
Abstract
Objective
The proportion of older people will soon include nearly a quarter of the world population. This leads to an increased prevalence of non-communicable diseases such as Alzheimer’s disease (AD), a progressive neurodegenerative disorder and the most common dementia. mild cognitive impairment (MCI) can be considered its prodromal stage. The early diagnosis of AD is a huge issue. We face it by solving these classification tasks: MCI-AD and cognitively normal (CN)-MCI-AD.
Methods
An intelligent computing system has been developed and implemented to face both challenges. A non-neural preprocessing module was followed by a processing one based on a hybrid and ontogenetic neural architecture, the modular hybrid growing neural gas (MyGNG). The MyGNG is hierarchically organized, with a growing neural gas (GNG) for clustering followed by a perceptron for labeling. For each task, 495 and 819 patients from the Alzheimer’s disease neuroimaging initiative (ADNI) database were used, respectively, each with 211 characteristics.
Results
Encouraging results have been obtained in the MCI-AD classification task, reaching values of area under the curve (AUC) of 0.96 and sensitivity of 0.91, whereas 0.86 and 0.9 in CN-MCI-AD. Furthermore, a comparative study with popular machine learning (ML) models was also performed for each of these tasks.
Conclusions
The MyGNG proved to be a better computational solution than the other ML methods analyzed. Also, it had a similar performance to other deep learning schemes with neuroimaging. Our findings suggest that our proposal may be an interesting computing solution for the early diagnosis of AD.
Keywords
Introduction
Rising older populations generates increased chronic and non-transferable illnesses, such as dementia and stroke, posing important socio-economical challenges. 1 Hence, dementia is considered a public healthcare issue, especially in countries with high life expectancy, as it is estimated that around 47 million people have dementia worldwide. 1
Alzheimer’s disease (AD), a progressive and irreversible neurodegenerative syndrome that produces dementia, accounts for approximately 70% of the global dementia cases2–4: an estimated 6.7 million have AD in the USA in 2023, rising to 13.8 million in 2060. 5 While aging is recognized as a very important risk factor of AD, 2 the exact etiology, development, and evolution of AD are not fully understood yet. Nevertheless, two pathological changes, amyloid plaques, and neurofibrillary tangles, have formed the most prominent lines of research trying to explain the etiological mechanisms of AD. 2 AD severely impairs daily activities and emotional states. 3
Researchers have been looking for biomarkers that allow the, preferably early, diagnosis and prognosis of AD. The main difficulty of these tasks is how similar AD symptoms are to those of other diseases, especially other types of dementia. So far, it cannot be said that there is a specific biomarker for AD that is accepted by the scientific and medical communities and is of standardized use, but several promising candidates have been discovered. Among them, Blennow and Zetterberg pointed out the neurogranin, a synaptic protein apparently specific for AD that may allow predicting future cognitive impairment. 6 Similarly, González-Sánchez et al. 7 concluded that lactoferrin, an antimicrobial peptide commonly found in saliva, has high sensitivity and is specific for AD diagnosis, as it was not found in cognitively normal (CN) and frontotemporal dementia subjects. Unfortunately, none of these promising biomarkers are among the most popular, a position occupied by neuroimaging techniques. 8 Furthermore, currently, there is no effective treatment for AD. Nevertheless, early interventions can enhance life quality for patients and caregivers, often family members or non-clinicians.2,4
MCI, marked by slight cognitive deficits without dementia and without affecting daily activities, may presage AD but does not always progress to it. Roughly 5% to 10% of MCI cases transition to dementia annually, 10% to 15% to AD.9,10
Because of these considered aspects and the dire consequences of AD prevalence, research into early AD and differential diagnosis is an absolute requirement.2,9 The lack of standardized diagnostic criteria turned the AD and MCI diagnosis into a complex problem, generating an important underdiagnosis.3,11,12
Our studies in this field are based on neural computation approaches. Our proposal applies a hybrid artificial neural network (ANN) to two classification tasks, a binary and a multiclass one: the differential diagnosis of AD and MCI, and the separation of CN, MCI, and AD subjects.
Many studies have employed deep learning (DL) and different ANN for facing this kind of binary classification, but typically using neuroimaging, such as magnetic resonance imaging (MRI) and positron emission tomography (PET).14,17,13,15,16,18 Less common are both the multiclass models19–21 or the prognosis or longitudinal approaches, where the progression of CN subjects to MCI or from MCI to AD is studied.22,23 In recent years, there is a predominant use of deep neural network (DNN),20,24,17,16,18 but also a great variety of ANN26,28,27,25 or even other mathematical methods 29 have been proposed. While effective, they often rely on invasive or costly criteria, limiting their primary care usage. 24 Approaches based on non-neuroimaging techniques normally have similar performance but have been less frequent in the last decade. 8
The main goal of this paper is twofold: to provide intelligent and effective computational solutions to aid in the classification of not only AD versus MCI subjects, but also CN versus MCI versus AD subjects. Our study presents a hybrid neural architecture called modular hybrid growing neural gas (MyGNG) for both classification tasks. This intelligent system facilitates early diagnosis and clinical decision-making across settings, particularly in primary care. 27 Finally, for each of these tasks, a comparative study of the performance of our ontogenetic neural architecture and several popular neural and non-neural machine learning (ML) models was included.
Dataset and method
Dataset
As two different classification problems were tackled in this work, two datasets were required, which will be described separately. They were built with data from the ADNI database. 1 Since 2003, ADNI, as a public–private partnership, has been providing a huge database where many medical tests from different patients have been collected over long periods of time. At the same time, ADNI has been studying comprehensively AD-related omics and imaging. 30 The main goals of ADNI are the early-as-possible diagnosis of AD, and to help improving its prevention, intervention, and treatment by finding new and reliable diagnostic techniques. 27
In order to facilitate more adequate comparisons with some previous works,27,25 the same dataset was used for the MCI-AD binary classification task. The first dataset comprised 345 MCI and 150 AD patients, that is, a total of 495 subjects, who started their participation in ADNI from the ADNI2 study. The “ground truth” label of these participants was given by clinicians following an exhaustive diagnosis criterion indicated by ADNI. Data from the baseline were utilized. The number of characteristics extracted for each subject was 211, which included demographic information, neuropsychological tests and their items, brain measurements obtained via MRI and PET, genetics, and other biomarkers.
The second dataset used in this work comprised 229 CN, 402 MCI, and 188 AD subjects, that is, a total of 819 patients. These participants belonged to the ADNI1 study and, similar to those in the previous dataset, they met an exhaustive diagnosis criterion given by ADNI. Data from the baseline were also used. An identical number of characteristics of the same modalities was extracted for each subject.
Method
Both classification tasks related to the early diagnosis of AD have been addressed in this work with neural computing methods, more specifically based on the GNG, 31 an ontogenic ANN. Ontogenetic neural architectures are ANN able not only to modify their connections during learning, as the rest of ANN, but also to automatically adjust their topology to the problem.32,33,25 Due to these characteristics, they are quite suitable for clustering, vector quantization and data visualization.33,25
In this work, we have used a two-module hybrid neural architecture named MyGNG, which is a simpler and improved version from the one that was introduced in Sosa-Marrero et al. 27 The MyGNG has two main modules, Figure 1: the first one is built with an unsupervised, self-organizing, and ontogenetic module, which was based on Fritzke’s GNG, 31 whereas the second module was based on a supervised neural architecture as is the perceptron.34,35

Structure of the MyGNG, where
MyGNG is hierarchically organized the way it is on purpose: first the data clustering and later the data labeling. The reason for doing the clustering, which other classifiers do not do, is to simplify the input space by projecting it to other reduced dimensions while preserving its topology in order to ease the classification done later by the labeling module. Apart from the expected increase in performance, it may also bring along decreased training times, as it also happens in other hybrid architectures such as the counterpropagation network. 19
These modules learn sequentially. That is, the training of the MyGNG is done in cascade: the second module (named “Supervised” in Figure 1) uses for its training the labels of the data and the output of the first module (named “GNG”) after this one has been trained.
In Figure 1, the structure of this improved MyGNG is depicted, with the input layer and its two sequential modules. The colors of the neurons indicate where two biologically related processes have happened (blue is the base one, and it is used for neurons that are adapting to the input data): neurogenesis and neural apoptosis. Green neurons represent new neurons, that is, they have been recently created (i.e. neurogenesis) where the GNG algorithm is considered more convenient (i.e. between the neuron with the greatest error and its neighbor with the greatest error). These green neurons require that the old connections be deleted (red lines) and new connections be created (green dashed lines). Conversely, red neurons are those that have been removed (i.e. neural apoptosis), which occur after all connections to them have been deleted.
The main difference between the improved MyGNG presented in this work and the original one in Sosa-Marrero et al. 27 is how the “Supervised module” is built, which will be explained later in (4). This module has now less complexity as it is based on a perceptron instead of the complex “Supervised module” of the original MyGNG, which made use of neural neighborhoods. 27 These neural neighborhoods are unnecessary and, hence, not used in the improved MyGNG introduced in the current work.
Regarding the first module of the MyGNG presented in this work, in Fritzke,31,33 the GNG is described as a self-organization map based on a dynamic graph of connected neurons. Starting from a low number of interconnected neurons, this graph will adapt, shrink, and grow, hence producing topological learning that will allow clustering of the input space. This generation and continuous update of the graph is made by a competitive learning algorithm,
36
where the winner neuron
2

A local error variable is calculated for the winner neuron in each iteration (2). This error is related to the neurogenesis (i.e. the creation of a neuron) process because it allows identifying regions where the input signals are not sufficiently correctly represented. That is, a new neuron needs to be inserted between the unit

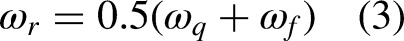
The responsible of the hybrid character of this MyGNG is the addition of a monolayer-perceptron-based output module (supervised learning) after the GNG-based one (unsupervised learning). The learning process of the perceptron is given by the “Perceptron rule” shown in (4), which indicates how the weights are updated.
35
In this equation, Create two neurons, Extract a sample Find All connections to Increment the local error variable of Move The age of the connection between Neural apoptosis: after removing all connections whose Neurogenesis (3): every Decrease all error variables. Go to Step 2 if the stopping criterion (e.g. epochs, performance metric, size of the network, etc.) of the GNG is not met yet. In our case, it is the epochs or number of times all the input samples are used for training the GNG. Obtain an output from the GNG and the associated class label (i.e. the expected output of the perceptron). Update the weights of the perceptron (4). Go to Step 12 if the stopping criterion of the perceptron is still not met. In our case, it is the epochs used for training the perceptron.
Regarding the computational complexity of the MyGNG,


MyGNG for the early diagnosis of AD
The intelligent hybrid system presented in this work is formed by two stages: a preprocessing one followed by a processing one. This system is considered hybrid because the first stage is non-neural whereas the second one is based on an ANN. The first stage comprised the next processes: imputation of missing values, feature ranking, data scaling, and data projection. The imputed, scaled, and projected data derived from the features that were ranked formed the input of the processing stage, which was based on the MyGNG.
Our system was mainly implemented with Python 3.10 and Tensorflow 2.10. Some preprocessing steps were implemented with “scikit-learn,” a library for ML. 38
In this work, two classification problems related to the early diagnosis of AD were studied, which will be analyzed separately in the “MCI versus AD” and “CN versus MCI versus AD” sections. For the global assessment of the intelligent computing system, the most common performance metrics in medicine, such as specificity, sensitivity (or recall), precision, and accuracy, were used.
28
Due to their adequacy for clinicians, both variants of the less popular metric clinical utility index (CUI) were also utilized
39
: CUI+ and CUI
In each of these two classification tasks eight different scenarios were studied, which asked the following three questions: “is the addition of AGE, a demographic data which is considered a risk factor in AD, 2 to the feature set beneficial to improve the classification performance?”, “is it better to project the data with 3 or 4 components?”, and “does scaling these datasets in the robust way provide an advantage over using the standard one?”
MCI versus AD
Before the input data were provided to our neural architecture and the other ML models which were later compared with, data required to be conveniently preprocessed. Imputation of missing values, feature ranking, data scaling, and data projection were four processes that needed to be carried out on our data before the processing stage. Thanks to them, the final datasets lacked missing values, the scales of all the features were in similar ranges, and their number decreased. This way, the original datasets were represented by a higher quality subset of features that will allow the models to require less training times and achieve better performance results. 41 As these preprocessing steps were not exactly identical for each classification problem, they will be described separately.
Missing values are generally considered a big handicap for most ML models. Due to the presence of missing values in several patients and attributes of our dataset, some imputation methods were analyzed: leaving the missing values untouched, discarding the participants with missing values in one of the used features, substituting the missing values with the median value for the class of that sample, idem but with the mean, and similar but with the mode. Imputing with the median value per class was deemed more robust and also produced the best results so it was finally selected for further usage.
Feature selection or ranking was performed due to the large number of attributes per subject, 211, in the MCI-AD dataset. As missing values were handled, this number remained identical for all participants. Two techniques were evaluated: Extreme Gradient Boosting (XGBOOST) 42 and fast correlation-based filter (FCBF). 43
XGBOOST is a scalable tree ensemble method that, as a byproduct, also generates a ranking of the features. Unlike FCBF, redundant features are never discarded internally, which results in rankings including more than one feature providing similar information. Hence, feature ranking with XGBOOST was considered of lower quality, and the one done with FCBF was preferred.
In Yu and Liu, 43 the hybrid filter and wrap feature selection method named FCBF was introduced. Based on symmetric uncertainty, which finds not only the correlation between features and categories but also the redundancy between the features, FCBF only selects features that are highly correlated to categories and, at the same time, lowly correlated to other features. This way, calculation efficiency, and hence speed, is enhanced, thus improving the recognition rate. 27 In Yu and Liu, 43 FCBF demonstrated its good ability to identify redundant features in several difficult datasets after being able to reduce their dimensionality more than other methods.
A vector of the most adequate features for the MCI-AD classification task according to FCBF (i.e. those with the highest FCBF scores) was obtained. Thanks to this, the number of features was vastly reduced from 211 to 6, Table 1 and Figure 2. These six features derived from three neuropsychological tests: four from the mini-mental state examination (MMSE), 44 one from the Alzheimer’s disease assessment scale-cognitive subscale, 45 and the last one from the functional activities questionnaire (FAQ). 46
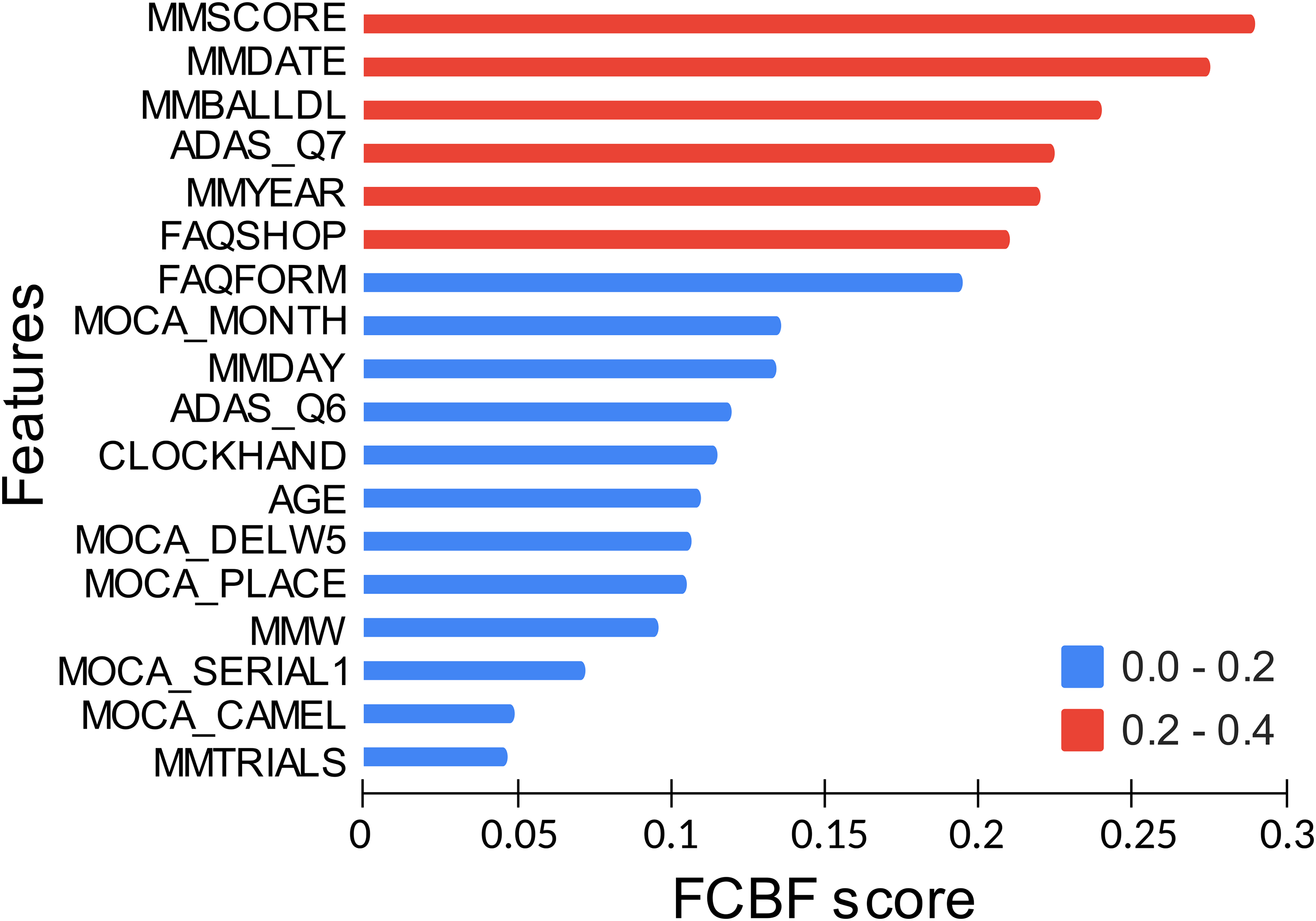
Ranking of features according to the FCBF method for MCI and AD subjects from ADNI2. FCBF: fast correlation-based filter; MCI: mild cognitive impairment; AD: Alzheimer’s disease; ADNI2: Alzheimer’s disease neuroimaging initiative 2.
Characteristics of the subjects: A demographic feature, and the six attributes used by the model as input, sorted according to their FCBF score.

FCBF: fast correlation-based filter; AD: Alzheimer’s disease; MCI: mild cognitive impairment; StD: standard deviation.
Scaling of the data was tested by applying several methods: not scaling the data, standard scaling (by removing the mean and scaling the data according to the standard deviation; the most popular method), and robust scaling (similarly, but with the median and the interquartile range, respectively, more robust to outliers). Unlike in Sosa-Marrero et al. 27 and Cabrera-León et al., 25 where using no scaling method was preferred, in our case both standard and robust scaling were studied and, as shown later, they provided similar performance, albeit the former was more beneficial for the MyGNG.
Unlike in Sosa-Marrero et al. 27 and Cabrera-León et al., 25 where principal component analysis was applied,48,47 in this work neighborhood component analysis (NCA) was utilized for data projection, although it can be used for classification too. 49 NCA is a supervised method aimed at finding the best input data projection or linear transformation for a stochastic nearest neighbors rule to yield the best classification accuracy in the transformed space, without assuming that the data have a parametric structure in the low-dimensional representation. 49 Among the methods for the initialization of the linear transformation in the NCA that were analyzed, “identity” was considered the most adequate option because similar ranges of values of the components were obtained in all the eight scenarios that were studied.
The stratified K-folds cross-validation method, with five folds as it kept the same training-test subsets proportion used in Sosa-Marrero et al. 27 and Cabrera-León et al., 25 was utilized for data partitioning. Its main advantage is that it keeps an identical proportion of samples for each class in all the folds. It was used by not only the MyGNG, but also the ML models studied in the “Comparative studies with ML models” section.
Several sets of values were given to the hyperparameters of the MyGNG in order to find the optimal combination. Two combinations were found of interest: one when 3 PCs were used and one when 4 PCs were used. For each of them, the same combination was found optimal when AGE was added to the feature set. Hence, for the 4 PCs scenario, with and without the AGE feature, the values of the hyperparameters for the GNG module were: training during eight epochs, 75 was the maximum number of neurons, five was the maximum age of any connection, 50 was the number of iterations before a new neuron is created, the learning rates
Performance results of the MyGNG in each of the eight scenarios studied (MCI-AD classification task).

MyGNG: modular hybrid growing neural gas; MCI: mild cognitive impairment; AD: Alzheimer’s disease; Accu: accuracy; AUC: area under the curve; PC: principal component; Sens: sensitivity; Spec: specificity.
The best values of the different performance metrics are highlighted in bold.
In order to do a brief qualitative comparative study, several articles from other authors that dealt with the MCI-AD binary classification task and made use of data from ADNI were selected from the existing literature, Table 3. It showed that our MyGNG sometimes yielded better performance results than proposals from other authors, despite not only using non-expensive, non-invasive, non-ionizing, and easily applicable diagnostic criteria, such as neuropsychological scales, but also the MyGNG not being based on DNN, whose performance is generally considered superior and have been considered the state-of-the-art for the last years. 8 For example, MyGNG was outperformed by Hosseini-Asl et al. 15 and Rashid et al., 16 which obtained above 0.98 accuracy with convolutional neural network (CNN) or variants. On the other hand, similar or worse results were reported in Basaia et al., 13 Song et al. 18 and Urooj et al., 50 especially sensitivity ones as low as 0.68.
Comparison with works from other authors that used ADNI data and dealt with the MCI-AD or the CN-MCI-AD classification tasks.

ADNI: Alzheimer’s disease neuroimaging initiative; MCI: mild cognitive impairment; CN: cognitively normal; AD: Alzheimer’s disease; 3D: three-dimensional; CNN: convolutional neural network; Accu: accuracy; APOE: apolipoprotein E; AUC: area under the curve; CSF: cerebrospinal fluid; DSA: deeply supervised adaptable; fMRI: functional magnetic resonance imaging; MyGNG: modular hybrid growing neural gas; NT: neuropsychological tests; PET: positron emission tomography; pMCI: progressive mild cognitive impairment; qMRI: quantitative magnetic resonance imaging; RVFL: random vector functional link; SaDE-WNN: self-adaptive differential evolution wavelet neural network; SAE: stacked auto-encoder; Sens: sensitivity; sMCI: stable mild cognitive impairment; sMRI: structural magnetic resonance imaging; SNP: single nucleotide polymorphism; Spec: specificity; EMCI: early mild cognitive impairment; LMCI: late mild cognitive impairment; RF: random forest; SVM; support vector machine; kNN: k-nearest neighbor.
CN versus MCI versus AD
Except for the feature selection, the same preprocessing techniques used in the binary dataset were applied to the multiclass one.
This feature selection process began with the ranking of the features with the FCBF method and keeping those with the highest FCBF score for this classification task. This is equivalent to what was done for the MCI-AD task and was described in the “MCI versus AD” subsection. The features ranked by FCBF were in this order, from greater to lesser significance: [“ABETA,” “MMDATE,” “AGE,” “MMDAY,” “CLOCKTIME,” “MMMONTH,” “MMFLOOR,” ‘’NPIG,” “MMHOSPIT,” “MMYEAR,” “MMREAD”]. That is, a cerebrospinal fluid (CSF) value that measures the amount of the amyloid beta (Abeta) biomarker, seven subscores of the MMSE test, an item of the clock drawing test, a subscore of the neuropsychiatric inventory scale, and the age of the patient. In this ranking, ABETA had an FCBF score of 0.4, whereas the second one, MMDATE, 0.15, and the rest, lower than 0.13.
A refining process of this feature set was carried out in order to reduce its size while trying to improve its quality for the multiclass task, which implied selecting other features. This refining process was iterative, one feature at a time, and its goal was to find a new set of features that ensured higher inter-class and lower intra-class distances than the set of features already marked as optimal, starting from the one based on the FCBF ranking. The final set, which was subsequently used to create the input vector of our neural computing system, should be the one where the samples from the same class remain near whereas higher distances exist between those from different classes. This extra process was carried out because of the higher complexity of the task due to being multiclass.
For this refining process, several information on the features were taken into account. Before adding a feature from the available ones, its biological relevance was analyzed according to AD-related clinical bibliography,51,52 and its adequacy for the diagnostic problem addressed by means of analyzing descriptive statistics (mean, standard deviation, and interval), and clustering quality metrics (Silhouette, Davies–Bouldin, and Calinski–Harabasz scores).53–55 Conversely, for the discarding of a feature, only the latter two sources were used. After the refining process, the optimal feature vector for this classification task is obtained.
The final set of features comprised, Table 4: a demographic data, a quantitative neuroimaging measurement that measures the volume of the ventricles, a CSF value that measures the quantity of Abeta, and the main scores of two neuropsychological tests (one of them and a subscore of the other were already used for the MCI-AD classification task). It should be noted that some of these features, such as the volume of the ventricles and the final score of the FAQ test, did not appear in the feature set obtained from the FCBF ranking as they were selected afterward during the iterative refining process. Also, all the subscores of the MMSE test were substituted with the total score. The AD-related bibliography was used to confirm if this final set of features was biologically relevant and could be extrapolated to other non-ADNI MCI and AD populations.
Characteristics of the subjects: The five attributes used by the model as input (AGE was used only in half of the scenarios).
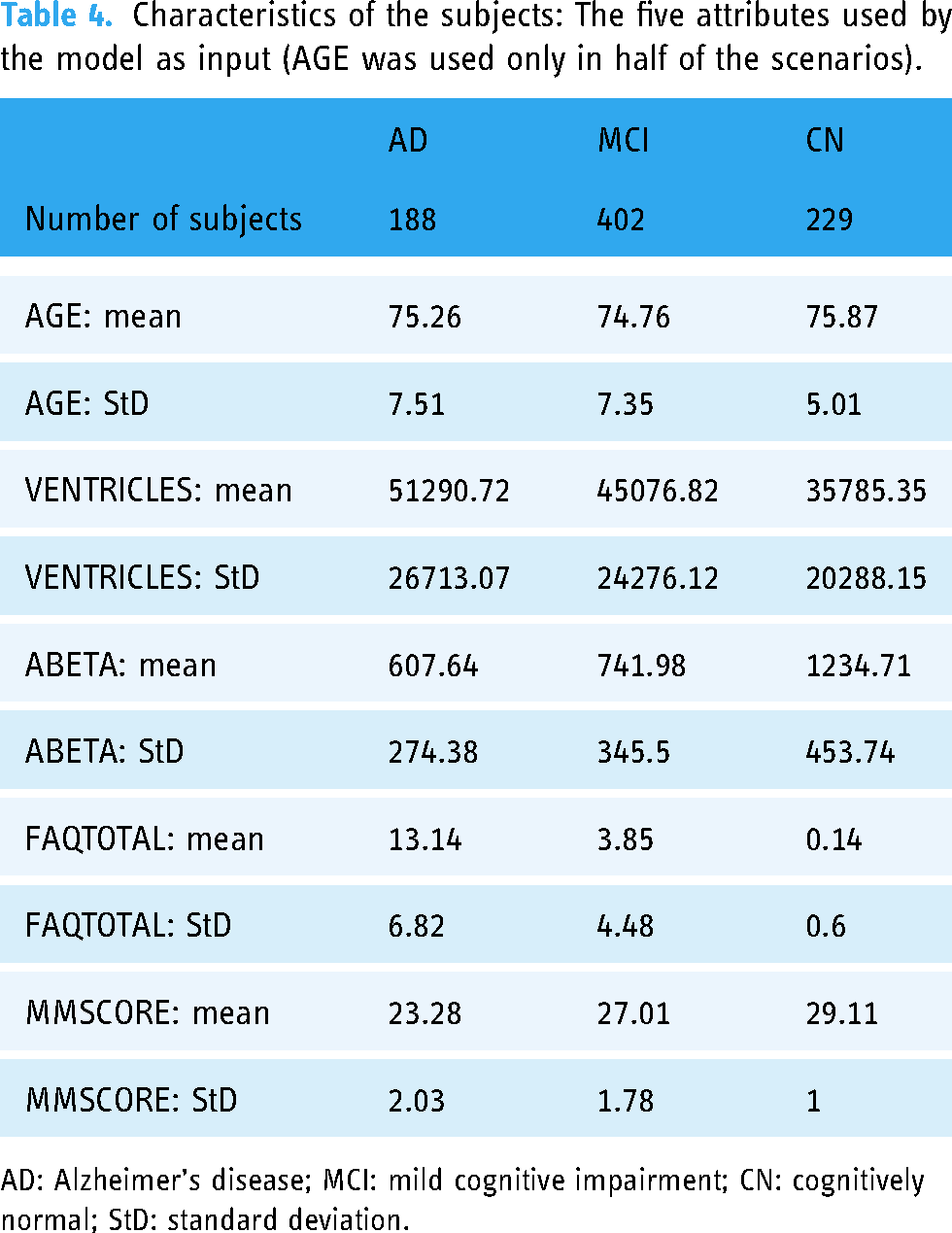
AD: Alzheimer’s disease; MCI: mild cognitive impairment; CN: cognitively normal; StD: standard deviation.
The same best combinations of hyperparameters of the MyGNG found in the “MCI versus AD” section, one when 4 PCs were used and another one when 3 PCs were used, were now tested in the CN-MCI-AD classification task. In Table 5, the performance results of the MyGNG in each of the eight scenarios that were studied are shown.
Performance results of the MyGNG in each of the eight scenarios studied (CN-MCI-AD classification task).
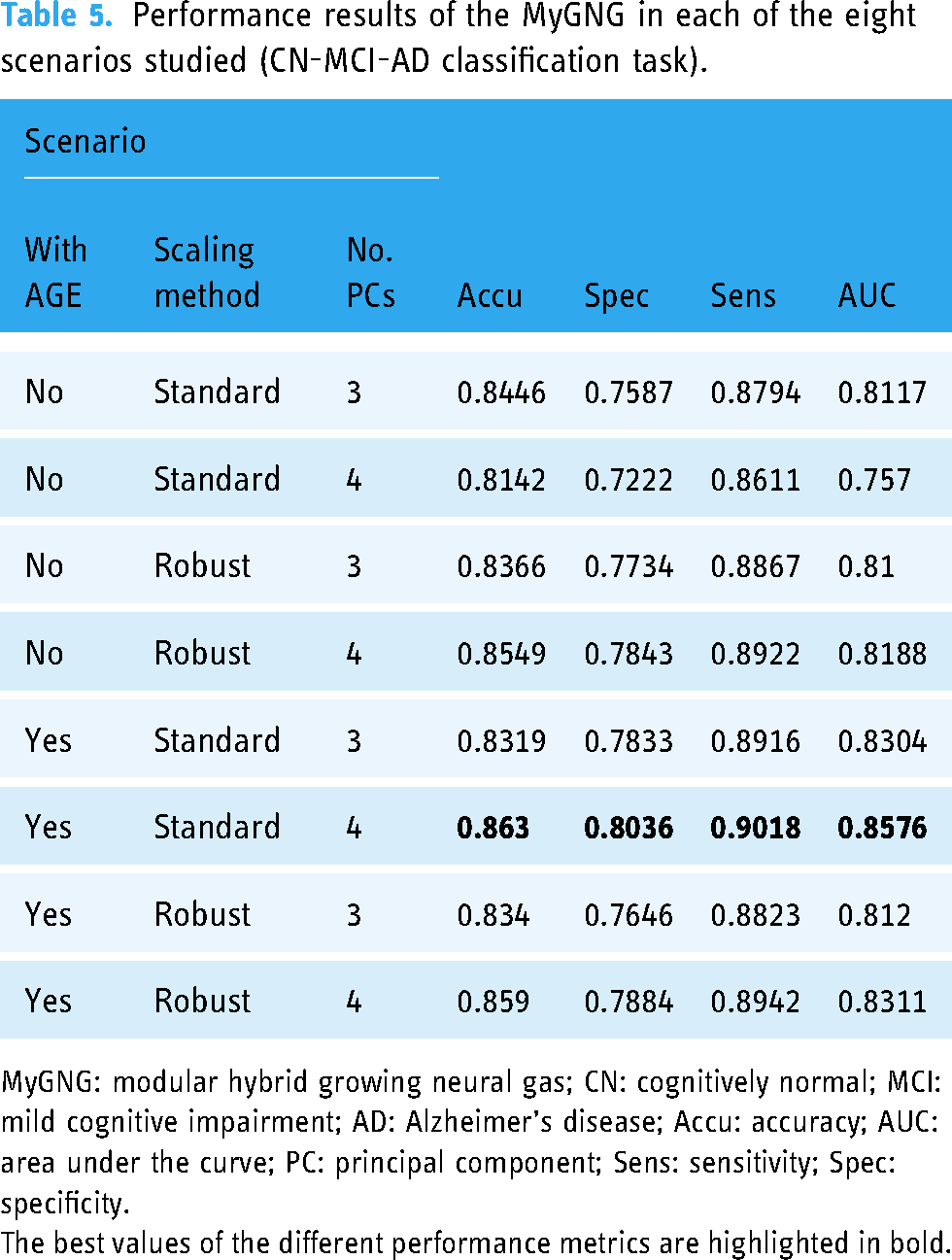
MyGNG: modular hybrid growing neural gas; CN: cognitively normal; MCI: mild cognitive impairment; AD: Alzheimer’s disease; Accu: accuracy; AUC: area under the curve; PC: principal component; Sens: sensitivity; Spec: specificity.
The best values of the different performance metrics are highlighted in bold.
Similar to what was done in the “MCI versus AD” subsection, some works from other researchers that tackled the CN-MCI-AD multiclass classification task and used data from ADNI were selected from the existing literature to qualitatively compare our method with, Table 3. Generally and as expected, performance results are lower than in the binary task. MyGNG yielded equivalent performance results, sometimes higher. Unlike in the binary task, our system made use of, apart from neuropsychological tests as in the binary task, quantitative neuroimaging and CSF. Those approaches that outperformed MyGNG varied from CNN variants (such as the VGG in Khan et al. 63 ) to non-monolithic approaches, such as modular methods that combined a CNN whether with an ensemble of random forest (RF) 61 or with an ensemble of random vector functional link (RVFL) networks plus a following module made from a single RVFL. 62
Comparative studies with ML models
For both classification tasks our ANN-based method, MyGNG, was compared with several popular supervised ML models: a decision tree (DT) (flowchart-like structure; easier to interpret than ANN), 64 a Naïve Bayes (NB) classifier (based on applying the Bayes’ theorem and assuming that the features are strongly independent given class), 65 an RF (an ensemble of DT, each trained with a random subset of features; the class that is returned is the one chosen by most DT), 64 a support vector machine (SVM) (builds an hyperplane usually in a high-dimensional space to separate classes; using certain kernel functions allow separation of non-linear data), 66 and a multilayer perceptron (MLP) (a feedforward ANN able to separate non-linear data, unlike the perceptron). 67
These ML models were implemented with “scikit-learn” and “Keras,” popular ML and DL Python modules, respectively.38,68 Best results were achieved by models with the following combinations of hyperparameters. For DT, Pruning = at least two instances in leaves; at least five instances in internal nodes; maximum depth = 100; Splitting: Stop splitting when majority reaches 95% (classification only); Binary trees: Yes for NB, scikit-learn’s default values. For RF, number of trees = 10; maximal number of considered features = unlimited; replicable training = No; maximal tree depth = unlimited; stop splitting nodes with maximum instances = 5. For SVM,
In Table 6, we compared the MyGNG performance results with those obtained by other popular ML methods in the scenario which was found optimal for the MyGNG: with AGE, standard scaling, and 3 PCs.
Comparison of the MyGNG and several popular neural and non-neural ML methods (MCI-AD classification task).

Accu: accuracy; AUC: area under the curve; CUI: clinical utility index; DT: decision tree; MLP: multilayer perceptron; MyGNG: modular hybrid growing neural gas; NB: Naïve Bayes; RF: random forest; Sens: sensitivity; Spec: specificity; SVM: support vector machine; ML: machine learning.
The best values of the different performance metrics are highlighted in bold.
A similar comparison can be found in Table 7 for the CN-MCI-AD classification task. In this case, the scenario that was considered optimal for the MyGNG was: with AGE, standard scaling and 4 PCs.
Comparison of the MyGNG and several popular neural and non-neural ML methods (CN-MCI-AD classification task).
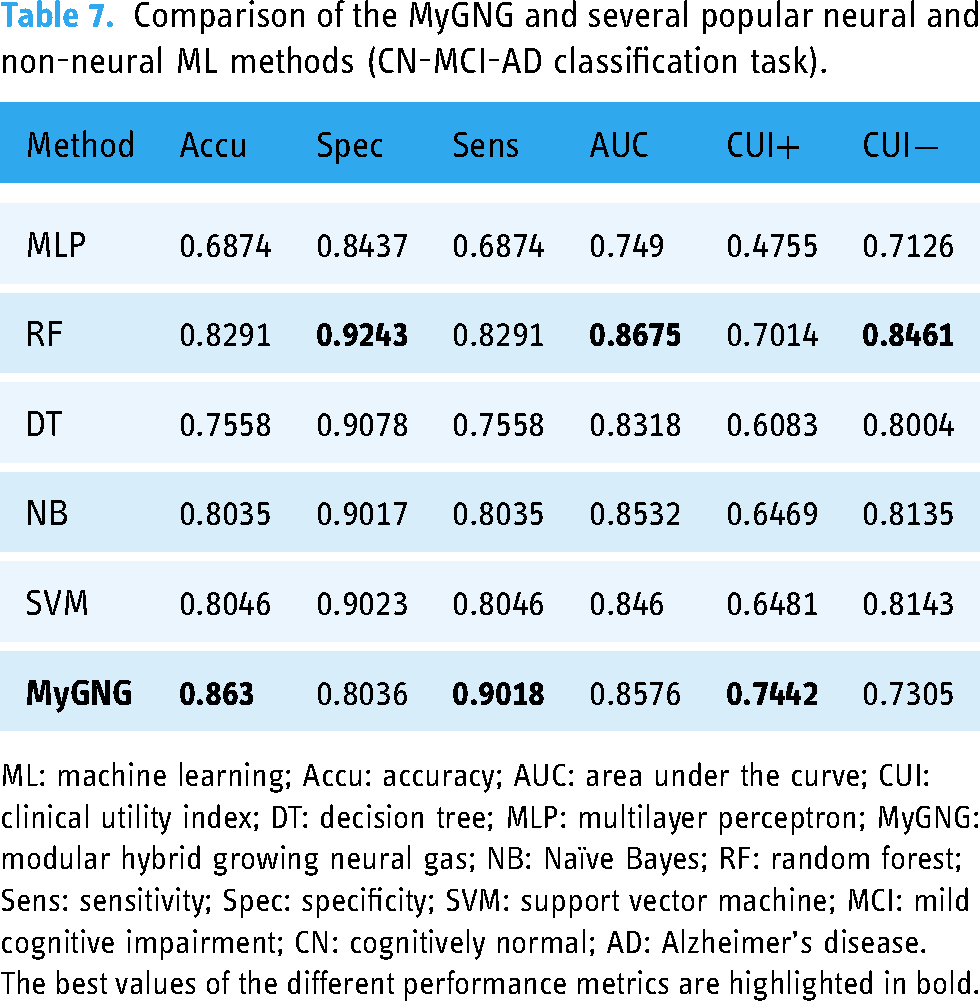
ML: machine learning; Accu: accuracy; AUC: area under the curve; CUI: clinical utility index; DT: decision tree; MLP: multilayer perceptron; MyGNG: modular hybrid growing neural gas; NB: Naïve Bayes; RF: random forest; Sens: sensitivity; Spec: specificity; SVM: support vector machine; MCI: mild cognitive impairment; CN: cognitively normal; AD: Alzheimer’s disease.
The best values of the different performance metrics are highlighted in bold.
Discussion
Throughout the “MCI versus AD” and “CN versus MCI versus AD” subsections it has been shown that our intelligent system based on the MyGNG is quite competent for both classification tasks related to the early diagnosis of AD, MCI-AD and CN-MCI-AD.
According to the eight different scenarios based on the three questions that we wanted to reply, the MyGNG considers beneficial data that have been scaled in the standard way, data that have been projected with 4 PCs, and adding AGE to the feature set. The latter occurred for the rest of ML algorithms as well, hence demonstrating the usefulness of also using this demographic information that is considered an AD risk factor.
Despite the fact that features obtained with neuroimaging techniques, mainly MRI, and CNN models, which are considered the state-of-the-art and prevalent combination, were used in all but one of the works found for MCI-AD and that used ADNI data,15,13,18,50,16 our MyGNG and neuropsychological tests combination performed better than some of them. Also, it required not only a fraction of the training time and computational power but also several orders of magnitude lower number of hyperparameters to tune. Taking into account the most reliable performance metric robust to class unbalanced datasets of those used in this work (i.e. AUC), the MyGNG was only outperformed by one of the ML models in CN-MCI-AD, Table 7, whereas it yielded the best values in MCI-AD, Table 6. In CN-MCI-AD, the winner ML model was an RF, a type of ensemble. Ensemble-based systems are generally considered more advantageous and powerful than single-expert systems, 69 as is the MyGNG. In addition to this, and according to our results, this gain existed but only occurred in the multiclass problem, which is more complex. In both classification tasks, the MyGNG yielded the highest CUI+ and sensitivity values. The latter indicates that it preferred to classify a subject as AD, the minority class, which is when more worrisome are the symptoms and more treatment is needed, something that is usually of interest to clinicians and health systems. On the contrary, the accuracy and specificity of the MyGNG were lower, values for the first metric might be explained by the class unbalanced dataset.
Our MyGNG was also compared with other ML models graphically presented by ROC curves, Figures 3 and 4. They showed that the MLP performed poorly in both tasks, whereas our MyGNG outperformed the others in the binary classification task, and all but one in the multiclass case. This is especially noticeable when the false positive rate (FPR) has higher values in both tasks and for almost any FPR values in the binary task. The rest of the ML algorithms behaved similarly to each other.
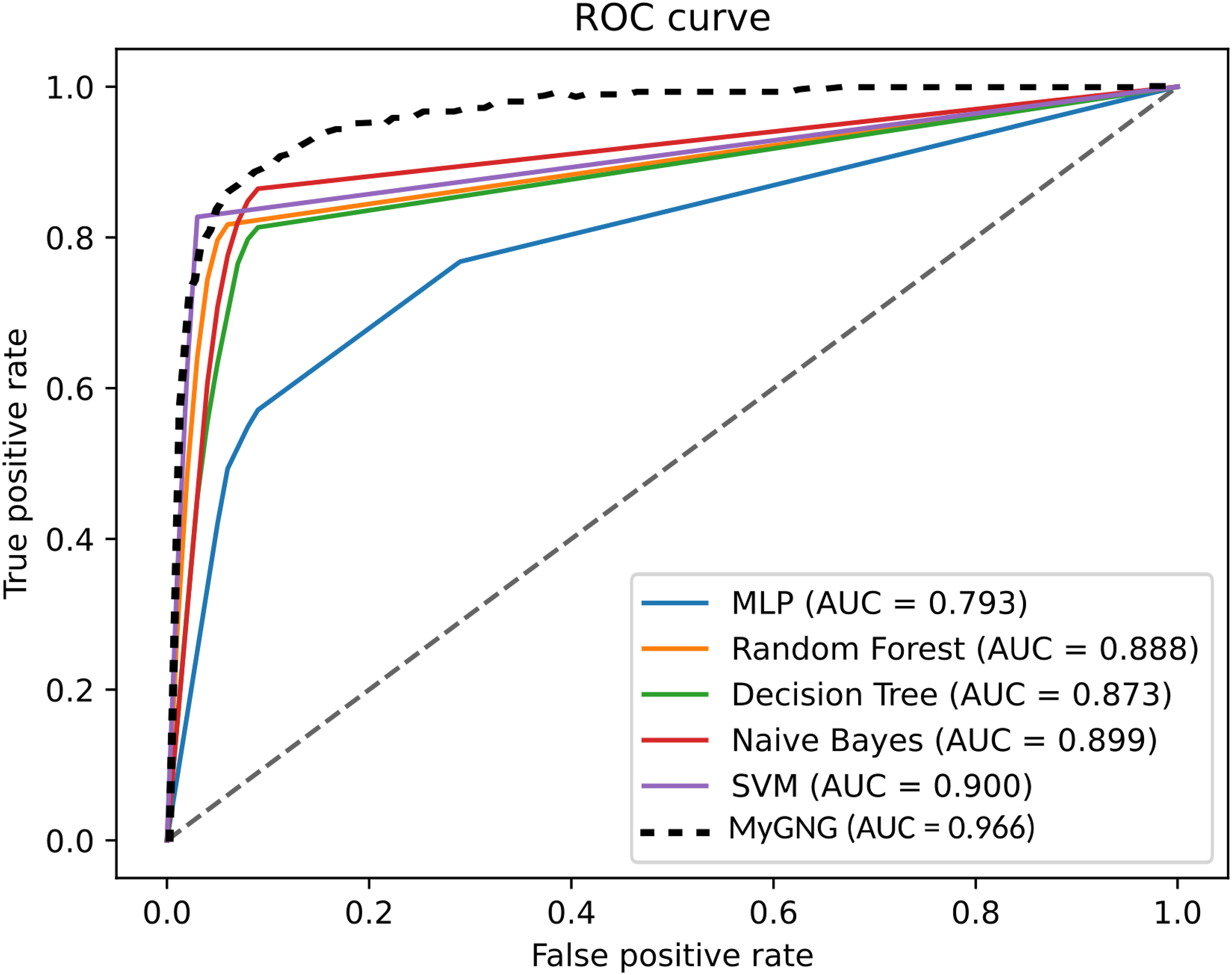
ROC curves of the MyGNG and the ML algorithms in the MCI-AD classification task. ROC: receiver operating characteristic; MyGNG: modular hybrid growing neural gas; ML: machine learning; MCI: mild cognitive impairment; AD: Alzheimer’s disease.

ROC curves of the MyGNG and the ML algorithms in the CN-MCI-AD classification task. ROC: receiver operating characteristic; MyGNG: modular hybrid growing neural gas; ML: machine learning; CN: cognitively normal; MCI: mild cognitive impairment; AD: Alzheimer’s disease.
Regarding the clinical relevance of our model, it is focused on primary care, albeit it can also be utilized in specialized one. The criteria that have been used are fast and non-expensive, even more so when in some cases the subscores of neuropsychological scales and not the total scores are required. As less time is needed for each patient, their quality of life might improve. On the other hand, performance results have been reported with the CUI metric, which measures the real clinical utility of diagnostic criteria so some authors consider it useful and relevant for clinicians.39,10 According to the interpretation in Mitchell,
39
MyGNG yielded CUI+ and CUI
This study has potential limitations. Regarding data, ADNI was the source of all the data we used, which might imply two shortcomings: a possibly reduced generalization to older populations from other regions, and the limitation to the cohorts/classes, modalities, and clinical criteria available in this database. Examples of these three limitations are: patients in ADNI have not been categorized within the AD continuum by means of Amyloid-Tau-Neurodegeneration (ATN) profiles (however, it could be possible with some of the criteria already available in ADNI 71 ); there is no optical coherence tomography angiography data; and several neuropsychological scales are unavailable). Unfortunately, no solution to these limitations is possible within ADNI unless ADNI procedures change, so other databases, probably private, would be required to surpass these shortcomings. About the method, MyGNG, although it can also be used in specialized attention, has been primarily focused on primary care, so it is currently unable to work with neuroimaging data unless they are in a quantitative format. Finally, our comparison with other authors’ works was limited, so a broader one will be of interest to researchers, especially if approaches based on non-neural methods are also included.
Conclusions
In this work, we have really improved the first proposal of the ontogenic ANN MyGNG, by just changing the supervised module for a simpler one, nothing more than a perceptron algorithm scheme. We have analyzed the behavior of the improved MyGNG in two classification tasks related to the early diagnosis of AD: MCI-AD and CN-MCI-AD. According to our results, this MyGNG proved to be a better computational solution than the other ML algorithms that were compared with and was only slightly outperformed by an ensemble method, an RF, in the multiclass task regarding some of the used performance measurements. Additionally, in both tasks, qualitative comparisons with proposals from other authors delivered surprising results, as most of them were DL-based and made use of data from neuroimaging techniques, the state-of-the-art. In MCI-AD, some of those works were outperformed by our MyGNG combined with only six features derived from three neuropsychological tests. Similarly happened in CN-MCI-AD with demographic data, a quantitative neuroimaging measurement, a CSF value, and two neuropsychological tests.
The main contributions of this work can be grouped into clinical and computational. In the first group, there are several. Our dataset is built with features obtained with non-invasive modalities, that are fast to collect. Another increase in speed in the data-gathering process is obtained thanks to the usage of subscales instead of the total score of the neuropsychological scales. A major advantage of our system is its low complexity, so it is convenient for both primary and specialized care and can be used not only in hospitals and medical sites but also in sociosanitary institutions. In the second group, our system is based on a new neural architecture, the MyGNG. This neural architecture is an ontogenic ANN so it is more adaptive to the space of the problem because it is also able to modify its structure, adjusting more and better to that space. Furthermore, a faster learning is enabled by its hybrid nature. On the other hand, the MyGNG has outperformed several DL approaches in the same classification tasks. Non-deep solutions as the one presented in this work have several times fewer parameters to configure, train a lot faster, and do not require expensive and complex hardware for the training process to be done in a reasonable time. Moreover, due to its modular design, it is possible for both modules in the MyGNG to learn dynamically. Finally, as with other methods, MyGNG can be integrated into eHealth systems, allowing its online use.
Regarding future works, the MyGNG tackling other classification tasks will be worthwhile. Further analysis of the features and preprocessing techniques may be helpful in these classification tasks, and probably mandatory with others. More complex ontogenetic neural architectures may arise, which will be more powerful and might perform optimally in these tasks. Other technical advances can also be incorporated such as better validation frameworks and faster computing, among others.
Footnotes
Acknowledgement
ADNI is funded by the National Institute on Aging, the National Institute of Bio-medical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol- Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; Euro-Immun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support several ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (![]() ). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. Data from ADNI are disseminated by the Laboratory for Neuro Imaging at the University of Southern California. We also want to thank Alberto Sosa for providing us with his Bachelor’s thesis, which was the base of this work. Finally, we want to thank the Editor and the reviewers for their valuable comments, which helped us improve this work.
). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. Data from ADNI are disseminated by the Laboratory for Neuro Imaging at the University of Southern California. We also want to thank Alberto Sosa for providing us with his Bachelor’s thesis, which was the base of this work. Finally, we want to thank the Editor and the reviewers for their valuable comments, which helped us improve this work.
Contributorship
YCL contributed to experimental developments, original draft preparation, and English revision. PFL contributed to methodology, experimental developments, supervising the literature collection, and draft revision. PGB contributed to the structure of the paper, supervising the literature collection, and draft revision. KK contributed to experimental developments. JLNM contributed to comments on the used machine learning models and the final draft revision. CPSA contributed to conceptualization and ideas, experimental development revision, project administration, funding acquisition, and writing—review and editing.
Consent to participate
ADNI indicates that volunteers are required to provide written informed consent to participate.
Consent to publish
Not applicable.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data used in this work were obtained from the ADNI repository, which imposes some restrictions on public data access and sharing.
Ethics approval
ADNI studies were conducted according to, among others, Good Clinical Practice guidelines, and pursuant to US state and federal regulations. Regarding ethical standards, the ADNI protocols were approved by all the Institutional Review Boards of the participating institutions. Only data from volunteers who had provided written informed consent were used to complete these analyses.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Consejería de Gobierno de Vicepresidencia Primera y de Obras Públicas, Infraestructuras, Transporte y Movilidad del Cabildo de Gran Canaria under Grant Number 23/2021. The collection and sharing of the data used in this project was funded by the ADNI (National Institutes of Health Grant U01 AG024904) and DOD Alzheimer's Disease Neuroimaging Initiative (Department of Defense award number W81XWH-12-2-0012).