
Abstract
Objectives
Sharing medical data is hampered by technical, regulatory, and privacy challenges, including compliance with the Health Insurance Portability and Accountability Act of 1996. However, existing data anonymization methods are error-prone or vulnerable to re-identification, and synthetic data generation approaches are limited. This study introduces SYNNER, a novel synthetic data generation framework that overcomes existing limitations, preserving data utility while ensuring privacy.
Methods
We employ knowledge graph embeddings to encode data into a k-dimensional space, capturing complex relationships. For each entity, its nearest neighbors are identified, and their characteristics are used to generate a synthetic version that maintains statistical consistency. We evaluated SYNNER on seven publicly available datasets, measuring the preservation of original data signals and comparing macro-F1 scores across prediction tasks. A novel evaluation protocol for differential privacy was also introduced, simulating an adversarial attack to infer missing values.
Results
The evaluation shows that SYNNER maintains an average of 83.2% of the signals from the original datasets. In predictive tasks, models trained on SYNNER-generated data achieved a proportional average macro-F1 score of 74.4%, comparable to those trained on the original data. The proposed evaluation protocol for differential privacy assesses whether synthetic datasets meet expected privacy standards and highlights potential risks of individual data point reconstruction.
Conclusion
SYNNER provides a scalable and effective solution for generating synthetic data that maintains statistical fidelity. It overcomes the limitations of existing methods, providing a privacy-preserving solution for synthetic data generation and advancing research in sensitive domains such as healthcare.
Keywords
Introduction
In recent years, there has been a push for individualized treatment and preventive medicine. 1 These personalized approaches enable clinicians to identify disease risks and treatments for each patient, but require access to comprehensive datasets, since each patient has unique clinical circumstances. 2 However, precision medicine research has been slowed by the limited access to high-quality data, as hospitals and medical device companies often face significant barriers to making their data publicly available. The main difficulties reported in 2021, for example, include lack of technical or personnel capacity, complex interface issues, differences in vocabulary standards, and difficulty extracting relevant information from electronic health records (EHRs) to report. 3
In addition, publishing personally identifiable information without consent can have serious consequences. This refers to any data that could identify a specific individual, as enforced by The Health Insurance Portability and Accountability Act (HIPAA) of 1996. 4 In just ten years (2012–2022) the Office of Civil Rights has settled over $100 million HIPAA violations. 5 To comply with HIPAA, data can be manually anonymized or using professional-level products designed to automatically anonymize data, such as ARX, 6 CloverDX, 7 or Amnesia. 8 However, manual anonymization is time-consuming and prone to human error, while automated methods are vulnerable to attacks.9,10 Moreover, these methods often fail to accommodate the diversity of data formats, the variability in labeling, and terminology across medical practices.
In response to these challenges, synthetic data generation techniques have been proposed,11–18 which aim to mimic the trends in the original data using publicly available data and expert knowledge. Synthea 15 is one of the rule-based generators that create synthetic EHR for patients. Although such datasets can be both realistic and representative, their creation often entails significant overhead, and expert knowledge may be either difficult to integrate or subject to bias.19,20 Furthermore, expert knowledge is not easily transferable between domains; 21 for instance, knowledge used to generate synthetic healthcare data may not apply to the financial domain, and vice versa. Alternative approaches have emerged that do not rely on expert input; instead, they learn patterns directly from existing data. Conditional Probability Generators (CPGs) and Generative Adversarial Networks (GANs) have been widely used in the field of synthetic data, being applied not only for image generation, 22 but also to generate tabular data.
A key challenge in creating synthetic data is balancing utility and privacy. In methods that do not rely on expert knowledge (such as CPGs and GANs), there is a risk of reproducing exact records from the source data. To comply with HIPAA, Differential Privacy (DP) 23 must be satisfied. A differentiable private dataset limits the influence of any single individual’s data on the analysis output, preventing data reconstruction or re-identification, and ensuring strong privacy guarantees. However, outliers pose an additional challenge, as their inclusion or removal can disproportionately affect the learned distributions, 24 which requires specialized strategies to mitigate this effect.
In this study, we use a Knowledge Graph Embeddings (KGEs)
25
to enhance synthetic data generation and produce privacy-differentiable data. Our proposed method, SYNNER, uses KGE to map entities into a
We applied SYNNER to seven publicly available datasets, demonstrating its ability to replicate feature distributions and relationships while balancing data utility (i.e., realism) and privacy. The generated data closely mirrors the original in predictive tasks without duplicating real records. SYNNER also addresses common challenges in traditional synthetic data generation approaches (such as domain generalization and high duplication rates) by using an embedding representation that captures, on average, over 83% of the signals from the original data, preserving key relationships between features. The resulting synthetic data can be used not only to substitute training sets in the intended prediction tasks effectively, but also to achieve an average macro F1 score ratio of 74.4% compared to the resulting F1 score when using the original data as a training set.
Finally, to evaluate DP, we propose a label-prediction task in a simulated adversarial setting. The setup assumes that an attacker has access to the original data, the embeddings, the synthetic dataset, the embedding model, and attempts to infer a missing feature value. Through predictive experiments comparing the performance of integrating synthetic or embedded data with the original dataset, we show that while embeddings alone do not substantially improve accuracy, adding synthetic data can enhance performance on certain features, potentially revealing sensitive patterns. These findings underscore the need for mitigation strategies, such as calibrated noise, to balance data utility and privacy.
Literature review
In pursuit of generating realistic synthetic data, researchers have explored various approaches, including rule-based and machine learning methods. Rule-based approaches rely heavily on expert knowledge, using statistical modeling and schema-driven techniques to capture population characteristics and simulate real-world data. While these approaches can produce highly realistic synthetic datasets, they tend to lack generalizability across domains and often risk duplicating records from the original data. On the other hand, machine learning approaches offer more flexibility by learning patterns directly from data. GANs 26 methods, for example, leverage adversarial training to learn data distributions and ensure privacy preservation. However, these approaches face challenges such as potential leakage of sensitive information, limited generalization in low-sample or imbalanced scenarios, and difficulty in modeling structured or multi-relational data.
In this section, we review related work on rule-based and machine learning approaches to synthetic data generation. We also introduce an alternative direction based on KGEs, which serves as the foundation for SYNNER. KGE techniques represent entities and their relationships in a continuous vector space, capturing complex structural patterns through unsupervised learning.
Rule based approaches
Rule-based approaches rely on domain expertise and predefined statistical rules to generate synthetic data, rather than learning directly from source datasets. These methods typically incorporate publicly available statistics, ontologies, or schema constraints to simulate realistic data that reflect expected distributions and logical relationships within a given domain.
Publicly Available Data Approach to Realistic Synthetic EHR (PADARSER), 16 for example, uses publicly available health statistics and care flows to generate realistic EHR. Care flows are generated from clinical practice guidelines, without using real patient data. Although the use of expert knowledge is helpful in creating realistic data, it is not transferable to other domains.
Graph Differential Dependencies (GDDx) 17 is a schema-driven knowledge graph generator. The generation process relies on expert-defined schemas that impose constraints on the relationships between entities. While this ensures structural coherence, it requires significant domain knowledge, which limits the generalizability of the approach across different contexts.
Synthpop 11 uses conditional distributions to generate synthetic data. It models each column of the source data as a conditional distribution, where the value of a given attribute is sampled based on previously generated attributes in the same row. This creates a more realistic version of each entry in the resulting synthetic data. However, synthetic data generators based on conditional probabilities usually face a vanishing distribution problem when there are too many features and not enough data to support those features. As each feature is conditionally sampled, the subset of eligible entities becomes increasingly narrow. In cases where no entities exist with a given combination of previously selected features, the generation process may fail due to an empty distribution. This issue can lead to the vanishing gradient problem, 27 where generators that use conditional distributions can leak individuals from the source data that match less frequent combinations of feature values. In neural networks, the vanishing gradient problem occurs when the values used to update the internal parameters become extremely small as they are passed backward through many layers. This makes it hard for the earlier layers to adjust their weights, which in turn slows down or even blocks the training process. 28 In embedding processes, the vanishing gradient problem progressively reduces the embedding vector magnitudes during training, which can happen when similarity measures such as cosine similarity fall into saturation regions, or when positive and negative pairs produce nearly identical distances. As a result, the embeddings lose their ability to distinguish between inputs. 29 In both scenarios, the vanishing gradient problem can be understood as a form of forgetting.
Machine learning approaches
Unlike rule-based methods, machine learning approaches generate synthetic data by learning directly from source data, rather than relying solely on expert knowledge. These approaches can learn the underlying patterns and distributions in the data, enabling the generation of high-fidelity synthetic data.
GANs 26 have been widely used to generate discrete and continuous tabular data. One example is medGAN, 12 an autoencoder combined with a GAN that aims to learn the distributions of multi-label discrete features in a medical context. The autoencoder helps the GAN learn the distribution of the variables by putting the data into a latent or encoded space. The synthetic encoded data are then decoded back into discrete variables. However, GANs may leak sensitive information, particularly when trained on small datasets or when feature distributions are highly imbalanced. 14 At the same time, GANs can undergo mode collapse, 30 which results in the GAN producing the same entity over and over instead of a representative variety of entities. When experiencing mode collapse, the generator produces only a narrow subset of possible outputs rather than reflecting the full diversity of the data. This means that, although the generated samples may look realistic, they fail to represent all variations present in the original dataset. Instead of capturing all possible modes of the data (e.g., different classes, variations, or styles), the generator keeps producing very similar samples, preventing the model from generating a full range of realistic data. 31
DPGAN 14 is a differentially private GAN that improves on medGAN. DPGAN uses the Wasserstein distance, 32 as opposed to Jensen-Shannon divergence or Kullback–Leibler divergence 33 to approximate the difference between the probability distributions of the real data and the generated data. DPGAN achieves high-quality data point generation while also ensuring the protection of individuals. This is done by adding noise to the Wasserstein gradient during training. Although DPGAN improves on the mode collapse and gradient vanishing problems, the method cannot produce multi-relational data.
Conditional Tabular GAN (CTGAN 13 ) is a generative model specifically designed to address the unique challenges of tabular data synthesis. Traditional tabular data often include a combination of continuous and discrete variables, making modeling difficult, especially when continuous variables have multiple modes or when discrete variables are imbalanced. Unlike standard deep learning or statistical methods, which often struggle with this complexity, CTGAN introduces a conditional generator that effectively models the joint distribution of tabular data. This approach enables it to generate realistic synthetic rows that reflect the structure and variability of the original dataset.
TabularARGN 18 is an auto-regressive neural network architecture designed specifically to generate high-quality, privacy-preserving synthetic tabular data. TabularARGN addresses the unique challenges of real-world datasets, including mixed data types, missing values, and variable-length sequences, by modeling all possible conditional probabilities between features. This design enables advanced features such as conditional generation, missing value imputation, and fairness-aware synthesis, while maintaining DP safeguards.
Knowledge graph embeddings
To overcome the limitations of rule-based and machine learning approaches (e.g., reliance on domain-specific knowledge, lack of generalizability, and risk of privacy leakage), KGEs offer a promising alternative. KGE methods represent entities and their relationships in a continuous vector space, effectively capturing complex, multi-relational structures without requiring explicit rules or full generative modeling.
Traditionally, embeddings have been used to visualize clusters of high-dimensional data in low-dimensional space, providing a way to naturally group similar entities without explicitly sorting them together. Moreover, they are more effective forms of representing knowledge to encode known information that allows inference and reasoning,34–36 making them particularly suitable for synthetic data generation scenarios where preserving underlying data semantics and generalization across domains are essential.
Static knowledge graphs (knowledge graphs that encode facts that are assumed to be universally or permanently true) are not suitable for embedding time-series or time-linked events, where many facts are only valid within a specific time frame. TKG embedding models aim to capture dynamic patterns and evolving relationships over time. While earlier models relied on random sampling to generate negative training examples, more recent work has shown that generating plausible but false negative samples using adversarial techniques improves the quality of the learned embeddings. 25 This results in more semantically rich and temporally-aware representations—an important feature for modeling longitudinal data such as patient histories.
The training architecture proposed in Tissot and Pedebos 25 improves on previous work by choosing more likely false facts to use as training data for the GAN instead of uniform random sampling. This creates a more semantically rich TKG embedding. After training the 5 different TKG models, the methods that were trained using the proposed adversarial model yielded slightly better results.
Despite the growing interest in KGEs for tasks such as clustering, reasoning, and representation learning, their application in the context of synthetic data generation remains relatively underexplored. Although existing studies demonstrate their effectiveness in capturing structured patterns and performing semantic reasoning, their potential to produce synthetic data has not been fully realized, particularly in sensitive domains like healthcare. Our work aims to bridge this gap by leveraging KGE techniques as the foundation for SYNNER, a synthetic data generator designed to preserve utility while enhancing privacy through embedding-based sampling.
Methods
In this section, we outline SYNNER, our proposed method for generating synthetic data that closely emulates the characteristics and statistical properties of diverse datasets. Our approach handles both categorical and continuous attributes, generating realistic individual entities and ensuring an appropriate level of privacy. SYNNER implements a synthetic data generation pipeline that is structured into three main phases, as shown in Figure 1:

Overview of the SYNNER framework, structured into three phases: (A) Embeddings generation and evaluation, (B) synthetic data generation using embedding-based sampling, and (C) differential privacy evaluation through simulated adversarial inference tasks. The pipeline highlights how embeddings capture feature relationships, synthetic data preserves structure without duplicating records, and privacy is empirically assessed under attack scenarios.
To address and evaluate diverse challenges in our proposed synthetic data generation process, we used the benchmark data described below. They were selected to represent different types of data and challenges in the generation of synthetic data and were preprocessed to obtain training and test splits when not provided (https://github.com/hextrato/SYNNER).
Additional details about each dataset are presented in Table 1, including the number of instances in each training and test set, the number of categorical and continuous features, and the distribution of the target label values.
Characteristics of benchmark datasets used in this study, including number of training and test instances, number of continuous and categorical features, and class label distribution.

These datasets represent a range of clinical and non-clinical domains with diverse data types and prediction tasks.
Embeddings generation
To address the dependency between features in the source data, we use embeddings to organize entities into a multidimensional space where similar instances are naturally grouped together. We use KRAL (https://github.com/hextrato/kral), an unsupervised learning approach based on KGEs,
35
to generate embedding spaces that capture feature similarities and patterns present in the original datasets (see Figure 1(a)). KRAL has been chosen for its ability to handle not only categorical, but also continuous features when embedding a knowledge graph. While embeddings for categorical features are learned using translational projections of entities and relations, continuous features are embedded along a random choice of a dimension
After generating the embeddings based on the training set, we applied the learned transformations to generate embeddings for the test set. This approach ensures that the test embeddings are derived solely from the relationships captured in the training phase, without introducing additional information from the test set itself. In the next step (Figure 1(A.2)), the embeddings are evaluated in the same label prediction task proposed for each original dataset, so that we can assess their ability to capture meaningful patterns and relevant structures. In general, this step enables us to quantify the amount of meaningful signal that can be captured from each dataset, and to estimate how effectively the synthetic data could represent the underlying structure of the original data.
In
Evaluation of embeddings as input features for prediction tasks across all benchmark datasets.

Macro F1 scores are compared between models trained on original data and embedding representations. The relative F1 performance quantifies the signal preservation achieved by embeddings.
Synthetic data generation: Embedding space sampling
Following an initial validation of the effectiveness of the embeddings in a predictive task, we re-run the embedding process using the same KGE algorithm, this time incorporating class labels (see Figure 1B). Integrating label information into the embedding process enables embeddings to capture label-dependent patterns and relationships. As a result, entities that exhibit similar features or associations with specific labels are embedded in close proximity within the latent space.
Sampling strategy
A commonly used strategy to generate synthetic data is random sampling.
43
Although this approach allows the creation of an unlimited number of synthetic records, it often fails to preserve essential data structures, resulting in unrealistic or unrepresentative samples. To enhance the fidelity of the synthetic data with respect to the original distribution, we adopt a density-based sampling strategy.
44
In this method, synthetic instances are generated within clusters formed by the
The density analysis step utilizes the resulting embeddings from the source dataset to determine the appropriate parameters for the synthetic data generation process, including the minimum and maximum number of neighbors and the maximum radius. Let
Because each feature value is sampled independently from the distributions of its nearest neighbors, some higher-order dependencies may not be fully preserved. This includes temporal dynamics and strong inter-feature correlations, which are particularly relevant in clinical datasets. We revisit this limitation in Section 5 and suggest potential extensions to address it.
Maximum cluster radius
The selection of a suitable maximum radius (
Avoiding replicating outliers
To mitigate the risk of replicating outliers, we impose a minimum neighbor count constraint (
Cluster quality
To refine the quality of each cluster, we introduce a maximum neighbor constraint (
An illustrative example based on the Fetal Health dataset is shown in Figure 2. For a given pair of neighbor constraints

Density analysis for the Fetal Health dataset in the embedding space. The number of neighbors within varying radius thresholds is plotted (log scale), showing the trade-off between outlier frequency (¡16 neighbors) and local density (>32 neighbors). Results guide the selection of the maximum cluster radius (
Data utility
Finally, we evaluate how each resulting synthetic dataset performs as a training set in the original label prediction task. We analyze the resulting F1 score from the test set, comparing two models: (a) One trained with the original training data and (b) another trained with synthetic data generated from the original training set. There are no specific expectations regarding the F1 score resulting from synthetic data, but we use these results to assess the representativeness of synthetic data with respect to the original data. These results are presented in Table 3 and discussed in Section “Synthetic data evaluation”.
Comparison of predictive performance between models trained on original training data versus synthetic data generated by SYNNER.
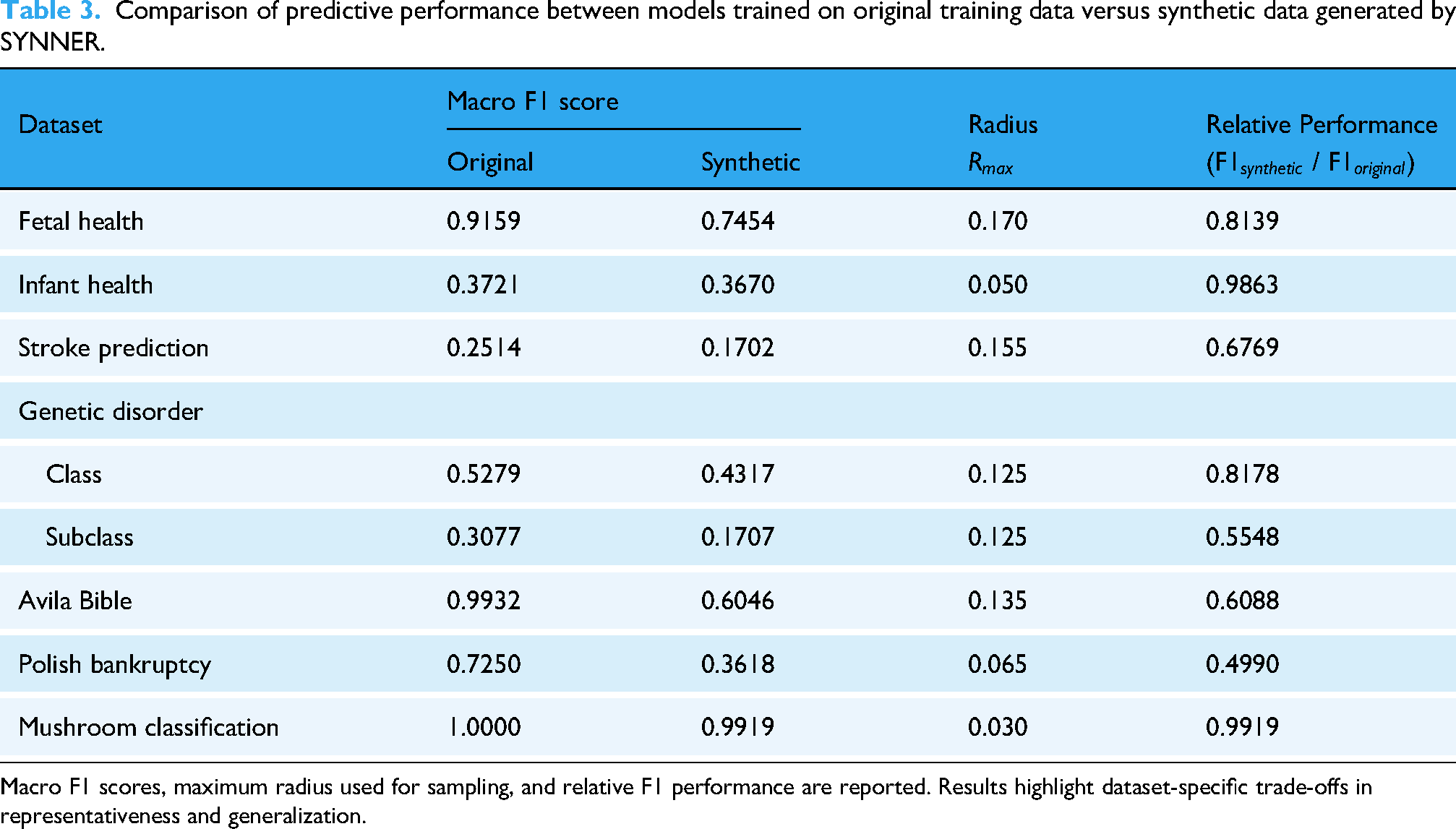
Macro F1 scores, maximum radius used for sampling, and relative F1 performance are reported. Results highlight dataset-specific trade-offs in representativeness and generalization.
Differential privacy
Now that we have a synthetic version of the original training set, to ensure its practical applicability, it is essential to evaluate how well the synthetic dataset balances data utility and privacy protection. One concern when generating synthetic data is the risk of reconstructing sensitive or confidential information. When synthetic samples are too closely aligned with real data points, especially in high-dimensional representations, there is a risk that models trained on the combined datasets may overfit or expose patterns that could compromise individual privacy. In other words, the integration of real and synthetic data, particularly those generated from embedding spaces, could inadvertently improve a model’s predictive performance to the extent that it enables the reconstruction of sensitive or missing information from the original data.
To assess the trade-off between data utility and privacy, we propose evaluating how well synthetic datasets perform in prediction tasks when combined with the original dataset and/or their corresponding embeddings (see Figure 1(C)). We run prediction tasks on each feature assuming the scenario in which an attacker gains access to all versions of the same dataset: Synthetic data (
Taking into account this adversarial scenario, we quantified the attempt to reconstruct the missing value through a comparative evaluation in four experimental settings: (1) Inference using only the original dataset
Results
In this section, we present the results of our work in producing synthetic data for different datasets. We first performed a preliminary evaluation that shows how noise and the choice of
As proposed in Section “Methods”, we use KGEs to enhance synthetic data generation and ensure DP in generated data. According to Dwork and Roth, 23 adding calibrated noise can protect sensitive information while preserving the statistical properties of the original dataset. Whether noise is an intrinsic feature of the data or added in a controlled way, it is essential to demonstrate how it affects the embedding process’s ability to capture signals from the data.
To this end, we used FormulAI. 42 This rule-based dataset generation framework systematically adds a specified level of noise to a dataset, to evaluate the robustness of the embedding representations at different levels of noise. We used six variants, adding noise from 0% to 50%, to test their effect on the embedding process. Then, using the XGBoost model, 46 we compare macro F1 scores across the original data and their corresponding embeddings.
This evaluation was intentionally kept simple, consisting of only two categorical and two continuous features, along with a multilabel target with six distinct values. Embeddings were generated using a
Preliminary evaluation of the impact of increasing noise levels (0%–50%) on embedding representations.

Macro F1 scores are reported for the original data and embeddings, with relative F1 performance defined as the ratio of the embedding-based score to the original data score. Results highlight how embeddings encode noise and how this affects predictive performance.
We also used the FormulAI dataset to assess how different
Table 5 shows that the higher the dimensional space, the better the embedding process can accommodate the different entities that represent each instance of the original data. In other words, the higher the
Comparison of embedding performance across different embedding space dimensionalities (
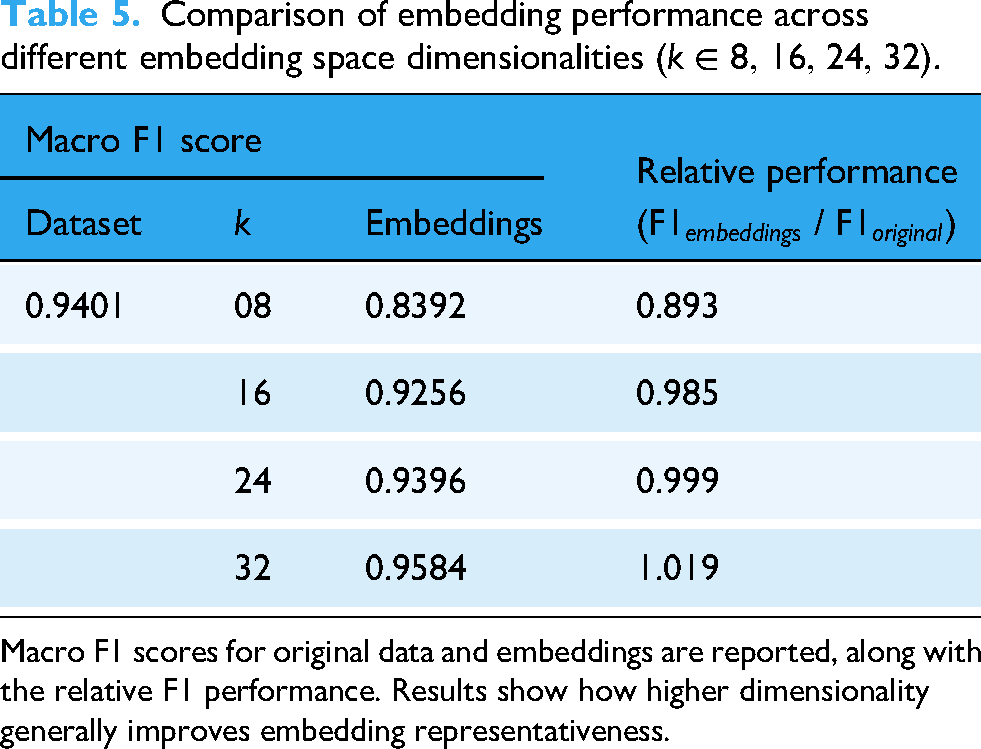
Macro F1 scores for original data and embeddings are reported, along with the relative F1 performance. Results show how higher dimensionality generally improves embedding representativeness.
The choice of
Embeddings evaluation
As described in the first step of the SYNNER pipeline (Figure 1(A)), we generate embedding representations for the training and test partitions of the original datasets, without including the target labels, as they could influence the relationships learned. Once the embeddings were generated, we evaluated their utility as synthetic data by using XGBoost to predict the original labels. The results are shown in Table 2.
An interesting exception occurs in the Infant Health dataset, where embeddings slightly outperform the original data (Macro F1
When comparing results to the same task performed on the original datasets, we observed that embeddings typically achieve lower performance, as some signal is lost during the embedding process. In each dataset, the loss ratio in a prediction task relative to the original data varies with data complexity and the difficulty of predicting the target label. For example, in the Mushroom dataset, widely considered straightforward and easy to resolve, embeddings maintain a high predictive performance. In contrast, in the subclass prediction task in the Genetic Disorder dataset, embeddings achieve only 50% of the same performance as the original data.
Furthermore, in the Infant Health dataset, we observed that the F1 score using embeddings improved by nearly 3% compared to the original dataset. Although designed to reduce dimensionality, the embedding transformation can also enhance representation by capturing correlations between similar feature-value pairs, as becomes more evident in inherently difficult-to-learn prediction tasks.
Overall, this assessment confirms that embeddings can preserve data patterns. Most importantly, since embeddings typically underperform compared to the original data, they may provide a suitable level of privacy for subsequent synthetic data generation steps.
Synthetic data evaluation
In this section, we evaluate the effectiveness of our synthetic data generation framework by analyzing several key factors, including comparisons between density-based and random sampling approaches and the influence of radius and neighbor constraints in balancing trade-offs between privacy, utility, and generalizability. We also examine how these parameters affect class-level prediction performance and discuss the implications of dataset-specific parameter tuning. The results are reported in Table 3 and Figures 3 and 4.

Impact of varying the maximum radius (

Effect of varying minimum and maximum neighbor constraints (
As discussed previously, unlike the embedding evaluation in the previous section, we used embeddings learned from the full original datasets, including target labels, to improve the semantic reliability of synthetic data generated from latent representations. The resulting synthetic records retain a substantial portion of the discriminative structure of the original data when we incorporate class labels into the KGE process. For example, as shown in Table 3, in the Fetal Health dataset, although the F1 score decreases from 0.9159 (original) to 0.7454 (synthetic), the retention ratio of 0.8139 reflects how strongly signals can be preserved during the embedding and synthetic data generation processes. Similarly, in the Mushroom dataset, the synthetic-based model achieves a macro F1 score of 0.9919, indicating minimal information loss, as expected for an easy-to-resolve task. However, in tasks with more granular class structures, such as when predicting the subclass label in the Genetic Disorder dataset, the drop in performance is more noticeable (ratio
From a clinical perspective, these observed performance gaps carry essential implications. For example, in the Fetal Health dataset, a 10%–15% reduction in the Macro F1 score does not imply that models trained solely on synthetic data can be safely applied in patient care. Even modest declines in predictive accuracy could translate into an increase in Type II errors (false negatives)—instances in which a pathological or high-risk case is incorrectly classified as normal. Instead, these results demonstrate that synthetic datasets preserve sufficient predictive signal to support model screening, prototyping, and hypothesis generation. In practice, synthetic data can help identify promising approaches while maintaining privacy. Still, final models must be retrained and independently validated on the original clinical data to ensure safety and reliability.
Density-based vs. random sampling
As mentioned in Section “Synthetic data generation: Embedding space sampling”, we adopted a density-based sampling strategy within the embedding space, which uses the K-nearest neighbors within a maximum radius constraint (
Balancing utility and generalization via max radius
Selecting an appropriate radius parameter (
Minimum and maximum neighbor constraints to prevent outlier duplication and preserve local structure
As described in Section “Synthetic data generation: Embedding space sampling”, we apply a minimum neighbor constraint (
In addition to
Using the Fetal Health dataset as an example, we observe that relaxing
Similarly to the effect of increasing
Evaluation using prediction performance
When analyzing the macro F1 scores shown in Table 3, we observed that although models trained with synthetic data are expected to underperform relative to those trained with real data, our results show that SYNNER can generate synthetic datasets that can approximate the performance of their original counterparts in specific scenarios. For example, in the Infant Health dataset, the synthetic trained model achieves an F1 ratio of 0.9863, in a task that can be considered difficult to resolve (
However, the limitations of this method become apparent in datasets with weak or sparse local structures. In the Avila Bible and the Polish Bankruptcy datasets, for example, the F1 ratio decreased to 0.6088 and 0.4990, respectively. Insufficient density in the embedding space, likely due to the lack of categorical features, may have hindered the formation of meaningful synthetic clusters, underscoring the importance of local density in the design of sampling strategies for high-fidelity synthetic data generation. These performance drops may in part reflect the limitation of independent feature sampling, which can weaken the preservation of fine-grained correlations or subgroup-specific structures. This effect is especially noticeable in complex or heterogeneous datasets, where capturing relationships beyond local neighbor distributions is essential.
Finally, neighborhood constraints may affect the predictive performance of synthetic data unevenly across different label types within the same task. This effect is evident in the Genetic Disorder dataset, where
The evaluation results presented thus far have focused on the utility and representativeness of the synthetic data. However, in privacy-sensitive domains such as healthcare, it is equally important to assess how well synthetic data preserves privacy. It mitigates the risk of exposing identifiable or sensitive information. To this end, we conduct a DP Evaluation in the following subsection, examining how well the synthetic data resists inference attacks under adversarial conditions.
Differential privacy evaluation
As mentioned in Section “Differential privacy”, we conducted a DP Evaluation to assess the balance between utility and privacy on the generated synthetic data. This task is performed through a label prediction task, considering a critical scenario in which an attacker gains access to the original and synthetic data, embeddings, and the embedding model, then tries to predict a missing feature value, such as some sensitive information about a patient.
As illustrated in Figure 1(C), three experimental settings were considered, using only the original dataset (

Differential privacy evaluation across benchmark datasets. Predictive performance (F1 for categorical features, MRR for continuous) is shown under four adversarial conditions: Using only the original dataset (DS), DS+Synthetic (DS+Syn), DS+Embeddings (DS+Emb), and DS+Syn+Emb. While embeddings alone rarely improve inference, the inclusion of synthetic data substantially improves prediction for some features (e.g., Infant Health: CXR, XRR, LF), underscoring both utility gains and privacy risks. (a)
These datasets were chosen for their diverse feature sets and distinctive performance trends. We observed that combining the original dataset with embeddings alone does not significantly improve the F1 and MRR scores for any of the evaluated features. In contrast, incorporating synthetic data leads to notable performance gains across several features (e.g., CXR, XRR, and LF) in the Infant Health dataset (see Figure 5(b)). Although this underscores the potential of synthetic data to enhance model effectiveness, it also raises concerns about inadvertently exposing sensitive patterns. If performance improvements exceed acceptable privacy thresholds, mitigation strategies such as adding calibrated noise during generation (or post hoc to the synthetic data) can help reduce re-identification or leakage risks. Alternatively, increasing the
When performance improvements suggest potential privacy leakage, it is essential to implement safeguards that limit the risk of revealing sensitive information without compromising the usefulness of the resulting synthetic data. To that end, we evaluated two complementary strategies: (a) Increasing the minimum number of neighbors (
Figure 4 shows how increasing the number of minimum and maximum neighbors used to generate synthetic data can negatively affect the performance of the resulting synthetic dataset. This evaluation compares synthetic versions generated using
We also evaluated the effect of introducing calibrated noise directly into the resulting synthetic dataset, aiming to obscure fine-grained patterns that could otherwise enable re-identification or reveal rare feature combinations. We experimented with two noise injection strategies: (a) Adding noise only to specific target features considered more privacy sensitive or highly predictive, and (b) applying noise uniformly across all features in the dataset. In Figure 6, we contrast these two strategies with the idea of increasing

Comparison of three strategies to mitigate privacy leakage in the Infant Health dataset: (a) Increasing nearest neighbor constraints, (b) adding noise to specific sensitive features (CXR = Chest X-Ray; XRR = X-Ray Report, LF = Lung Flow), and (c) adding noise across all features. Results show that global noise injection is most effective at reducing predictive performance for sensitive features, suggesting it as a stronger safeguard than targeted feature noise or neighborhood expansion alone.
Finally, we analyzed duplicate records using two benchmark datasets: (a) Mushroom (in Table 6), which consists entirely of categorical features, and (b) Avila Bible (in Table 7), which contains continuous features (except for the target label), all normalized to similar scales. We compared the characteristics of the original datasets with their corresponding synthetic versions generated by four tools, including SYNNER.
Analysis of duplicate and unique instances in the mushroom dataset when synthetic data are generated by different tools (synthpop, ARGN, Conditional tabular generative adversarial network (CTGAN), SYNNER).

Percentages of unique instances, duplicate ratios relative to the original dataset, and F1 scores for the original classification task are reported. Results show that while SYNNER generates fewer unique records than CTGAN, it achieves higher predictive accuracy, placing it in an intermediate position that balances utility and duplication risk.
Analysis of duplicate and unique instances in the avila Bible dataset under different synthetic generation tools.

Continuous variables were rounded to one decimal place when computing duplicates. Metrics reported include percentage of unique instances, duplicate ratios relative to the original dataset, macro F1 scores, and average minimum pairwise Euclidean distance (“Avg Min Diff”) as a measure of similarity between records. Results indicate that SYNNER avoids generating exact duplicates, while achieving a similarity profile (“Avg Min Diff”) closer to the original dataset than other methods, balancing fidelity with privacy preservation.
We considered two instances in the Mushroom dataset to be duplicates if they shared identical values across all features. In the original training set, nearly 95% of the instances are unique. As expected, synthetic data generation tools may reproduce this tendency to duplicate records. Synthpop, ARG, and SYNNER generated synthetic datasets in which only about 50% of the instances were unique, yet they still maintained high predictive accuracy in the test set. Synthpop was also effective in avoiding duplication of instances from the original data ( 7%). CTGAN, on the other hand, produced far fewer internal duplicate records and just 12% duplicates of the original data, but showed a notable drop in performance, with nearly a 7% reduction in the F1 score, suggesting that the resulting synthetic data loses utility as much as it becomes more randomly generated. Although SYNNER stays in an intermediate position when balancing internal versus original duplicates, the resulting synthetic data still performs accurately in the prediction task.
In the Avila Bible dataset, we considered two instances as duplicates if they shared identical values after rounding each continuous feature to one decimal place. In the original training set, there are only a few duplicates (actually very similar instances), and only Synthpop produced internal and original duplicates at a ration of less than 2% of the resulting synthetic dataset, leading to a higher prediction performance, but also raising concerns about privacy and data leakage. For each instance, we also computed its closest pair, defined as the minimum Euclidean distance (L2 norm) over all feature values, reported in Table 7 as ”Avg Min Diff”. The less the difference, the more similar the instances are within the resulting dataset. SYNNER approximates the best when instances differ from each other in the original data.
Finally, we computed the number of unique instances and the duplicate ratio in each of the evaluated datasets (original and synthetic versions produced by our approach), as shown in Table 8. We highlight the large number of duplicates in the original Stroke Prediction dataset when considering categorical features only, with less than 3% of its instances being unique, a behavior captured by SYNNER, which generated only 3.46% of unique synthetic combinations of categorical values, also reflected in the high duplication ratio compared to the original data (only
Comparison of unique instance percentages and duplicate ratios between original datasets and SYNNER-generated synthetic versions.

Results are reported separately for categorical-only features and continuous-inclusive features (rounded as indicated). Findings illustrate dataset-specific duplication behaviors in both original and synthetic data. While some duplicates appear in SYNNER-generated data, these are not intentional replications of original records; rather, they arise from the probabilistic sampling process, where feature values are drawn independently from the distributions of nearest neighbors, which reflects the balance between preserving local feature distributions and minimizing overfitting to individual records.
Our privacy analysis evaluates empirical resilience against adversarial privacy attacks. While these simulations demonstrate robustness, they do not constitute a formal DP guarantee. Thus, we report empirical reductions in privacy risk but do not claim provable DP compliance. We acknowledge that highly sensitive applications, such as those involving the infant health dataset, require stronger safeguards. Several mitigation strategies can reduce leakage risks if our method is deployed in practice. First, formal DP mechanisms can be integrated during training by injecting calibrated noise into gradients or outputs,48,49 thereby providing provable guarantees that individual records cannot be inferred. Second, data minimization and aggregation strategies should be applied, where rarely occurring or uniquely identifying variables are generalized or grouped to reduce the risk of re-identification. Third, generating synthetic data under DP constraints can serve as a privacy-preserving alternative, particularly in cases where rare events, such as neonatal conditions, could otherwise be memorized by the model. Furthermore, because membership inference attacks 50 remain a particularly significant threat in health data scenarios, where an adversary attempts to determine whether the record of a specific individual was part of the training set, our framework could be extended with adversarial training or defenses based on DP to mitigate this risk further. Finally, robust access control and audit mechanisms should be implemented to monitor the use of trained models with limited exposure of potentially sensitive outputs.
Real-world applicability
A central motivation for SYNNER is its potential use in clinical settings, where hospitals often need predictive models but face critical constraints on sharing sensitive patient data. In such scenarios, external companies or research groups may offer candidate solutions, yet they cannot be granted access to the original clinical data at the outset. SYNNER provides a practical pathway to overcome this barrier by enabling hospitals to generate synthetic datasets that preserve a substantial fraction of the original predictive signal (approximately 83.2% in our experiments).
Consider a real-world example: A hospital needs to develop a predictive model but cannot grant immediate access to its clinical data. In this scenario, SYNNER enables the hospital to generate synthetic datasets that capture a significant portion of the predictive signal while maintaining robust privacy safeguards. These synthetic datasets can be shared with external research groups or companies for prototyping models without direct access to the original clinical data.
Internally, the hospital can then evaluate candidate models against held-out real test data, thus quantifying the performance gap between models trained on synthetic data and those trained on the original data. This screening step substantially reduces the number of external agents that ultimately require access to sensitive clinical data, ensuring that only the most robust approaches move forward and thereby minimizing exposure risks.
However, it is essential to note that synthetic data alone is not intended for the final deployment of clinical models. Their role is to support pre-evaluation and model screening, allowing institutions to identify promising approaches while preserving patient privacy. The representativeness of synthetic datasets, even when relatively high, does not guarantee preservation of all feature dependencies or subgroup-specific relationships. Therefore, once candidate models have been identified, they must undergo independent validation and retraining on the original, unseen clinical data as an indispensable step to confirm reliability and safety before deployment. In this sense, the contribution of SYNNER is to enable privacy-preserving prototyping and collaboration, not to replace validated clinical models.
SYNNER’s built-in DP evaluation further strengthens this workflow by quantifying privacy risks and supporting mitigation strategies such as tighter neighborhood constraints or calibrated noise injection. These safeguards should be viewed as mechanisms to measure and manage potential biases in model performance and re-identification risks, rather than as a means to eliminate them.
Discussion
In this study, we present SYNNER, our proposal for generating synthetic data. SYNNER implements a pipeline structured in three phases: (a) Embedding generation, (b) synthetic data generation, and (c) DP evaluation. In the first phase, we generate embeddings from the original dataset using feature similarities and patterns within the data. In the second phase, we generated synthetic entities by randomly sampling feature values from their k-nearest neighbors in the embedding space, preserving the original relational properties while avoiding instance replication. In the last phase, we assess the DP of the generated synthetic datasets to ensure that sensitive data cannot be reconstructed.
Our framework included an empirical density analysis to establish neighborhood constraints to reduce the influence of outliers. With the analysis, we found that the effectiveness of SYNNER’s embedding-based sampling is highly sensitive to the maximum radius (
Across seven publicly available datasets, SYNNER preserved, on average, 83.2% of the original predictive signal, achieving 74.4% classification performance on synthetic data compared to models trained on original data. Our DP evaluation protocol further confirms that SYNNER-generated datasets meet stringent privacy standards, ensuring individual data protection. For cases where privacy risk remains, mitigation strategies such as tighter sampling constraints or calibrated noise can be applied during pre- or post-processing. This evaluation stage serves as a comprehensive diagnostic to assess the effectiveness of our design choices, including embedding strategies and sampling parameters. By identifying where synthetic data fall short in preserving predictive signal and privacy, researchers are better positioned to refine and tune their generative parameters.
Overall, our research contributes to ongoing efforts to generate synthetic data, providing insights into techniques for producing more realistic synthetic data. Most importantly, by addressing the limitations of existing approaches, SYNNER offers a scalable, privacy-preserving solution for synthetic data generation, paving the way for responsible research in sensitive areas such as healthcare.
Although our method has shown promising results in generating synthetic data, it has limitations, including the need to sample feature values for each synthetic instance independently. Specifically, each feature is sampled from a weighted distribution computed over the nearest neighbors in the embedding space. As a result, specific relational characteristics, such as temporal dependencies or feature correlations tied to demographic groups (e.g., sex-specific traits), may only be preserved by chance. This limitation becomes more pronounced in scenarios where data relationships evolve over time or exhibit structural dependencies. Future work should explore approaches that preserve these dependencies, for example, through sequence-aware models to retain temporal dynamics in longitudinal data, or conditional generative methods (CGMs) to enforce demographic and clinical subgroup consistency. These methods have been used in the medical/biomedical domain as effective means to capture evolving patterns and generate patient-specific synthetic data while maintaining subgroup consistency and realistic joint distributions.51,52
Because SYNNER is designed to capture feature distributions of continuous and categorical tabular data, it is less suited for scenarios involving dynamic entity relationships or longitudinal structures. Extending the framework with temporal modeling or subgroup-aware sampling would address this limitation and broaden its applicability to complex healthcare datasets. In this direction, we also plan to create synthetic versions of the publicly available Medical Information Mart for Intensive Care datasets (MIMIC-III and MIMIC-IV).
As noted in Sections “Synthetic data generation: Embedding space sampling” and “Synthetic data evaluation”, an important limitation of SYNNER is that feature values are sampled independently from local neighbor distributions in the embedding space. While this strategy helps avoid direct record duplication, it may fail to preserve higher-order dependencies, such as temporal dynamics and strong inter-feature correlations, which are relevant to clinical data. As a result, specific relational characteristics, such as disease progression patterns or demographic subgroup associations, may be preserved only by chance. Future work should address this limitation by exploring sequence-aware models that retain temporal information or CGMs that explicitly enforce subgroup consistency and joint feature dependencies.
Finally, our investigation of instance duplication offers valuable insights for both utility and privacy assessment in synthetic data. Although we were able to identify cases in which full-instance duplicates occur in both the original and synthetic data based on categorical features (as observed in the Mushroom dataset), comparing continuous features is more subjective. It is influenced by factors such as bin size or similarity thresholds. Addressing this complexity is essential for more precise evaluations of fidelity and privacy. Future research could build on our work by developing adaptive similarity measures or incorporating domain-specific knowledge to assess similarity in continuous data. These directions not only enhance the robustness of synthetic data evaluation but also reinforce the practical utility of SYNNER for generating synthetic data in complex real-world scenarios.
Conclusions
In this study, we present SYNNER, our proposal for generating synthetic data, designed to capture feature distributions of continuous and categorical tabular data. It is less suited for scenarios involving dynamic entity relationships or longitudinal structures. SYNNER implements a pipeline structured in three phases: (a) Embedding generation, (b) synthetic data generation, and (c) DP evaluation. In the first phase, we generate embeddings from the original dataset using feature similarities and patterns within the data. In the second phase, we generated synthetic entities by randomly sampling feature values from their
Footnotes
Acknowledgment
The authors would like to acknowledge the support of INSAFEDARE Project (Grant agreement ID: 101095661), which made this research possible.
Contributorship
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work has been partially funded by the INSAFEDARE Project (Grant agreement ID: 101095661).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
CEA LIST, France.