
Abstract
Background
Traditional Chinese medicine (TCM) tongue diagnosis, through the comprehensive observation of tongue’s diverse characteristics, allows an understanding of the state of the body’s viscera as well as Qi and blood levels. Automatic tongue image recognition methods could support TCM practitioners by providing auxiliary diagnostic suggestions. However, most learning-based methods often address a narrow scope of the tongue’s attributes, failing to fully exploit the information contained within the tongue images.
Objective
To classify multifaceted tongue characteristics, and fully utilize the latent correlation information between tongue segmentation and classification tasks, we proposed a multi-task joint learning network for simultaneous tongue body segmentation and multi-label Classification, named SSC-Net.
Methods
Firstly, the shared feature encoder extracts features for both segmentation and classification tasks, where the segmentation result is utilized to mask redundant features that may impede classification accuracy. Subsequently, the ROI extraction module locates and extracts the tongue body region, and the feature fusion module combines tongue body features from bottom to top. Finally, a fine-grained classification module is employed for multi-label classification on multiple tongue characteristics.
Results
To evaluate the performance of the SSC-Net, we collected a tongue image dataset, BUCM, and conducted extensive experiments on it. The experimental results show that the proposed method when segmenting and classifying simultaneously, achieved 0.9943 DSC for the segmentation task, 92.02 mAP, and 0.851 overall F1-score for the classification task.
Conclusion
The proposed method can effectively classify multiple tongue characteristics with the support of the multi-task learning strategy and the integration of a fine-grained classification module. Code is available here.
Keywords
Introduction
Tongue plays a crucial role in the observation of conditions in traditional Chinese medicine (TCM) and serves as an important basis for differentiation and treatment. 1 According to TCM theory, the appearance of the tongue is closely related to the fluctuations of Qi and blood within the body’s viscera. By observing the spirit, color, shape, and dynamics of the tongue, practitioners can understand the changes in physiological and pathological functions of the human body. 2 However, traditional tongue diagnosis faces the following challenges: (a) Subjectivity: Traditional tongue diagnosis lacks objective and quantitative standards, leading the tongue recognition results heavily relies on the clinician’s experience and subjective judgment; (b) Instability: Traditional tongue diagnosis could be affected by environmental factors, such as changes in lighting and viewing angle, which can lead to deviations in recognition results. These problems have impacted the clinical application and further development of tongue diagnosis, thus necessitating an automatic tongue recognition method to enhance its objectivity and accuracy.
In recent years, the rapid development of computer vision and related technologies has led to their widespread application in medical image analysis. Deep learning has been applied to tongue diagnosis, including the classification of tongue colors3,4 and shapes, 5 recognition of teeth marks 6 and cracks on the tongue body, and diagnosis of diseases from tongue appearance, such as diabetes mellitus 7 and gastrointestinal diseases. 8 Learning-based tongue recognition methods typically consist of two parts: tongue segmentation and tongue classification. Tongue segmentation involves extracting the tongue part from the captured images to avoid interference from redundant information such as the face and lips, which is a prerequisite for subsequent tongue classification. Tongue classification involves classifying various characteristics of the segmented tongue body and coating, such as color, shape, texture, and so on, and the results can be used to assist clinicians in diagnosis.
Among these characteristics, we observed that the identification of the tongue body and coating colors is usually more straightforward due to their distinct visual differences in images. In contrast, the recognition of teeth marks and cracks is more complex, as they occupy a smaller proportion of the image, and their identification accuracy is influenced by image quality and lighting conditions. Each image in Figure 1 showcases these different characteristics, with Figure 1(a) to 1(e) all displaying characteristics like tongue body color, tongue coating color, and tongue coating thickness, and Figure 1(d) and 1(e) also showing teeth marks or cracks. Therefore, we regard multiple characteristics classification of tongue images as a multi-label classification task. Table 1 provides detailed explanations of the classification of characteristics in Figure 1 and their corresponding clinical significance in TCM.

Representative images corresponding to the tongue characteristics. Here, (a) to (e) all display tongue body color, tongue coating color, and tongue coating thickness, while (d) and (e) also display teeth marks or cracks.
The tongue characteristics classified in this work and their corresponding clinical significance in TCM.

Despite progress in learning-based methods, existing methods still face limitations. Single-task methods sequentially perform segmentation and classification, which neglects the intrinsic correlation between tongue body segmentation and tongue classification; While multi-task methods simultaneously execute both tasks, most existing multi-task methods inadequately address the comprehensive identification of tongue characteristics by overlooking their multi-label and fine-grained nature.
This work proposed SSC-Net, an end-to-end multi-task joint learning network specifically architected for concurrent tongue body segmentation and multi-label tongue classification. The network introduces a multi-label fine-grained classification method, enabling simultaneous identification of five pathologically significant characteristics: (a) tongue body color, (b) tongue coating color, (c) tongue coating thickness, (d) cracks, and (e) teeth marks.
Related works
Single-task methods for tongue segmentation or classification
The single-task tongue image segmentation or classification method involves only a single, isolated task of either segmentation or classification, with no connection between the two. Tongue image segmentation is essentially a semantic segmentation task, where masks are generated to remove non-tongue regions while retaining the tongue portion to avoid affecting the classification results. The accurate tongue segmentation results, especially with the smooth edge and few cavities, are helpful to the performance of teeth marks and tongue coating classification. Zhou et al. 9 proposed TongueNet for tongue body segmentation, similar to Mask R-CNN, 10 which locates and segments the tongue body through feature extraction, region proposal, and prediction, achieving 0.9796 DSC and 0.9774 mIoU on BioHit 11 dataset, respectively. Lin et al. 12 proposed DeepTongue based on ResNet 13 and DeepMask to achieve fast segmentation with 0.9458 mIoU on their custom dataset. Huang et al. 14 combined a residual soft connection module and a salient image fusion module with U-Net 15 for fast tongue body segmentation on mobile devices. Jiang et al. 16 incorporated the Mamba attention mechanism and multi-stage feature fusion, enhancing the accuracy and efficiency of U-Net in complex environments.
Single-task tongue image classification methods typically utilize classifiers to classify feature vectors extracted from input images. Li et al. 17 first generate suspicious areas with R-CNN then extract feature vectors with VGG16, 18 and finally identify tooth-marked tongues with SVM. Tang et al. 19 used a coarse-to-fine network to simultaneously detect tongue regions and key points, followed by using the fine-grained classification network DCN 20 to identify tooth marks. Ni et al. 3 combined CapsNet and residual blocks for a five-class classification of tongue colors, achieving 0.845 accuracy. However, these classification methods focus on one or a few categories of tongue characteristics and fail to fully explore the information contained in tongue images. We figured that tongue classification should consider the multiple labels of tongue images comprehensively to assist in TCM tongue diagnosis more effectively.
Multi-task methods for tongue segmentation and classification
Multi-task learning, which uses the knowledge from multiple tasks to assist each task, 21 especially achieves success in medical image analysis, such as COVID-19 diagnosis, 22 skin disease classification, 23 and tumor identification. 24 Multi-task learning methods for tongue image segmentation and classification convey information between the two tasks by using the predictions of the former as input for the latter. Multi-task methods can be divided into two categories: non-end-to-end trainable and end-to-end trainable. A considerable portion of methods for tongue segmentation and classification is not end-to-end trainable, that is, training two models for segmentation and classification separately. Li et al. 25 first using facial landmark recognition and U-Net for tongue body segmentation, then training multiple ResNet models to classify tongue characteristics. However, non-end-to-end methods repeatedly extract features for segmentation and classification, resulting in high computational costs as well as failing to fully utilize the potential information between different tasks.
In contrast, end-to-end methods can share latent information between different tasks. Xu et al. 26 proposed the first end-to-end trainable multi-task network that unifies tongue image segmentation and classification. They employed U-Net and DFL 27 for tongue body segmentation and fine-grained classification of tongue coating, However, Xu et al. 26 was limited to classifying the color and thickness of the tongue coating. Qiu et al. 28 performed classification on tongue coating and sublingual vein after segmenting the tongue surface and underside, based on MobileNetV2, 29 achieving feature extraction of tongue images on mobile devices. Shi et al. 30 proposed a multi-task joint learning model, Ammonia-Net, based on U-Net and ShuffleNetV2, applying the segmentation results of tooth marks to aid in the grade classification of tooth-marked tongues.
In summary, tongue image recognition faces the following challenges:
TCM synthesizes multi-dimensional characteristics of the tongue to support diagnosis. However, current methods for tongue image recognition predominantly focus on isolated classifications of single characteristic types (e.g. tongue color or coating thickness), neglecting the multi-label nature of tongue manifestations. Tongue image recognition methods typically consist of tongue body segmentation and tongue classification. How to use a multi-task network to utilize the associated information between them is a challenging task. The global features of tongue images show minor differences, whereas the local features exhibit relatively significant differences, making tongue image classification a natural fine-grained classification task.
This work proposed a multi-task joint learning network for tongue image recognition called SSC-Net, which can perform tongue body segmentation and multi-label classification simultaneously. The main contributions are as follows:
We performed multi-label and fine-grained tongue image classification on the key tongue characteristics closely related to diseases, including tongue body color, tongue coating color, coating thickness, cracks, and teeth marks. We proposed a multi-task joint learning network for tongue image recognition named SSC-Net, designed to perform tongue image segmentation and multi-label classification simultaneously. SSC-Net effectively connects the latent information between segmentation and classification tasks. A tongue image dataset, BUCM, consisting of 1500 images was constructed, with each image label verified by TCM experts to ensure data accuracy and reliability.
Material and method
BUCM dataset
Data collection
Given the scarcity of public datasets for tongue image classification, we collected 1571 tongue images from 774 participants during various treatment stages. The images were captured with a mobile device in an open clinical environment, each with a resolution of
Label annotation
The segmentation labels of the BUCM dataset were annotated as binary images, where white represents the tongue area and black represents the background. These annotations serve as segmentation ground truths (GTs). The classification labels were assigned by three professional TCM physicians for five critical tongue characteristics. These labels, detailed in Table 1, are categorized as follows: C1 (tongue body color): light-red, pale, red, C2 (tongue coating color): white, yellow, C3 (tongue coating thickness): thin, thick, C4 (cracks): with (w/), without (w/o), and C5 (teeth marks): with (w/), without (w/o). The labeling process strictly followed Chinese National Standard GB/T 40665.1-2021, employing a consensus-driven workflow: one physician performed initial classification, which was then independently verified by the other two experts. Finally, 71 images with annotation disagreements were excluded from the original collection of 1571 images, yielding a final dataset of 1500 consistently annotated samples.
Data augmentation
The BUCM dataset was randomly split into training and testing sets in an 8:2 ratio. To address inherent imbalances in categories C1 and C2, we implemented targeted offline augmentation in the training set, expanding its size to 3000 samples. Critically, no augmentation was applied to the testing set to maintain its original data distribution, ensuring unbiased evaluation on realistic scenarios. The following transformations were applied: (a) random vertical flipping, (b) cropping the width and height by random pixels between 0 and 10, (c) affine translation along the x- and y-axis by −10% to 10%, (d) affine rotation by a random value between −10°and 10°, (e) affine scaling along the width and height to sizes between 80% and 120%, (f) affine shear on the x- and y-axis by a random value between −5°and 5°, (g) additive Gaussian noise, and (h) Gaussian blur. Note that when offline and online data augmentation were applied to the images, the corresponding segmentation GTs were also transformed in the same way. The per-category sample counts of each subset after offline data augmentation is shown in Table 2.
Per-category sample sizes of training (original and augmented) and testing sets in BUCM dataset.

BioHit dataset
Another dataset used in this work is BioHit. 11 BioHit is a public tongue segmentation dataset, containing 300 standardized clinical tongue images captured using a structured imaging device. The image resolution is 768 × 576 pixels. In this work, all 300 images were utilized as a testing set to validate the generalization capability of the proposed method.
Proposed method
This work proposed SSC-Net, an end-to-end multi-task network that combines tongue image segmentation and classification. As shown in Figure 2, SSC-Net consists of (a) a shared feature encoder, (b) a segmentation module, (c) an ROI extraction module, (d) a feature fusion module, and (e) a classification module. Firstly, the shared feature encoder extracts multi-level deep features of the image, and the segmentation module predicts the segmentation result with these multi-level features. The ROI extraction module then locates, and extracts tongue body region based on the predicted segmentation result, the feature fusion module combines multi-level features for classification. Finally, the classification module performs multi-label and fine-grained classification on tongue body color, tongue coating color, coating thickness, and presence of teeth marks and cracks. In the following subsections, we will firstly introduce these five modules and finally introduce the joint loss function of SSC-Net.

The framework of our proposed SSC-Net. The main components include: (a) shared feature extractor: extracting multi-level features from input images; (b) segmentation module: predicting tongue segmentation results; (c) ROI extraction module: locating, extracting, and aligning tongue regions based on predicted segmentation results; (d) feature fusion module: fusing multi-level features from bottom to up for classification; (e) classification module: performing multi-label classification with multi-head CSRA; (f) SE-ResNetXt BottleNeck: a ResNetXt bottleneck integrated Squeeze-and-Excitation.
Shared feature encoder
The feature extraction module is designed to extract multi-scale features ranging from lower-level detailed features to higher-level semantic features, as shown in Figure 2(a), comprising five stages. When the input image
Tongue segmentation module
In the tongue segmentation module, shown in Figure 2(b), bilinear interpolation is used to upsample the input features 
ROI extraction module
The ROI extraction module was designed, as depicted in Figure 2(c), to locate and extract the tongue region while obscuring the surrounding facial redundant information in the input image. The predicted segmentation results are used to mask pixels in non-tongue regions. This module can be described as three steps:
Multiply the input image Locate the tongue region. As shown in Figure 3, firstly, decompose Extract and resize the tongue region. We applied ROI Align
10
on

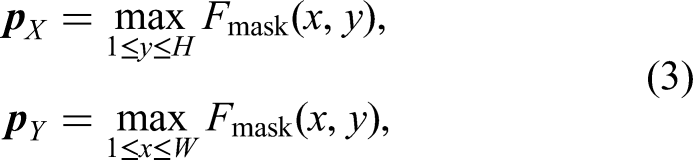


The visualization of tongue region localization.
Feature fusion module
Among some joint segmentation and classification methods for medical image analysis, 33 classification networks typically feed high-level features directly into classifiers for prediction. However, this paradigm fails to effectively integrate low-level structure features. Although high-level features contain rich semantic information, continuous downsampling operations degrade structural details, rendering classification based on high-level features insensitive to local pathological characteristics.
The feature fusion module is designed to combine the complementary strengths of high-level semantic information and low-level structural features, thereby boosting classification performance. As illustrated in Figure 2(d), it fuses features

The feature fusion module.
Fine-grained classification module
Tongue image classification is a naturally fine-grained image recognition task. Methods for fine-grained classification can roughly be divided into region localization methods and feature encoding methods. 34 Among fine-grained classification methods for tongue image recognition, Tang et al. 19 utilized the destruction and construction network (DCN 20 ) to extract discriminative information from the detected tongue region by shuffling and recovering the local regions of the input image. Xu et al. 26 employed DFL 27 to enhance the intermediate feature representation capability of CNNs by introducing a bank of discriminative filters.
In this work, we introduce multi-head category-specific residual attention (CSRA 35 ) to perform fine-grained and multi-label tongue classification. The CSRA, as shown in Figure 5, combines category-agnostic average pooling feature with category-specific spatial pooling feature to obtain category-specific residual attention feature for multi-label classification.

The architecture of CSRA. We extend a six-head CSRA as fine-grained classification module.
Specifically, input feature 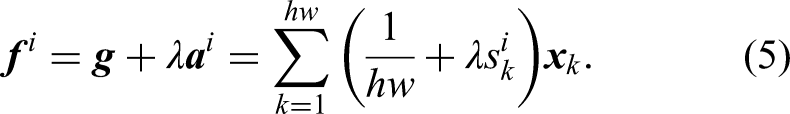
Finally, all these category-specific feature vectors are sent to the classifier to obtain the final logits
We extend a six-head CSRA to avoid tuning the temperature parameter T, as illustrated in Figure 2(e), the logits 
Loss function
Given a training dataset
For the segmentation task, we combine the Dice loss with the binary cross-entropy loss for supervision.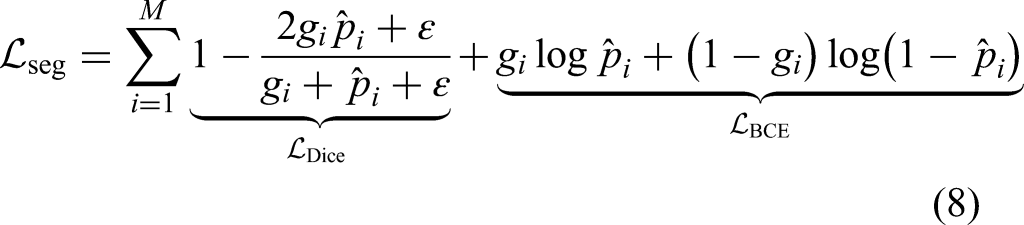
We use the binary cross-entropy loss for the multi-label classification task,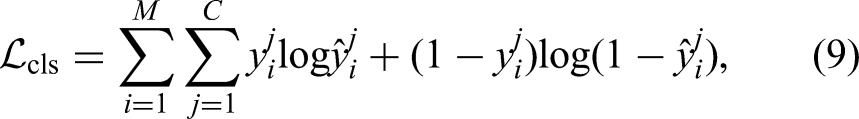
We define the final joint loss function as a weighted combination of segmentation loss and classification loss to optimize both tasks simultaneously.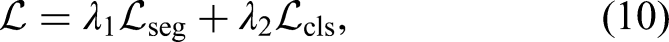
Experimental results
Implementation details
The multi-task learning model was trained for 100 epochs on an NVIDIA 2060 Super GPU, iteratively optimized by the root mean square propagation (RMSProp) algorithm, with a learning rate of 1e-6 and a batch size of 2. The hyperparameters
Evaluation metrics
Segmentation metrics
To evaluate segmentation performance, we employ the Dice Similarity Coefficient (DSC) and the Intersection over Union (IoU) as metrics.

Classification metrics
The classification performance mainly employs the average precision (AP) for each category and the mean average precision (mAP) for overall categories. The mAP is calculated by finding AP for each category and then average over C categories,

We also compute overall precision (OP), recall (OR), F1-score (OF1), and per-category precision (CP), recall (CR), F1-score (CF1) as follows:
Tongue segmentation results
In tongue segmentation experiments, we first train the segmentation branch of SSC-Net on our dataset BUCM. Then, we compared the segmentation performance with existing segmentation methods on testing sets of BUCM and BioHit. To rigorously evaluate cross-domain generalization, we performed zero-shot transfer of the BUCM-trained models to BioHit without fine-tuning. The compared methods are FCN-8s, 37 U-Net, 15 SegNet, 38 U-Net++, 39 DeepLabv3+, 40 and SegNeXt. 41
Segmentation results and analysis on BUCM
Table 3 shows the quantitative segmentation results on the BUCM dataset. Our SSC-Net achieves state-of-the-art performance with a DSC of 0.9963 and IoU of 0.9929, demonstrating high performance in tongue body segmentation. Specifically, SSC-Net surpasses the second-best method (SegNeXt) by 0.15% in DSC (0.9963 vs. 0.9948) and 0.35% in IoU (0.9929 vs. 0.9894). Notably, compared to the classical U-Net architecture, SSC-Net attains more substantial improvements of 0.94% in DSC and 1.42% in IoU. This performance gap highlights the effectiveness of our proposed feature extraction module in capturing discriminative details.
Comparisons of segmentation results of our method and other methods on the BUCM and BioHit dataset.

Segmentation results and analysis on BioHit
The right half of Table 3 reveals SSC-Net’s superior generalizability on the cross-device BioHit dataset, achieving 0.9719 DSC and 0.9471 IoU. Compared to the suboptimal method SegNeXt (0.9436 DSC and 0.8953 IoU), our method demonstrates improvements of 2.83% in DSC and 5.18% in IoU. These results validate that our method possesses good generalizability and robustness when applied to different capture devices.
Visualization and analysis
Figure 6 displays the representative prediction results by compared segmentation methods and corresponding GTs on BUCM and BioHit datasets. Despite the varying tongue appearance and complex background, SSC-Net achieved a more stable performance with few holes or redundancies on both datasets. In contrast, U-Net, SegNet, and U-Net++, are susceptible to the complex surroundings. The visual results support the potential of SSC-Net for accurate and reliable segmentation.

The visualization of segmentation results on (a) BUCM and (b) BioHit.
Tongue classification results
In this subsection, we report extensive experimental results and comparisons on single-task methods and multi-task methods to demonstrate the effectiveness of the proposed method. All these experiments were performed on the BUCM dataset.
Single-task classification results and analysis
For ease of comparison with the proposed multi-task method, before the single-task classification experiment, we pre-processed test images by inputting the segmentation predictions of SSC-Net into the ROI Extraction Module. The compared classification methods are AlexNet, 42 MobileNetV2, 29 VGG16, 18 ResNet50, 13 DenseNet121, 43 and ConvNeXt-T. 44 The mAP for overall categories, along with OP, OR, OF1, and CP, CR, CF1 of the single-task (STL) methods, are shown in Table 4. The average precision (AP) for all classification categories is presented in Table 5.
Comparisons of segmentation results and classification results on BUCM, where “STL” means single-task learning methods and “MTL” means multi-task learning methods.

Comparisons of AP (mean ± standard deviation in %) for all classification categories on BUCM.

The three columns within C1 represent three classes in category C1: light-red tongue, pale tongue, and red tongue.
The experimental results indicate that among the single-task classification methods, ConvNeXt approached the highest 90.16 mAP and 0.823 OF1. In terms of AP, these single-task methods excelled in classifying readily discernible characteristics like C1 and C2. For example, the highest-performing DenseNet121 achieved AP for light-red tongues that is only 0.2% lower than that of SSC-Net. However, comparative results reveal that traditional methods show notable limitations in fine-grained characteristics such as C4 and C5. For instance, the least effective AlexNet exhibits 40.5% and 30.9% lower APs than SSC-Net on these two categories, respectively. These results validate SSC-Net’s significant advantages in fine-grained characteristics classification.
Multi-task classification results and analysis
In the multi-task experiment, two branches of SSC-Net were trained to evaluate the performance of simultaneous segmentation and classification. To compare with other multi-task methods, the fine-grained classification module was replaced with either a fully connected layer (FC) or DFL, 27 The multi-task (MTL) experiment results are shown in Tables 4 and 5.
The classification experimental results indicate that, among the multi-task methods, SSC-Net outperformed in both segmentation and classification tasks compared to ours+FC and ours+DFL. In the classification task, SSC-Net achieved 0.851 OF1 and 0.830 CF1, which improved by 3.5% and 3.9% over the second-ranked multi-task method DFL, and by 3.9% and 2.2% over the single-task method DenseNet121. In terms of the average precision, SSC-Net achieved the best 92.02% mAP among all methods, which largely outperforms both Ours+DFL and DenseNet121 by 2.8%. Moreover, the proposed method stands out with the highest AP in most categories, particularly excelling in C4 and C5. Specifically, it outperforms DenseNet121 and Ours+DFL by 1.6% and 2.7% for C4, and by 7% and 2.2% for C5, respectively. These improvements can be attributed to CSRA’s capability to extract category-specific features, enabling precise classification of fine-grained characteristics.
When SSC-Net conducted both segmentation and classification simultaneously, despite a slight 0.2% decrease in DSC compared to performing segmentation alone, our multi-task segmentation performance remains at the forefront compared to other single-task segmentation methods in Table 3, regardless of the combined classification module.
From the results, our multi-task approach achieves performance improvements compared to both single-task and multi-task classification methods. These improvements in classification performance can be attributed to the multi-task learning strategy and the integration of a fine-grained classification module. The multi-task learning method effectively employs segmentation results to mitigate interference from non-tongue parts on classification features, while the fine-grained classification module improves the average precision across various categories by combining average pooling features with category-specific spatial pooling features.
Visualization and analysis
Grad-CAM 45 is a visualization technique that highlights discriminative regions in an image that are highly relevant to the target category. We calculate activation scores for each category from the last convolutional layer before models’ classifier and overlay them onto test images. Figure 7 shows the category-specific activation maps generated by the proposed method and compared methods on some representative images.

The visualization of each category activation maps by proposed method and compared methods on some representative images. The activation maps were resized to the same size as that of the test images.
In Figure 7, blue areas indicate less attention and red areas more attention. The visualization shows that the compared methods, that is MobileNetV2, ResNet50, and DenseNet121, focus on regions corresponding to the tongue body and tongue coating to varying extents. As mentioned in “Introduction” section, these regions exhibit noticeable visual distinctions in the images, thereby facilitating their identification. Notably, our approach not only succeeds in pinpointing the regions corresponding to the tongue body and tongue coating but, with the support of CSRA, also accurately and comprehensively identifies cracks and tiny teeth marks. The congruence between the visualization and the quantitative classification results indicates the model’s focus on discriminative regions, significantly increasing the interpretability of the proposed method.
Ablation study
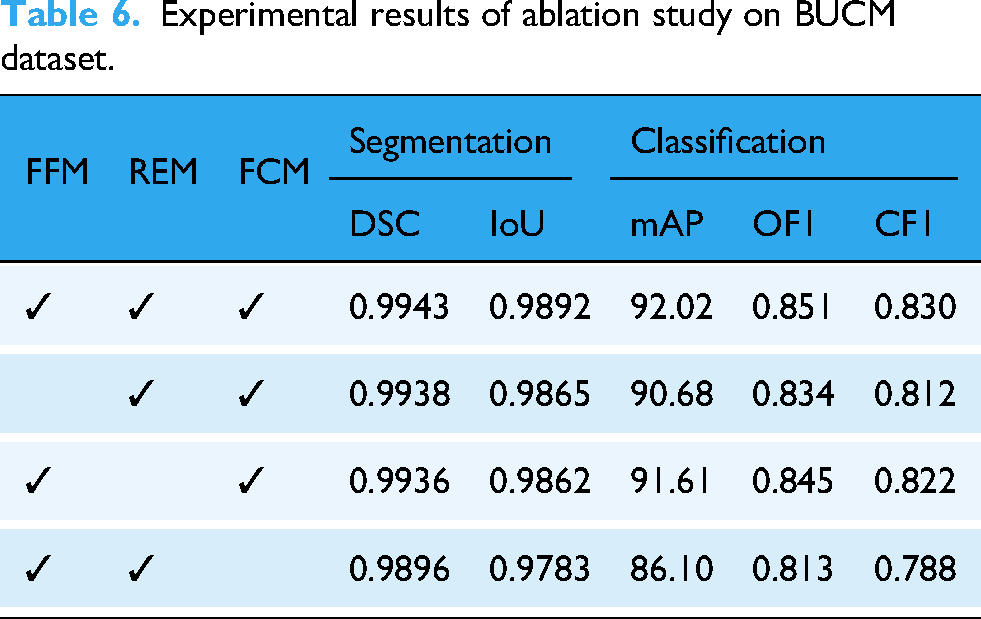
To validate the effectiveness of the proposed method, we conducted ablation studies on SSC-Net by removing the feature fusion module (FFM), ROI extration module (REM), and replacing the fine-grained classification module (FCM) with fully connected layers. The ablation experiments were conducted on our BUCM dataset. The results of the ablation study are shown in Table 6.
FFM effectiveness: Removing FFM from the baseline model (SSC-Net) marginally affected segmentation performance but reduced classification mAP by 1.4%, with OF1 and CF1 dropping by 1.9% and 2.1%, respectively. REM effectiveness: Removing REM caused negligible segmentation degradation but led to a 0.4% to 0.9% decline in classification metrics. FCM effectiveness: Replacing FCM with fully connected layers reduced the segmentation DSC by 0.4% and significantly degraded classification performance (mAP
Experimental results of ablation study on BUCM dataset.
Discussion
Previous studies on tongue image recognition mostly use repetitive feature extractors to derive deep features for segmentation and classification. While this approach may facilitate model optimization, it essentially obstructs the flow of potential information between the tasks and additionally increases unnecessary computational burdens. In contrast, the proposed multi-task network not only explicitly links the segmentation and classification tasks but also utilizes a shared-parameter encoder to extract tongue body features, leveraging the latent information of both tasks. Despite the potential challenge in optimizing multi-task models during training, we conducted extensive experiments to eliminate randomness and reported both mean and standard deviations. The results from Table 4 confirm that our multi-task model indeed improves the classification performance. Meanwhile, Table 4 indicates a balance between overall recall and precision, yet per-category recall are obviously lower than per-category precision. This discrepancy may be attributed to the lesser number of true positives in imbalanced categories, such as red tongues, leading the model to be more susceptible to false positives within those categories.
Clinical applicability
Leveraging the medical internet of things, SSC-Net could provide diagnostic decision support for professionals and health self-assessment for non-specialists. In outpatient clinics, TCM practitioners capture tongue images via mobile devices and obtain segmentation maps with classification reports, enabling real-time diagnostic assistance. In remote areas, community health workers conduct preliminary screenings using SSC-Net-powered mobile devices to analyze tongue images, facilitating expedited expert teleconsultations without requiring in-person specialist involvement. During public health crises (e.g. COVID-19), post-rehabilitation patients can perform contactless tongue image capture and evaluate treatment efficacy through weekly comparisons of tongue characteristics. Overall, this approach proves valuable for hospital triage, remote consultations, and post-rehabilitation services.
Limitations and future work
There are three limitations that need to be further investigated in the future. First, the BUCM dataset collected in this work is limited in size and contains unbalance class distributions, particularly for rare tongue types like dark-red and blue-purple colors. This limitation forced us to simplify the tongue color classification (currently covering only light-red, pale, and red types) instead of using the complete five-category in TCM. Second, the proposed method focuses only on tongue images without considering pulse information, which is equally important in real-world TCM diagnosis. Third, while the proposed framework achieves high accuracy, we did not analyze its computational cost for clinical deployment scenarios. The current model’s hardware requirements may limit its practicality in resource-constrained settings, such as mobile TCM diagnostic devices.
In the future, firstly, multicenter collaborations will be implemented to expand the scale of the dataset, enhancing diversity and class balance with particular emphasis on underrepresented categories. Second, based on the proposed tongue image recognition framework, we will integrate multimodal physiological data (e.g. pulse waveforms) to achieve comprehensive syndrome differentiation that better aligns with clinical TCM requirements. We believe that these enhancements could establish SSC-Net as a foundational component in standardized TCM diagnostic workflows.
Conclusion
This work proposed a multi-task joint learning network, SSC-Net, for tongue image recognition, performing both tongue body segmentation and multi-label classification. A fine-grained classification module is applied for multi-label tongue image classification. To the best of our knowledge, it is first to classify characteristics as many as tongue body color, coating color, coating thickness, cracks, and teeth marks simultaneously with a multi-task network. SSC-Net explicitly connects latent information in segmentation and classification tasks, systematically strengthening the relationship between tongue segmentation and classification. Experimental results show that SSC-Net achieved 92.02% mAP for tongue classification guided by tongue body segmentation results of 0.9943 DSC. Hopefully, the proposed method could provide clinical professionals with auxiliary diagnostic information and help non-professionals be aware of their physical health status. It is of great significance for promoting the standardization and objectification of TCM, as well as improving the level of health services that TCM offers to the public.
Footnotes
Acknowledgements
The authors express their gratitude to all the institutions and individuals that have provided support for this work.
Ethical considerations
This study was approved by the Ethics Committee of Northeastern University of China (approval no. NEU-EC-2024B049S).
Author contributions
The authors confirm contribution to the article as follows: Xiaopeng Sha did conceptualization, writing—review and editing, and supervision; Zheng Guan did methodology, investigation, and writing—original draft; Ying Wang and Jinglu Han did data curation and formal analysis; Yi Wang did investigation; Zhaojun Chen did writing—review and editing and supervision.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of China (No.62104034), the Natural Science Foundation of Hebei Province (No.F2024501044), and Central Guidance Local Science and Technology Development Project (No.246Z2002G).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
XS.