
Abstract
Objectives
Mild cognitive impairment (MCI) poses serious threats to health, safety, and independence in older adults by elevating fall risk and undermining the ability to complete essential tasks. Progression from MCI to dementia is common but often underdetected until significant decline has occurred. Functional decline serves as a proxy for cognitive decline, yet current assessments lack the ecological validity to capture real-world performance in instrumental activities of daily living (IADLs). This work investigates methods for detecting IADL subtasks as a foundation for longitudinal monitoring of cognitive and functional health.
Methods
We developed an ecologically valid grocery shopping task in which 26 older adults (12 with MCI, 14 without), instrumented with inertial sensors, took part. Subtask detection was performed using an interpretable deep learning framework trained on pooled data. Shapley Additive Explanations (SHAP) were used to interpret detection performance across subtask categories.
Results
Detection performance depended on subtask granularity: the framework excelled at identifying broad movement categories such as Walk and Turn but struggled with more granular subtasks, including discrete actions with ambiguous signatures and differentiating between similar subtasks like reaching to different heights. Model explanations revealed that detection errors were driven by overlapping motion signatures.
Conclusion
SHAP analysis revealed that orientation angles, particularly yaw and roll dominated classification. The cognitively unimpaired and MCI groups differed in how these features were weighted, suggesting population-specific motor signatures that may serve as candidate digital biomarkers for early functional decline.
Keywords
Introduction
Mild cognitive impairment (MCI) is common in later life and has practical consequences for health, safety, and independence. Recent global syntheses estimate that 19.7% of older adults live with MCI. 1 In the United States, nationally representative data indicate that among adults 65 years and older, 22% have MCI and 10% have dementia. 2 The risk of progression from MCI to dementia is substantial, with annual conversion rates around 5-10% depending on clinical versus community settings. 3 Functional mobility concerns are evident before dementia; a 12-month study reports falls in 43% of individuals with MCI. 4 Healthcare use and costs also begin to diverge at this stage. Annual direct medical expenditures are approximately 12.3% higher for individuals with MCI than for cognitively normal peers. 5 These observations motivate earlier ways to quantify everyday cognitive and physical function and its change over time. The growing interest in readily accessible digital biomarkers that harness advances in consumer-grade mobile and wearable technologies has further motivated this direction, as passive, high-frequency digital phenotyping may detect deviations from normal cognitive trajectories earlier than episodic clinical assessments. 6
Motor and cognitive functions are tightly linked in aging, and differences in motor control are evident in many individuals with MCI. Studies describe slower gait, diminished balance, impaired turning, and poorer dual-task performance patterns consistent with elevated fall risk and reduced life-space mobility.7–10 Because everyday activities draw on planning, attention, visuomotor control, and postural adjustments, even small deviations in how movements are executed may signal emerging cognitive vulnerability before overt loss of independence develops. Wearable accelerometer-based gait analysis has already shown promise in this regard, with distinct spatiotemporal gait signatures differentiating dementia disease subtypes, including Alzheimer’s disease, dementia with Lewy bodies, and Parkinson’s disease dementia, using a single body-worn sensor. 11 Selecting which everyday activities to measure is therefore crucial. Basic activities of daily living (ADLs), such as bathing, dressing, toileting, and feeding, are often preserved until later stages of cognitive decline. 12 In contrast, instrumental activities of daily living (IADLs), including managing finances and medications, using transportation, meal preparation, and shopping, become more difficult for those with MCI as they place greater demands on executive function, working memory, and divided attention.13,14 IADL difficulties in MCI carry weight as individuals with IADL difficulties progress to dementia more frequently than those with preserved IADLs (47.4% vs. 31.4%).15,16 Focusing exclusively on ADL performance risks encountering ceiling effects that obscure subtle but meaningful change. Targeting IADLs, and decomposing them into movement subtasks, offers a potentially more sensitive path to detecting early cognitive-motor changes. 17
A central challenge of examining IADLs is measurement. Common approaches include self-report scales (e.g., the Lawton-Brody Instrumental Activities of Daily Living scale 18 and the Katz Index of Activities of Daily Living 19 ) and informant questionnaires (such as the Functional Activities Questionnaire 20 ). These tools are quick and low cost, but rely on recall and judgment, are vulnerable to lack of insight, and compress behavior into coarse ordinal scores with ceiling effects and rater variability.12,17 Clinic-based capacity tests (e.g., gait speed over a fixed walkway, the Timed Up and Go, 21 the Berg Balance Scale, 22 or the Short Physical Performance Battery 23 ) standardize conditions and improve reliability, yet they strip away natural environmental demands and dual-tasking, limiting ecological validity and correlation with real-world performance.17,24,25 Performance-based IADL simulations (for example, structured bill payment or medication management tasks 26 ) narrow the gap but are episodic, resource-intensive, and difficult to scale beyond the clinic. To capture early changes in the coupling of cognition and motor control, assessments should observe how people perform complex routine activities under ecologically valid conditions.
Wearable sensors are well-suited to overcome previous limitations in objectively measuring IADLs because they travel with the person and record movement unobtrusively at high temporal resolution. Using multiple wearable sensing nodes increases observability of composite actions: sensors on the feet can capture stance and rotational components pertinent to gait events and turning; sensors on the lower back or torso track trunk orientation and postural adjustments; and head- or upper-body-mounted sensors are sensitive to reorientations that accompany visual search and reaching. Other form factors, such as wrist-worn or chest-worn devices, can additionally capture arm use and physiological state. In contrast, fixed laboratory systems provide precision but do not scale beyond the lab; camera-based systems offer spatial context but raise privacy, occlusion, and deployment barriers; ambient sensors detect room-level activity but lack fine motor detail; and smartphone-only sensing is convenient but is worn inconsistently on the body and often misses lower-limb kinematics. 17 Benchmark efforts such as the Opportunity dataset similarly emphasize realistic settings and composite behaviors, underscoring the need for algorithms that operate on complex routines. 27
Machine learning complements wearable sensory data by providing the data analysis capabilities that turns continuous wearable signals into structured information about behavior. Classical pipelines compute hand-crafted features from windowed IMU signals and classify them with models such as k-nearest neighbors, support vector machines, or random forests. These approaches can be effective for simple activities but require domain-specific feature design and may miss the hierarchical, multi-timescale structure of complex routines. End-to-end deep learning mitigates these limitations by learning representations directly from raw time series. 28 Recurrent models such as gated recurrent units (GRUs) capture sequential dependencies, and attention mechanisms focus computation on the most informative timesteps within a window. To translate these models into actionable measures, we anchor them in a standardized, naturalistic IADL with repeatable, labelable subtasks.
The literature on ecological validity and assessments led us to develop a structured grocery shopping activity as a grounded example of an IADL for probing cognitive functional decline via observable task performance and for evaluating machine learning-based recognition frameworks. Grocery shopping recruits route planning and navigation, visual search, list maintenance, and the physical execution of walking, turning, reaching to multiple shelf heights, and handling or carrying items, eliciting repeated movement primitives in a realistic but standardized setting. Chest-mounted video is used for ground truth and time-aligned IMU signals are used for analysis. Focusing on a single community activity balances ecological validity with experimental control and yields a rich distribution of mobility and object-interaction behaviors relevant to cognitive aging. Within this paradigm, subtask recognition is the core analytic step: our first goal is to recognize when predefined grocery subtasks are occurring in both groups - walking, turning, small in-place positional adjustments, and reaching to different shelf heights - using an end-to-end deep learning model. We train one binary model per subtask on pooled data from CU and MCI participants under leave-one-subject-out (LOSO) evaluation with a strict masking protocol and subject-level adaptation, yielding aligned, time-resolved segments for each behavior. With these segments in hand, we apply Shapley Additive Explanations (SHAP) 29 to this model and compute explanations separately within groups, isolating kinematic differences between CU and MCI that may serve as candidate digital biomarkers. For each prediction, SHAP assigns an importance value (a SHAP value) to every input feature, quantifying that feature’s marginal contribution to the model’s output relative to an expected baseline; these locally accurate attributions can be aggregated across instances to obtain global feature importance. Together, this ML and xAI pipeline potentially enables downstream, subtask-specific metrics of execution quality, such as turn stability and reach control, that we treat as hypothesis-generating proxies for cognitive functional decline, indicating features that warrant prospective validation and targeted monitoring.
This study addresses two questions. First, how accurately can an end-to-end model recognize predefined grocery subtasks from multi-sensor IMU data in older adults? Second, once subtasks are recognized, do feature attributions reveal consistent kinematic differences between CU and MCI groups that could serve as candidate digital biomarkers?
This paper provides four contributions: • IADL paradigm and dataset: A purpose-built grocery shopping activity that balances ecological validity with experimental control, yielding synchronized IMUs and chest-mounted video in older adults (n=14 cognitively unimpaired; n=12 MCI) and producing repeated instances of walking, turning, positional adjustments, and reaching at multiple heights. • Subtask recognition framework: Task-specific models sharing a bidirectional GRU with multi-head attention, trained on pooled data with LOSO evaluation, using only generic gravity-aligned orientation angles in addition to the raw IMU channels while preserving temporal context for brief and transitional actions. • Empirical findings on granularity: Robust recognition for the combined Walk and Turn class (F1 = 0.818 cognitively unimpaired; 0.824 MCI) and reduced performance for short, discrete actions with ambiguous kinematics. • Transparent explanations: SHAP exposes subtask-specific and group-sensitive kinematic drivers, with orientation angles (primarily yaw and roll, with smaller pitch contributions) from the feet, lumbar spine, and head emerging as the most influential features, supported by gyroscope angular-velocity channels and with accelerometer channels contributing little. These patterns prioritize specific sensor locations and feature types for prospective validation as clinically relevant digital markers.
The remainder of this paper is organized as follows: the Related Works section reviews literature on IADL and ADL assessment, sensor-based activity recognition, relevant ML/xAI applications, and ecological validity. The Methods section details our methodology, covering data acquisition and processing, the proposed deep learning framework with SHAP, and our evaluation protocol. The Results section presents experimental results on model performance and xAI-driven insights. The Discussion section interprets these findings and discusses the study’s strengths and limitations. Finally, the Conclusions and Future Work section summarizes our contributions and outlines future work.
Related works
Real-world activity monitoring and ecological validity
The limitations of subjective questionnaire-based assessments have driven a call for more ecologically valid measures that capture the objective performance of individuals as they carry out daily tasks. 30 Controlled, clinic-based assessments, while objective, often fail to measure the naturalistic movements and cognitive load required for real-world activities. In contrast, performance-based tasks that simulate real-world scenarios provide a more accurate window into an individual’s functional capabilities. Evidence suggests that the association between cognitive abilities and functional autonomy is stronger when IADLs are evaluated using objective, performance-based tasks rather than questionnaires.31,32
To assess true functional performance for activity recognition, there must be a shift from simplified lab tasks toward monitoring activities within complex, ecologically valid contexts. An IADL such as grocery shopping is an ideal paradigm for this type of assessment. It is a common, goal-directed activity that requires the integration of multiple cognitive and motor functions, including planning (navigating aisles), executive function (selecting items from a list), memory (recalling item locations), and physical execution (walking, turning, reaching, and carrying objects). By instrumenting and analyzing performance during a structured IADL like grocery shopping, it becomes possible to overcome the limitations of traditional methods and capture objective data on how an individual truly functions. 30 This approach allows for the measurement of naturalistic movements and provides a foundation for developing recognition models of functional ability, particularly in populations at risk for further cognitive and physical declines, like those with MCI.
We therefore evaluate objective, performance-based measurement during an ecologically valid grocery task. However, this raises a methodological challenge. While a task like grocery shopping can elicit naturalistic behaviors, manually observing and coding these complex, continuous movements is not scalable and is fraught with its own limitations. The next leap in methodology requires technology that can continuously capture the fine-grained kinematics of movement in order to objectively and automatically quantify performance during an IADL.
IADL recognition using wearable sensors
The direct solution for acquiring the high-quality, continuous data needed to analyze these activities is through the use of wearable sensor technology. Early systems demonstrated the feasibility of using wearable accelerometers to recognize a variety of ADLs, 33 with subsequent work showing that combining accelerometers with gyroscopes in IMUs enhances recognition performance.34,35 These sensors, commonly embedded in smartphones and dedicated wearable devices, are adept at capturing the detailed kinematics of human movement. 36
While much of the foundational human activity recognition (HAR) research has focused on classifying ADLs like walking, sitting, and standing,37,38 the methodology is directly applicable to the more complex multi-step sequences that constitute IADLs. Datasets like Opportunity have specifically been created to push research toward recognizing activities in more realistic scenarios, capturing data from multiple body-worn sensors as users perform complex daily routines in simulated home environments. 27 By instrumenting participants with IMUs, it is possible to capture high-fidelity, objective data on the component movements of an IADL, such as gait patterns during walking, the rotational velocity of a turn, or the complex trajectory of the limbs and trunk during a reach, thereby enabling a quantitative and scalable analysis of functional performance.
Machine learning and deep learning in healthcare for activity prediction
To translate the vast streams of kinematic data captured by this technology into meaningful insights, researchers have increasingly turned to powerful computational methods. The application of ML and end-to-end deep learning (DL) techniques has become central to analyzing wearable sensor data for activity recognition in healthcare. 28 Traditional ML approaches for HAR require the manual design and selection of features from sensor signals, a process that is time-consuming, necessitates specialized domain knowledge, and may not yield an optimal feature set.39–41 Deep learning models have been proposed to overcome these limitations by automatically learning hierarchical and salient features directly from raw sensor data, eliminating the need for manual feature engineering.42–44 Among the earliest end-to-end architectures for wearable HAR, a framework combining convolutional layers with LSTM recurrent units demonstrated that temporal modeling and automatic feature extraction from raw multi-sensor data can be unified, establishing a widely adopted baseline for on-body activity recognition on benchmark datasets including Opportunity. 45 This automated approach has been shown to be more precise in HAR than traditional methods and has strengthened the generalization capabilities of recognition models.
The potential of these advanced computational methods is particularly useful in healthcare, where they are used for remote health monitoring, diagnosis, and rehabilitation.46,47 The ability of DL to improve the sensitivity and specificity in recognizing movement dysfunction is a major advantage. By learning robust representations from raw, often noisy, sensor signals, DL models can better distinguish the subtle kinematic signatures of specific health-related events from background activity. This capability has been leveraged in a variety of clinical applications, including the continuous monitoring of symptoms for patients with Parkinson’s disease,48,49 the detection of falls in older adults, 50 and the assessment of functional recovery after stroke. 51 By enabling more accurate and objective quantification of movement, DL frameworks provide a powerful tool for understanding health status and functional ability outside of the clinic.
xAI in time-series prediction and healthcare
The “black-box” nature of deep learning models presents a barrier to their clinical adoption, as clinicians must be able to trust and understand the reasoning behind a recognition.52,53 This challenge is especially acute for models trained on wearable sensor data. Unlike images or text, raw time-series signals are not intuitively human-readable, making it difficult to verify a model’s logic. To address this, our framework uses a post-hoc explanation technique called SHAP to interrogate our trained model. 29 SHAP is a game theory-based method that precisely quantifies how much each input feature, such as high angular velocity from a back sensor, contributes to a specific recognition like ‘Turn’. By attributing importance to each feature rather than just highlighting a raw signal segment, SHAP provides clear, quantitative evidence of the model’s decision-making process. This bridges the gap between high recognition performance and the clinical need for interpretable insights.
Methods
Dataset and data acquisition
This section details the procedures employed for data collection, including the characteristics of the study participants, the experimental protocol, and the sensor modalities utilized.
Data collection protocol
The study protocol was approved by the Vanderbilt University Medical Center Institutional Review Board (250607), and written informed consent was obtained from all participants. Data collection was conducted at The George Washington University, where the study was originally initiated. A total of 30 older adults were enrolled in the study, including 15 CU and 15 MCI. After quality-control screening, four participants were excluded, yielding a final analytic sample of 26 participants (14 CU and 12 MCI) whose data were used in the analyses reported below. The diagnosis of MCI for participants in the study group was established by a qualified neuropsychologist. For the healthy control participants, inclusion required a score greater than or equal to 26 out of 30 on the Montreal Cognitive Assessment (MoCA), a widely used screening tool for cognitive dysfunction.
Eligible individuals were aged 60-75 years and had been grocery shopping at least twice in the preceding three months. Participants were recruited via email through the electronic medical records system of the George Washington University Medical Faculty Associates, with contacts limited to three per individual to avoid coercion. Participants received $50 compensation for the single study session plus reimbursement for parking costs. All individuals enrolled in the study were required to have eyesight corrected to normal levels, enabling them to accurately perceive and select items from a shopping list. They also needed to be capable of ambulating for a continuous period of 10 minutes without the use of an assistive device and were classified as non-frail, which was operationalized as achieving a score of 9 or greater on the brief physical performance battery. Specific exclusion criteria were established to minimize confounding variables: individuals were excluded if they were current smokers, had a diagnosed neurological disorder other than MCI, had experienced a myocardial infarction within the past year, suffered from a loss of sensation in their extremities, had pain that limited their ability to ambulate, bend, grasp objects, or reach, or had undergone a joint replacement or other joint surgery within the six months prior to enrollment. Additionally, information on several potential confounding factors was systematically collected for all participants, including details about their current medications, any history of falls, prior surgical history, and their body mass index.
The experimental task designed for this study centered on grocery shopping. We constructed a mock grocery store within a dedicated research laboratory space that was designed to be ecologically similar to a small neighborhood grocery store, with full-height shelving, clearly defined aisles, and realistic product placement (Figure 1). During the visit, participants were asked to find a predetermined list of items within this environment, with each participant completing five shopping lists. Each list contained common grocery items (e.g., Devil’s Food cake mix, seltzer water, and a basket of apples), as summarized in Table 1. This task was structured to elicit multiple repetitions of common movements associated with grocery shopping, with the protocol aiming for at least 10 repetitions of each subtask. Two different angles of the structured grocery store environment used for the experimental shopping task. These views illustrate the setting where participants performed the task. Specifications for five standardized item lists utilized in the behavioral coding protocol.

For the movement analyses in this paper, we focused on subtasks that are typically performed in a grocery store setting: Walk, defined as forward locomotion without large changes in heading; Turn, defined as walking that includes a reorientation of the body by more than 45°; Positional Adjustment, defined as small, in-place shifts or torso reorientations (less than 45°) without moving the feet; Reach Up, defined as reaching to retrieve an item from the top shelf; Reach Middle, defined as reaching to retrieve an item from the middle shelves; and Reach Down, defined as reaching to retrieve an item from the lowest shelf. These specific subtasks were selected to represent a range of movements and cognitive demands inherent in a real-world IADL. During analysis, the fine-grained behaviors captured on video were systematically grouped to create these and other target classes for model training.
Data collection for each participant was completed during a single study visit. Participants were instrumented with a total of four MbientLab MetaMotionR+ IMUs. These IMUs are lightweight, weighing only 0.2 ounces each, and were configured with a sampling frequency of 100Hz for data streaming. The placement of these sensors was standardized: one IMU was carefully affixed to the skin directly over the L4 spinous process, a frequently utilized anatomical landmark in movement research known for its utility in measuring gait kinematics. A second IMU was positioned on the posterior aspect of the cranium, clipped to a cap or a tightly fitting headband; this placement was chosen based on evidence suggesting it can enhance the recognizability of gait and other movement parameters and is particularly useful for recognizing reaching and bending movements by revealing head-on-trunk trajectories. Additionally, one IMU was securely attached to the dorsum of each foot to capture detailed lower limb movement and gait characteristics. To provide a verifiable record of the subtasks performed, all movements were captured using a chest-mounted RGB video recording, which served as the ground truth. SHAP summary of feature importance for the Turn model. SHAP summary of feature importance for the Walk model. SHAP summary of feature importance for the Walk & Turn model. SHAP summary of feature importance for the Positional Adjustment model. SHAP summary of feature importance for the Reach Down model. SHAP summary of feature importance for the Reach Middle model. SHAP summary of feature importance for the Reach Up model. SHAP summary of feature importance for the Reach All model.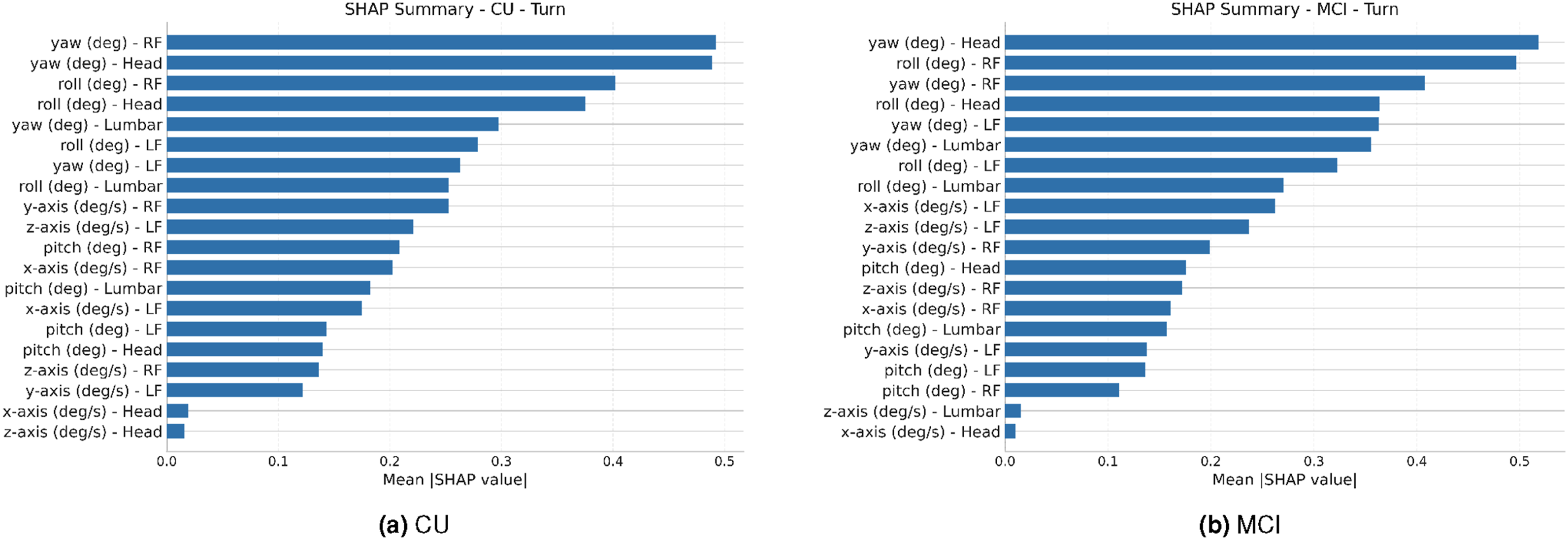






Data coding and labeling protocol
Description of durational behavioral codes and categories.

A team of four coders, who were students at the university where the research was conducted, was recruited for this task. The primary criteria for coder selection included a background in research methods to confirm a foundational understanding of data collection rigor. To ensure consistency and a shared understanding of the coding scheme before commencing the main dataset annotation, all four coders completed an initial training phase. During this phase, they independently coded video data from the same participant. This process allowed for the early identification and resolution of any discrepancies in interpretation or application of the coding protocol, thereby enhancing inter-rater reliability.
Following the initial training and calibration phase, before the distribution of the primary coding workload, inter-observer agreement (IOA) was assessed to ensure coding reliability and consistency. For this step, 20% of the total video files in the dataset were independently annotated by at least two members of the four-coder team. The Cohen’s Kappa statistic (κ) was employed as the metric for assessing IOA. When calculating agreement for specific event timings (e.g., start and end of a subtask), a one-second margin of tolerance was permitted between coders’ timestamps for an event to be considered concordant. A target agreement level of κ ≥ 0.80 was established as the minimum acceptable threshold. In instances where the calculated IOA on this subset fell below this target, the coders involved would meet to thoroughly discuss the points of disagreement. These discussions facilitated a consensus, and the specific video segments in question were then re-coded to ensure accuracy and adherence to the established protocol. Only after achieving the target IOA on this 20% subset did coders proceed with independent annotation of their assigned video lists. To further maintain coding stability and address any emerging questions or ambiguities throughout the lengthy coding process, the coding team held regular weekly meetings.
Temporal alignment of IMU and video data
A step in preparing the data for analysis was the synchronization of the behavioral event timestamps derived from the video data with the corresponding timestamps from the IMU sensor data. This process required careful manual alignment because the IMU data recording and the video recording did not commence simultaneously, and the precise start time of the video was not logged. To achieve synchronization, periods of planned calibration, during which participants were instructed to remain still, were identified in both the video recordings and the IMU data streams. By aligning these corresponding static calibration periods across the two data modalities, the IMU data and the video-derived behavioral labels were accurately time-locked, ensuring that each labeled subtask segment corresponded precisely to the relevant IMU sensor readings.
Signal processing and sequence preparation for end-to-end learning
Following data acquisition and initial synchronization with behavioral labels, several signal processing and sequence preparation steps were undertaken to prepare the IMU data for the end-to-end deep learning model.
Data synchronization and preprocessing
The initial data handling involved processing the raw time-series data from the multiple IMUs. For each participant and experimental list, data streams from the individual IMUs, each containing multi-axial accelerometer and gyroscope readings, were merged into a single comprehensive dataset based on their timestamps. This merged data was then uniformly resampled to a frequency of 100Hz using mean aggregation, ensuring a consistent temporal resolution across all recordings (as the accelerometer and gyroscope readings do not have perfectly synced timestamps). Following this resampling, a band-pass filter with cutoff frequencies of 0.25 Hz and 20 Hz was applied to each IMU signal to remove baseline drift and high-frequency noise, a range selected to isolate the signal component corresponding to human movement. The temporal alignment, established during the data coding phase by synchronizing video-identified calibration points with IMU data, ensured that the processed IMU signals correctly corresponded to the labeled subtasks. Missing data points, which could arise from the resampling process or slight misalignments during the outer join of data from different sensors, were subsequently handled prior to model training using mean imputation.
Orientation angle estimation
In addition to the raw tri-axial accelerometer and gyroscope channels, we derived orientation angles from each IMU. During the calibration phase at the beginning of each list, participants were instructed to remain still; we used this static interval to estimate the direction of gravity for each sensor and computed a rotation that aligned the gravity vector with the world z-axis. All subsequent IMU samples (accelerometer and gyroscope) were rotated into this common world frame before further processing. Magnetometer channels were not included in the analysis because not all participants had magnetometer values recorded.
For every timestep and sensor location (head, lumbar spine, left foot, right foot), we then computed roll and pitch in degrees, describing rotation about the sensor-fixed x- and y-axes, respectively, expressed in the world-aligned frame. These roll and pitch angles are therefore absolute with respect to gravity. We also maintained a yaw angle that captured changes in heading over time relative to the calibration posture; because we did not use magnetometer data, yaw is a relative heading measure rather than an absolute global orientation. The roll, pitch, and yaw angles were concatenated with the filtered accelerometer and gyroscope signals to form the full feature vector for each timestep that was passed to the deep learning model.
Temporal segmentation and sequence creation
To prepare continuous IMU data (feature matrix X, time-aligned labels y) for our sequence-based deep learning model, we employed temporal segmentation using a sliding window of 50 samples (half a second). This window was slid across the data with a one-sample stride, generating overlapping, fixed-length sequences of IMU sensor readings.
Each resulting sequence was assigned a single supervisory label, determined by the mode of binary labels from its constituent timesteps. At the finest level, timestep-level binary (‘1’ or ‘0’) labels were defined for individual subtasks - Walk, Turn, Positional Adjustment, Reach Up, Reach Middle, and Reach Down - based on the original video-derived annotations. To also examine these motions in a broader sense, we grouped fine-grained behaviors with similar operational characteristics into aggregated composite classes. For example, Walk and Turn were combined into a single Walk and Turn class, and the three reaching subtasks (Reach Up, Reach Middle, Reach Down) were pooled into a Reach All class. We therefore evaluated models at both levels of detail: granular subtask models and aggregated composite models. For the sake of conciseness, we refer to both the granular and aggregated task definitions as subtasks, yielding eight total target subtasks. For any given model configuration, whether targeting a single subtask or a composite class, an individual timestep received a label of ‘1’ if its original annotation corresponded to any elementary behavior within that target class, and ‘0’ otherwise (denoting background or other non-target subtasks).
IADL subtask prediction model: End-to-end deep learning framework
The core of our IADL recognition system is an end-to-end deep learning model designed to learn hierarchical feature representations from IMU time-series data (accelerometer, gyroscope, and derived orientation angles). This supervised learning model is tasked with classifying sequences corresponding to various IADL subtasks performed during a structured grocery shopping scenario.
Overall architecture (Bi-GRU with attention)
The primary sequential processing block consists of a Bi-GRU layer. This layer is designed to be bidirectional, allowing it to capture temporal dependencies from both past and future contexts within each input sequence. The Bi-GRU layer returns the full sequence of hidden states (rather than just the final state) to facilitate subsequent attention-based processing. Aside from the generic orientation-angle computation, this end-to-end approach avoids task-specific manual feature engineering, enabling the model to autonomously learn higher-level features from the IMU time-series data relevant to IADL classification.
Attention mechanism
To enhance the model’s ability to focus on the most informative segments within a sequence, a multi-head attention mechanism is integrated after the Bi-GRU layer. The sequence output from the Bi-GRU layer serves as the query, key, and value inputs for this attention layer. The output of the multi-head attention mechanism is then combined with the input sequence from the Bi-GRU layer via an additive residual connection. This combined output is subsequently passed through a layer normalization.
Classification layers
Following the attention mechanism, the attended sequence representation is transformed into a fixed-size vector suitable for classification. This transformation is achieved by a global average pooling layer, which computes the average over the temporal dimension of the attended features. The resulting pooled vector is then processed by a feed-forward network consisting of a dense layer and a rectified linear unit activation function. To aid in regularization and stabilize training, this dense layer is followed by a batch normalization layer and then a dropout layer. The final classification is performed by a single dense output unit with a sigmoid activation function. The model is compiled using the Adam optimizer and a binary cross-entropy loss function.
Experimental design and evaluation protocol
To rigorously assess the performance of our IADL subtask recognition model, we adopted a comprehensive experimental design and evaluation protocol, detailed below.
Training, validation, and testing strategy
We employed a leave-one-subject-out (LOSO) cross-validation to assess model generalization. In each LOSO fold, one participant’s data served as the hold-out test set, with remaining data used for training. All models are trained on pooled CU+MCI sequences from the non-held-out participants in each LOSO fold.
To mitigate domain shift arising from inter-subject variability, a supervised domain adaptation technique was used. For each fold, a 5% portion of the test subject’s sequences was randomly sampled from their entire dataset and incorporated into the training data. This percentage aimed to balance effective adaptation to the test subject’s characteristics against the need to preserve a sufficiently large and diverse set of unseen data for rigorous evaluation. Random sampling, rather than selecting contiguous blocks, was used to obtain a representative sample of the subject’s varied behaviors and sensor data patterns for more effective adaptation.
A strict masking protocol during testing ensured evaluation integrity and prevented data leakage. Sequences from the test subject utilized for domain adaptation were directly excluded from evaluation. Furthermore, to account for temporal dependencies in the time-series data and sequence generation, sequences temporally adjacent to the adapted ones were also masked from the evaluation set.
Finally, 5% of each fold’s combined training data (including data from other subjects and the adapted sequences from the test subject) was randomly allocated as a validation set to monitor training progress.
Model training details
The IADL recognition model, a Bi-GRU network with a multi-head attention mechanism (128 units for Bi-GRU, 8 attention heads with a key dimension of 16, followed by a 32-unit dense layer), was trained using the Adam optimizer with an initial learning rate of 0.001. The model was compiled with a binary cross-entropy loss function. Training was conducted for a maximum of 100 epochs with a batch size of 2048. The process was regulated by two callbacks: an EarlyStopping callback that monitored validation loss with a patience of 10 epochs and restored the best weights, and a ReduceLROnPlateau callback that reduced the learning rate by a factor of 0.5 after 5 epochs of a validation loss plateau, down to a minimum of 0.00001.
Performance metrics
Model performance was evaluated using a comprehensive suite of standard classification metrics, including accuracy, precision, recall, and F1-score. These metrics provide a multi-faceted understanding of the model’s effectiveness. Precision indicates the proportion of correctly identified positive subtask events among all events flagged as positive, thereby reflecting the model’s ability to minimize false alarms. Recall (or sensitivity) measures the proportion of actual positive subtask events that were correctly identified. Accuracy offers a general measure of overall correctness.
The F1-Score was particularly emphasized, as it calculates the harmonic mean of precision and recall, offering a measure of performance especially in scenarios with class imbalance, which is often characteristic of rare event recognition.
Model interpretability using xAI
To move beyond the “black-box” nature of our deep learning model and understand its recognitions for IADL classification, we utilize GradientExplainer, an algorithm within the SHAP framework that is highly optimized for deep neural networks. In our setting, each input feature corresponds either to a tri-axial accelerometer or gyroscope channel (x, y, or z) or to a derived orientation angle (yaw, roll, or pitch in degrees) from the IMUs on the head, lumbar spine, or either foot. SHAP values therefore quantify how much each sensor-feature channel contributes to a given recognition.
Local explanations assign a SHAP value (ϕ
i
) to each input feature for an individual recognition, quantifying its contribution to the model’s output. This allows for granular analysis of why specific recognitions are made. These SHAP values adhere to the property of additivity, meaning the model’s output f(x) for an instance x can be expressed as the sum of the SHAP values for its M features plus a base value ϕ0 (the expected model output over the training dataset):
The global explanations are derived by aggregating these local SHAP values (e.g., by averaging their absolute values) across the dataset. This reveals the overall importance of each feature, highlighting which sensor channels or temporal characteristics are generally most influential in the model’s decision-making process. GradientExplainer approximates SHAP values by selecting a background distribution of data and analyzing the gradients of the model’s output with respect to the input features. By integrating these gradients along the path from the background samples to the specific input instance, it efficiently estimates the contribution of each feature to the final recognition.
To apply this to our study, we implemented a systematic explanation process. First, local, instance-level SHAP values were calculated for each of the eight IADL subtask models. For each model, input sequences from a test-set participant were passed through the GradientExplainer to compute a specific SHAP value for every feature in that sequence, quantifying its contribution to that single recognition. To then generate global feature importance metrics, these local, per-sequence values were aggregated. For each participant, the mean absolute SHAP value was computed for each feature across all sequences belonging to a single experimental trial (i.e., one shopping list). This was performed separately for each of the five shopping lists completed by the participant. This procedure yields a distinct set of feature importance values for each list, for each participant, and for each IADL subtask.
Results
Data from the initial cohort of 30 participants (15 CU, 15 MCI) underwent a quality control process. Due to insufficient calibration data needed for temporal alignment of IMU and video streams, several participants were excluded. The final analytic sample therefore comprised 14 CU and 12 MCI participants. All models were trained on pooled CU+MCI data, and for clarity we report performance separately for the CU and MCI groups. This section presents the outcomes on this dataset, beginning with model performance, followed by a detailed analysis of IADL subtask recognition for each group, and concluding with insights from the xAI analysis.
IADL subtask prediction performance
The IADL subtask recognition models were trained and evaluated using the LOSO protocol. This subsection details the performance achieved, first by examining aggregated per-subtask metrics and then by looking at per-participant results for both CU and MCI groups.
Per-subtask performance for the CU group
Per-subtask IADL prediction performance metrics for the CU group, calculated across leave-one-subject-out cross-validation folds.

Per-participant, per-subtask performance for the CU group
Per-participant, per-subtask F1-scores for the CU group (N=14).

Per-subtask performance for the MCI group
Per-subtask IADL prediction performance metrics for the MCI group, calculated across leave-one-subject-out cross-validation folds.

Per-participant, per-subtask performance for the MCI group
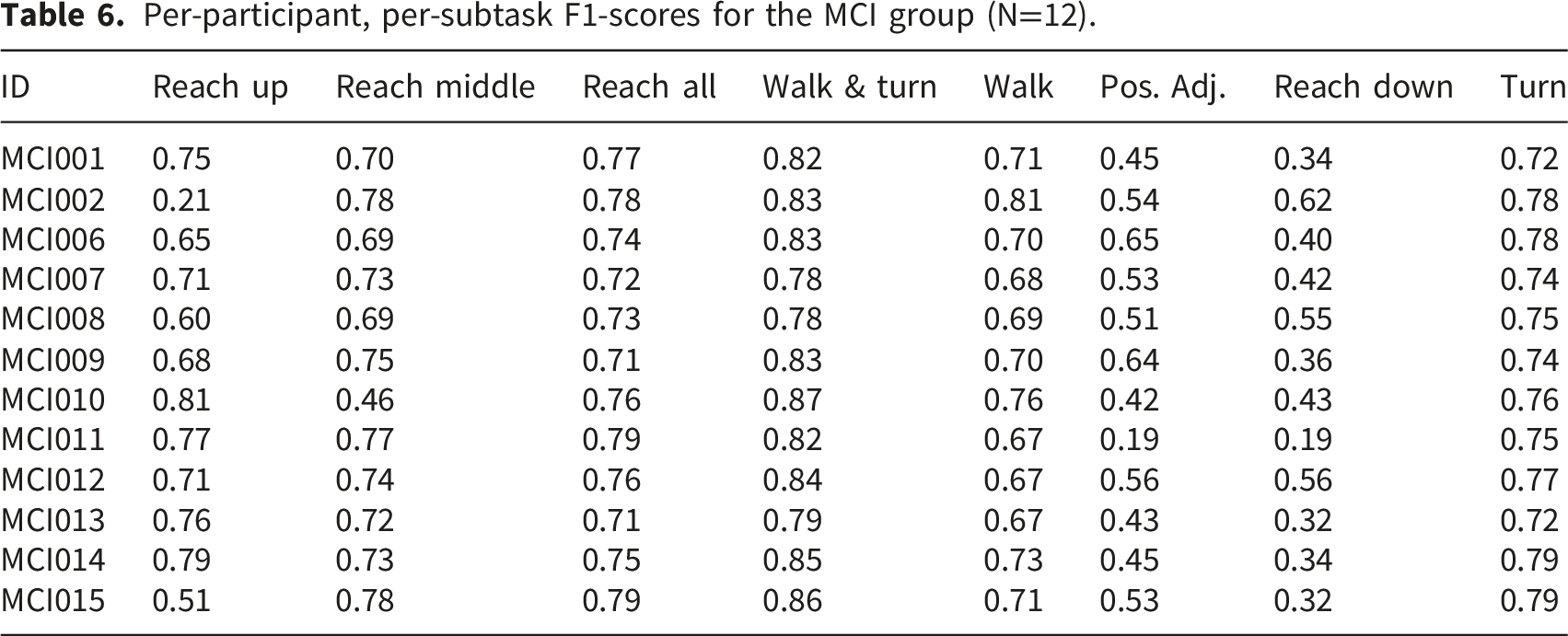
Per-participant, per-subtask F1-scores for the MCI group (N=12).
xAI insights: SHAP analysis
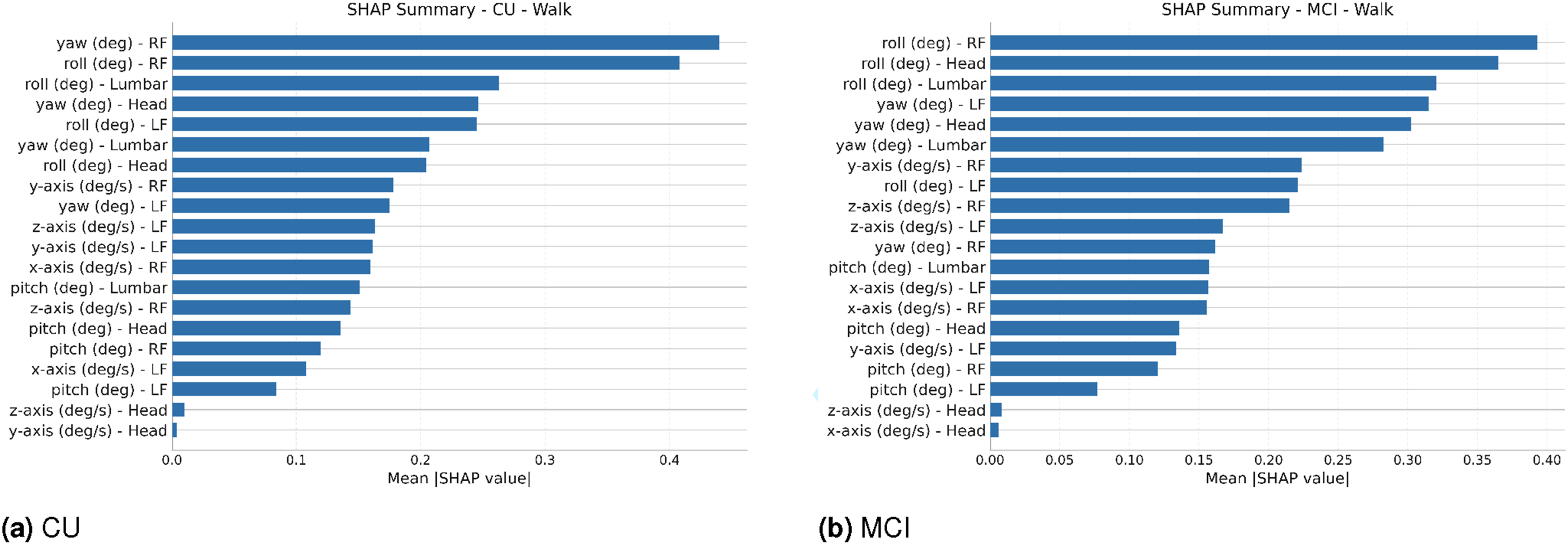
The SHAP analysis was used to determine the global feature importances for each model, revealing the primary kinematic signals driving classification. Across all eight subtasks and both cohorts, the largest contributions came from derived orientation angles (yaw, roll, and, to a lesser extent, pitch) from the head, lumbar spine, and both feet. When we aggregate mean absolute SHAP values by feature type, orientation angles consistently carry between roughly two- and four-times the importance of gyroscope angular-velocity channels, while accelerometer channels are several orders of magnitude smaller and do not appear among the top-ranked features for any subtask in either cohort. Within this orientation-dominated feature set, the relative weights of specific sensor-axis combinations vary systematically by subtask and cohort. SHAP summary plots for all eight subtask models, showing feature importance for the CU and MCI cohorts, are presented in (Figures 2–9).
Feature importance for the CU group
For the CU models, the ambulation subtasks (’Walk’, ’Turn’, and ‘Walk and Turn’) are dominated by yaw and roll angles from the feet, head, and lumbar spine, with gyroscope angular-velocity channels at the feet providing secondary detail. In the ‘Walk’ model, the largest SHAP values correspond to yaw and roll at the right foot, followed by roll at the lumbar spine and left foot and yaw at the head. The ‘Walk and Turn’ model emphasizes yaw at both feet and the head, with roll at the head, feet, and lumbar spine and lumbar yaw forming the next tier of contributors. For ‘Turn’, SHAP highlights yaw at the right foot and head, together with roll at these locations and yaw and roll at the lumbar spine, again indicating that orientation changes at the feet, trunk, and head jointly drive recognition. ‘Positional Adjustment’ shows a similar pattern: the most important features are roll and yaw at the lumbar spine and feet, along with yaw and roll at the head, consistent with small, coordinated in-place reorientations.
In the reaching subtasks, the composite ‘Reach All’ model for CU participants is driven primarily by yaw and roll at the head and lumbar spine, together with yaw and roll at the feet. The three height-specific models reweight these same channels. ‘Reach Up’ places greatest importance on yaw at the lumbar spine, followed by roll at the left foot and yaw and roll at the head, with orientation at the right foot contributing slightly less. ‘Reach Middle’ shifts weight toward roll at the right foot, head, and lumbar spine, with additional contribution from yaw at the right foot and roll at the left foot. ‘Reach Down’ is dominated by yaw at the left foot and head and roll at the right foot and lumbar spine, with roll at the head following closely. Overall, the CU models use a consistent combination of yaw and roll angles, with smaller pitch contributions, plus gyroscope rates from the feet and lumbar spine. Accelerometer channels have negligible importance compared to these orientation and gyroscope features.
Feature importance for the MCI group
For the MCI models, we observe the same core structure of feature use: orientation angles (yaw and roll) at the head, lumbar spine, and both feet dominate, with gyroscope channels again providing complementary information and accelerometers contributing very little. In the ‘Walk’ model, roll at the right foot, head, and lumbar spine form the top three features, followed by yaw at the left foot and head and roll at the left foot. In ‘Walk and Turn’, yaw at the left foot and lumbar spine and roll at the head and right foot carry the highest importance, with yaw at the head and roll at the lumbar spine and right foot close behind. The ‘Turn’ model is driven primarily by yaw at the head and right foot, together with roll at the right foot and head and yaw and roll at the lumbar spine and left foot. ‘Positional Adjustment’ again relies on roll and yaw at the lumbar spine and feet, with yaw at the head also contributing, indicating that small shifts in trunk and foot orientation form the main cue for this subtask.
For the composite ‘Reach All’ model and the three height-specific reaching models in the MCI group, the classifier uses similar orientation and gyroscope channels to those in the CU models, but with subtly different weightings. ‘Reach All’ primarily weights yaw and roll at the head, lumbar spine, and left foot. ‘Reach Up’ emphasizes yaw at the head and roll and yaw at the lumbar spine, with roll at the right foot also important. ‘Reach Middle’ is dominated by yaw and roll at the right foot and lumbar spine, along with roll at the head, while ‘Reach Down’ is driven by roll at the right foot and yaw at the head and both feet, together with roll at the lumbar spine. Taken together, SHAP indicates that both cohorts are characterized by movement signatures dominated by orientation angles (especially yaw and roll) at the head, lumbar spine, and feet, with gyroscope channels adding finer-grained timing information and accelerometers playing only a minor role. Cohort differences appear primarily as subtle reweightings of these shared features rather than entirely different sets of predictors.
Sensor ablation analysis
F1-scores (CU/MCI) for single-sensor configurations across all IADL subtasks, evaluated under leave-one-subject-out cross-validation.
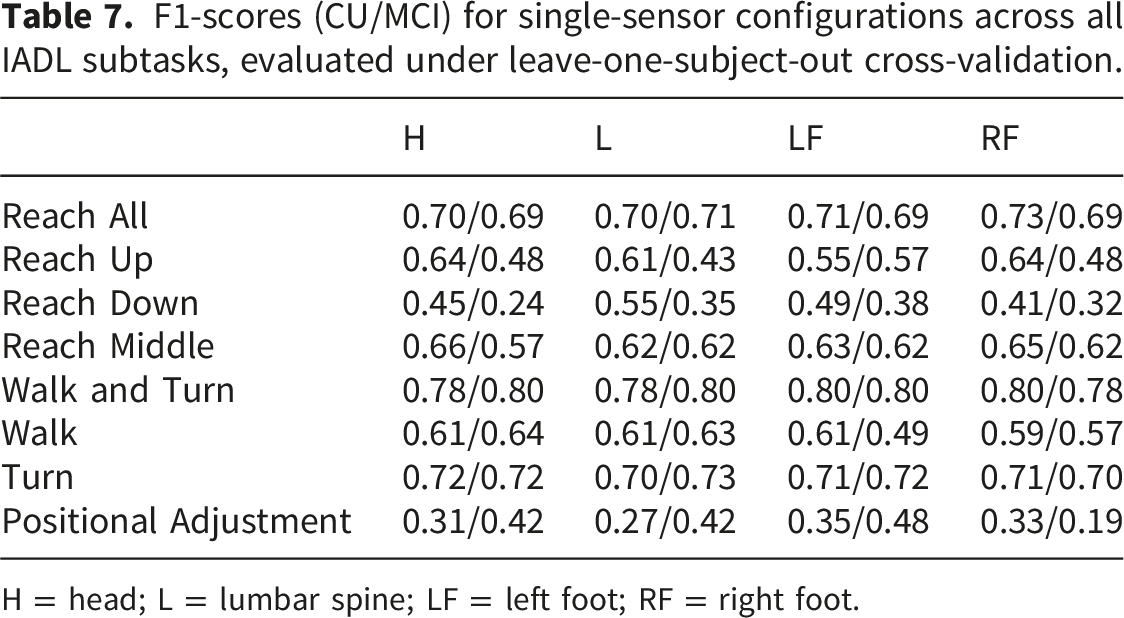
H = head; L = lumbar spine; LF = left foot; RF = right foot.
F1-scores (CU/MCI) for two-sensor combinations across all IADL subtasks, evaluated under leave-one-subject-out cross-validation.

The ‘+’ operator denotes sensor combinations. Notation follows Table 7.
F1-scores (CU/MCI) for three-sensor combinations and the full four-sensor configuration across all IADL subtasks, evaluated under leave-one-subject-out cross-validation.

Notation follows Table 7.
Performance degradation from sensor reduction was subtask-dependent. Broad categories such as Walk and Turn and Reach All were robust to sensor removal, with two-sensor configurations recovering to within a narrow margin of the full setup. In contrast, fine-grained subtasks such as Reach Down and Positional Adjustment showed greater sensitivity, with single-sensor configurations producing substantially lower F1-scores. Three-sensor configurations generally closed the remaining gap, though the marginal gain from adding a fourth sensor was most pronounced for fine-grained actions. These results suggest that sensor requirements scale with subtask granularity: broad mobility patterns can be captured with as few as two sensors, while fine-grained actions benefit from the full configuration.
Discussion
We report three findings. First, performance depended on task granularity: composite, sustained mobility patterns were recognized more reliably than brief or fine-grained actions. Walk and turn together outperformed models trained on walk or turn alone, and detecting any reach was easier than distinguishing reach heights. Second, recognition performance varied markedly across individuals, underscoring the value of limited subject-specific adaptation (applied with strict temporal masking) to improve generalization. Third, SHAP analyses explained these patterns: orientation angles (especially yaw and roll, with smaller pitch contributions) at the feet, head, and lumbar spine dominated feature importance, with gyroscope angular-velocity channels from the feet and lumbar sensor providing additional, but smaller, contributions and accelerometer channels contributing very little overall. Cohort differences emerged mainly as subtle shifts in how these shared orientation and gyroscope features were weighted rather than as entirely distinct feature sets. These results clarify why macro-patterns are more detectable, motivate personalization, and yield interpretable kinematic signatures relevant to functional assessment.
Interpretation of primary findings: Performance, variability, and the nature of IADLs
An analysis of the model’s performance provides insights into both the hierarchical structure of IADL subtasks and the impact of inter-subject variability on automated subtask recognition. The patterns of successful and unsuccessful classification are not random but instead reveal fundamental characteristics of the movements themselves.
The model’s performance is related to the level of granularity at which a subtask is defined. The framework demonstrated high performance on broad categories of related movements, such as the combined ‘Walk and Turn’ class (F1-score of 0.818 for CU, 0.824 for MCI) and the aggregate ‘Reach All’ category (F1-score of 0.757 for CU, 0.753 for MCI). This success can be attributed to the fact that these classes represent sustained actions with distinct, high-amplitude kinematic signatures that unfold over a longer temporal window. The Bi-GRU-Attention architecture effectively integrates this sequential data to learn a representation of the overall movement pattern. This finding is further illuminated when comparing the performance on composite classes to that on their granular sub-components. The ‘Walk and Turn’ model, for instance, outperformed models trained separately on ‘Walk’ or ‘Turn’. This suggests that the model learns the entire context-rich transitional sequence from walking to turning, a more stable and identifiable feature than the isolated rotational component of a turn, which can be brief and easily confused with other movements. Similarly, the ‘Reach All’ model effectively learned a generalized kinematic template for reaching, but was less successful at distinguishing between sub-types like ‘Reach Up’ and ‘Reach Down’. This differentiation relies on subtler kinematic features related to trunk posture, which exhibit higher variance and are more susceptible to confusion. This suggests that while the overall kinematic signature of a ‘reach’, likely involving preparatory shifts in balance captured by the foot and trunk sensors, is robust, the specific postural adjustments of the upper trunk that differentiate reach heights are more subtle. The sensor configuration used in this study may not be able to capture these fine-grained differences in upper-body kinematics with sufficient clarity to reliably distinguish between them. There is a clear hierarchy of recognizability, where macro-level movements with distinct, sustained patterns are more reliably classified from wearable sensor data than their more specific, micro-level counterparts.
Inter-subject variability
Our second finding relates to the inter-subject variability in model performance, which was a prominent feature in both the CU and MCI cohorts. While the model performed well for some individuals, its accuracy was lower for others. This finding suggests that a single, generalized model might struggle to accurately assess functional performance for all. Individual movement patterns are highly idiosyncratic, shaped by factors such as anthropometry, physical conditioning, and personal habits. In a clinical context, this variability is even more pronounced. The atypical kinematics of an outlier may not simply be noise, but could instead represent a compensatory strategy developed to manage an underlying motor or cognitive deficit. From this perspective, a low classification score from a generalized model can be an informative outcome in itself, effectively flagging an individual with a movement pattern that may require further clinical assessment. This underscores the importance of personalization in developing effective monitoring tools. The consistent performance improvement achieved through our supervised domain adaptation technique, whereby the model was fine-tuned with a small sample of a new user’s data, empirically validates this conclusion. It demonstrates that systems capable of adapting to an individual’s unique kinematic signature are needed to achieve the level of accuracy required for meaningful and reliable functional assessment.
Synthesizing findings: Connecting performance, xAI, and insights
The performance of our models provides a quantitative measure of subtask recognition. However, its true value is seen when we synthesize these performance metrics with model explanations from xAI to understand why certain subtasks were easier to classify than others. This synthesis transforms the model into an interpretive tool, allowing us to connect computational outcomes with the underlying kinematics of each task. In the following sections, we dissect the model’s performance on IADL subtasks and use the SHAP analysis to elucidate the kinematic drivers of the results for both the CU and MCI groups.
Dissecting ambulation: The relationship between Walk, Turn, and Walk and Turn
The performance gap between the composite ‘Walk and Turn’ model and the separate ‘Walk’ and ‘Turn’ models can be understood in terms of which channels SHAP identifies as most important. For both cohorts, all three ambulation models are driven primarily by orientation angles (yaw and roll) from the feet, head, and lumbar spine, with gyroscope angular-velocity channels at the feet and lumbar sensor providing additional signal. In the CU group, the ‘Walk’ model places its highest importance on yaw and roll at the right foot, together with roll at the lumbar spine and left foot and yaw at the head. In the MCI group, roll at the right foot, head, and lumbar spine forms the top features, followed by yaw at the left foot and head. The ‘Walk and Turn’ model balances these patterns: in both cohorts it assigns high importance to yaw at the feet and head and to roll at the head, feet, and lumbar spine, with lumbar yaw also contributing. The ‘Turn’ model is similarly dominated by yaw and roll at the head, right foot, and lumbar spine, with additional contributions from yaw and roll at the left foot and gyroscope channels at the feet. These feature-importance results indicate that all three ambulation subtasks rely on a shared lower-limb and trunk orientation signature, which helps explain why the composite ‘Walk and Turn’ classifier outperforms the stand-alone ‘Walk’ and ‘Turn’ models.
Fine-tuning stance: The kinematics of positional adjustment
‘Positional Adjustment’ illustrates the difficulties of recognizing brief, low-amplitude movements. Its F1-scores were among the lowest across subtasks in both groups - lowest in the CU cohort and second-lowest in the MCI cohort (only ‘Reach Down’ was lower). For CU participants, importance is distributed across roll and yaw angles at the lumbar spine and both feet, together with yaw and roll at the head and gyroscope angular-velocity channels at the feet. For MCI participants, roll and yaw at the lumbar spine and right and left feet carry the highest importance, with yaw at the head also contributing. These patterns indicate that the model relies on small but coordinated changes in trunk and foot orientation, supported by modest changes in angular velocity, to distinguish positional adjustments from background, making this subtask particularly sensitive to noise and inter-subject variability.
This is consistent with positional adjustments that involve subtle upper-body and whole-body reorientation with minimal stepping. Because these movements are short in duration, have modest signal-to-noise ratios, and can be expressed differently across individuals and cohorts, the model has less consistent kinematic structure to exploit, leading to the observed drop in F1-score.
The kinematics of reaching: General patterns vs. specific actions
The reaching subtasks further illustrate the trade-off between specificity and recognizability. The aggregate ‘Reach All’ models achieved higher F1-scores than the height-specific ‘Reach Up’, ‘Reach Middle’, and ‘Reach Down’ models in both cohorts, indicating that the classifier can reliably detect that a reach is occurring even when it struggles to map that reach to a precise shelf height. SHAP again points to a shared kinematic core. For both CU and MCI participants, the ‘Reach All’ models are driven primarily by yaw and roll angles at the head and lumbar spine, together with yaw and roll at the feet and supporting gyroscope angular-velocity channels at the feet and lumbar spine. Pitch angles contribute but are consistently smaller than yaw and roll.
When we fit separate models for the three reach heights, the same channels remain dominant; the models simply reweight them. In the CU group, ‘Reach Up’ places relatively more importance on roll and yaw at the right foot and head, ‘Reach Middle’ shifts weight toward roll at the right foot, head, and lumbar spine, and ‘Reach Down’ is driven most by yaw at the left foot and head and roll at the right foot and lumbar spine. In the MCI group, yaw and roll at the head and lumbar spine often rise to the top across the three heights, with yaw and roll at the feet and gyroscope rates at the feet sharing the remaining importance. The absence of strong, height-specific feature signatures—in other words, the fact that all reach models draw on nearly the same combination of orientation and angular-velocity features across sensors-helps explain why the classifier can detect reaching reliably but has difficulty discriminating between upper-, middle-, and lower-shelf actions.
In summary, this analysis provides a data-driven narrative that explains the model’s varied performance across different IADL subtasks. It reveals that high-performing models, like the one for the combined ‘Walk and Turn’ task, learned robust and cardinal kinematic signals expressed primarily in yaw and roll angles, with supporting gyroscope rates, while lower-performing models for subtle or brief events struggled with more ambiguous feature sets. Furthermore, the analysis consistently showed that the models trained for the CU and MCI cohorts often differed in how they weighted orientation features at the feet, lumbar spine, and head to identify the same subtask, underscoring that a single, fixed feature weighting is unlikely to be optimal for both populations. This work presents a deeper interpretation of the model’s behavior, validating its recognitions and laying the groundwork for discussing the broader implications of these findings.
Situating our contributions within HCI and clinical research
This research makes several contributions by addressing the challenge of measuring functional ability in complex, real-world settings. While the earliest signs of cognitive decline often manifest during IADLs, existing methods frequently lack the ecological validity to capture these changes objectively. Our work addresses this gap by moving assessment out of the controlled clinical environment and into a realistic, cognitively demanding task. By focusing on the granular subtasks of grocery shopping, we provide a framework for capturing a more authentic view of an individual’s functional performance and an opportunity to identify early cognitive-motor declines.
A valid assessment of how well an individual performs a subtask, however, is predicated on the ability to first reliably identify what subtask is being performed. This work establishes that foundational recognition layer. By developing a system that can accurately parse a continuous stream of movement data into discrete, meaningful events, such as a turn or a reach to a specific shelf, we create the temporal anchors required for a more nuanced analysis of performance quality. This recognition capability is the prerequisite for any objective, performance-based assessment.
Furthermore, our integration of an end-to-end deep learning model with xAI directly addresses a barrier to the clinical translation of such tools. The “black-box” nature of many advanced models can limit trust and utility. Our framework balances recognition accuracy with the clinical necessity for interpretability, providing not just classifications but also explanations for the underlying motor strategies. The discovery of divergent strategies in reaching and turning is more than a methodological artifact; it is a preliminary form of assessment in itself.
Finally, underpinning these advances is the creation of a richly annotated dataset. Comprising synchronized IMU and video data from a cohort of both cognitively healthy older adults and individuals with MCI, this dataset provides an invaluable resource for the research community. It enables the development and validation of new models for subtask recognition and will facilitate future investigations that build upon our work to develop the next generation of objective functional assessment tools.
It is important to note that the current framework captures the physical execution of IADL subtasks but does not directly model the cognitive processes that govern them. The grocery shopping task elicits planning, list maintenance, and visual search, and our coding scheme did include a “Reading Shopping List” behavior; however, reliably establishing ground truth for list-checking proved difficult because the chest-mounted egocentric camera often occluded the participant’s hands and gaze direction, limiting the accuracy of annotations for this behavior. Hesitations and pauses between subtasks are implicitly captured within the temporal structure of the movement data and thus influence the model’s learned representations, but they are not explicitly segmented or quantified as cognitive indicators in the current analysis. Directly modeling these cognitive dimensions of IADL performance represents an important layer of complexity for future work.
Sensor ablation and deployment implications
The ablation study reveals that sensor requirements are tied to subtask granularity. Broad mobility subtasks such, as Walk and Turn, were robust to sensor removal, with two-sensor configurations approaching full-setup performance, while fine-grained subtasks, such as Reach Down and Positional Adjustment, degraded more substantially. This granularity-dependent pattern aligns with a systematic review of physical activity type detection in real-life settings, which found that two accelerometers (thigh and hip) provide the minimal sensor configuration for reliably differentiating basic postures and motion activities, while also noting that increasing the number of sensors may improve classification of additional activity types at the cost of greater analytical complexity and participant burden. 55 A systematic evaluation of all 127 combinations of seven accelerometer positions for 23 complex daily activities further demonstrated that sensor position combinations affect not only average classification performance but also recognition of individual activities, with a four-sensor combination required to achieve the best overall performance. 56 Similarly, an analysis of 12 IMU placements for fall-direction classification found that the optimal configuration involved strategically combining sensors from the pelvis, upper legs, and lower legs, with sensors on the pelvis and upper legs being most effective in the lower body. 57
In our data, no single two-sensor configuration dominated across all subtasks, and the performance differences among two-sensor combinations were generally small, suggesting that the apparent advantage of any particular pairing may fall within the margin of estimation error under LOSO evaluation. More broadly, the ablation results indicate that sensor requirements are subtask-dependent: broad mobility categories such as Walk and Turn were robust to sensor removal regardless of which sensors were retained, whereas fine-grained actions such as Reach Down and Positional Adjustment benefited from additional sensing locations. This suggests that the number and placement of sensors in a deployable system should be optimized for the primary movement tasks of interest, balancing recognition performance against participant burden and practical constraints of the monitoring context.
Beyond optimizing the number and placement of research-grade IMUs, it is worth considering whether consumer-grade alternatives could serve a similar role for the most robust subtask categories. Modern smartphones embed accelerometers and gyroscopes comparable in bandwidth to dedicated IMUs, and are routinely carried on the body during daily activities. Given that broad mobility patterns such as Walk and Turn were relatively insensitive to sensor location and number in our ablation, it is plausible that a single smartphone worn at the waist or in a pocket could approximate the trunk-mounted IMU for these coarse categories, though this remains speculative and would require empirical validation. Such an approach would substantially lower the barrier to deployment in longitudinal community monitoring, where participant burden and device cost are primary constraints. Investigating whether and under what conditions embedded smartphone sensors can substitute for dedicated wearables in detecting coarse-grained IADL subtasks is a promising direction for future work in scalable digital health systems.
Conclusions and future work
In this work, we developed and validated an interpretable, end-to-end deep learning framework to recognize the subtasks of a complex real-world IADL from wearable sensor data in older adults with and without MCI. Our findings show that model performance is dependent on the subtask’s level of granularity. The framework excelled at identifying broad, combined categories of movement, achieving F1-scores of 0.818 and 0.824 for the ‘Walk and Turn’ subtask in the CU and MCI groups, respectively. However, its effectiveness diminished for more granular tasks, struggling to recognize brief, discrete actions and to differentiate between similar subtasks within a category (e.g., reaching to different heights). The integration of xAI provided an explanation for these performance disparities, revealing distinct kinematic signatures of each subtask.
Reliable subtask recognition is a prerequisite for evaluating how well tasks are performed; our model provides that layer with SHAP-based transparency. SHAP reveals which kinematic features matter for each population, enabling interpretable monitoring. The discovery that our model relies on different kinematic features to classify subtasks for the CU and MCI groups suggests these data-driven signatures are a promising area for research into early markers of cognitive-related functional change.
Building on this foundational work, several avenues for future research are now possible. First, expanding and diversifying the cohort and moving from the simulated store to community deployments could strengthen generalizability and ecological validity. Second, longitudinal designs with repeated measures could quantify within-person change in kinematics and cognition over time, assess the stability of SHAP-derived kinematic signatures, and monitor potential model drift. Third, reducing dependence on manual video coding is essential for scaling beyond controlled studies. The labor-intensive labeling protocol used here produced the high-quality ground truth needed to train the current models. In future deployments, these trained models can perform automatic subtask detection from sensor data alone, and their predictions can serve as pseudo-labels for newly collected sensor streams, enabling a self-supervised refinement loop that progressively reduces the need for manual annotation in longitudinal or larger-scale studies. Augmenting IMU data with complementary modalities such as mobile eye tracking or electroencephalography could provide direct measures of visual search, cognitive load, and attentional allocation that the current kinematic-only framework cannot capture, enabling integrated models of both the motor and cognitive dimensions of IADL performance. Fourth, extending the methodology to other IADLs rich in motor and planning demands (e.g., meal preparation) and using recognition outputs as objective endpoints could facilitate intervention studies.
Ultimately, the subtask-level outputs of the recognition framework could be integrated into mHealth applications for remote cognitive and functional monitoring. In such a pipeline, continuous or periodic sensor data collected during routine activities would be automatically segmented into recognized subtasks, and derived execution-quality metrics, such as reach smoothness or gait variability, could be tracked over time to establish individual baselines. Deviations from these baselines, for example a progressive increase in positional adjustments during shopping or a decline in reaching efficiency, could serve as early warning indicators that trigger triage for in-person clinical assessment or prompt adaptive interventions such as cognitive training exercises targeting the affected domains. The population-specific kinematic signatures identified by SHAP provide the interpretable feature sets needed to define such metrics, and the ablation results indicating that broad mobility subtasks can be captured with as few as two sensors support the feasibility of lightweight, home-based deployment. Evaluating these candidate digital biomarkers against established outcomes such as fall risk, MCI-to-dementia conversion, and standardized cognitive test scores in prospective longitudinal studies is a necessary next step toward translating the current framework into a clinically actionable screening and monitoring tool.
Footnotes
Acknowledgement
We thank Sean Gentry, Chang Dong, Sherry Yu, Vince Lin, and Kani Wani for their valuable contributions in coding the dataset. AI-assisted tools (Anthropic Claude) were used in an assistive capacity during manuscript preparation, specifically for grammar and language refinement of author-written text and verification of code. The literature review, identification of relevant sources, and all intellectual content, including research design, data analysis, interpretation of results, and writing of the, manuscript were performed entirely by the authors.
Ethical considerations
This study was approved by The George Washington University IRB (NCR224193) and the Vanderbilt University Medical Center IRB (250607).
Consent to participate
Written informed consent was obtained from all participants.
Author contributions
NK: Data curation, Formal analysis, Methodology, Software, Validation, Writing - original draft. LD: Conceptualization, Investigation, Resources, Writing - review & editing. NS: Methodology, Project administration, Supervision, Writing - review & editing. KC: Conceptualization, Data curation, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Writing - review & editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institutes of Health National Institute on Aging grant R21AG077404 and by the National Science Foundation grant 2124002.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on request.
Guarantor
KC.