
Abstract
Objective
Voice disorders resulting from organic vocal cord lesions, whether benign or malignant, often lack reliable non-invasive diagnostic tools, which can lead to delays in treatment. This study aims to identify distinctive acoustic biomarkers and develop machine learning models for accurate classification of these lesions and prediction of malignancy. We investigated the acoustic characteristics of voice production in patients with organic vocal cord lesions, comparing benign and malignant cases, and evaluated the diagnostic potential of machine learning models in distinguishing between healthy and pathological voices.
Methods
A total of 157 participants were enrolled, including 127 patients with organic vocal cord lesions (109 benign, 18 malignant) and 30 healthy controls. Acoustic analysis was performed on vowel sounds, assessing vocal fold vibration parameters. Machine learning models (eXtreme Gradient Boosting (XGBoost), Light Gradient-Boosting Machine (LightGBM)) were trained to classify lesion types and predict malignancy. Receiver operating characteristic analysis identified key diagnostic parameters.
Results
Comparative analysis revealed 63 statistically significant differences in acoustic parameters between healthy and lesion-affected groups, with skewness and kurtosis being particularly discriminative. Six key parameters (/u/skew, /i/skew, /o/kurt, /o/shapefactor, /o/impulsefactor, and /a/peak2valley) demonstrated high diagnostic value in distinguishing benign from malignant lesions. The XGBoost model achieved the best performance in classifying vocal cord lesions (area under the curve (AUC) = 0.735), while LightGBM excelled in malignancy prediction (AUC = 0.924). Age and specific acoustic parameters were significant predictors in the models.
Conclusion
The integration of acoustic analysis with machine learning significantly enhances the diagnostic accuracy for vocal cord lesions, particularly in differentiating between benign and malignant cases. These findings underscore the potential of artificial intelligence (AI)-assisted voice analysis as a non-invasive tool for early detection and clinical decision-making. Further validation in larger cohorts is necessary to refine predictive algorithms for broader clinical application.
Keywords
Introduction
Voice production is a complex process that depends on the harmonious coordination of the respiratory system, phonatory system, and vocal tract. 1 The respiratory system, driven by the lungs, generates airflow that reaches the vocal folds at the glottis, causing them to vibrate. This sound is then amplified through the resonating system of the vocal tract before emerging from the mouth and nasal cavities.
Dysphonia, a common challenge for otolaryngologists, refers to abnormal voice production characterised by symptoms such as hoarseness, changes in voice quality, weakness or tremulousness, and fatigue. 2 The underlying causes of voice problems are multifaceted and include inflammation, non-physiological vocal usage, benign vocal cord lesions, and nerve damage affecting the larynx. 3 Benign vocal fold lesions can be broadly categorised into epithelial lesions, such as papillomas, and lesions affecting Reinke's space (nodules, polyps, cysts, and oedema) or the arytenoid (granulomas). 4 Additionally, there is a risk of malignant transformation from dysplastic laryngeal lesions to laryngeal cancer. 5 Given the significant differences in treatment approaches for benign and malignant vocal fold lesions, a multidisciplinary approach is essential to accurately identify suspicious lesions. 6
Otolaryngologists can conduct a perceptual assessment of voice by listening to sustained vowels or continuous speech production. However, this method relies heavily on the clinician's expertise and experience, making it susceptible to subjective judgments that may introduce variability and unreliability.7,8 Perceptual voice evaluation shows inter-clinician variability, with ICCs of 0.38–0.59 for roughness and breathiness assessments. 9
Acoustic analysis is a widely used technique in both clinical practice and research, providing valuable insights into the vibratory properties of the vocal folds and the overall health of the voice production mechanism. 10 This method involves measuring voice signals to offer an objective and quantitative characterisation of voice quality. 11 By analysing acoustic parameters such as fundamental frequency, jitter, shimmer, and spectral tilt, clinicians can develop a comprehensive understanding of voice disorders and their impact on vocal function. 12 For example, changes in fundamental frequency may indicate the presence of nodules or polyps on the vocal folds, while alterations in jitter and shimmer may suggest oedema or other pathological changes. 13 However, despite its potential benefits in detecting and managing vocal fold lesions, the lack of standardisation in the use of these parameters for voice assessment remains a challenge, hindering the accurate diagnosis and treatment of voice disorders. 14 While acoustic parameters (e.g. jitter, shimmer) provide objective measures, their diagnostic utility is limited by overlapping values across different lesion types 15 and lack of consensus on optimal parameter combinations. 16 These limitations frequently lead to diagnostic uncertainty, particularly when differentiating benign lesions from early malignancies that may share similar acoustic features. 17 Furthermore, there is a lack of consensus on the optimal combinations of acoustic parameters that would enhance diagnostic accuracy, leaving a gap in the literature regarding the most effective methodologies for voice disorder classification. 18 In summary, while current methods for assessing voice disorders, including perceptual evaluation and acoustic analysis, provide valuable insights, they are hindered by subjectivity, variability, and a lack of standardisation, particularly in distinguishing between benign and malignant lesions.
To address these challenges, it is crucial to develop a more efficient and precise voice assessment system for otolaryngology patients by analysing recorded voice signals in conjunction with clinical data. The advancement of artificial intelligence (AI) has created numerous opportunities for voice assessment, including the identification of bio-indicators for diagnosis, classification, patient remote monitoring, and the enhancement of clinical practice. 19 Studies employing machine learning algorithms on acoustic signals have shown promising results in diagnosing conditions such as depression, autism, and Alzheimer's disease. 20 The analysis of acoustic signals for the identification of vocal fold lesions, supported by machine learning models, presents a compelling approach to improving clinical diagnosis. 21 The integration of explainable AI methodologies with established acoustic parameters could provide clinicians with more transparent and interpretable tools, yet this approach has not been extensively investigated in the context of voice disorders.
The present study integrated acoustic analysis with advanced machine learning algorithms. By systematically comparing the acoustic characteristics of normal voices with those affected by benign and malignant vocal cord lesions, we aim to identify distinctive acoustic biomarkers. Furthermore, we develop machine learning models, specifically eXtreme Gradient Boosting (XGBoost) and Light Gradient-Boosting Machine (LightGBM), to classify lesion types and predict malignancy. These algorithms have demonstrated promising results in various medical diagnostic applications due to their ability to handle complex data and provide accurate predictions. 22 The SHapley Additive exPlanations (SHAP) framework is employed to provide interpretability and understand the contribution of each acoustic parameter to the model predictions. 23
Our study aims to overcome the limitations of existing diagnostic methods by leveraging the power of acoustic analysis and machine learning. By providing a more objective, efficient, and interpretable tool for differentiating benign from malignant vocal cord lesions, we hope to support early detection and inform clinical decision-making processes. The main contribution of this work includes the following:
Comprehensive acoustic profiling: Systematic comparison of normal and pathological voices across benign and malignant conditions AI-enhanced diagnostics: Development of machine learning tools combining explainable AI with conventional acoustic parameters Clinical decision support: Creation of a framework that maintains interpretability while improving objectivity
This work is organised as follows: the literature section reviews the related literature; the methodology section presents the proposed approach; the results section reports the findings; the discussions section provides a discussion of the results; the limitations of the study section outlines the limitations of the study; and the final section concludes the paper and suggests future research directions.
Methods
Ethics statement
This study was approved by the Medical Ethics Committee of the First Affiliated Hospital of Chengdu Medical College (2022CYFYIRB-RA-Aug08). Written informed consent was obtained from all participants.
Participants
This retrospective diagnostic accuracy study analysed voice samples and medical records from patients who underwent laryngoscope examination at the First Affiliated Hospital of Chengdu Medical College between January 2021 and December 2023. The study design incorporated both comparative acoustic analysis of vocal parameters and development of machine learning models to evaluate their diagnostic performance for organic vocal cord lesions.
To facilitate an objective acoustic analysis of vocal cord lesions and normal vocal cords, participants were categorised into benign and malignant vocal cord groups. The inclusion criteria for the control group were as follows: age of ≥18 years, no relevant medical history or current dysphonia, and no structural or functional abnormalities in the larynx. The inclusion criteria for the malignant vocal cord group were as follows: diagnosis of glottic cancer via laryngoscopy and histopathology, with the tumour confined to the vocal cord (which may invade the anterior or posterior commissure) and with normal vocal cord movement; the ability to provide informed consent; and fluency in Mandarin. The inclusion criteria for the benign vocal cord lesion group were similar, namely a diagnosis of a vocal cord lesion via laryngoscopy and histopathology (or clinical examination in controls), the ability to provide informed consent, and fluency in Mandarin.
The exclusion criteria for both the benign and malignant vocal cord groups followed a similar pattern: treatment with medications that may induce voice changes, unwillingness or inability to provide informed consent, unconsciousness, severe cognitive impairment or psychiatric disorders affecting assessment, participation in other rehabilitation programmes, and an inability to accurately perform the study tasks.
Clinical data related to the patients were collected, including sex, age, smoking and alcohol consumption, disease side, body mass index, co-existing conditions such as pharyngitis and gastroesophageal reflux disease, and histopathological findings.
Sound acquisition and feature parameter extraction
The subjects were located in a quiet voice examination room where ambient noise was kept below 45 dB. The XION GmbH DIVAS2.5 was used for acquisition. Before the formal test, the physician assisted the subject to wear the headset microphone, kept the front and bottom of the microphone at 45° to the subject, informed the subject about the voice acquisition method, removed the subject's tension, and guided the patient to correctly and smoothly produce continuous vowels. Formal voice acquisition was performed until the subject mastered the correct pronunciation method. Each test syllable consisted of Chinese vowels /a/, /o/, /e/, /i/, /u/, /u/. Each vowel was repeated for at least three seconds at their usual pitch and loudness. The most stable audio clips were selected for recording.
The vowel selection (/a/, /o/, /e/, /i/, /u/, /ü/) was based on their distinct acoustic and articulatory characteristics, which are critical for comprehensive vocal assessment. The vowels /a/ and /o/ provide robust formant structures for spectral analysis, while /i/ and /u/ are essential for evaluating vocal tract configuration and tension. The inclusion of /e/ and /ü/ further enhances the detection of subtle pathological variations due to their intermediate articulatory positions. Each sound segment had a duration of approximately 3 s, with a total test duration averaging around 10 min per subject. The extracted acoustic parameters were obtained using a custom MATLAB script that performed wavelet transforms, Fourier functions, and acoustic parameter extraction. In total, 34 acoustic parameters were extracted: absomean, std, skew, kurt, max, min, peak2valley, rms, crestfactor, shapefactor, impulsefactor, marginfactor, energy, first_f0, middle_f0, last_f0, median_f0, mean_f0, f0variation, f0skew, f0kurt, max_f0, min_f0, range_f0, slope_start2max, slope_max2end, hnr, jitter, duration, hr_mean, hr_median, hr_std, hr_max, and hr_min (see Figure 1).



Comprehensive speech data processing and analysis pipeline for vocal cord disease detection.
Machine learning and visualisation analysis based on SHAP model
Machine learning and visualisation analysis based on SHAP model. This study developed predictive models for vocal pathologies using a dataset split into training (75%) and validation sets (25%) with three-fold cross-validation. To address the class imbalance between positive (benign) and negative (malignant) samples in this study, the Synthetic Minority Over-sampling Technique (SMOTE) was implemented to augment the minority class (malignant). The following models were trained and evaluated: LightGBM, an efficient gradient-boosting decision tree (DT); a support vector machine (SVM); logistic regression (LR); and a random forest (RF); DT; k-nearest neighbours (KNN); and XGBoost. Hyperparameter tuning was performed using these search spaces: Random Forest: n_estimators: [20], max_depth: [None, 10, 20], min_samples_split: [2, 5, 10], min_samples_leaf: [2, 4];Decision Tree: max_depth: [None, 10, 20], min_samples_split: [2, 5, 10], min_samples_leaf: [2];Logistic Regression: C: [0.1, 1, 10], penalty: [‘l1’, ‘l2’];KNN: n_neighbors: [3, 5, 7], weights: [‘uniform’, ‘distance’], algorithm: [‘auto’, ‘ball_tree’, ‘kd_tree’];XGBoost: n_estimators: [40], max_depth: [3, 5, 7], learning_rate: [0.01, 0.1, 0.3];LightGBM: n_estimators: [20], max_depth: [3, 5, 7], learning_rate: [0.01, 0.1, 0.3].
These models were assessed using precision, accuracy, recall, F1 score, and area under the curve (AUC), with clinical utility evaluated through decision curve analysis (DCA). The goal was to distinguish normal speakers from those with vocal cord pathology, including benign and malignant lesions, providing a robust tool for vocal disorder diagnosis and management.
SHAP is a powerful framework used for interpreting and understanding predictions made by machine learning models. 17 This study applied SHAP analysis to the model with the best classification performance to quantify the contribution of each feature to the prediction results, enabling feature contribution visualisation and model interpretation.18,19
Statistical analysis
Continuous variables are presented as mean ± standard deviation. Categorical variables are presented as frequency. One-way analysis of variance was used for statistical analysis, and variables with statistical differences were selected into the machine learning model. Among them, acoustic parameters were further screened by receiver operating characteristic (ROC) to select six acoustic parameters as included variables. Statistical analysis was performed using Stata 18 and Graphpad Prism, and statistical significance was set at p < .05.
Results
Demographics
To establish the baseline characteristics of the study population and identify potential demographic factors associated with vocal cord lesions, 157 patients were included in this study, comprising 127 patients with organic vocal cord lesions who underwent surgical treatment and 30 participants in the control group. Histopathological examination confirmed that the lesions were either benign (109 cases) or malignant (18 cases of laryngeal squamous cell carcinoma, Tis-T2 stage, with no cervical lymph node involvement or distant metastasis). The benign lesions included 77 cases of polyps, 15 cases of cysts, three cases of mycosis, five cases of granuloma, and nine cases of papilloma. The results are shown in Table 1. The malignant lesion group was significantly older compared to the benign lesion and control groups (p<.001). A higher proportion of males were present in the malignant lesion group compared to the benign lesion and control groups (p<.001). Significantly more patients in the malignant lesion group reported smoking and drinking alcohol compared to the benign and control groups (p<.001).
Baseline characteristics of the participants.

Objective analysis – parameters
To identify acoustic biomarkers that can differentiate between normal vocal cords, benign lesions, and malignant lesions, one-way analysis of variance revealed significant differences between groups in 62 of the 264 parameters across six different vowels (Table 2-1, 2-2, 2-3, 2-4, and 2-5). Based on these results, we selected at least two sets of parameters with inter-group differences between the three groups to depict the box plot (Figure 2). Eighteen parameters were depicted, although only the box plot of six parameters is shown in Figure 1. Further details are presented in Appendix 1. Comparative analysis revealed 63 statistically significant differences in acoustic parameters across six different vowels (/a/, /o/, /e/, /i/, /u/, /ü/) between the control, benign lesion, and malignant lesion groups (p < .05). Six key parameters (/u/skew, /i/skew, /o/kurt, /o/shapefactor, /o/impulsefactor, and /a/peak2valley) demonstrated high diagnostic value in distinguishing between benign and malignant lesions (p < .05).

Significant differences between normal subjects groups versus benign vocal cord lesions versus malignant vocal cord lesions.
Comparison of voice parameters in benign and malignant glottic lesions at different vowel.

Note: ANOVA, *p < .05.
Comparison of voice parameters in benign and malignant glottic lesions at different vowels.

Note: ANOVA, *p < .05.
Comparison of voice parameters in benign and malignant glottic lesions at different vowel.

Note: ANOVA, *p < .05.
Comparison of voice parameters in benign and malignant glottic lesions at different vowel.

Note: ANOVA, *p < .05.
Comparison of voice parameters in benign and malignant glottic lesions at different vowel.
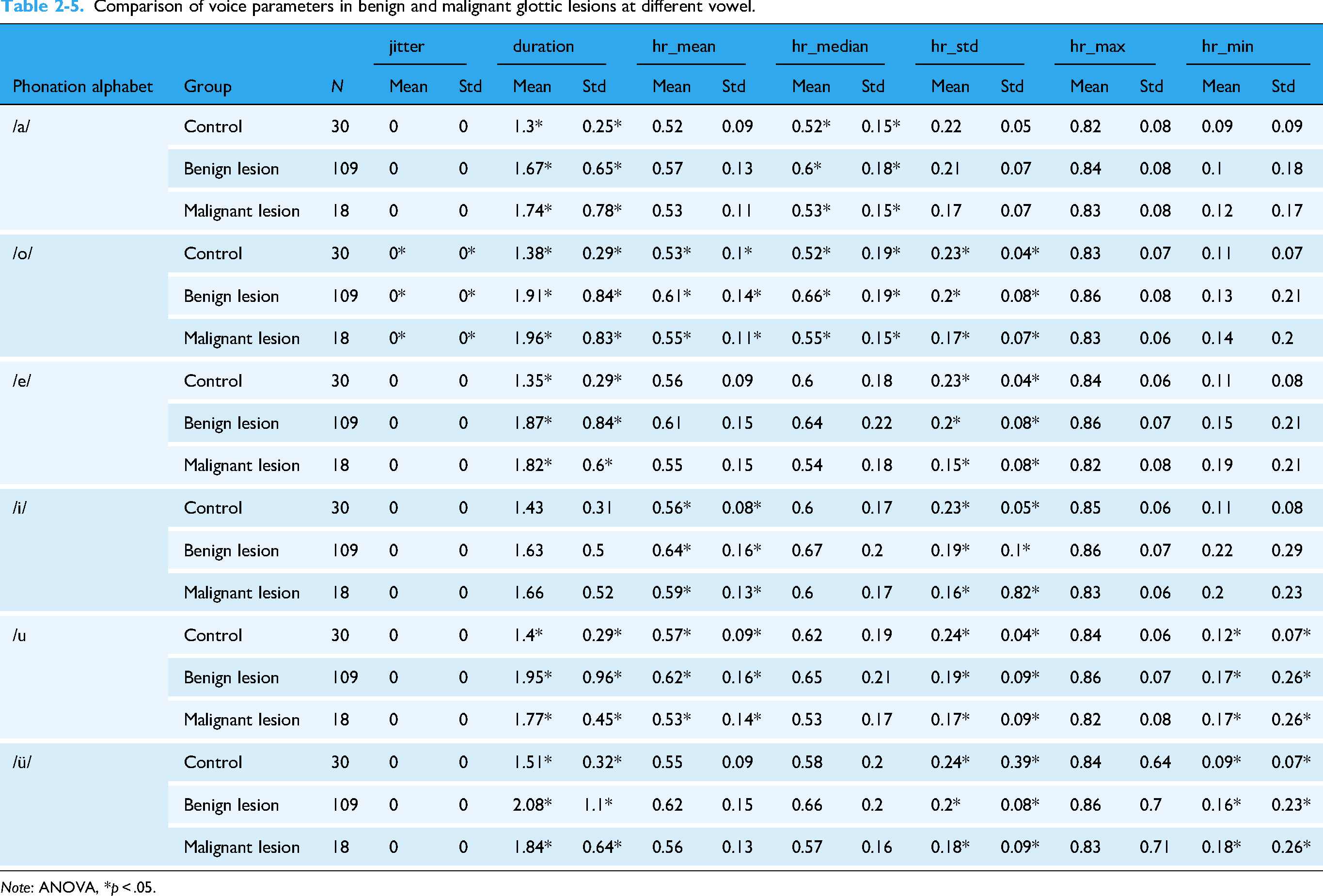
Note: ANOVA, *p < .05.
ROC curve analysis was used to evaluate the diagnostic performance of individual acoustic parameters in distinguishing between normal, benign, and malignant vocal cord conditions. The ROC curves of the single parameters that were statistically different (p < .05) in distinguishing normal-speaking subjects from those with organic vocal cord lesions were plotted. Only the top six parameters with the highest AUC are shown in Figures 3 and 4. Compared with the control group, /u/skew (AUC = 0.782, 95% CI [0.705–0.860]) had the highest AUC value, making it the strongest voice parameter to distinguish normal individuals from those with organic vocal cord lesions (Figure 3). When differentiating malignant from benign lesions, the strongest discriminant factors were /u/middle_f0 and /u/skew (Figure 4). The results of the ROC analysis for all differential parameters are presented in Appendix 2.

ROC curve of voice parameters to distinguish control versus vocal cord organic lesions.

ROC curve of voice parameters to distinguish benign and malignant lesions of vocal.
Machine learning prediction model for normal speaking subjects and patients with vocal cord organic lesions
Machine learning model development and evaluation analysis was used to develop and evaluate machine learning models for classifying vocal cord lesions and predicting malignancy based on acoustic parameters and demographic variables. A comprehensive analysis revealed that no single acoustic parameter could distinguish normal voices from benign or malignant vocal lesions. As a result, multivariate prediction models (XGBoost, LightGBM, Decision Tree, LR, RF, SVM, and KNN) were developed. The final model utilised six key acoustic features along with demographic variables (sex, age, smoking, and drinking). The XGBoost model demonstrated the best performance, with an AUC of 0.735, accuracy of 0.900, precision of 0.917, and recall of 0.971 (Table 3, Figure 5). The DCA curve showed that the XGBoost model provided a higher clinical net benefit than the all/none curves when the threshold probability was between 0.2 and 1 (Figure 6). Given that all patients had severe symptoms and sought treatment, the clinical net benefit of the overall intervention was similar to that of the model when the risk threshold probability was <0.2.

ROC curves of different classifiers.

DCA curve of XGBoost model.
The results of different classifiers for predicting organic lesions.

LightGBM: Light Gradient-Boosting Machine; SVM: support vector machine; KNN: k-nearest neighbours; XGBoost: eXtreme Gradient Boosting.
For the best-performing XGBoost model, SHAP analysis was employed to quantify and visualise the contribution of each feature to the prediction. The model identified /i/skew and /u/skew as the most significant contributors: higher /i/skew decreased the probability of vocal cord organic lesions, while higher /u/skew, /a/peak2valley, and /o/kurt also had a negative impact, although to a lesser extent. Low values of gastroesophageal reflux disease, sex, drinking, and smoking habits were associated with negative SHAP values, indicating a lower probability of lesions, while higher values increased the probability (Figure 7).

SHAP summary plot in control vs vocal cord organic lesions.
Machine learning prediction model for benign and malignant vocal cord lesions
A model was developed to identify malignancy in organic lesions using 13 predictors, including acoustic features and clinical variables. The LightGBM model demonstrated the best performance, with an AUC of 0.924, accuracy of 0.924, precision of 0.935, and recall of 0.906 (Table 4, Figure 8). The DCA curve indicated that the model's clinical net benefit was significantly higher than comprehensive or no intervention strategies when the risk threshold was between 0.1 and 1 (Figure 9), highlighting its value for clinical decision-making. SHAP analysis revealed that age, drinking, male sex, and smoking had a significant impact on the prediction, with drinking contributing more strongly than smoking (Figure 10).

ROC curve for predicting benign and malignant vocal cord lesions in models.

DCA curve of LightGBM model.
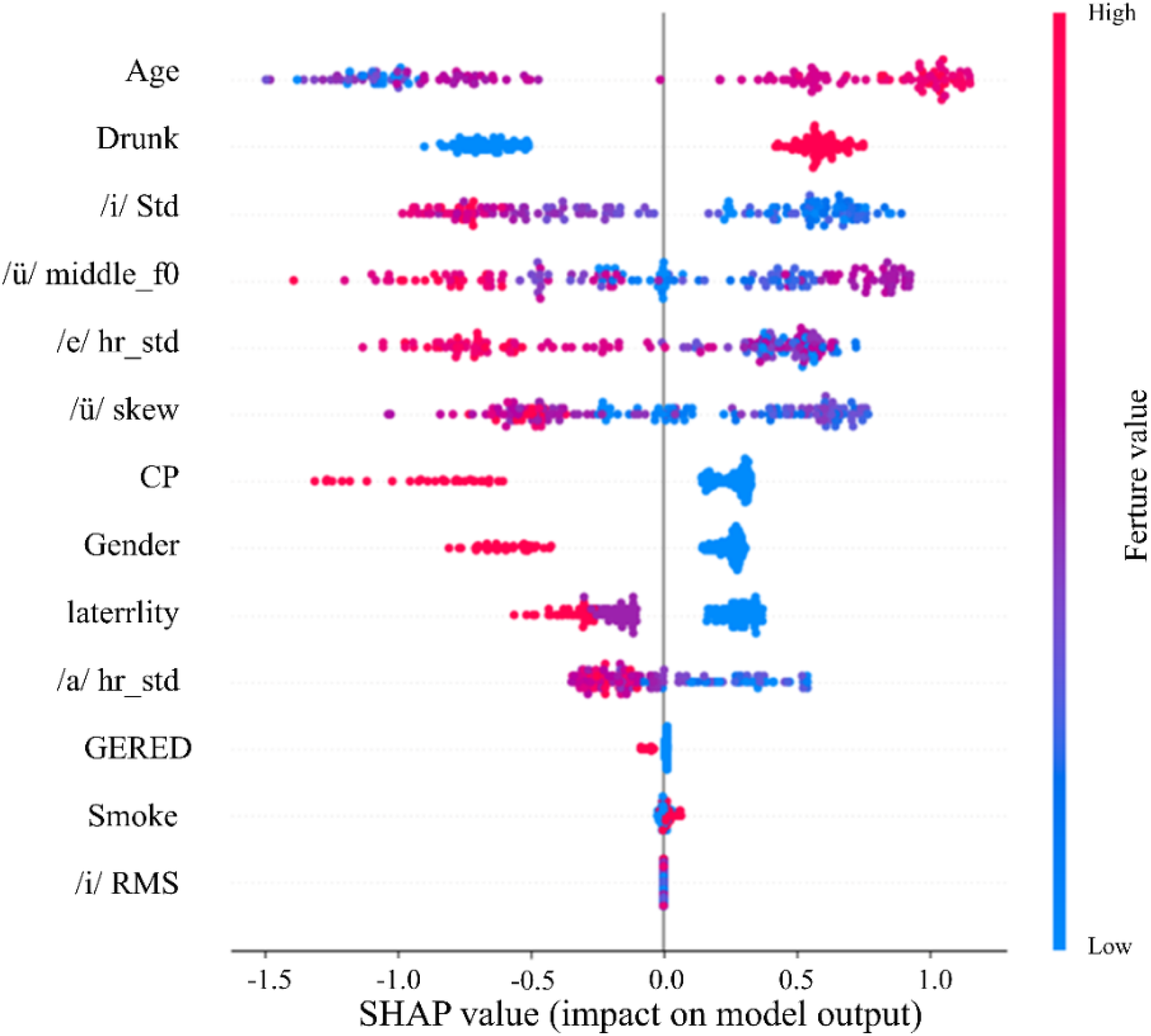
SHAP summary plot in benign versus malignant lesions of vocal.
The results of different classifiers for predicting benign and malignant vocal cord lesions.

LightGBM: Light Gradient-Boosting Machine; SVM: support vector machine; KNN: k-nearest neighbours; XGBoost: eXtreme Gradient Boosting.
Discussion
Current diagnostic approaches for vocal cord lesions include clinical evaluations such as comprehensive interviews, perceptual voice assessments, laryngoscopy, aerodynamic testing, and laryngeal electromyography. 24 However, these methods can be labour-intensive and costly, which hinders early diagnosis and treatment. As a result, there is an urgent need for a simpler and more efficient method to support the preliminary diagnosis of vocal cord lesions.
Vocal cord lesions can have a profound impact on an individual's voice quality. 25 Objective acoustic analysis plays a crucial role in assessing these changes by analysing specific acoustic parameters that provide valuable insights into the vibratory patterns and closure dynamics of the vocal cords. 26 In this study, we analysed a cohort of 157 patients, comprising 127 individuals with confirmed organic vocal cord lesions (109 benign and 18 malignant) and an additional 30 patients presenting with various otorhinolaryngological conditions. Significant differences were observed in demographic variables such as age, gender, smoking, and drinking habits between the control and lesion groups. These differences suggest that demographic factors may play a role in the development of vocal cord lesions. For example, older age and male gender were more prevalent in the malignant lesion group, highlighting potential risk factors.
Voice samples were obtained from all participants to enable objective acoustic analysis. The primary aim was to identify distinctive acoustic biomarkers capable of differentiating between normal vocal cords, benign lesions, and malignant lesions. Comparative analysis revealed 63 statistically significant differences in acoustic parameters between healthy and lesion-affected groups. Six key parameters (/u/skew, /i/skew, /o/kurt, /o/shapefactor, /o/impulsefactor, and /a/peak2valley) demonstrated high diagnostic value. These acoustic parameters reflect the impact of vocal cord lesions on vocal fold vibration, closure dynamics, and sound quality. Skewness quantifies the symmetry of vocal fold vibration waveforms. During normal vocal fold closure, the glottal wave exhibits an approximately symmetric triangular shape, with skewness values close to zero clinically observed. When benign lesions (e.g. polyps, cysts) develop on the vocal folds, the uneven mass distribution results in asynchronous glottal closure during vibration. This causes the vibratory waveform to shift towards one side, thereby increasing the skewness value (positive or negative skew). In cases of malignant tumours infiltrating the vocal fold muscle layer, vibrational symmetry is disrupted, potentially leading to more pronounced skewness abnormalities compared to benign conditions. In this study, the /u/ skewness achieved an AUC of 0.782 in distinguishing between normal and pathological voices. Compared with histopathological results, the skewness value showed a positive correlation with the degree of vocal fold mucosal wave asymmetry (r = 0.63, p < .01).In this study, the /u/ skewness achieved an AUC of 0.782 in distinguishing between normal and pathological voices. Compared with histopathological results, the skewness value showed a positive correlation with the degree of vocal fold mucosal wave asymmetry (r = 0.63, p < .01).
The application of machine learning algorithms to analyse voice samples offers a promising approach for classifying distinct vocal pathologies. The integration of these algorithms into the assessment of vocal cord lesions has the potential to significantly enhance both diagnostic accuracy and efficiency. 27 In this study, we implemented seven machine learning algorithms (XGBoost, KNN, LR, SVM, LightGBM, RF, and DT) to evaluate their performance in diagnosing vocal cord lesions. 28 To assess the effectiveness of these models, we employed a range of metrics, including accuracy, precision, recall, F1 score, and the AUC. 29 Our final model was designed to diagnose organic lesions in subjects with normal vocal characteristics using six key features identified for their predictive strength: /u/skew, /i/skew, /o/kurt, /o/shapefactor, /o/impulsefactor, and /a/peak2valley. We also incorporated demographic variables such as sex, age, smoking status, and alcohol consumption as predictors. 30
Our comparative analysis of machine learning models revealed distinct performance advantages: the XGBoost algorithm demonstrated superior capability in differentiating normal vocal cords from organic lesions (AUC = 0.894, accuracy = 0.893, precision = 0.903, recall = 0.876), while LightGBM achieved exceptional performance in malignancy prediction (AUC = 0.924, accuracy = 0.924, precision = 0.935, recall = 0.906). These results suggest LightGBM's particular clinical utility for early malignant lesion detection due to its robust predictive performance. This work contrasts with the OS-ELM approach employed by FT Al-Dhief et al. in speech pathology classification, highlighting how algorithm selection should be tailored to specific diagnostic objectives. 31 The demonstrated efficacy of gradient boosting methods (XGBoost/LightGBM) for vocal lesion analysis, combined with their computational efficiency, positions them as promising tools for clinical implementation. Future research directions should investigate hybrid systems incorporating online learning capabilities (e.g. OS-ELM) with our validated acoustic feature extraction pipeline to enable real-time diagnostic applications.
Through SHAP value analysis, we obtained critical interpretability insights that quantify the relative contribution of each feature to the model's predictive outcomes. The SHAP values and plots revealed that the skew of /i/, skew of /ü/, peak2valley of /a/, age, and shapefactor of /o/ were the most influential features in the XGBoost model for predicting vocal cord organic lesions. Conversely, smoking had a relatively minor contribution. Furthermore, SHAP plot analysis revealed that age had a significant impact on the prediction verification process, with older ages being strongly associated with a higher likelihood of vocal cord malignant organic lesions in the LightGBM model. Similarly, drinking, male sex, and smoking were identified as promoting factors. 18 Nuha Qais Abdulmajeed proposed a deep learning method based on unique feature selection that significantly improves the recognition of various speech pathologies, while our research focuses on distinguishing between benign and malignant vocal cord lesions and enhancing model interpretability through SHAP values, suggesting that integrating deep learning with explainability methods could further enhance the accuracy and clinical applicability of speech pathology recognition. 32
Our study explores the potential application of acoustic analysis combined with AI for diagnosing vocal cord lesions. This approach may offer an alternative pathway in otolaryngological diagnostics, potentially reducing dependence on invasive methods through non-invasive, AI-assisted solutions. The integration of machine learning models like XGBoost provides preliminary evidence supporting the feasibility of processing acoustic data for diagnostic purposes. Additionally, our use of explainable AI techniques (SHAP values) addresses interpretability considerations in medical AI, contributing to discussions about transparent healthcare technologies.
From a practical perspective, the methodology could potentially enable earlier lesion detection, which might improve clinical intervention timelines. The explainable components may offer clinicians insights into feature contributions, possibly supporting diagnostic confidence in clinical settings.
Limitations of this study
While this study demonstrates the promising application of acoustic analysis and machine learning in diagnosing vocal cord lesions, several limitations must be acknowledged:
The sample size of 157 participants, including only contain 18 malignant cases, may limit the generalisability of the findings, particularly for rare or aggressive lesions. The single-center design of the study could introduce selection bias, necessitating future multicenter studies with diverse populations to validate the results. Although 34 acoustic parameters were analysed under controlled recording conditions, natural speech variability (e.g. emotional state, fatigue) was not fully accounted for. Additionally, other potentially relevant features (e.g. nonlinear dynamic measures) were not included in the analysis. Despite attempting to address the imbalance in the dataset using over-sampling techniques (e.g. SMOTE), the training of the machine learning models was ultimately not performed using the over-sampled data due to observed degradation in performance. This decision may have further impacted the generalisability of the models.
Despite these limitations, the study highlights the potential of AI-assisted voice analysis as a non-invasive diagnostic tool for vocal cord lesions. Future research should address these constraints through expanded cohorts, multicenter validation, broader feature selection, and prospective clinical trials to fully realise its clinical potential.
Conclusion
This study theoretically advanced the field of voice disorder diagnostics by establishing a novel framework that integrates acoustic analysis with machine learning. The identification of 63 distinctive acoustic parameters between healthy and pathological voices provided a quantitative basis for understanding how vocal cord lesions alter phonatory dynamics. The SHAP analysis further unveiled the interpretability of AI models, demonstrating that features like age and acoustic skewness are key predictors of malignancy, which enriched the theoretical understanding of lesion classification. Practically, the developed XGBoost and LightGBM models offered a non-invasive, efficient alternative to traditional diagnostic methods, potentially reducing reliance on invasive laryngoscopy and improving early detection rates for vocal cord malignancies.
The research yielded tangible clinical benefits. First, the non-invasive nature of voice recording reduces patient discomfort and eliminates risks associated with invasive procedures. Second, the models’ high accuracy and rapid processing speed enable scalable screening in primary care settings, especially for populations with limited access to specialised ENT facilities. Third, the SHAP-based interpretability allows clinicians to validate AI outputs against patient demographics (e.g. age, smoking history) and acoustic features, enhancing diagnostic confidence.
Despite the promising results, this study was not without limitations. The sample size, particularly for malignant cases, was relatively small, which may limit the generalisability of the findings. Additionally, the single-center design might introduce selection bias. The analysis did not fully account for natural speech variability, and other potentially relevant features such as nonlinear dynamic measures were not included. Furthermore, while attempts were made to address class imbalance using SMOTE, the over-sampled data was not used in the final model training due to observed performance degradation.
Future research should aim to validate the findings in larger, multicenter studies with more diverse patient populations. Incorporating additional acoustic features, such as nonlinear dynamic measures, and accounting for natural speech variability could further enhance model performance. Additionally, hybrid systems combining online learning capabilities with the validated acoustic feature extraction pipeline could enable real-time diagnostic applications. Finally, prospective clinical trials are needed to fully realise the clinical potential of AI-assisted acoustic analysis in diagnosing vocal cord lesions.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251376264 - Supplemental material for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics
Supplemental material, sj-docx-1-dhj-10.1177_20552076251376264 for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics by Keyi Ma, Yi Wang, Yulin Zhou, Lan Chen, Tiecheng Zhang, Fan Xu and Xiaoli Peng in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251376264 - Supplemental material for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics
Supplemental material, sj-docx-2-dhj-10.1177_20552076251376264 for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics by Keyi Ma, Yi Wang, Yulin Zhou, Lan Chen, Tiecheng Zhang, Fan Xu and Xiaoli Peng in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251376264 - Supplemental material for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics
Supplemental material, sj-docx-3-dhj-10.1177_20552076251376264 for Acoustic signatures of organic lesions and the role of artificial intelligence in voice disorder diagnostics by Keyi Ma, Yi Wang, Yulin Zhou, Lan Chen, Tiecheng Zhang, Fan Xu and Xiaoli Peng in DIGITAL HEALTH
Footnotes
Acknowledgements
We thanks the valuable supports from the medical sound database from Chengdu Medical College (http://ama.cmc.edu.cn) and valuable expert suggestion from Chengdu Zhiju Data Technology Co.Ltd (![]() ).
).
Consent to participate
The participants provided their written informed consent to participate in this study.
Consent for publication
The authors all consent for publication.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Key Discipline Project at the School of Public Health, Chengdu, School joint funding, Sichuan Applied Psychology Research Centre, The National Key R&D Programme of China, National Natural Science Foundation of China, Research Staring Foundation of High-level Talent Introduction of The First Afflicted Hospital of Chengdu Medical College (Grant Nos. 21, CSXL-24215, 2023YFE0108400, 82073833, 8216050478, and CYFY-GQ19).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and material
Data are available upon request to the corresponding authors.
Code availability
Codes are available upon request to the corresponding authors.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.