
Abstract
Objective
Accurate assessment of physiotherapy exercises is critical for effective rehabilitation, particularly for elderly and mobility-impaired individuals. While telerehabilitation offers a viable alternative to in-clinic supervision, existing approaches often rely on single-modality sensors, limiting robustness and adaptability. This study aims to develop a multimodal, markerless framework for reliable home-based physiotherapy exercise recognition.
Methods
A deep learning–based multimodal framework is proposed that integrates synchronized RGB and depth streams. From RGB data, two-dimensional keypoints, semantic body-part labels, and contour-based visual descriptors are extracted. Depth silhouettes are used to estimate three-dimensional joint positions and reconstruct full-body meshes using the Skinned Multi-Person Linear model, along with global shape descriptors such as Zernike moments. Multimodal features are fused and refined using Kernel Fisher Discriminant Analysis, followed by classification using a Graph Convolutional Network to capture spatial and temporal relationships.
Results
The proposed framework was evaluated on three publicly available rehabilitation datasets: KIMORE, mRI, and UTKinect-Action3D. The system achieved classification accuracies of 95.30%, 92.70%, and 95.59%, respectively, demonstrating consistent performance across diverse rehabilitation-oriented benchmarks.
Conclusions
The results suggest that integrating complementary RGB and depth-based representations can enhance robustness and accuracy in physiotherapy exercise recognition under home-based settings. The proposed framework shows potential for supporting accessible telerehabilitation, while future work will focus on broader validation and practical deployment considerations.
Keywords
Introduction
Rehabilitation plays a vital role in restoring motor function and physical independence in elderly and disabled individuals. 1 Traditional physiotherapy models rely heavily on repeated, supervised clinical sessions, which are often inaccessible to patients living in remote, rural, or resource-constrained environments. 2 The lack of real-time monitoring and personalized feedback further increases the risk of incorrect exercise execution, potentially delaying recovery or causing secondary injuries. In light of the increasing demand for accessible and intelligent healthcare, there is a growing need for automated, vision-based rehabilitation systems that can operate reliably outside clinical settings.3,4
Telerehabilitation has emerged as a promising alternative, offering remote exercise supervision through camera-based sensing technologies.5,6 However, most existing systems are constrained by single-modality designs. RGB cameras, while visually rich, are highly sensitive to lighting variations, background clutter, and raise privacy concerns in home environments.7,8 Depth cameras, by contrast, offer geometric clarity and preserve privacy through silhouette abstraction, yet they often lack fine-grained visual detail and are susceptible to occlusion and sensor noise. These modality-specific limitations reduce the reliability and scalability of standalone systems.9,10
Recent research highlights the benefits of integrating RGB and depth modalities to capture both appearance-based and structural cues.11–13 Nevertheless, many existing solutions remain narrowly focused on joint angle estimation or skeletal tracking and fail to encode holistic body configuration or motion dynamics. 14 Moreover, global pose attributes such as limb symmetry, silhouette shape, and spatial coherence, critical for evaluating exercise correctness in real-world scenarios, are often overlooked. This gap underscores the need for a comprehensive multimodal framework capable of modeling both localized joint behavior and global body posture over time.
This study proposes a deep learning–based multimodal framework for physiotherapy exercise recognition using synchronized RGB and depth streams. RGB images are processed to extract 2D keypoints, semantic body part labels, and contour-based visual descriptors. In parallel, depth silhouettes are used to compute 3D joint positions, reconstruct parametric human meshes via the Skinned Multi-Person Linear (SMPL) model, and derive global shape descriptors using Zernike moments. These complementary features are fused into a unified representation that encodes both anatomical structure and dynamic motion characteristics. To enhance class separability, Kernel Fisher Discriminant Analysis (KFDA) is applied for feature refinement. The resulting discriminative features are classified using a Graph Convolutional Network (GCN) to support rehabilitation assessment in sensor-free, home-based settings.
The key contributions of this work include:
Multimodal RGB–Depth Framework for Markerless Motion Capture: A unified system that fuses RGB imagery and depth silhouettes to enable accurate, sensor-free physiotherapy exercise recognition. Adaptive 3D Anatomical Keypoint Localization (PoseKP-L/R): A novel silhouette-aware lightweight method for extracting 3D joint landmarks from depth maps, dynamically adjusting to upper-limb variations for precise anatomical mapping. Depth-to-Mesh Reconstruction for Structural Pose Modeling: Generation of full-body 3D meshes from depth silhouettes using novel lightweight PoseKP-L/R and SMPL, providing rich spatial and postural context without requiring physical markers or suits. Multilevel Feature Fusion and Discriminative Learning for Robust Classification: Integration of 2D keypoints (via FAST, Harris-Laplace), 3D mesh geometry, and handcrafted descriptors including Zernike moments and Gabor filters, followed by feature refinement using KFDA. The resulting discriminative features are classified using a GCN, enabling accurate, rotation-invariant, and temporally coherent exercise recognition.
The paper is structured as follows: “Literature review” section reviews related work, “System methodology” section details the system design, “Results and performance evaluation” section presents results, and “Conclusion and future direction” section concludes.
Literature review
Human Action Recognition (HAR) is a foundational task in telerehabilitation, enabling automated monitoring of patient movements for remote physiotherapy assessment. Traditional approaches have largely relied on wearable sensors, such as Inertial Measurement Units (IMUs), for capturing motion data with high temporal precision. García-de-Villa et al. 15 used multiple IMUs to recognize rehabilitation exercises with 88.4% accuracy, while Zhang et al. 16 demonstrated that a single waist-mounted IMU paired with a hybrid CNN–RNN architecture could monitor elderly activity with reasonable accuracy. Despite their effectiveness, these methods require users to wear devices, limiting practicality and comfort in nonclinical settings.
To address these limitations, vision-based HAR systems have gained traction, particularly those utilizing RGB or depth cameras. Kinect-based systems have shown early promise in exercise monitoring and fall detection but suffer from environmental dependencies such as poor lighting and occlusion sensitivity.17–19 As a result, RGB-based deep learning models have emerged, utilizing CNNs, LSTMs, and more recently, Transformers. Gupta et al. 20 and Li et al. 21 demonstrated the viability of RGB-only action recognition pipelines, though both approaches were affected by background noise and camera placement. Wang et al. 22 and Qiu et al. 23 attempted to mitigate these challenges using OpenPose and silhouette-guided dual-stream CNNs, but segmentation dependency and frame drop sensitivity remained persistent issues.
Recent studies have explored multimodal and hybrid HAR models, combining RGB, depth, and skeletal features to enhance robustness. Miao et al. 24 introduced a transformer-based HAR model using RGB and joint data, improving classification accuracy but remaining sensitive to keypoint extraction noise. Zanfir et al. 25 and Kanazawa et al. 26 advanced the field by incorporating 3D human mesh reconstruction using SMPL, enabling richer pose and shape modeling from monocular RGB input. Their work laid the foundation for markerless physiotherapy assessment by encoding both kinematic and structural information. Yi et al. 27 and Kocabas et al. 28 further demonstrated that temporally coherent SMPL predictions improved activity recognition accuracy under occlusion and motion blur.
Parallel research in depth-based and silhouette-driven HAR systems has shown strong potential for telerehabilitation. A study on depth-based HAR achieved 91% exercise classification accuracy and 82% correctness assessment by fusing skeletal and silhouette features. 29 Similarly, monocular pose estimation frameworks such as BlazePose and others have also demonstrated comparable performance to Kinect in controlled settings,30,31 although challenges remain in occlusion handling and depth ambiguity.
Several multi-sensor fusion techniques have also been proposed, combining RGB, depth, and inertial data through advanced feature integration methods such as DLRF, Genetic Algorithms, and spatiotemporal descriptors.32,33 While these approaches improve viewpoint robustness and classification accuracy, they often suffer from high computational overhead and limited applicability in home-based telerehabilitation. Tele-EvalNet 34 and other real-time AI-driven feedback systems have addressed aspects of movement quality prediction and exercise execution scoring, yet these systems remain limited by degraded skeleton tracking performance under occlusion and nonfrontal orientations.
In summary, existing HAR methods have made significant strides through deep learning and sensor fusion, yet face persistent challenges in real-world telerehabilitation scenarios. Most methods either lack integration of structural and appearance features or depend on sensor-heavy configurations unsuitable for home deployment. To address these limitations, this study proposes a multimodal HAR framework that fuses complementary appearance-based and structural features from RGB and depth streams. By integrating Zernike moment-based silhouette descriptors, SMPL-based 3D body modeling, and KFDA coupled GCN-based classification, the proposed system delivers accurate, occlusion-robust, and scalable performance for real-world telerehabilitation scenarios.
System methodology
This work presents a unified telerehabilitation framework that integrates both depth and RGB video analysis for accurate exercise monitoring in individuals with disabilities. The depth stream is processed using the Depth-based Keypoint Extraction and Mesh (D-KEM) pipeline for silhouette enhancement, 3D keypoint extraction, SMPL mesh reconstruction, and Zernike-based shape encoding, providing stable geometric structure and explicit spatial cues that are largely invariant to viewpoint changes and lighting conditions. Simultaneously, the RGB stream is analyzed through the Silhouette-based Tracking, Regional Analysis, and Parsing using RGB imagery (STRAP-RGB) pipeline, which performs silhouette segmentation, keypoint detection using FAST and Harris–Laplace, and feature extraction via Laws’ Texture Energy (LTE), Local Ternary Pattern (LTP), and Gabor filters, followed by semantic body-part labeling to capture fine-grained motion dynamics and appearance information. The integration of traditional and deep-learning modules has been carefully designed to exploit the complementary strengths of both modalities, combining the interpretability and texture-level robustness of handcrafted descriptors, particularly effective under occlusion or illumination variations, with the high-level semantic understanding and spatiotemporal abstraction of deep architectures. This complementary fusion allows depth cues to compensate when RGB information degrades, and vice versa, resulting in a balanced and cohesive system with enhanced robustness. A system overview is shown in Figure 1.
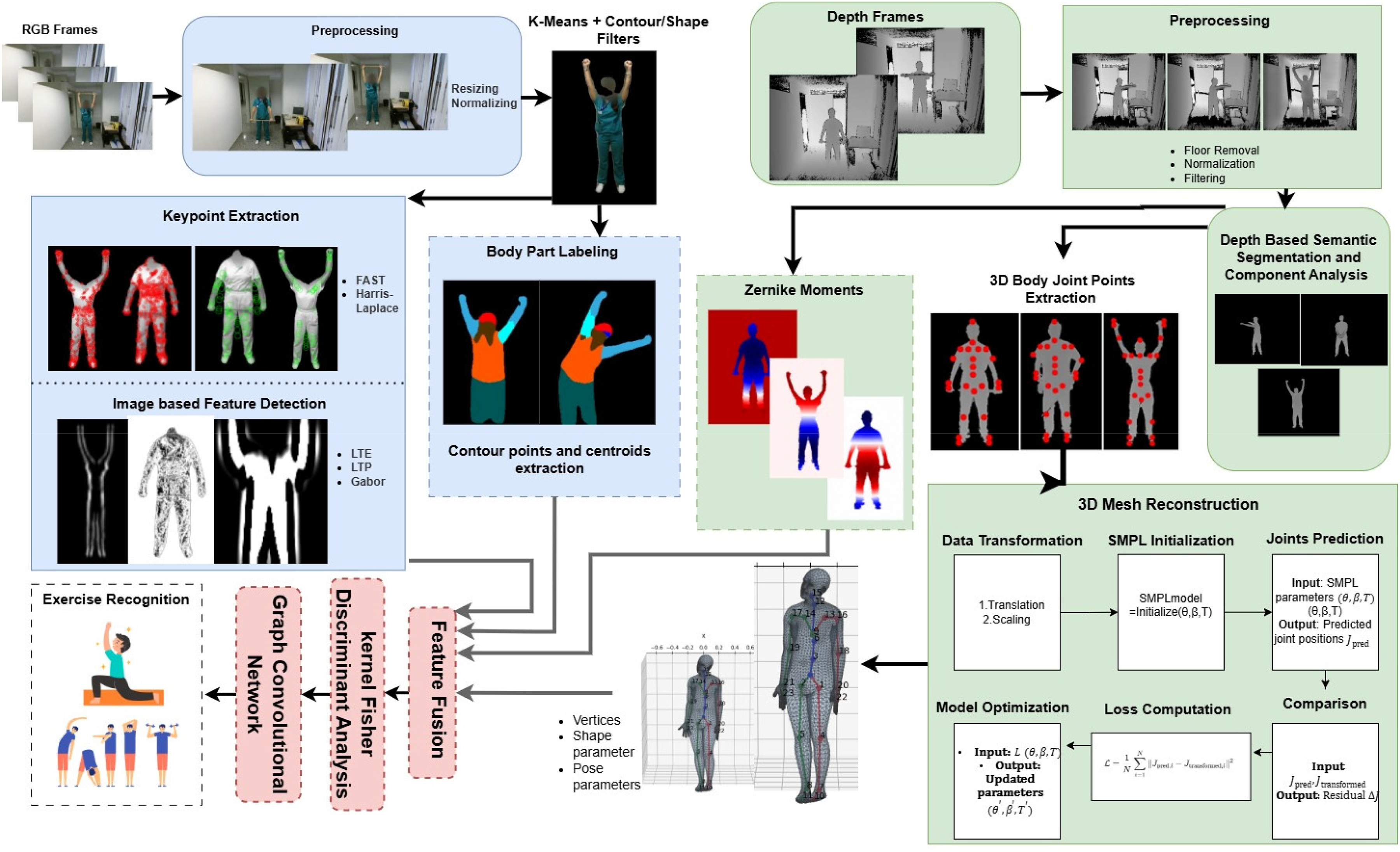
Unified RGB-depth telerehabilitation pipeline integrating Depth-based Keypoint Extraction and Mesh (D-KEM) and Silhouette-based Tracking, Regional Analysis, and Parsing using RGB imagery (STRAP-RGB) illustrating the integration of complementary visual and depth information for multimodal physiotherapy exercise recognition.
Data preprocessing and cross-modal synchronization
Before initiating the D-KEM and STRAP-RGB pipelines, all input recordings underwent a unified preprocessing stage to harmonize temporal and spatial parameters across modalities and datasets. Each RGB–Depth sequence was temporally aligned using sequential timestamps, ensuring that every RGB frame corresponded precisely to its depth counterpart captured at the same instant. To achieve temporal uniformity across datasets, the aligned streams were resampled to a common frame rate of 15 frames per second, and all sequences were standardized to a maximum duration of 260 frames for computational consistency.
Subsequently, al frames were spatially scaled to 256 × 256 pixels, establishing a consistent spatial resolution across datasets of varying native sizes. For intensity normalization, depth maps were converted to 16-bit precision and normalized using a Min–Max transformation defined in (1), ensuring consistent depth scaling and preservation of distance granularity:


Depth-based Keypoint Extraction and Mesh
We propose D-KEM modeling, a modular pipeline for 3D human body reconstruction from depth images. The process begins with preprocessing to enhance silhouette quality by removing noise, eliminating the floor, and improving contrast. Keypoints are then extracted using two pose-aware modules, PoseKP-L (Pose-aware KeyPoint extractor – Lowered Arms posture) and PoseKP-R (Pose-aware KeyPoint extractor – Raised Arms posture), designed for arms-down and arms-raised configurations, respectively. These modules rely on classical image processing techniques such as contour analysis and curvature detection to localize anatomical landmarks in
Preprocessing
This study utilizes the RANSAC algorithm to eliminate the floor from depth images by fitting a planar model to the identified floor points. Initially, pixels corresponding to the floor are detected based on their depth values, and a binary mask is employed to ensure that only foreground elements are considered. From these, a set of 3D coordinates representing the floor is constructed, as defined in (3):

Here, z denotes the depth value, and the binary mask ensures separation of foreground and background. RANSAC is then used to estimate a planar surface that best approximates the floor points, represented by (4):

Once the floor plane is estimated, any pixel with a depth value whose residual is less than a predefined threshold ε is classified as part of the floor and is consequently removed, as given in (5):

This approach effectively removes the floor while preserving the integrity of remaining depth values as shown in Figure 2. The resulting depth image, denoted as


Depth image preprocessing results showing (a) original depth frames; (b) corresponding frames after floor removal.

Depth image enhancement stages including (a) floor-removed frames, (b) normalized depth maps, (c) contrast enhancement using Contrast Limited Adaptive Histogram Equalization (CLAHE), and (d) final outputs after bilateral filtering.
To further improve local contrast while avoiding overamplification of noise, CLAHE (Contrast Limited Adaptive Histogram Equalization) is applied as shown in Figure 3(c). The transformation uses a clipped cumulative distribution function, denoted as

To enable compatibility with color-based processing techniques, the enhanced grayscale image is replicated across three channels, resulting in a pseudo-color image as shown in (8):

Finally, bilateral filtering is applied to suppress noise while preserving important edges as illustrated in Figure 3(d). This process is governed by (9):
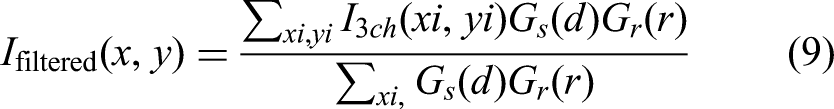
In this equation, d represents spatial distance, r indicates intensity difference, and
Depth-guided silhouette segmentation
Human localization in the preprocessed depth image is first performed using the Histogram of Oriented Gradients (HOG) descriptor. Gradient-based features extracted from the depth image are classified through a pretrained Support Vector Machine (SVM). Among all detections, the candidate with the maximum bounding box area is selected and enlarged using an expansion factor α, as depicted in Figure 4(a).

Depth-based human silhouette extraction stages: (a) Histogram of Oriented Gradient (HOG)-detected human bounding box, (b) initial silhouette obtained using GrabCut segmentation, (c) noise removal through connected component analysis, and (d) final refined human silhouette.
Once the human region is identified, GrabCut is employed to obtain an accurate silhouette. GrabCut treats foreground–background separation as an energy minimization problem by combining appearance modeling through a Gaussian Mixture Model (GMM) with spatial smoothness constraints, as illustrated in Figure 4(b). The overall energy function is expressed in (10):

Here,


In this formulation,

After segmentation, connected component analysis is applied to remove small or spurious regions. Each component is evaluated based on its area

Finally, the refined mask is applied to the floor-removed depth image to extract the human silhouette, as shown in Figure 4(d). The resulting silhouette is saved for subsequent analysis using (16):

PoseKP-L and PoseKP-R: Pose-Aware Keypoint Extraction Framework
The PoseKP-L (Pose-aware KeyPoint extractor – Lowered Arms posture) and PoseKP-R (Pose-aware KeyPoint extractor – Raised Arms posture) modules form a dynamic and adaptive framework designed to extract 24 anatomical keypoints from depth-based human silhouettes as shown in Figure 5. Unlike traditional static approaches, this system intelligently adapts to varying postures, body alignments, and arm positions, making it highly suitable for motion analysis, rehabilitation tracking, and activity recognition.
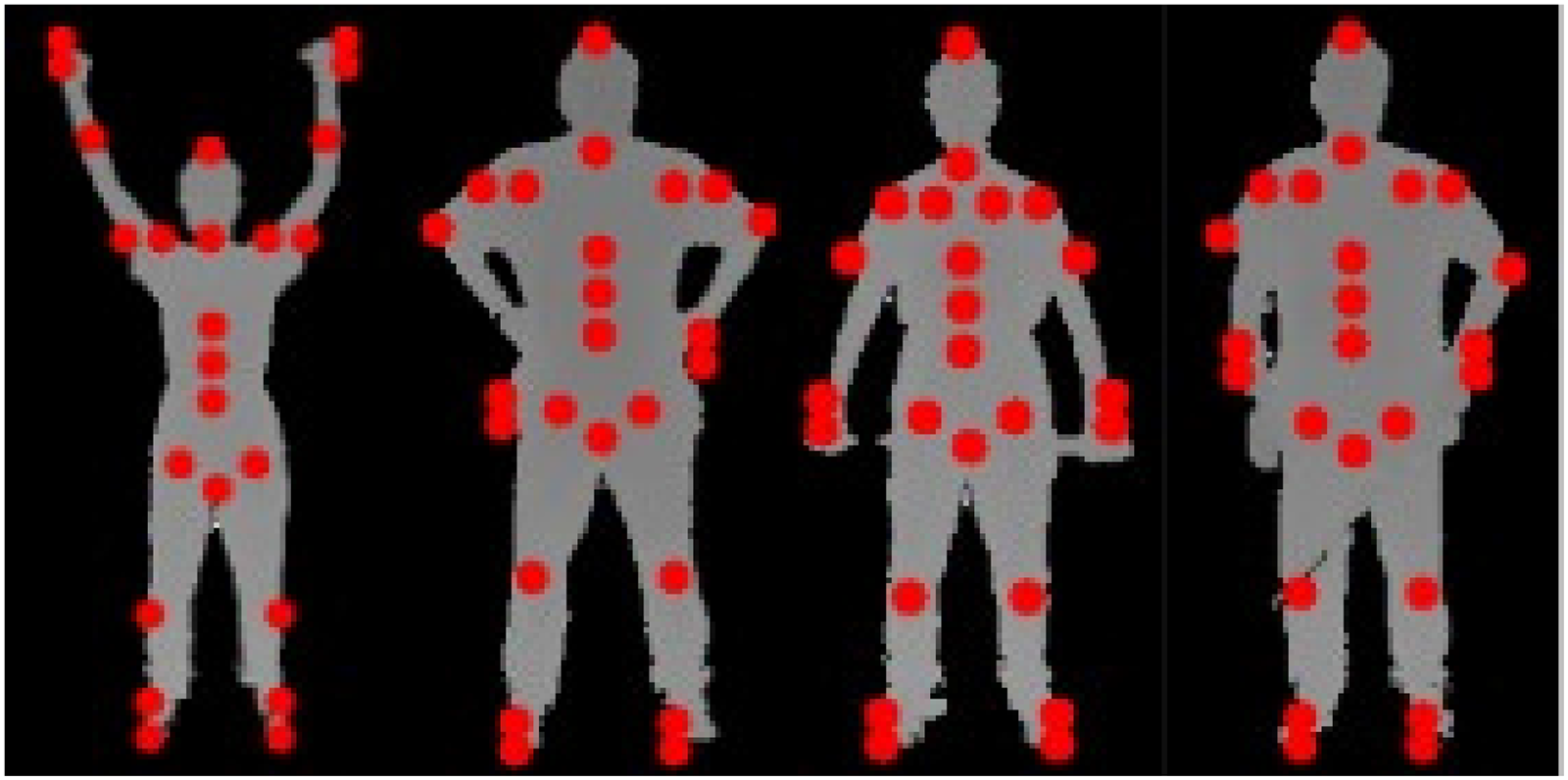
Visualization of detected anatomical keypoints for different human postures using the PoseKP-L and PoseKP-R modules.
The architecture incorporates two specialized pipelines for accurate 3D keypoint (x, y, z) extraction. PoseKP-L is tailored for scenarios where the arms are in a lowered position. It employs a contour-based strategy for robust keypoint estimation, as detailed in Algorithm 1:

PoseKP-R is optimized for postures with arms raised above shoulder level. This variation adjusts the localization process to maintain precise tracking of the shoulders, wrists, and hands, as described in Algorithm 2:

3D Human mesh reconstruction with SMPL fitting
In this study, we present a complete pipeline for reconstructing 3D human meshes and fitting the SMPL model,
47
leveraging multiple motion capture datasets. To ensure interoperability across different skeletal annotation formats, we implement a joint mapping mechanism that translates the extracted 24-point keyset from our PoseKP module into the SMPL-compatible structure. These mapped joints enable accurate 3D pose estimation and body mesh generation. The SMPL model provides a parametric human mesh with 6890 vertices and 13,776 triangular faces, offering a high-fidelity and computationally efficient solution for motion analysis and animation. The model is governed by two sets of parameters; Pose parameters, θ ∈ ℝ72, representing 3D axis-angle rotations across 24 joints and Shape parameters, β ∈ ℝ1⁰, representing identity-specific body shape variations learned from real body scans. The final mesh is computed using the linear blend skinning (LBS) framework defined by (17):
The SMPL model outputs three critical components: the vertex matrix V ∈
To optimize the SMPL parameters, a series of loss functions are formulated. First, the joint loss (L_joint) minimizes the Euclidean distance between predicted joints and the SMPL-derived joints, as defined by (18):

The shape regularization loss penalizes extreme body shapes and prevents unrealistic morphologies using the L2 norm of the shape parameters as shown in (20):
To ensure temporal coherence in multiframe sequences, a smoothness constraint is imposed by minimizing interframe joint displacement, reducing jitter and abrupt transitions. This is expressed in (21):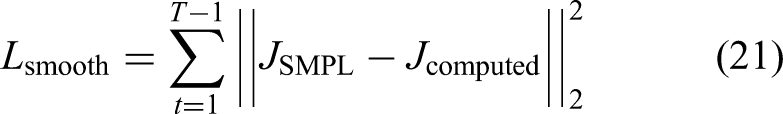


Optimization is carried out using the Adam optimizer, which updates the pose and shape parameters to produce accurate, smooth, and anatomically consistent 3D human meshes. Representative visualizations of the pipeline's output, comparing input depth frames with the reconstructed meshes, are shown in Figures 6 and 7 using sequences from the UTKinect-Action3D and KIMORE datasets.

3D reconstruction of a subject from the UTKinect-Action3D dataset illustrating (a) baseline stance, (b) asymmetric arm tilt, (c) dynamic crouch, and (d) recovery phase.

3D reconstruction of a subject from the KIMORE dataset illustrating (a) dynamic asymmetric arm gesture, (b) slight hand tilt with partial flexion, (c) dynamic asymmetric arm gesture, and (d) exaggerated torso lean with pronounced wrist angles.
Zernike moment-based silhouette shape analysis
To capture the global structure and symmetry of human silhouettes, we incorporate Zernike moments into our depth-based pipeline as robust shape descriptors.
48
These moments provide a compact and rotation-invariant representation of silhouette geometry, enabling effective comparison across different poses. Computed over a normalized binary silhouette, Zernike moments decompose shape information into orthogonal basis functions defined within the unit disk, allowing for consistent quantification of spatial distribution patterns in the silhouette. The Zernike moment of order n and repetition m, denoted as 
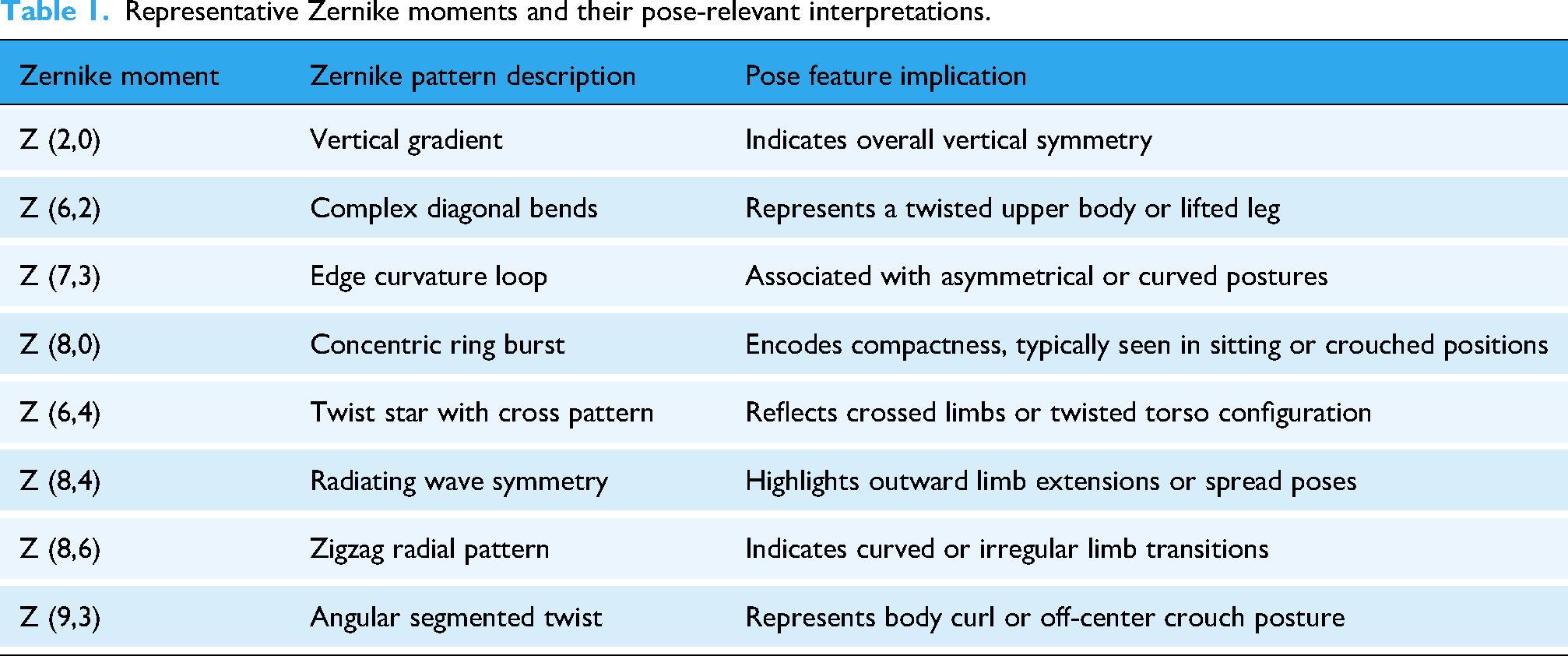
Table 1 illustrates a few representative Zernike moments that exemplify how different moment orders correspond to specific pose-relevant structural attributes. These examples help interpret the geometric significance of Zernike patterns, highlighting features such as body alignment, limb extension, compactness, and asymmetry across human silhouettes as shown in Figure 8. For instance, Z (2,0) captures vertical gradients and reflects overall body alignment, while Z (6,2) and Z (7,3) highlight diagonal bends and asymmetrical contours, typically observed in twisted or lifted limb postures. Higher-order terms such as Z (8,0), Z (8,6), and Z (9,3) encode complex patterns such as multilimb folding, radiating spreads, and crouched positions.

Zernike moment projections computed from pose-encoded silhouettes for different moment orders, including (a) Z (2,0), (b) Z (6,2), (c) Z (7,3), (d) Z (8,0), (e) Z (6,4), (f) Z (8,4), (g) Z (8,6), and (h) Z (9,3).
Representative Zernike moments and their pose-relevant interpretations.
To assess the effectiveness of Zernike moments in distinguishing human postures, we conducted a comparative analysis of moment magnitudes across silhouette pairs under both same-pose and different-pose conditions. As illustrated in Figures 9 and 10, silhouettes representing the same exercise or posture yield closely aligned Zernike magnitude distributions, demonstrating strong structural consistency and feature stability. In contrast, silhouette pairs from different exercises exhibit pronounced variations across multiple moment orders, particularly in mid-to-high frequency components. This divergence highlights the sensitivity of Zernike moments to global pose changes, such as limb extensions, curvature, and compactness. These findings confirm that Zernike-based descriptors exhibit strong robustness against noise and intraclass variability while significantly enhancing the discriminative representation of exercise categories. Their integration within the hybrid framework enables a complementary fusion with deep feature representations, effectively preserving global shape integrity. This interaction ensures that the resulting feature space remains geometrically coherent and semantically expressive, thereby strengthening the reliability of the overall classification system.

Comparative analysis of Zernike moment magnitudes for silhouette-based pose differentiation within the same posture, illustrating the consistency of moment distributions across similar pose instances.

Comparative analysis of Zernike moment magnitudes for silhouette-based pose differentiation across different postures, highlighting the discriminative variations observed between distinct pose configurations.
Silhouette-based Tracking, Regional Analysis, and Parsing using RGB
We propose STRAP-RGB imagery, a modular pipeline for human pose understanding from RGB video frames. The pipeline begins with frame-wise preprocessing, semantic segmentation, and silhouette extraction to isolate the human subject. Keypoints are detected using classical methods such as FAST and Harris-Laplace, which capture distinctive anatomical landmarks. The LTE, LTP, and Gabor filter features are extracted from the segmented regions to characterize texture and appearance. Additionally, semantic body part labeling (BPL) is performed using deep graph-based parsing models, enabling localized analysis of limbs, torso, and extremities. STRAP-RGB combines geometric precision with semantic richness, making it well-suited for human activity recognition.
Silhouette extraction
The silhouette extraction module plays a foundational role in the STRAP-RGB pipeline, serving as the initial step toward isolating the human figure from the surrounding environment. This module integrates a sequence of unsupervised segmentation and refinement stages to extract a clean silhouette of the subject using only RGB input. The proposed approach combines HOG-based localization, superpixel-level K-Means clustering, and GrabCut refinement to achieve high-quality segmentation without the need for deep-learning models or manual intervention.
Initially, a HOG detector identifies the region of interest (ROI) corresponding to the person in the input frame 
Within the localized ROI, Simple Linear Iterative Clustering (SLIC) is applied to partition the image into 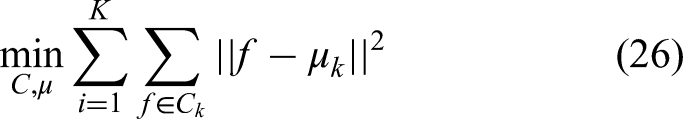
We empirically set 

Silhouette extraction pipeline: (a) original RGB image, (b) detected region of interest using Histogram of Oriented Gradient (HOG), (c) superpixel-based K-means segmentation, (d) binary mask obtained after GrabCut refinement, and (e) final cleaned silhouette.
Keypoints extraction
To extract meaningful structural keypoints from grayscale silhouette images, we employed a pair of classical keypoint detection algorithms that are grounded in image geometry and spatial intensity analysis. Each method emphasizes a different aspect of the silhouette structure; FAST focuses on localized contrast-based corners, while Harris–Laplace extends this analysis to capture scale-consistent anatomical landmarks. Both detectors are computationally efficient and remain stable under partial occlusion or lighting variations, making them well-suited for real-world telerehabilitation scenarios where sensor noise and environmental conditions can vary significantly.
Features from Accelerated Segment Test: high-speed intensity-based keypoint detector
The first method utilized is the FAST (Features from Accelerated Segment Test) detector,
49
which is designed for rapid keypoint identification based on local intensity contrast as shown in Figure 12(a). Given a candidate pixel p with intensity 

Keypoint detection results on silhouette images illustrating (a) FAST keypoints capturing prominent corner-like structures and (b) harris–laplace keypoints highlighting scale-invariant anatomical landmarks.
In this framework, FAST serves as a lightweight geometric feature extractor that enhances local boundary precision and contour-based shape representation. Its ability to detect consistent corner points under varying illumination and minor occlusion makes it well suited for dynamic human silhouettes. These geometric cues provide complementary low-level information that strengthens spatial consistency and supports the subsequent multimodal fusion and classification stages.
Harris-Laplace: multi-scale geometric keypoint detector
To complement this local approach, we employed the Harris-Laplace detector,
50
which extends classical Harris corner detection with a robust scale selection mechanism as shown in Figure 12(b). This handcrafted technique was chosen for its reliability in identifying stable geometric features across varying scales and imaging conditions, offering consistent performance without the need for extensive training or high-texture input. Initially, candidate keypoints are identified using the Harris corner response, derived from the second-order image gradients. The response function R is given by (29):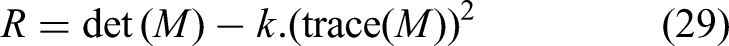

Here, 
Together, these two methods provide a complementary framework for keypoint extraction. While FAST efficiently captures high-frequency local structures within the silhouette, Harris-Laplace contributes scale-consistent landmark points that are robust to variations in subject size or camera distance. This dual-detection strategy enhances both spatial precision and scale stability, ensuring that geometric cues from the RGB silhouettes effectively complement high-level modules in the framework, thereby improving robustness and consistency in keypoint representation.
Feature detection
Following keypoint extraction, we computed a suite of classical feature descriptors designed to encode both the local texture and structural orientation of human silhouettes. To ensure comprehensive spatial representation, we employed three complementary techniques: LTE, LTP, and Gabor filter responses. Each of these methods captures a unique characteristic of the silhouette, ranging from edge directionality to microtextural patterns and spatial frequency signatures
Laws’ texture energy
The LTE is a handcrafted feature extraction method that captures spatial texture patterns by convolving the input image with a set of specially designed filters. 51 Unlike gradient-based descriptors, LTE focuses on localized intensity variations, making it particularly robust for silhouette-based pose analysis where directional edge information may be limited or noisy as shown in Figure 13.

Laws’ texture energy (LTE) maps computed using different filter combinations (L5E5, E5L5, E5E5, S5S5, W5W5, R5R5, E5S5, and L5S5), highlighting diverse spatial patterns such as edges, spots, ripples, and composite textures within silhouette images.
The process begins by defining a set of 1D convolution masks that encode primitive patterns such as level (L), edge (E), spot (S), wave (W), and ripple (R). These masks are combined pairwise using the outer product to generate a total of 25 unique 2D filters. Each resulting filter is sensitive to a distinct texture characteristic, such as horizontal edges, corner-like structures, or fine ripples, depending on the combination of row and column vectors.
Each 2D kernel 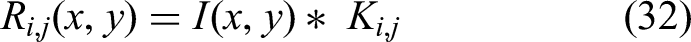
To measure the strength of each texture pattern, the local texture energy is computed by squaring the response values by (33):
These energy maps emphasize regions of the silhouette that strongly exhibit the corresponding pattern, such as arm contours (edge filters), body ripples (ripple filters), or flat torso regions (level filters). From each energy map, a statistical descriptor (typically the mean or standard deviation) is computed over the silhouette mask. The concatenation of these 25 values forms the final LTE feature vector, which encodes a multipattern texture signature of the human pose.
Local ternary patterns
Local Ternary Patterns
52
extend the Local Binary Pattern (LBP) operator by introducing a three-valued encoding scheme that enhances robustness against local intensity fluctuations and image noise as shown in Figure 14(a). Rather than assigning binary outcomes based solely on the sign of intensity differences, LTP introduces a threshold τ to define a tolerance zone around the center pixel intensity 
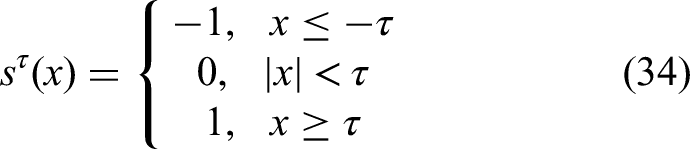

Texture feature extraction results showing (a) local ternary pattern (LTP) representations and (b) Gabor filter responses at 45° and 90° orientations, capturing local intensity variations and directional texture information.
This formulation creates a ternary string per pixel, where each bit can take values from {−1, 0, 1}. To facilitate efficient histogram representation and distance computation, the LTP descriptor is typically decomposed into two separate binary patterns: the upper LBP (encoding 1s and 0s) and the lower LBP (encoding −1s and 0s). Histograms of both components are then concatenated to form the final LTP feature vector. By suppressing minor intensity variations around the central pixel, LTP provides improved discrimination in scenarios where silhouettes may exhibit subtle noise or blurring.
Gabor filters
To further enrich the spatial-frequency representation, we applied a bank of Gabor filters
53
at multiple orientations shown in Figure 14(b). Gabor filters act as bandpass filters that are sensitive to specific frequencies and directions, effectively mimicking the response of human visual cortex cells. A 2D Gabor filter 
Collectively, the use of LTE, LTP, and Gabor filters enables a rich multiperspective description of the human silhouette. The LTE captures macrotextural patterns and spatial energy distributions, LTP captures microtextural variation, and Gabor encapsulates orientation-specific frequency response.
Body part labeling
To derive a semantically structured understanding of human silhouettes, we employed a BPL strategy based on the Graphonomy model 54 proposed by Gong et al. Graphonomy introduces a universal human parsing framework that leverages graph-based transfer learning to perform fine-grained pixel-wise classification of human body regions. Unlike traditional encoder-decoder models, Graphonomy integrates hierarchical graph reasoning over both the feature and label space, enabling significant performance across diverse domains, poses, and clothing variations.
The model was applied to the RGB silhouette images to generate segmentation maps, where each pixel is classified into one of N predefined anatomical categories. Formally, for each pixel location 
The final body part label map 
Here,

Semantic body part labeling of human silhouettes obtained using the graphonomy model, illustrating pixel-wise anatomical segmentation of different body regions.
To enhance geometric interpretation of the parsed silhouette, contour points and centroid positions were extracted for each anatomically segmented region. Following generation of the segmentation map

Contour points (red) and centroid locations (yellow) extracted from segmented body parts using graphonomy-based parsing, enabling region-wise geometric characterization.
Feature optimization
We adopted an early feature-level fusion approach, where multimodal features obtained from both the modalities were combined into a single unified vector before the discriminative learning stage as shown in (38):






Feature optimization using Kernel Fisher Discriminant Analysis (KFDA), illustrating the projection of fused features into a discriminative subspace.
This reformulation leads to a generalized eigenvalue problem involving kernel matrices, from which the optimal discriminant projections can be derived. The resulting lower-dimensional representation preserves nonlinear class boundaries, making it well-suited for tasks requiring robust class separation prior to classification algorithms such as GCNs.
Graph convolutional network
To enhance the discriminative capability of the input features prior to graph-based learning, after employing KFDA for nonlinear feature optimization, we employed GCN. Let the resulting transformed feature matrix be denoted as 
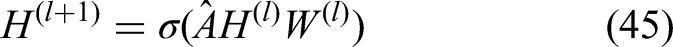

By integrating KFDA with GCN, the model benefits from both enhanced class discriminability in the input space and relational learning over the graph structure, leading to improved classification performance. The architecture of GCN is shown in Figure 18.

Proposed architecture of the Graph Convolutional Network (GCN), illustrating feature propagation through graph convolution layers followed by the final classification stage.
Algorithm 3 presents the complete algorithmic representation of the proposed multimodal framework, detailing each sequential stage from data preprocessing to final classification. It outlines the integrated operation of the D-KEM and STRAP-RGB pipelines, the early feature fusion process, KFDA-based optimization, and GCN-driven classification.

Results and Performance Evaluation
Datasets
The KIMORE dataset served as the foundation for this study, providing a clinically relevant benchmark for rehabilitation analysis. It includes recordings from 78 participants (44 healthy and 34 with lower back pain) performing five guided rehabilitation exercises, such as arm raises, trunk bends, lateral flexions, and squats. The dataset offers synchronized RGB–Depth videos, 25-joint skeletal data, and clinical assessment scores for each repetition. Its inclusion of participants with motor impairments makes it particularly valuable for developing and validating systems designed to support individuals with limited mobility or musculoskeletal disorders. 35
Building upon this foundation, the mRI dataset was integrated to extend the framework's adaptability to home-based rehabilitation and mobility monitoring. It contains over five million multimodal frames collected from 20 participants using RGB-D cameras, mmWave radar, and IMU sensors. The dataset captures repetitive, full-body movements, including bending, stretching, and reaching, that mirror functional activities practiced in rehabilitation and motor recovery programs. Its multimodal nature enables robust modeling of motion patterns across different sensor modalities, enhancing the framework's applicability in diverse rehabilitation environments. 36
To further evaluate the performance of the proposed framework, the UTKinect-Action3D dataset was employed. It features 10 subjects performing 10 everyday actions, including walking, sitting, standing up, bending, lifting, and side movements, captured through synchronized RGB, depth, and skeletal modalities. These actions closely align with the functional motor activities retrained during physical therapy, focusing on aspects such as trunk stability, balance, and coordination. Incorporating this dataset enables the framework to recognize natural daily movements that serve as indicators of rehabilitation progress and ensures consistent performance across varied movement patterns and physical conditions. 37
Experimental setup
Experiments were conducted on a Google Colab virtual machine equipped with an NVIDIA Tesla T4 GPU (16 GB GDDR6 VRAM, 2560 CUDA cores, and 320 Tensor cores) running Ubuntu 18.04.6 LTS. The development environment utilized Python 3.10.13, PyTorch 2.1.0 + cu118, and cuDNN 8.9.1, providing GPU-accelerated tensor computation and parallel convolution support for both the D-KEM and STRAP-RGB pipelines. Image preprocessing and segmentation were performed using OpenCV 4.9.0 and scikit-image 0.22.0, while NumPy 1.25.0 and Pandas 2.1.1 were employed for array-based data handling and performance logging. Visualization and quantitative analysis were carried out using Matplotlib 3.8.0.
Time-cost analysis
To assess the computational efficiency of the proposed framework, a time-cost analysis was conducted across all major components of the depth and RGB pipelines. Table 2 summarizes the average per-frame execution time and computational complexity (MFLOPs) for each module, measured under GPU execution in the same experimental environment described above. The analysis shows that the end-to-end processing remains computationally tractable, with the primary latency arising from 3D mesh reconstruction and semantic body-part labeling.
Time cost analysis.

Confusion matrices
Table 3 presents a confusion matrix for five classes (E1–E5) for KIMORE dataset. The diagonal values represent the true positive rates for each class, indicating how accurately the model classified instances within each category. Overall, the model demonstrates high classification performance, particularly for classes E3 (100%), E5 (95%), and E2 (89%), suggesting strong model precision in these areas.
Confusion matrix for KIMORE dataset.

Class E1 shows a true positive rate of 83%, with some misclassification into E2 (6%) and E5 (11%). Class E4 has a slightly lower accuracy (91%), with minor misclassification into E1, E3, and E5. These off-diagonal entries suggest that E1 and E4 might share overlapping features with adjacent classes. Despite this, the matrix indicates minimal confusion among most classes, supporting the model's overall reliability.
Table 4 presents the confusion matrix for the MRI dataset, showing a classification accuracy of 92.70%. Most classes demonstrate high performance, with E1 (92%), E3 (90%), E5 (90%), E9 (95%), E11 (98%), and E12 (98%) being classified accurately with minimal confusion. However, notable misclassifications occur in a few classes. E2 shows the lowest accuracy at 64%, with frequent confusion with E5 (14%), E6 (7%), E9 (6%), and E12 (5%). Similarly, E6 is correctly classified 73% of the time but is misidentified as E2 (9%) and E10 (14%). E10 also shows some confusion, mainly with E4 (12%) and E8 (3%), reducing its accuracy to 85%. These misclassifications, clearly indicated in the table, may result from overlapping feature characteristics or insufficient model discrimination between similar patterns. Enhancing feature representation or refining the model architecture could help reduce such classification errors.
Confusion matrix for MRI dataset.

The confusion matrix in Table 5 shows the performance of the human activity recognition model across ten activity classes, with an overall accuracy of 95.59%. Most actions such as sit down (98%), pick up (97%), carry (96%), push (98%), and clap hands (99%) are recognized with high accuracy. However, some misclassifications are evident. For example, stand up is often misclassified as walk, pick up, or throw, with only 81% of samples correctly identified. The most significant confusion occurs with the throw class, which has just 50% accuracy and is frequently mistaken for walk, sit down, stand up, pull, and wave hands. These errors, visible in the table, likely stem from the similarity in motion patterns between these dynamic activities. Enhancing temporal modeling or incorporating additional contextual cues could help reduce these misclassifications.
Confusion matrix for UTKinect-Action3D dataset.

Performance evaluation
As shown in the Table 6, the classification performance over the KIMORE dataset reveals that the model performs exceptionally well on most classes, with particularly high precision and recall for Classes E3 (Precision: 0.96, Recall: 1.00, F1-score: 0.98), E4 (0.98, 0.91, 0.94), and E5 (0.99, 0.95, 0.97), indicating strong accuracy and reliability. Class E2 also shows balanced and solid results (0.91, 0.89, 0.90), suggesting consistent detection with minimal misclassifications. However, Class E1 exhibits the weakest performance with a relatively low precision of 0.60 despite a high recall of 0.83, resulting in an F1-score of 0.70. This indicates that while the model is good at identifying actual E1 instances, it also tends to incorrectly classify other classes as E1, leading to a high false positive rate. Overall, the model demonstrates consistent performance across the evaluated datasets, but requires improvement in reducing misclassification for the lower-performing class (E1).
Precision, recall, and F1-score results over KIMORE.

As shown in the Table 7, classes E11 and E12 demonstrate the best overall performance, each achieving a precision of 0.97–0.99, recall of 0.98, and F1 score of 0.98. This indicates the model can accurately and consistently identify instances from these classes. Several other classes, including E1, E3, E5, E8, and E9, also perform well with F1 scores around 0.90 or higher, reflecting balanced and reliable classification. In contrast, class E6 shows the weakest performance, with the lowest precision (0.22) and F1 score (0.31), as seen in the table, suggesting the model struggles significantly with this class. Overall, the table highlights strong model performance on most classes, with only a few outliers needing improvement.
Precision, recall, and F1-score results over MRI.

As reported in Table 8, the model's precision, recall, and F1-score metrics across the ten activity classes from the UTKinect-Action3D dataset further confirm its strong performance. Most classes demonstrate consistently high scores, particularly “Clap hands” and “Push,” with near-perfect values (F1-score = 0.99). Other well-recognized actions include “Pick up” (F1 = 0.97), “Sit down” (F1 = 0.97), and “Carry” (F1 = 0.96), showing the model's ability to accurately distinguish structured, isolated movements. In contrast, “Throw” exhibits the lowest recall (0.50) and F1-score (0.62), reflecting confusion observed earlier in the confusion matrix (Table 6), likely due to overlapping motion patterns with other upper-body gestures. The “Stand up” action also shows a slightly lower F1-score of 0.83, primarily due to a reduced recall of 0.81, suggesting that transition-based activities are more challenging for the model. Overall, Table 7 indicates consistent performance across most activity classes, with some limitations in distinguishing actions involving subtle or overlapping gestures.
Precision, recall, and F1-score results over UTKinect-Action3D.

The ROC curves illustrated in Figure 19 depict the classification performance of the proposed model across five experimental evaluations (E1–E5) on the KIMORE dataset. The curves remain consistently above the random guessing line, confirming the model's strong discriminative capability. Among all, E3 achieves the highest performance with an AUC of 0.99, indicating near-perfect class separation. E4 and E5 also demonstrate excellent outcomes, with AUCs of 0.96 and 0.97, respectively, reflecting high reliability in prediction. Meanwhile, E2 and E1 yield slightly lower yet commendable results, with AUCs of 0.94 and 0.90, respectively, still indicating effective class differentiation. Overall, the mean AUC of 0.95 reflects the robustness and stability of the model across repeated experimental runs on the KIMORE dataset.

Results in terms of ROC curves for the KIMORE dataset, illustrating the classification performance across different exercise classes.
The ROC curves in Figure 20 depict the classification performance of the proposed model across twelve experimental evaluations (E1–E12) on the mRI dataset. The results show a mean AUC of 0.92, reflecting strong overall class separability and reliable predictive capability. Notably, E11 and E12 achieve exceptional performance with AUCs of 0.99, while E9 closely follows with an AUC of 0.98, confirming excellent model discrimination across these experiments. E1, E5, and E7 also demonstrate high accuracy, with AUCs ranging between 0.95 and 0.96. However, E6 (AUC = 0.74) and E2 (AUC = 0.82) indicate relatively weaker separation, suggesting that these categories may involve more complex or overlapping feature distributions. Overall, the ROC curves lie well above the random guessing line, indicating reliable discrimination across multiple test conditions on the mRI dataset.
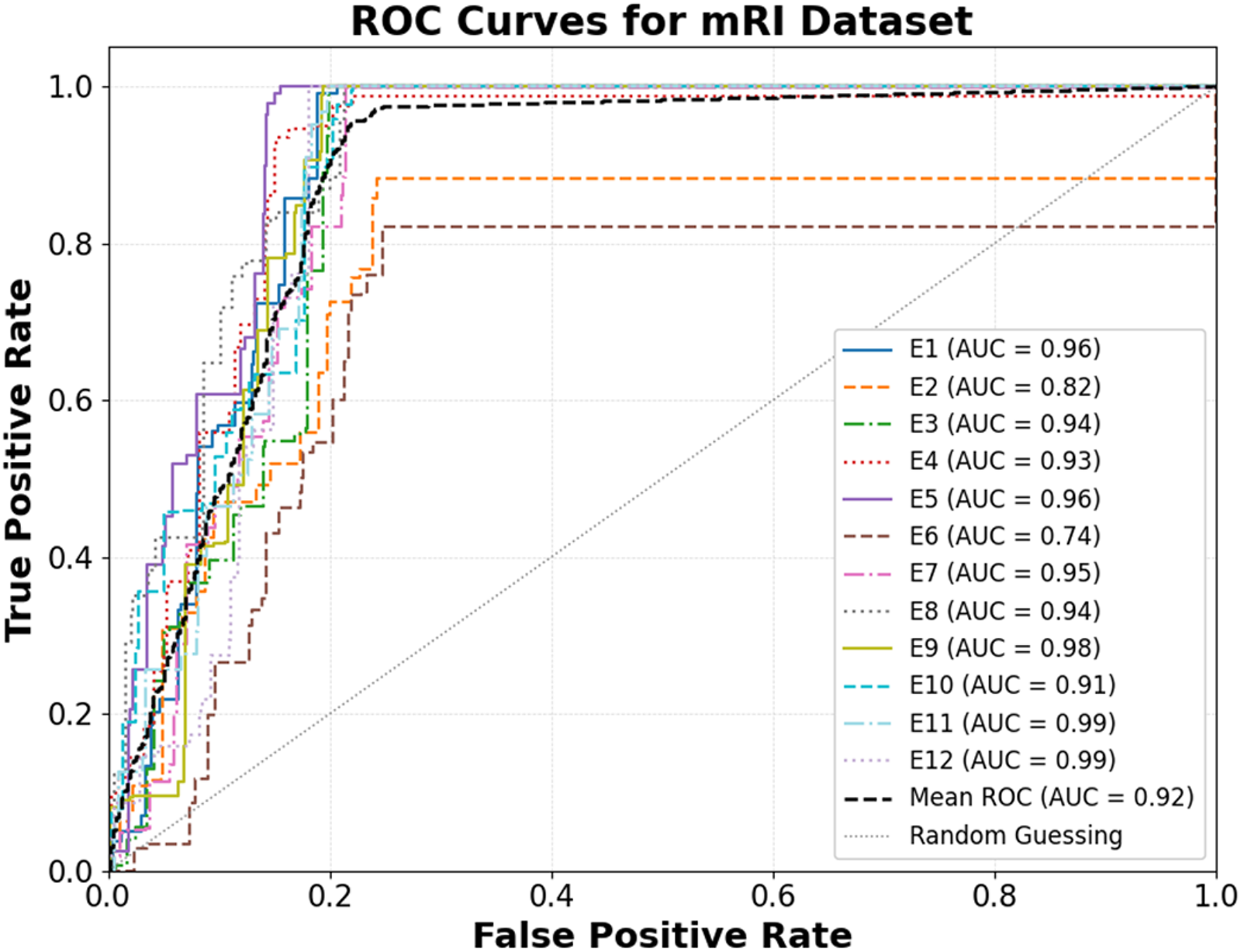
Results in terms of ROC curves for the mRI dataset, illustrating the classification performance across different exercise classes.
The ROC curves in Figure 21 illustrate the classification performance of the proposed model across various action classes in the UTKinect-Action3D dataset. The model achieves a mean AUC of 0.95, demonstrating strong discriminative capability and reliable performance across a wide range of movement variations. Among all actions, “Pick up,” “Push,” and “Clap hands” exhibit exceptional results, each attaining an AUC of 0.99, demonstrating nearly perfect separation between true and false positives. Similarly, “Sit down” and “Carry” perform excellently with AUCs of 0.98, further validating the model's robustness. Conversely, “Throw” (AUC = 0.75) shows comparatively weaker performance, suggesting that its dynamic motion characteristics may introduce classification ambiguity. Overall, the ROC visualization confirms that the model maintains high reliability across most activities, with all curves significantly above the random guessing line, signifying superior recognition accuracy on the UTKinect-Action3D dataset.

Results in terms of ROC curves for the UTKinect-Action3D dataset, illustrating the classification performance across different exercise classes.
Discussion
Ablation study
As detailed in Table 9, a comprehensive ablation study was conducted to quantify the contribution of individual feature-extraction components across the KIMORE, mRI, and UTKinect-Action3D datasets. The full configuration—integrating preprocessing, 3D pose and mesh features, 2D keypoints, and BPL-based contour descriptors—achieved the highest accuracies of 95.30%, 92.70%, and 95.59%, respectively. A clear hierarchy of contribution emerges from the ablation results. The 3D pose and mesh features act as the primary drivers of recognition accuracy; their removal leads to a substantial degradation (72.20%, 69.93%, and 71.82%), as these features encode explicit spatial structure, joint relationships, and volumetric motion cues that are central to exercise characterization. In contrast, excluding 2D keypoints results in moderate yet consistent accuracy reductions (82.39%, 78.00%, and 79.80%), indicating that while 2D motion cues are informative, the system retains a degree of robustness due to the continued presence of 3D mesh geometry and depth-derived structural information. Similarly, removing individual handcrafted descriptors such as FAST, Harris–Laplace, Gabor, LTE, or LTP produces comparatively smaller performance drops, as these components primarily refine local appearance and texture representation rather than defining the core motion semantics. Shape-based descriptors further strengthen discrimination; omitting Zernike moments (93.20%, 87.90%, and 89.20%) and BPL-based contour points (88.36%, 81.70%, and 86.11%) degrades accuracy but does not collapse performance, since global pose and mesh cues remain intact. Finally, excluding the KFDA optimization stage causes a pronounced decline (79.70%, 80.23%, and 81.20%), highlighting the importance of nonlinear feature optimization for enhancing class separability within the fused feature space. Overall, these findings confirm that reliable rehabilitation exercise recognition is driven primarily by 3D pose and mesh representations, while complementary 2D, shape, and contour features provide supportive gains that collectively strengthen robustness rather than acting as standalone determinants.
Ablation study on model configurations and their impact on exercise recognition accuracy.
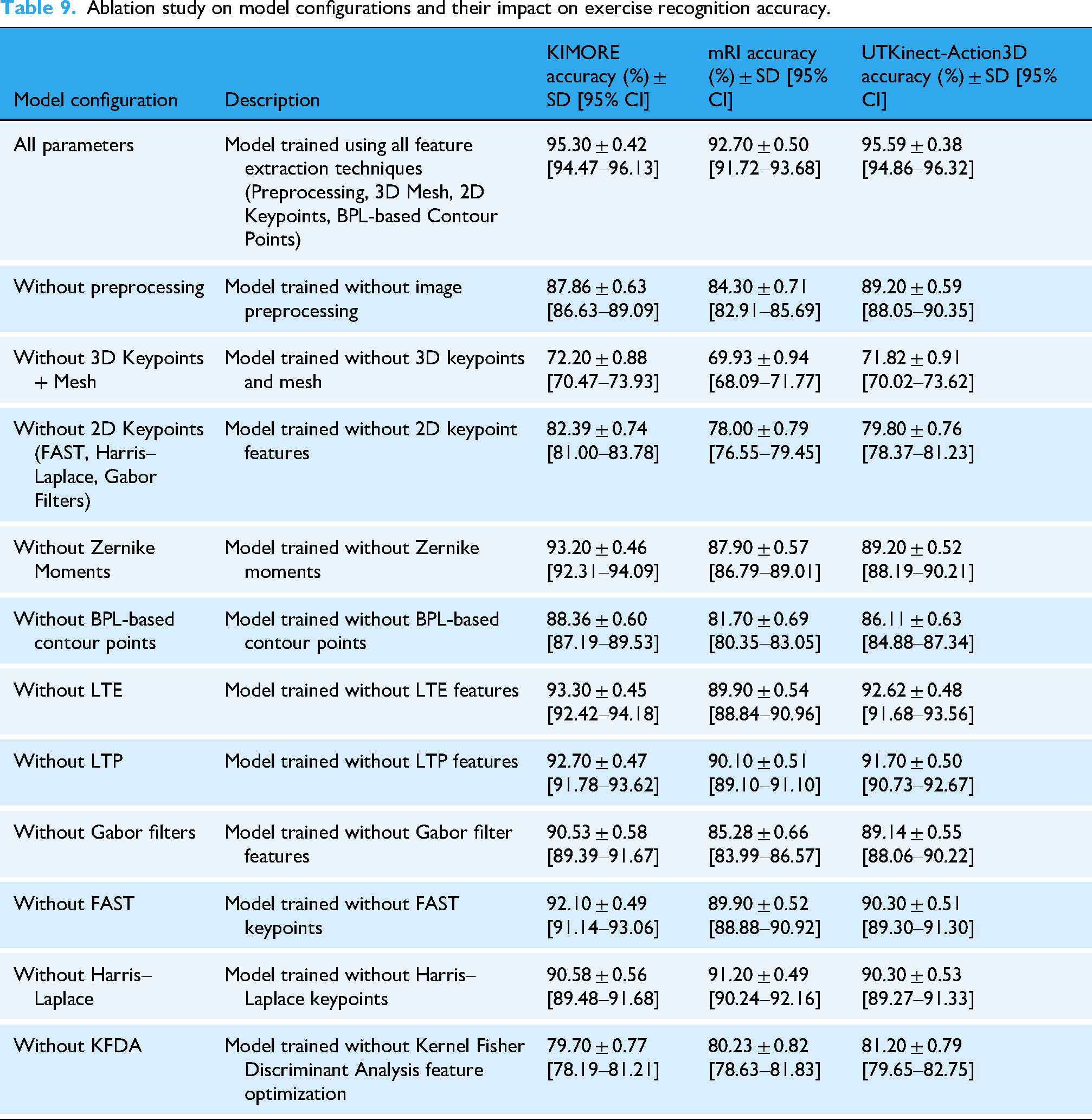
All ablation experiments were conducted using identical 80–20 train/test splits across datasets. Each configuration was repeated five times with randomized initialization. Reported values represent mean ± standard deviation, and 95% confidence intervals were estimated using nonparametric bootstrapping (n = 1000). The low variance demonstrates the framework's robustness and statistical reliability.
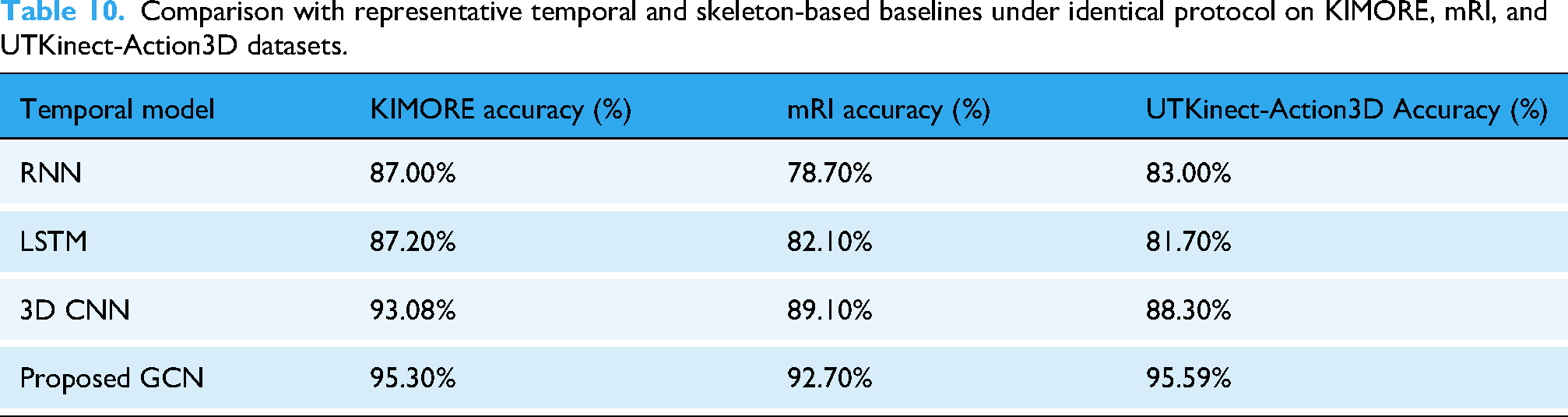
As summarized in Table 10, the impact of temporal feature modeling was examined by comparing the proposed GCN with representative sequence-based baselines, including RNN, LSTM, and 3D CNN. All baseline models were trained using the same subject-independent splits, input representations, and training protocol as the proposed framework. While RNN and LSTM achieved moderate performance and 3D CNN improved temporal representation, the proposed GCN consistently yielded higher accuracies (95.30%, 92.70%, and 95.59%) across the three datasets. These results indicate that graph-based temporal modeling, when coupled with the proposed multimodal representation, more effectively captures interjoint dependencies and motion continuity in rehabilitation exercises.
Comparison with representative temporal and skeleton-based baselines under identical protocol on KIMORE, mRI, and UTKinect-Action3D datasets.
Finally, Table 11 compares different fusion strategies: feature concatenation, attention-enabled fusion, and decision-level fusion. Feature concatenation provided the best overall results (95.30%, 92.70%, and 95.59%), while attention-based and decision-level fusion achieved lower accuracies. This trade-off illustrates that feature concatenation offers the optimal balance between accuracy and computational efficiency for rehabilitation applications.
Comparative evaluation of feature fusion techniques on KIMORE, mRI, and UTKinect-Action3D datasets.

Comparison with state-of-the-art methods
Table 12 provides a contextual comparison of our proposed model with representative state-of-the-art methods reported in the literature for rehabilitation exercise and HAR. Jleli et al. 38 applied a YOLO V5–ShuffleNet V2 model on the KIMORE dataset, achieving 87% accuracy. Zaher et al. 39 improved upon this using a CNN model enhanced through hyperparameter tuning, reaching 93.08%, while Zaher et al. 40 employed a feature-ranking strategy combining the Fast Correlation-Based Filter with an Extra Trees classifier, obtaining 81.85% accuracy. Among KIMORE-based end-to-end studies, Karlov et al. 41 integrated an ST-GCN with supervised contrastive learning, achieving 89% accuracy, and Abedi et al. 42 implemented a cross-modal RGB-to-skeleton augmentation network using RNN/LSTM, reporting 87% accuracy. For UTKinect-Action3D, Keceli et al. 43 utilized HOG-Deep features to achieve 93.4%, Ding et al. 44 adopted a Rotation Matrix Representation-Based 3D model with SVD and HMM, attaining 91.5%, and Kumar et al. 45 introduced a Time-Series Graph Matching approach that reached 93.5% accuracy. Meanwhile, Ashraf et al. 46 reported a deep multimodal biomechanical framework for lower back pain rehabilitation on the mRI dataset, achieving 91.00% accuracy.
Comparison with state-of-the-art methods.

While these recent end-to-end learning models demonstrate promising results, they often require substantial computational power, extensive training data, and high-end GPU configurations, making them less feasible for real-time or resource-limited rehabilitation settings. Additionally, such frameworks process the entire image, capturing unnecessary background information that may reduce focus on the actual rehabilitation movement. In contrast, the proposed hybrid multimodal framework emphasizes silhouette-based representations and interpretable structural features, allowing the system to isolate and analyze only the clinically relevant body regions performing the exercise. This focused approach enhances robustness under occlusion, illumination changes, and limited training data, while significantly reducing computational complexity. As summarized in Table 12, the proposed model achieves accuracies of 95.30% on KIMORE, 92.70% on mRI, and 95.59% on UTKinect-Action3D, indicating competitive performance across diverse rehabilitation-oriented benchmarks. These results suggest that the proposed framework provides a favorable balance between accuracy, interpretability, and robustness under the evaluated experimental settings.
Limitations and generalizability
The datasets utilized in this study (KIMORE, mRI, and UTKinect-Action3D) encompass diverse rehabilitation and activity scenarios but still have limited sample sizes and subject diversity, which may influence generalization. To evaluate the robustness of the proposed model, the UTKinect Action3D dataset was included, featuring everyday actions that closely resemble functional movements retrained during physiotherapy. The incorporation of KFDA optimization and multimodal RGB–Depth feature fusion enhances discriminative learning and reduces overfitting, enabling one modality to compensate when another underperforms. These design elements collectively support adaptability across varied users and environments. As reflected in the baseline comparisons in Table 10, this complementary behavior enables the proposed framework to maintain stable performance across datasets where simpler temporal or joint-only models exhibit performance degradation. While the proposed framework demonstrates consistent performance across the evaluated benchmarks, future work will focus on extending validation to larger and more diverse participant cohorts and exploring additional real-world rehabilitation settings to further assess its practical applicability.
Clinical applicability and integration
Although this study primarily focuses on technical validation across public datasets, the proposed framework aligns closely with the clinical objectives of physiotherapy, such as accurate motion tracking, posture correction, and progress monitoring. By providing objective, quantitative feedback on movement quality, the system can complement physiotherapists’ visual assessments and reduce interobserver variability. In practical scenarios, the model could assist clinicians in remote patient supervision, enabling timely correction of exercise performance during telerehabilitation sessions. The future work will involve user studies in collaboration with rehabilitation specialists to validate the interpretability and reliability of the model outputs in real-world sessions.
Conclusion and future direction
In conclusion, this study introduced a deep learning–based multimodal framework for physiotherapy exercise recognition that integrates synchronized RGB and depth streams to enable accurate, markerless assessment in home environments. The system effectively combines two dimensional keypoints, semantic body part labels, and visual descriptors from RGB images with three dimensional joint positions and full body mesh reconstructions from depth silhouettes using the SMPL model. Feature fusion and refinement using KFDA, followed by classification through a GCN, resulted in a highly discriminative representation of human motion. The framework achieved strong performance across three publicly available rehabilitation datasets, with accuracies of 95.30 percent on KIMORE, 92.70 percent on mRI, and 95.59 percent on UTKinect-Action3D, demonstrating that the integration of complementary RGB and depth-based representations provides both accuracy and robustness beyond what is typically achieved by streamlined temporal or joint-only models, though further validation is needed for deployment in real-world rehabilitation settings. Future work will focus on enhancing temporal modeling through attention mechanisms, adapting the framework for deployment on edge devices, and introducing user specific personalization to improve adaptability. Additional improvements may include integrating multi view camera setups to handle occlusion, incorporating physiological signals such as electromyography or heart rate to enrich feedback, and developing real time clinician interfaces for remote monitoring and adaptive therapy planning. These directions aim to transform the system into a comprehensive and intelligent rehabilitation assistant that bridges clinical precision with home-based accessibility.
Footnotes
Contributorship
AK and YW (equal contribution) conceptualized the study, designed the AI framework, and conducted the experiments and analysis. SN contributed to model optimization and performance evaluation. NAA assisted with data preparation and experimental protocols. AJ provided methodological guidance and technical oversight. HL supervised the research and guided the theoretical direction. AK and YW drafted the manuscript. All authors reviewed and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by NUIST Talent Start-up Fund (No. 1513142501062) and Jiangsu Distinguished Fund (No. R2025T07). The publication was also supported by the Open Access Initiative of the University of Bremen and the DFG via SuUB Bremen. This research is supported and funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R410), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All datasets utilized in this research. KIMORE, mRI, and UTKinect-Action3D are publicly available and were obtained from open-access repositories under their respective usage licenses. Each dataset adheres to ethical research standards and provides anonymized participant data for noncommercial academic use. No additional restrictions apply to their reuse beyond those specified by the original authors. KIMORE: https://vrai.dii.univpm.it/content/kimore-dataset; mRI: https://sizhean.github.io/mri; UTKinect-Action3D: ![]()