
Abstract
Objectives
To evaluate the quality of responses generated by GPT-4 in comparison to those written by hospital specialists and general practice physicians across multiple medical specialties. The goal was to assess whether large language models (LLMs) can support patient communication by providing accurate, useful, complete, and empathetic responses to real-world patient inquiries.
Methods
We collected 100 anonymized patient questions from a public online health forum covering five specialties: cardiology, infectious diseases, neurology, gynecology, and gastroenterology. Responses were generated by GPT-4, 50 hospital-based specialists, and 50 general practice physicians. A group of 50 specialists, blinded to response source, evaluated each answer using four 7-point Likert scales: accuracy, usefulness, completeness, and empathy. The study design and reporting were informed by the CONSORT-AI Extension to promote transparency in AI evaluation.
Results
The model received significantly higher ratings across all four categories compared to both physician groups. It was ranked best in 67% of evaluations, particularly outperforming physicians in completeness and empathy. While response length correlated positively with quality for physicians, model's longer responses were less useful when overly detailed. The model consistently produced longer, more comprehensive replies than human groups.
Discussion
The model's strong performance in completeness and empathy highlights its potential role in enhancing patient communication. Although it matched or exceeded physicians in accuracy and usefulness, caution is warranted due to risks like hallucinations and lack of true understanding.
Conclusion
This blinded evaluation suggests that AI-generated responses may support clinical practice by delivering accurate, comprehensive, and empathetic information for patient communication.
Introduction
Artificial intelligence (AI) is rapidly transforming medicine, particularly through the emergence of large language models (LLMs) that hold promise for enhancing patient communication. A recent systematic review analyzing 550 studies on LLMs highlighted their growing role in diagnostics, medical writing, education, and patient-facing applications, while emphasizing ethical challenges. 1 These technologies may improve patient–doctor communication, medical decision-making, and workflow efficiency, though issues of implementation, safety, and ethics remain critical.2,3
One of the most promising applications is automating responses to patient inquiries, a need accentuated during the COVID-19 pandemic, when increased message volumes overwhelmed physicians and led to delays or inadequate responses. LLMs have shown promise in mitigating this burden.4,5 Some studies found that LLM-generated replies were rated higher in quality and empathy than those by physicians, supporting their potential to improve patient engagement and reduce administrative overhead.4–6 For example, GPT-based tools have been used to generate follow-up clarifications and patient education content, including in type 2 diabetes, with generally valid and useful outputs. 7
However, uncertainty persists regarding standardized evaluation of LLM performance in complex clinical tasks. A systematic review by Bedi et al. 8 noted that existing assessments are fragmented and often omit real-world data, domain diversity, and bias analysis. Risks like hallucinations—plausible but incorrect outputs—remain, even in state-of-the-art models like GPT-4o.9,10 Moreover, models may reflect bias from uneven training data, privileging subspecialist over generalist perspectives. Regulatory bodies have responded: the EU AI Act and U.S. FDA guidelines now mandate validation, monitoring, and transparency for high-risk AI applications.11,12 Still, real-world adoption hinges on workflow integration and institutional support, which are often neglected in technical evaluations.13,14
This study addresses these gaps by comparing responses from GPT-4 to those from general practice physicians and hospital specialists on real patient inquiries. By evaluating across key quality dimensions—accuracy, completeness, usefulness, and empathy—we aim to assess whether LLMs can meet standards expected of virtual assistants in healthcare. We hypothesized that hospital specialists would score highest in accuracy and usefulness, GPT-4 would outperform general practitioners in completeness and empathy, and that these findings would offer insights into how LLMs may support, rather than replace, human clinicians.
Methods
Study design and participants
This study compared responses to patient inquiries from three sources: GPT-4, hospital-based specialists, and general practice physicians. It was conducted in two phases: the first involved collecting responses; the second involved evaluating them.
In Phase 1, 100 licensed physicians participated, 50 general practice physicians and 50 hospital specialists from cardiology, infectious diseases, gynecology, gastroenterology, and neurology. Each physician answered two real patient questions relevant to their field. General practitioners responded to randomly assigned questions across specialties. All physicians were recruited in Croatia, where medical training follows EU standards, and ethics approval was granted by the University of Zagreb School of Medicine. Snowball sampling was used to supplement recruitment.
Phase 2 involved a new cohort of 50 hospital specialists, who evaluated the responses. A small subset of respondents from Phase 1 also participated as evaluators. This allowed for diverse expertise in assessment and minimized potential evaluator fatigue.
Patient questions and response collection
One hundred patient questions were randomly sampled from the public health platform PlivaZdravlje.hr, which allows anonymous users to pose questions to licensed physicians across 26 medical specialties. We selected the five most frequent specialties and randomly chose 20 questions per specialty. Questions were distributed to respondents using survey forms containing two questions each.
General practitioners and hospital specialists were instructed to respond as they would in actual clinical settings. Simultaneously, the same 100 questions were submitted to GPT-4. The model was configured to respond in Croatian with an empathetic and professional tone, providing medically appropriate information while avoiding diagnosis or treatment advice. Consistency was ensured through predefined prompts and fixed generation parameters.
Evaluation procedure
Physician evaluators rated the quality of responses using a custom-built assessment form. Each evaluator received two patient questions with three anonymized responses per question, one each from a general practitioner, a hospital specialist, and GPT-4, randomly ordered to prevent bias. Questions were matched to evaluators by specialty. Each question was evaluated by a single blinded specialist, which enabled us to cover a larger set of patient inquiries rather than concentrating multiple evaluations on a smaller subset. As a result, inter-rater reliability could not be assessed; future studies should incorporate multi-rater evaluation to improve reliability. Each response was rated on four 7-point Likert scales: accuracy, usefulness, completeness, and empathy. These dimensions were chosen based on validated prior studies assessing AI and physician communication quality. Evaluators were blinded to the source of each response. After rating individual responses, evaluators were asked to rank the three answers per question from best to worst. Each specialist evaluated six responses (three per question) in total. The evaluation framework was designed to simulate real-world clinical review, balancing objectivity with subjective impressions across core quality indicators.
Statistical analysis
Descriptive statistics summarized ratings and rankings for each response group. For group comparisons across all criteria, the Kruskal-Wallis test was used, followed by Holm-Bonferroni corrections for multiple comparisons. Kendall's tau correlation assessed associations between response length and quality scores. All significance levels were set at p < 0.05. Additionally, to estimate the effect size between pairs of groups, Cliff's delta (δ) was employed. 15 Cliff's delta was chosen for its suitability for ordinal data, such as rating scales, and its robustness to extreme values. This non-parametric measure of effect size provides insights into the degree of overlap between the distributions of two groups, with the following interpretation of effect size: |δ| < 0.147 is considered negligible, 0.147 ≤ |δ| < 0.33 small, 0.33 ≤ |δ| < 0.474 medium, and |δ| ≥ 0.474 large. 16
Reporting framework
Although this study is not a clinical trial, its design and reporting were informed by the CONSORT-AI Extension guidelines. These guidelines support transparent evaluation of AI tools in healthcare. In line with these principles, we described the AI system (GPT-4), input source and comparator setup, evaluation procedures, and outcome metrics in detail. The text generation parameters used with GPT-4 were standardized across all questions and are detailed in the supplementary material.
Results
Statistical analyses revealed significant differences (P < 0.05) across all evaluated categories, consistently favoring the agent over physicians. In all metrics, accuracy, usefulness, completeness, and empathy, GPT-4 received the highest ratings, followed by hospital specialists, then general practice physicians (Figure 1).
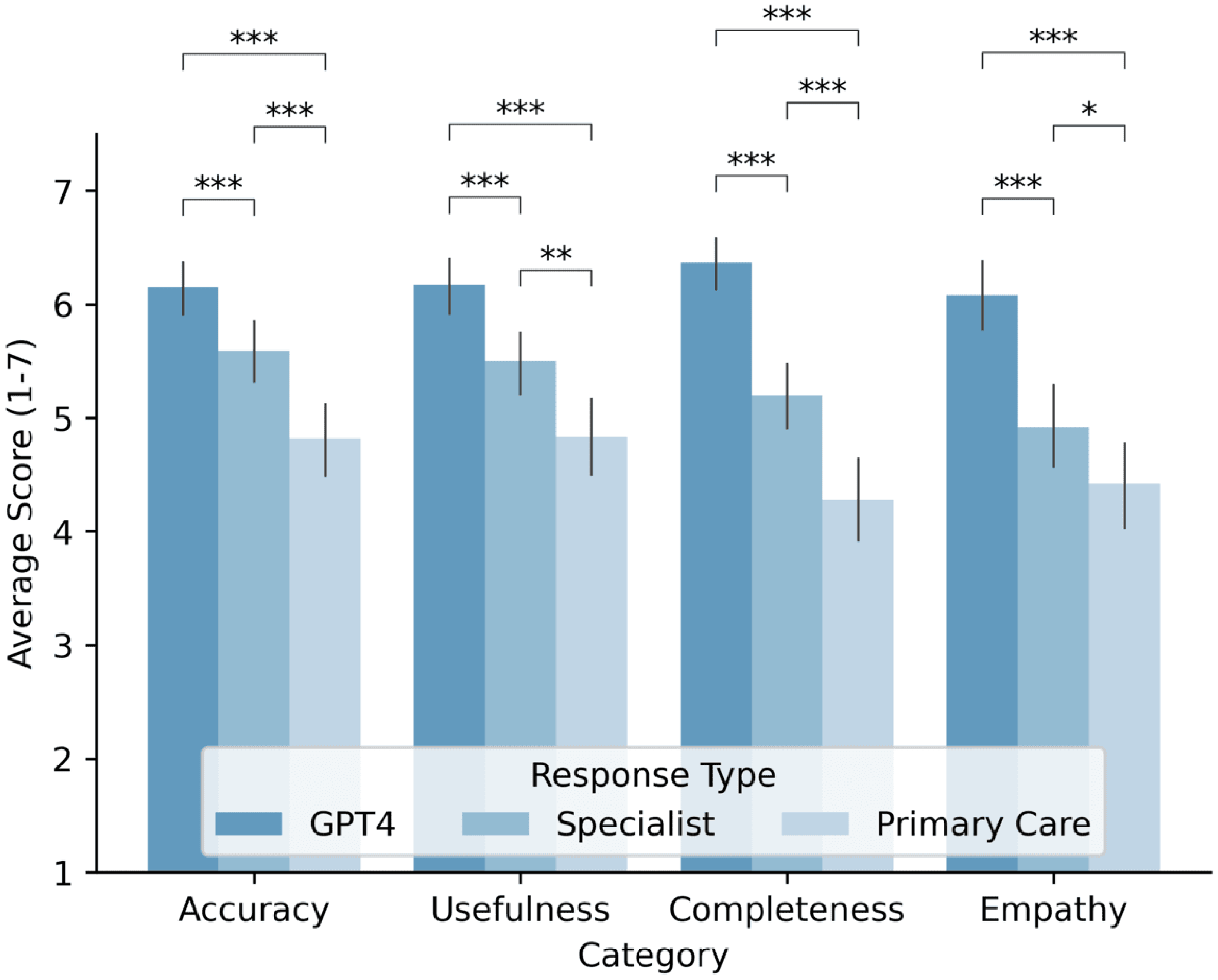
Average response ratings provided by GPT-4, hospital specialist physicians, and general practice physicians across four categories: accuracy, usefulness, completeness, and empathy. Ratings are displayed on a scale from 1 to 7, with bars indicating the 95% confidence interval for the mean.
For accuracy, average scores were: GPT-4 (6.15), specialists (5.59), and general practitioners (4.82). Effect sizes indicated a small effect between specialists and general practitioners (δ = 0.282), a large effect between general practitioners and the agent (δ = –0.511), and a small effect between specialists and the agent (δ = –0.271). Similar patterns were found for usefulness (agent: 6.17, specialists: 5.50, general practitioners: 4.83), with effect sizes indicating small (δ = 0.230), large (δ = –0.502), and medium (δ = –0.335) effects, respectively. Differences in completeness were more pronounced (agent: 6.37, specialists: 5.20, general practitioners: 4.28), with large effects between the agent and both physician groups. For empathy, the agent again led (6.08), followed by specialists (4.92) and general practitioners (4.42), with large (δ = –0.555) and medium (δ = –0.448) effects versus the agent.
Specialty-specific analyses (Figure 2) showed varying patterns. In neurology and gynecology, GPT-4 outperformed both physician groups. In infectious diseases and cardiology, differences were smaller and occasionally favored specialists. The largest gaps appeared in gastroenterology, favoring the model in all categories. However, the limited number of cases in each specialty (10 physicians) may have influenced these results, and these comparisons should therefore be interpreted with caution as exploratory rather than definitive.

Average response ratings provided by GPT-4, specialists, and general practice physicians across five medical specializations: neurology, infectious diseases, gynecology, cardiology, and gastroenterology. Ratings are displayed across four categories: accuracy, usefulness, completeness, and empathy.
Table 1 shows that GPT-4 consistently produced longer responses across all specialties. On average, its replies were 4.5 times longer than those of specialists and 8.8 times longer than those of general practitioners. Specialists’ responses are, on average, 1.9 times longer than those of general practice physicians.
The average number of characters in responses from the model, specialists, and general practice physicians, categorized by type of specialization.

GPT-4 was ranked best in 67% of all evaluations (95% CI, 57%–76%), compared to 27% for specialists (95% CI, 19%–36%) and 6% for general practitioners (95% CI, 0%–12%) (see Supplemental Table S1).
Correlation analyses (see Supplemental Tables S2 and S3 for detailed correlation matrices) showed that response length and quality dimensions (accuracy, usefulness, completeness, empathy) were strongly interrelated for both physicians and the model. Response length was positively associated with physician ratings but showed a slight negative correlation with GPT-4's usefulness ratings. Question length had negligible impact on both groups. This analysis indicates that the content and quality of the information in physician responses play the primary role in evaluation, while response length serves as a secondary, but notable, factor.
Discussion
This study presents one of the largest blinded comparisons of GPT-4 and physician responses across multiple specialties using real patient inquiries. Responses were evaluated by hospital specialists blinded to whether they were assessing outputs from a human or the language model, a methodological improvement over prior studies that often relied on smaller, unblinded panels.4,5 While the results reflect subjective impressions, they offer valuable insights into the model's performance from a clinician's perspective, evaluated under conditions that mimic real-world interpretation. GPT-4 consistently received higher ratings than both hospital specialists and general practice physicians across all categories, raising important considerations for its potential integration into clinical workflows.
Accuracy
Accuracy is critical when evaluating medical responses, especially due to the risk of hallucinations, plausible but incorrect outputs generated by LLMs. 17 Prior studies have found that LLMs tend to perform weakest in this category compared to physicians.4,5 In our study, GPT-4 still outperformed physicians in accuracy, though the difference was least pronounced compared to hospital specialists. This aligns with earlier findings and may reflect improvements in the GPT-4 architecture. Interestingly, we found that longer responses were positively correlated with higher accuracy scores. This may be due to more knowledgeable or more engaged physicians providing longer, more informative answers, or perhaps because evaluators perceived longer answers as more reliable. Nonetheless, response length alone does not ensure factual correctness and should not be equated with content validity. Despite the model's strong performance, it may still generate incorrect information with clinical consequences. This underscores the importance of maintaining human oversight and incorporating LLMs as assistive tools rather than standalone decision-makers. 18
Completeness
The importance of this evaluation category for patient questions lies in the fact that patients seeking information about their health expect responses from physicians to address all aspects of their inquiry. Comprehensive responses enhance patient satisfaction with the care provided, reassuring them that the physician has made an effort to answer their questions thoroughly. The agent's responses stood out, particularly in the completeness category, where they significantly outperformed those of physicians. The model's ability to generate extensive and detailed responses in a very short time enables it to cover all aspects of a patient's question. This capability is also reflected in the significant differences in response length between the agent and physicians, with the agent producing substantially longer responses. The longer responses of the model contributed to higher ratings in the categories of accuracy and completeness.
Usefulness
Usefulness is a critical category in evaluating medical responses, as it reflects how relevant and actionable the provided information is for patients. A useful response not only delivers practical guidance but also aligns with the patient's specific circumstances, enabling informed decision-making about their health. In this study, the model achieved the highest average score in this category, surpassing both hospital specialists and general practice physicians. An interesting finding was the statistically significant negative correlation between the length of the agent's responses and their perceived usefulness. Physician evaluators found overly lengthy responses to be somewhat less useful, emphasizing the importance of tailoring the scope of information to avoid overwhelming patients with excessive details.
Empathy
Based on prior research, it was anticipated that GPT-4 would outperform physicians in the empathy category, a finding confirmed in this study.4,5 This result highlights the model's consistency in generating empathetic responses to patient questions. Empathy, as a category for evaluating responses to patient inquiries, is crucial for establishing trust between healthcare providers and patients and ensuring patient satisfaction with the care provided. It is essential that LLMs, if employed for such purposes in practice, deliver empathetic responses. However, research has indicated that the mere knowledge that responses are generated by an AI model, rather than a human, can lead individuals to perceive these responses as less empathetic. 19 On a certain level, these results are understandable, as empathetic responses inherently involve emotional engagement from the responder toward the person posing the question and receiving the answer. Empathy is fundamentally a human trait; in this context, while the simulation of empathy by an AI model is significant, its true value for patients may be limited if they are aware they are communicating with a machine rather than a human who can genuinely understand their concerns. 19
While LLMs like GPT-4 can simulate empathy through sophisticated linguistic patterns, questions remain about the significance of this simulation for patients aware that they are interacting with an AI model rather than a human being capable of genuine understanding. Nevertheless, these models have demonstrated potential as supplementary tools for enhancing patient care. For instance, they can assist healthcare providers in delivering comprehensive responses more efficiently, allowing clinicians to focus on the human aspects of patient interaction and emotional support. Related research has also examined patient-centered applications of AI, where patients themselves contributed to evaluating responses. 20 Despite their limitations, LLMs could complement human empathy by enabling providers to spend more time addressing patients’ emotional and contextual needs, thereby enhancing overall care quality. This hybrid approach could lead to a synergistic relationship, where technology aids in delivering detailed information while maintaining the irreplaceable human touch essential for building trust and providing truly empathetic care. 19
Ethical concerns and limitations
While LLMs offer advantages in healthcare, their deployment raises ethical challenges, particularly around privacy, data security, transparency, and accountability. Patient confidentiality is crucial, as sensitive health data, if poorly anonymized or secured, can be misused, eroding trust.21,22 LLMs may also infer private information from benign data, further endangering privacy.19,21 Addressing this requires stringent data protocols, robust anonymization, and adherence to regulatory standards. 21 A key concern is the opacity of LLM outputs. The underlying data sources and interpretative mechanisms are often unclear, raising questions about bias and accuracy. Clinicians must validate such outputs, as their lack of explainability can hinder clinical trust and utility.21,23 Accountability is another issue: if AI-generated advice causes harm, it remains unclear whether responsibility lies with developers or deploying institutions.21,22 Ethical and legal frameworks, along with regulatory oversight, are needed to establish shared accountability.21,22
Hallucination, generating plausible yet incorrect outputs, poses particular risks in healthcare. Initiatives like Med-HALT aim to evaluate and reduce hallucinations in clinical contexts.23,24 Additionally, although LLMs can mimic empathy, they lack genuine understanding, and their outputs may be misleading. 21 The dominance of commercial entities in LLM development raises concerns about equitable access. Open, non-commercial LLM projects are essential to democratize medical AI. 25
This study has several limitations. It relied solely on GPT-4, while many medically tuned LLMs exist and have been released. However, it remains one of the most widely studied and cited LLMs in healthcare research. As such, documenting its performance provides a valuable benchmark for comparison with both current and future systems. Future studies should include a broader range of models. The study also lacked physician demographic information, such as age, subspecialty training, and institutional background, which could offer insights into the influence of professional experience on performance. Evaluating factual inaccuracies in both model and physician responses would provide a more objective comparison. Physicians’ effort levels in responding remain unknown, in contrast to LLMs, which provide consistent responses. One evaluator noted recognizing a model-generated answer due to its length and detail, uncommon in daily practice, yet still rated it highest. This reflects a potential “length bias” in evaluations. To minimize such bias, future studies could match the length and formatting of model and human responses. While consistent verbosity may inflate perceived completeness and empathy, truncating responses might isolate the value of their core content. Furthermore, empathy was assessed by physicians rather than patients; future work should incorporate patient perspectives as the ultimate recipients of communication. Ultimately, while LLMs performed strongly in this study, they should be viewed as tools to augment, not replace physician expertise. Their optimal use lies in supporting clinicians by drafting comprehensive responses, allowing professionals to focus on diagnostic reasoning, empathy, and personalized care.
Hallucination and bias mitigation
LLM limitations, especially hallucinations, must contextualize these findings. Despite safeguards, hallucination remains common: MedHEval benchmarks show even optimized medical LLMs hallucinate in 18–23% of open-domain clinical queries. 26 The model's strong performance in gastroenterology may reflect training data imbalances—gastroenterology literature constitutes 12% of PubMed content vs. cardiology's 7%. 27 Emerging mitigation techniques, such as HALO's retrieval-augmented generation 28 and MedHallu's binary detection frameworks, offer promising improvements. These methods have demonstrated potential to reduce hallucination rates by 38–42% while maintaining clinical applicability.8,28
Conclusion
The findings of this study revealed significant differences in the responses provided by GPT-4, hospital specialist physicians, and general practice physicians. Overall, the analysis demonstrated that the model's responses were rated higher than those of physicians across all observed categories, including accuracy, usefulness, completeness, and empathy. Notable variations were identified across evaluation categories and between the evaluated groups. The results confirmed the second part of the hypothesis, which posited that the responses of the model would surpass those of hospital specialist physicians and general practice physicians in the categories of completeness and empathy. However, the findings refuted the part of the hypothesis which suggested that hospital specialist physicians would outperform the language model in the categories of accuracy and usefulness. These results underscore the substantial potential of large language models to enhance patient communication by delivering high-quality, empathetic, and comprehensive responses. Importantly, this study highlights the opportunity for LLMs to complement, rather than replace, physicians in clinical workflows. By alleviating the administrative burden of creating detailed responses, AI systems could enable healthcare providers to focus more on direct patient care and the human aspects of their practice. This collaborative approach not only enhances the efficiency of healthcare delivery but also ensures that patients benefit from the combined strengths of human expertise and AI capabilities. Despite a lack of guidance about these tools and unclear work policies, general practice physicians report using generative AI to assist with their job. A recent survey of UK general practitioners confirmed that generative AI tools like ChatGPT are already being used in clinical settings, primarily for documentation and differential diagnosis support, even in the absence of formal policies or training. 29 While the study demonstrates the promise of LLMs like GPT-4, further research is essential to address challenges such as hallucinations, biases, and the ethical considerations surrounding their use. These findings provide a foundation for future investigations into the integration of AI in healthcare, fostering collaboration between physicians and artificial intelligence systems to enhance the accessibility, efficiency, and quality of healthcare.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251390001 - Supplemental material for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties
Supplemental material, sj-docx-1-dhj-10.1177_20552076251390001 for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties by Adrian Sallabi, Hrvoje Hrvoj and Andrija Štajduhar in DIGITAL HEALTH
Supplemental Material
sj-png-2-dhj-10.1177_20552076251390001 - Supplemental material for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties
Supplemental material, sj-png-2-dhj-10.1177_20552076251390001 for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties by Adrian Sallabi, Hrvoje Hrvoj and Andrija Štajduhar in DIGITAL HEALTH
Supplemental Material
sj-png-3-dhj-10.1177_20552076251390001 - Supplemental material for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties
Supplemental material, sj-png-3-dhj-10.1177_20552076251390001 for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties by Adrian Sallabi, Hrvoje Hrvoj and Andrija Štajduhar in DIGITAL HEALTH
Supplemental Material
sj-docx-4-dhj-10.1177_20552076251390001 - Supplemental material for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties
Supplemental material, sj-docx-4-dhj-10.1177_20552076251390001 for Blinded evaluation of GPT-4 and physician responses to patient inquiries across multiple specialties by Adrian Sallabi, Hrvoje Hrvoj and Andrija Štajduhar in DIGITAL HEALTH
Footnotes
Acknowledgements
We thank all participating physicians for their valuable time and contributions to this study. The authors acknowledge support from the School of Medicine, University of Zagreb (Project No. 10106-24-1602), which covered the article processing charge.
Ethical approval
This study was approved by the Ethics Committee of the Medical Faculty of the University of Zagreb (Ref: 251-59-10106-24-111/22; Class: 641-01/24-02/04) on February 22, 2024. All participating physicians provided informed consent prior to inclusion in the study.
Authorship contributions
Adrian Sallabi was responsible for writing the original draft, reviewing and editing the manuscript, validation, methodology, investigation, data curation, and conceptualization. Hrvoje Hrvoj contributed to writing the original draft, validation, software development, methodology, investigation, and conceptualization. Andrija Stajduhar provided supervision, reviewed and edited the manuscript, contributed resources and software, and was involved in methodology, investigation, formal analysis, funding acquisition, and conceptualization. All authors have read and approved the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data and software collected and used in this research, including anonymized patient questions, responses and model prompts, will be made available upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.