
Abstract
Objectives
The aim of this study was to comparatively evaluate four large language models (LLMs) used for patient education in ophthalmology in terms of accuracy, reliability, and patient safety across different ophthalmic subspecialties.
Methods
In this cross-sectional evaluation, a total of 50 frequently asked patient questions covering five ophthalmic subspecialties (strabismus/pediatric ophthalmology, oculoplastics, cataract and refractive surgery, retina, and dry eye) were included. All questions were submitted in a text-only format to ChatGPT o3 Mini High, Gemini 2.0 Pro, Claude-Sonnet 3.7, and LLaMA 3.1 405B. The generated responses were independently evaluated by five blinded ophthalmologists using a 10-point scale assessing accuracy, currency, informativeness/clarity, and patient safety. Potentially unsafe content was identified and categorized using a predefined structured error taxonomy.
Results
Marked differences in performance were observed among the models. Mean scores were 3.44 for Gemini, 2.99 for ChatGPT, 2.48 for Claude, and 1.09 for LLaMA. Gemini demonstrated higher performance across most subspecialties, whereas in the retina subspecialty, ChatGPT and Claude generated comparatively stronger responses. Of the 200 evaluated responses, 19 (9.5%) contained potentially unsafe content, with the lowest proportion observed for Gemini and the highest for LLaMA.
Conclusions
LLMs can generate useful responses for patient education in ophthalmology, but performance varies by model and subspecialty. Within this 50-question, text-only expert-rating framework, Gemini 2.0 Pro and ChatGPT o3 Mini High provided relatively higher accuracy and reliability in most areas, whereas LLaMA 3.1 405B lagged. Larger and clinically integrated evaluations, including direct assessment of patient understanding and behavior, are needed to define their safe use in practice.
Introduction
Vision plays a critical role in enabling individuals to carry out daily activities and maintain independent mobility. 1 Therefore, the preservation of ocular health is critically important not only for individual well-being but also for enhancing overall public health and alleviating the burden on healthcare systems. 2 Ophthalmology is a medical specialty that encompasses numerous subspecialties, including retinal diseases, pediatric ophthalmology and strabismus, cataract and refractive surgery, oculoplastics, and ocular surface and dry eye diseases, and demands a high level of expertise in both diagnosis and treatment. 3 As a result of this diversity, patients’ need to access information is heightened, further underscoring the importance of obtaining accurate, up-to-date, and reliable information.
The rapid pace of digitalization and the widespread availability of the internet have increased patients’ propensity to consult online resources when seeking answers to health-related questions. 4 In particular, restrictions on access to healthcare services during the COVID-19 pandemic have further accelerated the adoption of digital health advisors and online information resources. Recent research indicates that approximately 70–80% of internet users seek health-related information online, and a substantial proportion of these individuals specifically look for details about their own symptoms or potential diagnoses. 5 However, significant concerns exist regarding the accuracy and reliability of health information available online; decisions based on incorrect or incomplete information may adversely affect patients’ treatment processes. 6 Therefore, there is a need for new technological solutions to ensure that patients can access reliable, evidence-based information.
The origins of artificial intelligence (AI) date back to the mid-20th century; the term was first coined by John McCarthy at the Dartmouth Conference in 1956, marking the emergence of AI as a scientific discipline. 7 Over the decades, AI has evolved from simple rule-based systems to complex neural networks capable of processing vast amounts of data and generating human-like responses. The first significant application of AI in medicine dates back to the 1970s, when expert systems such as MYCIN were developed to assist physicians in diagnosing infectious diseases and recommending antibiotic therapies. 8
Recent significant advances in natural language processing technologies have enabled AI-based language models to play a pivotal role in healthcare. ChatGPT (Chat Generative Pretrained Transformer) was released to the public by OpenAI in 2022 and quickly reached millions of users, thereby spearheading the widespread adoption of AI-driven conversational agents in domains such as healthcare, education, and customer service. 9 LLaMA, developed by Meta, was announced in February 2023 and, owing to its open-source architecture, has enabled researchers to develop their own applications. 10 The Google Gemini model was introduced in December 2023. Developed by Google DeepMind, Gemini is a multimodal AI system capable of processing text, visual, and auditory data. The model is distinguished by its advanced reasoning and problem-solving capabilities and can generate highly accurate responses in medical, scientific, and technical domains. 11 Anthropic's Claude model was first announced in March 2023, and Claude-Sonnet was subsequently developed and released in 2024. These models are designed with a focus on security and ethical principles, aiming to interact with users in a more reliable and controlled manner. 12 Trained on vast amounts of textual data and grounded in medical literature and current clinical guidelines, these models possess the capacity to address even the most complex queries from patients and healthcare professionals.13,14 Several studies have demonstrated that AI-based chatbots deliver more accurate and consistent information in patient education settings than traditional search engines. 15 However, the accuracy, reliability, and impartiality of these models in generating medical information remain subjects of ongoing debate.
AI applications in ophthalmology have achieved significant successes, particularly in image analysis, diagnostic support systems, and patient management. 16 Deep learning algorithms have demonstrated high accuracy rates in the early diagnosis of conditions such as diabetic retinopathy, age-related macular degeneration, and glaucoma. 16 While most AI research in ophthalmology has traditionally focused on image-based diagnostics and clinical decision support, far less attention has been paid to AI systems designed for patient-facing education and question answering. More recently, several studies have begun to evaluate large language models (LLMs) specifically as text-based advisors for ophthalmology patients. 17 Esfahani et al. 18 examined ChatGPT's responses to 22 common ophthalmology questions derived from Google Trends and found that most answers were judged appropriate and highly comprehensive by board-certified ophthalmologists, but were written at about a 10th-grade reading level and showed weaker performance for queries related to glaucoma and cataract. Hamzeh et al. 19 focused on ChatGPT-4o and systematically quantified both the clinical accuracy and readability of its answers to ophthalmology patient questions, highlighting the need to balance medically detailed content with health-literacy-appropriate language. These studies support the promise of LLM-based chatbots for eye-care information, but they typically evaluate a single model, cover a limited set of conditions, and summarize performance with aggregate accuracy/readability scores. In contrast, our work compares four general-purpose LLMs across five major ophthalmology subspecialties using a standardized set of 50 high-frequency patient questions, and provides multidimensional expert ratings that separately characterize accuracy, currency, informativeness, and patient safety for each model–subspecialty combination.
Beyond text-based evaluations, multimodal LLMs have also been investigated in ophthalmology. Choi and Yoo 20 evaluated ChatGPT-4o using three image-focused tasks: direct interpretation of fundus, external ocular, and facial photographs without prior examples (zero-shot); the use of illustrative examples to improve image classification performance (in-context learning); and the automatic creation of a simple, browser-based diagnostic tool from a schematic clinical algorithm without coding. Their findings suggest that a single multimodal LLM can achieve diagnostic performance comparable to conventional convolutional neural networks for selected tasks, while also generating interactive decision-support tools that may facilitate clinical workflows.
In contrast, the present study focuses exclusively on text-based patient education rather than image interpretation. Popular questions frequently searched online by patients across five major ophthalmology subspecialties were submitted to four general-purpose LLMs, and the responses were independently evaluated by five ophthalmology experts. Model performance was assessed both overall and at the subspecialty level using multidimensional expert ratings encompassing accuracy, currency, informativeness, and patient safety. Through this approach, our study aims to objectively clarify the potential role and limitations of contemporary AI models in ophthalmology-related patient education.
Materials and methods
Study design and setting
This was a cross-sectional evaluation study based on expert assessment of AI-generated answers to patient questions. The study was conducted at Karakoçan State Hospital, Elazığ, Türkiye, in January 2025.
Development of the question set
At the outset of the study, we sought to construct a question set that would reflect the questions most commonly asked by patients in real-world ophthalmic practice. For each subspecialty, ophthalmologists with fellowship training and substantial clinical experience were first asked to list patient questions that they frequently encountered in outpatient visits. In parallel, we reviewed patient-facing online resources and the current literature to analyze topics of high patient interest and frequently asked questions reported in national and international studies. Scientific databases such as PubMed and Google Scholar were consulted, and quantitative information from keyword-based searches (e.g. “cataract surgery risks/complications/recovery,” “strabismus surgery success rate,” “ptosis surgery side effects,” “dry eye treatment options”) was used to complement clinician input. This process yielded an initial pool of candidate questions for each subspecialty. To reduce the risk that our test items would simply reproduce existing examination questions or vendor-provided examples, we avoided copying verbatim content and instead rephrased candidate items into original, patient-facing formulations before the final selection.
We then manually screened this pool for semantic overlap and removed questions that expressed essentially the same concern with only minor wording differences (e.g. “Is cataract surgery painful?” vs “Does cataract surgery hurt?”), keeping a single representative formulation by consensus. During this deduplication step we also excluded highly technical or clinician-oriented formulations and preferentially retained plain-language versions that would be understandable to the general adult population. To characterize the linguistic complexity of the final question set, we calculated readability scores for each English question using the Flesch–Kincaid Grade Level formula, which provides an approximate U.S. school grade level required to understand the text, with higher values indicating more complex language; scores were rounded to the nearest whole grade level for reporting in the supplemental materials. For each question, we also assigned a single primary topic cluster (e.g. indications, risks and complications, recovery, effectiveness, alternatives or daily-life impact) and recorded a representative keyword query string corresponding to typical patient search-engine behavior; these variables are reported in Supplemental Table S1. Finally, ophthalmology experts reviewed the refined pool to assess content validity and to ensure coverage of distinct patient concerns across indications, risks and complications, recovery, effectiveness and alternatives. On this basis, 10 questions per subspecialty (50 in total) were selected for inclusion in the study. The complete list of 50 questions, together with their subspecialty labels, topic clusters, example query strings and Flesch–Kincaid Grade Level scores, is provided in Supplemental Table S1. Taken together, these steps reduce ambiguity and overlapping phrasing and allow external researchers to reconstruct and extend the question set using the metadata summarized in Supplemental Table S1.
Prompt design
All models were queried using a standard instruction prompt that asked for concise, patient-friendly explanations without providing diagnoses or personalized medical advice. We used identical prompts for all four models, differing only in the model endpoint. The full prompt templates and example model outputs are provided in Supplemental Appendix A. We intentionally kept the prompts location-agnostic to mirror common real-world patient queries and to evaluate default model behavior when explicit geographic context is not provided; in many practical deployments, some implicit locale cues (e.g. interface language or regional/account settings) may still be available and can influence how responses are framed. All models were evaluated under a strictly zero-shot setting: each query consisted solely of the base instruction template and the question text, without any few-shot exemplars, chain-of-thought (CoT) demonstrations or other in-context learning signals. All four models were accessed as off-the-shelf systems via their standard interfaces, without any additional fine-tuning, custom training data or persistent chat history, and each question was submitted in a separate session to prevent information carry-over between items.
AI models and evaluation process
The designated questions were posed to four contemporary LLMs, namely ChatGPT o3 Mini High (OpenAI), Gemini 2.0 Pro (Google), Claude-Sonnet 3.7 (Anthropic), and LLaMA 3.1 405B (Meta). Each model provided responses via its native interface using default, non–user-specific settings. The models’ responses were recorded directly for analysis without any supplementary human intervention or editing. Each response was independently evaluated by five expert ophthalmologists affiliated with various universities and academic teaching hospitals. Responses were evaluated for accuracy, currency, clarity, and patient safety using a 10-point Likert scale (1 = very poor; 10 = excellent). Experts rated the responses in a blinded manner, without disclosure of the model identities. Detailed per-question model outputs and expert ratings are provided in Supplemental Table S2.
Statistical analysis
Because each of the 50 ophthalmology questions was answered by four LLMs and independently evaluated by five experts, the dataset followed a repeated-measures design. To assess differences in overall model performance, a repeated-measures ANOVA was performed with Model treated as the within-subject factor. When violations of the sphericity assumption were detected, appropriate corrections (Greenhouse–Geisser, Huynh–Feldt, and Lower-Bound) were automatically applied by the software.
To examine whether model performance varied across ophthalmology subspecialties, a linear mixed-effects model was constructed with Model, Subspecialty, and their interaction specified as fixed effects, while question identity was included as a random intercept to account for repeated observations. This approach enabled evaluation of both overall performance differences and subspecialty-specific patterns.
Because expert ratings were recorded on an ordinal 1–10 scale, a Friedman test was used to reduce reliance on parametric assumptions, followed by Tukey HSD pairwise comparisons when significant differences were observed. Interrater agreement among the five experts was quantified using a two-way random-effects intraclass correlation coefficient [ICC(2,1)], with confidence intervals estimated via bootstrap resampling.
To assess score calibration and consistency across models, mean scores were calculated for each question–model pair, bootstrap confidence intervals were generated, and score distributions were visualized using box-and-whisker plots.
Safety and error taxonomy
Safety-related errors were assessed using a structured error taxonomy. Each model response was independently coded by expert ophthalmologists across four error categories:
Results
According to the Friedman ranking test, significant performance differences were observed among the models (test statistic = 94.88, p = 1.95 × 10−2⁰). Across the entire dataset, mean rank scores were highest for Gemini 2.0 Pro, followed by ChatGPT o3 Mini High, Claude-Sonnet 3.7, and LLaMA 3.1 405B.
Subspecialty-level analysis showed that Gemini 2.0 Pro achieved the highest ranks in strabismus, oculoplastics, cataract and refractive surgery, and dry eye disease. In the retina subspecialty, ChatGPT o3 Mini High and Claude-Sonnet 3.7 achieved comparable top ranks. LLaMA 3.1 405B consistently recorded the lowest ranks across all subspecialties (Table 1).
Mean ranks of the four large language models across ophthalmology subspecialties based on the friedman ranking test (higher ranks indicate better performance).

As shown in the boxplots in Figure 1, Gemini 2.0 Pro and ChatGPT o3 Mini High achieved higher and more consistent expert scores across most ophthalmology subspecialties, whereas LLaMA 3.1 405B exhibited lower median scores and greater variability.

Boxplots showing the distribution of expert scores for four large language models (ChatGPT o3 Mini High, Gemini 2.0 Pro, Claude-Sonnet 3.7, and LLaMA 3.1 405B) across ophthalmology subspecialties and the full dataset. Top row: strabismus and pediatric ophthalmology, oculoplastics, and cataract and refractive surgery; bottom row: retina, dry eye, and all questions combined (“All data”). Boxplots display the median, interquartile range, and overall score dispersion.
Pairwise comparisons between the language models were conducted using the Tukey–Kramer post-hoc test following a significant repeated-measures analysis. The results are summarized in Table 2 and visualized in Figure 2.

Pairwise differences in mean expert scores between large language models. The horizontal bar chart shows mean score differences between model pairs across all questions and raters. The vertical dashed line at 0 indicates no difference between models; bars extending to the right indicate higher mean scores for the first model in the pair, whereas bars extending to the left indicate higher scores for the second model. The largest absolute difference is observed between Gemini 2.0 Pro and LLaMA 3.1 405B, reflecting the consistently superior performance of Gemini 2.0 Pro in patient question answering.
Summary of post hoc pairwise comparisons (Tukey–Kramer) among the four large language models.
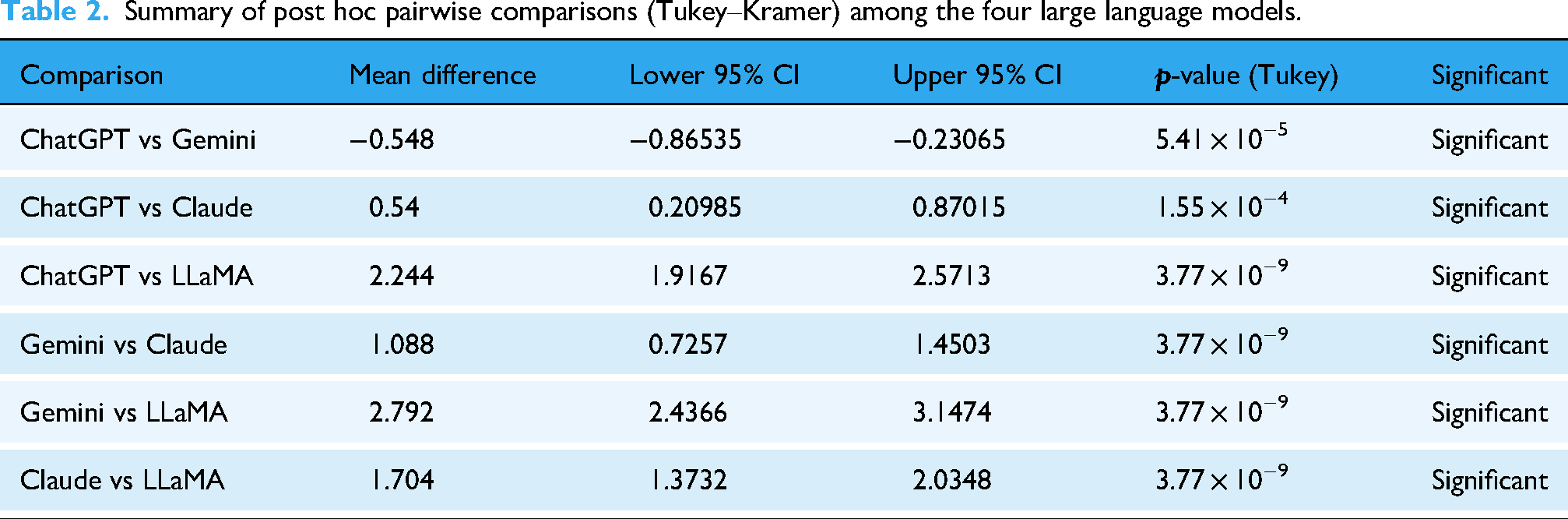
Pairwise Tukey–Kramer post hoc comparisons revealed statistically significant differences between all model pairs (all p < 0.001; Table 2). Gemini 2.0 Pro achieved significantly higher scores than Claude-Sonnet 3.7 and LLaMA 3.1 405B, while ChatGPT o3 Mini High also outperformed both models. Claude-Sonnet 3.7 demonstrated consistently higher performance than LLaMA 3.1 405B across comparisons.
Although the performance difference between Gemini 2.0 Pro and ChatGPT o3 Mini High was relatively small, it remained statistically significant, indicating a consistent advantage of Gemini 2.0 Pro across the evaluated items. Overall, the pairwise comparisons establish a clear performance hierarchy, with Gemini 2.0 Pro ranking highest, followed by ChatGPT o3 Mini High, Claude-Sonnet 3.7, and LLaMA 3.1 405B.
A positive mean difference indicates that the first model achieved a higher score than the second. The table reports statistically significant pairwise differences based on the overall dataset. Gemini 2.0 Pro and ChatGPT o3 Mini High achieved significantly higher scores than Claude-Sonnet 3.7 and LLaMA 3.1 405B, while LLaMA 3.1 405B consistently demonstrated the lowest performance across all comparisons.
As shown in Figure 2, Tukey–Kramer post-hoc comparisons revealed clear separation between the models, with the largest performance gap observed between Gemini 2.0 Pro and LLaMA 3.1 405B, indicating a substantial advantage of Gemini 2.0 Pro in patient question answering.
Table 3 presents the results of the ANOVA test. The F-value of 108.58 indicates that the observed mean score differences among the four models are unlikely to be due to chance. The uncorrected p-value was 4.18 × 10−37, and the Greenhouse–Geisser, Huynh–Feldt, and Lower-Bound corrected p-values remained on the order of 10−14, clearly demonstrating that even violations of the sphericity assumption do not affect the results. This statistical significance quantitatively confirms the hierarchy Gemini > ChatGPT > Claude > LLaMa observed in the Tukey HSD plot (Figure 2). Moreover, the relatively low residual mean square (0.672) indicates limited within-item variability in scores, supporting the stability of the observed model differences. Finally, the epsilon-corrected p-values remain below 10−13; therefore, even if the Mauchly test indicates a sphericity violation, the conclusions remain unaffected and the overall inference is robust to sphericity corrections.
Results of the ANOVA test conducted among the four large language models.

Note: Significant differences in scores were observed among the models, and the findings remained robust despite violations of the sphericity assumption.
In pairwise comparisons, Gemini 2.0 Pro and ChatGPT o3 Mini High were found to score significantly higher, particularly relative to Claude-Sonnet 3.7 and LLaMA 3.1 405B. LLaMA 3.1 405B exhibited the lowest performance across all comparisons. All statistical findings are detailed in Table 2 and Figure 2.
Across the 200 model–question instances, interrater agreement among the five ophthalmologists was poor to fair. The two-way random-effects intraclass correlation coefficient [ICC(2,1)] was 0.32, with a bootstrap 95% confidence interval of 0.26–0.37 (F(199,796) = 4.82, p < .001), indicating modest consistency in absolute scoring levels across experts. Importantly, despite variability in absolute ratings, the relative ranking of models remained consistent across both parametric and nonparametric analyses, supporting the robustness of the comparative findings despite modest absolute agreement.
To characterize score calibration independently of interrater agreement, item-level mean scores were calculated for each model by averaging the ratings of all five experts for each question–model pair. The resulting calibration metrics are summarized in Table 4.
Overall model calibration results.

Gemini 2.0 Pro achieved the highest overall mean quality score, followed by ChatGPT o3 Mini High, whereas Claude-Sonnet 3.7 demonstrated a moderate decline in calibration and LLaMA 3.1 405B showed the lowest overall performance. The nonoverlapping confidence intervals between Gemini 2.0 Pro and ChatGPT o3 Mini High indicate a statistically meaningful difference in calibration.
Subspecialty-level analysis revealed clinically relevant patterns. Gemini 2.0 Pro consistently outperformed other models across strabismus, oculoplastics, cataract, and dry eye disease. In contrast, retina questions exhibited a distinct ranking shift, with Claude-Sonnet 3.7 achieving the highest calibration, followed closely by ChatGPT o3 Mini High, while Gemini 2.0 Pro showed comparatively lower performance in this subspecialty. These findings suggest that retina-related clinical scenarios may present model-specific challenges (Table 5).
Subspecialty-wise calibration results of the evaluated language models.

The distributional characteristics of model performance are visualized in Figure 3. Box-and-whisker plots demonstrate tighter score dispersion for Gemini 2.0 Pro, indicating greater stability across items, whereas LLaMA 3.1 405B exhibits the widest variability and the lowest median values. These findings reinforce the aggregate results and underscore substantial performance stratification among the evaluated LLMs.

Distribution of item-level mean scores across the four large language models.
Overall, the calibration analysis demonstrates that although all models can generate generally plausible responses, Gemini exhibits the most consistent and highest-quality performance, except in retina-focused queries where Claude achieves a relative advantage. These specialty-specific differences have practical implications for clinical deployment and model selection.
Safety evaluation based on a structured error taxonomy identified unsafe or potentially harmful advice in 19 of 200 model-generated responses. Model-level unsafe content rates are summarized in Table 6 and illustrated in Figure 4. Gemini 2.0 Pro exhibited the lowest rate of unsafe content, whereas LLaMA 3.1 405B showed the highest proportion of unsafe responses; ChatGPT o3 Mini High and Claude-Sonnet 3.7 demonstrated intermediate safety profiles.

Model-level unsafe content rates across the four large language models, expressed as the percentage of responses classified as unsafe.
Summary of safety-related errors across large language models.

Across all models, unsafe responses were rarely isolated and most often co-occurred with other error types, particularly clinical inaccuracies and outdated guidance, highlighting the compound nature of safety-related failures. Although a chi-square (χ2) test comparing unsafe content prevalence across models did not reach statistical significance (χ2(3) = 6.22, p = 0.10, n = 200, Cramér's V = 0.18), the observed differences reveal meaningful model-level safety trends and are therefore reported descriptively.
Discussion
In recent years, the integration of AI technologies into healthcare has precipitated a profound shift in how patients and healthcare professionals obtain health-related information. A global survey conducted in 2022 found that 77% of internet users had searched for health information online at least once, and 35% had consulted health-related content on social media platforms. 21 However, the accuracy and currency of online health information are often disputed, posing a high risk of encountering inaccurate or incomplete data. In this context, AI-based applications hold significant promise for enabling patients to obtain reliable, evidence-based information.22,23
In this study, the 10 most frequently encountered and popular online patient questions across five ophthalmology subspecialties were identified and posed to various AI models. For each subspecialty, the accuracy and reliability of the models’ responses were independently evaluated by experienced ophthalmologists. This approach enabled a comparative analysis of AI performance across subspecialties, revealing which model delivered the most reliable results in each area. The findings indicate that AI-based information systems may exhibit variable performance depending on the subspecialty, underscoring the importance of model selection in clinical practice. Within this framework, Gemini 2.0 Pro and ChatGPT o3 Mini High achieved the highest expert ratings across most subspecialties in our sample, but their performance still varied by question type and subspecialty, and we did not evaluate real patient understanding or behavioral outcomes. Overall, expert ratings suggested a consistent ranking of model performance (Gemini 2.0 Pro > ChatGPT o3 Mini High > Claude-Sonnet 3.7 > LLaMA 3.1 405B), although this ordering shifted for retina questions, where ChatGPT o3 Mini High and Claude-Sonnet 3.7 performed similarly. Potentially unsafe or harmful advice was identified in 19 of 200 responses, highlighting the need for careful model selection and ongoing clinical oversight in patient-facing deployments. Because patient education depends not only on clinical accuracy but also on readability and clarity, future evaluations should explicitly incorporate health-literacy–appropriate communication as a core outcome alongside accuracy and safety. 19 To our knowledge, few studies have systematically compared the performance of multiple AI models by directing patient questions from more than one ophthalmology subspecialty.
Physician-evaluated studies across multiple specialties have examined the effectiveness of AI-based response systems for patient-facing questions. For example, Ayers et al. 24 compared physician- and AI-generated replies to patient questions posted on social media and reported that AI can provide meaningful and appropriate responses in this setting. In ophthalmology, an expert evaluation comparing AI-generated and physician-generated answers similarly emphasized that empathy and human interaction remain central to patient communication. 25 Other ophthalmology-focused studies have reported that ChatGPT may provide more accurate answers to glaucoma-related patient queries than conventional web search, 26 and that ChatGPT, Bing, and Bard can achieve comparable accuracy on pediatric ophthalmology and strabismus questions, although reliability concerns persist. 27 Beyond ophthalmology, Chiu et al. 28 showed that GPT-4.0 outperformed Gemini Pro and Claude 2 in clinical microbiology and infectious diseases on dimensions including accuracy, comprehensiveness, and harmlessness. Collectively, these findings support the promise of LLMs for patient education while underscoring the continued importance of clinician oversight; building on this evidence, our study offers a novel, subspecialty-specific comparison of multiple general-purpose AI models using high-frequency patient questions independently rated by experienced ophthalmologists.
Our findings also complement recent work on multimodal LLMs in ophthalmology. Choi and Yoo 20 showed that ChatGPT-4o can interpret fundus, external ocular and facial images with competitive diagnostic accuracy, particularly when guided by in-context exemplars (i.e. in-context learning (ICL), where example input–output pairs are included in the prompt to steer the model's responses), and can translate schematic diagnostic algorithms into functional HTML-based tools. In contrast, our study deliberately abstracts away from image data and code generation to examine a different part of the care pathway: text-based patient education. Rather than assessing diagnosis against reference labels, we evaluate how four widely used LLMs perform on frequently asked patient questions across five subspecialties, and we explicitly quantify “patient safety” as a separate dimension alongside accuracy, currency and informativeness. This design allows us to identify models that are not only accurate but also conservative in potentially risky scenarios, thereby providing complementary evidence to multimodal image-interpretation benchmarks on how LLMs might be safely integrated into ophthalmic care. Unlike Choi and Yoo, who explicitly leveraged ICL by providing exemplar image–label pairs to improve diagnostic performance, we intentionally used a strictly zero-shot configuration without any in-context examples. This design isolates how off-the-shelf LLMs behave on unseen ophthalmology patient questions under default-like conditions, but likely underestimates the performance that could be achieved with more structured prompting strategies (including CoT–style stepwise task decomposition) and retrieval-augmented generation (RAG) approaches that ground responses in up-to-date, trusted sources (e.g. clinical guidelines), which should be explored in future work.
In our study, significant performance differences were observed among the evaluated AI models. Notably, the Gemini 2.0 Pro model emerged as the top performer in the strabismus, oculoplastics, cataract, and dry eye subspecialties. In the retina subspecialty, ChatGPT o3 Mini High and Claude-Sonnet 3.7 delivered similarly high performance, with no statistically significant difference between them. This finding parallels the results of Bahir et al., 29 who compared ChatGPT and Gemini models in ophthalmology and reported that Gemini Advanced achieved superior overall accuracy while ChatGPT-4 also demonstrated high performance. In that work, both models were reported to approach expert-level performance in specific settings and tasks, including retina-related questions.
Additionally, in the strabismus and oculoplastics subspecialties, no significant differences were observed among ChatGPT o3 Mini High, Gemini 2.0 Pro, and Claude-Sonnet 3.7; however, all three models clearly outperformed LLaMA 3.1 405B. This outcome is consistent with Masalkhi et al.'s study 30 comparing the Gemini and ChatGPT models on ophthalmology patient queries, which found that both models produced similar and clinically appropriate responses in terms of patient education and guidance.
In the cataract, retina, and dry eye subspecialties, Gemini 2.0 Pro and ChatGPT o3 Mini High achieved significantly higher scores compared to Claude-Sonnet 3.7 and especially LLaMA 3.1 405B, suggesting that model selection may be crucial in patient education processes in these areas. Indeed, Casagrande and Gobira 31 demonstrated that Gemini 2.0 Advanced and ChatGPT-4.0 attained high accuracy rates in cataract knowledge on the Brazilian Council of Ophthalmology examination questions.
Importantly, potentially unsafe or harmful advice was identified in 19 of 200 model-generated responses, indicating that even high-performing systems may occasionally produce clinically risky content; descriptively, Gemini 2.0 Pro showed the lowest unsafe-content rate, whereas LLaMA 3.1 405B showed the highest. In most cases, safety concerns co-occurred with clinical inaccuracies and/or outdated guidance, suggesting that errors are often compound rather than isolated. Together, these findings support complementing accuracy-focused evaluation with structured safety screening and ongoing clinical oversight when LLMs are used for patient education.
The comparatively lower performance observed for LLaMA 3.1 405B may reflect differences across models in pretraining data composition and recency, posttraining alignment, safety tuning, and the characteristics of the deployed versions and interfaces. Conversely, the stronger performance of Gemini 2.0 Pro and ChatGPT o3 Mini High may indicate more effective alignment and response optimization for patient-facing question answering, including better adherence to contemporary clinical framing and clearer, more actionable explanations. Notably, Gemini's multimodal design and differences in system-level implementation may also influence response quality even in text-only settings, although the present study did not isolate specific mechanisms underlying these performance gaps.30,32
Our findings suggest that the performance of AI-based digital advisors across different ophthalmology subspecialties may vary depending on both the model and the subject matter. Other studies, in contrast to our results, have shown that AI-based models do not always deliver high accuracy and reliability in ophthalmology. For example, Mihalache et al. 33 reported that Google Gemini and Bard achieved a 71% accuracy rate on ophthalmology board examination questions when accessed from the United States; however, this rate varied significantly when accessed from other countries, and in some cases incorrect answers were delivered with considerable confidence. Similarly, in the study by Popovic and Muni 34 published in JAMA Ophthalmology, ChatGPT attained only a 54% accuracy rate on board-style ophthalmology questions and exhibited lower-than-expected performance in certain subspecialties (e.g. retina). These studies indicate that the performance of AI-based models may vary according to the model, the usage context, and the geographic access point, and that the risk of producing incorrect information remains a significant limitation. Therefore, the high-performance findings of our study should be interpreted in conjunction with the limitations and variability reported in the literature.
Cost and access questions are inherently locale-dependent. We deliberately asked pricing items without specifying a country or city to reflect typical patient behavior and to evaluate default responses under missing context. In such cases, estimates may not be locally applicable, highlighting the importance of locale-aware prompting and/or retrieval of up-to-date local resources in future evaluations.
This study has several limitations. First, it is uncertain whether the 10 questions selected for each subspecialty fully represent the information needs of the patient population and the clinical diversity encountered in real-world practice. Additionally, only text-based questions and responses were evaluated, and visual data analysis (e.g. fundus photographs and OCT images), which is of paramount importance in ophthalmology practice, was excluded. The involvement of only five ophthalmology experts in the evaluation process may limit the generalizability of the findings; inclusion of a larger and more heterogeneous expert panel could have enhanced the reliability of the assessment. Furthermore, the versions of the AI models used and the currency of their training datasets are important variables that may have influenced the results. Because we used a strictly zero-shot, off-the-shelf setup without CoT prompting or RAG, our results may underestimate how well these models can perform when they are guided with more structured prompts or supported with up-to-date external sources. A further limitation is that we cannot fully exclude some degree of data leakage between our question set and the proprietary pretraining corpora used for these models. Contemporary LLMs are trained on large-scale web and text collections that may contain patient-education materials and online FAQs similar to our items, so our findings should be interpreted as reflecting performance on realistically encountered queries rather than on a strictly held-out, out-of-distribution test set. Although we mitigated this risk by rewriting candidate questions into original, patient-facing formulations and by using off-the-shelf models without any additional fine-tuning or custom training data, complete separation from the models’ pretraining data cannot be guaranteed. Notably, employing newer model versions or updated training datasets in a similar study might yield different outcomes. Finally, only frequently encountered and general patient questions were assessed, while rare, complex, or multidisciplinary clinical scenarios were omitted. In light of these limitations, the results should be interpreted with caution and appropriate qualification.
Conclusion
This study offers a novel contribution to the literature by systematically comparing AI-based responses to the most frequently asked patient questions across different ophthalmology subspecialties through expert evaluations. The findings show that LLMs can exhibit significant performance differences in patient education processes depending on both the subspecialty and the model. Within the constraints of a 50-question, text-only evaluation, Gemini 2.0 Pro and ChatGPT o3 Mini High showed relatively strong and consistent performance compared with the other models, but their real-world reliability for patient education require confirmation in larger studies with direct patient-level outcomes. Nevertheless, considering AI-based systems as complementary tools in clinical practice does not diminish the indispensable roles of human expertise and ethical oversight. Future work aimed at further developing these models and optimizing their integration with healthcare professionals is expected to make a substantial contribution to patient safety and information quality.
Supplemental Material
sj-xlsx-1-dhj-10.1177_20552076261433657 - Supplemental material for Digital guides in eye care: Comparing AI model accuracy and reliability
Supplemental material, sj-xlsx-1-dhj-10.1177_20552076261433657 for Digital guides in eye care: Comparing AI model accuracy and reliability by Hakan Veli Savaş and Osman Altay in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076261433657 - Supplemental material for Digital guides in eye care: Comparing AI model accuracy and reliability
Supplemental material, sj-docx-2-dhj-10.1177_20552076261433657 for Digital guides in eye care: Comparing AI model accuracy and reliability by Hakan Veli Savaş and Osman Altay in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076261433657 - Supplemental material for Digital guides in eye care: Comparing AI model accuracy and reliability
Supplemental material, sj-docx-3-dhj-10.1177_20552076261433657 for Digital guides in eye care: Comparing AI model accuracy and reliability by Hakan Veli Savaş and Osman Altay in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors thank the five ophthalmology specialists who provided blinded ratings of the model responses and contributed valuable feedback on the study design and interpretation. The authors also acknowledge the support of the ophthalmology training clinics in Elazığ, Türkiye, where the expert evaluations were conducted.
Ethical considerations
This study did not involve patient interventions, access to medical records or collection of identifiable personal data. The question set was developed from expert opinion and a review of existing literature and patient education materials, without using individual patient records or identifiers. The dataset analyzed consisted of deidentified question texts and AI-generated responses evaluated by ophthalmology specialists. In accordance with local and national regulations, the project was considered exempt from formal ethics committee review. Informed consent was obtained from all expert evaluators prior to participation. All data included in the analyses are therefore considered ethically sourced.
Use of AI tools
Generative AI tools (e.g. ChatGPT, OpenAI) were used solely to assist with English-language editing and to improve clarity of expression in this manuscript. No AI tool was used to generate, process or analyze the study data. The authors carefully reviewed and edited all AI-assisted text and take full responsibility for the content of the manuscript.
Consent to participate
Informed consent was obtained from all expert ophthalmologists who participated in rating the AI-generated responses. No patients or members of the public were recruited as research participants.
Consent for publication
Not applicable. This article does not contain any individual person's data (including images, videos or quotations) that would require consent for publication.
Author contributions
Hakan Veli Savaş: conceptualization, methodology and instrument development, data acquisition and curation, formal analysis, interpretation of data, drafting of the manuscript, and writing—review and editing. Osman Altay: conceptualization, statistical analysis, visualization, and critical revision of the manuscript for important intellectual content. All authors read and approved the final version of the manuscript and agree to be accountable for all aspects of the work. Hakan Veli Savaş is the guarantor of the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The dataset analyzed in this study consists of anonymized question texts, AI-generated responses and aggregated rating scores. Deidentified data and analysis code are available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.