
Abstract
Keywords
Background
Hypertension is a global health concern, affecting approximately 1.13 billion people worldwide, according to the World Health Organization. 1 It is a leading risk factor for cardiovascular diseases, including stroke, myocardial infarction, and heart failure. The prevalence of hypertension is increasing, driven by factors such as aging populations, sedentary lifestyles, and unhealthy dietary habits. 1 Accurate and timely diagnosis of hypertension and related conditions is essential for effective management and prevention of adverse outcomes.
Ambulatory Blood Pressure Monitoring (ABPM) is a crucial tool in modern medicine, enabling the continuous measurement of blood pressure over a 24-h period. 2 This technique offers a comprehensive view of an individual's blood pressure fluctuations throughout the day and night, providing valuable insights that single-point measurements cannot. ABPM is particularly useful in diagnosing and managing conditions such as hypertension, hypotension, nocturnal hypertension, and other related cardiovascular anomalies. 2 However, the interpretation of ABPM data is often complex and time-consuming, requiring expert analysis to ensure accurate diagnosis and appropriate management. ABPM plays a vital role in the epidemiological landscape of hypertension. Studies have shown that ABPM provides more accurate and predictive information about cardiovascular risks compared to traditional office blood pressure measurements. It can help in identifying cases of white-coat hypertension, masked hypertension, and nocturnal hypertension, which are often missed during clinic visits. 3 Despite its benefits, the widespread adoption of ABPM is limited by the need for specialized interpretation, which is both resource-intensive and dependent on expert clinicians. 2
Artificial Intelligence (AI) has emerged as a transformative force in various fields, including healthcare.4,5 AI models, particularly those based on advanced neural networks, have shown remarkable potential in interpreting complex medical data. 6 It has increasingly been implemented in the field of hypertension. Machine learning (ML) models have shown superior performance over traditional methods in predicting hypertension, detecting early cardiac dysfunction, and accurately classifying heart failure (HF) stages, which can lead to more targeted and effective treatments. 7 The potential of AI involves prediction, diagnosis, and management of hypertension and HF, highlighting its ability to enhance patient care at every stage. ChatGPT and Natural language processing (NLP) AI have been tested in multiple fields ranging from answering board questions 8 to summarizing clinical guidelines, assisting in clinical decision support, and acting as an educational tool for both patients and healthcare providers. 9
The integration of AI in clinical practice promises to enhance diagnostic accuracy, streamline workflows, and ultimately improve patient outcomes. 10 Among these AI models, ChatGPT 4.0, developed by OpenAI, represents a significant advancement in natural language processing and understanding, with potential applications in the interpretation of medical data. 11 The utility of AI in interpreting ABPM data is increasingly recognized. AI models can analyze large volumes of data rapidly and consistently, potentially outperforming human experts in certain tasks. 11 Evaluating the accuracy of AI models, such as ChatGPT 4.0, in clinical settings can provide insights that facilitate their integration into healthcare processes, making ABPM analysis more accessible and reliable. Current guidelines recommend the use of ABPM for the diagnosis and classification of hypertension. 12 However, AI has not yet been widely applied to interpreting ambulatory blood pressure monitor readings. Image processing, one of AI's strong suits, can assist medical professionals, including hypertension specialists and nephrologists, in augmenting their interpretation of ABPM data. While AI cannot replace physicians, it can expedite the process, allowing more time for critical clinical tasks and enabling faster and more efficient extraction of data from 24-h blood pressure readings.
This study aims to assess the performance of ChatGPT 4.0 in interpreting 24-h ABPM records and compare its accuracy with expert interpretations, which could have significant implications for the future of hypertension management and the broader application of AI in healthcare. However, limited research has been conducted to validate the performance of these models against expert interpretations in real-world clinical scenarios. Most existing studies focus on the theoretical potential of AI, with few addressing practical implementation and validation. This gap in research hinders the adoption of AI in clinical practice, as clinicians and healthcare providers require robust evidence of the models’ accuracy and reliability before they can be integrated into patient care. This study addresses this critical gap by evaluating ChatGPT 4.0's performance in interpreting ABPM data from patients at Mayo Clinic, Minnesota.
Materials and methods
Case selection
The study was conducted at Mayo Clinic, Minnesota. The Mayo Clinic Institutional Review Board approved this study (IRB number 24-002829) and exempted the need for informed consent because this was a minimal risk study solely involving chart review.
To ensure internal validity, strict inclusion and exclusion criteria were applied to minimize confounding variables. Patients aged 18 years or older with complete 24-h ABPM recordings that met calibration standards were included. Pediatric patients, incomplete ABPM data, and recordings shorter than 24 h were excluded. A total of 53 ABPM records were randomly selected for this study. ABPM data were calibrated using a standardized protocol. Manual blood pressure measurements were taken in three positions (sitting, standing, and lying down) and compared to simultaneous automated measurements. Calibration was considered satisfactory if the difference between manual and automated systolic and diastolic averages was 8 mm Hg or lower. These calibrated readings ensured data accuracy and minimized variability. ABPM is routinely conducted in our department to diagnose hypertension, monitor management strategies, and assess nocturnal hypertension.
The data were deidentified to remove any patient identification information. Inclusion criteria required the availability of ABPM data at our facility for patients aged 18 years and older, with data collected over a one-month period and satisfactory ABPM results (as defined by the criteria stated above). Pediatric patients were excluded to maintain the homogeneity of the data. Additionally, 6- and 12-h ABPM readings were excluded from the study. Table 1 provides a detailed summary of the demographic characteristics of the study cohort. The mean age of the 53 patients was 66.74 years, with a gender distribution of 54.72% females and 45.28% males. The selection process ensured the inclusion of patients with diverse blood pressure profiles, including hypertension, nocturnal hypertension, normal nocturnal dipping, tachycardia, and bradycardia.
Patient sample demographics.

Patient sample demographics.
Acronyms: DM: Diabetes Mellitus, CKD: Chronic Kidney Disease, GERD: Gastroesophageal Reflux Disease, CAD: Coronary Artery Disease, IBS: Irritable Bowel Syndrome, BPPV: Benign Paroxysmal Positional Vertigo, POTS: Postural Orthostatic Tachycardia Syndrome, MDD: Major Depressive Disorder, MGUS: Monoclonal Gammopathy Of Unknown Significance, BPH: Benign Prostatic Hyperplasia, HIV: Human Immunodeficiency Virus, MCAD: Mast Cell Activation Disease, AAA: Abdominal Aortic Aneurysm, RAS: Renal Artery Stenosis, PTSD: Posttraumatic Stress Disorder
The ABPM data were collected using a validated 24-h ABPM device, specifically the Spacelabs ambulatory blood pressure monitors, which record blood pressure at regular intervals throughout the day and night. These devices provide a comprehensive dataset for each patient, including systolic and diastolic blood pressure readings, heart rate, and time-stamped annotations. The Spacelabs monitors are annually validated for calibration accuracy. Each year, all monitors are sent to our laboratory facility at the Mayo Clinic, where they undergo 24-h testing on specialized calibration devices to ensure proper functionality and accuracy before use.
For each patient, prior to initiating 24-h blood pressure monitoring, trained staff manually measure blood pressure in both arms across three positions (lying down, sitting, and standing) using a standard sphygmomanometer. These six manual measurements are compared with simultaneous readings from the ABPM device, and the device is considered calibrated if the difference in systolic and diastolic averages between manual and device measurements is ≤8 mmHg. Once calibrated, the cuff is connected to the patient, and 24-h readings are initiated. All ABPM data collected prior to this study were meticulously checked for completeness and consistency before being processed by ChatGPT.
Prompt development and structure
The prompt used with ChatGPT was carefully crafted to ensure clear and accurate alignment with the study's objectives. Our team undertook an iterative process to develop a structured and detailed prompt. It clearly defined parameters such as thresholds for hypertension, criteria for nocturnal dipping, and classifications for heart rate, following the American College of Cardiology/American Heart Association (ACC/AHA) guidelines. The goal was to create a straightforward, unambiguous command that would optimize ChatGPT's interpretative accuracy while minimizing irrelevant outputs. The exact prompt used in this study is provided in Table 2 for reference.
Prompt and parameter and definitions provided to chat GPT prior to interpretation of ABPM.
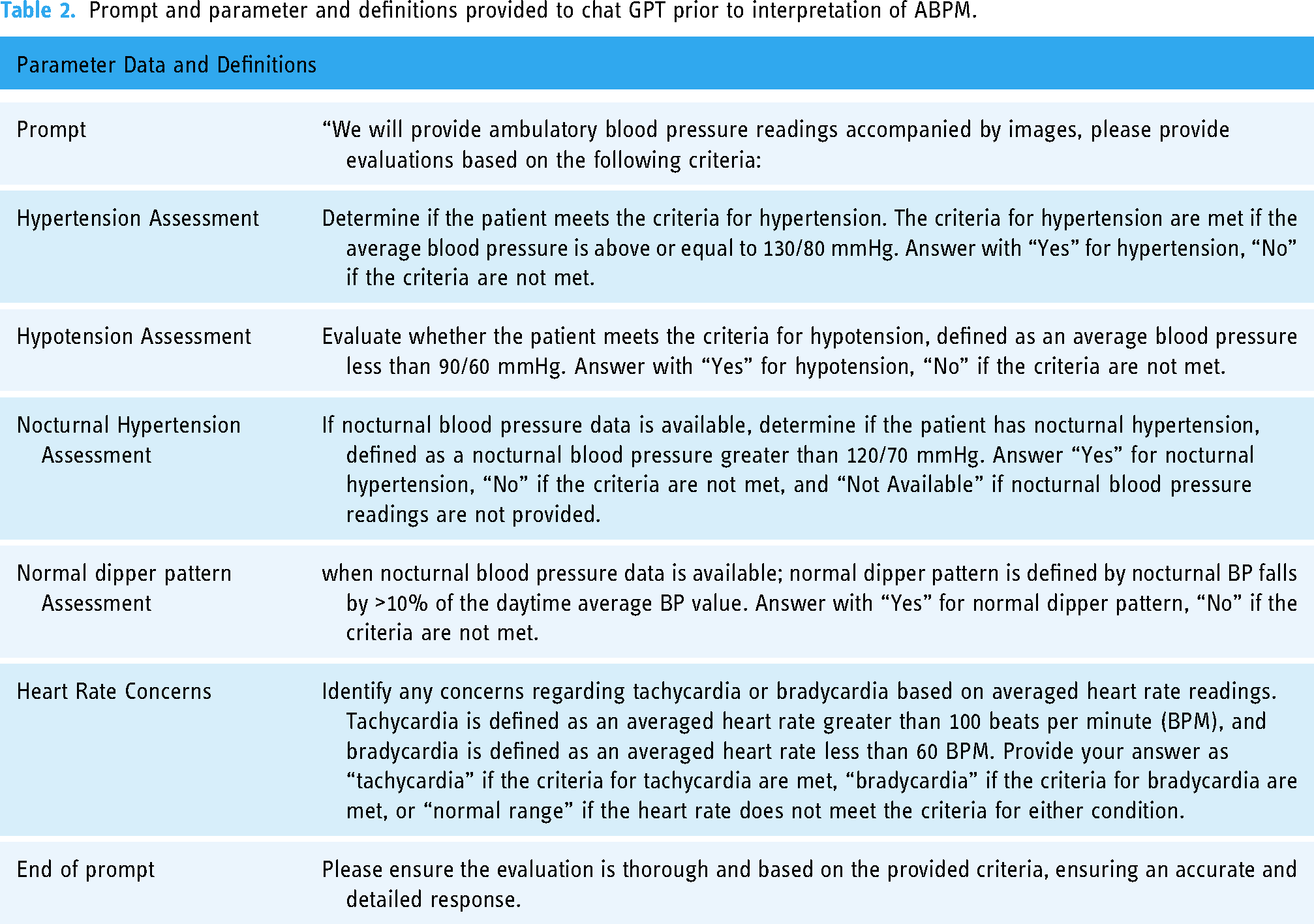
Prompt and parameter and definitions provided to chat GPT prior to interpretation of ABPM.
The ABPM recordings provided both graphical and numerical data outputs. The graphical representation (Figure 1(a)) depicted 24-h blood pressure trends, while the numerical dataset (Figure 1(b)) included key parameters such as average systolic and diastolic blood pressure readings, heart rate, and timestamps. The graphical data were processed as images, while the numerical values were extracted into a tabular format for standardization. This dual-input approach ensured that ChatGPT received comprehensive data for accurate interpretation. All graphical and numerical data were meticulously verified for completeness and consistency prior to being processed by ChatGPT.

(a) ABPM graph, (b) average numerical data.
ChatGPT 4.0, developed by OpenAI, is an advanced NLP model designed to interpret and analyze data. For this study, this feature was utilized. The NLP model was provided with visual data of ABPM readings that included both the graphical representation of 24 h blood pressure readings as well as average numerical value (Figure 1). To standardize reporting,a set of predefined criteria (prompt) was provided.
Evaluation procedure
The definitions (Table 2) of hypertension, nocturnal hypertension, normal nocturnal dipping, normal heart rate, tachycardia, and bradycardia according to the ACC/AHA guidelines, were provided to ChatGPT 4 before the query. The data were collected, and the image/graph and the average readings were extracted from each of the ABPM data. Since ChatGPT is an NLP model capable of interpreting image data, the extracted image was provided (Figure 1). The interpretation parameters (Table 2) were set and provided to Chat GPT prior to interpretation. Each ABPM record was individually entered into ChatGPT for evaluation. The evaluation of ChatGPT's performance in the same 53 ABPM records was independently conducted in two separate rounds in April and August 2024 to observe the consistency and reliability of ChatGPT's response over time. The same prompt was used for both rounds.
The prompt used with ChatGPT was carefully developed to ensure that the model accurately understood and adhered to our clinical objectives. This process included extensive testing and refinement to establish a standardized input format. The prompt clearly defined parameters such as thresholds for hypertension, criteria for nocturnal dipping, and classifications for heart rate, following the guidelines of the ACC/AHA. To enhance reproducibility and minimize variability, we provided ChatGPT with both graphical representations of 24-h ABPM data and the corresponding average numerical values for analysis. The detailed prompt is provided in Table 2.
Reference standard for ABPM readings
To establish a reliable reference standard for assessing ChatGPT's performance, two experienced nephrologists independently reviewed the ABPM data using predefined criteria and guidelines. In cases of disagreement, a structured consensus process was implemented, involving joint discussions to resolve discrepancies and ensure accurate interpretations based on the established parameter definitions. The level of agreement between the nephrologists prior to reaching a consensus was quantified using the kappa statistic. They reached a consensus on the presence or absence of specific conditions following the ACC/AHA guidelines and institutional criteria. These consensus interpretations served as the reference standard for evaluating ChatGPT's accuracy.
Statistical analysis
The accuracy of ChatGPT's responses was evaluated by comparing its outputs to the consensus opinion of a panel of experienced nephrologists, which served as the reference standard. To assess potential improvement in performance over time, the accuracy, sensitivity, and specificity of ChatGPT in interpreting ABPM data were analyzed across two assessment rounds using McNemar's test. McNemar's test is specifically designed to compare paired proportions, making it well-suited for this study, as the same set of ABPM records was evaluated in both rounds under comparable conditions. This test evaluates whether there is a statistically significant difference in paired binary outcomes (e.g., correct vs. incorrect interpretations) between two time points. The assumptions of McNemar's test, including the requirement for paired data and binary outcomes, were met. P-values from the test were reported to identify any significant differences between the two rounds.
The level of agreement between ChatGPT's interpretations in the first and second rounds was quantified using both percentage agreement and the Kappa statistic. The Kappa statistic adjusts for chance agreement and provides a robust measure of reliability, with values ranging from 0 (no agreement) to 1 (perfect agreement). For interpretive clarity, Kappa values were categorized into five levels: 0.01–0.20 indicating slight agreement, 0.21–0.40 indicating fair agreement, 0.41–0.60 indicating moderate agreement, 0.61–0.80 indicating substantial agreement, and 0.81–1.00 indicating near-perfect agreement. Additionally, the prevalence-adjusted bias-adjusted Kappa (PABAK) was calculated to account for potential biases introduced by the prevalence of certain conditions in the dataset. All statistical analyses were performed using JMP statistical software, version 17.0 (SAS Institute Inc., Cary, NC), which facilitated comprehensive data management and analysis. The software enabled the application of McNemar's test and calculation of both Kappa and PABAK statistics, ensuring a thorough evaluation of the agreement and reliability of ChatGPT's performance.
Results
The 53 ABPM records were selected after implementing the inclusion and exclusion criteria.
Accuracy of ChatGPT response in interpreting ABPM compared with nephrologist review
In the first round, ChatGPT correctly interpreted the presence or absence of hypertension in 46 (87%) records, nocturnal hypertension in 47 (89%) records, nocturnal dipping in 43 (81%) records, and an abnormal heart rate in 50 (94%) records (Figure 2). It correctly interpreted all conditions in 32 (60%) records. The sensitivity was 79% in identifying hypertension, 82% in nocturnal hypertension, 68% in nocturnal dipping, 71% in abnormal heart rate. The specificity was 96% in identifying hypertension, 92% in nocturnal hypertension, 96% in nocturnal dipping, and 98% in abnormal heart rate (Table 3).

Percentage of agreement between ChatGPT and nephrologist ABPM interpretation by category for each round.
Accuracy, Sensitivity, and Specificity of ChatGPT in ABPM Interpretation:Comparison of ChatGPT’s accuracy, sensitivity, and specificity in interpreting ambulatory blood pressure monitoring (ABPM) data, as assessed in two independent rounds. The AI model’s performance is evaluated against consensus interpretations by expert nephrologists, with p-values indicating statistical differences between the two rounds.

In the second round, ChatGPT correctly interpreted the presence or absence of hypertension in 48 (91%) records, nocturnal hypertension 49 (92%) records, nocturnal dipping in 45 (85%) records, and an abnormal heart rate in 51 (96%) records. It correctly answered all conditions in 36 (68%) records in this round. The sensitivity was 93% in identifying hypertension, 94% in nocturnal hypertension, 75% in nocturnal dipping, and 71% in abnormal heart rate. The specificity was 88% in identifying hypertension, 92% in nocturnal hypertension, 96% in nocturnal dipping, and 100% in abnormal heart rate (Table 3).
There was no significant difference in accuracy, sensitivity, and specificity between the first and second round (all p > 0.05).
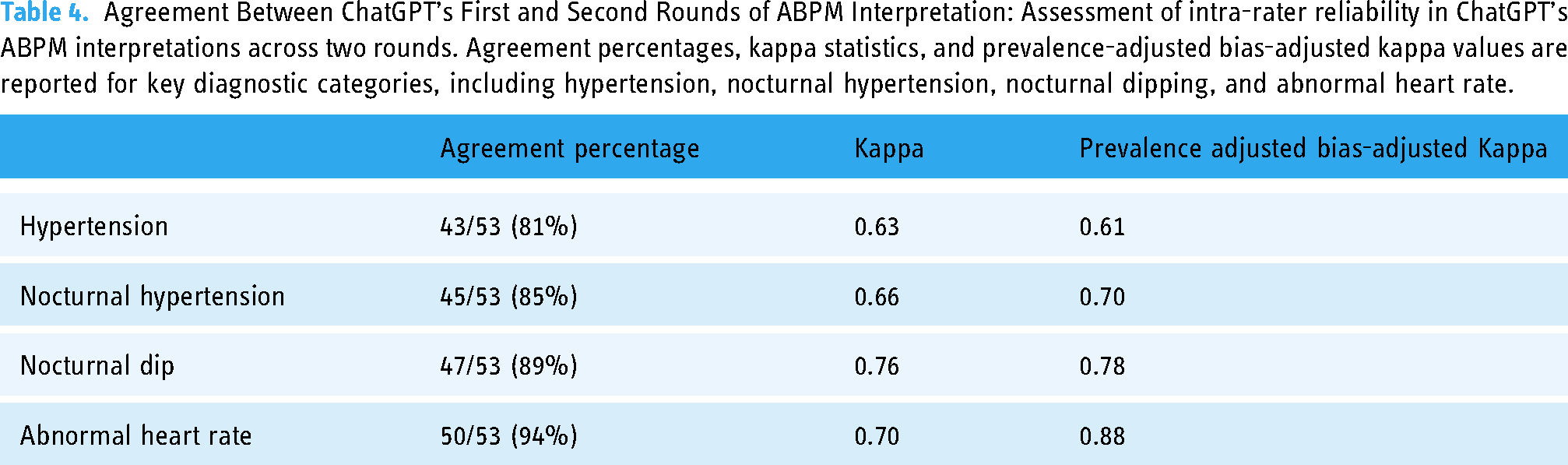
The percentage agreement between the first and second round of ChatGPT was 81% in identifying hypertension, 85% in nocturnal hypertension, 89% in nocturnal dipping, and 94% in abnormal heart rate (Figure 3). The Kappa agreement statistic was 0.63 in identifying hypertension, 0.66 in nocturnal hypertension, 0.76 in nocturnal dipping, and 0.70 in abnormal heart rate. The prevalence-adjusted bias-adjusted Kappa statistic was 0.61 in identifying hypertension, 0.70 nocturnal hypertension, 0.78 in nocturnal dipping, and 0.88 in abnormal heart rate (Table 4).

Intra-rater percentage of agreement between ChatGPT round 1 and ChatGPT round 2.
Agreement Between ChatGPT’s First and Second Rounds of ABPM Interpretation: Assessment of intra-rater reliability in ChatGPT’s ABPM interpretations across two rounds. Agreement percentages, kappa statistics, and prevalence-adjusted bias-adjusted kappa values are reported for key diagnostic categories, including hypertension, nocturnal hypertension, nocturnal dipping, and abnormal heart rate.
ChatGPT 4.0 demonstrated accuracy in detecting hypertension (84.91%) and hypotension (94.34%). These conditions have well-defined diagnostic thresholds, which likely contributed to the AI's strong performance. Hypertension is a significant risk factor for cardiovascular diseases, and accurate diagnosis is critical for effective management. The AI's ability to reliably identify hypertension could aid in early diagnosis and intervention, potentially reducing the burden of cardiovascular diseases.
Hypotension, although less common than hypertension, can also have serious health implications if left untreated. The AI's high accuracy in detecting hypotension highlights its potential utility in identifying this condition, which is often overlooked due to its less symptomatic nature. This capability is particularly valuable in clinical settings where quick and accurate diagnosis is essential.
The AI achieved an accuracy of 81.13% in detecting nocturnal hypertension and 75.47% in identifying a normal nocturnal dip. Nocturnal hypertension, characterized by elevated blood pressure during sleep, is a critical condition often associated with increased cardiovascular risks. Accurate identification of nocturnal hypertension is crucial as it often goes undetected with standard daytime measurements. The AI's performance in this area indicates a reliable level of accuracy, although further improvements are necessary. The normal nocturnal dip, the natural decrease in blood pressure during sleep, is an important indicator of cardiovascular health. 13 Deviations from the normal pattern can signal potential health issues. Enhancing the AI's accuracy in identifying a normal nocturnal dip could further improve its utility in clinical settings, aiding in the diagnosis of various cardiovascular conditions.
ChatGPT 4.0 showed good performance in identifying normal heart rates, with an accuracy of 90.57%. This result underscores the AI's capability in recognizing standard physiological parameters, which is fundamental for distinguishing between normal and abnormal conditions. High accuracy in this area is essential for ensuring that the AI does not flag normal readings as pathological, thereby reducing false positives and unnecessary interventions. The AI's performance in detecting tachycardia (73.58%) and bradycardia (71.70%) was comparatively lower. Tachycardia, defined as an abnormally high heart rate, can be indicative of various underlying conditions, including cardiac arrhythmias and other systemic issues. Bradycardia, characterized by an abnormally low heart rate, can sometimes be benign but may also indicate serious health problems, particularly if symptomatic. While the AI's accuracy in detecting tachycardia and bradycardia is promising, targeted improvements are necessary to enhance its reliability in these areas. Enhancing accuracy in detecting tachycardia and bradycardia would be beneficial, especially in preventing misdiagnosis and ensuring timely treatment.
The findings of this study align with previous research that highlights the potential of AI in medical diagnostics. 14 Prior studies have demonstrated the ability of AI models to accurately interpret various types of medical data, including imaging and laboratory results.6,14,15 However, most existing studies focus on the theoretical potential of AI, with few addressing practical implementation and validation in clinical settings.16,17 This study contributes to bridging this gap by providing evidence of ChatGPT 4.0's performance in a real-world clinical scenario. The accuracy rates for hypertension and hypotension are consistent with earlier findings that highlight AI's potential to enhance diagnostic accuracy. 18 However, the lower performance in tachycardia and bradycardia detection indicates specific areas where AI models still need improvement. This divergence from previous studies underscores the importance of validating AI models in diverse clinical settings to identify and address potential limitations.16,19
Several factors could explain the varied accuracy rates observed in this study. For conditions like hypertension and hypotension, clear diagnostic thresholds allow the AI to make accurate determinations. The well-defined nature of these conditions means that the AI can reliably identify patterns associated with elevated or reduced blood pressure. In contrast, conditions like tachycardia and bradycardia involve more nuanced patterns and variability in heart rate, which may challenge the AI's pattern recognition capabilities. The data used for the AI model may have been insufficient or imbalanced, limiting its ability to generalize to these more complex conditions. Additionally, the complexity of interpreting heart rate data, which can be influenced by a wide range of factors including physical activity, stress, and underlying health conditions, may contribute to the AI's lower performance in these areas.
The findings of this study have several implications for clinical practice. The high accuracy of ChatGPT 4.0 in detecting hypertension and hypotension suggests that AI can be a valuable tool in diagnosing these conditions. Integrating AI into clinical workflows could enhance diagnostic accuracy and efficiency, allowing healthcare providers to identify and manage cardiovascular conditions more effectively. 14 However, the lower performance in detecting tachycardia and bradycardia indicates that AI models need further refinement before they can be fully trusted in these areas. Continued development and training on more diverse datasets are necessary to improve the AI's accuracy and reliability. Additionally, incorporating feedback from clinical experts during the AI's training phase could help to fine-tune its diagnostic capabilities. Although we need to take into consideration the human errors in data interpretation.
This study has several strengths, but the limitations should be acknowledged. This study utilized 53 ABPM recordings to assess the performance of ChatGPT 4.0 in interpreting 24-h ABPM data compared to expert nephrologists. The sample size was limited due to the additional resources required to obtain 24-h ABPM data, which is less commonly performed compared to 6-h or 12-h recordings. While this smaller sample size reflects the constraints of this exploratory, proof-of-concept study, it serves as a foundation for evaluating the feasibility of leveraging AI in clinical settings. The patient cohort included individuals from diverse demographic and geographic backgrounds, spanning national and international origins, which enhances the representativeness of the dataset despite the sample size limitations. A random selection process was employed to minimize bias, and all data were de-identified before analysis. To ensure the broader applicability of these findings, future studies with larger sample sizes and more diverse populations are planned to validate and expand upon these preliminary results.
The relatively small sample size of 53 cases may limit the generalizability of the findings. A larger sample size would provide more robust data and potentially yield different results. This was an initial exploratory study, and in the future, larger studies with more patient data over longer periods of time should be evaluated. Additionally, the study was conducted at a single institution (Mayo Clinic), which may not represent the diversity of patient populations seen in other clinical settings, although at Mayo Clinic we have a wide array of patients from both national and international backgrounds; however, 83% of the patient sample was White. This study has several limitations that impact its internal and external validity. The small sample size and single-center design limit the generalizability of the findings. Additionally, while confounding variables were minimized through strict inclusion criteria and standardized ABPM calibration, unmeasured factors such as patient comorbidities and medication use were not explicitly controlled. Future studies will address these limitations by incorporating larger, multi-center datasets and more comprehensive patient-level data to enhance both internal and external validity. Multi-center studies involving varied patient demographics are necessary to validate the findings. Another limitation is the potential bias in the selection of cases. Although the cases were randomly selected, there may still be inherent biases in the dataset that could influence the results. Ensuring a truly representative sample of ABPM records, with balanced representation of different conditions, is crucial for accurately assessing the AI's performance. The potential general limitations of using AI in healthcare, such as data quality, generalizability, model transparency, complexity, resource constraints, and regulatory challenges, are also applicable in this setting. AI models can also have inherent bias based on training datasets, and continuous validation is resource-intensive. Automation bias and overreliance on AI are additional concerns that must be addressed.16,19
Future research should focus on expanding the dataset to include a more diverse patient population and a greater variety of clinical scenarios. This would help in training the AI model more comprehensively, potentially improving its accuracy in detecting conditions like tachycardia and bradycardia. Multi-center studies involving larger sample sizes and varied patient demographics are necessary to validate the findings and ensure the generalizability of the results. Additionally, studies should explore the practical implementation of AI in clinical workflows, assessing its impact on diagnostic accuracy, efficiency, and patient outcomes. Understanding how AI can be seamlessly integrated into existing healthcare processes is crucial for maximizing its benefits. Future research should also investigate the potential of AI to assist in other aspects of patient care, such as treatment planning and monitoring.20,21 AI-based technologies could leverage clinical BP records and apply methods like deep learning to enhance the accuracy of BP measurements and provide individualized cardiovascular risk assessments. 22
Conclusion
In summary, this study provides a comprehensive evaluation of ChatGPT 4.0's performance in interpreting 24-h ABPM data, comparing its accuracy with expert clinical interpretations. The findings suggest that AI has potential to assist in the interpretation of complex clinical data, with high accuracy in several key areas. The high accuracy rates for hypertension and hypotension indicate that AI can aid in diagnosing these common conditions, potentially improving patient outcomes through early diagnosis and intervention. However, the lower accuracy in detecting tachycardia and bradycardia highlights areas where further development is needed. The integration of AI in interpreting ABPM data could revolutionize hypertension management and improve patient outcomes. By comparing the performance of AI models against expert interpretations, this study contributes to the growing body of evidence supporting the use of AI in clinical settings. As AI technology continues to evolve, its role in healthcare is expected to expand, offering new opportunities for enhancing diagnostic accuracy and efficiency. However, continued research and development are necessary to address the limitations identified in this study and ensure the reliable performance of AI models across a wide range of clinical scenarios.
Footnotes
Acknowledgements
None
Contributorship
Author Contributions: Conceptualization, S.F.A., W.C.; Data curation, J.H.P.; Formal analysis, J.H.P.; Funding acquisition, J.H.P., W.C.; Investigation, J.H.P.; Methodology, J.H.P., J.M., I.M.C.; Project administration, C.T., S.F.A.; Resources, J.H.P.; Supervision, C.T., J.M., I.M.C.; Validation, W.C.; Visualization, J.H.P., W.C.; Writing – original draft, J.H.P., W.C.; Writing – review & editing, C.T., S.F.A., J.M., I.M.C., M.S.S., O.A.G.V., G.L.S., M.L.G.S. All authors have read and agreed to the published version of the manuscript.
Disclosure
The authors have nothing to disclose
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data underlying this article will be shared on reasonable request to the corresponding author.
Disclosure
All the authors declared no competing interest.
Ethics approval
The study was conducted at Mayo Clinic, Minnesota. The Mayo Clinic Institutional Review Board approved this study (IRB number 24-002829) and exempted the need for informed consent because this was a minimal risk study solely involving chart review.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Funding
None
Guarantor
C.T.
Language model use
The use of ChatGPT in this study was strictly limited to the response-generating protocol described in the methods section. ChatGPT was not used for data analysis, writing, or any other aspects of the production of this manuscript.