
Abstract
Purpose
Chat Generative Pre-trained Transformer (ChatGPT) is now utilized in various fields of healthcare in order to obtain answers to questions related to healthcare-related problems and to evaluate available information. Primary hyperparathyroidism is a common endocrine disorder. We aimed to evaluate the accuracy and quality of ChatGPT's responses to questions specific to hyperparathyroidism cases discussed at multidisciplinary endocrinology meetings.
Methods
ChatGPT-4 was asked to respond to 10 hyperparathyroidism cases evaluated at multidisciplinary endocrinology meetings. The accuracy, completeness, and quality of the responses were scored independently by two endocrinologists. Accuracy and completeness were evaluated on the Likert scale, and quality was evaluated on the global quality scale (GQS).
Results
No misleading information was detected in the responses. In terms of diagnosis, the mean accuracy scores (ranging from 1 to 5) were 4.9 ± 0.1 and the mean completeness scores (ranging from 1 to 3) were 3.0. In the responses given in terms of further examination, the mean accuracy and completeness scores were 4.8 ± 0.13 and 2.6 ± 0.16, respectively. The mean accuracy and completeness scores for treatment recommendations were 4.9 ± 0.1 and 2.4 ± 0.16, respectively. The GQS evaluation result was 80% high quality and 20% medium quality.
Conclusion
In this study, the accuracy and quality rates of ChatGPT-4 were generally high in responding to questions as to hyperparathyroidism patients. It can be concluded that artificial intelligence may serve as a valuable tool in healthcare. However, the limitations and risks of ChatGPT should also be evaluated.
Introduction
One of the most significant recent developments in artificial intelligence (AI) is considerable advances in the large language model technology. Chatbots are computer programs that simulate human communication using AI and a natural language processing (NLP) system. ChatGPT (Chat Generative Pre-trained Transformer) is an NLP model developed by OpenAI in November 2022. 1 In recent years, the ChatGPT chatbot has been used to provide answers to questions and evaluate information in various fields, including medicine, and the results have been outstanding.2,3
ChatGPT has been used in various areas of medicine. Stokel-Walker and van Noorden found that ChatGPT produced accurate answers to some open-ended medical questions that were close to what a doctor would do. 3 ChatGPT has also passed standardized exams in a wide range of professional medical fields in numerous countries, such as the United States Medical Licensing Examination® (USMLE).4,5 ChatGPT has also been successful in breast tumor councils’ individualized treatment recommendations and infectious disease consultation evaluations.6,7 ChatGPT has also been evaluated in many studies in the field of endocrinology. It has been shown that it is partially successful in the evaluation and management of obesity in type 2 diabetes mellitus and in the approach to prolactinoma, and that it is successful in the management of thyroid nodules, but it needs more up-to-date information on diabetes technology recommendations.8–11
Primary hyperparathyroidism (PHPT) is a common endocrine disorder characterized by excessive secretion of parathormone (PTH) from the parathyroid glands. There are a number of different clinical approaches to this disorder. Multidisciplinary team meetings are usually organized for the effective management of patients with parathyroid pathology. 12
The number of studies evaluating ChatGPT regarding endocrinological diseases is limited and there is no information yet on the approach to hyperparathyroidism patients. Therefore, in this study, we aimed to evaluate how accurately and comprehensively ChatGPT answers open-ended questions regarding hyperparathyroidism cases discussed in multidisciplinary endocrinology meetings and the quality of its answers.
Methods
Study population
In the present study, we evaluated a single disease group to create homogeneity and obtain clearer data about the specific disease. We asked ChatGPT-4 to comment on hyperparathyroidism patients evaluated at our multidisciplinary endocrine meetings as a case in 2023 (within the last year). Then we analyzed the answers given by ChatGPT-4. Our center is a tertiary education and research hospital and patients with hyperparathyroidism are evaluated at multidisciplinary endocrine meetings. In these meetings, the participants discuss diagnoses, differential diagnoses, further investigation if necessary, and treatment options for each patient. Treatment methods may differ as follow up, medical treatment, and surgery.
Model input
The medical data of the patients, which were discussed at the meeting, were input into ChatGPT. We performed the model testing using ChatGPT-4 because this is the latest version. A model entry was designed for each patient, consisting of first clinical and laboratory data and then open-ended questions investigating diagnosis, examination, and treatment. In the patient information section, the data that may affect the decision of diagnosis and treatment were shared. These include serum albumin-corrected calcium, serum phosphorus value, PTH, 25 OH vitamin D level, 24-hour urine calcium, estimated glomerular filtration rate, the result of bone mineral densitometry, and the results of imaging methods. Afterwards, ChatGPT was asked about the diagnosis, the need for additional examinations and treatment recommendations for the case whose data was entered. Table 1 presents a sample question and the answer generated by ChatGPT-4. All the questions were edited in terms of grammar by two authors for clarity before being entered to ChatGPT-4. To account for response-to-response variation, each prompt was tested in duplicate on different days.
Sample questions and ChatGPT-generated answers.
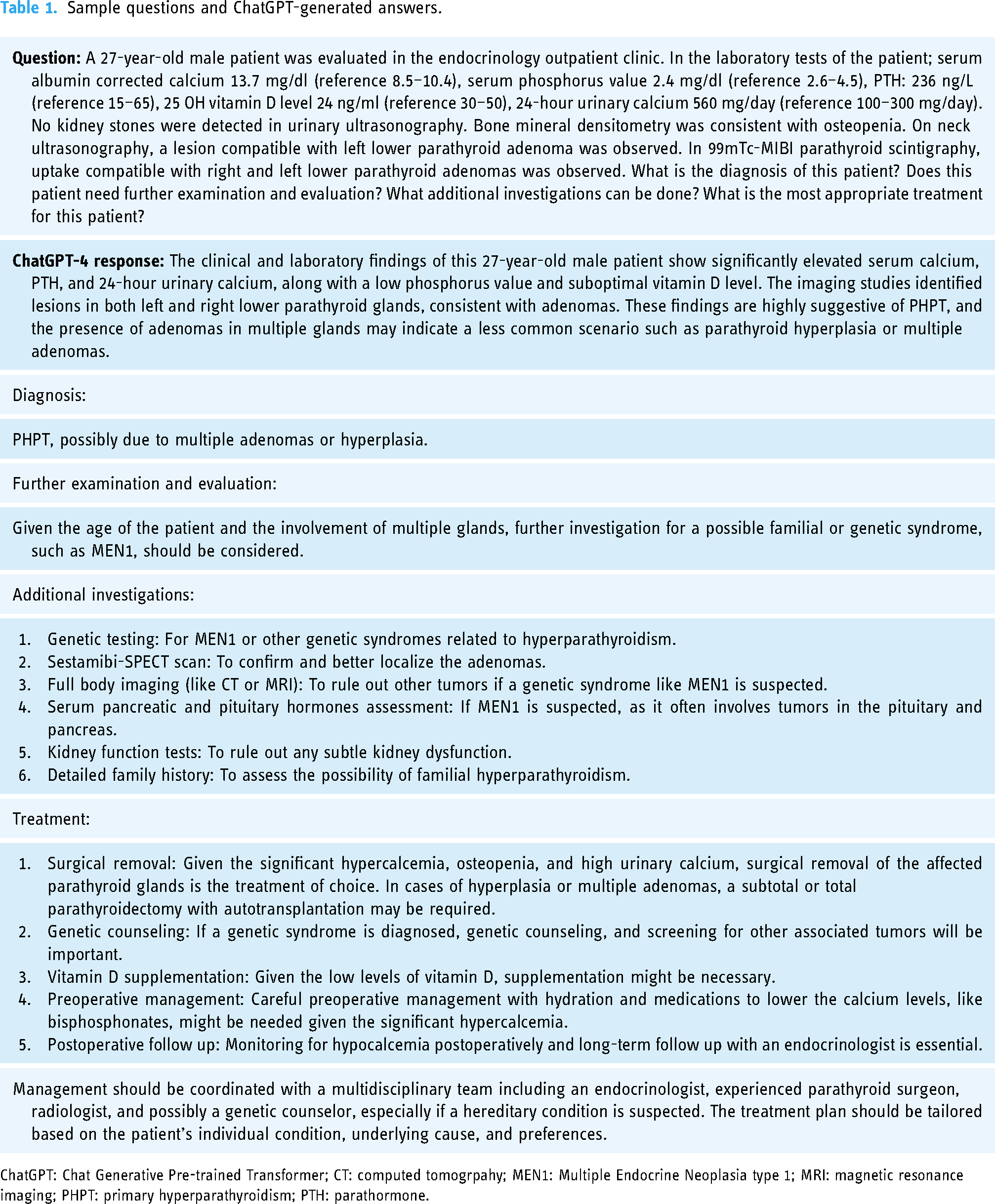
ChatGPT: Chat Generative Pre-trained Transformer; CT: computed tomogrpahy; MEN1: Multiple Endocrine Neoplasia type 1; MRI: magnetic resonance imaging; PHPT: primary hyperparathyroidism; PTH: parathormone.
Evaluation of accuracy, completeness, and quality
The responses were scored independently by two endocrinologists, and differences between the two evaluators were independently reviewed and resolved by a blinded endocrinologist with at least 20 years of experience in endocrinology for the final decision. The endocrinologists evaluated each chatbot response in three distinct categories as diagnosis and differential diagnosis, further investigation, and treatment recommendation. The evaluation was performed with regard to accuracy, completeness, and quality.
A five-point Likert scale was used for the accuracy scale (1—totally wrong, 2—mostly wrong, 3—right and wrong approximately equal, 4—mostly right, and 5—totally right). A three-point Likert scale was used as a completeness scale (1—incomplete, 2—partially incomplete, and 3—covers all aspects). 5
The previously used global quality scale (GQS) was applied to assess the quality of ChatGPT responses. Accordingly, 1 point indicates poor quality, and 5 points indicate excellent quality (Table 2). This scale is also used for quality classification. According to this classification, 1 and 2 points indicate low quality, 3 points moderate quality, and 4 and 5 points high quality. 13
Contents of GQS.

GQS: Global quality score.
Ethical approval
The study was approved by the Ankara Training and Research Hospital Ethics Committee (date and number: February 7, 2024/E24-3). It was conducted in accordance with the Declaration of Helsinki. The requirement for informed consent was waived due to the retrospective nature of this study.
Statistical analysis
All statistical analyses were performed using SPSS version 27 (IBM SPSS Statistics for Windows, Armonk, NY: IBM Corp). The agreement between the two authors who independently evaluated the ChatGPT responses was tested using Weighted Cohen's Kappa coefficient. The Shapiro-Wilk test was utilized to check the normality of the distribution. The Kruskal-Wallis and the Mann-Whitney U tests were implemented for the nonparametric variables of the relationship between the data.
Result
In total, 10 cases evaluated in endocrinology for hypercalcemia and hyperparathyroidism were input into ChatGPT-4. All of the queries involved questions about diagnosis, further investigation, and treatment options. No misleading information was detected in any of the ChatGPT-4 responses. All the questions and answers are presented in the Supplemental materials.
ChatGPT-4's responses to the questions were generally consistent between the first and second sessions. All of the responses emphasized the need for individualization of the treatment and the need to evaluate the cases by multidisciplinary health professionals who are experts in the field.
Evaluation of accuracy and completeness
The Weighted Cohen Kappa coefficient between the two authors was 0.714 and 0.760 for accuracy and 0.780 and 0.754 for completeness in the first and second sessions, respectively. Table 3 presents accuracy and incompleteness scores for each question in terms of diagnosis, further examination and evaluation, and treatment.
Grade of responses by ChatGPT in accuracy and completeness.
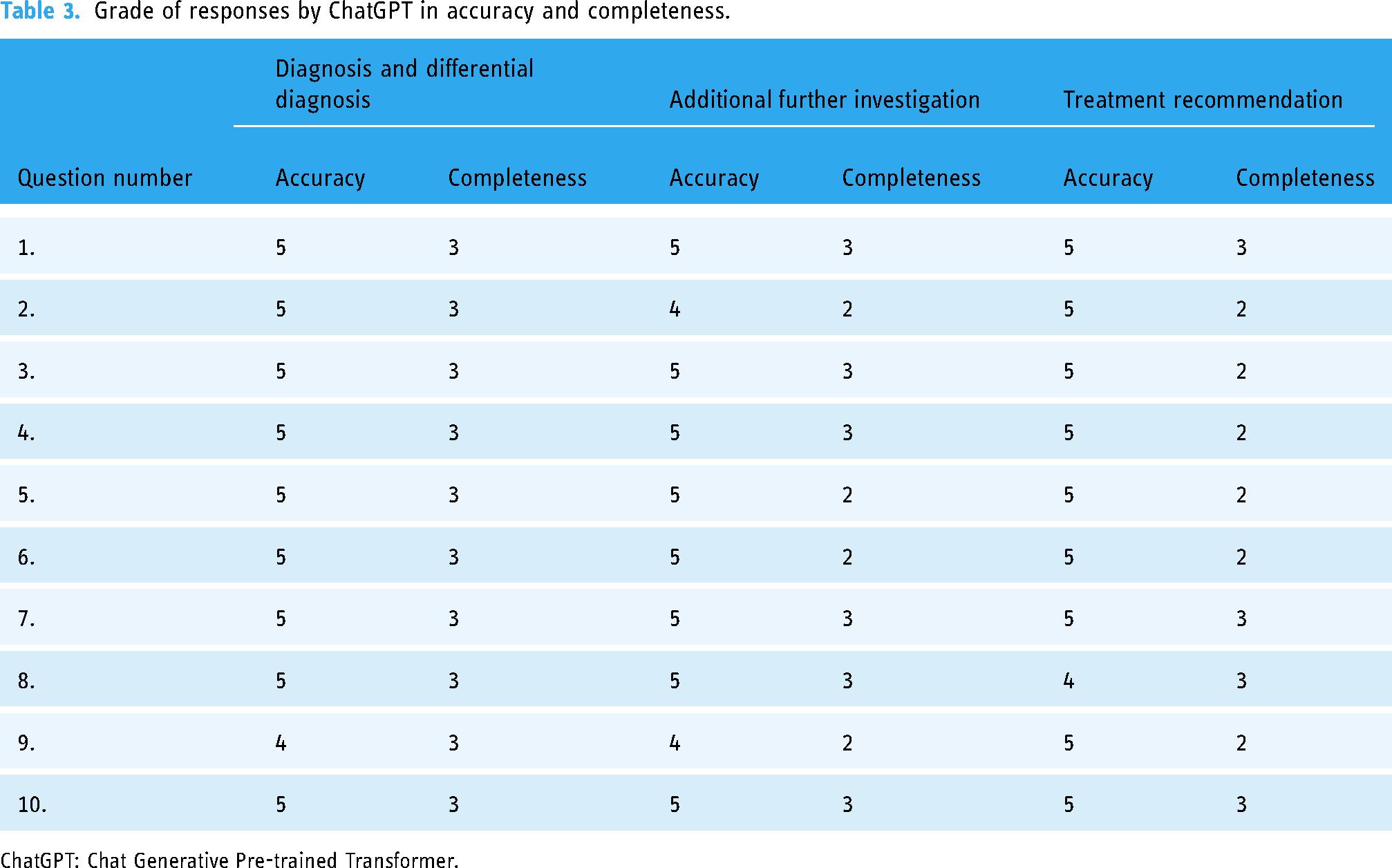
ChatGPT: Chat Generative Pre-trained Transformer.
With respect to diagnosis and differential diagnosis, in the accuracy assessments, 90% received 5 full points, and in the completeness assessment, full points were obtained in 100% of the cases. In the answers given in terms of further examination, 80% received a full score of 5 on the accuracy assessment, and 60% scored a full 3 points in the completeness assessment. When the answers given in terms of treatment recommendations were evaluated, the accuracy rate was 90% full. When evaluated in terms of completeness, 40% received full points and 60% received 2 points (partially incomplete).
For questions about diagnosis and differential diagnosis, the mean accuracy scores (1–5) were 4.9 ± 0.1 and the mean completeness scores (1–3) were 3.0. In the answers given in terms of further examination, the mean accuracy and completeness scores were 4.8 ± 0.13 and 2.6 ± 0.16, respectively. In the answers given in terms of treatment recommendations, the mean accuracy and completeness scores were 4.9 ± 0.1 and 2.4 ± 0.16, respectively (Figure 1).
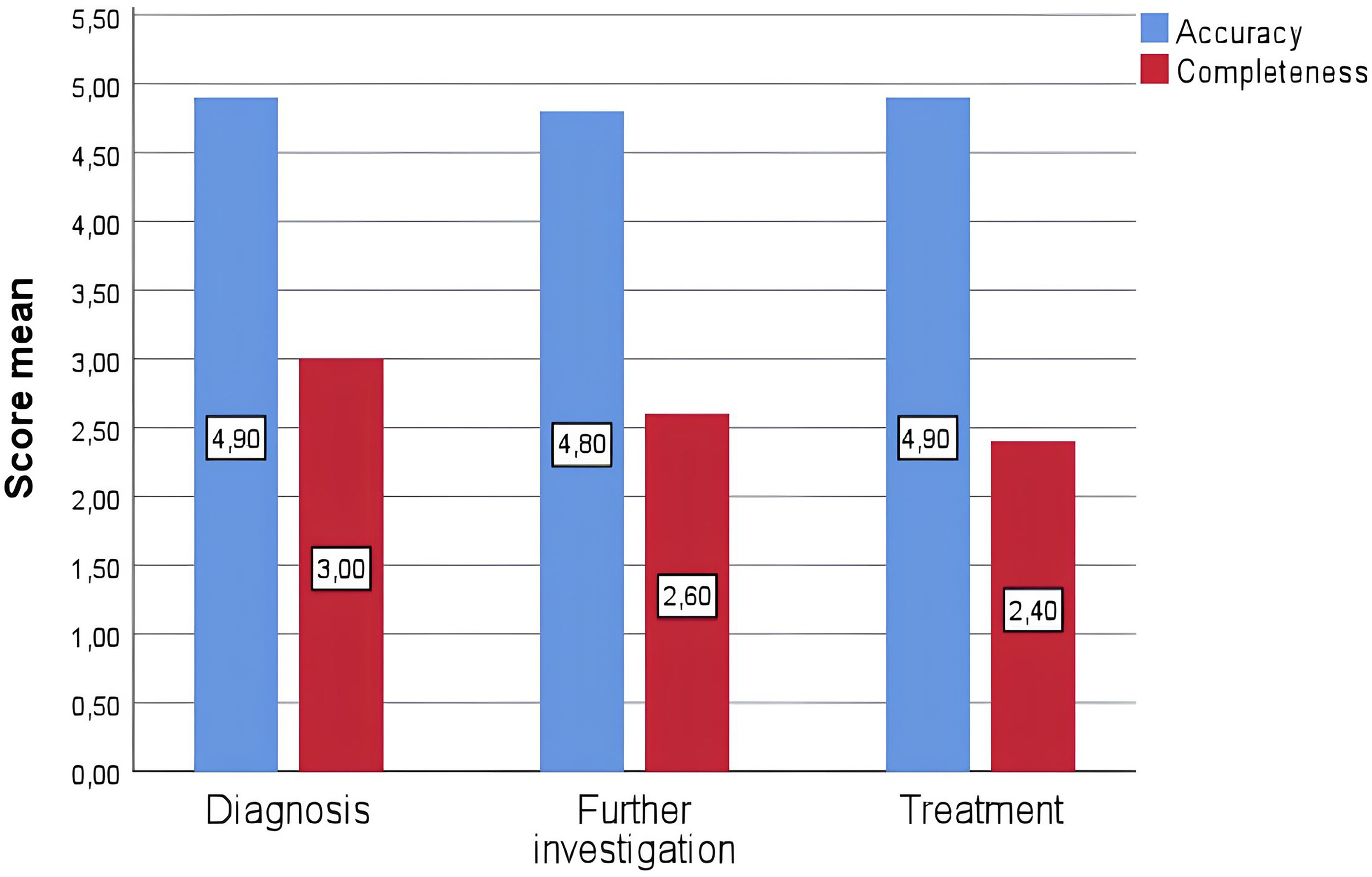
Graphical distribution model of grades assigned by the ChatGPT language model to answers to questions for accuracy and completeness in three different groups. ChatGPT: Chat Generative Pre-trained Transformer.
When the accuracy rates of the data were compared between the groups (in terms of diagnosis and differential diagnosis, further investigation, and treatment recommendation), no statistically significant difference was observed (p = 0.342). When the data completeness rates were compared between the groups (in terms of diagnosis and differential diagnosis, further investigation, and treatment recommendation), a statistically significant difference was observed (p = 0.017). When subgroup analyses were evaluated, a significant difference was observed between diagnosis and further investigation and between diagnosis and treatment recommendation, but no significant difference was observed between further investigation and treatment recommendation (p = 0.029, p = 0.004 and p = 0.384, respectively). It was observed that more incomplete recommendations were made in terms of treatment recommendations.
In the diagnosis and differential diagnosis section, familial hypocalciuric hypercalcemia (FHH) was stated in the differential diagnosis in only one case, even though the calcium value in the 24-hour urine was high, but this was not noted in the second session of the same case. Points were deducted for accuracy here. In the further examination section, in some cases of PHPT that could not be localized, 18F-fluorocholine (FCH) positron emission tomography/computed tomography (PET/CT) was not presented as a recommendation and points were deducted for completeness. In the treatment recommendations section, cinecalcet was not mentioned in some necessary cases, but cinecalcet was recommended in the second session of these cases. In some necessary cases, the neck exploration option and radiofrequency ablation option were not offered. Points were deducted for completeness here. Other than that, ChatGPT was quite successful. It was successful in detecting FHH, lithium use, and multiple endocrine neoplasia (MEN) syndrome when necessary in the differential diagnosis. ChatGPT was successful in its recommendations to assess additional comorbidities and evaluate other components when considering MEN syndrome. It was also very successful in detecting which patients had a surgical indication and some did not.
Evaluation of quality
The Weighted Cohen Kappa coefficient between the two authors was 0.730 and 0.737 for quality in the first and second sessions, respectively. Table 4 shows the score distribution of ChatGPT-4 responses to each question according to the GQS quality classification. The result of the evaluation was 80% high quality, and 20% moderate quality (Figure 2).

GQS quality classification of responses by the ChatGPT language model to questions. ChatGPT: Chat Generative Pre-trained Transformer; GQS: global quality score.
Grade of responses by ChatGPT inGQS.

ChatGPT: Chat Generative Pre-trained Transformer; GQS: global quality score.
Discussion
In this study, we evaluated the accuracy, comprehensiveness, and quality of the ChatGPT-4 language model in answering open-ended questions about diagnosis, further examination, and treatment by providing clinical information of hyperparathyroidism patients evaluated at endocrinology meetings. ChatGPT's responses, which were evaluated by endocrinologists, generated generally accurate and comprehensive information for diagnosis, further investigation, and treatment recommendations. The study results revealed that ChatGPT-4 responses were also generally of high quality.
Hyperparathyroidism is a disease that is commonly encountered in endocrinology outpatient clinics and can sometimes be confusing, requiring patient-based decisions in diagnosis and treatment. Therefore, it was planned to evaluate AI as an auxiliary tool for multidisciplinary councils. AI can be used as a supporting tool to increase efficiency in many areas of medicine, especially in radiology and pathology.14,15 The cases in our study were selected from cases frequently encountered in endocrine polyclinics, evaluated in real life in our own clinic, and evaluated in our own multidisciplinary meetings. International guidelines on this subject were taken into account when evaluating the accuracy and completeness of the questions [Fifth International Workshop on Primary Hyperparathyroidism: Summary statement and guidelines for the evaluation and management of primary hyperparathyroidism (2022), European Society of Endocrinology (ESE): European expert consensus on practical management of specific aspects of parathyroid disorders in adults and in pregnancy – Recommendations of the ESE Educational Program of Parathyroid Disorders (PARAT 2021), European Association of Nuclear Medicine (EANM): Practice guidelines for parathyroid imaging (2021)].
PHPT is a clinical condition characterized by elevated PTH and hypercalcemia-specific clinical symptoms and signs. Although mostly sporadic, sometimes familial cases may be included in the component of multiple endocrine neoplasia (MEN 1, MEN 2A). 16 Genetic tests are recommended in young patients (<30 years), those with a family history of PHPT, and those with multigland disease. 17 ChatGPT-4 was able to recommend genetic tests and examination for MEN in cases under the age of 30 and in cases with multigland involvement.
Familial hypocalciuric hypercalcemia and lithium treatment may also cause elevated serum calcium and PTH values, and therefore they should be evaluated in the differential diagnosis of PHPT. FHH is a hereditary disease caused by the mutation of calcium sensitive genes. The presence of hypocalciuria (excretion less than 50 mg/day) is essential for diagnosis. 18 Lithium therapy also leads to an acquired calcium receptor insensitivity. 19 It was observed that ChatGPT-4 could make a differential diagnosis in hypocalciuria patients and patients using lithium. ChatGPT-4 also suggested genetic examinations as further examination in cases where FHH is suspected. It was also observed that ChatGPT-4 could make the differential diagnosis of primary and tertiary hyperparathyroidism.
After diagnosis, localization should be performed. Imaging methods include ultrasonography, Tc99M-sestamibi imaging, magnetic resonance imaging, or preferably 4-dimensional computed tomography (4D CT). ChatGPT-4 was able to request these examinations including 4D CT. FCH PET/CT is also a novel imaging method for parathyroid pathologies. FCH PET/CT has been applied in some centers especially in Europe since 2017. 20 In our cases, FCH PET/CT was never mentioned among advanced examination and imaging methods in ChatGPT-4 responses. Presumably, ChatGPT-4 did not include FCH PET/CT in its responses as this method has not yet been included in hyperparathyroidism management guidelines and it is not yet widespread in the United States.21,22 Selective venous sampling is an invasive method for the localization of parathyroid. 23 This technique was also included in the recommendations put forward by ChatGPT-4. Bilateral exploration and intraoperative parathyroid hormone monitoring may be recommended by an experienced parathyroid surgeon for patients with primary hyperparathyroidism who are not localized but meet the operative criteria. 24 However, this surgical technique was not recommended by ChatGPT-4 in case questions that could not be localized.
Surgical treatment is recommended for symptomatic and asymptomatic individuals who meet the operating criteria of the Fifth International Workshop on Asymptomatic Primary Hyperparathyroidism guideline. 21 For some patients who meet surgical criteria but cannot or will not undergo surgery, medical treatments such as bisphosphonates or cinacalcet may be preferred.16,25 ChatCPT-4 was able to give correct answers in determining the operation indications. Also it was observed that ChatCPT-4 generally produced correct answers in recommending medical treatment to elderly and inoperable patients. However, in some cases, it was incomplete in recommending cinecalcet treatment and similarly in providing the radiofrequency ablation option. Additionally, it failed to offer the option of neck exploration in a patient whose parathyroid adenum could not be localized but who had an indication for surgery.
ChatGPT has also been used in several other professional healthcare fields before. Several studies evaluated ChatGPT's responses to questions on multiple choice medical exams, such as the USMLE and the Medical College Admission Test (MCAT). According to these studies, ChatGPT displayed a successful performance.4,26 In the literature, there is a study on the use of ChatGPT in situations that require a multidisciplinary approach, similar to our study. In this particular study, the recommendations of ChatGPT for primary breast cancer cases were compared with those of a multidisciplinary tumor board. The study results showed an agreement at a rate of 64.2%. 6 The relatively low rate of compliance in this study may have resulted from the fact that the treatment options in the oncology department change rather rapidly and the database of ChatGPT is restricted to information it learnt before 2021. The researchers noted that in this study, ChatGPT provided general responses but not individual specific recommendations. Unlike this one, our study showed that ChatGPT offered individual diagnosis, further examination, and treatment options to the cases under investigation. The available data on primary hyperparathyroidism approach is more stable in the literature, which may be the reason for this difference.
Another study analyzed ChatGPT's performance in Korean general surgery board exams. In this study, 280 questions were evaluated, and ChatGPT-4 had an accuracy rate of 76.4% in the specific exam. ChatGPT was found to be highly successful in understanding complex surgical clinical information. 27
Another study in the literature evaluated the accuracy and completeness of ChatGPT for medical questions. In this study, 284 medical questions were entered into ChatGPT. Accuracy was evaluated using a 6-point Likert scale, with a median accuracy score of 5.5 and an average accuracy score of 4.8. The completeness score was also evaluated using a three-point Likert scale. The data analysis revealed an average completeness score of 2.5. In conclusion, it was stated that ChatGPT produces largely accurate information for various medical queries. 5
However, in another study investigating the performances of ChatGPT-3 and ChatGPT-4 in gastroenterology self-assessment tests, the researchers reported that both models failed the test, and therefore they did not recommend their current use in gastroenterology medical education. 28
Our study had certain limitations. First, a small sample size may reduce the robustness of the findings, limiting the power of the tests to detect significant differences. Secondly, the responses were evaluated solely in English, so we cannot generalize the results to all languages. Although ChatGPT-4 is available in numerous other languages, studies conducted in English are in great majority within the literature. Moreover, ChatGPT does not produce standard answers to the questions asked; on the contrary, it may give different answers in different sessions. Although there is often consistency between the answers, this cannot be generalized to all situations. Furthermore, ChatGPT can only access data that predate 2021. It is not actively connected to the Internet and does not contain up-to-date data. Finally, no standard method exists for evaluating ChatGPT-4 responses, which may cause differences in assessments. And also, evaluation of responses reveals possible bias because they are not measured objectively.
Conclusion
In conclusion, this study demonstrated the potential of AI-based ChatGPT-4 to provide answers to open-ended questions about data of real hyperparathyroidism patients. The accuracy and quality rates of the answers were high. ChatGPT can be used as a valuable resource to enhance the efficiency of healthcare and patient-based individual decision making. However, the limitations and risks of ChatGPT as well as the potential benefits should be known, and clinicians and patients should be informed about them. The reliability of and ethical debates about ChatGPT in the medical field should be further clarified. It is not appropriate to use ChatGPT alone in patient management; diagnosis and treatment must be done by a physician. AI and ChatGPT can never replace medical professionals and doctors alone, but can only be a helpful tool in healthcare. Further studies are needed to more clearly evaluate the performance of chatGPT in the medical field.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241278692 - Supplemental material for Evaluation of the accuracy and quality of ChatGPT-4 responses for hyperparathyroidism patients discussed at multidisciplinary endocrinology meetings
Supplemental material, sj-docx-1-dhj-10.1177_20552076241278692 for Evaluation of the accuracy and quality of ChatGPT-4 responses for hyperparathyroidism patients discussed at multidisciplinary endocrinology meetings by Işılay Taşkaldıran, Çağatay Emir Önder, Püren Gökbulut, Gönül Koç and Şerife Mehlika Kuşkonmaz in DIGITAL HEALTH
Footnotes
Contributorship
All authors contributed to the understanding and design of the study. Material preparation, data collection, and analysis were carried out with IT, CEO, PG, GK, and SMK. The first draft of the article was written by IT, and all authors commented on previous versions of the article. All authors have read and approved the final article.
Data availability statement
The data that support the findings of this study are available on request from the corresponding author.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
The study was approved by the Ankara Training and Research Hospital Ethics Committee (date and number: February 7, 2024 / E24-3). It was conducted in accordance with the Declaration of Helsinki. The requirement for informed consent was waived due to the retrospective nature of this study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Guarantor
IT
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.