
Abstract
Objective
This study aimed to evaluate the effectiveness of ChatGPT in improving the standardization of ultrasound report writing among junior physicians.
Methods
A total of 20 junior residents involved in ultrasound work from January to August 2025 were randomly divided into an experimental group (ChatGPT-assisted group) and a control group (traditional training group). The experimental group utilized ChatGPT for real-time assistance in report writing and review, while the control group followed a conventional training model. The quality of report writing was compared between the two groups, focusing on completeness of content, accuracy of descriptions, use of professional terminology, and diagnostic accuracy.
Results
The quality scores for ultrasound reports in the experimental group were significantly higher than those in the control group across gastrointestinal, gynecological, and thyroid systems (all P < 0.05).
Conclusion
ChatGPT can effectively enhance the standardization of ultrasound report writing among junior physicians, demonstrating significant value for clinical education and training.
Background
In the context of continuous innovation in medical technology, ultrasound medicine has emerged as a core support technology in modern clinical diagnosis and treatment due to its significant advantages, such as non-invasiveness, ease of operation, and real-time dynamic imaging. 1 As an important part of the medical talent hierarchy, junior physicians face practical challenges in the standardized writing of ultrasound reports, including insufficient professional experience and deviations in the execution of standardized processes.
Junior physicians encounter the following challenges in ultrasound report writing:
Insufficient Standardization of Terminology: The field of ultrasound medicine encompasses a vast array of specialized terminology. Junior physicians, with limited clinical experience, often lack a systematic understanding of the semantic connotations and application norms of fundamental acoustic concepts—such as “hyperechoic,” “hypoechoic,” and “isoechoic”—across different anatomical sites and pathological conditions. This knowledge gap can lead to misapplication of terms or ambiguous semantics, thereby diminishing the diagnostic value of ultrasound reports. For example, when assessing hepatic lesions, junior physicians may struggle to accurately differentiate between hemangiomas and hepatocellular carcinoma based on echogenic features, often resorting to vague terms like “abnormal echogenicity,” which severely impacts the precision of clinical decision-making.
Lack of Logical Structure in Descriptions: Ultrasound imaging contains multidimensional diagnostic information. During the process of writing structured reports, junior physicians frequently fail to follow standardized information organization strategies, resulting in poor logical coherence of the report’s content. This is evident when lesion descriptions do not adhere to the scientific ordering principles based on clinical risk levels, or when they present adjacent tissue relationships before core lesion features, disrupting the narrative flow and clarity of information. For instance, in cases of multiple nodular lesions in the breast, presenting the locations and sizes of nodules in a disordered manner without highlighting high-risk nodules can significantly reduce the efficiency of clinical assessment.
Inadequate Management of Key Information: Junior physicians demonstrate significant shortcomings in information filtering and integration during ultrasound report writing. On one hand, they often lack sensitivity to critical indicators for assessing malignancy risk, such as the aspect ratio, margin morphology, and microcalcifications of thyroid nodules, leading to omissions of vital diagnostic information and severely undermining the clinical reference value of the reports. 2 On the other hand, they may present excessive, non-diagnostic information about normal tissues, creating distractions that significantly diminish the report’s readability and diagnostic efficacy, thereby affecting subsequent treatment strategies such as regular follow-up, further examinations, or surgical interventions. 3
This study aims to address the issues of imprecise terminology usage, disorganized logical descriptions, and omissions or redundancies of key information faced by junior physicians in ultrasound report writing. We explore the practical effectiveness of ChatGPT in standardizing report writing. By analyzing ChatGPT’s role in correcting and optimizing report terminology, structuring logical frameworks, and reviewing the completeness of key information, we seek to determine whether it can effectively enhance the standardization, professionalism, and practicality of ultrasound reports by junior physicians, thereby providing higher-quality reference data for clinical diagnosis and treatment.
Materials and methods
Study subjects
A total of 20 junior physicians specializing in ultrasound were selected. Inclusion criteria were: young physicians with 1-3 years of experience in ultrasound diagnostics, possessing a basic understanding of ultrasound principles and image recognition skills, and capable of independently performing simple ultrasound examinations. Exclusion criteria included any prior experience with AI-assisted ultrasound report writing and those with severe communication or cognitive impairments.
Grouping method
The junior physicians were paired and divided into an experimental group and a control group, with 10 participants in each group. Physicians in the experimental group utilized ChatGPT for assistance while writing ultrasound reports, while the control group used traditional independent writing methods. Randomization and fairness in grouping were ensured.
Intervention measures
Experimental group
To ensure that all resident physicians in the experimental group standardized their use of the GPT-4-turbo-2025-08-26 and to minimize variability during the intervention, this study provided a structured training session comprising 1 hour of theoretical instruction and 2 hours of hands-on practice, conducted collaboratively by an experienced ultrasound physician (with 12 years of clinical experience) and the hospital’s IT engineer. All 10 resident physicians in the experimental group participated in this training to guarantee consistency in the intervention.
The theoretical instruction covered the following key areas: (1) Technical Principles of the GPT-4-turbo-2025-08-26: This section explained the natural language processing capabilities and the logic behind medical terminology optimization; (2) Scope and Limitations of the Tool: It clarified the appropriate contexts for using the tool, highlighting its strengths in terminology correction, logical structuring, and key information reminders, while emphasizing that it cannot replace physicians’ interpretations of imaging or clinical diagnostic decisions; (3) Data Security and Privacy Protocols: This part stressed the importance of adhering to the hospital’s data protection policies.
Step-by-Step Process Demonstration: The training guided participants through the entire AI-assisted report writing process, including: (1) Drafting the initial report in the ultrasound system; (2) Utilizing standardized prompts to optimize the initial report; (3) Accessing a side-by-side comparison interface (original draft vs. AI revision) to interpret modifications highlighted in red; (4) Cross-validating AI suggestions with ultrasound images and clinical data; (5) Manually adjusting and finalizing the report.
Given the substantial performance and reliability differences across releases, all participants in this study used the identical snapshot GPT-4-turbo-2025-08-26 to ensure procedural consistency and full reproducibility.4,5 Before the experiment began, sixty model reports were uploaded to ChatGPT to prime the system, twenty for each of the gastrointestinal, thyroid and gynecologic domains. The physician input a standardized prompt: “Please optimize this ultrasound report according to clinical ultrasound reporting guidelines, including correcting unprofessional terminology, organizing descriptive logic in a structured manner, supplementing missing key diagnostic information, and removing redundant content. Ensure the revised report complies with the professional norms of [digestive/gynecological/thyroid] ultrasound.”ChatGPT generated a revised report within 10–30 seconds, highlighting modifications (e.g., terminology corrections, logical rearrangements, supplementary information) with bold formatting for the physician’s reference. Throughout each iterative exchange they could vary the length and focus of the submitted text at will, without following any standardized prompt format. Junior physicians in the experimental group could use ChatGPT for assistance during ultrasound examinations and report writing. This included inputting preliminary report content into ChatGPT to receive suggestions for terminology correction, logical structuring, and key information supplementation. Only the draft text of ultrasound reports was pasted into the ChatGPT dialog box; no images or DICOM data were uploaded. Consequently, the AI’s role was restricted to language refinement and did not include image interpretation.
Control group
Physicians in the control group completed ultrasound report writing independently according to traditional training methods, referencing ultrasound textbooks, diagnostic guidelines, and internal report writing standards. They were allowed to consult relevant ultrasound diagnostic literature and previous report templates but could not use any AI-assisted tools.
Both groups maintained consistent working conditions, patient sources, and received the same routine business guidance throughout the study. In accordance with standard departmental practice, participants in both groups cross-validated all ChatGPT-generated text against the original images and clinical history, and amended the reports accordingly, before final submission.
Observation indicators and data collection methods
Ultrasound report standardization scoring
The standardization capabilities of ultrasound report writing were assessed for both groups of junior physicians (Supplement 1). A uniform standardized case set was used, including two gastrointestinal reports, two thyroid reports, and two gynecological reports. Two experienced ultrasound physicians (with ≥10 years of experience) scored the reports blindly, and the average score was taken as the final score for each report. The accuracy and response time for identifying critical cases were also evaluated.
A standardized scoring sheet for ultrasound reports was developed, assessing completeness of content, accuracy of descriptions, appropriateness of terminology, and diagnostic accuracy, with a total score of 100 points. Completeness of content accounted for 40 points, requiring coverage of all key information from the ultrasound examination, such as organ size, morphology, echogenicity, presence of abnormal lesions, and lesion characteristics. Accuracy of description, corresponding to the actual images without errors or omissions, accounted for 25 points. Appropriate and accurate use of professional terminology was worth 15 points. Diagnostic accuracy, including correctness of the diagnostic conclusion and any omissions, accounted for 20 points.
Feedback from junior physicians on ChatGPT
A questionnaire was designed to survey the experimental group physicians regarding their satisfaction and experiences with ChatGPT in assisting ultrasound report writing. The questionnaire included satisfaction levels with ChatGPT’s functionalities (rated as very satisfied, satisfied, neutral, dissatisfied, and very dissatisfied), perceived helpfulness for report writing (rated as extremely helpful, fairly helpful, somewhat helpful, not very helpful, and not helpful at all), issues encountered during use, and suggestions for improvement. The questionnaire was administered to the experimental group immediately after the study, achieving a 100% effective response rate.
Statistical methods
Data were analyzed using SPSS 27.0 software. The Shapiro-Wilk test and histogram were employed to assess the normality of the distribution of continuous data, and Levene’s test was used to analyze the homogeneity of variances. Normally distributed data were expressed as xˉ±s, with comparisons between groups performed using t-tests. Non-normally distributed data were expressed as M (Q1, Q3), and comparisons were conducted using the Mann-Whitney U test. Categorical variables were expressed as counts (percentages), with group comparisons performed using chi-square tests. A p-value of <0.05 was considered statistically significant.
Results
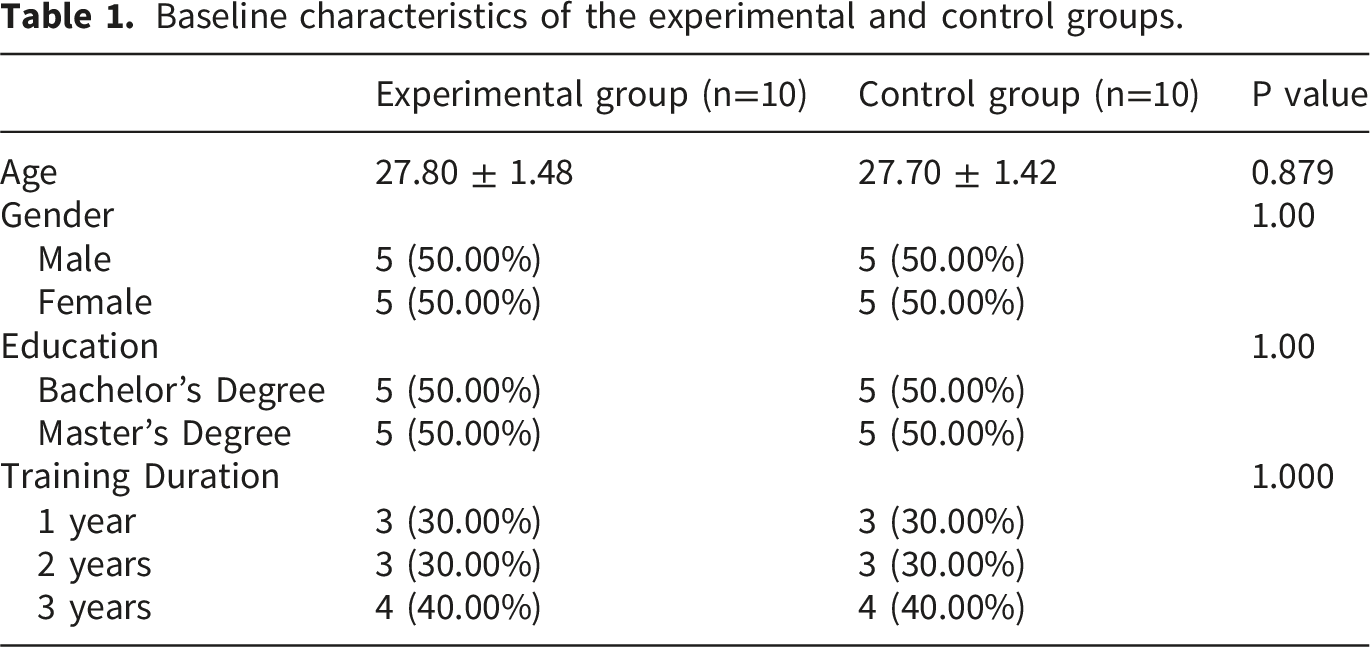
Baseline characteristics of subjects
Baseline characteristics of the experimental and control groups.
Scores for standardization of ultrasound reports
Overall performance of the experimental and control groups in generating ultrasound reports.


Violin plots comparing ultrasound reports generated by the experimental group (n = 60) and the control group (n = 60) in terms of content completeness (a), descriptive accuracy (b), use of professional terminology (c), diagnostic accuracy (d), total score (e), and time required for report generation (f).
In terms of completeness of content, the experimental group scored an average of 33.72 ± 1.1, while the control group scored 29.97 ± 1.71 (P < 0.001). For accuracy of descriptions, the experimental group achieved a score of 21.35 ± 0.90 compared to the control group’s score of 17.17 ± 1.57 (P < 0.001). Regarding the use of professional terminology, the experimental group averaged 11.30 ± 1.33, while the control group scored 8.58 ± 1.89 (P < 0.001). For diagnostic accuracy, the experimental group scored an average of 15.95 ± 1.10, in contrast to the control group’s score of 10.42 ± 1.29 (P < 0.001). Each sub-score indicated that the experimental group outperformed the control group. Individual analyses of the six reports also showed that the experimental group excelled in all aspects (Supplement 2).
Comparison of report completion time
The average time to complete reports in the experimental group was 9.77 ± 1.06 minutes, while the control group took 13.15 ± 1.72 minutes. Independent samples t-test results indicated that the difference in report completion times between the two groups was statistically significant (P < 0.001), suggesting that with the assistance of ChatGPT, junior physicians in the experimental group were able to complete ultrasound report writing more quickly. Individual analyses of the six reports also revealed that the experimental group consistently finished faster than the control group (Supplement 1).
Feedback from junior physicians on ChatGPT
In the satisfaction survey regarding ChatGPT’s functionalities, 60% of respondents were very satisfied, 30% satisfied, 10% neutral, and 0% dissatisfied or very dissatisfied. Seventy percent believed that ChatGPT provided significant assistance in report writing, while 20% felt it was fairly helpful, and 10% thought it offered some assistance; none reported that it was unhelpful.
The main issues reported by junior physicians during usage included that some content generated by ChatGPT did not fully match the actual ultrasound images, requiring further verification and modification (60%); descriptions of certain complex cases were not accurate or detailed enough (30%); and occasional internet connectivity issues affected usability (10%). Additionally, residents suggested improvements such as enhancing ultrasound image recognition capabilities, optimizing the medical knowledge database, and increasing the accuracy and relevance of generated content.
Discussion
ChatGPT, based on the Transformer architecture, has built a powerful language model through unsupervised learning on a vast amount of text data. 6 In the medical field, ChatGPT has already shown potential applications across various domains.7–10 In medical education, it can assist medical students by answering their queries and helping them understand complex medical concepts.11–13 In ultrasound medicine, studies have begun to explore the use of ChatGPT for generating ultrasound examination reports. Its advantages include the ability to quickly create standardized report frameworks, prompt junior physicians on key information to include, reduce omissions and errors in report writing, and improve writing efficiency, allowing junior physicians to devote more time and energy to analyzing and diagnosing ultrasound images.
ChatGPT possesses strong natural language processing capabilities. 14 Trained on extensive text data, it can accurately understand human natural language expressions. In the context of ultrasound report writing, junior physicians can describe ultrasound findings in everyday language, and ChatGPT can swiftly convert these into formal, professional ultrasound terminology. For instance, when a physician describes, “There’s a round bright thing in the liver,” ChatGPT can accurately translate this to “A round hyperechoic nodule is observed within the liver parenchyma,” significantly reducing the difficulty junior physicians face in memorizing and applying complex terminology, thus ensuring the accuracy and professionalism of the report language.
The extensive knowledge base of ChatGPT encompasses various medical fields, including typical and atypical ultrasound manifestations of diseases in ultrasound diagnostics, diagnostic criteria, and key points for differential diagnosis. Junior physicians can consult ChatGPT at any time while writing reports or assessing cases. For example, when encountering an uncommon superficial mass in ultrasound imaging, physicians can inquire about the ultrasound features of the mass, potential pathological types, and differentiation methods from other superficial lesions. ChatGPT can swiftly provide detailed and authoritative answers, acting like an experienced expert available online, thereby offering solid knowledge support to junior physicians.
ChatGPT’s contributions to standardizing ultrasound report writing manifest in several ways: Firstly, terminology Correction and Optimization: After completing a draft of an ultrasound report, junior physicians can input the text into ChatGPT to request checks and corrections for professional terminology. ChatGPT identifies erroneous expressions based on medical terminology standards and common practices in ultrasound diagnostics, providing correct suggestions. For example, it might correct “hyperechoic area in the liver” to “high echogenic area within the liver,” while explaining the precise meanings and applicable contexts of different terms, thereby helping junior physicians deepen their understanding of terminology. Long-term use can significantly enhance their ability to use terminology correctly, aligning report language with professional standards. Secondly, logical Structure Organization: ChatGPT can analyze the logical structure of report content and reorganize descriptive sequences according to ultrasound report writing standards. It can prioritize multiple lesions by size and importance, describing core features first before detailing surrounding tissue relationships and other relevant information, resulting in clear and well-structured reports. For instance, in a thyroid ultrasound report, ChatGPT can organize descriptions of nodules by listing larger, characteristic nodules first, followed by their location, size, echogenic structure, echogenicity, shape, margins, and echogenic foci, enhancing the clinical applicability of the report.15,16 Thirdly, completeness of Key Information Review: By learning from ultrasound report templates and common diagnostic points, ChatGPT can check for the completeness of key information in reports. It prompts junior physicians to include important ultrasound features that may be overlooked, such as blood flow signals in the assessment of thyroid nodules, while helping to eliminate redundant descriptions of normal tissues. For example, if a physician fails to describe the biliary system in a liver ultrasound report, ChatGPT will remind them to include this information, ensuring that the report is comprehensive and contains necessary diagnostic details, thereby improving report quality and diagnostic value. However, ChatGPT is not without its flaws; its medical knowledge may experience some lag in updates, and its accuracy in judging complex and rare cases still requires further enhancement. 17
Notably, our study identified no instance in which ChatGPT misled junior radiologists into a diagnostic error, delayed recognition of a critical finding, or prompted an inappropriate management decision. This reassuring outcome is best explained by the mandated verification protocol: every AI-generated statement had to be reconciled with the original images and clinical history, and amended as necessary, before the report was finalized. This systematic workflow of human AI collaboration followed by human cross-check ensured that potential inaccuracies, including hallucinations, were intercepted and corrected, preventing any erroneous content from being incorporated into the signed report.
Although ChatGPT assistance significantly improved short term report quality scores, its long term educational impact must be interpreted cautiously. From a clinical-practice perspective, junior residents already demonstrate limited proficiency in recognizing critical sonographic features, such as microcalcifications within thyroid nodules or marginal irregularities within breast masses. If ChatGPT generates a report that is terminologically precise and structurally polished, yet contains factual errors, for instance, stating microcalcifications are present when none exist, the trainee may be reassured by the apparent professionalism of the text and accept the erroneous conclusion without further verification. This type of occult mistake is far more hazardous than a report that is stylistically imperfect but factually accurate, the latter is easily detected and corrected by a supervising physician, whereas the former can lead to missed or incorrect diagnoses, for example, upgrading a benign nodule to a high-risk category and prompting unnecessary interventions. Educationally, an exclusive emphasis on using ChatGPT to improve report standardization, without parallel training on validating AI-generated facts, risks entrenching a form-over-verification mindset. Such an approach may weaken independent judgement and the habit of cross-checking imaging features, undermining the fundamental teaching goal of fostering autonomous diagnostic reasoning. By providing immediate terminology corrections and structural optimizations, the model reduces opportunities for active information retrieval, error recognition, and self correction, potentially diminishing the depth of knowledge encoding and subsequent retention. In contrast, participants in the conventional group, deprived of instantaneous external support, repeatedly consulted guidelines, templates, and images, underwent a longer cognitive processing cycle, and thereby may have established more stable conceptual networks and durable clinical reasoning pathways. Owing to the single time point design of the present study, delayed testing or post intervention reassessment without AI was not performed; consequently, we cannot determine whether the experimental cohort would sustain comparable performance once ChatGPT was withdrawn, nor can we exclude the risk of cognitive dependence. Future investigations should incorporate longitudinal follow up, repeating report quality evaluations at four and twelve weeks after training under AI free conditions, and employ retention rates and error recurrence as outcome measures to objectively appraise skill durability and independence. Additionally, mandatory reflective steps—requiring users to document the rationale for each revision—can be embedded within the AI assisted workflow to foster deeper processing and to ensure that gains in efficiency are accompanied by genuine competency development.
Despite the promising findings, this study has certain limitations. It was conducted in a single hospital with a relatively small sample size, which may affect the generalizability and applicability of the results. The short duration of the study did not allow for a long-term follow-up assessment of the effects of ChatGPT usage on the report writing abilities of junior physicians. Furthermore, this research focused solely on the standardization and time efficiency of report writing without delving into the clinical application value, such as its impact on diagnostic accuracy. Moreover, the present study was restricted to a single, cross-sectional assessment with a standardized case battery administered at the conclusion of the training block. Future work should therefore incorporate longitudinal learning-curve analyses to quantify how AI-supported instruction influences residents’ progressive mastery of ultrasonography in everyday clinical practice. Finally, ChatGPT is just one of the more representative large language models. Future studies could expand the sample size, conduct multi-center research, and extend the duration to comprehensively evaluate the overall effectiveness of various large language models in standardizing ultrasound report writing at different environments.
Conclusion
With the real-time assistance of GPT-4-turbo-2025-08-26, ultrasound reports generated by junior physicians can achieve a level of quality comparable to that of senior physicians, characterized by standardized terminology, clear structure, and comprehensive key information, while reducing writing time by nearly one-fourth. This advancement provides a valuable quality control tool for clinical practice education and holds significant promise for expansion into multi-center and multi-modal imaging applications.
Supplemental material
Supplemental material - Leveraging ChatGPT to Assist Junior Physicians in Standardizing Ultrasound Report Writing: A Promising Tool
Supplemental material for Leveraging ChatGPT to assist junior physicians in standardizing ultrasound report writing: A promising tool by Li Zhu, Huohu Zhong, Jing Bai, Xiaoying Wang, Peifeng Huang and Zhenhong Xu in Digital health.
Supplemental material
Supplemental material - Leveraging ChatGPT to Assist Junior Physicians in Standardizing Ultrasound Report Writing: A Promising Tool
Supplemental material for Leveraging ChatGPT to assist junior physicians in standardizing ultrasound report writing: A promising tool by Li Zhu, Huohu Zhong, Jing Bai, Xiaoying Wang, Peifeng Huang and Zhenhong Xu in Digital health.
Footnotes
Acknowledgements
The research is supported by the Science and Technology Bureau of Quanzhou.
Ethical considerations
The study was approved by the Second Affiliated Hospital of Fujian Medical University (2025-127).
Consent for publication
The study was reviewed and approved by the senior authors’ institutional review board and approved for publication.
Author contributions
L.Z.: Conceptualization; H.Z.: Methodology; J.B.: Validation; X.W.: Formal analysis; X.Z.: Investigation; P.H.: Resources; H.Z.: Data Curation; L.Z.: Writing - Original Draft; H.Z.: Writing - Review & Editing; J.B.: Visualization; Z.X.: Supervision, Project administration, L.Z.: Funding acquisition. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Science and Technology Bureau of Quanzhou [2025QZNY085].
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets used and analyzed in the current study are available from the corresponding author, [Z.X.], upon reasonable request.
Supplemental material
Supplemental material for this article is available online.