
Abstract
Introduction
Recent developments in the field of large language models have showcased impressive achievements in their ability to perform natural language processing tasks, opening up possibilities for use in critical domains like telehealth. We conducted a pilot study on the opportunities of utilizing large language models, specifically GPT-3.5, GPT-4, and LLaMA 2, in the context of zero-shot summarization of doctor–patient conversation during a palliative care teleconsultation.
Methods
We created a bespoke doctor–patient conversation to evaluate the quality of medical conversation summarization, employing established automatic metrics such as BLEU, ROUGE-L, METEOR, and BERTScore for quality assessment, and using the Flesch-Kincaid grade Level for readability to understand the efficacy and suitability of these models in the medical domain.
Results
For automatic metrics, LLaMA2-7B scored the highest in BLEU, indicating strong n-gram precision, while GPT-4 excelled in both ROUGE-L and METEOR, demonstrating its capability to capture longer sequences and semantic accuracy. GPT-4 also led in BERTScore, suggesting better semantic similarity at the token level compared to others. For readability, LLaMA 7B and LLaMA 13B produced summaries with Flesch-Kincaid grade levels of 11.9 and 12.6, respectively, which are somewhat more complex than the reference value of 10.6. LLaMA 70B generated summaries closest to the reference in simplicity, with a score of 10.7. GPT-3.5’s summaries were the most complex at a grade level of 15.2, while GPT-4’s summaries had a grade level of 13.1, making them moderately accessible.
Conclusion
Our findings indicate that all the models have similar performance for the palliative care consultation, with GPT-4 being slightly better at balancing understanding content and maintaining structural similarity to the source, which makes it a potentially better choice for creating patient-friendly medical summaries. Threats and limitations of such approaches are also embedded in our analysis.
Introduction
In the continuously developing field of text summarization research, fine-tuned pre-trained models have been widely adopted.1–4 However, these models often require large amounts of training data 1 which can be hard to obtain, or complex fine-tuning 3 processes which are very time-consuming and domain-specific, especially in specialized areas like medical conversation summarization. 5 The recent introduction of large language models (LLMs) such as GPT-3.5, 6 GPT-4, 7 and LLaMA 2 8 represents a significant change in natural language processing (NLP) research, because these models demonstrate remarkable zero-shot 9 capabilities, allowing them to perform complex tasks like summarization, translation, and question answering without the need for task-specific fine-tuning. For example, GPT-4 and LLaMA 2 can be used to summarize short stories 10 or develop effective meeting summarization systems. 11 It is reported that while LLMs can capture narrative elements, they struggle with specificity and interpreting nuanced subtext. 10 And comparatively, while closed-source models like GPT-4 often offer superior performance, open-source alternatives like LLaMA-2 provide a cost-effective and privacy-conscious option. 11 These models have also shown potential in the area of medical information delivery,12–21 as they can provide accurate and contextually relevant information about chronic diseases to patients, 14 handle drug-related inquiries with a level of safety and quality comparable to licensed pharmacists, 15 perform reliably in national licensing exams across various healthcare professions,16–18 generate synthetic medical conversations from clinical notes such as in the NoteChat dataset 20 and the MEDIQA-Chat, 21 and assist in complex tasks such as triage in emergency departments, 17 thereby enhancing the overall quality and accessibility of healthcare services.
Medical conversation summarization involves extracting key information from conversations between patients and healthcare professionals (HCPs) during medical consultations, producing concise yet comprehensive summaries. 22 Recently, there has been a growing trend in health care to provide post-consultation summaries, particularly after teleconsultations. These summaries benefit both patients and HCPs, as they provide a detailed account of the telehealth session, covering diagnosis, treatment plans, medication recommendations, and other important information. 23 By providing patients with these summaries, they are better informed about their health, leading to better decision-making. Additionally, these summaries are crucial for ensuring consistent and coordinated care, serving as a communication and coordination tool among different HCPs and specialists.
Recent studies have explored applying LLMs in medical data summarization, mainly for creating abstracts for biomedical literature or summarizing medical findings.24–28 However, there is a noticeable gap in research on the use of these techniques for medical conversation summarization, especially in the telehealth context. A few recent attempts include a study by Tang et al. 29 trying to summarize the abstracts (with a maximum words of 870) of Cochrane reviews into four sentences (around 100 words) using GPT-3.5 and GPT-4. Another study by Veen et al. 30 summarizes doctor–patient conversations (with an average word count of 1512) into “assessment and plan” paragraphs (211 words average), employing the ACI-Bench dataset and eight LLMs including LLaMA-2-7B, LLaMA-2-13b, GPT-3.5, and GPT-4.
In this short article, we aim to explore the opportunities of using the latest prompt-based LLMs, taking GPT-3.5, GPT-4, and LLaMA 2 as examples, for summarizing medical conversations in the setting of a palliative care medical consultation. The selection of GPT-3.5, GPT-4, and LLaMA models for this study was based on their demonstrated efficacy in prior research, popularity in NLP tasks, and their diverse capabilities in language understanding and generation. While other LLMs exist, these models were chosen due to their accessibility and relevance to the study’s objectives. The palliative care setting was chosen as it represents holistic patient-centred care encountered in many primary and specialist healthcare settings. To achieve this, we have manually crafted a benchmark conversation and summary that allows us to systematically test the accuracy issues associated with text summarization in the medical domain. Our study utilizes common evaluation metrics used in text summarization research, including BLEU, 31 ROUGE, 32 METEOR 33 scores, and BERTScore 34 to assess the comprehensiveness and quality of the generated summaries (Table 1 provides a summary of these metrics and what they measure). Importantly, we also utilize the Flesch-Kincaid grade Level 35 as a readability metric to assess the linguistic complexity of the generated summary. By doing so, we can gain a deeper understanding of the strengths and limitations of these models and their appropriateness for medical consultation summarization.
Description of various evaluation metrics used in text summarization.

Methods
In this study, we aimed to evaluate the zero-shot performance of summarizing a palliative care consultation using five state-of-the-art models: GPT-3.5 and GPT-4 from OpenAI, and LLaMA-2-7B, LLaMA-2-13B, and LLaMA-2-70B from Meta AI. GPT-4 is an improved iteration of the GPT-3.5 model, offering enhanced natural language understanding and generation capabilities. LLaMA-2-70B is an open source LLM trained with 70 billion parameters, compared to LLaMA-2-13B with 13 billion parameters and LLaMA-2-7B with 7 billion parameters, resulting in a model that can potentially generate more nuanced and contextually rich text but may require more computational resources for training and inference. Both GPT and LLaMA-2 have gathered significant attention due to their ability to generate high-quality and human-like responses to conversational text prompts. Despite their impressive capabilities, it remains unclear whether these LLMs can generalize and perform high-quality zero-shot summarization of medical conversations. Therefore, we sought to investigate the comparative performance of GPT models and Llama-2 models in summarizing medical conversations.
Benchmark conversation
The experimental data comprises a simulated doctor–patient conversation during teleconsultation. The conversation was carefully designed by a clinical expert on the multi-disciplinary research team to mimic authentic interactions that occur between patients and health care professionals. While the conversation was based on genuine medical scenarios, the issues discussed were carefully designed, allowing for controlled experimentation. To emulate the typical duration of a palliative care consultation, the conversation was constrained to a time frame of
It is important to note that the conversation was completely fictitious and had been constructed with ethical diligence. No personally identifiable information (PII) or sensitive patient data was included, which adheres to ethical guidelines and legal regulations in healthcare research.
Reference summary
In the experiment, the doctor–patient conversation was accompanied by a reference summary. The reference summary was carefully crafted by an experienced healthcare professional who was provided with a copy of the consulation dialogue. The clinician was instructed to write a summary letter for the patient and their carer as might be done in this practice setting.
The reference summary portrays a holistic approach to palliative care, focusing on patient education, symptom management, medication review, and continuous support, emphasizing palliative care’s role in improving the overall quality of life for patients with chronic and advanced illnesses. The use of the reference summary allowed for a standardized way of evaluating and comparing the performance of different summaries generated by LLMs. It was important not to just assess the presence of correct phrases but also the correct order and fluency of the generated text relative to how information was presented in the high-quality reference summary.
Model input and prompts
The input of each model was the benchmark doctor-patient conversation, referred to as “CONV.” For the prompts, in all settings, we used “You are a professional GP doctor, and just finished your consultation. Now you need to write up a consultation summary to the patient so that they can refer it back when they get home. Please summarize the following consultation into a consultation report: + CONV” to prompt the model to perform summarization.
Model output
In our study, the primary focus of evaluation was the output generated by the models, which entailed the critical task of summarizing medical conversations into concise consultation summaries. The quality and accuracy of these LLM-generated summaries was the cornerstone of our assessment, as they could directly impact the utility and effectiveness of telehealth in conveying crucial health care information to patients and facilitating seamless health care coordination among providers. 30
Similar to the reference summary, the output of each model was a consultation summary from a doctor’s perspective in a narrative format. Summary legnths generated by the different LLMs varied in the length from 200 to 350 words.
Model parameters
In both GPT and LLaMA models, we adopted the default parameters except temperature. Temperature is a parameter that controls the randomness of the LLM’s output. A higher temperature will result in more creative and imaginative text, while a lower temperature will result in more accurate and factual text. To get a stable output for each model, we set temperature as 0 in GPT models and 0.01 (the smallest possible value in the online LLaMA service 36 ) in LLaMA models.
Statistical analysis
We chose several automatic metrics which are widely-adopted and utilized in text generation and summarization assessment. These were BLEU, ROUGE-L, METEOR, and BERTScore. The details of the metrics are listed in Table 1. The values of these metrics range from 0 to 1, where 1 indicates the perfect matching between the LLM-generated summary and the reference, while 0 indicates no overlap.
In telehealth, a high BLEU score implies that the summaries of doctor–patient conversations accurately replicate specific medical terminologies and information as it was discussed. This accuracy is crucial for ensuring patients and other healthcare providers understand the exact recommendations and diagnoses made during the teleconsultation. ROUGE-L assesses the longest common subsequences between the generated summary and the reference. In practical terms, this means a summary with a high ROUGE-L score captures the essential content of the telehealth conversation, ensuring key points are not omitted. This is vital for maintaining the integrity of medical advice and actions to be taken post-consultation. METEOR evaluates the quality of translation by considering word-to-word matches with adjustments for synonyms and stemming, along with sentence structure. For telehealth, this translates to summaries that are not only accurate but also adaptable in language, making them accessible to patients with varying levels of health literacy. This adaptability enhances patient comprehension and facilitates better health outcomes. A high BERTScore indicates that the summary is semantically aligned with what was discussed, including the nuances and implications of the conversation. This is crucial for ensuring that summaries capture the tone and intended meaning, which can be particularly important in sensitive contexts such as discussing prognoses or treatment options.
Besides these commonly ultilized metrics for evaluating text summarization tasks, we also included Readability metric. Since our target audience for these summaries are the patients themselves, readability becomes a paramount consideration. These summaries need to be comprehensible and accessible to laypeople, ensuring that the conveyed information is clear, concise, and easily digestible. We employed the Flesch-Kincaid grade level (FKGL) as a fundamental readability metric to assess the linguistic complexity of the generated summary.
The FKGL is calculated using the following formula:
35
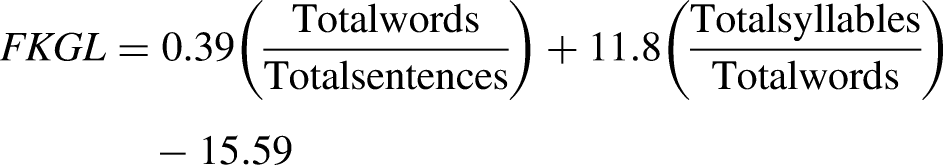
Results
Automatic metrics results
Figure 1 presents a comparative analysis of the five language models (three versions of LLaMA and two versions of GPT) on the palliative care conversation summarization task, regarding their performance on BLEU, ROUGE-L, METEOR, and BERTScore metrics. LLaMA2-7b scores highest in BLEU, indicating strong n-gram (sequences of n words) precision, and GPT-4 excels in both ROUGE-L and METEOR, demonstrating its capability to capture longer sequences and its semantic accuracy. GPT-4 also leads in BERTScore, suggesting better semantic similarity at the token level compared to others. The results point to a trade-off between models: LLaMA2-7b may be preferred for precision in wording, while GPT-4 could be favored for tasks requiring a more nuanced understanding of text and context, particularly in scenarios where readability for non-experts is essential.
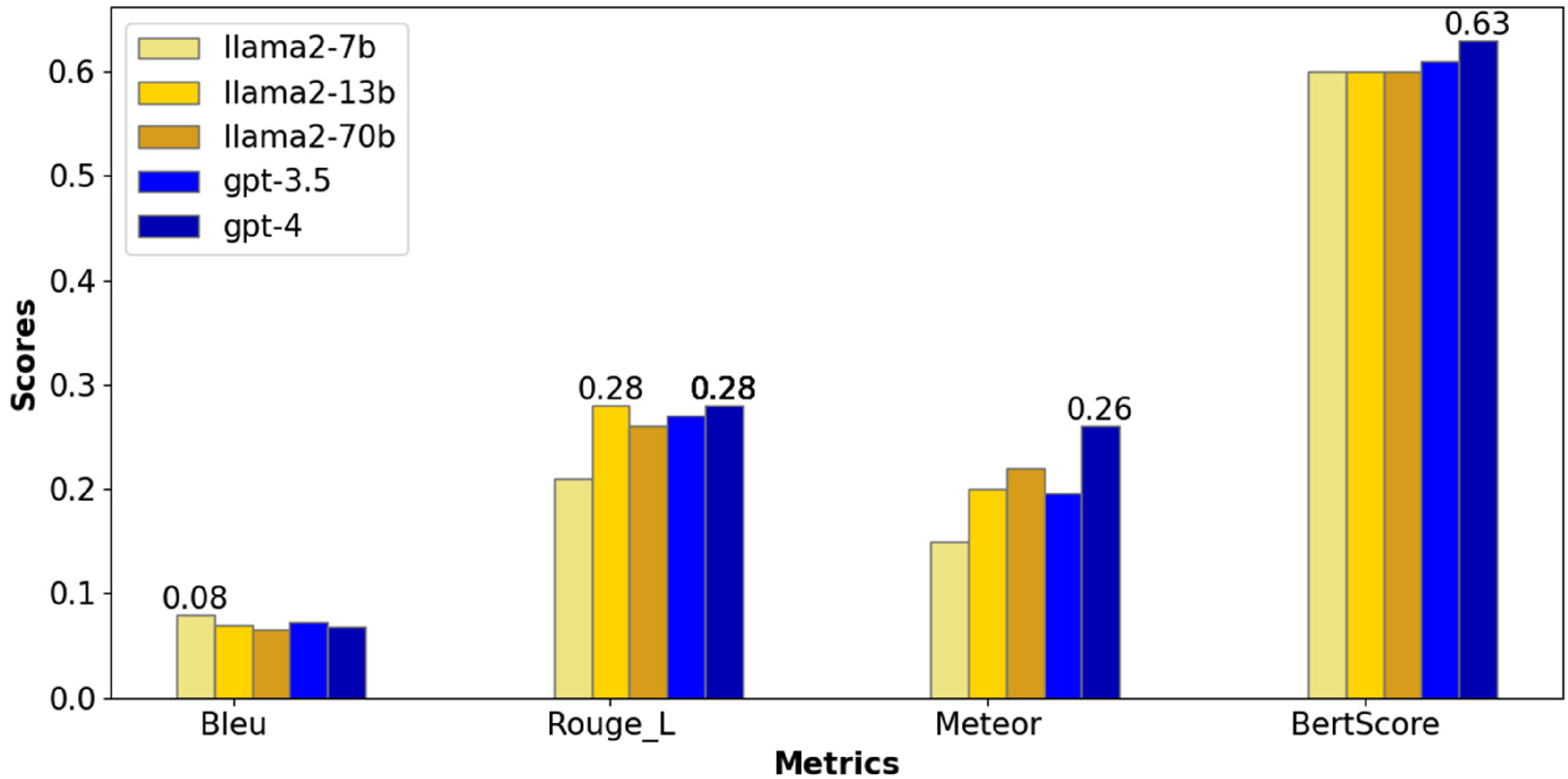
Performance of different LLMs for the palliative care conversation in automatic metrics, with the highest score in each metric shown on top of the model bar(s).
In the context of palliative care, where communication often involves conveying complex medical information in a compassionate and comprehensible manner, the choice between models like LLaMA2-7b and GPT-4 can be critical based on the specific needs of the scenario. When generating medication instructions for a patient, precision in wording is paramount to ensure patient safety and clarity. For instance, LLaMA2-7b could be used to summarize a text that specifies, “Take one 20 mg tablet of Prednisolone daily at 8 a.m., with food.” In this case, the exactness of the instructions, including dosage and timing, leaves little room for interpretation, minimizing the risk of errors. When discussing end-of-life care options, it is crucial to accurately convey the implications and considerations of various choices while being sensitive to the patient’s and family’s emotional state. GPT-4 could better summarize such narratives due to its high BERTScore, which indicates that GPT-4 is adept at capturing and reflecting the nuanced meanings embedded within the medical context, patient preferences, and the subtle emotional cues present in such conversations. The high BERTScore signifies GPT-4’s capacity to maintain the essence of the original narrative, ensuring that summaries are not only factually accurate but also resonate on a human-like level.
Readability
In Figure 2, the scores for the palliative care conversation summaries indicate that LLaMA 7b and LLaMA 13b produce summaries with grade levels slightly above the reference value of 10.6, at 11.9 and 12.6, respectively, suggesting that their summaries are somewhat more complex. LLaMA 70b generated summaries closest to the reference in terms of simplicity, with a score of 10.7, which might be more suitable for the general public. GPT-3.5’s summaries were the most complex at a 15.2 grade level, which could be challenging for a general audience to understand. GPT-4 sits in the middle with a 13.1 grade level, indicating summaries that were more complex than the reference but potentially less so than those from GPT-3.5, making it moderately accessible. Overall, summaries from LLaMA 70b may be the most approachable for a non-specialist audience, while GPT-3.5 might require a higher reading proficiency.
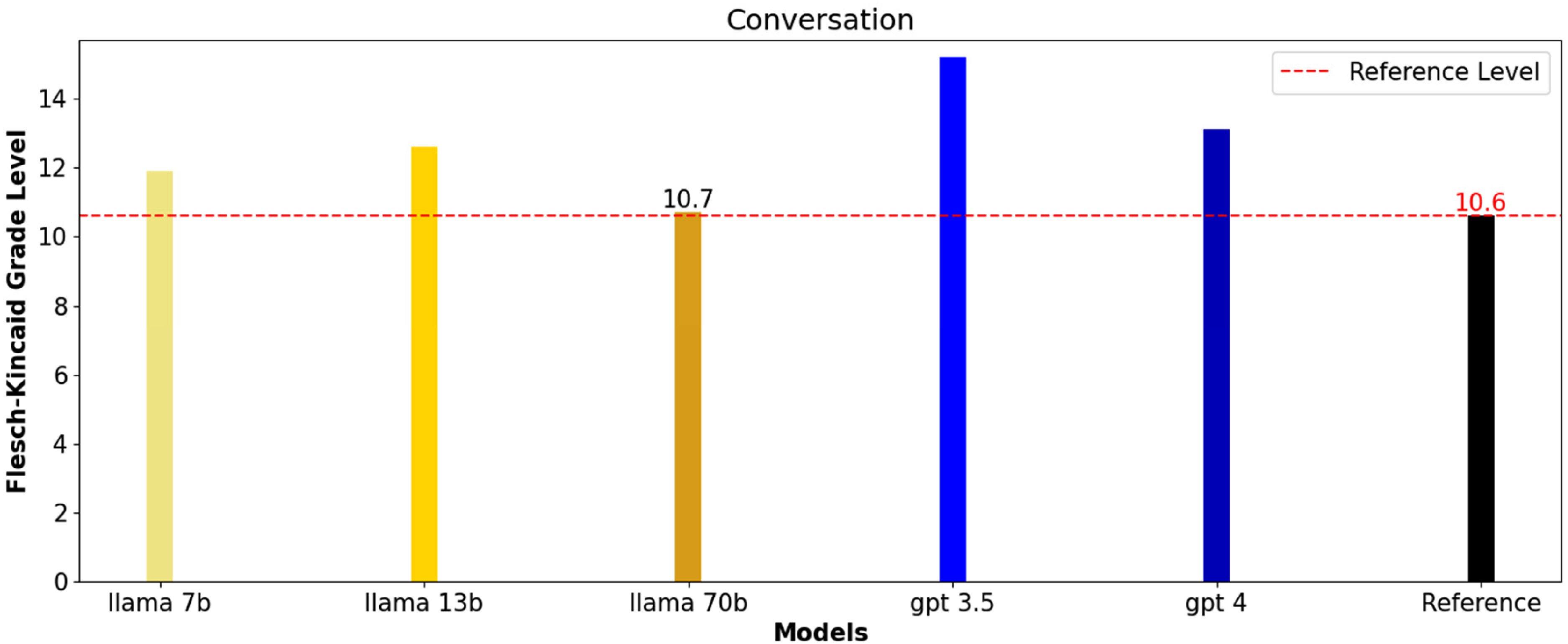
Flesch-Kincaid grade level of the reference summary and different LLM generated summaries for the palliative care conversation (where higher numbers indicate more complex texts and lower numbers indicate easier readability).
Discussion
The findings of this study highlight the potential of LLMs such as GPT-3.5, GPT-4, and LLaMA 2 for summarizing medical conversations, particularly within the context of palliative care teleconsultations. These models demonstrated varying degrees of success in understanding and summarizing complex medical dialogues, with GPT-4 showing a notable capacity for capturing longer sequences and maintaining semantic accuracy. This ability to grasp the essence of patient-healthcare provider interactions is particularly crucial in telehealth, where non-verbal cues are less observable, and clarity in communication is paramount.
Implications
The use of LLMs in summarizing palliative care consultations suggests the benefits that could extend across other healthcare domains such as general practice, oncology, geriatric medicine, and allied health. By generating concise and accurate summaries, these models have the potential to enhance patient comprehension, support better decision-making, and ensure consistent follow-up care. The integration of LLMs into telehealth and broader healthcare systems could streamline clinical documentation processes, reduce administrative burdens, and allow healthcare providers to focus more on direct patient care. Moreover, in the future, these models could be incorporated into electronic medical records (EMRs) to standardize documentation and promote continuity of care across different healthcare providers and settings.
Limitations and challenges
While the results are promising, several limitations must be acknowledged. Despite advancements in LLMs, the accuracy of the information generated by these models remains a critical concern. GPT-4, for example, excels in generating summaries with high semantic accuracy, as indicated by metrics like BERTScore. However, these models are still prone to generating “hallucinations,” which in the context of AI refers to the generation of content that is factually incorrect or not present in the original data. This poses significant risks in healthcare contexts, where the reliability of information is paramount. Additionally, the study’s reliance on synthetic data for model evaluation may limit the generalizability of the findings to real-world clinical settings. The practical implementation of LLMs in telehealth also presents challenges, including the need for integration with existing healthcare IT infrastructure, compliance with data privacy regulations, and ensuring that summaries are accessible to patients with varying levels of health literacy.
Future directions
To address these challenges, future research can focus on evaluating the performance of LLMs in real-world clinical settings, where the complexity and variability of medical conversations can be fully tested. It is essential to explore the cost-effectiveness of deploying LLMs at scale, balancing the benefits of improved documentation and patient care against the financial and resource investments required. Developing robust validation mechanisms is also crucial to mitigate the risks associated with LLM-generated summaries. Human evaluations should complement automatic metrics like BLEU, ROUGE-L, METEOR, and BERTScore to ensure that summaries are not only technically accurate but also clinically relevant and safe. Human evaluators can assess whether the summaries are comprehensible, whether they capture all necessary information without introducing errors, and whether they appropriately convey the tone and nuances critical in medical communication. Furthermore, exploring ways to enhance the integration of LLMs with existing EMR systems and telehealth platforms could support the practical application of these models in everyday healthcare settings.
Conclusion
This pilot study highlights the potential of LLMs, particularly GPT-3.5, GPT-4, and LLaMA 2, for summarizing palliative care consultations. Our findings suggest that GPT-4 offers a balance between understanding content and maintaining structural similarity to the source, making it a promising tool for generating patient-friendly summaries. While this study provides valuable insights into the potential of LLMs for summarizing palliative care consultations, it also underscores the need for continued research to address the limitations and challenges identified. By doing so, we can better understand how to harness the power of LLMs to improve healthcare delivery and outcomes across a wide range of medical contexts.
Footnotes
Acknowledgements
No third-party submissions or writing assistance were used.
Contributorship
Xiao and Wei designed and performed the experiments, and analysed the data. Andy assisted with the measurements. Xiao and Wei wrote the manuscript in consultation with Rashina, Peter, and Chris. All authors discussed the results and contributed to the final manuscript.
Data availability statement
The authors declare that all the data supporting the findings of this study are available in the Supplemental Material.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Ethical approval and patient consent were not applied in this study because no actual patient or doctor data was used.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Gurantor
Wei Zhou.
Informed consent
Patient consent was not applied in this study because no actual patient or doctor data was used.