
Abstract
Objective
This study is designed to evaluate the accuracy of ChatGPT models (3.5, 4.0 and 4 Turbo) in answering multiple-choice questions (MCQs) related to oral and maxillofacial pathology and oral radiology, thus, providing reliable information in the field of dentistry.
Methods
A set of 136 validated MCQs varies between knowledge and cognitive were used in the study. The questions covered different topics related to odontogenic cysts, tumours and bone lesions. Difficulty of the questions was evaluated by two MCQ-item writing, board-certified reviewers in the fields. The questions were entered into Chat GPT-3.5, ChatGPT-4 and ChatGPT-4 Turbo independently. Ten months later, ChatGPT was updated to newer versions, and the same set of questions was entered to evaluate the consistency of the ChatGPT responses.
Results
Fifty-six percent of the total questions were related to oral radiology, and 66% were categorised as easy. The dataset consisted primarily of questions testing knowledge (87%), with only 13% of questions assessing cognitive skills. ChatGPT-4 Turbo exhibited the highest accuracy, answering 90% of questions correctly, followed by ChatGPT-4.0 with 85% accuracy and ChatGPT-3.5 with 78% accuracy. Only 98 questions (72%) were correctly answered by the three models. Ten months later, the unpaid ChatGPT version showed a significant improvement in accuracy, while the paid versions maintained consistent performance over time with no significant differences.
Conclusion
This study found that ChatGPT-4 Turbo outperformed Models 4 and 3.5 in accuracy and speed. While the unpaid version showed significant improvement over time, the paid versions remained consistently accurate. The findings suggest that, while AI can be a helpful tool in dental education, limitations persist that must be addressed, particularly in terms of complex cognitive skills and image-based questions. This study provides valuable insights into the capabilities and potential improvements of AI applications in dental education.
Keywords
Introduction
The chatbot generative pretrained transformer (ChatGPT) developed by OpenAI is an advanced form of AI designed to generate human-like dialogue. 1 Enriched with advanced technology and techniques, ChatGPT effectively responds to user queries. Since its launch in November 2022, ChatGPT has become increasingly popular among students, faculty, professionals and researchers, transforming the landscape of teaching and learning.2,3 However, the integration of AI in pedagogical settings has been limited.4,5 Given the increasing reliance on AI in educational settings, it is crucial to measure its performance against established educational standards.
In the context of dental education, where precision and comprehensive understanding can have serious implications, assessing the efficacy and outcomes of using AI tools such as ChatGPT is essential.6–10 Furthermore, comparing the performance of various ChatGPT models to the use of dental textbooks alone may help to determine whether ChatGPT enhances human learning and identify its limitations in this respect. Several studies have examined the use of AI in dental education, highlighting both its potential and constraints.11–15
Questions are of particular interest in oral radiology and in determining oral and maxillofacial pathologies because they directly impact the diagnosis and treatment planning of dental conditions, which makes their accurate assessment important for ensuring comprehensive patient care. Thus, the use of multiple-choice questions (MCQs) in dental education is vital, as these questions reflect the necessary competencies for dental practice and are extensively used in major assessments of dental students, including university final exams and dental-licensing exams. 14
Research on ChatGPT performance and accuracy in answering questions related to oral and maxillofacial pathology and oral radiology is limited; thus, the thorough verification of the reliability of the responses of chatbots such as ChatGPT is a pressing issue. 16 This study compared the performance and accuracy of ChatGPT models’ answers to MCQs regarding oral and maxillofacial pathology and oral radiology. The results contribute to our understanding of the capabilities and limitations of different ChatGPT models in providing reliable information in the field of dentistry, and they can potentially guide the development and improvement of AI-driven dental-education frameworks.
Materials and methods
Selection of multiple-choice questions
For this study, two experts in the field of oral diagnostic sciences independently sourced questions from various textbooks, including Oral and Maxillofacial Pathology, fifth edition, published in 2023, 17 and Oral Radiology Principles and Interpretation, published in 2015, 18 as well as university-examination question pools. The experts verified the content validity of the questionnaire. Moreover, due to ChatGPT's inability to analyse visual content, answerability based on question text alone was defined as the primary inclusion criteria. The language used was simple and easy to understand, and each question had a single correct answer. The quality of the MCQs was assessed, and the wording of some questions was modified without altering the exact meaning of the question and the key answer to ensure the questions’ accuracy. Additionally, a pilot test was conducted with 10 MCQs to check their technical accuracy; these MCQs were excluded from the study. A total of 136 English questions were generated and screened for duplicates, vague meanings and variations across sources. Figure 1 shows the question-selection process used in this study.
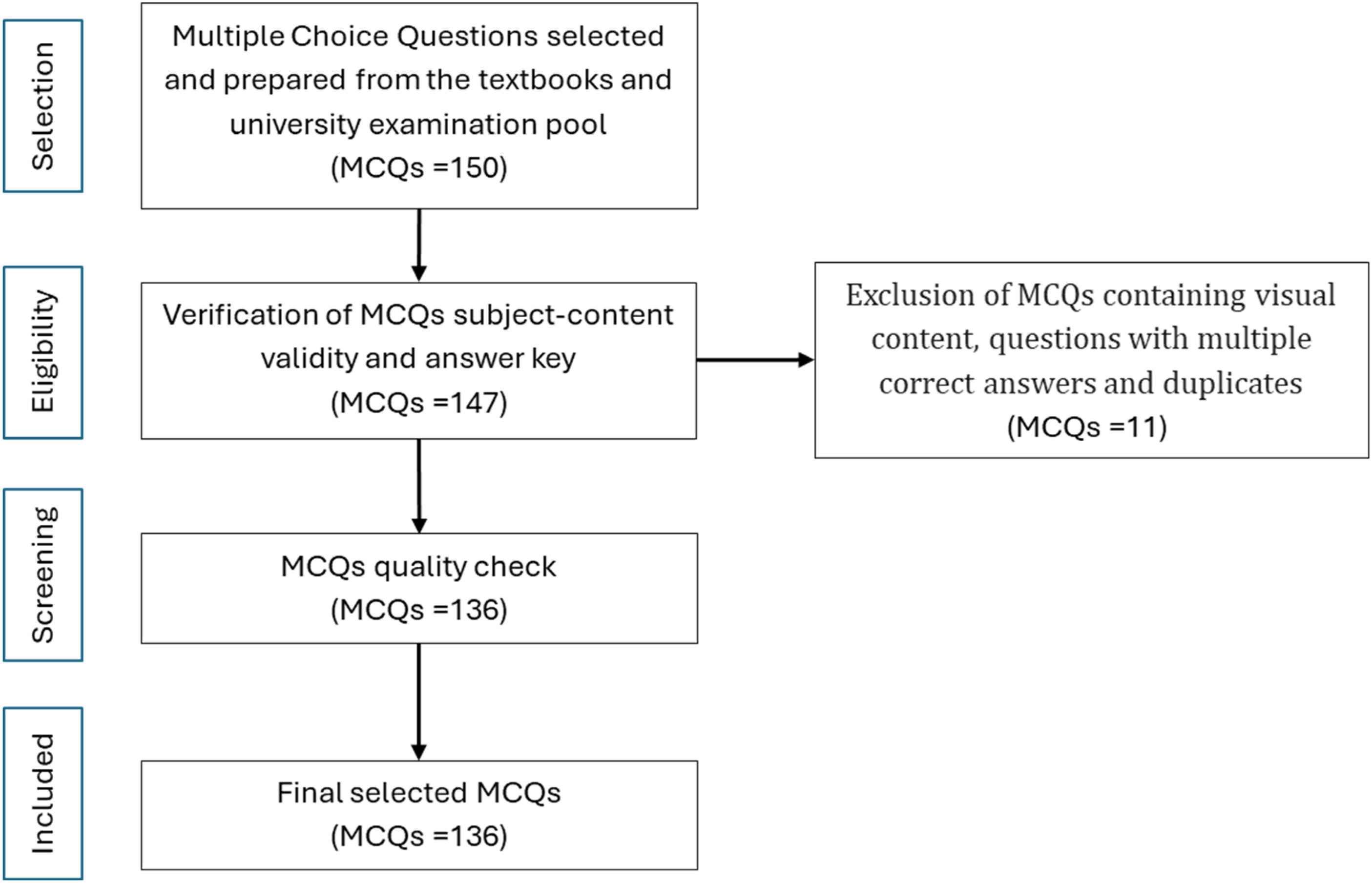
Flowchart of the MCQ-selection process. MCQ: multiple-choice question.
The selected questions covered a range of topics related to odontogenic cysts, tumours and bone lesions. The questions were categorised as follows: 30 questions focused on odontogenic cysts and tumour lesions; 16 questions dealt with bony lesions from a pathological perspective, and 36 questions were dedicated to cysts and benign tumours from a radiological perspective. In addition, 18 cognitive questions were added regarding odontogenic cysts and tumours (4 concerning oral radiology and 14 concerning oral pathology).
Some questions used in this study were developed by experts serving as Saudi Board examiners and were further validated through a review process. As they were responsible for determining whether each MCQ tested knowledge or higher-order-thinking, ‘cognitive’ skills. To determine the MCQ difficulty, the questions were also independently evaluated by two reviewers with over 10 years of experience in oral and maxillofacial pathology and oral radiology in tertiary care hospitals. The questions were categorised as either easy or difficult for undergraduate dental students in their fourth year or above based on predefined criteria. Easy questions were identified by their reliance on straightforward recall, single-step reasoning and common knowledge. Difficult questions required knowledge application, multi-step reasoning, in-depth understanding, similar choices exclusion and data interpretation. Clinical scenarios were considered more challenging due to the need for critical thinking and practical application.
The ChatGPT models used
ChatGPT-3.5 differs from previous models with its enhanced conversational capabilities, improved contextual understanding and greater accuracy in generating responses, making it more effective for a wider range of applications and providing a more natural interaction experience. ChatGPT-4 was launched to improve the tool's performance based on human feedback and a learning method that uses big data from the internet.9,19 The ChatGPT-3.5 language model serves as the foundation for ChatGPT's current free edition, whereas GPT-4 is presently only accessible with a paid ChatGPT Plus membership. 20 In contrast, ChatGPT-4 Turbo is faster and more efficient than ChatGPT-4, and it maintains the same accuracy and advanced capabilities.
Entry of multiple-choice questions into ChatGPT and response generation
Once the researchers were confident about the quality and readiness of the MCQs, each question was entered into ChatGPT-3.5, ChatGPT-4 and ChatGPT-4 Turbo version as a separate, independent prompt using the ‘new chat’ feature for each question during a specific time frame. No plugins were used to enhance the responses generated by all ChatGPT models. Each question was inserted once, maintaining its original format in each ChatGPT model, and the first response obtained was taken as the final response. The answers were judged based on the abovementioned textbooks; they were evaluated for accuracy and deemed either correct or incorrect. Ten months later, ChatGPT was updated to newer versions, and the same set of questions was entered into ChatGPT 4.o Mini (equivalent to ChatGPT-3.5 – unpaid version) and ChatGPT o3 Mini high (equivalent to ChatGPT-4 and ChatGPT-4 Turbo versions – paid version) to evaluate the consistency of the ChatGPT responses. The settings used were consistent with those described previously.
Statistical analysis
The data were recorded and analysed using IBM SPSS Statistics for Windows version 25.0 (IBM Corp., Armonk, NY, USA). The descriptive statistics of the question characteristics were expressed as frequencies and percentages. The accuracy rate was calculated for each model. The association between each ChatGPT model and the characteristics of the questions was examined using the chi-square test. The comparison of the three models was assessed using Cochran's Q test to account for binary outcomes across multiple related groups. A further pairwise comparison (McNemar's test) was performed to identify which models showed significant differences. To evaluate differences in accuracy of responses over time, a McNemar's test was conducted. This is an evaluative and comparative study conducted in Saudi Arabia during the first week of May 2024 and results were repeated during the last week of February 2025.
Ethical considerations
ChatGPT is a free, open-source online tool accessible to registered users. Because this study used publicly available programmes and did not involve human participants, it was deemed exempt by Taibah University College of Dentistry Research Ethics Committee (TUCDREC/13112024/DFelemban).
Results
Of the total 136 questions, 56% were related to oral radiology, and 66% were categorised as easy. The dataset consisted primarily of questions testing knowledge (87%), with only 13% of questions assessing cognitive skills (Table 1). ChatGPT-4 Turbo demonstrated a higher proportion (90%) of correct answers compared to both ChatGPT-3.5 (78%) and ChatGPT-4 (88%). Only 98 questions (72%) were correctly answered by the three models.
Characteristics of the questions and ChatGPT models’ accuracy rate (N = 136).

As shown in Table 2, the accuracy of the responses was evaluated based on various question characteristics: subject content, difficulty level and question type. The results indicate that while there were some variations in accuracy based on these characteristics among the ChatGPT models evaluated, such variations were not statistically significant. However, the Turbo model correctly answered 37% of difficult questions, while 70% of difficult questions were answered incorrectly (p = 0.03).
Association between the question characteristics and the ChatGPT models’ accuracy (N = 136).

chi-square test or Fisher's exact test.
Cochran's Q test indicated a significant difference in the proportion of correct responses between the three models (p = 0.001, Table 3) Supplementary table, which suggests that the models’ accuracy varied greatly. Pairwise comparisons revealed significantly higher proportions of correct responses for ChatGPT-4 vs ChatGPT-3.5 (p = 0.01), and ChatGPT-4 Turbo vs ChatGPT-3.5 (p = 0.002). Pairwise comparisons revealed significantly higher proportions of correct responses for ChatGPT-4 compared to ChatGPT-3.5 (p = 0.01), and for ChatGPT-4 Turbo compared to ChatGPT-3.5 (p = 0.002). However, in table 4, there was no significant differences were observed between the updated ChatGPT versions (p = 0.65). Ten months later, a self-comparison of the unpaid ChatGPT versions showed a significant improvement in accuracy, with ChatGPT-4.0 Mini achieving 120 correct responses compared to 106 correct responses by ChatGPT-3.5 (p = 0.01). Comparisons of ChatGPT 4 and ChatGPT 4 Turbo responses from 8 months ago with the current ChatGPT o.3 mini high showed consistency (p = 0.45 and 1.00, respectively), i.e. no differences.
Association between the question characteristics and the ChatGPT models’ accuracy 8 months later (N = 136).
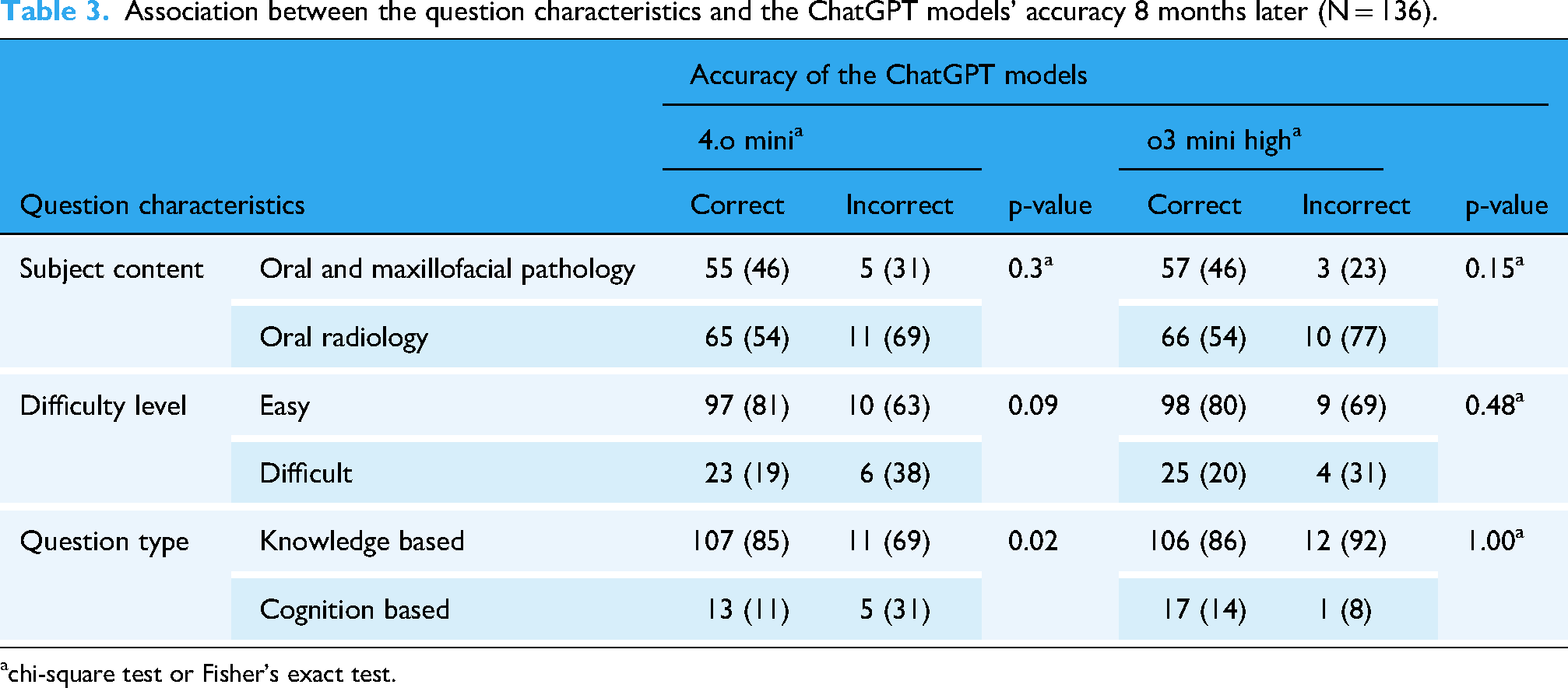
chi-square test or Fisher's exact test.
ChatGPT's performance across different models and over time.

Cochran's Q test and McNemar's test; p ≤ 0.01 deemed significant.
Discussion
ChatGPT is a major advancement on three different fronts: interpretability, accuracy and generalizability. As we have seen, every response includes some amount of useful information, and the option to pose follow-up questions gives the user more insight into the idea being asked about. 12 ChatGPT is often updated, and the different models are believed to be the result of training based on feedback from users.
This study found that ChatGPT-4 Turbo is more accurate and faster than ChatGPT-4 and ChatGPT-3.5; similarly, ChatGPT-4 is better than 3.5. The latter finding confirms the studies by Chau et al., 14 who used the dental-licence exam, and Rizzo et al. 21 who used the orthopaedic in-service training exam. A study conducted in Japan obtained similar results, even though the questions were asked in Japanese. 13 Thus far, no studies have used the newest version of ChatGPT (4 Turbo). The outstanding rating of GPT-4 may be credited to its vast database, dependable availability and thorough training in response to text inputs (prompts, inquiries and statements). 20
Answering MCQs with ChatGPT is a promising tool for self-education because, by using the tool, students can understand how to identify incorrect answers. However, in this study, errors in answering the questions appeared due to unspecified queries. Furthermore, some questions failed to receive answers due to the variation in numeric systems, including the teeth numeric system. Still, ChatGPT-4 Turbo explained the inclusion of answers.
The MCQs in our study covered shared topics in oral pathology and radiology, which were bone diseases and odontogenic cysts and tumours. This allowed us to conduct a detailed, objective evaluation of knowledge in a specific subject. However, a study with a broader range of questions produced results applicable to daily practice as licenses exams. 14 On other hand, misinformation can cause limitation in answering practical questions that affect the accuracy of data. 22
Scholars have found that ChatGPT-3's text-based technology makes it simple to utilise. Compared to a textbook, the use of a mobile application was more convenient and portable for oral maxillofacial radiology report writing and pathological diagnosis. 23
However, the lack of image processing in the publicly available versions of these models may hinder the incorporation of ChatGPT into the field. This aspect severely impedes these models because oral radiology relies extensively on imaging and vision for patient diagnosis and treatment. 21
According to our findings and the literature, among ChatGPT's drawbacks are a lack of reliability (erroneous, unnecessary or inconsistent responses) and transparency (the inability to identify the source of true information), potentially out-of-date content, a small database, the inability to conduct online searches and ethical issues.19,24,25
Furthermore, previous reports have indicated that ChatGPT may produce different answers when asked the same question is asked multiple times, by different users, at different times, 26,27 or with slight changes in phrasing. However, in our study, when the same questions were asked multiple times to assess response consistency over time, the results indicate that while the unpaid ChatGPT version showed significant improvement, the paid versions remained consistent, with no significant differences across updates. This suggests that while free models benefit from ongoing enhancements, advanced versions maintain stable performance, reflecting a mature and reliable system.
A potential limitation is that the study did not investigate the rationale behind ChatGPT's answers; it focused only on determining the proportion of right responses. The capacity of AI tools to continuously expand, obtain additional data and consider more parameters is another limitation of our research. If this study were to be conducted again using the same technique and updated models, its findings may vary. This is an inherent weakness of research looking at technological developments. In this study, the issue of variability was taken into account by gathering data over many versions.
Further research could also focus on comparing the performance of ChatGPT with that of students or professionals in oral radiology and pathology to assess its clinical and educational relevance. In addition, future studies could examine how well generative-AI models perform regarding different topics of oral diagnostic sciences by using subjective evaluations rather than MCQs. One example is the objective structured practical examination, which uses scenarios with images and open-ended questions. As ChatGPT and other generative-AI models become more advanced, studying the application of this technology to dentistry beyond diagnosis, screening and treatment planning will also be necessary. Aspects that may be included are automated patient interactions, oral-health education and clinic administration. The results of employing AI in patient management as reported by the patients could also investigate. Big-data gathering at the population level makes it possible for AI systems to analyse variances and offer precise disease diagnoses for all patients. Furthermore, scholars should thoroughly examine the veracity and accuracy of ChatGPT's responses.
Conclusion
This study found that the latest iteration of ChatGPT, Model 4 Turbo, outperformed Models 4 and 3.5 in both accuracy and response time. Notably, even when questions were asked at different times or using updated versions, the unpaid ChatGPT version showed a significant improvement in accuracy, while the paid versions maintained consistent performance over time with no significant changes.
This advancement marks significant progress in AI-driven educational tools, particularly in the field of dentistry. However, the limitations related to the variability of responses and the lack of image processing capabilities underscore the need for ongoing improvements. Future research should focus on expanding the scope of questions, incorporating subjective evaluations and exploring broader applications of generative AI in dental education, clinical practice and patient management.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251355847 - Supplemental material for Evaluating the accuracy of CHATGPT models in answering multiple-choice questions on oral and maxillofacial pathologies and oral radiology
Supplemental material, sj-docx-1-dhj-10.1177_20552076251355847 for Evaluating the accuracy of CHATGPT models in answering multiple-choice questions on oral and maxillofacial pathologies and oral radiology by Doaa Felemban, Ahoud Jazzar, Yasmin Mair, Maha Alsharif, Alla Alsharif and Saba Kassim in DIGITAL HEALTH
Footnotes
Author contributions
DF and AJ conceived and developed the theoretical framework and performed the experiments. AA, MA and SK aided in the analysis. YM supervised the project. All authors discussed the results and contributed to the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.