
Abstract
Objective
This study aimed to improve transcription accuracy for Korean hospital telephone consultations by fine-tuning the Whisper large-v3-turbo model. The goal was to assess whether domain-specific adaptation enhances automatic speech recognition (ASR) performance across speaker types in telemedicine.
Methods
I used a publicly available speech corpus comprising 1,272,630 Korean-language audio files (∼1,300 h) from telemedicine interactions involving doctors, nurses, and patients. Audio signals were standardized (16 kHz, 16-bit) and paired with normalized transcripts. The Whisper model was fine-tuned using supervised learning with data augmentation (SpecAugment, speed perturbation, noise injection) and speaker normalization. Performance was evaluated using word error rate (WER) and character error rate (CER), with statistical tests (Wilcoxon Signed-Rank and Sign Test) applied across speaker groups.
Results
The fine-tuned model consistently outperformed the baseline. In the patient group, WER improved from 22.92% to 22.42% and CER from 5.32% to 4.98%. Statistically significant improvements were observed for doctors and patients (p < .001), while changes in nurse data were not significant due to low baseline error. CER was found to better reflect transcription fidelity in Korean, as it was less affected by morphological variation and word segmentation errors typical in agglutinative languages. Loss monitoring confirmed stable convergence without overfitting.
Conclusion
Domain-specific fine-tuning of Whisper improves ASR performance in Korean telemedicine, especially for spontaneous patient speech. CER is more appropriate than WER for evaluating Korean ASR systems. These findings support the use of optimized ASR models for more accurate and reliable clinical documentation in digital health environments, with potential to reduce clinician documentation burden, support continuity of care, and improve patient safety.
Keywords
Introduction
Telephone consultations have become an essential communication tool in primary healthcare, supporting appointment scheduling, test result notifications, and providing advice for minor symptoms.1,2 However, traditional telephone consultations continue to face major documentation challenges.3,4 Because only about half of consultation content may be recorded, patient records can remain incomplete, undermining continuity of care. 2 Manual transcription further increases the risk of omissions, misinterpretations, and delays, while also adding cognitive and administrative burden for healthcare providers.5,6 In addition, unstructured records limit integration with electronic medical records (EMRs), complicate information retrieval, and restrict secondary data use.7–9 These issues have become even more pressing with the expansion of telemedicine during and after the COVID-19 pandemic, increasing the need for documentation systems that are efficient, secure, and accurate.10,11 ASR has emerged as a promising solution because it can automate transcription, reduce manual error, improve record accuracy, and support more efficient EMR-linked workflows and data-driven clinical decision-making.12–15
However, applying ASR in healthcare presents unique challenges. The complexity of medical terminology, variability in speech patterns, and the need for high transcription accuracy remain significant obstacles.15,16 Moreover, clinical environments involve background noise, overlapping speech, and variable audio quality, 17 while strict regulations such as HIPAA and GDPR necessitate robust data protection. 18
Despite recent advances, general-purpose ASR systems still perform suboptimally in medical transcription. 19 Clinical conversations contain technical terminology, abbreviations, and informal spoken expressions, and their recognition accuracy is further reduced by accent variation, disfluencies, and background noise.20–24 Earlier frameworks such as Kaldi offered flexibility but limited domain-specific adaptability, while end-to-end models including DeepSpeech and Wav2Vec 2.0 improved overall ASR performance yet remained constrained in healthcare applications.14,25–27 Transformer-based models, particularly Whisper, have further advanced ASR in noisy and multilingual settings. 28 Nevertheless, although Whisper shows strong general-domain performance, it still exhibits reduced accuracy in medical conversations because of vocabulary and discourse mismatches. 19 These limitations are likely to be amplified in Korean clinical telephone consultations, where informal speech, rapid turn-taking, and overlapping dialogue create additional complexity. 29 To the best of my knowledge, no previous study has examined the fine-tuning of Whisper or other large-scale ASR models using Korean clinical speech data, leaving an important gap in domain-specific adaptation for the Korean healthcare context.
Fine-tuning pre-trained ASR models on domain-specific datasets may improve recognition of medical terminology, better capture conversational structures unique to clinical interactions, and enhance overall transcription accuracy.30,31 When integrated with Electronic Medical Records (EMRs), such systems may also reduce administrative burden, streamline workflows, and support structured data storage for more effective clinical decision-making. 32
Recent studies suggest that ASR performance in clinical and telemedicine-related settings varies widely according to task and context. A recent systematic review reported that word error rates ranged from 0.087 in controlled dictation settings to over 50% in conversational or multi-speaker clinical scenarios. 33 In patient-clinician conversations recorded under relatively controlled conditions, specialized digital scribe models have reported WERs of 8.8% to 10.5%, whereas a psychotherapy study reported an overall WER of 25% and a WER of 34% for harm-related utterances, indicating that performance requirements differ substantially across use cases.34,35 Cross-language medical ASR studies have likewise shown marked variability across languages, highlighting that performance is not directly transferable across linguistic settings. 36 In addition, a recent Korean study in radiation oncology clinics reported a fine-tuned character error rate of 0.26 for clinician-patient conversations, highlighting both the feasibility and the continuing difficulty of domain-specific ASR in Korean medical speech. 37 Taken together, these findings suggest that there is no single universal WER or CER threshold that can be considered acceptable for all telemedicine applications. Instead, performance should be interpreted in relation to the intended clinical task, the linguistic properties of the target language, and the potential downstream impact of transcription errors.
To address this gap, the present study proposes an end-to-end system for hospital telephone consultation transcription using a fine-tuned Whisper ASR model. The system records calls, converts speech to text, and stores transcriptions in a centralized database linked to patient profiles, supporting efficient EMR management (Supplementary Figure S1). I fine-tuned Whisper using transfer learning on a Korean clinical telephone consultation dataset and evaluated its performance against the pre-trained model using word error rate (WER) and character error rate (CER). Results demonstrate substantial improvements in transcription accuracy, highlighting the value of domain-specific ASR adaptation for reducing documentation burdens and enhancing workflow efficiency in healthcare.
Methods
Study design and experimental pipeline
This study is a secondary analysis and model-development study that fine-tunes the Whisper large-v3-turbo model for improved transcription of hospital telephone consultations using a publicly available, de-identified dataset (AI-Hub: ‘Medical staff and patient voices for non-face-to-face treatment’).29,38 All data processing, supervised fine-tuning, and performance evaluation were conducted at Gyeongsang National University, Republic of Korea, between May 2024 and February 2025.
The overall experimental procedure followed a structured pipeline consisting of data preprocessing, supervised fine-tuning, and performance evaluation (Figure 1). Medical call audio files were extracted and preprocessed through an audio segmentation module to reduce noise and isolate clean speech segments. In parallel, the corresponding transcription text was normalized to remove punctuation and special characters to ensure consistent evaluation. The resulting paired data (clean audio and normalized text) were used to fine-tune the pre-trained Whisper large-v3-turbo model using supervised learning on domain-specific medical speech (approximately 1,300 h) from doctors, nurses, and patients. After training, performance was evaluated using standard speech recognition metrics, including word error rate (WER) and character error rate (CER), and compared with the baseline Whisper model. Workflow of supervised fine-tuning of the Whisper model for medical telephone consultation transcription.
Data collection and quality control
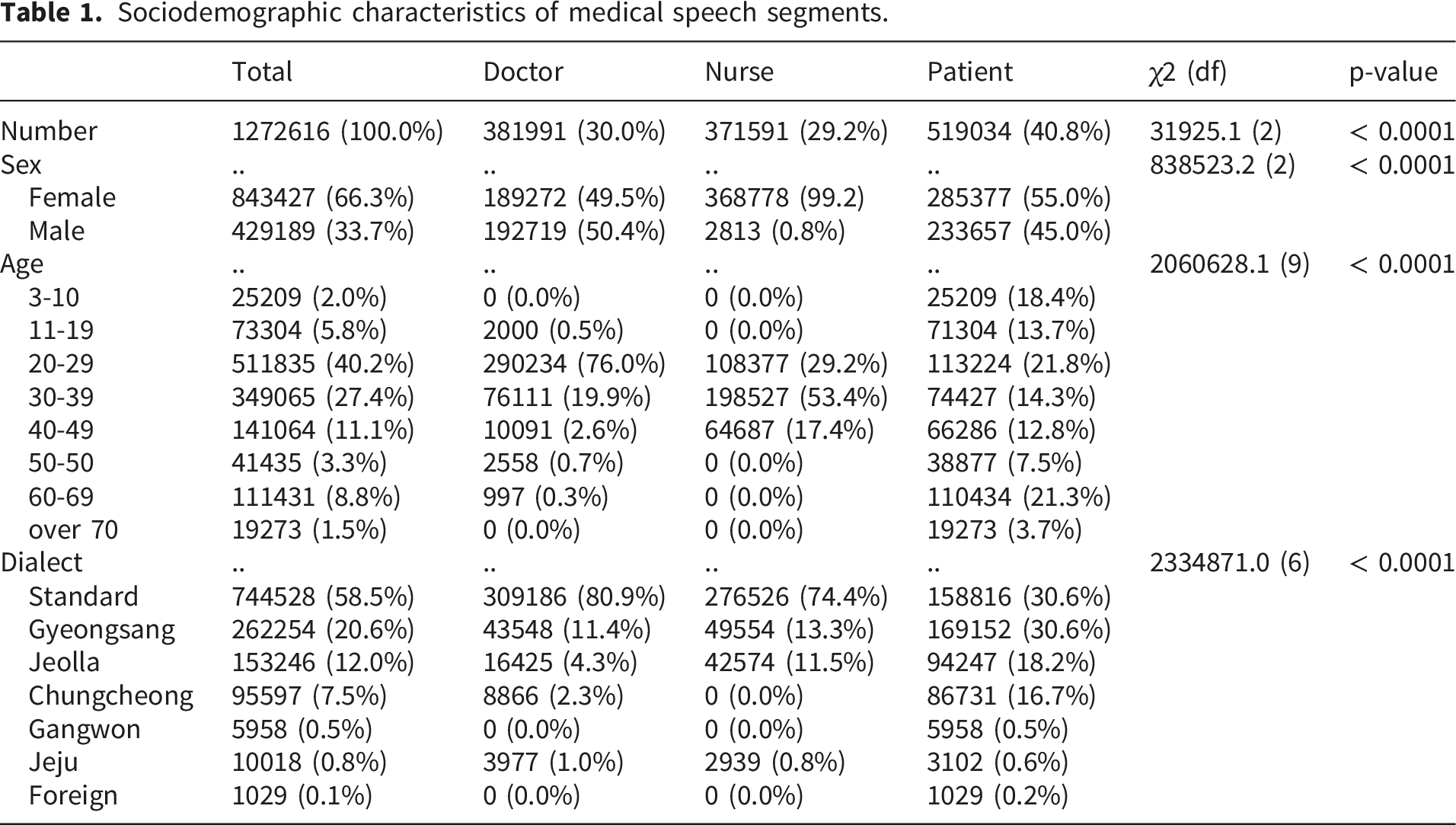
Sociodemographic characteristics of medical speech segments.
The dataset was created by first generating dialogue scripts representing possible communication patterns between healthcare professionals and patients in telemedicine scenarios. Accordingly, the recordings primarily reflect scripted/role-play teleconsultation scenarios rather than spontaneous, naturally occurring telephone consultations. These scripts were then read and recorded by 50 medical professionals from the Korea University Medical Center, including doctors and nurses across 15 clinical departments such as laboratory medicine, family medicine, dentistry, thoracic surgery, anesthesiology, neurosurgery, clinical pharmacology, gastroenterology, nuclear medicine, pulmonology, radiation oncology, otorhinolaryngology, rehabilitation medicine, orthopedics, and colorectal surgery. 38 In addition, 1,500 virtual patients participated, recruited through a crowdsourcing platform. Although the dataset provides broad clinical coverage and high-quality recordings, it may not fully capture spontaneous speech variability, including hesitations, self-repairs, interruptions, and overlapping speech. 38
A structured multi-stage QC workflow was implemented during dataset construction, including sequential checks for adherence to the recording/formatting guide, evaluation of content acceptability (semantic plausibility and conversational naturalness), and a final confirmation prior to inclusion; dedicated QC tools were used to support inspection. 38
Operational decision criteria were specified for deletion versus limited correction. When pronunciation is unclear (e.g., mumbling) or when an utterance contains misread content that may change meaning, the item is deleted. When the audio deviates from the script but meaning is preserved, a restricted refinement procedure is allowed in which the script text is minimally edited to match the audio, primarily limited to particles and endings; beyond these restricted cases (e.g., word omission, meaning-changing substitutions, or non-standard reading errors), the item is deleted. Concrete audio-quality thresholds and rejection rules were also specified. Recordings were required to be intelligible, free of electrical or unexplained noise, and to avoid long silences between words (e.g., pauses exceeding 2 s). Examples of deletion targets included intrusive non-speech events (e.g., large impacts, sirens/horns, footsteps/knocks), voices of other speakers, coughing or loud breathing, overly segmented speech, strong voice tremor, swallowing sounds, mumbling, stuttering, abnormal pronunciation, and persistent background noise unrelated to the recording context.
Because this study is a secondary analysis of a publicly released dataset, stage-wise rejection/correction rates, disagreement-resolution statistics, and inter-reviewer agreement indices are not available in the public documentation for this dataset and therefore cannot be reported here without introducing unverified estimates.
Sample size determination and justification
The sample size in this study was determined by the availability of the publicly released AI-Hub corpus rather than by prospective recruitment. I used the full set of eligible recordings provided after the dataset provider’s multi-stage quality control (N = 1,272,630 audio files; approximately 1,300 h). For model evaluation, the corpus was split into 85% for training and 15% for evaluation, resulting in an evaluation set of approximately 190,895 audio segments. Given this evaluation size, performance estimates are expected to be highly stable; for example, under a conservative binomial approximation (p = 0.50), the maximum 95% margin of error for an estimated proportion is 1.96 × √(p(1−p)/N), which corresponds to approximately 0.22 percentage points when N ≈ 190,895. Therefore, the selected sample size (i.e., the full available corpus with a large held-out evaluation subset) provides adequate statistical precision for comparing baseline and fine-tuned ASR performance.
Sociodemographic and contextual characteristics
Among the total speech segments, 30.0% originated from doctors (n = 381,991), 29.2% from nurses (n = 371,591), and 40.8% from patients (n = 519,034). Female speakers accounted for 66.3% of the overall dataset (n = 843,427), whereas male speakers accounted for 33.7% (n = 429,189) (Table 1).
Regarding age distribution, the largest proportion of speech data came from the 20–29 years group (40.2%, n = 511,835), followed by 30–39 years (27.4%, n = 349,065) and 40–49 years (11.1%, n = 141,064). Contributions from pediatric patients aged 3–10 years accounted for 2.0% of the dataset (n = 25,209) (Table 1).
The dataset also includes a wide range of dialectal variations, reflecting real-world clinical diversity. Standard Korean was used in 58.5% of the recordings (n = 744,528), while major regional dialects included Gyeongsang (20.6%, n = 262,254), Jeolla (12.0%, n = 153,246), and Chungcheong (7.5%, n = 95,597) (Table 1).
Contextual characteristics of medical speech across groups.

In terms of recording environments, home settings accounted for the largest share (83.6%, n = 1,063,772), followed by office environments (15.4%, n = 195,538). A small proportion of sessions was recorded in public spaces such as parks, stores, stations, and cars, which naturally introduced background noise from conversations, television sounds, and environmental activities. As a result, the dataset reflects realistic acoustic conditions encountered in telemedicine settings (Table 2).
Regarding the devices used, smartphones were the dominant medium (64.1%, n = 815,750), followed by laptops (26.8%, n = 340,605) and smart pads (9.0%, n = 114,988). Other devices, including dedicated recorders (0.1%, n = 792), contributed minimally (Table 2).
Dataset preprocessing
To optimize the model’s learning efficiency and ensure reproducible evaluation, all audio files were standardized to a 16 kHz sampling rate with 16-bit depth. Text normalization was applied deterministically using the same script across the entire dataset. Specifically, punctuation and typographic symbols were removed from transcripts, including sentence-final marks (., ?, !), commas, colons/semicolons, quotation marks, brackets/parentheses, and other non-alphanumeric symbols. Multiple whitespace characters were collapsed into a single space, and leading/trailing spaces were stripped. Korean characters and standard Latin letters were retained. Numerals and medically meaningful quantity expressions were preserved in their original surface form (e.g., “5 mg,” “2회 (twice),” “37.8”), and medically meaningful tokens (e.g., medication names, disease names, and clinical abbreviations) were retained without dictionary-based substitution.
Transfer learning of the whisper model
For fine-tuning the Whisper model, the following training configurations were applied. The model used in this study was Whisper large-v3-turbo, a transformer-based ASR model developed by OpenAI. 28 The model was chosen not only for computational efficiency but also for its strong multilingual ASR performance, robustness in noisy speech environments, and suitability for conversational speech transcription using a large-scale pre-trained transformer architecture. These characteristics were considered particularly relevant for Korean clinical telephone consultations, which involve domain-specific terminology, speaker variability, and acoustically heterogeneous recording conditions. In addition, the turbo variant was selected over the standard large-v3 model because the present study aimed to evaluate not only transcription performance but also practical feasibility for clinical deployment, where inference speed, scalability, and computational cost are important implementation considerations. 28
However, no separate preselection benchmarking experiment was conducted in this study to compare Whisper large-v3-turbo directly against the standard Whisper large-v3 model or alternative ASR architectures such as Conformer- or wav2vec 2.0-based systems before training. Therefore, the choice of Whisper large-v3-turbo was based on prior literature, its strong reported performance in multilingual and noisy ASR settings, and its practical suitability for domain adaptation, rather than on an internal head-to-head benchmark. 27 The Whisper large-v3-turbo model is structurally designed to process audio segments of up to 30 s, and for longer audio inputs, the model automatically applies a sliding-window or chunked segmentation approach to transcribe the entire recording seamlessly. 28 Because the model is designed for robust multilingual processing, it was used without applying any translation to the dataset.
The training process was conducted for a total of 1,400 steps, a value determined through preliminary experiments, which confirmed that the model sufficiently converged within this range. Notably, this value reflects an early stopping criterion based on validation loss monitoring, as extending training beyond 1,400 steps resulted in no further performance gains and a slight increase in test loss. Typically, Whisper fine-tuning for low-resource languages or domain-specific applications requires 3,000–4,000 steps, as suggested in previous studies.28,39,40 The corpus was split into 85% for training and 15% for evaluation using stratified partitioning to preserve the relative proportions of doctors, nurses, and patients across subsets, and the split was speaker-independent such that no individual speaker appeared in both subsets; overlap of scripts or scenarios across splits was not considered during partitioning.
The learning rate was set to 1e-5, a commonly used value for Whisper fine-tuning. This setting allows the model to adapt to the new domain while preserving the pre-trained weights without excessive deviation. Additionally, a gradual learning rate warm-up was applied for the first 500 steps to prevent abrupt weight changes at the start of training, ensuring stable convergence. This technique is a widely adopted approach in Transformer-based models.28,39,40
For memory optimization, the batch size was set to 16 during training and 8 during evaluation, a configuration found to be suitable for training the Whisper base model under GPU memory constraints. The gradient accumulation step was set to 1, as a batch size of 16 was sufficient for stable training. If a smaller batch size were required due to resource limitations, the gradient accumulation step could be increased to maintain an equivalent effective batch size.28,39,40
To maximize GPU utilization while improving training efficiency, gradient checkpointing and FP16 computation were applied. These optimizations reduce memory consumption while accelerating the training process.28,39 On average, the entire fine-tuning process required approximately 43 h and 57 min on the GPU environment used in this study.
To improve generalization in noisy, multi-speaker telemedicine speech, I applied data augmentation during fine-tuning. The overall fine-tuning workflow followed the official Hugging Face guidance for Whisper large-v3-turbo. 28 SpecAugment was applied to log-mel features using a conservative masking policy with two frequency masks (maximum width: 15 mel bins) and two time masks (maximum width: 70 frames; proportion parameter p = 0.2). 41 Additive noise injection was applied by mixing background-noise segments representative of telemedicine environments at a signal-to-noise ratio uniformly sampled between 10 and 20 dB, with a probability of 0.5 per training utterance. 42 Speed perturbation was implemented using speed factors of 0.9 and 1.1 (±10%), with a probability of 0.5 per training utterance. These augmentation settings were selected to improve robustness to moderate background noise and speaking-rate variability while preserving clinically meaningful lexical content, consistent with established ASR augmentation practices.28,39,40
During training, evaluation was conducted every 700 steps, and logging was performed every 25 steps to closely monitor training progress. For evaluation, decoding was performed using greedy generation (num_beams = 1) with a maximum generation length of 225 tokens. The decoding task was fixed to transcription rather than translation, and the target language was constrained to Korean to match the dataset. Temperature was fixed at 0.0 for deterministic decoding. For utterances longer than the model’s 30-second receptive field, the default sequential long-form decoding strategy was used, in which the audio was processed in consecutive 30-second windows rather than with chunked independent decoding. No additional custom suppression rules were introduced beyond the model’s default generation configuration, and no timestamp output was requested during evaluation. These settings were selected to ensure a stable and reproducible comparison between the baseline and fine-tuned models.
At the end of training, the best-performing model was selected based on the lowest CER on the validation set. This selection criterion was applied to prevent overfitting and enhance the model’s generalization performance.
Performance evaluation of the baseline model and the fine-tuned model
To assess the performance of the ASR models, I evaluated the Whisper Fine-tuned model trained on domain-specific data against the baseline Whisper large-v3-turbo model. The evaluation was conducted using two key metrics: WER and CER, both of which are widely used in Korean speech recognition assessments.43,44
WER measures the word-level transcription accuracy by calculating the number of deleted, inserted, and substituted words between the recognized text and the ground truth transcript. This metric is useful for evaluating sentence-level recognition performance, where a lower WER indicates higher ASR accuracy and better overall speech recognition quality. 44
However, WER has limitations in evaluating Korean speech recognition due to the linguistic structure of the language. As an agglutinative language, Korean frequently employs particles and verb endings, which leads to morphological variations and ambiguous word boundaries. This characteristic makes WER less effective for assessing transcription accuracy in Korean ASR models. 43
To address this issue, I incorporated CER as an additional metric, which provides a more reliable measure of ASR performance for Korean. CER evaluates transcription accuracy at the character level, making it particularly well-suited for languages with complex morphological structures. A lower CER indicates higher accuracy, and it is considered a more appropriate evaluation metric for Korean speech recognition.
WER and CER are computed as follows:

WER is calculated based on the number of deleted (D), inserted (I), and substituted (S) words, relative to the total number of words (N) in the ground truth transcript. CER is computed using the number of deleted (D c ), inserted (I c ), and substituted (S c ) characters, relative to the total number of characters (N c ) in the ground truth transcript. By utilizing both WER and CER, this study provides a comprehensive evaluation of ASR performance at both the word and character levels. WER and CER were computed using an in-house script implementing the standard definitions in Equations (1), (2). The same text-normalization procedure described above was applied to both the reference transcripts and the model hypotheses before computing WER and CER to ensure consistency and reproducibility.
Statistical analysis for performance comparison between the baseline and fine-tuned models
To determine whether there was a statistically significant difference in performance between the Whisper baseline model and Whisper Fine-tuned model, I formulated the following hypotheses: The null hypothesis (H 0 ) assumes that no statistically significant difference exists in performance (WER, CER) between the Whisper base model and Whisper Fine-tuned models, whereas the alternative hypothesis (H 1 ) posits that there is a statistically significant difference in performance (WER, CER) between the two models.
The dataset was categorized into three speaker groups (nurses, doctors, and patients) based on WER and CER scores, and the performance differences between the two models were evaluated for each speaker group as well as for the overall dataset. To assess the distribution of the data, I conducted Q–Q plot analysis and Shapiro–Wilk tests to examine normality. Based on the results, I selected the appropriate statistical method for comparing the models. If the data followed a normal distribution, I applied a paired t-test, which assumes normality and evaluates the mean difference between the two models on the same dataset. If the data did not follow a normal distribution, I employed the Wilcoxon Signed-Rank Test, a non-parametric method used to assess median differences between paired samples. Even in cases where the data did not meet normality assumptions, I proceeded with the paired t-test, as the sample size was sufficiently large to approximate normality. A p-value < 0.05 was considered statistically significant, indicating that the observed performance difference between the baseline and fine-tuned models was unlikely due to random variation.
Experimental environment and software
All experiments were conducted on a high-performance workstation equipped with four NVIDIA RTX 3090 GPUs (10,496 CUDA cores, 328 Tensor cores, 82 RT cores, base clock 1.40 GHz), an Intel® Core™ i9 X-series processor (3.7 GHz), and 192 GB of system memory, running on Ubuntu 18.04 LTS.
For ASR, I utilized the Whisper large-v3-turbo model, implemented via the OpenAI Whisper framework (v3.1.0). All training and inference processes were executed using Python (v3.10.13) with PyTorch (v2.2.1) as the primary deep learning backend. Audio preprocessing was performed with Torchaudio (v2.2.1), and raw speech decoding and encoding were handled using FFmpeg (v6.0).
To ensure reproducibility, all experiments were conducted within an isolated Conda environment (v23.11.0), with software dependencies and package versions carefully controlled throughout the study.
Results
Characteristics of recorded medical conversations
Descriptive statistics of the medical speech corpus.

The analysis of speech duration revealed clear differences among the three groups. Doctors produced the shortest speech segments, with a mean length of 2.69 s (SD = 0.76, range: 0.66–20.34 s), indicating relatively concise utterances during consultations. Nurses exhibited longer speech segments, with a mean length of 3.76 s (SD = 1.67, range: 0.18–16.92 s), while patients produced the longest speech segments overall, with a mean duration of 3.97 s (SD = 1.80, range: 0.48–57.66 s). The boxplot illustrates that doctors’ utterances are concentrated around shorter durations with low variability, whereas nurses and patients demonstrate broader distributions. Notably, some patient utterances extended beyond 50 s, highlighting the presence of prolonged and information-rich responses (Table 3 and Figure 2(a)). Distribution of Speech Length and Word Count Across Groups.
An analysis of word usage patterns revealed additional distinctions among the three groups. Doctors’ utterances contained an average of 4.47 words per segment (SD = 1.51, range: 1–17 words), suggesting that their speech was generally brief and focused. Nurses used longer expressions, averaging 6.18 words per segment (SD = 3.22, range: 1–25 words), whereas patients produced an average of 5.67 words per segment (SD = 3.11, range: 1–73 words), reflecting greater variability in lexical richness. The boxplot demonstrates that patient and nurse utterances tend to be more elaborate and varied compared to doctors’ speech, which remains shorter and more uniform (Table 3 and Figure 2(a)).
Overall, the medical speech corpus demonstrates notable variability in both duration and lexical richness across groups. While doctors generally provide concise instructions and targeted questions, nurses frequently deliver longer context-rich statements, and patients exhibit the highest heterogeneity in both segment length and word usage. These findings highlight the complexity of modeling natural medical dialogues and provide important insights for developing and optimizing ASR systems in telemedicine environments.
Comparison of speaker-specific performance before and after transfer learning
The performance comparison between the baseline Whisper model and the fine-tuned model was conducted by analyzing CER and WER across three speaker groups: nurses, doctors, and patients. The results indicate that the fine-tuned model consistently outperformed the baseline model, achieving lower WER and CER in all speaker groups.
For the nurse group, the baseline model exhibited an average WER of 11.0%, whereas the fine-tuned model achieved a slightly lower WER of 10.89%. Similarly, for the doctor group, the WER decreased from 14.66% in the baseline model to 14.44% in the fine-tuned model. A similar trend was observed in the patient group, where the baseline model’s WER of 22.92% was reduced to 22.42% after fine-tuning (Figure 3(a)). Comparison of WER and CER between the baseline and fine-tuned models across speaker groups.
When comparing CER between the two models, the fine-tuned model demonstrated an even more pronounced improvement than in WER. In the nurse group, the CER decreased from 2.50% in the baseline model to 2.44% in the fine-tuned model. For the doctor group, the CER was reduced from 3.35% to 3.20% after fine-tuning. Finally, in the patient group, the CER showed the most substantial improvement, dropping from 5.32% in the baseline model to 4.98% in the fine-tuned model (Figure 3(b)).
Comparison of Representative Transcription Errors Between Base and Fine-Tuned ASR Models on Patient Data set with Corresponding WER and CER.
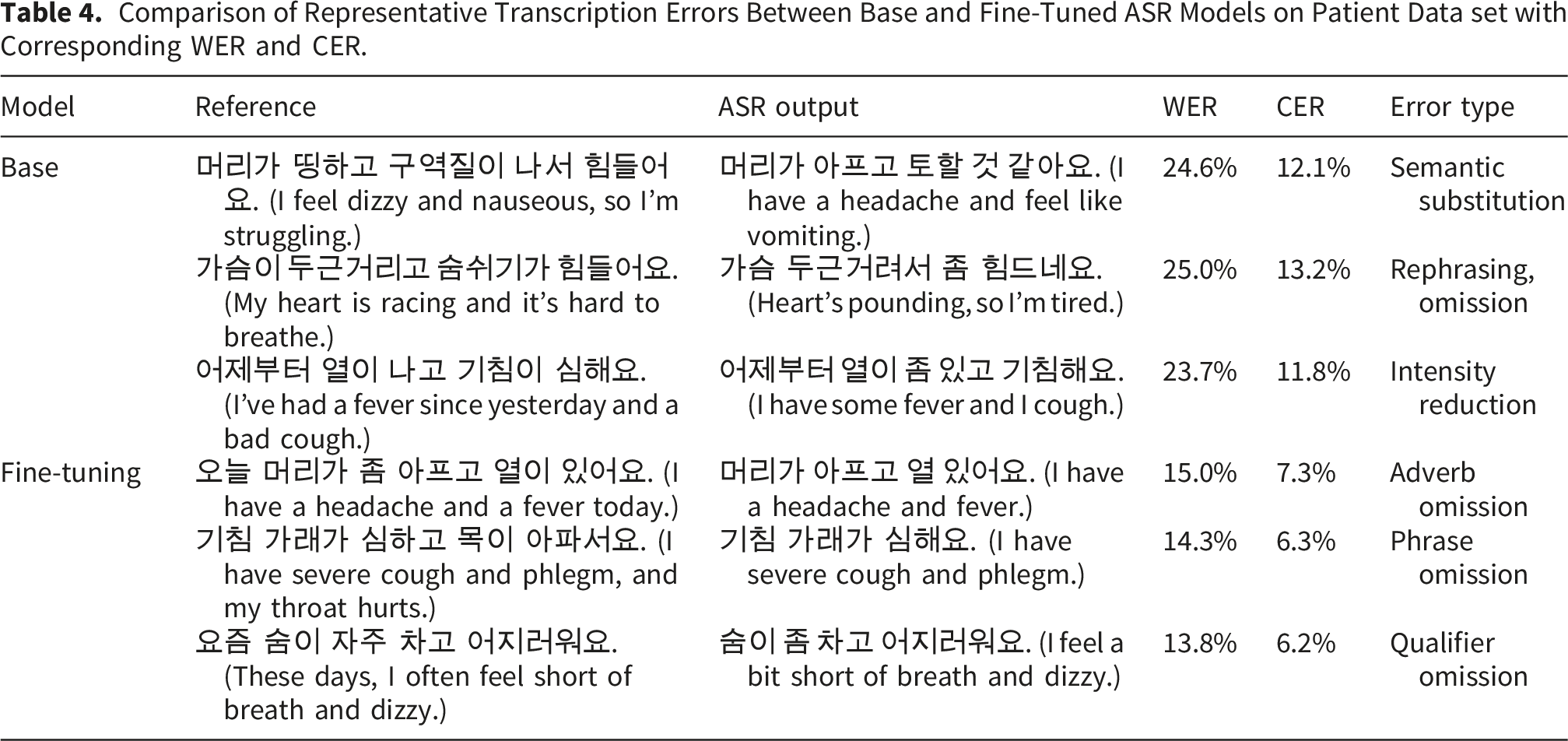
The WER and CER reductions in the patient group were notably greater compared to the nurse and doctor groups. This trend can be attributed to the unstructured nature of patient speech, which often involves non-standard pronunciation, diverse accents, and informal conversation patterns, making it inherently more challenging for ASR models to transcribe accurately. The results suggest that fine-tuning significantly enhances transcription accuracy, particularly in more variable speech conditions, such as those found in patient conversations.
Speaker-specific error pattern analysis
Representative transcription errors by speaker group with corresponding WER and CER.
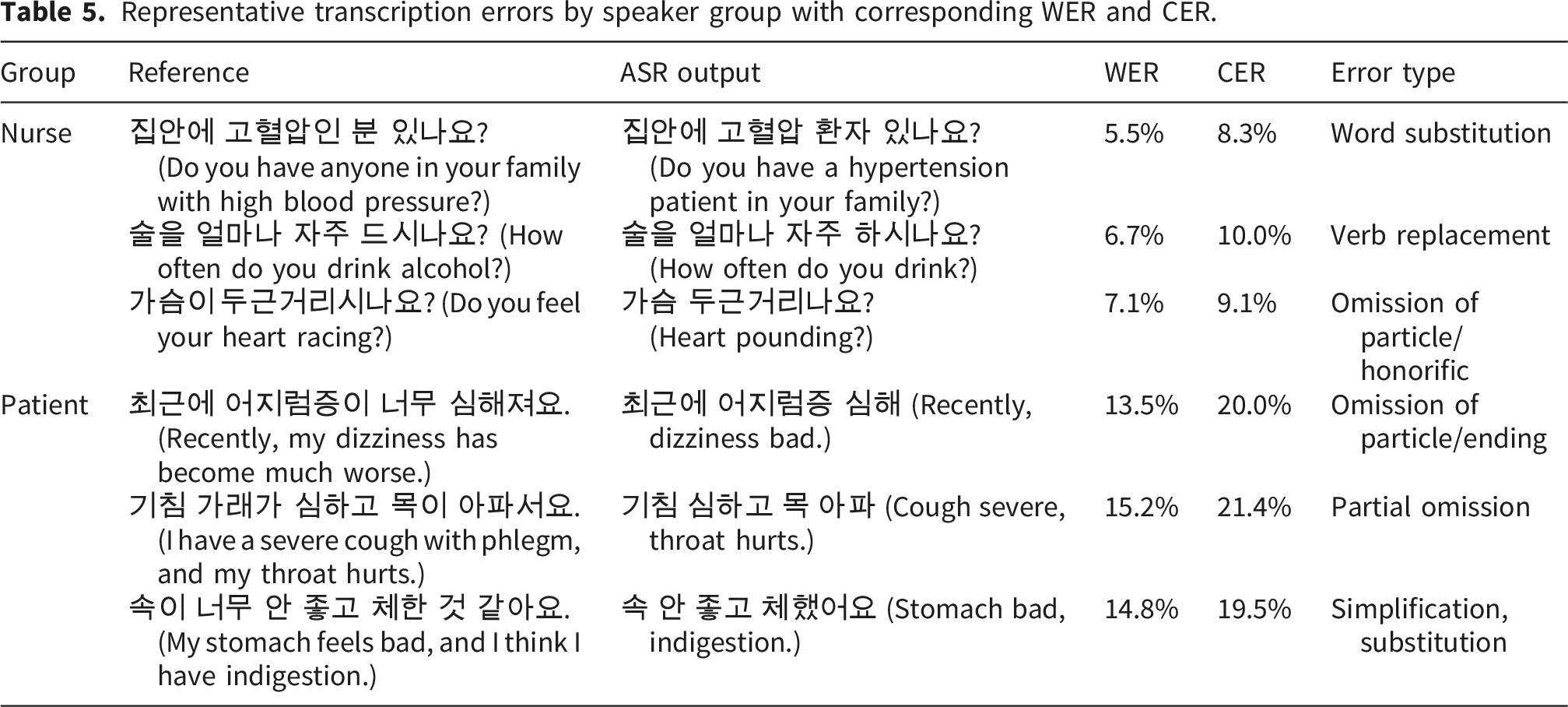
For the nurse group, error rates were consistently low due to their use of structured, concise, and context-driven language during consultations. Nurses tend to rely on predictable phrasing and medical terminology, resulting in fewer recognition errors. For example, phrases such as “혈압약을 드시고 계신가요? (Are you taking blood pressure medicine?)” were consistently transcribed with high accuracy, reflecting the low variability and standardized expressions used in nursing dialogues (Table 5).
Contrarily, patient utterances exhibited substantially higher WER and CER values, largely due to the spontaneous and unstructured nature of their speech. Patients often provided long, fragmented responses, self-corrections, or contextually ambiguous expressions, which significantly increased recognition difficulty. For instance, sentences such as “어제는 안 먹었는데 오늘은 먹었어요. (I didn’t eat it yesterday, but I ate it today.)” frequently resulted in substitutions and boundary shifts, leading to greater transcription variability (Table 5).
This difference suggests that automatic speech recognition systems face fewer challenges when processing structured, context-rich speech from healthcare professionals, while patient speech demands more robust handling of irregular syntax, overlapping clauses, and spontaneous discourse patterns (Table 5). These findings indicate that further model optimization should focus on accommodating the higher linguistic variability present in patient conversations.
Statistical analysis of performance differences before and after transfer learning
To statistically analyze the performance differences between the baseline model and the fine-tuned model, normality tests were first conducted. The Shapiro–Wilk test was used to assess whether the distribution of CER values followed a normal distribution, and Q–Q plot inspection was performed as a supplementary visual check. The Shapiro–Wilk test produced p-values below 0.05 for both models, confirming that neither dataset satisfied the assumption of normality. The Q–Q plot is provided in the Supplementary Material (Supplementary Figure S2).
Performance comparison between baseline and fine-tuned models using the Wilcoxon Signed-Rank test.
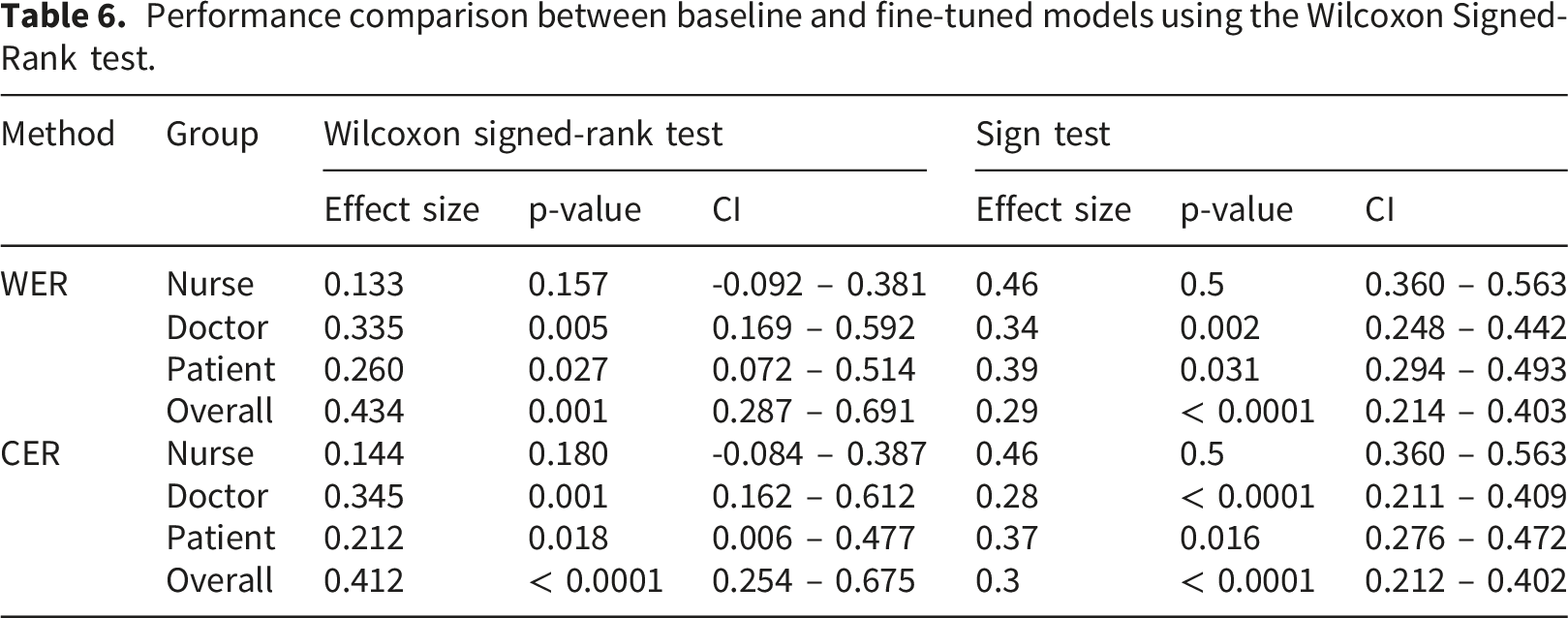
Results from the Sign test provided convergent evidence, indicating statistically significant differences for doctors, patients, and the overall dataset for both WER and CER, while no significant difference was observed for the nurse group (Table 6). Taken together, these results indicate that fine-tuning yielded statistically reliable improvements overall and in doctor and patient speech, with the largest and most stable effects observed at the corpus level and more modest effects within speaker subgroups.
Analysis of loss variations during training
To evaluate the model’s training performance and detect potential underfitting or overfitting, I analyzed the variations in training loss and test loss throughout the training process. During the initial 700 steps, both training and test loss decreased sharply, after which the rate of change became minimal. This indicates that the model had sufficiently learned the patterns in the data, confirming that underfitting did not occur (Figure 4). Training and test loss curves during supervised fine-tuning of the whisper model.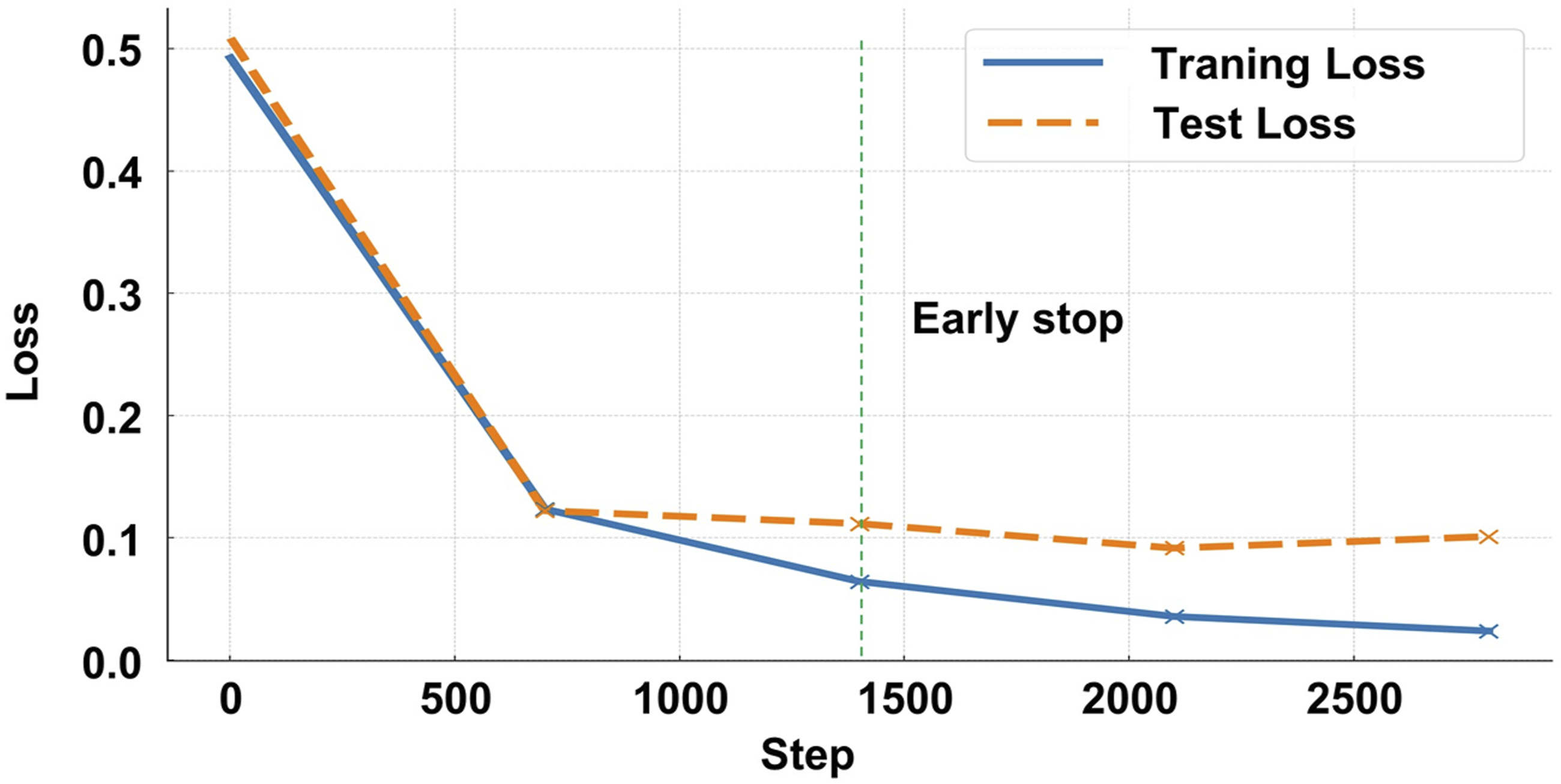
As training progressed, a gradual divergence between training and test loss was observed, suggesting a potential risk of overfitting. To mitigate this issue, training was halted at 1,400 steps, a point at which the model had optimized its learning without excessive overfitting (Figure 4).
Error pattern analysis of WER vs. CER discrepancies
To further investigate the difference between WER and CER performance metrics, an error pattern analysis was conducted using patient utterances from the test set. The analysis revealed that, in Korean medical conversations, WER often overestimates transcription errors compared to CER owing to the agglutinative nature of the Korean language. Minor variations such as particle omissions, synonym substitutions, and word order differences frequently cause disproportionately high WER values, even when the overall meaning is accurately preserved.
Patterns of Discrepancies Between WER and CER in Patient Speech Segments from Patient Data set.

These findings indicate that CER provides a more reliable performance metric for evaluating Korean ASR systems, particularly in medical transcription contexts where preserving semantic accuracy is essential. Although WER is highly sensitive to morphological and lexical variations typical of agglutinative languages, CER better reflects the true quality of the transcriptions when the conveyed meaning remains intact.
Discussion
This study demonstrates that fine-tuning the Whisper large-v3-turbo model improves ASR performance in Korean clinical telemedicine conversations. Leveraging approximately 1,300 hours of domain-specific speech data, the fine-tuned model showed lower WER and CER than the baseline model across speaker groups, with statistically significant paired-test improvements for doctors, patients, and the overall dataset; in contrast, differences for nurse speech were not statistically significant in the paired analyses (Table 6). Patient speech remained the most challenging condition, yet still exhibited statistically significant gains after fine-tuning, supporting the value of domain-specific adaptation for highly variable, unstructured consultation narratives (Table 6).
A key methodological contribution of this work is the validation of CER as a more suitable evaluation metric than WER for Korean ASR. Given the agglutinative structure of the Korean language, WER tends to overestimate transcription errors by penalizing morphological segmentation mismatches or omitted particles, even when the underlying semantic meaning is preserved. Our findings underscore that CER more accurately captures clinically meaningful transcription quality, especially for use in medical documentation.
Speaker-specific analyses further revealed systematic differences in transcription difficulty. Doctors’ structured and concise speech resulted in the lowest error rates. Nurses’ utterances, while context-rich, produced only modestly higher error rates. In contrast, patient speech showed considerable variability and yielded the highest WER and CER. Qualitative error analyses suggested that fine-tuning reduced meaning-altering substitutions and omissions in patient utterances and improved robustness to spontaneous, unstructured narratives. Nevertheless, aggregate WER/CER do not fully represent clinical criticality, because errors affecting negation, medications, dosage/frequency expressions, numbers/units, or symptom descriptors may have disproportionate downstream consequences even when overall error rates change modestly.
Recent evidence suggests that clinical ASR error rates should be interpreted in a task- and setting-sensitive manner rather than against a single universal deployment threshold. A recent systematic review reported that word error rates in clinical documentation ranged from 0.087 in highly controlled dictation settings to over 50% in conversational or multi-speaker scenarios, underscoring the large performance differences across documentation contexts. 33 Related review evidence also indicates that the clinical value of AI-powered voice-to-text systems should be evaluated not only in terms of transcription accuracy, but also in relation to documentation workflow, quality of care, and the specific outpatient or primary care context in which the technology is deployed. 45 Recent benchmark studies have likewise shown substantial variability across languages, accents, and conversational conditions: multilingual medical ASR results demonstrate marked cross-language differences in WER/CER even after domain adaptation, 36 spontaneous accented healthcare conversations can incur substantial performance degradation under natural dialogue conditions, 46 and Whisper itself has shown accent-related variability across speaker groups. 41 Viewed in this context, the present Korean telemedicine results should be interpreted relative to the difficulty of domain-specific conversational clinical speech rather than against a single universal error-rate threshold.
The dataset employed in this study spans a broad range of speaker roles, regional dialects, and recording environments, which may improve ecological relevance for telemedicine-oriented ASR development. However, because the corpus reflects scripted or role-play rather than spontaneous clinical telephone consultations, external validity to routine telemedicine settings should be interpreted cautiously. Real-world calls may involve more variable background noise, channel instability, rapid turn-taking, and overlapping speech, all of which may increase transcription difficulty beyond that observed in the present evaluation. Accordingly, safe deployment will require further validation under spontaneous, real-world telemedicine conditions and should be supported by implementation safeguards such as confidence-based flagging, human review, and monitoring of subgroup-specific error patterns.
The present study did not directly evaluate model performance stratified by gender, age, or dialect, and therefore no definitive conclusions can be drawn regarding subgroup equity. Although Table 1 provides descriptive metadata on these speaker characteristics, the dataset was not originally designed or statistically balanced for reliable subgroup-level ASR benchmarking. Accordingly, simple stratified WER/CER comparisons were not presented, because such analyses could be unstable and potentially misleading if interpreted as evidence of algorithmic bias. Nevertheless, fairness remains a critical consideration for clinical deployment, because even modest recognition disparities may accumulate into unequal documentation quality, communication burden, or clinical follow-up across patient groups. Future work should therefore incorporate prospectively designed subgroup-balanced evaluations and subgroup-specific error auditing to identify and mitigate systematic disparities before routine implementation.
The digital divide is also relevant to equitable deployment. ASR-enabled telemedicine systems may be less accessible to culturally and linguistically diverse communities, including patients who are more comfortable speaking languages other than the dominant clinical language, those who code-switch, and those with limited digital literacy or less stable access to high-quality devices and communication networks. In such settings, speech recognition errors may reflect not only model limitations but also structural inequities in access to linguistically appropriate care and digital infrastructure. Accordingly, future work should examine multilingual and dialect-aware adaptation, as well as the usability of ASR-supported telemedicine for patients from culturally and linguistically diverse backgrounds.
In addition to technical considerations, the implementation of ASR systems in Korean healthcare settings must comply with national regulatory, legal, and ethical standards. Korean-specific statutes such as the Personal Information Protection Act (PIPA) and the Medical Service Act impose strict requirements for data security, privacy, and clinical integrity, beyond those addressed by broader international frameworks such as HIPAA and GDPR. 18 Furthermore, the legal status of ASR-generated transcripts as admissible components of electronic medical records (EMRs) remains unresolved. Institutional policies must establish whether such transcripts can serve as formal documentation. To ensure safe integration, ASR systems should include periodic human validation, clinician-in-the-loop auditing, and automated error monitoring to prevent inaccuracies from entering patient care workflows.
Despite these strengths, several limitations must be acknowledged. The patient group, while exhibiting the greatest improvement, also showed the highest error rates, reflecting the complexity of unstructured clinical speech. To confirm generalizability and clinical utility, future research should validate the model on larger and more diverse datasets encompassing broader patient demographics, dialects, and spontaneous speech characteristics.12,44 Enhancing post-processing with NLP-based techniques may improve transcription usability, while speaker-aware modeling and contextual ASR could yield additional performance gains.47–49 Future work should also perform ablation analyses of SpecAugment, additive noise injection, speed perturbation, and amplitude normalization to quantify the individual contribution of each component and to identify the most effective augmentation strategy for real-world telemedicine speech.
Although early stopping at 1,400 steps based on validation loss was effective, further regularization strategies—such as dropout, adaptive learning rate scheduling, and flexible stopping criteria—may improve model convergence and generalization.28,39,40 Evaluating this framework across other professional domains could also provide insights into its broader scalability. 50
Only the Whisper large-v3-turbo model was assessed in this study, and no direct head-to-head benchmark was conducted against other Korean ASR solutions or commercial speech recognition services. Accordingly, the present findings should be interpreted as evidence of within-model improvement through domain-specific fine-tuning rather than as proof of superiority over alternative systems. Nevertheless, the observed gains are noteworthy in light of the broader Korean ASR landscape, where commercial platforms such as Naver CLOVA Speech and Google Cloud Speech-to-Text, as well as alternative open-source architectures including Kaldi, Wav2Vec2, and Conformer-based systems, represent relevant comparative baselines for future evaluation.25–27 From a practical perspective, the present results suggest that adapting a strong multilingual foundation ASR model to domain-specific Korean clinical telephone speech may offer a viable alternative to general-purpose speech recognition pipelines. However, because commercial and open-source ASR systems differ in training data, adaptation interfaces, decoding strategies, and deployment settings, meaningful comparison requires controlled benchmarking on the same corpus and evaluation protocol. Future work should therefore benchmark fine-tuned Whisper-based clinical ASR against these systems under matched evaluation conditions to better establish comparative performance, implementation trade-offs, and clinical utility. Subgroup-specific evaluation—including variations across dialects, age groups, and environments—remains essential to mitigate bias and ensure equitable deployment.50–52
Finally, although WER and CER are standard, they may not fully capture semantic or clinical adequacy. Future work should incorporate semantic-level metrics such as BERTScore and task-specific usability measures,53,54 while also addressing clinically important deployment challenges such as multi-speaker diarization, overlapping speech, accent and dialect variability, and speech from vulnerable populations, including older adults and those with dysarthria 52 . Such evaluation will be particularly important for determining whether ASR systems can be implemented safely and equitably across diverse telemedicine populations.
Conclusions
This study demonstrated that fine-tuning the Whisper large-v3-turbo model on 1,300 hours of Korean clinical speech significantly improved transcription accuracy, with the most substantial gains in patient speech. The validation of CER over WER provides a methodological advancement for Korean ASR evaluation. These findings support the feasibility of domain-specific adaptation and establish a foundation for scalable and equitable ASR deployment in clinical settings.
Supplemental material
Supplemental material - Optimizing whisper for Korean telemedicine: Fine-tuning domain-specific ASR for clinical telephone transcription
Supplemental material for Optimizing whisper for Korean telemedicine: Fine-tuning domain-specific ASR for clinical telephone transcription by Woongchang Yoon in Digital Health.
Footnotes
Acknowledgements
I thank Jong-In Yun for assistance with experiments.
Ethical considerations
Since this study utilized publicly available, de-identified datasets and involved no direct participant contact or new data collection, it was exempted from IRB review per the institutional guidelines of Gyeongsang National University (GIRB-D25-NX-0117). Written informed consent was obtained by the original data collectors during dataset creation as described in the provider’s documentation; no additional consent was obtained by the authors for this secondary analysis.
Author contributions
Conceptualization: WY, Data curation: WY, Formal analysis: WY, Funding acquisition: WY, Investigation: WY, Methodology: WY, Project administration: WY, Resources: WY, Supervision: WY, Validation: WY, Visualization: WY, Writing – original draft: WY, Writing – review & editing: WY.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the New Faculty Research Grant from Gyeongsang National University in 2025, GNU-NFRG-0085.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
AI tool disclosure
No AI tools were used in the development, writing, or editing of this manuscript.
Supplemental material
Supplemental material for this article is available online.