
Abstract
Background
In recent years, potential applications of ChatGPT in medication-related practices have drawn great attention for its intuitive user interfaces, chatbot, and powerful analytical capabilities. However, whether ChatGPT can be broadly applied in clinical practice remains controversial. Early screening, monitoring, and timely treatment are crucial for improving outcomes of interstitial lung disease (ILD) in systemic autoimmune rheumatic diseases (SARDs) due to its high morbidity and mortality rate. This study aimed to evaluate the reliability, repeatability, and confidence of ChatGPT models (GPT-4, GPT-4o mini, and GPT-4o) in delivering guideline-based recommendations for the screening, monitoring, and treatment of ILD in SARD patients.
Methods
Questions derived from the ACR/CHEST guideline for ILD patients with SARDs were used to benchmark three versions of ChatGPT (GPT-4, GPT-4o mini, and GPT-4o) across three separate attempts. The responses were recorded, and the reliability, repeatability, and confidence were analyzed with the recommendations from the guideline.
Results
GPT-4 demonstrated significant variability in reliability across the three attempts (P = .007). In contrast, the other versions showed no significant differences. GPT-4 and GPT-4o mini exhibited substantial interrater agreement (Kendall's W = 0.747 and 0.765, respectively), whereas GPT-4o demonstrated almost perfect interrater agreement (Kendall's W = 0.816). All three versions showed statistically significant differences in high confidence ratings (confidence score of ≥ 8 on the 1–10 scale) across the three attempts (P < .01). Given the higher consistency of GPT-4o and GPT-4o mini, a further comparison was conducted between them on the third attempt. No significant difference was observed in accuracy percentages across the third attempt between GPT-4o and GPT-4o mini (P = .597). Similarly, interrater agreement across the three attempts was not significantly different for both GPT-4o and GPT-4o mini (P = .152). Furthermore, the overconfidence percentage (confidence score of ≥8 assigned to incorrect answers) was 100% (22 of 22) for GPT-4o and 22.7% (10 of 44) for GPT-4o mini, respectively (P < .01).
Conclusions
GPT-4o mini and GPT-4o demonstrated stable reliability across all three attempts, whereas GPT-4 did not. The repeatability of GPT-4o tended to perform better than GPT-4o mini, although this difference was not statistically significant. Additionally, GPT-4o exhibited a higher tendency toward overconfidence compared to GPT-4o mini. Overall, the GPT-4o models performed most effectively in managing SARD-ILD but may exhibit overconfidence in certain scenarios.
Introduction
In recent years, artificial intelligence (AI) has been widely applied in the medical field, encompassing technologies such as image processing, computer vision, artificial neural networks, machine learning, convolutional neural networks, and deep learning. 1 These technologies have facilitated advancements in disease severity assessment,2,3 diagnosis, 4 treatment,5,6 pharmacological research 7 and other areas. The emergence of large language models (LLMs), such as ChatGPT, has further accelerated this trend due to their intuitive user interfaces and chatbot functionalities. 8 Some researchers have explored the potential applications of these models in medication-related practices, including data mining of free-text CT reports on lung cancer, assisting Japanese medical licensing examinations, and supporting neurosurgery written board examinations.9–11 However, whether ChatGPT can be widely applied in clinical practice remains controversial.
Systemic autoimmune rheumatic diseases (SARDs) refer to a broad spectrum of clinical conditions caused by autoimmune dysregulation and inflammatory responses. These diseases result in damage to joints, connective tissues, skin, blood elements, and other target organs. Historically, SARDs have also been referred to as connective tissue diseases (CTDs) or collagen vascular diseases. The prevalence of interstitial lung disease (ILD) varies across different SARD subtypes: 63% in systemic sclerosis (SSc), 12 58% in rheumatoid arthritis (RA), 13 19.9%–86% in inflammatory myositis (IIM), 14 16% in Sjögren's syndrome (SS), 15 and 52% in mixed connective tissue disease (MCTD). 16 Patients with CTD-ILD showing decreased FVC and/or DLCO and fibrotic signs on high-resolution computed tomography (HRCT). These patients have a worse prognosis than those with CTD alone. 17 Among patients diagnosed with RA, the 10-year mortality rate was significantly higher in those with ILD compared to those without ILD, at 60.1% versus 34.5%. 18 Given the high prevalence and impact of ILD in SARDs, early screening, monitoring, and timely treatment are crucial for improving outcomes.
This study aims to evaluate the reliability, repeatability, and confidence of ChatGPT models (GPT-4, GPT-4o mini, and GPT-4o) in delivering guideline-based recommendations19,20 for the screening, monitoring, and treatment of ILD in SARD patients.
Materials and methods
Three versions of ChatGPT: ChatGPT-4o (version release since May 2024), ChatGPT-4o mini (version release since July 2024), and ChatGPT-4 (version release since November 2023) were selected for investigation. Questions derived from the 2023 American College of Rheumatology (ACR)/American College of Chest Physicians (CHEST) guideline for ILD patients with SARDs were used to benchmark three versions of ChatGPT across three separate attempts. The responses were recorded, and the reliability, repeatability, and confidence were analyzed. The search flow diagram illustrating our study is presented in Figure 1.

The flowchart of this study consists of four sequential sections: “Question Selection and Classification,” “ChatGPT Prompting,” “Data Collection (ChatGPT Responses),” and “Statistical Analysis.”
Questions selection and classification
A total of 103 questions were extracted from the 2023 ACR/CHEST Guideline19,20 for ILD in patients with SARDs by two pulmonologists (CJX and XQ), and all questions were independently validated by pulmonary specialists (RYZ and YHW). Disagreements between the above investigators were settled by arbitration of the principal investigator (Minjie Lin and Yingwei Zhang). These questions were divided into two subgroups: “Screening and Monitoring” and “Treatment.” In this study, the reliability, repeatability, and confidence of all questions were evaluated across the three attempts. The questions and corresponding answers generated by ChatGPT are presented in Supplemental Material 1.
ChatGPT prompting
We used three versions of ChatGPT (GPT-4, GPT-4o mini, and GPT-4o) across three separate attempts at three distinct time points (15 August 2024, 17 August 2024, and 18 August 2024, respectively), and the responses were recorded. Prior to inputting our questions, we provided prompts to guide the models to act as specialists and determine which information should be fed back. The specific prompts and questions are provided in Supplemental Material 2, and a sample is illustrated in Figure 2.

We selected a sample question and conducted three inquiries in three GPT models, comparing the results with the recommendations provided in the guideline.
Statistical analysis
In this study, reliability was defined as accuracy over time; accuracy was the alignment rate between the provided answers and the guideline recommendations. Repeatability is defined as agreement over time, and confidence is a rating from 1 to 10. A confidence score ≥ 8 on the 1–10 scale was defined as “high confidence.” Overconfidence was defined as a confidence score ≥8 assigned to incorrect answers.
To assess the reliability of accuracy, overall performance across all three attempts for each model was compared using the Cochran Q test. To evaluate repeatability, inter-rater agreement among answers was analyzed using the Kendall W coefficient of concordance (KW). The KW ranges from 0 to 1, with values of 0.00–0.20 indicating slight agreement, 0.21–0.40 fair agreement, 0.41–0.60 moderate agreement, 0.61–0.80 substantial agreement, and > 0.80 almost perfect agreement. 21 The reliability, repeatability, and confidence between GPT-4o mini and GPT-4o were compared using the McNemar test. All statistical analyses were conducted using statistical software (SPSS, Version 19.0). P-value < .05 indicated statistical significance.
Results
Summary of the comparative analysis of GPT-4, GPT-4o mini, and GPT-4o is shown in Table 1 and Figures 3 and 4.

(a–c) Summary of results for GPT-4, GPT-4o mini, and GPT-4o (attempts 1–3 are shown from left to right). (d–f) For the subgroup of screening and monitoring (questions 1–21), a summary of results for GPT-4, GPT-4o mini, and GPT-4o (attempts 1–3 are shown from left to right). (h–i) For the subgroup of treatment (questions 22–103), summary of results for GPT-4, GPT-4o mini, and GPT-4o (attempts 1–3 are shown from left to right).

The accuracy, repeatability, and overconfidence percentages between GPT-4o and GPT-4o mini were compared on the third attempt.
Summary of the comparative analysis of GPT-4, GPT-4o mini, and GPT-4o.
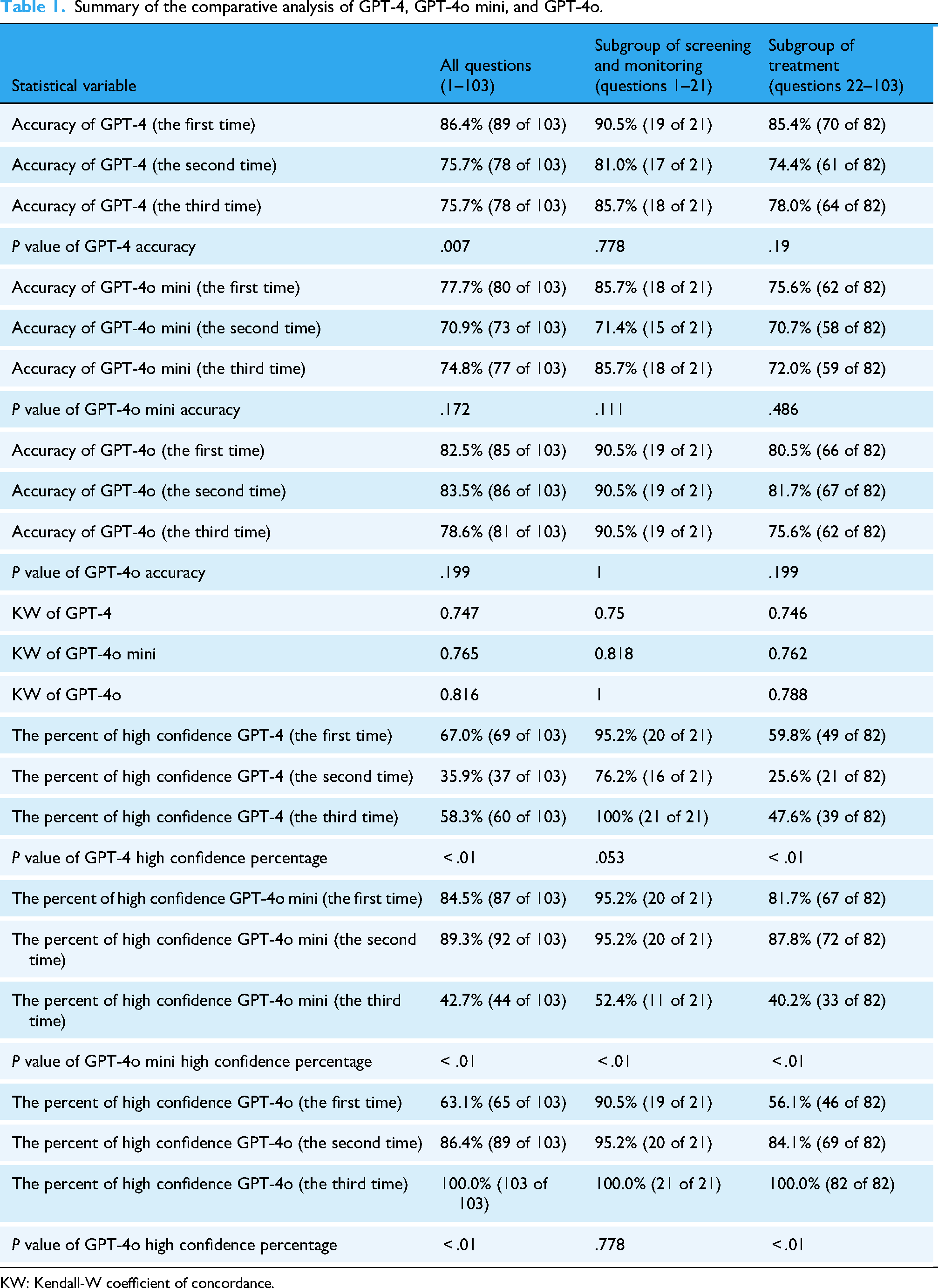
KW: Kendall-W coefficient of concordance.
Reliability
GPT-4 demonstrated unstable reliability across the three attempts, with accuracy rates of 86.4%, 75.7%, and 79.6%, respectively (P = .007). In contrast, GPT-4o mini showed no significant difference, with accuracies of 77.7%, 70.9%, and 74.8%, respectively (P = .172). Similarly, GPT-4o exhibited consistent performance, with accuracies of 82.5%, 83.5%, and 78.6%, respectively (P = .199).
Repeatability
GPT-4 and GPT-4o mini demonstrated substantial interrater agreement, with KW of 0.747 and 0.765, respectively. GPT-4o achieved almost perfect interrater agreement (KW = 0.816). The percentage of repeatable answers across the three attempts was 87.3% for GPT-4o, 81.6% for GPT-4o mini, and 79.6% for GPT-4.
Confidence
All three versions exhibited statistically significant differences in “high confidence” ratings across the three attempts. For GPT-4, high confidence ratings were 67.0%, 35.9%, and 58.3%, respectively, (P < .01). For GPT-4o mini, high confidence ratings were 84.5%, 89.3%, and 42.7%, respectively, (P < .01). For GPT-4o, high confidence ratings were 63.1%, 86.4%, and 100.0%, respectively, (P < .01).
Comparison of GPT-4o and GPT-4o mini
Given that GPT-4 exhibited variability in accuracy across the three attempts, whereas GPT-4o and GPT-4o mini were more reliable, we compared their reliability, repeatability, and overconfidence percentages. No significant difference was observed in accuracy percentages between GPT-4o and GPT-4o mini across the three attempts (P = .597). Similarly, interrater agreement rate did not differ significantly for either version (P = .152). However, the overconfidence percentage differed significantly: GPT-4o exhibited 100% overconfidence (22 of 22), while GPT-4o mini exhibited only 22.7% overconfidence (10 of 44) (P < .01).
Subgroup screening and monitoring (questions 1–21)
For the subgroup screening and monitoring, GPT-4 demonstrated accuracies of 90.5%, 81.0%, and 85.7% across the three attempts (P = .778). GPT-4o mini showed accuracies of 85.7%, 71.4%, and 85.7%, respectively, (P = .111). GPT-4o maintained consistent accuracy at 90.5% across all three attempts (P = 1). GPT-4 exhibited substantial interrater agreement (KW = 0.750), while GPT-4o mini and GPT-4o achieved almost perfect interrater agreement (KW = 0.818 and KW = 1, respectively). According to high confidence ratings across the three attempts: GPT-4 had ratings of 95.2%, 76.2%, and 100% (P = .053); GPT-4o mini had ratings of 95.2%, 95.2%, and 52.4% (P < .01); GPT-4o had ratings of 90.5%, 95.2%, and 100.0%, respectively (P = .778).
Subgroup treatment (questions 22–103)
For the treatment subgroup, GPT-4 demonstrated accuracies of 85.4%, 74.4%, and 78.0% across the three attempts (P = .19). GPT-4o mini showed accuracies of 75.6%, 70.7%, and 72.0%, respectively (P = .486). GPT-4o exhibited accuracies of 80.5%, 81.7%, and 75.6%, respectively (P = .199). All three versions demonstrated substantial interrater agreement, with KW of 0.746, 0.762, and 0.788 for GPT-4, GPT-4o mini, and GPT-4o, respectively. High confidence ratings varied significantly across the three attempts: GPT-4 had ratings of 59.8%, 25.6%, and 47.6% (P < .01); GPT-4o mini had ratings of 81.7%, 87.8%, and 40.2% (P < .01); and GPT-4o had ratings of 56.1%, 84.1%, and 100.0%, respectively (P < .01).
Discussion
This study evaluated the reliability, repeatability, and confidence of ChatGPT, including GPT-4, GPT-4o mini, and GPT-4o. Overall, GPT-4o mini and GPT-4o demonstrated higher reliability than GPT-4. GPT-4o achieved almost perfect interrater agreement (KW = 0.816), while GPT-4o mini showed substantial interrater agreement (KW = 0.765), although no statistically significant difference was observed. Additionally, GPT-4o tended to exhibit greater overconfidence compared to GPT-4o mini. Subgroup analysis revealed that all versions of ChatGPT, including GPT-4, GPT-4o mini, and GPT-4o, remained repeatability in both screening/monitoring and treatment, with substantial interrater agreement (KW ≥ 0.7) at least. Furthermore, all versions demonstrated inconsistent performance in confidence across treatment-related tasks, while within the subgroup of screening and monitoring tasks, only the GPT-4o mini version exhibited instability.
SARDs encompass conditions such as RA, SSc, IIM, MCTD, and SjD, 22 which are most likely to develop into SARD-ILD, which remains underdiagnosed and undertreated. 23 Therefore, guidelines developed using a multidisciplinary approach represent the first authoritative resource for managing SARD-ILD.19,20 Based on guideline recommendations, using ChatGPT to answer questions and comparing results to guidelines can effectively evaluate its reliability, repeatability, and confidence. In prior studies, multiple-choice examinations24–26 or questionnaires11,27,28 were commonly used to test ChatGPT, covering topics such as radiology board-style exams, retina-related questions, and gastroesophageal reflux disease. In our study, we generated a questionnaire based on the latest guideline associated with SARD-ILD,19,20 modifying each question according to guideline suggestions.
LLM-based AI applications (LLMAs), particularly ChatGPT, have previously demonstrated their utility in medical examination performance and clinical management. However, the reliability of LLMAs varies across studies. Some researchers have shown that the latest LLMAs achieve high accuracy rates. For example, in text-based questions from six topics of undergraduate endodontic education examinations, the accuracy rate of ChatGPT-4o was 92.8% which was significantly higher than that of ChatGPT-4 (81.7%, P < .001). 29 In evaluating 250 French orthopedic and trauma surgery exam questions (2020–2024), ChatGPT-4o scored similarly to residents over the past 5 years (74.8% vs. 70.8%, P = .32). 30 Despite these findings, some studies suggest that LLMAs can serve as useful assistants in medical management and education, but cannot replace conventional teaching methods at present. For example, in restorative dentistry and endodontics student assessments, ChatGPT-4o had an accuracy of only 72%. 31 In diagnosing oral potentially malignant lesions, GPT-4o had the accuracy of 27/42, which was even higher than GPT-4.0 (20/42), GPT-3.5 (18/42), and Gemini (15/42). 32 In our study, the accuracy rates of three attempts across the three versions of ChatGPT exceeded 70%, indicating that GPT-4, GPT-4o mini, and GPT-4o possess the ability to assist in managing SARD-ILD but cannot replace clinicians’ conventional practices. After three attempts, GPT-4o and GPT-4o mini demonstrated more reliable performance than GPT-4, with no significant difference between GPT-4o and GPT-4o mini (P = .597), although GPT-4o showed higher accuracy rates in each test, consistent with previous studies. Therefore, more advanced LLMAs tools are needed to further improve accuracy in medical management and education.
Repeatability is an essential variable in LLMAs in medical practice. Prior studies have shown unsatisfactory repeatability. For example, in a radiology board-style examination study, 61.3% (92 of 150) and 76.7% (115 of 150) of answer choices were consistent across three attempts for GPT-3.5 and GPT-4. 24 In ophthalmic multimodal image analysis, the overall repeatability of GPT-4V was 63.3% (38/60). 33 In our study, GPT-4 and GPT-4o mini demonstrated substantial interrater agreement (KW = 0.747 and 0.765, respectively), while GPT-4o achieved almost perfect interrater agreement (KW = 0.816). Data on repeatability percentages showed that 87.3% (90 of 103), 81.6% (84 of 103), and 79.6% (82 of 103) of answer choices were consistent across three attempts for GPT-4o, GPT-4o mini, and GPT-4, respectively, suggesting that all three versions of ChatGPT exhibit good repeatability in SARD-ILD management.
The variability of confidence can predict the probability of accuracy. Previous research indicated that ChatGPT tends to be overconfident. For example, in a study involving a medicine-related multiple-choice examination, GPT-3.5 and GPT-4 rated “high confidence” for most initial responses at 100% (150 of 150) and 94.0% (141 of 150), respectively, while their overconfidence percentages were 100% (59 of 59) and 77% (27 of 35), respectively (P = .89). 24 In our study, GPT-4, GPT-4o mini, and GPT-4o were unstable across three attempts for responses. In addition, the overconfidence percent of GPT-4o was 100% (22 of 22) and 22.7% (10 of 44) for GPT-4o mini (P < .01).It should be noted with caution that ChatGPT can answer any question with bold conviction, even when it is incorrect. 34 Moreover, the application has been shown to provide fake references in the past. 35 In the current models, there is no shown to provid process, which is a significant source of AI hallucinations and biases in the training data. It is necessary to understand that its textual expression may contain implicit or explicit biases. Therefore, ChatGPT may have potential beneficial and ethical uses, which lie in fully leveraging its advantages in structure and grammar while avoiding its shortcomings through human supervision and review. 36 Furthermore, in the application of GPT-4o in the medical field, its overconfident nature may bring certain clinical risks. This risk mainly lies in the fact that when answering complex or uncertain medical questions, the model may exhibit an overly high level of confidence, thereby misleading doctors to make incorrect judgments or decisions. This overconfidence sometimes stems from the model's conclusions based on past data rather than reasoning from specific evidence. Due to its smaller scale, GPT-4o-mini may be more cautious or conservative in its reasoning, thus showing a lower level of confidence compared to GPT-4o. Different versions of ChatGPT may have differences in their capabilities due to variations in model size and complexity, training and optimization processes, task handling capabilities, and generation strategies. Therefore, when applying such AI technologies to clinical decision-making support, extra caution is needed, and a comprehensive judgment should be made by integrating professional medical knowledge and practical experience. Reducing unintended hallucinations and improving the accuracy of judgment confidence should be addressed in future developments.
Advantages and limitations
To the best of our knowledge, this is the first study to comprehensively evaluate the reliability, repeatability, and confidence of GPT-4, GPT-4o mini, and GPT-4o in the context of screening, monitoring, and treatment for SARD-ILD. Furthermore, all questions were posed three times at different time points, which enhance the robustness of our conclusions. However, our study has several limitations that should be addressed. First, none of the GPT versions are infallible, despite our prompts request direct and clear responses, a small proportion of the responses may contain ambiguous meanings, which could potentially lead to errors in judgment. Second, while all questions were derived from established guidelines, real-world clinical scenarios may involve more complex situations that were not covered in this study, so our conclusions need external validation and an evaluation of generalizability in future research. Finally, although the evaluators were single-blinded, potential biases could still have been introduced into their assessments, as they are coauthors of the paper and might have had an inherent expectation for significant differences between the groups.
Conclusion
GPT-4o mini and GPT-4o demonstrated stable reliability across all three attempts, whereas GPT-4 did not. The repeatability of GPT-4o tended to be better than that of GPT-4o mini, although this difference was not statistically significant. Additionally, GPT-4o exhibited a higher tendency toward overconfidence compared to GPT-4o mini. Overall, GPT-4o models performed most effectively in managing SARD-ILD but may exhibit overconfidence in certain scenarios.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251384233 - Supplemental material for Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases
Supplemental material, sj-docx-1-dhj-10.1177_20552076251384233 for Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases by Minjie Lin, Chuanjun Xu, Xiang Qu, Biyun Xu, Yanghong Wang, Ruyi Zou and Yingwei Zhang in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251384233 - Supplemental material for Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases
Supplemental material, sj-docx-2-dhj-10.1177_20552076251384233 for Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases by Minjie Lin, Chuanjun Xu, Xiang Qu, Biyun Xu, Yanghong Wang, Ruyi Zou and Yingwei Zhang in DIGITAL HEALTH
Footnotes
Acknowledgements
None.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publication
Not applicable.
Authors’ contributions
YWZ and MJL contributed to the conception, methodology design, and writing of the manuscript. RYZ, XQ, BYX, CJX, and YHW took responsibilities for data abstraction and accuracy of data analysis. All authors are guarantors of this work.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Medical Scientific Research Foundation of Jiangsu Commission of Health, grant number Z2024043, Talent lifting project of Nanjing Second Hospital, grant number RCMS24003, and National Natural Science Foundation of China, grant number 82270076.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data generated or analyses in this study are included in this article. Further enquiries can be directed to the corresponding author.
Supplemental material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.