
Abstract
Objective
Empathy between doctors and patients is crucial in enhancing patient satisfaction with medical consultations. This study, grounded in empathy theory, employs natural language processing and machine learning algorithms to explore the factors influencing patient satisfaction in online healthcare services, particularly the impact of doctor–patient empathy.
Methods
Utilizing the three dimensions of the Jefferson Scale of Physician Empathy, seven variables were extracted from patient–doctor dialogs as independent variables, with patient satisfaction as the dependent variable. Employing machine learning algorithms, a classification model was constructed to identify the best-fitting model for exploring the pivotal factors influencing patient satisfaction in online medical services. The optimal model was then chosen to investigate the essential factors impacting patients’ satisfaction with online healthcare.
Results
A total of 7586 data points were collected, with 5447 consultation dialogs (71.8%) receiving a satisfactory rating from patients. LightGBM emerged as the best-performing model, achieving an F1 score of 0.78 and an area under the curve value of 0.81. Factors within the Standing in Patient's Shoes and Perspective Taking dimensions were identified as key determinants of patient satisfaction in online healthcare services.
Conclusion
This study broadens the conventional scope of applying empathy theory, signifying its crucial role in cultivating doctor–patient empathy within the realm of online healthcare and elevating the overall quality of medical services. The findings indicate that two pivotal factors influencing patients’ satisfaction with online healthcare are doctors’ perceived competence and ability to empathize, understanding patients’ perspectives, and offering assistance.
Introduction
Empathy, synonymous with sympathy, originates from Rogers, the progenitor of humanistic psychology. It entails contemplating and addressing issues from another individual's perspective, manifesting as a sensitive, immediate, and dynamically evolving emotional comprehension of the other person. 1 Mercer and Reynolds delineate clinical empathy as the capacity to grasp a patient's present circumstances, viewpoint, and emotions and to express this comprehension to the patient. This proficiency contributes to improved therapeutic outcomes achieved through precise treatment. 2 The Jefferson Scale of Physician Empathy (JSPE) is a psychometric tool developed by Professor Mohammadreza Hojat and colleagues at the Jefferson Medical College in the United States, based on extensive research literature. 3 The scale includes three dimensions: Perspective Taking (PT), Compassionate Care (CC), and Standing in Patient's Shoes (SPS).4,5 Scholars have constructed a “PT-CC-SPS” three-dimensional model based on JSPE to analyze empathy in physician–patient communication texts.1,6–8 Research has shown that medical professionals’ empathy is primarily reflected in patiently listening and deeply understanding patients’ emotional experiences, accurately expressing their understanding of the patients, adopting beneficial treatment plans, and reaching a consensus with the patients. 9 During the medical process, doctors should carefully listen to patient's needs, use an appropriate amount of medical terminology, thoroughly explain the issues of concern to patients, 10 and respond promptly and politely with content closely related to patients’ concerns.
Previous research on physician–patient empathy mainly focuses on traditional diagnostic processes. Jane et al. employed semistructured qualitative interviews to study empathy levels in primary care patients during telephone consultations. 11 Andrea et al. used questionnaires to demonstrate that chronic pain patients with higher perceived physician empathy have greater treatment satisfaction and fewer symptoms of depression and anxiety. 12 Amirreza et al. surveyed 211 adult patients, proving that perceived empathy helps reduce pain intensity. 13 The measurement methods in these studies primarily involve questionnaires and interviews, which are flexibly designed based on the target characteristics and provide a rich variety of data. 14 However, these methods may be subject to bias due to the respondents’ subjective factors. Compared to post-event questionnaires and interviews, real-world physician–patient interactions can minimize the interference of patients’ subjective factors. Additionally, while previous studies often used traditional statistical methods for small-scale data analysis, machine learning methods, with their flexible and efficient data processing and modeling capabilities, are better suited to handling large-scale, highly complex data. 15
The rapid development of network technology has advanced the maturity of Internet interaction models, with online medical platforms leveraging the real-time, free, and open characteristics of the Internet to establish effective communication bridges between doctors and patients. This has gradually formed the typical paradigm of “Internet + Healthcare.” As of June 2021, the number of Internet medical users in China reached 239 million, accounting for 23.7% of Internet users, indicating that Internet-based online healthcare has already achieved a significant scale. 16 However, due to the unique nature of online medical consultations, the quality of services provided by different platforms and doctors varies greatly, resulting in generally low patient satisfaction. 17 The factors influencing patient satisfaction in this context are therefore of significant research value. Compared to traditional consultations, online medical users often desire more psychological care 18 and enhancing doctors’ empathy in online settings can improve patient satisfaction. 14 Due to the limitations of the interaction method, empathy in online medical scenarios is often overlooked. Research has shown that inappropriate expressions by doctors during communication can lead to a lack of empathy, causing negative emotions such as anxiety and tension in patients, ultimately affecting their satisfaction with the medical service. 19 In-depth research on the factors influencing patient satisfaction in online healthcare is crucial for improving the quality of online medical services.
While previous studies have demonstrated the significance of empathy in traditional consultations, there is a notable gap in understanding how empathy can be effectively measured and analyzed in online medical consultations, where real-world interactions are less prone to subjective bias and where the scale of data requires more advanced analytical techniques. This study addresses this research gap by exploring the factors influencing satisfaction with online consultations on medical platforms from the perspective of empathy theory. This study is based on the previously proposed “PT-CC-SPS” three-dimensional model, focusing on online healthcare platforms. It extracts relevant variables from doctor–patient dialogue texts and employs machine learning algorithms to replace traditional statistical methods, constructing a classification model to analyze influencing factors. This study aims to more accurately represent physician–patient empathy in the online medical environment and analyze its impact on patient satisfaction. This approach provides a new avenue for improving the quality of online medical services. The overall research approach and methodology are illustrated in Figure 1.

Graphical illustration of research approach and methodology.
Methods
Data source
The data for this study were sourced from a well-known online medical platform in China. Using a Python-based web scraping algorithm, we collected information such as doctors’ details, physician–patient dialogue records, and patient evaluation texts. This included data fields such as doctor ID, dialogue ID, dialogue role, dialogue content, dialogue time, and consultation satisfaction ratings. From September 2016 to September 2021, we obtained a total of 8927 records, encompassing 416,548 doctor–patient dialogue texts. We removed entries from the patient evaluations that lacked either a doctor ID or a dialogue ID. For dialogs with matching doctor IDs and dialogue IDs and occurring within 24 h of each other, we considered them to belong to the same consultation session. The patient consultation texts and the corresponding doctor reply texts from these sessions were merged and stored, resulting in a dataset containing multiple consultation records. Each record in this dataset includes the doctor ID, dialogue ID, patient consultation text, doctor reply text, patient consultation time, doctor reply time, and patient satisfaction rating. The final dataset consists of 7586 records, with 5447 (71.8%) of the consultations rated as satisfactory by patients. Sample data are presented in Table 1.
Example of patient–doctor dialogue data.

Note. All original texts in this study were in Chinese. For ease of understanding and presentation, the dialogue texts in the samples have been translated into English.
Feature variable construction
This study employed the “PT-CC-SPS” three-dimensional model from the JSPE to construct an evaluation index system for online consultation satisfaction.4,5 In the JSPE, the PT dimension refers to the physician's ability to view issues from the patient's perspective, reflecting whether the physician understands and adopts the patient's viewpoint. Therefore, we selected the Similarity of doctor–patient question-and-answer texts and the Proportion of medical professional terms used by doctors as variables for this dimension. The Similarity of doctor–patient question-and-answer texts measures the extent to which the physician fully understands and addresses the patient's concerns, while the Proportion of medical professional terms used by doctors reflects the physician's ability to adjust their language to match the patient's level of understanding. The CC dimension refers to the expression of emotions in patient care and understanding of the patient's experiences, reflecting whether the physician demonstrates care and empathy toward the patient and maintains a positive attitude. For this dimension, we selected the Doctor's response time, the Emotional score of doctor's dialogue content, and the Proportion of positive language used by doctors as variables. The Doctor's response time indicates the physician's attentiveness to the patient's concerns, demonstrating care. The Emotional score of doctor's dialogue content quantifies the intensity of care or empathy expressed in the physician's words, and the Proportion of positive language used by doctors reflects the physician's tendency to encourage or comfort the patient. The SPS dimension refers to the physician's willingness to invest sufficient time and effort to consider the patient's needs. For this dimension, we chose the Length ratio of doctor–patient question-and-answer pairs and the Word count in doctor's dialogue as variables. The Length ratio of doctor–patient question-and-answer pairs measures whether the physician has invested adequate time and effort in the interaction, providing detailed responses to the patient's questions, while the Word count in doctor's dialogue reflects whether sufficient effective information was provided.
This study utilized Python for indicator extraction and computation. The process involved several steps: First, we obtained a stop word list (https://github.com/goto456/stopwords) and a medical word list (https://github.com/WENGSYX/Chinese-Word2vec-Medicine). We then employed the Jieba segmentation tool to tokenize both patient's dialogue and doctor's dialogue, removing stop words in the process. Next, we used the xmnlpv0.5.0 natural language processing tool (https://github.com/SeanLee97/xmnlp), which includes functions for sentiment analysis and sentence similarity computation, to analyze the processed dialogs. Details of the process and computation methods are illustrated in Figure 2. The sentiment analysis model in xmnlp is a Naive Bayes model trained on e-commerce review corpora, which provides the probability of a sentence or word having a positive sentiment. Sentence similarity is computed using SentenceBERT, a large-scale pretrained model that represents sentences and calculates cosine similarity between them. For example, in Table 1, we calculated the Doctor's response time by subtracting the Patient's inquiry time from the Doctor's response time, resulting in a response time of 7 min. The Jieba segmentation tool was used to segment both the Patient's Dialogue and Doctor's Dialogue, with a medical word list ensuring that specialized medical terms were correctly segmented. Stop words were removed using a stop word list. Next, the SentenceVector() function from the xmnlp natural language processing tool was employed to vectorize the Patient's Dialogue and Doctor's Dialogue after stop word removal. The cosine similarity between the two dialogs was calculated, yielding a Similarity of doctor–patient question-and-answer texts of 0.787. After word segmentation and stop word removal, the total number of words in the Doctor's Dialogue was calculated, resulting in a Word count in Doctor's Dialogue of 316. The sentiment() function was then used to compute the emotional score for each word in the Doctor's Dialogue, and words with a score higher than 0.5 (e.g. “thank you,” “progress”) were counted, totaling 8. Using this with the word count, we calculated the Proportion of positive language used by doctors to be 0.025. Each word in the Doctor's Dialogue (after stop word removal) was then checked against the medical word list. The number of words matching medical terms (e.g. “prescription,” “diarrhea”) was 16, and this was combined with the total word count to calculate the Proportion of medical professional terms used by doctors, which was 0.051. Finally, the len() function in Python was used to compute the total length of both the Patient's Dialogue and the Doctor's Dialogue. The length ratio of doctor–patient question-and-answer pairs was calculated by dividing the length of the Patient's Dialogue by the length of the Doctor's Dialogue, resulting in a value of 0.731. A sample of the processed data is shown in Table 2.
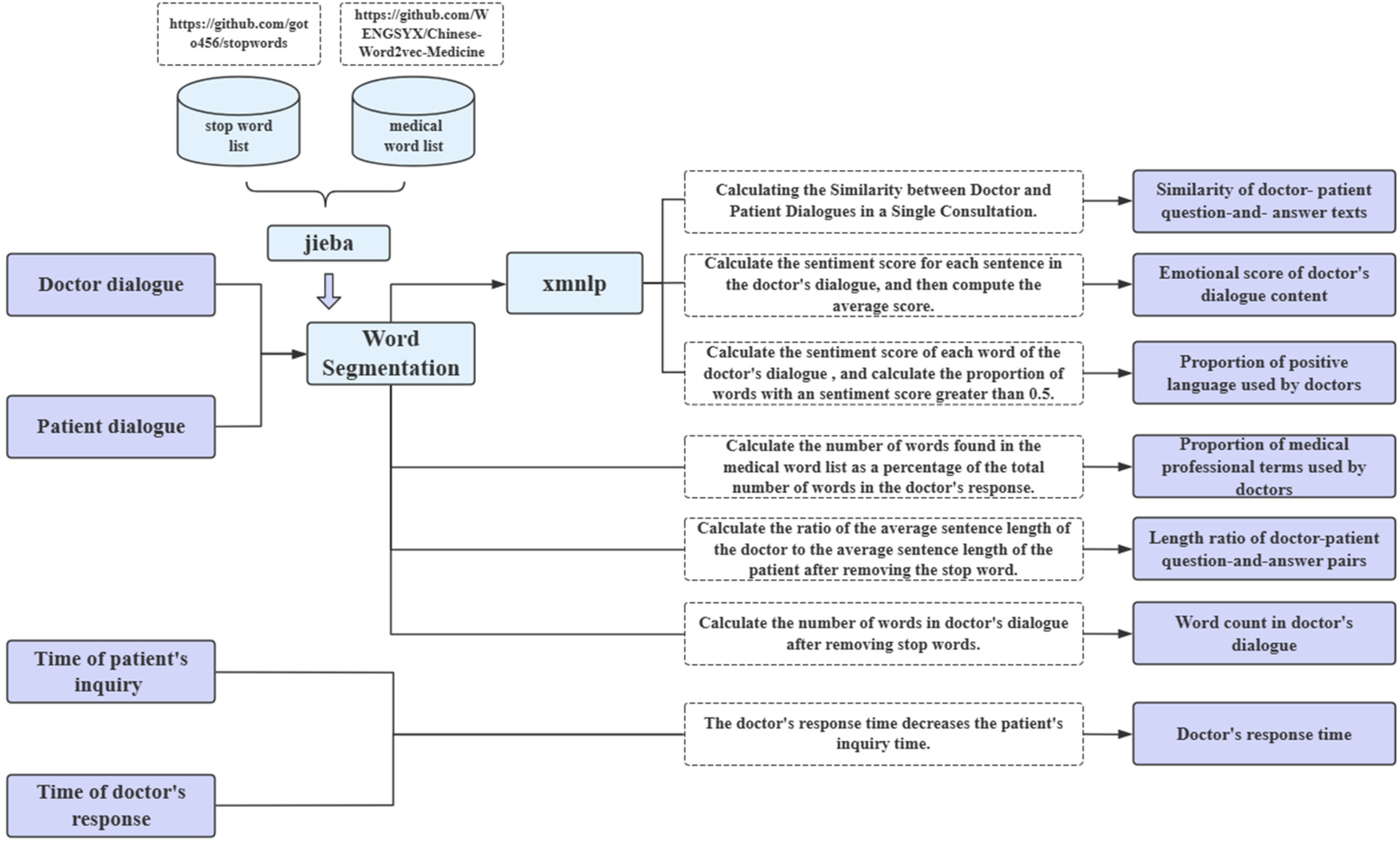
Variable extraction and computation methods.
Example of data after processing.

To avoid the adverse effects of multicollinearity on the predictive performance of the machine learning model and ensure its validity, a correlation test among the variables was necessary, 20 a Pearson correlation analysis was conducted on the cleaned final data, as illustrated in Figure 2. The correlation coefficient between the number of words in the physician's dialogue and the text similarity of the physician–patient dialogue was 0.42, while the Pearson correlation coefficients between other variables were all less than 0.4. This indicates that the correlation between the feature variables is low. Therefore, all features were included in the analysis, with patient satisfaction following online medical consultation as the dependent variable and the seven custom features as independent variables to construct a binary classification prediction model (Figure 3).

Correlation heatmap for variables used in the machine learning model.
Data preprocessing and descriptive statistics
We applied the Min-Max normalization method to the raw data, performing a linear transformation to map the values to the 0 to 1 range. This ensures that the differences between various indicators are not overly large, preventing lower-value indicators from diminishing the accuracy of the results and thus improving the classifier's accuracy. The Min-Max normalization formula is as follows:
SMOTEENN algorithm parameter settings.

Descriptive statistical analysis was performed on the preliminarily cleaned data. All independent variables were continuous quantitative variables and followed a normal distribution. However, the test for homogeneity of variances between groups failed. Therefore, the data were described using means and standard deviations, and nonparametric tests were used for group comparisons.
Model construction, training, evaluation, and analysis
Firstly, multiple independent classification models were constructed using Python 3.7, including LogisticRegression, XGBoost, AdaBoost, RandomForest, and LightGBM, with all models utilizing default parameter settings. Considering the SMOTEENN could produce noisy or less distinctive samples, potentially affecting model precision. To counterbalance this risk, these models were trained using 10-fold cross-validation, where the training set was further divided into 10 subsets. In each iteration, nine subsets were used for training, and the remaining one subset was used as the validation set. This process was repeated 10 times, with a different subset used as the validation set in each iteration. The final result was obtained by averaging the outcomes of these 10 validations. Subsequently, precision, recall, and F1 scores were used as evaluation metrics (formulas 1–3), where TP denotes the number of true positive instances, FP denotes the number of false positive instances, and FN denotes the number of false negative instances. Additionally, receiver operating characteristic (ROC) curves were plotted for each model, and the area under the ROC curve (AUC-ROC) was computed to further assess the accuracy of different models. Finally, the best-performing model was selected, and the SHAP (Shapley Additive Explanation) algorithm was employed for model interpretation and feature importance analysis. Shapley Additive Explanation is a machine learning explanation algorithm based on cooperative game theory, calculating additive contributions of each feature to represent its impact on the model's predictions
23
:


Results
Descriptive statistics
Based on the descriptive statistics in Table 4, all variables exhibit a p-value below 0.05, signifying the statistical significance of the difference in patient satisfaction. Descriptive statistics were further performed for selected outcome indicators related to patient satisfaction. The results revealed that out of the total, the patients rated 5447 questioning dialogs (71.8%) as satisfactory.
Descriptive statistics of each variable.

Performance of models
Table 5 presents the classification results of the machine learning algorithms. Among the models, LightGBM stands out as the top performer, achieving an F1 value of 0.78 and an AUC value of 0.81. The ROC curves for the five machine learning models are illustrated in Figure 4. Compared to traditional statistical models, machine learning algorithms can more comprehensively capture complex and nonlinear relationships. 15 However, due to differences in their structures, different models may exhibit varying performance when addressing the same problem. As shown in Table 5, the LightGBM model achieves a prediction accuracy of 78%, a recall rate of 79%, an F1 score greater than 0.78, and an AUC greater than 0.81, all of which are the highest values. The four ensemble learning models—XGBoost, AdaBoost, RandomForest, and LightGBM—demonstrate performance improvements over the single model LogisticRegression, indicating that integrating multiple weak classifiers helps enhance classifier accuracy.24,25 Among these models, LightGBM performed the best. While XGBoost uses a layer-wise tree growth strategy that may be slower for large-scale data, LightGBM adopts a leaf-wise growth approach, which can lead to faster training times and potentially better performance in handling large datasets. 26 AdaBoost, while useful in focusing on difficult-to-classify instances, is more sensitive to noise and data imbalance, which may have led to slightly lower performance in this dataset. 27 RandomForest, despite being robust in reducing overfitting through multiple decision trees, lacks the boosting mechanism present in LightGBM and is less efficient in capturing the finer patterns in complex, nonlinear data.26–28 LightGBM's leaf-wise growth strategy, histogram-based algorithm, and ability to handle sparse features allowed it to efficiently model intricate relationships without overfitting, making it particularly well-suited to the dataset's complexity and scale.

Receiver operating characteristic (ROC) curves for the individual predictive models (A) LogisticRegression (AUC: 0.78). (B) XGBoost (AUC: 0.79). (C) AdaBoost (AUC: 0.80) (D) RandomForest (AUC: 0.80). (E) LightGBM (AUC: 0.81). AUC: area under the curve.
Summary performance measures of predictive models in the testing dataset.

AUC: area under the curve.
Shapley Additive Explanation-based model interpretation analysis
The best-performing classification model (LightGBM) was interpreted using SHAP values to analyze the importance of seven predictor variables. The results are depicted in Figure 5, where the horizontal axis represents SHAP values. A SHAP value less than 0 indicates a negative impact of the feature on patient satisfaction, while a value greater than 0 indicates a positive impact. 29 Each data point represents a sample, with color denoting the magnitude of the feature value—ranging from blue to red indicating low to high feature values. The width of each point reflects the impact of the feature on the result: wider points indicate a greater influence.

Shapley Additive Explanation (SHAP) variable importance plots by LightGBM model.
The analysis reveals that the top three most important features contributing to patient satisfaction are Word count in doctor's dialogue, Length ratio of doctor–patient question-and-answer pairs, and Similarity of doctor–patient question-and-answer texts. These features demonstrate a significant positive correlation with patient satisfaction, as indicated by their concentration of red points in the region where SHAP values are greater than 0. Specifically, a higher Word count in doctor's dialogue and Length ratio of doctor–patient question-and-answer pairs may reflect a doctor's effort to provide detailed explanations and address patient concerns thoroughly, leading to higher patient satisfaction. Similarly, a higher similarity of doctor–patient question-and-answer texts might indicate that the doctor effectively tailors responses to match patient queries, fostering a sense of understanding and empathy. Conversely, the two least important features are the proportion of positive language used by doctors and the Proportion of medical professional terms used by doctors. These variables show a negative correlation with patient satisfaction, albeit with a lower impact, as evidenced by their concentration of red points in the region where SHAP values are less than 0. This lower impact may be due to the nuanced nature of doctor–patient communication. 30 For example, an excessive use of positive language, while well-intentioned, could be perceived as insincere or overly simplistic, especially if not paired with substantive answers to patient concerns. Similarly, the use of medical terminology, while important for accuracy, might overwhelm patients without sufficient contextual explanation, thereby diminishing its effect.
Discussion
Doctor's perceptual ability as a key factor influencing patient satisfaction in online medical consultations
In this study, the predictive model for patient satisfaction highlights two key features: Word count in doctor's dialogue and Length ratio of doctor–patient question-and-answer pairs. These features belong to the “SPS” dimension of empathy. In the context of online medical services, the perception of emotional attitudes by doctors and the application of empathy heavily rely on the expression of language and words.30,31 For instance, if a patient expresses negative emotions, a doctor who can perceive this and respond with comforting language such as “Please don't worry” or “Rest assured, it's not a major issue” demonstrates empathy effectively, thereby alleviating patient anxiety. The study results indicate a positive correlation between the Length ratio of doctor–patient question-and-answer pairs, Word count in doctor's dialogue, and patient satisfaction. This suggests that longer dialogue by doctors contributes to higher patient satisfaction rates. However, the quality of the content, such as the doctor's attentiveness, choice of words, and engagement with the patient's concerns also plays a crucial role.
In one example, a patient inquired about the combination of medications for folliculitis and Liuwei Dihuang Pills. The doctor responded by advising against using Liuwei Dihuang Pills immediately and provided dietary and lifestyle recommendations, demonstrating an understanding of the patient's concerns and providing concise advice. Despite the Length ratio of doctor–patient question-and-answer pairs being below average, the doctor successfully addressed the patient's primary concerns, explained the reasons for discontinuing Liuwei Dihuang Pills, and offered suggestions to meet the patient's needs, thus displaying empathy and enhancing the patient's confidence in the treatment plan. 32
Conversely, some doctors, due to factors like busy schedules, may provide comprehensive answers and recommendations but fail to express care or greetings, thus neglecting the emotional needs of patients and lacking empathy. This could lead to patient distrust and lower satisfaction with online medical consultations. 33 For instance, in a doctor–patient interaction, a consultant detailed her mother's history of hyperlipidemia, and recent symptoms such as dizziness, headache, and angina, seeking the doctor's advice on the urgency of the situation. “The doctor replied: Hello, to be actively treated, first of all, it is recommended to take musk cardio-protection pills or nitroglycerin tablets sublingual, to relieve angina pectoris, take aspirin 100 mg once a day, to rest, cannot work. Secondly, you can choose the treatment of proprietary Chinese medicine, each time, four capsules, three times a day. After treatment, the pain can be relieved, and you can elective treatment, if the relief is not obvious, it is best to timely treatment to prevent the occurrence of a heart attack.” In this doctor–patient dialogue, the consultant expressed her urgency and concern about her mother's condition at the same time as asking for a consultation, but the doctor focused only on proposing solutions, ignored the consultant's emotional needs, and did not provide sufficient emotional comfort, failing to achieve full empathy, which ultimately led to low patient satisfaction with online healthcare.
Regarding another variable in the “SPS” dimension—Proportion of medical professional terms used by doctors—this study found a negative correlation with patient satisfaction. Clinical medical terms are often concise and information-rich but may be challenging for ordinary patients to understand. Overuse of medical terminology can create communication barriers and hinder patient understanding.34,35
To improve patient satisfaction in online healthcare, doctors should enhance their communication skills by incorporating empathetic language and actively acknowledging patient concerns, balancing time constraints by expressing care even in brief interactions. Simplifying medical jargon into layman's terms can also foster better understanding and trust. Online medical platforms can support these efforts by developing empathy training programs for doctors, implementing AI-powered tools to analyze and improve doctor–patient dialogs in real time, and providing patient-friendly resources, such as glossaries for common medical terms. Encouraging doctors to address patient-specific concerns thoughtfully, especially in complex or emotionally charged cases, can further ensure that patients feel heard and supported, ultimately translating into higher satisfaction and better healthcare outcomes.
Perspective-taking behavior enhances patient satisfaction
In terms of feature importance, Similarity of doctor–patient question-and-answer texts ranks third, falling under the “Perspective Taking” dimension of empathy. Perspective taking involves accurately understanding the thoughts of communication partners by overcoming one's self-centered viewpoint and attempting to understand a specific communication scenario from their perspective, 36 often reflected in linguistic similarity. 37 The study findings indicate that lower doctor–patient dialogue text similarity correlates with lower patient satisfaction rates. Conversely, higher similarity complicates determining patient satisfaction. Typically, when faced with various patient inquiries or consultations, doctors need to succinctly state and address each issue raised by the patient. 38 For example, in a particular doctor–patient dialogue, the patient primarily consulted on four symptoms: (a) Increased warmth in hands and feet during nighttime anxiety. (b) Waking up during sleep with frequent dreams towards waking. (c) Reduced tinnitus compared to previous experiences. (d) Yellowish urine, occasionally with heat. “The doctor responded: The warmth in hands and feet indicates Yin deficiency and excessive internal heat, related to anxiety and emotional instability. Difficulty sleeping, easy waking, and vivid dreams are signs of liver Qi stagnation disturbing the heart's spirit. Please don't worry about recurring issues; everything progresses in a spiral. Please maintain confidence in your current treatment. Good night.” In this interaction, the doctor addressed each symptom point by point, emphasizing accurate understanding and providing explanations and care, making the patient more receptive to the doctor's concern and advice, thereby enhancing patient satisfaction.
However, some doctors achieve high dialogue text similarity by simply copying the patient's wording to describe symptoms without delving into explanations or providing concise summaries, failing to fully consider the patient's actual situation. For instance, a patient inquired about leg numbness following an abortion, whether they could consume Ginseng Bolus to invigorate the spleen, and treatments for pelvic inflammation, constipation, heavy dampness, and acne. The doctor replied: “Just had an abortion, Qi, and blood deficiency. You can eat some ginseng! Not recommended to eat more. You can take Shiquan Dabu Pills, they're not very harsh, take for half a month.” This response, although high in text similarity, was overly simplistic, lacked attention to the patient's specific questions, and failed to provide explanations, potentially leading the patient to perceive the doctor's attitude as perfunctory, 8 undermining patient trust and resulting in a negative medical consultation experience.
To address this, doctors should focus on achieving meaningful dialogue text similarity by actively engaging with the patient's specific concerns and offering detailed explanations rather than mirroring the patient's wording without added value. Training programs could emphasize perspective-taking skills, guiding doctors to identify and address underlying patient needs effectively. Online platforms can assist by integrating tools that provide feedback on the quality of doctor–patient interactions, highlighting areas needing more thorough responses.
Doctors need to further enhance empathetic care during diagnosis and treatment
In our study, while three variables in the “CC” dimension showed a relatively low impact on patient satisfaction, they remain crucial and should not be overlooked. 39 Existing research indicates that using positive language and emotions effectively enhances patients’ psychological care, promptly responding to patient queries, and helping alleviate negative emotions, thereby improving doctor–patient empathy and patient satisfaction. 40 This is because positive and supportive language conveys the doctor's concern, understanding, and support, and providing comfort and confidence to patients facing illness. Timely responses reduce patient wait times, avoiding unnecessary anxiety during the waiting period, aligning with our findings that emotional scores in doctor–patient dialogue and response times positively correlate with patient satisfaction. However, our study also found that excessively positive language does not necessarily enhance patient satisfaction; rather, it may lead patients to perceive the doctor's words as insincere or overly formal, thereby reducing trust. 41 Furthermore, doctors often focus more on showing concern for the medical condition rather than for the individual patient, 10 potentially increasing the emotional distance between doctors and patients, which also hampers empathy development and patient satisfaction.
Therefore, doctors should be mindful of their language use during diagnosis and treatment, maintaining sincerity and patience while avoiding excessive positive language. Additionally, doctors should further enhance their comprehensive understanding and application of empathy theory and skills to improve patient satisfaction and healthcare service quality.
Conclusion
This study employed machine learning algorithms from the perspective of empathy theory to analyze factors influencing patient satisfaction in online healthcare settings, exploring how doctor–patient empathy connections are established. The findings suggest that beyond basic medical care, doctors should enhance their ability to perceive patients’ needs, maintain a proactive and positive attitude, and provide thorough responses to questions. Additionally, doctors should strive to think from the patient's perspective and use language that resonates with patients to better meet their empathy needs, thereby improving patient satisfaction.
The main contributions of this study are as follows: first, it analyzes the impact of physician–patient empathy on patient satisfaction through the examination of dialogue texts from online medical platforms. Second, it applies machine learning models to the study of empathy in the online healthcare domain. Finally, it offers strategic recommendations to enhance physician–patient empathy in online healthcare, thereby improving patient satisfaction.
However, the study has limitations. One key limitation is the generalizability of the findings, as the data were sourced from a single online platform, which may not be representative of other healthcare platforms, geographic regions, or medical specialties. The absence of personal patient data, doctor-specific professional information, and audiovisual materials from doctor–patient interactions further limits the study's ability to capture the full spectrum of empathy-related dynamics. Additionally, the study could not fully address issues such as a class imbalance in the dataset, specifically the uneven distribution between satisfied and dissatisfied patient evaluations, potentially biasing positive predictions. Therefore, future research will aim to collect and integrate data from platforms that serve different geographic regions, socioeconomic backgrounds, or medical specialties, construct a more balanced dataset, and enhance the depth and breadth of the study. This will allow for more accurate capture of patient feedback, promoting fairer, more transparent healthcare services, and improved patient satisfaction.
Footnotes
Acknowledgments
This work is supported by, the Funds for the Industry-University-Research Innovation of Chinese Universities (grant numbers 2021LDA12004), Beijing University of Chinese Medicine Basic Research Fund (Open Bidding Leadership) Project (grant numbers 2023-JYB-JBZD-068), 2022 Educational Science Research Project of Beijing University of Chinese Medicine (grant numbers XJY22045), 2022 Basic Research Business Fund 'Top-Down Leadership' Project (grant numbers 2022JYBJBRW12), and 2024 Independent Research Projects for Postgraduate Students of Beijing University of Chinese Medicine (ZJKT2024033).
Contributorship
JC and GW participated in the method design, analyzed data, and drafted the initial manuscript. JC, GW, TZ, BZ, RW, XZ, and FG participated in text checking correction and helped to draft the manuscript. BZ, FG, and RW oversaw and provided input on all aspects of manuscript writing and the final analytical plan. All the authors read and approved the final manuscript.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work, the author(s) used chatGPT in order to improve language and readability. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
We would like to clarify that the data used in this study were obtained from publicly available sources on the Internet (e.g. ![]() ). Patients who used this online healthcare platform provided consent for their consultation records to be publicly accessible as part of the platform's terms of use. Furthermore, the platform had removed all personal identifiers from the data prior to our use, ensuring patient anonymity and privacy. We confirm that the content of the paper submitted by us does not involve any human or animal experiments. Therefore, we are not required to provide any ethical review documents or approvals related to human or animal experiments.
). Patients who used this online healthcare platform provided consent for their consultation records to be publicly accessible as part of the platform's terms of use. Furthermore, the platform had removed all personal identifiers from the data prior to our use, ensuring patient anonymity and privacy. We confirm that the content of the paper submitted by us does not involve any human or animal experiments. Therefore, we are not required to provide any ethical review documents or approvals related to human or animal experiments.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Industry-University-Research Innovation of Chinese Universities, 2024 Independent Research Projects for Postgraduate Students of Beijing University of Chinese Medicine, Beijing University of Chinese Medicine Basic Research Fund (Open Bidding Leadership) Project, Ministry of Education Industry-University Cooperative Education Program of China, (grant number 2021LDA12004, ZJKT2024033, 2023-JYB-JBZD-068, 202102001001).
Guarantor
JC, RW, XZ, FG.
Statement of human and animal rights
Our research primarily focuses on theoretical exploration, literature review, and data analysis and does not involve direct intervention or research on biological entities, whether human or animal.
Statement of informed consent
The data used in this study were obtained from publicly available sources on the Internet. Patients who used this online healthcare platform provided consent for their consultation records to be publicly accessible as part of the platform's terms of use. There is no human subject in this article and informed consent is not applicable.