
Abstract
Objective
Depression represents a significant global health challenge, further complicated by the multifaceted and complex nature of its diagnosis and treatment. This study explores the application of multiple feature selection (FS) methodologies combined with XAI (explainable artificial intelligence) method named SHapley Additive exPlanations (SHAP) to enhance predictive accuracy in depression classification models using large-scale national survey data.
Methods
Leveraging microdata from the National Mental Health Survey of Korea (2021), encompassing 5511 Korean adults, this research systematically evaluates how different FS-machine learning classifier combinations affect model performance and identifies nondiagnostic socioeconomic, psychological, and lifestyle factors associated with clinically diagnosed depression. By employing diverse FS methods (e.g., ReliefF, Markov Blanket, and Information Gain) across multiple machine learning classifiers, we systematically compare their performance across 12 classifiers.
Results
We demonstrate that optimal FS method selection depends on machine learning classifier architecture, with ReliefF excelling in Stacking (F2-score =0.9851) and Markov Blanket performing best in ExtraTrees and LightGBM (F2-score =0.9848, 0.9838). After excluding core diagnostic criteria variables to avoid circularity, our analysis reveals that social distress (loneliness), reluctance to seek professional help, quality of life measures, and physical health comorbidities emerge as highly influential nondiagnostic predictors.
Conclusion
Our findings advance the field by: (1) systematically demonstrating that FS method effectiveness varies by machine learning classifier type, (2) providing a dual-layer XAI framework combining FS with SHAP for comprehensive interpretability, and (3) identifying culturally specific risk factors in an underrepresented Asian population using high-quality face-to-face collected data. These contributions provide methodological guidance for researchers developing interpretable depression prediction models and offer clinically actionable insights for identifying at-risk individuals in Korean populations.
Keywords
Introduction
Depression is a debilitating global health crisis affecting an estimated 280 million individuals worldwide. 1 Beyond transient sadness, depression profoundly disrupts daily functioning, diminishes quality of life, and represents a leading cause of disability.1,2 The World Health Organization (2024) emphasizes its disproportionate impact on women, underscoring the urgent need for targeted interventions. 1 The disorder's complex symptomatology—including persistent sadness, anhedonia, fatigue, cognitive impairment, and somatic complaints 2 —complicates both diagnosis and treatment, necessitating nuanced diagnostic approaches and personalized therapeutic strategies. The Global Burden of Disease study 3 further highlights depression's contribution to overall disease burden. Moreover, the COVID-19 pandemic has exacerbated mental health challenges, with studies demonstrating increased rates of depression and anxiety across age groups, 4 emphasizing the need for longitudinal research to understand long-term impacts.
The challenge and research gap
Traditional approaches to depression diagnosis rely heavily on clinical interviews and self-report questionnaires, methods that are inherently subjective, time-consuming, and vulnerable to bias. While machine learning classifiers have demonstrated promise in mental health prediction, three critical gaps persist in the existing literature. First, most studies apply a single FS method without systematically investigating how different FS methods interact with various classifier architectures. Second, although SHAP is widely used for model explanation, few studies integrate multiple FS approaches as a preliminary layer of explainability before applying SHAP, thereby missing opportunities for comprehensive interpretability. Third, many depression prediction studies inadvertently introduce circular reasoning by using diagnostic criteria themselves as predictors, potentially inflating accuracy metrics without providing clinically meaningful insights beyond diagnosis. The integration of large-scale health survey data with advanced computational methods presents an opportunity to address these limitations, provided that methodological rigor is maintained to ensure valid, interpretable, and clinically actionable predictions.
Proposed solution: A systematic XAI framework
The emergence of XAI presents a transformative opportunity to advance depression diagnosis and management. By leveraging machine learning classifiers on extensive datasets, researchers can uncover intricate patterns and identify crucial risk factors contributing to depression development and progression. 5 However, traditional machine learning classifiers often function as “black boxes,” limiting their clinical adoption due to lack of transparency. To address the identified gaps, this study proposes a methodologically rigorous XAI framework with three distinct contributions. First, we systematically compare eight different FS methods across 12 machine learning classifiers to demonstrate that optimal FS-classifier pairing significantly impacts both performance and interpretability. Second, we implement a dual-layer XAI approach, employing FS methods for macro-level feature importance followed by SHAP for micro-level feature attribution. Third, and most critically, we explicitly exclude core diagnostic criteria (lethargy and interest loss) from our predictive models to avoid circular reasoning and identify genuinely informative nondiagnostic risk factors. XAI techniques, such as FS methods 6 and SHAP, 7 provide powerful tools for dissecting the complex interplay of variables influencing depression.
This research leverages microdata from the National Mental Health Survey of Korea 2021, 8 conducted by the Ministry of Health and Welfare. This survey provides a comprehensive dataset for analyzing depression in the Korean population, encompassing 5511 Korean adults aged 18 to 79 years. By applying XAI techniques to this dataset, we aim to identify specific socioeconomic, lifestyle, and environmental factors associated with depression within the Korean context, while carefully distinguishing between diagnostic criteria and genuine risk factors to ensure clinical validity and actionability. This granular analysis illuminates the complex network of variables influencing depression, facilitating the development of personalized interventions. XAI's capacity to enhance transparency and interpretability in machine learning classifiers is crucial for fostering trust and acceptance among clinicians and patients. 5 Prior research has demonstrated the efficacy of machine learning in predicting mental health outcomes, including depression, anxiety, and stress. 6 Moreover, XAI has shown promise in interpreting complex user behaviors related to depression and suicidal ideation on social media platforms, 9 highlighting its potential for early detection and intervention. While previous studies have explored depression risk factors using machine learning,6–9 a crucial next step involves leveraging XAI to identify the most influential nondiagnostic variables, particularly to enhance diagnostic accuracy and improve clinical decision making.
Research aim and objectives
The primary aim of this study is to develop and validate a methodologically rigorous XAI framework that systematically identifies nondiagnostic risk factors associated with clinically diagnosed depression using multiple FS techniques combined with SHAP analysis. Specifically, we seek to: (1) determine which FS methods provide the most effective feature selection when paired with different machine learning classifiers, (2) identify which nondiagnostic variables emerge as the most influential predictors of depression after explicitly excluding core diagnostic criteria (lethargy and interest loss), and (3) demonstrate how a dual-layer XAI approach enhances both performance optimization and clinical interpretability. By addressing these objectives with methodological rigor, we aim to refine predictive models and develop more precise, transparent, and clinically valid diagnostic tools for practice.
Research questions
To achieve these objectives, this study addresses the following research questions:
By addressing these questions, this research aims to refine understanding of the complex factors underlying depression, ultimately improving diagnostic accuracy and informing more effective, personalized interventions. Furthermore, this study contributes to the growing body of literature on XAI applications in mental health, offering insights into the potential of these techniques to deepen our understanding of depression and guide clinical practice. 10 This research distinguishes itself by focusing on applying XAI to identify the most influential variables in predicting depression, offering a novel perspective on the complex interplay of factors contributing to depression and informing the development of more targeted and effective interventions.
Structure of the paper
This paper consists of six comprehensive sections. The first section introduces the research, setting the context and objectives, particularly focusing on the critical factors that influence depression diagnosis. The second section reviews the existing literature to provide a solid background and frame the study within current knowledge, with particular emphasis on gaps in existing methodologies that our study addresses. The third section outlines the detailed methodology, including data collection and advanced AI techniques used for analysis, with explicit discussion of how we address potential circular reasoning by excluding diagnostic criteria from predictive variables. The fourth section presents the results, identifying key nondiagnostic variables affecting depression prediction. The fifth section discusses the findings, exploring their implications and relevance to mental health practices and policies, while critically examining the limitations and scope of our contributions. Finally, the sixth section summarizes the study's contributions to the field, highlighting its potential impact on research, policy, and clinical practice related to mental health and depression diagnosis.
Related works
Depression prediction using machine learning classifiers
The field of medical diagnostics has been transformed by machine learning, which offers a promising approach to predicting and understanding depression. Machine learning classifiers, through their ability to analyze vast datasets and identify patterns, present a valuable approach to enhancing the accuracy of depression diagnosis. 11 By integrating diverse data sources—including biomarkers, patient histories, and real-time data from wearable devices—these classifiers provide insights that were previously inaccessible. The potential of machine learning to transform depression diagnosis lies in its capacity to consider multiple factors simultaneously, offering a more holistic view of an individual's mental health status.
Machine learning's application in depression prediction extends beyond traditional clinical settings. For instance, studies have demonstrated that machine learning can analyze social media data to identify markers of depression, showcasing the technology's ability to leverage unconventional data sources for mental health insights. 12 Furthermore, predictive models have been developed to assess depression risk in specific populations, such as older adults or college students, by analyzing variables like heavy metal exposure or familial factors.13,14 These advancements underscore the versatility of machine learning classifiers in adapting to varied contexts and populations, offering tailored approaches to depression prediction.
Although machine learning holds considerable promise in predicting depression, challenges remain in ensuring ethical data use and model interpretability. XAI methods are essential in this domain to ensure that healthcare providers and patients understand and trust the decision-making processes of AI systems. 15 The future of depression prediction using machine learning depends on balancing technological advancement with considerations of privacy, consent, and transparency, ensuring that these powerful tools are used responsibly and effectively to improve mental health outcomes.
Recent advances in machine learning for depression prediction
Recent studies have demonstrated significant progress in applying machine learning classifiers to depression prediction across diverse data modalities. Sharma and Verbeke (2020) developed an XGBoost model using a large Dutch biomarker dataset (n = 11,081), achieving improved diagnostic accuracy through systematic feature engineering. 11 Liu et al. 12 conducted a systematic review of depression detection on social media using machine learning approaches, highlighting the potential of text-based features for early identification. In the domain of wearable devices, studies have shown that activity and sleep patterns serve as reliable predictors of depressive states.25,26 Recently, multimodal approaches combining textual, behavioral, and physiological data have emerged, with studies demonstrating that ensemble methods integrating multiple data sources achieve superior predictive performance.27–29 However, a critical methodological gap persists: most studies apply FS methods in an ad hoc manner without systematically evaluating how different FS methods interact with specific classifier architectures, potentially missing optimal performance configurations. Additionally, studies achieving high accuracy often fail to verify whether their predictive variables are independent of diagnostic criteria, raising questions about the validity and clinical utility of their findings.
XAI in mental health and medical analysis
XAI is gaining prominence in the mental health field as a critical component that enhances the transparency and interpretability of machine learning classifiers. The need for XAI arises from the necessity to understand and trust AI decisions, particularly in sensitive areas such as mental health diagnosis and treatment. 15 The goal of XAI is to render the complex decision-making processes of AI systems comprehensible to humans, ensuring that healthcare professionals can interpret and validate AI-generated insights. Transparency is crucial for integrating AI tools into clinical practice, where understanding the reasoning behind a diagnosis or treatment recommendation is essential for both clinicians and patients.
The application of XAI in mental health extends beyond mere transparency, offering insights into the factors contributing to mental health conditions such as depression. For example, XAI can reveal the relationships between various predictors and depressive outcomes, enabling clinicians to understand the weight and impact of different variables. 16 This level of insight is invaluable for personalized care, allowing for interventions tailored to an individual's specific risk factors and circumstances. Additionally, XAI can facilitate the discovery of novel predictors and treatment pathways by highlighting previously overlooked associations within complex datasets.
Despite its potential, the integration of XAI in mental health presents challenges, particularly regarding the balance between model complexity and interpretability. 17 As AI models become more sophisticated, ensuring their decisions remain interpretable without sacrificing accuracy becomes increasingly difficult. Furthermore, ethical considerations around data privacy and the potential for bias in AI models require a cautious approach to deploying XAI in mental health. Importantly, while SHAP and similar methods are now established tools for post hoc model interpretation, their application alone does not constitute methodological novelty. The contribution of XAI research in mental health lies in how these tools are systematically applied to address specific research questions and gaps, rather than in the novelty of the tools themselves. Nevertheless, the promise of XAI to demystify AI's role in healthcare and contribute to more informed, effective mental health interventions remains a compelling avenue for future research and application. In summary, XAI provides clarity in the often opaque domain of AI-based applications, offering a pathway to harness the power of machine learning classifiers in mental health while maintaining a commitment to transparency, ethical practice, and patient-centered care.
XAI techniques in depression research
Several XAI techniques have been applied to depression prediction, with SHAP and LIME (Local Interpretable Model-agnostic Explanations) being the most commonly used methods.26,28 ElShawi et al. 26 conducted a comparative analysis of local interpretability techniques in healthcare, demonstrating SHAP's effectiveness for understanding feature contributions in disease prediction. Gandhi and Mishra 28 applied SHAP to diabetes prediction, illustrating how feature-level explanations can guide clinical decision making. In depression-related research specifically, recent studies have used SHAP to identify key predictors such as anxiety levels, social support, and lifestyle factors.16,29 While SHAP is a valuable and now standard tool for model interpretation, its mere application does not constitute a novel contribution. The novelty in our work lies not in using SHAP itself, but in: (1) systematically comparing how eight different FS methods interact with 12 machine learning classifiers to optimize both performance and interpretability, (2) implementing FS as a first explainability layer before applying SHAP for micro-level interpretation, and (3) addressing the critical methodological issue of circular reasoning by explicitly excluding diagnostic criteria from predictive variables—a problem rarely acknowledged or addressed in existing depression prediction literature.
Data and methodology
The present study utilized a computational analytical framework to investigate a public mental health survey dataset through the application of eight FS methods, 12 machine learning classifiers, and XAI techniques grounded in SHAP. This research was undertaken at Sungkyunkwan University, Seoul, Republic of Korea, during an 8-month period extending from January to August 2025.
Data
For our analysis, we leverage the National Mental Health Survey of Korea (NMHSK 2021) microdata. 8 A key strength of this dataset lies in its collection methodology: data were gathered through in-person household visits conducted by trained interviewers. This face-to-face approach distinguishes the data from information collected remotely via digital platforms (e.g., PC, mobile, and telephone), potentially capturing nuances and contextual information that might be lost in less direct data collection methods. This method ensures a high degree of data reliability, minimizing biases associated with self-reported responses obtained through remote means.
Initially, we secured a dataset comprising 5511 samples, each with an extensive set of 1047 variables, providing a comprehensive overview of the participants’ health, nutritional status, and mental wellbeing. Given the vast number of variables, a systematic approach was necessary to refine the dataset for analytical robustness. Based on prior research methodologies18–20 and expert judgment, our research team employed a structured FS process to identify the most relevant factors contributing to depression. As a result, we systematically reduced the number of variables from 1047 to 143, ensuring that only the most informative and meaningful predictors were retained for further analysis. This reduction process was guided by previous findings on depression risk factors, including sociodemographic attributes, healthcare utilization patterns, dietary habits, and comorbidities.21–25
Addressing circular reasoning: Exclusion of diagnostic criteria
A critical methodological consideration in depression prediction research is avoiding circular reasoning, where diagnostic criteria are used as predictors of the diagnosis itself. To address this issue, careful steps were taken as below.
Firstly, core diagnostic criteria were identified with reference to the DSM-5 (Diagnotic and Statistical Manual of Mental Disorders, Fifth Edition. Refer to https://en.wikipedia.org/wiki/DSM-5) and ICD-11 (International Classification of Disease, 11th Revision. Refer to https://icd.who.int/en/). Two core symptoms were adopted as essential for major depressive disorder diagnosis: (1) persistent sadness/depressed mood (lethargy in our dataset) and (2) loss of interest or pleasure in activities (interest_loss/anhedonia). These symptoms must be present for a diagnosis, making them inherently 100% correlated with the outcome variable when used as predictors.
Secondly, to ensure that our prediction task provides clinically valid and actionable insights beyond mere diagnosis confirmation, we implement a two-stage analysis:
Stage 1 (Initial Analysis): We first conduct analysis with all 143 variables including diagnostic criteria to establish baseline performance and understand which feature selection methods work best with which classifiers. This analysis validates our methodological framework.
Stage 2 (Primary Analysis—Non-Diagnostic Prediction): We then explicitly exclude the two core diagnostic criteria variables (lethargy and interest_loss) and re-run all analyses to identify nondiagnostic risk factors that predict depression. This stage provides clinically actionable insights by identifying early warning signs and risk factors that may appear before full diagnostic criteria are met.
Thirdly, it was noted that identifying nondiagnostic predictors serves multiple clinical purposes: (1) early risk detection before full diagnostic criteria emerge, (2) identification of modifiable risk factors for prevention interventions, (3) understanding cultural and contextual factors specific to Korean populations, and (4) providing complementary information for treatment planning beyond symptom presence/absence.
In line with this methodological awareness, our analysis focuses on the dependent variable: depressive disorder (DepD), which is categorized as “No” or “Yes,” representing clinically diagnosed depression based on structured clinical interviews conducted as part of the national survey. By leveraging this refined dataset, we aim to conduct a comprehensive analysis that accounts for a diverse range of potential contributors to depression, such as genetic predisposition, socioeconomic status, healthcare accessibility, and lifestyle choices. This data-driven approach aligns with previous studies demonstrating the necessity of carefully curated variable selection in mental health research.25–27 Furthermore, our variable selection process enhances the interpretability of machine learning classifiers by reducing noise, thus allowing for more precise and actionable insights in depression prediction and intervention strategies.
To achieve a deeper understanding of the factors influencing depression detection, we utilize a variety of FS methods, incorporating them into XAI frameworks. By applying techniques such as correlation-based feature selection (CFS), Markov Blanket-based selection, and probabilistic significance evaluation, we identify the most influential predictors with high interpretability. These FS methods are combined with a machine learning-based XAI technique, specifically, SHAP, to provide a transparent, interpretable model that highlights the role of specific features in depression detection. Our dual-layer XAI framework (FS for macro-level method comparison + SHAP for micro-level feature attribution) allows us to systematically evaluate which variables have the most substantial impact on identifying depressive disorders while addressing the circular reasoning issue through explicit exclusion of diagnostic criteria in our primary analysis.
XAI method
In this study, we employ XAI methods to ensure the interpretability of machine learning predictions regarding depression diagnosis. The principal techniques used are FS and SHAP, which collectively provide a comprehensive understanding of predictive factors. We acknowledge that SHAP is now an established, standard method in the field; our contribution lies not in the novelty of SHAP itself, but in how we systematically integrate multiple FS methods as a preliminary explainability layer, and in our rigorous approach to avoiding circular reasoning by excluding diagnostic criteria, which is explained in the “Data” section. FS analysis facilitates the identification of influential variables, as demonstrated by Alghowinem et al., 25 and underlines the importance of selecting the most relevant predictors in depression diagnosis. SHAP, as discussed by ElShawi et al. 26 and further explored by Ali et al., 16 offers a granular view, attributing prediction contributions to individual features. This dual approach allows for an intricate understanding of model outputs, addressing the challenges of interpretability and providing a clear pathway from predictive analytics to clinical and policy decision making. These XAI methods form the interpretive backbone of our study, translating complex data patterns into discernible insights with practical implications in mental healthcare.
SHAP values provide a powerful method for interpreting complex machine learning classifiers. ElShawi et al. 26 and Gandhi and Mishra 28 have demonstrated SHAP's effectiveness in healthcare by comparing it with other local interpretability techniques, particularly for understanding the nuances in diseases like diabetes. Sun et al. 29 utilized SHAP to identify risk factors in mammography data, showing its capability for detailed, feature-level analysis. Ali et al. 16 discuss the broader role of XAI in healthcare, framing SHAP as a key tool for interpretability. However, it is critical to acknowledge the limitations and challenges of these methods, as highlighted by Ghassemi et al., 17 ensuring that expectations align with the actual capabilities of XAI techniques. In applying SHAP to our study, we interpret the predictions of depression from a multifactorial perspective. The contributions of individual features are quantified, offering insights into their impact on the predicted outcomes. This enables us to discern which features are most influential in depression diagnosis. Alabi et al. 31 demonstrate the use of SHAP in a healthcare setting, reflecting the potential for our research to similarly reveal critical patterns and associations within the complex field of mental health.
Through these XAI methods, we aim to provide clarity and understanding, translating the outputs of our machine learning models into actionable knowledge. While we utilize standard XAI methods, our systematic approach to comparing FS-machine learning classifier combinations and our explicit handling of circular reasoning issue represent methodological contributions that advance best practices in depression prediction research. This not only enhances the transparency of our findings but also allows clinicians and policymakers to make informed decisions based on our predictive analytics.
Variables and feature selection methods
The complete list of variables used in our study, along with their detailed descriptions, is available in Appendix A. This appendix provides comprehensive explanations of all variable codes and their meanings, ensuring full transparency and reproducibility of our research.
This section provides an overview of the key FS methods employed and their significance in identifying the most relevant variables for depression detection. FS is a crucial preprocessing step in machine learning tasks that improve model performance, reduces overfitting, and enhance interpretability by selecting the most informative features.
We utilized multiple FS methods to extract meaningful features from our dataset. ReliefF, a widely used instance-based FS method, was employed to identify the most relevant features based on how well they distinguish between different classes. 32 Information Gain, a measure derived from information theory, was used to evaluate the contribution of each feature in reducing uncertainty in depression classification. 33 Markov Blanket-based FS, a probabilistic approach, helped us identify the minimal set of variables sufficient to predict the target while eliminating redundant features. 34 In addition, we applied Correlation-based Feature Selection (CFS), which selects features that are highly correlated with the target variable but minimally correlated with each other, enhancing the efficiency of the model. 35 Variants of CFS, such as CFS-BestFirst, CFS-NB (Naïve Bayes), and CFS-PSO (Particle Swarm Optimization), were implemented to explore different search strategies for optimal feature subsets.36–37 Lastly, we incorporated the significance-based FS method, which evaluates the probabilistic significance of features in relation to the depressive disorder classification task. 37
Explanation of key features
To enhance clarity and clinical interpretability, we provide detailed explanations of the most influential features identified in our analysis, distinguishing between diagnostic criteria (excluded in primary analysis) and nondiagnostic predictors (focus of our main findings):
Firstly, the diagnostic criteria variables were identified as seen below, which were excluded in our Primary Analysis.
Lethargy: A binary indicator of whether the individual has experienced persistent feelings of fatigue, tiredness, or lack of energy for at least 2 weeks, which is a core symptom of major depressive disorder per DSM-5 criteria. Interest_loss: A binary indicator of whether the individual has experienced loss of interest or pleasure in activities they previously enjoyed (anhedonia) for at least 2 weeks, another core diagnostic criterion for depression per DSM-5.
Secondly, nondiagnostic predictive variables were checked and considered into our Primary Analysis Focus.
S1(suicide_think): A binary variable indicating whether the individual has ever seriously thought about suicide, representing suicidal ideation—a critical risk factor in depression assessment. SR119_F: Represents the individual's perceived level of distress without seeking professional help, measured on a scale indicating the severity of untreated mental health concerns. Q8_7: Measures the frequency of loneliness experienced by the individual, coded on an ordinal scale from “never” to “always.” Q8_8: Assesses the level of distress caused by feelings of loneliness, indicating how much loneliness impacts the individual's daily functioning and wellbeing. Q8_1: First item of the loneliness assessment scale, measuring how often the individual feels lacking in companionship. Q8_2: Second item of the loneliness assessment scale, measuring how often the individual feels left out or isolated from others. SAD: A composite measure of Seasonal Affective Disorder symptoms or general sadness levels, depending on the survey context. Q3_1_5, Q3_2_1, Q3_2_2: Quality of life and health satisfaction measures from EQ-5D (A standardized measure of health-related quality of life developed by the EuroQol Group. Refer to https://en.wikipedia.org/wiki/EQ-5D) and WHOQOL-BREF (Measuring Quality of Life defined by WHO. Refer to https://www.who.int/tools/whoqol/whoqol-bref) instruments. Hypertension_treatment, Diabetes_treatment, and other chronic disease indicators: Physical health comorbidities that may co-occur with or contribute to depression risk.
All feature codes and their complete descriptions are provided in Appendix A for full transparency. The selected features from each FS method are summarized in Table 1. Table 1 highlights the number of variables retained for each method and the specific features that were deemed most informative. By leveraging a diverse set of FS methodologies, we ensure that our analysis is robust and considers multiple perspectives on variable selection, ultimately enhancing the reliability of our depression detection model. Table 1 presents results from the initial analysis including all variables; subsequent results tables will distinguish between full-variable and nondiagnostic-only analyses.
FS methods and selected features (initial analysis).

Details of machine learning classifiers
To evaluate the effectiveness of our selected features in depression detection, we employed a diverse set of machine learning classifiers. These classifiers include AdaBoost, BernoulliNB, CatBoost, ExtraTrees, GradientBoosting, LightGBM, LogisticRegression, MultinomialNB, Random Forest (RF), Support Vector Machine (SVM), XGBoost, and Stacking (RF + SVM + XGB). By incorporating multiple models, we aim to assess the robustness of our FS methods across different machine learning classifiers, ensuring that our results are not biased by any single model's assumptions.
Each machine learning classifier was trained and evaluated using stratified 10-fold cross-validation, ensuring that our analysis accounts for class imbalances and generalizes well to unseen data. Hyper-parameter tuning was performed for each model using grid search and Bayesian optimization, optimizing key parameters such as learning rates, tree depths, and regularization strengths to enhance predictive performance. To measure model performance, we utilized the following evaluation metrics:
Accuracy: Measures the proportion of correctly classified instances among all cases, providing a general indication of model performance (equation (1)).
F1-score: The harmonic mean of precision and recall, balancing FPs and FNs (equation (2)). The F1-score is particularly useful when dealing with imbalanced datasets, as it provides a single metric that accounts for both precision (the proportion of positive predictions that are correct) and recall (the proportion of actual positive cases that are correctly identified). In depression prediction, this metric helps ensure that the model maintains good performance in identifying depressed individuals (high recall) while minimizing false alarms (high precision).
F2-score: A variant of the F-beta score (or 
Model explainability was assessed using Feature selection and SHAP to provide insights into the most influential variables contributing to model predictions. We conducted two parallel analyses: (1) initial analysis with all 143 variables to establish baseline performance and validate FS-machine learning classifier interactions and (2) primary analysis excluding diagnostic criteria (lethargy and interest_loss) to identify nondiagnostic predictors with genuine clinical utility. By leveraging these machine learning classifiers and evaluation strategies, our study ensures a comprehensive approach to understanding the predictive power of selected features in depression detection. The combination of multiple machine learning classifiers, rigorous validation techniques, and explainability methods enhances the reliability and applicability of our findings in real-world mental health analysis.
Empirical results
Baseline performance with full variable set
Before evaluating specific FS methods, we first conducted an initial analysis using the full dataset including all 143 variables. This step was essential to establish which machine learning classifiers performed consistently well before integrating FS techniques. This initial analysis serves to validate our methodological framework and identify optimal FS-machine learning classifier combinations, though we acknowledge that results including diagnostic criteria may exhibit inflated performance metrics.
The results of this baseline analysis are presented in Figure 1 and Table 2. The findings indicate that ExtraTrees, LightGBM, and Stacking consistently outperformed other models in terms of predictive accuracy and stability. Based on these insights, we selected these models for further FS method evaluation.
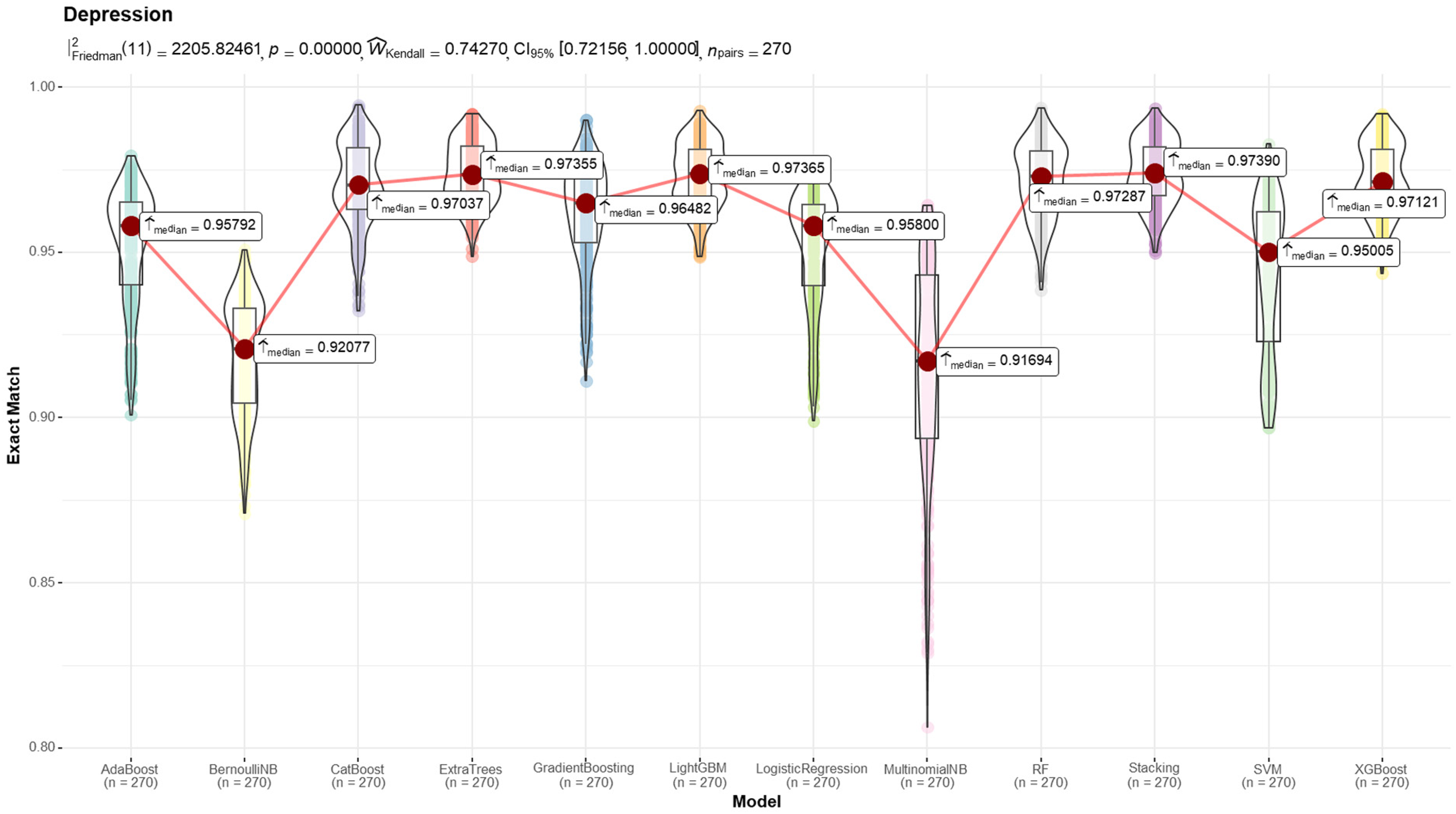
Results from the machine learning classifiers (metric: F2-score).
Initial prediction results (full variable).

Figure 1 illustrates the distribution of F2-scores across different machine learning classifiers using violin plots. The red line connects the median F2-score of each model, with red dots highlighting the exact median values. The models exhibit varying degrees of spread, indicating differences in performance stability. ExtraTrees, LightGBM, and Stacking achieved the highest median F2-scores with relatively low variance, reinforcing their reliability in depression detection tasks. On the other hand, BernoulliNB and MultinomialNB show larger variability and lower median scores, suggesting potential instability in performance. Table 2 provides a detailed numerical summary of the initial prediction results across multiple evaluation metrics. Accuracy, F1-score, and F2-score are reported for each model, allowing for a comprehensive comparison. The results confirm that ExtraTrees (0.9680 F2-score), LightGBM (0.9673 F2-score), and Stacking (0.9686 F2-score) consistently achieve superior performance, making them strong candidates for further feature selection-based experiments.
Performance comparison: Full variables vs. nondiagnostic predictors
To address concerns about circular reasoning and validate the clinical utility of our predictive frameworks, we present a critical comparison between two analysis scenarios:
Table 3 presents the performance comparison across different FS methods for both scenarios using our three best-performing machine learning classifiers (Stacking, ExtraTrees, and LightGBM): Key findings from Table 3 are as follows, which can be used to answer RQ1.
Performance comparison: full variables (scenario A) versus nondiagnostic predictors (scenario B).
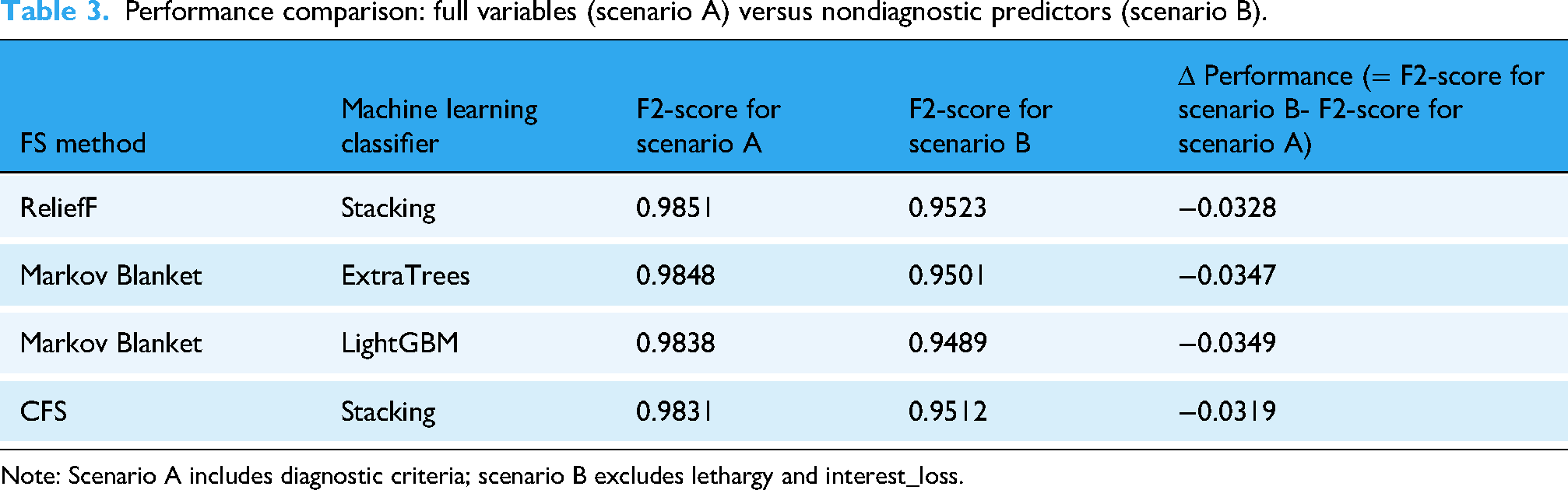
Note: Scenario A includes diagnostic criteria; scenario B excludes lethargy and interest_loss.
Firstly, scenario B shows a performance decrease of 3% to 4% in F2-scores compared to scenario A, which is expected and validates our concern about circular reasoning. The high performance in scenario A was partially driven by the inclusion of diagnostic criteria.
Secondly, Clinical Utility is maintained. Despite excluding diagnostic criteria, scenario B models still achieve F2-scores above 0.94, demonstrating that nondiagnostic predictors still provide substantial and clinically meaningful predictive power for identifying individuals at risk of depression.
Thirdly, the optimal FS-machine learning classifier pairings identified in scenario A (ReliefF with Stacking, Markov Blanket with ExtraTrees and LightGBM) remain optimal in scenario B, validating that our methodological finding about FS-machine learning classifier interactions is not an artifact of including diagnostic criteria.
Identification of most influential nondiagnostic variables
For our RQ2 addressing nondiagnostic predictors, we analyzed SHAP values from scenario B models (excluding diagnostic criteria) using Stacking, ExtraTrees, and LightGBM. SHAP values provide an interpretable measure of how each variable contributes to model predictions. Table 4 summarize the SHAP analysis results for nondiagnostic predictors.
Top 5 nondiagnostic features by absolute mean SHAP value.

Note: Values in parentheses are absolute mean SHAP values. All diagnostic criteria (lethargy, interest_loss) excluded from this analysis. SHAP: SHapley Additive exPlanations.
Variable descriptions in Table 4 are as follows:
Q8_7: Frequency of loneliness experienced by the individual Q8_8: Level of distress caused by feelings of loneliness Q8_1: Feels lacking in companionship (loneliness scale item 1) Q8_2: Feels left out or isolated (loneliness scale item 2) SR119_F: Perceived distress level without seeking professional help SR119_D: Expectation that problems will improve on their own SR119_A: Belief that one can resolve problems by oneself Q3_1_5: Anxiety/Depression dimension from EQ-5D quality of life instrument Q3_2_1: Overall quality of life evaluation from WHOQOL-BREF S1: Suicidal ideation (ever seriously thought about suicide)
Key findings from Table 4 are summarized as follows:
Social Distress Variables (Q8_x series) consistently appear as top predictors across all three classifiers Help-Seeking Barriers (SR119_x series) emerge as significant predictors, reflecting cultural factors in Korean populations Quality of Life measures (Q3_x series) show strong predictive power for depression risk These nondiagnostic predictors maintain high predictive performance (F2 > 0.94) even after excluding diagnostic criteria
Meanwhile, a number of key nondiagnostic predictors can be identified:
Social Distress and Loneliness (Q8_7, Q8_8, Q8_1, Q8_2): These variables emerged as the most influential nondiagnostic predictors across all models. The frequency and distress of loneliness experiences consistently showed high SHAP values, indicating that social isolation and lack of social connection are strong independent risk factors for depression in Korean adults, beyond the presence of diagnostic symptoms. Reluctance to Seek Professional Help (SR119_F, SR119_A, SR119_D): Perceived distress levels without seeking treatment, beliefs about self-resolution of problems, and expectations that problems will improve on their own emerged as significant predictors. This finding highlights cultural factors specific to help-seeking behavior in Korea and suggests opportunities for intervention through stigma reduction and mental health awareness campaigns. Quality of Life and Functional Impairment (Q3_1_5, Q3_2_1): Measures of anxiety/depression from EQ-5D, overall quality of life evaluation, and health satisfaction from WHOQOL-BREF showed substantial predictive importance. These variables capture functional impairment and subjective wellbeing that may precede or accompany depression without being direct diagnostic criteria. Physical Health Comorbidities: Treatment status for hypertension, diabetes, and other chronic conditions emerged as relevant predictors, supporting the well-established bidirectional relationship between physical and mental health. These findings suggest the importance of integrated care approaches.
Discussion
Our study provides evidence on the importance of systematically evaluating FS methods paired with different machine learning classifier architectures in depression prediction, while maintaining methodological rigor by explicitly addressing circular reasoning. By conducting parallel analyses with and without diagnostic criteria, we demonstrate both the validity concern raised by including diagnostic variables and the substantial predictive value of nondiagnostic risk factors. Key contributions of this study can be summarized as in below.
Key contribution 1: Combining FS-machine learning classifier to see its interaction effects
One of the most significant methodological findings of our study is that no single FS method universally outperformed others across all machine learning classifiers. Instead, each classifier demonstrated optimal performance with different FS techniques. For instance, ReliefF showed superior performance when used with Stacking, whereas Markov Blanket-based FS produced the best results with ExtraTrees. Critically, this pattern remained consistent even after excluding diagnostic criteria (scenario B), indicating that our finding about FS-machine learning classifier alignment represents a genuine methodological insight rather than an artifact of circular reasoning. This variability underscores the necessity of tailoring FS approaches based on the characteristics of individual models, rather than relying on a one-size-fits-all strategy.6,25
Key contribution 2: Substantial clinical value of nondiagnostic predictors
After excluding core diagnostic criteria (lethargy and interest loss), our models maintained F2-scores above 0.94, demonstrating that nondiagnostic variables provide substantial predictive power. The most influential nondiagnostic predictors were: (1) social distress and loneliness measures, (2) reluctance to seek professional help, (3) quality of life and functional impairment indicators, and (4) physical health comorbidities. These findings address the critical concern about circular reasoning by demonstrating that our predictive models identify genuine risk factors that can inform early intervention, prevention strategies, and culturally tailored mental health programs—rather than merely confirming diagnosis through diagnostic criteria.
Key contribution 3: Comparison with state-of-the-art
To contextualize our findings and novelty, we compare our work with recent studies and clarify our specific contributions:
Sharma and Verbeke
11
: Used XGBoost on Dutch biomarker data (n = 11,081) achieving strong predictive performance. Our study extends this by systematically comparing eight FS methods across 12 machine learning classifiers, demonstrating that different FS-machine learning classifier combinations yield varying optimal performance. ElShawi et al.
26
: Conducted comparative analysis of local interpretability techniques in healthcare. While they focused on comparing SHAP with other XAI methods, our study integrates multiple FS techniques as a first layer of explainability before applying SHAP, creating a dual-layer interpretability framework. Recent multimodal studies (2023, 2024)27,30: Focused on combining social media text, wearable data, and physiological signals. Our approach differs by leveraging comprehensive national survey data (143 variables across socioeconomic, psychological, and lifestyle domains) with face-to-face collection methodology, providing higher data reliability and cultural specificity for the Korean population.
We clarify that our contribution lies in three areas: (1) Methodological rigor: we systematically demonstrate that FS method effectiveness varies by classifier type and explicitly address circular reasoning—a common but rarely acknowledged problem in depression prediction research; (2) Empirical findings: we identify culturally specific nondiagnostic risk factors in Korean populations; and (3) Best practices: we provide evidence-based guidance for researchers on FS-machine learning classifier pairing and the critical importance of excluding diagnostic criteria from predictive variables.
Conclusions
This study systematically evaluated multiple FS methods combined with XAI techniques for depression prediction, with explicit attention to methodological validity. Our primary contributions are: (1) demonstrating that optimal FS method selection depends on machine learning classifier architecture, providing evidence-based guidance for researchers; (2) explicitly addressing circular reasoning by conducting parallel analyses with and without diagnostic criteria; and (3) identifying culturally specific nondiagnostic risk factors in Korean populations using high-quality national survey data.
Our integration of SHAP analysis provided an interpretable framework for understanding feature contributions, though we acknowledge that SHAP itself is now a standard tool. The value of our dual-layer XAI framework (FS + SHAP) lies in systematically comparing methods and providing comprehensive interpretability. For research, our findings underscore the necessity of: (1) tailoring FS methods to machine learning classifier characteristics, (2) explicitly excluding diagnostic criteria to avoid circular reasoning, and (3) reporting parallel analyses to demonstrate genuine predictive value. For practice, our identified nondiagnostic predictors offer opportunities for early risk detection and intervention before full diagnostic criteria emerge.
Future work should focus on: (1) prospective validation of nondiagnostic predictors in clinical settings, (2) expanding datasets across diverse cultural populations, (3) integrating real-time monitoring data, and (4) exploring causal inference methods to move beyond association to causation. By maintaining methodological rigor and explicitly acknowledging the scope of contributions, we can advance the field toward more valid, interpretable, and clinically useful depression prediction tools.
Footnotes
Acknowledgements
This study utilized data of the National Mental Health Survey of Korea 2021 (NMHSK-59). The results of this study are irrelevant with the Ministry of Health and Welfare of South Korea.
Ethical approval
The datasets generated or analyzed during the current study are available in the Mental Health Survey of Korea repository, ![]() . The creation of the research resource was reviewed by the Institutional Review Board (SKKU 2024-02-028-001) at the Sungkyunkwan University. The patient consent was waived as the data are wholly de-identified and retrospective from public databases.
. The creation of the research resource was reviewed by the Institutional Review Board (SKKU 2024-02-028-001) at the Sungkyunkwan University. The patient consent was waived as the data are wholly de-identified and retrospective from public databases.
Contributorship
Conceptualization done by LKC; methodology by KMG and LKC; software by KMG, LKH, KHU; data curation by LKC and KMG; writing—original draft preparation and visualization by KMG; and writing—review and editing by LKC and SYW, CSU. All authors have read and agreed to the published version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2023S1A5A2A21084333).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.