated moderate agreement for binary questions and low agreement for multiple-choice questions.
Conclusion
ChatGPT-5.2 demonstrated numerical improvement without statistically significant temporal difference and short-term performance change when answering guideline-based clinical questions on valvular heart disease. However, the relatively high initial error rate in multiple-choice questions represents a limitation for clinical reliability. At present, AI systems may be considered supportive tools for guideline-based information retrieval and clinical education.
Keywords
1. Introduction
Valvular heart disease (VHD) is a major cause of reduced functional capacity, heart failure, arrhythmias, recurrent hospitalizations, and premature mortality. 1 Many patients with VHD remain undiagnosed, are referred to specialists only at advanced stages of the disease, and consequently receive suboptimal treatment. 2
The increasing complexity of valvular heart disease management, particularly with the expanding role of transcatheter interventions such as mitral valve implantation, has further highlighted the need for advanced clinical decision-support systems. 3
In this context, modern transcatheter valve therapies have introduced new procedural and decision-making challenges, reinforcing the importance of rapid and reliable access to guideline-based information. 3
Decisions regarding the timing of surgical or transcatheter interventions, effective management of medical therapy, anticoagulation strategies, and accompanying comorbid conditions require clinicians to have rapid access to high-level clinical knowledge. In this context, the guidelines jointly developed by the European Society of Cardiology (ESC) and the European Association for Cardio-Thoracic Surgery (EACTS) represent the most widely accepted and referenced guidance in clinical practice. The 2025 ESC/EACTS Guidelines for the Management of Valvular Heart Disease (GMVHD) are the most recent guidelines available in this field. 4
Artificial intelligence applications in cardiology have also gained increasing attention in recent years, with large language models such as ChatGPT being explored for their potential role in clinical decision support and medical education. 5
In recent years, rapid advances in artificial intelligence (AI) have had positive effects across many sectors, including healthcare.6–8 Numerous AI-based tools have been introduced to improve diagnostic processes, support clinical decision-making, and enhance efficiency in patient care. Moreover, these tools have demonstrated the potential to become a fundamental component of modern healthcare systems.6,9 In cardiology, AI is expected to provide substantial benefits, particularly in the interpretation of imaging modalities such as echocardiography, cardiac magnetic resonance imaging, and computed tomography. 10 These technologies improve diagnostic accuracy and facilitate clinical decision-making processes. 11
Despite the growing potential of AI in healthcare, concerns persist regarding the consistency and reliability of AI-generated responses, particularly in scenarios requiring advanced clinical judgment.12,13 Although AI-based models such as ChatGPT can generate formally coherent and persuasive content, they may occasionally provide information that is questionable, misleading, or even incorrect. This underscores the need for critical evaluation by healthcare professionals before such outputs are used in clinical practice. 14
ChatGPT (Chat Generative Pre-trained Transformer), one of the large language models developed by OpenAI, is trained on large-scale textual datasets.15–17 By leveraging principles of deep learning and transformer-based architectures, it is capable of generating contextually meaningful and seemingly reliable responses. 18 In healthcare, ChatGPT has been considered a potential tool for clinical education, patient information, medical documentation, and decision-support processes.19,20 However, its role in VHD—an area characterized by complex diagnostic, follow-up, and treatment algorithms—has not yet been clearly established.
The aim of this study was to evaluate the level of agreement and temporal performance of AI-based ChatGPT with the 2025 ESC/EACTS GMVHD in supporting clinicians with foundational VHD knowledge by facilitating rapid access to high-level, evidence-based recommendations in diagnostic, follow-up, and treatment processes. In this respect, the study seeks to contribute to the growing literature on AI applications in cardiology from a VHD-focused perspective.
Although this study did not explicitly evaluate health equity, potential differences in guideline interpretation across diverse populations should be considered. Future research should explore AI performance across sociodemographic subgroups to assess fairness and generalizability.
2. Materials and methods
2.1. Study design
This observational, prospective test–retest study was designed to assess response variability across repeated testing of AI-based ChatGPT-5.2 with the 2025 ESC/EACTS GMVHD and the consistency of its performance over time. The study focused on performance change, variation across repeated testing or numerical improvement to assess the potential usability of ChatGPT as a clinical decision-support tool for clinicians managing patients with VHD.
2.2. Study environment
The 100-question set was systematically derived by two cardiology specialists (Ç.M. and Z.U from the 2025 ESC/EACTS Guidelines for the Management of Valvular Heart Disease, ensuring representation of major clinical domains. Questions were distributed across key guideline sections, including aortic, mitral, and tricuspid valve diseases, prosthetic valve management, and indications for surgical or transcatheter interventions. The question design aimed to achieve balanced coverage of diagnostic, follow-up, and therapeutic decision-making processes. In addition, questions were constructed to assess both factual knowledge recall and clinical reasoning abilities.
All questions were independently reviewed by two cardiologists for clarity, clinical relevance, and absence of ambiguity. Items were revised by consensus when necessary.
The sample size of 100 questions was pragmatically determined to ensure balanced representation of major guideline domains, while maintaining feasibility and interpretability of the test–retest design. This approach is consistent with prior studies evaluating artificial intelligence performance using structured clinical question sets.
ChatGPT (OpenAI) was accessed via the web-based interface and no API access was used. The model version was recorded as provided by the platform at the time of access, and the same user account was used at both time points. Each question was submitted in a new and independent chat session to prevent contextual carryover effects. Memory features were disabled, and no web browsing or external retrieval tools were enabled during the study. No hidden system prompts or additional instructions beyond the study-defined standardized input format were used.
The same question set was administered to ChatGPT-5.2 at two separate time points with a 14-day interval. To ensure outcome-focused rather than interpretive evaluation, ChatGPT was instructed to provide only answers without any explanatory comments. ChatGPT-generated responses were independently evaluated by two cardiologists (Y.K. and Ç.M.) and coded as correct (C) or incorrect (I). Complete inter-rater agreement was achieved for all items. Prior to the question–answer process, the relevant guideline was not uploaded into the ChatGPT environment, and the questions had not been previously tested on the ChatGPT platform.
Questions were presented sequentially using a standardized prompt format. Each question was queried once at each time point. This approach was intentionally chosen to reflect real-world usage, where clinicians typically interact with AI systems through single queries rather than repeated sampling.
For multiple-choice questions, answer options were presented in a fixed and standardized order, and no randomization of options was applied. The model was instructed to provide answers only, without any explanatory text. As the web-based interface was used, model parameters such as temperature could not be manually configured.
The full set of prompts and question formats is provided in the Supplementary Materials to ensure full reproducibility.
Although no formal difficulty scoring system was applied, the question set was intentionally designed to include varying levels of clinical complexity in order to reflect real-world guideline application.
A structured overview of the question bank according to guideline sections, clinical domains, and question types is provided in the Supplementary Materials. (Supplemental Tables S1 and S2).
2.3. Ethical statement and AI use declaration
This study was designed as an AI-based evaluation study and did not involve human or animal participants. No patient data, personal information, or clinical records were used. Therefore, ethics committee approval and informed consent were not required. Nevertheless, the study was conducted in accordance with the ethical principles of the Declaration of Helsinki.
2.4. Statistical analysis
Statistical analyses evaluated the responses provided by ChatGPT at two different time points (T1 and T2). Responses were coded as binary categorical variables (C or I). Descriptive statistics were presented as the number and percentage (%) of correct responses. Changes in responses between T1 and T2 were analyzed using the McNemar test. Test–retest reliability was assessed using Cohen’s kappa (κ) coefficient. In addition to point estimates, 95% confidence intervals were calculated for accuracy measures and Cohen’s kappa coefficients to provide a more robust assessment of estimate precision. Analyses were performed separately for binary questions, multiple-choice questions, and all questions combined. A p-value < 0.05 was considered statistically significant.
3. Results
3.1. Binary questions
In the analysis of binary questions, 58 of 60 questions were answered correctly at T1, yielding an accuracy rate of 96.7%. At T2, the number of correct responses remained unchanged, with the accuracy rate again calculated as 96.7%.
Item-level transition analysis showed that responses remained correct at both time points for 57 questions, while one question remained incorrect at both evaluations. One question changed from correct to incorrect (C→I), and one changed from incorrect to correct (I→C) (Figure 1). Based on this distribution, the observed overall agreement rate was 96.7%. Flowchart showing the variability in ChatGPT’s responses to the same binary choice questions posed by observers on day 0 and 14.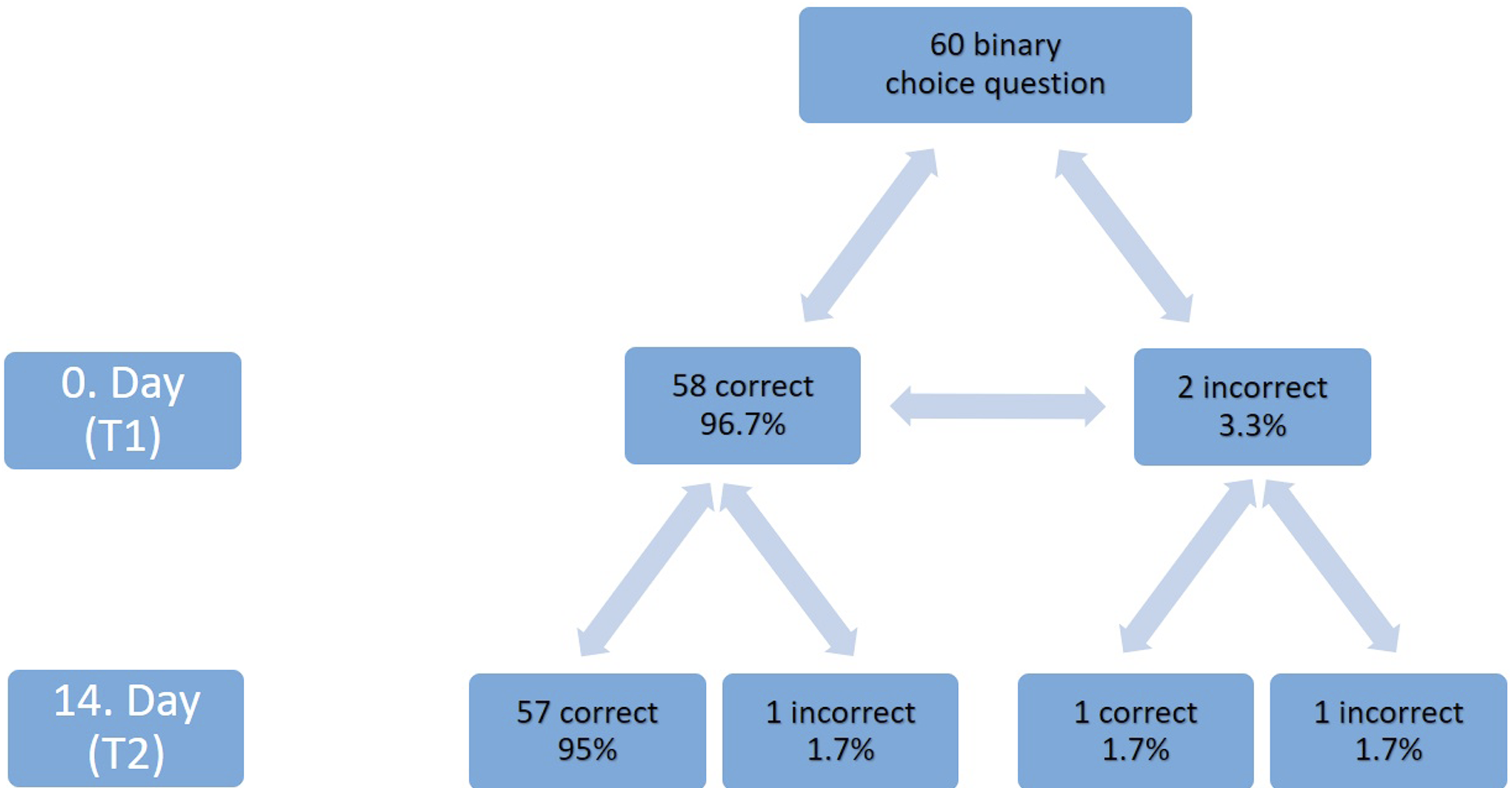
Test–retest performance of ChatGPT responses according to question type.
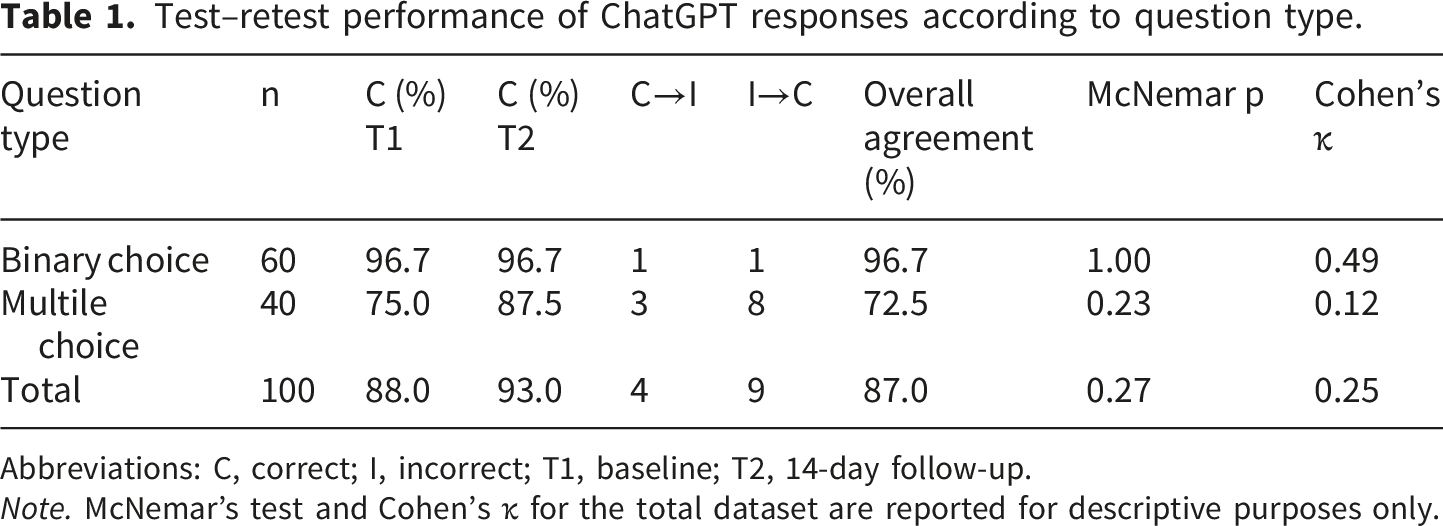
Abbreviations: C, correct; I, incorrect; T1, baseline; T2, 14-day follow-up.
Note. McNemar’s test and Cohen’s κ for the total dataset are reported for descriptive purposes only.
3.2. Multiple-choice questions
For multiple-choice questions, 30 of 40 questions were answered correctly at T1, corresponding to an accuracy rate of 75.0%. At T2, the number of correct responses increased to 35, yielding an accuracy rate of 87.5%.
Transition analysis demonstrated that 27 of the 30 initially correct responses remained correct at the second evaluation, while three changed to incorrect (C→I). Of the 10 questions initially answered incorrectly, eight were answered correctly at T2 (I→C), and two remained incorrect (Figure 2). The observed overall agreement rate was 72.5%. Flowchart showing the variability in ChatGPT’s responses to the same multiple choice questions posed by observers on day 0 and 14.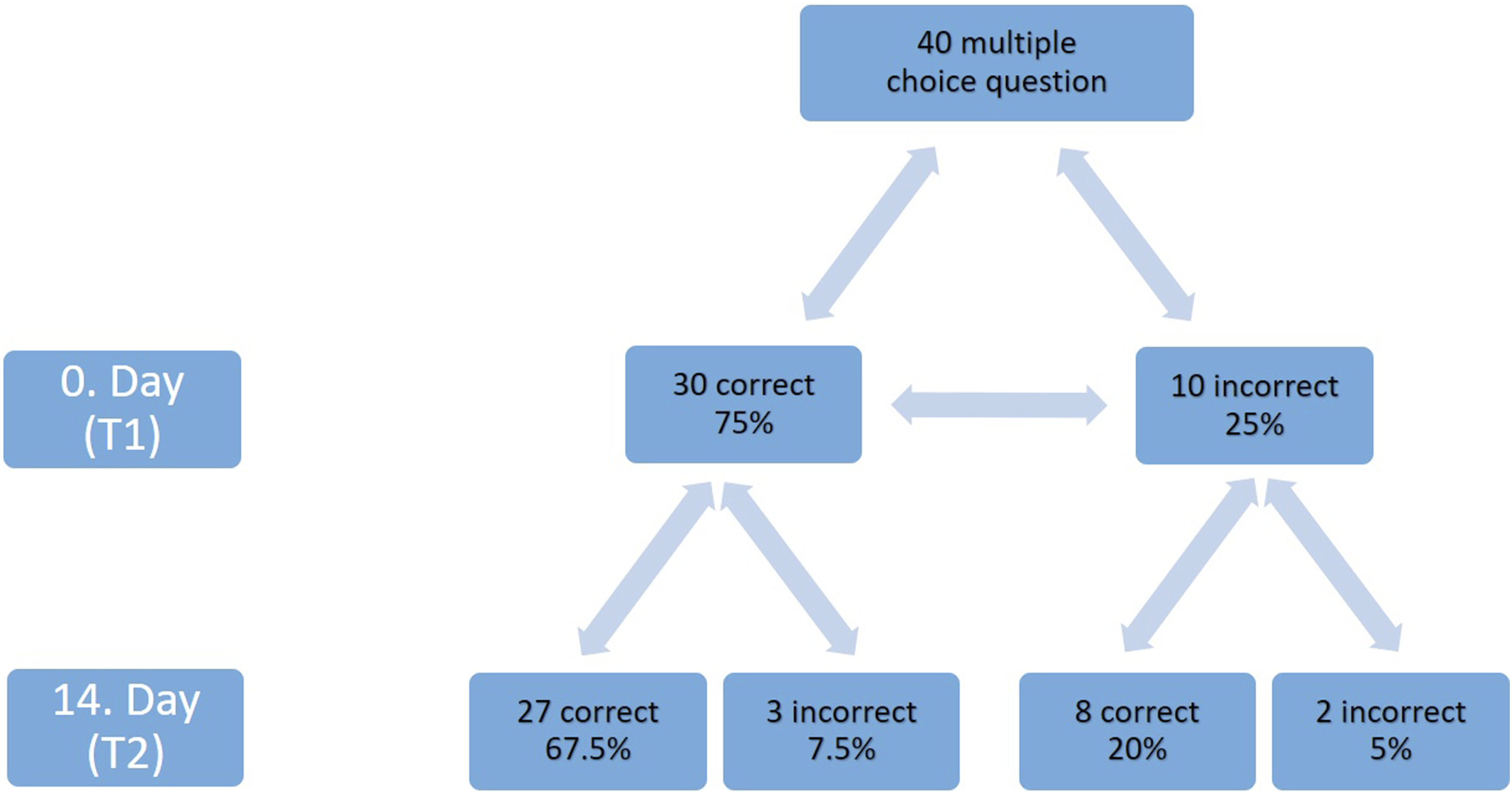
The McNemar test indicated no statistically significant difference between T1 and T2 for multiple-choice questions (p = 0.23). The Cohen’s kappa coefficient was 0.12 (Table 1).
3.3. Overall evaluation of all questions
When all questions were evaluated together, 88 of 100 questions were answered correctly at T1, yielding an accuracy rate of 88.0%. At T2, the number of correct responses increased to 93, with an accuracy rate of 93.0%.
Transition analysis showed that 84 of the 88 initially correct responses remained correct at the second evaluation, while four changed to incorrect (C→I). Of the 12 questions initially answered incorrectly, eight were answered correctly at T2 (I→C), while two remained incorrect. Based on this distribution, the observed overall agreement rate was 87.0%.
The McNemar test for the entire dataset demonstrated no statistically significant temporal change between T1 and T2 (p = 0.27). The Cohen’s kappa coefficient was 0.25 (Table 1).
4. Discussion
With population aging, the prevalence of VHD has increased steadily in recent years and is expected to continue rising in the coming decades. 2 The high morbidity and mortality associated with VHD highlight the need for clinicians to exercise caution when determining diagnostic and therapeutic strategies for these patients.
Recent literature has highlighted the emerging role of large language models in cardiology, including their potential applications in clinical reasoning support, education, and electrophysiology practice. 5
It is well recognized that ChatGPT can generate responses to scientific questions; however, some of the information and references it provides may consist of a mixture of verified data and fabricated content. 10 Responses lacking scientific references point to important challenges that must be addressed in the development of natural language processing-based AI tools.
Despite access to large datasets and advanced computational capabilities, large language models such as ChatGPT generate text based on statistical probabilities rather than true conceptual understanding. Their approach focuses on identifying linguistic patterns rather than comprehending information in a genuine sense.14,21 This probability-based generation process may result in misleading, non-source-based content, often referred to in the literature as “hallucinations.” Inconsistent, repetitive, or cyclical narratives may occasionally occur. Although such outputs may appear superficially accurate, they may not reflect reality and are not always easy to distinguish. 22
AI-related hallucinations raise serious safety concerns, particularly in medical practice where diagnostic and therapeutic decisions directly affect patient outcomes. This necessitates a cautious and controlled approach to the clinical use of AI models. To achieve more reliable outputs, these systems should be trained not only on large and diverse datasets but also on trustworthy, validated sources, and should be supported by continuous monitoring, user feedback, and performance evaluations. Such strategies may help reduce AI hallucinations as well as data drift and time-dependent performance degradation. 10
The number of studies systematically evaluating the accuracy of ChatGPT’s responses to guideline-based clinical questions remains limited. Nevertheless, some studies have shown that AI-based systems can achieve a certain level of success in generating appropriate medical responses.10,23–25 These findings suggest that such systems may have the potential to play a supportive role in clinicians’ decision-making processes.
In our study, ChatGPT provided correct responses to many clinical questions prepared on the basis of the 2025 ESC/EACTS GMVHD and focused on diagnostic, follow-up, and treatment decision-making in VHD. At baseline, ChatGPT correctly answered 96.7% of the 60 binary questions and 75.0% of the 40 multiple-choice questions. After 14 days, overall accuracy across all 100 questions increased from 88.0% to 93.0%, although a persistent error rate of 7% remained. As shown in Table 1, binary questions demonstrated higher test–retest stability, whereas multiple-choice questions exhibited greater response variability and a higher rate of incorrect-to-correct transitions. The observed differences between T1 and T2 should be interpreted as response variability rather than evidence of learning, as statistical comparisons did not demonstrate significant temporal differences.
The high accuracy and limited response variability observed in binary questions indicate that this format provides a more stable evaluation framework for ChatGPT. The dichotomous decision structure reduces ambiguity and enhances temporal consistency. In contrast, the marked improvement in accuracy for multiple-choice questions at the second assessment suggests that this format may be more susceptible to performance change, variation across repeated testing or numerical improvement without statistically significant temporal difference.
The initial accuracy of only 75.0% for multiple-choice questions—meaning that approximately one-quarter of responses were incorrect—represents a clinically significant concern. Although accuracy improved at the second assessment, this finding cannot be disregarded. In medical domains directly affecting patient management, such as diagnosis, treatment, and risk stratification, this level of error raises serious safety concerns. While improvement over time may reflect performance change or numerical improvement without statistically significant temporal difference, it does not eliminate the risk posed by incorrect information provided at the initial assessment.
The interpretation of Cohen’s kappa should be considered in the context of prevalence effects and class imbalance. Despite a high observed agreement in binary questions (96.7%), the moderate kappa value (0.49) likely reflects the dominance of correct responses, which can lead to paradoxically lower kappa estimates in highly imbalanced datasets.
Similarly, the low kappa value observed in multiple-choice questions (0.12), despite an increase in raw accuracy, indicates substantial response variability across repeated testing. This suggests that agreement metrics alone may not fully capture model behavior in structured clinical question settings.
Importantly, a distinction should be made between accuracy and stability. A system may demonstrate high average accuracy while still exhibiting variability across repeated measurements, which is clinically relevant when considering the reliability of AI-assisted decision support tools.
Therefore, both accuracy and stability metrics should be interpreted jointly when evaluating large language model performance in clinical contexts.
This study primarily evaluates the model’s ability to respond to structured, guideline-based knowledge questions rather than its capacity for real-world clinical reasoning or decision-making. Clinical decision-making in valvular heart disease involves complex, patient-specific considerations, integration of multimodal data, and dynamic risk assessment, which are not fully captured by structured question formats.
Therefore, the findings should be interpreted within the context of knowledge retrieval and guideline adherence rather than clinical competence. Importantly, these findings should be interpreted with caution, as each evaluation was based on only a single model response per question, which may increase the likelihood of responses being influenced by random variability. This methodological consideration is clinically relevant when evaluating the reliability and potential applicability of AI systems in guideline-based cardiovascular decision support. While the observed accuracy suggests potential utility in educational settings and rapid information access, the variability in responses—particularly in multiple-choice questions—highlights important limitations in reliability. Also the absence of a human comparator group limits the ability to contextualize the observed accuracy in relation to clinician performance. Therefore, the findings should be interpreted as an assessment of internal model performance rather than comparative clinical competence. As a result, the extent to which these findings reflect real-world clinical decision-making remains uncertain. Model fairness was not formally assessed in this study. Future investigations should evaluate potential biases in AI-generated responses across different clinical contexts and patient subgroups.
Importantly, this study does not provide evidence of learning or adaptive behavior in large language models. Any observed differences between repeated assessments reflect stochastic response variability rather than a mechanistic change in model performance.
In this context, AI-based systems such as ChatGPT may serve as supportive tools for reinforcing guideline-based knowledge; however, their role as clinical decision-support systems should be approached with caution. Their outputs should always be interpreted in conjunction with expert clinical judgment.
5. Limitations
This study has several limitations. First, the evaluation was conducted using a single AI system, which limits the generalizability of the findings to other AI models or versions.
Second, the question set was limited to 100 structured questions based on the 2025 ESC/EACTS GMVHD. Although clinically robust, this approach may not fully reflect the more complex and patient-centered decision-making processes encountered in real-world clinical practice.
Third, each question was queried only once at each time point. Given the stochastic nature of large language models, repeated querying with aggregation methods (e.g., majority voting) might have provided a more robust estimate of performance and reduced random variability. Future studies should consider incorporating such approaches to improve reliability assessment.
Another limitation is the absence of a human comparator group. Without direct comparison to clinicians with varying levels of expertise, it is difficult to determine the clinical significance of the observed accuracy. Future studies incorporating clinician benchmarks would provide more meaningful context for interpreting AI performance.
Finally, only binary and multiple-choice questions were used, limiting the assessment of AI performance in open-ended and more complex clinical queries.
6. Conclusions
This study examined the response variability or temporal instability of ChatGPT-5.2’s responses to guideline-based clinical knowledge using structured questions derived from the 2025 ESC/EACTS GMVHD.
However, the substantial rate of incorrect responses initially observed—particularly in multiple-choice questions—constitutes a significant limitation in terms of reliability. Although a reduction in incorrect responses was observed at the subsequent evaluation, this does not eliminate the existing risk. Given the direct impact of clinical decisions on patient outcomes, this margin of error supports the conclusion that AI outputs should not be used as standalone tools in clinical decision-making.
In summary, AI systems demonstrated variability in repeated assessments without statistically significant temporal change. Nevertheless, at their current levels of accuracy and consistency, they are not suitable substitutes for expert physician evaluation in clinical applications that directly affect human life.
Supplemental material
Supplemental material - ChatGPT response consistency to the 2025 ESC/EACTS guidelines for the management of valvular heart disease: A test–retest study using binary and multiple-choice questions
Supplemental material for ChatGPT response consistency to the 2025 ESC/EACTS guidelines for the management of valvular heart disease: A test–retest study using binary and multiple-choice questions by Çetin Mirzaoğlu, Zeynep Ulutaş, Yücel Karaca in DIGITAL HEALTH
Supplemental material
Supplemental material - ChatGPT response consistency to the 2025 ESC/EACTS guidelines for the management of valvular heart disease: A test–retest study using binary and multiple-choice questions
Supplemental material for ChatGPT response consistency to the 2025 ESC/EACTS guidelines for the management of valvular heart disease: A test–retest study using binary and multiple-choice questions by Çetin Mirzaoğlu, Zeynep Ulutaş, Yücel Karaca in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors would like to thank all colleagues who contributed indirectly to the conduct of this study.
Ethical considerations
This study was designed as an artificial intelligence–based evaluation study and did not involve human or animal participants. No patient data, personal information, or clinical records were used. Therefore, ethics committee approval was not required. The study was conducted in accordance with the ethical principles of the Declaration of Helsinki.
Consent to participate
Informed consent was not required because this study did not involve human participants and did not use any patient data.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Contributorship
The conception and design of the study were undertaken by Ç.M. and Y.K. The guideline-based question set was developed by Ç.M. and Z.U. Evaluation and coding of the ChatGPT-generated responses as correct or incorrect were performed by Y.K. and Ç.M. Statistical analyses were conducted by Z.U. The first draft of the manuscript was written by Z.U. All authors critically reviewed the manuscript, contributed important intellectual content, and approved the final version for publication.
Protocol and registration
This study was not prospectively registered, as it represents an exploratory evaluation of artificial intelligence performance. A formal study protocol is available from the corresponding author upon reasonable request.
AI use declaration
Artificial intelligence (AI) was used exclusively as the subject of evaluation in this study. ChatGPT-5.2 was utilized solely to generate responses to the predefined guideline-based clinical questions according to the study design. AI was not used for study design, data analysis, statistical evaluation, interpretation of results, or autonomous manuscript generation. All scientific content and editorial decisions were reviewed and approved by the authors.
Guarantor
All authors jointly serve as guarantors of this study and accept full responsibility for the integrity, accuracy, and completeness of the work from its conception to publication.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.