
Abstract
Objectives
Cardiovascular Disease (CVD) remains one of the leading causes of global mortality, accounting for millions of deaths annually. Early and accurate diagnosis plays a critical role in reducing mortality and healthcare burden. However, conventional diagnostic approaches often suffer from misdiagnosis, delayed treatment, and increased medical costs. Machine Learning (ML) has shown significant potential in supporting clinical decision-making for early CVD detection. Nevertheless, ML models often face challenges such as computationally expensive parameter tuning and susceptibility to local minima. This study aims to address these challenges by proposing a bio-inspired optimization framework to enhance diagnostic accuracy and efficiency.
Methods
This study employs Bacterial Colony Optimization (BCO) to optimize the hyperparameters of ten machine learning classifiers: Logistic Regression, Support Vector Machine (SVM), K-Nearest Neighbors, Multilayer Perceptron, Naïve Bayes, Random Forest (RF), Decision Tree, Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine, and AdaBoost. Principal Component Analysis (PCA) is integrated to handle feature dimensionality and multicollinearity. Experiments were conducted using the Cleveland Heart Disease dataset (CLE) and the IEEE DataPort dataset (HGR), applying a rigorous 5-fold Cross-Validation (CV) strategy to ensure reliability and stability.
Results
Experimental findings demonstrate that the integration of PCA, BCO, and ML classifiers significantly improves prediction performance compared to baseline models. The BCO-optimized RF model achieved the highest mean accuracy of 92.02% (95% CI: 89.93–94.10) on the HGR dataset, outperforming the baseline accuracy of 91.26%. Similarly, the BCO-SVM model achieved a mean accuracy of 85.79% on the CLE dataset. Confidence interval analysis further confirmed enhanced model stability and reduced prediction variance.
Conclusion
The proposed framework effectively enhances CVD diagnosis by improving classification accuracy and stability. By efficiently exploring the search space and mitigating local minima limitations, the framework provides a statistically robust and clinically reliable decision-support tool for early cardiovascular risk detection.
Keywords
Introduction
Cardiovascular Diseases (CVDs) comprise all the conditions that affect the heart’s normal functionality and its coronary vessels. It leads to the interruption of the blood circulation. CVDs are responsible for a significant portion of deaths globally, currently affecting almost 26 million people throughout the world, and the number continuously rises every year. 1 Over the past few decades, according to the World Health Organization (WHO), the prevalence of CVDs has grown substantially, and they are now responsible for 32% of global fatalities, with heart attacks and strokes responsible for the majority (85%). 2 In the United States, for example, heart disease continues to be the leading cause of death for people of all genders and from all racial and ethnic origins. It is alarming to consider that in the US, every 33 seconds a person dies because of CVDs. 3
The rise in CVD patients causes a significant burden on the healthcare infrastructure globally. 4 As a result, it is imperative to start treatment and counseling promptly by early identification of CVDs. The risk factors of causing CVDs include poor nutrition, inadequate exercise, obesity, diabetes, and alcohol consumption and cigarette smoking. 5 CVDs detected in the advanced stage result in major surgeries like angiography or bypass surgery, which can be painful for individuals. Age, sex, family history of cardiovascular diseases, blood pressure, cholesterol, and diabetes all have an impact on the prognosis of heart disease. 6 Additionally, a number of contributory factors, including hypertension, arrhythmia, and hyperlipidemia, make it difficult to diagnose early heart disease signs. 7 The creation of sophisticated CVD detection systems has been fueled by the urgent need for early CVD identification and the reduction of heart disease related fatalities. Artificial Intelligence (AI) enhances the healthcare system by making it possible to diagnose diseases earlier, saving lives. 8 Compared to traditional techniques, these intelligent systems not only enhance the detection process but also lower human error. These intelligent systems are capable of accurately predicting cardiovascular problems by examining patients’ medical data and establishing correlations between different health characteristics. 9
In the field of healthcare, ML has significant transformational potential. Its exceptional ability to analyze vast amounts of data, which exceeds human analytical capabilities, is partly responsible for its impressive advancement.10,11 With the speed and accuracy of machine learning, this capacity has enabled the creation of a plethora of AI driven applications for healthcare that provide creative answers to a range of clinical problems. A number of ML approaches have been exploited to identify cardiovascular conditions, and some of the predictive models face some issues that need to be addressed. Imbalanced datasets frequently lead to biased predictions. 12 Researchers have investigated hybrid approaches, which combine many methods, such as neural networks and other machine learning algorithms, to improve prediction accuracy and solve the difficulties. These studies provide valuable information, but the diversity of datasets, approaches, and results emphasizes how difficult this prediction task is. Alongside these advancements, further study is necessary to improve the efficacy of the models now in use in the prediction of cardiovascular disease. The wide range of ML applications in this field emphasizes the significance of doing further research in order to improve the precision, dependability, and generalizability of predictive models, which will eventually lead to better patient care and therapeutic interventions.13–16
The use of Deep Learning (DL) and ML in the prediction of CVDs is essential to modern healthcare because these methods can greatly increase the precision of risk factor identification, aid in the early detection of possible complications, and make it easier to create individualized treatment plans. Such technologies improve patient outcomes and lessen the burden of disease by facilitating prompt and proactive medical treatments. As a result, a great deal of study has been done to investigate and identify the best techniques for heart disease prediction.
Comparative summary of state-of-the-art studies in cardiovascular disease prediction.
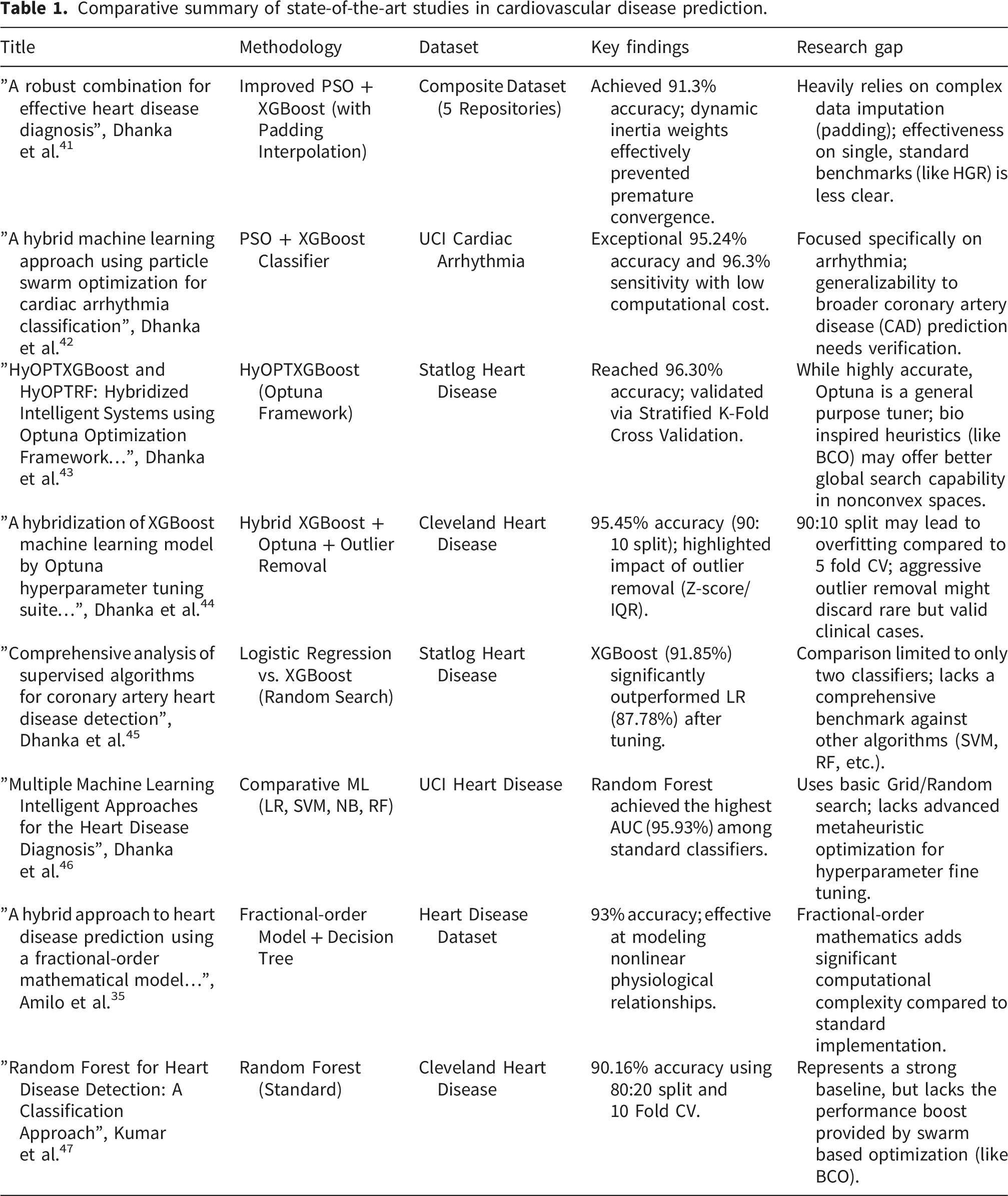
The field of medical diagnostics is quickly moving toward intelligent hybrid systems that blend sophisticated optimization methods with machine learning. According to a thorough analysis demonstrated in Ref. 48, feature selection and hyperparameter tweaking done simultaneously can increase diagnosis accuracy by 12 – 15% when compared to sequential approaches. Cardiology is not the only field seeing this trend; endocrinology and reproductive health are also seeing comparable developments. In order to manage complicated biological data, optimization techniques such as GA, and PSO are increasingly being used, as seen by recent studies on psoriasis prediction and hormonal diseases.49,50 In order to represent nonlinear biological dynamics, novel techniques in In Vitro Fertilization (IVF) have even started combining Artificial Neural Networks with Fractional Order Models (FOM). 51 The study in Ref. 52, exploits a Hybrid ML approach with Fractional Calculus for predicting diabetes risk. Hyper Tuned RBF SVM is exploited to detect breast cancer in Ref. 53.
However, significant difficulties arise as these models get increasingly intricate. One significant issue is the “fairness-accuracy trade-off.” An attempt to increase demographic fairness frequently results in a slight decrease in overall model accuracy, as stated in a recent systematic study of bias in AI. 54
Current research establishes that integrating ML with sophisticated optimization approaches is essential for enhancing the precision of CVD prediction. While previous studies have investigated a variety of feature selection techniques, swarm intelligence algorithms, and ensemble models to improve diagnostic performance, a critical gap remains. Achieving consistently high accuracy across heterogeneous datasets while preserving computational economy is a persistent challenge, often due to the tendency of standard algorithms to trap in local optima. Motivated by the need for a clinically dependable tool, this study utilizes Bacterial Colony Optimization (BCO) to optimize the hyperparameters of 10 distinct ML classifiers. This approach not only maximizes predictive power but also guarantees a robust, efficient framework capable of supporting reliable decision making in real world heart disease diagnosis.
According to current research, ML and sophisticated optimization approaches have the potential to increase the precision and effectiveness of CVD prediction. In order to improve diagnostic performance, previous research has investigated a variety of feature selection techniques, swarm intelligence algorithms, and ensemble models. Finding consistently high accuracy across many datasets while preserving computational efficiency is still difficult often due to the tendency of standard algorithms to become trapped in local optima. Motivated by the need for a clinically dependable tool, the current study uses BCO to optimize the parameters of 10 ML classifiers. This improves the classifiers’ predictive power and guarantees a more dependable and effective framework for the prediction of heart diseases.
Considering the increasing prevalence of CVDs around the world, creating precise and effective prediction systems is crucial. The traditional ML approaches show promising results; however, their efficacy mostly relay on choosing the best parameters, which may be difficult given the complexity and diversity of medical data. The large dimensionality and intrinsic multicollinearity of medical data make choosing the best parameters a hard nonlinear optimization issue, as highlighted in recent work, where typical approaches like Grid Search frequently fall short. Traditional algorithms sometimes suffer with feature redundancy or become stuck in local optima, resulting in unstable predictions that are difficult to generalize across a variety of patient cohorts. To improve the performance of 10 ML classifiers Logistic Regression (LR), Support Vector Machine (SVM), K Nearest Neighbors (KNN), Multilayer Perceptron (MLP), Naive Bayes (NB), Random Forest (RF), Decision Tree (DT), XGBoost, Light Gradient Boosting Machine (LGBM), and Adaptive Boosting (AdaBoost) for the prediction of heart disease, this study employs BCO technique. By combining classification and optimization, the suggested procedure seeks to improve CVDs prediction accuracy, robustness, and dependability. The key contribution of this study is outlined below- 1. The proposed framework effectively addresses multicollinearity and performs a global search for optimal hyperparameters accross 10 different ML classifiers. 2. The study validates the efficacy of BCO optimization using statistical validation tests. 3. The results of the proposed framework are compared with different optimizers to make a robust evaluation. 4. The suggested framework has the potential to be a useful decision support tool for medical professionals by improving prediction reliability, which would allow for early identification and prompt management for individuals at risk of cardiovascular illnesses.
The remainder of the article proceeds as follows: The proposed framework with a detailed procedure of BCO, the 10 ML classifiers, and a brief discussion on the datasets and features are listed in the Methodology section. The results section illustrates the outcomes of all the experiments with BCO and without BCO. The discussion section rigorously analyzes the Results mentioned in the Results section. The Conclusion section highlights the contributions of this study, with possible directions for further investigation.
Methodology
Feature reduction using Principal Component Analysis
A dimensionality reduction approach named PCA is exploited first in the proposed frame work to optimize the feature space and handle any multicollinearity across clinical characteristics. The cumulative explained variance ratio, which has a 95% goal threshold, determines which main components are selected. This criteria guarantees that low variance noise that might cause overfitting is eliminated while the great majority of the datasets’ useful information is kept. The initial feature sets are reduced to a smaller number of orthogonal components determined by this threshold.
In order to explore a more efficient search space, the BCO method moves the data into this uncorrelated coordinate system. Comparing this modification to the usage of raw, unadjusted features, it allows for better convergence and more robust hyperparameter adjustment. All ensuing classification and optimization activities use the resultant components as input, guaranteeing a balance between precision in diagnosis and computing efficiency (Figure 1). Proposed working procedure.
Hyperparameter tuning: Bacterial colony optimization
BCO, introduced by Niu and Wang, 55 is a population based heuristic optimization algorithm that simulates the foraging and communication behaviors of E. coli bacteria. Unlike Bacterial Foraging Optimization (BFO), which relies on individual swimming and tumbling, BCO utilizes bacterial communication to guide the search, thereby increasing both convergence efficiency and solution quality. 56 This study utilizes BCO to optimize classifier parameters for heart disease detection, achieving superior clinical precision while mitigating overfitting.
The BCO lifecycle progresses through chemotaxis, communication, elimination, reproduction, and migration, with each stage playing a crucial role in balancing exploration and exploitation during optimization. The behavior of the traditional BCO and its key procedural phases are described in the following:
Chemotaxis and communication
In BCO, chemotaxis is combined with communication throughout the optimization process. The chemotactic behavior of bacteria over their lifetime can generally be classified into two modes: tumbling and swimming. In the tumbling phase, the bacterium introduces a stochastic disturbance to its orientation, enabling random turbulence to impact the optimal search direction. As a result, the position of each bacterium is updated according to Equation (1), where both the turbulent director and the optimal search director jointly determine the movement.
55
In contrast, the bacterium moves without turbulence and smoothly in the direction of optimal exploitation during the swimming phase, updating its position according to Equation (2). The BCO employs an adaptive chemotaxis step, developed to guide bacterial movement during the search process, as defined by Equation (3).


This formulation balances stochastic exploration and directed convergence, with tumbling promoting randomness to escape local optima and swimming guiding bacteria toward promising regions (Pbest and Gbest).
Elimination and reproduction
Each bacterium is assigned an energy level reflecting its search capability and fitness in heart disease detection. The decision rules for elimination and reproduction, which determine the removal of less fit bacteria and the reproduction of fitter ones, are defined by Equation (4), ensuring the colony progressively converges toward optimal solutions.
55

Migration
In BCO, bacterial migration moves individuals to new random positions when specific conditions—such as energy level, similarity among bacteria, or chemotaxis efficiency—are met, as described by Equation (5).
55
This process helps to avoid local optima, strengthens global search ability, and ensures efficient exploration. 
Hypothesized advantages of BCO in hyperparameter tuning
In contrast to traditional optimization algorithms that employ independent or velocity driven parameter updates, BCO is hypothesized to navigate the intricate, nonconvex search spaces associated with the heterogeneous classifiers studied in this literature. The communication mechanism in BCO plays a critical role in mitigating premature convergence. Tuning parameters for the classifiers such as SVM, RF, the search space includes numerous local optima that misleads to the region of high accuracy not representing the global optimum. Bacterial agents exchange information on nutrient concentration, which is respective to model accuracy for the classifier, and orientation.39,40 This collaborating communication phase enables the population to discriminate local and global optimal areas and prevents the stagnation in suboptimal hyperparameter spaces, which is commonly observed in Particle Swarm Optimization. 38 Additionally, while tumbling and swimming, communication helps the chemotaxis process by directing the swarm away from low performing areas of the search arena. In high dimensional classifiers, where random exploration can result in needless computing expenditure, this tailored direction enhances search efficiency. 57
Evaluation methods
Support Vector Machine
In this research, the SVM was applied as a classifier with the aim of detecting the presence of cardiac disease. SVM derives an optimal hyperplane to separate two classes (patients with and without heart disease). Based on the training dataset, D =
The classifier learns a separating function:

Since nonlinear correlations are frequently observed in patient health data,
58
kernel functions are employed. The resulting decision function is:
SVM performance, determined by C and γ, was optimized using BCO, where candidate pairs are estimated by accuracy and the colony iteratively prefers high performing candidates.
Logistic regression
LR is a widely used and reliable supervised method for addressing binary classification problems in medical research, including the prediction of heart disease. Linear regression predicts continuous values, whereas LR predicts the probability of a category. This characteristic makes LR especially valuable in medical diagnostics, where the primary objective is to determine whether a disease is present or absent. The logistic regression model predicts the probability of an outcome (e.g., the existence of heart disease) based on a linear combination of input features (age, blood pressure, cholesterol, electrocardiogram (ECG) results, blood sugar levels, etc.) weighted by coefficients
59
:
This linear predictor is passed through the sigmoid function to produce a probability ranging from 0 to 1, and then a decision threshold of 0.5 is applied to classify the class label.
K-Nearest Neighbors
The KNN algorithm is employed for heart disease detection by classifying patients in two groups: positive and negative cases, depending on their medical data.60,61 In this context, clinical attributes like age, blood pressure, cholesterol levels, resting ECG, and various types of chest pain are represented as a feature vector:
The affinity between two records, X and Y, is calculated based on the Euclidean distance:
In heart disease datasets, the feature ranges differ: for example, cholesterol spans 100 to 190, while age ranges from 40 to 80, which potentially biases distance calculations. To ensure that all features contribute equally to the distance metric, continuous attributes are standardized. 62
The class of an unknown patient is derived from the labels of its closest neighbors. The neighborhood size k and distance metric have an impact on the k-NN’s performance. To optimize these parameters, BCO is utilized, which iteratively estimates candidate (k, d) solutions based on classification accuracy to determine the optimal configuration (k*, d*) for a reliable prediction of heart disease.
Multilayer Perceptron
The MLP, a variant of artificial neural networks, studies heart disease factors such as age, blood pressure, cholesterol level, blood sugar, and electrocardiographic observations through multiple layers of interconnected neurons to capture nonlinear dependencies and provide accurate estimations of heart disease risk. It is structured as a feedforward neural network composed of an input layer, multiple hidden layers, and an output layer. 63
For a neuron j in layer l, the output is computed as:
The output layer generates the predicted class label for a patient.
The MLP’s performance relies on hyperparameters such as learning rate, hidden neuron numbers, and activation functions. The optimal configuration (θ*) for a reliable heart disease prediction is determined by employing BCO, which analyzes candidate configurations (θ) based on classification accuracy.
Naïve Bayes
NB is a supervised learning algorithm based on Bayes’ theorem, because of its simplicity, efficiency in computation, and consistent performance even with smaller datasets. 64 The model considers conditional independence among patient attributes, allowing the multivariate joint distribution to be represented as the product of individual probabilities.
For a patient with a feature vector, 
As P (X) is constant across all classes, the classification simplifies to:
To improve performance, BCO is utilized to choose the best parameters, such as feature subsets, smoothing factors, and variance estimations. Individual candidate configuration is evaluated as determined by classification accuracy, enhancing generalization while maintaining computational efficiency.
Random Forest
RF is a resilient method for ensemble learning that generates multiple decision trees, where each tree is trained on a bootstrapped sample of patient records and a randomly selected subset of clinical features. Random selection of data and features generates a variety of decision trees, mitigating overfitting and enhancing generalization.
65
Each tree estimates heart disease, and the final classification is aggregated using majority voting, boosting diagnostic accuracy and stability over a single decision tree. Figure 2 illustrates how the RF classifier operates, where the predictions of multiple decision trees are combined through majority voting to produce the final class. In the context of heart disease detection, the dataset is expressed as: Random Forest process to form a reliable ensemble from multiple trees using majority voting.

Each decision tree is built by determining the best splits depending on the Gini Index:
Majority voting is used to infer the final prediction for an unseen record x:
To improve prediction performance, BCO is utilized to optimize RF hyperparameters like the maximum depth and number of trees based on classification performance such as accuracy or F1-score.
Decision tree
A DT is a supervised classification method that uses recursive splitting of patient data, using clinical attributes to perform classification. At each decision node, the algorithm identifies the feature that maximizes class separation based on an impurity measure,
66
typically the Gini Index, as defined in Equation (14). The decision tree grows recursively until predefined stopping criteria, such as maximum tree depth or minimum samples per node, are satisfied, at which point the leaf nodes denote the predicted class (presence or absence of heart disease). At the leaf node, the final prediction for an unseen record x is determined on the basis of the majority class.
Similar to RF, BCO is employed to optimize key DT hyperparameters, including maximum depth and minimum samples per split, enriching DT performance based on classification metrics.
Extreme Gradient Boosting
XGBoost is a robust ensemble learning method that sequentially develops a number of weak classifiers, such as decision trees, with each successive tree trained to minimize the residual errors produced by the preceding trees. By repeatedly focusing on misclassified samples, XGBoost minimizes bias and increases predictive accuracy. 67 It also employs regularization to prevent overfitting and a learning rate to control each tree’s contribution, 68 which makes it effective for the detection of heart disease using clinical attributes.
Figure 3 demonstrates that the working procedure of XGBoost involves sequentially constructing decision trees, optimizing residual errors, and applying regularization to enhance predictive performance. XGBoost constructs decision trees that follow a structure parallel to the DT model as described earlier in the same section. Consequently, the node-splitting in XGBoost also relies on impurity measures such as the Gini Index as previously defined in Equation (14). XGBoost process of constructing an optimized ensemble classifier.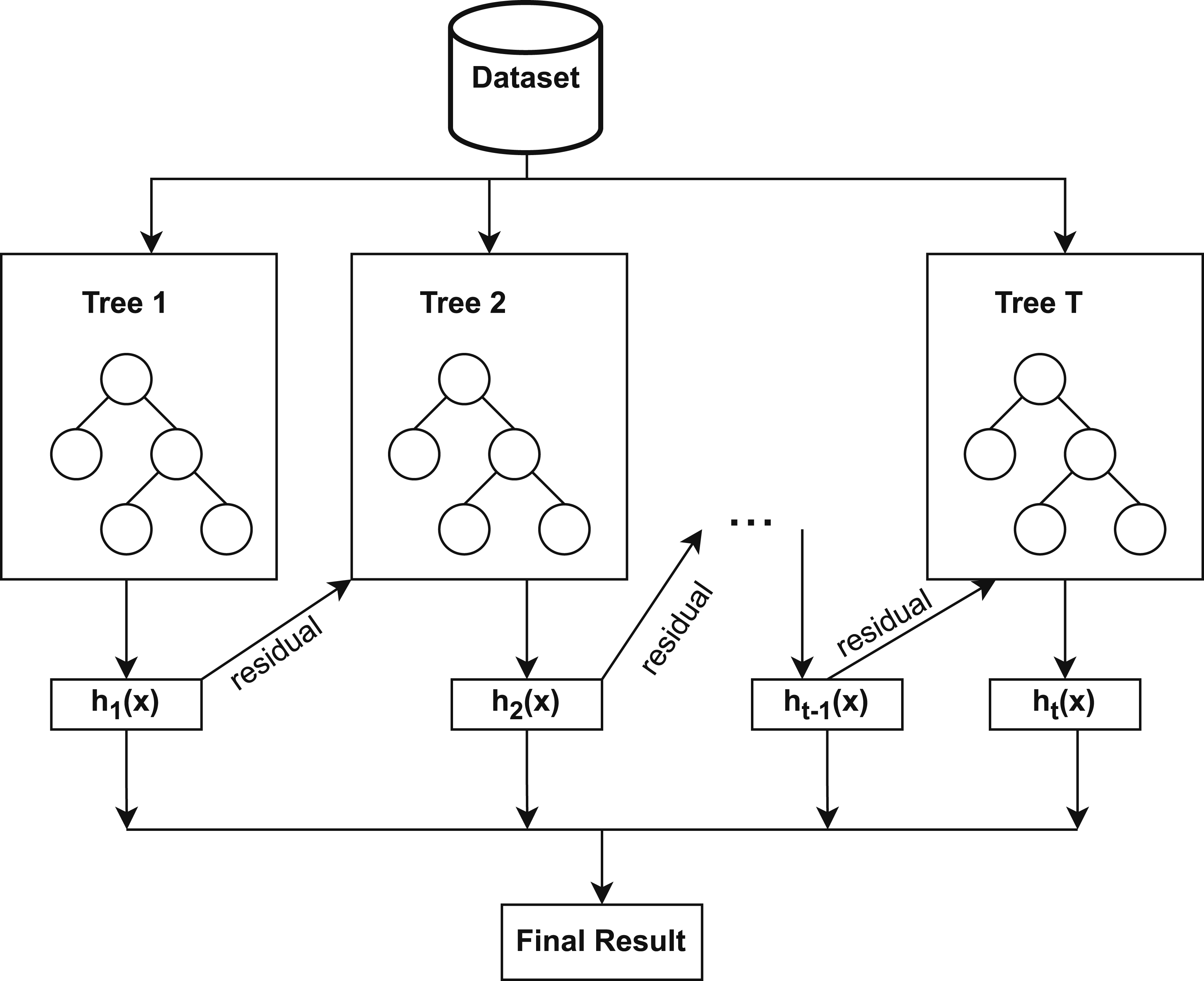
The final prediction is obtained by combining the outputs of all trees in the ensemble, weighted by their learning rates:
Similar to its application in DT and RF, BCO is applied to XGBoost to optimize hyperparameters, such as the learning rate, the maximum depth of the tree, and the number of trees, improving the performance of the model based on classification metrics.
Light Gradient Boosting Machine
LGBM is a tree-based gradient-boosted ensemble method similar to XGBoost, but it differs in its tree construction. It employs a leaf-wise tree growth strategy with depth constraints, 69 selecting the leaf that maximizes loss reduction at each step, rather than the level-wise growth used in XGBoost. As a result, LGBM captures complex feature interactions more effectively, trains faster with lower memory consumption, and achieves enhanced accuracy on large-scale, high-dimensional datasets. Similar to XGBoost models, LGBM utilizes clinical features, specifying splits based on impurity measures.
To further improve diagnostic performance, BCO is utilized to tune key hyperparameters such as learning rate, maximum depth, and number of trees.
Adaptive Boosting
AdaBoost is an ensemble learning technique that combines multiple weak classifiers, commonly shallow decision trees, to construct a strong classifier. In contrast to RF, which constructs trees separately and combines their votes, AdaBoost trains decision trees in sequential order, where each successive classifier assigns higher weight to misclassified patient samples,
70
forcing the model to address difficult samples. Figure 4 illustrates the AdaBoost procedure for generating a strong classifier from multiple weak learners. Process of AdaBoost in forming a strong classifier from weak learners.
For the training data (x
i
, y
i
), where y
i
∈ {−1, + 1}, AdaBoost assigns initial equal weights: w
i
= 1/N. At each iteration t, a weak classifier h
t
(x) is trained, and its weighted error is computed as: 
The weight of the classifier is then computed by:
Finally, the strong classifier is derived as:
Classifiers with lower error are assigned higher weights, enabling the model to focus on samples that are hard to classify and iteratively improve accuracy.
Like DT, RF, XGBoost, and LGBM, BCO is also used with AdaBoost to adjust key hyperparameters, such as the number of weak classifiers and the learning rate, thus enhancing the robustness and classification performance in the detection of heart disease.
Dataset description
Dataset description.

Feature details of CLE.

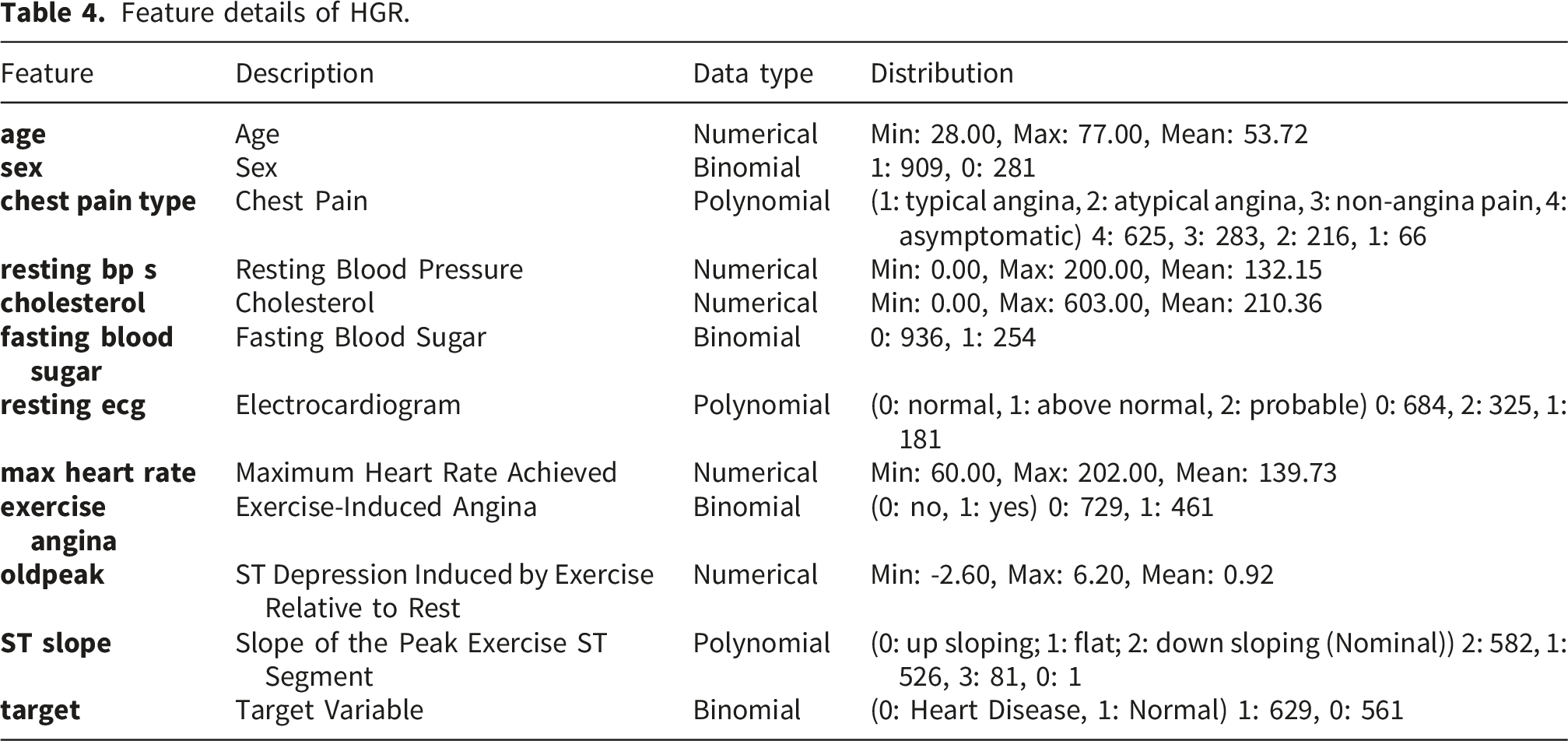
Feature details of HGR.
Results
Parameter tuning
Parameter setting for BCO.

Hyperparameter Search Space with best parameters.

Classification performance
Performance of ML classifiers without optimization technique for the CLE dataset.

Performance of ML classifiers with BCO optimization for the CLE dataset.

Performance improvement (%) after BCO optimization for the CLE dataset.

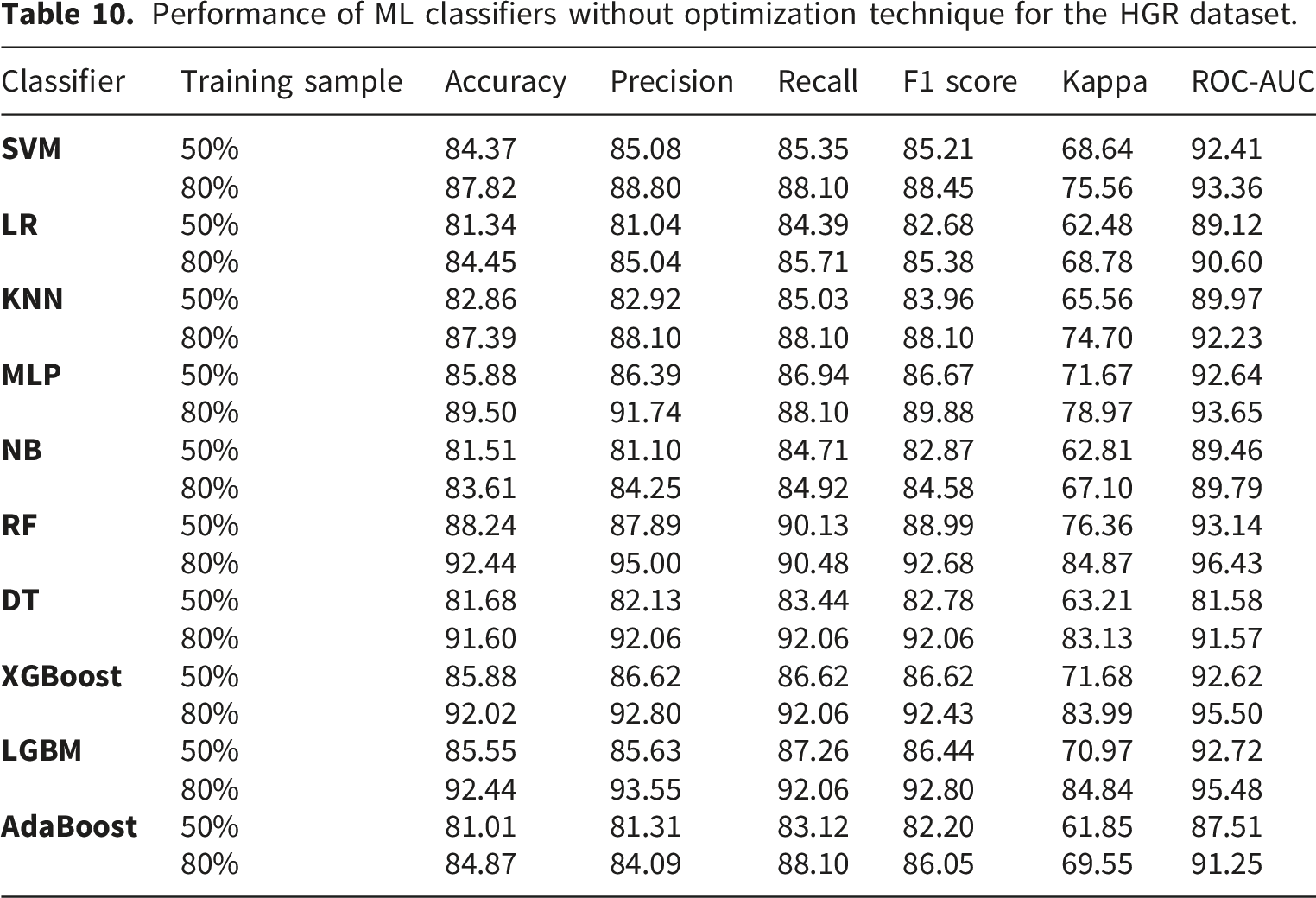
Performance of ML classifiers without optimization technique for the HGR dataset.
Performance of ML classifiers with BCO optimization for the HGR dataset.

Performance improvement (%) after BCO optimization for the HGR dataset.


Performance comparison for CLE dataset (50% training samples).

Performance comparison for CLE dataset (80% training samples).

Performance comparison for HGR dataset (50% training samples).

Performance comparison for HGR dataset (80% training samples).
Experimental results (mean ± std) for CLE 5 fold cross validation.

Experimental results (mean ± std) for HGR 5 fold cross validation.

Experimental results (95% CI) for CLE 5 fold cross validation.

Experimental results (95% CI) for HGR 5 fold cross validation.


Accuracy comparison for CLE using 5 fold cross validation.

Precision comparison for CLE using 5 fold cross validation.

Recall comparison for CLE using 5 fold cross validation.

F1 score comparison for CLE using 5 fold cross validation.

Accuracy comparison for HGR using 5 fold cross validation.

Precision comparison for HGR using 5 fold cross validation.

Recall comparison for HGR using 5 fold cross validation.

F1 score comparison for HGR using 5 fold cross validation.
Discussion
Train test split evaluation
BCO consistently improves ML classifier performance, as demonstrated by the experiments conducted on the CLE and HGR datasets in this study. Notable performance improvement is observed in the ensemble approaches. On the CLE dataset, BCO optimization produced significant improvements for XGBoost and SVM, which attained an accuracy of 91.80% compared to 86.89% without BCO for 80% training samples. The XGBoost performed decently well among the other classifiers for both 50% and 80% training samples for the CLE dataset. The performance of LGBM is also increased to 86.84% from 77.63% with BCO optimization and 50% training samples. AdaBoost shows a notable improvement of classification accuracy from 78.69% to 88.52% for CLE. Similarly, BCO driven optimization yielded impressive results on the HGR dataset, with SVM demonstrating a notable improvement from 87.82% to 90.76% accuracy with 80% training data, and XGBoost achieving 94.12% accuracy compared to 92.02% without BCO. After optimization, XGBoost consistently performed well on both datasets, obtaining the best accuracy metrics, demonstrating that the optimization was especially successful for algorithms with complicated parameter spaces. In addition, BCO illustrated strong generalization ability by preserving or raising ROC-AUC scores for all datasets and for most of the classifiers. The RF reaches to 97.08% on HGR, and NB reaches to 97.08% on CLE for ROC-AUC score. The increased F1 scores for most of the classifiers demonstrate the positive impact of BCO for precision-recall trade-offs. XGBoost shows a noteworthy improvement in F1 scores of 91.53% and 94.40% for CLE and HGR datasets, respectively, in consideration of 80% training samples. The gains in the Kappa statistic validate the dependability of classification improvements above chance agreement. The detailed performance of the investigated classifiers is illustrated in Tables 7 and 8 without and with BCO optimization, respectively, for the CLE dataset. For the HGR dataset, Tables 10 and 11 shows the results before and after BCO optimization, respectively. The positive values in the Tables 9 and 12 signify the improvements of the classifiers performance after applying BCO optimization for CLE and HGR datasets, respectively. The performance comparison for both the dataset can be observed from the Figures 5–8. These steady performance improvements on two different datasets confirm that BCO is a reliable hyperparameter optimization method that can handle a variety of problem domains and classifier architectures.
5 fold cross validation evaluation
In order to prove the efficacy of the proposed framework and avoid overfitting issues, 5 fold cross validation is also adopted along with the train test ratio. The proposed BCO optimized architecture continuously improves the prediction performance of machine learning classifiers on both the CLE and HGR datasets, according to the comparative study of the experimental findings. Based on the findings, the BCO optimized models performed better in terms of accuracy and stability than both their unoptimized counterparts and conventional optimization methods. The BCO-SVM model outperformed the Grid Search (85.13%) and PSO (84.47%) benchmarks with the maximum peak accuracy of 85.79% for the CLE dataset. Similar to this, the RF with clearly outperformed the unoptimized RF model (91.26%) for the HGR dataset, achieving a leading accuracy of 92.02%. Notably, the BCO-XGBoost classifier shown strong improvements in accuracy, rising from 89.92% to 91.26% on the HGR dataset and from a baseline of 81.50% to 84.48% on the CLE dataset. In addition to maintaining lower standard deviations, which are indicative of superior model stability, this consistent superiority implies that the BCO algorithm successfully traverses the high dimensional feature space to find global optima that conventional techniques like Grid Search might overlook.
The 95% CI offers important information about the dependability and worst case performance of the optimized models in addition to mean accuracy. The BCO framework considerably tightens these intervals, according to the experimental results, suggesting better stability. The BCO-SVM model, for example, not only increased accuracy but also generated a tighter, nonoverlapping range of [88.83 - 90.84] on the HGR dataset, whereas the unoptimized SVM classifier had a broad CI of [83.82 - 88.62]. This lack of overlap strongly suggests a significant improvement. The BCO-XGBoost model also showed a notable increase in the bottom limit of the confidence interval on the CLE dataset, increasing from 74.46% (No Optimization) to 80.15% applying BCO. This change shows that while the baseline model is prone to considerable volatility, the BCO optimized model maintains a high performance floor even in the worst case cross validation folds. The suggested approach guarantees a more consistent and clinically reliable diagnostic result by increasing the lower limits and reducing the interval widths across important classifiers.
Statistical validation of results
A rigorous statistical analysis framework is utilized to validate the robustness of the proposed BCO optimized classifiers. The Shapiro-Wilk test is used to determine if the changes between the Baseline and BCO optimized accuracy scores are normal, as performance matrices over cross validation folds may not always follow a normal distribution.
75
,
76
The Shapiro-Wilk test statistic W is denoted as,
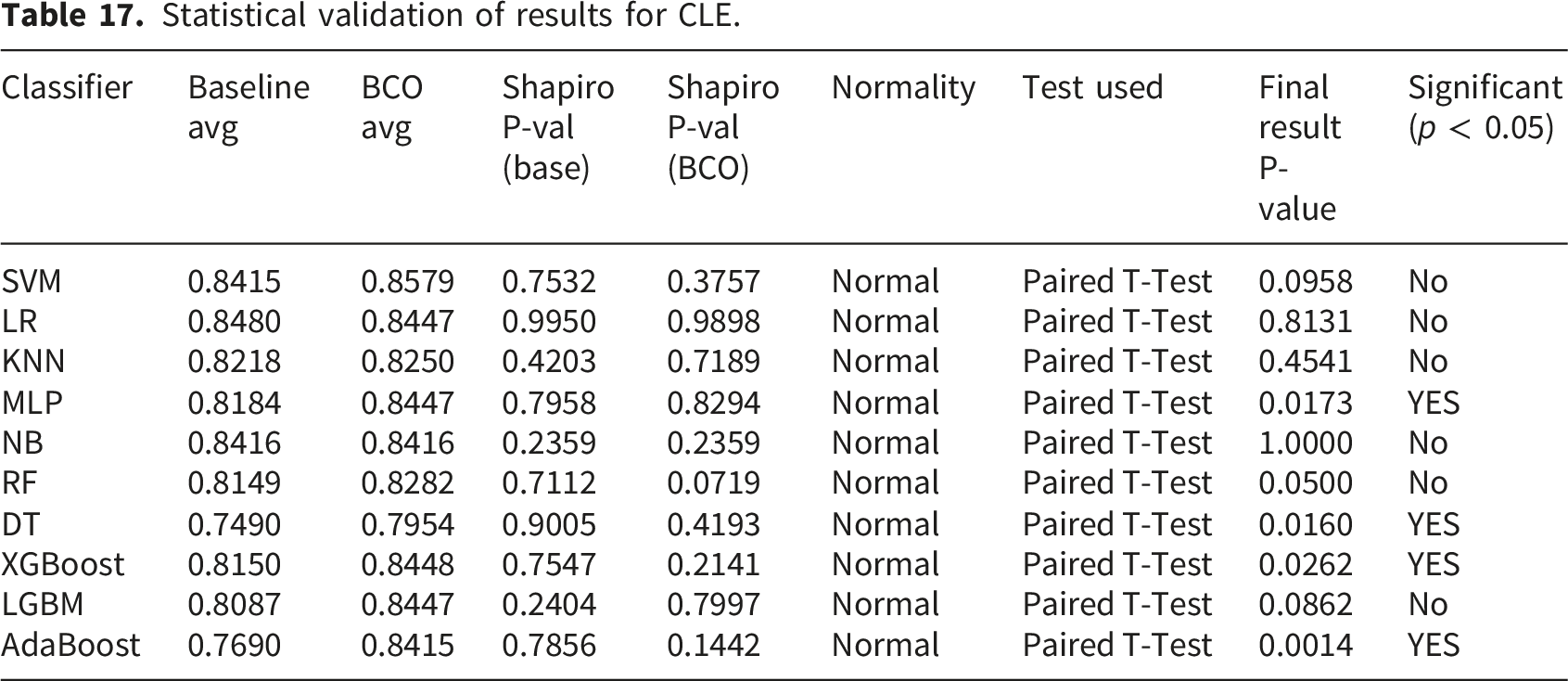
Statistical validation of results for CLE.
Statistical validation of results for HGR.

Feature importance and model interpretability
A post hoc feature significance analysis using 5 fold cross validation is conducted to verify the clinical transparency of the suggested framework and make sure the results were resilient to data splitting artifacts. The model’s decision logic for the CLE dataset is primarily influenced by sophisticated diagnostic markers; the most important predictors, as shown in Figure 17 for this dataset, are the number of major vessels (ca), chest pain type (cp), and thallium heart rate (thal). Because it gives priority to variables like thal and ca direct indicators of heart disease instead of merely generic risk factors like age or cholesterol, the model performs well. The model’s clinical validity is validated by the SHAP analysis Figure 18, which shows that lower thalach and thal (indicating reversible defects) are powerful predictors of positive disease prediction. Feature importance stability for CLE. Shap summary for CLE.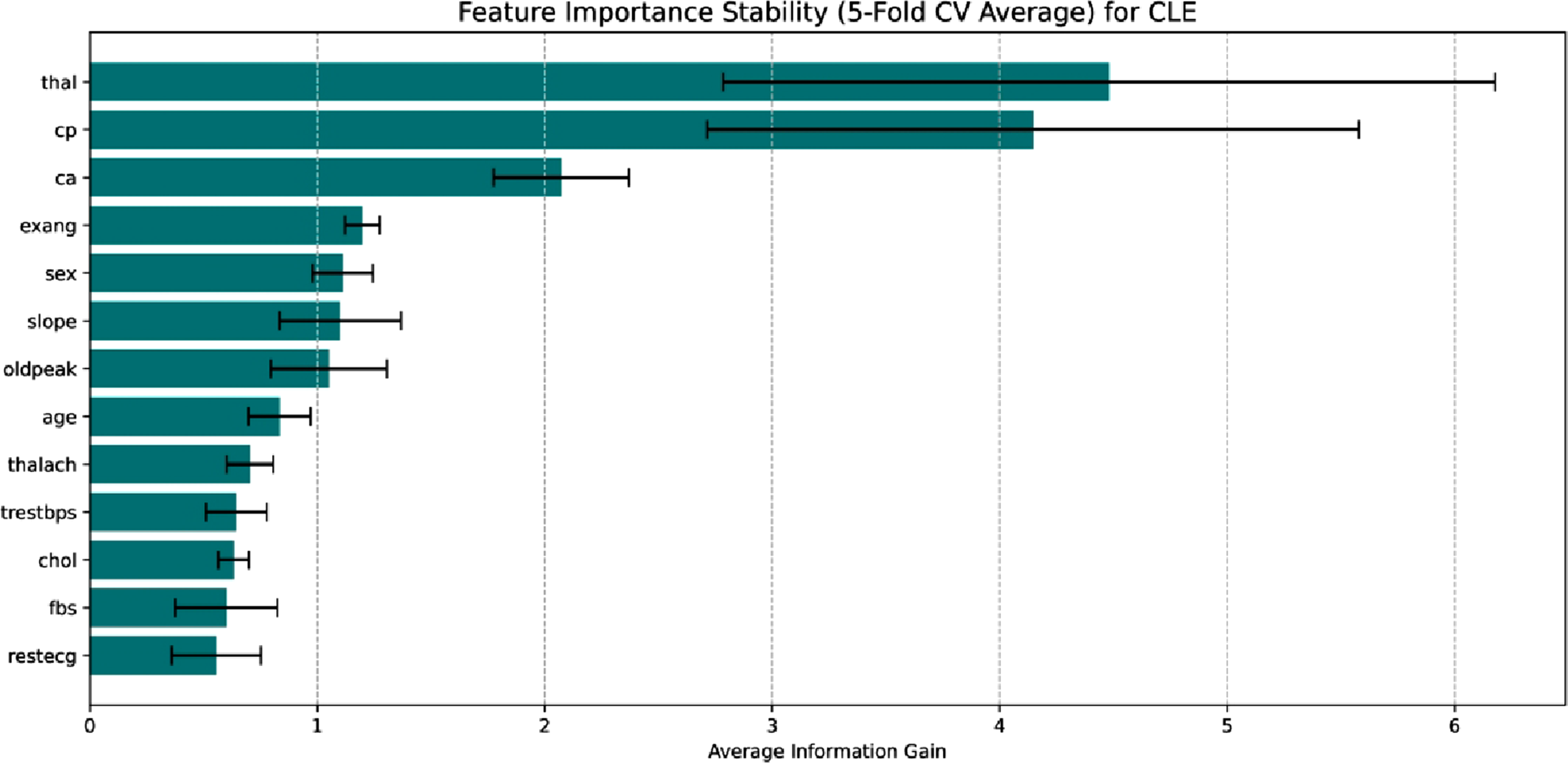

The Figure 19 shows a unique ECG and symptom driven prediction characteristic in the HGR dataset. The analysis identifies the slope of the peak exercise ST segment (STslope) as the most important factor, outperforming all other factors in terms of information gained. As a key indication of myocardial ischemia, ST segment abnormalities under stress make this clinically relevant. The secondary factors include chest pain type and exercise angina, demonstrating the model’s dependence on symptomatic presentation. The SHAP summary in Figure 20 determines exercise induce angina (exerciseangina) and abnormal ST slopes are powerful predictors of heart disease, whereas max heart rate acts as a protective factor. This demonstrates that in datasets, the framework learns to prioritize physiological stress responses above static demographic characteristics in a robust manner. Feature importance stability for HGR. Shap summary for HGR.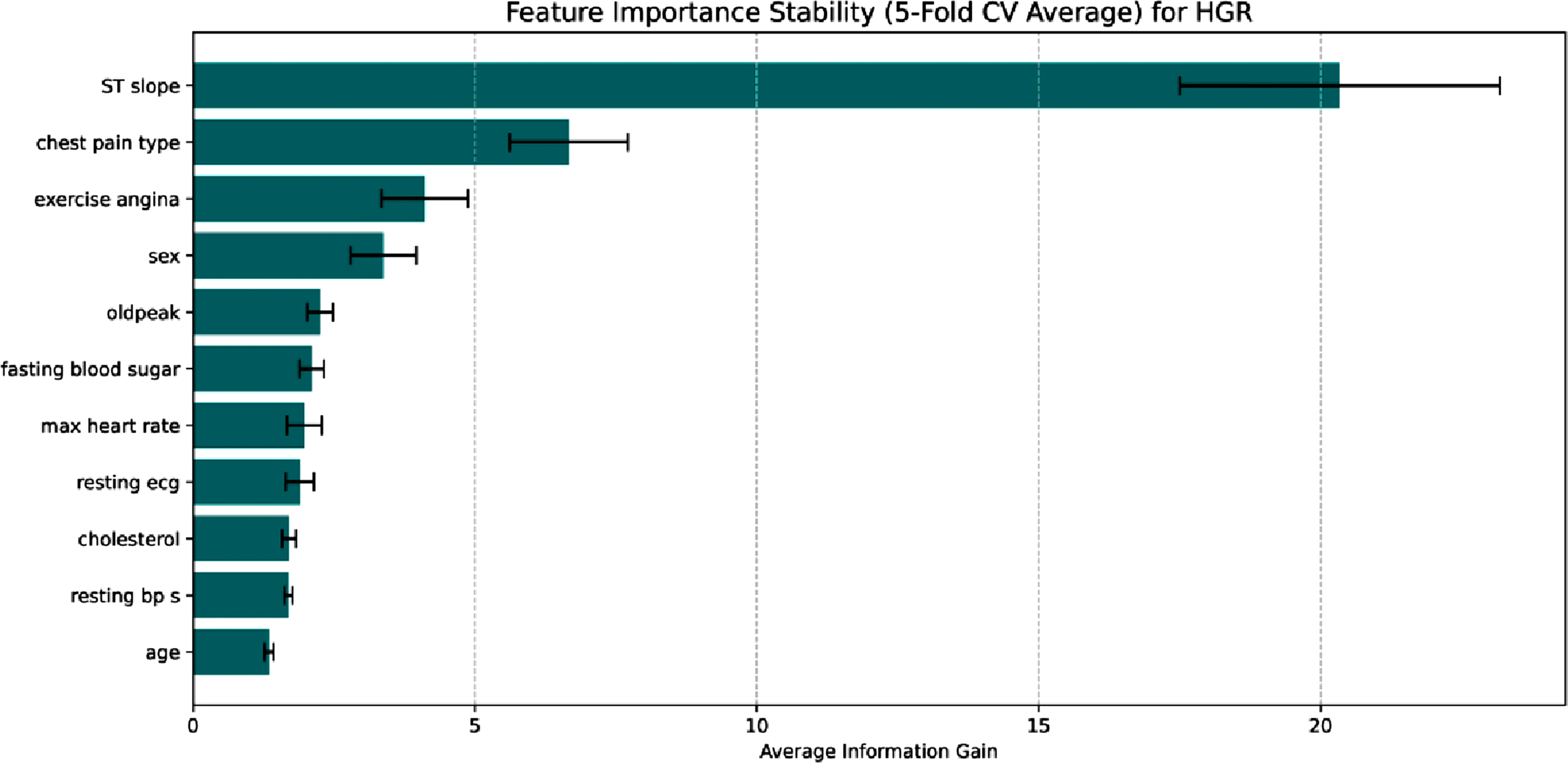

Computational cost analysis
For the assessment of the practical feasibility of the proposed approach, the computational burden related to the BCO based hyperparameter tuning is systematically recorded for the 10 classifiers. A workstation with 8GB RAM and Intel i5 11th generation processor is used for the optimization process, and the resultant execution times stay within reasonable bounds for clinical implementation. The BCO process takes an average of 169.07 seconds per classifier for the CLE dataset, with the RF model requiring the longest duration of 480.72 seconds. The mean optimization time jumps to 251.46 seconds for the larger HGR dataset, with the SVM classifier achieving a maximum of 745.82 seconds. It takes around 28 minutes for CLE and 42 minutes for HGR to optimize all 10 classifiers. The BCO phase, which is theoretically described as the primary factor governing the computational complexity of the suggested framework, is O (I ⋅ S ⋅ f (n)), where I denotes the number of iterations, colony size is denoted by S, and f (n) defines training cost of the base classifier. These findings show that the BCO technique effectively reaches a high level of convergence while striking a balance between excellent diagnostic accuracy and a controllable computing cost on typical consumer grade workstation.
Conclusion
The study conducts a rigorous investigation into the field of ML for classifying CVDs. The thorough experimental testing carried out on two different datasets, CLE and HGR, unambiguously shows that the proposed BCO framework produces statistically substantial performance gains across different classifiers, substantiating the fundamental contribution. The experiments signify BCO as an effective metaheuristic approach for hyperparameter tuning. BCO optimized classifiers consistently outperform their default parameter counterparts, especially boosting XGBoost to reach high accuracies of 91.80% and 94.12%, respectively, according to extensive testing across the CLE and HGR datasets based on train test split mechanism. The 5 fold cross validation along with statistical validation test and 95% CI, signifies BCO as a significant performance enhancer for different ML classifiers. The increases in accuracy and f1 score are critical from a clinical standpoint because they result in a quantifiable decrease in false negatives, which lowers the possibility of heart disease patients being overlooked during routine screenings. Focusing on the physiological stress responses found in our SHAP research, this paradigm can assist practitioners in prioritizing high risk patients when included in clinical workflows as a decision support tool. The next crucial stages to guarantee the framework’s adaptability to various patient groups are integration into Electronic Health Record (EHR) systems and prospective validation in actual clinical settings. Moreover, the future research will build on these pioneering contributions by exploring adaptive BCO variants, where parameters such as population size and run length self adjust based on convergence dynamics, and developing hybrid models that combine BCO with other metaheuristics, such as Particle Swarm Optimization, to improve search efficiency for even more intricate automated ML pipelines.
Footnotes
ORCID iDs
Ethical considerations
This research is relied on secondary analysis of previously established, completely anonymized, publicly available datasets, therefore, it did not require ethical approval or informed consent. Therefore, this study does not include human individuals and is not subject to formal Institutional Review Board (IRB) review.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.