
Abstract
Objective
Hypothyroidism, hyperthyroidism, thyroid nodules, and other thyroid disorders are common around the world, affect millions of people worldwide, and untreated health conditions may lead to serious health issues. An accurate and timely diagnosis serves as crucial for proper management and medication. This study utilizes a dataset from the UCI machine-learning repository to put forward the comprehensive machine-learning technique for diagnosing thyroid disorders.
Methods
The proposed methodology involved exploratory data analysis and preparation, which included handling missing values, encoding categorical values, and selecting features. The synthetic minority over-sampling technique technique is utilized to overcome the problem of class imbalance. Five advanced machine learning (ML) algorithms, logistic regression, support vector machine, decision tree, random forest, and gradient boosting are employed to develop predictive models. Further, an innovative stacking ensemble method is proposed with the help of four applied models. The results from these models are aggregated, and logistic regression serves as a meta-learner.
Results
A 10-fold cross-validation technique is utilized to ensure robust model evaluation and reduce the risk of overfitting by using one test set for each subset and training on the rest of the subsets. The ensemble model attained an accuracy of 99.86%, outperforming individual models.
Conclusion
These results reveal the capability of ML, especially ensemble approaches, to enhance accurate and timely diagnosis of thyroid disorders.
Keywords
Introduction
Thyroid disorders are one of the major problems of the modern world and are widespread in all countries, and the presence of symptoms of these diseases is often not even suspected. 1 These disorders, which result from malfunctioning of the thyroid gland, disturb the metabolism of the body and result in a number of health problems. The thyroid gland is a small, butterfly-shaped gland located at the base of the throat. It is actively involved in the production of hormones and is responsible for metabolic, growth, and development processes. Thyroid disorders primarily manifest in three forms: Hypothyroidism, hyperthyroidism, and thyroid nodules. 2 Hypothyroidism, associated with low hormone production, manifest as fatigue, depression, weight gain, and poor memory. Hyperthyroidism, characterized by overproduction of hormones, is associated with nervousness, weight loss, and an increased heart rate. Thyroid nodules are lumps that develop in the thyroid gland and may be malignant or benign. Thyroid cancer is the cancer with the highest increasing incidence rate among women. Thyroid disorders are relatively prevalent among women, as it is estimated that one in eight women would have the disease at some point in their lifetime. This higher prevalence is due to several reasons; such as hormonal changes during pregnancy and in the postpartum period making women more prone to thyroid disorders. Despite the significant impact of thyroid diseases on health, diagnosis is made in only half of the cases, as symptoms are often confused with other conditions.
Timely and accurate thyroid diagnosis is crucial for effective management and treatment. However, the thyroid disorders’ symptoms can be many, varied, and nonspecific, so mistakes can be made or the disease can take a long time to discover, which underlines the importance of better diagnostics. Thyroid disorders are challenging to diagnose and involve various clinical evaluations, biochemical tests, and imaging techniques. 3 Conventional diagnostic procedures take a lot of time and are normally executed by manpower hence are obscure. Over the last few years, it has been investigated whether using machine learning (ML) algorithms could enhance the accuracy and efficiency of thyroid condition diagnosis. Artificial intelligence utilizes algorithms to analyze vast datasets to uncover patterns and correlations, offering a promising alternative to traditional diagnostic methods.
Earlier work has addressed how different ML algorithms may be applicable when diagnosing thyroid disorder. For instance, Gyanendra Chaubey (2021) utilized predictive analytics with ML models such as k-nearest neighbors (KNNs), decision trees (DTs), and logistic regression (LR) to diagnose thyroid disorders, highlighting the potential of these algorithms in medical diagnostics. 4 In the same way, Ankita Tyagi (2018) focused on predicting thyroid disease using KNNs, support vector machine (SVM), and DTs, demonstrating the value of ML in improving diagnostic accuracy. 5
Previously, Yadav & Pal et al. 6 explored the use of ensemble data mining approaches, including Boosting, Bagging, Stacking, and Voting, achieving a high accuracy of 98.80%. Mehk et al. 7 investigates the use of RF, SVM, and LR. Dhamodaran et al. 8 investigates the application of ML algorithms like KNN, SVM and Naive Bayes for the diagnosis of hyper and hypothyroidism. Ahmad et al. 9 developed a hybrid decision support system for thyroid diagnosis, achieving a classification accuracy of 99.1%. These studies highlight the potential of ML in improving diagnostic accuracy and efficiency.
Chaganti et al. 10 improved thyroid disease prediction by utilizing advanced feature engineering techniques, achieving an accuracy of 0.99 with a RF classifier. Ahmad et al. 9 developed a hybrid decision support system for the diagnosis of thyroid conditions. With a 99.1% classification accuracy, their method proved to be efficient in both feature reduction and diagnostic precision. George Obaido et al. 11 study proposes a method for the identification of thyroid disease that combines a stacking ensemble of many machine-learning models with filter-based feature selection. Through the effective mitigation of data imbalance and reduction of model biases, this ensemble approach significantly boosts predictive accuracy and resilience by combining the capabilities of many base models. This approach significantly improves the performance of thyroid disease diagnosis, demonstrating the potential of ensemble methods over single-model approaches. Wu S. et al. 12 proposed a DT ensemble method for detecting thyroid, leveraging the UCI dataset.
Haneet Kour et al. 13 study introduces a bagged ensemble model using linear discriminant analysis (LDA) combined with synthetic minority over-sampling technique (SMOTE) for thyroid disorder prediction. The model employs a majority voting approach, integrating five LDA models trained on bootstrap samples augmented with SMOTE. Evaluated on primary (1092 records) and secondary (7200 records) datasets, the model achieved accuracies of 85.45% and 82.71%, respectively, significantly improving upon the classic LDA accuracy of 69.55% and 75.28%. The approach demonstrates enhanced efficiency in diagnosing thyroid disorders compared to conventional ML classifiers.
Ritesh Jha et al. 14 study focuses on enhancing thyroid disease prediction accuracy by applying dimension reduction techniques and data augmentation. By using these methods, along with classifying reduced-dimension data, the study achieved a high accuracy of 99.95% with a deep neural network model. The proposed two-stage approach outperforms existing techniques, demonstrating the effectiveness of these techniques in improving disease prediction accuracy. Stacking uses a meta-learner to integrate predictions from several base learners, which frequently leads to better performance. Abbad et al. 15 study evaluates various ML classifiers for diagnosing thyroid disease, including KNN, DT, Naive Bayes, SVM, and LR. It uses a unique dataset with additional features like pulse rate, BMI, and blood pressure.
Research gap
Despite these advancements, challenges remain. Imbalanced datasets, where the proportion of patients with thyroid disease is significantly lower than those without, can lead to biased models. Techniques such as resampling and synthetic data generation, like SMOTE, have been employed to address this issue. Additionally, missing values in medical datasets pose a significant challenge, with researchers using various imputation techniques to handle incomplete data.
16
Furthermore, the interpretability of complex models, such as neural networks or ensemble methods, remains a concern, as their decision-making processes are often difficult to understand.
15
While ML models have shown high accuracy in thyroid disease prediction, several challenges remain. Imbalanced datasets, where the proportion of patients with thyroid disease is significantly lower then those of those without, can lead to biased models. Techniques such as resampling and synthetic data generation have been employed to address this issue. Moreover, missing values in medical datasets pose a significant challenge. Researchers have used various imputation techniques to deal with missing data, such as mode, median, mean, and model-based imputations. Feature engineering is the process of developing new features from previous ones and has also been crucial in improving model performance. Interpretability of complex models, such as neural networks and ensemble methods, is another area of concern. While these models provide high accuracy, understanding their decision-making process is often difficult.
Contributions
This study employs five ML algorithms and implements a Stacking Ensemble method to address these challenges. The ensemble approach combines the strengths of individual models with LR as a meta-learner to enhance predictive accuracy. Our methodology includes data preprocessing, feature engineering, and SMOTE to handle class imbalance, ensuring unbiased predictions. We use k-fold cross-validation to improve model robustness and generalizability. This study highlights the effectiveness of ML in thyroid disorder detection and underscores the benefits of ensemble methods and rigorous validation in medical diagnostics.
Among this research paper’s primary contributions are:
The implementation and analysis of numerous ML models in contrast. The application of an innovative Stacking ensemble method with LR as a meta-learner, enhancing diagnostic accuracy. The application of SMOTE for handling class imbalance, improving the model’s capability to predict minority classes. A robust validation framework using 10-fold cross-validation, ensuring the generalizability of the results.
Methods
This study utilized a clinical dataset comprising 3772 patient records to develop a model for thyroid disorder detection, as shown in Figure 1. The dataset included various attributes, such as demographic information and laboratory test results. To ensure that the data is prepared for analysis, important preprocessing procedures included encoding categorical variables, normalizing numerical characteristics, and addressing missing values. The SMOTE is used to solve the issue of class imbalance, ensuring a fair representation of classes and improving the ability of the model to forecast minority class outcomes. Feature selection is conducted using recursive feature elimination (RFE), which identified the most relevant features by iteratively eliminating less significant ones. This approach optimized model performance and reduced complexity.

Analyzing of methodology process diagram for focused study.
In total, 80% of the dataset is allocated for training, while 20% is allocated for testing. K-fold cross-validation, specifically a 10-fold strategy, is employed during model training to ensure robust evaluation and minimize overfitting. This approach splits the data into ten subsets, training the model on nine and validating it on the one remaining subset, repeating this process ten times. Five advanced ML models, including LR, gradient boosting (GB), DT, RF, and SVM are developed and fine-tuned using hyperparameter optimization techniques like Grid Search. These models are subsequently analyzed according to their prediction accuracy and efficiency. A The stacking ensemble method is used to integrate the strengths of multiple models, combining their predictions into a final, more accurate model. This ensemble approach leveraged diverse model capabilities, enhancing overall prediction performance.
Dataset description
The dataset used in this study comes from the UCI ML Repository, a widely recognized and publicly available repository for ML datasets. 17 The study data collection was conducted at the Garavan Institute and first published year 2019. The dataset comprises 3772 instances and 30 attributes, including demographic information(e.g., age, sex), laboratory test results(e.g., TSH, T3, TT4), thyroid medication status, and diagnostic classes (e.g., negative, primary hypothyroid). The target attribute (Class) signifies the presence or absence of thyroid disorders, with subcategories like “compensated hypothyroid” and “secondary hypothyroid.”
Ethical considerations
The UCI dataset is publicly available and anonymized, ensuring no personally identifiable information is included. As such, ethical approval and consent are not required for its use in this study. However, all experiments were conducted in compliance with ethical guidelines for the use of publicly available datasets.
Data preprocessing
The study’s dataset is obtained from the UCI ML Repository and contains various attributes relevant to thyroid function. Data preprocessing is an important step before using the dataset in the ML approach. Initially, handling missing values is essential. Numeric values that are missing are substituted with each column’s median value, ensuring that the central tendency is preserved. For categorical variables with missing values, the most frequently occurring value (mode) in each column is used as a replacement to maintain the integrity of the data. Next, label encoding is applied to convert the categorical variables into numerical values. This process is crucial as it converts the categorical data into a format that ML algorithms can efficiently process, enabling the model to process the data accurately. Additionally, standardizing the numeric features is performed to ensure consistency in the feature scales. Each numeric feature is adjusted to have a mean of zero and a standard deviation of one, making certain that each feature has an equal impact on the model’s functionality. By taking this step, features with wider scales are kept from unreasonably impacting the model’s outcomes, as expressed in Figure 2.

The steps involved in data preprocessing.
Feature engineering
Feature engineering is undertaken to create new features or modify existing ones, enhancing the efficiency of ML models.
Addressing class imbalance
In order to balance the distribution of classes within the dataset, SMOTE is used to create synthetic samples for the minority class. This technique ensured that the classifier was not biased towards the majority class, facilitating a more accurate prediction of the minority class, as shown in Figure 3.

The class distribution histograms before and after applying synthetic minority over-sampling technique (SMOTE).
Feature selection
RFE is employed for feature selection, using LR as the base model. 18 RFE iteratively removed the least important features and selected the most relevant ones, optimizing the models predictive power by focusing on key attributes, as shown in Table 1.
The selected features description analysis.

Applied machine learning models
This section examines different ML techniques 19 used for the prediction of thyroid disorders. In our study, we assess several advanced machine-learning models for diagnosing thyroid disorders. Each model is selected based on its suitability for handling imbalanced medical datasets, interpretability, generalization ability, and performance in previous studies on similar classification tasks.
To understand how different features influence model predictions, we examined the learned coefficients of LR, as shown in Figure 4. The feature query hyperthyroid has the highest positive coefficient, indicating a strong influence in classifying cases. This aligns with clinical expectations, as query_hyperthyroid status is a critical indicator of thyroid disorders.

Bar plot showing the coefficients of each feature in the logistic regression (LR).
To gain insight into the predictive power of different features, we analyzed feature importance scores obtained from the GB model. As shown in Figure 5, the most influential features in predicting thyroid disorders are free thyroxine index (FTI), query hyperthyroid, and FTI measured. These features contribute the most to the model’s decisions. Additionally, thyroid-stimulating hormone (TSH) also plays a significant role, reinforcing its clinical relevance in thyroid disorder diagnosis. Other features such as thyroxine, TSH measured, and referral source have a lower but non-negligible impact on model predictions.

Bar plot showing the feature importance in the gradient boosting (GB).
DT provides an interpretable and non-parametric approach to classification by formulating decisions based on input attribute values. 22 DTC is particularly useful when transparency is required in model predictions, making it a valuable tool in medical diagnostics. The model can handle both numerical and categorical data while capturing non-linear relationships between features. However, DTs are prone to overfitting, which is managed using pruning techniques to enhance generalization.
Figure 6 presents the DT structure generated in our study. The root node (top-most decision point) is based on the onthyroxine feature, indicating its importance in classifying thyroid disorders. This suggests that whether a patient is on thyroxine medication is a key determinant in the decision-making process.

The structure of decision tree (DT) model.
Figure 7 illustrates the feature importance scores derived from the RF model. The queryhyperthyroid feature is the most influential predictor, followed by FTI and TSH. These findings align with medical knowledge, as these biomarkers play a crucial role in diagnosing thyroid disorders.
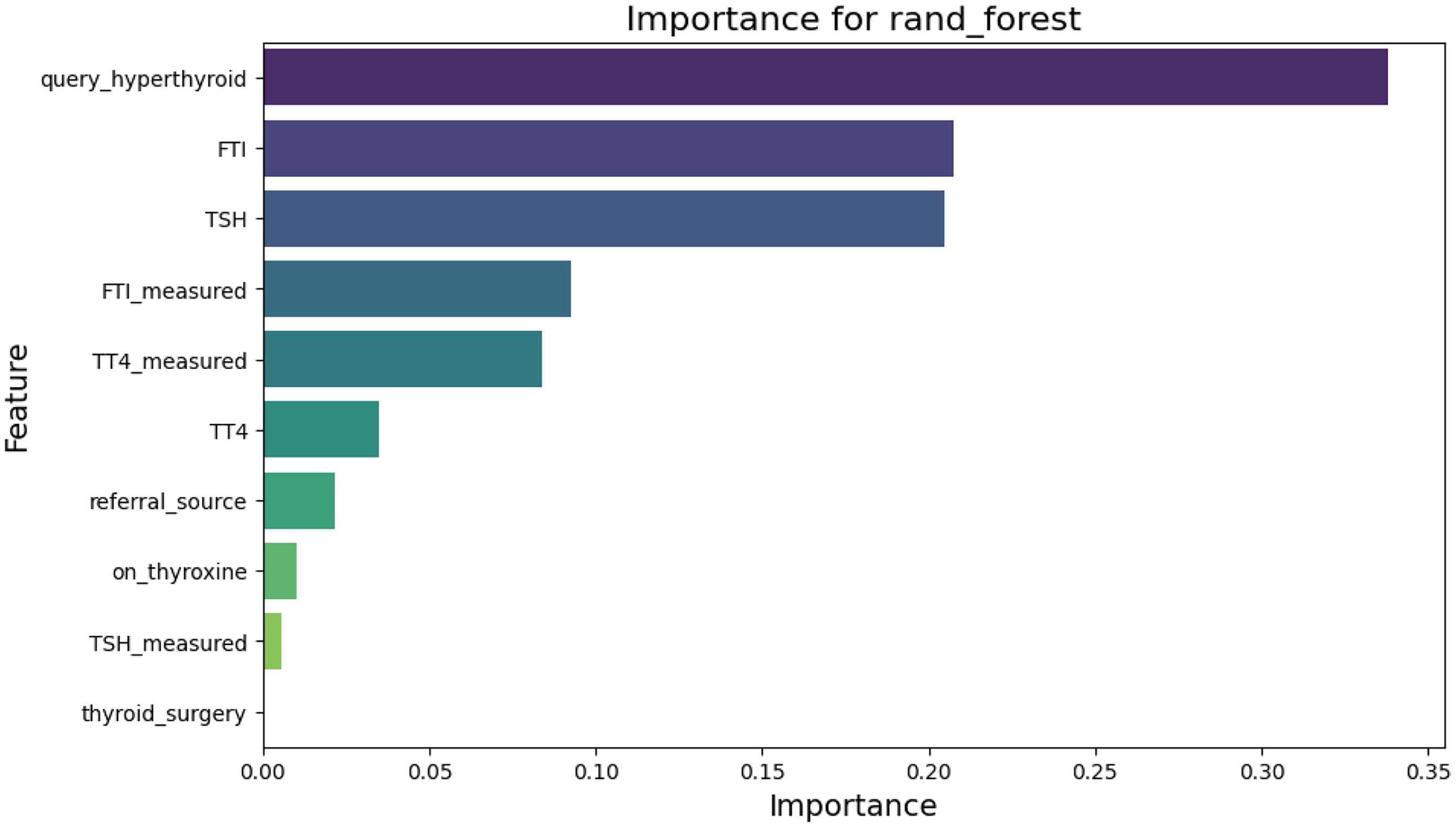
Bar plot showing feature importance in random forest (RF).
Figure 8 illustrates the decision boundaries of the SVM model using 2D PCA-transformed data. The visualization demonstrates how SVM separates different classes by defining distinct regions in the feature space. The support vectors, which influence the decision boundary, are shown at the class margins.

The decision boundary analysis of support vector machine (SVM).
Proposed stacking ensemble method
The stacking ensemble method is a powerful meta-learning technique that combines multiple base models to enhance predictive accuracy. Unlike bagging or boosting, which focus on aggregating similar models, stacking employs heterogeneous models and uses a meta-learner to make the final prediction. In this study, we employed five diverse ML algorithms—LR, GB, DT, RF, and SVM—as base models. Each base model is trained on the training dataset and generated predictions, which were then used as input features for the meta-learner. The meta-learner, implemented using LR, learned from these predictions and produced the final classification output.
The key advantage of stacking is that it leverages the strengths of multiple models while minimizing their weaknesses. For instance, tree-based models like RF and DTs capture complex patterns in the data, while LR provides robustness against overfitting. The combination of these models ensures a well-balanced predictive capability. The diversity of base models ensures that the ensemble captures a wide range of data patterns. For example, LR excels in modeling linear relationships, while GB and RF effectively handle non-linear interactions. This diversity allows the ensemble to generalize better across various data patterns inherent in thyroid datasets.
Additionally, the Stacking Ensemble, combined with SMOTE, effectively addresses class imbalance, a common issue in thyroid datasets where minority classes (e.g., rare thyroid conditions) are underrepresented. By leveraging the strengths of individual models, the ensemble improves predictions for minority classes, ensuring balanced and accurate results. The meta-learner (LR) plays a crucial role in optimizing the ensemble’s performance. It learns to combine the predictions of the base models, focusing on the most reliable outputs and reducing errors. This optimization process enhances the overall accuracy and robustness of the model.
Furthermore, thyroid datasets often contain noise due to measurement errors or variability in clinical data. The ensemble approach mitigates the impact of noise by averaging out errors from individual models, leading to more robust predictions. By combining these factors—diversity of base models, handling of class imbalance, meta-learner optimization, and robustness to noise—the Stacking Ensemble achieves state-of-the-art performance in thyroid disease prediction, outperforming individual models and other ensemble techniques.
A visual representation of our stacking ensemble architecture is provided in Figure 9. The base models generate intermediate predictions, which are fed into the meta-learner to refine the final classification. This hierarchical approach enables better generalization, particularly in imbalanced datasets such as those found in medical diagnostics.

The introduced stacking ensemble workflow analysis.
Models training and validation
To evaluate the predictive capabilities of different ML techniques, several algorithms are trained and assessed using K-fold cross-validation. The models included LR, GB, DT, RF, and SVM. The data is split into ten subsets as part of a 10-fold cross-validation technique. Each subset is used as a test set once, with the remaining subsets serving as the training set. This approach ensured that the model evaluation was robust and less prone to overfitting.
Hyperparameter tuning
The grid search approach is utilized for hyperparameter tuning to determine the optimal parameters for each model, improving their performance. This process tests various hyperparameter combinations, selecting those that yield the best results. The training set (80%) is used to train the models, and the testing set (20%) is used for evaluation. Table 2 contains the best hyperparameters and scores from grid search.
Best hyperparameters and scores from grid search.

SVM: support vector machine; RF: random forest; GB: gradient boosting; LR: logistic regression.
Statistical analysis
To evaluate the performance of the ML models and ensure the reliability of the results, the following statistical analyses are conducted:
Descriptive statistics: Descriptive statistics, including mean, median, and standard deviation, are calculated for all numerical features in the dataset. This provided insights into the central tendency and variability of the data.
Class distribution analysis: The distribution of the target classes (thyroid disorder categories) is analyzed before and after applying SMOTE to quantify the effectiveness of the balancing technique.
Performance metrics: The performance of each model is evaluated using standard metrics, including accuracy, precision, recall, and F1 score. These metrics are calculated for both the training and testing datasets to assess the model’s generalization ability.
Confidence intervals: Confidence intervals (95%) are calculated for the performance metrics (accuracy, precision, recall, F1 score) to assess the stability and reliability of the results across different folds of cross-validation.
Receiver operating characteristic (ROC) curve and area under the ROC curve (AUC) analysis: The AUC is calculated for each model to evaluate its ability to distinguish between classes. The ROC curves are plotted to visualize the trade-off between the true positive rate (TPR) and false positive rate (FPR) at various threshold settings.
Evaluation metrics



Results
The section explores the exploratory methods and the findings from the studies aimed at predicting thyroid disorders. The results, which include all relevant attributes, are presented, focusing on a multiclass classification task that uses the target attribute to figure out whether a patient has thyroid illness or not. To balance the dataset, the SMOTE technique is applied, and hyperparameter tuning is performed to improve the ML classifiers’ performance metrics. The ML algorithms are then trained using the balanced dataset.
Experiment design
The algorithm’s performance is evaluated using supervised ML models. The ML classifiers are developed using Scikit-Learn and Python. An 80:20 ratio is used to split the data into training and testing phases. The efficacy of the ML algorithms is evaluated using a variety of performance criteria. All of the tests are carried out in Python using different Scikit-Learn libraries. Measured metrics include recall, precision, accuracy, and f1 score.
Results without using SMOTE
This section examines the performance of various models trained and verified on the original dataset without using SMOTE. The analysis focuses on the metrics of recall, precision, accuracy, and F1 score to determine how well each model predicts the target classes in an imbalanced dataset. Figure 10 shows the accuracy plot without SMOTE.

The accuracy of all implemented models without the synthetic minority over-sampling technique (SMOTE).
Results validation using K-fold cross validation without SMOTE
Table 3 shows metrics for the performance of models validated by K-fold cross-validation without SMOTE. These metrics show how models perform in a situation of class imbalance, where some classes are underrepresented in the dataset.
Performance metrics without SMOTE.

SVM: support vector machine; RF: random forest; SMOTE: synthetic minority over-sampling technique; GB: gradient boosting; LR: logistic regression.
The LR model obtained an accuracy of 96.29%, with recall, precision, and F1 score all hovering around the same value. While these results are reasonable, the model’s performance suggests that it may struggle with correctly predicting the minority class due to the inherent imbalance in the data. The GB model demonstrated remarkable performance, attaining an accuracy of 99.74%. The consistency of the precision, recall, and F1 scores at 99.74% indicates that GB is highly effective even without addressing the class imbalance, though it might still benefit from techniques like SMOTE.
The DTC model also demonstrated strong performance with an accuracy of 99.60%. The high precision and recall values indicate that the model is fairly robust, but as with GB, there may be room for improvement by addressing the class imbalance. Similar to the DTC, the RF model achieved an accuracy of 99.60%, with precision and recall values closely aligned. The performance of the model indicates that it can handle imbalanced data relatively well, but like the other models, it might benefit from further enhancements.
The SVM model reached an accuracy of 97.75%, which is slightly less than the other models. The precision and recall are also slightly less, suggesting that the model may be more sensitive to class imbalance. The proposed Stacking Ensemble model matched the performance of GB with an accuracy of 99.74%, indicating that combining multiple models can lead to robust predictions even without balancing the dataset.
Classification report outcomes of implemented models without SMOTE
Table 4 provides the detailed classification report for each of the employed models without SMOTE, illustrating the precision, recall, f1 score, and support for each class. The data highlights how well each model performs in predicting both the majority and minority classes. The report reveals that models like Stacking Ensemble and GB perform well across all classes. Others, like LR and SVM, struggle with the minority class.
Class-wise summary report for each model based on specific target class without SMOTE.

SVM: support vector machine; RF: random forest; SMOTE: synthetic minority over-sampling technique; GB: gradient boosting; LR: logistic regression.
Study results using SMOTE
The SMOTE is applied to address the issue of class imbalance, which can greatly affect the efficiency of classification models. By generating synthetic examples for the minority class, SMOTE helps in achieving a more balanced training dataset. This section discusses the performance of the models when validated using K-fold cross-validation after applying SMOTE, providing a more robust understanding of the model’s predictive capabilities. Figure 11 shows the accuracy plot with SMOTE.

The accuracy result of all implemented algorithms with the use of synthetic minority over-sampling technique (SMOTE).
Table 5 presents the performance metrics for each model after applying SMOTE and validating with K-fold cross-validation. The application of SMOTE resulted in a significant improvement in the models ability to predict the minority class, as reflected in the increased precision, recall, and F1 scores.
Performance metrics with SMOTE.

SVM: support vector machine; RF: random forest; SMOTE: synthetic minority over-sampling technique; GB: gradient boosting; LR: logistic regression.
Classification report results of implemented models with SMOTE
Table 6 provides a detailed classification report for the employed models after applying SMOTE, showcasing the precision, recall, F1-score, and support for each class. The results clearly indicate that SMOTE significantly enhanced the model’s ability to accurately predict across all classes, particularly the minority classes, which are previously underrepresented in the dataset.
These results highlight the challenges that arise when models are trained on imbalanced datasets. Certain models, like the stacking Ensemble and GB, perform well even without SMOTE, and others, particularly LR and SVM, show a need for techniques that address class imbalance to improve their predictive accuracy across all classes.
Class-wise summary report for each model based on specific target class with SMOTE.

SVM: support vector machine; RF: random forest; SMOTE: synthetic minority over-sampling technique; GB: gradient boosting; LR: logistic regression.
Comparative analysis of the current study with and without SMOTE
The comparative analysis reveals significant performance improvements after balancing the dataset with SMOTE. Particularly, SMOTE enhanced the recall and F1 scores, underscoring its crucial role in predictive modeling for imbalanced medical datasets. The application of SMOTE is especially beneficial in improving the model’s capability to predict minority classes accurately, which is often a challenge in real-world medical scenarios.
Figure 12 illustrates the comparison of accuracy plots for models with and without SMOTE, highlighting the effectiveness of SMOTE in generating more reliable predictions. This graphical representation clearly shows that models trained on a balanced dataset perform significantly better, particularly in terms of recall and F1-score, which are critical metrics in medical diagnostics.

The accuracy result of all implemented algorithms with and without the synthetic minority over-sampling technique (SMOTE).
Confusion matrix analysis
A confusion matrix provides a thorough summary of the model’s predictions, displaying True Positives, True Negatives, False Positives, and False Negatives for each class. In this study, confusion matrices are generated for each ML model after applying the SMOTE to address class imbalance.
The confusion matrix for LR Figure 13(a) reveals the model’s ability to predict all classes. Although LR is generally efficient, but it showed some challenges in accurately predicting the minority class, even after SMOTE is applied. The matrix indicates a tendency towards misclassifying the minority class as the majority class, which highlights the models limitations in handling complex, imbalanced datasets.

The confusion matrix analysis.
Figure 13(b) demonstrates that GB’s confusion matrix performs well across all classes. The matrix reflects high accuracy, with balanced predictions, suggesting that the model clearly distinguishes between classes. This outcome aligns with the expectations for GB, known for its robustness and precision in classification tasks.
Figure 13(c) and (d) present the confusion matrices for the DTC and RF models, respectively. While both models performed reasonably well, The RF model has a greater TPR and lesser false negative rate than the DT. This suggests that RF, with its ensemble of DTs, provides better generalization and accuracy, particularly in predicting the minority class.
The SVM models confusion matrix Figure 13(e) highlights its capability in class distinction. The matrix shows that SVM is particularly effective in separating the classes, even in the presence of class imbalance. However, there is a slight inclination towards misclassifying instances of the minority class, although SMOTE helped mitigate this issue.
The Stacking Ensemble model, as depicted in Figure 13(f), showcased balanced predictions across all classes. The confusion matrix underscores the strength of ensemble methods and improved forecast performance by integrating numerous models. The matrix reveals that the The stacking Ensemble model successfully minimized both false positives and false negatives, indicating a well-rounded performance.
The confusion matrix analysis demonstrates that the Stacking Ensemble model outperformed the other models, providing balanced predictions across all classes. The GB and RF models also exhibited strong performance, particularly in accurately predicting the minority class. LR and SVM, while effective, showed some limitations in classifying minority instances, even with SMOTE applied. Overall, the application of SMOTE significantly improved the model’s ability to handle imbalanced data, with ensemble methods proving to be the most robust approach.
AUC and ROC curve analysis
The ROC curve and the AUC are essential tools for evaluating the performance of classification models, particularly in imbalanced datasets. The ROC curve plots the TPR against the FPR at various threshold settings, while the AUC provides a single metric to quantify the model’s ability to distinguish between classes. In this study, ROC curves and AUC values are generated for each ML model after applying SMOTE to address class imbalance.
The ROC curve for the LR model, as shown in Figure 14(a), demonstrates its ability to distinguish between classes. The AUC value of 0.98 indicates strong performance, with the model achieving a high TPR while maintaining a low FPR. However, the curve reveals a slight decline in performance for the minority class, suggesting that while LR is effective, it struggles slightly with complex, imbalanced datasets even after SMOTE is applied.

The ROC AUC curves analysis. ROC: receiver operating characteristic; AUC: area under the ROC curve.
Figure 14(b) highlights the exceptional performance of the GB model. With an AUC value of 0.99, the model achieves near-perfect class separation, reflecting its robustness and precision. The curve remains close to the top-left corner, indicating a high TPR and a low FPR across all thresholds. This outcome aligns with the expectations for GB, which is known for its ability to handle imbalanced data and complex relationships.
The ROC curve for the DT model, depicted in Figure 14(c), shows good performance with an AUC value of 0.97. However, the curve reveals a slight drop in TPR for the minority class, suggesting that the model may overfit to the majority class. While the DT performs well, it is less robust compared to ensemble methods like GB and RF.
Figure 14(d) demonstrates the superior performance of the RF model. With an AUC value of 0.99, the model achieves excellent class separation, outperforming the DT. The curve remains consistently high, indicating that the RF model generalizes well and maintains a high TPR even for the minority class. This result underscores the strength of ensemble methods in handling imbalanced datasets.
The ROC curve for the SVM model, as shown in Figure 14(e), highlights its capability in class distinction. With an AUC value of 0.98, the model performs well, particularly in separating the majority classes. However, the curve reveals a slight decline in TPR for the minority class, indicating that while SVM is effective, it still faces challenges in accurately predicting minority instances, even with SMOTE applied.
The ROC curve for the Stacking Ensemble model, depicted in Figure 14(f), showcases its balanced and robust performance. With an AUC value of 0.99, the model achieves near-perfect class separation, outperforming all individual models. The curve remains consistently close to the top-left corner, indicating a high TPR and a low FPR across all thresholds. This result underscores the strength of the Stacking Ensemble in integrating the predictions of multiple models to improve overall performance. The model successfully minimizes both false positives and false negatives, demonstrating its ability to handle imbalanced data effectively.
The AUC and ROC curve analysis demonstrates that the Stacking Ensemble model outperforms all other models, achieving the highest AUC value and maintaining a consistently high TPR across all classes. The GB and RF models also exhibit strong performance, with AUC values close to 0.99, reflecting their robustness in handling imbalanced data. While LR and SVM perform well, they show slight limitations in accurately predicting minority classes, even with SMOTE applied. Overall, the application of SMOTE significantly improves the models’ ability to handle imbalanced data, with ensemble methods proving to be the most effective approach.
Comparison with other related studies
Several research have explored the application of ML algorithms for predicting thyroid disease, each employing different methodologies and achieving varying levels of accuracy. A comparison with these studies underscore the efficiency of the proposed model in this research, as expressed in Table 7.
Comparison of machine learning approaches for thyroid disease prediction.

Yadav & Pal (2019) 6 utilized ensemble data mining techniques such as Boosting, Bagging, Stacking, and Voting, achieving an accuracy of 98.80%. Blagus (2013) 25 concentrated on effective feature selection and handling class imbalance, reaching an accuracy of 98.5%. Similarly, Waheed Ahmad (2018) 26 developed a hybrid decision support system that achieved 98.5% accuracy and 99.7% specificity. CHAI (2020) 27 integrated knowledge graph technology with a BiLSTM network, achieving an accuracy of 88.76%.
The proposed study beats earlier studies with an accuracy of 99.86% with the Stacking ensemble method. This superior performance can be attributed to the robust methodology, including extensive data preprocessing, feature engineering, and the application of SMOTE to address class imbalance. The use of a 10-fold cross-validation technique further ensures that the models are robust and reliable.
Multi-dataset validation
To evaluate the generalization capabilities of the proposed model, we validated its performance on two distinct thyroid disease datasets: The original dataset is UCI ML Repository dataset, and an additional Thyroid dataset publicly available on Kaggle. 28 This multi-dataset validation approach ensures that the model is robust and can perform well across different data sources and clinical settings.
The additional dataset, comprising 3772 records with a different class distribution, is used to test the model’s generalizability. Despite the differences in data characteristics, the Stacking Ensemble model achieved an accuracy of 97.40%, with precision, recall, and F1 scores consistently above 97%. This performance is comparable to the results on the original dataset, indicating that the model is not overfitting to the training data and can generalize well to new, unseen data.
The performance metrics for both datasets are summarized in Table 8. The Stacking Ensemble model consistently outperformed individual models, achieving the highest accuracy and F1 scores across both datasets. This highlights the effectiveness of combining multiple base models to improve predictive performance.
Performance metrics on original and additional datasets.

The results confirm that the proposed Stacking Ensemble model is not only accurate but also robust and generalizable, making it a promising tool for thyroid disease prediction in clinical practice.
Discussion
The results of this study demonstrate the effectiveness of ML algorithms, particularly ensemble methods, in improving the accuracy of thyroid disorder diagnosis. Without the application of SMOTE, models such as GB and the Stacking Ensemble achieved high accuracy (99.74%), precision, recall, and F1 scores, indicating their robustness even in the presence of imbalanced data. However, models like LR and SVM showed limitations in predicting the minority class, as reflected in their lower recall and F1 scores for underrepresented classes.
The application of SMOTE significantly improved the performance of all models, particularly for the minority class. For instance, the accuracy of LR increased from 96.29% to 98.99%, and its recall and F1 scores for the minority class improved substantially. This highlights the importance of addressing class imbalance in medical datasets, where minority classes often represent critical cases that require accurate prediction.
The Stacking Ensemble model consistently outperformed other models, achieving an accuracy of 99.86% with SMOTE. This superior performance can be attributed to the ensemble’s ability to combine the strengths of multiple base models, resulting in more robust and generalizable predictions. Similarly, GB and RF demonstrated strong performance, further validating the effectiveness of ensemble methods in handling imbalanced datasets.
In conclusion, this study contributes to the growing body of research on ML applications in healthcare by proposing a robust framework for thyroid disorder prediction. The results underscore the potential of ensemble methods and data-balancing techniques in improving diagnostic accuracy, while also highlighting the need for further research to address existing limitations and explore new avenues for innovation.
Limitations
However, while the results are promising, the study acknowledges that further advancements are needed. Future work could involve the exploration of deep learning techniques, which have shown significant potential in other areas of medical diagnostics due to their capability to extract attributes automatically from raw data. Additionally, applying the proposed model to bigger and more diverse datasets would be essential to improve its generalizability and reliability across different populations. This could involve the inclusion of data from various geographic regions, different demographic groups, and diverse clinical settings.
Conclusion
This research presents comprehensive ML techniques for predicting thyroid disorder, utilizing the well-known dataset from the UCI ML Repository. The research effectively addresses challenges such as class imbalance and model complexity through the implementation of data preprocessing techniques and SMOTE. These methods, combined with the advanced Stacking ensemble technique, resulted in a substantial improvement in predictive performance. Specifically, the ensemble model achieved an impressive accuracy of 99.86%, underscoring its effectiveness in identifying thyroid disorders. This high accuracy demonstrates the model’s potential to support clinicians in the early diagnosis and treatment of thyroid-related conditions, which is critical given the complexities of thyroid disorders and their impact on patient’s health.
Future work
Moreover, future studies could investigate the integration of this model into clinical workflows, evaluating its real-world performance and its impact on patient outcomes. Ultimately, the goal would be to refine the model further so that it can be a practical, reliable tool in the clinical environment, assisting healthcare professionals in making informed decisions regarding thyroid disease diagnosis and treatment.
Footnotes
Author contributions
Conceptualization, AH, SR, AR, MMI, AS, NLF, MS, and SWL; methodology, AH, SR, AR, NLF, MS, and SWL; validation, MMI and AS; formal analysis, AH, SR, AR, and NLF; investigation, MMIand AS; data curation, AH, SR, AR, and MMI,; writing—original draft preparation, AH, SR, AR, MMI, AS, and NLF; writing—review and editing, MS and SWL; visualization, AH, SR, AR, and NLF; supervision, MS and SWL; funding acquisition, MS and SWL. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Bio&Medical Technology Development Program of the National Research Foundation (NRF) funded by the Korean government (MSIT): NRF[2021-R1-I1A2(059735)]; RS[2024-0040(5650)]; RS[2024-0044(0881)]; RS[2019-II19(0421)].
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
SWL.