
Abstract
Objective
This retrospective, modeled study evaluates the accuracy of ChatGPT (GPT-4)-based warfarin dose adjustments compared to clinician recommendations at the Cardiology Clinic of Konya City Hospital, focusing on patients with international normalized ratio (INR) values outside the therapeutic range (2–3). We hypothesized that ChatGPT could provide reliable, consistent dose guidance.
Methods
We reviewed the records of warfarin-treated patients from 1 June 2022 through 24 November 2024. Clinical data used by physicians (e.g. baseline INR, warfarin indication, comorbidities, and current dose) were provided to ChatGPT to generate hypothetical weekly dose recommendations. ChatGPT's impact on INR normalization was modeled using standard dose–response assumptions and compared with actual outcomes under physician-guided therapy.
Results
A total of 180 patients met the inclusion criteria. ChatGPT's recommended doses were within ±1 mg/week of physician prescriptions in 74% of cases and within ±2 mg/week in 84%. The mean physician dose was 28.0 ± 6.1 mg/week versus ChatGPT's 27.5 ± 5.9 mg/week (p = .12). Seventy-two percent of patients achieved therapeutic INR under physician-managed dosing, while the model suggested a 69% success rate for ChatGPT-guided dosing (p = .15). Real-world adverse events were infrequent under physician management (1.1% major bleeding, 0.6% thrombotic events).
Conclusion
In this retrospective, exploratory analysis with modeled outcomes, ChatGPT's weekly dose suggestions showed high concordance with clinician dosing. These findings are hypothesis-generating and do not establish clinical efficacy or safety; prospective, physician-supervised trials—potentially integrated with home INR monitoring—are required for validation.
Introduction
Warfarin remains one of the most widely used oral anticoagulants worldwide for various indications, including nonvalvular atrial fibrillation (AF), mechanical heart valves, and moderate-to-severe mitral stenosis, despite the increasing use of direct oral anticoagulants (DOACs).1,2 Maintaining an optimal international normalized ratio (INR), typically between 2.0 and 3.0, is crucial for minimizing thrombotic events while avoiding excessive bleeding risk.3,4 Yet, warfarin dose adjustment poses a significant challenge due to a host of influencing factors, such as drug interactions, dietary changes, and individual genetic variability.5,6 As a result, clinicians often face a demanding process of frequent dose refinements and close INR monitoring.
Artificial intelligence (AI) has emerged as a potential approach to improve the safety and efficiency of warfarin management. Initial pharmacogenetic-based algorithms have shown promise for guiding dose selection, but their broad application is limited by the need for genetic testing, specialized expertise, and additional costs.7–9 More recently, large language models (LLMs)—exemplified by ChatGPT (GPT-4), developed by OpenAI—have demonstrated advanced reasoning abilities that may be suitable for handling complex, dynamic tasks such as anticoagulation dose titration.10–12 Although ChatGPT has shown utility in patient education, triage, and diagnostic suggestions, its role in managing treatments that demand ongoing dose adjustments, like warfarin, remains unclear.13–15
To our knowledge, published evidence on ChatGPT's ability to handle real-world warfarin dose adjustments is scarce, particularly in a retrospective clinical context. By retrospectively comparing ChatGPT's dose recommendations with those made by experienced clinicians at the Cardiology Clinic of Konya City Hospital, this study provides an early investigation into the feasibility of integrating an AI-based model into routine anticoagulation management. In focusing on patients whose INR fell outside the target therapeutic range, we aim to determine the alignment of ChatGPT's suggested doses with established clinical practice and assess its theoretical potential for maintaining therapeutic INR levels. If validated in future prospective trials, these findings could inform the design of physician supervised evaluations of AI-supported warfarin management, especially in resource-limited settings or among patients who might benefit from remote monitoring and home INR testing.
Materials and methods
Study design
This retrospective cohort study was conducted at the Cardiology Clinic of Konya City Hospital, evaluating patients receiving warfarin therapy from 1 June 2022, through 24 November 2024. This is a retrospective modeling/simulation study: ChatGPT-generated dose suggestions were not implemented in clinical care, and downstream outcomes were estimated using a modeled approach. The protocol was approved by the Necmettin Erbakan University Faculty of Medicine Ethics Committee (Protocol No. 2024/5359). Because this was a retrospective review using fully deidentified data with no direct patient contact or intervention, the Ethics Committee explicitly waived the requirement for written informed consent; the Committee does not issue a separate waiver number, and the consent waiver is recorded within Protocol No. 2024/5359. All identifiers were removed prior to analysis and before any variables were provided to ChatGPT (GPT-4). The study adhered to the Declaration of Helsinki and applicable local regulations and involved a comprehensive review of electronic health records to compare real-world, physician-guided warfarin dose adjustments with retrospective dose recommendations generated by ChatGPT.
Patient selection
Adult patients (≥ 18 years old) who had been on warfarin for at least three months were screened for inclusion if they had at least one documented INR value outside the therapeutic range of 2.0–3.0, as well as a follow-up INR measurement after a physician's dose adjustment. Patients were excluded if their medical records were incomplete or if they had severe hepatic or renal impairment requiring an atypical INR target, significant changes in diet or medication use not captured in the records, pregnancy, or active malignancy requiring alternative anticoagulation strategies.
Data collection
Patient information was extracted from electronic health records, including demographics (age, sex), warfarin indication (such as AF or mechanical heart valve replacement), relevant comorbidities, concomitant medications that could affect coagulation, and the baseline INR prior to a physician's adjustment. The actual physician-prescribed warfarin dose was recorded, as was the follow-up INR obtained at the next clinic visit. Patient records were accessed for research purposes between 01 December 2024 and 15 December 2024. These data points were used to characterize real-world dose adjustments and outcomes. Standardized ancestry/ethnicity fields were not systematically recorded in the EHR during the study window and were therefore not abstracted; no pharmacogenetic (e.g. CYP2C9, VKORC1) results were available.
Handling of missing data
We used a complete case approach. Episodes were included only if essential fields were available: (i) index INR prompting the physician's adjustment, (ii) current weekly warfarin dose at baseline, (iii) the physician prescribed weekly dose for that episode, and (iv) a follow-up INR. Episodes lacking any of these fields were excluded a priori. Optional covariates (e.g. comorbidities, interacting medications, and recently documented diet changes) were abstracted as recorded; when not present in the chart, they were coded “not documented/none.” No statistical imputation was performed.
ChatGPT dose recommendations
We generated AI recommendations using ChatGPT (GPT-4) via the web interface in December 2024. Model and access mode: All recommendations were generated in the ChatGPT web application (standard chat mode) with the model selector set to “GPT-4” (non-API); browsing, Code Interpreter, and plug-ins were not used. Sessions were conducted in December 2024. The web interface did not expose an internal build number or sampling parameters. To prevent context carry-over and maximize reproducibility, we started a new chat for each patient-episode and followed a fixed two-message protocol:
System-style instruction (fixed for all cases): defined scope as maintenance dosing only, required a single numeric total weekly dose (mg/week) as output, and specified a strict output rule (“return only ‘{number} mg/week’”). If essential inputs were missing, the instruction required the model to return “insufficient-data.”
User template (case-specific): a structured, deidentified set of inputs matching the variables available to clinicians at the time of the dose decision (age, sex, indication, target INR range, index INR, current weekly warfarin dose, relevant interacting medications, major comorbidities, and recent medication changes).
Because the web interface does not expose sampling parameters (e.g. temperature), we minimized variability by using a fixed prompt set, a single-turn interaction per case, and a constrained output format. If the model produced any extra text, we recorded the first valid numeric mg/week. If no numeric dose was returned, the case was re-run once in a fresh chat; persistent nonnumeric output was recorded as “insufficient-data.” No directly identifiable patient information (e.g. names, dates of birth, medical record numbers, contact details, free-text notes, or images) was transmitted; each case was labeled only as “Patient 001,” “Patient 002,” etc., and all inputs were strictly structured and deidentified. The verbatim system instruction and user template, the run protocol, and a filled example are provided in Supplemental Table S1 (Exact Prompt Template and Input Fields) for replication.
Because ChatGPT's recommendations were not implemented clinically, their potential effect on subsequent INR values was modeled using a standard dose–response assumption (proportional INR change relative to incremental dose adjustment), thereby enabling an initial, theoretical assessment of alignment with evidence-based warfarin dosing. These modeled estimates are reported as such and are contrasted with observed outcomes under physician-guided dosing.4,716–18
If essential inputs were unavailable for a given episode, the model was instructed to return “insufficient data”; such episodes were excluded from dose concordance and outcome modeling analyses.
Because we used the web-based ChatGPT interface, the model version and sampling parameters could not be locked, the provider may update the model without notice, and identical prompts can yield different outputs. To reduce variability, we used a fixed two-message prompt, opened a new chat per case, enforced a single-turn, numeric-only output, and recorded the first valid value; we did not perform repeated queries. As the web interface is nondeterministic and provider-updated, repeating cases post hoc would not replicate the original model behavior; therefore intracase variability was not estimated in this retrospective analysis.
Outcome modeling
We modeled INR normalization using a maintenance-phase, proportional dose–response assumption applied to small-to-moderate weekly dose changes, with the expected INR shift scaled to the observed follow-up interval to reflect partial attainment of steady state. Because AI-suggested doses were not used clinically, we modeled counterfactual next-visit INRs using a maintenance-phase proportional dose–response assumption: for small-to-moderate changes in weekly warfarin dose, the INR is expected to move proportionally toward the target (directionally consistent with the dose change), and the magnitude of movement is tempered by the observed follow-up interval to reflect partial attainment of steady state. This assumption mirrors widely used maintenance nomograms that recommend ∼5–20% adjustments in weekly dose when the INR is out of range and is consistent with clinical/algorithmic literature in which dose requirements behave approximately linearly over routine maintenance adjustments.4,18 We used this framework to compare the modeled effect of ChatGPT-suggested weekly doses to observed outcomes under physician-guided dosing. Accordingly, any “therapeutic INR at next visit” rate reported for the AI arm is a counterfactual estimate generated under this proportional maintenance assumption (scaled to the observed follow-up interval) and does not represent outcomes observed under AI-guided care.
To assess uncertainty in the proportional dose–response assumption, we performed a one-way sensitivity analysis varying the dose–response slope to 0.5×, 0.75×, 1.0× (base case), 1.25×, and 1.5×, and recalculated modeled next-visit INRs and the modeled proportion achieving therapeutic INR (2.0–3.0).
Statistical analysis
The primary analysis compared weekly warfarin doses recommended by ChatGPT with doses prescribed by physicians. The mean difference (in mg/week) and corresponding 95% confidence interval were determined, and the proportion of ChatGPT recommendations within ±1 mg/week and ±2 mg/week of physician doses was calculated to assess concordance. The secondary analysis compared the proportion of patients achieving an INR within the 2.0–3.0 range under actual physician guidance with a modeled estimate of therapeutic range attainment had ChatGPT's suggested doses been followed. Major bleeding and thrombotic events were documented in the physician-guided group but could only be speculated in the ChatGPT cohort. All categorical variables were evaluated using chi-square or Fisher's exact tests, whereas continuous variables were analyzed with nonparametric methods such as the Kruskal–Wallis or Mann–Whitney U test for skewed data. A two-tailed p-value below .05 was deemed statistically significant. This analytic framework was chosen to accommodate the inherent variability of warfarin dosing and INR levels in a diverse clinical population.
In addition to p-values, we report effect sizes with 95% confidence intervals (CIs) to convey magnitude and precision. For continuous outcomes, we report the mean difference (mg/week) with 95% CI and display agreement with a Bland–Altman plot (mean difference and 95% limits of agreement). For proportions, we report binomial 95% CIs (Wilson). For the therapeutic INR endpoint, we further report the absolute risk difference (ARD) with 95% CI (Newcombe, Wilson based) and the risk ratio (RR) with 95% CI (log method).
As an auxiliary continuous agreement metric, we pre specified the intraclass correlation coefficient (ICC) (A,1) (two way random effects, absolute agreement, single measurement), and we describe the Bland–Altman 95% limits of agreement in the figure caption.
All analyses were performed on the complete case dataset without imputation; denominators reported in tables/figures reflect episodes with nonmissing data for the corresponding outcome.
This was an exploratory, retrospective modeling study with a fixed sample size determined by all eligible episodes during the study window; no a priori power calculation was performed. Formal equivalence or noninferiority testing was not pre specified and is therefore not reported to avoid post hoc margin selection. Instead, we interpret the observed effects using precision based 95% CIs relative to practice relevant thresholds (e.g. ±1 mg/week for maintenance level dose differences). Future prospective studies will preregister equivalence/non inferiority margins and associated sample size calculations.
Results
A total of 180 patients met the inclusion criteria. Their mean age was 65.2 ± 10.1 years, and 56% identified as female. Warfarin was prescribed for nonvalvular AF in 53% of cases, mechanical heart valves in 31%, and moderate-to-severe mitral stenosis in 16%. The median duration of warfarin therapy among these patients was two years (interquartile range, 1–5). Standardized ancestry/ethnicity data were not available; this single-center cohort reflects the local referral population of a tertiary hospital in Turkey, and no genotype results were present in the record.
Table 1 presents a subset of patient-level data illustrating how ChatGPT's suggested weekly warfarin doses compared with the physician-prescribed doses. ChatGPT's recommendations ranged from 2 mg/week below to 2 mg/week above the physician-guided doses, with several instances matching exactly. The follow-up INR values listed in Table 1 reflect clinical measurements after physician-guided adjustments only; ChatGPT's recommended doses were not implemented, so their hypothetical effects on INR could not be directly observed.
Representative patient-level comparisons of physician versus ChatGPT weekly warfarin dose recommendations and follow-up INR.

Note: INR: international normalized ratio.
The ChatGPT weekly dose was not used in actual practice. The dose difference column shows ChatGPT's hypothetical recommendation relative to the real physician dose. Follow-up INR is reported from actual clinical data after the physician dose.
Aggregate data for all 180 patients are summarized in Table 2. The mean weekly dose recommended by ChatGPT was 27.5 ± 5.9 mg/week, compared with 28.0 ± 6.1 mg/week by physicians (p = .12), indicating no statistically significant difference. The corresponding mean difference (ChatGPT − Physician) was −0.5 mg/week (95% CI [−1.0 to +0.2]). In total, 74% of ChatGPT's recommendations fell within ±1 mg/week of physician doses, and 84% were within ±2 mg/week. These concordance rates corresponded to 74% (95% CI [67.0–79.8]) and 84% (95% CI [77.8–88.5]), respectively. Under real-world, physician-led dosing, 72% of patients returned to the therapeutic INR range (2.0–3.0), whereas the model projected that 69% would have achieved this goal under ChatGPT guidance (p = .15). This translates to an ARD (ChatGPT − Physician) of −3.3 percentage points (95% CI [−16.5 to +9.9]) and an RR of 0.95 (95% CI [0.83–1.09]). Although neither comparison reached statistical significance, the 95% CIs are wide and compatible with effects that could be clinically meaningful; therefore, equivalence cannot be inferred. For example, the ARD 95% CI spans −16.5 to +9.9 percentage points (RR 95% CI [0.83–1.09]), and the mean dose-difference 95% CI [−1.0 to +0.2 mg/week] lies largely within the ±1 mg/week maintenance band but does not exclude a small systematic offset. Although neither comparison reached statistical significance, the 95% CIs are wide and compatible with effects that could be clinically meaningful; therefore, equivalence cannot be inferred. For example, the ARD 95% CI spans −16.5 to +9.9 percentage points (RR 95% CI [0.83–1.09]), and the mean dose-difference 95% CI [−1.0 to +0.2 mg/week] lies largely within the ±1 mg/week maintenance band but does not exclude a small systematic offset. In sensitivity analyses varying the assumed dose–response slope from 0.5× to 1.5× of the base case, the modeled ChatGPT therapeutic-INR rate ranged approximately from ∼70% to ∼67% (corresponding AI–physician ARDs of approximately −1.6 to −5.0 percentage points), indicating that the 69% estimate is sensitive to the slope parameter and should be interpreted as an exploratory, counterfactual projection. Major adverse events were uncommon in the physician-treated cohort, comprising two major bleeding complications (1.1%) and one thrombotic event (0.6%). Since ChatGPT's recommendations were not applied clinically, the potential for such outcomes in the hypothetical ChatGPT arm remains uncertain. A Bland–Altman analysis illustrated agreement between weekly warfarin doses recommended by ChatGPT and those prescribed by clinicians, demonstrating a mean difference of −0.5 mg/week with the 95% limits of agreement displayed in Figure 1. The ICC for absolute agreement, ICC (A,1), was ≈ 0.77 (95% CI [0.70–0.82]), supporting high agreement between ChatGPT and physician weekly dose recommendations.

Agreement between ChatGPT (GPT-4) and physician recommended warfarin doses. Bland–Altman plot illustrating the agreement between weekly warfarin doses recommended by ChatGPT (GPT-4) and those prescribed by clinicians (n = 180). Points show the difference (ChatGPT − Physician, mg/week) plotted against the mean of the two recommendations. Blue dotted lines mark the prespecified ±1 mg/week threshold, which captures 74% (95% CI [67.0–79.8]) of recommendations and represents our primary concordance criterion. At the cohort's mean physician weekly dose (28.0 mg/week), ±1 mg/week corresponds to ≈3.6% and ±2 mg/week to ≈7.1% change. The red dashed line shows the mean difference (−0.5 mg/week, 95% limits of agreement are shown on the plot and described in the text), and the gray dashed lines indicate the 95% limits of agreement. (For context, 84% (95% CI [77.8–88.5]) of pairs lie within ±2 mg/week.) Negative values indicate ChatGPT recommended a lower weekly dose than the physician. The intraclass correlation coefficient for absolute agreement (A,1) was ≈ 0.77 (95% CI [0.70–0.82]).
Aggregate outcomes comparing physician versus ChatGPT recommendations.
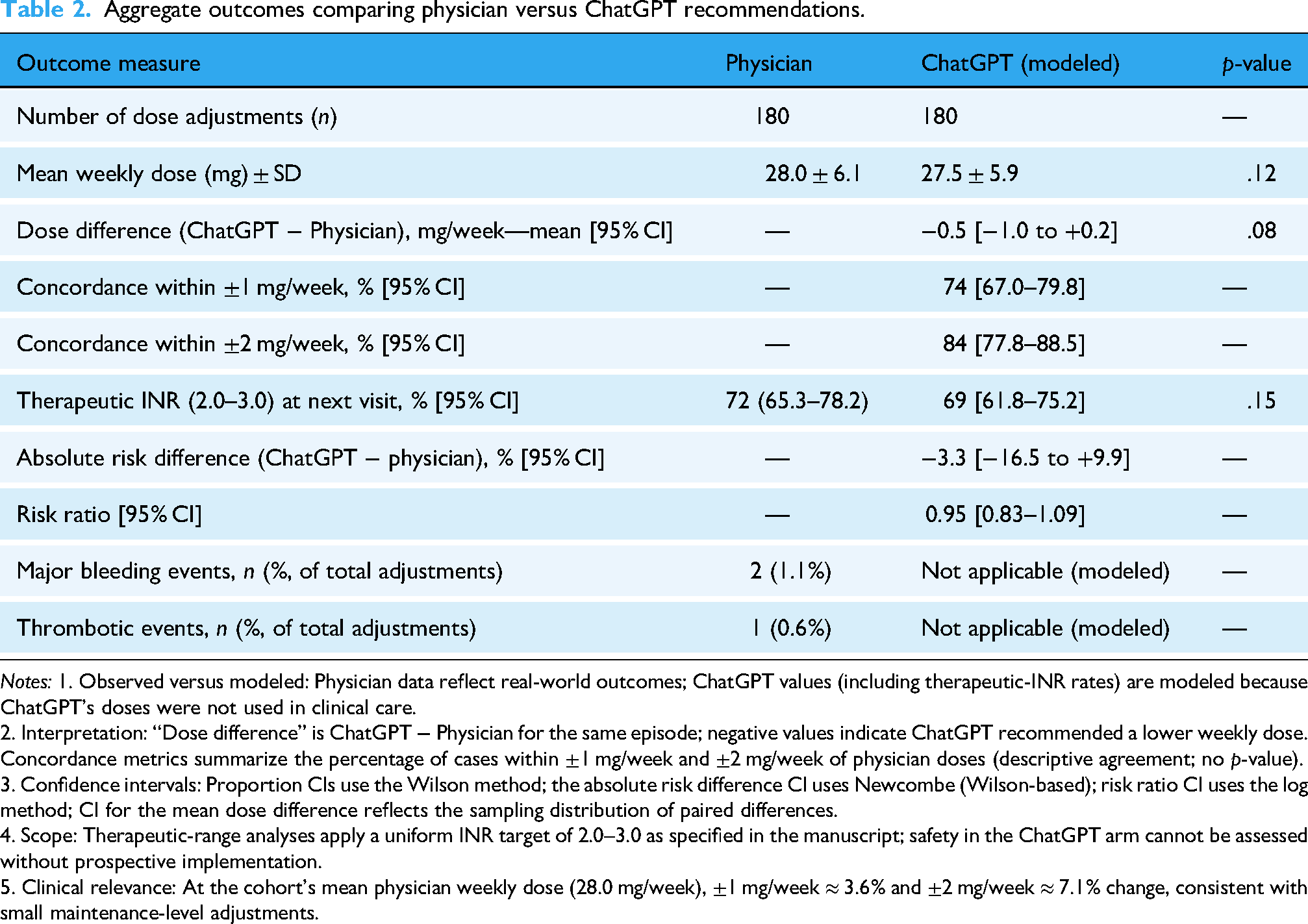
Notes: 1. Observed versus modeled: Physician data reflect real-world outcomes; ChatGPT values (including therapeutic-INR rates) are modeled because ChatGPT's doses were not used in clinical care.
2. Interpretation: “Dose difference” is ChatGPT − Physician for the same episode; negative values indicate ChatGPT recommended a lower weekly dose. Concordance metrics summarize the percentage of cases within ±1 mg/week and ±2 mg/week of physician doses (descriptive agreement; no p-value).
3. Confidence intervals: Proportion CIs use the Wilson method; the absolute risk difference CI uses Newcombe (Wilson-based); risk ratio CI uses the log method; CI for the mean dose difference reflects the sampling distribution of paired differences.
4. Scope: Therapeutic-range analyses apply a uniform INR target of 2.0–3.0 as specified in the manuscript; safety in the ChatGPT arm cannot be assessed without prospective implementation.
5. Clinical relevance: At the cohort's mean physician weekly dose (28.0 mg/week), ±1 mg/week ≈ 3.6% and ±2 mg/week ≈ 7.1% change, consistent with small maintenance-level adjustments.
Taken together, these findings suggest a high level of concordance between ChatGPT's retrospective dose recommendations and established clinical practice, although definitive conclusions regarding efficacy and safety would require prospective implementation of ChatGPT's dosing strategies.
Discussion
Warfarin has remained a mainstay oral anticoagulant for patients with conditions such as AF, mechanical heart valves, and moderate-to-severe mitral stenosis, despite the introduction of DOACs.1,2 However, the precise dose–response management of warfarin continues to be a challenge, as interindividual variability, dietary factors, and drug interactions demand frequent INR monitoring.3,5,6 Our data confirm that even with specialist oversight, maintaining INR in a narrow therapeutic window can be difficult. 2 This persistent challenge has increased interest in AI-driven tools that may lighten the burdens on both clinicians and patients.
AI has shown potential in clinical decision support, particularly LLMs like ChatGPT (GPT-4), which can rapidly analyze multiple patient variables and provide standardized recommendations.10,12,13 In this study, ChatGPT's recommended doses were highly concordant with physician-guided dosing, with the majority of its suggestions falling within ±1 mg/week of actual clinical practice. While this alignment does not guarantee improved clinical outcomes, it suggests that ChatGPT could potentially standardize dosing practices and reduce interclinician variability. Because the AI-suggested doses were not administered and all outcomes are counterfactual, the findings should be interpreted as hypothesis-generating rather than evidentiary for clinical effectiveness or safety. In particular, the reported 69% “therapeutic INR at next visit” for the AI arm should be read strictly as a counterfactual model output—dependent on the proportional maintenance assumption and follow-up timing—rather than as realized performance of AI-guided dosing.
Our fixed system instruction intentionally constrained the task to maintenance-phase warfarin adjustment and required a single numeric mg/week output to improve safety, standardization, and comparability across cases. 19 However, we acknowledge that including a directive consistent with proportional movement of INR toward target can partially embed the same maintenance logic used by guideline nomograms and clinicians, potentially increasing concordance by steering the model toward guideline-like outputs rather than unconstrained clinical reasoning. This concern is reinforced by prior work showing that LLM outputs and apparent performance can be highly sensitive to prompt wording, structure, and even minor rephrasings, and by healthcare studies demonstrating measurable dependence of model behavior on prompt design and perturbations.20–22 Accordingly, our concordance estimates should be interpreted as reflecting performance under a prespecified, directive prompt intended to approximate standard maintenance dosing logic. Future prospective evaluations should preregister and compare alternative prompt framings (e.g. less directive prompts vs structured guideline-anchored prompts), benchmark against simple rule-based nomograms and genotype-guided algorithms, and quantify stability via repeated runs using version-locked systems.
Warfarin maintenance dosing is commonly guided by published dosing nomograms and guideline-based percent-adjustment rules, and LLMs may have been exposed to such materials during training. Therefore, agreement between GPT-4 and clinician dosing may partly reflect retrieval of guideline-concordant patterns rather than demonstrable patient-specific reasoning, and our concordance results should be interpreted primarily as alignment with standard practice—not evidence of incremental benefit beyond a dosing nomogram. The current study was designed as an initial, hypothesis-generating assessment of whether GPT-4 produces maintenance-dose suggestions that are broadly consistent with clinician-guided care when provided the same structured inputs. Future work should include head-to-head benchmarking against a transparent rule-based dosing algorithm and focused evaluation of discordant episodes, including cases where clinicians intentionally deviate from nomograms with documented rationale (e.g. adherence concerns, interacting drugs, intercurrent illness), to determine whether and when LLMs add value beyond established dosing tables.
A practical application of AI assisted warfarin management lies in home INR monitoring. Prior research has demonstrated that self-testing and self-management can enhance time in therapeutic range and reduce complication rates. 23 By coupling these monitoring devices with ChatGPT's dosing recommendations, patients may be able to adjust therapy more frequently and in a timely manner under clinician oversight, alleviating the need for repeated in-person consultations. This model could be especially beneficial in resource-limited or remote settings, where access to specialized cardiology care may be limited. 24 Any such workflow would require clinician review and sign-off, predefined safety triggers, version-locked model access, and auditable decision logs.
Despite these prospects, caution is necessary when interpreting our findings. ChatGPT's efficacy in maintaining therapeutic INR levels was not tested in actual patients but inferred using dose–response modeling. Real-world outcomes can deviate due to unanticipated factors like inconsistent patient adherence, dietary changes, unreported drug interactions, and interpatient pharmacogenetic differences.7,8 Additionally, while AI offers consistency, it lacks the nuanced clinical judgment that can detect subtle signs of adverse events or complications—reinforcing the importance of physician oversight in any AI-guided protocol.
The potential for extending ChatGPT-based dosing to noncardiology practitioners or trained personnel is also intriguing. 15 In rural or otherwise underserved areas, the ability to rely on an AI model to guide routine dose adjustments might mitigate the shortage of experienced cardiologists. Future investigations could explore models in which AI-generated dosing is reviewed and signed off by a supervising clinician, preserving patient safety while reducing the workload on specialists.
Emerging evidence on LLMs in clinical decision support underscores both promise and the need for disciplined evaluation. A randomized clinical trial found that physicians given access to an LLM (GPT-4) did not significantly improve diagnostic reasoning compared with conventional resources, even though the LLM alone performed well—highlighting that interface design, guardrails, and oversight matter for real-world benefit. 25 Related vignette-based studies also report high standalone accuracy of GPT-4 on clinical problems, reinforcing the importance of prospective, workflow-aware testing rather than assuming performance will translate directly to practice. 26
In the medication-prescribing domain, comparative evaluations show substantial variability across LLMs in recommending drug choice, dose, and duration, with top models performing best yet still showing reduced accuracy as case complexity rises—evidence that supports our call for model version locking, monitoring, and domain-specific validation before clinical deployment. 27 Complementary analyses suggest LLMs can reliably assist guideline-concordant prescribing for common problems in primary care, again with the caveat that outputs require clinician review. 28 Perspective pieces similarly emphasize advantages (speed, standardization) and limitations (context gaps, hallucinations, variable dosage accuracy), recommending careful governance and prospective testing. 29
For warfarin specifically, prior AI work has focused on algorithmic dose prediction using clinical and pharmacogenetic variables; recent demonstrations show that GPT-4 with code-execution tools can orchestrate end-to-end modeling on the IWPC dataset, surface feature importance, and generate partial-dependence plots—illustrating technical feasibility but not clinical validation. 30 Our study adds complementary, clinically grounded evidence by comparing episode-matched dose suggestions from GPT-4 against physician practice in a real cohort.
Finally, considering humanitarian settings is well-taken. Case reports from conflict zones document warfarin-related pulmonary hemorrhage under severe resource constraints, illustrating how fragile anticoagulation management can become when diagnostics and follow-up are disrupted. 31 Reviews of AI for humanitarian healthcare argue that digital tools—when ethically governed—can strengthen crisis response, telemedical follow-up, and remote decision support. In such contexts, home-INR plus clinician-supervised AI dosing could help maintain continuity for stable patients, while preserving strict escalation protocols for high-risk scenarios. 32
Moving forward, prospective trials and real-world pilot programs are vital for verifying these retrospective results. Evaluating clinical endpoints—such as time in therapeutic range, rates of bleeding or thrombotic complications, quality of life, and cost-effectiveness—will provide clearer insight into how AI-driven warfarin management systems perform in daily practice. In sum, these retrospective, modeled results are hypothesis generating and require confirmation in prospective, physician supervised studies before any consideration of routine clinical use.
Generalizability of these modeled findings may vary across populations with different genetic and environmental contexts.33–35 Because this was a single-center cohort in Turkey and standardized ancestry/ethnicity fields were unavailable, we could not perform ancestry-stratified analyses; generalizability to populations with different CYP2C9/VKORC1 allele frequencies and dietary patterns may therefore be limited. Allele frequencies for CYP2C9 (e.g. *2/*3 and ancestry-enriched variants such as *5/*6/*8/*11) and VKORC1 (−1639G > A) differ by ancestry and are associated with meaningful shifts in warfarin maintenance dose, which could alter concordance between AI-suggested and clinician-selected doses in settings unlike our cohort.33–35 Dietary vitamin-K patterns also vary by region, culture, and season—and emerging data suggest interactions with the gut microbiome—potentially changing dose-response behavior and the stability of INR control.36,37 In addition, comedication profiles (e.g. amiodarone, rifampin, azoles, antibiotics) and care pathways (frequency of monitoring, availability of home-INR/telehealth) differ across health systems and may influence both clinician dosing and any future AI-assisted workflow.38,39 Accordingly, prospective evaluations should stratify by ancestry/ethnicity, incorporate genotype when available, assess diet-related variability, and test performance across diverse care settings with physician oversight.33–39
Multiple pharmacogenetic loci—most prominently CYP2C9 and VKORC1, and in some populations CYP4F2 and rs12777823—explain clinically meaningful variability in warfarin dose requirements and time to stable INR; allele frequencies differ across ancestries, with implications for generalizability. 40 Our dataset did not include PGx results and ChatGPT inputs did not capture genotype, so the present comparisons cannot account for genotype-driven dose differences. Evidence syntheses and guidelines support genotype-informed dosing when results are available, and large studies/algorithms (e.g. IWPC) integrate genetic with clinical data; randomized trials report mixed findings, with EU-PACT showing improved anticoagulation control with genotype-guided initiation and COAG showing no early improvement versus a clinical algorithm, underscoring the need for context-specific, prospective evaluation.9,16,41 Future work should incorporate genotype where available and evaluate performance across diverse ancestries. In cohorts where genotype-driven dose shifts are substantial—for example, higher frequencies of VKORC1−1639A/AA in East Asian populations or CYP2C9 *5/*6/*8/*11 and rs12777823 in individuals of African ancestry—the absence of genotype in the AI inputs could lower concordance with clinician dosing or shift the dose-difference distribution; conversely, long-term stable maintenance doses and prior INR history may partially reflect genotype effects. Accordingly, concordance and generalizability are likely to vary by ancestry and genotype prevalence. 9 33–35,40,41
This study has several limitations that warrant consideration. First, because it was retrospective in design, the study relied on existing medical records, which may have lacked comprehensive information on potential confounding factors, such as dietary variability and patient adherence to medication regimens. Accordingly, unmeasured or incompletely documented factors could bias both observed and modeled outcomes. Second, ChatGPT's dose recommendations were generated in a theoretical context and were not implemented in actual patient care. As a result, any impact on real-world clinical outcomes—including adverse events—remains speculative. Additionally, because warfarin nomograms and dosing guidelines are widely available and may be represented in LLM training data, the observed concordance may be partly expected and does not establish added value beyond a simple rule-based algorithm; we did not include a nomogram/algorithm comparator or systematically analyze clinician deviations from guideline-based rules, which should be addressed in future prospective evaluations. Third, the study was conducted at a single center with a relatively homogeneous patient population, which limits external validity and may not reflect practice patterns, comorbidities, or diet/genetic backgrounds in other settings. Fourth, pharmacogenetic factors were not systematically evaluated, and genotype data (e.g. CYP2C9/VKORC1) were unavailable, even though genetic variants can significantly influence warfarin metabolism and dosing requirements. This omission precluded benchmarking against genotype-guided dosing algorithms and may bias modeled outcomes and the observed concordance in populations enriched for dose-shifting alleles. Fifth, although we captured “recently documented” dietary changes and interacting drugs, we could not model day-to-day adherence, vitamin K intake, or unrecorded drug interactions; these time-varying, patient-level factors may attenuate or amplify INR responses. Sixth, for comparability, therapeutic-range analyses applied a uniform INR target of 2.0–3.0; this simplification may misclassify some indications that require different targets (e.g. selected mechanical-valve patients) and could influence the direction of modeled therapeutic attainment. Additionally, as with other LLMs, ChatGPT's outputs can vary between runs even when provided with identical inputs; while we sought to minimize variability by using a fixed prompt and structured, deidentified inputs, we did not requery cases to quantify reproducibility, and future studies should assess intracase variability and consider consensus procedures (e.g. multiple runs with adjudication) before clinical deployment. Use of the web interface limits strict reproducibility (no version lock, nonexposed parameters, and potential provider-side updates), so outputs may vary between runs or over time despite our fixed-prompt, single-turn protocol. This is clinically important for warfarin because small maintenance-dose differences (e.g. ±1–2 mg/week) may influence INR trajectories; however, we did not measure run-to-run variability for identical inputs, and the web interface does not permit version locking or parameter control. Future prospective evaluations should use a version-locked system and replicate a prespecified subset of cases to quantify within-case variability (e.g. distribution of repeated dose outputs and the proportion differing by >±1 mg/week and >±2 mg/week), with predefined consensus procedures under clinician oversight. For prospective evaluation, reproducibility procedures will include version-locked API access with deterministic decoding (e.g. temperature = 0), seed/parameter logging, multiple replicates per case to quantify within-case variability (e.g. SD/ICC), and a prespecified consensus rule (e.g. median of k runs) under clinician oversight. Furthermore, comparing hypothetical AI-guided dosing with observed physician decisions introduces potential biases, including regression-to-the-mean, differences in follow-up intervals, and unmeasured case-mix factors. Day-to-day INR variability and variable patient adherence (and diet or interacting medications not fully captured in the record) may attenuate or amplify INR responses and could differentially affect modeled versus observed outcomes. Accordingly, the width of some 95% CIs—reflecting modeled estimates and a fixed sample size—means that clinically meaningful differences cannot be excluded, and nonsignificant results should not be interpreted as evidence of equivalence.
This proportional maintenance assumption is an approximation rather than a mechanistic PK/PD model; it may be less reliable at extreme INR values, after recent vitamin K administration, with potent drug–drug interactions, during acute illness, or in the presence of poor adherence. Consistent with this, sensitivity analyses show that the modeled therapeutic-INR rate depends on the assumed dose–response slope; thus modeled outcome comparisons are illustrative and not definitive. Warfarin's pharmacology also introduces a lag between dose change and INR response, with near steady-state effects typically realized over ∼5–7 days, which we addressed by tempering expected movement by the actual follow-up interval.4,7,16,42 Although percent-change nomograms and dosing algorithms support proportional adjustment for maintenance-phase care, genotype, diet, and interaction effects can introduce nonlinearity not captured here. Finally, while the modeling approach used standard dose–response assumptions, real-life variance in INR control is influenced by multiple dynamic factors, so the findings should be regarded as exploratory and hypothesis-generating, underscoring the need for prospective trials to confirm the safety and efficacy of AI-based warfarin dose adjustment in routine clinical practice.
Conclusion
In this retrospective modeling study, ChatGPT (GPT 4) produced weekly warfarin dose suggestions that were broadly concordant with clinician dosing. Because the AI generated doses were not administered and all outcomes are counterfactual, these findings are hypothesis generating and should not be interpreted as evidence of clinical safety or efficacy. Any potential role for AI assisted anticoagulation management requires verification in prospective, physician supervised trials with predefined safety triggers, independent monitoring, and version locked systems. If validated, integration with home INR/telehealth workflows could then be evaluated for effects on time in therapeutic range, visit burden, and access.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251412985 - Supplemental material for Retrospective modeling study of ChatGPT (GPT 4) warfarin dose adjustment in patients with INRs outside the therapeutic range
Supplemental material, sj-docx-1-dhj-10.1177_20552076251412985 for Retrospective modeling study of ChatGPT (GPT 4) warfarin dose adjustment in patients with INRs outside the therapeutic range by Hüseyin Tezcan, Abdullah Tunçez, Yasin Özen, Muhammed Ulvi Yalçın and Kadri Murat Gürses in DIGITAL HEALTH
Footnotes
Ethics approval
Approved by the Necmettin Erbakan University ethics committee (Protocol No. 2024/5359). Patient consent was waived due to the retrospective design.
Informed consent
Written informed consent was explicitly waived by the committee because the study was a retrospective chart review using fully deidentified data and involved no direct patient contact or intervention. The committee does not issue a separate waiver number; the consent waiver is documented within Protocol No. 2024/5359. No directly identifiable patient information left the institutional environment; any model prompting used only structured, deidentified case inputs, and AI-generated dose suggestions were not used for patient care.
Authors’ contributions
HT conceived and designed the study; HT and AT collected and analyzed data; YO and MUY assisted with data interpretation; KMG supervised the study and critically revised the manuscript. All authors contributed to writing, approved the final manuscript, and take responsibility for its content.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability and materials
Data supporting the findings of this study are available from the corresponding author upon reasonable request.
Generative AI statement
The authors declare that generative AI (ChatGPT, OpenAI, San Francisco, CA, USA) was used as the subject of this research but was not used in the preparation or editing of this manuscript.
Guarantor
Hüseyin Tezcan, M.D.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.