
Abstract
Objective
The increasing use of large language models (LLMs) for manuscript preparation and content generation presents both opportunities and risks, creating an urgent need for clear guidance. While many journals have introduced directives, their consistency and scope remain unclear. This study aimed to assess the prevalence and nature of LLM use guidance in emergency medicine publishing.
Methods
We conducted a cross-sectional analysis of emergency medicine journals, reviewing websites for directives on LLM use by authors, and regarding the use of AI in the peer review process by editors and reviewers. Data were extracted on guidance existence, stakeholder requirements, publisher adoption, and association with journal metrics.
Results
Of the 56 journals, 38 (68%) provided a directive on LLM use. While all 38 (100%) permitted LLM use for writing, guidance for authors on image generation was conflicting: 32% permitted it, while 40% explicitly prohibited it. Directives for editors were similarly contradictory, with 24% prohibiting LLM use and one (3%) permitting it. For reviewers, 47% prohibited LLM use, while one (3%) permitted it. Publisher-driven fragmentation was profound, with adoption rates varying from 100% to 18%. Notably, no statistically significant differences were detected between the presence of a directive and journal quality metrics (P > .05).
Conclusions
Emergency medicine publishing demonstrates significant variations and conflicting guidance in its governance of LLM use. Existing directives present contradictory rules for authors, editors, and reviewers on key issues like image generation and use in peer review. To close this critical guidance gap, a comprehensive, standardized framework is urgently needed to resolve these conflicts and foster the responsible integration of digital technologies into scholarly publishing.
Keywords
Introduction
The recent emergence of large language models (LLMs) has profoundly impacted the landscape of academic and scientific writing.1,2 For researchers, these advanced tools offer significant efficiencies, assisting with tasks ranging from literature summarization and language polishing to drafting entire manuscript sections, thereby accelerating the publication timeline.3,4 However, this convenience is accompanied by considerable risks. Key concerns include the potential for generating factually inaccurate or “hallucinated” content, issues of plagiarism, the perpetuation of biases present in the training data, and a lack of accountability for the generated text, all of which pose a threat to the integrity of scholarly communication.1,5,6 However, the rapid pace of this technological advancement has outstripped the development of clear ethical and governance frameworks, creating systemic risks.
In response, major international bodies like the International Committee of Medical Journal Editors (ICMJE) and the Committee on Publication Ethics (COPE) have issued initial recommendations.7–9 Despite this, the implementation of these directives at the individual journal level appears highly variable. Studies in multiple medical specialties have revealed significant inconsistencies in the adoption and scope of guidance.7–12 For instance, the reported prevalence of LLM guidance varies widely across specialties, ranging from 100% in top cardiology and cardiovascular medicine journals to 70% in leading nursing journals and 43.9% in radiological journals.7,13,14 This variability highlights the need for specialty-specific analyses to understand the unique challenges and adoption patterns within different clinical fields.
The current state of LLM-related editorial directives within emergency medicine, a field where rapid and clear dissemination of research is paramount, has not yet been comprehensively examined.15,16 As a frontline, high-risk specialty characterized by time-sensitive decision-making, emergency medicine represents a particularly important case. The heavy reliance on readily accessible evidence, combined with a growing adoption of digital tools, makes the field both a prime beneficiary of LLM efficiencies and uniquely vulnerable to the risks of unregulated use.15,17 As emergency medicine serves as the frontline for a vast range of acute conditions, from significant orthopedic trauma like complex fractures to critical medical emergencies such as myocardial infarction, understanding the integrity of its published guidance is of broad interdisciplinary importance.15–18 Therefore, the purpose of this study was to systematically assess the prevalence and characteristics of LLM use guidance across emergency medicine journals. Our objectives were to: (1) document existing directives for authors, editors, and reviewers; (2) evaluate disparities across different publishers; and (3) assess the relationship between the adoption of guidance and journal quality metrics.
Methods
This cross-sectional study was designed to evaluate the prevalence and characteristics of guidance regarding the use of LLMs in emergency medicine journals. The study's methodology was informed by similar research previously published in other medical specialties.7–12
We identified a comprehensive list of journals from the 2024 Journal Citation Reports (JCR) under the “emergency medicine” category, resulting in an initial list of 56 academic outlets. Journals were excluded only if their general editorial guidelines (e.g. Instructions for Authors or editorial policy pages) were not publicly accessible online. Importantly, journals with accessible general guidelines were retained in the study even if they lacked specific mention of LLMs. We then comprehensively reviewed the official websites of these journals on June 20, 2025, focusing on publicly accessible documents such as instructions for authors, editorial policies, and guides for reviewers. To ensure data accuracy and minimize bias, the screening and data extraction process was performed independently by two investigators (Ying Du and Tianlin Wen). Any discrepancies in coding were resolved through discussion and adjudication by a third senior investigator (Xiyan Zhao) until a consensus was reached.
To identify relevant guidance, we used keywords such as large language model, LLM, artificial intelligence (AI), AI, ChatGPT, and generative AI. Publisher-level policies were included in our assessment only if the individual journal's website provided a direct link or explicit reference to them. This approach ensures that our findings reflect the actual guidance visible to an author preparing a submission for that specific journal. Regarding the scope of terminology, policies referencing broad terms such as “artificial intelligence,” “automated writing tools,” or “machine-generated text” were considered inclusive and classified as relevant guidance, as these categories encompass the use of LLMs. If no explicit mention of LLMs or related technologies was found after a thorough search, the journal was classified as “without LLM guidance.” For the non-English journals included in our sample, official websites were initially translated into English using Google Translate to facilitate data extraction, with key policy statements subsequently verified to ensure the accuracy of the interpretation.
For each journal, we extracted data on several key aspects. First, we determined the presence or absence of an explicit LLM directive. For journals with established guidance, we then collected detailed information on requirements pertaining to authors, editors, and reviewers. Specifically for authors, in addition to directives on authorship, content generation, and image creation, we coded for two core ethical dimensions: (1) transparency requirements (whether the policy explicitly mandates the disclosure of LLM use); and (2) human accountability (whether the policy explicitly states that authors bear full responsibility for the accuracy and integrity of any AI-generated content). We also documented the publisher of each journal to analyze publisher-level adoption rates. Finally, to assess the relationship between guidance presence and journal prestige, we collected the following scientometric data from Scopus and Web of Science (WoS): CiteScore, SCImago Journal Rank (SJR), Source Normalized Impact per Paper (SNIP), Journal Impact Factor (JIF), and Journal Citation Indicator (JCI).
All data were compiled and analyzed using IBM SPSS Statistics Version 26.0. Qualitative data are reported as frequencies and percentages. We assessed the normality of quantitative data using Kolmogorov–Smirnov test. Non-normally distributed quantitative data are presented as medians and interquartile ranges (IQR). The Mann–Whitney U test was used to compare nonparametric quantitative data. A P-value of less than 0.05 was considered statistically significant.
Results
Prevalence of LLM guidance
Of the 56 emergency medicine journals included in our analysis, 38 (68%) had established guidance regarding the use of LLMs. The remaining 18 journals (32%) had no publicly available LLM-related directives (Figure 1). These 56 journals were from 34 distinct publishers. Six publishers accounted for more than one journal: Elsevier (n = 11), Wiley (n = 5), Springer (n = 4), BMC (n = 4), Lippincott Williams & Wilkins (n = 2), and Wolters Kluwer (n = 2).

Proportion of emergency medicine journals with and without publicly available guidance on LLM use (n = 56).
Guidance for authors
Among the 38 journals with LLM directives, all 38 (100%) permitted the use of LLMs for generating manuscript content. Regarding authorship, 33 journals (87%) explicitly prohibited crediting LLMs as an author, with the remaining 5 (13%) having no available guidance on this point. Among the 38 journals with guidance, 34 (89%) explicitly required authors to disclose the use of LLMs. Furthermore, 30 (79%) of the directives explicitly stated that human authors ultimately bear full responsibility and accountability for the accuracy and integrity of the content. On the topic of LLM-generated images, the directives were varied: 12 journals (32%) permitted their use, 15 (39%) explicitly prohibited it, and 11 (29%) had no available guidance on the matter (Table 1).
Directives for authors in journals with established LLM guidance (n = 38).

LLM: Large language model.
Guidance for editors
Nine journals (24%) explicitly prohibited the use of LLMs in the editorial process, one journal (3%) permitted it, and the majority (28 journals, 74%) offered no available directive (Figure 2).

Directives for editor use of LLMs in journals with established guidance (n = 38).
Guidance for reviewers
For peer reviewers, 18 journals (47%) prohibited LLM use, one journal (3%) permitted it, and 19 (50%) had no available guidance on the topic (Figure 3).

Directives for reviewer use of LLMs in journals with established guidance (n = 38).
Publisher-level adoption rates
Adoption of guidance varied among publishers with more than one journal in the sample. The rates of adoption were: BMC (100%), Lippincott Williams & Wilkins (100%), Springer (75%), Wolters Kluwer (50%), Wiley (20%), and Elsevier (18%) (Figure 4).
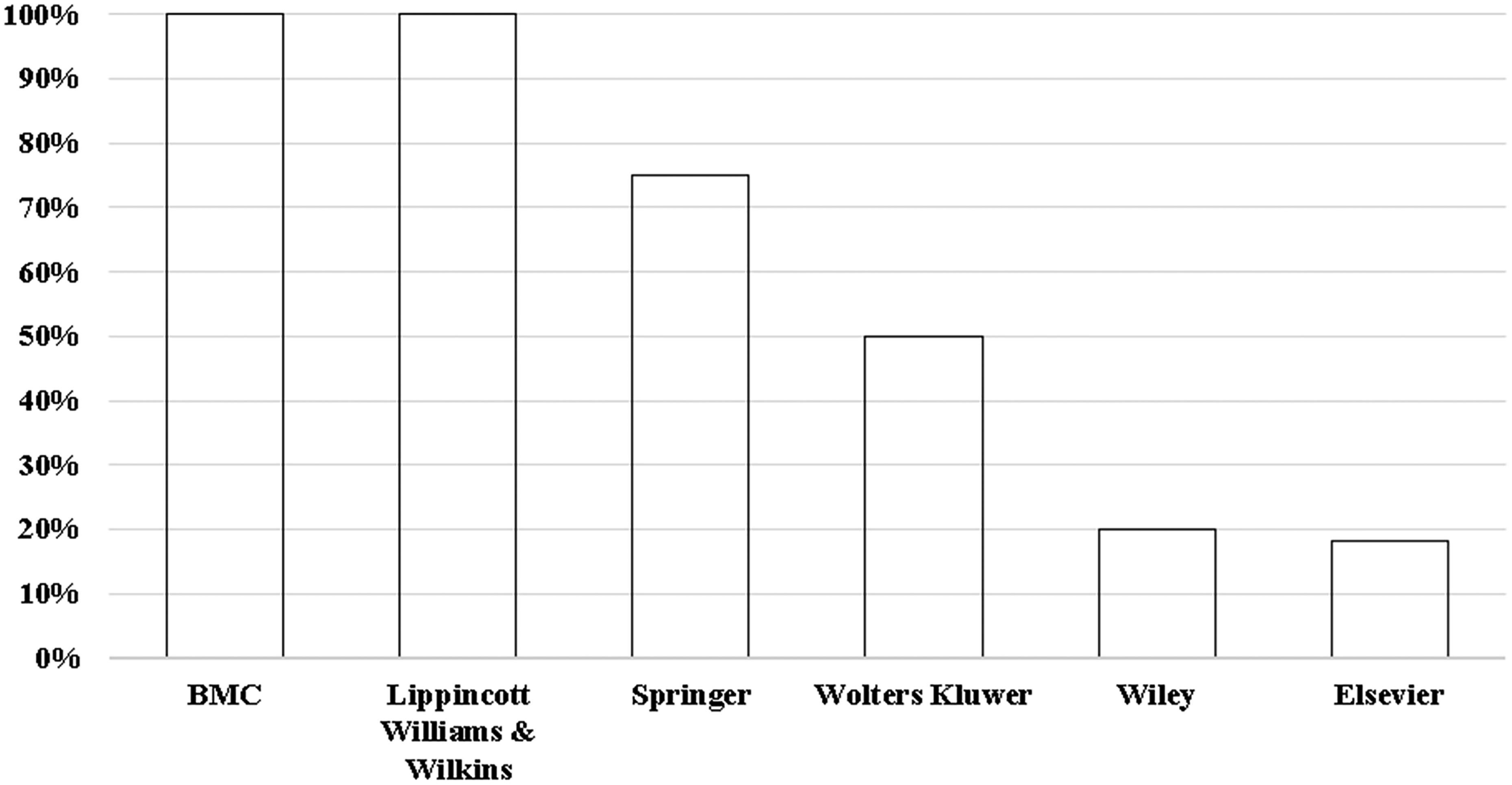
Adoption rates of LLM guidance among publishers with more than one emergency medicine journal.
Association with journal metrics
We detected no statistically significant differences in the medians of any of the analyzed metrics between journals with and without LLM guidance. For instance, the median JIF was 2.00 (IQR: 1.20–2.70) for journals with guidance compared to 1.80 (IQR: 0.70–3.20) for those without (P = .671). It is worth noting that since 100% of the journals with guidance permitted LLM use for text generation, this comparison effectively also reflects the relationship between “permission of use” and journal metrics. Similarly, no significant differences were observed for CiteScore (P = .490), SJR (P = .088), SNIP (P = .088), or JCI (P = .243) (Table 2).
Comparison of publication metrics between journals with and without LLM guidance.

Notes: Data are presented as median (interquartile range). P-values were calculated using the Mann–Whitney U test. A P-value less than .05 was considered statistically significant.
LLM: large language model; IQR: interquartile range; JIF: journal impact factor; JCI: journal citation indicator; SNIP: source normalized impact per paper; SJR: SCImago Journal Rank.
Discussion
This study systematically mapped the landscape of LLM guidance in emergency medicine publishing, revealing a governance framework plagued not just by gaps in coverage, but by direct and irreconcilable conflicts. Our findings point to several critical areas that require urgent attention from the academic community.
A key finding is the deep division within author guidance itself. While there is universal agreement on permitting LLM use for writing and a strong consensus against LLM authorship, this masks a fundamental disagreement on more complex technical applications.7–9 The fact that a researcher could be compliant with one journal's rules by using an LLM to generate an image, yet be in violation of another's for the very same action, highlights a lack of standardization.7–9,12 We acknowledge that individual journals generally maintain internal consistency, and that the variation across the field reflects a diversity of evolving perspectives. However, for authors, these distinct perspectives manifest as contradictory requirements across journals, creating a confusing and uncertain environment.7–9,19
The stakeholder gap for peer reviewers and editors is equally, if not more, notable. The guidance is not simply absent; it is deeply fragmented and contradictory. It is encouraging that a substantial number of journals have taken steps to protect manuscript confidentiality and editorial integrity by prohibiting LLM use by reviewers (47%) and editors (24%). 11 However, the fact that a large portion remains silent on these critical issues creates a significant gap in oversight. Most strikingly, the existence of journals that explicitly permit LLM use by editors and reviewers, directly contradicting the prohibitive stance of many others, exemplifies the current state of fragmentation. 20 This inconsistency means that the integrity and confidentiality of a submitted manuscript are dependent on the specific, often conflicting, rules of the journal to which it is sent.7–9,12
Furthermore, the highly fragmented adoption of guidance across different publishers exacerbates these issues, a fragmentation gap that creates a confusing and inequitable environment where standards are dictated by disparate corporate policies rather than unified disciplinary principles.7–9,12
Perhaps one of the most intriguing findings of this study is that we did not detect a statistically significant association between the presence of LLM guidance and journal quality metrics. While the median metrics were slightly higher for journals with guidance (e.g. JIF 2.00 vs. 1.80), these differences did not reach statistical significance, potentially due to the limited sample size of 56 journals. This contrasts with findings in other medical fields, such as ophthalmology, where a positive correlation was observed. 8 This divergence could suggest several possibilities. The adoption of these directives in emergency medicine may be in an earlier, more chaotic phase, not yet consolidated as a best practice among high-impact journals.7,12,21 Additionally, the practical, time-sensitive nature of much of the research in emergency medicine may lead higher-impact journals to prioritize guidance on clinical trial reporting or data-sharing over abstract ethical issues like LLM use.7,21,22 A third possibility is that the strong publisher-driven adoption model, as seen in our data, decouples the presence of guidance from the individual prestige of a journal, making publisher affiliation a stronger predictor than impact factor.8,9,12
A key strength of this study is its systematic and multi-dimensional analysis of LLM guidance in emergency medicine. By assessing directives for multiple stakeholders–including authors, editors, and reviewers—and evaluating publisher-level trends, our study offers a unique and granular perspective on the current state of governance.
The chaotic state of LLM guidance in emergency medicine serves as a cautionary case study for the integration of any new digital technology into established professional ecosystems. Our findings illustrate a classic governance vacuum where policy lags dangerously behind innovation. The fragmentation driven by publishers, rather than by a consensus of domain experts, highlights a failure in stakeholder accountability. This situation underscores a broader principle for the digital health community: without proactive, multi-stakeholder collaboration to develop ethical frameworks before a technology becomes deeply embedded, the risks of inconsistent standards, ethical breaches, and eroded trust are substantial. The challenge is not simply to regulate a tool, but to build robust governance structures capable of adapting to future technological advancements.
However, several limitations must be acknowledged to contextualize our findings. First, this analysis represents a snapshot in a rapidly evolving field, with data collected on a specific date. Given the dynamic nature of LLM technology and publishing standards, it is highly probable that some guidance has been introduced or updated since our review was conducted. Therefore, our findings should be considered a baseline measurement against which future changes can be tracked. Second, our review was confined to publicly accessible documents such as “Instructions for Authors” and editorial policy pages. It may not capture internal guidance communicated privately to editors or reviewers after manuscript submission or during the peer review invitation process. Consequently, our findings might represent a conservative estimate of the true prevalence of operational guidance within editorial workflows. Finally, our analysis was restricted to journals indexed in the JCR. While this ensured a sample of established and impactful journals, it means our findings may not be generalizable to the entire ecosystem of emergency medicine publishing. This includes regional, newer, or non-indexed journals which may have different, potentially even more varied, approaches to LLM guidance.
Conclusions
The governance of LLM use in emergency medicine publishing is defined by deep, multifaceted, and conflicting divisions. The problem is not merely an absence of rules, but the presence of contradictory ones. For authors, editors, and reviewers, the lack of a unified standard on critical issues like image generation and the use of LLMs in the editorial and peer review processes creates a challenging and inconsistent situation. We issue an urgent call to action for professional societies, editors, and publishers in emergency medicine to collaborate not just to fill the gaps, but to resolve the conflicts by creating a single, standardized, and robust framework. Such a framework should, at a minimum, include unified criteria for authorship, mandatory disclosure requirements, clear definitions of permissible LLM applications (e.g. for image generation), and strict confidentiality protocols for peer review. The responsible and ethical integration of powerful digital tools into medicine depends on minding, and closing, these critical gaps.
Footnotes
Abbreviations
Acknowledgements
None.
Ethics approval
Institutional review board approval was not required because the study did not involve human or animal participants.
Author contributorship
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Natural Science Foundation of China (82205089), National Key R & D Program of China (2022YFC3502100), Fundamental Research Funds for the Central Public Welfare Research Institutes (ZZ13-YQ-030), Scientific and Technological Innovation Project of China Academy of Chinese Medical Sciences (CI2021A01614), Clinical Research Center Construction Project of Guang’anmen Hospital, CACMS (2022LYJSZX13), High Level Chinese Medical Hospital Promotion Project (HLCMHPP2023009), and Noncommunicable Chronic Diseases-National Science and Technology Major Project (2025ZD0550900).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Guarantor
Zhiwei Jia